
text
stringlengths 29
317k
| id
stringlengths 22
166
| metadata
dict | __index_level_0__
int64 0
231
|
|---|---|---|---|
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the PyTorch VipLlava model."""
import unittest
import requests
from parameterized import parameterized
from transformers import (
AutoProcessor,
VipLlavaConfig,
VipLlavaForConditionalGeneration,
is_torch_available,
is_vision_available,
)
from transformers.testing_utils import (
cleanup,
require_bitsandbytes,
require_torch,
slow,
torch_device,
)
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
if is_torch_available():
import torch
if is_vision_available():
from PIL import Image
# Copied from transformers.tests.models.llava.test_modeling_llava.LlavaVisionText2TextModelTester with Llava->VipLlava
class VipLlavaVisionText2TextModelTester:
# Ignore copy
def __init__(
self,
parent,
ignore_index=-100,
image_token_index=0,
projector_hidden_act="gelu",
seq_length=7,
vision_feature_layers=[0, 0, 1, 1, 0],
text_config={
"model_type": "llama",
"seq_length": 7,
"is_training": True,
"use_input_mask": True,
"use_token_type_ids": False,
"use_labels": True,
"vocab_size": 99,
"hidden_size": 32,
"num_hidden_layers": 2,
"num_attention_heads": 4,
"intermediate_size": 37,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512,
"type_vocab_size": 16,
"type_sequence_label_size": 2,
"initializer_range": 0.02,
"num_labels": 3,
"num_choices": 4,
"pad_token_id": 1,
},
is_training=True,
vision_config={
"batch_size": 12,
"image_size": 8,
"patch_size": 2,
"num_channels": 3,
"is_training": True,
"hidden_size": 32,
"projection_dim": 32,
"num_hidden_layers": 2,
"num_attention_heads": 4,
"intermediate_size": 37,
"dropout": 0.1,
"attention_dropout": 0.1,
"initializer_range": 0.02,
},
):
self.parent = parent
self.ignore_index = ignore_index
self.image_token_index = image_token_index
self.projector_hidden_act = projector_hidden_act
self.vision_feature_layers = vision_feature_layers
self.text_config = text_config
self.vision_config = vision_config
self.pad_token_id = text_config["pad_token_id"]
self.num_hidden_layers = text_config["num_hidden_layers"]
self.vocab_size = text_config["vocab_size"]
self.hidden_size = text_config["hidden_size"]
self.num_attention_heads = text_config["num_attention_heads"]
self.is_training = is_training
self.batch_size = 3
self.num_channels = 3
self.image_size = 336
self.num_image_tokens = (self.vision_config["image_size"] // self.vision_config["patch_size"]) ** 2
self.seq_length = seq_length + self.num_image_tokens
self.encoder_seq_length = self.seq_length
def get_config(self):
return VipLlavaConfig(
text_config=self.text_config,
vision_config=self.vision_config,
ignore_index=self.ignore_index,
image_token_index=self.image_token_index,
projector_hidden_act=self.projector_hidden_act,
vision_feature_layers=self.vision_feature_layers,
image_seq_length=self.num_image_tokens,
)
def prepare_config_and_inputs(self):
pixel_values = floats_tensor(
[
self.batch_size,
self.vision_config["num_channels"],
self.vision_config["image_size"],
self.vision_config["image_size"],
]
)
config = self.get_config()
return config, pixel_values
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, pixel_values = config_and_inputs
input_ids = ids_tensor([self.batch_size, self.seq_length], config.text_config.vocab_size - 1) + 1
attention_mask = input_ids.ne(1).to(torch_device)
input_ids[input_ids == config.image_token_index] = self.pad_token_id
input_ids[:, : self.num_image_tokens] = config.image_token_index
inputs_dict = {
"pixel_values": pixel_values,
"input_ids": input_ids,
"attention_mask": attention_mask,
}
return config, inputs_dict
@require_torch
# Copied from transformers.tests.models.llava.test_modeling_llava.LlavaForConditionalGenerationModelTest with Llava->VipLlava
class VipLlavaForConditionalGenerationModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
"""
Model tester for `VipLlavaForConditionalGeneration`.
"""
all_model_classes = (VipLlavaForConditionalGeneration,) if is_torch_available() else ()
all_generative_model_classes = (VipLlavaForConditionalGeneration,) if is_torch_available() else ()
pipeline_model_mapping = {"image-text-to-text": VipLlavaForConditionalGeneration} if is_torch_available() else {}
fx_compatible = False
test_pruning = False
test_resize_embeddings = True
test_head_masking = False
_is_composite = True
def setUp(self):
self.model_tester = VipLlavaVisionText2TextModelTester(self)
common_properties = ["image_token_index", "vision_feature_layers", "image_seq_length"]
self.config_tester = ConfigTester(
self, config_class=VipLlavaConfig, has_text_modality=False, common_properties=common_properties
)
def test_config(self):
self.config_tester.run_common_tests()
# overwrite inputs_embeds tests because we need to delete "pixel values" for LVLMs
def test_inputs_embeds(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
model.to(torch_device)
model.eval()
inputs = self._prepare_for_class(inputs_dict, model_class)
input_ids = inputs["input_ids"]
del inputs["input_ids"]
del inputs["pixel_values"]
wte = model.get_input_embeddings()
inputs["inputs_embeds"] = wte(input_ids)
with torch.no_grad():
model(**inputs)
# overwrite inputs_embeds tests because we need to delete "pixel values" for LVLMs
# while some other models require pixel_values to be present
def test_inputs_embeds_matches_input_ids(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
model.to(torch_device)
model.eval()
inputs = self._prepare_for_class(inputs_dict, model_class)
input_ids = inputs["input_ids"]
del inputs["input_ids"]
del inputs["pixel_values"]
inputs_embeds = model.get_input_embeddings()(input_ids)
with torch.no_grad():
out_ids = model(input_ids=input_ids, **inputs)[0]
out_embeds = model(inputs_embeds=inputs_embeds, **inputs)[0]
torch.testing.assert_close(out_embeds, out_ids)
# Copied from tests.models.llava.test_modeling_llava.LlavaForConditionalGenerationModelTest.test_mismatching_num_image_tokens
def test_mismatching_num_image_tokens(self):
"""
Tests that VLMs through an error with explicit message saying what is wrong
when number of images don't match number of image tokens in the text.
Also we need to test multi-image cases when one prompr has multiple image tokens.
"""
config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config).to(torch_device)
_ = model(**input_dict) # successfull forward with no modifications
# remove one image but leave the image token in text
input_dict["pixel_values"] = input_dict["pixel_values"][-1:, ...]
with self.assertRaises(ValueError):
_ = model(**input_dict)
# simulate multi-image case by concatenating inputs where each has exactly one image/image-token
input_ids = input_dict["input_ids"][:1]
pixel_values = input_dict["pixel_values"][:1]
input_ids = torch.cat([input_ids, input_ids], dim=0)
# one image and two image tokens raise an error
with self.assertRaises(ValueError):
_ = model(input_ids=input_ids, pixel_values=pixel_values)
# two images and two image tokens don't raise an error
pixel_values = torch.cat([pixel_values, pixel_values], dim=0)
_ = model(input_ids=input_ids, pixel_values=pixel_values)
@parameterized.expand(
[
(-1,),
([-1],),
([-1, -2],),
],
)
def test_vision_feature_layers(self, vision_feature_layers):
"""
Test that we can use either one vision feature layer, or a list of
vision feature layers.
"""
# NOTE: vipllava uses vision_feature_layers instead of vision_feature_layer as the
# config key. The reason is that other llava classes supported one vision feature layer
# and added support for a list of layers with granite vision support, while vipllava
# originally supported multiple feature layers, and added support for a single layer for
# for compatibility reasons.
config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.vision_feature_layers = vision_feature_layers
num_feature_layers = 1 if isinstance(vision_feature_layers, int) else len(vision_feature_layers)
hidden_size = config.vision_config.hidden_size
expected_features = hidden_size * num_feature_layers
for model_class in self.all_model_classes:
model = model_class(config).to(torch_device)
# We should have the right number of input features,
# and should be able to run a forward pass without exploding
assert model.multi_modal_projector.linear_1.in_features == expected_features
model(**input_dict)
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
@unittest.skip(reason="Compile not yet supported because it is not yet supported in LLava")
def test_sdpa_can_compile_dynamic(self):
pass
@unittest.skip(reason="Compile not yet supported because in LLava models")
def test_sdpa_can_dispatch_on_flash(self):
pass
@unittest.skip("FlashAttention only support fp16 and bf16 data type")
def test_flash_attn_2_fp32_ln(self):
pass
@unittest.skip(
"VLMs need lots of steps to prepare images/mask correctly to get pad-free inputs. Can be tested as part of LLM test"
)
def test_flash_attention_2_padding_matches_padding_free_with_position_ids(self):
pass
@require_torch
class VipLlavaForConditionalGenerationIntegrationTest(unittest.TestCase):
def setUp(self):
self.processor = AutoProcessor.from_pretrained("llava-hf/vip-llava-7b-hf")
def tearDown(self):
cleanup(torch_device, gc_collect=True)
@slow
@require_bitsandbytes
def test_small_model_integration_test(self):
model_id = "llava-hf/vip-llava-7b-hf"
model = VipLlavaForConditionalGeneration.from_pretrained(model_id, load_in_4bit=True)
processor = AutoProcessor.from_pretrained(model_id)
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/compel-neg.png"
image = Image.open(requests.get(url, stream=True).raw)
prompt = "USER: <image>\nCan you please describe this image?\nASSISTANT:"
inputs = processor(prompt, image, return_tensors="pt").to(torch_device, torch.float16)
outputs = model.generate(**inputs, max_new_tokens=10)
EXPECTED_OUTPUT = "USER: \nCan you please describe this image?\nASSISTANT: The image features a brown and white cat sitting on"
self.assertEqual(processor.decode(outputs[0], skip_special_tokens=True), EXPECTED_OUTPUT)
|
transformers/tests/models/vipllava/test_modeling_vipllava.py/0
|
{
"file_path": "transformers/tests/models/vipllava/test_modeling_vipllava.py",
"repo_id": "transformers",
"token_count": 5978
}
| 200 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the TensorFlow ViT model."""
from __future__ import annotations
import inspect
import unittest
from transformers import ViTConfig
from transformers.testing_utils import require_tf, require_vision, slow
from transformers.utils import cached_property, is_tf_available, is_vision_available
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, floats_tensor, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_tf_available():
import tensorflow as tf
from transformers import TFViTForImageClassification, TFViTModel
from transformers.modeling_tf_utils import keras
if is_vision_available():
from PIL import Image
from transformers import ViTImageProcessor
class TFViTModelTester:
def __init__(
self,
parent,
batch_size=13,
image_size=30,
patch_size=2,
num_channels=3,
is_training=True,
use_labels=True,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
type_sequence_label_size=10,
initializer_range=0.02,
num_labels=3,
scope=None,
attn_implementation="eager",
):
self.parent = parent
self.batch_size = batch_size
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.is_training = is_training
self.use_labels = use_labels
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.scope = scope
self.attn_implementation = attn_implementation
# in ViT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
num_patches = (image_size // patch_size) ** 2
self.seq_length = num_patches + 1
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
config = self.get_config()
return config, pixel_values, labels
def get_config(self):
return ViTConfig(
image_size=self.image_size,
patch_size=self.patch_size,
num_channels=self.num_channels,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
is_decoder=False,
initializer_range=self.initializer_range,
attn_implementation=self.attn_implementation,
)
def create_and_check_model(self, config, pixel_values, labels):
model = TFViTModel(config=config)
result = model(pixel_values, training=False)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
# Test with an image with different size than the one specified in config.
image_size = self.image_size // 2
pixel_values = pixel_values[:, :, :image_size, :image_size]
result = model(pixel_values, interpolate_pos_encoding=True, training=False)
seq_length = (image_size // self.patch_size) ** 2 + 1
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, seq_length, self.hidden_size))
def create_and_check_for_image_classification(self, config, pixel_values, labels):
config.num_labels = self.type_sequence_label_size
model = TFViTForImageClassification(config)
result = model(pixel_values, labels=labels, training=False)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
# Test with an image with different size than the one specified in config.
image_size = self.image_size // 2
pixel_values = pixel_values[:, :, :image_size, :image_size]
result = model(pixel_values, interpolate_pos_encoding=True, training=False)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
# test greyscale images
config.num_channels = 1
model = TFViTForImageClassification(config)
pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
result = model(pixel_values)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, pixel_values, labels = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
@require_tf
class TFViTModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
"""
Here we also overwrite some of the tests of test_modeling_tf_common.py, as ViT does not use input_ids, inputs_embeds,
attention_mask and seq_length.
"""
all_model_classes = (TFViTModel, TFViTForImageClassification) if is_tf_available() else ()
pipeline_model_mapping = (
{"feature-extraction": TFViTModel, "image-classification": TFViTForImageClassification}
if is_tf_available()
else {}
)
test_resize_embeddings = False
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TFViTModelTester(self)
self.config_tester = ConfigTester(self, config_class=ViTConfig, has_text_modality=False, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
@unittest.skip(reason="ViT does not use inputs_embeds")
def test_inputs_embeds(self):
pass
@unittest.skip(reason="ViT does not use inputs_embeds")
def test_graph_mode_with_inputs_embeds(self):
pass
def test_model_common_attributes(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
self.assertIsInstance(model.get_input_embeddings(), (keras.layers.Layer))
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, keras.layers.Layer))
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
signature = inspect.signature(model.call)
# signature.parameters is an OrderedDict => so arg_names order is deterministic
arg_names = [*signature.parameters.keys()]
expected_arg_names = ["pixel_values"]
self.assertListEqual(arg_names[:1], expected_arg_names)
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_image_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
model = TFViTModel.from_pretrained("google/vit-base-patch16-224")
self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
def prepare_img():
image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
return image
@require_tf
@require_vision
class TFViTModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
return ViTImageProcessor.from_pretrained("google/vit-base-patch16-224") if is_vision_available() else None
@slow
def test_inference_image_classification_head(self):
model = TFViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
image_processor = self.default_image_processor
image = prepare_img()
inputs = image_processor(images=image, return_tensors="tf")
# forward pass
outputs = model(**inputs)
# verify the logits
expected_shape = tf.TensorShape((1, 1000))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = tf.constant([-0.2744, 0.8215, -0.0836])
tf.debugging.assert_near(outputs.logits[0, :3], expected_slice, atol=1e-4)
|
transformers/tests/models/vit/test_modeling_tf_vit.py/0
|
{
"file_path": "transformers/tests/models/vit/test_modeling_tf_vit.py",
"repo_id": "transformers",
"token_count": 3984
}
| 201 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the PyTorch VitPose backbone model."""
import inspect
import unittest
from transformers import VitPoseBackboneConfig
from transformers.testing_utils import require_torch
from transformers.utils import is_torch_available, is_vision_available
from ...test_backbone_common import BackboneTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
if is_torch_available():
from transformers import VitPoseBackbone
if is_vision_available():
pass
class VitPoseBackboneModelTester:
def __init__(
self,
parent,
batch_size=13,
image_size=[16 * 8, 12 * 8],
patch_size=[8, 8],
num_channels=3,
is_training=True,
use_labels=True,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
type_sequence_label_size=10,
initializer_range=0.02,
num_labels=2,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.is_training = is_training
self.use_labels = use_labels
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.scope = scope
# in VitPoseBackbone, the seq length equals the number of patches
num_patches = (image_size[0] // patch_size[0]) * (image_size[1] // patch_size[1])
self.seq_length = num_patches
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size[0], self.image_size[1]])
labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
config = self.get_config()
return config, pixel_values, labels
def get_config(self):
return VitPoseBackboneConfig(
image_size=self.image_size,
patch_size=self.patch_size,
num_channels=self.num_channels,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
initializer_range=self.initializer_range,
num_labels=self.num_labels,
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
pixel_values,
labels,
) = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
@require_torch
class VitPoseBackboneModelTest(ModelTesterMixin, unittest.TestCase):
"""
Here we also overwrite some of the tests of test_modeling_common.py, as VitPoseBackbone does not use input_ids, inputs_embeds,
attention_mask and seq_length.
"""
all_model_classes = (VitPoseBackbone,) if is_torch_available() else ()
fx_compatible = False
test_pruning = False
test_resize_embeddings = False
test_head_masking = False
def setUp(self):
self.model_tester = VitPoseBackboneModelTester(self)
self.config_tester = ConfigTester(
self, config_class=VitPoseBackboneConfig, has_text_modality=False, hidden_size=37
)
def test_config(self):
self.config_tester.run_common_tests()
@unittest.skip(reason="VitPoseBackbone does not support input and output embeddings")
def test_model_common_attributes(self):
pass
@unittest.skip(reason="VitPoseBackbone does not support input and output embeddings")
def test_inputs_embeds(self):
pass
@unittest.skip(reason="VitPoseBackbone does not support input and output embeddings")
def test_model_get_set_embeddings(self):
pass
@unittest.skip(reason="VitPoseBackbone does not support feedforward chunking")
def test_feed_forward_chunking(self):
pass
@unittest.skip(reason="VitPoseBackbone does not output a loss")
def test_retain_grad_hidden_states_attentions(self):
pass
@unittest.skip(reason="VitPoseBackbone does not support training yet")
def test_training(self):
pass
@unittest.skip(reason="VitPoseBackbone does not support training yet")
def test_training_gradient_checkpointing(self):
pass
@unittest.skip(reason="VitPoseBackbone does not support training yet")
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(reason="VitPoseBackbone does not support training yet")
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
signature = inspect.signature(model.forward)
# signature.parameters is an OrderedDict => so arg_names order is deterministic
arg_names = [*signature.parameters.keys()]
expected_arg_names = ["pixel_values"]
self.assertListEqual(arg_names[:1], expected_arg_names)
@require_torch
class VitPoseBackboneTest(unittest.TestCase, BackboneTesterMixin):
all_model_classes = (VitPoseBackbone,) if is_torch_available() else ()
config_class = VitPoseBackboneConfig
has_attentions = False
def setUp(self):
self.model_tester = VitPoseBackboneModelTester(self)
|
transformers/tests/models/vitpose_backbone/test_modeling_vitpose_backbone.py/0
|
{
"file_path": "transformers/tests/models/vitpose_backbone/test_modeling_vitpose_backbone.py",
"repo_id": "transformers",
"token_count": 2864
}
| 202 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
import shutil
import tempfile
import unittest
import numpy as np
from transformers.models.seamless_m4t import SeamlessM4TFeatureExtractor
from transformers.models.wav2vec2 import Wav2Vec2CTCTokenizer
from transformers.models.wav2vec2.tokenization_wav2vec2 import VOCAB_FILES_NAMES
from transformers.models.wav2vec2_bert import Wav2Vec2BertProcessor
from transformers.utils import FEATURE_EXTRACTOR_NAME
from ...test_processing_common import ProcessorTesterMixin
from ..wav2vec2.test_feature_extraction_wav2vec2 import floats_list
class Wav2Vec2BertProcessorTest(ProcessorTesterMixin, unittest.TestCase):
processor_class = Wav2Vec2BertProcessor
def setUp(self):
vocab = "<pad> <s> </s> <unk> | E T A O N I H S R D L U M W C F G Y P B V K ' X J Q Z".split(" ")
vocab_tokens = dict(zip(vocab, range(len(vocab))))
self.add_kwargs_tokens_map = {
"pad_token": "<pad>",
"unk_token": "<unk>",
"bos_token": "<s>",
"eos_token": "</s>",
}
feature_extractor_map = {
"feature_size": 80,
"padding_value": 0.0,
"sampling_rate": 16000,
"return_attention_mask": False,
"do_normalize": True,
}
self.tmpdirname = tempfile.mkdtemp()
self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
self.feature_extraction_file = os.path.join(self.tmpdirname, FEATURE_EXTRACTOR_NAME)
with open(self.vocab_file, "w", encoding="utf-8") as fp:
fp.write(json.dumps(vocab_tokens) + "\n")
with open(self.feature_extraction_file, "w", encoding="utf-8") as fp:
fp.write(json.dumps(feature_extractor_map) + "\n")
tokenizer = self.get_tokenizer()
tokenizer.save_pretrained(self.tmpdirname)
def get_tokenizer(self, **kwargs_init):
kwargs = self.add_kwargs_tokens_map.copy()
kwargs.update(kwargs_init)
return Wav2Vec2CTCTokenizer.from_pretrained(self.tmpdirname, **kwargs)
def get_feature_extractor(self, **kwargs):
return SeamlessM4TFeatureExtractor.from_pretrained(self.tmpdirname, **kwargs)
def tearDown(self):
shutil.rmtree(self.tmpdirname)
def test_save_load_pretrained_default(self):
tokenizer = self.get_tokenizer()
feature_extractor = self.get_feature_extractor()
processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
processor.save_pretrained(self.tmpdirname)
processor = Wav2Vec2BertProcessor.from_pretrained(self.tmpdirname)
self.assertEqual(processor.tokenizer.get_vocab(), tokenizer.get_vocab())
self.assertIsInstance(processor.tokenizer, Wav2Vec2CTCTokenizer)
self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor.to_json_string())
self.assertIsInstance(processor.feature_extractor, SeamlessM4TFeatureExtractor)
def test_save_load_pretrained_additional_features(self):
processor = Wav2Vec2BertProcessor(
tokenizer=self.get_tokenizer(), feature_extractor=self.get_feature_extractor()
)
processor.save_pretrained(self.tmpdirname)
tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
feature_extractor_add_kwargs = self.get_feature_extractor(do_normalize=False, padding_value=1.0)
processor = Wav2Vec2BertProcessor.from_pretrained(
self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
)
self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
self.assertIsInstance(processor.tokenizer, Wav2Vec2CTCTokenizer)
self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
self.assertIsInstance(processor.feature_extractor, SeamlessM4TFeatureExtractor)
def test_feature_extractor(self):
feature_extractor = self.get_feature_extractor()
tokenizer = self.get_tokenizer()
processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
raw_speech = floats_list((3, 1000))
input_feat_extract = feature_extractor(raw_speech, return_tensors="np")
input_processor = processor(raw_speech, return_tensors="np")
for key in input_feat_extract.keys():
self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
def test_tokenizer(self):
feature_extractor = self.get_feature_extractor()
tokenizer = self.get_tokenizer()
processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
input_str = "This is a test string"
encoded_processor = processor(text=input_str)
encoded_tok = tokenizer(input_str)
for key in encoded_tok.keys():
self.assertListEqual(encoded_tok[key], encoded_processor[key])
def test_padding_argument_not_ignored(self):
# padding, or any other overlap arg between audio extractor and tokenizer
# should be passed to both text and audio and not ignored
feature_extractor = self.get_feature_extractor()
tokenizer = self.get_tokenizer()
processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
batch_duration_in_seconds = [1, 3, 2, 6]
input_features = [np.random.random(16_000 * s) for s in batch_duration_in_seconds]
# padding = True should not raise an error and will if the audio processor popped its value to None
# processor(input_features, padding=True, sampling_rate=processor.feature_extractor.sampling_rate, return_tensors="pt")
_ = processor(
input_features, padding=True, sampling_rate=processor.feature_extractor.sampling_rate, return_tensors="pt"
)
def test_tokenizer_decode(self):
feature_extractor = self.get_feature_extractor()
tokenizer = self.get_tokenizer()
processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
decoded_processor = processor.batch_decode(predicted_ids)
decoded_tok = tokenizer.batch_decode(predicted_ids)
self.assertListEqual(decoded_tok, decoded_processor)
def test_model_input_names(self):
feature_extractor = self.get_feature_extractor()
tokenizer = self.get_tokenizer()
processor = Wav2Vec2BertProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
self.assertListEqual(
processor.model_input_names,
feature_extractor.model_input_names,
msg="`processor` and `feature_extractor` model input names do not match",
)
|
transformers/tests/models/wav2vec2_bert/test_processor_wav2vec2_bert.py/0
|
{
"file_path": "transformers/tests/models/wav2vec2_bert/test_processor_wav2vec2_bert.py",
"repo_id": "transformers",
"token_count": 3048
}
| 203 |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from huggingface_hub import ImageClassificationOutputElement
from transformers import (
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
PreTrainedTokenizerBase,
is_torch_available,
is_vision_available,
)
from transformers.pipelines import ImageClassificationPipeline, pipeline
from transformers.testing_utils import (
compare_pipeline_output_to_hub_spec,
is_pipeline_test,
nested_simplify,
require_tf,
require_torch,
require_torch_or_tf,
require_vision,
slow,
)
from .test_pipelines_common import ANY
if is_torch_available():
import torch
if is_vision_available():
from PIL import Image
else:
class Image:
@staticmethod
def open(*args, **kwargs):
pass
@is_pipeline_test
@require_torch_or_tf
@require_vision
class ImageClassificationPipelineTests(unittest.TestCase):
model_mapping = MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING
tf_model_mapping = TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING
def get_test_pipeline(
self,
model,
tokenizer=None,
image_processor=None,
feature_extractor=None,
processor=None,
torch_dtype="float32",
):
image_classifier = ImageClassificationPipeline(
model=model,
tokenizer=tokenizer,
feature_extractor=feature_extractor,
image_processor=image_processor,
processor=processor,
torch_dtype=torch_dtype,
top_k=2,
)
examples = [
Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png"),
"http://images.cocodataset.org/val2017/000000039769.jpg",
]
return image_classifier, examples
def run_pipeline_test(self, image_classifier, examples):
outputs = image_classifier("./tests/fixtures/tests_samples/COCO/000000039769.png")
self.assertEqual(
outputs,
[
{"score": ANY(float), "label": ANY(str)},
{"score": ANY(float), "label": ANY(str)},
],
)
import datasets
# we use revision="refs/pr/1" until the PR is merged
# https://hf.co/datasets/hf-internal-testing/fixtures_image_utils/discussions/1
dataset = datasets.load_dataset("hf-internal-testing/fixtures_image_utils", split="test", revision="refs/pr/1")
# Accepts URL + PIL.Image + lists
outputs = image_classifier(
[
Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png"),
"http://images.cocodataset.org/val2017/000000039769.jpg",
# RGBA
dataset[0]["image"],
# LA
dataset[1]["image"],
# L
dataset[2]["image"],
]
)
self.assertEqual(
outputs,
[
[
{"score": ANY(float), "label": ANY(str)},
{"score": ANY(float), "label": ANY(str)},
],
[
{"score": ANY(float), "label": ANY(str)},
{"score": ANY(float), "label": ANY(str)},
],
[
{"score": ANY(float), "label": ANY(str)},
{"score": ANY(float), "label": ANY(str)},
],
[
{"score": ANY(float), "label": ANY(str)},
{"score": ANY(float), "label": ANY(str)},
],
[
{"score": ANY(float), "label": ANY(str)},
{"score": ANY(float), "label": ANY(str)},
],
],
)
for single_output in outputs:
for output_element in single_output:
compare_pipeline_output_to_hub_spec(output_element, ImageClassificationOutputElement)
@require_torch
def test_small_model_pt(self):
small_model = "hf-internal-testing/tiny-random-vit"
image_classifier = pipeline("image-classification", model=small_model)
outputs = image_classifier("http://images.cocodataset.org/val2017/000000039769.jpg")
self.assertEqual(
nested_simplify(outputs, decimals=4),
[{"label": "LABEL_1", "score": 0.574}, {"label": "LABEL_0", "score": 0.426}],
)
outputs = image_classifier(
[
"http://images.cocodataset.org/val2017/000000039769.jpg",
"http://images.cocodataset.org/val2017/000000039769.jpg",
],
top_k=2,
)
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
[{"label": "LABEL_1", "score": 0.574}, {"label": "LABEL_0", "score": 0.426}],
[{"label": "LABEL_1", "score": 0.574}, {"label": "LABEL_0", "score": 0.426}],
],
)
@require_tf
def test_small_model_tf(self):
small_model = "hf-internal-testing/tiny-random-vit"
image_classifier = pipeline("image-classification", model=small_model, framework="tf")
outputs = image_classifier("http://images.cocodataset.org/val2017/000000039769.jpg")
self.assertEqual(
nested_simplify(outputs, decimals=4),
[{"label": "LABEL_1", "score": 0.574}, {"label": "LABEL_0", "score": 0.426}],
)
outputs = image_classifier(
[
"http://images.cocodataset.org/val2017/000000039769.jpg",
"http://images.cocodataset.org/val2017/000000039769.jpg",
],
top_k=2,
)
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
[{"label": "LABEL_1", "score": 0.574}, {"label": "LABEL_0", "score": 0.426}],
[{"label": "LABEL_1", "score": 0.574}, {"label": "LABEL_0", "score": 0.426}],
],
)
def test_custom_tokenizer(self):
tokenizer = PreTrainedTokenizerBase()
# Assert that the pipeline can be initialized with a feature extractor that is not in any mapping
image_classifier = pipeline(
"image-classification", model="hf-internal-testing/tiny-random-vit", tokenizer=tokenizer
)
self.assertIs(image_classifier.tokenizer, tokenizer)
@require_torch
def test_torch_float16_pipeline(self):
image_classifier = pipeline(
"image-classification", model="hf-internal-testing/tiny-random-vit", torch_dtype=torch.float16
)
outputs = image_classifier("http://images.cocodataset.org/val2017/000000039769.jpg")
self.assertEqual(
nested_simplify(outputs, decimals=3),
[{"label": "LABEL_1", "score": 0.574}, {"label": "LABEL_0", "score": 0.426}],
)
@require_torch
def test_torch_bfloat16_pipeline(self):
image_classifier = pipeline(
"image-classification", model="hf-internal-testing/tiny-random-vit", torch_dtype=torch.bfloat16
)
outputs = image_classifier("http://images.cocodataset.org/val2017/000000039769.jpg")
self.assertEqual(
nested_simplify(outputs, decimals=3),
[{"label": "LABEL_1", "score": 0.574}, {"label": "LABEL_0", "score": 0.426}],
)
@slow
@require_torch
def test_perceiver(self):
# Perceiver is not tested by `run_pipeline_test` properly.
# That is because the type of feature_extractor and model preprocessor need to be kept
# in sync, which is not the case in the current design
image_classifier = pipeline("image-classification", model="deepmind/vision-perceiver-conv")
outputs = image_classifier("http://images.cocodataset.org/val2017/000000039769.jpg")
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{"score": 0.4385, "label": "tabby, tabby cat"},
{"score": 0.321, "label": "tiger cat"},
{"score": 0.0502, "label": "Egyptian cat"},
{"score": 0.0137, "label": "crib, cot"},
{"score": 0.007, "label": "radiator"},
],
)
image_classifier = pipeline("image-classification", model="deepmind/vision-perceiver-fourier")
outputs = image_classifier("http://images.cocodataset.org/val2017/000000039769.jpg")
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{"score": 0.5658, "label": "tabby, tabby cat"},
{"score": 0.1309, "label": "tiger cat"},
{"score": 0.0722, "label": "Egyptian cat"},
{"score": 0.0707, "label": "remote control, remote"},
{"score": 0.0082, "label": "computer keyboard, keypad"},
],
)
image_classifier = pipeline("image-classification", model="deepmind/vision-perceiver-learned")
outputs = image_classifier("http://images.cocodataset.org/val2017/000000039769.jpg")
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{"score": 0.3022, "label": "tabby, tabby cat"},
{"score": 0.2362, "label": "Egyptian cat"},
{"score": 0.1856, "label": "tiger cat"},
{"score": 0.0324, "label": "remote control, remote"},
{"score": 0.0096, "label": "quilt, comforter, comfort, puff"},
],
)
@slow
@require_torch
def test_multilabel_classification(self):
small_model = "hf-internal-testing/tiny-random-vit"
# Sigmoid is applied for multi-label classification
image_classifier = pipeline("image-classification", model=small_model)
image_classifier.model.config.problem_type = "multi_label_classification"
outputs = image_classifier("http://images.cocodataset.org/val2017/000000039769.jpg")
self.assertEqual(
nested_simplify(outputs, decimals=4),
[{"label": "LABEL_1", "score": 0.5356}, {"label": "LABEL_0", "score": 0.4612}],
)
outputs = image_classifier(
[
"http://images.cocodataset.org/val2017/000000039769.jpg",
"http://images.cocodataset.org/val2017/000000039769.jpg",
]
)
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
[{"label": "LABEL_1", "score": 0.5356}, {"label": "LABEL_0", "score": 0.4612}],
[{"label": "LABEL_1", "score": 0.5356}, {"label": "LABEL_0", "score": 0.4612}],
],
)
@slow
@require_torch
def test_function_to_apply(self):
small_model = "hf-internal-testing/tiny-random-vit"
# Sigmoid is applied for multi-label classification
image_classifier = pipeline("image-classification", model=small_model)
outputs = image_classifier(
"http://images.cocodataset.org/val2017/000000039769.jpg",
function_to_apply="sigmoid",
)
self.assertEqual(
nested_simplify(outputs, decimals=4),
[{"label": "LABEL_1", "score": 0.5356}, {"label": "LABEL_0", "score": 0.4612}],
)
|
transformers/tests/pipelines/test_pipelines_image_classification.py/0
|
{
"file_path": "transformers/tests/pipelines/test_pipelines_image_classification.py",
"repo_id": "transformers",
"token_count": 5745
}
| 204 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import pytest
from transformers import (
MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
MBart50TokenizerFast,
MBartConfig,
MBartForConditionalGeneration,
TranslationPipeline,
pipeline,
)
from transformers.testing_utils import is_pipeline_test, require_tf, require_torch, slow
from .test_pipelines_common import ANY
@is_pipeline_test
class TranslationPipelineTests(unittest.TestCase):
model_mapping = MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING
tf_model_mapping = TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING
def get_test_pipeline(
self,
model,
tokenizer=None,
image_processor=None,
feature_extractor=None,
processor=None,
torch_dtype="float32",
):
if isinstance(model.config, MBartConfig):
src_lang, tgt_lang = list(tokenizer.lang_code_to_id.keys())[:2]
translator = TranslationPipeline(
model=model,
tokenizer=tokenizer,
feature_extractor=feature_extractor,
image_processor=image_processor,
processor=processor,
torch_dtype=torch_dtype,
src_lang=src_lang,
tgt_lang=tgt_lang,
)
else:
translator = TranslationPipeline(
model=model,
tokenizer=tokenizer,
feature_extractor=feature_extractor,
image_processor=image_processor,
processor=processor,
torch_dtype=torch_dtype,
)
return translator, ["Some string", "Some other text"]
def run_pipeline_test(self, translator, _):
outputs = translator("Some string")
self.assertEqual(outputs, [{"translation_text": ANY(str)}])
outputs = translator(["Some string"])
self.assertEqual(outputs, [{"translation_text": ANY(str)}])
outputs = translator(["Some string", "other string"])
self.assertEqual(outputs, [{"translation_text": ANY(str)}, {"translation_text": ANY(str)}])
@require_torch
def test_small_model_pt(self):
translator = pipeline("translation_en_to_ro", model="patrickvonplaten/t5-tiny-random", framework="pt")
outputs = translator("This is a test string", max_length=20)
self.assertEqual(
outputs,
[
{
"translation_text": (
"Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide"
" Beide Beide"
)
}
],
)
@require_tf
def test_small_model_tf(self):
translator = pipeline("translation_en_to_ro", model="patrickvonplaten/t5-tiny-random", framework="tf")
outputs = translator("This is a test string", max_length=20)
self.assertEqual(
outputs,
[
{
"translation_text": (
"Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide Beide"
" Beide Beide"
)
}
],
)
@require_torch
def test_en_to_de_pt(self):
translator = pipeline("translation_en_to_de", model="patrickvonplaten/t5-tiny-random", framework="pt")
outputs = translator("This is a test string", max_length=20)
self.assertEqual(
outputs,
[
{
"translation_text": (
"monoton monoton monoton monoton monoton monoton monoton monoton monoton monoton urine urine"
" urine urine urine urine urine urine urine"
)
}
],
)
@require_tf
def test_en_to_de_tf(self):
translator = pipeline("translation_en_to_de", model="patrickvonplaten/t5-tiny-random", framework="tf")
outputs = translator("This is a test string", max_length=20)
self.assertEqual(
outputs,
[
{
"translation_text": (
"monoton monoton monoton monoton monoton monoton monoton monoton monoton monoton urine urine"
" urine urine urine urine urine urine urine"
)
}
],
)
class TranslationNewFormatPipelineTests(unittest.TestCase):
@require_torch
@slow
def test_default_translations(self):
# We don't provide a default for this pair
with self.assertRaises(ValueError):
pipeline(task="translation_cn_to_ar")
# but we do for this one
translator = pipeline(task="translation_en_to_de")
self.assertEqual(translator._preprocess_params["src_lang"], "en")
self.assertEqual(translator._preprocess_params["tgt_lang"], "de")
@require_torch
@slow
def test_multilingual_translation(self):
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
translator = pipeline(task="translation", model=model, tokenizer=tokenizer)
# Missing src_lang, tgt_lang
with self.assertRaises(ValueError):
translator("This is a test")
outputs = translator("This is a test", src_lang="en_XX", tgt_lang="ar_AR")
self.assertEqual(outputs, [{"translation_text": "هذا إختبار"}])
outputs = translator("This is a test", src_lang="en_XX", tgt_lang="hi_IN")
self.assertEqual(outputs, [{"translation_text": "यह एक परीक्षण है"}])
# src_lang, tgt_lang can be defined at pipeline call time
translator = pipeline(task="translation", model=model, tokenizer=tokenizer, src_lang="en_XX", tgt_lang="ar_AR")
outputs = translator("This is a test")
self.assertEqual(outputs, [{"translation_text": "هذا إختبار"}])
@require_torch
def test_translation_on_odd_language(self):
model = "patrickvonplaten/t5-tiny-random"
translator = pipeline(task="translation_cn_to_ar", model=model)
self.assertEqual(translator._preprocess_params["src_lang"], "cn")
self.assertEqual(translator._preprocess_params["tgt_lang"], "ar")
@require_torch
def test_translation_default_language_selection(self):
model = "patrickvonplaten/t5-tiny-random"
with pytest.warns(UserWarning, match=r".*translation_en_to_de.*"):
translator = pipeline(task="translation", model=model)
self.assertEqual(translator.task, "translation_en_to_de")
self.assertEqual(translator._preprocess_params["src_lang"], "en")
self.assertEqual(translator._preprocess_params["tgt_lang"], "de")
@require_torch
def test_translation_with_no_language_no_model_fails(self):
with self.assertRaises(ValueError):
pipeline(task="translation")
|
transformers/tests/pipelines/test_pipelines_translation.py/0
|
{
"file_path": "transformers/tests/pipelines/test_pipelines_translation.py",
"repo_id": "transformers",
"token_count": 3494
}
| 205 |
# coding=utf-8
# Copyright 2022 The HuggingFace Team Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a clone of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import importlib.metadata
import tempfile
import unittest
from packaging import version
from transformers import (
AutoConfig,
AutoModel,
AutoModelForCausalLM,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoTokenizer,
BitsAndBytesConfig,
pipeline,
)
from transformers.models.opt.modeling_opt import OPTAttention
from transformers.testing_utils import (
apply_skip_if_not_implemented,
is_accelerate_available,
is_bitsandbytes_available,
is_torch_available,
require_accelerate,
require_bitsandbytes,
require_torch,
require_torch_gpu_if_bnb_not_multi_backend_enabled,
require_torch_multi_gpu,
slow,
torch_device,
)
def get_some_linear_layer(model):
if model.config.model_type == "gpt2":
return model.transformer.h[0].mlp.c_fc
elif model.config.model_type == "llama":
return model.model.layers[0].mlp.gate_proj
return model.transformer.h[0].mlp.dense_4h_to_h
if is_accelerate_available():
from accelerate import PartialState
from accelerate.logging import get_logger
logger = get_logger(__name__)
_ = PartialState()
if is_torch_available():
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
"""Wraps a linear layer with LoRA-like adapter - Used for testing purposes only"""
def __init__(self, module: nn.Module, rank: int, dtype: torch.dtype):
super().__init__()
self.module = module
self.adapter = nn.Sequential(
nn.Linear(module.in_features, rank, bias=False, dtype=dtype),
nn.Linear(rank, module.out_features, bias=False, dtype=dtype),
)
small_std = (2.0 / (5 * min(module.in_features, module.out_features))) ** 0.5
nn.init.normal_(self.adapter[0].weight, std=small_std)
nn.init.zeros_(self.adapter[1].weight)
self.adapter.to(module.weight.device)
def forward(self, input, *args, **kwargs):
return self.module(input, *args, **kwargs) + self.adapter(input)
if is_bitsandbytes_available():
import bitsandbytes as bnb
@require_bitsandbytes
@require_accelerate
@require_torch
@require_torch_gpu_if_bnb_not_multi_backend_enabled
@slow
class BaseMixedInt8Test(unittest.TestCase):
# We keep the constants inside the init function and model loading inside setUp function
# We need to test on relatively large models (aka >1b parameters otherwise the quantiztion may not work as expected)
# Therefore here we use only bloom-1b3 to test our module
model_name = "bigscience/bloom-1b7"
# Constant values
EXPECTED_RELATIVE_DIFFERENCE = (
1.540025 # This was obtained on a Quadro RTX 8000 so the number might slightly change
)
input_text = "Hello my name is"
EXPECTED_OUTPUTS = set()
EXPECTED_OUTPUTS.add("Hello my name is John.\nI am a friend of the family.\n")
# Expected values on a A10
EXPECTED_OUTPUTS.add("Hello my name is John.\nI am a friend of your father.\n")
MAX_NEW_TOKENS = 10
# Expected values with offload
EXPECTED_OUTPUTS.add("Hello my name is John and I am a professional photographer based in")
def setUp(self):
# Models and tokenizer
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
@apply_skip_if_not_implemented
class MixedInt8Test(BaseMixedInt8Test):
def setUp(self):
super().setUp()
# Models and tokenizer
self.model_fp16 = AutoModelForCausalLM.from_pretrained(
self.model_name, torch_dtype=torch.float16, device_map="auto"
)
self.model_8bit = AutoModelForCausalLM.from_pretrained(self.model_name, load_in_8bit=True, device_map="auto")
def tearDown(self):
r"""
TearDown function needs to be called at the end of each test to free the GPU memory and cache, also to
avoid unexpected behaviors. Please see: https://discuss.pytorch.org/t/how-can-we-release-gpu-memory-cache/14530/27
"""
del self.model_fp16
del self.model_8bit
gc.collect()
torch.cuda.empty_cache()
def test_get_keys_to_not_convert_trust_remote_code(self):
r"""
Test the `get_keys_to_not_convert` function with `trust_remote_code` models.
"""
from accelerate import init_empty_weights
from transformers.integrations.bitsandbytes import get_keys_to_not_convert
model_id = "mosaicml/mpt-7b"
config = AutoConfig.from_pretrained(
model_id, trust_remote_code=True, revision="ada218f9a93b5f1c6dce48a4cc9ff01fcba431e7"
)
with init_empty_weights():
model = AutoModelForCausalLM.from_config(
config, trust_remote_code=True, code_revision="ada218f9a93b5f1c6dce48a4cc9ff01fcba431e7"
)
self.assertEqual(get_keys_to_not_convert(model), ["transformer.wte"])
def test_get_keys_to_not_convert(self):
r"""
Test the `get_keys_to_not_convert` function.
"""
from accelerate import init_empty_weights
from transformers import AutoModelForMaskedLM, Blip2ForConditionalGeneration, MptForCausalLM, OPTForCausalLM
from transformers.integrations.bitsandbytes import get_keys_to_not_convert
model_id = "mosaicml/mpt-7b"
config = AutoConfig.from_pretrained(model_id, revision="72e5f594ce36f9cabfa2a9fd8f58b491eb467ee7")
with init_empty_weights():
model = MptForCausalLM(config)
# The order of the keys does not matter, so we sort them before comparing, same for the other tests.
self.assertEqual(get_keys_to_not_convert(model).sort(), ["lm_head", "transformer.wte"].sort())
model_id = "Salesforce/blip2-opt-2.7b"
config = AutoConfig.from_pretrained(model_id, revision="1ef7f63a8f0a144c13fdca8103eb7b4691c74cec")
with init_empty_weights():
model = Blip2ForConditionalGeneration(config)
self.assertEqual(
get_keys_to_not_convert(model).sort(),
["language_model.lm_head", "language_model.model.decoder.embed_tokens"].sort(),
)
model_id = "facebook/opt-350m"
config = AutoConfig.from_pretrained(model_id, revision="cb32f77e905cccbca1d970436fb0f5e6b58ee3c5")
with init_empty_weights():
model = OPTForCausalLM(config)
self.assertEqual(get_keys_to_not_convert(model).sort(), ["lm_head", "model.decoder.embed_tokens"].sort())
model_id = "FacebookAI/roberta-large"
config = AutoConfig.from_pretrained(model_id, revision="716877d372b884cad6d419d828bac6c85b3b18d9")
with init_empty_weights():
model = AutoModelForMaskedLM.from_config(config)
self.assertEqual(
get_keys_to_not_convert(model).sort(),
["'roberta.embeddings.word_embeddings', 'lm_head', 'lm_head.decoder"].sort(),
)
def test_quantization_config_json_serialization(self):
r"""
A simple test to check if the quantization config is correctly serialized and deserialized
"""
config = self.model_8bit.config
self.assertTrue(hasattr(config, "quantization_config"))
_ = config.to_dict()
_ = config.to_diff_dict()
_ = config.to_json_string()
def test_original_dtype(self):
r"""
A simple test to check if the model succesfully stores the original dtype
"""
self.assertTrue(hasattr(self.model_8bit.config, "_pre_quantization_dtype"))
self.assertFalse(hasattr(self.model_fp16.config, "_pre_quantization_dtype"))
self.assertTrue(self.model_8bit.config._pre_quantization_dtype == torch.float16)
def test_memory_footprint(self):
r"""
A simple test to check if the model conversion has been done correctly by checking on the
memory footprint of the converted model and the class type of the linear layers of the converted models
"""
from bitsandbytes.nn import Int8Params
mem_fp16 = self.model_fp16.get_memory_footprint()
mem_8bit = self.model_8bit.get_memory_footprint()
self.assertAlmostEqual(mem_fp16 / mem_8bit, self.EXPECTED_RELATIVE_DIFFERENCE, delta=1e-5)
self.assertTrue(get_some_linear_layer(self.model_8bit).weight.__class__ == Int8Params)
def test_linear_are_8bit(self):
r"""
A simple test to check if the model conversion has been done correctly by checking on the
memory footprint of the converted model and the class type of the linear layers of the converted models
"""
from transformers import T5PreTrainedModel
self.model_fp16.get_memory_footprint()
self.model_8bit.get_memory_footprint()
for name, module in self.model_8bit.named_modules():
if isinstance(module, torch.nn.Linear):
if name not in ["lm_head"] + T5PreTrainedModel._keep_in_fp32_modules:
self.assertTrue(module.weight.dtype == torch.int8)
def test_llm_skip(self):
r"""
A simple test to check if `llm_int8_skip_modules` works as expected
"""
quantization_config = BitsAndBytesConfig(load_in_8bit=True, llm_int8_skip_modules=["classifier"])
seq_classification_model = AutoModelForSequenceClassification.from_pretrained(
"FacebookAI/roberta-large-mnli", quantization_config=quantization_config
)
self.assertTrue(seq_classification_model.roberta.encoder.layer[0].output.dense.weight.dtype == torch.int8)
self.assertTrue(
isinstance(seq_classification_model.roberta.encoder.layer[0].output.dense, bnb.nn.Linear8bitLt)
)
self.assertTrue(isinstance(seq_classification_model.classifier.dense, nn.Linear))
self.assertTrue(seq_classification_model.classifier.dense.weight.dtype != torch.int8)
self.assertTrue(isinstance(seq_classification_model.classifier.out_proj, nn.Linear))
self.assertTrue(seq_classification_model.classifier.out_proj != torch.int8)
def test_generate_quality(self):
r"""
Test the generation quality of the quantized model and see that we are matching the expected output.
Given that we are operating on small numbers + the testing model is relatively small, we might not get
the same output across GPUs. So we'll generate few tokens (5-10) and check their output.
"""
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = self.model_8bit.generate(
input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10
)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
def test_generate_quality_config(self):
r"""
Test that loading the model with the config is equivalent
"""
bnb_config = BitsAndBytesConfig()
bnb_config.load_in_8bit = True
model_8bit_from_config = AutoModelForCausalLM.from_pretrained(
self.model_name, quantization_config=bnb_config, device_map="auto"
)
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = model_8bit_from_config.generate(
input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10
)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
def test_generate_quality_dequantize(self):
r"""
Test that loading the model and dequantizing it produce correct results
"""
bnb_config = BitsAndBytesConfig(load_in_8bit=True)
model_8bit = AutoModelForCausalLM.from_pretrained(
self.model_name, quantization_config=bnb_config, device_map="auto"
)
model_8bit.dequantize()
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = model_8bit.generate(
input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10
)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
def test_raise_if_config_and_load_in_8bit(self):
r"""
Test that loading the model with the config and `load_in_8bit` raises an error
"""
bnb_config = BitsAndBytesConfig()
with self.assertRaises(ValueError):
_ = AutoModelForCausalLM.from_pretrained(
self.model_name,
quantization_config=bnb_config,
load_in_8bit=True,
device_map="auto",
llm_int8_enable_fp32_cpu_offload=True,
)
def test_device_and_dtype_assignment(self):
r"""
Test whether attempting to change the device or cast the dtype of a model
after converting it to 8-bit precision will raise an appropriate error.
The test ensures that such operations are prohibited on 8-bit models
to prevent invalid conversions.
"""
with self.assertRaises(ValueError):
# Tries with `str`
self.model_8bit.to("cpu")
with self.assertRaises(ValueError):
# Tries with a `dtype``
self.model_8bit.to(torch.float16)
with self.assertRaises(ValueError):
# Tries with a `device`
self.model_8bit.to(torch.device(torch_device))
with self.assertRaises(ValueError):
# Tries to cast the 8-bit model to float32 using `float()`
self.model_8bit.float()
with self.assertRaises(ValueError):
# Tries to cast the 4-bit model to float16 using `half()`
self.model_8bit.half()
# Test if we did not break anything
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
self.model_fp16 = self.model_fp16.to(torch.float32)
_ = self.model_fp16.generate(input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10)
# Check this does not throw an error
_ = self.model_fp16.to("cpu")
# Check this does not throw an error
_ = self.model_fp16.half()
# Check this does not throw an error
_ = self.model_fp16.float()
def test_fp32_int8_conversion(self):
r"""
Test whether it is possible to mix both `int8` and `fp32` weights when using `keep_in_fp32_modules` correctly.
"""
model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small", load_in_8bit=True, device_map="auto")
self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wo.weight.dtype == torch.float32)
def test_int8_serialization(self):
r"""
Test whether it is possible to serialize a model in 8-bit.
"""
from bitsandbytes.nn import Int8Params
with tempfile.TemporaryDirectory() as tmpdirname:
self.model_8bit.save_pretrained(tmpdirname)
# check that the file `quantization_config` is present
config = AutoConfig.from_pretrained(tmpdirname)
self.assertTrue(hasattr(config, "quantization_config"))
model_from_saved = AutoModelForCausalLM.from_pretrained(tmpdirname, load_in_8bit=True, device_map="auto")
linear = get_some_linear_layer(model_from_saved)
self.assertTrue(linear.weight.__class__ == Int8Params)
self.assertTrue(hasattr(linear.weight, "SCB"))
# generate
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = model_from_saved.generate(
input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10
)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
def test_int8_serialization_regression(self):
r"""
Test whether it is possible to serialize a model in 8-bit - using not safetensors
"""
from bitsandbytes.nn import Int8Params
with tempfile.TemporaryDirectory() as tmpdirname:
self.model_8bit.save_pretrained(tmpdirname, safe_serialization=False)
# check that the file `quantization_config` is present
config = AutoConfig.from_pretrained(tmpdirname)
self.assertTrue(hasattr(config, "quantization_config"))
model_from_saved = AutoModelForCausalLM.from_pretrained(tmpdirname, load_in_8bit=True, device_map="auto")
linear = get_some_linear_layer(model_from_saved)
self.assertTrue(linear.weight.__class__ == Int8Params)
self.assertTrue(hasattr(linear.weight, "SCB"))
# generate
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = model_from_saved.generate(
input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10
)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
def test_int8_serialization_sharded(self):
r"""
Test whether it is possible to serialize a model in 8-bit - sharded version.
"""
from bitsandbytes.nn import Int8Params
with tempfile.TemporaryDirectory() as tmpdirname:
self.model_8bit.save_pretrained(tmpdirname, max_shard_size="200MB")
# check that the file `quantization_config` is present
config = AutoConfig.from_pretrained(tmpdirname)
self.assertTrue(hasattr(config, "quantization_config"))
model_from_saved = AutoModelForCausalLM.from_pretrained(tmpdirname)
linear = get_some_linear_layer(model_from_saved)
self.assertTrue(linear.weight.__class__ == Int8Params)
self.assertTrue(hasattr(linear.weight, "SCB"))
# generate
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = model_from_saved.generate(
input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10
)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
def test_int8_from_pretrained(self):
r"""
Test whether loading a 8bit model from the Hub works as expected
"""
from bitsandbytes.nn import Int8Params
model_id = "ybelkada/bloom-1b7-8bit"
model = AutoModelForCausalLM.from_pretrained(model_id)
linear = get_some_linear_layer(model)
self.assertTrue(linear.weight.__class__ == Int8Params)
self.assertTrue(hasattr(linear.weight, "SCB"))
# generate
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = model.generate(input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
@require_bitsandbytes
@require_accelerate
@require_torch
@require_torch_gpu_if_bnb_not_multi_backend_enabled
@slow
class MixedInt8T5Test(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.model_name = "google-t5/t5-small"
cls.dense_act_model_name = "google/flan-t5-small" # flan-t5 uses dense-act instead of dense-relu-dense
cls.tokenizer = AutoTokenizer.from_pretrained(cls.model_name)
cls.input_text = "Translate in German: Hello, my dog is cute"
def tearDown(self):
r"""
TearDown function needs to be called at the end of each test to free the GPU memory and cache, also to
avoid unexpected behaviors. Please see: https://discuss.pytorch.org/t/how-can-we-release-gpu-memory-cache/14530/27
"""
gc.collect()
torch.cuda.empty_cache()
def test_inference_without_keep_in_fp32(self):
r"""
Test whether it is possible to mix both `int8` and `fp32` weights when using `keep_in_fp32_modules` correctly.
`flan-t5-small` uses `T5DenseGatedActDense` whereas `google-t5/t5-small` uses `T5DenseReluDense`. We need to test
both cases.
"""
from transformers import T5ForConditionalGeneration
modules = T5ForConditionalGeneration._keep_in_fp32_modules
T5ForConditionalGeneration._keep_in_fp32_modules = None
# test with `google-t5/t5-small`
model = T5ForConditionalGeneration.from_pretrained(self.model_name, load_in_8bit=True, device_map="auto")
encoded_input = self.tokenizer(self.input_text, return_tensors="pt").to(model.device)
_ = model.generate(**encoded_input)
# test with `flan-t5-small`
model = T5ForConditionalGeneration.from_pretrained(
self.dense_act_model_name, load_in_8bit=True, device_map="auto"
)
encoded_input = self.tokenizer(self.input_text, return_tensors="pt").to(model.device)
_ = model.generate(**encoded_input)
T5ForConditionalGeneration._keep_in_fp32_modules = modules
def test_inference_with_keep_in_fp32(self):
r"""
Test whether it is possible to mix both `int8` and `fp32` weights when using `keep_in_fp32_modules` correctly.
`flan-t5-small` uses `T5DenseGatedActDense` whereas `google-t5/t5-small` uses `T5DenseReluDense`. We need to test
both cases.
"""
from transformers import T5ForConditionalGeneration
# test with `google-t5/t5-small`
model = T5ForConditionalGeneration.from_pretrained(self.model_name, load_in_8bit=True, device_map="auto")
# there was a bug with decoders - this test checks that it is fixed
self.assertTrue(isinstance(model.decoder.block[0].layer[0].SelfAttention.q, bnb.nn.Linear8bitLt))
encoded_input = self.tokenizer(self.input_text, return_tensors="pt").to(model.device)
_ = model.generate(**encoded_input)
# test with `flan-t5-small`
model = T5ForConditionalGeneration.from_pretrained(
self.dense_act_model_name, load_in_8bit=True, device_map="auto"
)
encoded_input = self.tokenizer(self.input_text, return_tensors="pt").to(model.device)
_ = model.generate(**encoded_input)
def test_inference_with_keep_in_fp32_serialized(self):
r"""
Test whether it is possible to mix both `int8` and `fp32` weights when using `keep_in_fp32_modules` correctly on
a serialized model.
`flan-t5-small` uses `T5DenseGatedActDense` whereas `google-t5/t5-small` uses `T5DenseReluDense`. We need to test
both cases.
"""
from transformers import T5ForConditionalGeneration
# test with `google-t5/t5-small`
model = T5ForConditionalGeneration.from_pretrained(self.model_name, load_in_8bit=True, device_map="auto")
with tempfile.TemporaryDirectory() as tmp_dir:
model.save_pretrained(tmp_dir)
model = T5ForConditionalGeneration.from_pretrained(tmp_dir)
# there was a bug with decoders - this test checks that it is fixed
self.assertTrue(isinstance(model.decoder.block[0].layer[0].SelfAttention.q, bnb.nn.Linear8bitLt))
encoded_input = self.tokenizer(self.input_text, return_tensors="pt").to(model.device)
_ = model.generate(**encoded_input)
# test with `flan-t5-small`
model = T5ForConditionalGeneration.from_pretrained(
self.dense_act_model_name, load_in_8bit=True, device_map="auto"
)
encoded_input = self.tokenizer(self.input_text, return_tensors="pt").to(model.device)
_ = model.generate(**encoded_input)
class MixedInt8ModelClassesTest(BaseMixedInt8Test):
def setUp(self):
super().setUp()
# model_name
self.model_name = "bigscience/bloom-560m"
self.seq_to_seq_name = "google-t5/t5-small"
# Different types of model
self.base_model = AutoModel.from_pretrained(self.model_name, load_in_8bit=True, device_map="auto")
# Sequence classification model
self.sequence_model = AutoModelForSequenceClassification.from_pretrained(
self.model_name, load_in_8bit=True, device_map="auto"
)
# CausalLM model
self.model_8bit = AutoModelForCausalLM.from_pretrained(self.model_name, load_in_8bit=True, device_map="auto")
# Seq2seq model
self.seq_to_seq_model = AutoModelForSeq2SeqLM.from_pretrained(
self.seq_to_seq_name, load_in_8bit=True, device_map="auto"
)
def tearDown(self):
r"""
TearDown function needs to be called at the end of each test to free the GPU memory and cache, also to
avoid unexpected behaviors. Please see: https://discuss.pytorch.org/t/how-can-we-release-gpu-memory-cache/14530/27
"""
del self.base_model
del self.sequence_model
del self.model_8bit
del self.seq_to_seq_model
gc.collect()
torch.cuda.empty_cache()
def test_correct_head_class(self):
r"""
A simple test to check if the last modules for some classes (AutoModelForCausalLM or SequenceClassification)
are kept in their native class.
"""
from bitsandbytes.nn import Int8Params
# last param of a base model should be a linear8bit module
self.assertTrue(self.base_model.h[-1].mlp.dense_4h_to_h.weight.__class__ == Int8Params)
# Other heads should be nn.Parameter
self.assertTrue(self.model_8bit.lm_head.weight.__class__ == torch.nn.Parameter)
self.assertTrue(self.sequence_model.score.weight.__class__ == torch.nn.Parameter)
self.assertTrue(self.seq_to_seq_model.lm_head.weight.__class__ == torch.nn.Parameter)
@apply_skip_if_not_implemented
class MixedInt8TestPipeline(BaseMixedInt8Test):
def setUp(self):
super().setUp()
def tearDown(self):
r"""
TearDown function needs to be called at the end of each test to free the GPU memory and cache, also to
avoid unexpected behaviors. Please see: https://discuss.pytorch.org/t/how-can-we-release-gpu-memory-cache/14530/27
"""
if hasattr(self, "pipe"):
del self.pipe
gc.collect()
torch.cuda.empty_cache()
def test_pipeline(self):
r"""
The aim of this test is to verify that the mixed int8 is compatible with `pipeline` from transformers. Since
we used pipline for inference speed benchmarking we want to make sure that this feature does not break anything
on pipline.
"""
# self._clear_cuda_cache()
self.pipe = pipeline(
"text-generation",
model=self.model_name,
model_kwargs={"device_map": "auto", "load_in_8bit": True},
max_new_tokens=self.MAX_NEW_TOKENS,
)
# Real second forward pass
pipeline_output = self.pipe(self.input_text)
self.assertIn(pipeline_output[0]["generated_text"], self.EXPECTED_OUTPUTS)
@require_torch_multi_gpu
@apply_skip_if_not_implemented
class MixedInt8TestMultiGpu(BaseMixedInt8Test):
def setUp(self):
super().setUp()
def test_multi_gpu_loading(self):
r"""
This tests that the model has been loaded and can be used correctly on a multi-GPU setup.
Let's just try to load a model on 2 GPUs and see if it works. The model we test has ~2GB of total, 3GB should suffice
"""
model_parallel = AutoModelForCausalLM.from_pretrained(
self.model_name, load_in_8bit=True, device_map="balanced"
)
# Check correct device map
self.assertEqual(set(model_parallel.hf_device_map.values()), {0, 1})
# Check that inference pass works on the model
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
# Second real batch
output_parallel = model_parallel.generate(
input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10
)
self.assertIn(self.tokenizer.decode(output_parallel[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
@require_torch_multi_gpu
@apply_skip_if_not_implemented
class MixedInt8TestCpuGpu(BaseMixedInt8Test):
def setUp(self):
super().setUp()
def check_inference_correctness(self, model):
# Check that inference pass works on the model
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
# Check the exactness of the results
output_parallel = model.generate(input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10)
# Get the generation
output_text = self.tokenizer.decode(output_parallel[0], skip_special_tokens=True)
self.assertIn(output_text, self.EXPECTED_OUTPUTS)
def test_cpu_gpu_loading_random_device_map(self):
r"""
A test to check is dispatching a model on cpu & gpu works correctly using a random `device_map`.
"""
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": 0,
"lm_head": 0,
"transformer.h.0": "cpu",
"transformer.h.1": "cpu",
"transformer.h.2": 0,
"transformer.h.3": 0,
"transformer.h.4": 0,
"transformer.h.5": 0,
"transformer.h.6": 0,
"transformer.h.7": 0,
"transformer.h.8": 0,
"transformer.h.9": 1,
"transformer.h.10": 0,
"transformer.h.11": 1,
"transformer.h.12": 0,
"transformer.h.13": 0,
"transformer.h.14": 1,
"transformer.h.15": 0,
"transformer.h.16": 0,
"transformer.h.17": 1,
"transformer.h.18": 1,
"transformer.h.19": 0,
"transformer.h.20": 1,
"transformer.h.21": 1,
"transformer.h.22": 0,
"transformer.h.23": 0,
"transformer.ln_f": 1,
}
bnb_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True, load_in_8bit=True)
model_8bit = AutoModelForCausalLM.from_pretrained(
self.model_name,
device_map=device_map,
quantization_config=bnb_config,
)
# Check that the model has been correctly set on device 0, 1, and `cpu`.
self.assertEqual(set(model_8bit.hf_device_map.values()), {0, 1, "cpu"})
self.check_inference_correctness(model_8bit)
def test_cpu_gpu_loading_custom_device_map(self):
r"""
A test to check is dispatching a model on cpu & gpu works correctly using a custom `device_map`.
This time the device map is more organized than the test above and uses the abstraction
`transformer.h` to encapsulate all the decoder layers.
"""
device_map = {
"transformer.word_embeddings": "cpu",
"transformer.word_embeddings_layernorm": "cpu",
"lm_head": "cpu",
"transformer.h": 0,
"transformer.ln_f": 1,
}
bnb_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True, load_in_8bit=True)
# Load model
model_8bit = AutoModelForCausalLM.from_pretrained(
self.model_name,
device_map=device_map,
quantization_config=bnb_config,
)
# Check that the model has been correctly set on device 0, 1, and `cpu`.
self.assertEqual(set(model_8bit.hf_device_map.values()), {0, 1, "cpu"})
self.check_inference_correctness(model_8bit)
def test_cpu_gpu_disk_loading_custom_device_map(self):
r"""
A test to check is dispatching a model on cpu & gpu works correctly using a custom `device_map`.
This time we also add `disk` on the device_map.
"""
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": "cpu",
"lm_head": 0,
"transformer.h": 1,
"transformer.ln_f": "disk",
}
bnb_config = BitsAndBytesConfig(llm_int8_enable_fp32_cpu_offload=True, load_in_8bit=True)
with tempfile.TemporaryDirectory() as tmpdirname:
# Load model
model_8bit = AutoModelForCausalLM.from_pretrained(
self.model_name,
device_map=device_map,
quantization_config=bnb_config,
offload_folder=tmpdirname,
)
# Check that the model has been correctly set on device 0, 1, and `cpu`.
self.assertEqual(set(model_8bit.hf_device_map.values()), {0, 1, "cpu", "disk"})
self.check_inference_correctness(model_8bit)
def test_cpu_gpu_disk_loading_custom_device_map_kwargs(self):
r"""
A test to check is dispatching a model on cpu & gpu works correctly using a custom `device_map`.
This time we also add `disk` on the device_map - using the kwargs directly instead of the quantization config
"""
device_map = {
"transformer.word_embeddings": 0,
"transformer.word_embeddings_layernorm": "cpu",
"lm_head": 0,
"transformer.h": 1,
"transformer.ln_f": "disk",
}
with tempfile.TemporaryDirectory() as tmpdirname:
# Load model
model_8bit = AutoModelForCausalLM.from_pretrained(
self.model_name,
device_map=device_map,
load_in_8bit=True,
llm_int8_enable_fp32_cpu_offload=True,
offload_folder=tmpdirname,
)
# Check that the model has been correctly set on device 0, 1, and `cpu`.
self.assertEqual(set(model_8bit.hf_device_map.values()), {0, 1, "cpu", "disk"})
self.check_inference_correctness(model_8bit)
@apply_skip_if_not_implemented
class MixedInt8TestTraining(BaseMixedInt8Test):
def setUp(self):
self.model_name = "facebook/opt-350m"
super().setUp()
def test_training(self):
if version.parse(importlib.metadata.version("bitsandbytes")) < version.parse("0.37.0"):
self.skipTest(reason="This test requires bitsandbytes>=0.37.0")
# Step 1: freeze all parameters
model = AutoModelForCausalLM.from_pretrained(self.model_name, load_in_8bit=True)
if torch.cuda.is_available():
self.assertEqual(set(model.hf_device_map.values()), {torch.cuda.current_device()})
elif torch.xpu.is_available():
self.assertEqual(set(model.hf_device_map.values()), {f"xpu:{torch.xpu.current_device()}"})
else:
self.assertTrue(all(param.device.type == "cpu" for param in model.parameters()))
for param in model.parameters():
param.requires_grad = False # freeze the model - train adapters later
# cast all non INT8 parameters to fp32
if param.dtype in (torch.float16, torch.bfloat16) and param.__class__.__name__ != "Params4bit":
param.data = param.data.to(torch.float32)
# Step 2: add adapters
for _, module in model.named_modules():
if isinstance(module, OPTAttention):
module.q_proj = LoRALayer(module.q_proj, rank=16, dtype=model.dtype)
module.k_proj = LoRALayer(module.k_proj, rank=16, dtype=model.dtype)
module.v_proj = LoRALayer(module.v_proj, rank=16, dtype=model.dtype)
# Step 3: dummy batch
batch = self.tokenizer("Test batch ", return_tensors="pt").to(torch_device)
# Step 4: Check if the gradient is not None
if torch_device in {"xpu", "cpu"}:
# XPU and CPU finetune do not support autocast for now.
out = model.forward(**batch)
out.logits.norm().backward()
else:
with torch.autocast(torch_device):
out = model.forward(**batch)
out.logits.norm().backward()
for module in model.modules():
if isinstance(module, LoRALayer):
self.assertTrue(module.adapter[1].weight.grad is not None)
self.assertTrue(module.adapter[1].weight.grad.norm().item() > 0)
elif isinstance(module, nn.Embedding):
self.assertTrue(module.weight.grad is None)
@apply_skip_if_not_implemented
@unittest.skipIf(torch_device == "xpu", reason="XPU has precision issue on gpt model, will test it once fixed")
class MixedInt8GPT2Test(MixedInt8Test):
model_name = "openai-community/gpt2-xl"
EXPECTED_RELATIVE_DIFFERENCE = 1.8720077507258357
EXPECTED_OUTPUTS = set()
EXPECTED_OUTPUTS.add("Hello my name is John Doe, and I'm a big fan of")
EXPECTED_OUTPUTS.add("Hello my name is John Doe, and I'm a fan of the")
# Expected values on a A10
EXPECTED_OUTPUTS.add("Hello my name is John Doe, and I am a member of the")
# Expected values on Intel CPU
EXPECTED_OUTPUTS.add("Hello my name is John Doe. I am a man. I am")
EXPECTED_OUTPUTS.add("Hello my name is John, and I'm a writer. I'm")
def test_int8_from_pretrained(self):
r"""
Test whether loading a 8bit model from the Hub works as expected
"""
from bitsandbytes.nn import Int8Params
model_id = "ybelkada/gpt2-xl-8bit"
model = AutoModelForCausalLM.from_pretrained(model_id)
linear = get_some_linear_layer(model)
self.assertTrue(linear.weight.__class__ == Int8Params)
self.assertTrue(hasattr(linear.weight, "SCB"))
# generate
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = model.generate(input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
class MixedInt8LlamaTest(MixedInt8Test):
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
EXPECTED_RELATIVE_DIFFERENCE = 1.7869331026479096
EXPECTED_OUTPUTS = set()
# Expected on Intel XPU
EXPECTED_OUTPUTS.add("Hello my name is John Smith and I am a software engineer. I")
# Expected on NVIDIA T4
EXPECTED_OUTPUTS.add("Hello my name is John and I am a software engineer. I have")
def test_int8_from_pretrained(self):
r"""
Test whether loading a 8bit model from the Hub works as expected
"""
from bitsandbytes.nn import Int8Params
model_id = "Jiqing/TinyLlama-1.1B-Chat-v1.0-bnb-8bit"
model = AutoModelForCausalLM.from_pretrained(model_id)
linear = get_some_linear_layer(model)
self.assertTrue(linear.weight.__class__ == Int8Params)
self.assertTrue(hasattr(linear.weight, "SCB"))
# generate
encoded_input = self.tokenizer(self.input_text, return_tensors="pt")
output_sequences = model.generate(input_ids=encoded_input["input_ids"].to(torch_device), max_new_tokens=10)
self.assertIn(self.tokenizer.decode(output_sequences[0], skip_special_tokens=True), self.EXPECTED_OUTPUTS)
|
transformers/tests/quantization/bnb/test_mixed_int8.py/0
|
{
"file_path": "transformers/tests/quantization/bnb/test_mixed_int8.py",
"repo_id": "transformers",
"token_count": 17432
}
| 206 |
import json
import logging
import os
import subprocess
from argparse import ArgumentParser
logger = logging.getLogger(__name__)
def parse_args():
parser = ArgumentParser()
parsed, unknown = parser.parse_known_args()
for arg in unknown:
if arg.startswith(("-", "--")):
parser.add_argument(arg.split("=")[0])
return parser.parse_args()
def main():
args = parse_args()
port = 8888
num_gpus = int(os.environ["SM_NUM_GPUS"])
hosts = json.loads(os.environ["SM_HOSTS"])
num_nodes = len(hosts)
current_host = os.environ["SM_CURRENT_HOST"]
rank = hosts.index(current_host)
os.environ["NCCL_DEBUG"] = "INFO"
if num_nodes > 1:
cmd = f"""python -m torch.distributed.launch \
--nnodes={num_nodes} \
--node_rank={rank} \
--nproc_per_node={num_gpus} \
--master_addr={hosts[0]} \
--master_port={port} \
./run_glue.py \
{"".join([f" --{parameter} {value}" for parameter,value in args.__dict__.items()])}"""
else:
cmd = f"""python -m torch.distributed.launch \
--nproc_per_node={num_gpus} \
./run_glue.py \
{"".join([f" --{parameter} {value}" for parameter,value in args.__dict__.items()])}"""
try:
subprocess.run(cmd, shell=True)
except Exception as e:
logger.info(e)
if __name__ == "__main__":
main()
|
transformers/tests/sagemaker/scripts/pytorch/run_ddp.py/0
|
{
"file_path": "transformers/tests/sagemaker/scripts/pytorch/run_ddp.py",
"repo_id": "transformers",
"token_count": 694
}
| 207 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import inspect
import json
import os
import random
import re
import unittest
from dataclasses import fields, is_dataclass
from pathlib import Path
from textwrap import dedent
from typing import get_args
from huggingface_hub import (
AudioClassificationInput,
AutomaticSpeechRecognitionInput,
DepthEstimationInput,
ImageClassificationInput,
ImageSegmentationInput,
ImageToTextInput,
ObjectDetectionInput,
QuestionAnsweringInput,
VideoClassificationInput,
ZeroShotImageClassificationInput,
)
from transformers.models.auto.processing_auto import PROCESSOR_MAPPING_NAMES
from transformers.pipelines import (
AudioClassificationPipeline,
AutomaticSpeechRecognitionPipeline,
DepthEstimationPipeline,
ImageClassificationPipeline,
ImageSegmentationPipeline,
ImageToTextPipeline,
ObjectDetectionPipeline,
QuestionAnsweringPipeline,
VideoClassificationPipeline,
ZeroShotImageClassificationPipeline,
)
from transformers.testing_utils import (
is_pipeline_test,
require_av,
require_pytesseract,
require_timm,
require_torch,
require_torch_or_tf,
require_vision,
)
from transformers.utils import direct_transformers_import, logging
from .pipelines.test_pipelines_audio_classification import AudioClassificationPipelineTests
from .pipelines.test_pipelines_automatic_speech_recognition import AutomaticSpeechRecognitionPipelineTests
from .pipelines.test_pipelines_depth_estimation import DepthEstimationPipelineTests
from .pipelines.test_pipelines_document_question_answering import DocumentQuestionAnsweringPipelineTests
from .pipelines.test_pipelines_feature_extraction import FeatureExtractionPipelineTests
from .pipelines.test_pipelines_fill_mask import FillMaskPipelineTests
from .pipelines.test_pipelines_image_classification import ImageClassificationPipelineTests
from .pipelines.test_pipelines_image_feature_extraction import ImageFeatureExtractionPipelineTests
from .pipelines.test_pipelines_image_segmentation import ImageSegmentationPipelineTests
from .pipelines.test_pipelines_image_text_to_text import ImageTextToTextPipelineTests
from .pipelines.test_pipelines_image_to_image import ImageToImagePipelineTests
from .pipelines.test_pipelines_image_to_text import ImageToTextPipelineTests
from .pipelines.test_pipelines_mask_generation import MaskGenerationPipelineTests
from .pipelines.test_pipelines_object_detection import ObjectDetectionPipelineTests
from .pipelines.test_pipelines_question_answering import QAPipelineTests
from .pipelines.test_pipelines_summarization import SummarizationPipelineTests
from .pipelines.test_pipelines_table_question_answering import TQAPipelineTests
from .pipelines.test_pipelines_text2text_generation import Text2TextGenerationPipelineTests
from .pipelines.test_pipelines_text_classification import TextClassificationPipelineTests
from .pipelines.test_pipelines_text_generation import TextGenerationPipelineTests
from .pipelines.test_pipelines_text_to_audio import TextToAudioPipelineTests
from .pipelines.test_pipelines_token_classification import TokenClassificationPipelineTests
from .pipelines.test_pipelines_translation import TranslationPipelineTests
from .pipelines.test_pipelines_video_classification import VideoClassificationPipelineTests
from .pipelines.test_pipelines_visual_question_answering import VisualQuestionAnsweringPipelineTests
from .pipelines.test_pipelines_zero_shot import ZeroShotClassificationPipelineTests
from .pipelines.test_pipelines_zero_shot_audio_classification import ZeroShotAudioClassificationPipelineTests
from .pipelines.test_pipelines_zero_shot_image_classification import ZeroShotImageClassificationPipelineTests
from .pipelines.test_pipelines_zero_shot_object_detection import ZeroShotObjectDetectionPipelineTests
pipeline_test_mapping = {
"audio-classification": {"test": AudioClassificationPipelineTests},
"automatic-speech-recognition": {"test": AutomaticSpeechRecognitionPipelineTests},
"depth-estimation": {"test": DepthEstimationPipelineTests},
"document-question-answering": {"test": DocumentQuestionAnsweringPipelineTests},
"feature-extraction": {"test": FeatureExtractionPipelineTests},
"fill-mask": {"test": FillMaskPipelineTests},
"image-classification": {"test": ImageClassificationPipelineTests},
"image-feature-extraction": {"test": ImageFeatureExtractionPipelineTests},
"image-segmentation": {"test": ImageSegmentationPipelineTests},
"image-text-to-text": {"test": ImageTextToTextPipelineTests},
"image-to-image": {"test": ImageToImagePipelineTests},
"image-to-text": {"test": ImageToTextPipelineTests},
"mask-generation": {"test": MaskGenerationPipelineTests},
"object-detection": {"test": ObjectDetectionPipelineTests},
"question-answering": {"test": QAPipelineTests},
"summarization": {"test": SummarizationPipelineTests},
"table-question-answering": {"test": TQAPipelineTests},
"text2text-generation": {"test": Text2TextGenerationPipelineTests},
"text-classification": {"test": TextClassificationPipelineTests},
"text-generation": {"test": TextGenerationPipelineTests},
"text-to-audio": {"test": TextToAudioPipelineTests},
"token-classification": {"test": TokenClassificationPipelineTests},
"translation": {"test": TranslationPipelineTests},
"video-classification": {"test": VideoClassificationPipelineTests},
"visual-question-answering": {"test": VisualQuestionAnsweringPipelineTests},
"zero-shot": {"test": ZeroShotClassificationPipelineTests},
"zero-shot-audio-classification": {"test": ZeroShotAudioClassificationPipelineTests},
"zero-shot-image-classification": {"test": ZeroShotImageClassificationPipelineTests},
"zero-shot-object-detection": {"test": ZeroShotObjectDetectionPipelineTests},
}
task_to_pipeline_and_spec_mapping = {
# Adding a task to this list will cause its pipeline input signature to be checked against the corresponding
# task spec in the HF Hub
"audio-classification": (AudioClassificationPipeline, AudioClassificationInput),
"automatic-speech-recognition": (AutomaticSpeechRecognitionPipeline, AutomaticSpeechRecognitionInput),
"depth-estimation": (DepthEstimationPipeline, DepthEstimationInput),
"image-classification": (ImageClassificationPipeline, ImageClassificationInput),
"image-segmentation": (ImageSegmentationPipeline, ImageSegmentationInput),
"image-to-text": (ImageToTextPipeline, ImageToTextInput),
"object-detection": (ObjectDetectionPipeline, ObjectDetectionInput),
"question-answering": (QuestionAnsweringPipeline, QuestionAnsweringInput),
"video-classification": (VideoClassificationPipeline, VideoClassificationInput),
"zero-shot-image-classification": (ZeroShotImageClassificationPipeline, ZeroShotImageClassificationInput),
}
for task, task_info in pipeline_test_mapping.items():
test = task_info["test"]
task_info["mapping"] = {
"pt": getattr(test, "model_mapping", None),
"tf": getattr(test, "tf_model_mapping", None),
}
# The default value `hf-internal-testing` is for running the pipeline testing against the tiny models on the Hub.
# For debugging purpose, we can specify a local path which is the `output_path` argument of a previous run of
# `utils/create_dummy_models.py`.
TRANSFORMERS_TINY_MODEL_PATH = os.environ.get("TRANSFORMERS_TINY_MODEL_PATH", "hf-internal-testing")
if TRANSFORMERS_TINY_MODEL_PATH == "hf-internal-testing":
TINY_MODEL_SUMMARY_FILE_PATH = os.path.join(Path(__file__).parent.parent, "tests/utils/tiny_model_summary.json")
else:
TINY_MODEL_SUMMARY_FILE_PATH = os.path.join(TRANSFORMERS_TINY_MODEL_PATH, "reports", "tiny_model_summary.json")
with open(TINY_MODEL_SUMMARY_FILE_PATH) as fp:
tiny_model_summary = json.load(fp)
PATH_TO_TRANSFORMERS = os.path.join(Path(__file__).parent.parent, "src/transformers")
# Dynamically import the Transformers module to grab the attribute classes of the processor form their names.
transformers_module = direct_transformers_import(PATH_TO_TRANSFORMERS)
logger = logging.get_logger(__name__)
class PipelineTesterMixin:
model_tester = None
pipeline_model_mapping = None
supported_frameworks = ["pt", "tf"]
def run_task_tests(self, task, torch_dtype="float32"):
"""Run pipeline tests for a specific `task`
Args:
task (`str`):
A task name. This should be a key in the mapping `pipeline_test_mapping`.
torch_dtype (`str`, `optional`, defaults to `'float32'`):
The torch dtype to use for the model. Can be used for FP16/other precision inference.
"""
if task not in self.pipeline_model_mapping:
self.skipTest(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')}_{torch_dtype} is skipped: `{task}` is not in "
f"`self.pipeline_model_mapping` for `{self.__class__.__name__}`."
)
model_architectures = self.pipeline_model_mapping[task]
if not isinstance(model_architectures, tuple):
model_architectures = (model_architectures,)
# We are going to run tests for multiple model architectures, some of them might be skipped
# with this flag we are control if at least one model were tested or all were skipped
at_least_one_model_is_tested = False
for model_architecture in model_architectures:
model_arch_name = model_architecture.__name__
model_type = model_architecture.config_class.model_type
# Get the canonical name
for _prefix in ["Flax", "TF"]:
if model_arch_name.startswith(_prefix):
model_arch_name = model_arch_name[len(_prefix) :]
break
if model_arch_name not in tiny_model_summary:
continue
tokenizer_names = tiny_model_summary[model_arch_name]["tokenizer_classes"]
# Sort image processors and feature extractors from tiny-models json file
image_processor_names = []
feature_extractor_names = []
processor_classes = tiny_model_summary[model_arch_name]["processor_classes"]
for cls_name in processor_classes:
if "ImageProcessor" in cls_name:
image_processor_names.append(cls_name)
elif "FeatureExtractor" in cls_name:
feature_extractor_names.append(cls_name)
# Processor classes are not in tiny models JSON file, so extract them from the mapping
# processors are mapped to instance, e.g. "XxxProcessor"
processor_names = PROCESSOR_MAPPING_NAMES.get(model_type, None)
if not isinstance(processor_names, (list, tuple)):
processor_names = [processor_names]
commit = None
if model_arch_name in tiny_model_summary and "sha" in tiny_model_summary[model_arch_name]:
commit = tiny_model_summary[model_arch_name]["sha"]
repo_name = f"tiny-random-{model_arch_name}"
if TRANSFORMERS_TINY_MODEL_PATH != "hf-internal-testing":
repo_name = model_arch_name
self.run_model_pipeline_tests(
task,
repo_name,
model_architecture,
tokenizer_names=tokenizer_names,
image_processor_names=image_processor_names,
feature_extractor_names=feature_extractor_names,
processor_names=processor_names,
commit=commit,
torch_dtype=torch_dtype,
)
at_least_one_model_is_tested = True
if task in task_to_pipeline_and_spec_mapping:
pipeline, hub_spec = task_to_pipeline_and_spec_mapping[task]
compare_pipeline_args_to_hub_spec(pipeline, hub_spec)
if not at_least_one_model_is_tested:
self.skipTest(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')}_{torch_dtype} is skipped: Could not find any "
f"model architecture in the tiny models JSON file for `{task}`."
)
def run_model_pipeline_tests(
self,
task,
repo_name,
model_architecture,
tokenizer_names,
image_processor_names,
feature_extractor_names,
processor_names,
commit,
torch_dtype="float32",
):
"""Run pipeline tests for a specific `task` with the give model class and tokenizer/processor class names
Args:
task (`str`):
A task name. This should be a key in the mapping `pipeline_test_mapping`.
repo_name (`str`):
A model repository id on the Hub.
model_architecture (`type`):
A subclass of `PretrainedModel` or `PretrainedModel`.
tokenizer_names (`List[str]`):
A list of names of a subclasses of `PreTrainedTokenizerFast` or `PreTrainedTokenizer`.
image_processor_names (`List[str]`):
A list of names of subclasses of `BaseImageProcessor`.
feature_extractor_names (`List[str]`):
A list of names of subclasses of `FeatureExtractionMixin`.
processor_names (`List[str]`):
A list of names of subclasses of `ProcessorMixin`.
commit (`str`):
The commit hash of the model repository on the Hub.
torch_dtype (`str`, `optional`, defaults to `'float32'`):
The torch dtype to use for the model. Can be used for FP16/other precision inference.
"""
# Get an instance of the corresponding class `XXXPipelineTests` in order to use `get_test_pipeline` and
# `run_pipeline_test`.
pipeline_test_class_name = pipeline_test_mapping[task]["test"].__name__
# If no image processor or feature extractor is found, we still need to test the pipeline with None
# otherwise for any empty list we might skip all the tests
tokenizer_names = tokenizer_names or [None]
image_processor_names = image_processor_names or [None]
feature_extractor_names = feature_extractor_names or [None]
processor_names = processor_names or [None]
test_cases = [
{
"tokenizer_name": tokenizer_name,
"image_processor_name": image_processor_name,
"feature_extractor_name": feature_extractor_name,
"processor_name": processor_name,
}
for tokenizer_name in tokenizer_names
for image_processor_name in image_processor_names
for feature_extractor_name in feature_extractor_names
for processor_name in processor_names
]
for test_case in test_cases:
tokenizer_name = test_case["tokenizer_name"]
image_processor_name = test_case["image_processor_name"]
feature_extractor_name = test_case["feature_extractor_name"]
processor_name = test_case["processor_name"]
do_skip_test_case = self.is_pipeline_test_to_skip(
pipeline_test_class_name,
model_architecture.config_class,
model_architecture,
tokenizer_name,
image_processor_name,
feature_extractor_name,
processor_name,
)
if do_skip_test_case:
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')}_{torch_dtype} is skipped: test is "
f"currently known to fail for: model `{model_architecture.__name__}` | tokenizer "
f"`{tokenizer_name}` | image processor `{image_processor_name}` | feature extractor {feature_extractor_name}."
)
continue
self.run_pipeline_test(
task,
repo_name,
model_architecture,
tokenizer_name=tokenizer_name,
image_processor_name=image_processor_name,
feature_extractor_name=feature_extractor_name,
processor_name=processor_name,
commit=commit,
torch_dtype=torch_dtype,
)
def run_pipeline_test(
self,
task,
repo_name,
model_architecture,
tokenizer_name,
image_processor_name,
feature_extractor_name,
processor_name,
commit,
torch_dtype="float32",
):
"""Run pipeline tests for a specific `task` with the give model class and tokenizer/processor class name
The model will be loaded from a model repository on the Hub.
Args:
task (`str`):
A task name. This should be a key in the mapping `pipeline_test_mapping`.
repo_name (`str`):
A model repository id on the Hub.
model_architecture (`type`):
A subclass of `PretrainedModel` or `PretrainedModel`.
tokenizer_name (`str`):
The name of a subclass of `PreTrainedTokenizerFast` or `PreTrainedTokenizer`.
image_processor_name (`str`):
The name of a subclass of `BaseImageProcessor`.
feature_extractor_name (`str`):
The name of a subclass of `FeatureExtractionMixin`.
processor_name (`str`):
The name of a subclass of `ProcessorMixin`.
commit (`str`):
The commit hash of the model repository on the Hub.
torch_dtype (`str`, `optional`, defaults to `'float32'`):
The torch dtype to use for the model. Can be used for FP16/other precision inference.
"""
repo_id = f"{TRANSFORMERS_TINY_MODEL_PATH}/{repo_name}"
model_type = model_architecture.config_class.model_type
if TRANSFORMERS_TINY_MODEL_PATH != "hf-internal-testing":
repo_id = os.path.join(TRANSFORMERS_TINY_MODEL_PATH, model_type, repo_name)
# -------------------- Load model --------------------
# TODO: We should check if a model file is on the Hub repo. instead.
try:
model = model_architecture.from_pretrained(repo_id, revision=commit)
except Exception:
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')}_{torch_dtype} is skipped: Could not find or load "
f"the model from `{repo_id}` with `{model_architecture}`."
)
self.skipTest(f"Could not find or load the model from {repo_id} with {model_architecture}.")
# -------------------- Load tokenizer --------------------
tokenizer = None
if tokenizer_name is not None:
tokenizer_class = getattr(transformers_module, tokenizer_name)
tokenizer = tokenizer_class.from_pretrained(repo_id, revision=commit)
# -------------------- Load processors --------------------
processors = {}
for key, name in zip(
["image_processor", "feature_extractor", "processor"],
[image_processor_name, feature_extractor_name, processor_name],
):
if name is not None:
try:
# Can fail if some extra dependencies are not installed
processor_class = getattr(transformers_module, name)
processor = processor_class.from_pretrained(repo_id, revision=commit)
processors[key] = processor
except Exception:
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')}_{torch_dtype} is skipped: "
f"Could not load the {key} from `{repo_id}` with `{name}`."
)
self.skipTest(f"Could not load the {key} from {repo_id} with {name}.")
# ---------------------------------------------------------
# TODO: Maybe not upload such problematic tiny models to Hub.
if tokenizer is None and "image_processor" not in processors and "feature_extractor" not in processors:
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')}_{torch_dtype} is skipped: Could not find or load "
f"any tokenizer / image processor / feature extractor from `{repo_id}`."
)
self.skipTest(f"Could not find or load any tokenizer / processor from {repo_id}.")
pipeline_test_class_name = pipeline_test_mapping[task]["test"].__name__
if self.is_pipeline_test_to_skip_more(pipeline_test_class_name, model.config, model, tokenizer, **processors):
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')}_{torch_dtype} is skipped: test is "
f"currently known to fail for: model `{model_architecture.__name__}` | tokenizer "
f"`{tokenizer_name}` | image processor `{image_processor_name}` | feature extractor `{feature_extractor_name}`."
)
self.skipTest(
f"Test is known to fail for: model `{model_architecture.__name__}` | tokenizer `{tokenizer_name}` "
f"| image processor `{image_processor_name}` | feature extractor `{feature_extractor_name}`."
)
# validate
validate_test_components(model, tokenizer)
if hasattr(model, "eval"):
model = model.eval()
# Get an instance of the corresponding class `XXXPipelineTests` in order to use `get_test_pipeline` and
# `run_pipeline_test`.
task_test = pipeline_test_mapping[task]["test"]()
pipeline, examples = task_test.get_test_pipeline(model, tokenizer, **processors, torch_dtype=torch_dtype)
if pipeline is None:
# The test can disable itself, but it should be very marginal
# Concerns: Wav2Vec2ForCTC without tokenizer test (FastTokenizer don't exist)
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')}_{torch_dtype} is skipped: Could not get the "
"pipeline for testing."
)
self.skipTest(reason="Could not get the pipeline for testing.")
task_test.run_pipeline_test(pipeline, examples)
def run_batch_test(pipeline, examples):
# Need to copy because `Conversation` are stateful
if pipeline.tokenizer is not None and pipeline.tokenizer.pad_token_id is None:
return # No batching for this and it's OK
# 10 examples with batch size 4 means there needs to be a unfinished batch
# which is important for the unbatcher
def data(n):
for _ in range(n):
# Need to copy because Conversation object is mutated
yield copy.deepcopy(random.choice(examples))
out = []
for item in pipeline(data(10), batch_size=4):
out.append(item)
self.assertEqual(len(out), 10)
run_batch_test(pipeline, examples)
@is_pipeline_test
def test_pipeline_audio_classification(self):
self.run_task_tests(task="audio-classification")
@is_pipeline_test
@require_torch
def test_pipeline_audio_classification_fp16(self):
self.run_task_tests(task="audio-classification", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_automatic_speech_recognition(self):
self.run_task_tests(task="automatic-speech-recognition")
@is_pipeline_test
@require_torch
def test_pipeline_automatic_speech_recognition_fp16(self):
self.run_task_tests(task="automatic-speech-recognition", torch_dtype="float16")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_depth_estimation(self):
self.run_task_tests(task="depth-estimation")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_depth_estimation_fp16(self):
self.run_task_tests(task="depth-estimation", torch_dtype="float16")
@is_pipeline_test
@require_pytesseract
@require_torch
@require_vision
def test_pipeline_document_question_answering(self):
self.run_task_tests(task="document-question-answering")
@is_pipeline_test
@require_pytesseract
@require_torch
@require_vision
def test_pipeline_document_question_answering_fp16(self):
self.run_task_tests(task="document-question-answering", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_feature_extraction(self):
self.run_task_tests(task="feature-extraction")
@is_pipeline_test
@require_torch
def test_pipeline_feature_extraction_fp16(self):
self.run_task_tests(task="feature-extraction", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_fill_mask(self):
self.run_task_tests(task="fill-mask")
@is_pipeline_test
@require_torch
def test_pipeline_fill_mask_fp16(self):
self.run_task_tests(task="fill-mask", torch_dtype="float16")
@is_pipeline_test
@require_torch_or_tf
@require_vision
def test_pipeline_image_classification(self):
self.run_task_tests(task="image-classification")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_image_classification_fp16(self):
self.run_task_tests(task="image-classification", torch_dtype="float16")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_image_segmentation(self):
self.run_task_tests(task="image-segmentation")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_image_segmentation_fp16(self):
self.run_task_tests(task="image-segmentation", torch_dtype="float16")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_image_text_to_text(self):
self.run_task_tests(task="image-text-to-text")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_image_text_to_text_fp16(self):
self.run_task_tests(task="image-text-to-text", torch_dtype="float16")
@is_pipeline_test
@require_vision
def test_pipeline_image_to_text(self):
self.run_task_tests(task="image-to-text")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_image_to_text_fp16(self):
self.run_task_tests(task="image-to-text", torch_dtype="float16")
@is_pipeline_test
@require_timm
@require_vision
@require_torch
def test_pipeline_image_feature_extraction(self):
self.run_task_tests(task="image-feature-extraction")
@is_pipeline_test
@require_timm
@require_vision
@require_torch
def test_pipeline_image_feature_extraction_fp16(self):
self.run_task_tests(task="image-feature-extraction", torch_dtype="float16")
@unittest.skip(reason="`run_pipeline_test` is currently not implemented.")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_mask_generation(self):
self.run_task_tests(task="mask-generation")
@unittest.skip(reason="`run_pipeline_test` is currently not implemented.")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_mask_generation_fp16(self):
self.run_task_tests(task="mask-generation", torch_dtype="float16")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_object_detection(self):
self.run_task_tests(task="object-detection")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_object_detection_fp16(self):
self.run_task_tests(task="object-detection", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_question_answering(self):
self.run_task_tests(task="question-answering")
@is_pipeline_test
@require_torch
def test_pipeline_question_answering_fp16(self):
self.run_task_tests(task="question-answering", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_summarization(self):
self.run_task_tests(task="summarization")
@is_pipeline_test
@require_torch
def test_pipeline_summarization_fp16(self):
self.run_task_tests(task="summarization", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_table_question_answering(self):
self.run_task_tests(task="table-question-answering")
@is_pipeline_test
@require_torch
def test_pipeline_table_question_answering_fp16(self):
self.run_task_tests(task="table-question-answering", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_text2text_generation(self):
self.run_task_tests(task="text2text-generation")
@is_pipeline_test
@require_torch
def test_pipeline_text2text_generation_fp16(self):
self.run_task_tests(task="text2text-generation", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_text_classification(self):
self.run_task_tests(task="text-classification")
@is_pipeline_test
@require_torch
def test_pipeline_text_classification_fp16(self):
self.run_task_tests(task="text-classification", torch_dtype="float16")
@is_pipeline_test
@require_torch_or_tf
def test_pipeline_text_generation(self):
self.run_task_tests(task="text-generation")
@is_pipeline_test
@require_torch
def test_pipeline_text_generation_fp16(self):
self.run_task_tests(task="text-generation", torch_dtype="float16")
@is_pipeline_test
@require_torch
def test_pipeline_text_to_audio(self):
self.run_task_tests(task="text-to-audio")
@is_pipeline_test
@require_torch
def test_pipeline_text_to_audio_fp16(self):
self.run_task_tests(task="text-to-audio", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_token_classification(self):
self.run_task_tests(task="token-classification")
@is_pipeline_test
@require_torch
def test_pipeline_token_classification_fp16(self):
self.run_task_tests(task="token-classification", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_translation(self):
self.run_task_tests(task="translation")
@is_pipeline_test
@require_torch
def test_pipeline_translation_fp16(self):
self.run_task_tests(task="translation", torch_dtype="float16")
@is_pipeline_test
@require_torch_or_tf
@require_vision
@require_av
def test_pipeline_video_classification(self):
self.run_task_tests(task="video-classification")
@is_pipeline_test
@require_vision
@require_torch
@require_av
def test_pipeline_video_classification_fp16(self):
self.run_task_tests(task="video-classification", torch_dtype="float16")
@is_pipeline_test
@require_torch
@require_vision
def test_pipeline_visual_question_answering(self):
self.run_task_tests(task="visual-question-answering")
@is_pipeline_test
@require_torch
@require_vision
def test_pipeline_visual_question_answering_fp16(self):
self.run_task_tests(task="visual-question-answering", torch_dtype="float16")
@is_pipeline_test
def test_pipeline_zero_shot(self):
self.run_task_tests(task="zero-shot")
@is_pipeline_test
@require_torch
def test_pipeline_zero_shot_fp16(self):
self.run_task_tests(task="zero-shot", torch_dtype="float16")
@is_pipeline_test
@require_torch
def test_pipeline_zero_shot_audio_classification(self):
self.run_task_tests(task="zero-shot-audio-classification")
@is_pipeline_test
@require_torch
def test_pipeline_zero_shot_audio_classification_fp16(self):
self.run_task_tests(task="zero-shot-audio-classification", torch_dtype="float16")
@is_pipeline_test
@require_vision
def test_pipeline_zero_shot_image_classification(self):
self.run_task_tests(task="zero-shot-image-classification")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_zero_shot_image_classification_fp16(self):
self.run_task_tests(task="zero-shot-image-classification", torch_dtype="float16")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_zero_shot_object_detection(self):
self.run_task_tests(task="zero-shot-object-detection")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_zero_shot_object_detection_fp16(self):
self.run_task_tests(task="zero-shot-object-detection", torch_dtype="float16")
# This contains the test cases to be skipped without model architecture being involved.
def is_pipeline_test_to_skip(
self,
pipeline_test_case_name,
config_class,
model_architecture,
tokenizer_name,
image_processor_name,
feature_extractor_name,
processor_name,
):
"""Skip some tests based on the classes or their names without the instantiated objects.
This is to avoid calling `from_pretrained` (so reducing the runtime) if we already know the tests will fail.
"""
# No fix is required for this case.
if (
pipeline_test_case_name == "DocumentQuestionAnsweringPipelineTests"
and tokenizer_name is not None
and not tokenizer_name.endswith("Fast")
):
# `DocumentQuestionAnsweringPipelineTests` requires a fast tokenizer.
return True
return False
def is_pipeline_test_to_skip_more(
self,
pipeline_test_case_name,
config,
model,
tokenizer,
image_processor=None,
feature_extractor=None,
processor=None,
): # noqa
"""Skip some more tests based on the information from the instantiated objects."""
# No fix is required for this case.
if (
pipeline_test_case_name == "QAPipelineTests"
and tokenizer is not None
and getattr(tokenizer, "pad_token", None) is None
and not tokenizer.__class__.__name__.endswith("Fast")
):
# `QAPipelineTests` doesn't work with a slow tokenizer that has no pad token.
return True
return False
def validate_test_components(model, tokenizer):
# TODO: Move this to tiny model creation script
# head-specific (within a model type) necessary changes to the config
# 1. for `BlenderbotForCausalLM`
if model.__class__.__name__ == "BlenderbotForCausalLM":
model.config.encoder_no_repeat_ngram_size = 0
# TODO: Change the tiny model creation script: don't create models with problematic tokenizers
# Avoid `IndexError` in embedding layers
CONFIG_WITHOUT_VOCAB_SIZE = ["CanineConfig"]
if tokenizer is not None:
# Removing `decoder=True` in `get_text_config` can lead to conflicting values e.g. in MusicGen
config_vocab_size = getattr(model.config.get_text_config(decoder=True), "vocab_size", None)
# For CLIP-like models
if config_vocab_size is None:
if hasattr(model.config, "text_encoder"):
config_vocab_size = getattr(model.config.text_config, "vocab_size", None)
if config_vocab_size is None and model.config.__class__.__name__ not in CONFIG_WITHOUT_VOCAB_SIZE:
raise ValueError(
"Could not determine `vocab_size` from model configuration while `tokenizer` is not `None`."
