
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
pytorch/pytorch
| 70,094
|
how to get the pre operator of current opeartor in PyTorch?
|
### 🚀 The feature, motivation and pitch
I want to get the pre operator of current operator in forward? Can pytorch support this now?
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/pytorch/issues/70094
|
closed
|
[] | 2021-12-17T07:01:52Z
| 2021-12-17T14:36:30Z
| null |
kevinVegBird
|
pytorch/data
| 140
|
Installing torchdata installs `example` folder as well
|
### 🐛 Describe the bug
Looks like installing torchdata also installs `examples`. This should probably be removed from `setup.py` so that only the `torchdata` folder gets installed.
Example of what happens when trying to uninstall torchdata
```
fmassa@devfair0163:~/work/vision_datasets$ pip uninstall torchdata
Found existing installation: torchdata 0.3.0a0+6bad0e5
Uninstalling torchdata-0.3.0a0+6bad0e5:
Would remove:
/private/home/fmassa/.conda/envs/xformers/lib/python3.8/site-packages/examples/vision/*
/private/home/fmassa/.conda/envs/xformers/lib/python3.8/site-packages/torchdata-0.3.0a0+6bad0e5.dist-info/*
/private/home/fmassa/.conda/envs/xformers/lib/python3.8/site-packages/torchdata/*
Proceed (y/n)?
```
### Versions
Lasted one from master
|
https://github.com/meta-pytorch/data/issues/140
|
closed
|
[
"bug"
] | 2021-12-15T14:09:24Z
| 2021-12-16T17:05:20Z
| 0
|
fmassa
|
pytorch/TensorRT
| 772
|
❓ [Question] Is there support for optional arguments in model's `forward()`?
|
## ❓ Question
Is there support for optional arguments in model's `forward()`? For example, I have the following: `def forward(self, x, y: Optional[Tensor] = None):` where `y` is an optional tensor. The return result is `x + y` if `y` is provided, otherwise just `x`.
## What you have already tried
I added a second `torch_tensorrt.Input()` in the input spec, then at inference time got the error:
`Expected dimension specifications for all input tensors, but found 1 input tensors and 2 dimension specs`
I then removed the `Optional` annotation and just pass in `None` or the actual tensor for `y`. When `None` is passed in, I got the error: `RuntimeError: forward() Expected a value of type 'Tensor' for argument 'input_1' but instead found type 'NoneType'.`
I also tried passing in just 1 argument for `x`, and got:
`RuntimeError: forward() is missing value for argument 'input_1'`
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.10.0+cu113
- CPU Architecture:
- OS (e.g., Linux): Ubuntu 18.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): `pip`
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.7.11
- CUDA version: 11.1
- GPU models and configuration: Tesla V100 with 32GB memory
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/772
|
closed
|
[
"question",
"component: core",
"No Activity"
] | 2021-12-14T22:14:55Z
| 2023-02-27T00:02:28Z
| null |
lhai37
|
pytorch/data
| 132
|
[TODO] can this also have a timeout?
|
This issue is generated from the TODO line
https://github.com/pytorch/data/blob/f102d25f9f444de3380c6d49bf7aaf52c213bb1f/build/lib/torchdata/datapipes/iter/load/online.py#L113
|
https://github.com/meta-pytorch/data/issues/132
|
closed
|
[
"todo"
] | 2021-12-10T20:09:55Z
| 2022-01-07T21:29:12Z
| 0
|
VitalyFedyunin
|
pytorch/tensorpipe
| 417
|
how to install pytensorpipe
|
I built tensorpipe with ninja and try to build python package running `python setup.py`, it tells me:
```
make: *** No rule to make target 'pytensorpipe'. Stop.
```
|
https://github.com/pytorch/tensorpipe/issues/417
|
closed
|
[] | 2021-12-10T14:21:30Z
| 2021-12-10T14:27:30Z
| null |
eedalong
|
pytorch/TensorRT
| 771
|
❓ [Question] Get no indications on the exact code that cause errors?
|
## ❓ Question
Hi, thanks for making this amazing tool! I met some errors when converting my model. However, for some of the errors, there is only information about unsupported operators without any indication of the exact code that causes the errors.
Why does this happen and are there any potential solutions?
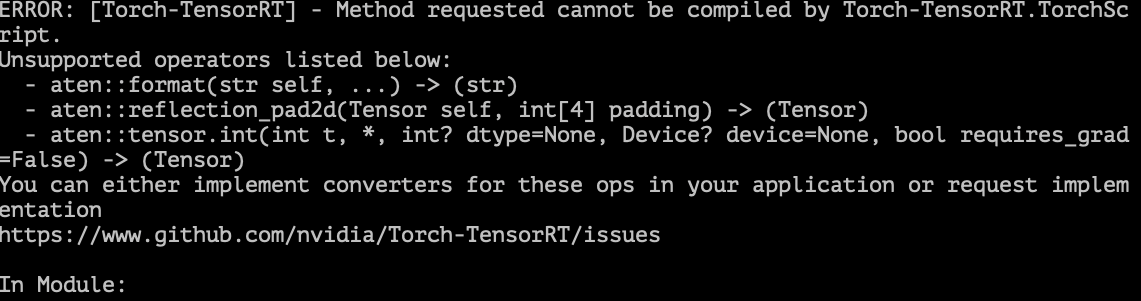
|
https://github.com/pytorch/TensorRT/issues/771
|
closed
|
[
"question",
"No Activity"
] | 2021-12-10T13:22:59Z
| 2022-04-01T00:02:18Z
| null |
DeriZSY
|
pytorch/TensorRT
| 767
|
❓ [Question] Handling non-tensor input of module
|
## ❓ Question
Can `torch_tensorrt.compile` handle non-tensor input of the module (for example boolean and integer)? How should I do it?
|
https://github.com/pytorch/TensorRT/issues/767
|
closed
|
[
"question",
"No Activity"
] | 2021-12-09T09:46:12Z
| 2022-04-01T00:02:18Z
| null |
DeriZSY
|
pytorch/pytorch
| 69,610
|
[Question] How to extract/expose the complete PyTorch computation graph (forward and backward)?
|
How to extract the complete computation graph PyTorch generates?
Here is my understanding:
1. The forward graph can be generated by `jit.trace` or `jit.script`
2. The backward graph is created from scratch each time `loss.backward()` is invoked in the training loop.
I am attempting to lower the computation graph generated by PyTorch into GLOW manually for some custom downstream optimization. I am not able to extract the complete computation graph at the framework level (forward AND backward).
Any help or guidance in this regard is greatly appreciated.
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
|
https://github.com/pytorch/pytorch/issues/69610
|
open
|
[
"module: autograd",
"triaged",
"oncall: visualization"
] | 2021-12-08T14:37:00Z
| 2025-12-24T06:43:52Z
| null |
anubane
|
pytorch/TensorRT
| 765
|
❓ [Question] Sometimes inference time is too slow..
|
## ❓ Question
Thank you for this nice project, I successfully converted [my model](https://github.com/sejong-rcv/MLPD-Multi-Label-Pedestrian-Detection), which feeds multispectral images, using Torch-TensorRT as below.
