
dataset_info:
features:
- name: x
sequence: float64
- name: 'y'
dtype: int64
splits:
- name: train
num_bytes: 1328000
num_examples: 4000
- name: test
num_bytes: 332000
num_examples: 1000
download_size: 2009200
dataset_size: 1660000
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
license: apache-2.0
pretty_name: The MNIST-1D Dataset
size_categories:
- 1K<n<10K
This dataset card is based on the README file of the authors' GitHub repository: https://github.com/greydanus/mnist1d
The MNIST-1D Dataset
Most machine learning models get around the same ~99% test accuracy on MNIST. The MNIST-1D dataset is 100x smaller (default sample size: 4000+1000; dimensionality: 40) and does a better job of separating between models with/without nonlinearity and models with/without spatial inductive biases.
MNIST-1D is a core teaching dataset in Simon Prince's Understanding Deep Learning textbook.

Comparing MNIST and MNIST-1D
| Dataset | Logistic Regression | MLP | CNN | GRU* | Human Expert |
|---|---|---|---|---|---|
| MNIST | 92% | 99+% | 99+% | 99+% | 99+% |
| MNIST-1D | 32% | 68% | 94% | 91% | 96% |
| MNIST-1D (shuffle**) | 32% | 68% | 56% | 57% | ~30% |
*Training the GRU takes at least 10x the walltime of the CNN.
**The term "shuffle" refers to shuffling the spatial dimension of the dataset, as in Zhang et al. (2017).
Visualizing the MNIST and MNIST-1D datasets with t-SNE. The well-defined clusters in the MNIST plot indicate that the majority of the examples are separable via a kNN classifier in pixel space. The MNIST-1D plot, meanwhile, reveals a lack of well-defined clusters which suggests that learning a nonlinear representation of the data is much more important to achieve successful classification.

Dataset Creation
Hugging Face Dataset
This version of the dataset was created from the pickle file (mnist1d_data.pkl) provided by the dataset authors in the original repository:
import sys ; sys.path.append('..') # useful if you're running locally
import mnist1d
from datasets import Dataset, DatasetDict
# Load the data using the mnist1d library
args = mnist1d.get_dataset_args()
data = mnist1d.get_dataset(args, path='./mnist1d_data.pkl', download=True) # This is the default setting
# Load the data into a Hugging Face dataset and push it to the hub
train = Dataset.from_dict({"x": data["x"], "y":data["y"]})
test = Dataset.from_dict({"x": data["x_test"], "y":data["y_test"]})
DatasetDict({"train":train, "test":test}).push_to_hub("christopher/mnist1d")
MNIST-1D
This is a synthetically-generated dataset which, by default, consists of 4000 training examples and 1000 testing examples (you can change this as you wish). Each example contains a template pattern that resembles a handwritten digit between 0 and 9. These patterns are analogous to the digits in the original MNIST dataset.
Original MNIST digits

1D template patterns

1D templates as lines

In order to build the synthetic dataset, the templates go through a series of random transformations. This includes adding random amounts of padding, translation, correlated noise, iid noise, and scaling. These transformations are relevant for both 1D signals and 2D images. So even though the dataset is 1D, one can expect some of the findings to hold for 2D (image) data. For example, one can study the advantage of using a translation-invariant model (eg. a CNN) by making a dataset where signals occur at different locations in the sequence. This can be done by using large padding and translation coefficients. Here's an animation of how those transformations are applied.
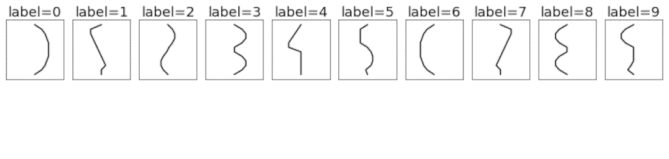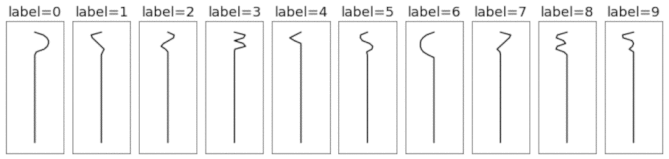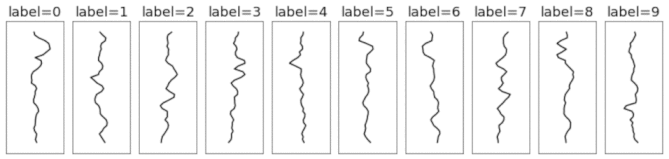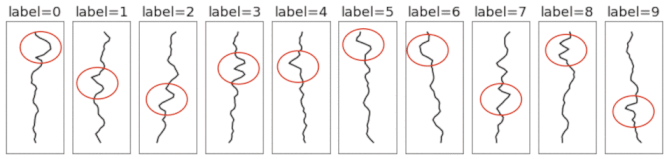
Unlike the original MNIST dataset, which consisted of 2D arrays of pixels (each image had 28x28=784 dimensions), this dataset consists of 1D timeseries of length 40. This means each example is ~20x smaller, making the dataset much quicker and easier to iterate over. Another nice thing about this toy dataset is that it does a good job of separating different types of deep learning models, many of which get the same 98-99% test accuracy on MNIST.
Dataset Usage
Using the datasets library:
from datasets import load_dataset
train = load_dataset("christopher/mnist1d", split="train")
test = load_dataset("christopher/mnist1d", split="test")
train_test = load_dataset("christopher/mnist1d", split="train+test")
Then to get the data as numpy arrays:
train.set_format("numpy")
x = train["x"]
y = train["y"]
Citation
@inproceedings{greydanus2024scaling,
title={Scaling down deep learning with {MNIST}-{1D}},
author={Greydanus, Sam and Kobak, Dmitry},
booktitle={Proceedings of the 41st International Conference on Machine Learning},
year={2024}
}