)
def get_arg_names_from_hub_spec(hub_spec, first_level=True):
# This util is used in pipeline tests, to verify that a pipeline's documented arguments
# match the Hub specification for that task
arg_names = []
for field in fields(hub_spec):
# Recurse into nested fields, but max one level
if is_dataclass(field.type):
arg_names.extend([field.name for field in fields(field.type)])
continue
# Next, catch nested fields that are part of a Union[], which is usually caused by Optional[]
for param_type in get_args(field.type):
if is_dataclass(param_type):
# Again, recurse into nested fields, but max one level
arg_names.extend([field.name for field in fields(param_type)])
break
else:
# Finally, this line triggers if it's not a nested field
arg_names.append(field.name)
return arg_names
def parse_args_from_docstring_by_indentation(docstring):
# This util is used in pipeline tests, to extract the argument names from a google-format docstring
# to compare them against the Hub specification for that task. It uses indentation levels as a primary
# source of truth, so these have to be correct!
docstring = dedent(docstring)
lines_by_indent = [
(len(line) - len(line.lstrip()), line.strip()) for line in docstring.split("\n") if line.strip()
]
args_lineno = None
args_indent = None
args_end = None
for lineno, (indent, line) in enumerate(lines_by_indent):
if line == "Args:":
args_lineno = lineno
args_indent = indent
continue
elif args_lineno is not None and indent == args_indent:
args_end = lineno
break
if args_lineno is None:
raise ValueError("No args block to parse!")
elif args_end is None:
args_block = lines_by_indent[args_lineno + 1 :]
else:
args_block = lines_by_indent[args_lineno + 1 : args_end]
outer_indent_level = min(line[0] for line in args_block)
outer_lines = [line for line in args_block if line[0] == outer_indent_level]
arg_names = [re.match(r"(\w+)\W", line[1]).group(1) for line in outer_lines]
return arg_names
def compare_pipeline_args_to_hub_spec(pipeline_class, hub_spec):
ALLOWED_TRANSFORMERS_ONLY_ARGS = ["timeout"]
docstring = inspect.getdoc(pipeline_class.__call__).strip()
docstring_args = set(parse_args_from_docstring_by_indentation(docstring))
hub_args = set(get_arg_names_from_hub_spec(hub_spec))
# Special casing: We allow the name of this arg to differ
js_generate_args = [js_arg for js_arg in hub_args if js_arg.startswith("generate")]
docstring_generate_args = [
docstring_arg for docstring_arg in docstring_args if docstring_arg.startswith("generate")
]
if (
len(js_generate_args) == 1
and len(docstring_generate_args) == 1
and js_generate_args != docstring_generate_args
):
hub_args.remove(js_generate_args[0])
docstring_args.remove(docstring_generate_args[0])
# Special casing 2: We permit some transformers-only arguments that don't affect pipeline output
for arg in ALLOWED_TRANSFORMERS_ONLY_ARGS:
if arg in docstring_args and arg not in hub_args:
docstring_args.remove(arg)
if hub_args != docstring_args:
error = [f"{pipeline_class.__name__} differs from JS spec {hub_spec.__name__}"]
matching_args = hub_args & docstring_args
huggingface_hub_only = hub_args - docstring_args
transformers_only = docstring_args - hub_args
if matching_args:
error.append(f"Matching args: {matching_args}")
if huggingface_hub_only:
error.append(f"Huggingface Hub only: {huggingface_hub_only}")
if transformers_only:
error.append(f"Transformers only: {transformers_only}")
raise ValueError("\n".join(error))
|
transformers/tests/test_pipeline_mixin.py/0
|
{
"file_path": "transformers/tests/test_pipeline_mixin.py",
"repo_id": "transformers",
"token_count": 16841
}
| 208 |
# coding=utf-8
# Copyright 2018 the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import unittest
import numpy as np
from transformers.data.data_collator import default_data_collator
from transformers.testing_utils import require_accelerate, require_torch
from transformers.trainer_utils import RemoveColumnsCollator, find_executable_batch_size
from transformers.utils import is_torch_available
if is_torch_available():
import torch
from torch import nn
from torch.utils.data import IterableDataset
from transformers.modeling_outputs import SequenceClassifierOutput
from transformers.tokenization_utils_base import BatchEncoding
from transformers.trainer_pt_utils import (
DistributedLengthGroupedSampler,
DistributedSamplerWithLoop,
DistributedTensorGatherer,
EvalLoopContainer,
IterableDatasetShard,
LabelSmoother,
LengthGroupedSampler,
SequentialDistributedSampler,
ShardSampler,
get_parameter_names,
numpy_pad_and_concatenate,
torch_pad_and_concatenate,
)
class TstLayer(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.linear1 = nn.Linear(hidden_size, hidden_size)
self.ln1 = nn.LayerNorm(hidden_size)
self.linear2 = nn.Linear(hidden_size, hidden_size)
self.ln2 = nn.LayerNorm(hidden_size)
self.bias = nn.Parameter(torch.zeros(hidden_size))
def forward(self, x):
h = self.ln1(nn.functional.relu(self.linear1(x)))
h = nn.functional.relu(self.linear2(x))
return self.ln2(x + h + self.bias)
class RandomIterableDataset(IterableDataset):
# For testing, an iterable dataset of random length
def __init__(self, p_stop=0.01, max_length=1000):
self.p_stop = p_stop
self.max_length = max_length
self.generator = torch.Generator()
def __iter__(self):
count = 0
stop = False
while not stop and count < self.max_length:
yield count
count += 1
number = torch.rand(1, generator=self.generator).item()
stop = number < self.p_stop
@require_torch
class TrainerUtilsTest(unittest.TestCase):
def test_distributed_tensor_gatherer(self):
# Simulate a result with a dataset of size 21, 4 processes and chunks of lengths 2, 3, 1
world_size = 4
num_samples = 21
input_indices = [
[0, 1, 6, 7, 12, 13, 18, 19],
[2, 3, 4, 8, 9, 10, 14, 15, 16, 20, 0, 1],
[5, 11, 17, 2],
]
predictions = np.random.normal(size=(num_samples, 13))
gatherer = DistributedTensorGatherer(world_size=world_size, num_samples=num_samples)
for indices in input_indices:
gatherer.add_arrays(predictions[indices])
result = gatherer.finalize()
self.assertTrue(np.array_equal(result, predictions))
# With nested tensors
gatherer = DistributedTensorGatherer(world_size=world_size, num_samples=num_samples)
for indices in input_indices:
gatherer.add_arrays([predictions[indices], [predictions[indices], predictions[indices]]])
result = gatherer.finalize()
self.assertTrue(isinstance(result, list))
self.assertEqual(len(result), 2)
self.assertTrue(isinstance(result[1], list))
self.assertEqual(len(result[1]), 2)
self.assertTrue(np.array_equal(result[0], predictions))
self.assertTrue(np.array_equal(result[1][0], predictions))
self.assertTrue(np.array_equal(result[1][1], predictions))
def test_distributed_tensor_gatherer_different_shapes(self):
# Simulate a result with a dataset of size 21, 4 processes and chunks of lengths 2, 3, 1
world_size = 4
num_samples = 21
input_indices = [
[0, 1, 6, 7, 12, 13, 18, 19],
[2, 3, 4, 8, 9, 10, 14, 15, 16, 20, 0, 1],
[5, 11, 17, 2],
]
sequence_lengths = [8, 10, 13]
predictions = np.random.normal(size=(num_samples, 13))
gatherer = DistributedTensorGatherer(world_size=world_size, num_samples=num_samples)
for indices, seq_length in zip(input_indices, sequence_lengths):
gatherer.add_arrays(predictions[indices, :seq_length])
result = gatherer.finalize()
# Remove the extra samples added at the end for a round multiple of num processes.
actual_indices = [input_indices[0], input_indices[1][:-2], input_indices[2][:-1]]
for indices, seq_length in zip(actual_indices, sequence_lengths):
self.assertTrue(np.array_equal(result[indices, :seq_length], predictions[indices, :seq_length]))
# With nested tensors
predictions = np.random.normal(size=(num_samples, 13))
gatherer = DistributedTensorGatherer(world_size=world_size, num_samples=num_samples)
for indices, seq_length in zip(input_indices, sequence_lengths):
gatherer.add_arrays([predictions[indices, :seq_length], predictions[indices]])
result = gatherer.finalize()
for indices, seq_length in zip(actual_indices, sequence_lengths):
self.assertTrue(np.array_equal(result[0][indices, :seq_length], predictions[indices, :seq_length]))
self.assertTrue(np.array_equal(result[1], predictions))
# Check if works if varying seq_length is second
gatherer = DistributedTensorGatherer(world_size=world_size, num_samples=num_samples)
for indices, seq_length in zip(input_indices, sequence_lengths):
gatherer.add_arrays([predictions[indices], predictions[indices, :seq_length]])
result = gatherer.finalize()
self.assertTrue(np.array_equal(result[0], predictions))
for indices, seq_length in zip(actual_indices, sequence_lengths):
self.assertTrue(np.array_equal(result[1][indices, :seq_length], predictions[indices, :seq_length]))
def test_label_smoothing(self):
epsilon = 0.1
num_labels = 12
random_logits = torch.randn(4, 5, num_labels)
random_labels = torch.randint(0, num_labels, (4, 5))
loss = nn.functional.cross_entropy(random_logits.view(-1, num_labels), random_labels.view(-1))
model_output = SequenceClassifierOutput(logits=random_logits)
label_smoothed_loss = LabelSmoother(0.1)(model_output, random_labels)
log_probs = -nn.functional.log_softmax(random_logits, dim=-1)
expected_loss = (1 - epsilon) * loss + epsilon * log_probs.mean()
torch.testing.assert_close(label_smoothed_loss, expected_loss)
# With a few -100 labels
random_labels[0, 1] = -100
random_labels[2, 1] = -100
random_labels[2, 3] = -100
loss = nn.functional.cross_entropy(random_logits.view(-1, num_labels), random_labels.view(-1))
model_output = SequenceClassifierOutput(logits=random_logits)
label_smoothed_loss = LabelSmoother(0.1)(model_output, random_labels)
log_probs = -nn.functional.log_softmax(random_logits, dim=-1)
# Mask the log probs with the -100 labels
log_probs[0, 1] = 0.0
log_probs[2, 1] = 0.0
log_probs[2, 3] = 0.0
expected_loss = (1 - epsilon) * loss + epsilon * log_probs.sum() / (num_labels * 17)
torch.testing.assert_close(label_smoothed_loss, expected_loss)
def test_group_by_length(self):
# Get some inputs of random lengths
lengths = torch.randint(0, 25, (100,)).tolist()
# Put one bigger than the others to check it ends up in first position
lengths[32] = 50
indices = list(LengthGroupedSampler(4, lengths=lengths))
# The biggest element should be first
self.assertEqual(lengths[indices[0]], 50)
# The indices should be a permutation of range(100)
self.assertEqual(sorted(indices), list(range(100)))
def test_group_by_length_with_dict(self):
# Get some inputs of random lengths
data = []
for _ in range(6):
input_ids = torch.randint(0, 25, (100,)).tolist()
data.append({"input_ids": input_ids})
# Put one bigger than the others to check it ends up in first position
data[3]["input_ids"] = torch.randint(0, 25, (105,)).tolist()
indices = list(LengthGroupedSampler(4, dataset=data))
# The biggest element should be first
self.assertEqual(len(data[indices[0]]["input_ids"]), 105)
# The indices should be a permutation of range(6)
self.assertEqual(sorted(indices), list(range(6)))
def test_group_by_length_with_batch_encoding(self):
# Get some inputs of random lengths
data = []
for _ in range(6):
input_ids = torch.randint(0, 25, (100,)).tolist()
data.append(BatchEncoding({"input_ids": input_ids}))
# Put one bigger than the others to check it ends up in first position
data[3]["input_ids"] = torch.randint(0, 25, (105,)).tolist()
indices = list(LengthGroupedSampler(4, dataset=data))
# The biggest element should be first
self.assertEqual(len(data[indices[0]]["input_ids"]), 105)
# The indices should be a permutation of range(6)
self.assertEqual(sorted(indices), list(range(6)))
def test_distributed_length_grouped(self):
# Get some inputs of random lengths
lengths = torch.randint(0, 25, (100,)).tolist()
# Put one bigger than the others to check it ends up in first position
lengths[32] = 50
indices_process_0 = list(DistributedLengthGroupedSampler(4, num_replicas=2, rank=0, lengths=lengths))
indices_process_1 = list(DistributedLengthGroupedSampler(4, num_replicas=2, rank=1, lengths=lengths))
# The biggest element should be first
self.assertEqual(lengths[indices_process_0[0]], 50)
# The indices should be a permutation of range(100)
self.assertEqual(sorted(indices_process_0 + indices_process_1), list(range(100)))
def test_get_parameter_names(self):
model = nn.Sequential(TstLayer(128), nn.ModuleList([TstLayer(128), TstLayer(128)]))
# fmt: off
self.assertEqual(
get_parameter_names(model, [nn.LayerNorm]),
['0.linear1.weight', '0.linear1.bias', '0.linear2.weight', '0.linear2.bias', '0.bias', '1.0.linear1.weight', '1.0.linear1.bias', '1.0.linear2.weight', '1.0.linear2.bias', '1.0.bias', '1.1.linear1.weight', '1.1.linear1.bias', '1.1.linear2.weight', '1.1.linear2.bias', '1.1.bias']
)
# fmt: on
def test_distributed_sampler_with_loop(self):
batch_size = 16
for length in [23, 64, 123]:
dataset = list(range(length))
shard1 = DistributedSamplerWithLoop(dataset, batch_size, num_replicas=2, rank=0)
shard2 = DistributedSamplerWithLoop(dataset, batch_size, num_replicas=2, rank=1)
# Set seeds
shard1.set_epoch(0)
shard2.set_epoch(0)
# Sample
samples1 = list(shard1)
samples2 = list(shard2)
self.assertTrue(len(samples1) % batch_size == 0)
self.assertTrue(len(samples2) % batch_size == 0)
total = []
for sample1, sample2 in zip(samples1, samples2):
total += [sample1, sample2]
self.assertEqual(set(total[:length]), set(dataset))
self.assertEqual(set(total[length:]), set(total[: (len(total) - length)]))
def test_sequential_distributed_sampler(self):
batch_size = 16
for length in [23, 64, 123]:
dataset = list(range(length))
shard1 = SequentialDistributedSampler(dataset, num_replicas=2, rank=0)
shard2 = SequentialDistributedSampler(dataset, num_replicas=2, rank=1)
# Sample
samples1 = list(shard1)
samples2 = list(shard2)
total = samples1 + samples2
self.assertListEqual(total[:length], dataset)
self.assertListEqual(total[length:], dataset[: (len(total) - length)])
# With a batch_size passed
shard1 = SequentialDistributedSampler(dataset, num_replicas=2, rank=0, batch_size=batch_size)
shard2 = SequentialDistributedSampler(dataset, num_replicas=2, rank=1, batch_size=batch_size)
# Sample
samples1 = list(shard1)
samples2 = list(shard2)
self.assertTrue(len(samples1) % batch_size == 0)
self.assertTrue(len(samples2) % batch_size == 0)
total = samples1 + samples2
self.assertListEqual(total[:length], dataset)
self.assertListEqual(total[length:], dataset[: (len(total) - length)])
def check_iterable_dataset_shard(self, dataset, batch_size, drop_last, num_processes=2, epoch=0):
# Set the seed for the base dataset to get the proper reference.
dataset.generator.manual_seed(epoch)
reference = list(dataset)
shards = [
IterableDatasetShard(
dataset, batch_size=batch_size, drop_last=drop_last, num_processes=num_processes, process_index=i
)
for i in range(num_processes)
]
for shard in shards:
shard.set_epoch(epoch)
shard_lists = [list(shard) for shard in shards]
for shard in shard_lists:
# All shards have a number of samples that is a round multiple of batch size
self.assertTrue(len(shard) % batch_size == 0)
# All shards have the same number of samples
self.assertEqual(len(shard), len(shard_lists[0]))
for shard in shards:
# All shards know the total number of samples
self.assertEqual(shard.num_examples, len(reference))
observed = []
for idx in range(0, len(shard_lists[0]), batch_size):
for shard in shard_lists:
observed += shard[idx : idx + batch_size]
# If drop_last is False we loop through samples at the beginning to have a size that is a round multiple of
# batch_size
if not drop_last:
while len(reference) < len(observed):
reference += reference
self.assertListEqual(observed, reference[: len(observed)])
# Check equivalence between IterableDataset and ShardSampler
dataset.generator.manual_seed(epoch)
reference = list(dataset)
sampler_shards = [
ShardSampler(
reference, batch_size=batch_size, drop_last=drop_last, num_processes=num_processes, process_index=i
)
for i in range(num_processes)
]
for shard, sampler_shard in zip(shard_lists, sampler_shards):
self.assertListEqual(shard, list(sampler_shard))
def test_iterable_dataset_shard(self):
dataset = RandomIterableDataset()
self.check_iterable_dataset_shard(dataset, 4, drop_last=True, num_processes=2, epoch=0)
self.check_iterable_dataset_shard(dataset, 4, drop_last=False, num_processes=2, epoch=0)
self.check_iterable_dataset_shard(dataset, 4, drop_last=True, num_processes=3, epoch=42)
self.check_iterable_dataset_shard(dataset, 4, drop_last=False, num_processes=3, epoch=42)
def test_iterable_dataset_shard_with_length(self):
sampler_shards = [
IterableDatasetShard(list(range(100)), batch_size=4, drop_last=True, num_processes=2, process_index=i)
for i in range(2)
]
# Build expected shards: each process will have batches of size 4 until there is not enough elements to
# form two full batches (so we stop at 96 = (100 // (4 * 2)) * 4)
expected_shards = [[], []]
current_shard = 0
for i in range(0, 96, 4):
expected_shards[current_shard].extend(list(range(i, i + 4)))
current_shard = 1 - current_shard
self.assertListEqual([list(shard) for shard in sampler_shards], expected_shards)
self.assertListEqual([len(shard) for shard in sampler_shards], [len(shard) for shard in expected_shards])
sampler_shards = [
IterableDatasetShard(list(range(100)), batch_size=4, drop_last=False, num_processes=2, process_index=i)
for i in range(2)
]
# When drop_last=False, we get two last full batches by looping back to the beginning.
expected_shards[0].extend(list(range(96, 100)))
expected_shards[1].extend(list(range(0, 4)))
self.assertListEqual([list(shard) for shard in sampler_shards], expected_shards)
self.assertListEqual([len(shard) for shard in sampler_shards], [len(shard) for shard in expected_shards])
def check_shard_sampler(self, dataset, batch_size, drop_last, num_processes=2):
shards = [
ShardSampler(
dataset, batch_size=batch_size, drop_last=drop_last, num_processes=num_processes, process_index=i
)
for i in range(num_processes)
]
shard_lists = [list(shard) for shard in shards]
for shard in shard_lists:
# All shards have a number of samples that is a round multiple of batch size
self.assertTrue(len(shard) % batch_size == 0)
# All shards have the same number of samples
self.assertEqual(len(shard), len(shard_lists[0]))
observed = []
for idx in range(0, len(shard_lists[0]), batch_size):
for shard in shard_lists:
observed += shard[idx : idx + batch_size]
# If drop_last is False we loop through samples at the beginning to have a size that is a round multiple of
# batch_size
reference = copy.copy(dataset)
if not drop_last:
while len(reference) < len(observed):
reference += reference
self.assertListEqual(observed, reference[: len(observed)])
def test_shard_sampler(self):
for n_elements in [64, 123]:
dataset = list(range(n_elements))
self.check_shard_sampler(dataset, 4, drop_last=True, num_processes=2)
self.check_shard_sampler(dataset, 4, drop_last=False, num_processes=2)
self.check_shard_sampler(dataset, 4, drop_last=True, num_processes=3)
self.check_shard_sampler(dataset, 4, drop_last=False, num_processes=3)
@require_accelerate
def test_executable_batch_size(self):
batch_sizes = []
@find_executable_batch_size(starting_batch_size=64, auto_find_batch_size=True)
def mock_training_loop_function(batch_size):
nonlocal batch_sizes
batch_sizes.append(batch_size)
if batch_size > 16:
raise RuntimeError("CUDA out of memory.")
mock_training_loop_function()
self.assertEqual(batch_sizes, [64, 32, 16])
@require_accelerate
def test_executable_batch_size_no_search(self):
batch_sizes = []
@find_executable_batch_size(starting_batch_size=64, auto_find_batch_size=False)
def mock_training_loop_function(batch_size):
nonlocal batch_sizes
batch_sizes.append(batch_size)
mock_training_loop_function()
self.assertEqual(batch_sizes, [64])
@require_accelerate
def test_executable_batch_size_with_error(self):
@find_executable_batch_size(starting_batch_size=64, auto_find_batch_size=False)
def mock_training_loop_function(batch_size):
raise RuntimeError("CUDA out of memory.")
with self.assertRaises(RuntimeError) as cm:
mock_training_loop_function()
self.assertEqual("CUDA out of memory", cm.args[0])
def test_pad_and_concatenate_with_1d(self):
"""Tests whether pad_and_concatenate works with scalars."""
array1 = 1.0
array2 = 2.0
result = numpy_pad_and_concatenate(array1, array2)
self.assertTrue(np.array_equal(np.array([1.0, 2.0]), result))
tensor1 = torch.tensor(1.0)
tensor2 = torch.tensor(2.0)
result = torch_pad_and_concatenate(tensor1, tensor2)
self.assertTrue(torch.equal(result, torch.Tensor([1.0, 2.0])))
def test_remove_columns_collator(self):
class MockLogger:
def __init__(self) -> None:
self.called = 0
def info(self, msg):
self.called += 1
self.last_msg = msg
data_batch = [
{"col1": 1, "col2": 2, "col3": 3},
{"col1": 1, "col2": 2, "col3": 3},
]
logger = MockLogger()
remove_columns_collator = RemoveColumnsCollator(
default_data_collator, ["col1", "col2"], logger, "model", "training"
)
self.assertNotIn("col3", remove_columns_collator(data_batch))
# check that the logging message is printed out only once
remove_columns_collator(data_batch)
remove_columns_collator(data_batch)
self.assertEqual(logger.called, 1)
self.assertIn("col3", logger.last_msg)
def test_eval_loop_container(self):
batch_1 = [
torch.ones([8, 5]),
{"loss": torch.tensor(1.0)},
(torch.ones([8, 2, 3]), torch.ones([8, 2])),
]
batch_2 = [
torch.ones([4, 5]),
{"loss": torch.tensor(2.0)},
(torch.ones([4, 2, 3]), torch.ones([4, 6])),
]
concat_container = EvalLoopContainer(do_nested_concat=True, padding_index=-100)
concat_container.add(batch_1)
concat_container.add(batch_2)
concat_container.to_cpu_and_numpy()
arrays = concat_container.get_arrays()
# Test two nested batches concatenation
self.assertIsInstance(arrays, list)
self.assertEqual(len(arrays), 3)
self.assertIsInstance(arrays[0], np.ndarray)
self.assertEqual(arrays[0].shape, (12, 5))
self.assertIsInstance(arrays[1], dict)
self.assertIsInstance(arrays[1]["loss"], np.ndarray)
self.assertEqual(arrays[1]["loss"].shape, (2,))
self.assertTrue(np.allclose(arrays[1]["loss"], np.array([1.0, 2.0])))
self.assertIsInstance(arrays[2], tuple)
self.assertEqual(len(arrays[2]), 2)
self.assertEqual(arrays[2][0].shape, (12, 2, 3))
self.assertEqual(arrays[2][1].shape, (12, 6))
# check that first batch padded with padding index -100 after concatenation
self.assertEqual(arrays[2][1][0][2], -100)
# Test two batches with no concatenation
list_container = EvalLoopContainer(do_nested_concat=False)
list_container.add(batch_1)
list_container.add(batch_2)
list_container.to_cpu_and_numpy()
arrays = list_container.get_arrays()
self.assertEqual(len(arrays), 2)
self.assertIsInstance(arrays, list)
np_batch_1, np_batch_2 = arrays
self.assertIsInstance(np_batch_1, list)
self.assertEqual(len(np_batch_1), 3)
self.assertIsInstance(np_batch_1[0], np.ndarray)
self.assertIsInstance(np_batch_1[1], dict)
self.assertIsInstance(np_batch_1[2], tuple)
self.assertEqual(np_batch_1[0].shape, (8, 5))
self.assertEqual(np_batch_1[1]["loss"].shape, ())
self.assertEqual(np_batch_1[2][0].shape, (8, 2, 3))
self.assertEqual(np_batch_1[2][1].shape, (8, 2))
self.assertIsInstance(np_batch_2, list)
self.assertEqual(len(np_batch_2), 3)
self.assertIsInstance(np_batch_2[0], np.ndarray)
self.assertIsInstance(np_batch_2[1], dict)
self.assertIsInstance(np_batch_2[2], tuple)
self.assertEqual(np_batch_2[0].shape, (4, 5))
self.assertEqual(np_batch_2[1]["loss"].shape, ())
self.assertEqual(np_batch_2[2][0].shape, (4, 2, 3))
self.assertEqual(np_batch_2[2][1].shape, (4, 6))
# Test no batches
none_arr = EvalLoopContainer(do_nested_concat=True, padding_index=-100).get_arrays()
self.assertIsNone(none_arr)
none_arr = EvalLoopContainer(do_nested_concat=False).get_arrays()
self.assertIsNone(none_arr)
# Test one batch
concat_container = EvalLoopContainer(do_nested_concat=True, padding_index=-100)
concat_container.add(batch_1)
arrays = concat_container.get_arrays()
self.assertIsInstance(arrays, list)
self.assertEqual(len(arrays), 3)
self.assertIsInstance(arrays[0], np.ndarray)
self.assertEqual(arrays[0].shape, (8, 5))
self.assertIsInstance(arrays[1], dict)
self.assertIsInstance(arrays[1]["loss"], np.ndarray)
self.assertEqual(arrays[1]["loss"].shape, ())
self.assertTrue(np.allclose(arrays[1]["loss"], np.array([1.0])))
self.assertIsInstance(arrays[2], tuple)
self.assertEqual(len(arrays[2]), 2)
self.assertEqual(arrays[2][0].shape, (8, 2, 3))
self.assertEqual(arrays[2][1].shape, (8, 2))
|
transformers/tests/trainer/test_trainer_utils.py/0
|
{
"file_path": "transformers/tests/trainer/test_trainer_utils.py",
"repo_id": "transformers",
"token_count": 11500
}
| 209 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import warnings
from parameterized import parameterized
from transformers import __version__, is_torch_available
from transformers.testing_utils import require_torch_gpu
from transformers.utils.deprecation import deprecate_kwarg
if is_torch_available():
import torch
INFINITE_VERSION = "9999.0.0"
class DeprecationDecoratorTester(unittest.TestCase):
def test_rename_kwarg(self):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
@deprecate_kwarg("deprecated_name", new_name="new_name", version=INFINITE_VERSION)
def dummy_function(new_name=None, other_name=None):
return new_name, other_name
# Test keyword argument is renamed
value, other_value = dummy_function(deprecated_name="old_value")
self.assertEqual(value, "old_value")
self.assertIsNone(other_value)
# Test deprecated keyword argument not passed
value, other_value = dummy_function(new_name="new_value")
self.assertEqual(value, "new_value")
self.assertIsNone(other_value)
# Test other keyword argument
value, other_value = dummy_function(other_name="other_value")
self.assertIsNone(value)
self.assertEqual(other_value, "other_value")
# Test deprecated and new args are passed, the new one should be returned
value, other_value = dummy_function(deprecated_name="old_value", new_name="new_value")
self.assertEqual(value, "new_value")
self.assertIsNone(other_value)
def test_rename_multiple_kwargs(self):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
@deprecate_kwarg("deprecated_name1", new_name="new_name1", version=INFINITE_VERSION)
@deprecate_kwarg("deprecated_name2", new_name="new_name2", version=INFINITE_VERSION)
def dummy_function(new_name1=None, new_name2=None, other_name=None):
return new_name1, new_name2, other_name
# Test keyword argument is renamed
value1, value2, other_value = dummy_function(deprecated_name1="old_value1", deprecated_name2="old_value2")
self.assertEqual(value1, "old_value1")
self.assertEqual(value2, "old_value2")
self.assertIsNone(other_value)
# Test deprecated keyword argument is not passed
value1, value2, other_value = dummy_function(new_name1="new_value1", new_name2="new_value2")
self.assertEqual(value1, "new_value1")
self.assertEqual(value2, "new_value2")
self.assertIsNone(other_value)
# Test other keyword argument is passed and correctly returned
value1, value2, other_value = dummy_function(other_name="other_value")
self.assertIsNone(value1)
self.assertIsNone(value2)
self.assertEqual(other_value, "other_value")
def test_warnings(self):
# Test warning is raised for future version
@deprecate_kwarg("deprecated_name", new_name="new_name", version=INFINITE_VERSION)
def dummy_function(new_name=None, other_name=None):
return new_name, other_name
with self.assertWarns(FutureWarning):
dummy_function(deprecated_name="old_value")
# Test warning is not raised for past version, but arg is still renamed
@deprecate_kwarg("deprecated_name", new_name="new_name", version="0.0.0")
def dummy_function(new_name=None, other_name=None):
return new_name, other_name
with warnings.catch_warnings(record=True) as raised_warnings:
warnings.simplefilter("always")
value, other_value = dummy_function(deprecated_name="old_value")
self.assertEqual(value, "old_value")
self.assertIsNone(other_value)
self.assertEqual(len(raised_warnings), 0, f"Warning raised: {[w.message for w in raised_warnings]}")
# Test warning is raised for future version if warn_if_greater_or_equal_version is set
@deprecate_kwarg("deprecated_name", version="0.0.0", warn_if_greater_or_equal_version=True)
def dummy_function(deprecated_name=None):
return deprecated_name
with self.assertWarns(FutureWarning):
value = dummy_function(deprecated_name="deprecated_value")
self.assertEqual(value, "deprecated_value")
# Test arg is not renamed if new_name is not specified, but warning is raised
@deprecate_kwarg("deprecated_name", version=INFINITE_VERSION)
def dummy_function(deprecated_name=None):
return deprecated_name
with self.assertWarns(FutureWarning):
value = dummy_function(deprecated_name="deprecated_value")
self.assertEqual(value, "deprecated_value")
def test_raises(self):
# Test if deprecated name and new name are both passed and raise_if_both_names is set -> raise error
@deprecate_kwarg("deprecated_name", new_name="new_name", version=INFINITE_VERSION, raise_if_both_names=True)
def dummy_function(new_name=None, other_name=None):
return new_name, other_name
with self.assertRaises(ValueError):
dummy_function(deprecated_name="old_value", new_name="new_value")
# Test for current version == deprecation version
@deprecate_kwarg("deprecated_name", version=__version__, raise_if_greater_or_equal_version=True)
def dummy_function(deprecated_name=None):
return deprecated_name
with self.assertRaises(ValueError):
dummy_function(deprecated_name="old_value")
# Test for current version > deprecation version
@deprecate_kwarg("deprecated_name", version="0.0.0", raise_if_greater_or_equal_version=True)
def dummy_function(deprecated_name=None):
return deprecated_name
with self.assertRaises(ValueError):
dummy_function(deprecated_name="old_value")
def test_additional_message(self):
# Test additional message is added to the warning
@deprecate_kwarg("deprecated_name", version=INFINITE_VERSION, additional_message="Additional message")
def dummy_function(deprecated_name=None):
return deprecated_name
with warnings.catch_warnings(record=True) as raised_warnings:
warnings.simplefilter("always")
dummy_function(deprecated_name="old_value")
self.assertTrue("Additional message" in str(raised_warnings[0].message))
@parameterized.expand(["0.0.0", __version__, INFINITE_VERSION])
def test_warning_for_both_names(self, version):
# We should raise warning if both names are passed for any specified version
@deprecate_kwarg("deprecated_name", new_name="new_name", version=version)
def dummy_function(new_name=None, **kwargs):
return new_name
with self.assertWarns(FutureWarning):
result = dummy_function(deprecated_name="old_value", new_name="new_value")
self.assertEqual(result, "new_value")
@require_torch_gpu
def test_compile_safe(self):
@deprecate_kwarg("deprecated_factor", new_name="new_factor", version=INFINITE_VERSION)
def dummy_function(new_factor=None, **kwargs):
return new_factor * torch.ones(1, device="cuda")
compiled_function = torch.compile(dummy_function, fullgraph=True)
# Check that we can correctly call the compiled function with the old name, without raising errors
out = compiled_function(deprecated_factor=2)
self.assertEqual(out.item(), 2)
# Check that we can correctly call the compiled function with the new name, without raising errors
out = compiled_function(new_factor=2)
self.assertEqual(out.item(), 2)
# Check that we can correctly call the compiled function with both names, without raising errors
out = compiled_function(new_factor=2, deprecated_factor=10)
self.assertEqual(out.item(), 2)
|
transformers/tests/utils/test_deprecation.py/0
|
{
"file_path": "transformers/tests/utils/test_deprecation.py",
"repo_id": "transformers",
"token_count": 3428
}
| 210 |
# coding=utf-8
# Copyright 2019 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import copy
import os
import tempfile
from importlib import import_module
from math import isnan
from transformers import is_tf_available
from transformers.models.auto import get_values
from transformers.testing_utils import _tf_gpu_memory_limit, require_tf, slow
from ..test_modeling_tf_common import ids_tensor
if is_tf_available():
import numpy as np
import tensorflow as tf
from transformers import (
TF_MODEL_FOR_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
TF_MODEL_FOR_MASKED_LM_MAPPING,
TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING,
TF_MODEL_FOR_PRETRAINING_MAPPING,
TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING,
TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
TFSharedEmbeddings,
)
from transformers.modeling_tf_utils import keras
if _tf_gpu_memory_limit is not None:
gpus = tf.config.list_physical_devices("GPU")
for gpu in gpus:
# Restrict TensorFlow to only allocate x GB of memory on the GPUs
try:
tf.config.set_logical_device_configuration(
gpu, [tf.config.LogicalDeviceConfiguration(memory_limit=_tf_gpu_memory_limit)]
)
logical_gpus = tf.config.list_logical_devices("GPU")
print("Logical GPUs", logical_gpus)
except RuntimeError as e:
# Virtual devices must be set before GPUs have been initialized
print(e)
@require_tf
class TFCoreModelTesterMixin:
model_tester = None
all_model_classes = ()
all_generative_model_classes = ()
test_mismatched_shapes = True
test_resize_embeddings = True
test_head_masking = True
is_encoder_decoder = False
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False) -> dict:
inputs_dict = copy.deepcopy(inputs_dict)
if model_class in get_values(TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING):
inputs_dict = {
k: tf.tile(tf.expand_dims(v, 1), (1, self.model_tester.num_choices) + (1,) * (v.ndim - 1))
if isinstance(v, tf.Tensor) and v.ndim > 0
else v
for k, v in inputs_dict.items()
}
if return_labels:
if model_class in get_values(TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING):
inputs_dict["labels"] = tf.ones(self.model_tester.batch_size, dtype=tf.int32)
elif model_class in get_values(TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING):
inputs_dict["start_positions"] = tf.zeros(self.model_tester.batch_size, dtype=tf.int32)
inputs_dict["end_positions"] = tf.zeros(self.model_tester.batch_size, dtype=tf.int32)
elif model_class in [
*get_values(TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING),
*get_values(TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING),
]:
inputs_dict["labels"] = tf.zeros(self.model_tester.batch_size, dtype=tf.int32)
elif model_class in get_values(TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING):
inputs_dict["next_sentence_label"] = tf.zeros(self.model_tester.batch_size, dtype=tf.int32)
elif model_class in [
*get_values(TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING),
*get_values(TF_MODEL_FOR_CAUSAL_LM_MAPPING),
*get_values(TF_MODEL_FOR_MASKED_LM_MAPPING),
*get_values(TF_MODEL_FOR_PRETRAINING_MAPPING),
*get_values(TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING),
]:
inputs_dict["labels"] = tf.zeros(
(self.model_tester.batch_size, self.model_tester.seq_length), dtype=tf.int32
)
return inputs_dict
@slow
def test_graph_mode(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes[:2]:
inputs = self._prepare_for_class(inputs_dict, model_class)
model = model_class(config)
@tf.function
def run_in_graph_mode():
return model(inputs)
outputs = run_in_graph_mode()
self.assertIsNotNone(outputs)
@slow
def test_xla_mode(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes[:2]:
inputs = self._prepare_for_class(inputs_dict, model_class)
model = model_class(config)
@tf.function(experimental_compile=True)
def run_in_graph_mode():
return model(inputs)
outputs = run_in_graph_mode()
self.assertIsNotNone(outputs)
@slow
def test_xla_fit(self):
# This is a copy of the test_keras_fit method, but we use XLA compilation instead of eager
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes[:2]:
model = model_class(config)
if getattr(model, "hf_compute_loss", None):
# Test that model correctly compute the loss with kwargs
prepared_for_class = self._prepare_for_class(inputs_dict.copy(), model_class, return_labels=True)
# Is there a better way to remove these decoder inputs?
prepared_for_class = {
key: val
for key, val in prepared_for_class.items()
if key not in ("head_mask", "decoder_head_mask", "cross_attn_head_mask", "decoder_input_ids")
}
possible_label_cols = {
"labels",
"label",
"label_ids",
"start_positions",
"start_position",
"end_positions",
"end_position",
"next_sentence_label",
}
label_names = possible_label_cols.intersection(set(prepared_for_class))
self.assertGreater(len(label_names), 0, msg="No matching label names found!")
labels = {key: val for key, val in prepared_for_class.items() if key in label_names}
inputs_minus_labels = {key: val for key, val in prepared_for_class.items() if key not in label_names}
self.assertGreater(len(inputs_minus_labels), 0)
# Make sure it works with XLA!
model.compile(optimizer=keras.optimizers.SGD(0.0), jit_compile=True)
# Make sure the model fits without crashing regardless of where we pass the labels
history = model.fit(
prepared_for_class,
validation_data=prepared_for_class,
steps_per_epoch=1,
validation_steps=1,
shuffle=False,
verbose=0,
)
loss = history.history["loss"][0]
self.assertTrue(not isnan(loss))
val_loss = history.history["val_loss"][0]
self.assertTrue(not isnan(val_loss))
# Now test it with separate labels, to make sure that path works in XLA too.
model = model_class(config)
model.compile(optimizer=keras.optimizers.SGD(0.0), jit_compile=True)
history = model.fit(
inputs_minus_labels,
labels,
validation_data=(inputs_minus_labels, labels),
steps_per_epoch=1,
validation_steps=1,
shuffle=False,
verbose=0,
)
loss = history.history["loss"][0]
self.assertTrue(not isnan(loss))
val_loss = history.history["val_loss"][0]
self.assertTrue(not isnan(val_loss))
@slow
def test_saved_model_creation_extended(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.output_hidden_states = True
config.output_attentions = True
if hasattr(config, "use_cache"):
config.use_cache = True
encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", self.model_tester.seq_length)
encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
for model_class in self.all_model_classes[:2]:
class_inputs_dict = self._prepare_for_class(inputs_dict, model_class)
model = model_class(config)
model.build_in_name_scope()
num_out = len(model(class_inputs_dict))
for key in list(class_inputs_dict.keys()):
# Remove keys not in the serving signature, as the SavedModel will not be compiled to deal with them
if key not in model.input_signature:
del class_inputs_dict[key]
# Check it's a tensor, in case the inputs dict has some bools in it too
elif isinstance(class_inputs_dict[key], tf.Tensor) and class_inputs_dict[key].dtype.is_integer:
class_inputs_dict[key] = tf.cast(class_inputs_dict[key], tf.int32)
if set(class_inputs_dict.keys()) != set(model.input_signature.keys()):
continue # Some models have inputs that the preparation functions don't create, we skip those
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname, saved_model=True)
saved_model_dir = os.path.join(tmpdirname, "saved_model", "1")
model = keras.models.load_model(saved_model_dir)
outputs = model(class_inputs_dict)
if self.is_encoder_decoder:
output_hidden_states = outputs["encoder_hidden_states"]
output_attentions = outputs["encoder_attentions"]
else:
output_hidden_states = outputs["hidden_states"]
output_attentions = outputs["attentions"]
self.assertEqual(len(outputs), num_out)
expected_num_layers = getattr(
self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
)
self.assertEqual(len(output_hidden_states), expected_num_layers)
self.assertListEqual(
list(output_hidden_states[0].shape[-2:]),
[self.model_tester.seq_length, self.model_tester.hidden_size],
)
self.assertEqual(len(output_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(output_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
)
@slow
def test_mixed_precision(self):
keras.mixed_precision.set_global_policy("mixed_float16")
# try/finally block to ensure subsequent tests run in float32
try:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes[:2]:
class_inputs_dict = self._prepare_for_class(inputs_dict, model_class)
model = model_class(config)
outputs = model(class_inputs_dict)
self.assertIsNotNone(outputs)
finally:
keras.mixed_precision.set_global_policy("float32")
@slow
def test_train_pipeline_custom_model(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
# head_mask and decoder_head_mask has different shapes than other input args
if "head_mask" in inputs_dict:
del inputs_dict["head_mask"]
if "decoder_head_mask" in inputs_dict:
del inputs_dict["decoder_head_mask"]
if "cross_attn_head_mask" in inputs_dict:
del inputs_dict["cross_attn_head_mask"]
tf_main_layer_classes = {
module_member
for model_class in self.all_model_classes
for module in (import_module(model_class.__module__),)
for module_member_name in dir(module)
if module_member_name.endswith("MainLayer")
for module_member in (getattr(module, module_member_name),)
if isinstance(module_member, type)
and keras.layers.Layer in module_member.__bases__
and getattr(module_member, "_keras_serializable", False)
}
for main_layer_class in tf_main_layer_classes:
# T5MainLayer needs an embed_tokens parameter when called without the inputs_embeds parameter
if "T5" in main_layer_class.__name__:
# Take the same values than in TFT5ModelTester for this shared layer
shared = TFSharedEmbeddings(self.model_tester.vocab_size, self.model_tester.hidden_size, name="shared")
config.use_cache = False
main_layer = main_layer_class(config, embed_tokens=shared)
else:
main_layer = main_layer_class(config)
symbolic_inputs = {
name: keras.Input(tensor.shape[1:], dtype=tensor.dtype) for name, tensor in inputs_dict.items()
}
if hasattr(self.model_tester, "num_labels"):
num_labels = self.model_tester.num_labels
else:
num_labels = 2
X = tf.data.Dataset.from_tensor_slices(
(inputs_dict, np.ones((self.model_tester.batch_size, self.model_tester.seq_length, num_labels, 1)))
).batch(1)
hidden_states = main_layer(symbolic_inputs)[0]
outputs = keras.layers.Dense(num_labels, activation="softmax", name="outputs")(hidden_states)
model = keras.models.Model(inputs=symbolic_inputs, outputs=[outputs])
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["binary_accuracy"])
model.fit(X, epochs=1)
with tempfile.TemporaryDirectory() as tmpdirname:
filepath = os.path.join(tmpdirname, "keras_model.h5")
model.save(filepath)
if "T5" in main_layer_class.__name__:
model = keras.models.load_model(
filepath,
custom_objects={
main_layer_class.__name__: main_layer_class,
"TFSharedEmbeddings": TFSharedEmbeddings,
},
)
else:
model = keras.models.load_model(
filepath, custom_objects={main_layer_class.__name__: main_layer_class}
)
assert isinstance(model, keras.Model)
model(inputs_dict)
@slow
def test_graph_mode_with_inputs_embeds(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes[:2]:
model = model_class(config)
inputs = copy.deepcopy(inputs_dict)
if not self.is_encoder_decoder:
input_ids = inputs["input_ids"]
del inputs["input_ids"]
else:
encoder_input_ids = inputs["input_ids"]
decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids)
del inputs["input_ids"]
inputs.pop("decoder_input_ids", None)
if not self.is_encoder_decoder:
inputs["inputs_embeds"] = model.get_input_embeddings()(input_ids)
else:
inputs["inputs_embeds"] = model.get_input_embeddings()(encoder_input_ids)
inputs["decoder_inputs_embeds"] = model.get_input_embeddings()(decoder_input_ids)
inputs = self._prepare_for_class(inputs, model_class)
@tf.function
def run_in_graph_mode():
return model(inputs)
outputs = run_in_graph_mode()
self.assertIsNotNone(outputs)
def _generate_random_bad_tokens(self, num_bad_tokens, model):
# special tokens cannot be bad tokens
special_tokens = []
if model.config.bos_token_id is not None:
special_tokens.append(model.config.bos_token_id)
if model.config.pad_token_id is not None:
special_tokens.append(model.config.pad_token_id)
if model.config.eos_token_id is not None:
special_tokens.append(model.config.eos_token_id)
# create random bad tokens that are not special tokens
bad_tokens = []
while len(bad_tokens) < num_bad_tokens:
token = tf.squeeze(ids_tensor((1, 1), self.model_tester.vocab_size), 0).numpy()[0]
if token not in special_tokens:
bad_tokens.append(token)
return bad_tokens
def _check_generated_ids(self, output_ids):
for token_id in output_ids[0].numpy().tolist():
self.assertGreaterEqual(token_id, 0)
self.assertLess(token_id, self.model_tester.vocab_size)
def _check_match_tokens(self, generated_ids, bad_words_ids):
# for all bad word tokens
for bad_word_ids in bad_words_ids:
# for all slices in batch
for generated_ids_slice in generated_ids:
# for all word idx
for i in range(len(bad_word_ids), len(generated_ids_slice)):
# if tokens match
if generated_ids_slice[i - len(bad_word_ids) : i] == bad_word_ids:
return True
return False
|
transformers/tests/utils/test_modeling_tf_core.py/0
|
{
"file_path": "transformers/tests/utils/test_modeling_tf_core.py",
"repo_id": "transformers",
"token_count": 9190
}
| 211 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utility that checks all docstrings of public objects have an argument section matching their signature.
Use from the root of the repo with:
```bash
python utils/check_docstrings.py
```
for a check that will error in case of inconsistencies (used by `make repo-consistency`).
To auto-fix issues run:
```bash
python utils/check_docstrings.py --fix_and_overwrite
```
which is used by `make fix-copies` (note that this fills what it cans, you might have to manually fill information
like argument descriptions).
"""
import argparse
import ast
import enum
import inspect
import operator as op
import re
from pathlib import Path
from typing import Any, Optional, Tuple, Union
from check_repo import ignore_undocumented
from git import Repo
from transformers.utils import direct_transformers_import
PATH_TO_REPO = Path(__file__).parent.parent.resolve()
PATH_TO_TRANSFORMERS = Path("src").resolve() / "transformers"
# This is to make sure the transformers module imported is the one in the repo.
transformers = direct_transformers_import(PATH_TO_TRANSFORMERS)
OPTIONAL_KEYWORD = "*optional*"
# Re pattern that catches args blocks in docstrings (with all variation around the name supported).
_re_args = re.compile(r"^\s*(Args?|Arguments?|Attributes?|Params?|Parameters?):\s*$")
# Re pattern that parses the start of an arg block: catches <name> (<description>) in those lines.
_re_parse_arg = re.compile(r"^(\s*)(\S+)\s+\((.+)\)(?:\:|$)")
# Re pattern that parses the end of a description of an arg (catches the default in *optional*, defaults to xxx).
_re_parse_description = re.compile(r"\*optional\*, defaults to (.*)$")
# This is a temporary list of objects to ignore while we progressively fix them. Do not add anything here, fix the
# docstrings instead. If formatting should be ignored for the docstring, you can put a comment # no-format on the
# line before the docstring.
OBJECTS_TO_IGNORE = [
# Deprecated
"InputExample",
"InputFeatures",
# Signature is *args/**kwargs
"TFSequenceSummary",
"TFBertTokenizer",
"TFGPT2Tokenizer",
# Going through an argument deprecation cycle, remove after v4.46
"HybridCache",
"MambaCache",
"SlidingWindowCache",
"StaticCache",
# Missing arguments in the docstring
"ASTFeatureExtractor",
"AlbertModel",
"AlbertTokenizerFast",
"AlignTextModel",
"AlignVisionConfig",
"AudioClassificationPipeline",
"AutoformerConfig",
"AutomaticSpeechRecognitionPipeline",
"BarkCoarseConfig",
"BarkConfig",
"BarkFineConfig",
"BarkSemanticConfig",
"BartConfig",
"BartTokenizerFast",
"BarthezTokenizerFast",
"BeitModel",
"BertConfig",
"BertJapaneseTokenizer",
"BertModel",
"BertTokenizerFast",
"BigBirdConfig",
"BigBirdForQuestionAnswering",
"BigBirdModel",
"BigBirdPegasusConfig",
"BigBirdTokenizerFast",
"BitImageProcessor",
"BlenderbotConfig",
"BlenderbotSmallConfig",
"BlenderbotSmallTokenizerFast",
"BlenderbotTokenizerFast",
"Blip2QFormerConfig",
"Blip2VisionConfig",
"BlipTextConfig",
"BlipVisionConfig",
"BloomConfig",
"BloomTokenizerFast",
"BridgeTowerTextConfig",
"BridgeTowerVisionConfig",
"BrosModel",
"CamembertConfig",
"CamembertModel",
"CamembertTokenizerFast",
"CanineModel",
"CanineTokenizer",
"ChineseCLIPTextModel",
"ClapTextConfig",
"ConditionalDetrConfig",
"ConditionalDetrImageProcessor",
"ConvBertConfig",
"ConvBertTokenizerFast",
"ConvNextConfig",
"ConvNextV2Config",
"CpmAntTokenizer",
"CvtConfig",
"CvtModel",
"DeiTImageProcessor",
"DPRReaderTokenizer",
"DPRReaderTokenizerFast",
"DPTModel",
"Data2VecAudioConfig",
"Data2VecTextConfig",
"Data2VecTextModel",
"Data2VecVisionModel",
"DataCollatorForLanguageModeling",
"DebertaConfig",
"DebertaV2Config",
"DebertaV2Tokenizer",
"DebertaV2TokenizerFast",
"DecisionTransformerConfig",
"DeformableDetrConfig",
"DeformableDetrImageProcessor",
"DeiTModel",
"DepthEstimationPipeline",
"DetaConfig",
"DetaImageProcessor",
"DetrConfig",
"DetrImageProcessor",
"DinatModel",
"DistilBertConfig",
"DistilBertTokenizerFast",
"DocumentQuestionAnsweringPipeline",
"DonutSwinModel",
"EarlyStoppingCallback",
"EfficientFormerConfig",
"EfficientFormerImageProcessor",
"EfficientNetConfig",
"ElectraConfig",
"ElectraTokenizerFast",
"EncoderDecoderModel",
"ErnieMModel",
"ErnieModel",
"ErnieMTokenizer",
"EsmConfig",
"EsmModel",
"FlaxAlbertForMaskedLM",
"FlaxAlbertForMultipleChoice",
"FlaxAlbertForPreTraining",
"FlaxAlbertForQuestionAnswering",
"FlaxAlbertForSequenceClassification",
"FlaxAlbertForTokenClassification",
"FlaxAlbertModel",
"FlaxBartForCausalLM",
"FlaxBartForConditionalGeneration",
"FlaxBartForQuestionAnswering",
"FlaxBartForSequenceClassification",
"FlaxBartModel",
"FlaxBeitForImageClassification",
"FlaxBeitForMaskedImageModeling",
"FlaxBeitModel",
"FlaxBertForCausalLM",
"FlaxBertForMaskedLM",
"FlaxBertForMultipleChoice",
"FlaxBertForNextSentencePrediction",
"FlaxBertForPreTraining",
"FlaxBertForQuestionAnswering",
"FlaxBertForSequenceClassification",
"FlaxBertForTokenClassification",
"FlaxBertModel",
"FlaxBigBirdForCausalLM",
"FlaxBigBirdForMaskedLM",
"FlaxBigBirdForMultipleChoice",
"FlaxBigBirdForPreTraining",
"FlaxBigBirdForQuestionAnswering",
"FlaxBigBirdForSequenceClassification",
"FlaxBigBirdForTokenClassification",
"FlaxBigBirdModel",
"FlaxBlenderbotForConditionalGeneration",
"FlaxBlenderbotModel",
"FlaxBlenderbotSmallForConditionalGeneration",
"FlaxBlenderbotSmallModel",
"FlaxBloomForCausalLM",
"FlaxBloomModel",
"FlaxCLIPModel",
"FlaxDinov2ForImageClassification",
"FlaxDinov2Model",
"FlaxDistilBertForMaskedLM",
"FlaxDistilBertForMultipleChoice",
"FlaxDistilBertForQuestionAnswering",
"FlaxDistilBertForSequenceClassification",
"FlaxDistilBertForTokenClassification",
"FlaxDistilBertModel",
"FlaxElectraForCausalLM",
"FlaxElectraForMaskedLM",
"FlaxElectraForMultipleChoice",
"FlaxElectraForPreTraining",
"FlaxElectraForQuestionAnswering",
"FlaxElectraForSequenceClassification",
"FlaxElectraForTokenClassification",
"FlaxElectraModel",
"FlaxEncoderDecoderModel",
"FlaxGPT2LMHeadModel",
"FlaxGPT2Model",
"FlaxGPTJForCausalLM",
"FlaxGPTJModel",
"FlaxGPTNeoForCausalLM",
"FlaxGPTNeoModel",
"FlaxLlamaForCausalLM",
"FlaxLlamaModel",
"FlaxGemmaForCausalLM",
"FlaxGemmaModel",
"FlaxMBartForConditionalGeneration",
"FlaxMBartForQuestionAnswering",
"FlaxMBartForSequenceClassification",
"FlaxMBartModel",
"FlaxMarianMTModel",
"FlaxMarianModel",
"FlaxMistralForCausalLM",
"FlaxMistralModel",
"FlaxOPTForCausalLM",
"FlaxPegasusForConditionalGeneration",
"FlaxPegasusModel",
"FlaxRegNetForImageClassification",
"FlaxRegNetModel",
"FlaxResNetForImageClassification",
"FlaxResNetModel",
"FlaxRoFormerForMaskedLM",
"FlaxRoFormerForMultipleChoice",
"FlaxRoFormerForQuestionAnswering",
"FlaxRoFormerForSequenceClassification",
"FlaxRoFormerForTokenClassification",
"FlaxRoFormerModel",
"FlaxRobertaForCausalLM",
"FlaxRobertaForMaskedLM",
"FlaxRobertaForMultipleChoice",
"FlaxRobertaForQuestionAnswering",
"FlaxRobertaForSequenceClassification",
"FlaxRobertaForTokenClassification",
"FlaxRobertaModel",
"FlaxRobertaPreLayerNormForCausalLM",
"FlaxRobertaPreLayerNormForMaskedLM",
"FlaxRobertaPreLayerNormForMultipleChoice",
"FlaxRobertaPreLayerNormForQuestionAnswering",
"FlaxRobertaPreLayerNormForSequenceClassification",
"FlaxRobertaPreLayerNormForTokenClassification",
"FlaxRobertaPreLayerNormModel",
"FlaxSpeechEncoderDecoderModel",
"FlaxViTForImageClassification",
"FlaxViTModel",
"FlaxVisionEncoderDecoderModel",
"FlaxVisionTextDualEncoderModel",
"FlaxWav2Vec2ForCTC",
"FlaxWav2Vec2ForPreTraining",
"FlaxWav2Vec2Model",
"FlaxWhisperForAudioClassification",
"FlaxWhisperForConditionalGeneration",
"FlaxWhisperModel",
"FlaxWhisperTimeStampLogitsProcessor",
"FlaxXGLMForCausalLM",
"FlaxXGLMModel",
"FlaxXLMRobertaForCausalLM",
"FlaxXLMRobertaForMaskedLM",
"FlaxXLMRobertaForMultipleChoice",
"FlaxXLMRobertaForQuestionAnswering",
"FlaxXLMRobertaForSequenceClassification",
"FlaxXLMRobertaForTokenClassification",
"FlaxXLMRobertaModel",
"FNetConfig",
"FNetModel",
"FNetTokenizerFast",
"FSMTConfig",
"FeatureExtractionPipeline",
"FillMaskPipeline",
"FlaubertConfig",
"FlavaConfig",
"FlavaForPreTraining",
"FlavaImageModel",
"FlavaImageProcessor",
"FlavaMultimodalModel",
"FlavaTextConfig",
"FlavaTextModel",
"FocalNetModel",
"FunnelTokenizerFast",
"GPTBigCodeConfig",
"GPTJConfig",
"GPTNeoXConfig",
"GPTNeoXJapaneseConfig",
"GPTNeoXTokenizerFast",
"GPTSanJapaneseConfig",
"GitConfig",
"GitVisionConfig",
"GraphormerConfig",
"GroupViTTextConfig",
"GroupViTVisionConfig",
"HerbertTokenizerFast",
"HubertConfig",
"HubertForCTC",
"IBertConfig",
"IBertModel",
"IdeficsConfig",
"IdeficsProcessor",
"IJepaModel",
"ImageClassificationPipeline",
"ImageFeatureExtractionPipeline",
"ImageGPTConfig",
"ImageSegmentationPipeline",
"ImageTextToTextPipeline",
"ImageToImagePipeline",
"ImageToTextPipeline",
"InformerConfig",
"JukeboxPriorConfig",
"JukeboxTokenizer",
"LEDConfig",
"LEDTokenizerFast",
"LayoutLMForQuestionAnswering",
"LayoutLMTokenizerFast",
"LayoutLMv2Config",
"LayoutLMv2ForQuestionAnswering",
"LayoutLMv2TokenizerFast",
"LayoutLMv3Config",
"LayoutLMv3ImageProcessor",
"LayoutLMv3TokenizerFast",
"LayoutXLMTokenizerFast",
"LevitConfig",
"LiltConfig",
"LiltModel",
"LongT5Config",
"LongformerConfig",
"LongformerModel",
"LongformerTokenizerFast",
"LukeModel",
"LukeTokenizer",
"LxmertTokenizerFast",
"M2M100Config",
"M2M100Tokenizer",
"MarkupLMProcessor",
"MaskGenerationPipeline",
"MBart50TokenizerFast",
"MBartConfig",
"MCTCTFeatureExtractor",
"MPNetConfig",
"MPNetModel",
"MPNetTokenizerFast",
"MT5Config",
"MT5TokenizerFast",
"MarianConfig",
"MarianTokenizer",
"MarkupLMConfig",
"MarkupLMModel",
"MarkupLMTokenizer",
"MarkupLMTokenizerFast",
"Mask2FormerConfig",
"MaskFormerConfig",
"MaxTimeCriteria",
"MegaConfig",
"MegaModel",
"MegatronBertConfig",
"MegatronBertForPreTraining",
"MegatronBertModel",
"MobileBertConfig",
"MobileBertModel",
"MobileBertTokenizerFast",
"MobileNetV1ImageProcessor",
"MobileNetV1Model",
"MobileNetV2ImageProcessor",
"MobileNetV2Model",
"MobileViTModel",
"MobileViTV2Model",
"MLukeTokenizer",
"MraConfig",
"MusicgenDecoderConfig",
"MusicgenForConditionalGeneration",
"MusicgenMelodyForConditionalGeneration",
"MvpConfig",
"MvpTokenizerFast",
"MT5Tokenizer",
"NatModel",
"NerPipeline",
"NezhaConfig",
"NezhaModel",
"NllbMoeConfig",
"NllbTokenizer",
"NllbTokenizerFast",
"NystromformerConfig",
"OPTConfig",
"ObjectDetectionPipeline",
"OneFormerProcessor",
"OpenAIGPTTokenizerFast",
"OpenLlamaConfig",
"PLBartConfig",
"PegasusConfig",
"PegasusTokenizer",
"PegasusTokenizerFast",
"PegasusXConfig",
"PerceiverImageProcessor",
"PerceiverModel",
"PerceiverTokenizer",
"PersimmonConfig",
"Pipeline",
"Pix2StructConfig",
"Pix2StructTextConfig",
"PLBartTokenizer",
"Pop2PianoConfig",
"PreTrainedTokenizer",
"PreTrainedTokenizerBase",
"PreTrainedTokenizerFast",
"PrefixConstrainedLogitsProcessor",
"ProphetNetConfig",
"QDQBertConfig",
"QDQBertModel",
"QuestionAnsweringPipeline",
"RagConfig",
"RagModel",
"RagRetriever",
"RagSequenceForGeneration",
"RagTokenForGeneration",
"RealmConfig",
"RealmForOpenQA",
"RealmScorer",
"RealmTokenizerFast",
"ReformerConfig",
"ReformerTokenizerFast",
"RegNetConfig",
"RemBertConfig",
"RemBertModel",
"RemBertTokenizer",
"RemBertTokenizerFast",
"RetriBertConfig",
"RetriBertTokenizerFast",
"RoCBertConfig",
"RoCBertModel",
"RoCBertTokenizer",
"RoFormerConfig",
"RobertaConfig",
"RobertaModel",
"RobertaPreLayerNormConfig",
"RobertaPreLayerNormModel",
"RobertaTokenizerFast",
"SEWConfig",
"SEWDConfig",
"SEWDForCTC",
"SEWForCTC",
"SamConfig",
"SamPromptEncoderConfig",
"SeamlessM4TConfig", # use of unconventional markdown
"SeamlessM4Tv2Config", # use of unconventional markdown
"Seq2SeqTrainingArguments",
"SpecialTokensMixin",
"Speech2Text2Config",
"Speech2Text2Tokenizer",
"Speech2TextTokenizer",
"SpeechEncoderDecoderModel",
"SpeechT5Config",
"SpeechT5Model",
"SplinterConfig",
"SplinterTokenizerFast",
"SqueezeBertTokenizerFast",
"SummarizationPipeline",
"Swin2SRImageProcessor",
"Swinv2Model",
"SwitchTransformersConfig",
"T5Config",
"T5Tokenizer",
"T5TokenizerFast",
"TableQuestionAnsweringPipeline",
"TableTransformerConfig",
"TapasConfig",
"TapasModel",
"TapasTokenizer",
"Text2TextGenerationPipeline",
"TextClassificationPipeline",
"TextGenerationPipeline",
"TFBartForConditionalGeneration",
"TFBartForSequenceClassification",
"TFBartModel",
"TFBertModel",
"TFConvNextModel",
"TFData2VecVisionModel",
"TFDeiTModel",
"TFEncoderDecoderModel",
"TFEsmModel",
"TFMobileViTModel",
"TFRagModel",
"TFRagSequenceForGeneration",
"TFRagTokenForGeneration",
"TFRepetitionPenaltyLogitsProcessor",
"TFSwinModel",
"TFViTModel",
"TFVisionEncoderDecoderModel",
"TFVisionTextDualEncoderModel",
"TFXGLMForCausalLM",
"TFXGLMModel",
"TimeSeriesTransformerConfig",
"TokenClassificationPipeline",
"TrOCRConfig",
"TrainerState",
"TrainingArguments",
"TrajectoryTransformerConfig",
"TranslationPipeline",
"TvltImageProcessor",
"UMT5Config",
"UperNetConfig",
"UperNetForSemanticSegmentation",
"ViTHybridImageProcessor",
"ViTHybridModel",
"ViTMSNModel",
"ViTModel",
"VideoClassificationPipeline",
"ViltConfig",
"ViltForImagesAndTextClassification",
"ViltModel",
"VisionEncoderDecoderModel",
"VisionTextDualEncoderModel",
"VisualBertConfig",
"VisualBertModel",
"VisualQuestionAnsweringPipeline",
"VitMatteForImageMatting",
"VitsTokenizer",
"VivitModel",
"Wav2Vec2BertForCTC",
"Wav2Vec2CTCTokenizer",
"Wav2Vec2Config",
"Wav2Vec2ConformerConfig",
"Wav2Vec2ConformerForCTC",
"Wav2Vec2FeatureExtractor",
"Wav2Vec2PhonemeCTCTokenizer",
"WavLMConfig",
"WavLMForCTC",
"WhisperConfig",
"WhisperFeatureExtractor",
"WhisperForAudioClassification",
"XCLIPTextConfig",
"XCLIPVisionConfig",
"XGLMConfig",
"XGLMModel",
"XGLMTokenizerFast",
"XLMConfig",
"XLMProphetNetConfig",
"XLMRobertaConfig",
"XLMRobertaModel",
"XLMRobertaTokenizerFast",
"XLMRobertaXLConfig",
"XLMRobertaXLModel",
"XLNetConfig",
"XLNetTokenizerFast",
"XmodConfig",
"XmodModel",
"YolosImageProcessor",
"YolosModel",
"YosoConfig",
"ZeroShotAudioClassificationPipeline",
"ZeroShotClassificationPipeline",
"ZeroShotImageClassificationPipeline",
"ZeroShotObjectDetectionPipeline",
]
# Supported math operations when interpreting the value of defaults.
MATH_OPERATORS = {
ast.Add: op.add,
ast.Sub: op.sub,
ast.Mult: op.mul,
ast.Div: op.truediv,
ast.Pow: op.pow,
ast.BitXor: op.xor,
ast.USub: op.neg,
}
def find_indent(line: str) -> int:
"""
Returns the number of spaces that start a line indent.
"""
search = re.search(r"^(\s*)(?:\S|$)", line)
if search is None:
return 0
return len(search.groups()[0])
def stringify_default(default: Any) -> str:
"""
Returns the string representation of a default value, as used in docstring: numbers are left as is, all other
objects are in backtiks.
Args:
default (`Any`): The default value to process
Returns:
`str`: The string representation of that default.
"""
if isinstance(default, bool):
# We need to test for bool first as a bool passes isinstance(xxx, (int, float))
return f"`{default}`"
elif isinstance(default, enum.Enum):
# We need to test for enum first as an enum with int values will pass isinstance(xxx, (int, float))
return f"`{str(default)}`"
elif isinstance(default, int):
return str(default)
elif isinstance(default, float):
result = str(default)
return str(round(default, 2)) if len(result) > 6 else result
elif isinstance(default, str):
return str(default) if default.isnumeric() else f'`"{default}"`'
elif isinstance(default, type):
return f"`{default.__name__}`"
else:
return f"`{default}`"
def eval_math_expression(expression: str) -> Optional[Union[float, int]]:
# Mainly taken from the excellent https://stackoverflow.com/a/9558001
"""
Evaluate (safely) a mathematial expression and returns its value.
Args:
expression (`str`): The expression to evaluate.
Returns:
`Optional[Union[float, int]]`: Returns `None` if the evaluation fails in any way and the value computed
otherwise.
Example:
```py
>>> eval_expr('2^6')
4
>>> eval_expr('2**6')
64
>>> eval_expr('1 + 2*3**(4^5) / (6 + -7)')
-5.0
```
"""
try:
return eval_node(ast.parse(expression, mode="eval").body)
except TypeError:
return
def eval_node(node):
if isinstance(node, ast.Num): # <number>
return node.n
elif isinstance(node, ast.BinOp): # <left> <operator> <right>
return MATH_OPERATORS[type(node.op)](eval_node(node.left), eval_node(node.right))
elif isinstance(node, ast.UnaryOp): # <operator> <operand> e.g., -1
return MATH_OPERATORS[type(node.op)](eval_node(node.operand))
else:
raise TypeError(node)
def replace_default_in_arg_description(description: str, default: Any) -> str:
"""
Catches the default value in the description of an argument inside a docstring and replaces it by the value passed.
Args:
description (`str`): The description of an argument in a docstring to process.
default (`Any`): The default value that whould be in the docstring of that argument.
Returns:
`str`: The description updated with the new default value.
"""
# Lots of docstrings have `optional` or **opational** instead of *optional* so we do this fix here.
description = description.replace("`optional`", OPTIONAL_KEYWORD)
description = description.replace("**optional**", OPTIONAL_KEYWORD)
if default is inspect._empty:
# No default, make sure the description doesn't have any either
idx = description.find(OPTIONAL_KEYWORD)
if idx != -1:
description = description[:idx].rstrip()
if description.endswith(","):
description = description[:-1].rstrip()
elif default is None:
# Default None are not written, we just set `*optional*`. If there is default that is not None specified in the
# description, we do not erase it (as sometimes we set the default to `None` because the default is a mutable
# object).
idx = description.find(OPTIONAL_KEYWORD)
if idx == -1:
description = f"{description}, {OPTIONAL_KEYWORD}"
elif re.search(r"defaults to `?None`?", description) is not None:
len_optional = len(OPTIONAL_KEYWORD)
description = description[: idx + len_optional]
else:
str_default = None
# For numbers we may have a default that is given by a math operation (1/255 is really popular). We don't
# want to replace those by their actual values.
if isinstance(default, (int, float)) and re.search("defaults to `?(.*?)(?:`|$)", description) is not None:
# Grab the default and evaluate it.
current_default = re.search("defaults to `?(.*?)(?:`|$)", description).groups()[0]
if default == eval_math_expression(current_default):
try:
# If it can be directly converted to the type of the default, it's a simple value
str_default = str(type(default)(current_default))
except Exception:
# Otherwise there is a math operator so we add a code block.
str_default = f"`{current_default}`"
elif isinstance(default, enum.Enum) and default.name == current_default.split(".")[-1]:
# When the default is an Enum (this is often the case for PIL.Image.Resampling), and the docstring
# matches the enum name, keep the existing docstring rather than clobbering it with the enum value.
str_default = f"`{current_default}`"
if str_default is None:
str_default = stringify_default(default)
# Make sure default match
if OPTIONAL_KEYWORD not in description:
description = f"{description}, {OPTIONAL_KEYWORD}, defaults to {str_default}"
elif _re_parse_description.search(description) is None:
idx = description.find(OPTIONAL_KEYWORD)
len_optional = len(OPTIONAL_KEYWORD)
description = f"{description[:idx + len_optional]}, defaults to {str_default}"
else:
description = _re_parse_description.sub(rf"*optional*, defaults to {str_default}", description)
return description
def get_default_description(arg: inspect.Parameter) -> str:
"""
Builds a default description for a parameter that was not documented.
Args:
arg (`inspect.Parameter`): The argument in the signature to generate a description for.
Returns:
`str`: The description.
"""
if arg.annotation is inspect._empty:
arg_type = "<fill_type>"
elif hasattr(arg.annotation, "__name__"):
arg_type = arg.annotation.__name__
else:
arg_type = str(arg.annotation)
if arg.default is inspect._empty:
return f"`{arg_type}`"
elif arg.default is None:
return f"`{arg_type}`, {OPTIONAL_KEYWORD}"
else:
str_default = stringify_default(arg.default)
return f"`{arg_type}`, {OPTIONAL_KEYWORD}, defaults to {str_default}"
def find_source_file(obj: Any) -> Path:
"""
Finds the source file of an object.
Args:
obj (`Any`): The object whose source file we are looking for.
Returns:
`Path`: The source file.
"""
module = obj.__module__
obj_file = PATH_TO_TRANSFORMERS
for part in module.split(".")[1:]:
obj_file = obj_file / part
return obj_file.with_suffix(".py")
def match_docstring_with_signature(obj: Any) -> Optional[Tuple[str, str]]:
"""
Matches the docstring of an object with its signature.
Args:
obj (`Any`): The object to process.
Returns:
`Optional[Tuple[str, str]]`: Returns `None` if there is no docstring or no parameters documented in the
docstring, otherwise returns a tuple of two strings: the current documentation of the arguments in the
docstring and the one matched with the signature.
"""
if len(getattr(obj, "__doc__", "")) == 0:
# Nothing to do, there is no docstring.
return
# Read the docstring in the source code to see if there is a special command to ignore this object.
try:
source, _ = inspect.getsourcelines(obj)
except OSError:
source = []
idx = 0
while idx < len(source) and '"""' not in source[idx]:
idx += 1
ignore_order = False
if idx < len(source):
line_before_docstring = source[idx - 1]
if re.search(r"^\s*#\s*no-format\s*$", line_before_docstring):
# This object is ignored
return
elif re.search(r"^\s*#\s*ignore-order\s*$", line_before_docstring):
ignore_order = True
# Read the signature
signature = inspect.signature(obj).parameters
obj_doc_lines = obj.__doc__.split("\n")
# Get to the line where we start documenting arguments
idx = 0
while idx < len(obj_doc_lines) and _re_args.search(obj_doc_lines[idx]) is None:
idx += 1
if idx == len(obj_doc_lines):
# Nothing to do, no parameters are documented.
return
indent = find_indent(obj_doc_lines[idx])
arguments = {}
current_arg = None
idx += 1
start_idx = idx
# Keep going until the arg section is finished (nonempty line at the same indent level) or the end of the docstring.
while idx < len(obj_doc_lines) and (
len(obj_doc_lines[idx].strip()) == 0 or find_indent(obj_doc_lines[idx]) > indent
):
if find_indent(obj_doc_lines[idx]) == indent + 4:
# New argument -> let's generate the proper doc for it
re_search_arg = _re_parse_arg.search(obj_doc_lines[idx])
if re_search_arg is not None:
_, name, description = re_search_arg.groups()
current_arg = name
if name in signature:
default = signature[name].default
if signature[name].kind is inspect._ParameterKind.VAR_KEYWORD:
default = None
new_description = replace_default_in_arg_description(description, default)
else:
new_description = description
init_doc = _re_parse_arg.sub(rf"\1\2 ({new_description}):", obj_doc_lines[idx])
arguments[current_arg] = [init_doc]
elif current_arg is not None:
arguments[current_arg].append(obj_doc_lines[idx])
idx += 1
# We went too far by one (perhaps more if there are a lot of new lines)
idx -= 1
if current_arg:
while len(obj_doc_lines[idx].strip()) == 0:
arguments[current_arg] = arguments[current_arg][:-1]
idx -= 1
# And we went too far by one again.
idx += 1
old_doc_arg = "\n".join(obj_doc_lines[start_idx:idx])
old_arguments = list(arguments.keys())
arguments = {name: "\n".join(doc) for name, doc in arguments.items()}
# Add missing arguments with a template
for name in set(signature.keys()) - set(arguments.keys()):
arg = signature[name]
# We ignore private arguments or *args/**kwargs (unless they are documented by the user)
if name.startswith("_") or arg.kind in [
inspect._ParameterKind.VAR_KEYWORD,
inspect._ParameterKind.VAR_POSITIONAL,
]:
arguments[name] = ""
else:
arg_desc = get_default_description(arg)
arguments[name] = " " * (indent + 4) + f"{name} ({arg_desc}): <fill_docstring>"
# Arguments are sorted by the order in the signature unless a special comment is put.
if ignore_order:
new_param_docs = [arguments[name] for name in old_arguments if name in signature]
missing = set(signature.keys()) - set(old_arguments)
new_param_docs.extend([arguments[name] for name in missing if len(arguments[name]) > 0])
else:
new_param_docs = [arguments[name] for name in signature.keys() if len(arguments[name]) > 0]
new_doc_arg = "\n".join(new_param_docs)
return old_doc_arg, new_doc_arg
def fix_docstring(obj: Any, old_doc_args: str, new_doc_args: str):
"""
Fixes the docstring of an object by replacing its arguments documentaiton by the one matched with the signature.
Args:
obj (`Any`):
The object whose dostring we are fixing.
old_doc_args (`str`):
The current documentation of the parameters of `obj` in the docstring (as returned by
`match_docstring_with_signature`).
new_doc_args (`str`):
The documentation of the parameters of `obj` matched with its signature (as returned by
`match_docstring_with_signature`).
"""
# Read the docstring in the source code and make sure we have the right part of the docstring
source, line_number = inspect.getsourcelines(obj)
# Get to the line where we start documenting arguments
idx = 0
while idx < len(source) and _re_args.search(source[idx]) is None:
idx += 1
if idx == len(source):
# Args are not defined in the docstring of this object
return
# Get to the line where we stop documenting arguments
indent = find_indent(source[idx])
idx += 1
start_idx = idx
while idx < len(source) and (len(source[idx].strip()) == 0 or find_indent(source[idx]) > indent):
idx += 1
idx -= 1
while len(source[idx].strip()) == 0:
idx -= 1
idx += 1
if "".join(source[start_idx:idx])[:-1] != old_doc_args:
# Args are not fully defined in the docstring of this object
return
obj_file = find_source_file(obj)
with open(obj_file, "r", encoding="utf-8") as f:
content = f.read()
# Replace content
lines = content.split("\n")
lines = lines[: line_number + start_idx - 1] + [new_doc_args] + lines[line_number + idx - 1 :]
print(f"Fixing the docstring of {obj.__name__} in {obj_file}.")
with open(obj_file, "w", encoding="utf-8") as f:
f.write("\n".join(lines))
def check_docstrings(overwrite: bool = False, check_all: bool = False):
"""
Check docstrings of all public objects that are callables and are documented. By default, only checks the diff.
Args:
overwrite (`bool`, *optional*, defaults to `False`):
Whether to fix inconsistencies or not.
check_all (`bool`, *optional*, defaults to `False`):
Whether to check all files.
"""
module_diff_files = None
if not check_all:
module_diff_files = set()
repo = Repo(PATH_TO_REPO)
# Diff from index to unstaged files
for modified_file_diff in repo.index.diff(None):
if modified_file_diff.a_path.startswith("src/transformers"):
module_diff_files.add(modified_file_diff.a_path)
# Diff from index to `main`
for modified_file_diff in repo.index.diff(repo.refs.main.commit):
if modified_file_diff.a_path.startswith("src/transformers"):
module_diff_files.add(modified_file_diff.a_path)
# quick escape route: if there are no module files in the diff, skip this check
if len(module_diff_files) == 0:
return
print(" Checking docstrings in the following files:" + "\n - " + "\n - ".join(module_diff_files))
failures = []
hard_failures = []
to_clean = []
for name in dir(transformers):
# Skip objects that are private or not documented.
if name.startswith("_") or ignore_undocumented(name) or name in OBJECTS_TO_IGNORE:
continue
obj = getattr(transformers, name)
if not callable(obj) or not isinstance(obj, type) or getattr(obj, "__doc__", None) is None:
continue
# If we are checking against the diff, we skip objects that are not part of the diff.
if module_diff_files is not None:
object_file = find_source_file(getattr(transformers, name))
object_file_relative_path = "src/" + str(object_file).split("/src/")[1]
if object_file_relative_path not in module_diff_files:
continue
# Check docstring
try:
result = match_docstring_with_signature(obj)
if result is not None:
old_doc, new_doc = result
else:
old_doc, new_doc = None, None
except Exception as e:
print(e)
hard_failures.append(name)
continue
if old_doc != new_doc:
if overwrite:
fix_docstring(obj, old_doc, new_doc)
else:
failures.append(name)
elif not overwrite and new_doc is not None and ("<fill_type>" in new_doc or "<fill_docstring>" in new_doc):
to_clean.append(name)
# Deal with errors
error_message = ""
if len(hard_failures) > 0:
error_message += (
"The argument part of the docstrings of the following objects could not be processed, check they are "
"properly formatted."
)
error_message += "\n" + "\n".join([f"- {name}" for name in hard_failures])
if len(failures) > 0:
error_message += (
"The following objects docstrings do not match their signature. Run `make fix-copies` to fix this. "
"In some cases, this error may be raised incorrectly by the docstring checker. If you think this is the "
"case, you can manually check the docstrings and then add the object name to `OBJECTS_TO_IGNORE` in "
"`utils/check_docstrings.py`."
)
error_message += "\n" + "\n".join([f"- {name}" for name in failures])
if len(to_clean) > 0:
error_message += (
"The following objects docstrings contain templates you need to fix: search for `<fill_type>` or "
"`<fill_docstring>`."
)
error_message += "\n" + "\n".join([f"- {name}" for name in to_clean])
if len(error_message) > 0:
error_message = "There was at least one problem when checking docstrings of public objects.\n" + error_message
raise ValueError(error_message)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--fix_and_overwrite", action="store_true", help="Whether to fix inconsistencies.")
parser.add_argument(
"--check_all", action="store_true", help="Whether to check all files. By default, only checks the diff"
)
args = parser.parse_args()
check_docstrings(overwrite=args.fix_and_overwrite, check_all=args.check_all)
|
transformers/utils/check_docstrings.py/0
|
{
"file_path": "transformers/utils/check_docstrings.py",
"repo_id": "transformers",
"token_count": 14475
}
| 212 |
import argparse
import json
import os
import time
import zipfile
from get_ci_error_statistics import download_artifact, get_artifacts_links
from transformers import logging
logger = logging.get_logger(__name__)
def extract_warnings_from_single_artifact(artifact_path, targets):
"""Extract warnings from a downloaded artifact (in .zip format)"""
selected_warnings = set()
buffer = []
def parse_line(fp):
for line in fp:
if isinstance(line, bytes):
line = line.decode("UTF-8")
if "warnings summary (final)" in line:
continue
# This means we are outside the body of a warning
elif not line.startswith(" "):
# process a single warning and move it to `selected_warnings`.
if len(buffer) > 0:
warning = "\n".join(buffer)
# Only keep the warnings specified in `targets`
if any(f": {x}: " in warning for x in targets):
selected_warnings.add(warning)
buffer.clear()
continue
else:
line = line.strip()
buffer.append(line)
if from_gh:
for filename in os.listdir(artifact_path):
file_path = os.path.join(artifact_path, filename)
if not os.path.isdir(file_path):
# read the file
if filename != "warnings.txt":
continue
with open(file_path) as fp:
parse_line(fp)
else:
try:
with zipfile.ZipFile(artifact_path) as z:
for filename in z.namelist():
if not os.path.isdir(filename):
# read the file
if filename != "warnings.txt":
continue
with z.open(filename) as fp:
parse_line(fp)
except Exception:
logger.warning(
f"{artifact_path} is either an invalid zip file or something else wrong. This file is skipped."
)
return selected_warnings
def extract_warnings(artifact_dir, targets):
"""Extract warnings from all artifact files"""
selected_warnings = set()
paths = [os.path.join(artifact_dir, p) for p in os.listdir(artifact_dir) if (p.endswith(".zip") or from_gh)]
for p in paths:
selected_warnings.update(extract_warnings_from_single_artifact(p, targets))
return selected_warnings
if __name__ == "__main__":
def list_str(values):
return values.split(",")
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument("--workflow_run_id", type=str, required=True, help="A GitHub Actions workflow run id.")
parser.add_argument(
"--output_dir",
type=str,
required=True,
help="Where to store the downloaded artifacts and other result files.",
)
parser.add_argument("--token", default=None, type=str, help="A token that has actions:read permission.")
# optional parameters
parser.add_argument(
"--targets",
default="DeprecationWarning,UserWarning,FutureWarning",
type=list_str,
help="Comma-separated list of target warning(s) which we want to extract.",
)
parser.add_argument(
"--from_gh",
action="store_true",
help="If running from a GitHub action workflow and collecting warnings from its artifacts.",
)
args = parser.parse_args()
from_gh = args.from_gh
if from_gh:
# The artifacts have to be downloaded using `actions/download-artifact@v4`
pass
else:
os.makedirs(args.output_dir, exist_ok=True)
# get download links
artifacts = get_artifacts_links(args.workflow_run_id, token=args.token)
with open(os.path.join(args.output_dir, "artifacts.json"), "w", encoding="UTF-8") as fp:
json.dump(artifacts, fp, ensure_ascii=False, indent=4)
# download artifacts
for idx, (name, url) in enumerate(artifacts.items()):
print(name)
print(url)
print("=" * 80)
download_artifact(name, url, args.output_dir, args.token)
# Be gentle to GitHub
time.sleep(1)
# extract warnings from artifacts
selected_warnings = extract_warnings(args.output_dir, args.targets)
selected_warnings = sorted(selected_warnings)
with open(os.path.join(args.output_dir, "selected_warnings.json"), "w", encoding="UTF-8") as fp:
json.dump(selected_warnings, fp, ensure_ascii=False, indent=4)
|
transformers/utils/extract_warnings.py/0
|
{
"file_path": "transformers/utils/extract_warnings.py",
"repo_id": "transformers",
"token_count": 2110
}
| 213 |
#!/usr/bin/env python3
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# this script dumps information about the environment
import os
import sys
import transformers
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
print("Python version:", sys.version)
print("transformers version:", transformers.__version__)
try:
import torch
print("Torch version:", torch.__version__)
print("Cuda available:", torch.cuda.is_available())
print("Cuda version:", torch.version.cuda)
print("CuDNN version:", torch.backends.cudnn.version())
print("Number of GPUs available:", torch.cuda.device_count())
print("NCCL version:", torch.cuda.nccl.version())
except ImportError:
print("Torch version:", None)
try:
import deepspeed
print("DeepSpeed version:", deepspeed.__version__)
except ImportError:
print("DeepSpeed version:", None)
try:
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
print("TF GPUs available:", bool(tf.config.list_physical_devices("GPU")))
print("Number of TF GPUs available:", len(tf.config.list_physical_devices("GPU")))
except ImportError:
print("TensorFlow version:", None)
|
transformers/utils/print_env.py/0
|
{
"file_path": "transformers/utils/print_env.py",
"repo_id": "transformers",
"token_count": 546
}
| 214 |
from transformers import ProcessorMixin
class CustomProcessor(ProcessorMixin):
feature_extractor_class = "AutoFeatureExtractor"
tokenizer_class = "AutoTokenizer"
|
transformers/utils/test_module/custom_processing.py/0
|
{
"file_path": "transformers/utils/test_module/custom_processing.py",
"repo_id": "transformers",
"token_count": 51
}
| 215 |
# Troubleshooting
This is a document explaining how to deal with various issues on Circle-CI. The entries may include actual solutions or pointers to Issues that cover those.
## Circle CI
* pytest worker runs out of resident RAM and gets killed by `cgroups`: https://github.com/huggingface/transformers/issues/11408
|
transformers/.circleci/TROUBLESHOOT.md/0
|
{
"file_path": "transformers/.circleci/TROUBLESHOOT.md",
"repo_id": "transformers",
"token_count": 80
}
| 0 |
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, caste, color, religion, or sexual
identity and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the overall
community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or advances of
any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email address,
without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
feedback@huggingface.co.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series of
actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or permanent
ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within the
community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.1, available at
[https://www.contributor-covenant.org/version/2/1/code_of_conduct.html][v2.1].
Community Impact Guidelines were inspired by
[Mozilla's code of conduct enforcement ladder][Mozilla CoC].
For answers to common questions about this code of conduct, see the FAQ at
[https://www.contributor-covenant.org/faq][FAQ]. Translations are available at
[https://www.contributor-covenant.org/translations][translations].
[homepage]: https://www.contributor-covenant.org
[v2.1]: https://www.contributor-covenant.org/version/2/1/code_of_conduct.html
[Mozilla CoC]: https://github.com/mozilla/diversity
[FAQ]: https://www.contributor-covenant.org/faq
[translations]: https://www.contributor-covenant.org/translations
|
transformers/CODE_OF_CONDUCT.md/0
|
{
"file_path": "transformers/CODE_OF_CONDUCT.md",
"repo_id": "transformers",
"token_count": 1206
}
| 1 |
CREATE TABLE IF NOT EXISTS benchmarks (
benchmark_id SERIAL PRIMARY KEY,
branch VARCHAR(255),
commit_id VARCHAR(72),
commit_message VARCHAR(70),
metadata jsonb,
created_at timestamp without time zone NOT NULL DEFAULT (current_timestamp AT TIME ZONE 'UTC')
);
CREATE INDEX IF NOT EXISTS benchmarks_benchmark_id_idx ON benchmarks (benchmark_id);
CREATE INDEX IF NOT EXISTS benchmarks_branch_idx ON benchmarks (branch);
CREATE TABLE IF NOT EXISTS device_measurements (
measurement_id SERIAL PRIMARY KEY,
benchmark_id int REFERENCES benchmarks (benchmark_id),
cpu_util double precision,
mem_megabytes double precision,
gpu_util double precision,
gpu_mem_megabytes double precision,
time timestamp without time zone NOT NULL DEFAULT (current_timestamp AT TIME ZONE 'UTC')
);
CREATE INDEX IF NOT EXISTS device_measurements_branch_idx ON device_measurements (benchmark_id);
CREATE TABLE IF NOT EXISTS model_measurements (
measurement_id SERIAL PRIMARY KEY,
benchmark_id int REFERENCES benchmarks (benchmark_id),
measurements jsonb,
time timestamp without time zone NOT NULL DEFAULT (current_timestamp AT TIME ZONE 'UTC')
);
CREATE INDEX IF NOT EXISTS model_measurements_branch_idx ON model_measurements (benchmark_id);
|
transformers/benchmark/init_db.sql/0
|
{
"file_path": "transformers/benchmark/init_db.sql",
"repo_id": "transformers",
"token_count": 391
}
| 2 |
FROM python:3.10-slim
ENV PYTHONDONTWRITEBYTECODE=1
ARG REF=main
USER root
RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git g++ cmake pkg-config openssh-client git
ENV UV_PYTHON=/usr/local/bin/python
RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
RUN uv pip install --no-deps accelerate
RUN pip install --no-cache-dir 'torch' 'torchvision' 'torchaudio' --index-url https://download.pytorch.org/whl/cpu
RUN pip install --no-cache-dir "scipy<1.13" "git+https://github.com/huggingface/transformers.git@${REF}#egg=transformers[flax,audio,sklearn,sentencepiece,vision,testing]"
# RUN pip install --no-cache-dir "scipy<1.13" "transformers[flax,testing,sentencepiece,flax-speech,vision]"
RUN pip uninstall -y transformers
RUN apt-get clean && rm -rf /var/lib/apt/lists/* && apt-get autoremove && apt-get autoclean
|
transformers/docker/torch-jax-light.dockerfile/0
|
{
"file_path": "transformers/docker/torch-jax-light.dockerfile",
"repo_id": "transformers",
"token_count": 335
}
| 3 |
FROM nvidia/cuda:11.8.0-cudnn8-devel-ubuntu22.04
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
# Use login shell to read variables from `~/.profile` (to pass dynamic created variables between RUN commands)
SHELL ["sh", "-lc"]
# The following `ARG` are mainly used to specify the versions explicitly & directly in this docker file, and not meant
# to be used as arguments for docker build (so far).
ARG PYTORCH='2.5.1'
# Example: `cu102`, `cu113`, etc.
ARG CUDA='cu118'
RUN apt update
RUN apt install -y git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-pip ffmpeg
RUN python3 -m pip install --no-cache-dir --upgrade pip
ARG REF=main
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
RUN [ ${#PYTORCH} -gt 0 ] && VERSION='torch=='$PYTORCH'.*' || VERSION='torch'; echo "export VERSION='$VERSION'" >> ~/.profile
RUN echo torch=$VERSION
# `torchvision` and `torchaudio` should be installed along with `torch`, especially for nightly build.
# Currently, let's just use their latest releases (when `torch` is installed with a release version)
RUN python3 -m pip install --no-cache-dir -U $VERSION torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/$CUDA
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch]
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/accelerate@main#egg=accelerate
# needed in bnb and awq
RUN python3 -m pip install --no-cache-dir einops
# Add bitsandbytes for mixed int8 testing
RUN python3 -m pip install --no-cache-dir bitsandbytes
# Add auto-gptq for gtpq quantization testing, installed from source for pytorch==2.5.1 compatibility
# TORCH_CUDA_ARCH_LIST="7.5+PTX" is added to make the package compile for Tesla T4 gpus available for the CI.
RUN pip install gekko
RUN git clone https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQ && TORCH_CUDA_ARCH_LIST="7.5+PTX" python3 setup.py install
# Add optimum for gptq quantization testing
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/optimum@main#egg=optimum
# Add PEFT
RUN python3 -m pip install --no-cache-dir git+https://github.com/huggingface/peft@main#egg=peft
# Add aqlm for quantization testing
RUN python3 -m pip install --no-cache-dir aqlm[gpu]==1.0.2
# Add vptq for quantization testing
RUN python3 -m pip install --no-cache-dir vptq
# Add hqq for quantization testing
RUN python3 -m pip install --no-cache-dir hqq
# For GGUF tests
RUN python3 -m pip install --no-cache-dir gguf
# Add autoawq for quantization testing
# >=v0.2.7 needed for compatibility with transformers > 4.46
RUN python3 -m pip install --no-cache-dir https://github.com/casper-hansen/AutoAWQ/releases/download/v0.2.7.post2/autoawq-0.2.7.post2-py3-none-any.whl
# Add quanto for quantization testing
RUN python3 -m pip install --no-cache-dir optimum-quanto
# Add eetq for quantization testing
RUN python3 -m pip install git+https://github.com/NetEase-FuXi/EETQ.git
# Add flute-kernel and fast_hadamard_transform for quantization testing
RUN python3 -m pip install --no-cache-dir flute-kernel==0.3.0 -i https://flute-ai.github.io/whl/cu118
RUN python3 -m pip install --no-cache-dir fast_hadamard_transform==1.0.4.post1
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
|
transformers/docker/transformers-quantization-latest-gpu/Dockerfile/0
|
{
"file_path": "transformers/docker/transformers-quantization-latest-gpu/Dockerfile",
"repo_id": "transformers",
"token_count": 1191
}
| 4 |
# بناء نماذج مخصصة
تم تصميم مكتبة 🤗 Transformers لتكون قابلة للتوسيع بسهولة. كل نموذج مُشفّر بالكامل في مجلد فرعي معين بالمستودع، دون أي تجريد، لذلك يمكنك بسهولة نسخ ملف النمذجة وتعديله وفقًا لاحتياجاتك.
إذا كنت تُنشئ نموذجًا جديدًا تمامًا، فقد يكون من الأسهل البدء من الصفر. في هذا البرنامج التعليمي، سنُرِيك كيفية كتابة نموذج مخصص وتكوينه ليُستخدم داخل Transformers، وكيفية مشاركته مع المجتمع (مع الكود الذي يعتمد عليه) بحيث يمكن لأي شخص استخدامه، حتى إذا لم يكن موجودًا في مكتبة 🤗 Transformers. سنرى كيفية البناء على المحولات ونوسّع الإطار باستخدام الأدوات التي يمكن استخدامها لتعديل سلوك الإطار (hooks) والتعليمات البرمجية المخصصة.
سنوضح كل هذا من خلال نموذج ResNet، بتغليف فئة ResNet من
[مكتبة timm](https://github.com/rwightman/pytorch-image-models) داخل [`PreTrainedModel`].
## كتابة إعدادات مخصصة
لنبدأ بكتابة إعدادات النموذج. إعدادات النموذج هو كائنٌ يحتوي على جميع المعلومات اللازمة لبنائه. كما سنرى لاحقًا، يتطلب النموذج كائن `config` لتهيئته، لذا يجب أن يكون هذا الكائن كاملاً.
<Tip>
تتبع النماذج في مكتبة `transformers` اتفاقية قبول كائن `config` في دالة `__init__` الخاصة بها، ثم تمرر كائن `config` بالكامل إلى الطبقات الفرعية في النموذج، بدلاً من تقسيمه إلى معامﻻت متعددة. يؤدي كتابة نموذجك بهذا الأسلوب إلى كود أبسط مع "مصدر حقيقة" واضح لأي فرط معلمات، كما يسهل إعادة استخدام الكود من نماذج أخرى في `transformers`.
</Tip>
في مثالنا، سنعدّل بعض الوسائط في فئة ResNet التي قد نرغب في ضبطها. ستعطينا التكوينات المختلفة أنواع ResNets المختلفة الممكنة. سنقوم بتخزين هذه الوسائط بعد التحقق من صحته.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
الأشياء الثلاثة المهمة التي يجب تذكرها عند كتابة تكوينك الخاص هي:
- يجب أن ترث من `PretrainedConfig`،
- يجب أن تقبل دالة `__init__` الخاصة بـ `PretrainedConfig` أي معامﻻت إضافية kwargs،
- يجب تمرير هذه المعامﻻت الإضافية إلى دالة `__init__` فى الفئة الأساسية الاعلى.
يضمن الإرث حصولك على جميع الوظائف من مكتبة 🤗 Transformers، في حين أن القيدين التانى والثالث يأتيان من حقيقة أن `PretrainedConfig` لديه المزيد من الحقول أكثر من تلك التي تقوم بتعيينها. عند إعادة تحميل تكوين باستخدام طريقة `from_pretrained`، يجب أن يقبل تكوينك هذه الحقول ثم إرسالها إلى الفئة الأساسية الأعلى.
تحديد `model_type` لتكوينك (هنا `model_type="resnet"`) ليس إلزاميًا، ما لم ترغب في
تسجيل نموذجك باستخدام الفئات التلقائية (راجع القسم الأخير).
مع القيام بذلك، يمكنك بسهولة إنشاء تكوينك وحفظه مثلما تفعل مع أي تكوين نموذج آخر في
المكتبة. إليك كيفية إنشاء تكوين resnet50d وحفظه:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
سيؤدي هذا إلى حفظ ملف باسم `config.json` داخل مجلد `custom-resnet`. يمكنك بعد ذلك إعادة تحميل تكوينك باستخدام
طريقة `from_pretrained`:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
يمكنك أيضًا استخدام أي طريقة أخرى من فئة [`PretrainedConfig`]، مثل [`~PretrainedConfig.push_to_hub`] لتحميل تكوينك مباشرة إلى Hub.
## كتابة نموذج مخصص
الآن بعد أن أصبح لدينا تكوين ResNet، يمكننا المتابعة لإنشاء نموذجين: الأول يستخرج الميزات المخفية من دفعة من الصور (مثل [`BertModel`]) والآخر مناسب لتصنيف الصور (مثل [`BertForSequenceClassification`]).
كما ذكرنا سابقًا، سنقوم ببناء نموذج مبسط لتسهيل الفهم في هذا المثال. الخطوة الوحيدة المطلوبة قبل كتابة هذه الفئة هي لربط أنواع وحدات البناء بفئات ذات وحدات بناء فعلية. بعد ذلك، يُعرّف النموذج من خلال التكوين عبر تمرير كل شيء إلى فئة `ResNet`:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
بالنسبة للنموذج الذي سيصنف الصور، فإننا نغير فقط طريقة التقديم:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
في كلتا الحالتين، لاحظ كيف نرث من `PreTrainedModel` ونستدعي مُهيئ الفئة الرئيسية باستخدام `config` (كما تفعل عند إنشاء وحدة `torch.nn.Module` عادية). ليس من الضروري تعريف `config_class` إلا إذا كنت ترغب في تسجيل نموذجك مع الفئات التلقائية (راجع القسم الأخير).
<Tip>
إذا كان نموذجك مشابهًا جدًا لنموذج داخل المكتبة، فيمكنك إعادة استخدام نفس التكوين مثل هذا النموذج.
</Tip>
يمكن لنموذجك أن يعيد أي شيء تريده، ولكن إعادة قاموس مثلما فعلنا لـ
`ResnetModelForImageClassification`، مع تضمين الخسارة عند تمرير العلامات، سيجعل نموذجك قابلًا للاستخدام مباشرة داخل فئة [`Trainer`]. يعد استخدام تنسيق إخراج آخر أمرًا جيدًا طالما أنك تخطط لاستخدام حلقة تدريب خاصة بك أو مكتبة أخرى للتدريب.
الآن بعد أن أصبح لدينا فئة النموذج، دعنا ننشئ واحدة:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
يمكنك استخدام أي من طرق فئة [`PreTrainedModel`]، مثل [`~PreTrainedModel.save_pretrained`] أو
[`~PreTrainedModel.push_to_hub`]. سنستخدم الثاني في القسم التالي، وسنرى كيفية دفع أوزان النموذج مع كود نموذجنا. ولكن أولاً، دعنا نحمل بعض الأوزان المُعلمة مسبقًا داخل نموذجنا.
في حالة الاستخدام الخاصة بك، فمن المحتمل أن تقوم بتدريب نموذجك المخصص على بياناتك الخاصة. للانتقال بسرعة خلال هذا البرنامج التعليمي،
سنستخدم الإصدار المُعلم مسبقًا من resnet50d. نظرًا لأن نموذجنا هو مجرد غلاف حوله، فمن السهل نقل هذه الأوزان:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
الآن دعونا نرى كيفية التأكد من أنه عند قيامنا بـ [`~PreTrainedModel.save_pretrained`] أو [`~PreTrainedModel.push_to_hub`]، يتم حفظ كود النموذج.
## تسجيل نموذج مع كود مخصص للفئات التلقائية
إذا كنت تكتب مكتبة توسع 🤗 Transformers، فقد ترغب في توسيع الفئات التلقائية لتشمل نموذجك الخاص. يختلف هذا عن نشر الكود إلى Hub بمعنى أن المستخدمين سيحتاجون إلى استيراد مكتبتك للحصول على النماذج المخصصة (على عكس تنزيل كود النموذج تلقائيًا من Hub).
ما دام تكوينك يحتوي على معامل `model_type` مختلفة عن أنواع النماذج الحالية، وأن فئات نماذجك لديك لديها الخصائص الصحيحة `config_class`، فيمكنك ببساطة إضافتها إلى الفئات التلقائية مثل هذا:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
لاحظ أن الحجة الأولى المستخدمة عند تسجيل تكوينك المخصص لـ [`AutoConfig`] يجب أن تتطابق مع `model_type`
من تكوينك المخصص، والحجة الأولى المستخدمة عند تسجيل نماذجك المخصصة لأي فئة نموذج تلقائي يجب
أن تتطابق مع `config_class` من تلك النماذج.
## إرسال الكود إلى Hub
<Tip warning={true}>
هذا API تجريبي وقد يكون له بعض التغييرات الطفيفة في الإصدارات القادمة.
</Tip>
أولاً، تأكد من تعريف نموذجك بالكامل في ملف `.py`. يمكن أن يعتمد على الاستيراد النسبي لملفات أخرى طالما أن جميع الملفات موجودة في نفس الدليل (لا ندعم الوحدات الفرعية لهذه الميزة حتى الآن). في مثالنا، سنحدد ملف `modeling_resnet.py` وملف `configuration_resnet.py` في مجلد باسم "resnet_model" في دليل العمل الحالي. يحتوي ملف التكوين على كود لـ `ResnetConfig` ويحتوي ملف النمذجة على كود لـ `ResnetModel` و`ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
يمكن أن يكون ملف `__init__.py` فارغًا، فهو موجود فقط حتى يتمكن Python من اكتشاف أن `resnet_model` يمكن استخدامه كموديل.
<Tip warning={true}>
إذا كنت تقوم بنسخ ملفات النمذجة من المكتبة، فسوف تحتاج إلى استبدال جميع الواردات النسبية في أعلى الملف
لاستيرادها من حزمة `transformers`.