```
model = torch.load(model_path)['model']
model = model.to(device)
model.eval()
scripted_model = torch.jit.script(model)
# For static size shape=[1, 3, 224, 224]
compile_settings = {
"inputs": [torch_tensorrt.Input(
min_shape=[1, 3, 512, 640],
opt_shape=[1, 3, 512, 640],
max_shape=[1, 3, 512, 640],
dtype=torch.half),
torch_tensorrt.Input(
min_shape=[1, 1, 512, 640],
opt_shape=[1, 1, 512, 640],
max_shape=[1, 1, 512, 640],
dtype=torch.half
)],
"enabled_precisions": {torch.half} # Run with FP16
}
trt_ts_module = torch_tensorrt.ts.compile(scripted_model, **compile_settings)
fake_vis_fp16 = torch.ones((1, 3, 512, 640)).half().cuda()
fake_lwir_fp16 = torch.ones((1, 1, 512, 640)).half().cuda()
fake_vis_fp32 = torch.ones((1, 3, 512, 640)).float().cuda()
fake_lwir_fp32 = torch.ones((1, 1, 512, 640)).float().cuda()
torch.jit.save(trt_ts_module, "MLPD_trt_torchscript_module.ts") # save the TRT embedded Torchscript
```
Then, I tested the inference time of the model. I found that sometimes it is too slow as below.

How can i solve this problem..? Performance(Miss-rate) of converted model is the same as performance of original model.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 3.7
- OS (e.g., Linux): Linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): conda
- Python version: 3.8.12
- CPU Architecture:
- CUDA version: 11.4
- GPU models and configuration: 2080Ti
- Any other relevant information: I used docker image
## Additional context
|
https://github.com/pytorch/TensorRT/issues/765
|
closed
|
[
"question",
"No Activity"
] | 2021-12-08T09:57:32Z
| 2022-04-01T00:02:19Z
| null |
socome
|
pytorch/vision
| 5,045
|
[Discussion] How do we want to handle `torchvision.prototype.features.Feature`'s?
|
This issue should spark a discussion about how we want to handle `Feature`'s in the future. There are a lot of open questions I'm trying to summarize. I'll give my opinion to each of them. You can find the current implementation under `torchvision.prototype.features`.
## What are `Feature`'s?
`Feature`'s are subclasses of `torch.Tensor` and their purpose is threefold:
1. With their type, e.g. `Image`, they information about the data they carry. The prototype transformations (`torchvision.prototype.transforms`) use this information to automatically dispatch an input to the correct kernel.
2. They can optionally carry additional meta data that might be needed for transforming the feature. For example, most geometric transformations can only be performed on bounding boxes if the size of the corresponding image is known.
3. They provide a convenient interface for feature specific functionality, for example transforming the format of a bounding box.
There are currently three `Feature`'s implemented
- `Image`,
- `BoundingBox`, and
- `Label`,
but in the future we should add at least three more:
- `SemanticSegmentationMask`,
- `InstanceSegementationMask`, and
- `Video`.
## What is the policy of adding new `Feature`'s?
We could allow subclassing of `Feature`'s. On the one hand, this would make it easier for datasets to conveniently bundle meta data. For example, the COCO dataset could return a `CocoLabel`, which in addition to the default `Label.category` could also have the `super_category` field. On the other hand, this would also mean that the transforms need to handle subclasses of features well, for example a `CocoLabel` could be treated the same as a `Label`.
I see two downsides with that:
1. What if a transform needs the additional meta data carried by a feature subclass? Imagine I've added a special transformation that needs `CocoLabel.super_category`. Although from the surface this now supports plain `Label`'s this will fail at runtime.
2. Documentation custom features is more complicated than documenting a separate field in the sample dictionary of a dataset.
Thus, I'm leaning towards only having a few base classes.
## From what data should a `Feature` be instantiable?
Some of the features like `Image` or `Video` have non-tensor objects that carry the data. Should these features know how to handle them? For example should something like `Image(PIL.Image.open(...))` work?
My vote is out for yes. IMO this is very convenient and also not an unexpected semantic compared to passing the data directly, e.g. `Image(torch.rand(3, 256, 256))`
## Should `Feature`'s have a fixed shape?
Consider the following table:
| `Feature` | `.shape` |
|-----------------------------|-------------------------------|
| `Image` | `(*, C, H, W)` |
| `Label` | `(*)` |
| `BoundingBox` | `(*, 4)` |
| `SemanticSegmentationMask` | `(*, H, W)` or `(*, C, H, W)` |
| `InstanceSegementationMask` | `(*, N, H, W)` |
| `Video` | `(*, T, C, H, W)` |
(For `SemanticSegmentationMask` I'm not sure about the shape yet. Having an extra channel dimension makes the tensor unnecessarily large, but it aligns well with segmentation image files, which are usually stored as RGB)
Should we fix the shape to a single feature, i.e. remove the `*` from the table above, or should we only care about the shape in the last dimensions to be correct?
My vote is out for having a flexible shape, since otherwise batching is not possible. For example, if we fix bounding boxes to shape `(4,)` a transformation would need to transform `N` bounding boxes individually, while for shape `(N, 4)` it could make use of parallelism.
On the same note, if we go for the flexible shape, do we keep the singular name of the feature? For example, do we regard a batch of images with shape `(B, C, H, W)` still as `Image` or should we go for the plural `Images` in general? My vote is out for always keeping the singular, since I've often seen something like:
```python
for image, target in data_loader(dataset, batch_size=4):
...
```
## Should `Feature`'s have a fixed dtype?
This makes sense for `InstanceSegementationMask` which should always be `torch.bool`. For all the other features I'm unsure. My gut says to use a default dtype, but also allow other dtypes.
## What meta data should `Feature`'s carry?
IMO, this really depends on the decision above about the fixed / flexible shapes. If we go for fixed shapes, it can basically carry any information. If we go for flexible shapes instead, we should only have meta data, which is the same for batched features. For example, `BoundingBox.image_size` is fine, but `Label.category` is not.
## What methods should `Feature`'s provide?
For now I've only in
|
https://github.com/pytorch/vision/issues/5045
|
open
|
[
"needs discussion",
"prototype"
] | 2021-12-07T13:17:58Z
| 2022-02-11T11:42:36Z
| null |
pmeier
|
pytorch/data
| 113
|
datapipe serialization support / cloudpickle / parallel support
|
I've been looking at how we might go about supporting torchdata within TorchX and with components. I was wondering what the serialization options were for transforms and what that might look like.
There's a couple of common patterns that would be nice to support:
* general data transforms (with potentially distributed preprocessing via torch elastic/ddp)
* data splitting into train/validation sets
* summary statistic computation
For the general transforms and handling arbitrary user data we were wondering how we might go about serializing the data pipes and transforms for use in a pipeline with TorchX.
There's a couple of options here:
1. add serialization support to the transforms so you can serialize them (lambdas?)
1. generate a .py file from a provided user function
1. pickle the transform using something like cloudpickle/torch.package and load it in a trainer app
1. ask the user to write a .py file that uses the datapipes as the transform and create a TorchX component (what we currently have)
Has there been any thought about how to support this well? Is there extra work that should be done here to make this better?
Are DataPipes guaranteed to be pickle safe and is there anything that needs to be done to support that?
I was also wondering if there's multiprocessing based datapipes and how that works since this seems comparable. I did see https://github.com/pytorch/pytorch/blob/master/torch/utils/data/distributed.py but didn't see any examples on how to use that to achieve a traditional PyTorch dataloader style workers.
P.S. should this be on the pytorch discussion forums instead? it's half feature request half questions so wasn't sure where best to put it
cc @kiukchung
|
https://github.com/meta-pytorch/data/issues/113
|
open
|
[] | 2021-12-04T00:46:36Z
| 2022-12-09T15:34:39Z
| 7
|
d4l3k
|
pytorch/TensorRT
| 761
|
can i server my model with triton inference server
|
## ❓ Question
<!-- Your question -->
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):
- CPU Architecture:
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:
- CUDA version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/761
|
closed
|
[
"question",
"No Activity"
] | 2021-12-03T14:10:51Z
| 2024-09-12T16:27:05Z
| null |
leo-XUKANG
|
pytorch/pytorch
| 69,352
|
I want to know how to read the LMDB file once when using DDP
|
Hi, I meet a question. I have an LMDB dataset of about 50G. My machine has 100G memory and 8 V100 GPUs of 32GB.
the format of My dataset is like:
```
class MyDataset(Dataset):
def __init__(self, img_lmdb_dir) -> None:
super().__init__()
self.env = lmdb.open( # open LMDB dataset
img_lmdb_dir, readonly=True,
create=False)
self.txn = self.env.begin(buffers=True)
def __len__(self) -> int:
raise NotImplemented
def __getitem__(self, index: int):
...
return ...
