
File size: 3,964 Bytes
812edd7 ab56304 812edd7 66225e4 4d8e028 812edd7 4d8e028 812edd7 4d8e028 812edd7 1e561b9 4d8e028 812edd7 1e561b9 66225e4 812edd7 4d8e028 0904c79 4d8e028 812edd7 4d8e028 1e561b9 4d8e028 812edd7 4d8e028 1e561b9 4d8e028 812edd7 4d8e028 812edd7 4d8e028 1e561b9 4d8e028 812edd7 4d8e028 1e561b9 09ae39b 4d8e028 66225e4 812edd7 4d8e028 1e561b9 4d8e028 812edd7 4d8e028 812edd7 4d8e028 66225e4 4d8e028 812edd7 4d8e028 812edd7 4d8e028 1e561b9 4d8e028 812edd7 4d8e028 1e561b9 4d8e028 812edd7 4d8e028 812edd7 4d8e028 1e561b9 66225e4 4d8e028 1e561b9 4d8e028 812edd7 4d8e028 1e561b9 4d8e028 812edd7 4d8e028 812edd7 4d8e028 1e561b9 4d8e028 4b8c79d 9f5b714 22e9451 9f5b714 812edd7 4d8e028 812edd7 4d8e028 812edd7 4d8e028 1e561b9 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 |
---
annotations_creators:
- expert-generated
language_creators:
- found
language:
- en
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- multi-class-classification
- sentiment-classification
paperswithcode_id: null
pretty_name: Auditor_Review
---
# Dataset Card for Auditor_Review
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
## Dataset Description
Auditor review data collected by News Department
- **Point of Contact:**
Talked to COE for Auditing, currently sue@demo.org
### Dataset Summary
Auditor sentiment dataset of sentences from financial news. The dataset consists of 3500 sentences from English language financial news categorized by sentiment. The dataset is divided by the agreement rate of 5-8 annotators.
### Supported Tasks and Leaderboards
Sentiment Classification
### Languages
English
## Dataset Structure
### Data Instances
```
"sentence": "Pharmaceuticals group Orion Corp reported a fall in its third-quarter earnings that were hit by larger expenditures on R&D and marketing .",
"label": "negative"
```
### Data Fields
- sentence: a tokenized line from the dataset
- label: a label corresponding to the class as a string: 'positive' - (2), 'neutral' - (1), or 'negative' - (0)
Complete data code is [available here](https://www.datafiles.samhsa.gov/get-help/codebooks/what-codebook)
### Data Splits
A train/test split was created randomly with a 75/25 split
## Dataset Creation
### Curation Rationale
To gather our auditor evaluations into one dataset. Previous attempts using off-the-shelf sentiment had only 70% F1, this dataset was an attempt to improve upon that performance.
### Source Data
#### Initial Data Collection and Normalization
The corpus used in this paper is made out of English news reports.
#### Who are the source language producers?
The source data was written by various auditors.
### Annotations
#### Annotation process
This release of the auditor reviews covers a collection of 4840
sentences. The selected collection of phrases was annotated by 16 people with
adequate background knowledge of financial markets. The subset here is where inter-annotation agreement was greater than 75%.
#### Who are the annotators?
They were pulled from the SME list, names are held by sue@demo.org
### Personal and Sensitive Information
There is no personal or sensitive information in this dataset.
## Considerations for Using the Data
### Discussion of Biases
All annotators were from the same institution and so interannotator agreement
should be understood with this taken into account.
The [Dataset Measurement tool](https://huggingface.co/spaces/huggingface/data-measurements-tool) identified these bias statistics:
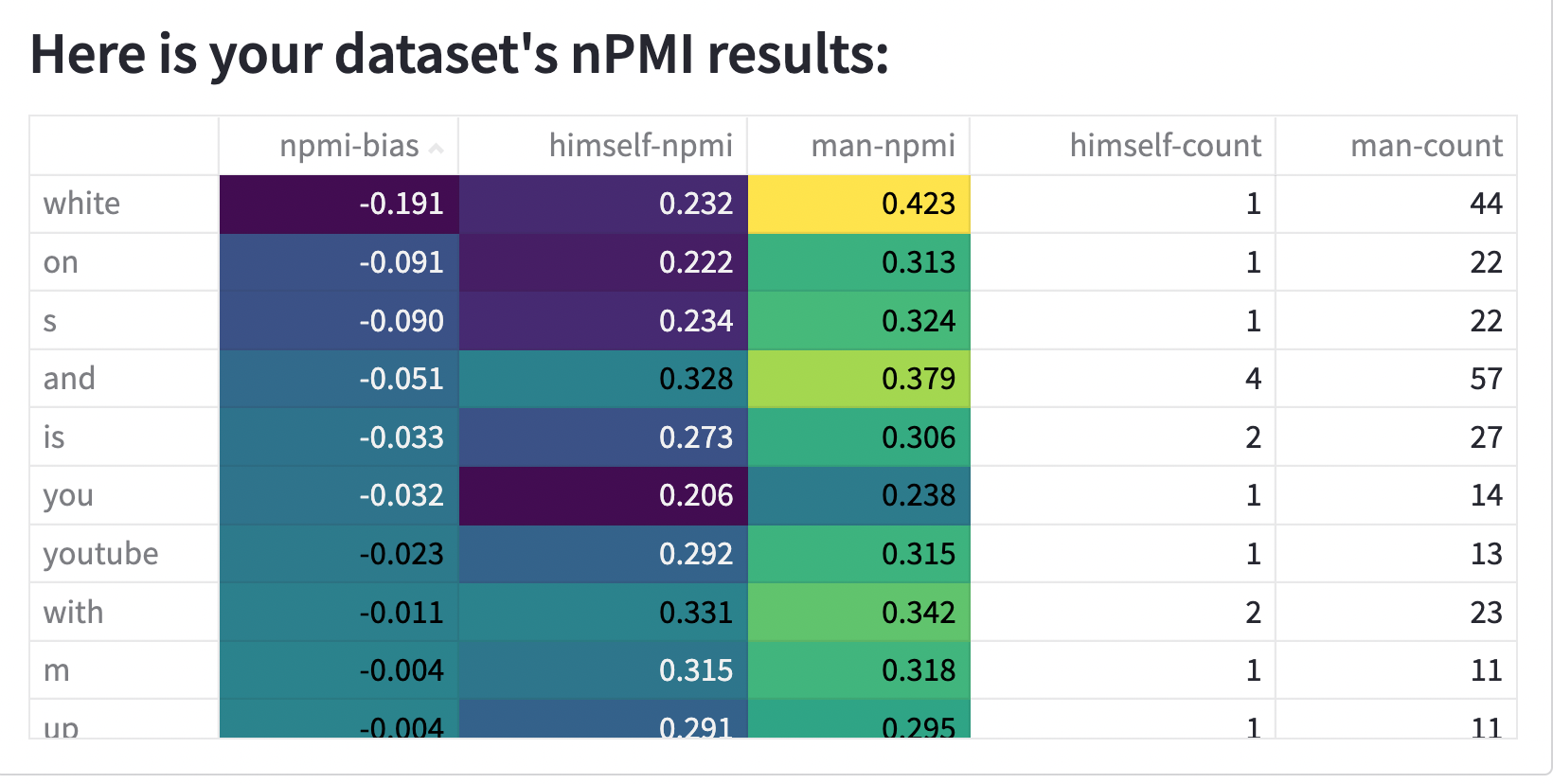
### Other Known Limitations
[More Information Needed]
### Licensing Information
License: Demo.Org Proprietary - DO NOT SHARE |