</Tip>
لاحظ أنه يمكنك إعادة استخدام (أو توسيع) تكوين/نموذج موجود.
لمشاركة نموذجك مع المجتمع، اتبع الخطوات التالية: أولاً، قم باستيراد نموذج ResNet والتكوين من الملفات التي تم إنشاؤها حديثًا:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
بعد ذلك، يجب عليك إخبار المكتبة بأنك تريد نسخ ملفات الكود الخاصة بهذه الكائنات عند استخدام طريقة `save_pretrained`
وتسجيلها بشكل صحيح باستخدام فئة تلقائية (خاصة للنماذج)، ما عليك سوى تشغيل:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
لاحظ أنه لا توجد حاجة لتحديد فئة تلقائية للتكوين (هناك فئة تلقائية واحدة فقط لها،
[`AutoConfig`]) ولكن الأمر يختلف بالنسبة للنماذج. قد يكون نموذجك المخصص مناسبًا للعديد من المهام المختلفة، لذلك يجب
تحديد أي من الفئات التلقائية هو الصحيح لنموذجك.
<Tip>
استخدم `register_for_auto_class()` إذا كنت تريد نسخ ملفات الكود. إذا كنت تفضل استخدام الكود على Hub من مستودع آخر،
فلا تحتاج إلى استدعائه. في الحالات التي يوجد فيها أكثر من فئة تلقائية واحدة، يمكنك تعديل ملف `config.json` مباشرة باستخدام
الهيكل التالي:
```json
"auto_map": {
"AutoConfig": "<your-repo-name>--<config-name>",
"AutoModel": "<your-repo-name>--<config-name>",
"AutoModelFor<Task>": "<your-repo-name>--<config-name>",
},
```
</Tip>
بعد ذلك، دعنا نقوم بإنشاء التكوين والنماذج كما فعلنا من قبل:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
الآن لإرسال النموذج إلى Hub، تأكد من تسجيل الدخول. إما تشغيل في المحطة الأوامر الطرفية الخاصة بك:
```bash
huggingface-cli login
```
أو من دفتر ملاحظات:
```py
from huggingface_hub import notebook_login
notebook_login()
```
يمكنك بعد ذلك الضغط على مساحة الاسم الخاصة بك (أو منظمة أنت عضو فيها) مثل هذا:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
بالإضافة إلى أوزان النمذجة والتكوين بتنسيق json، فقد قام هذا أيضًا بنسخ ملفات النمذجة والتكوين `.py` في مجلد `custom-resnet50d` وتحميل النتيجة إلى Hub. يمكنك التحقق من النتيجة في هذا [مستودع النموذج](https://huggingface.co/sgugger/custom-resnet50d).
راجع [البرنامج التعليمي للمشاركة](model_sharing) لمزيد من المعلومات حول طريقة الدفع إلى المحور.
### استخدام نموذج مع كود مخصص
يمكنك استخدام أي تكوين أو نموذج أو مقسم لغوي مع ملفات برمجة مخصصة في مستودعه باستخدام الفئات التلقائية و دالة `from_pretrained`.تُفحص جميع الملفات والرموز المرفوع إلى Hub بحثًا عن البرامج الضارة (راجع وثائق [أمان Hub](https://huggingface.co/docs/hub/security#malware-scanning) لمزيد من المعلومات)، ولكن يجب عليك مراجعة كود النموذج والمؤلف لتجنب تنفيذ التعليمات البرمجية الضارة على جهازك. لتفعيل نموذج يحتوي على شفرة برمجية مخصصة، عيّن `trust_remote_code=True`:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
يُنصح بشدة بتحديد رقم إصدار (commit hash) كـ `revision` للتأكد من عدم تعديل مؤلف النموذج للشفرة لاحقًابإضافة أسطر ضارة (إلا إذا كنت تثق تمامًا بمؤلفي النموذج):
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d"، trust_remote_code=True، revision=commit_hash
)
```
لاحظ وجود زرّ لنسخ رقم إصدار بسهولة عند تصفح سجل التزامات مستودع النموذج على منصة Hugging Face.
|
transformers/docs/source/ar/custom_models.md/0
|
{
"file_path": "transformers/docs/source/ar/custom_models.md",
"repo_id": "transformers",
"token_count": 10048
}
| 5 |
# تحميل المحوّلات باستخدام 🤗 PEFT
[[open-in-colab]]
تقنية "التدريب الدقيق ذو الكفاءة البارامتيرية" (PEFT)](https://huggingface.co/blog/peft) تقوم بتجميد معلمات النموذج المُدرب مسبقًا أثناء الضبط الدقيق وتضيف عدد صغير من المعلمات القابلة للتدريب (المحولات) فوقه. يتم تدريب المحوّلات لتعلم معلومات خاصة بالمهام. وقد ثبت أن هذا النهج فعال للغاية من حيث استخدام الذاكرة مع انخفاض استخدام الكمبيوتر أثناء إنتاج نتائج قمماثلة للنموذج مضبوط دقيقًا بالكامل.
عادة ما تكون المحولات المدربة باستخدام PEFT أصغر بمقدار كبير من حيث الحجم من النموذج الكامل، مما يجعل من السهل مشاركتها وتخزينها وتحميلها.
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">تبلغ أوزان المحول لطراز OPTForCausalLM المخزن على Hub حوالي 6 ميجابايت مقارنة بالحجم الكامل لأوزان النموذج، والتي يمكن أن تكون حوالي 700 ميجابايت.</figcaption>
</div>
إذا كنت مهتمًا بمعرفة المزيد عن مكتبة 🤗 PEFT، فراجع [الوثائق](https://huggingface.co/docs/peft/index).
## الإعداد
ابدأ بتثبيت 🤗 PEFT:
```bash
pip install peft
```
إذا كنت تريد تجربة الميزات الجديدة تمامًا، فقد تكون مهتمًا بتثبيت المكتبة من المصدر:
```bash
pip install git+https://github.com/huggingface/peft.git
```
## نماذج PEFT المدعومة
يدعم 🤗 Transformers بشكلٍ أصلي بعض طرق PEFT، مما يعني أنه يمكنك تحميل أوزان المحول المخزنة محليًا أو على Hub وتشغيلها أو تدريبها ببضع سطور من التعليمات البرمجية. الطرق المدعومة هي:
- [محولات الرتبة المنخفضة](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
إذا كنت تريد استخدام طرق PEFT الأخرى، مثل تعلم المحث أو ضبط المحث، أو حول مكتبة 🤗 PEFT بشكل عام، يرجى الرجوع إلى [الوثائق](https://huggingface.co/docs/peft/index).
## تحميل محول PEFT
لتحميل نموذج محول PEFT واستخدامه من 🤗 Transformers، تأكد من أن مستودع Hub أو الدليل المحلي يحتوي على ملف `adapter_config.json` وأوزان المحوّل، كما هو موضح في صورة المثال أعلاه. بعد ذلك، يمكنك تحميل نموذج محوّل PEFT باستخدام فئة `AutoModelFor`. على سبيل المثال، لتحميل نموذج محول PEFT للنمذجة اللغوية السببية:
1. حدد معرف النموذج لPEFT
2. مرره إلى فئة [`AutoModelForCausalLM`]
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
```
<Tip>
يمكنك تحميل محول PEFT باستخدام فئة `AutoModelFor` أو فئة النموذج الأساسي مثل `OPTForCausalLM` أو `LlamaForCausalLM`.
</Tip>
يمكنك أيضًا تحميل محول PEFT عن طريق استدعاء طريقة `load_adapter`:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
```
راجع قسم [وثائق API](#transformers.integrations.PeftAdapterMixin) أدناه لمزيد من التفاصيل.
## التحميل في 8 بت أو 4 بت
راجع قسم [وثائق API](#transformers.integrations.PeftAdapterMixin) أدناه لمزيد من التفاصيل.
## التحميل في 8 بت أو 4 بت
يدعم تكامل `bitsandbytes` أنواع بيانات الدقة 8 بت و4 بت، والتي تكون مفيدة لتحميل النماذج الكبيرة لأنها توفر مساحة في الذاكرة (راجع دليل تكامل `bitsandbytes` [guide](./quantization#bitsandbytes-integration) لمعرفة المزيد). أضف المعلمات`load_in_8bit` أو `load_in_4bit` إلى [`~PreTrainedModel.from_pretrained`] وقم بتعيين `device_map="auto"` لتوزيع النموذج بشكل فعال على الأجهزة لديك:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
```
## إضافة محول جديد
يمكنك استخدام الدالة [`~peft.PeftModel.add_adapter`] لإضافة محوّل جديد إلى نموذج يحتوي بالفعل على محوّل آخر طالما أن المحول الجديد مطابقًا للنوع الحالي. على سبيل المثال، إذا كان لديك محول LoRA موجود مرتبط بنموذج:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")
```
لإضافة محول جديد:
```py
# قم بتعليق محول جديد بنفس التكوين
model.add_adapter(lora_config, adapter_name="adapter_2")
```
الآن يمكنك استخدام [`~peft.PeftModel.set_adapter`] لتعيين المحول الذي سيتم استخدامه:
```py
# استخدم adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# استخدم adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
```
## تمكين وتعطيل المحولات
بمجرد إضافة محول إلى نموذج، يمكنك تمكين أو تعطيل وحدة المحول. لتمكين وحدة المحول:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# لبدء تشغيله بأوزان عشوائية
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)
```
لإيقاف تشغيل وحدة المحول:
```py
model.disable_adapters()
output = model.generate(**inputs)
```
## تدريب محول PEFT
يدعم محول PEFT فئة [`Trainer`] بحيث يمكنك تدريب محول لحالتك الاستخدام المحددة. فهو يتطلب فقط إضافة بضع سطور أخرى من التعليمات البرمجية. على سبيل المثال، لتدريب محول LoRA:
<Tip>
إذا لم تكن معتادًا على ضبط نموذج دقيق باستخدام [`Trainer`، فراجع البرنامج التعليمي](training) لضبط نموذج مُدرب مسبقًا.
</Tip>
1. حدد تكوين المحول باستخدام نوع المهمة والمعاملات الزائدة (راجع [`~peft.LoraConfig`] لمزيد من التفاصيل حول وظيفة هذه المعلمات).
```py
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM"،
)
```
2. أضف المحول إلى النموذج.
```py
model.add_adapter(peft_config)
```
3. الآن يمكنك تمرير النموذج إلى [`Trainer`]!
```py
trainer = Trainer(model=model, ...)
trainer.train()
```
لحفظ محول المدرب وتحميله مرة أخرى:
```py
model.save_pretrained(save_dir)
model = AutoModelForCausalLM.from_pretrained(save_dir)
```
## إضافة طبقات قابلة للتدريب إضافية إلى محول PEFT
```py
model.save_pretrained(save_dir)
model = AutoModelForCausalLM.from_pretrained(save_dir)
```
## إضافة طبقات قابلة للتدريب إضافية إلى محول PEFT
يمكنك أيضًا إجراء تدريب دقيق لمحوّلات قابلة للتدريب إضافية فوق نموذج يحتوي بالفعل على محوّلات عن طريق تمرير معلم `modules_to_save` في تكوين PEFT الخاص بك. على سبيل المثال، إذا كنت تريد أيضًا ضبط دقيق لرأس النموذج اللغوي`lm_head` فوق نموذج بمحوّل LoRA:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import LoraConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
modules_to_save=["lm_head"]،
)
model.add_adapter(lora_config)
```
## وثائق API
[[autodoc]] integrations.PeftAdapterMixin
- load_adapter
- add_adapter
- set_adapter
- disable_adapters
- enable_adapters
- active_adapters
- get_adapter_state_dict
<!--
TODO: (@younesbelkada @stevhliu)
- Link to PEFT docs for further details
- Trainer
- 8-bit / 4-bit examples ?
-->
|
transformers/docs/source/ar/peft.md/0
|
{
"file_path": "transformers/docs/source/ar/peft.md",
"repo_id": "transformers",
"token_count": 5151
}
| 6 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Vortrainierte Instanzen mit einer AutoClass laden
Bei so vielen verschiedenen Transformator-Architekturen kann es eine Herausforderung sein, eine für Ihren Checkpoint zu erstellen. Als Teil der 🤗 Transformers Kernphilosophie, die Bibliothek leicht, einfach und flexibel nutzbar zu machen, leitet eine `AutoClass` automatisch die richtige Architektur aus einem gegebenen Checkpoint ab und lädt sie. Mit der Methode `from_pretrained()` kann man schnell ein vortrainiertes Modell für eine beliebige Architektur laden, so dass man keine Zeit und Ressourcen aufwenden muss, um ein Modell von Grund auf zu trainieren. Die Erstellung dieser Art von Checkpoint-agnostischem Code bedeutet, dass Ihr Code, wenn er für einen Checkpoint funktioniert, auch mit einem anderen Checkpoint funktionieren wird - solange er für eine ähnliche Aufgabe trainiert wurde - selbst wenn die Architektur unterschiedlich ist.
<Tip>
Denken Sie daran, dass sich die Architektur auf das Skelett des Modells bezieht und die Checkpoints die Gewichte für eine bestimmte Architektur sind. Zum Beispiel ist [BERT](https://huggingface.co/google-bert/bert-base-uncased) eine Architektur, während `google-bert/bert-base-uncased` ein Checkpoint ist. Modell ist ein allgemeiner Begriff, der entweder Architektur oder Prüfpunkt bedeuten kann.
</Tip>
In dieser Anleitung lernen Sie, wie man:
* Einen vortrainierten Tokenizer lädt.
* Einen vortrainierten Merkmalsextraktor lädt.
* Einen vortrainierten Prozessor lädt.
* Ein vortrainiertes Modell lädt.
## AutoTokenizer
Nahezu jede NLP-Aufgabe beginnt mit einem Tokenizer. Ein Tokenizer wandelt Ihre Eingabe in ein Format um, das vom Modell verarbeitet werden kann.
Laden Sie einen Tokenizer mit [`AutoTokenizer.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
```
Dann tokenisieren Sie Ihre Eingabe wie unten gezeigt:
```py
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoFeatureExtractor
Für Audio- und Bildverarbeitungsaufgaben verarbeitet ein Merkmalsextraktor das Audiosignal oder Bild in das richtige Eingabeformat.
Laden Sie einen Merkmalsextraktor mit [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
Multimodale Aufgaben erfordern einen Prozessor, der zwei Arten von Vorverarbeitungswerkzeugen kombiniert. Das Modell [LayoutLMV2](model_doc/layoutlmv2) beispielsweise benötigt einen Feature-Extraktor für Bilder und einen Tokenizer für Text; ein Prozessor kombiniert beide.
Laden Sie einen Prozessor mit [`AutoProcessor.from_pretrained`]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
Mit den `AutoModelFor`-Klassen können Sie schließlich ein vortrainiertes Modell für eine bestimmte Aufgabe laden (siehe [hier](model_doc/auto) für eine vollständige Liste der verfügbaren Aufgaben). Laden Sie zum Beispiel ein Modell für die Sequenzklassifikation mit [`AutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Sie können denselben Prüfpunkt problemlos wiederverwenden, um eine Architektur für eine andere Aufgabe zu laden:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
<Tip warning={true}>
Für PyTorch-Modelle verwendet die Methode `from_pretrained()` `torch.load()`, die intern `pickle` verwendet und als unsicher bekannt ist. Generell sollte man niemals ein Modell laden, das aus einer nicht vertrauenswürdigen Quelle stammen könnte, oder das manipuliert worden sein könnte. Dieses Sicherheitsrisiko wird für öffentliche Modelle, die auf dem Hugging Face Hub gehostet werden, teilweise gemildert, da diese bei jeder Übertragung [auf Malware](https://huggingface.co/docs/hub/security-malware) gescannt werden. Siehe die [Hub-Dokumentation](https://huggingface.co/docs/hub/security) für Best Practices wie [signierte Commit-Verifizierung](https://huggingface.co/docs/hub/security-gpg#signing-commits-with-gpg) mit GPG.
TensorFlow- und Flax-Checkpoints sind nicht betroffen und können in PyTorch-Architekturen mit den Kwargs `from_tf` und `from_flax` für die Methode `from_pretrained` geladen werden, um dieses Problem zu umgehen.
</Tip>
Im Allgemeinen empfehlen wir die Verwendung der Klasse "AutoTokenizer" und der Klasse "AutoModelFor", um trainierte Instanzen von Modellen zu laden. Dadurch wird sichergestellt, dass Sie jedes Mal die richtige Architektur laden. Im nächsten [Tutorial] (Vorverarbeitung) erfahren Sie, wie Sie Ihren neu geladenen Tokenizer, Feature Extractor und Prozessor verwenden, um einen Datensatz für die Feinabstimmung vorzuverarbeiten.
</pt>
<tf>
Mit den Klassen `TFAutoModelFor` schließlich können Sie ein vortrainiertes Modell für eine bestimmte Aufgabe laden (siehe [hier](model_doc/auto) für eine vollständige Liste der verfügbaren Aufgaben). Laden Sie zum Beispiel ein Modell für die Sequenzklassifikation mit [`TFAutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Sie können denselben Prüfpunkt problemlos wiederverwenden, um eine Architektur für eine andere Aufgabe zu laden:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Im Allgemeinen empfehlen wir, die Klasse "AutoTokenizer" und die Klasse "TFAutoModelFor" zu verwenden, um vortrainierte Instanzen von Modellen zu laden. Dadurch wird sichergestellt, dass Sie jedes Mal die richtige Architektur laden. Im nächsten [Tutorial] (Vorverarbeitung) erfahren Sie, wie Sie Ihren neu geladenen Tokenizer, Feature Extractor und Prozessor verwenden, um einen Datensatz für die Feinabstimmung vorzuverarbeiten.
</tf>
</frameworkcontent>
|
transformers/docs/source/de/autoclass_tutorial.md/0
|
{
"file_path": "transformers/docs/source/de/autoclass_tutorial.md",
"repo_id": "transformers",
"token_count": 2644
}
| 7 |
# Optimizing inference
perf_infer_gpu_many: perf_infer_gpu_one
transformers_agents: agents
quantization: quantization/overview
|
transformers/docs/source/en/_redirects.yml/0
|
{
"file_path": "transformers/docs/source/en/_redirects.yml",
"repo_id": "transformers",
"token_count": 41
}
| 8 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Building custom models
The 🤗 Transformers library is designed to be easily extensible. Every model is fully coded in a given subfolder
of the repository with no abstraction, so you can easily copy a modeling file and tweak it to your needs.
If you are writing a brand new model, it might be easier to start from scratch. In this tutorial, we will show you
how to write a custom model and its configuration so it can be used inside Transformers, and how you can share it
with the community (with the code it relies on) so that anyone can use it, even if it's not present in the 🤗
Transformers library. We'll see how to build upon transformers and extend the framework with your hooks and
custom code.
We will illustrate all of this on a ResNet model, by wrapping the ResNet class of the
[timm library](https://github.com/rwightman/pytorch-image-models) into a [`PreTrainedModel`].
## Writing a custom configuration
Before we dive into the model, let's first write its configuration. The configuration of a model is an object that
will contain all the necessary information to build the model. As we will see in the next section, the model can only
take a `config` to be initialized, so we really need that object to be as complete as possible.
<Tip>
Models in the `transformers` library itself generally follow the convention that they accept a `config` object
in their `__init__` method, and then pass the whole `config` to sub-layers in the model, rather than breaking the
config object into multiple arguments that are all passed individually to sub-layers. Writing your model in this
style results in simpler code with a clear "source of truth" for any hyperparameters, and also makes it easier
to reuse code from other models in `transformers`.
</Tip>
In our example, we will take a couple of arguments of the ResNet class that we might want to tweak. Different
configurations will then give us the different types of ResNets that are possible. We then just store those arguments,
after checking the validity of a few of them.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
The three important things to remember when writing you own configuration are the following:
- you have to inherit from `PretrainedConfig`,
- the `__init__` of your `PretrainedConfig` must accept any kwargs,
- those `kwargs` need to be passed to the superclass `__init__`.
The inheritance is to make sure you get all the functionality from the 🤗 Transformers library, while the two other
constraints come from the fact a `PretrainedConfig` has more fields than the ones you are setting. When reloading a
config with the `from_pretrained` method, those fields need to be accepted by your config and then sent to the
superclass.
Defining a `model_type` for your configuration (here `model_type="resnet"`) is not mandatory, unless you want to
register your model with the auto classes (see last section).
With this done, you can easily create and save your configuration like you would do with any other model config of the
library. Here is how we can create a resnet50d config and save it:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
This will save a file named `config.json` inside the folder `custom-resnet`. You can then reload your config with the
`from_pretrained` method:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
You can also use any other method of the [`PretrainedConfig`] class, like [`~PretrainedConfig.push_to_hub`] to
directly upload your config to the Hub.
## Writing a custom model
Now that we have our ResNet configuration, we can go on writing the model. We will actually write two: one that
extracts the hidden features from a batch of images (like [`BertModel`]) and one that is suitable for image
classification (like [`BertForSequenceClassification`]).
As we mentioned before, we'll only write a loose wrapper of the model to keep it simple for this example. The only
thing we need to do before writing this class is a map between the block types and actual block classes. Then the
model is defined from the configuration by passing everything to the `ResNet` class:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
For the model that will classify images, we just change the forward method:
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.functional.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
In both cases, notice how we inherit from `PreTrainedModel` and call the superclass initialization with the `config`
(a bit like when you write a regular `torch.nn.Module`). The line that sets the `config_class` is not mandatory, unless
you want to register your model with the auto classes (see last section).
<Tip>
If your model is very similar to a model inside the library, you can re-use the same configuration as this model.
</Tip>
You can have your model return anything you want, but returning a dictionary like we did for
`ResnetModelForImageClassification`, with the loss included when labels are passed, will make your model directly
usable inside the [`Trainer`] class. Using another output format is fine as long as you are planning on using your own
training loop or another library for training.
Now that we have our model class, let's create one:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Again, you can use any of the methods of [`PreTrainedModel`], like [`~PreTrainedModel.save_pretrained`] or
[`~PreTrainedModel.push_to_hub`]. We will use the second in the next section, and see how to push the model weights
with the code of our model. But first, let's load some pretrained weights inside our model.
In your own use case, you will probably be training your custom model on your own data. To go fast for this tutorial,
we will use the pretrained version of the resnet50d. Since our model is just a wrapper around it, it's going to be
easy to transfer those weights:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Now let's see how to make sure that when we do [`~PreTrainedModel.save_pretrained`] or [`~PreTrainedModel.push_to_hub`], the
code of the model is saved.
## Registering a model with custom code to the auto classes
If you are writing a library that extends 🤗 Transformers, you may want to extend the auto classes to include your own
model. This is different from pushing the code to the Hub in the sense that users will need to import your library to
get the custom models (contrarily to automatically downloading the model code from the Hub).
As long as your config has a `model_type` attribute that is different from existing model types, and that your model
classes have the right `config_class` attributes, you can just add them to the auto classes like this:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Note that the first argument used when registering your custom config to [`AutoConfig`] needs to match the `model_type`
of your custom config, and the first argument used when registering your custom models to any auto model class needs
to match the `config_class` of those models.
## Sending the code to the Hub
<Tip warning={true}>
This API is experimental and may have some slight breaking changes in the next releases.
</Tip>
First, make sure your model is fully defined in a `.py` file. It can rely on relative imports to some other files as
long as all the files are in the same directory (we don't support submodules for this feature yet). For our example,
we'll define a `modeling_resnet.py` file and a `configuration_resnet.py` file in a folder of the current working
directory named `resnet_model`. The configuration file contains the code for `ResnetConfig` and the modeling file
contains the code of `ResnetModel` and `ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
The `__init__.py` can be empty, it's just there so that Python detects `resnet_model` can be use as a module.
<Tip warning={true}>
If copying a modeling files from the library, you will need to replace all the relative imports at the top of the file
to import from the `transformers` package.
</Tip>
Note that you can re-use (or subclass) an existing configuration/model.
To share your model with the community, follow those steps: first import the ResNet model and config from the newly
created files:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Then you have to tell the library you want to copy the code files of those objects when using the `save_pretrained`
method and properly register them with a given Auto class (especially for models), just run:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Note that there is no need to specify an auto class for the configuration (there is only one auto class for them,
[`AutoConfig`]) but it's different for models. Your custom model could be suitable for many different tasks, so you
have to specify which one of the auto classes is the correct one for your model.
<Tip>
Use `register_for_auto_class()` if you want the code files to be copied. If you instead prefer to use code on the Hub from another repo,
you don't need to call it. In cases where there's more than one auto class, you can modify the `config.json` directly using the
following structure:
```json
"auto_map": {
"AutoConfig": "<your-repo-name>--<config-name>",
"AutoModel": "<your-repo-name>--<config-name>",
"AutoModelFor<Task>": "<your-repo-name>--<config-name>",
},
```
</Tip>
Next, let's create the config and models as we did before:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Now to send the model to the Hub, make sure you are logged in. Either run in your terminal:
```bash
huggingface-cli login
```
or from a notebook:
```py
from huggingface_hub import notebook_login
notebook_login()
```
You can then push to your own namespace (or an organization you are a member of) like this:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
On top of the modeling weights and the configuration in json format, this also copied the modeling and
configuration `.py` files in the folder `custom-resnet50d` and uploaded the result to the Hub. You can check the result
in this [model repo](https://huggingface.co/sgugger/custom-resnet50d).
See the [sharing tutorial](model_sharing) for more information on the push to Hub method.
## Using a model with custom code
You can use any configuration, model or tokenizer with custom code files in its repository with the auto-classes and
the `from_pretrained` method. All files and code uploaded to the Hub are scanned for malware (refer to the [Hub security](https://huggingface.co/docs/hub/security#malware-scanning) documentation for more information), but you should still
review the model code and author to avoid executing malicious code on your machine. Set `trust_remote_code=True` to use
a model with custom code:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
It is also strongly encouraged to pass a commit hash as a `revision` to make sure the author of the models did not
update the code with some malicious new lines (unless you fully trust the authors of the models).
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Note that when browsing the commit history of the model repo on the Hub, there is a button to easily copy the commit
hash of any commit.
|
transformers/docs/source/en/custom_models.md/0
|
{
"file_path": "transformers/docs/source/en/custom_models.md",
"repo_id": "transformers",
"token_count": 4869
}
| 9 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Custom Layers and Utilities
This page lists all the custom layers used by the library, as well as the utility functions it provides for modeling.
Most of those are only useful if you are studying the code of the models in the library.
## Pytorch custom modules
[[autodoc]] pytorch_utils.Conv1D
[[autodoc]] modeling_utils.PoolerStartLogits
- forward
[[autodoc]] modeling_utils.PoolerEndLogits
- forward
[[autodoc]] modeling_utils.PoolerAnswerClass
- forward
[[autodoc]] modeling_utils.SquadHeadOutput
[[autodoc]] modeling_utils.SQuADHead
- forward
[[autodoc]] modeling_utils.SequenceSummary
- forward
## PyTorch Helper Functions
[[autodoc]] pytorch_utils.apply_chunking_to_forward
[[autodoc]] pytorch_utils.find_pruneable_heads_and_indices
[[autodoc]] pytorch_utils.prune_layer
[[autodoc]] pytorch_utils.prune_conv1d_layer
[[autodoc]] pytorch_utils.prune_linear_layer
## TensorFlow custom layers
[[autodoc]] modeling_tf_utils.TFConv1D
[[autodoc]] modeling_tf_utils.TFSequenceSummary
## TensorFlow loss functions
[[autodoc]] modeling_tf_utils.TFCausalLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMaskedLanguageModelingLoss
[[autodoc]] modeling_tf_utils.TFMultipleChoiceLoss
[[autodoc]] modeling_tf_utils.TFQuestionAnsweringLoss
[[autodoc]] modeling_tf_utils.TFSequenceClassificationLoss
[[autodoc]] modeling_tf_utils.TFTokenClassificationLoss
## TensorFlow Helper Functions
[[autodoc]] modeling_tf_utils.get_initializer
[[autodoc]] modeling_tf_utils.keras_serializable
[[autodoc]] modeling_tf_utils.shape_list
|
transformers/docs/source/en/internal/modeling_utils.md/0
|
{
"file_path": "transformers/docs/source/en/internal/modeling_utils.md",
"repo_id": "transformers",
"token_count": 729
}
| 10 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Feature Extractor
A feature extractor is in charge of preparing input features for audio or vision models. This includes feature extraction from sequences, e.g., pre-processing audio files to generate Log-Mel Spectrogram features, feature extraction from images, e.g., cropping image files, but also padding, normalization, and conversion to NumPy, PyTorch, and TensorFlow tensors.
## FeatureExtractionMixin
[[autodoc]] feature_extraction_utils.FeatureExtractionMixin
- from_pretrained
- save_pretrained
## SequenceFeatureExtractor
[[autodoc]] SequenceFeatureExtractor
- pad
## BatchFeature
[[autodoc]] BatchFeature
## ImageFeatureExtractionMixin
[[autodoc]] image_utils.ImageFeatureExtractionMixin
|
transformers/docs/source/en/main_classes/feature_extractor.md/0
|
{
"file_path": "transformers/docs/source/en/main_classes/feature_extractor.md",
"repo_id": "transformers",
"token_count": 383
}
| 11 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# AltCLIP
## Overview
The AltCLIP model was proposed in [AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities](https://arxiv.org/abs/2211.06679v2) by Zhongzhi Chen, Guang Liu, Bo-Wen Zhang, Fulong Ye, Qinghong Yang, Ledell Wu. AltCLIP
(Altering the Language Encoder in CLIP) is a neural network trained on a variety of image-text and text-text pairs. By switching CLIP's
text encoder with a pretrained multilingual text encoder XLM-R, we could obtain very close performances with CLIP on almost all tasks, and extended original CLIP's capabilities such as multilingual understanding.
The abstract from the paper is the following:
*In this work, we present a conceptually simple and effective method to train a strong bilingual multimodal representation model.
Starting from the pretrained multimodal representation model CLIP released by OpenAI, we switched its text encoder with a pretrained
multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of
teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art
performances on a bunch of tasks including ImageNet-CN, Flicker30k- CN, and COCO-CN. Further, we obtain very close performances with
CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding.*
This model was contributed by [jongjyh](https://huggingface.co/jongjyh).
## Usage tips and example
The usage of AltCLIP is very similar to the CLIP. the difference between CLIP is the text encoder. Note that we use bidirectional attention instead of casual attention
and we take the [CLS] token in XLM-R to represent text embedding.
AltCLIP is a multi-modal vision and language model. It can be used for image-text similarity and for zero-shot image
classification. AltCLIP uses a ViT like transformer to get visual features and a bidirectional language model to get the text
features. Both the text and visual features are then projected to a latent space with identical dimension. The dot
product between the projected image and text features is then used as a similar score.
To feed images to the Transformer encoder, each image is split into a sequence of fixed-size non-overlapping patches,
which are then linearly embedded. A [CLS] token is added to serve as representation of an entire image. The authors
also add absolute position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder.
The [`CLIPImageProcessor`] can be used to resize (or rescale) and normalize images for the model.
The [`AltCLIPProcessor`] wraps a [`CLIPImageProcessor`] and a [`XLMRobertaTokenizer`] into a single instance to both
encode the text and prepare the images. The following example shows how to get the image-text similarity scores using
[`AltCLIPProcessor`] and [`AltCLIPModel`].
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AltCLIPModel, AltCLIPProcessor
>>> model = AltCLIPModel.from_pretrained("BAAI/AltCLIP")
>>> processor = AltCLIPProcessor.from_pretrained("BAAI/AltCLIP")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
<Tip>
This model is based on `CLIPModel`, use it like you would use the original [CLIP](clip).
</Tip>
## AltCLIPConfig
[[autodoc]] AltCLIPConfig
- from_text_vision_configs
## AltCLIPTextConfig
[[autodoc]] AltCLIPTextConfig
## AltCLIPVisionConfig
[[autodoc]] AltCLIPVisionConfig
## AltCLIPProcessor
[[autodoc]] AltCLIPProcessor
## AltCLIPModel
[[autodoc]] AltCLIPModel
- forward
- get_text_features
- get_image_features
## AltCLIPTextModel
[[autodoc]] AltCLIPTextModel
- forward
## AltCLIPVisionModel
[[autodoc]] AltCLIPVisionModel
- forward
|
transformers/docs/source/en/model_doc/altclip.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/altclip.md",
"repo_id": "transformers",
"token_count": 1400
}
| 12 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BigBirdPegasus
## Overview
The BigBird model was proposed in [Big Bird: Transformers for Longer Sequences](https://arxiv.org/abs/2007.14062) by
Zaheer, Manzil and Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon,
Santiago and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a sparse-attention
based transformer which extends Transformer based models, such as BERT to much longer sequences. In addition to sparse
attention, BigBird also applies global attention as well as random attention to the input sequence. Theoretically, it
has been shown that applying sparse, global, and random attention approximates full attention, while being
computationally much more efficient for longer sequences. As a consequence of the capability to handle longer context,
BigBird has shown improved performance on various long document NLP tasks, such as question answering and
summarization, compared to BERT or RoBERTa.
The abstract from the paper is the following:
*Transformers-based models, such as BERT, have been one of the most successful deep learning models for NLP.
Unfortunately, one of their core limitations is the quadratic dependency (mainly in terms of memory) on the sequence
length due to their full attention mechanism. To remedy this, we propose, BigBird, a sparse attention mechanism that
reduces this quadratic dependency to linear. We show that BigBird is a universal approximator of sequence functions and
is Turing complete, thereby preserving these properties of the quadratic, full attention model. Along the way, our
theoretical analysis reveals some of the benefits of having O(1) global tokens (such as CLS), that attend to the entire
sequence as part of the sparse attention mechanism. The proposed sparse attention can handle sequences of length up to
8x of what was previously possible using similar hardware. As a consequence of the capability to handle longer context,
BigBird drastically improves performance on various NLP tasks such as question answering and summarization. We also
propose novel applications to genomics data.*
The original code can be found [here](https://github.com/google-research/bigbird).
## Usage tips
- For an in-detail explanation on how BigBird's attention works, see [this blog post](https://huggingface.co/blog/big-bird).
- BigBird comes with 2 implementations: **original_full** & **block_sparse**. For the sequence length < 1024, using
**original_full** is advised as there is no benefit in using **block_sparse** attention.
- The code currently uses window size of 3 blocks and 2 global blocks.
- Sequence length must be divisible by block size.
- Current implementation supports only **ITC**.
- Current implementation doesn't support **num_random_blocks = 0**.
- BigBirdPegasus uses the [PegasusTokenizer](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/tokenization_pegasus.py).
- BigBird is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## BigBirdPegasusConfig
[[autodoc]] BigBirdPegasusConfig
- all
## BigBirdPegasusModel
[[autodoc]] BigBirdPegasusModel
- forward
## BigBirdPegasusForConditionalGeneration
[[autodoc]] BigBirdPegasusForConditionalGeneration
- forward
## BigBirdPegasusForSequenceClassification
[[autodoc]] BigBirdPegasusForSequenceClassification
- forward
## BigBirdPegasusForQuestionAnswering
[[autodoc]] BigBirdPegasusForQuestionAnswering
- forward
## BigBirdPegasusForCausalLM
[[autodoc]] BigBirdPegasusForCausalLM
- forward
|
transformers/docs/source/en/model_doc/bigbird_pegasus.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/bigbird_pegasus.md",
"repo_id": "transformers",
"token_count": 1224
}
| 13 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convolutional Vision Transformer (CvT)
## Overview
The CvT model was proposed in [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan and Lei Zhang. The Convolutional vision Transformer (CvT) improves the [Vision Transformer (ViT)](vit) in performance and efficiency by introducing convolutions into ViT to yield the best of both designs.
The abstract from the paper is the following:
*We present in this paper a new architecture, named Convolutional vision Transformer (CvT), that improves Vision Transformer (ViT)
in performance and efficiency by introducing convolutions into ViT to yield the best of both designs. This is accomplished through
two primary modifications: a hierarchy of Transformers containing a new convolutional token embedding, and a convolutional Transformer
block leveraging a convolutional projection. These changes introduce desirable properties of convolutional neural networks (CNNs)
to the ViT architecture (\ie shift, scale, and distortion invariance) while maintaining the merits of Transformers (\ie dynamic attention,
global context, and better generalization). We validate CvT by conducting extensive experiments, showing that this approach achieves
state-of-the-art performance over other Vision Transformers and ResNets on ImageNet-1k, with fewer parameters and lower FLOPs. In addition,
performance gains are maintained when pretrained on larger datasets (\eg ImageNet-22k) and fine-tuned to downstream tasks. Pre-trained on
ImageNet-22k, our CvT-W24 obtains a top-1 accuracy of 87.7\% on the ImageNet-1k val set. Finally, our results show that the positional encoding,
a crucial component in existing Vision Transformers, can be safely removed in our model, simplifying the design for higher resolution vision tasks.*
This model was contributed by [anugunj](https://huggingface.co/anugunj). The original code can be found [here](https://github.com/microsoft/CvT).
## Usage tips
- CvT models are regular Vision Transformers, but trained with convolutions. They outperform the [original model (ViT)](vit) when fine-tuned on ImageNet-1K and CIFAR-100.
- You can check out demo notebooks regarding inference as well as fine-tuning on custom data [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (you can just replace [`ViTFeatureExtractor`] by [`AutoImageProcessor`] and [`ViTForImageClassification`] by [`CvtForImageClassification`]).
- The available checkpoints are either (1) pre-trained on [ImageNet-22k](http://www.image-net.org/) (a collection of 14 million images and 22k classes) only, (2) also fine-tuned on ImageNet-22k or (3) also fine-tuned on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/) (also referred to as ILSVRC 2012, a collection of 1.3 million
images and 1,000 classes).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with CvT.
<PipelineTag pipeline="image-classification"/>
- [`CvtForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## CvtConfig
[[autodoc]] CvtConfig
<frameworkcontent>
<pt>
## CvtModel
[[autodoc]] CvtModel
- forward
## CvtForImageClassification
[[autodoc]] CvtForImageClassification
- forward
</pt>
<tf>
## TFCvtModel
[[autodoc]] TFCvtModel
- call
## TFCvtForImageClassification
[[autodoc]] TFCvtForImageClassification
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/cvt.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/cvt.md",
"repo_id": "transformers",
"token_count": 1314
}
| 14 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Dilated Neighborhood Attention Transformer
## Overview
DiNAT was proposed in [Dilated Neighborhood Attention Transformer](https://arxiv.org/abs/2209.15001)
by Ali Hassani and Humphrey Shi.
It extends [NAT](nat) by adding a Dilated Neighborhood Attention pattern to capture global context,
and shows significant performance improvements over it.
The abstract from the paper is the following:
*Transformers are quickly becoming one of the most heavily applied deep learning architectures across modalities,
domains, and tasks. In vision, on top of ongoing efforts into plain transformers, hierarchical transformers have
also gained significant attention, thanks to their performance and easy integration into existing frameworks.
These models typically employ localized attention mechanisms, such as the sliding-window Neighborhood Attention (NA)
or Swin Transformer's Shifted Window Self Attention. While effective at reducing self attention's quadratic complexity,
local attention weakens two of the most desirable properties of self attention: long range inter-dependency modeling,
and global receptive field. In this paper, we introduce Dilated Neighborhood Attention (DiNA), a natural, flexible and
efficient extension to NA that can capture more global context and expand receptive fields exponentially at no
additional cost. NA's local attention and DiNA's sparse global attention complement each other, and therefore we
introduce Dilated Neighborhood Attention Transformer (DiNAT), a new hierarchical vision transformer built upon both.
DiNAT variants enjoy significant improvements over strong baselines such as NAT, Swin, and ConvNeXt.
Our large model is faster and ahead of its Swin counterpart by 1.5% box AP in COCO object detection,
1.3% mask AP in COCO instance segmentation, and 1.1% mIoU in ADE20K semantic segmentation.
Paired with new frameworks, our large variant is the new state of the art panoptic segmentation model on COCO (58.2 PQ)
and ADE20K (48.5 PQ), and instance segmentation model on Cityscapes (44.5 AP) and ADE20K (35.4 AP) (no extra data).
It also matches the state of the art specialized semantic segmentation models on ADE20K (58.2 mIoU),
and ranks second on Cityscapes (84.5 mIoU) (no extra data). *
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/dilated-neighborhood-attention-pattern.jpg"
alt="drawing" width="600"/>
<small> Neighborhood Attention with different dilation values.
Taken from the <a href="https://arxiv.org/abs/2209.15001">original paper</a>.</small>
This model was contributed by [Ali Hassani](https://huggingface.co/alihassanijr).
The original code can be found [here](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer).
## Usage tips
DiNAT can be used as a *backbone*. When `output_hidden_states = True`,
it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, height, width, num_channels)`.
Notes:
- DiNAT depends on [NATTEN](https://github.com/SHI-Labs/NATTEN/)'s implementation of Neighborhood Attention and Dilated Neighborhood Attention.
You can install it with pre-built wheels for Linux by referring to [shi-labs.com/natten](https://shi-labs.com/natten), or build on your system by running `pip install natten`.
Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet.
- Patch size of 4 is only supported at the moment.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiNAT.
<PipelineTag pipeline="image-classification"/>
- [`DinatForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## DinatConfig
[[autodoc]] DinatConfig
## DinatModel
[[autodoc]] DinatModel
- forward
## DinatForImageClassification
[[autodoc]] DinatForImageClassification
- forward
|
transformers/docs/source/en/model_doc/dinat.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/dinat.md",
"repo_id": "transformers",
"token_count": 1371
}
| 15 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ESM
## Overview
This page provides code and pre-trained weights for Transformer protein language models from Meta AI's Fundamental
AI Research Team, providing the state-of-the-art ESMFold and ESM-2, and the previously released ESM-1b and ESM-1v.
Transformer protein language models were introduced in the paper [Biological structure and function emerge from scaling
unsupervised learning to 250 million protein sequences](https://www.pnas.org/content/118/15/e2016239118) by
Alexander Rives, Joshua Meier, Tom Sercu, Siddharth Goyal, Zeming Lin, Jason Liu, Demi Guo, Myle Ott,
C. Lawrence Zitnick, Jerry Ma, and Rob Fergus.
The first version of this paper was [preprinted in 2019](https://www.biorxiv.org/content/10.1101/622803v1?versioned=true).
ESM-2 outperforms all tested single-sequence protein language models across a range of structure prediction tasks,
and enables atomic resolution structure prediction.
It was released with the paper [Language models of protein sequences at the scale of evolution enable accurate
structure prediction](https://doi.org/10.1101/2022.07.20.500902) by Zeming Lin, Halil Akin, Roshan Rao, Brian Hie,
Zhongkai Zhu, Wenting Lu, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido and Alexander Rives.
Also introduced in this paper was ESMFold. It uses an ESM-2 stem with a head that can predict folded protein
structures with state-of-the-art accuracy. Unlike [AlphaFold2](https://www.nature.com/articles/s41586-021-03819-2),
it relies on the token embeddings from the large pre-trained protein language model stem and does not perform a multiple
sequence alignment (MSA) step at inference time, which means that ESMFold checkpoints are fully "standalone" -
they do not require a database of known protein sequences and structures with associated external query tools
to make predictions, and are much faster as a result.
The abstract from
"Biological structure and function emerge from scaling unsupervised learning to 250
million protein sequences" is
*In the field of artificial intelligence, a combination of scale in data and model capacity enabled by unsupervised
learning has led to major advances in representation learning and statistical generation. In the life sciences, the
anticipated growth of sequencing promises unprecedented data on natural sequence diversity. Protein language modeling
at the scale of evolution is a logical step toward predictive and generative artificial intelligence for biology. To
this end, we use unsupervised learning to train a deep contextual language model on 86 billion amino acids across 250
million protein sequences spanning evolutionary diversity. The resulting model contains information about biological
properties in its representations. The representations are learned from sequence data alone. The learned representation
space has a multiscale organization reflecting structure from the level of biochemical properties of amino acids to
remote homology of proteins. Information about secondary and tertiary structure is encoded in the representations and
can be identified by linear projections. Representation learning produces features that generalize across a range of
applications, enabling state-of-the-art supervised prediction of mutational effect and secondary structure and
improving state-of-the-art features for long-range contact prediction.*
The abstract from
"Language models of protein sequences at the scale of evolution enable accurate structure prediction" is
*Large language models have recently been shown to develop emergent capabilities with scale, going beyond
simple pattern matching to perform higher level reasoning and generate lifelike images and text. While
language models trained on protein sequences have been studied at a smaller scale, little is known about
what they learn about biology as they are scaled up. In this work we train models up to 15 billion parameters,
the largest language models of proteins to be evaluated to date. We find that as models are scaled they learn
information enabling the prediction of the three-dimensional structure of a protein at the resolution of
individual atoms. We present ESMFold for high accuracy end-to-end atomic level structure prediction directly
from the individual sequence of a protein. ESMFold has similar accuracy to AlphaFold2 and RoseTTAFold for
sequences with low perplexity that are well understood by the language model. ESMFold inference is an
order of magnitude faster than AlphaFold2, enabling exploration of the structural space of metagenomic
proteins in practical timescales.*
The original code can be found [here](https://github.com/facebookresearch/esm) and was
was developed by the Fundamental AI Research team at Meta AI.
ESM-1b, ESM-1v and ESM-2 were contributed to huggingface by [jasonliu](https://huggingface.co/jasonliu)
and [Matt](https://huggingface.co/Rocketknight1).
ESMFold was contributed to huggingface by [Matt](https://huggingface.co/Rocketknight1) and
[Sylvain](https://huggingface.co/sgugger), with a big thank you to Nikita Smetanin, Roshan Rao and Tom Sercu for their
help throughout the process!
## Usage tips
- ESM models are trained with a masked language modeling (MLM) objective.
- The HuggingFace port of ESMFold uses portions of the [openfold](https://github.com/aqlaboratory/openfold) library. The `openfold` library is licensed under the Apache License 2.0.
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
## EsmConfig
[[autodoc]] EsmConfig
- all
## EsmTokenizer
[[autodoc]] EsmTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
<frameworkcontent>
<pt>
## EsmModel
[[autodoc]] EsmModel
- forward
## EsmForMaskedLM
[[autodoc]] EsmForMaskedLM
- forward
## EsmForSequenceClassification
[[autodoc]] EsmForSequenceClassification
- forward
## EsmForTokenClassification
[[autodoc]] EsmForTokenClassification
- forward
## EsmForProteinFolding
[[autodoc]] EsmForProteinFolding
- forward
</pt>
<tf>
## TFEsmModel
[[autodoc]] TFEsmModel
- call
## TFEsmForMaskedLM
[[autodoc]] TFEsmForMaskedLM
- call
## TFEsmForSequenceClassification
[[autodoc]] TFEsmForSequenceClassification
- call
## TFEsmForTokenClassification
[[autodoc]] TFEsmForTokenClassification
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/esm.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/esm.md",
"repo_id": "transformers",
"token_count": 1906
}
| 16 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Jukebox
<Tip warning={true}>
This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
You can do so by running the following command: `pip install -U transformers==4.40.2`.
</Tip>
## Overview
The Jukebox model was proposed in [Jukebox: A generative model for music](https://arxiv.org/pdf/2005.00341.pdf)
by Prafulla Dhariwal, Heewoo Jun, Christine Payne, Jong Wook Kim, Alec Radford,
Ilya Sutskever. It introduces a generative music model which can produce minute long samples that can be conditioned on
an artist, genres and lyrics.
The abstract from the paper is the following:
*We introduce Jukebox, a model that generates music with singing in the raw audio domain. We tackle the long context of raw audio using a multiscale VQ-VAE to compress it to discrete codes, and modeling those using autoregressive Transformers. We show that the combined model at scale can generate high-fidelity and diverse songs with coherence up to multiple minutes. We can condition on artist and genre to steer the musical and vocal style, and on unaligned lyrics to make the singing more controllable. We are releasing thousands of non cherry-picked samples, along with model weights and code.*
As shown on the following figure, Jukebox is made of 3 `priors` which are decoder only models. They follow the architecture described in [Generating Long Sequences with Sparse Transformers](https://arxiv.org/abs/1904.10509), modified to support longer context length.
First, a autoencoder is used to encode the text lyrics. Next, the first (also called `top_prior`) prior attends to the last hidden states extracted from the lyrics encoder. The priors are linked to the previous priors respectively via an `AudioConditioner` module. The`AudioConditioner` upsamples the outputs of the previous prior to raw tokens at a certain audio frame per second resolution.
The metadata such as *artist, genre and timing* are passed to each prior, in the form of a start token and positional embedding for the timing data. The hidden states are mapped to the closest codebook vector from the VQVAE in order to convert them to raw audio.

This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/openai/jukebox).
## Usage tips
- This model only supports inference. This is for a few reasons, mostly because it requires a crazy amount of memory to train. Feel free to open a PR and add what's missing to have a full integration with the hugging face trainer!
- This model is very slow, and takes 8h to generate a minute long audio using the 5b top prior on a V100 GPU. In order automaticallay handle the device on which the model should execute, use `accelerate`.
- Contrary to the paper, the order of the priors goes from `0` to `1` as it felt more intuitive : we sample starting from `0`.
- Primed sampling (conditioning the sampling on raw audio) requires more memory than ancestral sampling and should be used with `fp16` set to `True`.
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/openai/jukebox).
## JukeboxConfig
[[autodoc]] JukeboxConfig
## JukeboxPriorConfig
[[autodoc]] JukeboxPriorConfig
## JukeboxVQVAEConfig
[[autodoc]] JukeboxVQVAEConfig
## JukeboxTokenizer
[[autodoc]] JukeboxTokenizer
- save_vocabulary
## JukeboxModel
[[autodoc]] JukeboxModel
- ancestral_sample
- primed_sample
- continue_sample
- upsample
- _sample
## JukeboxPrior
[[autodoc]] JukeboxPrior
- sample
- forward
## JukeboxVQVAE
[[autodoc]] JukeboxVQVAE
- forward
- encode
- decode
|
transformers/docs/source/en/model_doc/jukebox.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/jukebox.md",
"repo_id": "transformers",
"token_count": 1309
}
| 17 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Longformer
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=longformer">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-longformer-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/longformer-base-4096-finetuned-squadv1">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The Longformer model was presented in [Longformer: The Long-Document Transformer](https://arxiv.org/pdf/2004.05150.pdf) by Iz Beltagy, Matthew E. Peters, Arman Cohan.
The abstract from the paper is the following:
*Transformer-based models are unable to process long sequences due to their self-attention operation, which scales
quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention
mechanism that scales linearly with sequence length, making it easy to process documents of thousands of tokens or
longer. Longformer's attention mechanism is a drop-in replacement for the standard self-attention and combines a local
windowed attention with a task motivated global attention. Following prior work on long-sequence transformers, we
evaluate Longformer on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In
contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream tasks. Our
pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new state-of-the-art results on
WikiHop and TriviaQA.*
This model was contributed by [beltagy](https://huggingface.co/beltagy). The Authors' code can be found [here](https://github.com/allenai/longformer).
## Usage tips
- Since the Longformer is based on RoBERTa, it doesn't have `token_type_ids`. You don't need to indicate which
token belongs to which segment. Just separate your segments with the separation token `tokenizer.sep_token` (or
`</s>`).
- A transformer model replacing the attention matrices by sparse matrices to go faster. Often, the local context (e.g., what are the two tokens left and right?) is enough to take action for a given token. Some preselected input tokens are still given global attention, but the attention matrix has way less parameters, resulting in a speed-up. See the local attention section for more information.
## Longformer Self Attention
Longformer self attention employs self attention on both a "local" context and a "global" context. Most tokens only
attend "locally" to each other meaning that each token attends to its \\(\frac{1}{2} w\\) previous tokens and
\\(\frac{1}{2} w\\) succeeding tokens with \\(w\\) being the window length as defined in
`config.attention_window`. Note that `config.attention_window` can be of type `List` to define a
different \\(w\\) for each layer. A selected few tokens attend "globally" to all other tokens, as it is
conventionally done for all tokens in `BertSelfAttention`.
Note that "locally" and "globally" attending tokens are projected by different query, key and value matrices. Also note
that every "locally" attending token not only attends to tokens within its window \\(w\\), but also to all "globally"
attending tokens so that global attention is *symmetric*.
The user can define which tokens attend "locally" and which tokens attend "globally" by setting the tensor
`global_attention_mask` at run-time appropriately. All Longformer models employ the following logic for
`global_attention_mask`:
- 0: the token attends "locally",
- 1: the token attends "globally".
For more information please also refer to [`~LongformerModel.forward`] method.
Using Longformer self attention, the memory and time complexity of the query-key matmul operation, which usually
represents the memory and time bottleneck, can be reduced from \\(\mathcal{O}(n_s \times n_s)\\) to
\\(\mathcal{O}(n_s \times w)\\), with \\(n_s\\) being the sequence length and \\(w\\) being the average window
size. It is assumed that the number of "globally" attending tokens is insignificant as compared to the number of
"locally" attending tokens.
For more information, please refer to the official [paper](https://arxiv.org/pdf/2004.05150.pdf).
## Training
[`LongformerForMaskedLM`] is trained the exact same way [`RobertaForMaskedLM`] is
trained and should be used as follows:
```python
input_ids = tokenizer.encode("This is a sentence from [MASK] training data", return_tensors="pt")
mlm_labels = tokenizer.encode("This is a sentence from the training data", return_tensors="pt")
loss = model(input_ids, labels=input_ids, masked_lm_labels=mlm_labels)[0]
```
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## LongformerConfig
[[autodoc]] LongformerConfig
## LongformerTokenizer
[[autodoc]] LongformerTokenizer
## LongformerTokenizerFast
[[autodoc]] LongformerTokenizerFast
## Longformer specific outputs
[[autodoc]] models.longformer.modeling_longformer.LongformerBaseModelOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerBaseModelOutputWithPooling
[[autodoc]] models.longformer.modeling_longformer.LongformerMaskedLMOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerQuestionAnsweringModelOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerSequenceClassifierOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerMultipleChoiceModelOutput
[[autodoc]] models.longformer.modeling_longformer.LongformerTokenClassifierOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerBaseModelOutputWithPooling
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerMaskedLMOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerQuestionAnsweringModelOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerSequenceClassifierOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerMultipleChoiceModelOutput
[[autodoc]] models.longformer.modeling_tf_longformer.TFLongformerTokenClassifierOutput
<frameworkcontent>
<pt>
## LongformerModel
[[autodoc]] LongformerModel
- forward
## LongformerForMaskedLM
[[autodoc]] LongformerForMaskedLM
- forward
## LongformerForSequenceClassification
[[autodoc]] LongformerForSequenceClassification
- forward
## LongformerForMultipleChoice
[[autodoc]] LongformerForMultipleChoice
- forward
## LongformerForTokenClassification
[[autodoc]] LongformerForTokenClassification
- forward
## LongformerForQuestionAnswering
[[autodoc]] LongformerForQuestionAnswering
- forward
</pt>
<tf>
## TFLongformerModel
[[autodoc]] TFLongformerModel
- call
## TFLongformerForMaskedLM
[[autodoc]] TFLongformerForMaskedLM
- call
## TFLongformerForQuestionAnswering
[[autodoc]] TFLongformerForQuestionAnswering
- call
## TFLongformerForSequenceClassification
[[autodoc]] TFLongformerForSequenceClassification
- call
## TFLongformerForTokenClassification
[[autodoc]] TFLongformerForTokenClassification
- call
## TFLongformerForMultipleChoice
[[autodoc]] TFLongformerForMultipleChoice
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/longformer.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/longformer.md",
"repo_id": "transformers",
"token_count": 2395
}
| 18 |
<!--Copyright 2021 NVIDIA Corporation and The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MegatronBERT
## Overview
The MegatronBERT model was proposed in [Megatron-LM: Training Multi-Billion Parameter Language Models Using Model
Parallelism](https://arxiv.org/abs/1909.08053) by Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley,
Jared Casper and Bryan Catanzaro.
The abstract from the paper is the following:
*Recent work in language modeling demonstrates that training large transformer models advances the state of the art in
Natural Language Processing applications. However, very large models can be quite difficult to train due to memory
constraints. In this work, we present our techniques for training very large transformer models and implement a simple,
efficient intra-layer model parallel approach that enables training transformer models with billions of parameters. Our
approach does not require a new compiler or library changes, is orthogonal and complimentary to pipeline model
parallelism, and can be fully implemented with the insertion of a few communication operations in native PyTorch. We
illustrate this approach by converging transformer based models up to 8.3 billion parameters using 512 GPUs. We sustain
15.1 PetaFLOPs across the entire application with 76% scaling efficiency when compared to a strong single GPU baseline
that sustains 39 TeraFLOPs, which is 30% of peak FLOPs. To demonstrate that large language models can further advance
the state of the art (SOTA), we train an 8.3 billion parameter transformer language model similar to GPT-2 and a 3.9
billion parameter model similar to BERT. We show that careful attention to the placement of layer normalization in
BERT-like models is critical to achieving increased performance as the model size grows. Using the GPT-2 model we
achieve SOTA results on the WikiText103 (10.8 compared to SOTA perplexity of 15.8) and LAMBADA (66.5% compared to SOTA
accuracy of 63.2%) datasets. Our BERT model achieves SOTA results on the RACE dataset (90.9% compared to SOTA accuracy
of 89.4%).*
This model was contributed by [jdemouth](https://huggingface.co/jdemouth). The original code can be found [here](https://github.com/NVIDIA/Megatron-LM).
That repository contains a multi-GPU and multi-node implementation of the Megatron Language models. In particular,
it contains a hybrid model parallel approach using "tensor parallel" and "pipeline parallel" techniques.
## Usage tips
We have provided pretrained [BERT-345M](https://ngc.nvidia.com/catalog/models/nvidia:megatron_bert_345m) checkpoints
for use to evaluate or finetuning downstream tasks.
To access these checkpoints, first [sign up](https://ngc.nvidia.com/signup) for and setup the NVIDIA GPU Cloud (NGC)
Registry CLI. Further documentation for downloading models can be found in the [NGC documentation](https://docs.nvidia.com/dgx/ngc-registry-cli-user-guide/index.html#topic_6_4_1).
Alternatively, you can directly download the checkpoints using:
BERT-345M-uncased:
```bash
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_uncased/zip
-O megatron_bert_345m_v0_1_uncased.zip
```
BERT-345M-cased:
```bash
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/megatron_bert_345m/versions/v0.1_cased/zip -O
megatron_bert_345m_v0_1_cased.zip
```
Once you have obtained the checkpoints from NVIDIA GPU Cloud (NGC), you have to convert them to a format that will
easily be loaded by Hugging Face Transformers and our port of the BERT code.
The following commands allow you to do the conversion. We assume that the folder `models/megatron_bert` contains
`megatron_bert_345m_v0_1_{cased, uncased}.zip` and that the commands are run from inside that folder:
```bash
python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_uncased.zip
```
```bash
python3 $PATH_TO_TRANSFORMERS/models/megatron_bert/convert_megatron_bert_checkpoint.py megatron_bert_345m_v0_1_cased.zip
```
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## MegatronBertConfig
[[autodoc]] MegatronBertConfig
## MegatronBertModel
[[autodoc]] MegatronBertModel
- forward
## MegatronBertForMaskedLM
[[autodoc]] MegatronBertForMaskedLM
- forward
## MegatronBertForCausalLM
[[autodoc]] MegatronBertForCausalLM
- forward
## MegatronBertForNextSentencePrediction
[[autodoc]] MegatronBertForNextSentencePrediction
- forward
## MegatronBertForPreTraining
[[autodoc]] MegatronBertForPreTraining
- forward
## MegatronBertForSequenceClassification
[[autodoc]] MegatronBertForSequenceClassification
- forward
## MegatronBertForMultipleChoice
[[autodoc]] MegatronBertForMultipleChoice
- forward
## MegatronBertForTokenClassification
[[autodoc]] MegatronBertForTokenClassification
- forward
## MegatronBertForQuestionAnswering
[[autodoc]] MegatronBertForQuestionAnswering
- forward
|
transformers/docs/source/en/model_doc/megatron-bert.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/megatron-bert.md",
"repo_id": "transformers",
"token_count": 1735
}
| 19 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Persimmon
## Overview
The Persimmon model was created by [ADEPT](https://www.adept.ai/blog/persimmon-8b), and authored by Erich Elsen, Augustus Odena, Maxwell Nye, Sağnak Taşırlar, Tri Dao, Curtis Hawthorne, Deepak Moparthi, Arushi Somani.
The authors introduced Persimmon-8B, a decoder model based on the classic transformers architecture, with query and key normalization. Persimmon-8B is a fully permissively-licensed model with approximately 8 billion parameters, released under the Apache license. Some of the key attributes of Persimmon-8B are long context size (16K), performance, and capabilities for multimodal extensions.
The authors showcase their approach to model evaluation, focusing on practical text generation, mirroring how users interact with language models. The work also includes a comparative analysis, pitting Persimmon-8B against other prominent models (MPT 7B Instruct and Llama 2 Base 7B 1-Shot), across various evaluation tasks. The results demonstrate Persimmon-8B's competitive performance, even with limited training data.
In terms of model details, the work outlines the architecture and training methodology of Persimmon-8B, providing insights into its design choices, sequence length, and dataset composition. The authors present a fast inference code that outperforms traditional implementations through operator fusion and CUDA graph utilization while maintaining code coherence. They express their anticipation of how the community will leverage this contribution to drive innovation, hinting at further upcoming releases as part of an ongoing series of developments.
This model was contributed by [ArthurZ](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/persimmon-ai-labs/adept-inference).
## Usage tips
<Tip warning={true}>
The `Persimmon` models were trained using `bfloat16`, but the original inference uses `float16` The checkpoints uploaded on the hub use `torch_dtype = 'float16'` which will be
used by the `AutoModel` API to cast the checkpoints from `torch.float32` to `torch.float16`.
The `dtype` of the online weights is mostly irrelevant, unless you are using `torch_dtype="auto"` when initializing a model using `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`. The reason is that the model will first be downloaded ( using the `dtype` of the checkpoints online) then it will be cast to the default `dtype` of `torch` (becomes `torch.float32`). Users should specify the `torch_dtype` they want, and if they don't it will be `torch.float32`.
Finetuning the model in `float16` is not recommended and known to produce `nan`, as such the model should be fine-tuned in `bfloat16`.
</Tip>
Tips:
- To convert the model, you need to clone the original repository using `git clone https://github.com/persimmon-ai-labs/adept-inference`, then get the checkpoints:
```bash
git clone https://github.com/persimmon-ai-labs/adept-inference
wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_base_model_release.tar
tar -xvf 8b_base_model_release.tar
python src/transformers/models/persimmon/convert_persimmon_weights_to_hf.py --input_dir /path/to/downloaded/persimmon/weights/ --output_dir /output/path \
--pt_model_path /path/to/8b_chat_model_release/iter_0001251/mp_rank_00/model_optim_rng.pt
--ada_lib_path /path/to/adept-inference
```
For the chat model:
```bash
wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_chat_model_release.tar
tar -xvf 8b_base_model_release.tar
```
Thereafter, models can be loaded via:
```py
from transformers import PersimmonForCausalLM, PersimmonTokenizer
model = PersimmonForCausalLM.from_pretrained("/output/path")
tokenizer = PersimmonTokenizer.from_pretrained("/output/path")
```
- Perismmon uses a `sentencepiece` based tokenizer, with a `Unigram` model. It supports bytefallback, which is only available in `tokenizers==0.14.0` for the fast tokenizer.
The `LlamaTokenizer` is used as it is a standard wrapper around sentencepiece. The `chat` template will be updated with the templating functions in a follow up PR!
- The authors suggest to use the following prompt format for the chat mode: `f"human: {prompt}\n\nadept:"`
## PersimmonConfig
[[autodoc]] PersimmonConfig
## PersimmonModel
[[autodoc]] PersimmonModel
- forward
## PersimmonForCausalLM
[[autodoc]] PersimmonForCausalLM
- forward
## PersimmonForSequenceClassification
[[autodoc]] PersimmonForSequenceClassification
- forward
## PersimmonForTokenClassification
[[autodoc]] PersimmonForTokenClassification
- forward
|
transformers/docs/source/en/model_doc/persimmon.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/persimmon.md",
"repo_id": "transformers",
"token_count": 1594
}
| 20 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RWKV
## Overview
The RWKV model was proposed in [this repo](https://github.com/BlinkDL/RWKV-LM)
It suggests a tweak in the traditional Transformer attention to make it linear. This way, the model can be used as recurrent network: passing inputs for timestamp 0 and timestamp 1 together is the same as passing inputs at timestamp 0, then inputs at timestamp 1 along with the state of timestamp 0 (see example below).
This can be more efficient than a regular Transformer and can deal with sentence of any length (even if the model uses a fixed context length for training).
This model was contributed by [sgugger](https://huggingface.co/sgugger).
The original code can be found [here](https://github.com/BlinkDL/RWKV-LM).
## Usage example
```py
import torch
from transformers import AutoTokenizer, RwkvConfig, RwkvModel
model = RwkvModel.from_pretrained("sgugger/rwkv-430M-pile")
tokenizer = AutoTokenizer.from_pretrained("sgugger/rwkv-430M-pile")
inputs = tokenizer("This is an example.", return_tensors="pt")
# Feed everything to the model
outputs = model(inputs["input_ids"])
output_whole = outputs.last_hidden_state
outputs = model(inputs["input_ids"][:, :2])
output_one = outputs.last_hidden_state
# Using the state computed on the first inputs, we will get the same output
outputs = model(inputs["input_ids"][:, 2:], state=outputs.state)
output_two = outputs.last_hidden_state
torch.allclose(torch.cat([output_one, output_two], dim=1), output_whole, atol=1e-5)
```
If you want to make sure the model stops generating when `'\n\n'` is detected, we recommend using the following stopping criteria:
```python
from transformers import StoppingCriteria
class RwkvStoppingCriteria(StoppingCriteria):
def __init__(self, eos_sequence = [187,187], eos_token_id = 537):
self.eos_sequence = eos_sequence
self.eos_token_id = eos_token_id
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
last_2_ids = input_ids[:,-2:].tolist()
return self.eos_sequence in last_2_ids
output = model.generate(inputs["input_ids"], max_new_tokens=64, stopping_criteria = [RwkvStoppingCriteria()])
```
## RwkvConfig
[[autodoc]] RwkvConfig
## RwkvModel
[[autodoc]] RwkvModel
- forward
## RwkvLMHeadModel
[[autodoc]] RwkvForCausalLM
- forward
## Rwkv attention and the recurrent formulas
In a traditional auto-regressive Transformer, attention is written as
$$O = \hbox{softmax}(QK^{T} / \sqrt{d}) V$$
with \\(Q\\), \\(K\\) and \\(V\\) are matrices of shape `seq_len x hidden_size` named query, key and value (they are actually bigger matrices with a batch dimension and an attention head dimension but we're only interested in the last two, which is where the matrix product is taken, so for the sake of simplicity we only consider those two). The product \\(QK^{T}\\) then has shape `seq_len x seq_len` and we can take the matrix product with \\(V\\) to get the output \\(O\\) of the same shape as the others.
Replacing the softmax by its value gives:
$$O_{i} = \frac{\sum_{j=1}^{i} e^{Q_{i} K_{j}^{T} / \sqrt{d}} V_{j}}{\sum_{j=1}^{i} e^{Q_{i} K_{j}^{T} / \sqrt{d}}}$$
Note that the entries in \\(QK^{T}\\) corresponding to \\(j > i\\) are masked (the sum stops at j) because the attention is not allowed to look at future tokens (only past ones).
In comparison, the RWKV attention is given by
$$O_{i} = \sigma(R_{i}) \frac{\sum_{j=1}^{i} e^{W_{i-j} + K_{j}} V_{j}}{\sum_{j=1}^{i} e^{W_{i-j} + K_{j}}}$$
where \\(R\\) is a new matrix called receptance by the author, \\(K\\) and \\(V\\) are still the key and value (\\(\sigma\\) here is the sigmoid function). \\(W\\) is a new vector that represents the position of the token and is given by
$$W_{0} = u \hbox{ and } W_{k} = (k-1)w \hbox{ for } k \geq 1$$
with \\(u\\) and \\(w\\) learnable parameters called in the code `time_first` and `time_decay` respectively. The numerator and denominator can both be expressed recursively. Naming them \\(N_{i}\\) and \\(D_{i}\\) we have:
$$N_{i} = e^{u + K_{i}} V_{i} + \hat{N}_{i} \hbox{ where } \hat{N}_{i} = e^{K_{i-1}} V_{i-1} + e^{w + K_{i-2}} V_{i-2} \cdots + e^{(i-2)w + K_{1}} V_{1}$$
so \\(\hat{N}_{i}\\) (called `numerator_state` in the code) satisfies
$$\hat{N}_{0} = 0 \hbox{ and } \hat{N}_{j+1} = e^{K_{j}} V_{j} + e^{w} \hat{N}_{j}$$
and
$$D_{i} = e^{u + K_{i}} + \hat{D}_{i} \hbox{ where } \hat{D}_{i} = e^{K_{i-1}} + e^{w + K_{i-2}} \cdots + e^{(i-2)w + K_{1}}$$
so \\(\hat{D}_{i}\\) (called `denominator_state` in the code) satisfies
$$\hat{D}_{0} = 0 \hbox{ and } \hat{D}_{j+1} = e^{K_{j}} + e^{w} \hat{D}_{j}$$
The actual recurrent formula used are a tiny bit more complex, as for numerical stability we don't want to compute exponentials of big numbers. Usually the softmax is not computed as is, but the exponential of the maximum term is divided of the numerator and denominator:
$$\frac{e^{x_{i}}}{\sum_{j=1}^{n} e^{x_{j}}} = \frac{e^{x_{i} - M}}{\sum_{j=1}^{n} e^{x_{j} - M}}$$
with \\(M\\) the maximum of all \\(x_{j}\\). So here on top of saving the numerator state (\\(\hat{N}\\)) and the denominator state (\\(\hat{D}\\)) we also keep track of the maximum of all terms encountered in the exponentials. So we actually use
$$\tilde{N}_{i} = e^{-M_{i}} \hat{N}_{i} \hbox{ and } \tilde{D}_{i} = e^{-M_{i}} \hat{D}_{i}$$
defined by the following recurrent formulas:
$$\tilde{N}_{0} = 0 \hbox{ and } \tilde{N}_{j+1} = e^{K_{j} - q} V_{j} + e^{w + M_{j} - q} \tilde{N}_{j} \hbox{ where } q = \max(K_{j}, w + M_{j})$$
and
$$\tilde{D}_{0} = 0 \hbox{ and } \tilde{D}_{j+1} = e^{K_{j} - q} + e^{w + M_{j} - q} \tilde{D}_{j} \hbox{ where } q = \max(K_{j}, w + M_{j})$$
and \\(M_{j+1} = q\\). With those, we can then compute
$$N_{i} = e^{u + K_{i} - q} V_{i} + e^{M_{i}} \tilde{N}_{i} \hbox{ where } q = \max(u + K_{i}, M_{i})$$
and
$$D_{i} = e^{u + K_{i} - q} + e^{M_{i}} \tilde{D}_{i} \hbox{ where } q = \max(u + K_{i}, M_{i})$$
which finally gives us
$$O_{i} = \sigma(R_{i}) \frac{N_{i}}{D_{i}}$$
|
transformers/docs/source/en/model_doc/rwkv.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/rwkv.md",
"repo_id": "transformers",
"token_count": 2548
}
| 21 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TimmWrapper
## Overview
Helper class to enable loading timm models to be used with the transformers library and its autoclasses.
```python
>>> import torch
>>> from PIL import Image
>>> from urllib.request import urlopen
>>> from transformers import AutoModelForImageClassification, AutoImageProcessor
>>> # Load image
>>> image = Image.open(urlopen(
... 'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
... ))
>>> # Load model and image processor
>>> checkpoint = "timm/resnet50.a1_in1k"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint)
>>> model = AutoModelForImageClassification.from_pretrained(checkpoint).eval()
>>> # Preprocess image
>>> inputs = image_processor(image)
>>> # Forward pass
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # Get top 5 predictions
>>> top5_probabilities, top5_class_indices = torch.topk(logits.softmax(dim=1) * 100, k=5)
```
## Resources:
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with TimmWrapper.
<PipelineTag pipeline="image-classification"/>
- [Collection of Example Notebook](https://github.com/ariG23498/timm-wrapper-examples) 🌎
> [!TIP]
> For a more detailed overview please read the [official blog post](https://huggingface.co/blog/timm-transformers) on the timm integration.
## TimmWrapperConfig
[[autodoc]] TimmWrapperConfig
## TimmWrapperImageProcessor
[[autodoc]] TimmWrapperImageProcessor
- preprocess
## TimmWrapperModel
[[autodoc]] TimmWrapperModel
- forward
## TimmWrapperForImageClassification
[[autodoc]] TimmWrapperForImageClassification
- forward
|
transformers/docs/source/en/model_doc/timm_wrapper.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/timm_wrapper.md",
"repo_id": "transformers",
"token_count": 732
}
| 22 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ViLT
## Overview
The ViLT model was proposed in [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334)
by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design
for Vision-and-Language Pre-training (VLP).
The abstract from the paper is the following:
*Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks.
Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision
(e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we
find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more
computation than the multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive
power of the visual embedder and its predefined visual vocabulary. In this paper, we present a minimal VLP model,
Vision-and-Language Transformer (ViLT), monolithic in the sense that the processing of visual inputs is drastically
simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of
times faster than previous VLP models, yet with competitive or better downstream task performance.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vilt_architecture.jpg"
alt="drawing" width="600"/>
<small> ViLT architecture. Taken from the <a href="https://arxiv.org/abs/2102.03334">original paper</a>. </small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/dandelin/ViLT).
## Usage tips
- The quickest way to get started with ViLT is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/ViLT)
(which showcase both inference and fine-tuning on custom data).
- ViLT is a model that takes both `pixel_values` and `input_ids` as input. One can use [`ViltProcessor`] to prepare data for the model.
This processor wraps a image processor (for the image modality) and a tokenizer (for the language modality) into one.
- ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a `pixel_mask` that indicates
which pixel values are real and which are padding. [`ViltProcessor`] automatically creates this for you.
- The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes
additional embedding layers for the language modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
## ViltConfig
[[autodoc]] ViltConfig
## ViltFeatureExtractor
[[autodoc]] ViltFeatureExtractor
- __call__
## ViltImageProcessor
[[autodoc]] ViltImageProcessor
- preprocess
## ViltProcessor
[[autodoc]] ViltProcessor
- __call__
## ViltModel
[[autodoc]] ViltModel
- forward
## ViltForMaskedLM
[[autodoc]] ViltForMaskedLM
- forward
## ViltForQuestionAnswering
[[autodoc]] ViltForQuestionAnswering
- forward
## ViltForImagesAndTextClassification
[[autodoc]] ViltForImagesAndTextClassification
- forward
## ViltForImageAndTextRetrieval
[[autodoc]] ViltForImageAndTextRetrieval
- forward
## ViltForTokenClassification
[[autodoc]] ViltForTokenClassification
- forward
|
transformers/docs/source/en/model_doc/vilt.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/vilt.md",
"repo_id": "transformers",
"token_count": 1225
}
| 23 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Wav2Vec2
## Overview
The Wav2Vec2 model was proposed in [wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations](https://arxiv.org/abs/2006.11477) by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli.
The abstract from the paper is the following:
*We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on
transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks
the speech input in the latent space and solves a contrastive task defined over a quantization of the latent
representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the
clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state
of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and
pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech
recognition with limited amounts of labeled data.*
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
Note: Meta (FAIR) released a new version of [Wav2Vec2-BERT 2.0](https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert) - it's pretrained on 4.5M hours of audio. We especially recommend using it for fine-tuning tasks, e.g. as per [this guide](https://huggingface.co/blog/fine-tune-w2v2-bert).
## Usage tips
- Wav2Vec2 is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Wav2Vec2 model was trained using connectionist temporal classification (CTC) so the model output has to be decoded
using [`Wav2Vec2CTCTokenizer`].
## Using Flash Attention 2
Flash Attention 2 is an faster, optimized version of the model.
### Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the [official documentation](https://github.com/Dao-AILab/flash-attention#installation-and-features). If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered [above](https://huggingface.co/docs/transformers/main/en/model_doc/bark#using-better-transformer).
Next, [install](https://github.com/Dao-AILab/flash-attention#installation-and-features) the latest version of Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
### Usage
To load a model using Flash Attention 2, we can pass the argument `attn_implementation="flash_attention_2"` to [`.from_pretrained`](https://huggingface.co/docs/transformers/main/en/main_classes/model#transformers.PreTrainedModel.from_pretrained). We'll also load the model in half-precision (e.g. `torch.float16`), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
```python
>>> from transformers import Wav2Vec2Model
model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-large-960h-lv60-self", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
...
```
### Expected speedups
Below is an expected speedup diagram comparing the pure inference time between the native implementation in transformers of the `facebook/wav2vec2-large-960h-lv60-self` model and the flash-attention-2 and sdpa (scale-dot-product-attention) versions. . We show the average speedup obtained on the `librispeech_asr` `clean` validation split:
<div style="text-align: center">
<img src="https://huggingface.co/datasets/kamilakesbi/transformers_image_doc/resolve/main/data/Wav2Vec2_speedup.png">
</div>
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Wav2Vec2. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="audio-classification"/>
- A notebook on how to [leverage a pretrained Wav2Vec2 model for emotion classification](https://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb). 🌎
- [`Wav2Vec2ForCTC`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/audio-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
- [Audio classification task guide](../tasks/audio_classification)
<PipelineTag pipeline="automatic-speech-recognition"/>
- A blog post on [boosting Wav2Vec2 with n-grams in 🤗 Transformers](https://huggingface.co/blog/wav2vec2-with-ngram).
- A blog post on how to [finetune Wav2Vec2 for English ASR with 🤗 Transformers](https://huggingface.co/blog/fine-tune-wav2vec2-english).
- A blog post on [finetuning XLS-R for Multi-Lingual ASR with 🤗 Transformers](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2).
- A notebook on how to [create YouTube captions from any video by transcribing audio with Wav2Vec2](https://colab.research.google.com/github/Muennighoff/ytclipcc/blob/main/wav2vec_youtube_captions.ipynb). 🌎
- [`Wav2Vec2ForCTC`] is supported by a notebook on [how to finetune a speech recognition model in English](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/speech_recognition.ipynb), and [how to finetune a speech recognition model in any language](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multi_lingual_speech_recognition.ipynb).
- [Automatic speech recognition task guide](../tasks/asr)
🚀 Deploy
- A blog post on how to deploy Wav2Vec2 for [Automatic Speech Recognition with Hugging Face's Transformers & Amazon SageMaker](https://www.philschmid.de/automatic-speech-recognition-sagemaker).
## Wav2Vec2Config
[[autodoc]] Wav2Vec2Config
## Wav2Vec2CTCTokenizer
[[autodoc]] Wav2Vec2CTCTokenizer
- __call__
- save_vocabulary
- decode
- batch_decode
- set_target_lang
## Wav2Vec2FeatureExtractor
[[autodoc]] Wav2Vec2FeatureExtractor
- __call__
## Wav2Vec2Processor
[[autodoc]] Wav2Vec2Processor
- __call__
- pad
- from_pretrained
- save_pretrained
- batch_decode
- decode
## Wav2Vec2ProcessorWithLM
[[autodoc]] Wav2Vec2ProcessorWithLM
- __call__
- pad
- from_pretrained
- save_pretrained
- batch_decode
- decode
### Decoding multiple audios
If you are planning to decode multiple batches of audios, you should consider using [`~Wav2Vec2ProcessorWithLM.batch_decode`] and passing an instantiated `multiprocessing.Pool`.
Otherwise, [`~Wav2Vec2ProcessorWithLM.batch_decode`] performance will be slower than calling [`~Wav2Vec2ProcessorWithLM.decode`] for each audio individually, as it internally instantiates a new `Pool` for every call. See the example below:
```python
>>> # Let's see how to use a user-managed pool for batch decoding multiple audios
>>> from multiprocessing import get_context
>>> from transformers import AutoTokenizer, AutoProcessor, AutoModelForCTC
>>> from datasets import load_dataset
>>> import datasets
>>> import torch
>>> # import model, feature extractor, tokenizer
>>> model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm").to("cuda")
>>> processor = AutoProcessor.from_pretrained("patrickvonplaten/wav2vec2-base-100h-with-lm")
>>> # load example dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> dataset = dataset.cast_column("audio", datasets.Audio(sampling_rate=16_000))
>>> def map_to_array(batch):
... batch["speech"] = batch["audio"]["array"]
... return batch
>>> # prepare speech data for batch inference
>>> dataset = dataset.map(map_to_array, remove_columns=["audio"])
>>> def map_to_pred(batch, pool):
... inputs = processor(batch["speech"], sampling_rate=16_000, padding=True, return_tensors="pt")
... inputs = {k: v.to("cuda") for k, v in inputs.items()}
... with torch.no_grad():
... logits = model(**inputs).logits
... transcription = processor.batch_decode(logits.cpu().numpy(), pool).text
... batch["transcription"] = transcription
... return batch
>>> # note: pool should be instantiated *after* `Wav2Vec2ProcessorWithLM`.
>>> # otherwise, the LM won't be available to the pool's sub-processes
>>> # select number of processes and batch_size based on number of CPU cores available and on dataset size
>>> with get_context("fork").Pool(processes=2) as pool:
... result = dataset.map(
... map_to_pred, batched=True, batch_size=2, fn_kwargs={"pool": pool}, remove_columns=["speech"]
... )
>>> result["transcription"][:2]
['MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL', "NOR IS MISTER COULTER'S MANNER LESS INTERESTING THAN HIS MATTER"]
```
## Wav2Vec2 specific outputs
[[autodoc]] models.wav2vec2_with_lm.processing_wav2vec2_with_lm.Wav2Vec2DecoderWithLMOutput
[[autodoc]] models.wav2vec2.modeling_wav2vec2.Wav2Vec2BaseModelOutput
[[autodoc]] models.wav2vec2.modeling_wav2vec2.Wav2Vec2ForPreTrainingOutput
[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2BaseModelOutput
[[autodoc]] models.wav2vec2.modeling_flax_wav2vec2.FlaxWav2Vec2ForPreTrainingOutput
<frameworkcontent>
<pt>
## Wav2Vec2Model
[[autodoc]] Wav2Vec2Model
- forward
## Wav2Vec2ForCTC
[[autodoc]] Wav2Vec2ForCTC
- forward
- load_adapter
## Wav2Vec2ForSequenceClassification
[[autodoc]] Wav2Vec2ForSequenceClassification
- forward
## Wav2Vec2ForAudioFrameClassification
[[autodoc]] Wav2Vec2ForAudioFrameClassification
- forward
## Wav2Vec2ForXVector
[[autodoc]] Wav2Vec2ForXVector
- forward
## Wav2Vec2ForPreTraining
[[autodoc]] Wav2Vec2ForPreTraining
- forward
</pt>
<tf>
## TFWav2Vec2Model
[[autodoc]] TFWav2Vec2Model
- call
## TFWav2Vec2ForSequenceClassification
[[autodoc]] TFWav2Vec2ForSequenceClassification
- call
## TFWav2Vec2ForCTC
[[autodoc]] TFWav2Vec2ForCTC
- call
</tf>
<jax>
## FlaxWav2Vec2Model
[[autodoc]] FlaxWav2Vec2Model
- __call__
## FlaxWav2Vec2ForCTC
[[autodoc]] FlaxWav2Vec2ForCTC
- __call__
## FlaxWav2Vec2ForPreTraining
[[autodoc]] FlaxWav2Vec2ForPreTraining
- __call__
</jax>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/wav2vec2.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/wav2vec2.md",
"repo_id": "transformers",
"token_count": 3788
}
| 24 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# YOSO
## Overview
The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714)
by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh. YOSO approximates standard softmax self-attention
via a Bernoulli sampling scheme based on Locality Sensitive Hashing (LSH). In principle, all the Bernoulli random variables can be sampled with
a single hash.
The abstract from the paper is the following:
*Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is
the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically
on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling
attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear.
We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random
variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant).
This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of
LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence
length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark,
for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable
speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL*
This model was contributed by [novice03](https://huggingface.co/novice03). The original code can be found [here](https://github.com/mlpen/YOSO).
## Usage tips
- The YOSO attention algorithm is implemented through custom CUDA kernels, functions written in CUDA C++ that can be executed multiple times
in parallel on a GPU.
- The kernels provide a `fast_hash` function, which approximates the random projections of the queries and keys using the Fast Hadamard Transform. Using these
hash codes, the `lsh_cumulation` function approximates self-attention via LSH-based Bernoulli sampling.
- To use the custom kernels, the user should set `config.use_expectation = False`. To ensure that the kernels are compiled successfully,
the user must install the correct version of PyTorch and cudatoolkit. By default, `config.use_expectation = True`, which uses YOSO-E and
does not require compiling CUDA kernels.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/yoso_architecture.jpg"
alt="drawing" width="600"/>
<small> YOSO Attention Algorithm. Taken from the <a href="https://arxiv.org/abs/2111.09714">original paper</a>.</small>
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/multiple_choice)
## YosoConfig
[[autodoc]] YosoConfig
## YosoModel
[[autodoc]] YosoModel
- forward
## YosoForMaskedLM
[[autodoc]] YosoForMaskedLM
- forward
## YosoForSequenceClassification
[[autodoc]] YosoForSequenceClassification
- forward
## YosoForMultipleChoice
[[autodoc]] YosoForMultipleChoice
- forward
## YosoForTokenClassification
[[autodoc]] YosoForTokenClassification
- forward
## YosoForQuestionAnswering
[[autodoc]] YosoForQuestionAnswering
- forward
|
transformers/docs/source/en/model_doc/yoso.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/yoso.md",
"repo_id": "transformers",
"token_count": 1243
}
| 25 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Optimize inference using torch.compile()
This guide aims to provide a benchmark on the inference speed-ups introduced with [`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) for [computer vision models in 🤗 Transformers](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending).
## Benefits of torch.compile
Depending on the model and the GPU, `torch.compile()` yields up to 30% speed-up during inference. To use `torch.compile()`, simply install any version of `torch` above 2.0.
Compiling a model takes time, so it's useful if you are compiling the model only once instead of every time you infer.
To compile any computer vision model of your choice, call `torch.compile()` on the model as shown below:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to(DEVICE)
+ model = torch.compile(model)
```
`compile()` comes with multiple modes for compiling, which essentially differ in compilation time and inference overhead. `max-autotune` takes longer than `reduce-overhead` but results in faster inference. Default mode is fastest for compilation but is not as efficient compared to `reduce-overhead` for inference time. In this guide, we used the default mode. You can learn more about it [here](https://pytorch.org/get-started/pytorch-2.0/#user-experience).
We benchmarked `torch.compile` with different computer vision models, tasks, types of hardware, and batch sizes on `torch` version 2.0.1.
## Benchmarking code
Below you can find the benchmarking code for each task. We warm up the GPU before inference and take the mean time of 300 inferences, using the same image each time.
### Image Classification with ViT
```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
from accelerate.test_utils.testing import get_backend
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to(device)
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device)
with torch.no_grad():
_ = model(**processed_input)
```
#### Object Detection with DETR
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
from accelerate.test_utils.testing import get_backend
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to(device)
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to(device)
with torch.no_grad():
_ = model(**inputs)
```
#### Image Segmentation with Segformer
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
from accelerate.test_utils.testing import get_backend
device, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to(device)
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to(device)
with torch.no_grad():
_ = model(**seg_inputs)
```
Below you can find the list of the models we benchmarked.
**Image Classification**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/microsoft/resnet-50)
**Image Segmentation**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**Object Detection**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
Below you can find visualization of inference durations with and without `torch.compile()` and percentage improvements for each model in different hardware and batch sizes.
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
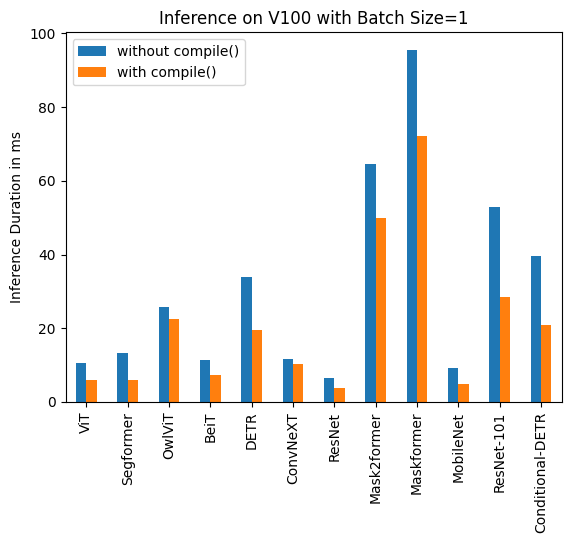
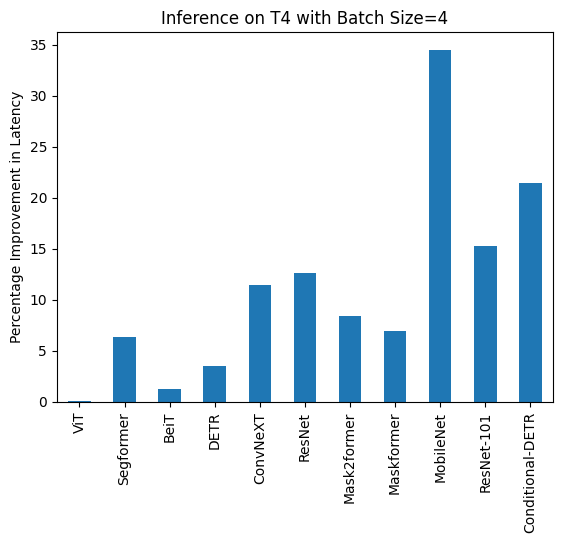
Below you can find inference durations in milliseconds for each model with and without `compile()`. Note that OwlViT results in OOM in larger batch sizes.
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
We also benchmarked on PyTorch nightly (2.1.0dev, find the wheel [here](https://download.pytorch.org/whl/nightly/cu118)) and observed improvement in latency both for uncompiled and compiled models.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## Reduce Overhead
We benchmarked `reduce-overhead` compilation mode for A100 and T4 in Nightly.
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
transformers/docs/source/en/perf_torch_compile.md/0
|
{
"file_path": "transformers/docs/source/en/perf_torch_compile.md",
"repo_id": "transformers",
"token_count": 5998
}
| 26 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BitNet
[BitNet](https://arxiv.org/abs/2402.17764) replaces traditional Linear layers in Multi-Head Attention and Feed-Forward Networks with specialized layers called BitLinear with ternary (or binary in the older version) precision. The BitLinear layers introduced here quantize the weights using ternary precision (with values of -1, 0, and 1) and quantize the activations to 8-bit precision.
<figure style="text-align: center;">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/1.58llm_extreme_quantization/bitlinear.png" alt="Alt Text" />
<figcaption>The architecture of BitNet with BitLinear layers</figcaption>
</figure>
During training, we start by quantizing the weights into ternary values, using symmetric per tensor quantization. First, we compute the average of the absolute values of the weight matrix and use this as a scale. We then divide the weights by the scale, round the values, constrain them between -1 and 1, and finally rescale them to continue in full precision.
$$
scale_w = \frac{1}{\frac{1}{nm} \sum_{ij} |W_{ij}|}
$$
$$
W_q = \text{clamp}_{[-1,1]}(\text{round}(W*scale))
$$
$$
W_{dequantized} = W_q*scale_w
$$
Activations are then quantized to a specified bit-width (e.g., 8-bit) using [absmax](https://arxiv.org/pdf/2208.07339) quantization (symmetric per channel quantization). This involves scaling the activations into a range [−128,127[. The quantization formula is:
$$
scale_x = \frac{127}{|X|_{\text{max}, \, \text{dim}=-1}}
$$
$$
X_q = \text{clamp}_{[-128,127]}(\text{round}(X*scale))
$$
$$
X_{dequantized} = X_q * scale_x
$$
To learn more about how we trained, and fine-tuned bitnet models checkout the blogpost [here](https://huggingface.co/blog/1_58_llm_extreme_quantization)
## Load a BitNet Model from the Hub
BitNet models can't be quantized on the fly—they need to be pre-trained or fine-tuned with the quantization applied (it's a Quantization aware training technique). Once trained, these models are already quantized and available as packed versions on the hub.
A quantized model can be load :
```py
from transformers import AutoModelForCausalLM
path = "/path/to/model"
model = AutoModelForCausalLM.from_pretrained(path, device_map="auto")
```
## Pre-training / Fine-tuning a BitNet Model
If you're looking to pre-train or fine-tune your own 1.58-bit model using Nanotron, check out this [PR](https://github.com/huggingface/nanotron/pull/180), all you need to get started is there !
For fine-tuning, you'll need to convert the model from Hugging Face format to Nanotron format (which has some differences). You can find the conversion steps in this [PR](https://github.com/huggingface/nanotron/pull/174).
## Kernels
In our initial version, we chose to use `@torch.compile` to unpack the weights and perform the forward pass. It’s very straightforward to implement and delivers significant speed improvements. We plan to integrate additional optimized kernels in future versions.
|
transformers/docs/source/en/quantization/bitnet.md/0
|
{
"file_path": "transformers/docs/source/en/quantization/bitnet.md",
"repo_id": "transformers",
"token_count": 1092
}
| 27 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Masked language modeling
[[open-in-colab]]
<Youtube id="mqElG5QJWUg"/>
Masked language modeling predicts a masked token in a sequence, and the model can attend to tokens bidirectionally. This
means the model has full access to the tokens on the left and right. Masked language modeling is great for tasks that
require a good contextual understanding of an entire sequence. BERT is an example of a masked language model.
This guide will show you how to:
1. Finetune [DistilRoBERTa](https://huggingface.co/distilbert/distilroberta-base) on the [r/askscience](https://www.reddit.com/r/askscience/) subset of the [ELI5](https://huggingface.co/datasets/eli5) dataset.
2. Use your finetuned model for inference.
<Tip>
To see all architectures and checkpoints compatible with this task, we recommend checking the [task-page](https://huggingface.co/tasks/fill-mask)
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
```
We encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load ELI5 dataset
Start by loading the first 5000 examples from the [ELI5-Category](https://huggingface.co/datasets/eli5_category) dataset with the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
```py
>>> from datasets import load_dataset
>>> eli5 = load_dataset("eli5_category", split="train[:5000]")
```
Split the dataset's `train` split into a train and test set with the [`~datasets.Dataset.train_test_split`] method:
```py
>>> eli5 = eli5.train_test_split(test_size=0.2)
```
Then take a look at an example:
```py
>>> eli5["train"][0]
{'q_id': '7h191n',
'title': 'What does the tax bill that was passed today mean? How will it affect Americans in each tax bracket?',
'selftext': '',
'category': 'Economics',
'subreddit': 'explainlikeimfive',
'answers': {'a_id': ['dqnds8l', 'dqnd1jl', 'dqng3i1', 'dqnku5x'],
'text': ["The tax bill is 500 pages long and there were a lot of changes still going on right to the end. It's not just an adjustment to the income tax brackets, it's a whole bunch of changes. As such there is no good answer to your question. The big take aways are: - Big reduction in corporate income tax rate will make large companies very happy. - Pass through rate change will make certain styles of business (law firms, hedge funds) extremely happy - Income tax changes are moderate, and are set to expire (though it's the kind of thing that might just always get re-applied without being made permanent) - People in high tax states (California, New York) lose out, and many of them will end up with their taxes raised.",
'None yet. It has to be reconciled with a vastly different house bill and then passed again.',
'Also: does this apply to 2017 taxes? Or does it start with 2018 taxes?',
'This article explains both the House and senate bills, including the proposed changes to your income taxes based on your income level. URL_0'],
'score': [21, 19, 5, 3],
'text_urls': [[],
[],
[],
['https://www.investopedia.com/news/trumps-tax-reform-what-can-be-done/']]},
'title_urls': ['url'],
'selftext_urls': ['url']}
```
While this may look like a lot, you're only really interested in the `text` field. What's cool about language modeling tasks is you don't need labels (also known as an unsupervised task) because the next word *is* the label.
## Preprocess
<Youtube id="8PmhEIXhBvI"/>
For masked language modeling, the next step is to load a DistilRoBERTa tokenizer to process the `text` subfield:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilroberta-base")
```
You'll notice from the example above, the `text` field is actually nested inside `answers`. This means you'll need to extract the `text` subfield from its nested structure with the [`flatten`](https://huggingface.co/docs/datasets/process#flatten) method:
```py
>>> eli5 = eli5.flatten()
>>> eli5["train"][0]
{'q_id': '7h191n',
'title': 'What does the tax bill that was passed today mean? How will it affect Americans in each tax bracket?',
'selftext': '',
'category': 'Economics',
'subreddit': 'explainlikeimfive',
'answers.a_id': ['dqnds8l', 'dqnd1jl', 'dqng3i1', 'dqnku5x'],
'answers.text': ["The tax bill is 500 pages long and there were a lot of changes still going on right to the end. It's not just an adjustment to the income tax brackets, it's a whole bunch of changes. As such there is no good answer to your question. The big take aways are: - Big reduction in corporate income tax rate will make large companies very happy. - Pass through rate change will make certain styles of business (law firms, hedge funds) extremely happy - Income tax changes are moderate, and are set to expire (though it's the kind of thing that might just always get re-applied without being made permanent) - People in high tax states (California, New York) lose out, and many of them will end up with their taxes raised.",
'None yet. It has to be reconciled with a vastly different house bill and then passed again.',
'Also: does this apply to 2017 taxes? Or does it start with 2018 taxes?',
'This article explains both the House and senate bills, including the proposed changes to your income taxes based on your income level. URL_0'],
'answers.score': [21, 19, 5, 3],
'answers.text_urls': [[],
[],
[],
['https://www.investopedia.com/news/trumps-tax-reform-what-can-be-done/']],
'title_urls': ['url'],
'selftext_urls': ['url']}
```
Each subfield is now a separate column as indicated by the `answers` prefix, and the `text` field is a list now. Instead
of tokenizing each sentence separately, convert the list to a string so you can jointly tokenize them.
Here is a first preprocessing function to join the list of strings for each example and tokenize the result:
```py
>>> def preprocess_function(examples):
... return tokenizer([" ".join(x) for x in examples["answers.text"]])
```
To apply this preprocessing function over the entire dataset, use the 🤗 Datasets [`~datasets.Dataset.map`] method. You can speed up the `map` function by setting `batched=True` to process multiple elements of the dataset at once, and increasing the number of processes with `num_proc`. Remove any columns you don't need:
```py
>>> tokenized_eli5 = eli5.map(
... preprocess_function,
... batched=True,
... num_proc=4,
... remove_columns=eli5["train"].column_names,
... )
```
This dataset contains the token sequences, but some of these are longer than the maximum input length for the model.
You can now use a second preprocessing function to
- concatenate all the sequences
- split the concatenated sequences into shorter chunks defined by `block_size`, which should be both shorter than the maximum input length and short enough for your GPU RAM.
```py
>>> block_size = 128
>>> def group_texts(examples):
... # Concatenate all texts.
... concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
... total_length = len(concatenated_examples[list(examples.keys())[0]])
... # We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
... # customize this part to your needs.
... if total_length >= block_size:
... total_length = (total_length // block_size) * block_size
... # Split by chunks of block_size.
... result = {
... k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
... for k, t in concatenated_examples.items()
... }
... return result
```
Apply the `group_texts` function over the entire dataset:
```py
>>> lm_dataset = tokenized_eli5.map(group_texts, batched=True, num_proc=4)
```
Now create a batch of examples using [`DataCollatorForLanguageModeling`]. It's more efficient to *dynamically pad* the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
<frameworkcontent>
<pt>
Use the end-of-sequence token as the padding token and specify `mlm_probability` to randomly mask tokens each time you iterate over the data:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> tokenizer.pad_token = tokenizer.eos_token
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15)
```
</pt>
<tf>
Use the end-of-sequence token as the padding token and specify `mlm_probability` to randomly mask tokens each time you iterate over the data:
```py
>>> from transformers import DataCollatorForLanguageModeling
>>> data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load DistilRoBERTa with [`AutoModelForMaskedLM`]:
```py
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("distilbert/distilroberta-base")
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model).
2. Pass the training arguments to [`Trainer`] along with the model, datasets, and data collator.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_eli5_mlm_model",
... eval_strategy="epoch",
... learning_rate=2e-5,
... num_train_epochs=3,
... weight_decay=0.01,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=lm_dataset["train"],
... eval_dataset=lm_dataset["test"],
... data_collator=data_collator,
... tokenizer=tokenizer,
... )
>>> trainer.train()
```
Once training is completed, use the [`~transformers.Trainer.evaluate`] method to evaluate your model and get its perplexity:
```py
>>> import math
>>> eval_results = trainer.evaluate()
>>> print(f"Perplexity: {math.exp(eval_results['eval_loss']):.2f}")
Perplexity: 8.76
```
Then share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
If you aren't familiar with finetuning a model with Keras, take a look at the basic tutorial [here](../training#train-a-tensorflow-model-with-keras)!