```
As you can see, I open an LMDB dataset at the "init" method. However, if I use 8 GPUs. The each process will build this dataset and open LMDB dataset 8 times. One LMDB need 50G, so 8 LMDB needs 400G, which is more than my machine's memory.
So, I want to know how to use the LMDB file to accelerate to load training data and meanwhile total memory cost is lower than in my environment.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang
|
https://github.com/pytorch/pytorch/issues/69352
|
open
|
[
"oncall: distributed",
"module: dataloader"
] | 2021-12-03T07:34:16Z
| 2022-12-29T14:32:17Z
| null |
shoutOutYangJie
|
pytorch/pytorch
| 69,283
|
how to get required arguments name in forward
|
I want to get the required arguments name in different model's forward, removing optional arguments. I used python inspect, but got all inputs' name. I have no idea to deal it. please help
|
https://github.com/pytorch/pytorch/issues/69283
|
closed
|
[] | 2021-12-02T08:14:49Z
| 2021-12-02T17:47:53Z
| null |
TXacs
|
pytorch/pytorch
| 69,204
|
How to assign tensor to tensor
|
I have a 3D tensor J, and I want to assign values to it. Below is my code
```
import torch
J = torch.eye(2).unsqueeze(0).expand(5, 2, 2)
for i in range(2):
J[:, i, :] = torch.randn([5, 2])
```
Then there is an error: unsupported operation: more than one element of the written-to tensor refers to a single memory location. Please clone() the tensor before performing the operation.
|
https://github.com/pytorch/pytorch/issues/69204
|
closed
|
[] | 2021-12-01T10:45:06Z
| 2021-12-01T20:33:43Z
| null |
LeZhengThu
|
pytorch/pytorch
| 69,070
|
how to compute the real Jacobian matrix using autograd tool
|
I want to compute the real Jacobian matrix instead of the vector-Jacobian product. For example, I have
```f=(f1, f2, f3), f1=x1^2+2*x2+x3, f2=x1+x2^3+x3^2, f3=2*x1+x2^2+x3^3```
Then the Jacobian is ```J=[2*x1, 2, 1; 1, 3*x2^2, 2*x3; 2, 2*x2, 3*x3^2] ```
But backward() or grad() only gives the vector-Jacobian product. The following is my test code
```
import torch
import numpy as np
x = torch.tensor(np.array([[1,2,3]]), requires_grad=True, dtype=torch.float)
y = torch.randn(3)
y[0] = x[0][0]**2+2*x[0][1]+x[0][2]
y[1] = x[0][0]+x[0][1]**3+x[0][2]**2
y[2] = 2*x[0][0]+x[0][1]**2+x[0][2]**3
torch.autograd.grad(y, x, torch.ones_like(y))
```
The result is tensor([[5,18,34]]). This is the result of J*[1;1;1] since I put torch.ones_like(y) in the code. Of course, I can use [1,0,0] to get each element of J, but that is too slow. Do we have any faster way to achieve this?
BTW, when I try to replace torch.ones_like(y) with torch.eye(y.shape[0]), an error occurs: Mismatch in shape: grad_output[0] has a shape of torch.Size([3, 3]) and output[0] has a shape of torch.Size([3]).
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
|
https://github.com/pytorch/pytorch/issues/69070
|
closed
|
[
"module: autograd",
"triaged"
] | 2021-11-30T10:05:01Z
| 2021-12-01T19:44:55Z
| null |
LeZhengThu
|
pytorch/pytorch
| 69,068
|
how to build libtorch without mkl?
|
## ❓ Questions and Help
I download the libtorch(CPU) 1.3.0 from [pytorch](https://download.pytorch.org/libtorch/cpu/libtorch-cxx11-abi-shared-with-deps-1.3.0%2Bcpu.zip), The dependency library is follow:

But the library is not available in my environment due to the gcc version is 4.8.5, so I builded it from pytorch source and the dependency library is follow:

```
export BLAS=Eigen
export USE_CUDA=False
export BUILD_TEST=False
export USE_NINJA=OFF
export BUILD_CAFFE2_MOBILE=OFF
export BUILD_CAFFE2_OPS=OFF
export USE_MKL=OFF
export USE_MKLDNN=OFF
```
For some reason, I want not to depended on mkl, so how to build libtorch without mkl?
cc @malfet @seemethere
|
https://github.com/pytorch/pytorch/issues/69068
|
closed
|
[
"module: build",
"triaged"
] | 2021-11-30T09:52:16Z
| 2021-12-01T02:26:05Z
| null |
zhoujinhai
|
pytorch/serve
| 1,347
|
how to use body in json format to predict
|
## 📚 Documentation
i have a model named greedy as a demo, and use baseHander
i can't find the doc to deal with input of predictions api
examples all use the file to predict, can i use body for application/json format to predict
and this is the curl
```bash
curl --location --request POST 'http://localhost:6080/predictions/greedy' \
--header 'Content-Type: application/json' \
--data-raw '{
"model_name": "greedy",
"model_version ": 1.0,
"input": {
"data": [
1,
2,
3
]
}
}'
```
|
https://github.com/pytorch/serve/issues/1347
|
closed
|
[] | 2021-11-26T14:36:43Z
| 2021-11-26T16:00:39Z
| null |
SpringTY
|
pytorch/TensorRT
| 744
|
how to convert the pytorch quantized model to trt model ?
|
I use the pytorch qat method to train the model and save the quantized model ( int8 ) .
But when I use torch_tensorrt.ts.compile interface to convert the int8 model to trt , errors happen, such as "ERROR: [Torch-TensorRT] - **Unsupported operator: quantized::linear**" , "**Unsupported operator: quantized::conv2d.new**" , and so on.
Dose the torch_tensorrt.ts.compile support pytorch quantized model? how to solve the problem?
|
https://github.com/pytorch/TensorRT/issues/744
|
closed
|
[
"question",
"No Activity"
] | 2021-11-26T11:11:00Z
| 2022-03-13T00:02:19Z
| null |
jiinhui
|
pytorch/pytorch
| 68,925
|
How to implement `bucket_by_sequence_length` with IterableDataset and DataLoader
|
## How to implement `bucket_by_sequence_length` with IterableDataset and DataLoader?
I have a custom **IterableDataset** for question answering, which reads training data from a huge file. And I want to bucket the tranining exampels by their sequence length, like `tf.data.Dataset.bucket_by_sequence_length`.