</Tip>
To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
```py
>>> from transformers import create_optimizer, AdamWeightDecay
>>> optimizer = AdamWeightDecay(learning_rate=2e-5, weight_decay_rate=0.01)
```
Then you can load DistilRoBERTa with [`TFAutoModelForMaskedLM`]:
```py
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForMaskedLM.from_pretrained("distilbert/distilroberta-base")
```
Convert your datasets to the `tf.data.Dataset` format with [`~transformers.TFPreTrainedModel.prepare_tf_dataset`]:
```py
>>> tf_train_set = model.prepare_tf_dataset(
... lm_dataset["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_test_set = model.prepare_tf_dataset(
... lm_dataset["test"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
Configure the model for training with [`compile`](https://keras.io/api/models/model_training_apis/#compile-method). Note that Transformers models all have a default task-relevant loss function, so you don't need to specify one unless you want to:
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
```
This can be done by specifying where to push your model and tokenizer in the [`~transformers.PushToHubCallback`]:
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> callback = PushToHubCallback(
... output_dir="my_awesome_eli5_mlm_model",
... tokenizer=tokenizer,
... )
```
Finally, you're ready to start training your model! Call [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) with your training and validation datasets, the number of epochs, and your callback to finetune the model:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_test_set, epochs=3, callbacks=[callback])
```
Once training is completed, your model is automatically uploaded to the Hub so everyone can use it!
</tf>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for masked language modeling, take a look at the corresponding
[PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)
or [TensorFlow notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Come up with some text you'd like the model to fill in the blank with, and use the special `<mask>` token to indicate the blank:
```py
>>> text = "The Milky Way is a <mask> galaxy."
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for fill-mask with your model, and pass your text to it. If you like, you can use the `top_k` parameter to specify how many predictions to return:
```py
>>> from transformers import pipeline
>>> mask_filler = pipeline("fill-mask", "username/my_awesome_eli5_mlm_model")
>>> mask_filler(text, top_k=3)
[{'score': 0.5150994658470154,
'token': 21300,
'token_str': ' spiral',
'sequence': 'The Milky Way is a spiral galaxy.'},
{'score': 0.07087188959121704,
'token': 2232,
'token_str': ' massive',
'sequence': 'The Milky Way is a massive galaxy.'},
{'score': 0.06434620916843414,
'token': 650,
'token_str': ' small',
'sequence': 'The Milky Way is a small galaxy.'}]
```
<frameworkcontent>
<pt>
Tokenize the text and return the `input_ids` as PyTorch tensors. You'll also need to specify the position of the `<mask>` token:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("username/my_awesome_eli5_mlm_model")
>>> inputs = tokenizer(text, return_tensors="pt")
>>> mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
```
Pass your inputs to the model and return the `logits` of the masked token:
```py
>>> from transformers import AutoModelForMaskedLM
>>> model = AutoModelForMaskedLM.from_pretrained("username/my_awesome_eli5_mlm_model")
>>> logits = model(**inputs).logits
>>> mask_token_logits = logits[0, mask_token_index, :]
```
Then return the three masked tokens with the highest probability and print them out:
```py
>>> top_3_tokens = torch.topk(mask_token_logits, 3, dim=1).indices[0].tolist()
>>> for token in top_3_tokens:
... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a massive galaxy.
The Milky Way is a small galaxy.
```
</pt>
<tf>
Tokenize the text and return the `input_ids` as TensorFlow tensors. You'll also need to specify the position of the `<mask>` token:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("username/my_awesome_eli5_mlm_model")
>>> inputs = tokenizer(text, return_tensors="tf")
>>> mask_token_index = tf.where(inputs["input_ids"] == tokenizer.mask_token_id)[0, 1]
```
Pass your inputs to the model and return the `logits` of the masked token:
```py
>>> from transformers import TFAutoModelForMaskedLM
>>> model = TFAutoModelForMaskedLM.from_pretrained("username/my_awesome_eli5_mlm_model")
>>> logits = model(**inputs).logits
>>> mask_token_logits = logits[0, mask_token_index, :]
```
Then return the three masked tokens with the highest probability and print them out:
```py
>>> top_3_tokens = tf.math.top_k(mask_token_logits, 3).indices.numpy()
>>> for token in top_3_tokens:
... print(text.replace(tokenizer.mask_token, tokenizer.decode([token])))
The Milky Way is a spiral galaxy.
The Milky Way is a massive galaxy.
The Milky Way is a small galaxy.
```
</tf>
</frameworkcontent>
|
transformers/docs/source/en/tasks/masked_language_modeling.md/0
|
{
"file_path": "transformers/docs/source/en/tasks/masked_language_modeling.md",
"repo_id": "transformers",
"token_count": 5580
}
| 28 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Zero-shot object detection
[[open-in-colab]]
Traditionally, models used for [object detection](object_detection) require labeled image datasets for training,
and are limited to detecting the set of classes from the training data.
Zero-shot object detection is supported by the [OWL-ViT](../model_doc/owlvit) model which uses a different approach. OWL-ViT
is an open-vocabulary object detector. It means that it can detect objects in images based on free-text queries without
the need to fine-tune the model on labeled datasets.
OWL-ViT leverages multi-modal representations to perform open-vocabulary detection. It combines [CLIP](../model_doc/clip) with
lightweight object classification and localization heads. Open-vocabulary detection is achieved by embedding free-text queries with the text encoder of CLIP and using them as input to the object classification and localization heads,
which associate images with their corresponding textual descriptions, while ViT processes image patches as inputs. The authors
of OWL-ViT first trained CLIP from scratch and then fine-tuned OWL-ViT end to end on standard object detection datasets using
a bipartite matching loss.
With this approach, the model can detect objects based on textual descriptions without prior training on labeled datasets.
In this guide, you will learn how to use OWL-ViT:
- to detect objects based on text prompts
- for batch object detection
- for image-guided object detection
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install -q transformers
```
## Zero-shot object detection pipeline
The simplest way to try out inference with OWL-ViT is to use it in a [`pipeline`]. Instantiate a pipeline
for zero-shot object detection from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?other=owlvit):
```python
>>> from transformers import pipeline
>>> checkpoint = "google/owlv2-base-patch16-ensemble"
>>> detector = pipeline(model=checkpoint, task="zero-shot-object-detection")
```
Next, choose an image you'd like to detect objects in. Here we'll use the image of astronaut Eileen Collins that is
a part of the [NASA](https://www.nasa.gov/multimedia/imagegallery/index.html) Great Images dataset.
```py
>>> import skimage
>>> import numpy as np
>>> from PIL import Image
>>> image = skimage.data.astronaut()
>>> image = Image.fromarray(np.uint8(image)).convert("RGB")
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_1.png" alt="Astronaut Eileen Collins"/>
</div>
Pass the image and the candidate object labels to look for to the pipeline.
Here we pass the image directly; other suitable options include a local path to an image or an image url. We also pass text descriptions for all items we want to query the image for.
```py
>>> predictions = detector(
... image,
... candidate_labels=["human face", "rocket", "nasa badge", "star-spangled banner"],
... )
>>> predictions
[{'score': 0.3571370542049408,
'label': 'human face',
'box': {'xmin': 180, 'ymin': 71, 'xmax': 271, 'ymax': 178}},
{'score': 0.28099656105041504,
'label': 'nasa badge',
'box': {'xmin': 129, 'ymin': 348, 'xmax': 206, 'ymax': 427}},
{'score': 0.2110239565372467,
'label': 'rocket',
'box': {'xmin': 350, 'ymin': -1, 'xmax': 468, 'ymax': 288}},
{'score': 0.13790413737297058,
'label': 'star-spangled banner',
'box': {'xmin': 1, 'ymin': 1, 'xmax': 105, 'ymax': 509}},
{'score': 0.11950037628412247,
'label': 'nasa badge',
'box': {'xmin': 277, 'ymin': 338, 'xmax': 327, 'ymax': 380}},
{'score': 0.10649408400058746,
'label': 'rocket',
'box': {'xmin': 358, 'ymin': 64, 'xmax': 424, 'ymax': 280}}]
```
Let's visualize the predictions:
```py
>>> from PIL import ImageDraw
>>> draw = ImageDraw.Draw(image)
>>> for prediction in predictions:
... box = prediction["box"]
... label = prediction["label"]
... score = prediction["score"]
... xmin, ymin, xmax, ymax = box.values()
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{label}: {round(score,2)}", fill="white")
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_2.png" alt="Visualized predictions on NASA image"/>
</div>
## Text-prompted zero-shot object detection by hand
Now that you've seen how to use the zero-shot object detection pipeline, let's replicate the same
result manually.
Start by loading the model and associated processor from a [checkpoint on the Hugging Face Hub](https://huggingface.co/models?other=owlvit).
Here we'll use the same checkpoint as before:
```py
>>> from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection
>>> model = AutoModelForZeroShotObjectDetection.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
```
Let's take a different image to switch things up.
```py
>>> import requests
>>> url = "https://unsplash.com/photos/oj0zeY2Ltk4/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8MTR8fHBpY25pY3xlbnwwfHx8fDE2Nzc0OTE1NDk&force=true&w=640"
>>> im = Image.open(requests.get(url, stream=True).raw)
>>> im
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_3.png" alt="Beach photo"/>
</div>
Use the processor to prepare the inputs for the model. The processor combines an image processor that prepares the
image for the model by resizing and normalizing it, and a [`CLIPTokenizer`] that takes care of the text inputs.
```py
>>> text_queries = ["hat", "book", "sunglasses", "camera"]
>>> inputs = processor(text=text_queries, images=im, return_tensors="pt")
```
Pass the inputs through the model, post-process, and visualize the results. Since the image processor resized images before
feeding them to the model, you need to use the [`~OwlViTImageProcessor.post_process_object_detection`] method to make sure the predicted bounding
boxes have the correct coordinates relative to the original image:
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(**inputs)
... target_sizes = torch.tensor([im.size[::-1]])
... results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)[0]
>>> draw = ImageDraw.Draw(im)
>>> scores = results["scores"].tolist()
>>> labels = results["labels"].tolist()
>>> boxes = results["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{text_queries[label]}: {round(score,2)}", fill="white")
>>> im
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_4.png" alt="Beach photo with detected objects"/>
</div>
## Batch processing
You can pass multiple sets of images and text queries to search for different (or same) objects in several images.
Let's use both an astronaut image and the beach image together.
For batch processing, you should pass text queries as a nested list to the processor and images as lists of PIL images,
PyTorch tensors, or NumPy arrays.
```py
>>> images = [image, im]
>>> text_queries = [
... ["human face", "rocket", "nasa badge", "star-spangled banner"],
... ["hat", "book", "sunglasses", "camera"],
... ]
>>> inputs = processor(text=text_queries, images=images, return_tensors="pt")
```
Previously for post-processing you passed the single image's size as a tensor, but you can also pass a tuple, or, in case
of several images, a list of tuples. Let's create predictions for the two examples, and visualize the second one (`image_idx = 1`).
```py
>>> with torch.no_grad():
... outputs = model(**inputs)
... target_sizes = [x.size[::-1] for x in images]
... results = processor.post_process_object_detection(outputs, threshold=0.1, target_sizes=target_sizes)
>>> image_idx = 1
>>> draw = ImageDraw.Draw(images[image_idx])
>>> scores = results[image_idx]["scores"].tolist()
>>> labels = results[image_idx]["labels"].tolist()
>>> boxes = results[image_idx]["boxes"].tolist()
>>> for box, score, label in zip(boxes, scores, labels):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="red", width=1)
... draw.text((xmin, ymin), f"{text_queries[image_idx][label]}: {round(score,2)}", fill="white")
>>> images[image_idx]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_4.png" alt="Beach photo with detected objects"/>
</div>
## Image-guided object detection
In addition to zero-shot object detection with text queries, OWL-ViT offers image-guided object detection. This means
you can use an image query to find similar objects in the target image.
Unlike text queries, only a single example image is allowed.
Let's take an image with two cats on a couch as a target image, and an image of a single cat
as a query:
```py
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image_target = Image.open(requests.get(url, stream=True).raw)
>>> query_url = "http://images.cocodataset.org/val2017/000000524280.jpg"
>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
```
Let's take a quick look at the images:
```py
>>> import matplotlib.pyplot as plt
>>> fig, ax = plt.subplots(1, 2)
>>> ax[0].imshow(image_target)
>>> ax[1].imshow(query_image)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_5.png" alt="Cats"/>
</div>
In the preprocessing step, instead of text queries, you now need to use `query_images`:
```py
>>> inputs = processor(images=image_target, query_images=query_image, return_tensors="pt")
```
For predictions, instead of passing the inputs to the model, pass them to [`~OwlViTForObjectDetection.image_guided_detection`]. Draw the predictions
as before except now there are no labels.
```py
>>> with torch.no_grad():
... outputs = model.image_guided_detection(**inputs)
... target_sizes = torch.tensor([image_target.size[::-1]])
... results = processor.post_process_image_guided_detection(outputs=outputs, target_sizes=target_sizes)[0]
>>> draw = ImageDraw.Draw(image_target)
>>> scores = results["scores"].tolist()
>>> boxes = results["boxes"].tolist()
>>> for box, score in zip(boxes, scores):
... xmin, ymin, xmax, ymax = box
... draw.rectangle((xmin, ymin, xmax, ymax), outline="white", width=4)
>>> image_target
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/zero-sh-obj-detection_6.png" alt="Cats with bounding boxes"/>
</div>
|
transformers/docs/source/en/tasks/zero_shot_object_detection.md/0
|
{
"file_path": "transformers/docs/source/en/tasks/zero_shot_object_detection.md",
"repo_id": "transformers",
"token_count": 3897
}
| 29 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Carga instancias preentrenadas con un AutoClass
Con tantas arquitecturas diferentes de Transformer puede ser retador crear una para tu checkpoint. Como parte de la filosofía central de 🤗 Transformers para hacer que la biblioteca sea fácil, simple y flexible de usar; una `AutoClass` automáticamente infiere y carga la arquitectura correcta desde un checkpoint dado. El método `from_pretrained` te permite cargar rápidamente un modelo preentrenado para cualquier arquitectura, por lo que no tendrás que dedicar tiempo y recursos para entrenar uno desde cero. Producir este tipo de código con checkpoint implica que si funciona con uno, funcionará también con otro (siempre que haya sido entrenado para una tarea similar) incluso si la arquitectura es distinta.
<Tip>
Recuerda, la arquitectura se refiere al esqueleto del modelo y los checkpoints son los pesos para una arquitectura dada. Por ejemplo, [BERT](https://huggingface.co/google-bert/bert-base-uncased) es una arquitectura, mientras que `google-bert/bert-base-uncased` es un checkpoint. Modelo es un término general que puede significar una arquitectura o un checkpoint.
</Tip>
En este tutorial, aprenderás a:
* Cargar un tokenizador pre-entrenado.
* Cargar un extractor de características (feature extractor en inglés) pre-entrenado.
* Cargar un procesador pre-entrenado.
* Cargar un modelo pre-entrenado.
## AutoTokenizer
Casi cualquier tarea de Procesamiento de Lenguaje Natural comienza con un tokenizador. Un tokenizador convierte tu input a un formato que puede ser procesado por el modelo.
Carga un tokenizador con [`AutoTokenizer.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
```
Luego tokeniza tu input como lo mostrado a continuación:
```py
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
## AutoFeatureExtractor
Para tareas de audio y visión, un extractor de características procesa la señal de audio o imagen al formato de input correcto.
Carga un extractor de características con [`AutoFeatureExtractor.from_pretrained`]:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
## AutoProcessor
Las tareas multimodales requieren un procesador que combine dos tipos de herramientas de preprocesamiento. Por ejemplo, el modelo [LayoutLMV2](model_doc/layoutlmv2) requiere que un extractor de características maneje las imágenes y que un tokenizador maneje el texto; un procesador combina ambas.
Carga un procesador con [`AutoProcessor.from_pretrained`]:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")
```
## AutoModel
<frameworkcontent>
<pt>
Finalmente, las clases `AutoModelFor` te permiten cargar un modelo preentrenado para una tarea dada (revisa [aquí](model_doc/auto) para conocer la lista completa de tareas disponibles). Por ejemplo, cargue un modelo para clasificación de secuencias con [`AutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Reutiliza fácilmente el mismo checkpoint para cargar una aquitectura para alguna tarea diferente:
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Generalmente recomendamos utilizar las clases `AutoTokenizer` y `AutoModelFor` para cargar instancias pre-entrenadas de modelos. Ésto asegurará que cargues la arquitectura correcta en cada ocasión. En el siguiente [tutorial](preprocessing), aprende a usar tu tokenizador recién cargado, el extractor de características y el procesador para preprocesar un dataset para fine-tuning.
</pt>
<tf>
Finalmente, la clase `TFAutoModelFor` te permite cargar tu modelo pre-entrenado para una tarea dada (revisa [aquí](model_doc/auto) para conocer la lista completa de tareas disponibles). Por ejemplo, carga un modelo para clasificación de secuencias con [`TFAutoModelForSequenceClassification.from_pretrained`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Reutiliza fácilmente el mismo checkpoint para cargar una aquitectura para alguna tarea diferente:
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Generalmente recomendamos utilizar las clases `AutoTokenizer` y `TFAutoModelFor` para cargar instancias de modelos pre-entrenados. Ésto asegurará que cargues la arquitectura correcta cada vez. En el siguiente [tutorial](preprocessing), aprende a usar tu tokenizador recién cargado, el extractor de características y el procesador para preprocesar un dataset para fine-tuning.
</tf>
</frameworkcontent>
|
transformers/docs/source/es/autoclass_tutorial.md/0
|
{
"file_path": "transformers/docs/source/es/autoclass_tutorial.md",
"repo_id": "transformers",
"token_count": 2066
}
| 30 |
<!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Rendimiento y Escalabilidad
Entrenar modelos grandes de transformadores y desplegarlos en producción presenta varios desafíos. Durante el entrenamiento, el modelo puede requerir más memoria de GPU de la disponible o mostrar una velocidad de entrenamiento lenta. En la fase de implementación, el modelo puede tener dificultades para manejar el rendimiento necesario en un entorno de producción.
Esta documentación tiene como objetivo ayudarte a superar estos desafíos y encontrar la configuración óptima para tu caso de uso. Las guías están divididas en secciones de entrenamiento e inferencia, ya que cada una presenta diferentes desafíos y soluciones. Dentro de cada sección, encontrarás guías separadas para diferentes configuraciones de hardware, como GPU única vs. multi-GPU para el entrenamiento o CPU vs. GPU para la inferencia.
Utiliza este documento como punto de partida para navegar hacia los métodos que se ajusten a tu escenario.
## Entrenamiento
Entrenar modelos grandes de transformadores de manera eficiente requiere un acelerador como una GPU o TPU. El caso más común es cuando tienes una GPU única. Los métodos que puedes aplicar para mejorar la eficiencia de entrenamiento en una GPU única también se aplican a otras configuraciones, como múltiples GPU. Sin embargo, también existen técnicas específicas para entrenamiento con múltiples GPU o CPU, las cuales cubrimos en secciones separadas.
* [Métodos y herramientas para un entrenamiento eficiente en una sola GPU](https://huggingface.co/docs/transformers/perf_train_gpu_one): comienza aquí para aprender enfoques comunes que pueden ayudar a optimizar la utilización de memoria de la GPU, acelerar el entrenamiento o ambas cosas.
* [Sección de entrenamiento con varias GPU](https://huggingface.co/docs/transformers/perf_train_gpu_many): explora esta sección para conocer métodos de optimización adicionales que se aplican a configuraciones con varias GPU, como paralelismo de datos, tensores y canalizaciones.
* [Sección de entrenamiento en CPU](https://huggingface.co/docs/transformers/perf_train_cpu): aprende sobre entrenamiento de precisión mixta en CPU.
* [Entrenamiento eficiente en múltiples CPUs](https://huggingface.co/docs/transformers/perf_train_cpu_many): aprende sobre el entrenamiento distribuido en CPU.
* [Entrenamiento en TPU con TensorFlow](https://huggingface.co/docs/transformers/perf_train_tpu_tf): si eres nuevo en TPUs, consulta esta sección para obtener una introducción basada en opiniones sobre el entrenamiento en TPUs y el uso de XLA.
* [Hardware personalizado para el entrenamiento](https://huggingface.co/docs/transformers/perf_hardware): encuentra consejos y trucos al construir tu propia plataforma de aprendizaje profundo.
* [Búsqueda de hiperparámetros utilizando la API del Entrenador](https://huggingface.co/docs/transformers/hpo_train)
## Inferencia
Realizar inferencias eficientes con modelos grandes en un entorno de producción puede ser tan desafiante como entrenarlos. En las siguientes secciones, describimos los pasos para ejecutar inferencias en CPU y configuraciones con GPU única/múltiple.
* [Inferencia en una sola CPU](https://huggingface.co/docs/transformers/perf_infer_cpu)
* [Inferencia en una sola GPU](https://huggingface.co/docs/transformers/perf_infer_gpu_one)
* [Inferencia con múltiples GPU](https://huggingface.co/docs/transformers/perf_infer_gpu_one)
* [Integración de XLA para modelos de TensorFlow](https://huggingface.co/docs/transformers/tf_xla)
## Entrenamiento e Inferencia
Aquí encontrarás técnicas, consejos y trucos que aplican tanto si estás entrenando un modelo como si estás ejecutando inferencias con él.
* [Instanciar un modelo grande](https://huggingface.co/docs/transformers/big_models)
* [Solución de problemas de rendimiento](https://huggingface.co/docs/transformers/debugging)
## Contribuir
Este documento está lejos de estar completo y aún se deben agregar muchas cosas, así que si tienes adiciones o correcciones que hacer, no dudes en abrir un PR. Si no estás seguro, inicia un Issue y podemos discutir los detalles allí.
Cuando hagas contribuciones que indiquen que A es mejor que B, intenta incluir un benchmark reproducible y/o un enlace a la fuente de esa información (a menos que provenga directamente de ti).
|
transformers/docs/source/es/performance.md/0
|
{
"file_path": "transformers/docs/source/es/performance.md",
"repo_id": "transformers",
"token_count": 1751
}
| 31 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Selección múltiple
La tarea de selección múltiple es parecida a la de responder preguntas, con la excepción de que se dan varias opciones de respuesta junto con el contexto. El modelo se entrena para escoger la respuesta correcta
entre varias opciones a partir del contexto dado.
Esta guía te mostrará como hacerle fine-tuning a [BERT](https://huggingface.co/google-bert/bert-base-uncased) en la configuración `regular` del dataset [SWAG](https://huggingface.co/datasets/swag), de forma
que seleccione la mejor respuesta a partir de varias opciones y algún contexto.
## Cargar el dataset SWAG
Carga el dataset SWAG con la biblioteca 🤗 Datasets:
```py
>>> from datasets import load_dataset
>>> swag = load_dataset("swag", "regular")
```
Ahora, échale un vistazo a un ejemplo del dataset:
```py
>>> swag["train"][0]
{'ending0': 'passes by walking down the street playing their instruments.',
'ending1': 'has heard approaching them.',
'ending2': "arrives and they're outside dancing and asleep.",
'ending3': 'turns the lead singer watches the performance.',
'fold-ind': '3416',
'gold-source': 'gold',
'label': 0,
'sent1': 'Members of the procession walk down the street holding small horn brass instruments.',
'sent2': 'A drum line',
'startphrase': 'Members of the procession walk down the street holding small horn brass instruments. A drum line',
'video-id': 'anetv_jkn6uvmqwh4'}
```
Los campos `sent1` y `sent2` muestran cómo comienza una oración, y cada campo `ending` indica cómo podría terminar. Dado el comienzo de la oración, el modelo debe escoger el final de oración correcto indicado por el campo `label`.
## Preprocesmaiento
Carga el tokenizer de BERT para procesar el comienzo de cada oración y los cuatro finales posibles:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")
```
La función de preprocesmaiento debe hacer lo siguiente:
1. Hacer cuatro copias del campo `sent1` de forma que se pueda combinar cada una con el campo `sent2` para recrear la forma en que empieza la oración.
2. Combinar `sent2` con cada uno de los cuatro finales de oración posibles.
3. Aplanar las dos listas para que puedas tokenizarlas, y luego des-aplanarlas para que cada ejemplo tenga los campos `input_ids`, `attention_mask` y `labels` correspondientes.
```py
>>> ending_names = ["ending0", "ending1", "ending2", "ending3"]
>>> def preprocess_function(examples):
... first_sentences = [[context] * 4 for context in examples["sent1"]]
... question_headers = examples["sent2"]
... second_sentences = [
... [f"{header} {examples[end][i]}" for end in ending_names] for i, header in enumerate(question_headers)
... ]
... first_sentences = sum(first_sentences, [])
... second_sentences = sum(second_sentences, [])
... tokenized_examples = tokenizer(first_sentences, second_sentences, truncation=True)
... return {k: [v[i : i + 4] for i in range(0, len(v), 4)] for k, v in tokenized_examples.items()}
```
Usa la función [`~datasets.Dataset.map`] de 🤗 Datasets para aplicarle la función de preprocesamiento al dataset entero. Puedes acelerar la función `map` haciendo `batched=True` para procesar varios elementos del dataset a la vez.
```py
tokenized_swag = swag.map(preprocess_function, batched=True)
```
🤗 Transformers no tiene un collator de datos para la tarea de selección múltiple, así que tendrías que crear uno. Puedes adaptar el [`DataCollatorWithPadding`] para crear un lote de ejemplos para selección múltiple. Este también
le *añadirá relleno de manera dinámica* a tu texto y a las etiquetas para que tengan la longitud del elemento más largo en su lote, de forma que tengan una longitud uniforme. Aunque es posible rellenar el texto en la función `tokenizer` haciendo
`padding=True`, el rellenado dinámico es más eficiente.
El `DataCollatorForMultipleChoice` aplanará todas las entradas del modelo, les aplicará relleno y luego des-aplanará los resultados:
<frameworkcontent>
<pt>
```py
>>> from dataclasses import dataclass
>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
>>> from typing import Optional, Union
>>> import torch
>>> @dataclass
... class DataCollatorForMultipleChoice:
... """
... Collator de datos que le añadirá relleno de forma automática a las entradas recibidas para
... una tarea de selección múltiple.
... """
... tokenizer: PreTrainedTokenizerBase
... padding: Union[bool, str, PaddingStrategy] = True
... max_length: Optional[int] = None
... pad_to_multiple_of: Optional[int] = None
... def __call__(self, features):
... label_name = "label" if "label" in features[0].keys() else "labels"
... labels = [feature.pop(label_name) for feature in features]
... batch_size = len(features)
... num_choices = len(features[0]["input_ids"])
... flattened_features = [
... [{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
... ]
... flattened_features = sum(flattened_features, [])
... batch = self.tokenizer.pad(
... flattened_features,
... padding=self.padding,
... max_length=self.max_length,
... pad_to_multiple_of=self.pad_to_multiple_of,
... return_tensors="pt",
... )
... batch = {k: v.view(batch_size, num_choices, -1) for k, v in batch.items()}
... batch["labels"] = torch.tensor(labels, dtype=torch.int64)
... return batch
```
</pt>
<tf>
```py
>>> from dataclasses import dataclass
>>> from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
>>> from typing import Optional, Union
>>> import tensorflow as tf
>>> @dataclass
... class DataCollatorForMultipleChoice:
... """
... Data collator that will dynamically pad the inputs for multiple choice received.
... """
... tokenizer: PreTrainedTokenizerBase
... padding: Union[bool, str, PaddingStrategy] = True
... max_length: Optional[int] = None
... pad_to_multiple_of: Optional[int] = None
... def __call__(self, features):
... label_name = "label" if "label" in features[0].keys() else "labels"
... labels = [feature.pop(label_name) for feature in features]
... batch_size = len(features)
... num_choices = len(features[0]["input_ids"])
... flattened_features = [
... [{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
... ]
... flattened_features = sum(flattened_features, [])
... batch = self.tokenizer.pad(
... flattened_features,
... padding=self.padding,
... max_length=self.max_length,
... pad_to_multiple_of=self.pad_to_multiple_of,
... return_tensors="tf",
... )
... batch = {k: tf.reshape(v, (batch_size, num_choices, -1)) for k, v in batch.items()}
... batch["labels"] = tf.convert_to_tensor(labels, dtype=tf.int64)
... return batch
```
</tf>
</frameworkcontent>
## Entrenamiento
<frameworkcontent>
<pt>
Carga el modelo BERT con [`AutoModelForMultipleChoice`]:
```py
>>> from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer
>>> model = AutoModelForMultipleChoice.from_pretrained("google-bert/bert-base-uncased")
```
<Tip>
Para familiarizarte con el fine-tuning con [`Trainer`], ¡mira el tutorial básico [aquí](../training#finetune-with-trainer)!
</Tip>
En este punto, solo quedan tres pasos:
1. Definir tus hiperparámetros de entrenamiento en [`TrainingArguments`].
2. Pasarle los argumentos del entrenamiento al [`Trainer`] jnto con el modelo, el dataset, el tokenizer y el collator de datos.
3. Invocar el método [`~Trainer.train`] para realizar el fine-tuning del modelo.
```py
>>> training_args = TrainingArguments(
... output_dir="./results",
... eval_strategy="epoch",
... learning_rate=5e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=3,
... weight_decay=0.01,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_swag["train"],
... eval_dataset=tokenized_swag["validation"],
... processing_class=tokenizer,
... data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer),
... )
>>> trainer.train()
```
</pt>
<tf>
Para realizar el fine-tuning de un modelo en TensorFlow, primero convierte tus datasets al formato `tf.data.Dataset` con el método [`~TFPreTrainedModel.prepare_tf_dataset`].
```py
>>> data_collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_swag["train"],
... shuffle=True,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_swag["validation"],
... shuffle=False,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
```
<Tip>
Para familiarizarte con el fine-tuning con Keras, ¡mira el tutorial básico [aquí](training#finetune-with-keras)!
</Tip>
Prepara una función de optimización, un programa para la tasa de aprendizaje y algunos hiperparámetros de entrenamiento:
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 2
>>> total_train_steps = (len(tokenized_swag["train"]) // batch_size) * num_train_epochs
>>> optimizer, schedule = create_optimizer(init_lr=5e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
```
Carga el modelo BERT con [`TFAutoModelForMultipleChoice`]:
```py
>>> from transformers import TFAutoModelForMultipleChoice
>>> model = TFAutoModelForMultipleChoice.from_pretrained("google-bert/bert-base-uncased")
```
Configura el modelo para entrenarlo con [`compile`](https://keras.io/api/models/model_training_apis/#compile-method):
```py
>>> model.compile(optimizer=optimizer)
```
Invoca el método [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) para realizar el fine-tuning del modelo:
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=2)
```
</tf>
</frameworkcontent>
|
transformers/docs/source/es/tasks/multiple_choice.md/0
|
{
"file_path": "transformers/docs/source/es/tasks/multiple_choice.md",
"repo_id": "transformers",
"token_count": 4170
}
| 32 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Ce que 🤗 Transformers peut faire
🤗 Transformers est une bibliothèque de modèles préentraînés à la pointe de la technologie pour les tâches de traitement du langage naturel (NLP), de vision par ordinateur et de traitement audio et de la parole. Non seulement la bibliothèque contient des modèles Transformer, mais elle inclut également des modèles non-Transformer comme des réseaux convolutionnels modernes pour les tâches de vision par ordinateur. Si vous regardez certains des produits grand public les plus populaires aujourd'hui, comme les smartphones, les applications et les téléviseurs, il est probable qu'une technologie d'apprentissage profond soit derrière. Vous souhaitez supprimer un objet de fond d'une photo prise avec votre smartphone ? C'est un exemple de tâche de segmentation panoptique (ne vous inquiétez pas si vous ne savez pas encore ce que cela signifie, nous le décrirons dans les sections suivantes !).
Cette page fournit un aperçu des différentes tâches de traitement de la parole et de l'audio, de vision par ordinateur et de NLP qui peuvent être résolues avec la bibliothèque 🤗 Transformers en seulement trois lignes de code !
## Audio
Les tâches de traitement audio et de la parole sont légèrement différentes des autres modalités principalement parce que l'audio en tant que donnée d'entrée est un signal continu. Contrairement au texte, un signal audio brut ne peut pas discrétisé de la manière dont une phrase peut être divisée en mots. Pour contourner cela, le signal audio brut est généralement échantillonné à intervalles réguliers. Si vous prenez plus d'échantillons dans un intervalle, le taux d'échantillonnage est plus élevé et l'audio ressemble davantage à la source audio originale.
Les approches précédentes prétraitaient l'audio pour en extraire des caractéristiques utiles. Il est maintenant plus courant de commencer les tâches de traitement audio et de la parole en donnant directement le signal audio brut à un encodeur de caractéristiques (*feature encoder* en anglais) pour extraire une représentation de l'audio. Cela correspond à l'étape de prétraitement et permet au modèle d'apprendre les caractéristiques les plus essentielles du signal.
### Classification audio
La classification audio est une tâche qui consiste à attribuer une classe, parmi un ensemble de classes prédéfini, à un audio. La classification audio englobe de nombreuses applications spécifiques, dont certaines incluent :
* la classification d'environnements sonores : attribuer une classe (catégorie) à l'audio pour indiquer l'environnement associé, tel que "bureau", "plage" ou "stade".
* la détection d'événements sonores : étiqueter l'audio avec une étiquette d'événement sonore ("klaxon de voiture", "appel de baleine", "verre brisé")
* l'identification d'éléments sonores : attribuer des tags (*étiquettes* en français) à l'audio pour marquer des sons spécifiques, comme "chant des oiseaux" ou "identification du locuteur lors d'une réunion".
* la classification musicale : attribuer un genre à la musique, comme "metal", "hip-hop" ou "country".
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4532, 'label': 'hap'},
{'score': 0.3622, 'label': 'sad'},
{'score': 0.0943, 'label': 'neu'},
{'score': 0.0903, 'label': 'ang'}]
```
### Reconnaissance vocale
La reconnaissance vocale (*Automatic Speech Recognition* ou ASR en anglais) transcrit la parole en texte. C'est l'une des tâches audio les plus courantes en partie parce que la parole est une forme de communication la plus naturelle pour nous, humains. Aujourd'hui, les systèmes ASR sont intégrés dans des produits technologiques "intelligents" comme les enceintes, les téléphones et les voitures. Il est désormais possible de demander à nos assistants virtuels de jouer de la musique, de définir des rappels et de nous indiquer la météo.
Mais l'un des principaux défis auxquels les architectures Transformer contribuent à résoudre est celui des langues à faibles ressources, c'est-à-dire des langues pour lesquelles il existe peu de données étiquetées. En préentraînant sur de grandes quantités de données vocales d'un autre language plus ou moins similaire, le réglage fin (*fine-tuning* en anglais) du modèle avec seulement une heure de données vocales étiquetées dans une langue à faibles ressources peut tout de même produire des résultats de haute qualité comparés aux systèmes ASR précédents entraînés sur 100 fois plus de données étiquetées.
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
## Vision par ordinateur
L'une des premières réussites en vision par ordinateur a été la reconnaissance des numéros de code postal à l'aide d'un [réseau de neurones convolutionnel (CNN)](glossary#convolution). Une image est composée de pixels, chacun ayant une valeur numérique, ce qui permet de représenter facilement une image sous forme de matrice de valeurs de pixels. Chaque combinaison de valeurs de pixels correspond aux couleurs d'une image.
Il existe deux approches principales pour résoudre les tâches de vision par ordinateur :
1. Utiliser des convolutions pour apprendre les caractéristiques hiérarchiques d'une image, des détails de bas niveau aux éléments abstraits de plus haut niveau.
2. Diviser l'image en morceaux (*patches* en anglais) et utiliser un Transformer pour apprendre progressivement comment chaque morceau est lié aux autres pour former l'image complète. Contrairement à l'approche ascendante des CNNs, cette méthode ressemble à un processus où l'on démarre avec une image floue pour ensuite la mettre au point petit à petit.
### Classification d'images
La classification d'images consiste à attribuer une classe, parmi un ensemble de classes prédéfini, à toute une image. Comme pour la plupart des tâches de classification, les cas d'utilisation pratiques sont nombreux, notamment :
- Santé : classification d'images médicales pour détecter des maladies ou surveiller l'état de santé des patients.
- Environnement : classification d'images satellites pour suivre la déforestation, aider à la gestion des terres ou détecter les incendies de forêt.
- Agriculture : classification d'images de cultures pour surveiller la santé des plantes ou des images satellites pour analyser l'utilisation des terres.
- Écologie : classification d'images d'espèces animales ou végétales pour suivre les populations fauniques ou les espèces menacées.
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="image-classification")
>>> preds = classifier(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.4335, 'label': 'lynx, catamount'}
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
{'score': 0.0239, 'label': 'Egyptian cat'}
{'score': 0.0229, 'label': 'tiger cat'}
```
### Détection d'objets
La détection d'objets, à la différence de la classification d'images, identifie plusieurs objets dans une image ainsi que leurs positions, généralement définies par des boîtes englobantes (*bounding boxes* en anglais). Voici quelques exemples d'applications :
- Véhicules autonomes : détection des objets de la circulation, tels que les véhicules, piétons et feux de signalisation.
- Télédétection : surveillance des catastrophes, planification urbaine et prévisions météorologiques.
- Détection de défauts : identification des fissures ou dommages structurels dans les bâtiments, ainsi que des défauts de fabrication.
```py
>>> from transformers import pipeline
>>> detector = pipeline(task="object-detection")
>>> preds = detector(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
>>> preds
[{'score': 0.9865,
'label': 'cat',
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
```
### Segmentation d'images
La segmentation d'images est une tâche qui consiste à attribuer une classe à chaque pixel d'une image, ce qui la rend plus précise que la détection d'objets, qui se limite aux boîtes englobantes (*bounding boxes* en anglais). Elle permet ainsi de détecter les objets à la précision du pixel. Il existe plusieurs types de segmentation d'images :
- Segmentation d'instances : en plus de classifier un objet, elle identifie chaque instance distincte d'un même objet (par exemple, "chien-1", "chien-2").
- Segmentation panoptique : combine segmentation sémantique et segmentation d'instances, attribuant à chaque pixel une classe sémantique **et** une instance spécifique.
Ces techniques sont utiles pour les véhicules autonomes, qui doivent cartographier leur environnement pixel par pixel pour naviguer en toute sécurité autour des piétons et des véhicules. Elles sont également précieuses en imagerie médicale, où la précision au niveau des pixels permet de détecter des anomalies cellulaires ou des caractéristiques d'organes. Dans le commerce en ligne, la segmentation est utilisée pour des essayages virtuels de vêtements ou des expériences de réalité augmentée, en superposant des objets virtuels sur des images du monde réel via la caméra.
```py
>>> from transformers import pipeline
>>> segmenter = pipeline(task="image-segmentation")
>>> preds = segmenter(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.9879, 'label': 'LABEL_184'}
{'score': 0.9973, 'label': 'snow'}
{'score': 0.9972, 'label': 'cat'}
```
### Estimation de la profondeur
L'estimation de la profondeur consiste à prédire la distance de chaque pixel d'une image par rapport à la caméra. Cette tâche est cruciale pour comprendre et reconstruire des scènes réelles. Par exemple, pour les voitures autonomes, il est essentiel de déterminer la distance des objets tels que les piétons, les panneaux de signalisation et les autres véhicules pour éviter les collisions. L'estimation de la profondeur permet également de créer des modèles 3D à partir d'images 2D, ce qui est utile pour générer des représentations détaillées de structures biologiques ou de bâtiments.
Il existe deux principales approches pour estimer la profondeur :
- Stéréo : la profondeur est estimée en comparant deux images d'une même scène prises sous des angles légèrement différents.
- Monoculaire : la profondeur est estimée à partir d'une seule image.
```py
>>> from transformers import pipeline
>>> depth_estimator = pipeline(task="depth-estimation")
>>> preds = depth_estimator(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
```
## Traitement du langage naturel
Les tâches de traitement du langage naturel (*Natural Language Processing* ou *NLP* en anglais) sont courantes car le texte est une forme naturelle de communication pour nous. Pour qu'un modèle puisse traiter le texte, celui-ci doit être *tokenisé*, c'est-à-dire divisé en mots ou sous-mots appelés "*tokens*", puis converti en nombres. Ainsi, une séquence de texte peut être représentée comme une séquence de nombres, qui peut ensuite être utilisée comme données d'entrée pour un modèle afin de résoudre diverses tâches de traitement du langage naturel.
### Classification de texte
La classification de texte attribue une classe à une séquence de texte (au niveau d'une phrase, d'un paragraphe ou d'un document) à partir d'un ensemble de classes prédéfini. Voici quelques applications pratiques :
- **Analyse des sentiments** : étiqueter le texte avec une polarité telle que `positive` ou `négative`, ce qui aide à la prise de décision dans des domaines comme la politique, la finance et le marketing.
- **Classification de contenu** : organiser et filtrer les informations en attribuant des *tags* sur des sujets spécifiques, comme `météo`, `sports` ou `finance`, dans les flux d'actualités et les réseaux sociaux.
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="sentiment-analysis")
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.9991, 'label': 'POSITIVE'}]
```
### Classification des tokens
Dans les tâches de traitement du language naturel, le texte est d'abord prétraité en le séparant en mots ou sous-mots individuels, appelés *[tokens](glossary#token)*. La classification des tokens attribue une classe à chaque token à partir d'un ensemble de classes prédéfini.
Voici deux types courants de classification des tokens :
- **Reconnaissance d'entités nommées (*Named Entity Recognition* ou *NER* en anglais)** : étiqueter un token selon une catégorie d'entité, telle qu'organisation, personne, lieu ou date. La NER est particulièrement utilisée dans les contextes biomédicaux pour identifier des gènes, des protéines et des noms de médicaments.
- **Étiquetage des parties du discours (*Part of Speech* ou *POS* en anglais)** : étiqueter un token en fonction de sa partie du discours, comme nom, verbe ou adjectif. Le POS est utile pour les systèmes de traduction afin de comprendre comment deux mots identiques peuvent avoir des rôles grammaticaux différents (par exemple, "banque" comme nom versus "banque" comme verbe).
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="ner")
>>> preds = classifier("Hugging Face is a French company based in New York City.")
>>> preds = [
... {
... "entity": pred["entity"],
... "score": round(pred["score"], 4),
... "index": pred["index"],
... "word": pred["word"],
... "start": pred["start"],
... "end": pred["end"],
... }
... for pred in preds
... ]
>>> print(*preds, sep="\n")
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
```
### Réponse à des questions - (*Question Answering*)
La réponse à des questions (*Question Answering* ou *QA* en anglais) est une tâche de traitement du language naturel qui consiste à fournir une réponse à une question, parfois avec l'aide d'un contexte (domaine ouvert) et d'autres fois sans contexte (domaine fermé). Cette tâche intervient lorsqu'on interroge un assistant virtuel, par exemple pour savoir si un restaurant est ouvert. Elle est également utilisée pour le support client, technique, et pour aider les moteurs de recherche à fournir des informations pertinentes.
Il existe deux types courants de réponse à des questions :
- **Extractive** : pour une question donnée et un contexte fourni, la réponse est extraite directement du texte du contexte par le modèle.
- **Abstractive** : pour une question donnée et un contexte, la réponse est générée à partir du contexte. Cette approche utilise le [`Text2TextGenerationPipeline`] plutôt que le [`QuestionAnsweringPipeline`] montré ci-dessous.
```py
>>> from transformers import pipeline
>>> question_answerer = pipeline(task="question-answering")
>>> preds = question_answerer(
... question="What is the name of the repository?",
... context="The name of the repository is huggingface/transformers",
... )
>>> print(
... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
... )
score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
```
### Résumé de texte - (*Summarization*)
Le résumé de text consiste à créer une version plus courte d'un texte tout en conservant l'essentiel du sens du document original. C'est une tâche de séquence à séquence qui produit un texte plus condensé à partir du texte initial. Cette technique est utile pour aider les lecteurs à saisir rapidement les points clés de longs documents, comme les projets de loi, les documents juridiques et financiers, les brevets, et les articles scientifiques.
Il existe deux types courants de summarization :
- **Extractive** : identifier et extraire les phrases les plus importantes du texte original.
- **Abstractive** : générer un résumé qui peut inclure des mots nouveaux non présents dans le texte d'origine. Le [`SummarizationPipeline`] utilise l'approche abstractive.
```py
>>> from transformers import pipeline
>>> summarizer = pipeline(task="summarization")
>>> summarizer(
... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
... )
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
```
### Traduction
La traduction convertit un texte d'une langue à une autre. Elle facilite la communication entre personnes de différentes langues, permet de toucher des audiences plus larges et peut aussi servir d'outil d'apprentissage pour ceux qui apprennent une nouvelle langue. Comme le résumé de texte, la traduction est une tâche de séquence à séquence, où le modèle reçoit une séquence d'entrée (un texte est ici vu comme une séquence de mots, ou plus précisément de tokens) et produit une séquence de sortie dans la langue cible.
Initialement, les modèles de traduction étaient principalement monolingues, mais il y a eu récemment un intérêt croissant pour les modèles multilingues capables de traduire entre plusieurs paires de langues.
```py
>>> from transformers import pipeline
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
>>> translator = pipeline(task="translation", model="google-t5/t5-small")
>>> translator(text)
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
```
### Modélisation du langage
La modélisation du langage consiste à prédire un mot dans un texte. Cette tâche est devenue très populaire en traitement du language naturel, car un modèle de langage préentraîné sur cette tâche peut ensuite être ajusté (*finetuned*) pour accomplir de nombreuses autres tâches. Récemment, les grands modèles de langage (LLMs) ont suscité beaucoup d'intérêt pour leur capacité à apprendre avec peu ou pas de données spécifiques à une tâche, ce qui leur permet de résoudre des problèmes pour lesquels ils n'ont pas été explicitement entraînés. Ces modèles peuvent générer du texte fluide et convaincant, bien qu'il soit important de vérifier leur précision.
Il existe deux types de modélisation du langage :
- **Causale** : le modèle prédit le token suivant dans une séquence, avec les tokens futurs masqués.
```py
>>> from transformers import pipeline
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
>>> generator = pipeline(task="text-generation")
>>> generator(prompt) # doctest: +SKIP
```
- **Masquée** : le modèle prédit un token masqué dans une séquence en ayant accès à tous les autres tokens de la séquence (passé et futur).
```py
>>> text = "Hugging Face is a community-based open-source <mask> for machine learning."
>>> fill_mask = pipeline(task="fill-mask")
>>> preds = fill_mask(text, top_k=1)
>>> preds = [
... {
... "score": round(pred["score"], 4),
... "token": pred["token"],
... "token_str": pred["token_str"],
... "sequence": pred["sequence"],
... }
... for pred in preds
... ]
>>> preds
[{'score': 0.2236,
'token': 1761,
'token_str': ' platform',
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
```
## Multimodal
Les tâches multimodales nécessitent qu'un modèle traite plusieurs types de données (texte, image, audio, vidéo) pour résoudre un problème spécifique. Par exemple, la génération de légendes pour les images est une tâche multimodale où le modèle prend une image en entrée et produit une séquence de texte décrivant l'image ou ses propriétés.
Bien que les modèles multimodaux traitent divers types de données, ils convertissent toutes ces données en *embeddings* (vecteurs ou listes de nombres contenant des informations significatives). Pour des tâches comme la génération de légendes pour les images, le modèle apprend les relations entre les *embeddings* d'images et ceux de texte.
### Réponse à des questions sur des documents - (*Document Question Answering*)
La réponse à des questions sur des documents consiste à répondre à des questions en langage naturel en utilisant un document comme référence. Contrairement à la réponse à des questions au niveau des tokens, qui prend du texte en entrée, cette tâche prend une image d'un document ainsi qu'une question concernant ce document, et fournit une réponse. Elle est utile pour analyser des données structurées et extraire des informations clées. Par exemple, à partir d'un reçu, on peut extraire des informations telles que le montant total et le change dû.
```py
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> url = "https://huggingface.co/datasets/hf-internal-testing/example-documents/resolve/main/jpeg_images/2.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> doc_question_answerer = pipeline("document-question-answering", model="magorshunov/layoutlm-invoices")
>>> preds = doc_question_answerer(
... question="What is the total amount?",
... image=image,
... )
>>> preds
[{'score': 0.8531, 'answer': '17,000', 'start': 4, 'end': 4}]
```
En espérant que cette page vous ait donné plus d'informations sur les différents types de tâches dans chaque modalité et l'importance pratique de chacune d'elles. Dans la [section suivante](tasks_explained), vous découvrirez **comment** 🤗 Transformers fonctionne pour résoudre ces tâches.
|
transformers/docs/source/fr/task_summary.md/0
|
{
"file_path": "transformers/docs/source/fr/task_summary.md",
"repo_id": "transformers",
"token_count": 8189
}
| 33 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Crea un'architettura personalizzata
Una [`AutoClass`](model_doc/auto) deduce automaticamente il modello dell'architettura e scarica la configurazione e i pesi pre-allenati. Generalmente, noi consigliamo di usare un `AutoClass` per produrre un codice indipendente dal checkpoint. Ma gli utenti che desiderano un controllo maggiore su parametri specifici del modello possono creare un modello 🤗 Transformers personalizzato da poche classi base. Questo potrebbe essere particolarmente utile per qualunque persona sia interessata nel studiare, allenare o sperimentare con un modello 🤗 Transformers. In questa guida, approfondisci la creazione di un modello personalizzato senza `AutoClass`. Impara come:
- Caricare e personalizzare una configurazione del modello.
- Creare un'architettura modello.
- Creare un tokenizer lento e veloce per il testo.
- Creare un estrattore di caratteristiche per attività riguardanti audio o immagini.
- Creare un processore per attività multimodali.
## Configurazione
Una [configurazione](main_classes/configuration) si riferisce agli attributi specifici di un modello. Ogni configurazione del modello ha attributi diversi; per esempio, tutti i modelli npl hanno questi attributi in comune `hidden_size`, `num_attention_heads`, `num_hidden_layers` e `vocab_size`. Questi attributi specificano il numero di attention heads o strati nascosti con cui costruire un modello.
Dai un'occhiata più da vicino a [DistilBERT](model_doc/distilbert) accedendo a [`DistilBertConfig`] per ispezionare i suoi attributi:
```py
>>> from transformers import DistilBertConfig
>>> config = DistilBertConfig()
>>> print(config)
DistilBertConfig {
"activation": "gelu",
"attention_dropout": 0.1,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
[`DistilBertConfig`] mostra tutti gli attributi predefiniti usati per costruire una base [`DistilBertModel`]. Tutti gli attributi sono personalizzabili, creando uno spazio per sperimentare. Per esempio, puoi configurare un modello predefinito per:
- Provare un funzione di attivazione diversa con il parametro `activation`.
- Utilizzare tasso di drop out più elevato per le probalità di attention con il parametro `attention_dropout`.
```py
>>> my_config = DistilBertConfig(activation="relu", attention_dropout=0.4)
>>> print(my_config)
DistilBertConfig {
"activation": "relu",
"attention_dropout": 0.4,
"dim": 768,
"dropout": 0.1,
"hidden_dim": 3072,
"initializer_range": 0.02,
"max_position_embeddings": 512,
"model_type": "distilbert",
"n_heads": 12,
"n_layers": 6,
"pad_token_id": 0,
"qa_dropout": 0.1,
"seq_classif_dropout": 0.2,
"sinusoidal_pos_embds": false,
"transformers_version": "4.16.2",
"vocab_size": 30522
}
```
Nella funzione [`~PretrainedConfig.from_pretrained`] possono essere modificati gli attributi del modello pre-allenato:
```py
>>> my_config = DistilBertConfig.from_pretrained("distilbert/distilbert-base-uncased", activation="relu", attention_dropout=0.4)
```
Quando la configurazione del modello ti soddisfa, la puoi salvare con [`~PretrainedConfig.save_pretrained`]. Il file della tua configurazione è memorizzato come file JSON nella save directory specificata:
```py
>>> my_config.save_pretrained(save_directory="./your_model_save_path")
```
Per riutilizzare la configurazione del file, caricalo con [`~PretrainedConfig.from_pretrained`]:
```py
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
```
<Tip>
Puoi anche salvare il file di configurazione come dizionario oppure come la differenza tra gli attributi della tua configurazione personalizzata e gli attributi della configurazione predefinita! Guarda la documentazione [configuration](main_classes/configuration) per più dettagli.
</Tip>
## Modello
Il prossimo passo e di creare [modello](main_classes/models). Il modello - vagamente riferito anche come architettura - definisce cosa ogni strato deve fare e quali operazioni stanno succedendo. Attributi come `num_hidden_layers` provenienti dalla configurazione sono usati per definire l'architettura. Ogni modello condivide la classe base [`PreTrainedModel`] e alcuni metodi comuni come il ridimensionamento degli input embeddings e la soppressione delle self-attention heads . Inoltre, tutti i modelli sono la sottoclasse di [`torch.nn.Module`](https://pytorch.org/docs/stable/generated/torch.nn.Module.html), [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) o [`flax.linen.Module`](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html). Cio significa che i modelli sono compatibili con l'uso di ciascun di framework.
<frameworkcontent>
<pt>
Carica gli attributi della tua configurazione personalizzata nel modello:
```py
>>> from transformers import DistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> model = DistilBertModel(my_config)
```
Questo crea modelli con valori casuali invece di pesi pre-allenati. Non sarai in grado di usare questo modello per niente di utile finché non lo alleni. L'allenamento è un processo costoso e che richiede tempo . Generalmente è meglio usare un modello pre-allenato per ottenere risultati migliori velocemente, utilizzando solo una frazione delle risorse neccesarie per l'allenamento.
Crea un modello pre-allenato con [`~PreTrainedModel.from_pretrained`]:
```py
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
```
Quando carichi pesi pre-allenati, la configurazione del modello predefinito è automaticamente caricata se il modello è fornito da 🤗 Transformers. Tuttavia, puoi ancora sostituire gli attributi - alcuni o tutti - di configurazione del modello predefinito con i tuoi se lo desideri:
```py
>>> model = DistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
```
</pt>
<tf>
Carica gli attributi di configurazione personalizzati nel modello:
```py
>>> from transformers import TFDistilBertModel
>>> my_config = DistilBertConfig.from_pretrained("./your_model_save_path/my_config.json")
>>> tf_model = TFDistilBertModel(my_config)
```
Questo crea modelli con valori casuali invece di pesi pre-allenati. Non sarai in grado di usare questo modello per niente di utile finché non lo alleni. L'allenamento è un processo costoso e che richiede tempo . Generalmente è meglio usare un modello pre-allenato per ottenere risultati migliori velocemente, utilizzando solo una frazione delle risorse neccesarie per l'allenamento.
Crea un modello pre-allenoto con [`~TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased")
```
Quando carichi pesi pre-allenati, la configurazione del modello predefinito è automaticamente caricato se il modello è fornito da 🤗 Transformers. Tuttavia, puoi ancora sostituire gli attributi - alcuni o tutti - di configurazione del modello predefinito con i tuoi se lo desideri:
```py
>>> tf_model = TFDistilBertModel.from_pretrained("distilbert/distilbert-base-uncased", config=my_config)
```
</tf>
</frameworkcontent>
### Model head
A questo punto, hai un modello DistilBERT base i cui output sono gli *hidden states* (in italiano stati nascosti). Gli stati nascosti sono passati come input a un model head per produrre l'output finale. 🤗 Transformers fornisce un model head diverso per ogni attività fintanto che il modello supporta l'attività (i.e., non puoi usare DistilBERT per un attività sequence-to-sequence come la traduzione).
<frameworkcontent>
<pt>
Per esempio, [`DistilBertForSequenceClassification`] è un modello DistilBERT base con una testa di classificazione per sequenze. La sequenza di classificazione head è uno strato lineare sopra gli output ragruppati.
```py
>>> from transformers import DistilBertForSequenceClassification
>>> model = DistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Riutilizza facilmente questo checkpoint per un'altra attività passando ad un model head differente. Per un attività di risposta alle domande, utilizzerai il model head [`DistilBertForQuestionAnswering`]. La head per compiti di question answering è simile alla classificazione di sequenza head tranne per il fatto che è uno strato lineare sopra l'output degli stati nascosti (hidden states in inglese)
```py
>>> from transformers import DistilBertForQuestionAnswering
>>> model = DistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
</pt>
<tf>
Per esempio, [`TFDistilBertForSequenceClassification`] è un modello DistilBERT base con classificazione di sequenza head. La classificazione di sequenza head è uno strato lineare sopra gli output raggruppati.
```py
>>> from transformers import TFDistilBertForSequenceClassification
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
```
Riutilizza facilmente questo checkpoint per un altra attività passando ad un modello head diverso. Per un attività di risposta alle domande, utilizzerai il model head [`TFDistilBertForQuestionAnswering`]. Il head di risposta alle domande è simile alla sequenza di classificazione head tranne per il fatto che è uno strato lineare sopra l'output degli stati nascosti (hidden states in inglese)
```py
>>> from transformers import TFDistilBertForQuestionAnswering
>>> tf_model = TFDistilBertForQuestionAnswering.from_pretrained("distilbert/distilbert-base-uncased")
```
</tf>
</frameworkcontent>
## Tokenizer
L'ultima classe base di cui hai bisogno prima di utilizzare un modello per i dati testuali è un [tokenizer](main_classes/tokenizer) per convertire il testo grezzo in tensori. Ci sono due tipi di tokenizer che puoi usare con 🤗 Transformers:
- [`PreTrainedTokenizer`]: un'implementazione Python di un tokenizer.
- [`PreTrainedTokenizerFast`]: un tokenizer dalla nostra libreria [🤗 Tokenizer](https://huggingface.co/docs/tokenizers/python/latest/) basata su Rust. Questo tipo di tokenizer è significativamente più veloce, specialmente durante la batch tokenization, grazie alla sua implementazione Rust. Il tokenizer veloce offre anche metodi aggiuntivi come *offset mapping* che associa i token alle loro parole o caratteri originali.
Entrambi i tokenizer supportano metodi comuni come la codifica e la decodifica, l'aggiunta di nuovi token e la gestione di token speciali.
<Tip warning={true}>
Non tutti i modelli supportano un tokenizer veloce. Dai un'occhiata a questo [tabella](index#supported-frameworks) per verificare se un modello ha il supporto per tokenizer veloce.
</Tip>
Se hai addestrato il tuo tokenizer, puoi crearne uno dal tuo file *vocabolario*:
```py
>>> from transformers import DistilBertTokenizer
>>> my_tokenizer = DistilBertTokenizer(vocab_file="my_vocab_file.txt", do_lower_case=False, padding_side="left")
```
È importante ricordare che il vocabolario di un tokenizer personalizzato sarà diverso dal vocabolario generato dal tokenizer di un modello preallenato. È necessario utilizzare il vocabolario di un modello preallenato se si utilizza un modello preallenato, altrimenti gli input non avranno senso. Crea un tokenizer con il vocabolario di un modello preallenato con la classe [`DistilBertTokenizer`]:
```py
>>> from transformers import DistilBertTokenizer
>>> slow_tokenizer = DistilBertTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
```
Crea un tokenizer veloce con la classe [`DistilBertTokenizerFast`]:
```py
>>> from transformers import DistilBertTokenizerFast
>>> fast_tokenizer = DistilBertTokenizerFast.from_pretrained("distilbert/distilbert-base-uncased")
```
<Tip>
Per l'impostazione predefinita, [`AutoTokenizer`] proverà a caricare un tokenizer veloce. Puoi disabilitare questo comportamento impostando `use_fast=False` in `from_pretrained`.
</Tip>
## Estrattore Di Feature
Un estrattore di caratteristiche (feature in inglese) elabora input audio o immagini. Eredita dalla classe [`~feature_extraction_utils.FeatureExtractionMixin`] base e può anche ereditare dalla classe [`ImageFeatureExtractionMixin`] per l'elaborazione delle caratteristiche dell'immagine o dalla classe [`SequenceFeatureExtractor`] per l'elaborazione degli input audio.
A seconda che tu stia lavorando a un'attività audio o visiva, crea un estrattore di caratteristiche associato al modello che stai utilizzando. Ad esempio, crea un [`ViTFeatureExtractor`] predefinito se stai usando [ViT](model_doc/vit) per la classificazione delle immagini:
```py
>>> from transformers import ViTFeatureExtractor
>>> vit_extractor = ViTFeatureExtractor()
>>> print(vit_extractor)
ViTFeatureExtractor {
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
<Tip>
Se non stai cercando alcuna personalizzazione, usa il metodo `from_pretrained` per caricare i parametri di default dell'estrattore di caratteristiche di un modello.
</Tip>
Modifica uno qualsiasi dei parametri [`ViTFeatureExtractor`] per creare il tuo estrattore di caratteristiche personalizzato:
```py
>>> from transformers import ViTFeatureExtractor
>>> my_vit_extractor = ViTFeatureExtractor(resample="PIL.Image.BOX", do_normalize=False, image_mean=[0.3, 0.3, 0.3])
>>> print(my_vit_extractor)
ViTFeatureExtractor {
"do_normalize": false,
"do_resize": true,
"feature_extractor_type": "ViTFeatureExtractor",
"image_mean": [
0.3,
0.3,
0.3
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": "PIL.Image.BOX",
"size": 224
}
```
Per gli input audio, puoi creare un [`Wav2Vec2FeatureExtractor`] e personalizzare i parametri in modo simile:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> w2v2_extractor = Wav2Vec2FeatureExtractor()
>>> print(w2v2_extractor)
Wav2Vec2FeatureExtractor {
"do_normalize": true,
"feature_extractor_type": "Wav2Vec2FeatureExtractor",
"feature_size": 1,
"padding_side": "right",
"padding_value": 0.0,
"return_attention_mask": false,
"sampling_rate": 16000
}
```
## Processore
Per modelli che supportano attività multimodali, 🤗 Transformers offre una classe di processore che racchiude comodamente un estrattore di caratteristiche e un tokenizer in un unico oggetto. Ad esempio, utilizziamo [`Wav2Vec2Processor`] per un'attività di riconoscimento vocale automatico (ASR). ASR trascrive l'audio in testo, quindi avrai bisogno di un estrattore di caratteristiche e di un tokenizer.
Crea un estrattore di feature per gestire gli input audio:
```py
>>> from transformers import Wav2Vec2FeatureExtractor
>>> feature_extractor = Wav2Vec2FeatureExtractor(padding_value=1.0, do_normalize=True)
```
Crea un tokenizer per gestire gli input di testo:
```py
>>> from transformers import Wav2Vec2CTCTokenizer
>>> tokenizer = Wav2Vec2CTCTokenizer(vocab_file="my_vocab_file.txt")
```
Combinare l'estrattore di caratteristiche e il tokenizer in [`Wav2Vec2Processor`]:
```py
>>> from transformers import Wav2Vec2Processor
>>> processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
```
Con due classi di base - configurazione e modello - e una classe di preelaborazione aggiuntiva (tokenizer, estrattore di caratteristiche o processore), puoi creare qualsiasi modello supportato da 🤗 Transformers. Ognuna di queste classi base è configurabile, consentendoti di utilizzare gli attributi specifici che desideri. È possibile impostare facilmente un modello per l'addestramento o modificare un modello preallenato esistente per la messa a punto.
|
transformers/docs/source/it/create_a_model.md/0
|
{
"file_path": "transformers/docs/source/it/create_a_model.md",
"repo_id": "transformers",
"token_count": 5882
}
| 34 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Addestramento su TPU
<Tip>
Nota: Molte delle strategie introdotte nella [sezione sulla GPU singola](perf_train_gpu_one) (come mixed precision training o gradient accumulation) e [sezione multi-GPU](perf_train_gpu_many) sono generiche e applicabili all'addestramento di modelli in generale quindi assicurati di dargli un'occhiata prima di immergerti in questa sezione.
</Tip>
Questo documento sarà presto completato con informazioni su come effettuare la formazione su TPU.
|
transformers/docs/source/it/perf_train_tpu.md/0
|
{
"file_path": "transformers/docs/source/it/perf_train_tpu.md",
"repo_id": "transformers",
"token_count": 337
}
| 35 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Model outputs
すべてのモデルには、[`~utils.ModelOutput`] のサブクラスのインスタンスである出力があります。それらは
モデルによって返されるすべての情報を含むデータ構造ですが、タプルまたは
辞書。
これがどのようになるかを例で見てみましょう。
```python
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(**inputs, labels=labels)
```
`outputs`オブジェクトは[`~modeling_outputs.SequenceClassifierOutput`]である。
これは、オプションで `loss`、`logits`、オプションで `hidden_states`、オプションで `attentions` 属性を持つことを意味します。
オプションの `attentions` 属性を持つことを意味する。ここでは、`labels`を渡したので`loss`があるが、`hidden_states`と`attentions`はない。
`output_hidden_states=True`や`output_attentions=True`を渡していないので、`hidden_states`と`attentions`はない。
`output_attentions=True`を渡さなかったからだ。
<Tip>
`output_hidden_states=True`を渡すと、`outputs.hidden_states[-1]`が `outputs.last_hidden_states` と正確に一致することを期待するかもしれない。
しかし、必ずしもそうなるとは限りません。モデルによっては、最後に隠された状態が返されたときに、正規化やその後の処理を適用するものもあります。
</Tip>
通常と同じように各属性にアクセスできます。その属性がモデルから返されなかった場合は、
は `None`を取得します。ここで、たとえば`outputs.loss`はモデルによって計算された損失であり、`outputs.attentions`は
`None`。
`outputs`オブジェクトをタプルとして考える場合、`None`値を持たない属性のみが考慮されます。
たとえば、ここには 2 つの要素、`loss`、次に`logits`があります。
```python
outputs[:2]
```
たとえば、タプル `(outputs.loss, Outputs.logits)` を返します。
`outputs`オブジェクトを辞書として考慮する場合、「None」を持たない属性のみが考慮されます。
価値観。たとえば、ここには`loss` と `logits`という 2 つのキーがあります。
ここでは、複数のモデル タイプで使用される汎用モデルの出力を文書化します。具体的な出力タイプは次のとおりです。
対応するモデルのページに記載されています。
## ModelOutput
[[autodoc]] utils.ModelOutput
- to_tuple
## BaseModelOutput
[[autodoc]] modeling_outputs.BaseModelOutput
## BaseModelOutputWithPooling
[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
## BaseModelOutputWithCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
## BaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
## BaseModelOutputWithPast
[[autodoc]] modeling_outputs.BaseModelOutputWithPast
## BaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
## Seq2SeqModelOutput
[[autodoc]] modeling_outputs.Seq2SeqModelOutput
## CausalLMOutput
[[autodoc]] modeling_outputs.CausalLMOutput
## CausalLMOutputWithCrossAttentions
[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
## CausalLMOutputWithPast
[[autodoc]] modeling_outputs.CausalLMOutputWithPast
## MaskedLMOutput
[[autodoc]] modeling_outputs.MaskedLMOutput
## Seq2SeqLMOutput
[[autodoc]] modeling_outputs.Seq2SeqLMOutput
## NextSentencePredictorOutput
[[autodoc]] modeling_outputs.NextSentencePredictorOutput
## SequenceClassifierOutput
[[autodoc]] modeling_outputs.SequenceClassifierOutput
## Seq2SeqSequenceClassifierOutput
[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
## MultipleChoiceModelOutput
[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
## TokenClassifierOutput
[[autodoc]] modeling_outputs.TokenClassifierOutput
## QuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
## Seq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
## Seq2SeqSpectrogramOutput
[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
## SemanticSegmenterOutput
[[autodoc]] modeling_outputs.SemanticSegmenterOutput
## ImageClassifierOutput
[[autodoc]] modeling_outputs.ImageClassifierOutput
## ImageClassifierOutputWithNoAttention
[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
## DepthEstimatorOutput
[[autodoc]] modeling_outputs.DepthEstimatorOutput
## Wav2Vec2BaseModelOutput
[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
## XVectorOutput
[[autodoc]] modeling_outputs.XVectorOutput
## Seq2SeqTSModelOutput
[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
## Seq2SeqTSPredictionOutput
[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
## SampleTSPredictionOutput
[[autodoc]] modeling_outputs.SampleTSPredictionOutput
## TFBaseModelOutput
[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
## TFBaseModelOutputWithPooling
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
## TFBaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
## TFBaseModelOutputWithPast
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
## TFBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
## TFSeq2SeqModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
## TFCausalLMOutput
[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
## TFCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
## TFCausalLMOutputWithPast
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
## TFMaskedLMOutput
[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
## TFSeq2SeqLMOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
## TFNextSentencePredictorOutput
[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
## TFSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
## TFSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
## TFMultipleChoiceModelOutput
[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
## TFTokenClassifierOutput
[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
## TFQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
## TFSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
## FlaxBaseModelOutput
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
## FlaxBaseModelOutputWithPast
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
## FlaxBaseModelOutputWithPooling
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
## FlaxBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
## FlaxSeq2SeqModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
## FlaxCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
## FlaxMaskedLMOutput
[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
## FlaxSeq2SeqLMOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
## FlaxNextSentencePredictorOutput
[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
## FlaxSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
## FlaxSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
## FlaxMultipleChoiceModelOutput
[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
## FlaxTokenClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
## FlaxQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
## FlaxSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
|
transformers/docs/source/ja/main_classes/output.md/0
|
{
"file_path": "transformers/docs/source/ja/main_classes/output.md",
"repo_id": "transformers",
"token_count": 3347
}
| 36 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BARTpho
## Overview
BARTpho モデルは、Nguyen Luong Tran、Duong Minh Le、Dat Quoc Nguyen によって [BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnam](https://arxiv.org/abs/2109.09701) で提案されました。
論文の要約は次のとおりです。
*BARTpho には、BARTpho_word と BARTpho_syllable の 2 つのバージョンがあり、初の公開された大規模な単一言語です。
ベトナム語用に事前トレーニングされたシーケンスツーシーケンス モデル。当社の BARTpho は「大規模な」アーキテクチャと事前トレーニングを使用します
シーケンス間ノイズ除去モデル BART のスキームなので、生成 NLP タスクに特に適しています。実験
ベトナム語テキスト要約の下流タスクでは、自動評価と人間による評価の両方で、BARTpho が
強力なベースライン mBART を上回り、最先端の性能を向上させます。将来を容易にするためにBARTphoをリリースします
生成的なベトナム語 NLP タスクの研究と応用。*
このモデルは [dqnguyen](https://huggingface.co/dqnguyen) によって提供されました。元のコードは [こちら](https://github.com/VinAIResearch/BARTpho) にあります。
## Usage example
```python
>>> import torch
>>> from transformers import AutoModel, AutoTokenizer
>>> bartpho = AutoModel.from_pretrained("vinai/bartpho-syllable")
>>> tokenizer = AutoTokenizer.from_pretrained("vinai/bartpho-syllable")
>>> line = "Chúng tôi là những nghiên cứu viên."
>>> input_ids = tokenizer(line, return_tensors="pt")
>>> with torch.no_grad():
... features = bartpho(**input_ids) # Models outputs are now tuples
>>> # With TensorFlow 2.0+:
>>> from transformers import TFAutoModel
>>> bartpho = TFAutoModel.from_pretrained("vinai/bartpho-syllable")
>>> input_ids = tokenizer(line, return_tensors="tf")
>>> features = bartpho(**input_ids)
```
## Usage tips
- mBARTに続いて、BARTphoはBARTの「大規模な」アーキテクチャを使用し、その上に追加の層正規化層を備えています。
エンコーダとデコーダの両方。したがって、[BART のドキュメント](bart) の使用例は、使用に適応する場合に使用されます。
BARTpho を使用する場合は、BART に特化したクラスを mBART に特化した対応するクラスに置き換えることによって調整する必要があります。
例えば:
```python
>>> from transformers import MBartForConditionalGeneration
>>> bartpho = MBartForConditionalGeneration.from_pretrained("vinai/bartpho-syllable")
>>> TXT = "Chúng tôi là <mask> nghiên cứu viên."
>>> input_ids = tokenizer([TXT], return_tensors="pt")["input_ids"]
>>> logits = bartpho(input_ids).logits
>>> masked_index = (input_ids[0] == tokenizer.mask_token_id).nonzero().item()
>>> probs = logits[0, masked_index].softmax(dim=0)
>>> values, predictions = probs.topk(5)
>>> print(tokenizer.decode(predictions).split())
```
- この実装はトークン化のみを目的としています。`monolingual_vocab_file`はベトナム語に特化した型で構成されています
多言語 XLM-RoBERTa から利用できる事前トレーニング済み SentencePiece モデル`vocab_file`から抽出されます。
他の言語 (サブワードにこの事前トレーニング済み多言語 SentencePiece モデル`vocab_file`を使用する場合)
セグメンテーションにより、独自の言語に特化した`monolingual_vocab_file`を使用して BartphoTokenizer を再利用できます。
## BartphoTokenizer
[[autodoc]] BartphoTokenizer
|
transformers/docs/source/ja/model_doc/bartpho.md/0
|
{
"file_path": "transformers/docs/source/ja/model_doc/bartpho.md",
"repo_id": "transformers",
"token_count": 1761
}
| 37 |
<!--Copyright 2023 The Intel Labs Team Authors, The Microsoft Research Team Authors and HuggingFace Inc. team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BridgeTower
## Overview
BridgeTower モデルは、Xiao Xu、Chenfei Wu、Shachar Rosenman、Vasudev Lal、Wanxiang Che、Nan Duan [BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning](https://arxiv.org/abs/2206.08657) で提案されました。ドゥアン。このモデルの目標は、
各ユニモーダル エンコーダとクロスモーダル エンコーダの間のブリッジにより、クロスモーダル エンコーダの各層での包括的かつ詳細な対話が可能になり、追加のパフォーマンスと計算コストがほとんど無視できる程度で、さまざまな下流タスクで優れたパフォーマンスを実現します。
この論文は [AAAI'23](https://aaai.org/Conferences/AAAI-23/) 会議に採択されました。
論文の要約は次のとおりです。
*TWO-TOWER アーキテクチャを備えたビジョン言語 (VL) モデルは、近年の視覚言語表現学習の主流となっています。
現在の VL モデルは、軽量のユニモーダル エンコーダーを使用して、ディープ クロスモーダル エンコーダーで両方のモダリティを同時に抽出、位置合わせ、融合することを学習するか、事前にトレーニングされたディープ ユニモーダル エンコーダーから最終層のユニモーダル表現を上部のクロスモーダルエンコーダー。
どちらのアプローチも、視覚言語表現の学習を制限し、モデルのパフォーマンスを制限する可能性があります。この論文では、ユニモーダル エンコーダの最上位層とクロスモーダル エンコーダの各層の間の接続を構築する複数のブリッジ層を導入する BRIDGETOWER を提案します。
これにより、効果的なボトムアップのクロスモーダル調整と、クロスモーダル エンコーダー内の事前トレーニング済みユニモーダル エンコーダーのさまざまなセマンティック レベルの視覚表現とテキスト表現の間の融合が可能になります。 BRIDGETOWER は 4M 画像のみで事前トレーニングされており、さまざまな下流の視覚言語タスクで最先端のパフォーマンスを実現します。
特に、VQAv2 テスト標準セットでは、BRIDGETOWER は 78.73% の精度を達成し、同じ事前トレーニング データとほぼ無視できる追加パラメータと計算コストで以前の最先端モデル METER を 1.09% 上回りました。
特に、モデルをさらにスケーリングすると、BRIDGETOWER は 81.15% の精度を達成し、桁違いに大きなデータセットで事前トレーニングされたモデルを上回りました。*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/bridgetower_architecture%20.jpg"
alt="drawing" width="600"/>
<small> ブリッジタワー アーキテクチャ。 <a href="https://arxiv.org/abs/2206.08657">元の論文から抜粋。</a> </small>
このモデルは、[Anahita Bhiwandiwalla](https://huggingface.co/anahita-b)、[Tiep Le](https://huggingface.co/Tile)、[Shaoyen Tseng](https://huggingface.co/shaoyent) 。元のコードは [ここ](https://github.com/microsoft/BridgeTower) にあります。
## Usage tips and examples
BridgeTower は、ビジュアル エンコーダー、テキスト エンコーダー、および複数の軽量ブリッジ レイヤーを備えたクロスモーダル エンコーダーで構成されます。
このアプローチの目標は、各ユニモーダル エンコーダーとクロスモーダル エンコーダーの間にブリッジを構築し、クロスモーダル エンコーダーの各層で包括的かつ詳細な対話を可能にすることでした。
原則として、提案されたアーキテクチャでは、任意のビジュアル、テキスト、またはクロスモーダル エンコーダを適用できます。
[`BridgeTowerProcessor`] は、[`RobertaTokenizer`] と [`BridgeTowerImageProcessor`] を単一のインスタンスにラップし、両方の機能を実現します。
テキストをエンコードし、画像をそれぞれ用意します。
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForContrastiveLearning`] を使用して対照学習を実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs
```
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForImageAndTextRetrieval`] を使用して画像テキストの取得を実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
```
次の例は、[`BridgeTowerProcessor`] と [`BridgeTowerForMaskedLM`] を使用してマスクされた言語モデリングを実行する方法を示しています。
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
```
チップ:
- BridgeTower のこの実装では、[`RobertaTokenizer`] を使用してテキスト埋め込みを生成し、OpenAI の CLIP/ViT モデルを使用して視覚的埋め込みを計算します。
- 事前トレーニングされた [bridgeTower-base](https://huggingface.co/BridgeTower/bridgetower-base) および [bridgetower マスクされた言語モデリングと画像テキスト マッチング](https://huggingface.co/BridgeTower/bridgetower--base-itm-mlm) のチェックポイント がリリースされました。
- 画像検索およびその他の下流タスクにおける BridgeTower のパフォーマンスについては、[表 5](https://arxiv.org/pdf/2206.08657.pdf) を参照してください。
- このモデルの PyTorch バージョンは、torch 1.10 以降でのみ使用できます。
## BridgeTowerConfig
[[autodoc]] BridgeTowerConfig
## BridgeTowerTextConfig
[[autodoc]] BridgeTowerTextConfig
## BridgeTowerVisionConfig
[[autodoc]] BridgeTowerVisionConfig
## BridgeTowerImageProcessor
[[autodoc]] BridgeTowerImageProcessor
- preprocess
## BridgeTowerProcessor
[[autodoc]] BridgeTowerProcessor
- __call__
## BridgeTowerModel
[[autodoc]] BridgeTowerModel
- forward
## BridgeTowerForContrastiveLearning
[[autodoc]] BridgeTowerForContrastiveLearning
- forward
## BridgeTowerForMaskedLM
[[autodoc]] BridgeTowerForMaskedLM
- forward
## BridgeTowerForImageAndTextRetrieval
[[autodoc]] BridgeTowerForImageAndTextRetrieval
- forward
|
transformers/docs/source/ja/model_doc/bridgetower.md/0
|
{
"file_path": "transformers/docs/source/ja/model_doc/bridgetower.md",
"repo_id": "transformers",
"token_count": 3672
}
| 38 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CPM
## Overview
CPM モデルは、Zhengyan Zhang、Xu Han、Hao Zhou、Pei Ke、Yuxian Gu によって [CPM: A Large-scale Generative Chinese Pre-trained Language Model](https://arxiv.org/abs/2012.00413) で提案されました。葉徳明、秦裕佳、
Yusheng Su、Haozhe Ji、Jian Guan、Fanchao Qi、Xiaozi Wang、Yanan Zheng、Guoyang Zeng、Huanqi Cao、Shengqi Chen、
Daixuan Li、Zhenbo Sun、Zhiyuan Liu、Minlie Huang、Wentao Han、Jie Tang、Juanzi Li、Xiaoyan Zhu、Maosong Sun。
論文の要約は次のとおりです。
*事前トレーニングされた言語モデル (PLM) は、さまざまな下流の NLP タスクに有益であることが証明されています。最近ではGPT-3、
1,750億個のパラメータと570GBの学習データを備え、数回の撮影(1枚でも)の容量で大きな注目を集めました
ゼロショット)学習。ただし、GPT-3 を適用して中国語の NLP タスクに対処することは依然として困難です。
GPT-3 の言語は主に英語であり、パラメーターは公開されていません。この技術レポートでは、
大規模な中国語トレーニング データに対する生成的事前トレーニングを備えた中国語事前トレーニング済み言語モデル (CPM)。最高に
私たちの知識の限りでは、26 億のパラメータと 100GB の中国語トレーニング データを備えた CPM は、事前トレーニングされた中国語としては最大のものです。
言語モデルは、会話、エッセイの作成、
クローゼテストと言語理解。広範な実験により、CPM が多くの環境で優れたパフォーマンスを達成できることが実証されています。
少数ショット (ゼロショットでも) 学習の設定での NLP タスク。*
このモデルは [canwenxu](https://huggingface.co/canwenxu) によって提供されました。オリジナルの実装が見つかります
ここ: https://github.com/TsinghuaAI/CPM-Generate
<Tip>
CPM のアーキテクチャは、トークン化方法を除いて GPT-2 と同じです。詳細については、[GPT-2 ドキュメント](openai-community/gpt2) を参照してください。
API リファレンス情報。
</Tip>
## CpmTokenizer
[[autodoc]] CpmTokenizer
## CpmTokenizerFast
[[autodoc]] CpmTokenizerFast
|
transformers/docs/source/ja/model_doc/cpm.md/0
|
{
"file_path": "transformers/docs/source/ja/model_doc/cpm.md",
"repo_id": "transformers",
"token_count": 1259
}
| 39 |
<!--
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ このファイルはMarkdownですが、Hugging Faceのドキュメントビルダー(MDXに類似)向けの特定の構文を含んでいるため、Markdownビューアーで適切にレンダリングされないことがあります。
-->
# Share a Model
最後の2つのチュートリアルでは、PyTorch、Keras、および🤗 Accelerateを使用してモデルをファインチューニングする方法を示しました。次のステップは、モデルをコミュニティと共有することです!Hugging Faceでは、知識とリソースを公開的に共有し、人工知能を誰にでも提供することを信じています。他の人々が時間とリソースを節約できるように、モデルをコミュニティと共有することを検討することをお勧めします。
このチュートリアルでは、訓練済みまたはファインチューニングされたモデルを[Model Hub](https://huggingface.co/models)に共有する2つの方法を学びます:
- プログラムでファイルをHubにプッシュする。
- ウェブインターフェースを使用してファイルをHubにドラッグアンドドロップする。
<iframe width="560" height="315" src="https://www.youtube.com/embed/XvSGPZFEjDY" title="YouTube video player"
frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope;
picture-in-picture" allowfullscreen></iframe>
<Tip>
コミュニティとモデルを共有するには、[huggingface.co](https://huggingface.co/join)でアカウントが必要です。既存の組織に参加したり、新しい組織を作成したりすることもできます。
</Tip>
## Repository Features
Model Hub上の各リポジトリは、通常のGitHubリポジトリのように動作します。リポジトリはバージョニング、コミット履歴、違いの視覚化の機能を提供します。
Model Hubの組み込みバージョニングはgitおよび[git-lfs](https://git-lfs.github.com/)に基づいています。言い換えれば、モデルを1つのリポジトリとして扱うことができ、より大きなアクセス制御とスケーラビリティを実現します。バージョン管理には*リビジョン*があり、コミットハッシュ、タグ、またはブランチ名で特定のモデルバージョンをピン留めする方法です。
その結果、`revision`パラメータを使用して特定のモデルバージョンをロードできます:
```py
>>> model = AutoModel.from_pretrained(
... "julien-c/EsperBERTo-small", revision="4c77982" # タグ名、またはブランチ名、またはコミットハッシュ
... )
```
ファイルはリポジトリ内で簡単に編集でき、コミット履歴と差分を表示できます:

## Set Up
モデルをHubに共有する前に、Hugging Faceの認証情報が必要です。ターミナルへのアクセス権がある場合、🤗 Transformersがインストールされている仮想環境で以下のコマンドを実行します。これにより、アクセストークンがHugging Faceのキャッシュフォルダに保存されます(デフォルトでは `~/.cache/` に保存されます):
```bash
huggingface-cli login
```
JupyterやColaboratoryのようなノートブックを使用している場合、[`huggingface_hub`](https://huggingface.co/docs/hub/adding-a-library)ライブラリがインストールされていることを確認してください。
このライブラリを使用すると、Hubとプログラム的に対話できます。
```bash
pip install huggingface_hub
```
次に、`notebook_login`を使用してHubにサインインし、[こちらのリンク](https://huggingface.co/settings/token)にアクセスしてログインに使用するトークンを生成します:
```python
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Convert a Model for all frameworks
異なるフレームワークで作業している他のユーザーがあなたのモデルを使用できるようにするために、
PyTorchおよびTensorFlowのチェックポイントでモデルを変換してアップロードすることをお勧めします。
このステップをスキップすると、ユーザーは異なるフレームワークからモデルをロードできますが、
モデルをオンザフライで変換する必要があるため、遅くなります。
別のフレームワーク用にチェックポイントを変換することは簡単です。
PyTorchとTensorFlowがインストールされていることを確認してください(インストール手順については[こちら](installation)を参照)し、
その後、他のフレームワーク向けに特定のタスク用のモデルを見つけます。
<frameworkcontent>
<pt>
TensorFlowからPyTorchにチェックポイントを変換するには、`from_tf=True`を指定します:
```python
>>> pt_model = DistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_tf=True)
>>> pt_model.save_pretrained("path/to/awesome-name-you-picked")
```
</pt>
<tf>
指定して、PyTorchからTensorFlowにチェックポイントを変換するには `from_pt=True` を使用します:
```python
>>> tf_model = TFDistilBertForSequenceClassification.from_pretrained("path/to/awesome-name-you-picked", from_pt=True)
```
新しいTensorFlowモデルとその新しいチェックポイントを保存できます:
```python
>>> tf_model.save_pretrained("path/to/awesome-name-you-picked")
```
</tf>
<tf>
<jax>
Flaxでモデルが利用可能な場合、PyTorchからFlaxへのチェックポイントの変換も行うことができます:
```py
>>> flax_model = FlaxDistilBertForSequenceClassification.from_pretrained(
... "path/to/awesome-name-you-picked", from_pt=True
... )
```
</jax>
</frameworkcontent>
## Push a model during traning
<frameworkcontent>
<pt>
<Youtube id="Z1-XMy-GNLQ"/>
モデルをHubにプッシュすることは、追加のパラメーターまたはコールバックを追加するだけで簡単です。
[ファインチューニングチュートリアル](training)から思い出してください、[`TrainingArguments`]クラスはハイパーパラメーターと追加のトレーニングオプションを指定する場所です。
これらのトレーニングオプションの1つに、モデルを直接Hubにプッシュする機能があります。[`TrainingArguments`]で`push_to_hub=True`を設定します:
```py
>>> training_args = TrainingArguments(output_dir="my-awesome-model", push_to_hub=True)
```
Pass your training arguments as usual to [`Trainer`]:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
[`Trainer`]に通常通りトレーニング引数を渡します:
```py
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... )
```
ファインチューニングが完了したら、[`Trainer`]で[`~transformers.Trainer.push_to_hub`]を呼び出して、トレーニング済みモデルをHubにプッシュします。🤗 Transformersは、トレーニングのハイパーパラメータ、トレーニング結果、およびフレームワークのバージョンを自動的にモデルカードに追加します!
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
[`PushToHubCallback`]を使用してモデルをHubに共有します。[`PushToHubCallback`]関数には、次のものを追加します:
- モデルの出力ディレクトリ。
- トークナイザ。
- `hub_model_id`、つまりHubのユーザー名とモデル名。
```python
>>> from transformers import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="./your_model_save_path", tokenizer=tokenizer, hub_model_id="your-username/my-awesome-model"
... )
```
🤗 Transformersは[`fit`](https://keras.io/api/models/model_training_apis/)にコールバックを追加し、トレーニング済みモデルをHubにプッシュします:
```py
>>> model.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=3, callbacks=push_to_hub_callback)
```
</tf>
</frameworkcontent>
## `push_to_hub` 関数を使用する
また、モデルを直接Hubにアップロードするために、`push_to_hub` を呼び出すこともできます。
`push_to_hub` でモデル名を指定します:
```py
>>> pt_model.push_to_hub("my-awesome-model")
```
これにより、ユーザー名の下にモデル名 `my-awesome-model` を持つリポジトリが作成されます。
ユーザーは、`from_pretrained` 関数を使用してモデルをロードできます:
```py
>>> from transformers import AutoModel
>>> model = AutoModel.from_pretrained("your_username/my-awesome-model")
```
組織に所属し、モデルを組織名のもとにプッシュしたい場合、`repo_id` にそれを追加してください:
```python
>>> pt_model.push_to_hub("my-awesome-org/my-awesome-model")
```
`push_to_hub`関数は、モデルリポジトリに他のファイルを追加するためにも使用できます。例えば、トークナイザをモデルリポジトリに追加します:
```py
>>> tokenizer.push_to_hub("my-awesome-model")
```
あるいは、ファインチューニングされたPyTorchモデルのTensorFlowバージョンを追加したいかもしれません:
```python
>>> tf_model.push_to_hub("my-awesome-model")
```
Hugging Faceプロフィールに移動すると、新しく作成したモデルリポジトリが表示されるはずです。**Files**タブをクリックすると、リポジトリにアップロードしたすべてのファイルが表示されます。
リポジトリにファイルを作成およびアップロードする方法の詳細については、Hubドキュメンテーション[こちら](https://huggingface.co/docs/hub/how-to-upstream)を参照してください。
## Upload with the web interface
コードを書かずにモデルをアップロードしたいユーザーは、Hubのウェブインターフェースを使用してモデルをアップロードできます。[huggingface.co/new](https://huggingface.co/new)を訪れて新しいリポジトリを作成します:

ここから、モデルに関するいくつかの情報を追加します:
- リポジトリの**所有者**を選択します。これはあなた自身または所属している組織のいずれかです。
- モデルの名前を選択します。これはリポジトリの名前にもなります。
- モデルが公開か非公開かを選択します。
- モデルのライセンス使用方法を指定します。
その後、**Files**タブをクリックし、**Add file**ボタンをクリックしてリポジトリに新しいファイルをアップロードします。次に、ファイルをドラッグアンドドロップしてアップロードし、コミットメッセージを追加します。

## Add a model card
ユーザーがモデルの機能、制限、潜在的な偏り、倫理的な考慮事項を理解できるようにするために、モデルリポジトリにモデルカードを追加してください。モデルカードは`README.md`ファイルで定義されます。モデルカードを追加する方法:
* 手動で`README.md`ファイルを作成およびアップロードする。
* モデルリポジトリ内の**Edit model card**ボタンをクリックする。
モデルカードに含めるべき情報の例については、DistilBert [モデルカード](https://huggingface.co/distilbert/distilbert-base-uncased)をご覧ください。`README.md`ファイルで制御できる他のオプション、例えばモデルの炭素フットプリントやウィジェットの例などについての詳細は、[こちらのドキュメンテーション](https://huggingface.co/docs/hub/models-cards)を参照してください。
|
transformers/docs/source/ja/model_sharing.md/0
|
{
"file_path": "transformers/docs/source/ja/model_sharing.md",
"repo_id": "transformers",
"token_count": 5371
}
| 40 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Image tasks with IDEFICS
[[open-in-colab]]
個別のタスクは特殊なモデルを微調整することで対処できますが、別のアプローチも可能です。
最近登場して人気を博しているのは、微調整を行わずにさまざまなタスクに大規模なモデルを使用することです。
たとえば、大規模な言語モデルは、要約、翻訳、分類などの NLP タスクを処理できます。
このアプローチは、テキストなどの単一のモダリティに限定されなくなりました。このガイドでは、次のような方法を説明します。
IDEFICS と呼ばれる大規模なマルチモーダル モデルを使用して、画像とテキストのタスクを解決します。
[IDEFICS](../model_doc/idefics) は、[Flamingo](https://huggingface.co/papers/2204.14198) に基づくオープンアクセスのビジョンおよび言語モデルです。
DeepMind によって最初に開発された最先端の視覚言語モデル。モデルは任意の画像シーケンスを受け入れます
テキストを入力し、出力として一貫したテキストを生成します。画像に関する質問に答えたり、視覚的なコンテンツについて説明したり、
複数のイメージに基づいたストーリーを作成するなど。 IDEFICS には 2 つのバリエーションがあります - [800 億パラメータ](https://huggingface.co/HuggingFaceM4/idefics-80b)
および [90 億のパラメータ](https://huggingface.co/HuggingFaceM4/idefics-9b)、どちらも 🤗 Hub で入手できます。各バリエーションについて、細かく調整された指示も見つけることができます。
会話のユースケースに適応したモデルのバージョン。
このモデルは非常に多用途で、幅広い画像タスクやマルチモーダル タスクに使用できます。しかし、
大規模なモデルであるということは、大量の計算リソースとインフラストラクチャが必要であることを意味します。それはあなた次第です
このアプローチは、個別のタスクごとに特化したモデルを微調整するよりも、ユースケースに適しています。
このガイドでは、次の方法を学習します。
- [IDEFICS をロード](#loading-the-model) および [モデルの量子化バージョンをロード](#quantized-model)
- IDEFICS を次の目的で使用します。
- [画像キャプション](#image-captioning)
- [プロンプト画像キャプション](#prompted-image-captioning)
- [Few-shot プロンプト](#few-shot-prompting)
- [ビジュアル質問回答](#visual-question-answering)
- [画像分類](#image-classification)
- [画像ガイド付きテキスト生成](#image-guided-text-generation)
- [バッチモードで推論を実行する](#running-inference-in-batch-mode)
- [会話用に IDEFICS 命令を実行](#idefics-instruct-for-conversational-use)
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install -q bitsandbytes sentencepiece accelerate transformers
```
<Tip>
量子化されていないバージョンのモデル チェックポイントを使用して次の例を実行するには、少なくとも 20GB の GPU メモリが必要です。
</Tip>
## Loading the model
まずはモデルの 90 億個のパラメーターのチェックポイントをロードしましょう。
```py
>>> checkpoint = "HuggingFaceM4/idefics-9b"
```
他の Transformers モデルと同様に、プロセッサとモデル自体をチェックポイントからロードする必要があります。
IDEFICS プロセッサは、[`LlamaTokenizer`] と IDEFICS 画像プロセッサを単一のプロセッサにラップして処理します。
モデルのテキストと画像の入力を準備します。
```py
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16, device_map="auto")
```
`device_map`を`auto`に設定すると、モデルの重みを最も最適化された状態でロードおよび保存する方法が自動的に決定されます。
既存のデバイスを考慮した方法。
### Quantized model
ハイメモリ GPU の可用性が問題となる場合は、モデルの量子化されたバージョンをロードできます。モデルと
プロセッサを 4 ビット精度で使用する場合、`BitsAndBytesConfig`を`from_pretrained`メソッドに渡すと、モデルが圧縮されます。
ロード中にその場で。
```py
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor, BitsAndBytesConfig
>>> quantization_config = BitsAndBytesConfig(
... load_in_4bit=True,
... bnb_4bit_compute_dtype=torch.float16,
... )
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> model = IdeficsForVisionText2Text.from_pretrained(
... checkpoint,
... quantization_config=quantization_config,
... device_map="auto"
... )
```
提案された方法のいずれかでモデルをロードしたので、IDEFICS を使用できるタスクの探索に進みましょう。
## Image captioning
画像のキャプション付けは、特定の画像のキャプションを予測するタスクです。一般的な用途は視覚障害者を支援することです
人々はさまざまな状況をナビゲートします。たとえば、オンラインで画像コンテンツを探索します。
タスクを説明するには、キャプションを付ける画像を取得します。例:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-im-captioning.jpg" alt="Image of a puppy in a flower bed"/>
</div>
写真提供:[Hendo Wang](https://unsplash.com/@hendoo)
IDEFICS はテキストと画像のプロンプトを受け入れます。ただし、画像にキャプションを付けるには、テキスト プロンプトをユーザーに提供する必要はありません。
モデル、前処理された入力画像のみ。テキスト プロンプトがない場合、モデルはテキストの生成を開始します。
BOS (Beginning-of-sequence) トークンによりキャプションが作成されます。
モデルへの画像入力として、画像オブジェクト (`PIL.Image`) または画像を取得できる URL のいずれかを使用できます。
```py
>>> prompt = [
... "https://images.unsplash.com/photo-1583160247711-2191776b4b91?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3542&q=80",
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
A puppy in a flower bed
```
<Tip>
増加時に発生するエラーを避けるために、`generate`の呼び出しに`bad_words_ids`を含めることをお勧めします。
`max_new_tokens`: モデルは、新しい `<image>` または `<fake_token_around_image>` トークンを生成する必要があります。
モデルによって画像が生成されていません。
このガイドのようにオンザフライで設定することも、[テキスト生成戦略](../generation_strategies) ガイドで説明されているように `GenerationConfig` に保存することもできます。
</Tip>
## Prompted image captioning
テキスト プロンプトを提供することで画像キャプションを拡張でき、モデルは画像を指定して続行します。持っていきましょう
別の図で説明します。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-prompted-im-captioning.jpg" alt="Image of the Eiffel Tower at night"/>
</div>
写真提供:[Denys Nevozhai](https://unsplash.com/@dnevozhai)。
テキストおよび画像のプロンプトを単一のリストとしてモデルのプロセッサに渡し、適切な入力を作成できます。
```py
>>> prompt = [
... "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
... "This is an image of ",
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
This is an image of the Eiffel Tower in Paris, France.
```
## Few-shot prompting
IDEFICS はゼロショットで優れた結果を示しますが、タスクによっては特定の形式のキャプションが必要になる場合や、キャプションが付属する場合があります。
タスクの複雑さを増大させるその他の制限または要件。少数のショットのプロンプトを使用して、コンテキスト内の学習を有効にすることができます。
プロンプトに例を指定することで、指定された例の形式を模倣した結果を生成するようにモデルを操作できます。
前のエッフェル塔の画像をモデルの例として使用し、モデルにデモンストレーションするプロンプトを作成してみましょう。
画像内のオブジェクトが何であるかを知ることに加えて、それに関する興味深い情報も取得したいと考えています。
次に、自由の女神の画像に対して同じ応答形式を取得できるかどうかを見てみましょう。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-few-shot.jpg" alt="Image of the Statue of Liberty"/>
</div>
写真提供:[Juan Mayobre](https://unsplash.com/@jmayobres)。
```py
>>> prompt = ["User:",
... "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
... "Describe this image.\nAssistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.\n",
... "User:",
... "https://images.unsplash.com/photo-1524099163253-32b7f0256868?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3387&q=80",
... "Describe this image.\nAssistant:"
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=30, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
User: Describe this image.
Assistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.
User: Describe this image.
Assistant: An image of the Statue of Liberty. Fun fact: the Statue of Liberty is 151 feet tall.
```
モデルは 1 つの例 (つまり、1 ショット) だけからタスクの実行方法を学習していることに注目してください。より複雑なタスクの場合は、
より多くの例 (3 ショット、5 ショットなど) を自由に試してみてください。
## Visual question answering
Visual Question Answering (VQA) は、画像に基づいて自由形式の質問に答えるタスクです。画像に似ている
キャプションは、アクセシビリティ アプリケーションだけでなく、教育 (視覚資料についての推論) にも使用できます。
サービス(画像を基にした商品に関する質問)、画像検索など。
このタスク用に新しい画像を取得しましょう。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-vqa.jpg" alt="Image of a couple having a picnic"/>
</div>
写真提供 [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
適切な指示をプロンプトすることで、モデルを画像キャプションから視覚的な質問への応答に導くことができます。
```py
>>> prompt = [
... "Instruction: Provide an answer to the question. Use the image to answer.\n",
... "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
... "Question: Where are these people and what's the weather like? Answer:"
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=20, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Provide an answer to the question. Use the image to answer.
Question: Where are these people and what's the weather like? Answer: They're in a park in New York City, and it's a beautiful day.
```
## Image classification
IDEFICS は、次のデータを含むデータについて明示的にトレーニングしなくても、画像をさまざまなカテゴリに分類できます。
これらの特定のカテゴリからのラベル付きの例。カテゴリのリストを指定し、その画像とテキストを使用して理解する
機能を利用すると、モデルは画像がどのカテゴリに属する可能性が高いかを推測できます。
たとえば、次のような野菜スタンドの画像があるとします。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-classification.jpg" alt="Image of a vegetable stand"/>
</div>
写真提供:[Peter Wendt](https://unsplash.com/@peterwendt)。
画像を次のいずれかのカテゴリに分類するようにモデルに指示できます。
```py
>>> categories = ['animals','vegetables', 'city landscape', 'cars', 'office']
>>> prompt = [f"Instruction: Classify the following image into a single category from the following list: {categories}.\n",
... "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
... "Category: "
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=6, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Classify the following image into a single category from the following list: ['animals', 'vegetables', 'city landscape', 'cars', 'office'].
Category: Vegetables
```
上の例では、画像を 1 つのカテゴリに分類するようにモデルに指示していますが、ランク分類を行うようにモデルに指示することもできます。
## Image-guided text generation
よりクリエイティブなアプリケーションの場合は、画像ガイド付きテキスト生成を使用して、画像に基づいてテキストを生成できます。これは可能です
製品、広告、シーンの説明などを作成するのに役立ちます。
IDEFICS に、赤いドアの単純な画像に基づいてストーリーを書くように促してみましょう。
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-story-generation.jpg" alt="Image of a red door with a pumpkin on the steps"/>
</div>
写真提供:[Craig Tidball](https://unsplash.com/@devonshiremedia)。
```py
>>> prompt = ["Instruction: Use the image to write a story. \n",
... "https://images.unsplash.com/photo-1517086822157-2b0358e7684a?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=2203&q=80",
... "Story: \n"]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, num_beams=2, max_new_tokens=200, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Use the image to write a story.
Story:
Once upon a time, there was a little girl who lived in a house with a red door. She loved her red door. It was the prettiest door in the whole world.
One day, the little girl was playing in her yard when she noticed a man standing on her doorstep. He was wearing a long black coat and a top hat.
The little girl ran inside and told her mother about the man.
Her mother said, “Don’t worry, honey. He’s just a friendly ghost.”
The little girl wasn’t sure if she believed her mother, but she went outside anyway.
When she got to the door, the man was gone.
The next day, the little girl was playing in her yard again when she noticed the man standing on her doorstep.
He was wearing a long black coat and a top hat.
The little girl ran
```
IDEFICS は玄関先にあるカボチャに気づき、幽霊に関する不気味なハロウィーンの話をしたようです。
<Tip>
このような長い出力の場合、テキスト生成戦略を微調整すると大きなメリットが得られます。これは役に立ちます
生成される出力の品質が大幅に向上します。 [テキスト生成戦略](../generation_strategies) を確認してください。
詳しく知ることができ。
</Tip>
## Running inference in batch mode
これまでのすべてのセクションでは、IDEFICS を 1 つの例として説明しました。非常に似た方法で、推論を実行できます。
プロンプトのリストを渡すことにより、サンプルのバッチを取得します。
```py
>>> prompts = [
... [ "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
... "This is an image of ",
... ],
... [ "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
... "This is an image of ",
... ],
... [ "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
... "This is an image of ",
... ],
... ]
>>> inputs = processor(prompts, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> for i,t in enumerate(generated_text):
... print(f"{i}:\n{t}\n")
0:
This is an image of the Eiffel Tower in Paris, France.
1:
This is an image of a couple on a picnic blanket.
2:
This is an image of a vegetable stand.
```
## IDEFICS instruct for conversational use
会話型のユースケースの場合は、🤗 ハブでモデルの微調整された指示されたバージョンを見つけることができます。
`HuggingFaceM4/idefics-80b-instruct` および `HuggingFaceM4/idefics-9b-instruct`。
これらのチェックポイントは、教師ありモデルと命令モデルを組み合わせたそれぞれの基本モデルを微調整した結果です。
データセットを微調整することで、ダウンストリームのパフォーマンスを向上させながら、会話設定でモデルをより使いやすくします。
会話での使用とプロンプトは、基本モデルの使用と非常に似ています。
```py
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> checkpoint = "HuggingFaceM4/idefics-9b-instruct"
>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> prompts = [
... [
... "User: What is in this image?",
... "https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
... "<end_of_utterance>",
... "\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
... "\nUser:",
... "https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
... "And who is that?<end_of_utterance>",
... "\nAssistant:",
... ],
... ]
>>> # --batched mode
>>> inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
>>> # --single sample mode
>>> # inputs = processor(prompts[0], return_tensors="pt").to(device)
>>> # Generation args
>>> exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> for i, t in enumerate(generated_text):
... print(f"{i}:\n{t}\n")
```
|
transformers/docs/source/ja/tasks/idefics.md/0
|
{
"file_path": "transformers/docs/source/ja/tasks/idefics.md",
"repo_id": "transformers",
"token_count": 9887
}
| 41 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Token classification
[[open-in-colab]]
<Youtube id="wVHdVlPScxA"/>
トークン分類では、文内の個々のトークンにラベルを割り当てます。最も一般的なトークン分類タスクの 1 つは、固有表現認識 (NER) です。 NER は、人、場所、組織など、文内の各エンティティのラベルを見つけようとします。
このガイドでは、次の方法を説明します。
1. [WNUT 17](https://huggingface.co/datasets/wnut_17) データセットで [DistilBERT](https://huggingface.co/distilbert/distilbert-base-uncased) を微調整して、新しいエンティティを検出します。
2. 微調整されたモデルを推論に使用します。
<Tip>
このタスクと互換性のあるすべてのアーキテクチャとチェックポイントを確認するには、[タスクページ](https://huggingface.co/tasks/token-classification) を確認することをお勧めします。
</Tip>
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install transformers datasets evaluate seqeval
```
モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load WNUT 17 dataset
まず、🤗 データセット ライブラリから WNUT 17 データセットをロードします。
```py
>>> from datasets import load_dataset
>>> wnut = load_dataset("wnut_17")
```
次に、例を見てみましょう。
```py
>>> wnut["train"][0]
{'id': '0',
'ner_tags': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 7, 8, 8, 0, 7, 0, 0, 0, 0, 0, 0, 0, 0],
'tokens': ['@paulwalk', 'It', "'s", 'the', 'view', 'from', 'where', 'I', "'m", 'living', 'for', 'two', 'weeks', '.', 'Empire', 'State', 'Building', '=', 'ESB', '.', 'Pretty', 'bad', 'storm', 'here', 'last', 'evening', '.']
}
```
`ner_tags`内の各数字はエンティティを表します。数値をラベル名に変換して、エンティティが何であるかを調べます。
```py
>>> label_list = wnut["train"].features[f"ner_tags"].feature.names
>>> label_list
[
"O",
"B-corporation",
"I-corporation",
"B-creative-work",
"I-creative-work",
"B-group",
"I-group",
"B-location",
"I-location",
"B-person",
"I-person",
"B-product",
"I-product",
]
```
各 `ner_tag` の前に付く文字は、エンティティのトークンの位置を示します。
- `B-` はエンティティの始まりを示します。
- `I-` は、トークンが同じエンティティ内に含まれていることを示します (たとえば、`State` トークンは次のようなエンティティの一部です)
`Empire State Building`)。
- `0` は、トークンがどのエンティティにも対応しないことを示します。
## Preprocess
<Youtube id="iY2AZYdZAr0"/>
次のステップでは、DistilBERT トークナイザーをロードして`tokens`フィールドを前処理します。
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
```
上の `tokens`フィールドの例で見たように、入力はすでにトークン化されているようです。しかし、実際には入力はまだトークン化されていないため、単語をサブワードにトークン化するには`is_split_into_words=True` を設定する必要があります。例えば:
```py
>>> example = wnut["train"][0]
>>> tokenized_input = tokenizer(example["tokens"], is_split_into_words=True)
>>> tokens = tokenizer.convert_ids_to_tokens(tokenized_input["input_ids"])
>>> tokens
['[CLS]', '@', 'paul', '##walk', 'it', "'", 's', 'the', 'view', 'from', 'where', 'i', "'", 'm', 'living', 'for', 'two', 'weeks', '.', 'empire', 'state', 'building', '=', 'es', '##b', '.', 'pretty', 'bad', 'storm', 'here', 'last', 'evening', '.', '[SEP]']
```
ただし、これによりいくつかの特別なトークン `[CLS]` と `[SEP]` が追加され、サブワードのトークン化により入力とラベルの間に不一致が生じます。 1 つのラベルに対応する 1 つの単語を 2 つのサブワードに分割できるようになりました。次の方法でトークンとラベルを再調整する必要があります。
1. [`word_ids`](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.BatchEncoding.word_ids) メソッドを使用して、すべてのトークンを対応する単語にマッピングします。
2. 特別なトークン `[CLS]` と `[SEP]` にラベル `-100` を割り当て、それらが PyTorch 損失関数によって無視されるようにします ([CrossEntropyLoss](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html))。
3. 特定の単語の最初のトークンのみにラベルを付けます。同じ単語の他のサブトークンに `-100`を割り当てます。
トークンとラベルを再調整し、シーケンスを DistilBERT の最大入力長以下に切り詰める関数を作成する方法を次に示します。
```py
>>> def tokenize_and_align_labels(examples):
... tokenized_inputs = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
... labels = []
... for i, label in enumerate(examples[f"ner_tags"]):
... word_ids = tokenized_inputs.word_ids(batch_index=i) # Map tokens to their respective word.
... previous_word_idx = None
... label_ids = []
... for word_idx in word_ids: # Set the special tokens to -100.
... if word_idx is None:
... label_ids.append(-100)
... elif word_idx != previous_word_idx: # Only label the first token of a given word.
... label_ids.append(label[word_idx])
... else:
... label_ids.append(-100)
... previous_word_idx = word_idx
... labels.append(label_ids)
... tokenized_inputs["labels"] = labels
... return tokenized_inputs
```
データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `batched=True` を設定してデータセットの複数の要素を一度に処理することで、`map` 関数を高速化できます。
```py
>>> tokenized_wnut = wnut.map(tokenize_and_align_labels, batched=True)
```
次に、[`DataCollatorWithPadding`] を使用してサンプルのバッチを作成します。データセット全体を最大長までパディングするのではなく、照合中にバッチ内の最長の長さまで文を *動的にパディング* する方が効率的です。
<frameworkcontent>
<pt>
```py
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
```
</pt>
<tf>
```py
>>> from transformers import DataCollatorForTokenClassification
>>> data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer, return_tensors="tf")
```
</tf>
</frameworkcontent>
## Evaluate
トレーニング中にメトリクスを含めると、多くの場合、モデルのパフォーマンスを評価するのに役立ちます。 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) ライブラリを使用して、評価メソッドをすばやくロードできます。このタスクでは、[seqeval](https://huggingface.co/spaces/evaluate-metric/seqeval) フレームワークを読み込みます (🤗 Evaluate [クイック ツアー](https://huggingface.co/docs/evaluate/a_quick_tour) を参照してください) ) メトリクスの読み込みと計算の方法について詳しくは、こちらをご覧ください)。 Seqeval は実際に、精度、再現率、F1、精度などのいくつかのスコアを生成します。
```py
>>> import evaluate
>>> seqeval = evaluate.load("seqeval")
```
まず NER ラベルを取得してから、真の予測と真のラベルを [`~evaluate.EvaluationModule.compute`] に渡してスコアを計算する関数を作成します。
```py
>>> import numpy as np
>>> labels = [label_list[i] for i in example[f"ner_tags"]]
>>> def compute_metrics(p):
... predictions, labels = p
... predictions = np.argmax(predictions, axis=2)
... true_predictions = [
... [label_list[p] for (p, l) in zip(prediction, label) if l != -100]
... for prediction, label in zip(predictions, labels)
... ]
... true_labels = [
... [label_list[l] for (p, l) in zip(prediction, label) if l != -100]
... for prediction, label in zip(predictions, labels)
... ]
... results = seqeval.compute(predictions=true_predictions, references=true_labels)
... return {
... "precision": results["overall_precision"],
... "recall": results["overall_recall"],
... "f1": results["overall_f1"],
... "accuracy": results["overall_accuracy"],
... }
```
これで`compute_metrics`関数の準備が整いました。トレーニングをセットアップするときにこの関数に戻ります。
## Train
モデルのトレーニングを開始する前に、`id2label`と`label2id`を使用して、予想される ID とそのラベルのマップを作成します。
```py
>>> id2label = {
... 0: "O",
... 1: "B-corporation",
... 2: "I-corporation",
... 3: "B-creative-work",
... 4: "I-creative-work",
... 5: "B-group",
... 6: "I-group",
... 7: "B-location",
... 8: "I-location",
... 9: "B-person",
... 10: "I-person",
... 11: "B-product",
... 12: "I-product",
... }
>>> label2id = {
... "O": 0,
... "B-corporation": 1,
... "I-corporation": 2,
... "B-creative-work": 3,
... "I-creative-work": 4,
... "B-group": 5,
... "I-group": 6,
... "B-location": 7,
... "I-location": 8,
... "B-person": 9,
... "I-person": 10,
... "B-product": 11,
... "I-product": 12,
... }
```
<frameworkcontent>
<pt>
<Tip>
[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[ここ](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
</Tip>
これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForTokenClassification`] を使用して、予期されるラベルの数とラベル マッピングを指定して DistilBERT を読み込みます。
```py
>>> from transformers import AutoModelForTokenClassification, TrainingArguments, Trainer
>>> model = AutoModelForTokenClassification.from_pretrained(
... "distilbert/distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
... )
```
この時点で残っているステップは 3 つだけです。
1. [`TrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。各エポックの終了時に、[`Trainer`] は連続スコアを評価し、トレーニング チェックポイントを保存します。
2. トレーニング引数を、モデル、データセット、トークナイザー、データ照合器、および `compute_metrics` 関数とともに [`Trainer`] に渡します。
3. [`~Trainer.train`] を呼び出してモデルを微調整します。
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_wnut_model",
... learning_rate=2e-5,
... per_device_train_batch_size=16,
... per_device_eval_batch_size=16,
... num_train_epochs=2,
... weight_decay=0.01,
... eval_strategy="epoch",
... save_strategy="epoch",
... load_best_model_at_end=True,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=tokenized_wnut["train"],
... eval_dataset=tokenized_wnut["test"],
... processing_class=tokenizer,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
```py
>>> trainer.push_to_hub()
```
</pt>
<tf>
<Tip>
Keras を使用したモデルの微調整に慣れていない場合は、[こちら](../training#train-a-tensorflow-model-with-keras) の基本的なチュートリアルをご覧ください。
</Tip>
TensorFlow でモデルを微調整するには、オプティマイザー関数、学習率スケジュール、およびいくつかのトレーニング ハイパーパラメーターをセットアップすることから始めます。
```py
>>> from transformers import create_optimizer
>>> batch_size = 16
>>> num_train_epochs = 3
>>> num_train_steps = (len(tokenized_wnut["train"]) // batch_size) * num_train_epochs
>>> optimizer, lr_schedule = create_optimizer(
... init_lr=2e-5,
... num_train_steps=num_train_steps,
... weight_decay_rate=0.01,
... num_warmup_steps=0,
... )
```
次に、[`TFAutoModelForTokenClassification`] を使用して、予期されるラベルの数とラベル マッピングを指定して DistilBERT をロードできます。
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained(
... "distilbert/distilbert-base-uncased", num_labels=13, id2label=id2label, label2id=label2id
... )
```
[`~transformers.TFPreTrainedModel.prepare_tf_dataset`] を使用して、データセットを `tf.data.Dataset` 形式に変換します。
```py
>>> tf_train_set = model.prepare_tf_dataset(
... tokenized_wnut["train"],
... shuffle=True,
... batch_size=16,
... collate_fn=data_collator,
... )
>>> tf_validation_set = model.prepare_tf_dataset(
... tokenized_wnut["validation"],
... shuffle=False,
... batch_size=16,
... collate_fn=data_collator,
... )
```
[`compile`](https://keras.io/api/models/model_training_apis/#compile-method) を使用してトレーニング用のモデルを設定します。 Transformers モデルにはすべてデフォルトのタスク関連の損失関数があるため、次の場合を除き、損失関数を指定する必要はないことに注意してください。
```py
>>> import tensorflow as tf
>>> model.compile(optimizer=optimizer) # No loss argument!
```
トレーニングを開始する前にセットアップする最後の 2 つのことは、予測から連続スコアを計算することと、モデルをハブにプッシュする方法を提供することです。どちらも [Keras コールバック](../main_classes/keras_callbacks) を使用して行われます。
`compute_metrics` 関数を [`~transformers.KerasMetricCallback`] に渡します。
```py
>>> from transformers.keras_callbacks import KerasMetricCallback
>>> metric_callback = KerasMetricCallback(metric_fn=compute_metrics, eval_dataset=tf_validation_set)
```
[`~transformers.PushToHubCallback`] でモデルとトークナイザーをプッシュする場所を指定します。
```py
>>> from transformers.keras_callbacks import PushToHubCallback
>>> push_to_hub_callback = PushToHubCallback(
... output_dir="my_awesome_wnut_model",
... tokenizer=tokenizer,
... )
```
次に、コールバックをまとめてバンドルします。
```py
>>> callbacks = [metric_callback, push_to_hub_callback]
```
ついに、モデルのトレーニングを開始する準備が整いました。トレーニングおよび検証データセット、エポック数、コールバックを指定して [`fit`](https://keras.io/api/models/model_training_apis/#fit-method) を呼び出し、モデルを微調整します。
```py
>>> model.fit(x=tf_train_set, validation_data=tf_validation_set, epochs=3, callbacks=callbacks)
```
トレーニングが完了すると、モデルは自動的にハブにアップロードされ、誰でも使用できるようになります。
</tf>
</frameworkcontent>
<Tip>
トークン分類のモデルを微調整する方法のより詳細な例については、対応するセクションを参照してください。
[PyTorch ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)
または [TensorFlow ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)。
</Tip>
## Inference
モデルを微調整したので、それを推論に使用できるようになりました。
推論を実行したいテキストをいくつか取得します。
```py
>>> text = "The Golden State Warriors are an American professional basketball team based in San Francisco."
```
推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用して NER の`pipeline`をインスタンス化し、テキストをそれに渡します。
```py
>>> from transformers import pipeline
>>> classifier = pipeline("ner", model="stevhliu/my_awesome_wnut_model")
>>> classifier(text)
[{'entity': 'B-location',
'score': 0.42658573,
'index': 2,
'word': 'golden',
'start': 4,
'end': 10},
{'entity': 'I-location',
'score': 0.35856336,
'index': 3,
'word': 'state',
'start': 11,
'end': 16},
{'entity': 'B-group',
'score': 0.3064001,
'index': 4,
'word': 'warriors',
'start': 17,
'end': 25},
{'entity': 'B-location',
'score': 0.65523505,
'index': 13,
'word': 'san',
'start': 80,
'end': 83},
{'entity': 'B-location',
'score': 0.4668663,
'index': 14,
'word': 'francisco',
'start': 84,
'end': 93}]
```
必要に応じて、`pipeline`の結果を手動で複製することもできます。
<frameworkcontent>
<pt>
テキストをトークン化して PyTorch テンソルを返します。
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="pt")
```
入力をモデルに渡し、`logits`を返します。
```py
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
最も高い確率でクラスを取得し、モデルの `id2label` マッピングを使用してそれをテキスト ラベルに変換します。
```py
>>> predictions = torch.argmax(logits, dim=2)
>>> predicted_token_class = [model.config.id2label[t.item()] for t in predictions[0]]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
```
</pt>
<tf>
テキストをトークン化し、TensorFlow テンソルを返します。
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> inputs = tokenizer(text, return_tensors="tf")
```
入力をモデルに渡し、`logits`を返します。
```py
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("stevhliu/my_awesome_wnut_model")
>>> logits = model(**inputs).logits
```
最も高い確率でクラスを取得し、モデルの `id2label` マッピングを使用してそれをテキスト ラベルに変換します。
```py
>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
>>> predicted_token_class = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]
>>> predicted_token_class
['O',
'O',
'B-location',
'I-location',
'B-group',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'O',
'B-location',
'B-location',
'O',
'O']
```
</tf>
</frameworkcontent>
|
transformers/docs/source/ja/tasks/token_classification.md/0
|
{
"file_path": "transformers/docs/source/ja/tasks/token_classification.md",
"repo_id": "transformers",
"token_count": 8903
}
| 42 |
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: 둘러보기
- local: installation
title: 설치방법
title: 시작하기
- sections:
- local: pipeline_tutorial
title: Pipeline으로 추론하기
- local: autoclass_tutorial
title: AutoClass로 사전 학습된 인스턴스 로드하기
- local: preprocessing
title: 데이터 전처리하기
- local: training
title: 사전 학습된 모델 미세 조정하기
- local: run_scripts
title: 스크립트로 학습하기
- local: accelerate
title: 🤗 Accelerate로 분산 학습 구성하기
- local: peft
title: 🤗 PEFT로 어댑터 로드 및 학습하기
- local: model_sharing
title: 만든 모델 공유하기
- local: transformers_agents
title: 에이전트
- local: llm_tutorial
title: 대규모 언어 모델로 생성하기
- local: conversations
title: Transformers로 채팅하기
title: 튜토리얼
- sections:
- isExpanded: false
sections:
- local: tasks/sequence_classification
title: 텍스트 분류
- local: tasks/token_classification
title: 토큰 분류
- local: tasks/question_answering
title: 질의 응답(Question Answering)
- local: tasks/language_modeling
title: 인과적 언어 모델링(Causal language modeling)
- local: tasks/masked_language_modeling
title: 마스킹된 언어 모델링(Masked language modeling)
- local: tasks/translation
title: 번역
- local: tasks/summarization
title: 요약
- local: tasks/multiple_choice
title: 객관식 문제(Multiple Choice)
title: 자연어처리
- isExpanded: false
sections:
- local: tasks/audio_classification
title: 오디오 분류
- local: tasks/asr
title: 자동 음성 인식
title: 오디오
- isExpanded: false
sections:
- local: tasks/image_classification
title: 이미지 분류
- local: tasks/semantic_segmentation
title: 의미적 분할(Semantic segmentation)
- local: tasks/video_classification
title: 영상 분류
- local: tasks/object_detection
title: 객체 탐지
- local: tasks/zero_shot_object_detection
title: 제로샷(zero-shot) 객체 탐지
- local: tasks/zero_shot_image_classification
title: 제로샷(zero-shot) 이미지 분류
- local: tasks/monocular_depth_estimation
title: 단일 영상 기반 깊이 추정
- local: tasks/image_to_image
title: Image-to-Image
- local: tasks/image_feature_extraction
title: 이미지 특징 추출
- local: tasks/mask_generation
title: 마스크 생성
- local: tasks/knowledge_distillation_for_image_classification
title: 컴퓨터 비전(이미지 분류)를 위한 지식 증류(knowledge distillation)
title: 컴퓨터 비전
- isExpanded: false
sections:
- local: tasks/image_captioning
title: 이미지 캡셔닝
- local: tasks/document_question_answering
title: 문서 질의 응답(Document Question Answering)
- local: tasks/visual_question_answering
title: 시각적 질의응답 (Visual Question Answering)
- local: in_translation
title: (번역중) Text to speech
title: 멀티모달
- isExpanded: false
sections:
- local: generation_strategies
title: 텍스트 생성 전략 사용자 정의
title: 생성
- isExpanded: false
sections:
- local: tasks/idefics
title: IDEFICS를 이용한 이미지 작업
- local: tasks/prompting
title: 대규모 언어 모델 프롬프팅 가이드
title: 프롬프팅
title: 태스크 가이드
- sections:
- local: fast_tokenizers
title: 🤗 Tokenizers 라이브러리에서 토크나이저 사용하기
- local: multilingual
title: 다국어 모델 추론하기
- local: create_a_model
title: 모델별 API 사용하기
- local: custom_models
title: 사용자 정의 모델 공유하기
- local: chat_templating
title: 챗봇 템플릿 익히기
- local: trainer
title: Trainer 사용하기
- local: sagemaker
title: Amazon SageMaker에서 학습 실행하기
- local: serialization
title: ONNX로 내보내기
- local: tflite
title: TFLite로 내보내기
- local: torchscript
title: TorchScript로 내보내기
- local: in_translation
title: (번역중) Notebooks with examples
- local: community
title: 커뮤니티 리소스
- local: troubleshooting
title: 문제 해결
- local: gguf
title: GGUF 파일들과의 상호 운용성
- local: modular_transformers
title: transformers에서의 모듈성
title: (번역중) 개발자 가이드
- sections:
- local: in_translation
title: (번역중) Getting started
- local: quantization/bitsandbytes
title: bitsandbytes
- local: quantization/gptq
title: GPTQ
- local: quantization/awq
title: AWQ
- local: in_translation
title: (번역중) AQLM
- local: in_translation
title: (번역중) VPTQ
- local: quantization/quanto
title: Quanto
- local: quantization/eetq
title: EETQ
- local: in_translation
title: (번역중) HQQ
- local: in_translation
title: (번역중) Optimum
- local: in_translation
title: (번역중) Contribute new quantization method
title: (번역중) 경량화 메소드
- sections:
- local: performance
title: 성능 및 확장성
- local: in_translation
title: (번역중) Quantization
- local: llm_optims
title: LLM 추론 최적화
- sections:
- local: in_translation
title: (번역중) Methods and tools for efficient training on a single GPU
- local: perf_train_gpu_many
title: 다중 GPU에서 훈련 진행하기
- local: deepspeed
title: DeepSpeed
- local: fsdp
title: 완전 분할 데이터 병렬 처리
- local: perf_train_cpu
title: CPU에서 훈련
- local: perf_train_cpu_many
title: 다중 CPU에서 훈련하기
- local: perf_train_tpu_tf
title: TensorFlow로 TPU에서 훈련하기
- local: perf_train_special
title: Apple 실리콘에서 PyTorch 학습
- local: perf_hardware
title: 훈련용 사용자 맞춤형 하드웨어
- local: hpo_train
title: Trainer API를 사용한 하이퍼파라미터 탐색
title: (번역중) 효율적인 학습 기술들
- sections:
- local: perf_infer_cpu
title: CPU로 추론하기
- local: perf_infer_gpu_one
title: 하나의 GPU를 활용한 추론
title: 추론 최적화하기
- local: big_models
title: 대형 모델을 인스턴스화
- local: debugging
title: 디버깅
- local: tf_xla
title: TensorFlow 모델을 위한 XLA 통합
- local: in_translation
title: (번역중) Optimize inference using `torch.compile()`
title: (번역중) 성능 및 확장성
- sections:
- local: contributing
title: 🤗 Transformers에 기여하는 방법
- local: add_new_model
title: 🤗 Transformers에 새로운 모델을 추가하는 방법
- local: add_new_pipeline
title: 어떻게 🤗 Transformers에 파이프라인을 추가하나요?
- local: testing
title: 테스트
- local: pr_checks
title: Pull Request에 대한 검사
title: 기여하기
- sections:
- local: philosophy
title: 이념과 목표
- local: in_translation
title: (번역중) Glossary
- local: task_summary
title: 🤗 Transformers로 할 수 있는 작업
- local: tasks_explained
title: 🤗 Transformers로 작업을 해결하는 방법
- local: model_summary
title: Transformer 모델군
- local: tokenizer_summary
title: 토크나이저 요약
- local: attention
title: 어텐션 매커니즘
- local: pad_truncation
title: 패딩과 잘라내기
- local: bertology
title: BERTology
- local: perplexity
title: 고정 길이 모델의 펄플렉서티(Perplexity)
- local: pipeline_webserver
title: 추론 웹 서버를 위한 파이프라인
- local: model_memory_anatomy
title: 모델 학습 해부하기
- local: llm_tutorial_optimization
title: LLM을 최대한 활용하기
title: (번역중) 개념 가이드
- sections:
- sections:
- local: main_classes/agent
title: 에이전트와 도구
- local: model_doc/auto
title: 자동 클래스
- local: in_translation
title: (번역중) Backbones
- local: main_classes/callback
title: 콜백
- local: main_classes/configuration
title: 구성
- local: main_classes/data_collator
title: 데이터 콜레이터
- local: main_classes/keras_callbacks
title: 케라스 콜백
- local: main_classes/logging
title: 로깅
- local: main_classes/model
title: Models
- local: main_classes/text_generation
title: 텍스트 생성
- local: main_classes/onnx
title: ONNX
- local: in_translation
title: (번역중) Optimization
- local: in_translation
title: 모델 출력
- local: main_classes/output
title: (번역중) Pipelines
- local: in_translation
title: (번역중) Processors
- local: main_classes/quantization
title: 양자화
- local: in_translation
title: (번역중) Tokenizer
- local: main_classes/trainer
title: Trainer
- local: deepspeed
title: DeepSpeed
- local: main_classes/executorch
title: ExecuTorch
- local: main_classes/feature_extractor
title: 특성 추출기
- local: in_translation
title: (번역중) Image Processor
title: (번역중) 메인 클래스
- sections:
- isExpanded: false
sections:
- local: in_translation
title: (번역중) ALBERT
- local: model_doc/bart
title: BART
- local: model_doc/barthez
title: BARThez
- local: model_doc/bartpho
title: BARTpho
- local: model_doc/bert
title: BERT
- local: in_translation
title: (번역중) BertGeneration
- local: model_doc/bert-japanese
title: 일본어 Bert
- local: model_doc/bertweet
title: Bertweet
- local: in_translation
title: (번역중) BigBird
- local: in_translation
title: (번역중) BigBirdPegasus
- local: model_doc/biogpt
title: BioGpt
- local: in_translation
title: (번역중) Blenderbot
- local: in_translation
title: (번역중) Blenderbot Small
- local: in_translation
title: (번역중) BLOOM
- local: in_translation
title: (번역중) BORT
- local: in_translation
title: (번역중) ByT5
- local: in_translation
title: (번역중) CamemBERT
- local: in_translation
title: (번역중) CANINE
- local: in_translation
title: (번역중) CodeGen
- local: model_doc/cohere
title: Cohere
- local: model_doc/convbert
title: ConvBERT
- local: in_translation
title: (번역중) CPM
- local: in_translation
title: (번역중) CPMANT
- local: in_translation
title: (번역중) CTRL
- local: model_doc/dbrx
title: DBRX
- local: model_doc/deberta
title: DeBERTa
- local: model_doc/deberta-v2
title: DeBERTa-v2
- local: in_translation
title: (번역중) DialoGPT
- local: in_translation
title: (번역중) DistilBERT
- local: in_translation
title: (번역중) DPR
- local: in_translation
title: (번역중) ELECTRA
- local: model_doc/encoder-decoder
title: 인코더 디코더 모델
- local: in_translation
title: (번역중) ERNIE
- local: in_translation
title: (번역중) ErnieM
- local: model_doc/esm
title: ESM
- local: in_translation
title: (번역중) FLAN-T5
- local: in_translation
title: (번역중) FLAN-UL2
- local: in_translation
title: (번역중) FlauBERT
- local: in_translation
title: (번역중) FNet
- local: in_translation
title: (번역중) FSMT
- local: in_translation
title: (번역중) Funnel Transformer
- local: model_doc/gemma
title: Gemma
- local: model_doc/gemma2
title: Gemma2
- local: model_doc/openai-gpt
title: GPT
- local: in_translation
title: (번역중) GPT Neo
- local: in_translation
title: (번역중) GPT NeoX
- local: model_doc/gpt_neox_japanese
title: GPT NeoX Japanese
- local: in_translation
title: (번역중) GPT-J
- local: in_translation
title: (번역중) GPT2
- local: in_translation
title: (번역중) GPTBigCode
- local: in_translation
title: (번역중) GPTSAN Japanese
- local: in_translation
title: (번역중) GPTSw3
- local: in_translation
title: (번역중) HerBERT
- local: in_translation
title: (번역중) I-BERT
- local: in_translation
title: (번역중) Jukebox
- local: in_translation
title: (번역중) LED
- local: model_doc/llama
title: LLaMA
- local: model_doc/llama2
title: LLaMA2
- local: model_doc/llama3
title: LLaMA3
- local: in_translation
title: (번역중) Longformer
- local: in_translation
title: (번역중) LongT5
- local: in_translation
title: (번역중) LUKE
- local: in_translation
title: (번역중) M2M100
- local: model_doc/mamba
title: Mamba
- local: model_doc/mamba2
title: Mamba2
- local: model_doc/marian
title: MarianMT
- local: in_translation
title: (번역중) MarkupLM
- local: in_translation
title: (번역중) MBart and MBart-50
- local: in_translation
title: (번역중) MEGA
- local: in_translation
title: (번역중) MegatronBERT
- local: in_translation
title: (번역중) MegatronGPT2
- local: model_doc/mistral
title: Mistral
- local: in_translation
title: (번역중) mLUKE
- local: in_translation
title: (번역중) MobileBERT
- local: in_translation
title: (번역중) MPNet
- local: in_translation
title: (번역중) MT5
- local: in_translation
title: (번역중) MVP
- local: in_translation
title: (번역중) NEZHA
- local: in_translation
title: (번역중) NLLB
- local: in_translation
title: (번역중) NLLB-MoE
- local: in_translation
title: (번역중) Nyströmformer
- local: in_translation
title: (번역중) Open-Llama
- local: in_translation
title: (번역중) OPT
- local: in_translation
title: (번역중) Pegasus
- local: in_translation
title: (번역중) PEGASUS-X
- local: in_translation
title: (번역중) PhoBERT
- local: in_translation
title: (번역중) PLBart
- local: in_translation
title: (번역중) ProphetNet
- local: in_translation
title: (번역중) QDQBert
- local: model_doc/rag
title: RAG(검색 증강 생성)
- local: in_translation
title: (번역중) REALM
- local: in_translation
title: (번역중) Reformer
- local: in_translation
title: (번역중) RemBERT
- local: in_translation
title: (번역중) RetriBERT
- local: in_translation
title: (번역중) RoBERTa
- local: in_translation
title: (번역중) RoBERTa-PreLayerNorm
- local: in_translation
title: (번역중) RoCBert
- local: in_translation
title: (번역중) RoFormer
- local: in_translation
title: (번역중) Splinter
- local: in_translation
title: (번역중) SqueezeBERT
- local: in_translation
title: (번역중) SwitchTransformers
- local: in_translation
title: (번역중) T5
- local: in_translation
title: (번역중) T5v1.1
- local: in_translation
title: (번역중) TAPEX
- local: in_translation
title: (번역중) Transformer XL
- local: in_translation
title: (번역중) UL2
- local: in_translation
title: (번역중) X-MOD
- local: in_translation
title: (번역중) XGLM
- local: in_translation
title: (번역중) XLM
- local: in_translation
title: (번역중) XLM-ProphetNet
- local: in_translation
title: (번역중) XLM-RoBERTa
- local: in_translation
title: (번역중) XLM-RoBERTa-XL
- local: in_translation
title: (번역중) XLM-V
- local: in_translation
title: (번역중) XLNet
- local: in_translation
title: (번역중) YOSO
title: (번역중) 텍스트 모델
- isExpanded: false
sections:
- local: in_translation
title: (번역중) BEiT
- local: in_translation
title: (번역중) BiT
- local: in_translation
title: (번역중) Conditional DETR
- local: in_translation
title: (번역중) ConvNeXT
- local: in_translation
title: (번역중) ConvNeXTV2
- local: in_translation
title: (번역중) CvT
- local: in_translation
title: (번역중) Deformable DETR
- local: in_translation
title: (번역중) DeiT
- local: in_translation
title: (번역중) DETA
- local: in_translation
title: (번역중) DETR
- local: in_translation
title: (번역중) DiNAT
- local: in_translation
title: (번역중) DiT
- local: in_translation
title: (번역중) DPT
- local: in_translation
title: (번역중) EfficientFormer
- local: in_translation
title: (번역중) EfficientNet
- local: in_translation
title: (번역중) FocalNet
- local: in_translation
title: (번역중) GLPN
- local: in_translation
title: (번역중) ImageGPT
- local: in_translation
title: (번역중) LeViT
- local: in_translation
title: (번역중) Mask2Former
- local: in_translation
title: (번역중) MaskFormer
- local: in_translation
title: (번역중) MobileNetV1
- local: in_translation
title: (번역중) MobileNetV2
- local: in_translation
title: (번역중) MobileViT
- local: in_translation
title: (번역중) NAT
- local: in_translation
title: (번역중) PoolFormer
- local: in_translation
title: (번역중) RegNet
- local: in_translation
title: (번역중) ResNet
- local: in_translation
title: (번역중) SegFormer
- local: model_doc/swin
title: Swin Transformer
- local: model_doc/swinv2
title: Swin Transformer V2
- local: model_doc/swin2sr
title: Swin2SR
- local: in_translation
title: (번역중) Table Transformer
- local: in_translation
title: (번역중) TimeSformer
- local: in_translation
title: (번역중) UperNet
- local: in_translation
title: (번역중) VAN
- local: in_translation
title: (번역중) VideoMAE
- local: in_translation
title: Vision Transformer (ViT)
- local: model_doc/vit
title: (번역중) ViT Hybrid
- local: in_translation
title: (번역중) ViTMAE
- local: in_translation
title: (번역중) ViTMSN
- local: in_translation
title: (번역중) YOLOS
title: (번역중) 비전 모델
- isExpanded: false
sections:
- local: in_translation
title: (번역중) Audio Spectrogram Transformer
- local: in_translation
title: (번역중) CLAP
- local: in_translation
title: (번역중) Hubert
- local: in_translation
title: (번역중) MCTCT
- local: in_translation
title: (번역중) SEW
- local: in_translation
title: (번역중) SEW-D
- local: in_translation
title: (번역중) Speech2Text
- local: in_translation
title: (번역중) Speech2Text2
- local: in_translation
title: (번역중) SpeechT5
- local: in_translation
title: (번역중) UniSpeech
- local: in_translation
title: (번역중) UniSpeech-SAT
- local: in_translation
title: (번역중) Wav2Vec2
- local: in_translation
title: (번역중) Wav2Vec2-Conformer
- local: in_translation
title: (번역중) Wav2Vec2Phoneme
- local: in_translation
title: (번역중) WavLM
- local: model_doc/whisper
title: Whisper
- local: in_translation
title: (번역중) XLS-R
- local: in_translation
title: (번역중) XLSR-Wav2Vec2
title: (번역중) 오디오 모델
- isExpanded: false
sections:
- local: model_doc/timesformer
title: TimeSformer
- local: in_translation
title: (번역중) VideoMAE
- local: model_doc/vivit
title: ViViT
title: (번역중) 비디오 모델
- isExpanded: false
sections:
- local: in_translation
title: (번역중) ALIGN
- local: model_doc/altclip
title: AltCLIP
- local: model_doc/blip-2
title: BLIP-2
- local: model_doc/blip
title: BLIP
- local: in_translation
title: (번역중) BridgeTower
- local: model_doc/chameleon
title: Chameleon
- local: in_translation
title: (번역중) Chinese-CLIP
- local: model_doc/clip
title: CLIP
- local: in_translation
title: (번역중) CLIPSeg
- local: in_translation
title: (번역중) Data2Vec
- local: in_translation
title: (번역중) DePlot
- local: in_translation
title: (번역중) Donut
- local: in_translation
title: (번역중) FLAVA
- local: in_translation
title: (번역중) GIT
- local: in_translation
title: (번역중) GroupViT
- local: in_translation
title: (번역중) LayoutLM
- local: in_translation
title: (번역중) LayoutLMV2
- local: in_translation
title: (번역중) LayoutLMV3
- local: in_translation
title: (번역중) LayoutXLM
- local: in_translation
title: (번역중) LiLT
- local: in_translation
title: (번역중) LXMERT
- local: in_translation
title: (번역중) MatCha
- local: in_translation
title: (번역중) MGP-STR
- local: in_translation
title: (번역중) OneFormer
- local: in_translation
title: (번역중) OWL-ViT
- local: model_doc/paligemma
title: PaliGemma
- local: in_translation
title: (번역중) Perceiver
- local: in_translation
title: (번역중) Pix2Struct
- local: in_translation
title: (번역중) Segment Anything
- local: in_translation
title: (번역중) Speech Encoder Decoder Models
- local: in_translation
title: (번역중) TAPAS
- local: in_translation
title: (번역중) TrOCR
- local: in_translation
title: (번역중) TVLT
- local: in_translation
title: (번역중) ViLT
- local: in_translation
title: (번역중) Vision Encoder Decoder Models
- local: in_translation
title: (번역중) Vision Text Dual Encoder
- local: in_translation
title: (번역중) VisualBERT
- local: in_translation
title: (번역중) X-CLIP
title: (번역중) 멀티모달 모델
- isExpanded: false
sections:
- local: in_translation
title: (번역중) Decision Transformer
- local: model_doc/trajectory_transformer
title: 궤적 트랜스포머
title: (번역중) 강화학습 모델
- isExpanded: false
sections:
- local: model_doc/autoformer
title: Autoformer
- local: model_doc/informer
title: Informer
- local: model_doc/patchtsmixer
title: PatchTSMixer
- local: model_doc/patchtst
title: PatchTST
- local: model_doc/time_series_transformer
title: 시계열 트랜스포머
title: 시계열 모델
- isExpanded: false
sections:
- local: model_doc/graphormer
title: Graphormer
title: 그래프 모델
title: (번역중) 모델
- sections:
- local: internal/modeling_utils
title: 사용자 정의 레이어 및 유틸리티
- local: internal/pipelines_utils
title: 파이프라인을 위한 유틸리티
- local: internal/tokenization_utils
title: 토크나이저를 위한 유틸리티
- local: internal/trainer_utils
title: Trainer를 위한 유틸리티
- local: internal/generation_utils
title: 생성을 위한 유틸리티
- local: internal/image_processing_utils
title: 이미지 프로세서를 위한 유틸리티
- local: internal/audio_utils
title: 오디오 처리를 위한 유틸리티
- local: internal/file_utils
title: 일반 유틸리티
- local: internal/time_series_utils
title: 시계열을 위한 유틸리티
title: (번역중) Internal Helpers
title: (번역중) API
|
transformers/docs/source/ko/_toctree.yml/0
|
{
"file_path": "transformers/docs/source/ko/_toctree.yml",
"repo_id": "transformers",
"token_count": 14158
}
| 43 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Tokenizers 라이브러리의 토크나이저 사용하기[[use-tokenizers-from-tokenizers]]
[`PreTrainedTokenizerFast`]는 [🤗 Tokenizers](https://huggingface.co/docs/tokenizers) 라이브러리에 기반합니다. 🤗 Tokenizers 라이브러리의 토크나이저는
🤗 Transformers로 매우 간단하게 불러올 수 있습니다.
구체적인 내용에 들어가기 전에, 몇 줄의 코드로 더미 토크나이저를 만들어 보겠습니다:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
우리가 정의한 파일을 통해 이제 학습된 토크나이저를 갖게 되었습니다. 이 런타임에서 계속 사용하거나 JSON 파일로 저장하여 나중에 사용할 수 있습니다.
## 토크나이저 객체로부터 직접 불러오기[[loading-directly-from-the-tokenizer-object]]
🤗 Transformers 라이브러리에서 이 토크나이저 객체를 활용하는 방법을 살펴보겠습니다.
[`PreTrainedTokenizerFast`] 클래스는 인스턴스화된 *토크나이저* 객체를 인수로 받아 쉽게 인스턴스화할 수 있습니다:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
이제 `fast_tokenizer` 객체는 🤗 Transformers 토크나이저에서 공유하는 모든 메소드와 함께 사용할 수 있습니다! 자세한 내용은 [토크나이저 페이지](main_classes/tokenizer)를 참조하세요.
## JSON 파일에서 불러오기[[loading-from-a-JSON-file]]
<!--In order to load a tokenizer from a JSON file, let's first start by saving our tokenizer:-->
JSON 파일에서 토크나이저를 불러오기 위해, 먼저 토크나이저를 저장해 보겠습니다:
```python
>>> tokenizer.save("tokenizer.json")
```
JSON 파일을 저장한 경로는 `tokenizer_file` 매개변수를 사용하여 [`PreTrainedTokenizerFast`] 초기화 메소드에 전달할 수 있습니다:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
이제 `fast_tokenizer` 객체는 🤗 Transformers 토크나이저에서 공유하는 모든 메소드와 함께 사용할 수 있습니다! 자세한 내용은 [토크나이저 페이지](main_classes/tokenizer)를 참조하세요.
|
transformers/docs/source/ko/fast_tokenizers.md/0
|
{
"file_path": "transformers/docs/source/ko/fast_tokenizers.md",
"repo_id": "transformers",
"token_count": 1829
}
| 44 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer를 위한 유틸리티 (Utilities for Trainer) [[utilities-for-trainer]]
이 페이지는 [`Trainer`]에서 사용되는 모든 유틸리티 함수들을 나열합니다.
이 함수들 대부분은 라이브러리에 있는 Trainer 코드를 자세히 알아보고 싶을 때만 유용합니다.
## 유틸리티 (Utilities) [[transformers.EvalPrediction]]
[[autodoc]] EvalPrediction
[[autodoc]] IntervalStrategy
[[autodoc]] enable_full_determinism
[[autodoc]] set_seed
[[autodoc]] torch_distributed_zero_first
## 콜백 내부 (Callbacks internals) [[transformers.trainer_callback.CallbackHandler]]
[[autodoc]] trainer_callback.CallbackHandler
## 분산 평가 (Distributed Evaluation) [[transformers.trainer_pt_utils.DistributedTensorGatherer]]
[[autodoc]] trainer_pt_utils.DistributedTensorGatherer
## Trainer 인자 파서 (Trainer Argument Parser) [[transformers.HfArgumentParser]]
[[autodoc]] HfArgumentParser
## 디버그 유틸리티 (Debug Utilities) [[transformers.debug_utils.DebugUnderflowOverflow]]
[[autodoc]] debug_utils.DebugUnderflowOverflow
|
transformers/docs/source/ko/internal/trainer_utils.md/0
|
{
"file_path": "transformers/docs/source/ko/internal/trainer_utils.md",
"repo_id": "transformers",
"token_count": 703
}
| 45 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 생성 [[generation]]
각 프레임워크에는 해당하는 `GenerationMixin` 클래스에서 구현된 텍스트 생성을 위한 generate 메소드가 있습니다:
- PyTorch에서는 [`~generation.GenerationMixin.generate`]가 [`~generation.GenerationMixin`]에 구현되어 있습니다.
- TensorFlow에서는 [`~generation.TFGenerationMixin.generate`]가 [`~generation.TFGenerationMixin`]에 구현되어 있습니다.
- Flax/JAX에서는 [`~generation.FlaxGenerationMixin.generate`]가 [`~generation.FlaxGenerationMixin`]에 구현되어 있습니다.
사용하는 프레임워크에 상관없이, generate 메소드는 [`~generation.GenerationConfig`] 클래스 인스턴스로 매개변수화 할 수 있습니다. generate 메소드의 동작을 제어하는 모든 생성 매개변수 목록을 확인하려면 이 클래스를 참조하세요.
모델의 생성 설정을 어떻게 확인하고, 기본값이 무엇인지, 매개변수를 어떻게 임시로 변경하는지, 그리고 사용자 지정 생성 설정을 만들고 저장하는 방법을 배우려면 [텍스트 생성 전략 가이드](../generation_strategies)를 참조하세요. 이 가이드는 토큰 스트리밍과 같은 관련 기능을 사용하는 방법도 설명합니다.
## GenerationConfig [[transformers.GenerationConfig]]
[[autodoc]] generation.GenerationConfig
- from_pretrained
- from_model_config
- save_pretrained
- update
- validate
- get_generation_mode
[[autodoc]] generation.WatermarkingConfig
## GenerationMixin [[transformers.GenerationMixin]]
[[autodoc]] generation.GenerationMixin
- generate
- compute_transition_scores
## TFGenerationMixin [[transformers.TFGenerationMixin]]
[[autodoc]] generation.TFGenerationMixin
- generate
- compute_transition_scores
## FlaxGenerationMixin [[transformers.FlaxGenerationMixin]]
[[autodoc]] generation.FlaxGenerationMixin
- generate
|
transformers/docs/source/ko/main_classes/text_generation.md/0
|
{
"file_path": "transformers/docs/source/ko/main_classes/text_generation.md",
"repo_id": "transformers",
"token_count": 1306
}
| 46 |
# Cohere[[cohere]]
## 개요[[overview]]
The Cohere Command-R 모델은 Cohere팀이 [Command-R: 프로덕션 규모의 검색 증강 생성](https://txt.cohere.com/command-r/)라는 블로그 포스트에서 소개 되었습니다.
논문 초록:
*Command-R은 기업의 프로덕션 규모 AI를 가능하게 하기 위해 RAG(검색 증강 생성)와 도구 사용을 목표로 하는 확장 가능한 생성 모델입니다. 오늘 우리는 대규모 프로덕션 워크로드를 목표로 하는 새로운 LLM인 Command-R을 소개합니다. Command-R은 높은 효율성과 강력한 정확성의 균형을 맞추는 '확장 가능한' 모델 카테고리를 대상으로 하여, 기업들이 개념 증명을 넘어 프로덕션 단계로 나아갈 수 있게 합니다.*
*Command-R은 검색 증강 생성(RAG)이나 외부 API 및 도구 사용과 같은 긴 문맥 작업에 최적화된 생성 모델입니다. 이 모델은 RAG 애플리케이션을 위한 최고 수준의 통합을 제공하고 기업 사용 사례에서 뛰어난 성능을 발휘하기 위해 우리의 업계 선도적인 Embed 및 Rerank 모델과 조화롭게 작동하도록 설계되었습니다. 기업이 대규모로 구현할 수 있도록 만들어진 모델로서, Command-R은 다음과 같은 특징을 자랑합니다:
- RAG 및 도구 사용에 대한 강력한 정확성
- 낮은 지연 시간과 높은 처리량
- 더 긴 128k 컨텍스트와 낮은 가격
- 10개의 주요 언어에 걸친 강력한 기능
- 연구 및 평가를 위해 HuggingFace에서 사용 가능한 모델 가중치
모델 체크포인트는 [이곳](https://huggingface.co/CohereForAI/c4ai-command-r-v01)에서 확인하세요.
이 모델은 [Saurabh Dash](https://huggingface.co/saurabhdash)과 [Ahmet Üstün](https://huggingface.co/ahmetustun)에 의해 기여 되었습니다. Hugging Face에서 이 코드의 구현은 [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)에 기반하였습니다.
## 사용 팁[[usage-tips]]
<Tip warning={true}>
Hub에 업로드된 체크포인트들은 `torch_dtype = 'float16'`을 사용합니다.
이는 `AutoModel` API가 체크포인트를 `torch.float32`에서 `torch.float16`으로 변환하는 데 사용됩니다.
온라인 가중치의 `dtype`은 `model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")`를 사용하여 모델을 초기화할 때 `torch_dtype="auto"`를 사용하지 않는 한 대부분 무관합니다. 그 이유는 모델이 먼저 다운로드되고(온라인 체크포인트의 `dtype` 사용), 그 다음 `torch`의 기본 `dtype`으로 변환되며(이때 `torch.float32`가 됨), 마지막으로 config에 `torch_dtype`이 제공된 경우 이를 사용하기 때문입니다.
모델을 `float16`으로 훈련하는 것은 권장되지 않으며 `nan`을 생성하는 것으로 알려져 있습니다. 따라서 모델은 `bfloat16`으로 훈련해야 합니다.
</Tip>
모델과 토크나이저는 다음과 같이 로드할 수 있습니다:
```python
# pip install transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "CohereForAI/c4ai-command-r-v01"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# Format message with the command-r chat template
messages = [{"role": "user", "content": "Hello, how are you?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Hello, how are you?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
```
- Flash Attention 2를 `attn_implementation="flash_attention_2"`를 통해 사용할 때는, `from_pretrained` 클래스 메서드에 `torch_dtype`을 전달하지 말고 자동 혼합 정밀도 훈련(Automatic Mixed-Precision training)을 사용하세요. `Trainer`를 사용할 때는 단순히 `fp16` 또는 `bf16`을 `True`로 지정하면 됩니다. 그렇지 않은 경우에는 `torch.autocast`를 사용하고 있는지 확인하세요. 이는 Flash Attention이 `fp16`와 `bf16` 데이터 타입만 지원하기 때문에 필요합니다.
## 리소스[[resources]]
Command-R을 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
<PipelineTag pipeline="text-generation"/>
FP16 모델 로딩
```python
# pip install transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "CohereForAI/c4ai-command-r-v01"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# command-r 챗 템플릿으로 메세지 형식을 정하세요
messages = [{"role": "user", "content": "Hello, how are you?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Hello, how are you?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
```
bitsandbytes 라이브러리를 이용해서 4bit 양자화된 모델 로딩
```python
# pip install transformers bitsandbytes accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(load_in_4bit=True)
model_id = "CohereForAI/c4ai-command-r-v01"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config)
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
```
## CohereConfig[[transformers.CohereConfig]]
[[autodoc]] CohereConfig
## CohereTokenizerFast[[transformers.CohereTokenizerFast]]
[[autodoc]] CohereTokenizerFast
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- update_post_processor
- save_vocabulary
## CohereModel[[transformers.CohereModel]]
[[autodoc]] CohereModel
- forward
## CohereForCausalLM[[transformers.CohereForCausalLM]]
[[autodoc]] CohereForCausalLM
- forward
|
transformers/docs/source/ko/model_doc/cohere.md/0
|
{
"file_path": "transformers/docs/source/ko/model_doc/cohere.md",
"repo_id": "transformers",
"token_count": 4111
}
| 47 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 맘바2[[mamba-2]]
## 개요[[overview]]
맘바2 모델은 Tri Dao, Albert Gu가 제안한 [트랜스포머는 SSM이다: 구조화된 상태 공간 이중성을 통한 일반화된 모델과 효율적인 알고리즘](https://arxiv.org/abs/2405.21060)라는 논문에서 소개되었습니다. 맘바2는 맘바1과 유사한 상태 공간 모델로, 단순화된 아키텍처에서 더 나은 성능을 보입니다.
해당 논문의 초록입니다:
*트랜스포머는 언어 모델링에서 딥러닝 성공의 주요 아키텍처였지만, 맘바와 같은 상태 공간 모델(SSM)이 최근 소규모 혹은 중간 규모에서 트랜스포머와 대등하거나 더 나은 성능을 보이는 것으로 나타났습니다. 우리는 이러한 모델 계열들이 실제로 매우 밀접하게 연관되어 있음을 파악했습니다. 그리고 구조화된 준분리(semiseparable) 행렬 중 연구가 잘 이루어진 클래스의 다양한 분해를 통해 연결된 SSM과 어텐션 변형 사이의 풍부한 이론적 연결 프레임워크를 개발했습니다. 상태 공간 이중성(SSD) 프레임워크를 통해 맘바1의 선택적 SSM을 개선한 새로운 아키텍처를 설계할 수 있었고, 트랜스포머와 경쟁력을 유지하면서도 속도는 2~8배 더 빠른 성능을 냅니다.*
팁:
이 버전은 맘바2 구현을 지원해야 하며, 특히 Mistral AI의 [Mamba-2 codestral](https://huggingface.co/mistralai/Mamba-Codestral-7B-v0.1)을 지원합니다. 특히, mamba 2 codestral은 8개의 `groups`로 출시되었는데, 이는 어텐션 기반 모델의 KV 헤드 수와 유사하다고 판단 가능합니다.
이 모델은 `torch_forward`와 `cuda_kernels_forward`라는 두 가지 다른 전방 패스를 가집니다. `cuda_kernels_forward`는 환경에서 cuda 커널을 찾으면 이를 사용하며, prefill에서는 더 느립니다. 즉, 높은 CPU 오버헤드로 인해 "웜업 실행"이 필요하기 때문입니다. 관련 내용은 [이곳](https://github.com/state-spaces/mamba/issues/389#issuecomment-2171755306)과 [이곳](https://github.com/state-spaces/mamba/issues/355#issuecomment-2147597457)을 참고하세요.
컴파일 없이는 `torch_forward` 구현이 3~4배 빠릅니다. 또한, 이 모델에는 위치 임베딩이 없지만 `attention_mask`와 배치 생성의 경우 두 곳에서 은닉 상태(hidden state)를 마스킹하는 특정 로직이 있습니다. 관련 내용은 [이곳](https://github.com/state-spaces/mamba/issues/66#issuecomment-1863563829)을 참고하세요.
이로인해 맘바2 커널의 재구현과 함께 배치 생성 및 캐시된 생성에서 약간의 차이가 예상됩니다. 또한 cuda 커널 또는 torch forward가 제공하는 결과가 약간 다를 것으로 예상됩니다. SSM 알고리즘은 텐서 수축에 크게 의존하는데, 이는 matmul과 동등하지만 연산 순서가 약간 다르며, 이로 인해 더 작은 정밀도에서 차이가 더 커집니다.
또 다른 참고사항으로, 패딩 토큰에 해당하는 은닉 상태(hidden state)의 종료는 두 곳에서 이루어지며 주로 왼쪽 패딩으로 테스트되었습니다. 오른쪽 패딩은 노이즈를 전파하므로 만족스러운 결과를 보장하지 않습니다. `tokenizer.padding_side = "left"`를 사용하면 올바른 패딩 방향을 사용할 수 있습니다.
이 모델은 [Molbap](https://huggingface.co/Molbap)이 기여했으며, [Anton Vlasjuk](https://github.com/vasqu)의 큰 도움을 받았습니다.
원본 코드는 [이곳](https://github.com/state-spaces/mamba)에서 확인할 수 있습니다.
# 사용
### 간단한 생성 예:
```python
from transformers import Mamba2Config, Mamba2ForCausalLM, AutoTokenizer
import torch
model_id = 'mistralai/Mamba-Codestral-7B-v0.1'
tokenizer = AutoTokenizer.from_pretrained(model_id, revision='refs/pr/9', from_slow=True, legacy=False)
model = Mamba2ForCausalLM.from_pretrained(model_id, revision='refs/pr/9')
input_ids = tokenizer("Hey how are you doing?", return_tensors= "pt")["input_ids"]
out = model.generate(input_ids, max_new_tokens=10)
print(tokenizer.batch_decode(out))
```
이곳은 미세조정을 위한 초안 스크립트입니다:
```python
from trl import SFTTrainer
from peft import LoraConfig
from transformers import AutoTokenizer, Mamba2ForCausalLM, TrainingArguments
model_id = 'mistralai/Mamba-Codestral-7B-v0.1'
tokenizer = AutoTokenizer.from_pretrained(model_id, revision='refs/pr/9', from_slow=True, legacy=False)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left" #왼쪽 패딩으로 설정
model = Mamba2ForCausalLM.from_pretrained(model_id, revision='refs/pr/9')
dataset = load_dataset("Abirate/english_quotes", split="train")
# CUDA 커널없이는, 배치크기 2가 80GB 장치를 하나 차지합니다.
# 하지만 정확도는 감소합니다.
# 실험과 시도를 환영합니다!
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=2,
logging_dir='./logs',
logging_steps=10,
learning_rate=2e-3
)
lora_config = LoraConfig(
r=8,
target_modules=["embeddings", "in_proj", "out_proj"],
task_type="CAUSAL_LM",
bias="none"
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
args=training_args,
peft_config=lora_config,
train_dataset=dataset,
dataset_text_field="quote",
)
trainer.train()
```
## Mamba2Config
[[autodoc]] Mamba2Config
## Mamba2Model
[[autodoc]] Mamba2Model
- forward
## Mamba2LMHeadModel
[[autodoc]] Mamba2ForCausalLM
- forward
|
transformers/docs/source/ko/model_doc/mamba2.md/0
|
{
"file_path": "transformers/docs/source/ko/model_doc/mamba2.md",
"repo_id": "transformers",
"token_count": 3943
}
| 48 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Whisper [[whisper]]
## 개요 [[overview]]
Whisper 모델은 Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, Ilya Sutskever에 의해 [Robust Speech Recognition via Large-Scale Weak Supervision](https://cdn.openai.com/papers/whisper.pdf)에서 제안되었습니다.
논문의 초록은 다음과 같습니다:
*우리는 인터넷에서 대량의 오디오를 글로 옮긴 것을 예측하도록 간단히 훈련된 음성 처리 시스템의 성능을 연구합니다. 68만 시간의 다국어 및 다중 작업 지도(multitask supervision)에 확장했을 때, 결과 모델은 표준 벤치마크에 잘 일반화되며, 미세 조정이 필요 없는 제로샷 전송 설정에서 이전의 완전히 지도된(fully-supervised) 결과와 경쟁할 수 있는 경우가 많습니다. 사람과 비교하면, 이 모델은 사람의 정확도와 견고성에 근접합니다. 우리는 강력한 음성 처리를 위한 추가 작업의 기반이 될 모델과 추론 코드를 공개합니다.*
팁:
- 이 모델은 일반적으로 별도의 미세 조정 없이도 잘 작동합니다.
- 아키텍처는 고전적인 인코더-디코더 아키텍처를 따르기 때문에, 추론을 위해 [`~generation.GenerationMixin.generate`] 함수를 사용합니다.
- 현재 추론은 짧은 형식에만 구현되어 있으며, 오디오는 30초 미만의 세그먼트로 미리 분할되어야 합니다. 타임스탬프를 포함한 긴 형식에 대한 추론은 향후 릴리스에서 구현될 예정입니다.
- [`WhisperProcessor`]를 사용하여 모델에 사용할 오디오를 준비하고, 예측된 ID를 텍스트로 디코딩할 수 있습니다.
- 모델과 프로세서를 변환하려면 다음을 사용하는 것이 좋습니다:
```bash
python src/transformers/models/whisper/convert_openai_to_hf.py --checkpoint_path "" --pytorch_dump_folder_path "Arthur/whisper-3" --convert_preprocessor True
```
스크립트는 OpenAI 체크포인트에서 필요한 모든 매개변수를 자동으로 결정합니다. OpenAI 변환을 수행하려면 `tiktoken` 라이브러리를 설치해야 합니다.
라이브러리를 설치해야 OpenAI 토큰화기를 `tokenizers` 버전으로 변환할 수 있습니다.
이 모델은 [Arthur Zucker](https://huggingface.co/ArthurZ)에 의해 제공되었습니다. 이 모델의 Tensorflow 버전은 [amyeroberts](https://huggingface.co/amyeroberts)에 의해 제공되었습니다.
원본 코드는 [여기](https://github.com/openai/whisper)에서 찾을 수 있습니다.
## WhisperConfig [[whisperconfig]]
[[autodoc]] WhisperConfig
## WhisperTokenizer [[whispertokenizer]]
[[autodoc]] WhisperTokenizer
- set_prefix_tokens
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## WhisperTokenizerFast [[whispertokenizerfast]]
[[autodoc]] WhisperTokenizerFast
- set_prefix_tokens
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## WhisperFeatureExtractor [[whisperfeatureextractor]]
[[autodoc]] WhisperFeatureExtractor
- __call__
## WhisperProcessor [[whisperprocessor]]
[[autodoc]] WhisperProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
## WhisperModel [[whispermodel]]
[[autodoc]] WhisperModel
- forward
- _mask_input_features
## WhisperForConditionalGeneration [[whisperforconditionalgeneration]]
[[autodoc]] WhisperForConditionalGeneration
- forward
## WhisperForAudioClassification [[whisperforaudioclassification]]
[[autodoc]] WhisperForAudioClassification
- forward
## TFWhisperModel [[tfwhispermodel]]
[[autodoc]] TFWhisperModel
- call
## TFWhisperForConditionalGeneration [[tfwhisperforconditionalgeneration]]
[[autodoc]] TFWhisperForConditionalGeneration
- call
## FlaxWhisperModel [[flaxwhispermodel]]
[[autodoc]] FlaxWhisperModel
- __call__
## FlaxWhisperForConditionalGeneration [[flaxwhisperforconditionalgeneration]]
[[autodoc]] FlaxWhisperForConditionalGeneration
- __call__
## FlaxWhisperForAudioClassification [[flaxwhisperforaudioclassification]]
[[autodoc]] FlaxWhisperForAudioClassification
- __call__
|
transformers/docs/source/ko/model_doc/whisper.md/0
|
{
"file_path": "transformers/docs/source/ko/model_doc/whisper.md",
"repo_id": "transformers",
"token_count": 2696
}
| 49 |
<!---
Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 성능 및 확장성 [[performance-and-scalability]]
점점 더 큰 규모의 트랜스포머 모델을 훈련하고 프로덕션에 배포하는 데에는 다양한 어려움이 따릅니다. 훈련 중에는 모델이 사용 가능한 GPU 메모리보다 더 많은 메모리를 필요로 하거나 훈련 속도가 매우 느릴 수 있으며, 추론을 위해 배포할 때는 제품 환경에서 요구되는 처리량으로 인해 과부하가 발생할 수 있습니다. 이 문서는 이러한 문제를 극복하고 사용 사례에 가장 적합한 설정을 찾도록 도움을 주기 위해 설계되었습니다. 훈련과 추론으로 가이드를 분할했는데, 이는 각각 다른 문제와 해결 방법이 있기 때문입니다. 그리고 각 가이드에는 다양한 종류의 하드웨어 설정에 대한 별도의 가이드가 있습니다(예: 훈련을 위한 단일 GPU vs 다중 GPU 또는 추론을 위한 CPU vs GPU).
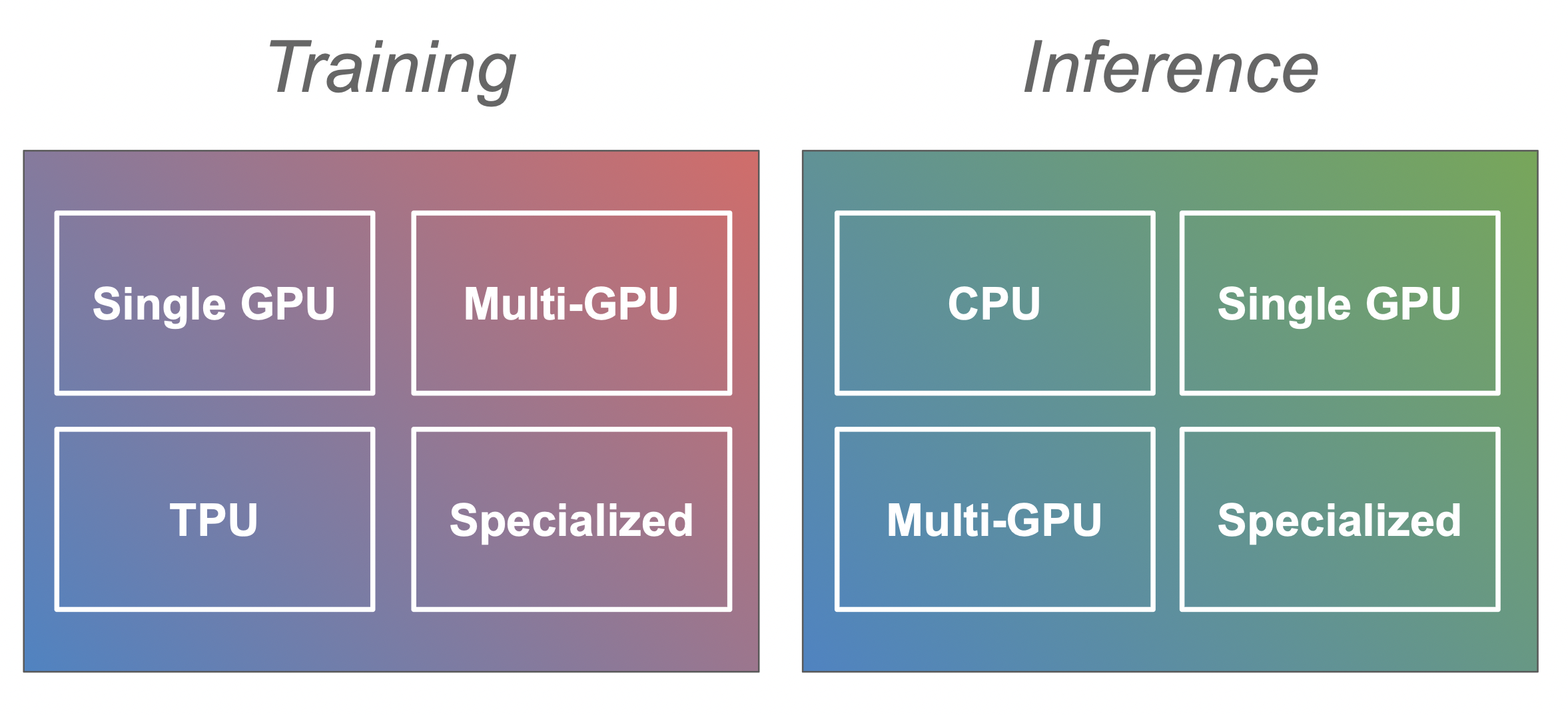
이 문서는 사용자의 상황에 유용할 수 있는 방법들에 대한 개요 및 시작점 역할을 합니다.
## 훈련 [[training]]
효율적인 트랜스포머 모델 훈련에는 GPU나 TPU와 같은 가속기가 필요합니다. 가장 일반적인 경우는 단일 GPU만 사용하는 경우지만, 다중 GPU 및 CPU 훈련에 대한 섹션도 있습니다(곧 더 많은 내용이 추가될 예정).
<Tip>
참고: 단일 GPU 섹션에서 소개된 대부분의 전략(예: 혼합 정밀도 훈련 또는 그라디언트 누적)은 일반적인 모델 훈련에도 적용되므로, 다중 GPU나 CPU 훈련과 같은 섹션을 살펴보기 전에 꼭 참고하시길 바랍니다.
</Tip>
### 단일 GPU [[single-gpu]]
단일 GPU에서 대규모 모델을 훈련하는 것은 어려울 수 있지만, 이를 가능하게 하는 여러 가지 도구와 방법이 있습니다. 이 섹션에서는 혼합 정밀도 훈련, 그라디언트 누적 및 체크포인팅, 효율적인 옵티마이저, 최적의 배치 크기를 결정하기 위한 전략 등에 대해 논의합니다.
[단일 GPU 훈련 섹션으로 이동](perf_train_gpu_one)
### 다중 GPU [[multigpu]]
단일 GPU에서 훈련하는 것이 너무 느리거나 대규모 모델에 적합하지 않은 경우도 있습니다. 다중 GPU 설정으로 전환하는 것은 논리적인 단계이지만, 여러 GPU에서 한 번에 훈련하려면 각 GPU마다 모델의 전체 사본을 둘지, 혹은 모델 자체도 여러 GPU에 분산하여 둘지 등 새로운 결정을 내려야 합니다. 이 섹션에서는 데이터, 텐서 및 파이프라인 병렬화에 대해 살펴봅니다.
[다중 GPU 훈련 섹션으로 이동](perf_train_gpu_many)
### CPU [[cpu]]
[CPU 훈련 섹션으로 이동](perf_train_cpu)
### TPU [[tpu]]
[_곧 제공될 예정_](perf_train_tpu)
### 특수한 하드웨어 [[specialized-hardware]]
[_곧 제공될 예정_](perf_train_special)
## 추론 [[inference]]
제품 및 서비스 환경에서 대규모 모델을 효율적으로 추론하는 것은 모델을 훈련하는 것만큼 어려울 수 있습니다. 이어지는 섹션에서는 CPU 및 단일/다중 GPU 설정에서 추론을 진행하는 단계를 살펴봅니다.
### CPU [[cpu]]
[CPU 추론 섹션으로 이동](perf_infer_cpu)
### 단일 GPU [[single-gpu]]
[단일 GPU 추론 섹션으로 이동](perf_infer_gpu_one)
### 다중 GPU [[multigpu]]
[다중 GPU 추론 섹션으로 이동](perf_infer_gpu_many)
### 특수한 하드웨어 [[specialized-hardware]]
[_곧 제공될 예정_](perf_infer_special)
## 하드웨어 [[hardware]]
하드웨어 섹션에서는 자신만의 딥러닝 장비를 구축할 때 유용한 팁과 요령을 살펴볼 수 있습니다.
[하드웨어 섹션으로 이동](perf_hardware)
## 기여하기 [[contribute]]
이 문서는 완성되지 않은 상태이며, 추가해야 할 내용이나 수정 사항이 많이 있습니다. 따라서 추가하거나 수정할 내용이 있으면 주저하지 말고 PR을 열어 주시거나, 자세한 내용을 논의하기 위해 Issue를 시작해 주시기 바랍니다.
A가 B보다 좋다고 하는 기여를 할 때는, 재현 가능한 벤치마크와/또는 해당 정보의 출처 링크를 포함해주세요(당신으로부터의 직접적인 정보가 아닌 경우).
|
transformers/docs/source/ko/performance.md/0
|
{
"file_path": "transformers/docs/source/ko/performance.md",
"repo_id": "transformers",
"token_count": 3692
}
| 50 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 🤗 Transformers로 할 수 있는 것[[what__transformers_can_do]]
🤗 Transformers는 자연어처리(NLP), 컴퓨터 비전, 오디오 및 음성 처리 작업에 대한 사전훈련된 최첨단 모델 라이브러리입니다.
이 라이브러리는 트랜스포머 모델뿐만 아니라 컴퓨터 비전 작업을 위한 현대적인 합성곱 신경망과 같은 트랜스포머가 아닌 모델도 포함하고 있습니다.
스마트폰, 앱, 텔레비전과 같은 오늘날 가장 인기 있는 소비자 제품을 살펴보면, 딥러닝 기술이 그 뒤에 사용되고 있을 확률이 높습니다.
스마트폰으로 촬영한 사진에서 배경 객체를 제거하고 싶다면 어떻게 할까요? 이는 파놉틱 세그멘테이션 작업의 예입니다(아직 이게 무엇인지 모른다면, 다음 섹션에서 설명하겠습니다!).
이 페이지는 다양한 음성 및 오디오, 컴퓨터 비전, NLP 작업을 🤗 Transformers 라이브러리를 활용하여 다루는 간단한 예제를 3줄의 코드로 제공합니다.
## 오디오[[audio]]
음성 및 오디오 처리 작업은 다른 모달리티와 약간 다릅니다. 이는 주로 오디오가 연속적인 신호로 입력되기 때문입니다.
텍스트와 달리 원본 오디오 파형(waveform)은 문장이 단어로 나눠지는 것처럼 깔끔하게 이산적인 묶음으로 나눌 수 없습니다.
이를 극복하기 위해 원본 오디오 신호는 일정한 간격으로 샘플링됩니다. 해당 간격 내에서 더 많은 샘플을 취할 경우 샘플링률이 높아지며, 오디오는 원본 오디오 소스에 더 가까워집니다.
과거의 접근 방식은 오디오에서 유용한 특징을 추출하기 위해 오디오를 전처리하는 것이었습니다.
하지만 현재는 원본 오디오 파형을 특성 인코더에 직접 넣어서 오디오 표현(representation)을 추출하는 것이 더 일반적입니다.
이렇게 하면 전처리 단계가 단순해지고 모델이 가장 중요한 특징을 학습할 수 있습니다.
### 오디오 분류[[audio_classification]]
오디오 분류는 오디오 데이터에 미리 정의된 클래스 집합의 레이블을 지정하는 작업입니다. 이는 많은 구체적인 응용 프로그램을 포함한 넓은 범주입니다.
일부 예시는 다음과 같습니다:
* 음향 장면 분류: 오디오에 장면 레이블("사무실", "해변", "경기장")을 지정합니다.
* 음향 이벤트 감지: 오디오에 소리 이벤트 레이블("차 경적", "고래 울음소리", "유리 파손")을 지정합니다.
* 태깅: 여러 가지 소리(새 지저귐, 회의에서의 화자 식별)가 포함된 오디오에 레이블을 지정합니다.
* 음악 분류: 음악에 장르 레이블("메탈", "힙합", "컨트리")을 지정합니다.
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="audio-classification", model="superb/hubert-base-superb-er")
>>> preds = classifier("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4532, 'label': 'hap'},
{'score': 0.3622, 'label': 'sad'},
{'score': 0.0943, 'label': 'neu'},
{'score': 0.0903, 'label': 'ang'}]
```
### 자동 음성 인식[[automatic_speech_recognition]]
자동 음성 인식(ASR)은 음성을 텍스트로 변환하는 작업입니다.
음성은 인간의 자연스러운 의사소통 형태이기 때문에 ASR은 가장 일반적인 오디오 작업 중 하나입니다.
오늘날 ASR 시스템은 스피커, 전화 및 자동차와 같은 "스마트" 기술 제품에 내장되어 있습니다.
우리는 가상 비서에게 음악 재생, 알림 설정 및 날씨 정보를 요청할 수 있습니다.
하지만 트랜스포머 아키텍처가 해결하는 데 도움을 준 핵심 도전 과제 중 하나는 양이 데이터 양이 적은 언어(low-resource language)에 대한 것입니다. 대량의 음성 데이터로 사전 훈련한 후 데이터 양이 적은 언어에서 레이블이 지정된 음성 데이터 1시간만으로 모델을 미세 조정하면 이전의 100배 많은 레이블이 지정된 데이터로 훈련된 ASR 시스템보다 훨씬 더 높은 품질의 결과를 얻을 수 있습니다.
```py
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition", model="openai/whisper-small")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}
```
## 컴퓨터 비전[[computer_vision]]
컴퓨터 비전 작업 중 가장 초기의 성공적인 작업 중 하나는 [합성곱 신경망(CNN)](glossary#convolution)을 사용하여 우편번호 숫자 이미지를 인식하는 것이었습니다. 이미지는 픽셀로 구성되어 있으며 각 픽셀은 숫자 값으로 표현됩니다. 이로써 이미지를 픽셀 값의 행렬로 나타내는 것이 쉬워집니다. 특정한 픽셀 값의 조합은 이미지의 색상을 의미합니다.
컴퓨터 비전 작업은 일반적으로 다음 두 가지 방법으로 접근 가능합니다:
1. 합성곱을 사용하여 이미지의 낮은 수준 특징에서 높은 수준의 추상적인 요소까지 계층적으로 학습합니다.
2. 이미지를 패치로 나누고 트랜스포머를 사용하여 점진적으로 각 이미지 패치가 서로 어떠한 방식으로 연관되어 이미지를 형성하는지 학습합니다. `CNN`에서 선호하는 상향식 접근법과는 달리, 이 방식은 흐릿한 이미지로 초안을 그리고 점진적으로 선명한 이미지로 만들어가는 것과 유사합니다.
### 이미지 분류[[image_classification]]
이미지 분류는 한 개의 전체 이미지에 미리 정의된 클래스 집합의 레이블을 지정하는 작업입니다.
대부분의 분류 작업과 마찬가지로, 이미지 분류에는 다양한 실용적인 용도가 있으며, 일부 예시는 다음과 같습니다:
* 의료: 질병을 감지하거나 환자 건강을 모니터링하기 위해 의료 이미지에 레이블을 지정합니다.
* 환경: 위성 이미지를 분류하여 산림 벌채를 감시하고 야생 지역 관리를 위한 정보를 제공하거나 산불을 감지합니다.
* 농업: 작물 이미지를 분류하여 식물 건강을 확인하거나 위성 이미지를 분류하여 토지 이용 관찰에 사용합니다.
* 생태학: 동물이나 식물 종 이미지를 분류하여 야생 동물 개체군을 조사하거나 멸종 위기에 처한 종을 추적합니다.
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="image-classification")
>>> preds = classifier(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.4335, 'label': 'lynx, catamount'}
{'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}
{'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}
{'score': 0.0239, 'label': 'Egyptian cat'}
{'score': 0.0229, 'label': 'tiger cat'}
```
### 객체 탐지[[object_detection]]
이미지 분류와 달리 객체 탐지는 이미지 내에서 여러 객체를 식별하고 바운딩 박스로 정의된 객체의 위치를 파악합니다.
객체 탐지의 몇 가지 응용 예시는 다음과 같습니다:
* 자율 주행 차량: 다른 차량, 보행자 및 신호등과 같은 일상적인 교통 객체를 감지합니다.
* 원격 감지: 재난 모니터링, 도시 계획 및 기상 예측 등을 수행합니다.
* 결함 탐지: 건물의 균열이나 구조적 손상, 제조 결함 등을 탐지합니다.
```py
>>> from transformers import pipeline
>>> detector = pipeline(task="object-detection")
>>> preds = detector(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"], "box": pred["box"]} for pred in preds]
>>> preds
[{'score': 0.9865,
'label': 'cat',
'box': {'xmin': 178, 'ymin': 154, 'xmax': 882, 'ymax': 598}}]
```
### 이미지 분할[[image_segmentation]]
이미지 분할은 픽셀 차원의 작업으로, 이미지 내의 모든 픽셀을 클래스에 할당합니다. 이는 객체 탐지와 다릅니다. 객체 탐지는 바운딩 박스를 사용하여 이미지 내의 객체를 레이블링하고 예측하는 반면, 분할은 더 세분화된 작업입니다. 분할은 픽셀 수준에서 객체를 감지할 수 있습니다.
이미지 분할에는 여러 유형이 있습니다:
* 인스턴스 분할: 개체의 클래스를 레이블링하는 것 외에도, 개체의 각 구분된 인스턴스에도 레이블을 지정합니다 ("개-1", "개-2" 등).
* 파놉틱 분할: 의미적 분할과 인스턴스 분할의 조합입니다. 각 픽셀을 의미적 클래스로 레이블링하는 **동시에** 개체의 각각 구분된 인스턴스로도 레이블을 지정합니다.
분할 작업은 자율 주행 차량에서 유용하며, 주변 환경의 픽셀 수준 지도를 생성하여 보행자와 다른 차량 주변에서 안전하게 탐색할 수 있습니다. 또한 의료 영상에서도 유용합니다. 분할 작업이 픽셀 수준에서 객체를 감지할 수 있기 때문에 비정상적인 세포나 장기의 특징을 식별하는 데 도움이 될 수 있습니다. 이미지 분할은 의류 가상 시착이나 카메라를 통해 실제 세계에 가상 개체를 덧씌워 증강 현실 경험을 만드는 등 전자 상거래 분야에서도 사용될 수 있습니다.
```py
>>> from transformers import pipeline
>>> segmenter = pipeline(task="image-segmentation")
>>> preds = segmenter(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> print(*preds, sep="\n")
{'score': 0.9879, 'label': 'LABEL_184'}
{'score': 0.9973, 'label': 'snow'}
{'score': 0.9972, 'label': 'cat'}
```
### 깊이 추정[[depth_estimation]]
깊이 추정은 카메라로부터 이미지 내부의 각 픽셀의 거리를 예측합니다. 이 컴퓨터 비전 작업은 특히 장면 이해와 재구성에 중요합니다. 예를 들어, 자율 주행 차량은 보행자, 교통 표지판 및 다른 차량과 같은 객체와의 거리를 이해하여 장애물과 충돌을 피해야 합니다. 깊이 정보는 또한 2D 이미지에서 3D 표현을 구성하는 데 도움이 되며 생물학적 구조나 건물의 고품질 3D 표현을 생성하는 데 사용될 수 있습니다.
깊이 추정에는 두 가지 접근 방식이 있습니다:
* 스테레오: 약간 다른 각도에서 촬영된 동일한 이미지 두 장을 비교하여 깊이를 추정합니다.
* 단안: 단일 이미지에서 깊이를 추정합니다.
```py
>>> from transformers import pipeline
>>> depth_estimator = pipeline(task="depth-estimation")
>>> preds = depth_estimator(
... "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
```
## 자연어처리[[natural_language_processing]]
텍스트는 인간이 의사 소통하는 자연스러운 방식 중 하나이기 때문에 자연어처리 역시 가장 일반적인 작업 유형 중 하나입니다. 모델이 인식하는 형식으로 텍스트를 변환하려면 토큰화해야 합니다. 이는 텍스트 시퀀스를 개별 단어 또는 하위 단어(토큰)로 분할한 다음 이러한 토큰을 숫자로 변환하는 것을 의미합니다. 결과적으로 텍스트 시퀀스를 숫자 시퀀스로 표현할 수 있으며, 숫자 시퀀스를 다양한 자연어처리 작업을 해결하기 위한 모델에 입력할 수 있습니다!
### 텍스트 분류[[text_classification]]
다른 모달리티에서의 분류 작업과 마찬가지로 텍스트 분류는 미리 정의된 클래스 집합에서 텍스트 시퀀스(문장 수준, 단락 또는 문서 등)에 레이블을 지정합니다. 텍스트 분류에는 다양한 실용적인 응용 사례가 있으며, 일부 예시는 다음과 같습니다:
* 감성 분석: 텍스트를 `긍정` 또는 `부정`과 같은 어떤 극성에 따라 레이블링하여 정치, 금융, 마케팅과 같은 분야에서 의사 결정에 정보를 제공하고 지원할 수 있습니다.
* 콘텐츠 분류: 텍스트를 주제에 따라 레이블링(날씨, 스포츠, 금융 등)하여 뉴스 및 소셜 미디어 피드에서 정보를 구성하고 필터링하는 데 도움이 될 수 있습니다.
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="sentiment-analysis")
>>> preds = classifier("Hugging Face is the best thing since sliced bread!")
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.9991, 'label': 'POSITIVE'}]
```
### 토큰 분류[[token_classification]]
모든 자연어처리 작업에서는 텍스트가 개별 단어나 하위 단어로 분리되어 전처리됩니다. 분리된 단어를 [토큰](/glossary#token)이라고 합니다. 토큰 분류는 각 토큰에 미리 정의된 클래스 집합의 레이블을 할당합니다.
토큰 분류의 두 가지 일반적인 유형은 다음과 같습니다:
* 개체명 인식 (NER): 토큰을 조직, 인물, 위치 또는 날짜와 같은 개체 범주에 따라 레이블링합니다. NER은 특히 유전체학적인 환경에서 유전자, 단백질 및 약물 이름에 레이블을 지정하는 데 널리 사용됩니다.
* 품사 태깅 (POS): 명사, 동사, 형용사와 같은 품사에 따라 토큰에 레이블을 할당합니다. POS는 번역 시스템이 동일한 단어가 문법적으로 어떻게 다른지 이해하는 데 도움이 됩니다 (명사로 사용되는 "bank(은행)"과 동사로 사용되는 "bank(예금을 예치하다)"과 같은 경우).
```py
>>> from transformers import pipeline
>>> classifier = pipeline(task="ner")
>>> preds = classifier("Hugging Face is a French company based in New York City.")
>>> preds = [
... {
... "entity": pred["entity"],
... "score": round(pred["score"], 4),
... "index": pred["index"],
... "word": pred["word"],
... "start": pred["start"],
... "end": pred["end"],
... }
... for pred in preds
... ]
>>> print(*preds, sep="\n")
{'entity': 'I-ORG', 'score': 0.9968, 'index': 1, 'word': 'Hu', 'start': 0, 'end': 2}
{'entity': 'I-ORG', 'score': 0.9293, 'index': 2, 'word': '##gging', 'start': 2, 'end': 7}
{'entity': 'I-ORG', 'score': 0.9763, 'index': 3, 'word': 'Face', 'start': 8, 'end': 12}
{'entity': 'I-MISC', 'score': 0.9983, 'index': 6, 'word': 'French', 'start': 18, 'end': 24}
{'entity': 'I-LOC', 'score': 0.999, 'index': 10, 'word': 'New', 'start': 42, 'end': 45}
{'entity': 'I-LOC', 'score': 0.9987, 'index': 11, 'word': 'York', 'start': 46, 'end': 50}
{'entity': 'I-LOC', 'score': 0.9992, 'index': 12, 'word': 'City', 'start': 51, 'end': 55}
```
### 질의응답[[question_answering]]
질의응답은 또 하나의 토큰 차원의 작업으로, 문맥이 있을 때(개방형 도메인)와 문맥이 없을 때(폐쇄형 도메인) 질문에 대한 답변을 반환합니다. 이 작업은 가상 비서에게 식당이 영업 중인지와 같은 질문을 할 때마다 발생할 수 있습니다. 고객 지원 또는 기술 지원을 제공하거나 검색 엔진이 요청한 정보를 검색하는 데 도움을 줄 수 있습니다.
질문 답변에는 일반적으로 두 가지 유형이 있습니다:
* 추출형: 질문과 문맥이 주어졌을 때, 모델이 주어진 문맥의 일부에서 가져온 텍스트의 범위를 답변으로 합니다.
* 생성형: 질문과 문맥이 주어졌을 때, 주어진 문맥을 통해 답변을 생성합니다. 이 접근 방식은 [`QuestionAnsweringPipeline`] 대신 [`Text2TextGenerationPipeline`]을 통해 처리됩니다.
```py
>>> from transformers import pipeline
>>> question_answerer = pipeline(task="question-answering")
>>> preds = question_answerer(
... question="What is the name of the repository?",
... context="The name of the repository is huggingface/transformers",
... )
>>> print(
... f"score: {round(preds['score'], 4)}, start: {preds['start']}, end: {preds['end']}, answer: {preds['answer']}"
... )
score: 0.9327, start: 30, end: 54, answer: huggingface/transformers
```
### 요약[[summarization]]
요약은 원본 문서의 의미를 최대한 보존하면서 긴 문서를 짧은 문서로 만드는 작업입니다. 요약은 `sequence-to-sequence` 작업입니다. 입력보다 짧은 텍스트 시퀀스를 출력합니다. 요약 작업은 독자가 장문 문서들의 주요 포인트를 빠르게 이해하는 데 도움을 줄 수 있습니다. 입법안, 법률 및 금융 문서, 특허 및 과학 논문은 요약 작업이 독자의 시간을 절약하고 독서 보조 도구로 사용될 수 있는 몇 가지 예시입니다.
질문 답변과 마찬가지로 요약에는 두 가지 유형이 있습니다:
* 추출형: 원본 텍스트에서 가장 중요한 문장을 식별하고 추출합니다.
* 생성형: 원본 텍스트에서 목표 요약을 생성합니다. 입력 문서에 없는 새로운 단어를 포함할 수도 있습니다. [`SummarizationPipeline`]은 생성형 접근 방식을 사용합니다.
```py
>>> from transformers import pipeline
>>> summarizer = pipeline(task="summarization")
>>> summarizer(
... "In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention. For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles."
... )
[{'summary_text': ' The Transformer is the first sequence transduction model based entirely on attention . It replaces the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention . For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers .'}]
```
### 번역[[translation]]
번역은 한 언어로 된 텍스트 시퀀스를 다른 언어로 변환하는 작업입니다. 이는 서로 다른 배경을 가진 사람들이 서로 소통하는 데 도움을 주는 중요한 역할을 합니다. 더 넓은 대중에게 콘텐츠를 번역하여 전달하거나, 새로운 언어를 배우는 데 도움이 되는 학습 도구가 될 수도 있습니다. 요약과 마찬가지로, 번역은 `sequence-to-sequence` 작업입니다. 즉, 모델은 입력 시퀀스를 받아서 출력이 되는 목표 시퀀스를 반환합니다.
초기의 번역 모델은 대부분 단일 언어로 이루어져 있었지만, 최근에는 많은 언어 쌍 간에 번역을 수행할 수 있는 다중 언어 모델에 대한 관심이 높아지고 있습니다.
```py
>>> from transformers import pipeline
>>> text = "translate English to French: Hugging Face is a community-based open-source platform for machine learning."
>>> translator = pipeline(task="translation", model="google-t5/t5-small")
>>> translator(text)
[{'translation_text': "Hugging Face est une tribune communautaire de l'apprentissage des machines."}]
```
### 언어 모델링[[language_modeling]]
언어 모델링은 텍스트 시퀀스에서 단어를 예측하는 작업입니다. 사전 훈련된 언어 모델은 많은 다른 하위 작업에 따라 미세 조정될 수 있기 때문에 매우 인기 있는 자연어처리 작업이 되었습니다. 최근에는 제로 샷(zero-shot) 또는 퓨 샷(few-shot) 학습이 가능한 대규모 언어 모델(Large Language Models, LLM)에 대한 많은 관심이 발생하고 있습니다. 이는 모델이 명시적으로 훈련되지 않은 작업도 해결할 수 있다는 것을 의미합니다! 언어 모델은 유창하고 설득력 있는 텍스트를 생성하는 데 사용될 수 있지만, 텍스트가 항상 정확하지는 않을 수 있으므로 주의가 필요합니다.
언어 모델링에는 두 가지 유형이 있습니다:
* 인과적 언어 모델링: 이 모델의 목적은 시퀀스에서 다음 토큰을 예측하는 것이며, 미래 토큰이 마스킹 됩니다.
```py
>>> from transformers import pipeline
>>> prompt = "Hugging Face is a community-based open-source platform for machine learning."
>>> generator = pipeline(task="text-generation")
>>> generator(prompt) # doctest: +SKIP
```
* 마스킹된 언어 모델링: 이 모델의 목적은 시퀀스 내의 마스킹된 토큰을 예측하는 것이며, 시퀀스 내의 모든 토큰에 대한 접근이 제공됩니다.
```py
>>> text = "Hugging Face is a community-based open-source <mask> for machine learning."
>>> fill_mask = pipeline(task="fill-mask")
>>> preds = fill_mask(text, top_k=1)
>>> preds = [
... {
... "score": round(pred["score"], 4),
... "token": pred["token"],
... "token_str": pred["token_str"],
... "sequence": pred["sequence"],
... }
... for pred in preds
... ]
>>> preds
[{'score': 0.2236,
'token': 1761,
'token_str': ' platform',
'sequence': 'Hugging Face is a community-based open-source platform for machine learning.'}]
```
이 페이지를 통해 각 모달리티의 다양한 작업 유형과 각 작업의 실용적 중요성에 대해 추가적인 배경 정보를 얻으셨기를 바랍니다. 다음 [섹션](tasks_explained)에서는 🤗 Transformer가 이러한 작업을 해결하는 **방법**에 대해 알아보실 수 있습니다.
|
transformers/docs/source/ko/task_summary.md/0
|
{
"file_path": "transformers/docs/source/ko/task_summary.md",
"repo_id": "transformers",
"token_count": 15732
}
| 51 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 대규모 언어 모델(LLM) 프롬프팅 가이드 [[llm-prompting-guide]]
[[open-in-colab]]
Falcon, LLaMA 등의 대규모 언어 모델은 사전 훈련된 트랜스포머 모델로, 초기에는 주어진 입력 텍스트에 대해 다음 토큰을 예측하도록 훈련됩니다. 이들은 보통 수십억 개의 매개변수를 가지고 있으며, 장기간에 걸쳐 수조 개의 토큰으로 훈련됩니다. 그 결과, 이 모델들은 매우 강력하고 다재다능해져서, 자연어 프롬프트로 모델에 지시하여 다양한 자연어 처리 작업을 즉시 수행할 수 있습니다.
최적의 출력을 보장하기 위해 이러한 프롬프트를 설계하는 것을 흔히 "프롬프트 엔지니어링"이라고 합니다. 프롬프트 엔지니어링은 상당한 실험이 필요한 반복적인 과정입니다. 자연어는 프로그래밍 언어보다 훨씬 유연하고 표현력이 풍부하지만, 동시에 모호성을 초래할 수 있습니다. 또한, 자연어 프롬프트는 변화에 매우 민감합니다. 프롬프트의 사소한 수정만으로도 완전히 다른 출력이 나올 수 있습니다.
모든 경우에 적용할 수 있는 정확한 프롬프트 생성 공식은 없지만, 연구자들은 더 일관되게 최적의 결과를 얻는 데 도움이 되는 여러 가지 모범 사례를 개발했습니다.
이 가이드에서는 더 나은 대규모 언어 모델 프롬프트를 작성하고 다양한 자연어 처리 작업을 해결하는 데 도움이 되는 프롬프트 엔지니어링 모범 사례를 다룹니다:
- [프롬프팅의 기초](#basics-of-prompting)
- [대규모 언어 모델 프롬프팅의 모범 사례](#best-practices-of-llm-prompting)
- [고급 프롬프팅 기법: 퓨샷(Few-shot) 프롬프팅과 생각의 사슬(Chain-of-thought, CoT) 기법](#advanced-prompting-techniques)
- [프롬프팅 대신 미세 조정을 해야 하는 경우](#prompting-vs-fine-tuning)
<Tip>
프롬프트 엔지니어링은 대규모 언어 모델 출력 최적화 과정의 일부일 뿐입니다. 또 다른 중요한 구성 요소는 최적의 텍스트 생성 전략을 선택하는 것입니다. 학습 가능한 매개변수를 수정하지 않고도 대규모 언어 모델이 텍스트를 생성하리 때 각각의 후속 토큰을 선택하는 방식을 사용자가 직접 정의할 수 있습니다. 텍스트 생성 매개변수를 조정함으로써 생성된 텍스트의 반복을 줄이고 더 일관되고 사람이 말하는 것 같은 텍스트를 만들 수 있습니다. 텍스트 생성 전략과 매개변수는 이 가이드의 범위를 벗어나지만, 다음 가이드에서 이러한 주제에 대해 자세히 알아볼 수 있습니다:
* [대규모 언어 모델을 이용한 생성](../llm_tutorial)
* [텍스트 생성 전략](../generation_strategies)
</Tip>
## 프롬프팅의 기초 [[basics-of-prompting]]
### 모델의 유형 [[types-of-models]]
현대의 대부분의 대규모 언어 모델은 디코더만을 이용한 트랜스포머입니다. 예를 들어 [LLaMA](../model_doc/llama),
[Llama2](../model_doc/llama2), [Falcon](../model_doc/falcon), [GPT2](../model_doc/gpt2) 등이 있습니다. 그러나 [Flan-T5](../model_doc/flan-t5)와 [BART](../model_doc/bart)와 같은 인코더-디코더 기반의 트랜스포머 대규모 언어 모델을 접할 수도 있습니다.
인코더-디코더 기반의 모델은 일반적으로 출력이 입력에 **크게** 의존하는 생성 작업에 사용됩니다. 예를 들어, 번역과 요약 작업에 사용됩니다. 디코더 전용 모델은 다른 모든 유형의 생성 작업에 사용됩니다.
파이프라인을 사용하여 대규모 언어 모델으로 텍스트를 생성할 때, 어떤 유형의 대규모 언어 모델을 사용하고 있는지 아는 것이 중요합니다. 왜냐하면 이들은 서로 다른 파이프라인을 사용하기 때문입니다.
디코더 전용 모델로 추론을 실행하려면 `text-generation` 파이프라인을 사용하세요:
```python
>>> from transformers import pipeline
>>> import torch
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> generator = pipeline('text-generation', model = 'openai-community/gpt2')
>>> prompt = "Hello, I'm a language model"
>>> generator(prompt, max_length = 30)
[{'generated_text': "Hello, I'm a language model programmer so you can use some of my stuff. But you also need some sort of a C program to run."}]
```
인코더-디코더로 추론을 실행하려면 `text2text-generation` 파이프라인을 사용하세요:
```python
>>> text2text_generator = pipeline("text2text-generation", model = 'google/flan-t5-base')
>>> prompt = "Translate from English to French: I'm very happy to see you"
>>> text2text_generator(prompt)
[{'generated_text': 'Je suis très heureuse de vous rencontrer.'}]
```
### 기본 모델 vs 지시/채팅 모델 [[base-vs-instructchat-models]]
🤗 Hub에서 최근 사용 가능한 대부분의 대규모 언어 모델 체크포인트는 기본 버전과 지시(또는 채팅) 두 가지 버전이 제공됩니다. 예를 들어, [`tiiuae/falcon-7b`](https://huggingface.co/tiiuae/falcon-7b)와 [`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct)가 있습니다.
기본 모델은 초기 프롬프트가 주어졌을 때 텍스트를 완성하는 데 탁월하지만, 지시를 따라야 하거나 대화형 사용이 필요한 자연어 처리작업에는 이상적이지 않습니다. 이때 지시(채팅) 버전이 필요합니다. 이러한 체크포인트는 사전 훈련된 기본 버전을 지시사항과 대화 데이터로 추가 미세 조정한 결과입니다. 이 추가적인 미세 조정으로 인해 많은 자연어 처리 작업에 더 적합한 선택이 됩니다.
[`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct)를 사용하여 일반적인 자연어 처리 작업을 해결하는 데 사용할 수 있는 몇 가지 간단한 프롬프트를 살펴보겠습니다.
### 자연어 처리 작업 [[nlp-tasks]]
먼저, 환경을 설정해 보겠습니다:
```bash
pip install -q transformers accelerate
```
다음으로, 적절한 파이프라인("text-generation")을 사용하여 모델을 로드하겠습니다:
```python
>>> from transformers import pipeline, AutoTokenizer
>>> import torch
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> model = "tiiuae/falcon-7b-instruct"
>>> tokenizer = AutoTokenizer.from_pretrained(model)
>>> pipe = pipeline(
... "text-generation",
... model=model,
... tokenizer=tokenizer,
... torch_dtype=torch.bfloat16,
... device_map="auto",
... )
```
<Tip>
Falcon 모델은 bfloat16 데이터 타입을 사용하여 훈련되었으므로, 같은 타입을 사용하는 것을 권장합니다. 이를 위해서는 최신 버전의 CUDA가 필요하며, 최신 그래픽 카드에서 가장 잘 작동합니다.
</Tip>
이제 파이프라인을 통해 모델을 로드했으니, 프롬프트를 사용하여 자연어 처리 작업을 해결하는 방법을 살펴보겠습니다.
#### 텍스트 분류 [[text-classification]]
텍스트 분류의 가장 일반적인 형태 중 하나는 감정 분석입니다. 이는 텍스트 시퀀스에 "긍정적", "부정적" 또는 "중립적"과 같은 레이블을 할당합니다. 주어진 텍스트(영화 리뷰)를 분류하도록 모델에 지시하는 프롬프트를 작성해 보겠습니다. 먼저 지시사항을 제공한 다음, 분류할 텍스트를 지정하겠습니다. 여기서 주목할 점은 단순히 거기서 끝내지 않고, 응답의 시작 부분인 `"Sentiment: "`을 추가한다는 것입니다:
```python
>>> torch.manual_seed(0)
>>> prompt = """Classify the text into neutral, negative or positive.
... Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
... Sentiment:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result: Classify the text into neutral, negative or positive.
Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
Sentiment:
Positive
```
결과적으로, 우리가 지시사항에서 제공한 목록에서 선택된 분류 레이블이 정확하게 포함되어 생성된 것을 확인할 수 있습니다!
<Tip>
프롬프트 외에도 `max_new_tokens` 매개변수를 전달하는 것을 볼 수 있습니다. 이 매개변수는 모델이 생성할 토큰의 수를 제어하며, [텍스트 생성 전략](../generation_strategies) 가이드에서 배울 수 있는 여러 텍스트 생성 매개변수 중 하나입니다.
</Tip>
#### 개체명 인식 [[named-entity-recognition]]
개체명 인식(Named Entity Recognition, NER)은 텍스트에서 인물, 장소, 조직과 같은 명명된 개체를 찾는 작업입니다. 프롬프트의 지시사항을 수정하여 대규모 언어 모델이 이 작업을 수행하도록 해보겠습니다. 여기서는 `return_full_text = False`로 설정하여 출력에 프롬프트가 포함되지 않도록 하겠습니다:
```python
>>> torch.manual_seed(1) # doctest: +IGNORE_RESULT
>>> prompt = """Return a list of named entities in the text.
... Text: The Golden State Warriors are an American professional basketball team based in San Francisco.
... Named entities:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=15,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
- Golden State Warriors
- San Francisco
```
보시다시피, 모델이 주어진 텍스트에서 두 개의 명명된 개체를 정확하게 식별했습니다.
#### 번역 [[translation]]
대규모 언어 모델이 수행할 수 있는 또 다른 작업은 번역입니다. 이 작업을 위해 인코더-디코더 모델을 사용할 수 있지만, 여기서는 예시의 단순성을 위해 꽤 좋은 성능을 보이는 Falcon-7b-instruct를 계속 사용하겠습니다. 다시 한 번, 모델에게 영어에서 이탈리아어로 텍스트를 번역하도록 지시하는 기본적인 프롬프트를 작성하는 방법은 다음과 같습니다:
```python
>>> torch.manual_seed(2) # doctest: +IGNORE_RESULT
>>> prompt = """Translate the English text to Italian.