Any documents or tutorials about this?
cc @SsnL @VitalyFedyunin @ejguan @NivekT
|
https://github.com/pytorch/pytorch/issues/68925
|
open
|
[
"module: dataloader",
"triaged",
"module: data"
] | 2021-11-26T03:06:17Z
| 2021-11-30T15:32:48Z
| null |
luozhouyang
|
pytorch/TensorRT
| 740
|
What's the difference compared to native tensort sdk?
|
I used to convert a pytorch model to onnx format,and try to run it using native TensorRT SDK,but I failed for some operators in model is not supported by trt sdk; So if I use Torch-TensorRT to run the model, will I still have the same problem? Is there any more operators added compared to the native trt sdk?
|
https://github.com/pytorch/TensorRT/issues/740
|
closed
|
[
"question"
] | 2021-11-23T08:09:14Z
| 2021-11-29T20:14:45Z
| null |
pango99
|
pytorch/android-demo-app
| 213
|
how to converto torchscript_int8@tracing file to pt file?
|
i have a custom model file,ie model.jit,how can i convert to d2go.pt?
|
https://github.com/pytorch/android-demo-app/issues/213
|
closed
|
[] | 2021-11-23T03:34:57Z
| 2022-06-29T08:42:41Z
| null |
cloveropen
|
pytorch/pytorch
| 68,729
|
How to specify the backends when running on CPU
|
## ❓ Questions and Help
### How to specify the backends when running on CPU.
Hi, I noticed that there are multiple backends available on CPU in pytorch: mkl, mkldnn, openmp.
How do I know which backend pytorch is using in current model and can I specify the backend?
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/68729
|
closed
|
[] | 2021-11-22T13:54:35Z
| 2021-11-22T18:53:55Z
| null |
zheng-ningxin
|
huggingface/transformers
| 14,482
|
where can I find the dataset bert-base-chinese is pretrained on?
|
https://github.com/huggingface/transformers/issues/14482
|
closed
|
[] | 2021-11-22T09:22:51Z
| 2021-12-30T15:02:07Z
| null |
BoomSky0416
|
|
pytorch/xla
| 3,221
|
[Question] How to do deterministic training on GPUs.
|
## ❓ Questions and Help
Hi, I'm testing torch xla on GPU. The script used is based on the test_train_mp_mnist.py. I changed the data input to be consistent for all workers (use the same dataset, no distributed sampler, turn off shuffle), don't adjust the learning rate, adding deterministic functions, andd adding logic to run with torch native.
The loss trends of the standalone torch xla and torch native are mostly aligned, although not bitwise, but given the nature of floating point calculations, the results are mostly satisfactory.
However, I noticed a rather strange behavior, as the torch native results are consistent for each round of the run with two cards, even with the single card bitwise. However, the loss of torch xla with two cards kept changing, and with XLA_SYNC_WAIT on, the consistent results with torch xla standalone was gotten (I'm not sure if it's always that).
I would like to know why, is there something wrong with my code? Thanks!
## code
```
import args_parse
FLAGS = args_parse.parse_common_options(
datadir="/tmp/mnist-data",
batch_size=128,
momentum=0.5,
lr=0.01,
target_accuracy=98.0,
num_epochs=18,
)
import os
import shutil
import sys
import numpy as np
import torch
import random
import numpy as np
from torch.nn.parallel import DistributedDataParallel as DDP
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import torch_xla
import torch_xla.debug.metrics as met
import torch_xla.distributed.parallel_loader as pl
import torch_xla.utils.utils as xu
import torch_xla.core.xla_model as xm
import torch_xla.distributed.xla_multiprocessing as xmp
import torch_xla.test.test_utils as test_utils
def set_deterministic(seed=101):
torch.manual_seed(seed)
random.seed(seed)
np.random.seed(seed)
torch.use_deterministic_algorithms(True)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ['CUBLAS_WORKSPACE_CONFIG']=':4096:8'
os.environ['TF_CUDNN_DETERMINISTIC']='1'
os.environ['TF_DETERMINISTIC_OPS']='1'
xm.set_rng_state(seed)
torch_xla._XLAC._xla_set_use_full_mat_mul_precision(
use_full_mat_mul_precision=True)
class MNIST(nn.Module):
def __init__(self):
super(MNIST, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.bn1 = nn.BatchNorm2d(10)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.bn2 = nn.BatchNorm2d(20)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = self.bn1(x)
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = self.bn2(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
def _train_update(device, x, loss, tracker, writer):
test_utils.print_training_update(
device, x, loss.item(), tracker.rate(), tracker.global_rate(), summary_writer=writer
)
def train_mnist(flags, **kwargs):
if flags.fake_data:
train_loader = xu.SampleGenerator(
data=(
torch.zeros(flags.batch_size, 1, 28, 28),
torch.zeros(flags.batch_size, dtype=torch.int64),
),
sample_count=60000 // flags.batch_size // xm.xrt_world_size(),
)
test_loader = xu.SampleGenerator(
data=(
torch.zeros(flags.batch_size, 1, 28, 28),
torch.zeros(flags.batch_size, dtype=torch.int64),
),
sample_count=10000 // flags.batch_size // xm.xrt_world_size(),
)
else:
train_dataset = datasets.MNIST(
os.path.join(flags.datadir, str(xm.get_ordinal())),
train=True,
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
)
test_dataset = datasets.MNIST(
os.path.join(flags.datadir, str(xm.get_ordinal())),
train=False,
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
),
)
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=flags.batch_size,
sampler=train_sampler,
drop_last=flags.drop_last,
shuffle=False,
num_workers=flags.num_workers,
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=flags.batch_size,
drop_last=flags.drop_last,
shuffle=False
|
https://github.com/pytorch/xla/issues/3221
|
closed
|
[
"stale",
"xla:gpu"
] | 2021-11-22T09:16:11Z
| 2022-04-28T00:10:33Z
| null |
cicirori
|
pytorch/hub
| 254
|
How to use hub if don't have network?
|
Downloading: "https://github.com/ultralytics/yolov5/archive/master.zip" to /root/.cache/torch/hub/master.zip
I always stop in last line.
Is there anyway to use hub offline.
|
https://github.com/pytorch/hub/issues/254
|
closed
|
[] | 2021-11-22T08:44:47Z
| 2021-11-22T09:40:01Z
| null |
Skypow2012
|
pytorch/tutorials
| 1,747
|
Is it possible to perform partial conversion of a pytorch model to ONNX?
|
I have the following VAE model in pytorch that I would like to convert to ONNX (and eventually to TensorFlow):
https://github.com/jlalvis/VAE_SGD/blob/master/VAE/autoencoder_in.py
I am only interested in the decoding part of the model. Is it possible to convert only the decoder to ONNX?
Thanks in advance :)
cc @BowenBao
|
https://github.com/pytorch/tutorials/issues/1747
|
closed
|
[
"question",
"onnx"
] | 2021-11-19T10:49:56Z
| 2023-03-07T17:36:34Z
| null |
ShiLevy
|
pytorch/functorch
| 280
|
How to update the original model parameters after calling make_functional?
|
As per the title, I find that updating the tensors pointed by the `params` returned by `make_functional` does not update the real parameters in the original model.
Is there a way to do this? I find that it would be extremely useful to implement optimization algorithms in a way that is more similar to their mathematical description.
To provide more context I add an example script of what standard Gradient Descent should look like in this way:
```python
import torch
from torch import nn
from functorch import make_functional
learning_rate = 0.1
def optstep(params, jacobians):
with torch.no_grad():
for i, param in enumerate(params):
param.add_(jacobians[i], alpha=-learning_rate)
if __name__ == '__main__':
model = nn.Linear(3, 5)
x, targets = torch.randn(2, 3), torch.randn(2, 5)
criterion = nn.MSELoss()
print("INITIAL LOSS:", criterion(model(x), targets).item())
# Render the model functional and compute the jacobian
func_model, params = make_functional(model)
def f(*params):
out = func_model(params, x)
return criterion(out, targets)
jacobian = torch.autograd.functional.jacobian(f, params)
# Ideally would train on the current input
optstep(params, jacobian)
# Now compute the new loss
print("NEW LOSS:", criterion(model(x), targets).item())
```
Executing the script shows that the parameters are not updated since the loss doesn't change
```
INITIAL LOSS: 1.2894147634506226
NEW LOSS: 1.2894147634506226
```
|
https://github.com/pytorch/functorch/issues/280
|
open
|
[
"actionable"
] | 2021-11-19T08:54:25Z
| 2022-04-13T22:32:19Z
| null |
trenta3
|
pytorch/TensorRT
| 733
|
Unable to use any Torch-TensorRT methods
|
I'm facing this error:
> AttributeError: module 'torch_tensorrt' has no attribute 'compile'
I also get this error when I try to use any other method like Input().
This is how I installed Torch-TensorRT:
`pip install torch-tensorrt -f github.com/NVIDIA/Torch-TensorRT/releases`
Code (from official documentation):
```
import torch_tensorrt
model = model.eval()
compile_settings = {
"input_shapes": [
{
"min": [1, 1, 16, 16],
"opt": [1, 1, 32, 32],
"max": [1, 1, 64, 64]
},
],
"op_precision": torch.half # Run with fp16
}
enabled_precisions = {torch.float, torch.half}
trt_ts_module = torch_tensorrt.compile(model, inputs=compile_settings, enabled_precisions=enabled_precisions)
```
Stack Trace:
```
AttributeError Traceback (most recent call last)
<command-3167120371910218> in <module>
14 enabled_precisions = {torch.float, torch.half}
15
---> 16 trt_ts_module = torch_tensorrt.compile(model, inputs=compile_settings, enabled_precisions=enabled_precisions)
AttributeError: module 'torch_tensorrt' has no attribute 'compile'
```
Please let me know how I can fix this issue.
|
https://github.com/pytorch/TensorRT/issues/733
|
closed
|
[
"question",
"No Activity",
"channel: windows"
] | 2021-11-18T20:40:58Z
| 2022-10-27T13:01:48Z
| null |
Arjunp24
|
pytorch/TensorRT
| 732
|
❓ [Question] More average batch time for torch-tensorrt compiled model than torchscript model (fp32 mode).
|
## ❓ Question
I am comparing the performances of the torchscript model and the torch-tensorrt compiled model, when I am running in float32 mode, the average batch time is more for torch-tensorrt model. Is this expected?1. I am running the below code to compare torchscript model and torch-tensorrt compiled models,
```
class LeNetFeatExtractor(nn.Module):
def __init__(self):
super(LeNetFeatExtractor, self).__init__()
self.conv1 = nn.Conv2d(1, 128, 3)
self.conv2 = nn.Conv2d(128, 16, 3)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
return x
class LeNetClassifier(nn.Module):
def __init__(self):
super(LeNetClassifier, self).__init__()
self.fc1 = nn.Linear(16 * 6 * 6, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = torch.flatten(x,1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.feat = LeNetFeatExtractor()
self.classifer = LeNetClassifier()
def forward(self, x):
x = self.feat(x)
x = self.classifer(x)
return x
def benchmark(model, input_shape=(1024, 1, 32, 32), dtype='fp32', nwarmup=50, nruns=100):
input_data = torch.randn(input_shape)
input_data = input_data.to("cuda")
if dtype=='fp16':
input_data = input_data.half()
print("Warm up ...")
with torch.no_grad():
for _ in range(nwarmup):
features = model(input_data)
torch.cuda.synchronize()
print("Start timing ...")
timings = []
with torch.no_grad():
for i in range(1, nruns+1):
start_time = time.time()
features = model(input_data)
torch.cuda.synchronize()
end_time = time.time()
timings.append(end_time - start_time)
if i%100==0:
print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
print("Input shape:", input_data.size())
print("Output features size:", features.size())
print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
model = LeNet()
model.to("cuda").eval()
benchmark(model, dtype="fp32")
inpt = torch.empty([1,1,32,32]).to("cuda")
traced_model = torch.jit.trace(model, inpt)
benchmark(traced_model, dtype="fp32")
script_model = torch.jit.script(model)
benchmark(script_model, dtype="fp32")
compile_settings = {
"inputs": [torch_tensorrt.Input(
min_shape=[1024, 1, 32, 32],
opt_shape=[1024, 1, 33, 33],
max_shape=[1024, 1, 34, 34],
dtype=torch.float
)],
"enabled_precisions": {torch.float} # Run with FP16
}
trt_ts_module = torch_tensorrt.compile(traced_model, **compile_settings)
benchmark(trt_ts_module, input_shape=(1024, 1, 32, 32), dtype="fp32")
```
2. Check below my performance comparison results:
```
Warm up ...
Start timing ...
Iteration 100/100, ave batch time 39.72 ms
Input shape: torch.Size([1024, 1, 32, 32])
Output features size: torch.Size([1024, 10])
Average batch time: 39.72 ms
Warm up ...
Start timing ...
Iteration 100/100, ave batch time 39.74 ms
Input shape: torch.Size([1024, 1, 32, 32])
Output features size: torch.Size([1024, 10])
Average batch time: 39.74 ms
Warm up ...
Start timing ...
Iteration 100/100, ave batch time 39.77 ms
Input shape: torch.Size([1024, 1, 32, 32])
Output features size: torch.Size([1024, 10])
Average batch time: 39.77 ms
WARNING: [Torch-TensorRT] - Dilation not used in Max pooling converter
WARNING: [Torch-TensorRT] - Dilation not used in Max pooling converter
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 10.2.2
WARNING: [Torch-TensorRT TorchScript Conversion Context] - Detected invalid timing cache, setup a local cache instead
WARNING: [Torch-TensorRT TorchScript Conversion Context] - Max value of this profile is not valid
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 10.2.2
WARNING: [Torch-TensorRT] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 10.2.2
WARNING: [Torch-TensorRT] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 10.2.2
Warm up ...
Start timing ...
Iteration 100/100, ave batch time 57.29 ms
Input shape: torch.Size([1024, 1, 32, 32])
Output features size: torch.Size([1024, 10])
Average batch time: 57.29 ms
```
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.10
|
https://github.com/pytorch/TensorRT/issues/732
|
closed
|
[
"question",
"No Activity"
] | 2021-11-18T17:58:10Z
| 2022-02-28T17:49:23Z
| null |
harishkool
|
huggingface/transformers
| 14,440
|
What does "is_beam_sample_gen_mode" mean
|
Hi, I find there are many ways for generating sequences in `Transformers`(when calling the `generate` method).
According to the code there:
https://github.com/huggingface/transformers/blob/01f8e639d35feb91f16fd3c31f035df11a726cc5/src/transformers/generation_utils.py#L947-L951
As far as I known:
`is_greedy_gen_mode` stands for Greedy Search.
`is_sample_gen_mode` stands for Sampling(with top_k and top_p).
`is_beam_gen_mode` stands for Beam Search .
But what does `is_beam_sample_gen_mode` mean?
Besides, I want to know how do I choose the correct way for generating. I have tried serval ways, but:
1. I find the sequences out from "beam search" mode becomes too similar.
2. I also find the sequences out from "sample" mode, while being diverse, are lacking context coherence.
Thank you!
|
https://github.com/huggingface/transformers/issues/14440
|
closed
|
[] | 2021-11-18T06:31:52Z
| 2023-02-28T05:13:29Z
| null |
huhk-sysu
|
pytorch/TensorRT
| 730
|
Convert YoloV5 models
|
It is my understanding that the new stable release should be able to convert any PyTorch model with fallback to PyTorch when operations cannot be directly converted to TensorRT. I am trying to convert
I am trying to convert YoloV5s6 to TensorRT using the code that you can find below. I believe that it would be great to be able to convert this particular model given its popularity.
During the conversion I am encountering some errors. Is this because the model cannot be converted to TorchScript? I also noticed that the model is composed of classes which extends `nn.Module`.