... Text: Sometimes, I've believed as many as six impossible things before breakfast.
... Translation:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=20,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
A volte, ho creduto a sei impossibili cose prima di colazione.
```
여기서는 모델이 출력을 생성할 때 조금 더 유연해질 수 있도록 `do_sample=True`와 `top_k=10`을 추가했습니다.
#### 텍스트 요약 [[text-summarization]]
번역과 마찬가지로, 텍스트 요약은 출력이 입력에 크게 의존하는 또 다른 생성 작업이며, 인코더-디코더 기반 모델이 더 나은 선택일 수 있습니다. 그러나 디코더 기반의 모델도 이 작업에 사용될 수 있습니다. 이전에는 프롬프트의 맨 처음에 지시사항을 배치했습니다. 하지만 프롬프트의 맨 끝도 지시사항을 넣을 적절한 위치가 될 수 있습니다. 일반적으로 지시사항을 양 극단 중 하나에 배치하는 것이 더 좋습니다.
```python
>>> torch.manual_seed(3) # doctest: +IGNORE_RESULT
>>> prompt = """Permaculture is a design process mimicking the diversity, functionality and resilience of natural ecosystems. The principles and practices are drawn from traditional ecological knowledge of indigenous cultures combined with modern scientific understanding and technological innovations. Permaculture design provides a framework helping individuals and communities develop innovative, creative and effective strategies for meeting basic needs while preparing for and mitigating the projected impacts of climate change.
... Write a summary of the above text.
... Summary:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=30,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
Permaculture is an ecological design mimicking natural ecosystems to meet basic needs and prepare for climate change. It is based on traditional knowledge and scientific understanding.
```
#### 질의 응답 [[question-answering]]
질의 응답 작업을 위해 프롬프트를 다음과 같은 논리적 구성요소로 구조화할 수 있습니다. 지시사항, 맥락, 질문, 그리고 모델이 답변 생성을 시작하도록 유도하는 선도 단어나 구문(`"Answer:"`) 을 사용할 수 있습니다:
```python
>>> torch.manual_seed(4) # doctest: +IGNORE_RESULT
>>> prompt = """Answer the question using the context below.
... Context: Gazpacho is a cold soup and drink made of raw, blended vegetables. Most gazpacho includes stale bread, tomato, cucumbers, onion, bell peppers, garlic, olive oil, wine vinegar, water, and salt. Northern recipes often include cumin and/or pimentón (smoked sweet paprika). Traditionally, gazpacho was made by pounding the vegetables in a mortar with a pestle; this more laborious method is still sometimes used as it helps keep the gazpacho cool and avoids the foam and silky consistency of smoothie versions made in blenders or food processors.
... Question: What modern tool is used to make gazpacho?
... Answer:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result: Modern tools often used to make gazpacho include
```
#### 추론 [[reasoning]]
추론은 대규모 언어 모델(LLM)에게 가장 어려운 작업 중 하나이며, 좋은 결과를 얻기 위해서는 종종 [생각의 사슬(Chain-of-thought, CoT)](#chain-of-thought)과 같은 고급 프롬프팅 기법을 적용해야 합니다. 간단한 산술 작업에 대해 기본적인 프롬프트로 모델이 추론할 수 있는지 시도해 보겠습니다:
```python
>>> torch.manual_seed(5) # doctest: +IGNORE_RESULT
>>> prompt = """There are 5 groups of students in the class. Each group has 4 students. How many students are there in the class?"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=30,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result:
There are a total of 5 groups, so there are 5 x 4=20 students in the class.
```
정확한 답변이 생성되었습니다! 복잡성을 조금 높여보고 기본적인 프롬프트로도 여전히 해결할 수 있는지 확인해 보겠습니다:
```python
>>> torch.manual_seed(6)
>>> prompt = """I baked 15 muffins. I ate 2 muffins and gave 5 muffins to a neighbor. My partner then bought 6 more muffins and ate 2. How many muffins do we now have?"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result:
The total number of muffins now is 21
```
정답은 12여야 하는데 21이라는 잘못된 답변이 나왔습니다. 이 경우, 프롬프트가 너무 기본적이거나 모델의 크기가 작아서 생긴 문제일 수 있습니다. 우리는 Falcon의 가장 작은 버전을 선택했습니다. 추론은 큰 모델에게도 어려운 작업이지만, 더 큰 모델들이 더 나은 성능을 보일 가능성이 높습니다.
## 대규모 언어 모델 프롬프트 작성의 모범 사례 [[best-practices-of-llm-prompting]]
이 섹션에서는 프롬프트 결과를 향상시킬 수 있는 모범 사례 목록을 작성했습니다:
* 작업할 모델을 선택할 때 최신 및 가장 강력한 모델이 더 나은 성능을 발휘할 가능성이 높습니다.
* 간단하고 짧은 프롬프트로 시작하여 점진적으로 개선해 나가세요.
* 프롬프트의 시작 부분이나 맨 끝에 지시사항을 배치하세요. 대규모 컨텍스트를 다룰 때, 모델들은 어텐션 복잡도가 2차적으로 증가하는 것을 방지하기 위해 다양한 최적화를 적용합니다. 이렇게 함으로써 모델이 프롬프트의 중간보다 시작이나 끝 부분에 더 주의를 기울일 수 있습니다.
* 지시사항을 적용할 텍스트와 명확하게 분리해보세요. (이에 대해서는 다음 섹션에서 더 자세히 다룹니다.)
* 작업과 원하는 결과에 대해 구체적이고 풍부한 설명을 제공하세요. 형식, 길이, 스타일, 언어 등을 명확하게 작성해야 합니다.
* 모호한 설명과 지시사항을 피하세요.
* "하지 말라"는 지시보다는 "무엇을 해야 하는지"를 말하는 지시를 사용하는 것이 좋습니다.
* 첫 번째 단어를 쓰거나 첫 번째 문장을 시작하여 출력을 올바른 방향으로 "유도"하세요.
* [퓨샷(Few-shot) 프롬프팅](#few-shot-prompting) 및 [생각의 사슬(Chain-of-thought, CoT)](#chain-of-thought) 같은 고급 기술을 사용해보세요.
* 프롬프트의 견고성을 평가하기 위해 다른 모델로도 테스트하세요.
* 프롬프트의 버전을 관리하고 성능을 추적하세요.
## 고급 프롬프트 기법 [[advanced-prompting-techniques]]
### 퓨샷(Few-shot) 프롬프팅 [[few-shot-prompting]]
위 섹션의 기본 프롬프트들은 "제로샷(Zero-shot)" 프롬프트의 예시입니다. 이는 모델에 지시사항과 맥락은 주어졌지만, 해결책이 포함된 예시는 제공되지 않았다는 의미입니다. 지시 데이터셋으로 미세 조정된 대규모 언어 모델은 일반적으로 이러한 "제로샷" 작업에서 좋은 성능을 보입니다. 하지만 여러분의 작업이 더 복잡하거나 미묘한 차이가 있을 수 있고, 아마도 지시사항만으로는 모델이 포착하지 못하는 출력에 대한 요구사항이 있을 수 있습니다. 이런 경우에는 퓨샷(Few-shot) 프롬프팅이라는 기법을 시도해 볼 수 있습니다.
퓨샷 프롬프팅에서는 프롬프트에 예시를 제공하여 모델에 더 많은 맥락을 주고 성능을 향상시킵니다. 이 예시들은 모델이 예시의 패턴을 따라 출력을 생성하도록 조건화합니다.
다음은 예시입니다:
```python
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> prompt = """Text: The first human went into space and orbited the Earth on April 12, 1961.
... Date: 04/12/1961
... Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
... Date:"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=8,
... do_sample=True,
... top_k=10,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result: Text: The first human went into space and orbited the Earth on April 12, 1961.
Date: 04/12/1961
Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
Date: 09/28/1960
```
위의 코드 스니펫에서는 모델에 원하는 출력을 보여주기 위해 단일 예시를 사용했으므로, 이를 "원샷(One-shot)" 프롬프팅이라고 부를 수 있습니다. 그러나 작업의 복잡성에 따라 하나 이상의 예시를 사용해야 할 수도 있습니다.
퓨샷 프롬프팅 기법의 한계:
- 대규모 언어 모델이 예시의 패턴을 파악할 수 있지만, 이 기법은 복잡한 추론 작업에는 잘 작동하지 않습니다.
- 퓨샷 프롬프팅을 적용하면 프롬프트의 길이가 길어집니다. 토큰 수가 많은 프롬프트는 계산량과 지연 시간을 증가시킬 수 있으며 프롬프트 길이에도 제한이 있습니다.
- 때로는 여러 예시가 주어질 때, 모델은 의도하지 않은 패턴을 학습할 수 있습니다. 예를 들어, 세 번째 영화 리뷰가 항상 부정적이라고 학습할 수 있습니다.
### 생각의 사슬(Chain-of-thought, CoT) [[chain-of-thought]]
생각의 사슬(Chain-of-thought, CoT) 프롬프팅은 모델이 중간 추론 단계를 생성하도록 유도하는 기법으로, 복잡한 추론 작업의 결과를 개선합니다.
모델이 추론 단계를 생성하도록 유도하는 두 가지 방법이 있습니다:
- 질문에 대한 상세한 답변을 예시로 제시하는 퓨샷 프롬프팅을 통해 모델에게 문제를 어떻게 해결해 나가는지 보여줍니다.
- "단계별로 생각해 봅시다" 또는 "깊게 숨을 쉬고 문제를 단계별로 해결해 봅시다"와 같은 문구를 추가하여 모델에게 추론하도록 지시합니다.
[reasoning section](#reasoning)의 머핀 예시에 생각의 사슬(Chain-of-thought, CoT) 기법을 적용하고 [HuggingChat](https://huggingface.co/chat/)에서 사용할 수 있는 (`tiiuae/falcon-180B-chat`)과 같은 더 큰 모델을 사용하면, 추론 결과가 크게 개선됩니다:
```text
단계별로 살펴봅시다:
1. 처음에 15개의 머핀이 있습니다.
2. 2개의 머핀을 먹으면 13개의 머핀이 남습니다.
3. 이웃에게 5개의 머핀을 주면 8개의 머핀이 남습니다.
4. 파트너가 6개의 머핀을 더 사오면 총 머핀 수는 14개가 됩니다.
5. 파트너가 2개의 머핀을 먹으면 12개의 머핀이 남습니다.
따라서, 현재 12개의 머핀이 있습니다.
```
## 프롬프팅 vs 미세 조정 [[prompting-vs-fine-tuning]]
프롬프트를 최적화하여 훌륭한 결과를 얻을 수 있지만, 여전히 모델을 미세 조정하는 것이 더 좋을지 고민할 수 있습니다. 다음은 더 작은 모델을 미세 조정하는 것이 선호되는 시나리오입니다:
- 도메인이 대규모 언어 모델이 사전 훈련된 것과 크게 다르고 광범위한 프롬프트 최적화로도 충분한 결과를 얻지 못한 경우.
- 저자원 언어에서 모델이 잘 작동해야 하는 경우.
- 엄격한 규제 하에 있는 민감한 데이터로 모델을 훈련해야 하는 경우.
- 비용, 개인정보 보호, 인프라 또는 기타 제한으로 인해 작은 모델을 사용해야 하는 경우.
위의 모든 예시에서, 모델을 미세 조정하기 위해 충분히 큰 도메인별 데이터셋을 이미 가지고 있거나 합리적인 비용으로 쉽게 얻을 수 있는지 확인해야 합니다. 또한 모델을 미세 조정할 충분한 시간과 자원이 필요합니다.
만약 위의 예시들이 여러분의 경우에 해당하지 않는다면, 프롬프트를 최적화하는 것이 더 유익할 수 있습니다.
|
transformers/docs/source/ko/tasks/prompting.md/0
|
{
"file_path": "transformers/docs/source/ko/tasks/prompting.md",
"repo_id": "transformers",
"token_count": 15930
}
| 52 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TorchScript로 내보내기[[export-to-torchscript]]
<Tip>
TorchScript를 활용한 실험은 아직 초기 단계로, 가변적인 입력 크기 모델들을 통해 그 기능성을 계속 탐구하고 있습니다.
이 기능은 저희가 관심을 두고 있는 분야 중 하나이며,
앞으로 출시될 버전에서 더 많은 코드 예제, 더 유연한 구현, 그리고 Python 기반 코드와 컴파일된 TorchScript를 비교하는 벤치마크를 등을 통해 분석을 심화할 예정입니다.
</Tip>
[TorchScript 문서](https://pytorch.org/docs/stable/jit.html)에서는 이렇게 말합니다.
> TorchScript는 PyTorch 코드에서 직렬화 및 최적화 가능한 모델을 생성하는 방법입니다.
[JIT과 TRACE](https://pytorch.org/docs/stable/jit.html)는 개발자가 모델을 내보내서 효율 지향적인 C++ 프로그램과 같은 다른 프로그램에서 재사용할 수 있도록 하는 PyTorch 모듈입니다.
PyTorch 기반 Python 프로그램과 다른 환경에서 모델을 재사용할 수 있도록, 🤗 Transformers 모델을 TorchScript로 내보낼 수 있는 인터페이스를 제공합니다.
이 문서에서는 TorchScript를 사용하여 모델을 내보내고 사용하는 방법을 설명합니다.
모델을 내보내려면 두 가지가 필요합니다:
- `torchscript` 플래그로 모델 인스턴스화
- 더미 입력을 사용한 순전파(forward pass)
이 필수 조건들은 아래에 자세히 설명된 것처럼 개발자들이 주의해야 할 여러 사항들을 의미합니다.
## TorchScript 플래그와 묶인 가중치(tied weights)[[torchscript-flag-and-tied-weights]]
`torchscript` 플래그가 필요한 이유는 대부분의 🤗 Transformers 언어 모델에서 `Embedding` 레이어와 `Decoding` 레이어 간의 묶인 가중치(tied weights)가 존재하기 때문입니다.
TorchScript는 묶인 가중치를 가진 모델을 내보낼 수 없으므로, 미리 가중치를 풀고 복제해야 합니다.
`torchscript` 플래그로 인스턴스화된 모델은 `Embedding` 레이어와 `Decoding` 레이어가 분리되어 있으므로 이후에 훈련해서는 안 됩니다.
훈련을 하게 되면 두 레이어 간 동기화가 해제되어 예상치 못한 결과가 발생할 수 있습니다.
언어 모델 헤드를 갖지 않은 모델은 가중치가 묶여 있지 않아서 이 문제가 발생하지 않습니다.
이러한 모델들은 `torchscript` 플래그 없이 안전하게 내보낼 수 있습니다.
## 더미 입력과 표준 길이[[dummy-inputs-and-standard-lengths]]
더미 입력(dummy inputs)은 모델의 순전파(forward pass)에 사용됩니다.
입력 값이 레이어를 통해 전파되는 동안, PyTorch는 각 텐서에서 실행된 다른 연산을 추적합니다.
이러한 기록된 연산은 모델의 *추적(trace)*을 생성하는 데 사용됩니다.
추적은 입력의 차원을 기준으로 생성됩니다.
따라서 더미 입력의 차원에 제한되어, 다른 시퀀스 길이나 배치 크기에서는 작동하지 않습니다.
다른 크기로 시도할 경우 다음과 같은 오류가 발생합니다:
```
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
```
추론 중 모델에 공급될 가장 큰 입력만큼 큰 더미 입력 크기로 모델을 추적하는 것이 좋습니다.
패딩은 누락된 값을 채우는 데 도움이 될 수 있습니다.
그러나 모델이 더 큰 입력 크기로 추적되기 때문에, 행렬의 차원이 커지고 계산량이 많아집니다.
다양한 시퀀스 길이 모델을 내보낼 때는 각 입력에 대해 수행되는 총 연산 횟수에 주의하고 성능을 주의 깊게 확인하세요.
## Python에서 TorchScript 사용하기[[using-torchscript-in-python]]
이 섹션에서는 모델을 저장하고 가져오는 방법, 추적을 사용하여 추론하는 방법을 보여줍니다.
### 모델 저장하기[[saving-a-model]]
`BertModel`을 TorchScript로 내보내려면 `BertConfig` 클래스에서 `BertModel`을 인스턴스화한 다음, `traced_bert.pt`라는 파일명으로 디스크에 저장하면 됩니다.
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
# 입력 텍스트 토큰화하기
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# 입력 토큰 중 하나를 마스킹하기
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# 더미 입력 만들기
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# torchscript 플래그로 모델 초기화하기
# 이 모델은 LM 헤드가 없으므로 필요하지 않지만, 플래그를 True로 설정합니다.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# 모델을 인스턴트화하기
model = BertModel(config)
# 모델을 평가 모드로 두어야 합니다.
model.eval()
# 만약 *from_pretrained*를 사용하여 모델을 인스턴스화하는 경우, TorchScript 플래그를 쉽게 설정할 수 있습니다
model = BertModel.from_pretrained("google-bert/bert-base-uncased", torchscript=True)
# 추적 생성하기
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
### 모델 가져오기[[loading-a-model]]
이제 이전에 저장한 `BertModel`, 즉 `traced_bert.pt`를 디스크에서 가져오고, 이전에 초기화한 `dummy_input`에서 사용할 수 있습니다.
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
### 추적된 모델을 사용하여 추론하기[[using-a-traced-model-for-inference]]
`__call__` 이중 언더스코어(dunder) 메소드를 사용하여 추론에 추적된 모델을 사용하세요:
```python
traced_model(tokens_tensor, segments_tensors)
```
## Neuron SDK로 Hugging Face TorchScript 모델을 AWS에 배포하기[[deploy-hugging-face-torchscript-models-to-aws-with-the-neuron-sdk]]
AWS가 클라우드에서 저비용, 고성능 머신 러닝 추론을 위한 [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) 인스턴스 제품군을 출시했습니다.
Inf1 인스턴스는 딥러닝 추론 워크로드에 특화된 맞춤 하드웨어 가속기인 AWS Inferentia 칩으로 구동됩니다.
[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#)은 Inferentia를 위한 SDK로, Inf1에 배포하기 위한 transformers 모델 추적 및 최적화를 지원합니다.
Neuron SDK는 다음과 같은 기능을 제공합니다:
1. 코드 한 줄만 변경하면 클라우드 추론를 위해 TorchScript 모델을 추적하고 최적화할 수 있는 쉬운 API
2. 즉시 사용 가능한 성능 최적화로 [비용 효율 향상](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>)
3. [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html) 또는 [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html)로 구축된 Hugging Face transformers 모델 지원
### 시사점[[implications]]
[BERT (Bidirectional Encoder Representations from Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert) 아키텍처 또는 그 변형인 [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) 및 [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta)를 기반으로 한 Transformers 모델은 추출 기반 질의응답, 시퀀스 분류 및 토큰 분류와 같은 비생성 작업 시 Inf1에서 최상의 성능을 보입니다.
그러나 텍스트 생성 작업도 [AWS Neuron MarianMT 튜토리얼](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html)을 따라 Inf1에서 실행되도록 조정할 수 있습니다.
Inferentia에서 바로 변환할 수 있는 모델에 대한 자세한 정보는 Neuron 문서의 [Model Architecture Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia) 섹션에서 확인할 수 있습니다.
### 종속성[[dependencies]]
AWS Neuron을 사용하여 모델을 변환하려면 [Neuron SDK 환경](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide)이 필요합니다.
이는 [AWS Deep Learning AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html)에 미리 구성되어 있습니다.
### AWS Neuron으로 모델 변환하기[[converting-a-model-for-aws-neuron]]
`BertModel`을 추적하려면, [Python에서 TorchScript 사용하기](torchscript#using-torchscript-in-python)에서와 동일한 코드를 사용해서 AWS NEURON용 모델을 변환합니다.
`torch.neuron` 프레임워크 익스텐션을 가져와 Python API를 통해 Neuron SDK의 구성 요소에 접근합니다:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
다음 줄만 수정하면 됩니다:
```diff
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
```
이로써 Neuron SDK가 모델을 추적하고 Inf1 인스턴스에 최적화할 수 있게 됩니다.
AWS Neuron SDK의 기능, 도구, 예제 튜토리얼 및 최신 업데이트에 대해 자세히 알아보려면 [AWS NeuronSDK 문서](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html)를 참조하세요.
|
transformers/docs/source/ko/torchscript.md/0
|
{
"file_path": "transformers/docs/source/ko/torchscript.md",
"repo_id": "transformers",
"token_count": 6894
}
| 53 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Modelos multilinguísticos para inferência
[[open-in-colab]]
Existem vários modelos multilinguísticos no 🤗 Transformers e seus usos para inferência diferem dos modelos monolíngues.
No entanto, nem *todos* os usos dos modelos multilíngues são tão diferentes.
Alguns modelos, como o [google-bert/bert-base-multilingual-uncased](https://huggingface.co/google-bert/bert-base-multilingual-uncased),
podem ser usados como se fossem monolíngues. Este guia irá te ajudar a usar modelos multilíngues cujo uso difere
para o propósito de inferência.
## XLM
O XLM tem dez checkpoints diferentes dos quais apenas um é monolíngue.
Os nove checkpoints restantes do modelo são subdivididos em duas categorias:
checkpoints que usam de language embeddings e os que não.
### XLM com language embeddings
Os seguintes modelos de XLM usam language embeddings para especificar a linguagem utilizada para a inferência.
- `FacebookAI/xlm-mlm-ende-1024` (Masked language modeling, English-German)
- `FacebookAI/xlm-mlm-enfr-1024` (Masked language modeling, English-French)
- `FacebookAI/xlm-mlm-enro-1024` (Masked language modeling, English-Romanian)
- `FacebookAI/xlm-mlm-xnli15-1024` (Masked language modeling, XNLI languages)
- `FacebookAI/xlm-mlm-tlm-xnli15-1024` (Masked language modeling + translation, XNLI languages)
- `FacebookAI/xlm-clm-enfr-1024` (Causal language modeling, English-French)
- `FacebookAI/xlm-clm-ende-1024` (Causal language modeling, English-German)
Os language embeddings são representados por um tensor de mesma dimensão que os `input_ids` passados ao modelo.
Os valores destes tensores dependem do idioma utilizado e se identificam pelos atributos `lang2id` e `id2lang` do tokenizador.
Neste exemplo, carregamos o checkpoint `FacebookAI/xlm-clm-enfr-1024`(Causal language modeling, English-French):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
```
O atributo `lang2id` do tokenizador mostra os idiomas deste modelo e seus ids:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
Em seguida, cria-se um input de exemplo:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size of 1
```
Estabelece-se o id do idioma, por exemplo `"en"`, e utiliza-se o mesmo para definir a language embedding.
A language embedding é um tensor preenchido com `0`, que é o id de idioma para o inglês.
Este tensor deve ser do mesmo tamanho que os `input_ids`.
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # We reshape it to be of size (batch_size, sequence_length)
>>> langs = langs.view(1, -1) # is now of shape [1, sequence_length] (we have a batch size of 1)
```
Agora você pode passar os `input_ids` e a language embedding ao modelo:
```py
>>> outputs = model(input_ids, langs=langs)
```
O script [run_generation.py](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-generation/run_generation.py) pode gerar um texto com language embeddings utilizando os checkpoints `xlm-clm`.
### XLM sem language embeddings
Os seguintes modelos XLM não requerem o uso de language embeddings durante a inferência:
- `FacebookAI/xlm-mlm-17-1280` (Modelagem de linguagem com máscara, 17 idiomas)
- `FacebookAI/xlm-mlm-100-1280` (Modelagem de linguagem com máscara, 100 idiomas)
Estes modelos são utilizados para representações genéricas de frase diferentemente dos checkpoints XLM anteriores.
## BERT
Os seguintes modelos do BERT podem ser utilizados para tarefas multilinguísticas:
- `google-bert/bert-base-multilingual-uncased` (Modelagem de linguagem com máscara + Previsão de frases, 102 idiomas)
- `google-bert/bert-base-multilingual-cased` (Modelagem de linguagem com máscara + Previsão de frases, 104 idiomas)
Estes modelos não requerem language embeddings durante a inferência. Devem identificar a linguagem a partir
do contexto e realizar a inferência em sequência.
## XLM-RoBERTa
Os seguintes modelos do XLM-RoBERTa podem ser utilizados para tarefas multilinguísticas:
- `FacebookAI/xlm-roberta-base` (Modelagem de linguagem com máscara, 100 idiomas)
- `FacebookAI/xlm-roberta-large` Modelagem de linguagem com máscara, 100 idiomas)
O XLM-RoBERTa foi treinado com 2,5 TB de dados do CommonCrawl recém-criados e testados em 100 idiomas.
Proporciona fortes vantagens sobre os modelos multilinguísticos publicados anteriormente como o mBERT e o XLM em tarefas
subsequentes como a classificação, a rotulagem de sequências e à respostas a perguntas.
## M2M100
Os seguintes modelos de M2M100 podem ser utilizados para traduções multilinguísticas:
- `facebook/m2m100_418M` (Tradução)
- `facebook/m2m100_1.2B` (Tradução)
Neste exemplo, o checkpoint `facebook/m2m100_418M` é carregado para traduzir do mandarim ao inglês. É possível
estabelecer o idioma de origem no tokenizador:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
Tokenização do texto:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
O M2M100 força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
Os seguintes modelos do MBart podem ser utilizados para tradução multilinguística:
- `facebook/mbart-large-50-one-to-many-mmt` (Tradução automática multilinguística de um a vários, 50 idiomas)
- `facebook/mbart-large-50-many-to-many-mmt` (Tradução automática multilinguística de vários a vários, 50 idiomas)
- `facebook/mbart-large-50-many-to-one-mmt` (Tradução automática multilinguística vários a um, 50 idiomas)
- `facebook/mbart-large-50` (Tradução multilinguística, 50 idiomas)
- `facebook/mbart-large-cc25`
Neste exemplo, carrega-se o checkpoint `facebook/mbart-large-50-many-to-many-mmt` para traduzir do finlandês ao inglês.
Pode-se definir o idioma de origem no tokenizador:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
Tokenizando o texto:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
O MBart força o id do idioma de destino como o primeiro token gerado para traduzir ao idioma de destino.
É definido o `forced_bos_token_id` como `en` no método `generate` para traduzir ao inglês.
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id("en_XX"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
Se estiver usando o checkpoint `facebook/mbart-large-50-many-to-one-mmt` não será necessário forçar o id do idioma de destino
como sendo o primeiro token generado, caso contrário a usagem é a mesma.
|
transformers/docs/source/pt/multilingual.md/0
|
{
"file_path": "transformers/docs/source/pt/multilingual.md",
"repo_id": "transformers",
"token_count": 3212
}
| 54 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 智能体和工具
[[在colab里打开]]
### 什么是智能体 (Agent)?
大型语言模型(LLM)经过 [因果语言建模训练](./tasks/language_modeling) 可以应对各种任务,但在一些基本任务(如逻辑推理、计算和搜索)上常常表现不佳。当它们被用在自己不擅长的领域时,往往无法生成我们期望的答案。
为了解决这个问题,可以创建**智能体**.
智能体是一个系统,它使用 LLM 作为引擎,并且能够访问称为**工具**的功能。
这些**工具**是执行任务的函数,包含所有必要的描述信息,帮助智能体正确使用它们。
智能体可以被编程为:
- 一次性设计一系列工具并同时执行它们,像 [`CodeAgent`]
- 一次执行一个工具,并等待每个工具的结果后再启动下一个,像 [`ReactJsonAgent`]
### 智能体类型
#### 代码智能体
此智能体包含一个规划步骤,然后生成 Python 代码一次性执行所有任务。它原生支持处理不同输入和输出类型,因此推荐用于多模态任务。
#### 推理智能体
这是解决推理任务的首选代理,因为 ReAct 框架 ([Yao et al., 2022](https://huggingface.co/papers/2210.03629)) 使其在基于之前观察进行推理时非常高效。
我们实现了两种版本的 ReactJsonAgent:
- [`ReactJsonAgent`] 将工具调用作为 JSON 格式输出。
- [`ReactCodeAgent`] 是 ReactJsonAgent 的一种新型,生成工具调用的代码块,对于具备强大编程能力的 LLM 非常适用。
> [TIP]
> 阅读 [Open-source LLMs as LangChain Agents](https://huggingface.co/blog/open-source-llms-as-agents) 博文,了解更多关于推理智能体的信息。
<div class="flex justify-center">
<img
class="block dark:hidden"
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/Agent_ManimCE.gif"
/>
<img
class="hidden dark:block"
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/Agent_ManimCE.gif"
/>
</div>

以下是一个推理代码智能体如何处理以下问题的示例:
```py3
>>> agent.run(
... "How many more blocks (also denoted as layers) in BERT base encoder than the encoder from the architecture proposed in Attention is All You Need?",
... )
=====New task=====
How many more blocks (also denoted as layers) in BERT base encoder than the encoder from the architecture proposed in Attention is All You Need?
====Agent is executing the code below:
bert_blocks = search(query="number of blocks in BERT base encoder")
print("BERT blocks:", bert_blocks)
====
Print outputs:
BERT blocks: twelve encoder blocks
====Agent is executing the code below:
attention_layer = search(query="number of layers in Attention is All You Need")
print("Attention layers:", attention_layer)
====
Print outputs:
Attention layers: Encoder: The encoder is composed of a stack of N = 6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position- 2 Page 3 Figure 1: The Transformer - model architecture.
====Agent is executing the code below:
bert_blocks = 12
attention_layers = 6
diff = bert_blocks - attention_layers
print("Difference in blocks:", diff)
final_answer(diff)
====
Print outputs:
Difference in blocks: 6
Final answer: 6
```
### 如何构建智能体?
要初始化一个智能体,您需要以下参数:
- **一个 LLM** 来驱动智能体——智能体本身并不是 LLM,而是一个使用 LLM 作为引擎的程序。
- **一个系统提示**:告诉 LLM 引擎应该如何生成输出。
- **一个工具箱**,智能体可以从中选择工具执行。
- **一个解析器**,从 LLM 输出中提取出哪些工具需要调用,以及使用哪些参数。
在智能体系统初始化时,工具属性将生成工具描述,并嵌入到智能体的系统提示中,告知智能体可以使用哪些工具,并且为什么使用它们。
**安装依赖**
首先,您需要安装**智能体**所需的额外依赖:
```bash
pip install transformers[agents]
```
**创建LLM引擎**
定义一个 `llm_engine` 方法,该方法接受一系列[消息](./chat_templating)并返回文本。该 `callable` 还需要接受一个 `stop` 参数,用于指示何时停止生成输出。
```python
from huggingface_hub import login, InferenceClient
login("<YOUR_HUGGINGFACEHUB_API_TOKEN>")
client = InferenceClient(model="meta-llama/Meta-Llama-3-70B-Instruct")
def llm_engine(messages, stop_sequences=["Task"]) -> str:
response = client.chat_completion(messages, stop=stop_sequences, max_tokens=1000)
answer = response.choices[0].message.content
return answer
```
您可以使用任何符合以下要求的 `llm_engine` 方法:
1. [输入格式](./chat_templating)为 (`List[Dict[str, str]]`),并且返回一个字符串。
2. 它在 `stop_sequences` 参数传递的序列处停止生成输出。
此外,`llm_engine` 还可以接受一个 `grammar` 参数。如果在智能体初始化时指定了 `grammar`,则该参数将传递给 `llm_engine` 的调用,以允许[受限生成](https://huggingface.co/docs/text-generation-inference/conceptual/guidance),以强制生成格式正确的智能体输出。
您还需要一个 `tools` 参数,它接受一个 `Tools` 列表 —— 可以是空列表。您也可以通过定义可选参数 `add_base_tools=True` 来将默认工具箱添加到工具列表中。
现在,您可以创建一个智能体,例如 [`CodeAgent`],并运行它。您还可以创建一个 [`TransformersEngine`],使用 `transformers` 在本地机器上运行预初始化的推理管道。 为了方便起见,由于智能体行为通常需要更强大的模型,例如 `Llama-3.1-70B-Instruct`,它们目前较难在本地运行,我们还提供了 [`HfApiEngine`] 类,它在底层初始化了一个 `huggingface_hub.InferenceClient`。
```python
from transformers import CodeAgent, HfApiEngine
llm_engine = HfApiEngine(model="meta-llama/Meta-Llama-3-70B-Instruct")
agent = CodeAgent(tools=[], llm_engine=llm_engine, add_base_tools=True)
agent.run(
"Could you translate this sentence from French, say it out loud and return the audio.",
sentence="Où est la boulangerie la plus proche?",
)
```
当你急需某个东西时这将会很有用!
您甚至可以将 `llm_engine` 参数留空,默认情况下会创建一个 [`HfApiEngine`]。
```python
from transformers import CodeAgent
agent = CodeAgent(tools=[], add_base_tools=True)
agent.run(
"Could you translate this sentence from French, say it out loud and give me the audio.",
sentence="Où est la boulangerie la plus proche?",
)
```
请注意,我们使用了额外的 `sentence` 参数:您可以将文本作为附加参数传递给模型。
您还可以使用这个来指定本地或远程文件的路径供模型使用:
```py
from transformers import ReactCodeAgent
agent = ReactCodeAgent(tools=[], llm_engine=llm_engine, add_base_tools=True)
agent.run("Why does Mike not know many people in New York?", audio="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/recording.mp3")
```
系统提示和输出解析器会自动定义,但您可以通过调用智能体的 `system_prompt_template` 来轻松查看它们。
```python
print(agent.system_prompt_template)
```
尽可能清楚地解释您要执行的任务非常重要。 每次 [`~Agent.run`] 操作都是独立的,并且由于智能体是由 LLM 驱动的,提示中的细微变化可能会导致完全不同的结果。
您还可以连续运行多个任务,每次都会重新初始化智能体的 `agent.task` 和 `agent.logs` 属性。
#### 代码执行
Python 解释器在一组输入和工具上执行代码。 这应该是安全的,因为只能调用您提供的工具(特别是 Hugging Face 的工具)和 print 函数,因此您已经限制了可以执行的操作。
Python 解释器默认不允许导入不在安全列表中的模块,因此大多数明显的攻击问题应该不成问题。 您仍然可以通过在 [`ReactCodeAgent`] 或 [`CodeAgent`] 初始化时通过 `additional_authorized_imports` 参数传递一个授权的模块列表来授权额外的导入:
```py
>>> from transformers import ReactCodeAgent
>>> agent = ReactCodeAgent(tools=[], additional_authorized_imports=['requests', 'bs4'])
>>> agent.run("Could you get me the title of the page at url 'https://huggingface.co/blog'?")
(...)
'Hugging Face – Blog'
```
如果有任何代码尝试执行非法操作,或者生成的代码出现常规 Python 错误,执行将停止。
> [!WARNING]
> 在使用大语言模型(LLM)生成代码时,生成的代码会被执行,避免导入或使用任何不安全的库或模块。
### 系统提示
智能体,或者说驱动智能体的 LLM,根据系统提示生成输出。系统提示可以定制并根据目标任务进行调整。例如,检查 [`ReactCodeAgent`] 的系统提示(以下版本经过简化)。
```text
You will be given a task to solve as best you can.
You have access to the following tools:
<<tool_descriptions>>
To solve the task, you must plan forward to proceed in a series of steps, in a cycle of 'Thought:', 'Code:', and 'Observation:' sequences.
At each step, in the 'Thought:' sequence, you should first explain your reasoning towards solving the task, then the tools that you want to use.
Then in the 'Code:' sequence, you should write the code in simple Python. The code sequence must end with '/End code' sequence.
During each intermediate step, you can use 'print()' to save whatever important information you will then need.
These print outputs will then be available in the 'Observation:' field, for using this information as input for the next step.
In the end you have to return a final answer using the `final_answer` tool.
Here are a few examples using notional tools:
---
{examples}
Above example were using notional tools that might not exist for you. You only have acces to those tools:
<<tool_names>>
You also can perform computations in the python code you generate.
Always provide a 'Thought:' and a 'Code:\n```py' sequence ending with '```<end_code>' sequence. You MUST provide at least the 'Code:' sequence to move forward.
Remember to not perform too many operations in a single code block! You should split the task into intermediate code blocks.
Print results at the end of each step to save the intermediate results. Then use final_answer() to return the final result.
Remember to make sure that variables you use are all defined.
Now Begin!
```
系统提示包括:
- 解释智能体应该如何工作以及工具的**介绍**。
- 所有工具的描述由 `<<tool_descriptions>>` 标记在运行时动态替换,这样智能体就知道可以使用哪些工具及其用途。
- 工具的描述来自工具的属性,`name`、`description`、`inputs` 和 `output_type`,以及一个简单的 `jinja2` 模板,您可以根据需要进行调整。
- 期望的输出格式。
您可以通过向 `system_prompt` 参数传递自定义提示来最大程度地提高灵活性,从而覆盖整个系统提示模板。
```python
from transformers import ReactJsonAgent
from transformers.agents import PythonInterpreterTool
agent = ReactJsonAgent(tools=[PythonInterpreterTool()], system_prompt="{your_custom_prompt}")
```
> [WARNING]
> 必须在`template`中定义 `<<tool_descriptions>>` 这个变量,以便智能体能够正确地识别并使用可用的工具
### 检查智能体的运行
以下是检查运行后发生了什么的一些有用属性:
- `agent.logs` 存储了智能体的详细日志。每一步的所有内容都会存储在一个字典中,然后附加到 `agent.logs`。
- 运行 `agent.write_inner_memory_from_logs()` 会从日志中创建智能体的内存,以便 LLM 查看,作为一系列聊天消息。此方法会遍历日志的每个步骤,只保存其感兴趣的消息:例如,它会单独保存系统提示和任务,然后为每个步骤保存 LLM 输出的消息,以及工具调用输出的消息。如果您想要更高层次的查看发生了什么,可以使用此方法 —— 但并不是每个日志都会被此方法转录。
## 工具
工具是智能体使用的基本功能。
例如,您可以检查 [`PythonInterpreterTool`]:它有一个名称、描述、输入描述、输出类型和 `__call__` 方法来执行该操作。
当智能体初始化时,工具属性会用来生成工具描述,然后将其嵌入到智能体的系统提示中,这让智能体知道可以使用哪些工具以及为什么使用它们。
### 默认工具箱
Transformers 提供了一个默认工具箱,用于增强智能体,您可以在初始化时通过 `add_base_tools=True` 参数将其添加到智能体中:
- **文档问答**:给定一个文档(如图像格式的 PDF),回答关于该文档的问题([Donut](./model_doc/donut))
- **图像问答**:给定一张图片,回答关于该图像的问题([VILT](./model_doc/vilt))
- **语音转文本**:给定一个人讲述的音频录音,将其转录为文本(Whisper)
- **文本转语音**:将文本转换为语音([SpeechT5](./model_doc/speecht5))
- **翻译**:将给定的句子从源语言翻译为目标语言
- **DuckDuckGo 搜索**:使用 `DuckDuckGo` 浏览器进行网络搜索
- **Python 代码解释器**:在安全环境中运行 LLM 生成的 Python 代码。只有在初始化 [`ReactJsonAgent`] 时将 `add_base_tools=True` 时,代码智能体才会添加此工具,因为基于代码的智能体已经能够原生执行 Python 代码
您可以通过调用 [`load_tool`] 函数来手动使用某个工具并执行任务。
```python
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")
```
### 创建新工具
您可以为 `Hugging Face` 默认工具无法涵盖的用例创建自己的工具。
例如,假设我们要创建一个返回在 `Hugging Face Hub` 上某个任务中下载次数最多的模型的工具。
您将从以下代码开始:
```python
from huggingface_hub import list_models
task = "text-classification"
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
print(model.id)
```
这段代码可以很快转换为工具,只需将其包装成一个函数,并添加 `tool` 装饰器:
```py
from transformers import tool
@tool
def model_download_tool(task: str) -> str:
"""
This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub.
It returns the name of the checkpoint.
Args:
task: The task for which
"""
model = next(iter(list_models(filter="text-classification", sort="downloads", direction=-1)))
return model.id
```
该函数需要:
- 一个清晰的名称。名称通常描述工具的功能。由于代码返回某个任务中下载次数最多的模型,因此我们将其命名为 `model_download_tool`。
- 对输入和输出进行类型提示
- 描述,其中包括 "`Args`:" 部分,描述每个参数(这次不需要类型指示,它会从类型提示中获取)。
所有这些将自动嵌入到智能体的系统提示中,因此请尽量使它们尽可能清晰!
> [TIP]
> 这个定义格式与 apply_chat_template 中使用的工具模式相同,唯一的区别是添加了 tool 装饰器:可以在我们的工具使用 API 中[了解更多](https://huggingface.co/blog/unified-tool-use#passing-tools-to-a-chat-template).
然后,您可以直接初始化您的智能体:
```py
from transformers import CodeAgent
agent = CodeAgent(tools=[model_download_tool], llm_engine=llm_engine)
agent.run(
"Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub?"
)
```
您将得到以下输出:
```text
======== New task ========
Can you give me the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub?
==== Agent is executing the code below:
most_downloaded_model = model_download_tool(task="text-to-video")
print(f"The most downloaded model for the 'text-to-video' task is {most_downloaded_model}.")
====
```
输出:
`"The most downloaded model for the 'text-to-video' task is ByteDance/AnimateDiff-Lightning."`
### 管理智能体的工具箱
如果您已经初始化了一个智能体,但想添加一个新的工具,重新初始化智能体会很麻烦。借助 Transformers,您可以通过添加或替换工具来管理智能体的工具箱。
让我们将 `model_download_tool` 添加到一个仅初始化了默认工具箱的现有智能体中。
```python
from transformers import CodeAgent
agent = CodeAgent(tools=[], llm_engine=llm_engine, add_base_tools=True)
agent.toolbox.add_tool(model_download_tool)
```
现在,我们可以同时使用新工具和之前的文本到语音工具:
```python
agent.run(
"Can you read out loud the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub and return the audio?"
)
```
| **Audio** |
|------------------------------------------------------------------------------------------------------------------------------------------------------|
| <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/damo.wav" type="audio/wav"/> |
> [WARNING]
> 当向一个已经运行良好的代理添加工具时要小心,因为这可能会导致选择偏向你的工具,或者选择已经定义的工具之外的其他工具。
使用 agent.toolbox.update_tool() 方法可以替换智能体工具箱中的现有工具。
如果您的新工具完全替代了现有工具,这非常有用,因为智能体已经知道如何执行该特定任务。
只需确保新工具遵循与替换工具相同的 API,或者调整系统提示模板,以确保所有使用替换工具的示例都得到更新。
### 使用工具集合
您可以通过使用 ToolCollection 对象来利用工具集合,指定您想要使用的工具集合的 slug。
然后将这些工具作为列表传递给智能体进行初始化,并开始使用它们!
```py
from transformers import ToolCollection, ReactCodeAgent
image_tool_collection = ToolCollection(collection_slug="huggingface-tools/diffusion-tools-6630bb19a942c2306a2cdb6f")
agent = ReactCodeAgent(tools=[*image_tool_collection.tools], add_base_tools=True)
agent.run("Please draw me a picture of rivers and lakes.")
```
为了加速启动,工具仅在智能体调用时加载。
这将生成如下图像:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png">
|
transformers/docs/source/zh/agents.md/0
|
{
"file_path": "transformers/docs/source/zh/agents.md",
"repo_id": "transformers",
"token_count": 10263
}
| 55 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DeepSpeed集成
[DeepSpeed](https://github.com/microsoft/DeepSpeed)实现了[ZeRO论文](https://arxiv.org/abs/1910.02054)中描述的所有内容。目前,它提供对以下功能的全面支持:
1. 优化器状态分区(ZeRO stage 1)
2. 梯度分区(ZeRO stage 2)
3. 参数分区(ZeRO stage 3)
4. 自定义混合精度训练处理
5. 一系列基于CUDA扩展的快速优化器
6. ZeRO-Offload 到 CPU 和 NVMe
ZeRO-Offload有其自己的专门论文:[ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)。而NVMe支持在论文[ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)中进行了描述。
DeepSpeed ZeRO-2主要用于训练,因为它的特性对推理没有用处。
DeepSpeed ZeRO-3也可以用于推理,因为它允许将单个GPU无法加载的大模型加载到多个GPU上。
🤗 Transformers通过以下两种方式集成了[DeepSpeed](https://github.com/microsoft/DeepSpeed):
1. 通过[`Trainer`]集成核心的DeepSpeed功能。这是一种“为您完成一切”式的集成 - 您只需提供自定义配置文件或使用我们的模板配置文件。本文档的大部分内容都集中在这个功能上。
2. 如果您不使用[`Trainer`]并希望在自己的Trainer中集成DeepSpeed,那么像`from_pretrained`和`from_config`这样的核心功能函数将包括ZeRO stage 3及以上的DeepSpeed的基础部分,如`zero.Init`。要利用此功能,请阅读有关[非Trainer DeepSpeed集成](#nontrainer-deepspeed-integration)的文档。
集成的内容:
训练:
1. DeepSpeed ZeRO训练支持完整的ZeRO stages 1、2和3,以及ZeRO-Infinity(CPU和NVMe offload)。
推理:
1. DeepSpeed ZeRO推理支持ZeRO stage 3和ZeRO-Infinity。它使用与训练相同的ZeRO协议,但不使用优化器和学习率调度器,只有stage 3与推理相关。更多详细信息请参阅:[zero-inference](#zero-inference)。
此外还有DeepSpeed推理 - 这是一种完全不同的技术,它使用张量并行而不是ZeRO(即将推出)。
<a id='deepspeed-trainer-integration'></a>
## Trainer DeepSpeed 集成
<a id='deepspeed-installation'></a>
### 安装
通过pypi安装库:
```bash
pip install deepspeed
```
或通过 `transformers` 的 `extras`安装:
```bash
pip install transformers[deepspeed]
```
或在 [DeepSpeed 的 GitHub 页面](https://github.com/microsoft/deepspeed#installation) 和
[高级安装](https://www.deepspeed.ai/tutorials/advanced-install/) 中查找更多详细信息。
如果构建过程中仍然遇到问题,请首先确保阅读 [CUDA 扩展安装注意事项](trainer#cuda-extension-installation-notes)。
如果您没有预先构建扩展而是在运行时构建它们,而且您尝试了以上所有解决方案都无效,下一步可以尝试在安装之前预先构建扩展。
进行 DeepSpeed 的本地构建:
```bash
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log
```
如果您打算使用 NVMe offload,您还需要在上述说明中添加 `DS_BUILD_AIO=1`(并且还需要在系统范围内安装 *libaio-dev*)。
编辑 `TORCH_CUDA_ARCH_LIST` 以插入您打算使用的 GPU 卡的架构代码。假设您的所有卡都是相同的,您可以通过以下方式获取架构:
```bash
CUDA_VISIBLE_DEVICES=0 python -c "import torch; print(torch.cuda.get_device_capability())"
```
因此,如果您得到 `8, 6`,则使用 `TORCH_CUDA_ARCH_LIST="8.6"`。如果您有多个不同的卡,您可以像这样列出所有卡 `TORCH_CUDA_ARCH_LIST="6.1;8.6"`。
如果您需要在多台机器上使用相同的设置,请创建一个二进制 wheel:
```bash
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 \
python setup.py build_ext -j8 bdist_wheel
```
它将生成类似于 `dist/deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl` 的文件,现在您可以在本地或任何其他机器上安装它,如 `pip install deepspeed-0.3.13+8cd046f-cp38-cp38-linux_x86_64.whl`。
再次提醒确保调整 `TORCH_CUDA_ARCH_LIST` 以匹配目标架构。
您可以在[这里](https://developer.nvidia.com/cuda-gpus)找到完整的 NVIDIA GPU 列表及其对应的 **计算能力**(与此上下文中的架构相同)。
您可以使用以下命令检查 PyTorch 构建时使用的架构:
```bash
python -c "import torch; print(torch.cuda.get_arch_list())"
```
以下是如何查找已安装 GPU 中的一张卡的架构。例如,对于 GPU 0:
```bash
CUDA_VISIBLE_DEVICES=0 python -c "import torch; \
print(torch.cuda.get_device_properties(torch.device('cuda')))"
```
如果输出结果如下:
```bash
_CudaDeviceProperties(name='GeForce RTX 3090', major=8, minor=6, total_memory=24268MB, multi_processor_count=82)
```
然后您就知道这张卡的架构是 `8.6`。
您也可以完全省略 `TORCH_CUDA_ARCH_LIST`,然后构建程序将自动查询构建所在的 GPU 的架构。这可能与目标机器上的 GPU 不匹配,因此最好明确指定所需的架构。
如果尝试了所有建议的方法仍然遇到构建问题,请继续在 [Deepspeed](https://github.com/microsoft/DeepSpeed/issues)的 GitHub Issue 上提交问题。
<a id='deepspeed-multi-gpu'></a>
### 多GPU启用
为了启用DeepSpeed 集成,调整 [`Trainer`] 的命令行参数,添加一个新的参数 `--deepspeed ds_config.json`,其中 `ds_config.json` 是 DeepSpeed 配置文件,如文档 [这里](https://www.deepspeed.ai/docs/config-json/) 所述。文件命名由您决定。
建议使用 DeepSpeed 的 `add_config_arguments` 程序将必要的命令行参数添加到您的代码中。
有关更多信息,请参阅 [DeepSpeed 的参数解析](https://deepspeed.readthedocs.io/en/latest/initialize.html#argument-parsing) 文档。
在这里,您可以使用您喜欢的启动器。您可以继续使用 PyTorch 启动器:
```bash
torch.distributed.run --nproc_per_node=2 your_program.py <normal cl args> --deepspeed ds_config.json
```
或使用由 `deepspeed` 提供的启动器:
```bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json
```
正如您所见,这两个启动器的参数不同,但对于大多数需求,任何一个都可以满足工作需求。有关如何配置各个节点和 GPU 的完整详细信息,请查看 [此处](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node)。
当您使用 `deepspeed` 启动器并且希望使用所有可用的 GPU 时,您可以简单地省略 `--num_gpus` 标志。
以下是在 DeepSpeed 中启用使用所有可用 GPU情况下, 运行 `run_translation.py` 的示例:
```bash
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
请注意,在 DeepSpeed 文档中,您可能会看到 `--deepspeed --deepspeed_config ds_config.json` - 即两个与 DeepSpeed 相关的参数,但为简单起见,并且因为已经有很多参数要处理,我们将两者合并为一个单一参数。
有关一些实际使用示例,请参阅 [此帖](https://github.com/huggingface/transformers/issues/8771#issuecomment-759248400)。
<a id='deepspeed-one-gpu'></a>
### 单GPU启用
要使用一张 GPU 启用 DeepSpeed,调整 [`Trainer`] 的命令行参数如下:
```bash
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero2.json \
--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
这与多 GPU 的情况几乎相同,但在这里我们通过 `--num_gpus=1` 明确告诉 DeepSpeed 仅使用一张 GPU。默认情况下,DeepSpeed 启用给定节点上可以看到的所有 GPU。如果您一开始只有一张 GPU,那么您不需要这个参数。以下 [文档](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) 讨论了启动器的选项。
为什么要在仅使用一张 GPU 的情况下使用 DeepSpeed 呢?
1. 它具有 ZeRO-offload 功能,可以将一些计算和内存委托给主机的 CPU 和 内存,从而为模型的需求保留更多 GPU 资源 - 例如更大的批处理大小,或启用正常情况下无法容纳的非常大模型。
2. 它提供了智能的 GPU 内存管理系统,最小化内存碎片,这再次允许您容纳更大的模型和数据批次。
虽然接下来我们将详细讨论配置,但在单个 GPU 上通过 DeepSpeed 实现巨大性能提升的关键是在配置文件中至少有以下配置:
```json
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true
}
}
```
这会启用`optimizer offload `和一些其他重要功能。您可以尝试不同的buffer大小,有关详细信息,请参见下面的讨论。
关于这种启用类型的实际使用示例,请参阅 [此帖](https://github.com/huggingface/transformers/issues/8771#issuecomment-759176685)。
您还可以尝试使用本文后面进一步解释的支持`CPU 和 NVMe offload`功能的ZeRO-3 。
<!--- TODO: Benchmark whether we can get better performance out of ZeRO-3 vs. ZeRO-2 on a single GPU, and then
recommend ZeRO-3 config as starting one. -->
注意:
- 如果您需要在特定的 GPU 上运行,而不是 GPU 0,则无法使用 `CUDA_VISIBLE_DEVICES` 来限制可用 GPU 的可见范围。相反,您必须使用以下语法:
```bash
deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py ...
```
在这个例子中,我们告诉 DeepSpeed 使用 GPU 1(第二个 GPU)。
<a id='deepspeed-multi-node'></a>
### 多节点启用
这一部分的信息不仅适用于 DeepSpeed 集成,也适用于任何多节点程序。但 DeepSpeed 提供了一个比其他启动器更易于使用的 `deepspeed` 启动器,除非您在 SLURM 环境中。
在本节,让我们假设您有两个节点,每个节点有 8 张 GPU。您可以通过 `ssh hostname1` 访问第一个节点,通过 `ssh hostname2` 访问第二个节点,两者必须能够在本地通过 ssh 无密码方式相互访问。当然,您需要将这些主机(节点)名称重命名为您实际使用的主机名称。
#### torch.distributed.run启动器
例如,要使用 `torch.distributed.run`,您可以执行以下操作:
```bash
python -m torch.distributed.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
--master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
```
您必须 ssh 到每个节点,并在每个节点上运行相同的命令!不用担心,启动器会等待两个节点同步完成。
有关更多信息,请参阅 [torchrun](https://pytorch.org/docs/stable/elastic/run.html)。顺便说一下,这也是替代了几个 PyTorch 版本前的 `torch.distributed.launch` 的启动器。
#### deepspeed启动器
要改用 `deepspeed` 启动器,首先需要创建一个 `hostfile` 文件:
```
hostname1 slots=8
hostname2 slots=8
```
然后,您可以这样启动:
```bash
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
```
与 `torch.distributed.run` 启动器不同,`deepspeed` 将自动在两个节点上启动此命令!
更多信息,请参阅[资源配置(多节点)](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node)。
#### 在 SLURM 环境中启动
在 SLURM 环境中,可以采用以下方法。以下是一个 SLURM 脚本 `launch.slurm`,您需要根据您的具体 SLURM 环境进行调整。
```bash
#SBATCH --job-name=test-nodes # name
#SBATCH --nodes=2 # nodes
#SBATCH --ntasks-per-node=1 # crucial - only 1 task per dist per node!
#SBATCH --cpus-per-task=10 # number of cores per tasks
#SBATCH --gres=gpu:8 # number of gpus
#SBATCH --time 20:00:00 # maximum execution time (HH:MM:SS)
#SBATCH --output=%x-%j.out # output file name
export GPUS_PER_NODE=8
export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
export MASTER_PORT=9901
srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
--nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
--master_addr $MASTER_ADDR --master_port $MASTER_PORT \
your_program.py <normal cl args> --deepspeed ds_config.json'
```
剩下的就是运行它:
```bash
sbatch launch.slurm
```
`srun` 将负责在所有节点上同时启动程序。
#### 使用非共享文件系统
默认情况下,DeepSpeed 假定多节点环境使用共享存储。如果不是这种情况,每个节点只能看到本地文件系统,你需要调整配置文件,包含一个 [`checkpoint` 部分](https://www.deepspeed.ai/docs/config-json/#checkpoint-options)并设置如下选项:
```json
{
"checkpoint": {
"use_node_local_storage": true
}
}
```
或者,你还可以使用 [`Trainer`] 的 `--save_on_each_node` 参数,上述配置将自动添加。
<a id='deepspeed-notebook'></a>
### 在Notebooks启用
在将`notebook cells`作为脚本运行的情况下,问题在于没有正常的 `deepspeed` 启动器可依赖,因此在某些设置下,我们必须仿真运行它。
如果您只使用一个 GPU,以下是如何调整notebook中的训练代码以使用 DeepSpeed。
```python
# DeepSpeed requires a distributed environment even when only one process is used.
# This emulates a launcher in the notebook
import os
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "9994" # modify if RuntimeError: Address already in use
os.environ["RANK"] = "0"
os.environ["LOCAL_RANK"] = "0"
os.environ["WORLD_SIZE"] = "1"
# Now proceed as normal, plus pass the deepspeed config file
training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
trainer = Trainer(...)
trainer.train()
```
注意:`...` 代表您传递给函数的正常参数。
如果要使用多于一个 GPU,您必须在 DeepSpeed 中使用多进程环境。也就是说,您必须使用专门的启动器来实现这一目的,而不能通过仿真本节开头呈现的分布式环境来完成。
如果想要在notebook中动态创建配置文件并保存在当前目录,您可以在一个专用的cell中使用:
```python no-style
%%bash
cat <<'EOT' > ds_config_zero3.json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
EOT
```
如果训练脚本在一个普通文件中而不是在notebook cells中,您可以通过笔记本中的 shell 正常启动 `deepspeed`。例如,要使用 `run_translation.py`,您可以这样启动:
```python no-style
!git clone https://github.com/huggingface/transformers
!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
```
或者使用 `%%bash` 魔术命令,您可以编写多行代码,用于运行 shell 程序:
```python no-style
%%bash
git clone https://github.com/huggingface/transformers
cd transformers
deepspeed examples/pytorch/translation/run_translation.py ...
```
在这种情况下,您不需要本节开头呈现的任何代码。
注意:虽然 `%%bash` 魔术命令很方便,但目前它会缓冲输出,因此在进程完成之前您看不到日志。
<a id='deepspeed-config'></a>
### 配置
有关可以在 DeepSpeed 配置文件中使用的完整配置选项的详细指南,请参阅[以下文档](https://www.deepspeed.ai/docs/config-json/)。
您可以在 [DeepSpeedExamples 仓库](https://github.com/microsoft/DeepSpeedExamples)中找到解决各种实际需求的数十个 DeepSpeed 配置示例。
```bash
git clone https://github.com/microsoft/DeepSpeedExamples
cd DeepSpeedExamples
find . -name '*json'
```
延续上面的代码,假设您要配置 Lamb 优化器。那么您可以通过以下方式在示例的 `.json` 文件中进行搜索:
```bash
grep -i Lamb $(find . -name '*json')
```
还可以在[主仓](https://github.com/microsoft/DeepSpeed)中找到更多示例。
在使用 DeepSpeed 时,您总是需要提供一个 DeepSpeed 配置文件,但是一些配置参数必须通过命令行进行配置。您将在本指南的剩余章节找到这些细微差别。
为了了解 DeepSpeed 配置文件,这里有一个激活 ZeRO stage 2 功能的示例,包括优化器状态的 CPU offload,使用 `AdamW` 优化器和 `WarmupLR` 调度器,并且如果传递了 `--fp16` 参数将启用混合精度训练:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
}
```
当您执行程序时,DeepSpeed 将把它从 [`Trainer`] 收到的配置日志输出到console,因此您可以看到传递给它的最终配置。
<a id='deepspeed-config-passing'></a>
### 传递配置
正如本文档讨论的那样,通常将 DeepSpeed 配置作为指向 JSON 文件的路径传递,但如果您没有使用命令行界面配置训练,而是通过 [`TrainingArguments`] 实例化 [`Trainer`],那么对于 `deepspeed` 参数,你可以传递一个嵌套的 `dict`。这使您能够即时创建配置,而无需在将其传递给 [`TrainingArguments`] 之前将其写入文件系统。
总结起来,您可以这样做:
```python
TrainingArguments(..., deepspeed="/path/to/ds_config.json")
```
或者:
```python
ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
TrainingArguments(..., deepspeed=ds_config_dict)
```
<a id='deepspeed-config-shared'></a>
### 共享配置
<Tip warning={true}>
这一部分是必读的。
</Tip>
一些配置值对于 [`Trainer`] 和 DeepSpeed 正常运行都是必需的,因此,为了防止定义冲突及导致的难以检测的错误,我们选择通过 [`Trainer`] 命令行参数配置这些值。
此外,一些配置值是基于模型的配置自动派生的,因此,与其记住手动调整多个值,最好让 [`Trainer`] 为您做大部分配置。
因此,在本指南的其余部分,您将找到一个特殊的配置值:`auto`,当设置时将自动将参数替换为正确或最有效的值。请随意选择忽略此建议或显式设置该值,在这种情况下,请务必确保 [`Trainer`] 参数和 DeepSpeed 配置保持一致。例如,您是否使用相同的学习率、批量大小或梯度累积设置?如果这些不匹配,训练可能以非常难以检测的方式失败。请重视该警告。
还有一些参数是仅适用于 DeepSpeed 的,并且这些参数必须手动设置以适应您的需求。
在您自己的程序中,如果您想要作为主动修改 DeepSpeed 配置并以此配置 [`TrainingArguments`],您还可以使用以下方法。步骤如下:
1. 创建或加载要用作主配置的 DeepSpeed 配置
2. 根据这些参数值创建 [`TrainingArguments`] 对象
请注意,一些值,比如 `scheduler.params.total_num_steps`,是在 [`Trainer`] 的 `train` 过程中计算的,但当然您也可以自己计算这些值。
<a id='deepspeed-zero'></a>
### ZeRO
[Zero Redundancy Optimizer (ZeRO)](https://www.deepspeed.ai/tutorials/zero/) 是 DeepSpeed 的工作核心。它支持3个不同级别(stages)的优化。Stage 1 对于扩展性来说不是很有趣,因此本文档重点关注Stage 2和Stage 3。Stage 3通过最新的 ZeRO-Infinity 进一步改进。你可以在 DeepSpeed 文档中找到更详细的信息。
配置文件的 `zero_optimization` 部分是最重要的部分([文档](https://www.deepspeed.ai/docs/config-json/#zero-optimizations-for-fp16-training)),因为在这里您定义了要启用哪些 ZeRO stages 以及如何配置它们。您可以在 DeepSpeed 文档中找到每个参数的解释。
这一部分必须通过 DeepSpeed 配置文件单独配置 - [`Trainer`] 不提供相应的命令行参数。
注意:目前 DeepSpeed 不验证参数名称,因此如果您拼错了任何参数,它将使用拼写错误的参数的默认设置。您可以观察 DeepSpeed 引擎启动日志消息,看看它将使用哪些值。
<a id='deepspeed-zero2-config'></a>
#### ZeRO-2 配置
以下是 ZeRO stage 2 的配置示例:
```json
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true
}
}
```
**性能调优:**
- 启用 `offload_optimizer` 应该减少 GPU 内存使用(需要 `"stage": 2`)。
- `"overlap_comm": true` 通过增加 GPU 内存使用来降低all-reduce 的延迟。 `overlap_comm` 使用了 `allgather_bucket_size` 和 `reduce_bucket_size` 值的4.5倍。因此,如果它们设置为 `5e8`,这将需要一个9GB的内存占用(`5e8 x 2Bytes x 2 x 4.5`)。因此,如果您的 GPU 内存为8GB或更小,为了避免出现OOM错误,您需要将这些参数减小到约 `2e8`,这将需要3.6GB。如果您的 GPU 容量更大,当您开始遇到OOM时,你可能也需要这样做。
- 当减小这些buffers时,您以更慢的通信速度来换取更多的 GPU 内存。buffers大小越小,通信速度越慢,GPU 可用于其他任务的内存就越多。因此,如果更大的批处理大小很重要,那么稍微减慢训练时间可能是一个很好的权衡。
此外,`deepspeed==0.4.4` 添加了一个新选项 `round_robin_gradients`,您可以通过以下方式启用:
```json
{
"zero_optimization": {
"round_robin_gradients": true
}
}
```
这是一个用于 CPU offloading 的stage 2优化,通过细粒度梯度分区在 ranks 之间并行复制到 CPU 内存,从而实现了性能的提升。性能优势随着梯度累积步骤(在优化器步骤之间进行更多复制)或 GPU 数量(增加并行性)增加而增加。
<a id='deepspeed-zero3-config'></a>
#### ZeRO-3 配置
以下是 ZeRO stage 3的配置示例:
```json
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
如果您因为你的模型或激活值超过 GPU 内存而遇到OOM问题,并且您有未使用的 CPU 内存,可以通股票使用 `"device": "cpu"` 将优化器状态和参数卸载到 CPU 内存中,来解决这个限制。如果您不想卸载到 CPU 内存,可以在 `device` 条目中使用 `none` 代替 `cpu`。将优化器状态卸载到 NVMe 上会在后面进一步讨论。
通过将 `pin_memory` 设置为 `true` 启用固定内存。此功能会以减少可用于其他进程的内存为代价来提高吞吐量。固定内存被分配给特定请求它的进程,通常比普通 CPU 内存访问速度更快。
**性能调优:**
- `stage3_max_live_parameters`: `1e9`
- `stage3_max_reuse_distance`: `1e9`
如果遇到OOM问题,请减小 `stage3_max_live_parameters` 和 `stage3_max_reuse_distance`。它们对性能的影响应该很小,除非您正在进行激活值checkpointing。`1e9` 大约会消耗 ~2GB。内存由 `stage3_max_live_parameters` 和 `stage3_max_reuse_distance` 共享,所以它不是叠加的,而是总共2GB。
`stage3_max_live_parameters` 是在任何给定时间要在 GPU 上保留多少个完整参数的上限。"reuse distance" 是我们用来确定参数在将来何时会再次使用的度量标准,我们使用 `stage3_max_reuse_distance` 来决定是丢弃参数还是保留参数。如果一个参数在不久的将来(小于 `stage3_max_reuse_distance`)将被再次使用,那么我们将其保留以减少通信开销。这在启用激活值checkpoing时非常有用,其中我们以单层粒度进行前向重计算和反向传播,并希望在反向传播期间保留前向重计算中的参数。
以下配置值取决于模型的隐藏大小:
- `reduce_bucket_size`: `hidden_size*hidden_size`
- `stage3_prefetch_bucket_size`: `0.9 * hidden_size * hidden_size`
- `stage3_param_persistence_threshold`: `10 * hidden_size`
因此,将这些值设置为 `auto`,[`Trainer`] 将自动分配推荐的参数值。当然,如果您愿意,也可以显式设置这些值。
`stage3_gather_16bit_weights_on_model_save` 在模型保存时启用模型的 fp16 权重整合。对于大模型和多个 GPU,无论是在内存还是速度方面,这都是一项昂贵的操作。目前如果计划恢复训练,这是必需的。请注意未来的更新可能会删除此限制并让使用更加灵活。
如果您从 ZeRO-2 配置迁移,请注意 `allgather_partitions`、`allgather_bucket_size` 和 `reduce_scatter` 配置参数在 ZeRO-3 中不被使用。如果保留这些配置文件,它们将被忽略。
- `sub_group_size`: `1e9`
`sub_group_size` 控制在优化器步骤期间更新参数的粒度。参数被分组到大小为 `sub_group_size` 的桶中,每个桶逐个更新。在 ZeRO-Infinity 中与 NVMe offload一起使用时,`sub_group_size` 控制了在优化器步骤期间在 NVMe 和 CPU 内存之间移动模型状态的粒度。这可以防止非常大的模型耗尽 CPU 内存。
当不使用 NVMe offload时,可以将 `sub_group_size` 保留为其默认值 *1e9*。在以下情况下,您可能需要更改其默认值:
1. 在优化器步骤中遇到OOM:减小 `sub_group_size` 以减少临时buffers的内存利用
2. 优化器步骤花费很长时间:增加 `sub_group_size` 以提高由于增加的数据buffers而导致的带宽利用率。
#### ZeRO-0 配置
请注意,我们将 Stage 0 和 1 放在最后,因为它们很少使用。
Stage 0 禁用了所有类型的分片,只是将 DeepSpeed 作为 DDP 使用。您可以通过以下方式启用:
```json
{
"zero_optimization": {
"stage": 0
}
}
```
这将实质上禁用 ZeRO,而无需更改其他任何内容。
#### ZeRO-1 配置
Stage 1 等同于 Stage 2 减去梯度分片。您可以尝试使用以下配置,仅对优化器状态进行分片,以稍微加速:
```json
{
"zero_optimization": {
"stage": 1
}
}
```
<a id='deepspeed-nvme'></a>
### NVMe 支持
ZeRO-Infinity 通过使用 NVMe 内存扩展 GPU 和 CPU 内存,从而允许训练非常大的模型。由于智能分区和平铺算法,在offload期间每个 GPU 需要发送和接收非常小量的数据,因此 NVMe 被证明适用于训练过程中提供更大的总内存池。ZeRO-Infinity 需要启用 ZeRO-3。
以下配置示例启用 NVMe 来offload优化器状态和参数:
```json
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 5,
"buffer_size": 1e8,
"max_in_cpu": 1e9
},
"aio": {
"block_size": 262144,
"queue_depth": 32,
"thread_count": 1,
"single_submit": false,
"overlap_events": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
}
```
您可以选择将优化器状态和参数都卸载到 NVMe,也可以只选择其中一个,或者都不选择。例如,如果您有大量的 CPU 内存可用,只卸载到 CPU 内存训练速度会更快(提示:"device": "cpu")。
这是有关卸载 [优化器状态](https://www.deepspeed.ai/docs/config-json/#optimizer-offloading) 和 [参数](https://www.deepspeed.ai/docs/config-json/#parameter-offloading) 的完整文档。
确保您的 `nvme_path` 实际上是一个 NVMe,因为它与普通硬盘或 SSD 一起工作,但速度会慢得多。快速可扩展的训练是根据现代 NVMe 传输速度设计的(截至本文撰写时,可以达到 ~3.5GB/s 读取,~3GB/s 写入的峰值速度)。
为了找出最佳的 `aio` 配置块,您必须在目标设置上运行一个基准测试,具体操作请参见[说明](https://github.com/microsoft/DeepSpeed/issues/998)。
<a id='deepspeed-zero2-zero3-performance'></a>
#### ZeRO-2 和 ZeRO-3 性能对比
如果其他一切都配置相同,ZeRO-3 可能比 ZeRO-2 慢,因为前者除了 ZeRO-2 的操作外,还必须收集模型权重。如果 ZeRO-2 满足您的需求,而且您不需要扩展到几个 GPU 以上,那么您可以选择继续使用它。重要的是要理解,ZeRO-3 以速度为代价实现了更高的可扩展性。
可以调整 ZeRO-3 配置使其性能接近 ZeRO-2:
- 将 `stage3_param_persistence_threshold` 设置为一个非常大的数字 - 大于最大的参数,例如 `6 * hidden_size * hidden_size`。这将保留参数在 GPU 上。
- 关闭 `offload_params`,因为 ZeRO-2 没有这个选项。
即使不更改 `stage3_param_persistence_threshold`,仅将 `offload_params` 关闭,性能可能会显著提高。当然,这些更改将影响您可以训练的模型的大小。因此,这些更改可根据需求帮助您在可扩展性和速度之间进行权衡。
<a id='deepspeed-zero2-example'></a>
#### ZeRO-2 示例
这是一个完整的 ZeRO-2 自动配置文件 `ds_config_zero2.json`:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
这是一个完整的手动设置的启用所有功能的 ZeRO-2 配置文件。主要是为了让您看到典型的参数值是什么样的,但我们强烈建议使用其中包含多个 `auto` 设置的配置文件。
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
<a id='deepspeed-zero3-example'></a>
#### ZeRO-3 示例
这是一个完整的 ZeRO-3 自动配置文件 `ds_config_zero3.json`:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
这是一个完整的 手动设置的启用所有功能的ZeRO-3 配置文件。主要是为了让您看到典型的参数值是什么样的,但我们强烈建议使用其中包含多个 `auto` 设置的配置文件。
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 1e6,
"stage3_prefetch_bucket_size": 0.94e6,
"stage3_param_persistence_threshold": 1e4,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
#### 如何选择最佳性能的ZeRO Stage和 offloads
了解了这些不同stages后,现在您需要决定使用哪个stage。本节将尝试回答这个问题。
通常,以下规则适用:
- 速度方面(左边比右边快)
stage 0(DDP) > stage 1 > stage 2 > stage 2 + offload > stage 3 > stage3 + offload
- GPU内存使用方面(右边比左边更节省GPU内存)
stage 0(DDP) < stage 1 < stage 2 < stage 2 + offload < stage 3 < stage 3 + offload
所以,当您希望在尽量使用较少数量的GPU的同时获得最快的执行速度时,可以按照以下步骤进行。我们从最快的方法开始,如果遇到GPU内存溢出,然后切换到下一个速度较慢但使用的GPU内存更少的方法。以此类推。
首先,将批量大小设置为1(您始终可以使用梯度累积来获得任何所需的有效批量大小)。
1. 启用 `--gradient_checkpointing 1`(HF Trainer)或直接 `model.gradient_checkpointing_enable()` - 如果发生OOM(Out of Memory),则执行以下步骤。
2. 首先尝试 ZeRO stage 2。如果发生OOM,则执行以下步骤。
3. 尝试 ZeRO stage 2 + `offload_optimizer` - 如果发生OOM,则执行以下步骤。
4. 切换到 ZeRO stage 3 - 如果发生OOM,则执行以下步骤。
5. 启用 `offload_param` 到 `cpu` - 如果发生OOM,则执行以下步骤。
6. 启用 `offload_optimizer` 到 `cpu` - 如果发生OOM,则执行以下步骤。
7. 如果仍然无法适应批量大小为1,请首先检查各种默认值并尽可能降低它们。例如,如果使用 `generate` 并且不使用宽搜索束,将其缩小,因为它会占用大量内存。
8. 绝对要使用混合半精度而非fp32 - 在Ampere及更高的GPU上使用bf16,在旧的GPU体系结构上使用fp16。
9. 如果仍然发生OOM,可以添加更多硬件或启用ZeRO-Infinity - 即切换 `offload_param` 和 `offload_optimizer` 到 `nvme`。您需要确保它是非常快的NVMe。作为趣闻,我曾经能够在一个小型GPU上使用BLOOM-176B进行推理,使用了ZeRO-Infinity,尽管速度非常慢。但它奏效了!
当然,您也可以按相反的顺序进行这些步骤,从最节省GPU内存的配置开始,然后逐步反向进行,或者尝试进行二分法。
一旦您的批量大小为1不会导致OOM,就测量您的有效吞吐量。
接下来尝试将批量大小增加到尽可能大,因为批量大小越大,GPU的效率越高,特别是在它们乘法运算的矩阵很大时。
现在性能优化游戏开始了。您可以关闭一些offload特性,或者降低ZeRO stage,并增加/减少批量大小,再次测量有效吞吐量。反复尝试,直到满意为止。
不要花费太多时间,但如果您即将开始一个为期3个月的训练 - 请花几天时间找到吞吐量方面最有效的设置。这样您的训练成本将最低,而且您会更快地完成训练。在当前快节奏的机器学习世界中,如果您花费一个额外的月份来训练某样东西,你很可能会错过一个黄金机会。当然,这只是我分享的一种观察,我并不是在催促你。在开始训练BLOOM-176B之前,我花了2天时间进行这个过程,成功将吞吐量从90 TFLOPs提高到150 TFLOPs!这一努力为我们节省了一个多月的训练时间。
这些注释主要是为训练模式编写的,但它们在推理中也应该大部分适用。例如,在推理中,Gradient Checkpointing 是无用的,因为它只在训练过程中有用。此外,我们发现,如果你正在进行多GPU推理并且不使用 [DeepSpeed-Inference](https://www.deepspeed.ai/tutorials/inference-tutorial/),[Accelerate](https://huggingface.co/blog/bloom-inference-pytorch-scripts) 应该提供更优越的性能。
其他与性能相关的快速注释:
- 如果您从头开始训练某个模型,请尽量确保张量的形状可以被16整除(例如隐藏层大小)。对于批量大小,至少尝试可被2整除。如果您想从GPU中挤取更高性能,还有一些硬件特定的[wave和tile量化](https://developer.nvidia.com/blog/optimizing-gpu-performance-tensor-cores/)的可整除性。
### Activation Checkpointing 或 Gradient Checkpointing
Activation Checkpointing和Gradient Checkpointing是指相同方法的两个不同术语。这确实让人感到困惑,但事实就是这样。
Gradient Checkpointing允许通过牺牲速度来换取GPU内存,这要么使您能够克服GPU内存溢出,要么增加批量大小来获得更好的性能。
HF Transformers 模型对DeepSpeed的Activation Checkpointing一无所知,因此如果尝试在DeepSpeed配置文件中启用该功能,什么都不会发生。
因此,您有两种方法可以利用这个非常有益的功能:
1. 如果您想使用 HF Transformers 模型,你可以使用 `model.gradient_checkpointing_enable()` 或在 HF Trainer 中使用 `--gradient_checkpointing`,它会自动为您启用这个功能。在这里使用了 `torch.utils.checkpoint`。
2. 如果您编写自己的模型并希望使用DeepSpeed的Activation Checkpointing,可以使用[规定的API](https://deepspeed.readthedocs.io/en/latest/activation-checkpointing.html)。您还可以使用 HF Transformers 的模型代码,将 `torch.utils.checkpoint` 替换为 DeepSpeed 的API。后者更灵活,因为它允许您将前向激活值卸载到CPU内存,而不是重新计算它们。
### Optimizer 和 Scheduler
只要你不启用 `offload_optimizer`,您可以混合使用DeepSpeed和HuggingFace的调度器和优化器,但有一个例外,即不要使用HuggingFace调度器和DeepSpeed优化器的组合:
| Combos | HF Scheduler | DS Scheduler |
|:-------------|:-------------|:-------------|
| HF Optimizer | Yes | Yes |
| DS Optimizer | No | Yes |
在启用 `offload_optimizer` 的情况下,可以使用非DeepSpeed优化器,只要该优化器具有CPU和GPU的实现(除了LAMB)。
<a id='deepspeed-optimizer'></a>
#### Optimizer
DeepSpeed的主要优化器包括Adam、AdamW、OneBitAdam和Lamb。这些优化器已经与ZeRO进行了彻底的测试,因此建议使用它们。然而,也可以导入`torch`中的其他优化器。完整的文档在[这里](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters)。
如果在配置文件中不配置`optimizer`条目,[`Trainer`] 将自动将其设置为 `AdamW`,并使用提供的值或以下命令行参数的默认值:`--learning_rate`、`--adam_beta1`、`--adam_beta2`、`--adam_epsilon` 和 `--weight_decay`。
以下是`AdamW` 的自动配置示例:
```json
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
}
}
```
请注意,命令行参数将设置配置文件中的值。这是为了有一个明确的值来源,并避免在不同地方设置学习率等值时难以找到的错误。命令行参数配置高于其他。被覆盖的值包括:
- `lr` 的值为 `--learning_rate`
- `betas` 的值为 `--adam_beta1 --adam_beta2`
- `eps` 的值为 `--adam_epsilon`
- `weight_decay` 的值为 `--weight_decay`
因此,请记住在命令行上调整共享的超参数。
您也可以显式地设置这些值:
```json
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": 0.001,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
}
}
```
但在这种情况下,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
如果您想使用上面未列出的其他优化器,您将不得不将其添加到顶层配置中。
```json
{
"zero_allow_untested_optimizer": true
}
```
类似于 `AdamW`,您可以配置其他官方支持的优化器。只是记住这些可能有不同的配置值。例如,对于Adam,您可能需要将 `weight_decay` 设置在 `0.01` 左右。
此外,当与DeepSpeed的CPU Adam优化器一起使用时,offload的效果最好。如果您想在offload时使用不同的优化器,自 `deepspeed==0.8.3` 起,您还需要添加:
```json
{
"zero_force_ds_cpu_optimizer": false
}
```
到顶层配置中。
<a id='deepspeed-scheduler'></a>
#### Scheduler
DeepSpeed支持`LRRangeTest`、`OneCycle`、`WarmupLR`和`WarmupDecayLR`学习率调度器。完整文档在[这里](https://www.deepspeed.ai/docs/config-json/#scheduler-parameters)。
以下是🤗 Transformers 和 DeepSpeed 之间的调度器重叠部分:
- 通过 `--lr_scheduler_type constant_with_warmup` 实现 `WarmupLR`
- 通过 `--lr_scheduler_type linear` 实现 `WarmupDecayLR`。这也是 `--lr_scheduler_type` 的默认值,因此,如果不配置调度器,这将是默认配置的调度器。
如果在配置文件中不配置 `scheduler` 条目,[`Trainer`] 将使用 `--lr_scheduler_type`、`--learning_rate` 和 `--warmup_steps` 或 `--warmup_ratio` 的值来配置其🤗 Transformers 版本。
以下是 `WarmupLR` 的自动配置示例:
```json
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
```
由于使用了 *"auto"*,[`Trainer`] 的参数将在配置文件中设置正确的值。这是为了有一个明确的值来源,并避免在不同地方设置学习率等值时难以找到的错误。命令行配置高于其他。被设置的值包括:
- `warmup_min_lr` 的值为 `0`。
- `warmup_max_lr` 的值为 `--learning_rate`。
- `warmup_num_steps` 的值为 `--warmup_steps`(如果提供)。否则,将使用 `--warmup_ratio` 乘以训练步骤的数量,并四舍五入。
- `total_num_steps` 的值为 `--max_steps` 或者如果没有提供,将在运行时根据环境、数据集的大小和其他命令行参数(对于 `WarmupDecayLR` 来说需要)自动推导。
当然,您可以接管任何或所有的配置值,并自行设置这些值:
```json
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
}
}
```
但在这种情况下,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
例如,对于 `WarmupDecayLR`,您可以使用以下条目:
```json
{
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"last_batch_iteration": -1,
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
```
然后,`total_num_steps`、`warmup_max_lr`、`warmup_num_steps` 和 `total_num_steps` 将在加载时设置。
<a id='deepspeed-fp32'></a>
### fp32精度
DeepSpeed支持完整的fp32和fp16混合精度。
由于fp16混合精度具有更小的内存需求和更快的速度,唯一不使用它的时候是当您使用的模型在这种训练模式下表现不佳时。通常,当模型没有在fp16混合精度下进行预训练时(例如,bf16预训练模型经常出现这种情况),会出现这种情况。这样的模型可能会发生溢出或下溢,导致 `NaN` 损失。如果是这种情况,那么您将希望使用完整的fp32模式,通过显式禁用默认启用的fp16混合精度模式:
```json
{
"fp16": {
"enabled": false,
}
}
```
如果您使用基于Ampere架构的GPU,PyTorch版本1.7及更高版本将自动切换到使用更高效的tf32格式进行一些操作,但结果仍将以fp32格式呈现。有关详细信息和基准测试,请参见[TensorFloat-32(TF32) on Ampere devices](https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices)。如果出于某种原因您不希望使用它,该文档包括有关如何禁用此自动转换的说明。
在🤗 Trainer中,你可以使用 `--tf32` 来启用它,或使用 `--tf32 0` 或 `--no_tf32` 来禁用它。默认情况下,使用PyTorch的默认设置。
<a id='deepspeed-amp'></a>
### 自动混合精度
您可以使用自动混合精度,可以选择使用类似 PyTorch AMP 的方式,也可以选择使用类似 Apex 的方式:
### fp16
要配置PyTorch AMP-like 的 fp16(float16) 模式,请设置:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
并且,[`Trainer`]将根据`args.fp16_backend`的值自动启用或禁用它。其余的配置值由您决定。
当传递`--fp16 --fp16_backend amp`或`--fp16_full_eval`命令行参数时,此模式将被启用。
您也可以显式地启用/禁用此模式:
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
但是之后您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
以下是[相关文档](https://www.deepspeed.ai/docs/config-json/#fp16-training-options)
### bf16
如果需要使用bfloat16而不是fp16,那么可以使用以下配置部分:
```json
{
"bf16": {
"enabled": "auto"
}
}
```
bf16具有与fp32相同的动态范围,因此不需要损失缩放。
当传递`--bf16`或`--bf16_full_eval`命令行参数时,启用此模式。
您还可以显式地启用/禁用此模式:
```json
{
"bf16": {
"enabled": true
}
}
```
<Tip>
在`deepspeed==0.6.0`版本中,bf16支持是新的实验性功能。
如果您启用了bf16来进行[梯度累积](#gradient-accumulation),您需要意识到它会以bf16累积梯度,这可能不是您想要的,因为这种格式的低精度可能会导致lossy accumulation。
修复这个问题的工作正在努力进行,同时提供了使用更高精度的`dtype`(fp16或fp32)的选项。
</Tip>
### NCCL集合
在训练过程中,有两种数据类型:`dtype`和用于通信收集操作的`dtype`,如各种归约和收集/分散操作。
所有的gather/scatter操作都是在数据相同的`dtype`中执行的,所以如果您正在使用bf16的训练模式,那么它将在bf16中进行gather操作 - gather操作是非损失性的。
各种reduce操作可能会是非常损失性的,例如当梯度在多个gpu上平均时,如果通信是在fp16或bf16中进行的,那么结果可能是有损失性的 - 因为当在一个低精度中添加多个数字时,结果可能不是精确的。更糟糕的是,bf16比fp16具有更低的精度。通常,当平均梯度时,损失最小,这些梯度通常非常小。因此,对于半精度训练,默认情况下,fp16被用作reduction操作的默认值。但是,您可以完全控制这个功能,如果你选择的话,您可以添加一个小的开销,并确保reductions将使用fp32作为累积数据类型,只有当结果准备好时,它才会降级到您在训练中使用的半精度`dtype`。
要覆盖默认设置,您只需添加一个新的配置条目:
```json
{
"communication_data_type": "fp32"
}
```
根据这个信息,有效的值包括"fp16"、"bfp16"和"fp32"。
注意:在stage zero 3中,bf16通信数据类型存在一个bug,该问题已在`deepspeed==0.8.1`版本中得到修复。
### apex
配置apex AMP-like模式:
```json
"amp": {
"enabled": "auto",
"opt_level": "auto"
}
```
并且,[`Trainer`]将根据`args.fp16_backend`和`args.fp16_opt_level`的值自动配置它。
当传递`--fp16 --fp16_backend apex --fp16_opt_level 01`命令行参数时,此模式将被启用。
您还可以显式配置此模式:
```json
{
"amp": {
"enabled": true,
"opt_level": "O1"
}
}
```
但是,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
这里是[文档](https://www.deepspeed.ai/docs/config-json/#automatic-mixed-precision-amp-training-options)
<a id='deepspeed-bs'></a>
### Batch Size
配置batch size可以使用如下参数:
```json
{
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto"
}
```
并且,[`Trainer`]将自动将`train_micro_batch_size_per_gpu`设置为`args.per_device_train_batch_size`的值,并将`train_batch_size`设置为`args.world_size * args.per_device_train_batch_size * args.gradient_accumulation_steps`。
您也可以显式设置这些值:
```json
{
"train_batch_size": 12,
"train_micro_batch_size_per_gpu": 4
}
```
但是,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
<a id='deepspeed-grad-acc'></a>
### Gradient Accumulation
配置gradient accumulation设置如下:
```json
{
"gradient_accumulation_steps": "auto"
}
```
并且,[`Trainer`]将自动将其设置为`args.gradient_accumulation_steps`的值。
您也可以显式设置这个值:
```json
{
"gradient_accumulation_steps": 3
}
```
但是,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
<a id='deepspeed-grad-clip'></a>
### Gradient Clipping
配置gradient clipping如下:
```json
{
"gradient_clipping": "auto"
}
```
并且,[`Trainer`]将自动将其设置为`args.max_grad_norm`的值。
您也可以显式设置这个值:
```json
{
"gradient_clipping": 1.0
}
```
但是,您需要自己同步[`Trainer`]命令行参数和DeepSpeed配置。
<a id='deepspeed-weight-extraction'></a>
### 获取模型权重
只要您继续使用DeepSpeed进行训练和恢复,您就不需要担心任何事情。DeepSpeed在其自定义检查点优化器文件中存储fp32主权重,这些文件是`global_step*/*optim_states.pt`(这是glob模式),并保存在正常的checkpoint下。
**FP16权重:**
当模型保存在ZeRO-2下时,您最终会得到一个包含模型权重的普通`pytorch_model.bin`文件,但它们只是权重的fp16版本。
在ZeRO-3下,事情要复杂得多,因为模型权重分布在多个GPU上,因此需要`"stage3_gather_16bit_weights_on_model_save": true`才能让`Trainer`保存fp16版本的权重。如果这个设置是`False`,`pytorch_model.bin`将不会被创建。这是因为默认情况下,DeepSpeed的`state_dict`包含一个占位符而不是实际的权重。如果我们保存这个`state_dict`,就无法再加载它了。
```json
{
"zero_optimization": {
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
**FP32权重:**
虽然fp16权重适合恢复训练,但如果您完成了模型的微调并希望将其上传到[models hub](https://huggingface.co/models)或传递给其他人,您很可能想要获取fp32权重。这最好不要在训练期间完成,因为这需要大量内存,因此最好在训练完成后离线进行。但是,如果需要并且有充足的空闲CPU内存,可以在相同的训练脚本中完成。以下部分将讨论这两种方法。
**实时FP32权重恢复:**
如果您的模型很大,并且在训练结束时几乎没有剩余的空闲CPU内存,这种方法可能不起作用。
如果您至少保存了一个检查点,并且想要使用最新的一个,可以按照以下步骤操作:
```python
from transformers.trainer_utils import get_last_checkpoint
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = get_last_checkpoint(trainer.args.output_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
如果您在使用`--load_best_model_at_end`类:*~transformers.TrainingArguments*参数(用于跟踪最佳
检查点),那么你可以首先显式地保存最终模型,然后再执行相同的操作:
```python
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = os.path.join(trainer.args.output_dir, "checkpoint-final")
trainer.deepspeed.save_checkpoint(checkpoint_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
<Tip>
注意,一旦运行了`load_state_dict_from_zero_checkpoint`,该模型将不再可以在相同的应用程序的DeepSpeed上下文中使用。也就是说,您需要重新初始化deepspeed引擎,因为`model.load_state_dict(state_dict)`会从其中移除所有的DeepSpeed相关点。所以您只能训练结束时这样做。
</Tip>
当然,您不必使用类:*~transformers.Trainer*,您可以根据你的需求调整上面的示例。
如果您出于某种原因想要更多的优化,您也可以提取权重的fp32 `state_dict`并按照以下示例进行操作:
```python
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) # already on cpu
model = model.cpu()
model.load_state_dict(state_dict)
```
**离线FP32权重恢复:**
DeepSpeed会创建一个特殊的转换脚本`zero_to_fp32.py`,并将其放置在checkpoint文件夹的顶层。使用此脚本,您可以在任何时候提取权重。该脚本是独立的,您不再需要配置文件或`Trainer`来执行提取操作。
假设您的checkpoint文件夹如下所示:
```bash
$ ls -l output_dir/checkpoint-1/
-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
```
在这个例子中,只有一个DeepSpeed检查点子文件夹*global_step1*。因此,要重构fp32权重,只需运行:
```bash
python zero_to_fp32.py . pytorch_model.bin
```
这就是它。`pytorch_model.bin`现在将包含从多个GPUs合并的完整的fp32模型权重。
该脚本将自动能够处理ZeRO-2或ZeRO-3 checkpoint。
`python zero_to_fp32.py -h`将为您提供使用细节。
该脚本将通过文件`latest`的内容自动发现deepspeed子文件夹,在当前示例中,它将包含`global_step1`。
注意:目前该脚本需要2倍于最终fp32模型权重的通用内存。
### ZeRO-3 和 Infinity Nuances
ZeRO-3与ZeRO-2有很大的不同,主要是因为它的参数分片功能。
ZeRO-Infinity进一步扩展了ZeRO-3,以支持NVMe内存和其他速度和可扩展性改进。
尽管所有努力都是为了在不需要对模型进行任何特殊更改的情况下就能正常运行,但在某些情况下,您可能需要以下信息。
#### 构建大模型
DeepSpeed/ZeRO-3可以处理参数量达到数万亿的模型,这些模型可能无法适应现有的内存。在这种情况下,如果您还是希望初始化更快地发生,可以使用*deepspeed.zero.Init()*上下文管理器(也是一个函数装饰器)来初始化模型,如下所示:
```python
from transformers import T5ForConditionalGeneration, T5Config
import deepspeed
with deepspeed.zero.Init():
config = T5Config.from_pretrained("google-t5/t5-small")
model = T5ForConditionalGeneration(config)
```
如您所见,这会为您随机初始化一个模型。
如果您想使用预训练模型,`model_class.from_pretrained`将在`is_deepspeed_zero3_enabled()`返回`True`的情况下激活此功能,目前这是通过传递的DeepSpeed配置文件中的ZeRO-3配置部分设置的。因此,在调用`from_pretrained`之前,您必须创建**TrainingArguments**对象。以下是可能的顺序示例:
```python
from transformers import AutoModel, Trainer, TrainingArguments
training_args = TrainingArguments(..., deepspeed=ds_config)
model = AutoModel.from_pretrained("google-t5/t5-small")
trainer = Trainer(model=model, args=training_args, ...)
```
如果您使用的是官方示例脚本,并且命令行参数中包含`--deepspeed ds_config.json`且启用了ZeRO-3配置,那么一切都已经为您准备好了,因为这是示例脚本的编写方式。
注意:如果模型的fp16权重无法适应单个GPU的内存,则必须使用此功能。
有关此方法和其他相关功能的完整详细信息,请参阅[构建大模型](https://deepspeed.readthedocs.io/en/latest/zero3.html#constructing-massive-models)。
此外,在加载fp16预训练模型时,您希望`from_pretrained`使用`torch_dtype=torch.float16`。详情请参见[from_pretrained-torch-dtype](#from_pretrained-torch-dtype)。
#### 参数收集
在多个GPU上使用ZeRO-3时,没有一个GPU拥有所有参数,除非它是当前执行层的参数。因此,如果您需要一次访问所有层的所有参数,有一个特定的方法可以实现。
您可能不需要它,但如果您需要,请参考[参数收集](https://deepspeed.readthedocs.io/en/latest/zero3.html#manual-parameter-coordination)。
然而,我们在多个地方确实使用了它,其中一个例子是在`from_pretrained`中加载预训练模型权重。我们一次加载一层,然后立即将其分区到所有参与的GPU上,因为对于非常大的模型,无法在一个GPU上一次性加载并将其分布到多个GPU上,因为内存限制。
此外,在ZeRO-3下,如果您编写自己的代码并遇到看起来像这样的模型参数权重:
```python
tensor([1.0], device="cuda:0", dtype=torch.float16, requires_grad=True)
```
强调`tensor([1.])`,或者如果您遇到一个错误,它说参数的大小是`1`,而不是某个更大的多维形状,这意味着参数被划分了,你看到的是一个ZeRO-3占位符。
<a id='deepspeed-zero-inference'></a>
### ZeRO 推理
"ZeRO 推断" 使用与 "ZeRO-3 训练" 相同的配置。您只需要去掉优化器和调度器部分。实际上,如果您希望与训练共享相同的配置文件,您可以将它们保留在配置文件中,它们只会被忽略。
您只需要传递通常的[`TrainingArguments`]参数。例如:
```bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.json
```
唯一的重要事情是您需要使用ZeRO-3配置,因为ZeRO-2对于推理没有任何优势,因为只有ZeRO-3才对参数进行分片,而ZeRO-1则对梯度和优化器状态进行分片。
以下是在DeepSpeed下运行`run_translation.py`启用所有可用GPU的示例:
```bash
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path google-t5/t5-small --output_dir output_dir \
--do_eval --max_eval_samples 50 --warmup_steps 50 \
--max_source_length 128 --val_max_target_length 128 \
--overwrite_output_dir --per_device_eval_batch_size 4 \
--predict_with_generate --dataset_config "ro-en" --fp16 \
--source_lang en --target_lang ro --dataset_name wmt16 \
--source_prefix "translate English to Romanian: "
```
由于在推理阶段,优化器状态和梯度不需要额外的大量内存,您应该能够将更大的批次和/或序列长度放到相同的硬件上。
此外,DeepSpeed目前正在开发一个名为Deepspeed-Inference的相关产品,它与ZeRO技术无关,而是使用张量并行来扩展无法适应单个GPU的模型。这是一个正在进行的工作,一旦该产品完成,我们将提供集成。
### 内存要求
由于 DeepSpeed ZeRO 可以将内存卸载到 CPU(和 NVMe),该框架提供了一些工具,允许根据使用的 GPU 数量告知将需要多少 CPU 和 GPU 内存。
让我们估计在单个GPU上微调"bigscience/T0_3B"所需的内存:
```bash
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 1 GPU per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
```
因此,您可以将模型拟合在单个80GB的GPU上,不进行CPU offload,或者使用微小的8GB GPU,但需要约60GB的CPU内存。(请注意,这仅是参数、优化器状态和梯度所需的内存 - 您还需要为CUDA内核、激活值和临时变量分配更多的内存。)
然后,这是成本与速度的权衡。购买/租用较小的 GPU(或较少的 GPU,因为您可以使用多个 GPU 进行 Deepspeed ZeRO)。但这样会更慢,因此即使您不关心完成某项任务的速度,减速也直接影响 GPU 使用的持续时间,从而导致更大的成本。因此,请进行实验并比较哪种方法效果最好。
如果您有足够的GPU内存,请确保禁用CPU/NVMe卸载,因为这会使所有操作更快。
例如,让我们重复相同的操作,使用2个GPU:
```bash
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=2, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 2 GPUs per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 2.84GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.74GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=1
31.11GB | 23.58GB | offload_param=none, offload_optimizer=none, zero_init=0
```
所以,您需要2个32GB或更高的GPU,且不进行CPU卸载。
如需了解更多信息,请参阅[内存估算器](https://deepspeed.readthedocs.io/en/latest/memory.html)。
### 归档Issues
请按照以下步骤提交问题,以便我们能够迅速找到问题并帮助您解除工作阻塞。
在您的报告中,请始终包括以下内容:
1. 完整的Deepspeed配置文件
2. 如果使用了[`Trainer`],则包括命令行参数;如果自己编写了Trainer设置,则包括[`TrainingArguments`]参数。请不要导出[`TrainingArguments`],因为它有几十个与问题无关的条目。
3. 输出:
```bash
python -c 'import torch; print(f"torch: {torch.__version__}")'
python -c 'import transformers; print(f"transformers: {transformers.__version__}")'
python -c 'import deepspeed; print(f"deepspeed: {deepspeed.__version__}")'
```
4. 如果可能,请包含一个Google Colab notebook链接,我们可以使用它来重现问题。您可以使用这个[notebook](https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb)作为起点。
5. 除非不可能,否则请始终使用标准数据集,而不是自定义数据集。
6. 如果可能,尝试使用现有[示例](https://github.com/huggingface/transformers/tree/main/examples/pytorch)之一来重现问题。
需要考虑的因素:
- Deepspeed通常不是问题的原因。
一些已提交的问题被证明与Deepspeed无关。也就是说,一旦将Deepspeed从设置中移除,问题仍然存在。
因此,如果问题明显与DeepSpeed相关,例如您可以看到有一个异常并且可以看到DeepSpeed模块涉及其中,请先重新测试没有DeepSpeed的设置。只有当问题仍然存在时,才向Deepspeed提供所有必需的细节。
- 如果您明确问题是在Deepspeed核心中而不是集成部分,请直接向[Deepspeed](https://github.com/microsoft/DeepSpeed/)提交问题。如果您不确定,请不要担心,无论使用哪个issue跟踪问题都可以,一旦您发布问题,我们会弄清楚并将其重定向到另一个issue跟踪(如果需要的话)。
### Troubleshooting
#### 启动时`deepspeed`进程被终止,没有回溯
如果启动时`deepspeed`进程被终止,没有回溯,这通常意味着程序尝试分配的CPU内存超过了系统的限制或进程被允许分配的内存,操作系统内核杀死了该进程。这是因为您的配置文件很可能将`offload_optimizer`或`offload_param`或两者都配置为卸载到`cpu`。如果您有NVMe,可以尝试在ZeRO-3下卸载到NVMe。这里是如何[估计特定模型所需的内存](https://deepspeed.readthedocs.io/en/latest/memory.html)。
#### 训练和/或评估/预测loss为`NaN`
这种情况通常发生在使用bf16混合精度模式预训练的模型试图在fp16(带或不带混合精度)下使用时。大多数在TPU上训练的模型以及由谷歌发布的模型都属于这个类别(例如,几乎所有基于t5的模型)。在这种情况下,解决方案是要么使用fp32,要么在支持的情况下使用bf16(如TPU、Ampere GPU或更新的版本)。
另一个问题可能与使用fp16有关。当您配置此部分时:
```json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
并且您在日志中看到Deepspeed报告`OVERFLOW`如下
```
0%| | 0/189 [00:00<?, ?it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 262144
1%|▌ | 1/189 [00:00<01:26, 2.17it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 131072.0
1%|█▏
[...]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
14%|████████████████▌ | 27/189 [00:14<01:13, 2.21it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▏ | 28/189 [00:14<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▊ | 29/189 [00:15<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
[...]