Of course, YoloV5 code can be found here: https://github.com/ultralytics/yolov5
Thank you!
## To Reproduce
```
import torch
import torch_tensorrt
model = torch.hub.load("ultralytics/yolov5", "yolov5s6")
model.eval()
compile_settings = {
"inputs": [torch_tensorrt.Input(
# For static size
shape=[1, 3, 640, 640], # TODO: depends on the model size
# For dynamic size
# min_shape=[1, 3, 224, 224],
# opt_shape=[1, 3, 512, 512],
# max_shape=[1, 3, 1024, 1024],
dtype=torch.half, # Datatype of input tensor. Allowed options torch.(float|half|int8|int32|bool)
)],
# "require_full_compilation": False,
"enabled_precisions": {torch.half}, # Run with FP16
"torch_fallback": {
"enabled": True, # Turn on or turn off falling back to PyTorch if operations are not supported in TensorRT
}
}
trt_ts_module = torch_tensorrt.compile(model, **compile_settings)
```
Output:
```
Using cache found in /home/ubuntu/.cache/torch/hub/ultralytics_yolov5_master
YOLOv5 🚀 2021-11-17 torch 1.10.0+cu113 CUDA:0 (Tesla T4, 15110MiB)
Fusing layers...
Model Summary: 280 layers, 12612508 parameters, 0 gradients
Adding AutoShape...
Traceback (most recent call last):
File "/usr/lib/python3.6/code.py", line 91, in runcode
exec(code, self.locals)
File "<input>", line 21, in <module>
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch_tensorrt/_compile.py", line 96, in compile
ts_mod = torch.jit.script(module)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_script.py", line 1258, in script
obj, torch.jit._recursive.infer_methods_to_compile
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_recursive.py", line 451, in create_script_module
return create_script_module_impl(nn_module, concrete_type, stubs_fn)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_recursive.py", line 513, in create_script_module_impl
script_module = torch.jit.RecursiveScriptModule._construct(cpp_module, init_fn)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_script.py", line 587, in _construct
init_fn(script_module)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_recursive.py", line 491, in init_fn
scripted = create_script_module_impl(orig_value, sub_concrete_type, stubs_fn)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_recursive.py", line 517, in create_script_module_impl
create_methods_and_properties_from_stubs(concrete_type, method_stubs, property_stubs)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_recursive.py", line 368, in create_methods_and_properties_from_stubs
concrete_type._create_methods_and_properties(property_defs, property_rcbs, method_defs, method_rcbs, method_defaults)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_script.py", line 1433, in _recursive_compile_class
return _compile_and_register_class(obj, rcb, _qual_name)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/_recursive.py", line 42, in _compile_and_register_class
ast = get_jit_class_def(obj, obj.__name__)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/frontend.py", line 201, in get_jit_class_def
is_classmethod=is_classmethod(obj)) for (name, obj) in methods]
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/frontend.py", line 201, in <listcomp>
is_classmethod=is_classmethod(obj)) for (name, obj) in methods]
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/frontend.py", line 264, in get_jit_def
return build_def(parsed_def.ctx, fn_def, type_line, def_name, self_name=self_name, pdt_arg_types=pdt_arg_types)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/frontend.py", line 302, in build_def
param_list = build_param_list(ctx, py_def.args, self_name, pdt_arg_types)
File "/home/ubuntu/pycharm/venv/lib/python3.6/site-packages/torch/jit/frontend.py", line 330, in build_param_list
raise NotSupportedError(ctx_range, _vararg_kwarg_err)
torch.jit.frontend.NotSupportedError: Compiled functions can't take variable number of arguments or use keyword-only arguments with defaults:
File "/usr
|
https://github.com/pytorch/TensorRT/issues/730
|
closed
|
[
"question",
"No Activity",
"component: partitioning"
] | 2021-11-17T18:37:44Z
| 2023-02-27T00:02:29Z
| null |
mfoglio
|
pytorch/TensorRT
| 727
|
I trained a model by libtorch,how to convert it to tensorrt?
|
by libtorch,not by pytorch.
how to convert the model to tensorrt?
|
https://github.com/pytorch/TensorRT/issues/727
|
closed
|
[
"question",
"No Activity"
] | 2021-11-17T07:35:55Z
| 2022-02-26T00:01:58Z
| null |
henbucuoshanghai
|
pytorch/vision
| 4,949
|
GPU usage keeps increasing marginally with each inference request
|
### 🐛 Describe the bug
I have been trying to deploy the RetinaNet pre-trained model available in torchvision. However, after every inference request with exactly same image, the gpu usage keeps increasing marginally (by roughly 10 MiB, as visible in nvidia-smi). (Same behavior is noticed if I try the same with other Object Detection models like fasterrcnn_resnet50_fpn, fasterrcnn_mobilenet_v3_large_fpn.)
The brief code used for inference
```python
# load the model
self.Model = retinanet_resnet50_fpn(pretrained=True)
self.Model.to(torch.device('cuda'))
self.Model.eval()
# inference fn
@torch.no_grad()
def DetectObjects(self, image, threshold=0.4)->dict:
image = convert_image_dtype(torch.stack([image]), dtype=torch.float)
image = image.to(torch.device('cuda'))
results = self.Model(image)[0]
gt = results['scores']>threshold
labels, boxes, scores = results['labels'][gt].cpu().tolist(), results['boxes'][gt].cpu().tolist(), results['scores'][gt].cpu().tolist()
torch.cuda.empty_cache()
return boxes, labels, scores
```
### Versions
```
Collecting environment information...
PyTorch version: 1.10.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.6 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Libc version: glibc-2.17
Python version: 3.7.10 (default, Feb 20 2021, 21:21:24) [GCC 5.4.0 20160609] (64-bit runtime)
Python platform: Linux-4.15.0-162-generic-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: NVIDIA GeForce GTX 1660 SUPER
Nvidia driver version: 465.19.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.2.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.2.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.21.4
[pip3] torch==1.10.0
[pip3] torchvision==0.11.1
[conda] Could not collect
```
cc @datumbox
|
https://github.com/pytorch/vision/issues/4949
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2021-11-16T19:43:49Z
| 2024-02-28T15:01:40Z
| null |
shv07
|
pytorch/android-demo-app
| 209
|
How to add language model in ASR demo
|
The wav2vec2 used in the SpeechRecognition example does not have a language model. How to add language model in the demo app?
|
https://github.com/pytorch/android-demo-app/issues/209
|
open
|
[] | 2021-11-16T10:55:43Z
| 2021-12-10T11:36:07Z
| null |
guijuzhejiang
|
pytorch/pytorch
| 68,414
|
I used libtorch train a model,how to convert it to onnx?
|
libtorch trained a model
|
https://github.com/pytorch/pytorch/issues/68414
|
closed
|
[
"module: onnx",
"triaged"
] | 2021-11-16T07:30:36Z
| 2021-11-17T00:03:41Z
| null |
henbucuoshanghai
|
pytorch/torchx
| 345
|
slurm_scheduler: handle OCI images
|
## Description
<!-- concise description of the feature/enhancement -->
Add support for running TorchX components via the Slurm OCI interface.
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
Slurm 21.08+ has support for running OCI containers as the environment. This matches well with our other docker/k8s images that we use by default. With workspaces + OCI we can support slurm like the docker based environments.
## Detailed Proposal
<!-- provide a detailed proposal -->
The new slurm container support doesn't handle the image finding the same way docker/podman does. This means that the images need to be placed on disk in the same way a virutalenv would be supported which would have to be a user configurable path.
This also means that we have to interact with docker/buildah to download the images and export them to an OCI image on disk. There's some extra questions about image management to avoid disk space issues etc.
The cluster would have to be configured with `nvidia-container-runtime` for use with GPUs.