```
这意味着Deepspeed损失缩放器无法找到一个克服损失溢出的缩放系数。
在这种情况下,通常需要提高`initial_scale_power`的值。将其设置为`"initial_scale_power": 32`通常会解决问题。
### 注意事项
- 尽管 DeepSpeed 有一个可安装的 PyPI 包,但强烈建议从源代码安装它,以最好地匹配您的硬件,如果您需要启用某些功能,如 1-bit Adam,这些功能在 pypi 发行版中不可用。
- 您不必使用🤗 Transformers的 [`Trainer`] 来使用 DeepSpeed - 您可以使用任何模型与自己的训练器,您还需要根据 [DeepSpeed 集成说明](https://www.deepspeed.ai/getting-started/#writing-deepspeed-models) 调整后者。
## Non-Trainer Deepspeed集成
当`Trainer`没有被使用时,`~integrations.HfDeepSpeedConfig`被用来将Deepspeed集成到huggingface的Transformers核心功能中。它唯一做的事情就是在`from_pretrained`调用期间处理Deepspeed ZeRO-3参数收集和将模型自动分割到多个GPU上。除此之外,您需要自己完成其他所有工作。
当使用`Trainer`时,所有事情都自动得到了处理。
当不使用`Trainer`时,为了高效地部署Deepspeed ZeRO-3,您必须在实例化模型之前实例化`~integrations.HfDeepSpeedConfig`对象并保持该对象活跃。
如果您正在使用Deepspeed ZeRO-1或ZeRO-2,您根本不需要使用`HfDeepSpeedConfig`。
以预训练模型为例:
```python
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
model = AutoModel.from_pretrained("openai-community/gpt2")
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
或者以非预训练模型为例:
```python
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel, AutoConfig
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
config = AutoConfig.from_pretrained("openai-community/gpt2")
model = AutoModel.from_config(config)
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
请注意,如果您没有使用[`Trainer`]集成,您完全需要自己动手。基本上遵循[Deepspeed](https://www.deepspeed.ai/)网站上的文档。同时,您必须显式配置配置文件 - 不能使用`"auto"`值,而必须放入实际值。
## HfDeepSpeedConfig
[[autodoc]] integrations.HfDeepSpeedConfig
- all
### 自定义DeepSpeed ZeRO推理
以下是一个示例,演示了在无法将模型放入单个 GPU 时如果不使用[Trainer]进行 DeepSpeed ZeRO 推理 。该解决方案包括使用额外的 GPU 或/和将 GPU 内存卸载到 CPU 内存。
这里要理解的重要细微差别是,ZeRO的设计方式可以让您在不同的GPU上并行处理不同的输入。
这个例子有很多注释,并且是自文档化的。
请确保:
1. 如果您有足够的GPU内存(因为这会减慢速度),禁用CPU offload。
2. 如果您拥有Ampere架构或更新的GPU,启用bf16以加快速度。如果您没有这种硬件,只要不使用任何在bf16混合精度下预训练的模型(如大多数t5模型),就可以启用fp16。否则这些模型通常在fp16中溢出,您会看到输出无效结果。
```python
#!/usr/bin/env python
# This script demonstrates how to use Deepspeed ZeRO in an inference mode when one can't fit a model
# into a single GPU
#
# 1. Use 1 GPU with CPU offload
# 2. Or use multiple GPUs instead
#
# First you need to install deepspeed: pip install deepspeed
#
# Here we use a 3B "bigscience/T0_3B" model which needs about 15GB GPU RAM - so 1 largish or 2
# small GPUs can handle it. or 1 small GPU and a lot of CPU memory.
#
# To use a larger model like "bigscience/T0" which needs about 50GB, unless you have an 80GB GPU -
# you will need 2-4 gpus. And then you can adapt the script to handle more gpus if you want to
# process multiple inputs at once.
#
# The provided deepspeed config also activates CPU memory offloading, so chances are that if you
# have a lot of available CPU memory and you don't mind a slowdown you should be able to load a
# model that doesn't normally fit into a single GPU. If you have enough GPU memory the program will
# run faster if you don't want offload to CPU - so disable that section then.
#
# To deploy on 1 gpu:
#
# deepspeed --num_gpus 1 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=1 t0.py
#
# To deploy on 2 gpus:
#
# deepspeed --num_gpus 2 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=2 t0.py
from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
from transformers.integrations import HfDeepSpeedConfig
import deepspeed
import os
import torch
os.environ["TOKENIZERS_PARALLELISM"] = "false" # To avoid warnings about parallelism in tokenizers
# distributed setup
local_rank = int(os.getenv("LOCAL_RANK", "0"))
world_size = int(os.getenv("WORLD_SIZE", "1"))
torch.cuda.set_device(local_rank)
deepspeed.init_distributed()
model_name = "bigscience/T0_3B"
config = AutoConfig.from_pretrained(model_name)
model_hidden_size = config.d_model
# batch size has to be divisible by world_size, but can be bigger than world_size
train_batch_size = 1 * world_size
# ds_config notes
#
# - enable bf16 if you use Ampere or higher GPU - this will run in mixed precision and will be
# faster.
#
# - for older GPUs you can enable fp16, but it'll only work for non-bf16 pretrained models - e.g.
# all official t5 models are bf16-pretrained
#
# - set offload_param.device to "none" or completely remove the `offload_param` section if you don't
# - want CPU offload
#
# - if using `offload_param` you can manually finetune stage3_param_persistence_threshold to control
# - which params should remain on gpus - the larger the value the smaller the offload size
#
# For in-depth info on Deepspeed config see
# https://huggingface.co/docs/transformers/main/main_classes/deepspeed
# keeping the same format as json for consistency, except it uses lower case for true/false
# fmt: off
ds_config = {
"fp16": {
"enabled": False
},
"bf16": {
"enabled": False
},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": True
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_bucket_size": model_hidden_size * model_hidden_size,
"stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
"stage3_param_persistence_threshold": 10 * model_hidden_size
},
"steps_per_print": 2000,
"train_batch_size": train_batch_size,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": False
}
# fmt: on
# next line instructs transformers to partition the model directly over multiple gpus using
# deepspeed.zero.Init when model's `from_pretrained` method is called.
#
# **it has to be run before loading the model AutoModelForSeq2SeqLM.from_pretrained(model_name)**
#
# otherwise the model will first be loaded normally and only partitioned at forward time which is
# less efficient and when there is little CPU RAM may fail
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
# now a model can be loaded.
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# initialise Deepspeed ZeRO and store only the engine object
ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
ds_engine.module.eval() # inference
# Deepspeed ZeRO can process unrelated inputs on each GPU. So for 2 gpus you process 2 inputs at once.
# If you use more GPUs adjust for more.
# And of course if you have just one input to process you then need to pass the same string to both gpus
# If you use only one GPU, then you will have only rank 0.
rank = torch.distributed.get_rank()
if rank == 0:
text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
elif rank == 1:
text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
with torch.no_grad():
outputs = ds_engine.module.generate(inputs, synced_gpus=True)
text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"rank{rank}:\n in={text_in}\n out={text_out}")
```
让我们保存它为 `t0.py`并运行:
```bash
$ deepspeed --num_gpus 2 t0.py
rank0:
in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
out=Positive
rank1:
in=Is this review positive or negative? Review: this is the worst restaurant ever
out=negative
```
这是一个非常基本的例子,您需要根据自己的需求进行修改。
### `generate` 的差异
在使用ZeRO stage 3的多GPU时,需要通过调用`generate(..., synced_gpus=True)`来同步GPU。如果一个GPU在其它GPU之前完成生成,整个系统将挂起,因为其他GPU无法从停止生成的GPU接收权重分片。
从`transformers>=4.28`开始,如果没有明确指定`synced_gpus`,检测到这些条件后它将自动设置为`True`。但如果您需要覆盖`synced_gpus`的值,仍然可以这样做。
## 测试 DeepSpeed 集成
如果您提交了一个涉及DeepSpeed集成的PR,请注意我们的CircleCI PR CI设置没有GPU,因此我们只在另一个CI夜间运行需要GPU的测试。因此,如果您在PR中获得绿色的CI报告,并不意味着DeepSpeed测试通过。
要运行DeepSpeed测试,请至少运行以下命令:
```bash
RUN_SLOW=1 pytest tests/deepspeed/test_deepspeed.py
```
如果你更改了任何模型或PyTorch示例代码,请同时运行多模型测试。以下将运行所有DeepSpeed测试:
```bash
RUN_SLOW=1 pytest tests/deepspeed
```
## 主要的DeepSpeed资源
- [项目GitHub](https://github.com/microsoft/deepspeed)
- [使用文档](https://www.deepspeed.ai/getting-started/)
- [API文档](https://deepspeed.readthedocs.io/en/latest/index.html)
- [博客文章](https://www.microsoft.com/en-us/research/search/?q=deepspeed)
论文:
- [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/abs/1910.02054)
- [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://arxiv.org/abs/2101.06840)
- [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://arxiv.org/abs/2104.07857)
最后,请记住,HuggingFace [`Trainer`]仅集成了DeepSpeed,因此如果您在使用DeepSpeed时遇到任何问题或疑问,请在[DeepSpeed GitHub](https://github.com/microsoft/DeepSpeed/issues)上提交一个issue。
|
transformers/docs/source/zh/main_classes/deepspeed.md/0
|
{
"file_path": "transformers/docs/source/zh/main_classes/deepspeed.md",
"repo_id": "transformers",
"token_count": 49134
}
| 56 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 用于推理的多语言模型
[[open-in-colab]]
🤗 Transformers 中有多种多语言模型,它们的推理用法与单语言模型不同。但是,并非*所有*的多语言模型用法都不同。一些模型,例如 [google-bert/bert-base-multilingual-uncased](https://huggingface.co/google-bert/bert-base-multilingual-uncased) 就可以像单语言模型一样使用。本指南将向您展示如何使用不同用途的多语言模型进行推理。
## XLM
XLM 有十个不同的检查点,其中只有一个是单语言的。剩下的九个检查点可以归为两类:使用语言嵌入的检查点和不使用语言嵌入的检查点。
### 带有语言嵌入的 XLM
以下 XLM 模型使用语言嵌入来指定推理中使用的语言:
- `FacebookAI/xlm-mlm-ende-1024` (掩码语言建模,英语-德语)
- `FacebookAI/xlm-mlm-enfr-1024` (掩码语言建模,英语-法语)
- `FacebookAI/xlm-mlm-enro-1024` (掩码语言建模,英语-罗马尼亚语)
- `FacebookAI/xlm-mlm-xnli15-1024` (掩码语言建模,XNLI 数据集语言)
- `FacebookAI/xlm-mlm-tlm-xnli15-1024` (掩码语言建模+翻译,XNLI 数据集语言)
- `FacebookAI/xlm-clm-enfr-1024` (因果语言建模,英语-法语)
- `FacebookAI/xlm-clm-ende-1024` (因果语言建模,英语-德语)
语言嵌入被表示一个张量,其形状与传递给模型的 `input_ids` 相同。这些张量中的值取决于所使用的语言,并由分词器的 `lang2id` 和 `id2lang` 属性识别。
在此示例中,加载 `FacebookAI/xlm-clm-enfr-1024` 检查点(因果语言建模,英语-法语):
```py
>>> import torch
>>> from transformers import XLMTokenizer, XLMWithLMHeadModel
>>> tokenizer = XLMTokenizer.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
>>> model = XLMWithLMHeadModel.from_pretrained("FacebookAI/xlm-clm-enfr-1024")
```
分词器的 `lang2id` 属性显示了该模型的语言及其对应的id:
```py
>>> print(tokenizer.lang2id)
{'en': 0, 'fr': 1}
```
接下来,创建一个示例输入:
```py
>>> input_ids = torch.tensor([tokenizer.encode("Wikipedia was used to")]) # batch size 为 1
```
将语言 id 设置为 `"en"` 并用其定义语言嵌入。语言嵌入是一个用 `0` 填充的张量,这个张量应该与 `input_ids` 大小相同。
```py
>>> language_id = tokenizer.lang2id["en"] # 0
>>> langs = torch.tensor([language_id] * input_ids.shape[1]) # torch.tensor([0, 0, 0, ..., 0])
>>> # 我们将其 reshape 为 (batch_size, sequence_length) 大小
>>> langs = langs.view(1, -1) # 现在的形状是 [1, sequence_length] (我们的 batch size 为 1)
```
现在,你可以将 `input_ids` 和语言嵌入传递给模型:
```py
>>> outputs = model(input_ids, langs=langs)
```
[run_generation.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-generation/run_generation.py) 脚本可以使用 `xlm-clm` 检查点生成带有语言嵌入的文本。
### 不带语言嵌入的 XLM
以下 XLM 模型在推理时不需要语言嵌入:
- `FacebookAI/xlm-mlm-17-1280` (掩码语言建模,支持 17 种语言)
- `FacebookAI/xlm-mlm-100-1280` (掩码语言建模,支持 100 种语言)
与之前的 XLM 检查点不同,这些模型用于通用句子表示。
## BERT
以下 BERT 模型可用于多语言任务:
- `google-bert/bert-base-multilingual-uncased` (掩码语言建模 + 下一句预测,支持 102 种语言)
- `google-bert/bert-base-multilingual-cased` (掩码语言建模 + 下一句预测,支持 104 种语言)
这些模型在推理时不需要语言嵌入。它们应该能够从上下文中识别语言并进行相应的推理。
## XLM-RoBERTa
以下 XLM-RoBERTa 模型可用于多语言任务:
- `FacebookAI/xlm-roberta-base` (掩码语言建模,支持 100 种语言)
- `FacebookAI/xlm-roberta-large` (掩码语言建模,支持 100 种语言)
XLM-RoBERTa 使用 100 种语言的 2.5TB 新创建和清理的 CommonCrawl 数据进行了训练。与之前发布的 mBERT 或 XLM 等多语言模型相比,它在分类、序列标记和问答等下游任务上提供了更强大的优势。
## M2M100
以下 M2M100 模型可用于多语言翻译:
- `facebook/m2m100_418M` (翻译)
- `facebook/m2m100_1.2B` (翻译)
在此示例中,加载 `facebook/m2m100_418M` 检查点以将中文翻译为英文。你可以在分词器中设置源语言:
```py
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> chinese_text = "不要插手巫師的事務, 因為他們是微妙的, 很快就會發怒."
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="zh")
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
```
对文本进行分词:
```py
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
```
M2M100 强制将目标语言 id 作为第一个生成的标记,以进行到目标语言的翻译。在 `generate` 方法中将 `forced_bos_token_id` 设置为 `en` 以翻译成英语:
```py
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
'Do not interfere with the matters of the witches, because they are delicate and will soon be angry.'
```
## MBart
以下 MBart 模型可用于多语言翻译:
- `facebook/mbart-large-50-one-to-many-mmt` (一对多多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50-many-to-many-mmt` (多对多多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50-many-to-one-mmt` (多对一多语言机器翻译,支持 50 种语言)
- `facebook/mbart-large-50` (多语言翻译,支持 50 种语言)
- `facebook/mbart-large-cc25`
在此示例中,加载 `facebook/mbart-large-50-many-to-many-mmt` 检查点以将芬兰语翻译为英语。 你可以在分词器中设置源语言:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> en_text = "Do not meddle in the affairs of wizards, for they are subtle and quick to anger."
>>> fi_text = "Älä sekaannu velhojen asioihin, sillä ne ovat hienovaraisia ja nopeasti vihaisia."
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/mbart-large-50-many-to-many-mmt", src_lang="fi_FI")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/mbart-large-50-many-to-many-mmt")
```
对文本进行分词:
```py
>>> encoded_en = tokenizer(en_text, return_tensors="pt")
```
MBart 强制将目标语言 id 作为第一个生成的标记,以进行到目标语言的翻译。在 `generate` 方法中将 `forced_bos_token_id` 设置为 `en` 以翻译成英语:
```py
>>> generated_tokens = model.generate(**encoded_en, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Don't interfere with the wizard's affairs, because they are subtle, will soon get angry."
```
如果你使用的是 `facebook/mbart-large-50-many-to-one-mmt` 检查点,则无需强制目标语言 id 作为第一个生成的令牌,否则用法是相同的。
|
transformers/docs/source/zh/multilingual.md/0
|
{
"file_path": "transformers/docs/source/zh/multilingual.md",
"repo_id": "transformers",
"token_count": 4377
}
| 57 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 用于 TensorFlow 模型的 XLA 集成
[[open-in-colab]]
加速线性代数,也称为XLA,是一个用于加速TensorFlow模型运行时间的编译器。从[官方文档](https://www.tensorflow.org/xla)中可以看到:
XLA(加速线性代数)是一种针对线性代数的特定领域编译器,可以在可能不需要更改源代码的情况下加速TensorFlow模型。
在TensorFlow中使用XLA非常简单——它包含在`tensorflow`库中,并且可以使用任何图创建函数中的`jit_compile`参数来触发,例如[`tf.function`](https://www.tensorflow.org/guide/intro_to_graphs)。在使用Keras方法如`fit()`和`predict()`时,只需将`jit_compile`参数传递给`model.compile()`即可启用XLA。然而,XLA不仅限于这些方法 - 它还可以用于加速任何任意的`tf.function`。
在🤗 Transformers中,几个TensorFlow方法已经被重写为与XLA兼容,包括[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2)、[T5](https://huggingface.co/docs/transformers/model_doc/t5)和[OPT](https://huggingface.co/docs/transformers/model_doc/opt)等文本生成模型,以及[Whisper](https://huggingface.co/docs/transformers/model_doc/whisper)等语音处理模型。
虽然确切的加速倍数很大程度上取决于模型,但对于🤗 Transformers中的TensorFlow文本生成模型,我们注意到速度提高了约100倍。本文档将解释如何在这些模型上使用XLA获得最大的性能。如果您有兴趣了解更多关于基准测试和我们在XLA集成背后的设计哲学的信息,我们还将提供额外的资源链接。
## 使用 XLA 运行 TensorFlow 函数
让我们考虑以下TensorFlow 中的模型:
```py
import tensorflow as tf
model = tf.keras.Sequential(
[tf.keras.layers.Dense(10, input_shape=(10,), activation="relu"), tf.keras.layers.Dense(5, activation="softmax")]
)
```
上述模型接受维度为 `(10,)` 的输入。我们可以像下面这样使用模型进行前向传播:
```py
# Generate random inputs for the model.
batch_size = 16
input_vector_dim = 10
random_inputs = tf.random.normal((batch_size, input_vector_dim))
# Run a forward pass.
_ = model(random_inputs)
```
为了使用 XLA 编译的函数运行前向传播,我们需要执行以下操作:
```py
xla_fn = tf.function(model, jit_compile=True)
_ = xla_fn(random_inputs)
```
`model`的默认`call()`函数用于编译XLA图。但如果你想将其他模型函数编译成XLA,也是可以的,如下所示:
```py
my_xla_fn = tf.function(model.my_xla_fn, jit_compile=True)
```
## 在🤗 Transformers库中使用XLA运行TensorFlow文本生成模型
要在🤗 Transformers中启用XLA加速生成,您需要安装最新版本的`transformers`。您可以通过运行以下命令来安装它:
```bash
pip install transformers --upgrade
```
然后您可以运行以下代码:
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
# Will error if the minimal version of Transformers is not installed.
from transformers.utils import check_min_version
check_min_version("4.21.0")
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
input_string = ["TensorFlow is"]
# One line to create an XLA generation function
xla_generate = tf.function(model.generate, jit_compile=True)
tokenized_input = tokenizer(input_string, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
# Generated -- TensorFlow is an open-source, open-source, distributed-source application # framework for the
```
正如您所注意到的,在`generate()`上启用XLA只需要一行代码。其余部分代码保持不变。然而,上面的代码片段中有一些与XLA相关的注意事项。您需要了解这些注意事项,以充分利用XLA可能带来的性能提升。我们将在下面的部分讨论这些内容。
## 需要关注的注意事项
当您首次执行启用XLA的函数(如上面的`xla_generate()`)时,它将在内部尝试推断计算图,这是一个耗时的过程。这个过程被称为[“tracing”](https://www.tensorflow.org/guide/intro_to_graphs#when_is_a_function_tracing)。
您可能会注意到生成时间并不快。连续调用`xla_generate()`(或任何其他启用了XLA的函数)不需要再次推断计算图,只要函数的输入与最初构建计算图时的形状相匹配。对于具有固定输入形状的模态(例如图像),这不是问题,但如果您正在处理具有可变输入形状的模态(例如文本),则必须注意。
为了确保`xla_generate()`始终使用相同的输入形状,您可以在调用`tokenizer`时指定`padding`参数。
```py
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
input_string = ["TensorFlow is"]
xla_generate = tf.function(model.generate, jit_compile=True)
# Here, we call the tokenizer with padding options.
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
decoded_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)
print(f"Generated -- {decoded_text}")
```
通过这种方式,您可以确保`xla_generate()`的输入始终具有它跟踪的形状,从而加速生成时间。您可以使用以下代码来验证这一点:
```py
import time
import tensorflow as tf
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2", padding_side="left", pad_token="</s>")
model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
xla_generate = tf.function(model.generate, jit_compile=True)
for input_string in ["TensorFlow is", "TensorFlow is a", "TFLite is a"]:
tokenized_input = tokenizer(input_string, pad_to_multiple_of=8, padding=True, return_tensors="tf")
start = time.time_ns()
generated_tokens = xla_generate(**tokenized_input, num_beams=2)
end = time.time_ns()
print(f"Execution time -- {(end - start) / 1e6:.1f} ms\n")
```
在Tesla T4 GPU上,您可以期望如下的输出:
```bash
Execution time -- 30819.6 ms
Execution time -- 79.0 ms
Execution time -- 78.9 ms
```
第一次调用`xla_generate()`会因为`tracing`而耗时,但后续的调用会快得多。请注意,任何时候对生成选项的更改都会触发重新`tracing`,从而导致生成时间减慢。
在本文档中,我们没有涵盖🤗 Transformers提供的所有文本生成选项。我们鼓励您阅读文档以了解高级用例。
## 附加资源
以下是一些附加资源,如果您想深入了解在🤗 Transformers和其他库下使用XLA:
* [这个Colab Notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/91_tf_xla_generate.ipynb) 提供了一个互动演示,让您可以尝试使用XLA兼容的编码器-解码器(例如[T5](https://huggingface.co/docs/transformers/model_doc/t5))和仅解码器(例如[GPT2](https://huggingface.co/docs/transformers/model_doc/gpt2))文本生成模型。
* [这篇博客文章](https://huggingface.co/blog/tf-xla-generate) 提供了XLA兼容模型的比较基准概述,以及关于在TensorFlow中使用XLA的友好介绍。
* [这篇博客文章](https://blog.tensorflow.org/2022/11/how-hugging-face-improved-text-generation-performance-with-xla.html) 讨论了我们在🤗 Transformers中为TensorFlow模型添加XLA支持的设计理念。
* 推荐用于更多学习XLA和TensorFlow图的资源:
* [XLA:面向机器学习的优化编译器](https://www.tensorflow.org/xla)
* [图和tf.function简介](https://www.tensorflow.org/guide/intro_to_graphs)
* [使用tf.function获得更好的性能](https://www.tensorflow.org/guide/function)
|
transformers/docs/source/zh/tf_xla.md/0
|
{
"file_path": "transformers/docs/source/zh/tf_xla.md",
"repo_id": "transformers",
"token_count": 4549
}
| 58 |
#!/usr/bin/env python3
import time
from argparse import ArgumentParser
import jax
import numpy as np
from transformers import BertConfig, FlaxBertModel
parser = ArgumentParser()
parser.add_argument("--precision", type=str, choices=["float32", "bfloat16"], default="float32")
args = parser.parse_args()
dtype = jax.numpy.float32
if args.precision == "bfloat16":
dtype = jax.numpy.bfloat16
VOCAB_SIZE = 30522
BS = 32
SEQ_LEN = 128
def get_input_data(batch_size=1, seq_length=384):
shape = (batch_size, seq_length)
input_ids = np.random.randint(1, VOCAB_SIZE, size=shape).astype(np.int32)
token_type_ids = np.ones(shape).astype(np.int32)
attention_mask = np.ones(shape).astype(np.int32)
return {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": attention_mask}
inputs = get_input_data(BS, SEQ_LEN)
config = BertConfig.from_pretrained("bert-base-uncased", hidden_act="gelu_new")
model = FlaxBertModel.from_pretrained("bert-base-uncased", config=config, dtype=dtype)
@jax.jit
def func():
outputs = model(**inputs)
return outputs
(nwarmup, nbenchmark) = (5, 100)
# warmpup
for _ in range(nwarmup):
func()
# benchmark
start = time.time()
for _ in range(nbenchmark):
func()
end = time.time()
print(end - start)
print(f"Throughput: {((nbenchmark * BS)/(end-start)):.3f} examples/sec")
|
transformers/examples/flax/language-modeling/run_bert_flax.py/0
|
{
"file_path": "transformers/examples/flax/language-modeling/run_bert_flax.py",
"repo_id": "transformers",
"token_count": 526
}
| 59 |
<!---
Copyright 2021 The Google Flax Team Authors and HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Text classification examples
## GLUE tasks
Based on the script [`run_flax_glue.py`](https://github.com/huggingface/transformers/blob/main/examples/flax/text-classification/run_flax_glue.py).
Fine-tuning the library models for sequence classification on the GLUE benchmark: [General Language Understanding
Evaluation](https://gluebenchmark.com/). This script can fine-tune any of the models on the [hub](https://huggingface.co/models) and can also be used for a
dataset hosted on our [hub](https://huggingface.co/datasets) or your own data in a csv or a JSON file (the script might need some tweaks in that case,
refer to the comments inside for help).
GLUE is made up of a total of 9 different tasks. Here is how to run the script on one of them:
```bash
export TASK_NAME=mrpc
python run_flax_glue.py \
--model_name_or_path google-bert/bert-base-cased \
--task_name ${TASK_NAME} \
--max_seq_length 128 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--eval_steps 100 \
--output_dir ./$TASK_NAME/ \
--push_to_hub
```
where task name can be one of cola, mnli, mnli_mismatched, mnli_matched, mrpc, qnli, qqp, rte, sst2, stsb, wnli.
Using the command above, the script will train for 3 epochs and run eval after each epoch.
Metrics and hyperparameters are stored in Tensorflow event files in `--output_dir`.
You can see the results by running `tensorboard` in that directory:
```bash
$ tensorboard --logdir .
```
or directly on the hub under *Training metrics*.
### Accuracy Evaluation
We train five replicas and report mean accuracy and stdev on the dev set below.
We use the settings as in the command above (with an exception for MRPC and
WNLI which are tiny and where we used 5 epochs instead of 3), and we use a total
train batch size of 32 (we train on 8 Cloud v3 TPUs, so a per-device batch size of 4),
On the task other than MRPC and WNLI we train for 3 these epochs because this is the standard,
but looking at the training curves of some of them (e.g., SST-2, STS-b), it appears the models
are undertrained and we could get better results when training longer.
In the Tensorboard results linked below, the random seed of each model is equal to the ID of the run. So in order to reproduce run 1, run the command above with `--seed=1`. The best run used random seed 3, which is the default in the script. The results of all runs are in [this Google Sheet](https://docs.google.com/spreadsheets/d/1p3XzReMO75m_XdEJvPue-PIq_PN-96J2IJpJW1yS-10/edit?usp=sharing).
| Task | Metric | Acc (best run) | Acc (avg/5runs) | Stdev | Metrics |
|-------|------------------------------|----------------|-----------------|-----------|--------------------------------------------------------------------------|
| CoLA | Matthews corr | 60.57 | 59.04 | 1.06 | [tfhub.dev](https://tensorboard.dev/experiment/lfr2adVpRtmLDALKrElkzg/) |
| SST-2 | Accuracy | 92.66 | 92.23 | 0.57 | [tfhub.dev](https://tensorboard.dev/experiment/jYvfv2trRHKMjoWnXVwrZA/) |
| MRPC | F1/Accuracy | 89.90/85.78 | 88.97/84.36 | 0.72/1.09 | [tfhub.dev](https://tensorboard.dev/experiment/bo3W3DEoRw2Q7YXjWrJkfg/) |
| STS-B | Pearson/Spearman corr. | 89.04/88.70 | 88.94/88.63 | 0.07/0.07 | [tfhub.dev](https://tensorboard.dev/experiment/fxVwbLD7QpKhbot0r9rn2w/) |
| QQP | Accuracy/F1 | 90.81/87.58 | 90.76/87.51 | 0.05/0.06 | [tfhub.dev](https://tensorboard.dev/experiment/di089Rc9TZmsnKRMrYNLsA/) |
| MNLI | Matched acc. | 84.10 | 83.80 | 0.16 | [tfhub.dev](https://tensorboard.dev/experiment/JgNCGHDJSRaW6HBx6YQFYQ/) |
| QNLI | Accuracy | 91.01 | 90.82 | 0.17 | [tfhub.dev](https://tensorboard.dev/experiment/Bq7cMGJnQMSggYgL8qNGeQ/) |
| RTE | Accuracy | 66.06 | 64.76 | 1.04 | [tfhub.dev](https://tensorboard.dev/experiment/66Eq24bhRjqN6CEhgDSGqQ/) |
| WNLI | Accuracy | 46.48 | 37.01 | 6.83 | [tfhub.dev](https://tensorboard.dev/experiment/TAqcnddqTkWvVEeGaWwIdQ/) |
Some of these results are significantly different from the ones reported on the test set of GLUE benchmark on the
website. For QQP and WNLI, please refer to [FAQ #12](https://gluebenchmark.com/faq) on the website.
### Runtime evaluation
We also ran each task once on a single V100 GPU, 8 V100 GPUs, and 8 Cloud v3 TPUs and report the
overall training time below. For comparison we ran Pytorch's [run_glue.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-classification/run_glue.py) on a single GPU (last column).
| Task | TPU v3-8 | 8 GPU | [1 GPU](https://tensorboard.dev/experiment/mkPS4Zh8TnGe1HB6Yzwj4Q) | 1 GPU (Pytorch) |
|-------|-----------|------------|------------|-----------------|
| CoLA | 1m 42s | 1m 26s | 3m 9s | 4m 6s |
| SST-2 | 5m 12s | 6m 28s | 22m 33s | 34m 37s |
| MRPC | 1m 29s | 1m 14s | 2m 20s | 2m 56s |
| STS-B | 1m 30s | 1m 12s | 2m 16s | 2m 48s |
| QQP | 22m 50s | 31m 48s | 1h 59m 41s | 2h 54m |
| MNLI | 25m 03s | 33m 55s | 2h 9m 37s | 3h 7m 6s |
| QNLI | 7m30s | 9m 40s | 34m 40s | 49m 8s |
| RTE | 1m 20s | 55s | 1m 10s | 1m 16s |
| WNLI | 1m 11s | 48s | 39s | 36s |
|-------|
| **TOTAL** | 1h 03m | 1h 28m | 5h 16m | 6h 37m |
*All experiments are ran on Google Cloud Platform.
GPU experiments are ran without further optimizations besides JAX
transformations. GPU experiments are ran with full precision (fp32). "TPU v3-8"
are 8 TPU cores on 4 chips (each chips has 2 cores), while "8 GPU" are 8 GPU chips.
|
transformers/examples/flax/text-classification/README.md/0
|
{
"file_path": "transformers/examples/flax/text-classification/README.md",
"repo_id": "transformers",
"token_count": 2760
}
| 60 |
import argparse
import logging
import os
from pathlib import Path
from typing import Any, Dict
import pytorch_lightning as pl
from pytorch_lightning.utilities import rank_zero_info
from transformers import (
AdamW,
AutoConfig,
AutoModel,
AutoModelForPreTraining,
AutoModelForQuestionAnswering,
AutoModelForSeq2SeqLM,
AutoModelForSequenceClassification,
AutoModelForTokenClassification,
AutoModelWithLMHead,
AutoTokenizer,
PretrainedConfig,
PreTrainedTokenizer,
)
from transformers.optimization import (
Adafactor,
get_cosine_schedule_with_warmup,
get_cosine_with_hard_restarts_schedule_with_warmup,
get_linear_schedule_with_warmup,
get_polynomial_decay_schedule_with_warmup,
)
from transformers.utils.versions import require_version
logger = logging.getLogger(__name__)
require_version("pytorch_lightning>=1.0.4")
MODEL_MODES = {
"base": AutoModel,
"sequence-classification": AutoModelForSequenceClassification,
"question-answering": AutoModelForQuestionAnswering,
"pretraining": AutoModelForPreTraining,
"token-classification": AutoModelForTokenClassification,
"language-modeling": AutoModelWithLMHead,
"summarization": AutoModelForSeq2SeqLM,
"translation": AutoModelForSeq2SeqLM,
}
# update this and the import above to support new schedulers from transformers.optimization
arg_to_scheduler = {
"linear": get_linear_schedule_with_warmup,
"cosine": get_cosine_schedule_with_warmup,
"cosine_w_restarts": get_cosine_with_hard_restarts_schedule_with_warmup,
"polynomial": get_polynomial_decay_schedule_with_warmup,
# '': get_constant_schedule, # not supported for now
# '': get_constant_schedule_with_warmup, # not supported for now
}
arg_to_scheduler_choices = sorted(arg_to_scheduler.keys())
arg_to_scheduler_metavar = "{" + ", ".join(arg_to_scheduler_choices) + "}"
class BaseTransformer(pl.LightningModule):
def __init__(
self,
hparams: argparse.Namespace,
num_labels=None,
mode="base",
config=None,
tokenizer=None,
model=None,
**config_kwargs,
):
"""Initialize a model, tokenizer and config."""
super().__init__()
# TODO: move to self.save_hyperparameters()
# self.save_hyperparameters()
# can also expand arguments into trainer signature for easier reading
self.save_hyperparameters(hparams)
self.step_count = 0
self.output_dir = Path(self.hparams.output_dir)
cache_dir = self.hparams.cache_dir if self.hparams.cache_dir else None
if config is None:
self.config = AutoConfig.from_pretrained(
self.hparams.config_name if self.hparams.config_name else self.hparams.model_name_or_path,
**({"num_labels": num_labels} if num_labels is not None else {}),
cache_dir=cache_dir,
**config_kwargs,
)
else:
self.config: PretrainedConfig = config
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
for p in extra_model_params:
if getattr(self.hparams, p, None):
assert hasattr(self.config, p), f"model config doesn't have a `{p}` attribute"
setattr(self.config, p, getattr(self.hparams, p))
if tokenizer is None:
self.tokenizer = AutoTokenizer.from_pretrained(
self.hparams.tokenizer_name if self.hparams.tokenizer_name else self.hparams.model_name_or_path,
cache_dir=cache_dir,
)
else:
self.tokenizer: PreTrainedTokenizer = tokenizer
self.model_type = MODEL_MODES[mode]
if model is None:
self.model = self.model_type.from_pretrained(
self.hparams.model_name_or_path,
from_tf=bool(".ckpt" in self.hparams.model_name_or_path),
config=self.config,
cache_dir=cache_dir,
)
else:
self.model = model
def load_hf_checkpoint(self, *args, **kwargs):
self.model = self.model_type.from_pretrained(*args, **kwargs)
def get_lr_scheduler(self):
get_schedule_func = arg_to_scheduler[self.hparams.lr_scheduler]
scheduler = get_schedule_func(
self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=self.total_steps()
)
scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
return scheduler
def configure_optimizers(self):
"""Prepare optimizer and schedule (linear warmup and decay)"""
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.hparams.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
if self.hparams.adafactor:
optimizer = Adafactor(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, scale_parameter=False, relative_step=False
)
else:
optimizer = AdamW(
optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon
)
self.opt = optimizer
scheduler = self.get_lr_scheduler()
return [optimizer], [scheduler]
def test_step(self, batch, batch_nb):
return self.validation_step(batch, batch_nb)
def test_epoch_end(self, outputs):
return self.validation_end(outputs)
def total_steps(self) -> int:
"""The number of total training steps that will be run. Used for lr scheduler purposes."""
num_devices = max(1, self.hparams.gpus) # TODO: consider num_tpu_cores
effective_batch_size = self.hparams.train_batch_size * self.hparams.accumulate_grad_batches * num_devices
return (self.dataset_size / effective_batch_size) * self.hparams.max_epochs
def setup(self, mode):
if mode == "test":
self.dataset_size = len(self.test_dataloader().dataset)
else:
self.train_loader = self.get_dataloader("train", self.hparams.train_batch_size, shuffle=True)
self.dataset_size = len(self.train_dataloader().dataset)
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False):
raise NotImplementedError("You must implement this for your task")
def train_dataloader(self):
return self.train_loader
def val_dataloader(self):
return self.get_dataloader("dev", self.hparams.eval_batch_size, shuffle=False)
def test_dataloader(self):
return self.get_dataloader("test", self.hparams.eval_batch_size, shuffle=False)
def _feature_file(self, mode):
return os.path.join(
self.hparams.data_dir,
"cached_{}_{}_{}".format(
mode,
list(filter(None, self.hparams.model_name_or_path.split("/"))).pop(),
str(self.hparams.max_seq_length),
),
)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("best_tfmr")
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
@staticmethod
def add_model_specific_args(parser, root_dir):
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default=None,
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--encoder_layerdrop",
type=float,
help="Encoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--decoder_layerdrop",
type=float,
help="Decoder layer dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--dropout",
type=float,
help="Dropout probability (Optional). Goes into model.config",
)
parser.add_argument(
"--attention_dropout",
type=float,
help="Attention dropout probability (Optional). Goes into model.config",
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--lr_scheduler",
default="linear",
choices=arg_to_scheduler_choices,
metavar=arg_to_scheduler_metavar,
type=str,
help="Learning rate scheduler",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--num_workers", default=4, type=int, help="kwarg passed to DataLoader")
parser.add_argument("--num_train_epochs", dest="max_epochs", default=3, type=int)
parser.add_argument("--train_batch_size", default=32, type=int)
parser.add_argument("--eval_batch_size", default=32, type=int)
parser.add_argument("--adafactor", action="store_true")
class LoggingCallback(pl.Callback):
def on_batch_end(self, trainer, pl_module):
lr_scheduler = trainer.lr_schedulers[0]["scheduler"]
lrs = {f"lr_group_{i}": lr for i, lr in enumerate(lr_scheduler.get_lr())}
pl_module.logger.log_metrics(lrs)
def on_validation_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Validation results *****")
metrics = trainer.callback_metrics
# Log results
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
def on_test_end(self, trainer: pl.Trainer, pl_module: pl.LightningModule):
rank_zero_info("***** Test results *****")
metrics = trainer.callback_metrics
# Log and save results to file
output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
with open(output_test_results_file, "w") as writer:
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
rank_zero_info("{} = {}\n".format(key, str(metrics[key])))
writer.write("{} = {}\n".format(key, str(metrics[key])))
def add_generic_args(parser, root_dir) -> None:
# To allow all pl args uncomment the following line
# parser = pl.Trainer.add_argparse_args(parser)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O2",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--n_tpu_cores", dest="tpu_cores", type=int)
parser.add_argument("--max_grad_norm", dest="gradient_clip_val", default=1.0, type=float, help="Max gradient norm")
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_predict", action="store_true", help="Whether to run predictions on the test set.")
parser.add_argument(
"--gradient_accumulation_steps",
dest="accumulate_grad_batches",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the training files for the CoNLL-2003 NER task.",
)
def generic_train(
model: BaseTransformer,
args: argparse.Namespace,
early_stopping_callback=None,
logger=True, # can pass WandbLogger() here
extra_callbacks=[],
checkpoint_callback=None,
logging_callback=None,
**extra_train_kwargs,
):
pl.seed_everything(args.seed)
# init model
odir = Path(model.hparams.output_dir)
odir.mkdir(exist_ok=True)
# add custom checkpoints
if checkpoint_callback is None:
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=1
)
if early_stopping_callback:
extra_callbacks.append(early_stopping_callback)
if logging_callback is None:
logging_callback = LoggingCallback()
train_params = {}
# TODO: remove with PyTorch 1.6 since pl uses native amp
if args.fp16:
train_params["precision"] = 16
train_params["amp_level"] = args.fp16_opt_level
if args.gpus > 1:
train_params["distributed_backend"] = "ddp"
train_params["accumulate_grad_batches"] = args.accumulate_grad_batches
train_params["accelerator"] = extra_train_kwargs.get("accelerator", None)
train_params["profiler"] = extra_train_kwargs.get("profiler", None)
trainer = pl.Trainer.from_argparse_args(
args,
weights_summary=None,
callbacks=[logging_callback] + extra_callbacks,
logger=logger,
checkpoint_callback=checkpoint_callback,
**train_params,
)
if args.do_train:
trainer.fit(model)
return trainer
|
transformers/examples/legacy/pytorch-lightning/lightning_base.py/0
|
{
"file_path": "transformers/examples/legacy/pytorch-lightning/lightning_base.py",
"repo_id": "transformers",
"token_count": 6603
}
| 61 |
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Sequence-to-Sequence Training and Evaluation
This directory contains examples for finetuning and evaluating transformers on summarization and translation tasks.
For deprecated `bertabs` instructions, see [`bertabs/README.md`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/bertabs/README.md).
### Supported Architectures
- `BartForConditionalGeneration`
- `MarianMTModel`
- `PegasusForConditionalGeneration`
- `MBartForConditionalGeneration`
- `FSMTForConditionalGeneration`
- `T5ForConditionalGeneration`
### Download the Datasets
#### XSUM
```bash
cd examples/legacy/seq2seq
wget https://cdn-datasets.huggingface.co/summarization/xsum.tar.gz
tar -xzvf xsum.tar.gz
export XSUM_DIR=${PWD}/xsum
```
this should make a directory called `xsum/` with files like `test.source`.
To use your own data, copy that files format. Each article to be summarized is on its own line.
#### CNN/DailyMail
```bash
cd examples/legacy/seq2seq
wget https://cdn-datasets.huggingface.co/summarization/cnn_dm_v2.tgz
tar -xzvf cnn_dm_v2.tgz # empty lines removed
mv cnn_cln cnn_dm
export CNN_DIR=${PWD}/cnn_dm
```
this should make a directory called `cnn_dm/` with 6 files.
#### WMT16 English-Romanian Translation Data
download with this command:
```bash
wget https://cdn-datasets.huggingface.co/translation/wmt_en_ro.tar.gz
tar -xzvf wmt_en_ro.tar.gz
export ENRO_DIR=${PWD}/wmt_en_ro
```
this should make a directory called `wmt_en_ro/` with 6 files.
#### WMT English-German
```bash
wget https://cdn-datasets.huggingface.co/translation/wmt_en_de.tgz
tar -xzvf wmt_en_de.tgz
export DATA_DIR=${PWD}/wmt_en_de
```
#### FSMT datasets (wmt)
Refer to the scripts starting with `eval_` under:
https://github.com/huggingface/transformers/tree/main/scripts/fsmt
#### Pegasus (multiple datasets)
Multiple eval datasets are available for download from:
https://github.com/stas00/porting/tree/master/datasets/pegasus
#### Your Data
If you are using your own data, it must be formatted as one directory with 6 files:
```
train.source
train.target
val.source
val.target
test.source
test.target
```
The `.source` files are the input, the `.target` files are the desired output.
### Potential issues
- native AMP (`--fp16` and no apex) may lead to a huge memory leak and require 10x gpu memory. This has been fixed in pytorch-nightly and the minimal official version to have this fix will be pytorch-1.7.1. Until then if you have to use mixed precision please use AMP only with pytorch-nightly or NVIDIA's apex. Reference: https://github.com/huggingface/transformers/issues/8403
### Tips and Tricks
General Tips:
- since you need to run from `examples/legacy/seq2seq`, and likely need to modify code, the easiest workflow is fork transformers, clone your fork, and run `pip install -e .` before you get started.
- try `--freeze_encoder` or `--freeze_embeds` for faster training/larger batch size. (3hr per epoch with bs=8, see the "xsum_shared_task" command below)
- `fp16_opt_level=O1` (the default works best).
- In addition to the pytorch-lightning .ckpt checkpoint, a transformers checkpoint will be saved.
Load it with `BartForConditionalGeneration.from_pretrained(f'{output_dir}/best_tfmr)`.
- At the moment, `--do_predict` does not work in a multi-gpu setting. You need to use `evaluate_checkpoint` or the `run_eval.py` code.
- This warning can be safely ignored:
> "Some weights of BartForConditionalGeneration were not initialized from the model checkpoint at facebook/bart-large-xsum and are newly initialized: ['final_logits_bias']"
- Both finetuning and eval are 30% faster with `--fp16`. For that you need to [install apex](https://github.com/NVIDIA/apex#quick-start).
- Read scripts before you run them!
Summarization Tips:
- (summ) 1 epoch at batch size 1 for bart-large takes 24 hours and requires 13GB GPU RAM with fp16 on an NVIDIA-V100.
- If you want to run experiments on improving the summarization finetuning process, try the XSUM Shared Task (below). It's faster to train than CNNDM because the summaries are shorter.
- For CNN/DailyMail, the default `val_max_target_length` and `test_max_target_length` will truncate the ground truth labels, resulting in slightly higher rouge scores. To get accurate rouge scores, you should rerun calculate_rouge on the `{output_dir}/test_generations.txt` file saved by `trainer.test()`
- `--max_target_length=60 --val_max_target_length=60 --test_max_target_length=100 ` is a reasonable setting for XSUM.
- `wandb` can be used by specifying `--logger_name wandb`. It is useful for reproducibility. Specify the environment variable `WANDB_PROJECT='hf_xsum'` to do the XSUM shared task.
- If you are finetuning on your own dataset, start from `distilbart-cnn-12-6` if you want long summaries and `distilbart-xsum-12-6` if you want short summaries.
(It rarely makes sense to start from `bart-large` unless you are a researching finetuning methods).
**Update 2018-07-18**
Datasets: `LegacySeq2SeqDataset` will be used for all tokenizers without a `prepare_seq2seq_batch` method. Otherwise, `Seq2SeqDataset` will be used.
Future work/help wanted: A new dataset to support multilingual tasks.
### Fine-tuning using Seq2SeqTrainer
To use `Seq2SeqTrainer` for fine-tuning you should use the `finetune_trainer.py` script. It subclasses `Trainer` to extend it for seq2seq training. Except the `Trainer`-related `TrainingArguments`, it shares the same argument names as that of `finetune.py` file. One notable difference is that calculating generative metrics (BLEU, ROUGE) is optional and is controlled using the `--predict_with_generate` argument.
With PyTorch 1.6+ it'll automatically use `native AMP` when `--fp16` is set.
To see all the possible command line options, run:
```bash
python finetune_trainer.py --help
```
For multi-gpu training use `torch.distributed.launch`, e.g. with 2 gpus:
```bash
torchrun --nproc_per_node=2 finetune_trainer.py ...
```
**At the moment, `Seq2SeqTrainer` does not support *with teacher* distillation.**
All `Seq2SeqTrainer`-based fine-tuning scripts are included in the `builtin_trainer` directory.
#### TPU Training
`Seq2SeqTrainer` supports TPU training with few caveats
1. As `generate` method does not work on TPU at the moment, `predict_with_generate` cannot be used. You should use `--prediction_loss_only` to only calculate loss, and do not set `--do_predict` and `--predict_with_generate`.
2. All sequences should be padded to be of equal length to avoid extremely slow training. (`finetune_trainer.py` does this automatically when running on TPU.)
We provide a very simple launcher script named `xla_spawn.py` that lets you run our example scripts on multiple TPU cores without any boilerplate. Just pass a `--num_cores` flag to this script, then your regular training script with its arguments (this is similar to the `torch.distributed.launch` helper for `torch.distributed`).
`builtin_trainer/finetune_tpu.sh` script provides minimal arguments needed for TPU training.
The following command fine-tunes `sshleifer/student_marian_en_ro_6_3` on TPU V3-8 and should complete one epoch in ~5-6 mins.
```bash
./builtin_trainer/train_distil_marian_enro_tpu.sh
```
## Evaluation Commands
To create summaries for each article in dataset, we use `run_eval.py`, here are a few commands that run eval for different tasks and models.
If 'translation' is in your task name, the computed metric will be BLEU. Otherwise, ROUGE will be used.
For t5, you need to specify --task translation_{src}_to_{tgt} as follows:
```bash
export DATA_DIR=wmt_en_ro
./run_eval.py google-t5/t5-base \
$DATA_DIR/val.source t5_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path enro_bleu.json \
--task translation_en_to_ro \
--n_obs 100 \
--device cuda \
--fp16 \
--bs 32
```
This command works for MBART, although the BLEU score is suspiciously low.
```bash
export DATA_DIR=wmt_en_ro
./run_eval.py facebook/mbart-large-en-ro $DATA_DIR/val.source mbart_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path enro_bleu.json \
--task translation \
--n_obs 100 \
--device cuda \
--fp16 \
--bs 32
```
Summarization (xsum will be very similar):
```bash
export DATA_DIR=cnn_dm
./run_eval.py sshleifer/distilbart-cnn-12-6 $DATA_DIR/val.source dbart_val_generations.txt \
--reference_path $DATA_DIR/val.target \
--score_path cnn_rouge.json \
--task summarization \
--n_obs 100 \
th 56 \
--fp16 \
--bs 32
```
### Multi-GPU Evaluation
here is a command to run xsum evaluation on 8 GPUS. It is more than linearly faster than run_eval.py in some cases
because it uses SortishSampler to minimize padding. You can also use it on 1 GPU. `data_dir` must have
`{type_path}.source` and `{type_path}.target`. Run `./run_distributed_eval.py --help` for all clargs.
```bash
torchrun --nproc_per_node=8 run_distributed_eval.py \
--model_name sshleifer/distilbart-large-xsum-12-3 \
--save_dir xsum_generations \
--data_dir xsum \
--fp16 # you can pass generate kwargs like num_beams here, just like run_eval.py
```
Contributions that implement this command for other distributed hardware setups are welcome!
#### Single-GPU Eval: Tips and Tricks
When using `run_eval.py`, the following features can be useful:
* if you running the script multiple times and want to make it easier to track what arguments produced that output, use `--dump-args`. Along with the results it will also dump any custom params that were passed to the script. For example if you used: `--num_beams 8 --early_stopping true`, the output will be:
```json
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True}
```
`--info` is an additional argument available for the same purpose of tracking the conditions of the experiment. It's useful to pass things that weren't in the argument list, e.g. a language pair `--info "lang:en-ru"`. But also if you pass `--info` without a value it will fallback to the current date/time string, e.g. `2020-09-13 18:44:43`.
If using `--dump-args --info`, the output will be:
```json
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': '2020-09-13 18:44:43'}
```
If using `--dump-args --info "pair:en-ru chkpt=best`, the output will be:
```json
{'bleu': 26.887, 'n_obs': 10, 'runtime': 1, 'seconds_per_sample': 0.1, 'num_beams': 8, 'early_stopping': True, 'info': 'pair=en-ru chkpt=best'}
```
* if you need to perform a parametric search in order to find the best ones that lead to the highest BLEU score, let `run_eval_search.py` to do the searching for you.
The script accepts the exact same arguments as `run_eval.py`, plus an additional argument `--search`. The value of `--search` is parsed, reformatted and fed to ``run_eval.py`` as additional args.
The format for the `--search` value is a simple string with hparams and colon separated values to try, e.g.:
```
--search "num_beams=5:10 length_penalty=0.8:1.0:1.2 early_stopping=true:false"
```
which will generate `12` `(2*3*2)` searches for a product of each hparam. For example the example that was just used will invoke `run_eval.py` repeatedly with:
```
--num_beams 5 --length_penalty 0.8 --early_stopping true
--num_beams 5 --length_penalty 0.8 --early_stopping false
[...]
--num_beams 10 --length_penalty 1.2 --early_stopping false
```
On completion, this function prints a markdown table of the results sorted by the best BLEU score and the winning arguments.
```
bleu | num_beams | length_penalty | early_stopping
----- | --------- | -------------- | --------------
26.71 | 5 | 1.1 | 1
26.66 | 5 | 0.9 | 1
26.66 | 5 | 0.9 | 0
26.41 | 5 | 1.1 | 0
21.94 | 1 | 0.9 | 1
21.94 | 1 | 0.9 | 0
21.94 | 1 | 1.1 | 1
21.94 | 1 | 1.1 | 0
Best score args:
stas/wmt19-en-ru data/en-ru/val.source data/en-ru/test_translations.txt --reference_path data/en-ru/val.target --score_path data/en-ru/test_bleu.json --bs 8 --task translation --num_beams 5 --length_penalty 1.1 --early_stopping True
```
If you pass `--info "some experiment-specific info"` it will get printed before the results table - this is useful for scripting and multiple runs, so one can tell the different sets of results from each other.
### Contributing
- follow the standard contributing guidelines and code of conduct.
- add tests to `test_seq2seq_examples.py`
- To run only the seq2seq tests, you must be in the root of the repository and run:
```bash
pytest examples/seq2seq/
```
### Converting pytorch-lightning checkpoints
pytorch lightning ``-do_predict`` often fails, after you are done training, the best way to evaluate your model is to convert it.
This should be done for you, with a file called `{save_dir}/best_tfmr`.
If that file doesn't exist but you have a lightning `.ckpt` file, you can run
```bash
python convert_pl_checkpoint_to_hf.py PATH_TO_CKPT randomly_initialized_hf_model_path save_dir/best_tfmr
```
Then either `run_eval` or `run_distributed_eval` with `save_dir/best_tfmr` (see previous sections)
# Experimental Features
These features are harder to use and not always useful.
### Dynamic Batch Size for MT
`finetune.py` has a command line arg `--max_tokens_per_batch` that allows batches to be dynamically sized.
This feature can only be used:
- with fairseq installed
- on 1 GPU
- without sortish sampler
- after calling `./save_len_file.py $tok $data_dir`
For example,
```bash
./save_len_file.py Helsinki-NLP/opus-mt-en-ro wmt_en_ro
./dynamic_bs_example.sh --max_tokens_per_batch=2000 --output_dir benchmark_dynamic_bs
```
splits `wmt_en_ro/train` into 11,197 uneven length batches and can finish 1 epoch in 8 minutes on a v100.
For comparison,
```bash
./dynamic_bs_example.sh --sortish_sampler --train_batch_size 48
```
uses 12,723 batches of length 48 and takes slightly more time 9.5 minutes.
The feature is still experimental, because:
+ we can make it much more robust if we have memory mapped/preprocessed datasets.
+ The speedup over sortish sampler is not that large at the moment.
|
transformers/examples/legacy/seq2seq/README.md/0
|
{
"file_path": "transformers/examples/legacy/seq2seq/README.md",
"repo_id": "transformers",
"token_count": 5089
}
| 62 |
### Motivation
Without processing, english-> romanian mbart-large-en-ro gets BLEU score 26.8 on the WMT data.
With post processing, it can score 37..
Here is the postprocessing code, stolen from @mjpost in this [issue](https://github.com/pytorch/fairseq/issues/1758)
### Instructions
Note: You need to have your test_generations.txt before you start this process.
(1) Setup `mosesdecoder` and `wmt16-scripts`
```bash
cd $HOME
git clone git@github.com:moses-smt/mosesdecoder.git
cd mosesdecoder
git clone git@github.com:rsennrich/wmt16-scripts.git
```
(2) define a function for post processing.
It removes diacritics and does other things I don't understand
```bash
ro_post_process () {
sys=$1
ref=$2
export MOSES_PATH=$HOME/mosesdecoder
REPLACE_UNICODE_PUNCT=$MOSES_PATH/scripts/tokenizer/replace-unicode-punctuation.perl
NORM_PUNC=$MOSES_PATH/scripts/tokenizer/normalize-punctuation.perl
REM_NON_PRINT_CHAR=$MOSES_PATH/scripts/tokenizer/remove-non-printing-char.perl
REMOVE_DIACRITICS=$MOSES_PATH/wmt16-scripts/preprocess/remove-diacritics.py
NORMALIZE_ROMANIAN=$MOSES_PATH/wmt16-scripts/preprocess/normalise-romanian.py
TOKENIZER=$MOSES_PATH/scripts/tokenizer/tokenizer.perl
lang=ro
for file in $sys $ref; do
cat $file \
| $REPLACE_UNICODE_PUNCT \
| $NORM_PUNC -l $lang \
| $REM_NON_PRINT_CHAR \
| $NORMALIZE_ROMANIAN \
| $REMOVE_DIACRITICS \
| $TOKENIZER -no-escape -l $lang \
> $(basename $file).tok
done
# compute BLEU
cat $(basename $sys).tok | sacrebleu -tok none -s none -b $(basename $ref).tok
}
```
(3) Call the function on test_generations.txt and test.target
For example,
```bash
ro_post_process enro_finetune/test_generations.txt wmt_en_ro/test.target
```
This will split out a new blue score and write a new fine called `test_generations.tok` with post-processed outputs.
```
|
transformers/examples/legacy/seq2seq/romanian_postprocessing.md/0
|
{
"file_path": "transformers/examples/legacy/seq2seq/romanian_postprocessing.md",
"repo_id": "transformers",
"token_count": 723
}
| 63 |
import logging
import os
from typing import List, TextIO, Union
from conllu import parse_incr
from utils_ner import InputExample, Split, TokenClassificationTask
logger = logging.getLogger(__name__)
class NER(TokenClassificationTask):
def __init__(self, label_idx=-1):
# in NER datasets, the last column is usually reserved for NER label
self.label_idx = label_idx
def read_examples_from_file(self, data_dir, mode: Union[Split, str]) -> List[InputExample]:
if isinstance(mode, Split):
mode = mode.value
file_path = os.path.join(data_dir, f"{mode}.txt")
guid_index = 1
examples = []
with open(file_path, encoding="utf-8") as f:
words = []
labels = []
for line in f:
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
if words:
examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
guid_index += 1
words = []
labels = []
else:
splits = line.split(" ")
words.append(splits[0])
if len(splits) > 1:
labels.append(splits[self.label_idx].replace("\n", ""))
else:
# Examples could have no label for mode = "test"
labels.append("O")
if words:
examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
return examples
def write_predictions_to_file(self, writer: TextIO, test_input_reader: TextIO, preds_list: List):
example_id = 0
for line in test_input_reader:
if line.startswith("-DOCSTART-") or line == "" or line == "\n":
writer.write(line)
if not preds_list[example_id]:
example_id += 1
elif preds_list[example_id]:
output_line = line.split()[0] + " " + preds_list[example_id].pop(0) + "\n"
writer.write(output_line)
else:
logger.warning("Maximum sequence length exceeded: No prediction for '%s'.", line.split()[0])
def get_labels(self, path: str) -> List[str]:
if path:
with open(path, "r") as f:
labels = f.read().splitlines()
if "O" not in labels:
labels = ["O"] + labels
return labels
else:
return ["O", "B-MISC", "I-MISC", "B-PER", "I-PER", "B-ORG", "I-ORG", "B-LOC", "I-LOC"]
class Chunk(NER):
def __init__(self):
# in CONLL2003 dataset chunk column is second-to-last
super().__init__(label_idx=-2)
def get_labels(self, path: str) -> List[str]:
if path:
with open(path, "r") as f:
labels = f.read().splitlines()
if "O" not in labels:
labels = ["O"] + labels
return labels
else:
return [
"O",
"B-ADVP",
"B-INTJ",
"B-LST",
"B-PRT",
"B-NP",
"B-SBAR",
"B-VP",
"B-ADJP",
"B-CONJP",
"B-PP",
"I-ADVP",
"I-INTJ",
"I-LST",
"I-PRT",
"I-NP",
"I-SBAR",
"I-VP",
"I-ADJP",
"I-CONJP",
"I-PP",
]
class POS(TokenClassificationTask):
def read_examples_from_file(self, data_dir, mode: Union[Split, str]) -> List[InputExample]:
if isinstance(mode, Split):
mode = mode.value
file_path = os.path.join(data_dir, f"{mode}.txt")
guid_index = 1
examples = []
with open(file_path, encoding="utf-8") as f:
for sentence in parse_incr(f):
words = []
labels = []
for token in sentence:
words.append(token["form"])
labels.append(token["upos"])
assert len(words) == len(labels)
if words:
examples.append(InputExample(guid=f"{mode}-{guid_index}", words=words, labels=labels))
guid_index += 1
return examples
def write_predictions_to_file(self, writer: TextIO, test_input_reader: TextIO, preds_list: List):
example_id = 0
for sentence in parse_incr(test_input_reader):
s_p = preds_list[example_id]
out = ""
for token in sentence:
out += f'{token["form"]} ({token["upos"]}|{s_p.pop(0)}) '
out += "\n"
writer.write(out)
example_id += 1
def get_labels(self, path: str) -> List[str]:
if path:
with open(path, "r") as f:
return f.read().splitlines()
else:
return [
"ADJ",
"ADP",
"ADV",
"AUX",
"CCONJ",
"DET",
"INTJ",
"NOUN",
"NUM",
"PART",
"PRON",
"PROPN",
"PUNCT",
"SCONJ",
"SYM",
"VERB",
"X",
]
|
transformers/examples/legacy/token-classification/tasks.py/0
|
{
"file_path": "transformers/examples/legacy/token-classification/tasks.py",
"repo_id": "transformers",
"token_count": 3163
}
| 64 |
import torch.nn as nn
from transformers.models.bert.modeling_bert import BertEmbeddings, BertModel
class RobertaEmbeddings(BertEmbeddings):
def __init__(self, config):
super().__init__(config)
self.pad_token_id = config.pad_token_id
self.position_embeddings = nn.Embedding(
config.max_position_embeddings, config.hidden_size, config.pad_token_id
)
class RobertaModel(BertModel):
def __init__(self, config, add_pooling_layer=True):
super().__init__(self, config)
|
transformers/examples/modular-transformers/modular_roberta.py/0
|
{
"file_path": "transformers/examples/modular-transformers/modular_roberta.py",
"repo_id": "transformers",
"token_count": 215
}
| 65 |
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Image pretraining examples
This directory contains Python scripts that allow you to pre-train Transformer-based vision models (like [ViT](https://huggingface.co/docs/transformers/model_doc/vit), [Swin Transformer](https://huggingface.co/docs/transformers/model_doc/swin)) on your own data, after which you can easily load the weights into a [`AutoModelForImageClassification`](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForImageClassification). It currently includes scripts for:
- [SimMIM](#simmim) (by Microsoft Research)
- [MAE](#mae) (by Facebook AI).
NOTE: If you encounter problems/have suggestions for improvement, open an issue on Github and tag @NielsRogge.
## SimMIM
The `run_mim.py` script can be used to pre-train any Transformer-based vision model in the library (concretely, any model supported by the `AutoModelForMaskedImageModeling` API) for masked image modeling as proposed in [SimMIM: A Simple Framework for Masked Image Modeling](https://arxiv.org/abs/2111.09886) using PyTorch.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/simmim_architecture.jpg"
alt="drawing" width="300"/>
<small> SimMIM framework. Taken from the <a href="https://arxiv.org/abs/2111.09886">original paper</a>. </small>
The goal for the model is to predict raw pixel values for the masked patches, using just a linear layer as prediction head. The model is trained using a simple L1 loss.
### Using datasets from 🤗 datasets
Here we show how to pre-train a `ViT` from scratch for masked image modeling on the [cifar10](https://huggingface.co/datasets/cifar10) dataset.
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "google/vit-base-patch16-224-in21k" for example (and not specifying the `model_type` argument).
```bash
!python run_mim.py \
--model_type vit \
--output_dir ./outputs/ \
--overwrite_output_dir \
--remove_unused_columns False \
--label_names bool_masked_pos \
--do_train \
--do_eval \
--learning_rate 2e-5 \
--weight_decay 0.05 \
--num_train_epochs 100 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--eval_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
```
Here, we train for 100 epochs with a learning rate of 2e-5. Note that the SimMIM authors used a more sophisticated learning rate schedule, see the [config files](https://github.com/microsoft/SimMIM/blob/main/configs/vit_base__800ep/simmim_pretrain__vit_base__img224__800ep.yaml) for more info. One can easily tweak the script to include this learning rate schedule (several learning rate schedulers are supported via the [training arguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments)).
We can also for instance replicate the pre-training of a Swin Transformer using the same architecture as used by the SimMIM authors. For this, we first create a custom configuration and save it locally:
```python
from transformers import SwinConfig
IMAGE_SIZE = 192
PATCH_SIZE = 4
EMBED_DIM = 128
DEPTHS = [2, 2, 18, 2]
NUM_HEADS = [4, 8, 16, 32]
WINDOW_SIZE = 6
config = SwinConfig(
image_size=IMAGE_SIZE,
patch_size=PATCH_SIZE,
embed_dim=EMBED_DIM,
depths=DEPTHS,
num_heads=NUM_HEADS,
window_size=WINDOW_SIZE,
)
config.save_pretrained("path_to_config")
```
Next, we can run the script by providing the path to this custom configuration (replace `path_to_config` below with your path):
```bash
!python run_mim.py \
--config_name_or_path path_to_config \
--model_type swin \
--output_dir ./outputs/ \
--overwrite_output_dir \
--remove_unused_columns False \
--label_names bool_masked_pos \
--do_train \
--do_eval \
--learning_rate 2e-5 \
--num_train_epochs 5 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--eval_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
```
This will train a Swin Transformer from scratch.
### Using your own data
To use your own dataset, the training script expects the following directory structure:
```bash
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
```
Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
```bash
python run_mim.py \
--model_type vit \
--dataset_name nateraw/image-folder \
--train_dir <path-to-train-root> \
--output_dir ./outputs/ \
--remove_unused_columns False \
--label_names bool_masked_pos \
--do_train \
--do_eval
```
## MAE
The `run_mae.py` script can be used to pre-train a Vision Transformer as a masked autoencoder (MAE), as proposed in [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377). The script can be used to train a `ViTMAEForPreTraining` model in the Transformers library, using PyTorch. After self-supervised pre-training, one can load the weights of the encoder directly into a `ViTForImageClassification`. The MAE method allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data.
The goal for the model is to predict raw pixel values for the masked patches. As the model internally masks patches and learns to reconstruct them, there's no need for any labels. The model uses the mean squared error (MSE) between the reconstructed and original images in the pixel space.
### Using datasets from 🤗 `datasets`
One can use the following command to pre-train a `ViTMAEForPreTraining` model from scratch on the [cifar10](https://huggingface.co/datasets/cifar10) dataset:
```bash
python run_mae.py \
--dataset_name cifar10 \
--output_dir ./vit-mae-demo \
--remove_unused_columns False \
--label_names pixel_values \
--mask_ratio 0.75 \
--norm_pix_loss \
--do_train \
--do_eval \
--base_learning_rate 1.5e-4 \
--lr_scheduler_type cosine \
--weight_decay 0.05 \
--num_train_epochs 800 \
--warmup_ratio 0.05 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--eval_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
```
Here we set:
- `mask_ratio` to 0.75 (to mask 75% of the patches for each image)
- `norm_pix_loss` to use normalized pixel values as target (the authors reported better representations with this enabled)
- `base_learning_rate` to 1.5e-4. Note that the effective learning rate is computed by the [linear schedule](https://arxiv.org/abs/1706.02677): `lr` = `blr` * total training batch size / 256. The total training batch size is computed as `training_args.train_batch_size` * `training_args.gradient_accumulation_steps` * `training_args.world_size`.
This replicates the same hyperparameters as used in the original implementation, as shown in the table below.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/mae_pretraining_setting.png"
alt="drawing" width="300"/>
<small> Original hyperparameters. Taken from the <a href="https://arxiv.org/abs/2111.06377">original paper</a>. </small>
Alternatively, one can decide to further pre-train an already pre-trained (or fine-tuned) checkpoint from the [hub](https://huggingface.co/). This can be done by setting the `model_name_or_path` argument to "facebook/vit-mae-base" for example.
### Using your own data
To use your own dataset, the training script expects the following directory structure:
```bash
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
```
Note that you can put images in dummy subfolders, whose names will be ignored by default (as labels aren't required). You can also just place all images into a single dummy subfolder. Once you've prepared your dataset, you can run the script like this:
```bash
python run_mae.py \
--model_type vit_mae \
--dataset_name nateraw/image-folder \
--train_dir <path-to-train-root> \
--output_dir ./outputs/ \
--remove_unused_columns False \
--label_names pixel_values \
--do_train \
--do_eval
```
#### 💡 The above will split the train dir into training and evaluation sets
- To control the split amount, use the `--train_val_split` flag.
- To provide your own validation split in its own directory, you can pass the `--validation_dir <path-to-val-root>` flag.
## Sharing your model on 🤗 Hub
0. If you haven't already, [sign up](https://huggingface.co/join) for a 🤗 account
1. Make sure you have `git-lfs` installed and git set up.
```bash
$ apt install git-lfs
$ git config --global user.email "you@example.com"
$ git config --global user.name "Your Name"
```
2. Log in with your HuggingFace account credentials using `huggingface-cli`
```bash
$ huggingface-cli login
# ...follow the prompts
```
3. When running the script, pass the following arguments:
```bash
python run_xxx.py \
--push_to_hub \
--push_to_hub_model_id <name-of-your-model> \
...
```
|
transformers/examples/pytorch/image-pretraining/README.md/0
|
{
"file_path": "transformers/examples/pytorch/image-pretraining/README.md",
"repo_id": "transformers",
"token_count": 3469
}
| 66 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for masked language modeling (BERT, ALBERT, RoBERTa...)
on a text file or a dataset without using HuggingFace Trainer.
Here is the full list of checkpoints on the hub that can be fine-tuned by this script:
https://huggingface.co/models?filter=fill-mask
"""
# You can also adapt this script on your own mlm task. Pointers for this are left as comments.
import argparse
import json
import logging
import math
import os
import random
from itertools import chain
from pathlib import Path
import datasets
import torch
from accelerate import Accelerator, DistributedType
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from datasets import load_dataset
from huggingface_hub import HfApi
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import transformers
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AutoConfig,
AutoModelForMaskedLM,
AutoTokenizer,
DataCollatorForLanguageModeling,
SchedulerType,
get_scheduler,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.49.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/language-modeling/requirements.txt")
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a Masked Language Modeling task")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--validation_split_percentage",
default=5,
help="The percentage of the train set used as validation set in case there's no validation split",
)
parser.add_argument(
"--pad_to_max_length",
action="store_true",
help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=False,
)
parser.add_argument(
"--config_name",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--use_slow_tokenizer",
action="store_true",
help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--model_type",
type=str,
default=None,
help="Model type to use if training from scratch.",
choices=MODEL_TYPES,
)
parser.add_argument(
"--max_seq_length",
type=int,
default=None,
help=(
"The maximum total input sequence length after tokenization. Sequences longer than this will be truncated."
),
)
parser.add_argument(
"--line_by_line",
type=bool,
default=False,
help="Whether distinct lines of text in the dataset are to be handled as distinct sequences.",
)
parser.add_argument(
"--preprocessing_num_workers",
type=int,
default=None,
help="The number of processes to use for the preprocessing.",
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument(
"--mlm_probability", type=float, default=0.15, help="Ratio of tokens to mask for masked language modeling loss"
)
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--trust_remote_code",
action="store_true",
help=(
"Whether to trust the execution of code from datasets/models defined on the Hub."
" This option should only be set to `True` for repositories you trust and in which you have read the"
" code, as it will execute code present on the Hub on your local machine."
),
)
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to enable experiment trackers for logging.",
)
parser.add_argument(
"--report_to",
type=str,
default="all",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
"Only applicable when `--with_tracking` is passed."
),
)
parser.add_argument(
"--low_cpu_mem_usage",
action="store_true",
help=(
"It is an option to create the model as an empty shell, then only materialize its parameters when the pretrained weights are loaded. "
"If passed, LLM loading time and RAM consumption will be benefited."
),
)
args = parser.parse_args()
# Sanity checks
if args.dataset_name is None and args.train_file is None and args.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
if extension not in ["csv", "json", "txt"]:
raise ValueError("`train_file` should be a csv, json or txt file.")
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
if extension not in ["csv", "json", "txt"]:
raise ValueError("`validation_file` should be a csv, json or txt file.")
if args.push_to_hub:
if args.output_dir is None:
raise ValueError("Need an `output_dir` to create a repo when `--push_to_hub` is passed.")
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_mlm_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
# in the environment
accelerator_log_kwargs = {}
if args.with_tracking:
accelerator_log_kwargs["log_with"] = args.report_to
accelerator_log_kwargs["project_dir"] = args.output_dir
accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
# Retrieve of infer repo_name
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
# Create repo and retrieve repo_id
api = HfApi()
repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(
args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
)
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
args.dataset_name,
args.dataset_config_name,
split=f"train[:{args.validation_split_percentage}%]",
trust_remote_code=args.trust_remote_code,
)
raw_datasets["train"] = load_dataset(
args.dataset_name,
args.dataset_config_name,
split=f"train[{args.validation_split_percentage}%:]",
trust_remote_code=args.trust_remote_code,
)
else:
data_files = {}
if args.train_file is not None:
data_files["train"] = args.train_file
extension = args.train_file.split(".")[-1]
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.validation_file.split(".")[-1]
if extension == "txt":
extension = "text"
raw_datasets = load_dataset(extension, data_files=data_files)
# If no validation data is there, validation_split_percentage will be used to divide the dataset.
if "validation" not in raw_datasets.keys():
raw_datasets["validation"] = load_dataset(
extension,
data_files=data_files,
split=f"train[:{args.validation_split_percentage}%]",
)
raw_datasets["train"] = load_dataset(
extension,
data_files=data_files,
split=f"train[{args.validation_split_percentage}%:]",
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if args.config_name:
config = AutoConfig.from_pretrained(args.config_name, trust_remote_code=args.trust_remote_code)
elif args.model_name_or_path:
config = AutoConfig.from_pretrained(args.model_name_or_path, trust_remote_code=args.trust_remote_code)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if args.tokenizer_name:
tokenizer = AutoTokenizer.from_pretrained(
args.tokenizer_name, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
)
elif args.model_name_or_path:
tokenizer = AutoTokenizer.from_pretrained(
args.model_name_or_path, use_fast=not args.use_slow_tokenizer, trust_remote_code=args.trust_remote_code
)
else:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if args.model_name_or_path:
model = AutoModelForMaskedLM.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
low_cpu_mem_usage=args.low_cpu_mem_usage,
trust_remote_code=args.trust_remote_code,
)
else:
logger.info("Training new model from scratch")
model = AutoModelForMaskedLM.from_config(config, trust_remote_code=args.trust_remote_code)
# We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
# on a small vocab and want a smaller embedding size, remove this test.
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
model.resize_token_embeddings(len(tokenizer))
# Preprocessing the datasets.
# First we tokenize all the texts.
column_names = raw_datasets["train"].column_names
text_column_name = "text" if "text" in column_names else column_names[0]
if args.max_seq_length is None:
max_seq_length = tokenizer.model_max_length
if max_seq_length > 1024:
logger.warning(
"The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value"
" of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can"
" override this default with `--block_size xxx`."
)
max_seq_length = 1024
else:
if args.max_seq_length > tokenizer.model_max_length:
logger.warning(
f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
)
max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
if args.line_by_line:
# When using line_by_line, we just tokenize each nonempty line.
padding = "max_length" if args.pad_to_max_length else False
def tokenize_function(examples):
# Remove empty lines
examples[text_column_name] = [
line for line in examples[text_column_name] if len(line) > 0 and not line.isspace()
]
return tokenizer(
examples[text_column_name],
padding=padding,
truncation=True,
max_length=max_seq_length,
# We use this option because DataCollatorForLanguageModeling (see below) is more efficient when it
# receives the `special_tokens_mask`.
return_special_tokens_mask=True,
)
with accelerator.main_process_first():
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=[text_column_name],
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on dataset line_by_line",
)
else:
# Otherwise, we tokenize every text, then concatenate them together before splitting them in smaller parts.
# We use `return_special_tokens_mask=True` because DataCollatorForLanguageModeling (see below) is more
# efficient when it receives the `special_tokens_mask`.
def tokenize_function(examples):
return tokenizer(examples[text_column_name], return_special_tokens_mask=True)
with accelerator.main_process_first():
tokenized_datasets = raw_datasets.map(
tokenize_function,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on every text in dataset",
)
# Main data processing function that will concatenate all texts from our dataset and generate chunks of
# max_seq_length.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, and if the total_length < max_seq_length we exclude this batch and return an empty dict.
# We could add padding if the model supported it instead of this drop, you can customize this part to your needs.
total_length = (total_length // max_seq_length) * max_seq_length
# Split by chunks of max_len.
result = {
k: [t[i : i + max_seq_length] for i in range(0, total_length, max_seq_length)]
for k, t in concatenated_examples.items()
}
return result
# Note that with `batched=True`, this map processes 1,000 texts together, so group_texts throws away a
# remainder for each of those groups of 1,000 texts. You can adjust that batch_size here but a higher value
# might be slower to preprocess.
#
# To speed up this part, we use multiprocessing. See the documentation of the map method for more information:
# https://huggingface.co/docs/datasets/process#map
with accelerator.main_process_first():
tokenized_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=args.preprocessing_num_workers,
load_from_cache_file=not args.overwrite_cache,
desc=f"Grouping texts in chunks of {max_seq_length}",
)
train_dataset = tokenized_datasets["train"]
eval_dataset = tokenized_datasets["validation"]
# Conditional for small test subsets
if len(train_dataset) > 3:
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# Data collator
# This one will take care of randomly masking the tokens.
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=args.mlm_probability)
# DataLoaders creation:
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Note -> the training dataloader needs to be prepared before we grab his length below (cause its length will be
# shorter in multiprocess)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps
if overrode_max_train_steps
else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
if accelerator.distributed_type == DistributedType.TPU:
model.tie_weights()
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("mlm_no_trainer", experiment_config)
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
checkpoint_path = args.resume_from_checkpoint
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
checkpoint_path = path
path = os.path.basename(checkpoint_path)
accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
accelerator.load_state(checkpoint_path)
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
completed_steps = resume_step // args.gradient_accumulation_steps
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We skip the first `n` batches in the dataloader when resuming from a checkpoint
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
with accelerator.accumulate(model):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
output_dir = f"step_{completed_steps}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if completed_steps >= args.max_train_steps:
break
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
losses = torch.cat(losses)
try:
eval_loss = torch.mean(losses)
perplexity = math.exp(eval_loss)
except OverflowError:
perplexity = float("inf")
logger.info(f"epoch {epoch}: perplexity: {perplexity} eval_loss: {eval_loss}")
if args.with_tracking:
accelerator.log(
{
"perplexity": perplexity,
"eval_loss": eval_loss,
"train_loss": total_loss.item() / len(train_dataloader),
"epoch": epoch,
"step": completed_steps,
},
step=completed_steps,
)
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
api.upload_folder(
commit_message=f"Training in progress epoch {epoch}",
folder_path=args.output_dir,
repo_id=repo_id,
repo_type="model",
token=args.hub_token,
)
if args.checkpointing_steps == "epoch":
output_dir = f"epoch_{epoch}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if args.with_tracking:
accelerator.end_training()
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
if args.push_to_hub:
api.upload_folder(
commit_message="End of training",
folder_path=args.output_dir,
repo_id=repo_id,
repo_type="model",
token=args.hub_token,
)
with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
json.dump({"perplexity": perplexity}, f)
if __name__ == "__main__":
main()
|
transformers/examples/pytorch/language-modeling/run_mlm_no_trainer.py/0
|
{
"file_path": "transformers/examples/pytorch/language-modeling/run_mlm_no_trainer.py",
"repo_id": "transformers",
"token_count": 13824
}
| 67 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning XLNet for question answering with beam search using 🤗 Accelerate.
"""
# You can also adapt this script on your own question answering task. Pointers for this are left as comments.
import argparse
import json
import logging
import math
import os
import random
from pathlib import Path
import datasets
import evaluate
import numpy as np
import torch
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from datasets import load_dataset
from huggingface_hub import HfApi
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
from utils_qa import postprocess_qa_predictions_with_beam_search
import transformers
from transformers import (
AdamW,
DataCollatorWithPadding,
EvalPrediction,
SchedulerType,
XLNetConfig,
XLNetForQuestionAnswering,
XLNetTokenizerFast,
default_data_collator,
get_scheduler,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.49.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/question-answering/requirements.txt")
logger = get_logger(__name__)
def save_prefixed_metrics(results, output_dir, file_name: str = "all_results.json", metric_key_prefix: str = "eval"):
"""
Save results while prefixing metric names.
Args:
results: (:obj:`dict`):
A dictionary of results.
output_dir: (:obj:`str`):
An output directory.
file_name: (:obj:`str`, `optional`, defaults to :obj:`all_results.json`):
An output file name.
metric_key_prefix: (:obj:`str`, `optional`, defaults to :obj:`eval`):
A metric name prefix.
"""
# Prefix all keys with metric_key_prefix + '_'
for key in list(results.keys()):
if not key.startswith(f"{metric_key_prefix}_"):
results[f"{metric_key_prefix}_{key}"] = results.pop(key)
with open(os.path.join(output_dir, file_name), "w") as f:
json.dump(results, f, indent=4)
def parse_args():
parser = argparse.ArgumentParser(description="Finetune a transformers model on a Question Answering task")
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--trust_remote_code",
action="store_true",
help=(
"Whether to trust the execution of code from datasets/models defined on the Hub."
" This option should only be set to `True` for repositories you trust and in which you have read the"
" code, as it will execute code present on the Hub on your local machine."
),
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--preprocessing_num_workers", type=int, default=1, help="A csv or a json file containing the training data."
)
parser.add_argument("--do_predict", action="store_true", help="Eval the question answering model")
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--test_file", type=str, default=None, help="A csv or a json file containing the Prediction data."
)
parser.add_argument(
"--max_seq_length",
type=int,
default=384,
help=(
"The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
" sequences shorter will be padded if `--pad_to_max_length` is passed."
),
)
parser.add_argument(
"--pad_to_max_length",
action="store_true",
help="If passed, pad all samples to `max_seq_length`. Otherwise, dynamic padding is used.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=True,
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--doc_stride",
type=int,
default=128,
help="When splitting up a long document into chunks how much stride to take between chunks.",
)
parser.add_argument(
"--n_best_size",
type=int,
default=20,
help="The total number of n-best predictions to generate when looking for an answer.",
)
parser.add_argument(
"--null_score_diff_threshold",
type=float,
default=0.0,
help=(
"The threshold used to select the null answer: if the best answer has a score that is less than "
"the score of the null answer minus this threshold, the null answer is selected for this example. "
"Only useful when `version_2_with_negative=True`."
),
)
parser.add_argument(
"--version_2_with_negative",
action="store_true",
help="If true, some of the examples do not have an answer.",
)
parser.add_argument(
"--max_answer_length",
type=int,
default=30,
help=(
"The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another."
),
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--max_eval_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
),
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument(
"--max_predict_samples",
type=int,
default=None,
help="For debugging purposes or quicker training, truncate the number of prediction examples to this",
)
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to load in all available experiment trackers from the environment and use them for logging.",
)
args = parser.parse_args()
# Sanity checks
if (
args.dataset_name is None
and args.train_file is None
and args.validation_file is None
and args.test_file is None
):
raise ValueError("Need either a dataset name or a training/validation/test file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if args.test_file is not None:
extension = args.test_file.split(".")[-1]
assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
if args.push_to_hub:
assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_qa_beam_search_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will pick up all supported trackers
# in the environment
accelerator_log_kwargs = {}
if args.with_tracking:
accelerator_log_kwargs["log_with"] = args.report_to
accelerator_log_kwargs["project_dir"] = args.output_dir
accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, **accelerator_log_kwargs)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
# Retrieve of infer repo_name
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
# Create repo and retrieve repo_id
api = HfApi()
repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
# 'text' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(
args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
)
else:
data_files = {}
if args.train_file is not None:
data_files["train"] = args.train_file
extension = args.train_file.split(".")[-1]
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.validation_file.split(".")[-1]
if args.test_file is not None:
data_files["test"] = args.test_file
extension = args.test_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files, field="data")
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = XLNetConfig.from_pretrained(args.model_name_or_path)
tokenizer = XLNetTokenizerFast.from_pretrained(args.model_name_or_path)
model = XLNetForQuestionAnswering.from_pretrained(
args.model_name_or_path, from_tf=bool(".ckpt" in args.model_name_or_path), config=config
)
# Preprocessing the datasets.
# Preprocessing is slightly different for training and evaluation.
column_names = raw_datasets["train"].column_names
question_column_name = "question" if "question" in column_names else column_names[0]
context_column_name = "context" if "context" in column_names else column_names[1]
answer_column_name = "answers" if "answers" in column_names else column_names[2]
# Padding side determines if we do (question|context) or (context|question).
pad_on_right = tokenizer.padding_side == "right"
if args.max_seq_length > tokenizer.model_max_length:
logger.warning(
f"The max_seq_length passed ({args.max_seq_length}) is larger than the maximum length for the "
f"model ({tokenizer.model_max_length}). Using max_seq_length={tokenizer.model_max_length}."
)
max_seq_length = min(args.max_seq_length, tokenizer.model_max_length)
# Training preprocessing
def prepare_train_features(examples):
# Some of the questions have lots of whitespace on the left, which is not useful and will make the
# truncation of the context fail (the tokenized question will take a lots of space). So we remove that
# left whitespace
examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples[question_column_name if pad_on_right else context_column_name],
examples[context_column_name if pad_on_right else question_column_name],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_seq_length,
stride=args.doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
return_special_tokens_mask=True,
return_token_type_ids=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# The offset mappings will give us a map from token to character position in the original context. This will
# help us compute the start_positions and end_positions.
offset_mapping = tokenized_examples.pop("offset_mapping")
# The special tokens will help us build the p_mask (which indicates the tokens that can't be in answers).
special_tokens = tokenized_examples.pop("special_tokens_mask")
# Let's label those examples!
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
tokenized_examples["is_impossible"] = []
tokenized_examples["cls_index"] = []
tokenized_examples["p_mask"] = []
for i, offsets in enumerate(offset_mapping):
# We will label impossible answers with the index of the CLS token.
input_ids = tokenized_examples["input_ids"][i]
if tokenizer.cls_token_id in input_ids:
cls_index = input_ids.index(tokenizer.cls_token_id)
elif tokenizer.bos_token_id in input_ids:
cls_index = input_ids.index(tokenizer.bos_token_id)
else:
cls_index = 0
tokenized_examples["cls_index"].append(cls_index)
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples["token_type_ids"][i]
for k, s in enumerate(special_tokens[i]):
if s:
sequence_ids[k] = 3
context_idx = 1 if pad_on_right else 0
# Build the p_mask: non special tokens and context gets 0.0, the others get 1.0.
# The cls token gets 1.0 too (for predictions of empty answers).
tokenized_examples["p_mask"].append(
[
0.0 if (not special_tokens[i][k] and s == context_idx) or k == cls_index else 1.0
for k, s in enumerate(sequence_ids)
]
)
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
answers = examples[answer_column_name][sample_index]
# If no answers are given, set the cls_index as answer.
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
tokenized_examples["is_impossible"].append(1.0)
else:
# Start/end character index of the answer in the text.
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# Start token index of the current span in the text.
token_start_index = 0
while sequence_ids[token_start_index] != context_idx:
token_start_index += 1
# End token index of the current span in the text.
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != context_idx:
token_end_index -= 1
# Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
tokenized_examples["is_impossible"].append(1.0)
else:
# Otherwise move the token_start_index and token_end_index to the two ends of the answer.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
tokenized_examples["is_impossible"].append(0.0)
return tokenized_examples
if "train" not in raw_datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = raw_datasets["train"]
if args.max_train_samples is not None:
# We will select sample from whole data if argument is specified
train_dataset = train_dataset.select(range(args.max_train_samples))
# Create train feature from dataset
with accelerator.main_process_first():
train_dataset = train_dataset.map(
prepare_train_features,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on train dataset",
)
if args.max_train_samples is not None:
# Number of samples might increase during Feature Creation, We select only specified max samples
train_dataset = train_dataset.select(range(args.max_train_samples))
# Validation preprocessing
def prepare_validation_features(examples):
# Some of the questions have lots of whitespace on the left, which is not useful and will make the
# truncation of the context fail (the tokenized question will take a lots of space). So we remove that
# left whitespace
examples[question_column_name] = [q.lstrip() for q in examples[question_column_name]]
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples[question_column_name if pad_on_right else context_column_name],
examples[context_column_name if pad_on_right else question_column_name],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_seq_length,
stride=args.doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
return_special_tokens_mask=True,
return_token_type_ids=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# The special tokens will help us build the p_mask (which indicates the tokens that can't be in answers).
special_tokens = tokenized_examples.pop("special_tokens_mask")
# For evaluation, we will need to convert our predictions to substrings of the context, so we keep the
# corresponding example_id and we will store the offset mappings.
tokenized_examples["example_id"] = []
# We still provide the index of the CLS token and the p_mask to the model, but not the is_impossible label.
tokenized_examples["cls_index"] = []
tokenized_examples["p_mask"] = []
for i, input_ids in enumerate(tokenized_examples["input_ids"]):
# Find the CLS token in the input ids.
if tokenizer.cls_token_id in input_ids:
cls_index = input_ids.index(tokenizer.cls_token_id)
elif tokenizer.bos_token_id in input_ids:
cls_index = input_ids.index(tokenizer.bos_token_id)
else:
cls_index = 0
tokenized_examples["cls_index"].append(cls_index)
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples["token_type_ids"][i]
for k, s in enumerate(special_tokens[i]):
if s:
sequence_ids[k] = 3
context_idx = 1 if pad_on_right else 0
# Build the p_mask: non special tokens and context gets 0.0, the others 1.0.
tokenized_examples["p_mask"].append(
[
0.0 if (not special_tokens[i][k] and s == context_idx) or k == cls_index else 1.0
for k, s in enumerate(sequence_ids)
]
)
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_idx else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
if "validation" not in raw_datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_examples = raw_datasets["validation"]
if args.max_eval_samples is not None:
# We will select sample from whole data
eval_examples = eval_examples.select(range(args.max_eval_samples))
# Validation Feature Creation
with accelerator.main_process_first():
eval_dataset = eval_examples.map(
prepare_validation_features,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on validation dataset",
)
if args.max_eval_samples is not None:
# During Feature creation dataset samples might increase, we will select required samples again
eval_dataset = eval_dataset.select(range(args.max_eval_samples))
if args.do_predict:
if "test" not in raw_datasets:
raise ValueError("--do_predict requires a test dataset")
predict_examples = raw_datasets["test"]
if args.max_predict_samples is not None:
# We will select sample from whole data
predict_examples = predict_examples.select(range(args.max_predict_samples))
# Predict Feature Creation
with accelerator.main_process_first():
predict_dataset = predict_examples.map(
prepare_validation_features,
batched=True,
num_proc=args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not args.overwrite_cache,
desc="Running tokenizer on prediction dataset",
)
if args.max_predict_samples is not None:
# During Feature creation dataset samples might increase, we will select required samples again
predict_dataset = predict_dataset.select(range(args.max_predict_samples))
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# DataLoaders creation:
if args.pad_to_max_length:
# If padding was already done ot max length, we use the default data collator that will just convert everything
# to tensors.
data_collator = default_data_collator
else:
# Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
# the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
# of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
# For fp8, we pad to multiple of 16.
if accelerator.mixed_precision == "fp8":
pad_to_multiple_of = 16
elif accelerator.mixed_precision != "no":
pad_to_multiple_of = 8
else:
pad_to_multiple_of = None
data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataset_for_model = eval_dataset.remove_columns(["example_id", "offset_mapping"])
eval_dataloader = DataLoader(
eval_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
)
if args.do_predict:
predict_dataset_for_model = predict_dataset.remove_columns(["example_id", "offset_mapping"])
predict_dataloader = DataLoader(
predict_dataset_for_model, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size
)
# Post-processing:
def post_processing_function(examples, features, predictions, stage="eval"):
# Post-processing: we match the start logits and end logits to answers in the original context.
predictions, scores_diff_json = postprocess_qa_predictions_with_beam_search(
examples=examples,
features=features,
predictions=predictions,
version_2_with_negative=args.version_2_with_negative,
n_best_size=args.n_best_size,
max_answer_length=args.max_answer_length,
start_n_top=model.config.start_n_top,
end_n_top=model.config.end_n_top,
output_dir=args.output_dir,
prefix=stage,
)
# Format the result to the format the metric expects.
if args.version_2_with_negative:
formatted_predictions = [
{"id": k, "prediction_text": v, "no_answer_probability": scores_diff_json[k]}
for k, v in predictions.items()
]
else:
formatted_predictions = [{"id": k, "prediction_text": v} for k, v in predictions.items()]
references = [{"id": ex["id"], "answers": ex[answer_column_name]} for ex in examples]
return EvalPrediction(predictions=formatted_predictions, label_ids=references)
metric = evaluate.load("squad_v2" if args.version_2_with_negative else "squad")
def create_and_fill_np_array(start_or_end_logits, dataset, max_len):
"""
Create and fill numpy array of size len_of_validation_data * max_length_of_output_tensor
Args:
start_or_end_logits(:obj:`tensor`):
This is the output predictions of the model. We can only enter either start or end logits.
eval_dataset: Evaluation dataset
max_len(:obj:`int`):
The maximum length of the output tensor. ( See the model.eval() part for more details )
"""
step = 0
# create a numpy array and fill it with -100.
logits_concat = np.full((len(dataset), max_len), -100, dtype=np.float32)
# Now since we have create an array now we will populate it with the outputs gathered using accelerator.gather_for_metrics
for i, output_logit in enumerate(start_or_end_logits): # populate columns
# We have to fill it such that we have to take the whole tensor and replace it on the newly created array
# And after every iteration we have to change the step
batch_size = output_logit.shape[0]
cols = output_logit.shape[1]
if step + batch_size < len(dataset):
logits_concat[step : step + batch_size, :cols] = output_logit
else:
logits_concat[step:, :cols] = output_logit[: len(dataset) - step]
step += batch_size
return logits_concat
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps
if overrode_max_train_steps
else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("qa_beam_search_no_trainer", experiment_config)
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
checkpoint_path = args.resume_from_checkpoint
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
checkpoint_path = path
path = os.path.basename(checkpoint_path)
accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
accelerator.load_state(checkpoint_path)
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
completed_steps = resume_step // args.gradient_accumulation_steps
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We skip the first `n` batches in the dataloader when resuming from a checkpoint
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
with accelerator.accumulate(model):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
accelerator.save_state(f"step_{completed_steps}")
if completed_steps >= args.max_train_steps:
break
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
api.upload_folder(
commit_message=f"Training in progress epoch {epoch}",
folder_path=args.output_dir,
repo_id=repo_id,
repo_type="model",
token=args.hub_token,
)
# initialize all lists to collect the batches
all_start_top_log_probs = []
all_start_top_index = []
all_end_top_log_probs = []
all_end_top_index = []
all_cls_logits = []
model.eval()
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
start_top_log_probs = outputs.start_top_log_probs
start_top_index = outputs.start_top_index
end_top_log_probs = outputs.end_top_log_probs
end_top_index = outputs.end_top_index
cls_logits = outputs.cls_logits
if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
start_top_log_probs = accelerator.pad_across_processes(start_top_log_probs, dim=1, pad_index=-100)
start_top_index = accelerator.pad_across_processes(start_top_index, dim=1, pad_index=-100)
end_top_log_probs = accelerator.pad_across_processes(end_top_log_probs, dim=1, pad_index=-100)
end_top_index = accelerator.pad_across_processes(end_top_index, dim=1, pad_index=-100)
cls_logits = accelerator.pad_across_processes(cls_logits, dim=1, pad_index=-100)
all_start_top_log_probs.append(accelerator.gather_for_metrics(start_top_log_probs).cpu().numpy())
all_start_top_index.append(accelerator.gather_for_metrics(start_top_index).cpu().numpy())
all_end_top_log_probs.append(accelerator.gather_for_metrics(end_top_log_probs).cpu().numpy())
all_end_top_index.append(accelerator.gather_for_metrics(end_top_index).cpu().numpy())
all_cls_logits.append(accelerator.gather_for_metrics(cls_logits).cpu().numpy())
max_len = max([x.shape[1] for x in all_end_top_log_probs]) # Get the max_length of the tensor
# concatenate all numpy arrays collected above
start_top_log_probs_concat = create_and_fill_np_array(all_start_top_log_probs, eval_dataset, max_len)
start_top_index_concat = create_and_fill_np_array(all_start_top_index, eval_dataset, max_len)
end_top_log_probs_concat = create_and_fill_np_array(all_end_top_log_probs, eval_dataset, max_len)
end_top_index_concat = create_and_fill_np_array(all_end_top_index, eval_dataset, max_len)
cls_logits_concat = np.concatenate(all_cls_logits, axis=0)
# delete the list of numpy arrays
del start_top_log_probs
del start_top_index
del end_top_log_probs
del end_top_index
del cls_logits
outputs_numpy = (
start_top_log_probs_concat,
start_top_index_concat,
end_top_log_probs_concat,
end_top_index_concat,
cls_logits_concat,
)
prediction = post_processing_function(eval_examples, eval_dataset, outputs_numpy)
eval_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
logger.info(f"Evaluation metrics: {eval_metric}")
if args.do_predict:
# initialize all lists to collect the batches
all_start_top_log_probs = []
all_start_top_index = []
all_end_top_log_probs = []
all_end_top_index = []
all_cls_logits = []
model.eval()
for step, batch in enumerate(predict_dataloader):
with torch.no_grad():
outputs = model(**batch)
start_top_log_probs = outputs.start_top_log_probs
start_top_index = outputs.start_top_index
end_top_log_probs = outputs.end_top_log_probs
end_top_index = outputs.end_top_index
cls_logits = outputs.cls_logits
if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
start_top_log_probs = accelerator.pad_across_processes(start_top_log_probs, dim=1, pad_index=-100)
start_top_index = accelerator.pad_across_processes(start_top_index, dim=1, pad_index=-100)
end_top_log_probs = accelerator.pad_across_processes(end_top_log_probs, dim=1, pad_index=-100)
end_top_index = accelerator.pad_across_processes(end_top_index, dim=1, pad_index=-100)
cls_logits = accelerator.pad_across_processes(cls_logits, dim=1, pad_index=-100)
all_start_top_log_probs.append(accelerator.gather_for_metrics(start_top_log_probs).cpu().numpy())
all_start_top_index.append(accelerator.gather_for_metrics(start_top_index).cpu().numpy())
all_end_top_log_probs.append(accelerator.gather_for_metrics(end_top_log_probs).cpu().numpy())
all_end_top_index.append(accelerator.gather_for_metrics(end_top_index).cpu().numpy())
all_cls_logits.append(accelerator.gather_for_metrics(cls_logits).cpu().numpy())
max_len = max([x.shape[1] for x in all_end_top_log_probs]) # Get the max_length of the tensor
# concatenate all numpy arrays collected above
start_top_log_probs_concat = create_and_fill_np_array(all_start_top_log_probs, predict_dataset, max_len)
start_top_index_concat = create_and_fill_np_array(all_start_top_index, predict_dataset, max_len)
end_top_log_probs_concat = create_and_fill_np_array(all_end_top_log_probs, predict_dataset, max_len)
end_top_index_concat = create_and_fill_np_array(all_end_top_index, predict_dataset, max_len)
cls_logits_concat = np.concatenate(all_cls_logits, axis=0)
# delete the list of numpy arrays
del start_top_log_probs
del start_top_index
del end_top_log_probs
del end_top_index
del cls_logits
outputs_numpy = (
start_top_log_probs_concat,
start_top_index_concat,
end_top_log_probs_concat,
end_top_index_concat,
cls_logits_concat,
)
prediction = post_processing_function(predict_examples, predict_dataset, outputs_numpy)
predict_metric = metric.compute(predictions=prediction.predictions, references=prediction.label_ids)
logger.info(f"Predict metrics: {predict_metric}")
if args.with_tracking:
log = {
"squad_v2" if args.version_2_with_negative else "squad": eval_metric,
"train_loss": total_loss,
"epoch": epoch,
"step": completed_steps,
}
if args.do_predict:
log["squad_v2_predict" if args.version_2_with_negative else "squad_predict"] = predict_metric
accelerator.log(log)
if args.checkpointing_steps == "epoch":
accelerator.save_state(f"epoch_{epoch}")
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
if args.push_to_hub:
api.upload_folder(
commit_message="End of training",
folder_path=args.output_dir,
repo_id=repo_id,
repo_type="model",
token=args.hub_token,
)
logger.info(json.dumps(eval_metric, indent=4))
save_prefixed_metrics(eval_metric, args.output_dir)
if __name__ == "__main__":
main()
|
transformers/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py/0
|
{
"file_path": "transformers/examples/pytorch/question-answering/run_qa_beam_search_no_trainer.py",
"repo_id": "transformers",
"token_count": 20571
}
| 68 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Fine-tuning a 🤗 Transformers CTC adapter model for automatic speech recognition"""
import functools
import json
import logging
import os
import re
import sys
import warnings
from dataclasses import dataclass, field
from typing import Dict, List, Optional, Union
import datasets
import evaluate
import numpy as np
import torch
from datasets import DatasetDict, load_dataset
from safetensors.torch import save_file as safe_save_file
import transformers
from transformers import (
AutoConfig,
AutoFeatureExtractor,
AutoModelForCTC,
AutoProcessor,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
Wav2Vec2Processor,
set_seed,
)
from transformers.models.wav2vec2.modeling_wav2vec2 import WAV2VEC2_ADAPTER_SAFE_FILE
from transformers.trainer_utils import get_last_checkpoint, is_main_process
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.49.0.dev0")
require_version("datasets>=1.18.0", "To fix: pip install -r examples/pytorch/speech-recognition/requirements.txt")
logger = logging.getLogger(__name__)
def list_field(default=None, metadata=None):
return field(default_factory=lambda: default, metadata=metadata)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
tokenizer_name_or_path: Optional[str] = field(
default=None,
metadata={"help": "Path to pretrained tokenizer or tokenizer identifier from huggingface.co/models"},
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
final_dropout: float = field(
default=0.0,
metadata={"help": "The dropout probability for the final projection layer."},
)
mask_time_prob: float = field(
default=0.05,
metadata={
"help": (
"Probability of each feature vector along the time axis to be chosen as the start of the vector "
"span to be masked. Approximately ``mask_time_prob * sequence_length // mask_time_length`` feature "
"vectors will be masked along the time axis."
)
},
)
mask_time_length: int = field(
default=10,
metadata={"help": "Length of vector span to mask along the time axis."},
)
mask_feature_prob: float = field(
default=0.0,
metadata={
"help": (
"Probability of each feature vector along the feature axis to be chosen as the start of the vectorspan"
" to be masked. Approximately ``mask_feature_prob * sequence_length // mask_feature_length`` feature"
" bins will be masked along the time axis."