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
## Additional context/links
<!-- link to code, documentation, etc. -->
https://slurm.schedmd.com/containers.html
|
https://github.com/meta-pytorch/torchx/issues/345
|
open
|
[
"enhancement",
"module: runner",
"slurm"
] | 2021-11-15T23:25:21Z
| 2021-11-15T23:25:21Z
| 0
|
d4l3k
|
pytorch/torchx
| 344
|
workspace notebook UX
|
## Description
<!-- concise description of the feature/enhancement -->
We should add some notebook specific integrations to make working with workspace and launching remote jobs first class. This builds upon the workspace support tracked by #333.
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
Currently there's no specific TorchX integrations for running from within notebooks. It's possible but it's not as fleshed out as it could be.
## Detailed Proposal
<!-- provide a detailed proposal -->
### Jupyter Custom Magics
We want to add a custom magic to allow adding files to the workspace.
https://ipython.readthedocs.io/en/stable/config/custommagics.html#defining-custom-magics
```py
from torchx.notebook import register_magics, get_workspace
register_magics()
```
```py
%%workspacefile train.py
print("train Hello world!")
```
```py
from torchx.components.utils import python
from torchx.runner import get_runner
app = python(m="train")
app_id = runner.run(app, scheduler="local_docker", workspace=get_workspace())
print(app_id)
status = runner.wait(app_id)
print(status)
```
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
This can already be accomplished by writing out a file and directly calling docker build etc. That's a lot more work on the user and requires having an on disk project so the notebook isn't fully self contained.
## Additional context/links
<!-- link to code, documentation, etc. -->
Workspace/canary tracking #333
|
https://github.com/meta-pytorch/torchx/issues/344
|
open
|
[
"enhancement",
"module: runner"
] | 2021-11-15T22:50:59Z
| 2021-11-15T22:50:59Z
| 0
|
d4l3k
|
pytorch/android-demo-app
| 208
|
How to run model with grayscale input?
|
https://github.com/pytorch/android-demo-app/issues/208
|
open
|
[] | 2021-11-15T09:59:11Z
| 2021-11-15T09:59:11Z
| null |
bartproo
|
|
pytorch/torchx
| 340
|
Advanced Pipeline Example Errors on KFP
|
## 📚 Documentation
## Link
https://pytorch.org/torchx/main/examples_pipelines/kfp/advanced_pipeline.html#sphx-glr-examples-pipelines-kfp-advanced-pipeline-py
## What does it currently say?
The pipeline.yaml can be generated and run on Kubeflow
## What should it say?
Unknown, I believe it is a race condition in the code where the pipeline begins execution before the download of the data is complete.
## Why?
<img width="804" alt="Screen Shot 2021-11-13 at 1 36 46 AM" src="https://user-images.githubusercontent.com/43734688/141608949-e41c0d23-4131-4eb8-82c6-e86aeb579e8e.png">
|
https://github.com/meta-pytorch/torchx/issues/340
|
closed
|
[] | 2021-11-13T06:40:22Z
| 2022-01-04T05:06:42Z
| 2
|
sam-h-bean
|
pytorch/torchx
| 339
|
separate .torchxconfig for fb/ and oss
|
## Description
We want to have a FB internal .torchxconfig file to specify scheduler_args for internal cluster and a OSS .torchxconfig file to run on public clusters
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
## Detailed Proposal
<!-- provide a detailed proposal -->
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
## Additional context/links
<!-- link to code, documentation, etc. -->
|
https://github.com/meta-pytorch/torchx/issues/339
|
closed
|
[] | 2021-11-12T19:34:39Z
| 2021-11-16T00:31:48Z
| 1
|
colin2328
|
pytorch/xla
| 3,212
|
How to enable oneDNN optimization?
|
## ❓ Questions and Help
I am doing training and inference on XLA_CPU, but I find that the training speed is particularly slow. Compared with pytorch, the training speed is about 10 times slower.
According to the log, I found that mklcnn acceleration is enabled by default during pytorch training, but when I use xla training, mklcnn is not enabled.
2021-11-12 16:12:44.683410: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE3 SSE4.1 SSE4.2 AVX AVX2 AVX512F FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
How can I enable mkldnn on xla to get training acceleration?
|
https://github.com/pytorch/xla/issues/3212
|
closed
|
[
"question",
"stale"
] | 2021-11-12T08:26:47Z
| 2022-04-16T13:44:03Z
| null |
ZhongYFeng
|
pytorch/TensorRT
| 708
|
ImportError: libtorch_cuda_cu.so: cannot open shared object file: No such file or directory
|
I installed torch-tensorrt via pip: `pip3 install torch-tensorrt -f github.com/NVIDIA/Torch-TensorRT/releases`. And when I try to import it the _ImportError_ raises:
_ImportError: libtorch_cuda_cu.so: cannot open shared object file: No such file or directory_
The full error:
```
ImportError Traceback (most recent call last)
<ipython-input-13-82536c89b207> in <module>
13 from vision.utils.misc import str2bool, Timer, freeze_net_layers, store_labels
14
---> 15 import torch_tensorrt as torchtrt
16
17 # import pytorch_quantization
~/.local/lib/python3.6/site-packages/torch_tensorrt/__init__.py in <module>
9
10 from torch_tensorrt._version import __version__
---> 11 from torch_tensorrt._compile import *
12 from torch_tensorrt._util import *
13 from torch_tensorrt import ts
~/.local/lib/python3.6/site-packages/torch_tensorrt/_compile.py in <module>
1 from typing import List, Dict, Any
----> 2 from torch_tensorrt import _enums
3 import torch_tensorrt.ts
4 from torch_tensorrt import logging
5 import torch
~/.local/lib/python3.6/site-packages/torch_tensorrt/_enums.py in <module>
----> 1 from torch_tensorrt._C import dtype, DeviceType, EngineCapability, TensorFormat
ImportError: libtorch_cuda_cu.so: cannot open shared object file: No such file or directory
```
## Environment
- PyTorch Version (e.g., 1.0): 1.10.0
- CPU Architecture: x86_64
- OS (e.g., Linux): Ubuntu 18.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip3 install torch-tensorrt -f github.com/NVIDIA/Torch-TensorRT/releases
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.6
- CUDA version: 10.2
- GPU models and configuration: GeForce RTX 2080 Ti
- Any other relevant information:
|
https://github.com/pytorch/TensorRT/issues/708
|
closed
|
[
"question"
] | 2021-11-11T09:04:07Z
| 2022-07-29T15:02:57Z
| null |
anvarganiev
|
pytorch/TensorRT
| 697
|
why https://github.com/NVIDIA/Torch-TensorRT/releases/torch_tensorrt-1.0.0-cp36-cp36m-linux_x86_64.whl depends on cuda 10.2 library
|
why https://github.com/NVIDIA/Torch-TensorRT/releases/torch_tensorrt-1.0.0-cp36-cp36m-linux_x86_64.whl depends on cuda 10.2 library
<!-- Your question -->
when I try to install torch-tensorrt and import torch_tensorrt ,It was reported ImportError:libcudart.so.10.2: cannot open shared object file: No such file or directory
## Environment
> ImportError Traceback (most recent call last)
><ipython-input-1-291a947ced8e> in <module>
>----> 1 import torch_tensorrt
>
>/usr/local/python3/lib/python3.6/site-packages/torch_tensorrt/__init__.py in <module>
> 9
> 10 from torch_tensorrt._version import __version__
>---> 11 from torch_tensorrt._compile import *
> 12 from torch_tensorrt._util import *
> 13 from torch_tensorrt import ts
>
>/usr/local/python3/lib/python3.6/site-packages/torch_tensorrt/_compile.py in <module>
> 1 from typing import List, Dict, Any
>----> 2 from torch_tensorrt import _enums
> 3 import torch_tensorrt.ts
> 4 from torch_tensorrt import logging
> 5 import torch
>
>/usr/local/python3/lib/python3.6/site-packages/torch_tensorrt/_enums.py in <module>
>----> 1 from torch_tensorrt._C import dtype, DeviceType, EngineCapability, TensorFormat
>
>ImportError: libcudart.so.10.2: cannot open shared object file: No such file or directory
- PyTorch Version (e.g., 1.0):torch_1.10+cu113
- CPU Architecture: x86_64
- OS (e.g., Linux): Centos 7
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip3
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: python3.6
- CUDA version: cuda-11.3
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/697
|
closed
|
[
"question"