)
},
)
mask_feature_length: int = field(
default=10,
metadata={"help": "Length of vector span to mask along the feature axis."},
)
layerdrop: float = field(default=0.0, metadata={"help": "The LayerDrop probability."})
ctc_loss_reduction: Optional[str] = field(
default="mean", metadata={"help": "The way the ctc loss should be reduced. Should be one of 'mean' or 'sum'."}
)
adapter_attn_dim: int = field(
default=16,
metadata={
"help": "The hidden dimension of the adapter layers that will be randomly initialized and trained. The higher the dimension, the more capacity is given to the adapter weights. Note that only the adapter weights are fine-tuned."
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
Using `HfArgumentParser` we can turn this class
into argparse arguments to be able to specify them on
the command line.
"""
dataset_name: str = field(
metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
target_language: Optional[str] = field(
metadata={
"help": (
"The target language on which the adapter attention layers"
" should be trained on in ISO 693-3 code, e.g. `tur` for Turkish"
" Wav2Vec2's MMS ISO codes can be looked up here: https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html"
" If you are not training the adapter layers on a language, simply choose"
" another acronym that fits your data."
)
},
)
dataset_config_name: str = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_split_name: str = field(
default="train+validation",
metadata={
"help": (
"The name of the training data set split to use (via the datasets library). Defaults to "
"'train+validation'"
)
},
)
eval_split_name: str = field(
default="test",
metadata={
"help": "The name of the evaluation data set split to use (via the datasets library). Defaults to 'test'"
},
)
audio_column_name: str = field(
default="audio",
metadata={"help": "The name of the dataset column containing the audio data. Defaults to 'audio'"},
)
text_column_name: str = field(
default="text",
metadata={"help": "The name of the dataset column containing the text data. Defaults to 'text'"},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of validation examples to this "
"value if set."
)
},
)
chars_to_ignore: Optional[List[str]] = list_field(
default=None,
metadata={"help": "A list of characters to remove from the transcripts."},
)
eval_metrics: List[str] = list_field(
default=["wer"],
metadata={"help": "A list of metrics the model should be evaluated on. E.g. `'wer cer'`"},
)
max_duration_in_seconds: float = field(
default=20.0,
metadata={
"help": (
"Filter audio files that are longer than `max_duration_in_seconds` seconds to"
" 'max_duration_in_seconds`"
)
},
)
min_duration_in_seconds: float = field(
default=0.0, metadata={"help": "Filter audio files that are shorter than `min_duration_in_seconds` seconds"}
)
preprocessing_only: bool = field(
default=False,
metadata={
"help": (
"Whether to only do data preprocessing and skip training. This is especially useful when data"
" preprocessing errors out in distributed training due to timeout. In this case, one should run the"
" preprocessing in a non-distributed setup with `preprocessing_only=True` so that the cached datasets"
" can consequently be loaded in distributed training"
)
},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether to trust the execution of code from datasets/models defined on the Hub."
" This option should only be set to `True` for repositories you trust and in which you have read the"
" code, as it will execute code present on the Hub on your local machine."
)
},
)
unk_token: str = field(
default="[UNK]",
metadata={"help": "The unk token for the tokenizer"},
)
pad_token: str = field(
default="[PAD]",
metadata={"help": "The padding token for the tokenizer"},
)
word_delimiter_token: str = field(
default="|",
metadata={"help": "The word delimiter token for the tokenizer"},
)
overwrite_lang_vocab: bool = field(
default=False,
metadata={"help": ("If :obj:`True`, will overwrite existing `target_language` vocabulary of tokenizer.")},
)
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.AutoProcessor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
max_length_labels (:obj:`int`, `optional`):
Maximum length of the ``labels`` returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
processor: AutoProcessor
padding: Union[bool, str] = "longest"
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
pad_to_multiple_of=self.pad_to_multiple_of_labels,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
if "attention_mask" in batch:
batch["attention_mask"] = batch["attention_mask"].to(torch.long)
return batch
def create_vocabulary_from_data(
datasets: DatasetDict,
word_delimiter_token: Optional[str] = None,
unk_token: Optional[str] = None,
pad_token: Optional[str] = None,
):
# Given training and test labels create vocabulary
def extract_all_chars(batch):
all_text = " ".join(batch["target_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = datasets.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=datasets["train"].column_names,
)
# take union of all unique characters in each dataset
vocab_set = functools.reduce(
lambda vocab_1, vocab_2: set(vocab_1["vocab"][0]) | set(vocab_2["vocab"][0]), vocabs.values()
)
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_set))}
# replace white space with delimiter token
if word_delimiter_token is not None:
vocab_dict[word_delimiter_token] = vocab_dict[" "]
del vocab_dict[" "]
# add unk and pad token
if unk_token is not None:
vocab_dict[unk_token] = len(vocab_dict)
if pad_token is not None:
vocab_dict[pad_token] = len(vocab_dict)
return vocab_dict
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_speech_recognition_ctc_adapter", model_args, data_args)
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
logger.info("Training/evaluation parameters %s", training_args)
# Set seed before initializing model.
set_seed(training_args.seed)
# 1. First, let's load the dataset
raw_datasets = DatasetDict()
if training_args.do_train:
raw_datasets["train"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=data_args.train_split_name,
token=data_args.token,
trust_remote_code=data_args.trust_remote_code,
)
if data_args.audio_column_name not in raw_datasets["train"].column_names:
raise ValueError(
f"--audio_column_name '{data_args.audio_column_name}' not found in dataset '{data_args.dataset_name}'."
" Make sure to set `--audio_column_name` to the correct audio column - one of"
f" {', '.join(raw_datasets['train'].column_names)}."
)
if data_args.text_column_name not in raw_datasets["train"].column_names:
raise ValueError(
f"--text_column_name {data_args.text_column_name} not found in dataset '{data_args.dataset_name}'. "
"Make sure to set `--text_column_name` to the correct text column - one of "
f"{', '.join(raw_datasets['train'].column_names)}."
)
if data_args.max_train_samples is not None:
raw_datasets["train"] = raw_datasets["train"].select(range(data_args.max_train_samples))
if training_args.do_eval:
raw_datasets["eval"] = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
split=data_args.eval_split_name,
token=data_args.token,
trust_remote_code=data_args.trust_remote_code,
)
if data_args.max_eval_samples is not None:
raw_datasets["eval"] = raw_datasets["eval"].select(range(data_args.max_eval_samples))
# 2. We remove some special characters from the datasets
# that make training complicated and do not help in transcribing the speech
# E.g. characters, such as `,` and `.` do not really have an acoustic characteristic
# that could be easily picked up by the model
chars_to_ignore_regex = (
f'[{"".join(data_args.chars_to_ignore)}]' if data_args.chars_to_ignore is not None else None
)
text_column_name = data_args.text_column_name
def remove_special_characters(batch):
if chars_to_ignore_regex is not None:
batch["target_text"] = re.sub(chars_to_ignore_regex, "", batch[text_column_name]).lower() + " "
else:
batch["target_text"] = batch[text_column_name].lower() + " "
return batch
with training_args.main_process_first(desc="dataset map special characters removal"):
raw_datasets = raw_datasets.map(
remove_special_characters,
remove_columns=[text_column_name],
desc="remove special characters from datasets",
)
# save special tokens for tokenizer
word_delimiter_token = data_args.word_delimiter_token
unk_token = data_args.unk_token
pad_token = data_args.pad_token
# 3. Next, let's load the config as we might need it to create
# the tokenizer
# load config
config = AutoConfig.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
token=data_args.token,
trust_remote_code=data_args.trust_remote_code,
)
# 4. Next, if no tokenizer file is defined,
# we create the vocabulary of the model by extracting all unique characters from
# the training and evaluation datasets
# We need to make sure that only first rank saves vocabulary
# make sure all processes wait until vocab is created
tokenizer_name_or_path = model_args.tokenizer_name_or_path
tokenizer_kwargs = {}
vocab_dict = {}
if tokenizer_name_or_path is not None:
# load vocabulary of other adapter languages so that new language can be appended
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
token=data_args.token,
trust_remote_code=data_args.trust_remote_code,
)
vocab_dict = tokenizer.vocab.copy()
if tokenizer.target_lang is None:
raise ValueError("Make sure to load a multi-lingual tokenizer with a set target language.")
if data_args.target_language in tokenizer.vocab and not data_args.overwrite_lang_vocab:
logger.info(
"Adapter language already exists."
" Skipping vocabulary creating. If you want to create a new vocabulary"
f" for {data_args.target_language} make sure to add '--overwrite_lang_vocab'"
)
else:
tokenizer_name_or_path = None
if tokenizer_name_or_path is None:
# save vocab in training output dir
tokenizer_name_or_path = training_args.output_dir
vocab_file = os.path.join(tokenizer_name_or_path, "vocab.json")
with training_args.main_process_first():
if training_args.overwrite_output_dir and os.path.isfile(vocab_file):
try:
os.remove(vocab_file)
except OSError:
# in shared file-systems it might be the case that
# two processes try to delete the vocab file at the some time
pass
with training_args.main_process_first(desc="dataset map vocabulary creation"):
if not os.path.isfile(vocab_file):
os.makedirs(tokenizer_name_or_path, exist_ok=True)
lang_dict = create_vocabulary_from_data(
raw_datasets,
word_delimiter_token=word_delimiter_token,
unk_token=unk_token,
pad_token=pad_token,
)
# if we doing adapter language training, save
# vocab with adpter language
if data_args.target_language is not None:
vocab_dict[data_args.target_language] = lang_dict
# save vocab dict to be loaded into tokenizer
with open(vocab_file, "w") as file:
json.dump(vocab_dict, file)
# if tokenizer has just been created
# it is defined by `tokenizer_class` if present in config else by `model_type`
tokenizer_kwargs = {
"config": config if config.tokenizer_class is not None else None,
"tokenizer_type": config.model_type if config.tokenizer_class is None else None,
"unk_token": unk_token,
"pad_token": pad_token,
"word_delimiter_token": word_delimiter_token,
"target_lang": data_args.target_language,
}
# 5. Now we can instantiate the feature extractor, tokenizer and model
# Note for distributed training, the .from_pretrained methods guarantee that only
# one local process can concurrently download model & vocab.
# load feature_extractor and tokenizer
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path,
token=data_args.token,
trust_remote_code=data_args.trust_remote_code,
**tokenizer_kwargs,
)
feature_extractor = AutoFeatureExtractor.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
token=data_args.token,
trust_remote_code=data_args.trust_remote_code,
)
# adapt config
config.update(
{
"final_dropout": model_args.final_dropout,
"mask_time_prob": model_args.mask_time_prob,
"mask_time_length": model_args.mask_time_length,
"mask_feature_prob": model_args.mask_feature_prob,
"mask_feature_length": model_args.mask_feature_length,
"gradient_checkpointing": training_args.gradient_checkpointing,
"layerdrop": model_args.layerdrop,
"ctc_loss_reduction": model_args.ctc_loss_reduction,
"pad_token_id": tokenizer.pad_token_id,
"vocab_size": len(tokenizer),
"adapter_attn_dim": model_args.adapter_attn_dim,
}
)
# create model
model = AutoModelForCTC.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
config=config,
token=data_args.token,
trust_remote_code=data_args.trust_remote_code,
ignore_mismatched_sizes=True,
)
# if attn adapter is defined, freeze all non-adapter weights
if model.config.adapter_attn_dim is not None:
model.init_adapter_layers()
# first we freeze the whole base model
model.freeze_base_model()
# next we unfreeze all adapter layers
adapter_weights = model._get_adapters()
for param in adapter_weights.values():
param.requires_grad = True
# 6. Now we preprocess the datasets including loading the audio, resampling and normalization
# Thankfully, `datasets` takes care of automatically loading and resampling the audio,
# so that we just need to set the correct target sampling rate and normalize the input
# via the `feature_extractor`
# make sure that dataset decodes audio with correct sampling rate
dataset_sampling_rate = next(iter(raw_datasets.values())).features[data_args.audio_column_name].sampling_rate
if dataset_sampling_rate != feature_extractor.sampling_rate:
raw_datasets = raw_datasets.cast_column(
data_args.audio_column_name, datasets.features.Audio(sampling_rate=feature_extractor.sampling_rate)
)
# derive max & min input length for sample rate & max duration
max_input_length = data_args.max_duration_in_seconds * feature_extractor.sampling_rate
min_input_length = data_args.min_duration_in_seconds * feature_extractor.sampling_rate
audio_column_name = data_args.audio_column_name
num_workers = data_args.preprocessing_num_workers
# Preprocessing the datasets.
# We need to read the audio files as arrays and tokenize the targets.
def prepare_dataset(batch):
# load audio
sample = batch[audio_column_name]
inputs = feature_extractor(sample["array"], sampling_rate=sample["sampling_rate"])
batch["input_values"] = inputs.input_values[0]
batch["input_length"] = len(batch["input_values"])
# encode targets
batch["labels"] = tokenizer(batch["target_text"]).input_ids
return batch
with training_args.main_process_first(desc="dataset map preprocessing"):
vectorized_datasets = raw_datasets.map(
prepare_dataset,
remove_columns=next(iter(raw_datasets.values())).column_names,
num_proc=num_workers,
desc="preprocess datasets",
)
def is_audio_in_length_range(length):
return length > min_input_length and length < max_input_length
# filter data that is shorter than min_input_length
vectorized_datasets = vectorized_datasets.filter(
is_audio_in_length_range,
num_proc=num_workers,
input_columns=["input_length"],
)
# 7. Next, we can prepare the training.
# Let's use word error rate (WER) as our evaluation metric,
# instantiate a data collator and the trainer
# Define evaluation metrics during training, *i.e.* word error rate, character error rate
eval_metrics = {metric: evaluate.load(metric, cache_dir=model_args.cache_dir) for metric in data_args.eval_metrics}
# for large datasets it is advised to run the preprocessing on a
# single machine first with ``args.preprocessing_only`` since there will mostly likely
# be a timeout when running the script in distributed mode.
# In a second step ``args.preprocessing_only`` can then be set to `False` to load the
# cached dataset
if data_args.preprocessing_only:
logger.info(f"Data preprocessing finished. Files cached at {vectorized_datasets.cache_files}")
return
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = tokenizer.pad_token_id
pred_str = tokenizer.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = tokenizer.batch_decode(pred.label_ids, group_tokens=False)
metrics = {k: v.compute(predictions=pred_str, references=label_str) for k, v in eval_metrics.items()}
return metrics
# Now save everything to be able to create a single processor later
# make sure all processes wait until data is saved
with training_args.main_process_first():
# only the main process saves them
if is_main_process(training_args.local_rank):
# save feature extractor, tokenizer and config
feature_extractor.save_pretrained(training_args.output_dir)
tokenizer.save_pretrained(training_args.output_dir)
config.save_pretrained(training_args.output_dir)
try:
processor = AutoProcessor.from_pretrained(training_args.output_dir)
except (OSError, KeyError):
warnings.warn(
"Loading a processor from a feature extractor config that does not"
" include a `processor_class` attribute is deprecated and will be removed in v5. Please add the following "
" attribute to your `preprocessor_config.json` file to suppress this warning: "
" `'processor_class': 'Wav2Vec2Processor'`",
FutureWarning,
)
processor = Wav2Vec2Processor.from_pretrained(training_args.output_dir)
# Instantiate custom data collator
data_collator = DataCollatorCTCWithPadding(processor=processor)
# Initialize Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=vectorized_datasets["train"] if training_args.do_train else None,
eval_dataset=vectorized_datasets["eval"] if training_args.do_eval else None,
processing_class=processor,
)
# 8. Finally, we can start training
# Training
if training_args.do_train:
# use last checkpoint if exist
if last_checkpoint is not None:
checkpoint = last_checkpoint
elif os.path.isdir(model_args.model_name_or_path):
checkpoint = model_args.model_name_or_path
else:
checkpoint = None
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model()
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples
if data_args.max_train_samples is not None
else len(vectorized_datasets["train"])
)
metrics["train_samples"] = min(max_train_samples, len(vectorized_datasets["train"]))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
max_eval_samples = (
data_args.max_eval_samples if data_args.max_eval_samples is not None else len(vectorized_datasets["eval"])
)
metrics["eval_samples"] = min(max_eval_samples, len(vectorized_datasets["eval"]))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Write model card and (optionally) push to hub
config_name = data_args.dataset_config_name if data_args.dataset_config_name is not None else "na"
kwargs = {
"finetuned_from": model_args.model_name_or_path,
"tasks": "automatic-speech-recognition",
"tags": ["automatic-speech-recognition", data_args.dataset_name, "mms"],
"dataset_args": (
f"Config: {config_name}, Training split: {data_args.train_split_name}, Eval split:"
f" {data_args.eval_split_name}"
),
"dataset": f"{data_args.dataset_name.upper()} - {config_name.upper()}",
}
if "common_voice" in data_args.dataset_name:
kwargs["language"] = config_name
# make sure that adapter weights are saved seperately
adapter_file = WAV2VEC2_ADAPTER_SAFE_FILE.format(data_args.target_language)
adapter_file = os.path.join(training_args.output_dir, adapter_file)
logger.info(f"Saving adapter weights under {adapter_file}...")
safe_save_file(model._get_adapters(), adapter_file, metadata={"format": "pt"})
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
return results
if __name__ == "__main__":
main()
|
transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py/0
|
{
"file_path": "transformers/examples/pytorch/speech-recognition/run_speech_recognition_ctc_adapter.py",
"repo_id": "transformers",
"token_count": 13686
}
| 69 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Conditional text generation with the auto-regressive models of the library (GPT/GPT-2/CTRL/Transformer-XL/XLNet)"""
import argparse
import inspect
import logging
from typing import Tuple
import torch
from accelerate import PartialState
from accelerate.utils import set_seed
from transformers import (
AutoTokenizer,
BloomForCausalLM,
BloomTokenizerFast,
CTRLLMHeadModel,
CTRLTokenizer,
GenerationMixin,
GPT2LMHeadModel,
GPT2Tokenizer,
GPTJForCausalLM,
LlamaForCausalLM,
LlamaTokenizer,
OpenAIGPTLMHeadModel,
OpenAIGPTTokenizer,
OPTForCausalLM,
TransfoXLLMHeadModel,
TransfoXLTokenizer,
XLMTokenizer,
XLMWithLMHeadModel,
XLNetLMHeadModel,
XLNetTokenizer,
)
from transformers.modeling_outputs import CausalLMOutputWithPast
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger = logging.getLogger(__name__)
MAX_LENGTH = int(10000) # Hardcoded max length to avoid infinite loop
MODEL_CLASSES = {
"gpt2": (GPT2LMHeadModel, GPT2Tokenizer),
"ctrl": (CTRLLMHeadModel, CTRLTokenizer),
"openai-gpt": (OpenAIGPTLMHeadModel, OpenAIGPTTokenizer),
"xlnet": (XLNetLMHeadModel, XLNetTokenizer),
"transfo-xl": (TransfoXLLMHeadModel, TransfoXLTokenizer),
"xlm": (XLMWithLMHeadModel, XLMTokenizer),
"gptj": (GPTJForCausalLM, AutoTokenizer),
"bloom": (BloomForCausalLM, BloomTokenizerFast),
"llama": (LlamaForCausalLM, LlamaTokenizer),
"opt": (OPTForCausalLM, GPT2Tokenizer),
}
# Padding text to help Transformer-XL and XLNet with short prompts as proposed by Aman Rusia
# in https://github.com/rusiaaman/XLNet-gen#methodology
# and https://medium.com/@amanrusia/xlnet-speaks-comparison-to-gpt-2-ea1a4e9ba39e
PREFIX = """In 1991, the remains of Russian Tsar Nicholas II and his family
(except for Alexei and Maria) are discovered.
The voice of Nicholas's young son, Tsarevich Alexei Nikolaevich, narrates the
remainder of the story. 1883 Western Siberia,
a young Grigori Rasputin is asked by his father and a group of men to perform magic.
Rasputin has a vision and denounces one of the men as a horse thief. Although his
father initially slaps him for making such an accusation, Rasputin watches as the
man is chased outside and beaten. Twenty years later, Rasputin sees a vision of
the Virgin Mary, prompting him to become a priest. Rasputin quickly becomes famous,
with people, even a bishop, begging for his blessing. <eod> </s> <eos>"""
#
# Functions to prepare models' input
#
def prepare_ctrl_input(args, _, tokenizer, prompt_text):
if args.temperature > 0.7:
logger.info("CTRL typically works better with lower temperatures (and lower top_k).")
encoded_prompt = tokenizer.encode(prompt_text, add_special_tokens=False)
if not any(encoded_prompt[0] == x for x in tokenizer.control_codes.values()):
logger.info("WARNING! You are not starting your generation from a control code so you won't get good results")
return prompt_text
def prepare_xlm_input(args, model, tokenizer, prompt_text):
# kwargs = {"language": None, "mask_token_id": None}
# Set the language
use_lang_emb = hasattr(model.config, "use_lang_emb") and model.config.use_lang_emb
if hasattr(model.config, "lang2id") and use_lang_emb:
available_languages = model.config.lang2id.keys()
if args.xlm_language in available_languages:
language = args.xlm_language
else:
language = None
while language not in available_languages:
language = input("Using XLM. Select language in " + str(list(available_languages)) + " >>> ")
model.config.lang_id = model.config.lang2id[language]
# kwargs["language"] = tokenizer.lang2id[language]
# TODO fix mask_token_id setup when configurations will be synchronized between models and tokenizers
# XLM masked-language modeling (MLM) models need masked token
# is_xlm_mlm = "mlm" in args.model_name_or_path
# if is_xlm_mlm:
# kwargs["mask_token_id"] = tokenizer.mask_token_id
return prompt_text
def prepare_xlnet_input(args, _, tokenizer, prompt_text):
prefix = args.prefix if args.prefix else args.padding_text if args.padding_text else PREFIX
prompt_text = prefix + prompt_text
return prompt_text
def prepare_transfoxl_input(args, _, tokenizer, prompt_text):
prefix = args.prefix if args.prefix else args.padding_text if args.padding_text else PREFIX
prompt_text = prefix + prompt_text
return prompt_text
PREPROCESSING_FUNCTIONS = {
"ctrl": prepare_ctrl_input,
"xlm": prepare_xlm_input,
"xlnet": prepare_xlnet_input,
"transfo-xl": prepare_transfoxl_input,
}
def adjust_length_to_model(length, max_sequence_length):
if length < 0 and max_sequence_length > 0:
length = max_sequence_length
elif 0 < max_sequence_length < length:
length = max_sequence_length # No generation bigger than model size
elif length < 0:
length = MAX_LENGTH # avoid infinite loop
return length
def sparse_model_config(model_config):
embedding_size = None
if hasattr(model_config, "hidden_size"):
embedding_size = model_config.hidden_size
elif hasattr(model_config, "n_embed"):
embedding_size = model_config.n_embed
elif hasattr(model_config, "n_embd"):
embedding_size = model_config.n_embd
num_head = None
if hasattr(model_config, "num_attention_heads"):
num_head = model_config.num_attention_heads
elif hasattr(model_config, "n_head"):
num_head = model_config.n_head
if embedding_size is None or num_head is None or num_head == 0:
raise ValueError("Check the model config")
num_embedding_size_per_head = int(embedding_size / num_head)
if hasattr(model_config, "n_layer"):
num_layer = model_config.n_layer
elif hasattr(model_config, "num_hidden_layers"):
num_layer = model_config.num_hidden_layers
else:
raise ValueError("Number of hidden layers couldn't be determined from the model config")
return num_layer, num_head, num_embedding_size_per_head
def generate_past_key_values(model, batch_size, seq_len):
num_block_layers, num_attention_heads, num_embedding_size_per_head = sparse_model_config(model.config)
if model.config.model_type == "bloom":
past_key_values = tuple(
(
torch.empty(int(num_attention_heads * batch_size), num_embedding_size_per_head, seq_len)
.to(model.dtype)
.to(model.device),
torch.empty(int(num_attention_heads * batch_size), seq_len, num_embedding_size_per_head)
.to(model.dtype)
.to(model.device),
)
for _ in range(num_block_layers)
)
else:
past_key_values = tuple(
(
torch.empty(batch_size, num_attention_heads, seq_len, num_embedding_size_per_head)
.to(model.dtype)
.to(model.device),
torch.empty(batch_size, num_attention_heads, seq_len, num_embedding_size_per_head)
.to(model.dtype)
.to(model.device),
)
for _ in range(num_block_layers)
)
return past_key_values
def prepare_jit_inputs(inputs, model, tokenizer):
batch_size = len(inputs)
dummy_input = tokenizer.batch_encode_plus(inputs, return_tensors="pt")
dummy_input = dummy_input.to(model.device)
if model.config.use_cache:
dummy_input["past_key_values"] = generate_past_key_values(model, batch_size, 1)
dummy_input["attention_mask"] = torch.cat(
[
torch.zeros(dummy_input["attention_mask"].shape[0], 1)
.to(dummy_input["attention_mask"].dtype)
.to(model.device),
dummy_input["attention_mask"],
],
-1,
)
return dummy_input
class _ModelFallbackWrapper(GenerationMixin):
__slots__ = ("_optimized", "_default")
def __init__(self, optimized, default):
self._optimized = optimized
self._default = default
def __call__(self, *args, **kwargs):
if kwargs["past_key_values"] is None and self._default.config.use_cache:
kwargs["past_key_values"] = generate_past_key_values(self._default, kwargs["input_ids"].shape[0], 0)
kwargs.pop("position_ids", None)
for k in list(kwargs.keys()):
if kwargs[k] is None or isinstance(kwargs[k], bool):
kwargs.pop(k)
outputs = self._optimized(**kwargs)
lm_logits = outputs[0]
past_key_values = outputs[1]
fixed_output = CausalLMOutputWithPast(
loss=None,
logits=lm_logits,
past_key_values=past_key_values,
hidden_states=None,
attentions=None,
)
return fixed_output
def __getattr__(self, item):
return getattr(self._default, item)
def prepare_inputs_for_generation(
self, input_ids, past_key_values=None, inputs_embeds=None, use_cache=None, **kwargs
):
return self._default.prepare_inputs_for_generation(
input_ids, past_key_values=past_key_values, inputs_embeds=inputs_embeds, use_cache=use_cache, **kwargs
)
def _reorder_cache(
self, past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
) -> Tuple[Tuple[torch.Tensor]]:
"""
This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
[`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
beam_idx at every generation step.
"""
return self._default._reorder_cache(past_key_values, beam_idx)
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_type",
default=None,
type=str,
required=True,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument("--prompt", type=str, default="")
parser.add_argument("--length", type=int, default=20)
parser.add_argument("--stop_token", type=str, default=None, help="Token at which text generation is stopped")
parser.add_argument(
"--temperature",
type=float,
default=1.0,
help="temperature of 1.0 has no effect, lower tend toward greedy sampling",
)
parser.add_argument(
"--repetition_penalty", type=float, default=1.0, help="primarily useful for CTRL model; in that case, use 1.2"
)
parser.add_argument("--k", type=int, default=0)
parser.add_argument("--p", type=float, default=0.9)
parser.add_argument("--prefix", type=str, default="", help="Text added prior to input.")
parser.add_argument("--padding_text", type=str, default="", help="Deprecated, the use of `--prefix` is preferred.")
parser.add_argument("--xlm_language", type=str, default="", help="Optional language when used with the XLM model.")
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument(
"--use_cpu",
action="store_true",
help="Whether or not to use cpu. If set to False, " "we will use gpu/npu or mps device if available",
)
parser.add_argument("--num_return_sequences", type=int, default=1, help="The number of samples to generate.")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument("--jit", action="store_true", help="Whether or not to use jit trace to accelerate inference")
args = parser.parse_args()
# Initialize the distributed state.
distributed_state = PartialState(cpu=args.use_cpu)
logger.warning(f"device: {distributed_state.device}, 16-bits inference: {args.fp16}")
if args.seed is not None:
set_seed(args.seed)
# Initialize the model and tokenizer
try:
args.model_type = args.model_type.lower()
model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
except KeyError:
raise KeyError("the model {} you specified is not supported. You are welcome to add it and open a PR :)")
tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model = model_class.from_pretrained(args.model_name_or_path)
# Set the model to the right device
model.to(distributed_state.device)
if args.fp16:
model.half()
max_seq_length = getattr(model.config, "max_position_embeddings", 0)
args.length = adjust_length_to_model(args.length, max_sequence_length=max_seq_length)
logger.info(args)
prompt_text = args.prompt if args.prompt else input("Model prompt >>> ")
# Different models need different input formatting and/or extra arguments
requires_preprocessing = args.model_type in PREPROCESSING_FUNCTIONS.keys()
if requires_preprocessing:
prepare_input = PREPROCESSING_FUNCTIONS.get(args.model_type)
preprocessed_prompt_text = prepare_input(args, model, tokenizer, prompt_text)
if model.__class__.__name__ in ["TransfoXLLMHeadModel"]:
tokenizer_kwargs = {"add_space_before_punct_symbol": True}
else:
tokenizer_kwargs = {}
encoded_prompt = tokenizer.encode(
preprocessed_prompt_text, add_special_tokens=False, return_tensors="pt", **tokenizer_kwargs
)
else:
prefix = args.prefix if args.prefix else args.padding_text
encoded_prompt = tokenizer.encode(prefix + prompt_text, add_special_tokens=False, return_tensors="pt")
encoded_prompt = encoded_prompt.to(distributed_state.device)
if encoded_prompt.size()[-1] == 0:
input_ids = None
else:
input_ids = encoded_prompt
if args.jit:
jit_input_texts = ["enable jit"]
jit_inputs = prepare_jit_inputs(jit_input_texts, model, tokenizer)
torch._C._jit_set_texpr_fuser_enabled(False)
model.config.return_dict = False
if hasattr(model, "forward"):
sig = inspect.signature(model.forward)
else:
sig = inspect.signature(model.__call__)
jit_inputs = tuple(jit_inputs[key] for key in sig.parameters if jit_inputs.get(key, None) is not None)
traced_model = torch.jit.trace(model, jit_inputs, strict=False)
traced_model = torch.jit.freeze(traced_model.eval())
traced_model(*jit_inputs)
traced_model(*jit_inputs)
model = _ModelFallbackWrapper(traced_model, model)
output_sequences = model.generate(
input_ids=input_ids,
max_length=args.length + len(encoded_prompt[0]),
temperature=args.temperature,
top_k=args.k,
top_p=args.p,
repetition_penalty=args.repetition_penalty,
do_sample=True,
num_return_sequences=args.num_return_sequences,
)
# Remove the batch dimension when returning multiple sequences
if len(output_sequences.shape) > 2:
output_sequences.squeeze_()
generated_sequences = []
for generated_sequence_idx, generated_sequence in enumerate(output_sequences):
print(f"=== GENERATED SEQUENCE {generated_sequence_idx + 1} ===")
generated_sequence = generated_sequence.tolist()
# Decode text
text = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True)
# Remove all text after the stop token
text = text[: text.find(args.stop_token) if args.stop_token else None]
# Add the prompt at the beginning of the sequence. Remove the excess text that was used for pre-processing
total_sequence = (
prompt_text + text[len(tokenizer.decode(encoded_prompt[0], clean_up_tokenization_spaces=True)) :]
)
generated_sequences.append(total_sequence)
print(total_sequence)
return generated_sequences
if __name__ == "__main__":
main()
|
transformers/examples/pytorch/text-generation/run_generation.py/0
|
{
"file_path": "transformers/examples/pytorch/text-generation/run_generation.py",
"repo_id": "transformers",
"token_count": 6876
}
| 70 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Finetuning the library models for sequence classification on HANS."""
import logging
import os
from dataclasses import dataclass, field
from typing import Dict, List, Optional
import numpy as np
import torch
from utils_hans import HansDataset, InputFeatures, hans_processors, hans_tasks_num_labels
import transformers
from transformers import (
AutoConfig,
AutoModelForSequenceClassification,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
default_data_collator,
set_seed,
)
from transformers.trainer_utils import is_main_process
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
task_name: str = field(
metadata={"help": "The name of the task to train selected in the list: " + ", ".join(hans_processors.keys())}
)
data_dir: str = field(
metadata={"help": "The input data dir. Should contain the .tsv files (or other data files) for the task."}
)
max_seq_length: int = field(
default=128,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
def hans_data_collator(features: List[InputFeatures]) -> Dict[str, torch.Tensor]:
"""
Data collator that removes the "pairID" key if present.
"""
batch = default_data_collator(features)
_ = batch.pop("pairID", None)
return batch
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
" --overwrite_output_dir to overcome."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
training_args.local_rank,
training_args.device,
training_args.n_gpu,
bool(training_args.local_rank != -1),
training_args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
logger.info("Training/evaluation parameters %s", training_args)
# Set seed
set_seed(training_args.seed)
try:
num_labels = hans_tasks_num_labels[data_args.task_name]
except KeyError:
raise ValueError("Task not found: %s" % (data_args.task_name))
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
)
model = AutoModelForSequenceClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
# Get datasets
train_dataset = (
HansDataset(
data_dir=data_args.data_dir,
tokenizer=tokenizer,
task=data_args.task_name,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
)
if training_args.do_train
else None
)
eval_dataset = (
HansDataset(
data_dir=data_args.data_dir,
tokenizer=tokenizer,
task=data_args.task_name,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
evaluate=True,
)
if training_args.do_eval
else None
)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=hans_data_collator,
)
# Training
if training_args.do_train:
trainer.train(
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
)
trainer.save_model()
# For convenience, we also re-save the tokenizer to the same directory,
# so that you can share your model easily on huggingface.co/models =)
if trainer.is_world_master():
tokenizer.save_pretrained(training_args.output_dir)
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
output = trainer.predict(eval_dataset)
preds = output.predictions
preds = np.argmax(preds, axis=1)
pair_ids = [ex.pairID for ex in eval_dataset]
output_eval_file = os.path.join(training_args.output_dir, "hans_predictions.txt")
label_list = eval_dataset.get_labels()
if trainer.is_world_master():
with open(output_eval_file, "w") as writer:
writer.write("pairID,gold_label\n")
for pid, pred in zip(pair_ids, preds):
writer.write("ex" + str(pid) + "," + label_list[int(pred)] + "\n")
trainer._log(output.metrics)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
|
transformers/examples/research_projects/adversarial/run_hans.py/0
|
{
"file_path": "transformers/examples/research_projects/adversarial/run_hans.py",
"repo_id": "transformers",
"token_count": 3302
}
| 71 |
# coding=utf-8
# Copyright 2019 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
import torch
from .utils_summarization import build_mask, compute_token_type_ids, process_story, truncate_or_pad
class SummarizationDataProcessingTest(unittest.TestCase):
def setUp(self):
self.block_size = 10
def test_fit_to_block_sequence_too_small(self):
"""Pad the sequence with 0 if the sequence is smaller than the block size."""
sequence = [1, 2, 3, 4]
expected_output = [1, 2, 3, 4, 0, 0, 0, 0, 0, 0]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_fit_to_block_sequence_fit_exactly(self):
"""Do nothing if the sequence is the right size."""
sequence = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
expected_output = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_fit_to_block_sequence_too_big(self):
"""Truncate the sequence if it is too long."""
sequence = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
expected_output = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
self.assertEqual(truncate_or_pad(sequence, self.block_size, 0), expected_output)
def test_process_story_no_highlights(self):
"""Processing a story with no highlights returns an empty list for the summary."""
raw_story = """It was the year of Our Lord one thousand seven hundred and
seventy-five.\n\nSpiritual revelations were conceded to England at that
favoured period, as at this."""
_, summary_lines = process_story(raw_story)
self.assertEqual(summary_lines, [])
def test_process_empty_story(self):
"""An empty story returns an empty collection of lines."""
raw_story = ""
story_lines, summary_lines = process_story(raw_story)
self.assertEqual(story_lines, [])
self.assertEqual(summary_lines, [])
def test_process_story_with_missing_period(self):
raw_story = (
"It was the year of Our Lord one thousand seven hundred and "
"seventy-five\n\nSpiritual revelations were conceded to England "
"at that favoured period, as at this.\n@highlight\n\nIt was the best of times"
)
story_lines, summary_lines = process_story(raw_story)
expected_story_lines = [
"It was the year of Our Lord one thousand seven hundred and seventy-five.",
"Spiritual revelations were conceded to England at that favoured period, as at this.",
]
self.assertEqual(expected_story_lines, story_lines)
expected_summary_lines = ["It was the best of times."]
self.assertEqual(expected_summary_lines, summary_lines)
def test_build_mask_no_padding(self):
sequence = torch.tensor([1, 2, 3, 4])
expected = torch.tensor([1, 1, 1, 1])
np.testing.assert_array_equal(build_mask(sequence, 0).numpy(), expected.numpy())
def test_build_mask(self):
sequence = torch.tensor([1, 2, 3, 4, 23, 23, 23])
expected = torch.tensor([1, 1, 1, 1, 0, 0, 0])
np.testing.assert_array_equal(build_mask(sequence, 23).numpy(), expected.numpy())
def test_build_mask_with_padding_equal_to_one(self):
sequence = torch.tensor([8, 2, 3, 4, 1, 1, 1])
expected = torch.tensor([1, 1, 1, 1, 0, 0, 0])
np.testing.assert_array_equal(build_mask(sequence, 1).numpy(), expected.numpy())
def test_compute_token_type_ids(self):
separator = 101
batch = torch.tensor([[1, 2, 3, 4, 5, 6], [1, 2, 3, 101, 5, 6], [1, 101, 3, 4, 101, 6]])
expected = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 1, 1, 0, 0, 0], [1, 0, 0, 0, 1, 1]])
result = compute_token_type_ids(batch, separator)
np.testing.assert_array_equal(result, expected)
|
transformers/examples/research_projects/bertabs/test_utils_summarization.py/0
|
{
"file_path": "transformers/examples/research_projects/bertabs/test_utils_summarization.py",
"repo_id": "transformers",
"token_count": 1749
}
| 72 |
import gzip
import json
import multiprocessing
import os
import re
import shutil
import time
from pathlib import Path
import numpy as np
from arguments import PreprocessingArguments
from datasets import load_dataset
from huggingface_hub.utils import insecure_hashlib
from minhash_deduplication import deduplicate_dataset
from transformers import AutoTokenizer, HfArgumentParser
PATTERN = re.compile(r"\s+")
def get_hash(example):
"""Get hash of content field."""
return {"hash": insecure_hashlib.md5(re.sub(PATTERN, "", example["content"]).encode("utf-8")).hexdigest()}
def line_stats(example):
"""Calculates mean and max line length of file."""
line_lengths = [len(line) for line in example["content"].splitlines()]
return {"line_mean": np.mean(line_lengths), "line_max": max(line_lengths)}
def alpha_stats(example):
"""Calculates mean and max line length of file."""
alpha_frac = np.mean([c.isalnum() for c in example["content"]])
return {"alpha_frac": alpha_frac}
def check_uniques(example, uniques):
"""Check if current hash is still in set of unique hashes and remove if true."""
if example["hash"] in uniques:
uniques.remove(example["hash"])
return True
else:
return False
def is_autogenerated(example, scan_width=5):
"""Check if file is autogenerated by looking for keywords in the first few lines of the file."""
keywords = ["auto-generated", "autogenerated", "automatically generated"]
lines = example["content"].splitlines()
for _, line in zip(range(scan_width), lines):
for keyword in keywords:
if keyword in line.lower():
return {"autogenerated": True}
else:
return {"autogenerated": False}
def is_config_or_test(example, scan_width=5, coeff=0.05):
"""Check if file is a configuration file or a unit test by :
1- looking for keywords in the first few lines of the file.
2- counting number of occurrence of the words 'config' and 'test' with respect to number of lines.
"""
keywords = ["unit tests", "test file", "configuration file"]
lines = example["content"].splitlines()
count_config = 0
count_test = 0
# first test
for _, line in zip(range(scan_width), lines):
for keyword in keywords:
if keyword in line.lower():
return {"config_or_test": True}
# second test
nlines = example["content"].count("\n")
threshold = int(coeff * nlines)
for line in lines:
count_config += line.lower().count("config")
count_test += line.lower().count("test")
if count_config > threshold or count_test > threshold:
return {"config_or_test": True}
return {"config_or_test": False}
def has_no_keywords(example):
"""Check if a python file has none of the keywords for: funcion, class, for loop, while loop."""
keywords = ["def ", "class ", "for ", "while "]
lines = example["content"].splitlines()
for line in lines:
for keyword in keywords:
if keyword in line.lower():
return {"has_no_keywords": False}
return {"has_no_keywords": True}
def has_few_assignments(example, minimum=4):
"""Check if file uses symbol '=' less than `minimum` times."""
lines = example["content"].splitlines()
counter = 0
for line in lines:
counter += line.lower().count("=")
if counter > minimum:
return {"has_few_assignments": False}
return {"has_few_assignments": True}
def char_token_ratio(example):
"""Compute character/token ratio of the file with tokenizer."""
input_ids = tokenizer(example["content"], truncation=False)["input_ids"]
ratio = len(example["content"]) / len(input_ids)
return {"ratio": ratio}
def preprocess(example):
"""Chain all preprocessing steps into one function to not fill cache."""
results = {}
results.update(get_hash(example))
results.update(line_stats(example))
results.update(alpha_stats(example))
results.update(char_token_ratio(example))
results.update(is_autogenerated(example))
results.update(is_config_or_test(example))
results.update(has_no_keywords(example))
results.update(has_few_assignments(example))
return results
def filter(example, uniques, args):
"""Filter dataset with heuristics. Config, test and has_no_keywords files are removed with a given probability."""
if not check_uniques(example, uniques):
return False
elif example["autogenerated"]:
return False
elif example["line_max"] > args.line_max:
return False
elif example["line_mean"] > args.line_mean:
return False
elif example["alpha_frac"] < args.alpha_frac:
return False
elif example["ratio"] < args.min_token_ratio:
return False
elif example["config_or_test"] and np.random.rand() <= args.filter_proba:
return False
elif example["has_no_keywords"] and np.random.rand() <= args.filter_proba:
return False
elif example["has_few_assignments"]:
return False
else:
return True
def compress_file(file_path):
"""Compress a file with g-zip."""
with open(file_path, "rb") as f_in:
with gzip.open(str(file_path) + ".gz", "wb", compresslevel=6) as f_out:
shutil.copyfileobj(f_in, f_out)
os.unlink(file_path)
# Settings
parser = HfArgumentParser(PreprocessingArguments)
args = parser.parse_args()
if args.num_workers is None:
args.num_workers = multiprocessing.cpu_count()
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_dir)
# Load dataset
t_start = time.time()
ds = load_dataset(args.dataset_name, split="train")
print(f"Time to load dataset: {time.time()-t_start:.2f}")
# Run preprocessing
t_start = time.time()
ds = ds.map(preprocess, num_proc=args.num_workers)
print(f"Time to preprocess dataset: {time.time()-t_start:.2f}")
# Deduplicate hashes
uniques = set(ds.unique("hash"))
frac = len(uniques) / len(ds)
print(f"Fraction of duplicates: {1-frac:.2%}")
# Deduplicate data and apply heuristics
t_start = time.time()
ds_filter = ds.filter(filter, fn_kwargs={"uniques": uniques, "args": args})
print(f"Time to filter dataset: {time.time()-t_start:.2f}")
print(f"Size of filtered dataset: {len(ds_filter)}")
# Deduplicate with minhash and jaccard similarity
if args.near_deduplication:
t_start = time.time()
ds_filter, duplicate_clusters = deduplicate_dataset(ds_filter, args.jaccard_threshold)
print(f"Time to deduplicate dataset: {time.time()-t_start:.2f}")
print(f"Size of deduplicate dataset: {len(ds_filter)}")
# Save data in batches of samples_per_file
output_dir = Path(args.output_dir)
output_dir.mkdir(exist_ok=True)
# save duplicate_clusters in the output_dir as artifacts
# not sure it is the right place the save it
if args.near_deduplication:
with open(output_dir / "duplicate_clusters.json", "w") as f:
json.dump(duplicate_clusters, f)
data_dir = output_dir / "data"
data_dir.mkdir(exist_ok=True)
t_start = time.time()
for file_number, index in enumerate(range(0, len(ds_filter), args.samples_per_file)):
file_path = str(data_dir / f"file-{file_number+1:012}.json")
end_index = min(len(ds_filter), index + args.samples_per_file)
ds_filter.select(list(range(index, end_index))).to_json(file_path)
compress_file(file_path)
print(f"Time to save dataset: {time.time()-t_start:.2f}")
|
transformers/examples/research_projects/codeparrot/scripts/preprocessing.py/0
|
{
"file_path": "transformers/examples/research_projects/codeparrot/scripts/preprocessing.py",
"repo_id": "transformers",
"token_count": 2776
}
| 73 |
#!/bin/bash
export CUDA_VISIBLE_DEVICES=0
PATH_TO_DATA=/h/xinji/projects/GLUE
MODEL_TYPE=bert # bert or roberta
MODEL_SIZE=base # base or large
DATASET=MRPC # SST-2, MRPC, RTE, QNLI, QQP, or MNLI
MODEL_NAME=${MODEL_TYPE}-${MODEL_SIZE}
EPOCHS=10
if [ $MODEL_TYPE = 'bert' ]
then
EPOCHS=3
MODEL_NAME=${MODEL_NAME}-uncased
fi
python -u run_glue_deebert.py \
--model_type $MODEL_TYPE \
--model_name_or_path $MODEL_NAME \
--task_name $DATASET \
--do_train \
--do_eval \
--do_lower_case \
--data_dir $PATH_TO_DATA/$DATASET \
--max_seq_length 128 \
--per_gpu_eval_batch_size=1 \
--per_gpu_train_batch_size=8 \
--learning_rate 2e-5 \
--num_train_epochs $EPOCHS \
--overwrite_output_dir \
--seed 42 \
--output_dir ./saved_models/${MODEL_TYPE}-${MODEL_SIZE}/$DATASET/two_stage \
--plot_data_dir ./results/ \
--save_steps 0 \
--overwrite_cache \
--eval_after_first_stage
|
transformers/examples/research_projects/deebert/train_deebert.sh/0
|
{
"file_path": "transformers/examples/research_projects/deebert/train_deebert.sh",
"repo_id": "transformers",
"token_count": 417
}
| 74 |
{
"vocab_size": 50265,
"hidden_size": 768,
"num_hidden_layers": 6,
"num_attention_heads": 12,
"intermediate_size": 3072,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 514,
"type_vocab_size": 1,
"initializer_range": 0.02,
"layer_norm_eps": 0.00001
}
|
transformers/examples/research_projects/distillation/training_configs/distilroberta-base.json/0
|
{
"file_path": "transformers/examples/research_projects/distillation/training_configs/distilroberta-base.json",
"repo_id": "transformers",
"token_count": 178
}
| 75 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The Google Research Authors and The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Utilities for constructing PyTrees of PartitionSpecs."""
# utils adapted from https://github.com/google-research/google-research/blob/master/flax_models/t5x/partitions.py
import re
from flax.core.frozen_dict import freeze
from flax.traverse_util import flatten_dict, unflatten_dict
from jax.experimental import PartitionSpec as P
# Sentinels
_unmatched = object()
# For specifying empty leaf dict `{}`
empty_dict = object()
def _match(qs, ks):
"""Return True if regexes in qs match any window of strings in tuple ks."""
# compile regexes and force complete match
qts = tuple((re.compile(x + "$") for x in qs))
for i in range(len(ks) - len(qs) + 1):
matches = [x.match(y) for x, y in zip(qts, ks[i:])]
if matches and all(matches):
return True
return False
def _replacement_rules(rules):
def replace(key, val):
for rule, replacement in rules:
if _match(rule, key):
return replacement
return val
return replace
# PartitionSpec for GPTNeo
# replicate the hidden dim and shard feed-forward and head dim
def _get_partition_rules():
return [
# embeddings
(("transformer", "wpe", "embedding"), P("mp", None)),
(("transformer", "wte", "embedding"), P("mp", None)),
# atention
(("attention", "(q_proj|k_proj|v_proj)", "kernel"), P(None, "mp")),
(("attention", "out_proj", "kernel"), P("mp", None)),
(("attention", "out_proj", "bias"), None),
# mlp
(("mlp", "c_fc", "kernel"), P(None, "mp")),
(("mlp", "c_fc", "bias"), P("mp")),
(("mlp", "c_proj", "kernel"), P("mp", None)),
(("mlp", "c_proj", "bias"), None),
# layer norms
((r"ln_\d+", "bias"), None),
((r"\d+", r"ln_\d+", "scale"), None),
(("ln_f", "bias"), None),
(("ln_f", "scale"), None),
]
def set_partitions(in_dict):
rules = _get_partition_rules()
replace = _replacement_rules(rules)
initd = {k: _unmatched for k in flatten_dict(in_dict)}
result = {k: replace(k, v) for k, v in initd.items()}
assert _unmatched not in result.values(), "Incomplete partition spec."
return freeze(unflatten_dict(result))
|
transformers/examples/research_projects/jax-projects/model_parallel/partitions.py/0
|
{
"file_path": "transformers/examples/research_projects/jax-projects/model_parallel/partitions.py",
"repo_id": "transformers",
"token_count": 1130
}
| 76 |
import getopt
import json
import os
# import numpy as np
import sys
from collections import OrderedDict
import datasets
import numpy as np
import torch
from modeling_frcnn import GeneralizedRCNN
from processing_image import Preprocess
from utils import Config
"""
USAGE:
``python extracting_data.py -i <img_dir> -o <dataset_file>.datasets <batch_size>``
"""
TEST = False
CONFIG = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
DEFAULT_SCHEMA = datasets.Features(
OrderedDict(
{
"attr_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"attr_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"boxes": datasets.Array2D((CONFIG.MAX_DETECTIONS, 4), dtype="float32"),
"img_id": datasets.Value("int32"),
"obj_ids": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"obj_probs": datasets.Sequence(length=CONFIG.MAX_DETECTIONS, feature=datasets.Value("float32")),
"roi_features": datasets.Array2D((CONFIG.MAX_DETECTIONS, 2048), dtype="float32"),
"sizes": datasets.Sequence(length=2, feature=datasets.Value("float32")),
"preds_per_image": datasets.Value(dtype="int32"),
}
)
)
class Extract:
def __init__(self, argv=sys.argv[1:]):
inputdir = None
outputfile = None
subset_list = None
batch_size = 1
opts, args = getopt.getopt(argv, "i:o:b:s", ["inputdir=", "outfile=", "batch_size=", "subset_list="])
for opt, arg in opts:
if opt in ("-i", "--inputdir"):
inputdir = arg
elif opt in ("-o", "--outfile"):
outputfile = arg
elif opt in ("-b", "--batch_size"):
batch_size = int(arg)
elif opt in ("-s", "--subset_list"):
subset_list = arg
assert inputdir is not None # and os.path.isdir(inputdir), f"{inputdir}"
assert outputfile is not None and not os.path.isfile(outputfile), f"{outputfile}"
if subset_list is not None:
with open(os.path.realpath(subset_list)) as f:
self.subset_list = {self._vqa_file_split()[0] for x in tryload(f)}
else:
self.subset_list = None
self.config = CONFIG
if torch.cuda.is_available():
self.config.model.device = "cuda"
self.inputdir = os.path.realpath(inputdir)
self.outputfile = os.path.realpath(outputfile)
self.preprocess = Preprocess(self.config)
self.model = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=self.config)
self.batch = batch_size if batch_size != 0 else 1
self.schema = DEFAULT_SCHEMA
def _vqa_file_split(self, file):
img_id = int(file.split(".")[0].split("_")[-1])
filepath = os.path.join(self.inputdir, file)
return (img_id, filepath)
@property
def file_generator(self):
batch = []
for i, file in enumerate(os.listdir(self.inputdir)):
if self.subset_list is not None and i not in self.subset_list:
continue
batch.append(self._vqa_file_split(file))
if len(batch) == self.batch:
temp = batch
batch = []
yield list(map(list, zip(*temp)))
for i in range(1):
yield list(map(list, zip(*batch)))
def __call__(self):
# make writer
if not TEST:
writer = datasets.ArrowWriter(features=self.schema, path=self.outputfile)
# do file generator
for i, (img_ids, filepaths) in enumerate(self.file_generator):
images, sizes, scales_yx = self.preprocess(filepaths)
output_dict = self.model(
images,
sizes,
scales_yx=scales_yx,
padding="max_detections",
max_detections=self.config.MAX_DETECTIONS,
pad_value=0,
return_tensors="np",
location="cpu",
)
output_dict["boxes"] = output_dict.pop("normalized_boxes")
if not TEST:
output_dict["img_id"] = np.array(img_ids)
batch = self.schema.encode_batch(output_dict)
writer.write_batch(batch)
if TEST:
break
# finalizer the writer
if not TEST:
num_examples, num_bytes = writer.finalize()
print(f"Success! You wrote {num_examples} entry(s) and {num_bytes >> 20} mb")
def tryload(stream):
try:
data = json.load(stream)
try:
data = list(data.keys())
except Exception:
data = [d["img_id"] for d in data]
except Exception:
try:
data = eval(stream.read())
except Exception:
data = stream.read().split("\n")
return data
if __name__ == "__main__":
extract = Extract(sys.argv[1:])
extract()
if not TEST:
dataset = datasets.Dataset.from_file(extract.outputfile)
# wala!
# print(np.array(dataset[0:2]["roi_features"]).shape)
|
transformers/examples/research_projects/lxmert/extracting_data.py/0
|
{
"file_path": "transformers/examples/research_projects/lxmert/extracting_data.py",
"repo_id": "transformers",
"token_count": 2528
}
| 77 |
# Copyright 2020-present, the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Count remaining (non-zero) weights in the encoder (i.e. the transformer layers).
Sparsity and remaining weights levels are equivalent: sparsity % = 100 - remaining weights %.
"""
import argparse
import os
import torch
from emmental.modules import ThresholdBinarizer, TopKBinarizer
def main(args):
serialization_dir = args.serialization_dir
pruning_method = args.pruning_method
threshold = args.threshold
st = torch.load(os.path.join(serialization_dir, "pytorch_model.bin"), map_location="cpu")
remaining_count = 0 # Number of remaining (not pruned) params in the encoder
encoder_count = 0 # Number of params in the encoder
print("name".ljust(60, " "), "Remaining Weights %", "Remaining Weight")
for name, param in st.items():
if "encoder" not in name:
continue
if "mask_scores" in name:
if pruning_method == "topK":
mask_ones = TopKBinarizer.apply(param, threshold).sum().item()
elif pruning_method == "sigmoied_threshold":
mask_ones = ThresholdBinarizer.apply(param, threshold, True).sum().item()
elif pruning_method == "l0":
l, r = -0.1, 1.1
s = torch.sigmoid(param)
s_bar = s * (r - l) + l
mask = s_bar.clamp(min=0.0, max=1.0)
mask_ones = (mask > 0.0).sum().item()
else:
raise ValueError("Unknown pruning method")
remaining_count += mask_ones
print(name.ljust(60, " "), str(round(100 * mask_ones / param.numel(), 3)).ljust(20, " "), str(mask_ones))
else:
encoder_count += param.numel()
if "bias" in name or "LayerNorm" in name:
remaining_count += param.numel()
print("")
print("Remaining Weights (global) %: ", 100 * remaining_count / encoder_count)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--pruning_method",
choices=["l0", "topK", "sigmoied_threshold"],
type=str,
required=True,
help=(
"Pruning Method (l0 = L0 regularization, topK = Movement pruning, sigmoied_threshold = Soft movement"
" pruning)"
),
)
parser.add_argument(
"--threshold",
type=float,
required=False,
help=(
"For `topK`, it is the level of remaining weights (in %) in the fine-pruned model. "
"For `sigmoied_threshold`, it is the threshold \tau against which the (sigmoied) scores are compared. "
"Not needed for `l0`"
),
)
parser.add_argument(
"--serialization_dir",
type=str,
required=True,
help="Folder containing the model that was previously fine-pruned",
)
args = parser.parse_args()
main(args)
|
transformers/examples/research_projects/movement-pruning/counts_parameters.py/0
|
{
"file_path": "transformers/examples/research_projects/movement-pruning/counts_parameters.py",
"repo_id": "transformers",
"token_count": 1429
}
| 78 |
# coding=utf-8
# Copyright 2021 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Helper functions for training models with pytorch-quantization"""
import logging
import re
import pytorch_quantization
import pytorch_quantization.nn as quant_nn
import torch
from pytorch_quantization import calib
from pytorch_quantization.tensor_quant import QuantDescriptor
logger = logging.getLogger(__name__)
name_width = 50 # max width of layer names
qname_width = 70 # max width of quantizer names
# ========================================== Quant Trainer API ==========================================
def add_arguments(parser):
"""Add arguments to parser for functions defined in quant_trainer."""
group = parser.add_argument_group("quant_trainer arguments")
group.add_argument("--wprec", type=int, default=8, help="weight precision")
group.add_argument("--aprec", type=int, default=8, help="activation precision")
group.add_argument("--quant-per-tensor", action="store_true", help="per tensor weight scaling")
group.add_argument("--quant-disable", action="store_true", help="disable all quantizers")
group.add_argument("--quant-disable-embeddings", action="store_true", help="disable all embeddings quantizers")
group.add_argument("--quant-disable-keyword", type=str, nargs="+", help="disable quantizers by keyword")
group.add_argument("--quant-disable-layer-module", type=str, help="disable quantizers by keyword under layer.")
group.add_argument("--quant-enable-layer-module", type=str, help="enable quantizers by keyword under layer")
group.add_argument("--calibrator", default="max", help="which quantization range calibrator to use")
group.add_argument("--percentile", default=None, type=float, help="percentile for PercentileCalibrator")
group.add_argument("--fuse-qkv", action="store_true", help="use the same scale factor for qkv")
group.add_argument("--clip-gelu", metavar="N", type=float, help="clip gelu output maximum value to N")
group.add_argument(
"--recalibrate-weights",
action="store_true",
help=(
"recalibrate weight amaxes by taking the max of the weights."
" amaxes will be computed with the current quantization granularity (axis)."
),
)
def set_default_quantizers(args):
"""Set default quantizers before creating the model."""
if args.calibrator == "max":
calib_method = "max"
elif args.calibrator == "percentile":
if args.percentile is None:
raise ValueError("Specify --percentile when using percentile calibrator")
calib_method = "histogram"
elif args.calibrator == "mse":
calib_method = "histogram"
else:
raise ValueError(f"Invalid calibrator {args.calibrator}")
input_desc = QuantDescriptor(num_bits=args.aprec, calib_method=calib_method)
weight_desc = QuantDescriptor(num_bits=args.wprec, axis=(None if args.quant_per_tensor else (0,)))
quant_nn.QuantLinear.set_default_quant_desc_input(input_desc)
quant_nn.QuantLinear.set_default_quant_desc_weight(weight_desc)
def configure_model(model, args, calib=False, eval=False):
"""Function called before the training loop."""
logger.info("Configuring Model for Quantization")
logger.info(f"using quantization package {pytorch_quantization.__file__}")
if not calib:
if args.quant_disable_embeddings:
set_quantizer_by_name(model, ["embeddings"], which="weight", _disabled=True)
if args.quant_disable:
set_quantizer_by_name(model, [""], _disabled=True)
if args.quant_disable_keyword:
set_quantizer_by_name(model, args.quant_disable_keyword, _disabled=True)
if args.quant_disable_layer_module:
set_quantizer_by_name(model, [r"layer.\d+." + args.quant_disable_layer_module], _disabled=True)
if args.quant_enable_layer_module:
set_quantizer_by_name(model, [r"layer.\d+." + args.quant_enable_layer_module], _disabled=False)
if args.recalibrate_weights:
recalibrate_weights(model)
if args.fuse_qkv:
fuse_qkv(model, args)
if args.clip_gelu:
clip_gelu(model, args.clip_gelu)
# if args.local_rank in [-1, 0] and not calib:
print_quant_summary(model)
def enable_calibration(model):
"""Enable calibration of all *_input_quantizer modules in model."""
logger.info("Enabling Calibration")
for name, module in model.named_modules():
if name.endswith("_quantizer"):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
logger.info(f"{name:80}: {module}")
def finish_calibration(model, args):
"""Disable calibration and load amax for all "*_input_quantizer modules in model."""
logger.info("Loading calibrated amax")
for name, module in model.named_modules():
if name.endswith("_quantizer"):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax("percentile", percentile=args.percentile)
module.enable_quant()
module.disable_calib()
else:
module.enable()
model.cuda()
print_quant_summary(model)
# ========================================== Helper Function ==========================================
def fuse_qkv(model, args):
"""Adjust quantization ranges to match an implementation where the QKV projections are implemented with a single GEMM.
Force the weight and output scale factors to match by taking the max of (Q,K,V).
"""
def fuse3(qq, qk, qv):
for mod in [qq, qk, qv]:
if not hasattr(mod, "_amax"):
print(" WARNING: NO AMAX BUFFER")
return
q = qq._amax.detach().item()
k = qk._amax.detach().item()
v = qv._amax.detach().item()
amax = max(q, k, v)
qq._amax.fill_(amax)
qk._amax.fill_(amax)
qv._amax.fill_(amax)
logger.info(f" q={q:5.2f} k={k:5.2f} v={v:5.2f} -> {amax:5.2f}")
for name, mod in model.named_modules():
if name.endswith(".attention.self"):
logger.info(f"FUSE_QKV: {name:{name_width}}")
fuse3(mod.matmul_q_input_quantizer, mod.matmul_k_input_quantizer, mod.matmul_v_input_quantizer)
if args.quant_per_tensor:
fuse3(mod.query._weight_quantizer, mod.key._weight_quantizer, mod.value._weight_quantizer)
def clip_gelu(model, maxval):
"""Clip activations generated by GELU to maxval when quantized.
Implemented by adjusting the amax of the following input_quantizer.
"""
for name, mod in model.named_modules():
if name.endswith(".output.dense") and not name.endswith("attention.output.dense"):
amax_init = mod._input_quantizer._amax.data.detach().item()
mod._input_quantizer._amax.data.detach().clamp_(max=maxval)
amax = mod._input_quantizer._amax.data.detach().item()
logger.info(f"CLIP_GELU: {name:{name_width}} amax: {amax_init:5.2f} -> {amax:5.2f}")
def expand_amax(model):
"""Expand per-tensor amax to be per channel, where each channel is assigned the per-tensor amax."""
for name, mod in model.named_modules():
if hasattr(mod, "_weight_quantizer") and mod._weight_quantizer.axis is not None:
k = mod.weight.shape[0]
amax = mod._weight_quantizer._amax.detach()
mod._weight_quantizer._amax = torch.ones(k, dtype=amax.dtype, device=amax.device) * amax
print(f"expanding {name} {amax} -> {mod._weight_quantizer._amax}")
def recalibrate_weights(model):
"""Performs max calibration on the weights and updates amax."""
for name, mod in model.named_modules():
if hasattr(mod, "_weight_quantizer"):
if not hasattr(mod.weight_quantizer, "_amax"):
print("RECALIB: {name:{name_width}} WARNING: NO AMAX BUFFER")
continue
# determine which axes to reduce across
# e.g. a 4D tensor quantized per axis 0 should reduce over (1,2,3)
axis_set = set() if mod._weight_quantizer.axis is None else set(mod._weight_quantizer.axis)
reduce_axis = set(range(len(mod.weight.size()))) - axis_set
amax = pytorch_quantization.utils.reduce_amax(mod.weight, axis=reduce_axis, keepdims=True).detach()
logger.info(f"RECALIB: {name:{name_width}} {mod._weight_quantizer._amax.flatten()} -> {amax.flatten()}")
mod._weight_quantizer._amax = amax
def print_model_summary(model, name_width=25, line_width=180, ignore=None):
"""Print model quantization configuration."""
if ignore is None:
ignore = []
elif not isinstance(ignore, list):
ignore = [ignore]
name_width = 0
for name, mod in model.named_modules():
if not hasattr(mod, "weight"):
continue
name_width = max(name_width, len(name))
for name, mod in model.named_modules():
input_q = getattr(mod, "_input_quantizer", None)
weight_q = getattr(mod, "_weight_quantizer", None)
if not hasattr(mod, "weight"):
continue
if type(mod) in ignore:
continue
if [True for s in ignore if isinstance(s, str) and s in name]:
continue
act_str = f"Act:{input_q.extra_repr()}"
wgt_str = f"Wgt:{weight_q.extra_repr()}"
s = f"{name:{name_width}} {act_str} {wgt_str}"
if len(s) <= line_width:
logger.info(s)
else:
logger.info(f"{name:{name_width}} {act_str}")
logger.info(f'{" ":{name_width}} {wgt_str}')
def print_quant_summary(model):
"""Print summary of all quantizer modules in the model."""
count = 0
for name, mod in model.named_modules():
if isinstance(mod, pytorch_quantization.nn.TensorQuantizer):
print(f"{name:80} {mod}")
count += 1
print(f"{count} TensorQuantizers found in model")
def set_quantizer(name, mod, quantizer, k, v):
"""Set attributes for mod.quantizer."""
quantizer_mod = getattr(mod, quantizer, None)
if quantizer_mod is not None:
assert hasattr(quantizer_mod, k)
setattr(quantizer_mod, k, v)
else:
logger.warning(f"{name} has no {quantizer}")
def set_quantizers(name, mod, which="both", **kwargs):
"""Set quantizer attributes for mod."""
s = f"Warning: changing {which} quantizers of {name:{qname_width}}"
for k, v in kwargs.items():
s += f" {k}={v}"
if which in ["input", "both"]:
set_quantizer(name, mod, "_input_quantizer", k, v)
if which in ["weight", "both"]:
set_quantizer(name, mod, "_weight_quantizer", k, v)
logger.info(s)
def set_quantizer_by_name(model, names, **kwargs):
"""Set quantizer attributes for layers where name contains a substring in names."""
for name, mod in model.named_modules():
if hasattr(mod, "_input_quantizer") or hasattr(mod, "_weight_quantizer"):
for n in names:
if re.search(n, name):
set_quantizers(name, mod, **kwargs)
elif name.endswith("_quantizer"):
for n in names:
if re.search(n, name):
s = f"Warning: changing {name:{name_width}}"
for k, v in kwargs.items():
s += f" {k}={v}"
setattr(mod, k, v)
logger.info(s)
|
transformers/examples/research_projects/quantization-qdqbert/quant_trainer.py/0
|
{
"file_path": "transformers/examples/research_projects/quantization-qdqbert/quant_trainer.py",
"repo_id": "transformers",
"token_count": 5092
}
| 79 |
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
What does Moses' rod turn into ?
Who is Aron?
Where did Moses grow up ?
What happens at the command of the Moses ?
Who manages the Pokémon ?
Who owned the Pokémon trademark ?
What else include in Pokémon franchise ?
How many seasons in Pokémon animme series ?
|
transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source/0
|
{
"file_path": "transformers/examples/research_projects/rag-end2end-retriever/test_run/dummy-train-data/train.source",
"repo_id": "transformers",
"token_count": 377
}
| 80 |
"""Finetuning script for RAG models. Adapted from examples.seq2seq.finetune.py"""
import argparse
import logging
import os
import sys
import time
from collections import defaultdict
from pathlib import Path
from typing import Any, Dict, List, Tuple
import numpy as np
import pytorch_lightning as pl
import torch
import torch.distributed as dist
import torch.distributed as torch_distrib
from pytorch_lightning.plugins.training_type import DDPPlugin
from torch.utils.data import DataLoader
from transformers import (
AutoConfig,
AutoTokenizer,
BartForConditionalGeneration,
BatchEncoding,
RagConfig,
RagSequenceForGeneration,
RagTokenForGeneration,
RagTokenizer,
T5ForConditionalGeneration,
)
from transformers import logging as transformers_logging
from transformers.integrations import is_ray_available
if is_ray_available():
import ray
from distributed_ray_retriever import RagRayDistributedRetriever, RayRetriever
from callbacks_rag import ( # noqa: E402 # isort:skipq
get_checkpoint_callback,
get_early_stopping_callback,
Seq2SeqLoggingCallback,
)
from distributed_pytorch_retriever import RagPyTorchDistributedRetriever # noqa: E402 # isort:skip
from utils_rag import ( # noqa: E402 # isort:skip
calculate_exact_match,
flatten_list,
get_git_info,
is_rag_model,
lmap,
pickle_save,
save_git_info,
save_json,
set_extra_model_params,
Seq2SeqDataset,
)
# need the parent dir module
sys.path.insert(2, str(Path(__file__).resolve().parents[1]))
from lightning_base import BaseTransformer, add_generic_args, generic_train # noqa
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
transformers_logging.set_verbosity_info()
class AttrDict(dict):
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
class CustomDDP(DDPPlugin):
def init_ddp_connection(self, global_rank=None, world_size=None) -> None:
module = self.model
global_rank = global_rank if global_rank is not None else self.cluster_environment.global_rank()
world_size = world_size if world_size is not None else self.cluster_environment.world_size()
os.environ["MASTER_ADDR"] = self.cluster_environment.master_address()
os.environ["MASTER_PORT"] = str(self.cluster_environment.master_port())
if not torch.distributed.is_initialized():
logger.info(f"initializing ddp: GLOBAL_RANK: {global_rank}, MEMBER: {global_rank + 1}/{world_size}")
torch_distrib.init_process_group(self.torch_distributed_backend, rank=global_rank, world_size=world_size)
if module.is_rag_model:
self.distributed_port = module.hparams.distributed_port
if module.distributed_retriever == "pytorch":
module.model.rag.retriever.init_retrieval(self.distributed_port)
elif module.distributed_retriever == "ray" and global_rank == 0:
# For the Ray retriever, only initialize it once when global
# rank is 0.
module.model.rag.retriever.init_retrieval()
class GenerativeQAModule(BaseTransformer):
mode = "generative_qa"
loss_names = ["loss"]
metric_names = ["em"]
val_metric = "em"
def __init__(self, hparams, **kwargs):
# when loading from a pytorch lightning checkpoint, hparams are passed as dict
if isinstance(hparams, dict):
hparams = AttrDict(hparams)
if hparams.model_type == "rag_sequence":
self.model_class = RagSequenceForGeneration
elif hparams.model_type == "rag_token":
self.model_class = RagTokenForGeneration
elif hparams.model_type == "bart":
self.model_class = BartForConditionalGeneration
else:
self.model_class = T5ForConditionalGeneration
self.is_rag_model = is_rag_model(hparams.model_type)
config_class = RagConfig if self.is_rag_model else AutoConfig
config = config_class.from_pretrained(hparams.model_name_or_path)
# set retriever parameters
config.index_name = hparams.index_name or config.index_name
config.passages_path = hparams.passages_path or config.passages_path
config.index_path = hparams.index_path or config.index_path
config.use_dummy_dataset = hparams.use_dummy_dataset
# set extra_model_params for generator configs and load_model
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "attention_dropout", "dropout")
if self.is_rag_model:
if hparams.prefix is not None:
config.generator.prefix = hparams.prefix
config.label_smoothing = hparams.label_smoothing
hparams, config.generator = set_extra_model_params(extra_model_params, hparams, config.generator)
if hparams.distributed_retriever == "pytorch":
retriever = RagPyTorchDistributedRetriever.from_pretrained(hparams.model_name_or_path, config=config)
elif hparams.distributed_retriever == "ray":
# The Ray retriever needs the handles to the retriever actors.
retriever = RagRayDistributedRetriever.from_pretrained(
hparams.model_name_or_path, hparams.actor_handles, config=config
)
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config, retriever=retriever)
prefix = config.question_encoder.prefix
else:
if hparams.prefix is not None:
config.prefix = hparams.prefix
hparams, config = set_extra_model_params(extra_model_params, hparams, config)
model = self.model_class.from_pretrained(hparams.model_name_or_path, config=config)
prefix = config.prefix
tokenizer = (
RagTokenizer.from_pretrained(hparams.model_name_or_path)
if self.is_rag_model
else AutoTokenizer.from_pretrained(hparams.model_name_or_path)
)
super().__init__(hparams, config=config, tokenizer=tokenizer, model=model)
save_git_info(self.hparams.output_dir)
self.output_dir = Path(self.hparams.output_dir)
self.metrics_save_path = Path(self.output_dir) / "metrics.json"
self.hparams_save_path = Path(self.output_dir) / "hparams.pkl"
pickle_save(self.hparams, self.hparams_save_path)
self.step_count = 0
self.metrics = defaultdict(list)
self.dataset_kwargs: dict = {
"data_dir": self.hparams.data_dir,
"max_source_length": self.hparams.max_source_length,
"prefix": prefix or "",
}
n_observations_per_split = {
"train": self.hparams.n_train,
"val": self.hparams.n_val,
"test": self.hparams.n_test,
}
self.n_obs = {k: v if v >= 0 else None for k, v in n_observations_per_split.items()}
self.target_lens = {
"train": self.hparams.max_target_length,
"val": self.hparams.val_max_target_length,
"test": self.hparams.test_max_target_length,
}
assert self.target_lens["train"] <= self.target_lens["val"], f"target_lens: {self.target_lens}"
assert self.target_lens["train"] <= self.target_lens["test"], f"target_lens: {self.target_lens}"
self.hparams.git_sha = get_git_info()["repo_sha"]
self.num_workers = hparams.num_workers
self.distributed_port = self.hparams.distributed_port
# For single GPU training, init_ddp_connection is not called.
# So we need to initialize the retrievers here.
if hparams.gpus <= 1:
if hparams.distributed_retriever == "ray":
self.model.retriever.init_retrieval()
elif hparams.distributed_retriever == "pytorch":
self.model.retriever.init_retrieval(self.distributed_port)
self.distributed_retriever = hparams.distributed_retriever
def forward(self, input_ids, **kwargs):
return self.model(input_ids, **kwargs)
def ids_to_clean_text(self, generated_ids: List[int]):
gen_text = self.tokenizer.batch_decode(
generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
return lmap(str.strip, gen_text)
def _step(self, batch: dict) -> Tuple:
source_ids, source_mask, target_ids = batch["input_ids"], batch["attention_mask"], batch["decoder_input_ids"]
rag_kwargs = {}
if isinstance(self.model, T5ForConditionalGeneration):
decoder_input_ids = self.model._shift_right(target_ids)
lm_labels = target_ids
elif isinstance(self.model, BartForConditionalGeneration):
decoder_input_ids = target_ids[:, :-1].contiguous()
lm_labels = target_ids[:, 1:].clone()
else:
assert self.is_rag_model
generator = self.model.rag.generator
if isinstance(generator, T5ForConditionalGeneration):
decoder_start_token_id = generator.config.decoder_start_token_id
decoder_input_ids = (
torch.cat(
[torch.tensor([[decoder_start_token_id]] * target_ids.shape[0]).to(target_ids), target_ids],
dim=1,
)
if target_ids.shape[0] < self.target_lens["train"]
else generator._shift_right(target_ids)
)
elif isinstance(generator, BartForConditionalGeneration):
decoder_input_ids = target_ids
lm_labels = decoder_input_ids
rag_kwargs["reduce_loss"] = True
assert decoder_input_ids is not None
outputs = self(
source_ids,
attention_mask=source_mask,
decoder_input_ids=decoder_input_ids,
use_cache=False,
labels=lm_labels,
**rag_kwargs,
)
loss = outputs["loss"]
return (loss,)
@property
def pad(self) -> int:
raise NotImplementedError("pad not implemented")
def training_step(self, batch, batch_idx) -> Dict:
loss_tensors = self._step(batch)
logs = {name: loss.detach() for name, loss in zip(self.loss_names, loss_tensors)}
# tokens per batch
tgt_pad_token_id = (
self.tokenizer.generator.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
src_pad_token_id = (
self.tokenizer.question_encoder.pad_token_id
if isinstance(self.tokenizer, RagTokenizer)
else self.tokenizer.pad_token_id
)
logs["tpb"] = (
batch["input_ids"].ne(src_pad_token_id).sum() + batch["decoder_input_ids"].ne(tgt_pad_token_id).sum()
)
return {"loss": loss_tensors[0], "log": logs}
def validation_step(self, batch, batch_idx) -> Dict:
return self._generative_step(batch)
def validation_epoch_end(self, outputs, prefix="val") -> Dict:
self.step_count += 1
losses = {k: torch.stack([x[k] for x in outputs]).mean() for k in self.loss_names}
loss = losses["loss"]
gen_metrics = {
k: np.array([x[k] for x in outputs]).mean() for k in self.metric_names + ["gen_time", "gen_len"]
}
metrics_tensor: torch.FloatTensor = torch.tensor(gen_metrics[self.val_metric]).type_as(loss)
gen_metrics.update({k: v.item() for k, v in losses.items()})
# fix for https://github.com/PyTorchLightning/pytorch-lightning/issues/2424
if dist.is_initialized():
dist.all_reduce(metrics_tensor, op=dist.ReduceOp.SUM)
metrics_tensor = metrics_tensor / dist.get_world_size()
gen_metrics.update({self.val_metric: metrics_tensor.item()})
losses.update(gen_metrics)
metrics = {f"{prefix}_avg_{k}": x for k, x in losses.items()}
metrics["step_count"] = self.step_count
self.save_metrics(metrics, prefix) # writes to self.metrics_save_path
preds = flatten_list([x["preds"] for x in outputs])
return {"log": metrics, "preds": preds, f"{prefix}_loss": loss, f"{prefix}_{self.val_metric}": metrics_tensor}
def save_metrics(self, latest_metrics, type_path) -> None:
self.metrics[type_path].append(latest_metrics)
save_json(self.metrics, self.metrics_save_path)
def calc_generative_metrics(self, preds, target) -> Dict:
return calculate_exact_match(preds, target)
def _generative_step(self, batch: dict) -> dict:
start_time = time.time()
batch = BatchEncoding(batch).to(device=self.model.device)
generated_ids = self.model.generate(
batch["input_ids"],
attention_mask=batch["attention_mask"],
do_deduplication=False, # rag specific parameter
use_cache=True,
min_length=1,
max_length=self.target_lens["val"],
)
gen_time = (time.time() - start_time) / batch["input_ids"].shape[0]
preds: List[str] = self.ids_to_clean_text(generated_ids)
target: List[str] = self.ids_to_clean_text(batch["decoder_input_ids"])
loss_tensors = self._step(batch)
base_metrics = dict(zip(self.loss_names, loss_tensors))
gen_metrics: Dict = self.calc_generative_metrics(preds, target)
summ_len = np.mean(lmap(len, generated_ids))
base_metrics.update(gen_time=gen_time, gen_len=summ_len, preds=preds, target=target, **gen_metrics)
return base_metrics
def test_step(self, batch, batch_idx):
return self._generative_step(batch)
def test_epoch_end(self, outputs):
return self.validation_epoch_end(outputs, prefix="test")
def get_dataset(self, type_path) -> Seq2SeqDataset:
n_obs = self.n_obs[type_path]
max_target_length = self.target_lens[type_path]
dataset = Seq2SeqDataset(
self.tokenizer,
type_path=type_path,
n_obs=n_obs,
max_target_length=max_target_length,
**self.dataset_kwargs,
)
return dataset
def get_dataloader(self, type_path: str, batch_size: int, shuffle: bool = False) -> DataLoader:
dataset = self.get_dataset(type_path)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
collate_fn=dataset.collate_fn,
shuffle=shuffle,
num_workers=self.num_workers,
)
return dataloader
def train_dataloader(self) -> DataLoader:
dataloader = self.get_dataloader("train", batch_size=self.hparams.train_batch_size, shuffle=True)
return dataloader
def val_dataloader(self) -> DataLoader:
return self.get_dataloader("val", batch_size=self.hparams.eval_batch_size)
def test_dataloader(self) -> DataLoader:
return self.get_dataloader("test", batch_size=self.hparams.eval_batch_size)
@pl.utilities.rank_zero_only
def on_save_checkpoint(self, checkpoint: Dict[str, Any]) -> None:
save_path = self.output_dir.joinpath("checkpoint{}".format(self.step_count))
self.model.config.save_step = self.step_count
self.model.save_pretrained(save_path)
self.tokenizer.save_pretrained(save_path)
@staticmethod
def add_model_specific_args(parser, root_dir):
BaseTransformer.add_model_specific_args(parser, root_dir)
add_generic_args(parser, root_dir)
parser.add_argument(
"--max_source_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--val_max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--test_max_target_length",
default=25,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument("--logger_name", type=str, choices=["default", "wandb", "wandb_shared"], default="default")
parser.add_argument("--n_train", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_val", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--n_test", type=int, default=-1, required=False, help="# examples. -1 means use all.")
parser.add_argument("--label_smoothing", type=float, default=0.0, required=False)
parser.add_argument(
"--prefix",
type=str,
default=None,
help="Prefix added at the beginning of each text, typically used with T5-based models.",
)
parser.add_argument(
"--early_stopping_patience",
type=int,
default=-1,
required=False,
help=(
"-1 means never early stop. early_stopping_patience is measured in validation checks, not epochs. So"
" val_check_interval will effect it."
),
)
parser.add_argument(
"--distributed-port", type=int, default=-1, required=False, help="Port number for distributed training."
)
parser.add_argument(
"--model_type",
choices=["rag_sequence", "rag_token", "bart", "t5"],
type=str,
help=(
"RAG model type: sequence or token, if none specified, the type is inferred from the"
" model_name_or_path"
),
)
return parser
@staticmethod
def add_retriever_specific_args(parser):
parser.add_argument(
"--index_name",
type=str,
default=None,
help=(
"Name of the index to use: 'hf' for a canonical dataset from the datasets library (default), 'custom'"
" for a local index, or 'legacy' for the orignal one)"
),
)
parser.add_argument(
"--passages_path",
type=str,
default=None,
help=(
"Path to the dataset of passages for custom index. More info about custom indexes in the RagRetriever"
" documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
parser.add_argument(
"--index_path",
type=str,
default=None,
help=(
"Path to the faiss index for custom index. More info about custom indexes in the RagRetriever"
" documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
parser.add_argument(
"--distributed_retriever",
choices=["ray", "pytorch"],
type=str,
default="pytorch",
help=(
"What implementation to use for distributed retriever? If "
"pytorch is selected, the index is loaded on training "
"worker 0, and torch.distributed is used to handle "
"communication between training worker 0, and the other "
"training workers. If ray is selected, the Ray library is "
"used to create load the index on separate processes, "
"and Ray handles the communication between the training "
"workers and the retrieval actors."
),
)
parser.add_argument(
"--use_dummy_dataset",
type=bool,
default=False,
help=(
"Whether to use the dummy version of the dataset index. More info about custom indexes in the"
" RagRetriever documentation as well as in `examples/rag/use_own_knowledge_dataset.py`"
),
)
return parser
@staticmethod
def add_ray_specific_args(parser):
# Ray cluster address.
parser.add_argument(
"--ray-address",
default="auto",
type=str,
help=(
"The address of the Ray cluster to connect to. If not "
"specified, Ray will attempt to automatically detect the "
"cluster. Has no effect if pytorch is used as the distributed "
"retriever."
),
)
parser.add_argument(
"--num_retrieval_workers",
type=int,
default=1,
help=(
"The number of retrieval actors to use when Ray is selected "
"for the distributed retriever. Has no effect when "
"distributed_retriever is set to pytorch."
),
)
return parser
def main(args=None, model=None) -> GenerativeQAModule:
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
parser = GenerativeQAModule.add_retriever_specific_args(parser)
args = args or parser.parse_args()
Path(args.output_dir).mkdir(exist_ok=True)
named_actors = []
if args.distributed_retriever == "ray" and args.gpus > 1:
if not is_ray_available():
raise RuntimeError("Please install Ray to use the Ray distributed retriever.")
# Connect to an existing Ray cluster.
try:
ray.init(address=args.ray_address, namespace="rag")
except (ConnectionError, ValueError):
logger.warning(
"Connection to Ray cluster failed. Make sure a Ray "
"cluster is running by either using Ray's cluster "
"launcher (`ray up`) or by manually starting Ray on "
"each node via `ray start --head` for the head node "
"and `ray start --address='<ip address>:6379'` for "
"additional nodes. See "
"https://docs.ray.io/en/master/cluster/index.html "
"for more info."
)
raise
# Create Ray actors only for rank 0.
if ("LOCAL_RANK" not in os.environ or int(os.environ["LOCAL_RANK"]) == 0) and (
"NODE_RANK" not in os.environ or int(os.environ["NODE_RANK"]) == 0
):
remote_cls = ray.remote(RayRetriever)
named_actors = [
remote_cls.options(name="retrieval_worker_{}".format(i)).remote()
for i in range(args.num_retrieval_workers)
]
else:
logger.info(
"Getting named actors for NODE_RANK {}, LOCAL_RANK {}".format(
os.environ["NODE_RANK"], os.environ["LOCAL_RANK"]
)
)
named_actors = [ray.get_actor("retrieval_worker_{}".format(i)) for i in range(args.num_retrieval_workers)]
args.actor_handles = named_actors
assert args.actor_handles == named_actors
if model is None:
model: GenerativeQAModule = GenerativeQAModule(args)
dataset = Path(args.data_dir).name
if (
args.logger_name == "default"
or args.fast_dev_run
or str(args.output_dir).startswith("/tmp")
or str(args.output_dir).startswith("/var")
):
training_logger = True # don't pollute wandb logs unnecessarily
elif args.logger_name == "wandb":
from pytorch_lightning.loggers import WandbLogger
project = os.environ.get("WANDB_PROJECT", dataset)
training_logger = WandbLogger(name=model.output_dir.name, project=project)
elif args.logger_name == "wandb_shared":
from pytorch_lightning.loggers import WandbLogger
training_logger = WandbLogger(name=model.output_dir.name, project=f"hf_{dataset}")
es_callback = (
get_early_stopping_callback(model.val_metric, args.early_stopping_patience)
if args.early_stopping_patience >= 0
else False
)
trainer: pl.Trainer = generic_train(
model,
args,
logging_callback=Seq2SeqLoggingCallback(),
checkpoint_callback=get_checkpoint_callback(args.output_dir, model.val_metric),
early_stopping_callback=es_callback,
logger=training_logger,
custom_ddp_plugin=CustomDDP() if args.gpus > 1 else None,
profiler=pl.profiler.AdvancedProfiler() if args.profile else None,
)
pickle_save(model.hparams, model.output_dir / "hparams.pkl")
if not args.do_predict:
return model
# test() without a model tests using the best checkpoint automatically
trainer.test()
return model
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = GenerativeQAModule.add_model_specific_args(parser, os.getcwd())
parser = GenerativeQAModule.add_retriever_specific_args(parser)
parser = GenerativeQAModule.add_ray_specific_args(parser)
# Pytorch Lightning Profiler
parser.add_argument(
"--profile",
action="store_true",
help="If True, use pytorch_lightning.profiler.AdvancedProfiler to profile the Trainer.",
)
args = parser.parse_args()
main(args)
|
transformers/examples/research_projects/rag/finetune_rag.py/0
|
{
"file_path": "transformers/examples/research_projects/rag/finetune_rag.py",
"repo_id": "transformers",
"token_count": 11834
}
| 81 |
# Script for verifying that run_bart_sum can be invoked from its directory
# Get tiny dataset with cnn_dm format (4 examples for train, val, test)
wget https://cdn-datasets.huggingface.co/summarization/cnn_tiny.tgz
tar -xzvf cnn_tiny.tgz
rm cnn_tiny.tgz
export OUTPUT_DIR_NAME=bart_utest_output
export CURRENT_DIR=${PWD}
export OUTPUT_DIR=${CURRENT_DIR}/${OUTPUT_DIR_NAME}
# Make output directory if it doesn't exist
mkdir -p $OUTPUT_DIR
# Add parent directory to python path to access lightning_base.py and testing_utils.py
export PYTHONPATH="../":"${PYTHONPATH}"
python finetune.py \
--data_dir=cnn_tiny/ \
--model_name_or_path=sshleifer/bart-tiny-random \
--learning_rate=3e-5 \
--train_batch_size=2 \
--eval_batch_size=2 \
--output_dir=$OUTPUT_DIR \
--num_train_epochs=1 \
--gpus=0 \
--do_train "$@"
rm -rf cnn_tiny
rm -rf $OUTPUT_DIR
|
transformers/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh/0
|
{
"file_path": "transformers/examples/research_projects/seq2seq-distillation/finetune_bart_tiny.sh",
"repo_id": "transformers",
"token_count": 333
}
| 82 |
# coding=utf-8
# Copyright 2024 Google DeepMind.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
from typing import Any, List, Optional, Tuple
import datasets
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import torch
import tqdm
from huggingface_hub import HfApi, create_repo
from huggingface_hub.utils import RepositoryNotFoundError
from sklearn import model_selection
import transformers
def pad_to_len(
arr: torch.Tensor,
target_len: int,
left_pad: bool,
eos_token: int,
device: torch.device,
) -> torch.Tensor:
"""Pad or truncate array to given length."""
if arr.shape[1] < target_len:
shape_for_ones = list(arr.shape)
shape_for_ones[1] = target_len - shape_for_ones[1]
padded = (
torch.ones(
shape_for_ones,
device=device,
dtype=torch.long,
)
* eos_token
)
if not left_pad:
arr = torch.concatenate((arr, padded), dim=1)
else:
arr = torch.concatenate((padded, arr), dim=1)
else:
arr = arr[:, :target_len]
return arr
def filter_and_truncate(
outputs: torch.Tensor,
truncation_length: Optional[int],
eos_token_mask: torch.Tensor,
) -> torch.Tensor:
"""Filter and truncate outputs to given length.
Args:
outputs: output tensor of shape [batch_size, output_len]
truncation_length: Length to truncate the final output.
eos_token_mask: EOS token mask of shape [batch_size, output_len]
Returns:
output tensor of shape [batch_size, truncation_length].
"""
if truncation_length:
outputs = outputs[:, :truncation_length]
truncation_mask = torch.sum(eos_token_mask, dim=1) >= truncation_length
return outputs[truncation_mask, :]
return outputs
def process_outputs_for_training(
all_outputs: List[torch.Tensor],
logits_processor: transformers.generation.SynthIDTextWatermarkLogitsProcessor,
tokenizer: Any,
pos_truncation_length: Optional[int],
neg_truncation_length: Optional[int],
max_length: int,
is_cv: bool,
is_pos: bool,
torch_device: torch.device,
) -> Tuple[List[torch.Tensor], List[torch.Tensor]]:
"""Process raw model outputs into format understandable by the detector.
Args:
all_outputs: sequence of outputs of shape [batch_size, output_len].
logits_processor: logits processor used for watermarking.
tokenizer: tokenizer used for the model.
pos_truncation_length: Length to truncate wm outputs.
neg_truncation_length: Length to truncate uwm outputs.
max_length: Length to pad truncated outputs so that all processed entries.
have same shape.
is_cv: Process given outputs for cross validation.
is_pos: Process given outputs for positives.
torch_device: torch device to use.
Returns:
Tuple of
all_masks: list of masks of shape [batch_size, max_length].
all_g_values: list of g_values of shape [batch_size, max_length, depth].
"""
all_masks = []
all_g_values = []
for outputs in tqdm.tqdm(all_outputs):
# outputs is of shape [batch_size, output_len].
# output_len can differ from batch to batch.
eos_token_mask = logits_processor.compute_eos_token_mask(
input_ids=outputs,
eos_token_id=tokenizer.eos_token_id,
)
if is_pos or is_cv:
# filter with length for positives for both train and CV.
# We also filter for length when CV negatives are processed.
outputs = filter_and_truncate(outputs, pos_truncation_length, eos_token_mask)
elif not is_pos and not is_cv:
outputs = filter_and_truncate(outputs, neg_truncation_length, eos_token_mask)
# If no filtered outputs skip this batch.
if outputs.shape[0] == 0:
continue
# All outputs are padded to max-length with eos-tokens.
outputs = pad_to_len(outputs, max_length, False, tokenizer.eos_token_id, torch_device)
# outputs shape [num_filtered_entries, max_length]
eos_token_mask = logits_processor.compute_eos_token_mask(
input_ids=outputs,
eos_token_id=tokenizer.eos_token_id,
)
context_repetition_mask = logits_processor.compute_context_repetition_mask(
input_ids=outputs,
)
# context_repetition_mask of shape [num_filtered_entries, max_length -
# (ngram_len - 1)].
context_repetition_mask = pad_to_len(context_repetition_mask, max_length, True, 0, torch_device)
# We pad on left to get same max_length shape.
# context_repetition_mask of shape [num_filtered_entries, max_length].
combined_mask = context_repetition_mask * eos_token_mask
g_values = logits_processor.compute_g_values(
input_ids=outputs,
)
# g_values of shape [num_filtered_entries, max_length - (ngram_len - 1),
# depth].
g_values = pad_to_len(g_values, max_length, True, 0, torch_device)
# We pad on left to get same max_length shape.
# g_values of shape [num_filtered_entries, max_length, depth].
all_masks.append(combined_mask)
all_g_values.append(g_values)
return all_masks, all_g_values
def tpr_at_fpr(detector, detector_inputs, w_true, minibatch_size, target_fpr=0.01) -> torch.Tensor:
"""Calculates true positive rate (TPR) at false positive rate (FPR)=target_fpr."""
positive_idxs = w_true == 1
negative_idxs = w_true == 0
num_samples = detector_inputs[0].size(0)
w_preds = []
for start in range(0, num_samples, minibatch_size):
end = start + minibatch_size
detector_inputs_ = (
detector_inputs[0][start:end],
detector_inputs[1][start:end],
)
with torch.no_grad():
w_pred = detector(*detector_inputs_)[0]
w_preds.append(w_pred)
w_pred = torch.cat(w_preds, dim=0) # Concatenate predictions
positive_scores = w_pred[positive_idxs]
negative_scores = w_pred[negative_idxs]
# Calculate the FPR threshold
# Note: percentile -> quantile
fpr_threshold = torch.quantile(negative_scores, 1 - target_fpr)
# Note: need to switch to FP32 since torch.mean doesn't work with torch.bool
return torch.mean((positive_scores >= fpr_threshold).to(dtype=torch.float32)).item() # TPR
def update_fn_if_fpr_tpr(detector, g_values_val, mask_val, watermarked_val, minibatch_size):
"""Loss function for negative TPR@FPR=1% as the validation loss."""
tpr_ = tpr_at_fpr(
detector=detector,
detector_inputs=(g_values_val, mask_val),
w_true=watermarked_val,
minibatch_size=minibatch_size,
)
return -tpr_
def process_raw_model_outputs(
logits_processor,
tokenizer,
pos_truncation_length,
neg_truncation_length,
max_padded_length,
tokenized_wm_outputs,
test_size,
tokenized_uwm_outputs,
torch_device,
):
# Split data into train and CV
train_wm_outputs, cv_wm_outputs = model_selection.train_test_split(tokenized_wm_outputs, test_size=test_size)
train_uwm_outputs, cv_uwm_outputs = model_selection.train_test_split(tokenized_uwm_outputs, test_size=test_size)
process_kwargs = {
"logits_processor": logits_processor,
"tokenizer": tokenizer,
"pos_truncation_length": pos_truncation_length,
"neg_truncation_length": neg_truncation_length,
"max_length": max_padded_length,
"torch_device": torch_device,
}
# Process both train and CV data for training
wm_masks_train, wm_g_values_train = process_outputs_for_training(
[torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in train_wm_outputs],
is_pos=True,
is_cv=False,
**process_kwargs,
)
wm_masks_cv, wm_g_values_cv = process_outputs_for_training(
[torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in cv_wm_outputs],
is_pos=True,
is_cv=True,
**process_kwargs,
)
uwm_masks_train, uwm_g_values_train = process_outputs_for_training(
[torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in train_uwm_outputs],
is_pos=False,
is_cv=False,
**process_kwargs,
)
uwm_masks_cv, uwm_g_values_cv = process_outputs_for_training(
[torch.tensor(outputs, device=torch_device, dtype=torch.long) for outputs in cv_uwm_outputs],
is_pos=False,
is_cv=True,
**process_kwargs,
)
# We get list of data; here we concat all together to be passed to the detector.
def pack(mask, g_values):
mask = torch.cat(mask, dim=0)
g = torch.cat(g_values, dim=0)
return mask, g
wm_masks_train, wm_g_values_train = pack(wm_masks_train, wm_g_values_train)
# Note: Use float instead of bool. Otherwise, the entropy calculation doesn't work
wm_labels_train = torch.ones((wm_masks_train.shape[0],), dtype=torch.float, device=torch_device)
wm_masks_cv, wm_g_values_cv = pack(wm_masks_cv, wm_g_values_cv)
wm_labels_cv = torch.ones((wm_masks_cv.shape[0],), dtype=torch.float, device=torch_device)
uwm_masks_train, uwm_g_values_train = pack(uwm_masks_train, uwm_g_values_train)
uwm_labels_train = torch.zeros((uwm_masks_train.shape[0],), dtype=torch.float, device=torch_device)
uwm_masks_cv, uwm_g_values_cv = pack(uwm_masks_cv, uwm_g_values_cv)
uwm_labels_cv = torch.zeros((uwm_masks_cv.shape[0],), dtype=torch.float, device=torch_device)
# Concat pos and negatives data together.
train_g_values = torch.cat((wm_g_values_train, uwm_g_values_train), dim=0).squeeze()
train_labels = torch.cat((wm_labels_train, uwm_labels_train), axis=0).squeeze()
train_masks = torch.cat((wm_masks_train, uwm_masks_train), axis=0).squeeze()
cv_g_values = torch.cat((wm_g_values_cv, uwm_g_values_cv), axis=0).squeeze()
cv_labels = torch.cat((wm_labels_cv, uwm_labels_cv), axis=0).squeeze()
cv_masks = torch.cat((wm_masks_cv, uwm_masks_cv), axis=0).squeeze()
# Shuffle data.
shuffled_idx = torch.randperm(train_g_values.shape[0]) # Use torch for GPU compatibility
train_g_values = train_g_values[shuffled_idx]
train_labels = train_labels[shuffled_idx]
train_masks = train_masks[shuffled_idx]
# Shuffle the cross-validation data
shuffled_idx_cv = torch.randperm(cv_g_values.shape[0]) # Use torch for GPU compatibility
cv_g_values = cv_g_values[shuffled_idx_cv]
cv_labels = cv_labels[shuffled_idx_cv]
cv_masks = cv_masks[shuffled_idx_cv]
# Del some variables so we free up GPU memory.
del (
wm_g_values_train,
wm_labels_train,
wm_masks_train,
wm_g_values_cv,
wm_labels_cv,
wm_masks_cv,
)
gc.collect()
torch.cuda.empty_cache()
return train_g_values, train_masks, train_labels, cv_g_values, cv_masks, cv_labels
def get_tokenized_uwm_outputs(num_negatives, neg_batch_size, tokenizer, device):
dataset, info = tfds.load("wikipedia/20230601.en", split="train", with_info=True)
dataset = dataset.take(num_negatives)
# Convert the dataset to a DataFrame
df = tfds.as_dataframe(dataset, info)
ds = tf.data.Dataset.from_tensor_slices(dict(df))
tf.random.set_seed(0)
ds = ds.shuffle(buffer_size=10_000)
ds = ds.batch(batch_size=neg_batch_size)
tokenized_uwm_outputs = []
# Pad to this length (on the right) for batching.
padded_length = 1000
for i, batch in tqdm.tqdm(enumerate(ds)):
responses = [val.decode() for val in batch["text"].numpy()]
inputs = tokenizer(
responses,
return_tensors="pt",
padding=True,
).to(device)
inputs = inputs["input_ids"].cpu().numpy()
if inputs.shape[1] >= padded_length:
inputs = inputs[:, :padded_length]
else:
inputs = np.concatenate(
[inputs, np.ones((neg_batch_size, padded_length - inputs.shape[1])) * tokenizer.eos_token_id], axis=1
)
tokenized_uwm_outputs.append(inputs)
if len(tokenized_uwm_outputs) * neg_batch_size > num_negatives:
break
return tokenized_uwm_outputs
def get_tokenized_wm_outputs(
model,
tokenizer,
watermark_config,
num_pos_batches,
pos_batch_size,
temperature,
max_output_len,
top_k,
top_p,
device,
):
eli5_prompts = datasets.load_dataset("Pavithree/eli5")
wm_outputs = []
for batch_id in tqdm.tqdm(range(num_pos_batches)):
prompts = eli5_prompts["train"]["title"][batch_id * pos_batch_size : (batch_id + 1) * pos_batch_size]
prompts = [prompt.strip('"') for prompt in prompts]
inputs = tokenizer(
prompts,
return_tensors="pt",
padding=True,
).to(device)
_, inputs_len = inputs["input_ids"].shape
outputs = model.generate(
**inputs,
watermarking_config=watermark_config,
do_sample=True,
max_length=inputs_len + max_output_len,
temperature=temperature,
top_k=top_k,
top_p=top_p,
)
wm_outputs.append(outputs[:, inputs_len:].cpu().detach())
del outputs, inputs, prompts
gc.collect()
gc.collect()
torch.cuda.empty_cache()
return wm_outputs
def upload_model_to_hf(model, hf_repo_name: str, private: bool = True):
api = HfApi()
# Check if the repository exists
try:
api.repo_info(repo_id=hf_repo_name, use_auth_token=True)
print(f"Repository '{hf_repo_name}' already exists.")
except RepositoryNotFoundError:
# If the repository does not exist, create it
print(f"Repository '{hf_repo_name}' not found. Creating it...")
create_repo(repo_id=hf_repo_name, private=private, use_auth_token=True)
print(f"Repository '{hf_repo_name}' created successfully.")
# Push the model to the Hugging Face Hub
print(f"Uploading model to Hugging Face repo '{hf_repo_name}'...")
model.push_to_hub(repo_id=hf_repo_name, use_auth_token=True)
|
transformers/examples/research_projects/synthid_text/utils.py/0
|
{
"file_path": "transformers/examples/research_projects/synthid_text/utils.py",
"repo_id": "transformers",
"token_count": 6460
}
| 83 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.