] | 2021-11-10T12:48:15Z
| 2021-11-10T17:02:41Z
| null |
ylz1104
|
pytorch/torchx
| 336
|
[docs] add context/intro to each docs page
|
## 📚 Documentation
## Link
Ex: https://pytorch.org/torchx/main/basics.html
and some other pages
## What does it currently say?
doesn't currently have an intro about the page and how it fits in context, just jumps right into the documentation
## What should it say?
<!-- the proposed new documentation -->
## Why?
<!-- (if not clear from the proposal) why is the new proposed documentation more correct/improvement over the existing one? -->
We got some good feedback from the documentation folks about adding context to each page so if someone gets linked to it they're not totally lost. This matches some of the user feedback we've received so would be good to update this.
|
https://github.com/meta-pytorch/torchx/issues/336
|
closed
|
[
"documentation"
] | 2021-11-08T23:26:47Z
| 2021-11-11T18:33:18Z
| 1
|
d4l3k
|
pytorch/pytorch
| 67,965
|
how to set the quantized data type in QAT
|
When I use the qat and extract the intermedia layer's output I find it's quint8
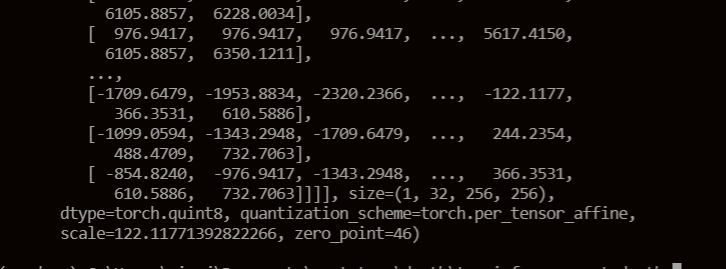
.
This datatype will be the input to the next layer I think.
But the weights are qint8 type. multiple a qint8 with quin8. Does this make sense?
Currently I use the default way to do the qat prepration:
`model_new.qconfig = torch.quantization.get_default_qat_qconfig('fbgemm')`
It seems the observer controls the data type. is there a way to set the data type and do QAT preparation?
cc @jerryzh168 @jianyuh @raghuramank100 @jamesr66a @vkuzo
|
https://github.com/pytorch/pytorch/issues/67965
|
closed
|
[
"oncall: quantization"
] | 2021-11-07T06:03:27Z
| 2021-11-09T13:45:28Z
| null |
mathmax12
|
pytorch/tutorials
| 1,742
|
ddp_pipeline
|
I ran the code as is on the cluster. Gives
`RuntimeError: unsupported operation: some elements of the input tensor and the written-to tensor refer to a single memory location. Please clone() the tensor before performing the operation.`
What could be wrong? Also, is there any way to run this code in Jupyter? By the way, the Colab [notebook](https://colab.research.google.com/github/pytorch/tutorials/blob/gh-pages/_downloads/8976a0b7cba4d8c4bc2a28205b91a7da/ddp_pipeline.ipynb) doesn't run and gives and error
`Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/r/roman-koshkin/miniconda3/envs/tranformer/lib/python3.8/multiprocessing/spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "/home/r/roman-koshkin/miniconda3/envs/tranformer/lib/python3.8/multiprocessing/spawn.py", line 126, in _main
self = reduction.pickle.load(from_parent)
AttributeError: Can't get attribute 'run_worker' on <module '__main__' (built-in)>
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/r/roman-koshkin/miniconda3/envs/tranformer/lib/python3.8/multiprocessing/spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "/home/r/roman-koshkin/miniconda3/envs/tranformer/lib/python3.8/multiprocessing/spawn.py", line 126, in _main
self = reduction.pickle.load(from_parent)
AttributeError: Can't get attribute 'run_worker' on <module '__main__' (built-in)>`
|
https://github.com/pytorch/tutorials/issues/1742
|
closed
|
[] | 2021-11-06T01:13:50Z
| 2022-09-28T15:11:42Z
| 2
|
RomanKoshkin
|
pytorch/pytorch
| 67,757
|
How to build libtorch on aarch64 machine?
|
I used command lines below to build libtorch on aarch64 machine.
```shell
git clone https://github.com/pytorch/pytorch --recursive
cd pytorch
pip3 install pyyaml # 缺失相关依赖,进行安装,如有其他缺失,依次安装即可
export USE_CUDA=False # 使用cpu
export BUILD_TEST=False # 不编译测试部分
python3 ../tools/build_libtorch.py # 会自动创建build文件夹,并进行相关编译
```
But when I test it like [example](https://pytorch.org/cppdocs/installing.html),it shows some error.

I see that size of my libtorch_cpu.so is only 100Mb,far less than the official one in cpu. But I dont konw whats wrong with it.
|
https://github.com/pytorch/pytorch/issues/67757
|
closed
|
[] | 2021-11-03T08:19:34Z
| 2021-11-04T13:43:36Z
| null |
zihaoliao
|
pytorch/pytorch
| 67,596
|
How to upgrade the NCCL version of pytorch 1.7.1 from 2.7.8 to 2.11.4?
|
I have installed version 2.11.4 in wsl2 and can pass the nccl-tests. However, when training the model, pytorch 1.7.1 still calls NCCL 2.7.8. In addition to rebuilding, is there a way for pytorch 1.7.1 to call NCCL 2.11.4 in the system instead of calling the compiled version NCCL 2.7.8?
|
https://github.com/pytorch/pytorch/issues/67596
|
closed
|
[] | 2021-10-31T09:01:45Z
| 2021-11-02T11:41:14Z
| null |
cascgu
|
pytorch/android-demo-app
| 198
|
How to reduce the size of pt file
|
Thanks for your Image Segmentation deepLab v3. I have used it to implement an android file, but the size is about 150MB. Can you enlighten me how can I reduce the size. Thanks.
|
https://github.com/pytorch/android-demo-app/issues/198
|
open
|
[] | 2021-10-31T07:36:36Z
| 2021-10-31T07:36:36Z
| null |
jjlchui
|
pytorch/vision
| 4,802
|
How to monitor and when to retrain the object detection model in production?
|
I recently moved regression model to production and I’m monitoring the model drift and data drift using statistical tests, based on their distributions i retrain the model.
Could you please tell me how to monitoring the object detection model and detect drifts ?
Do you use statistical test to detect drifts? If yes, how do you do that? And which value you as an input to detect?
Please guide me? Even if you could provide any relevant article also would help me
Thanks in advance😊
|
https://github.com/pytorch/vision/issues/4802
|
closed
|
[] | 2021-10-30T12:45:47Z
| 2021-10-31T14:33:09Z
| null |
IamExperimenting
|
pytorch/vision
| 4,795
|
[docs] Pretrained model docs should explain how to specify cache dir and norm_layer
|
### 🐛 Describe the bug
https://pytorch.org/vision/stable/models.html?highlight=resnet18#torchvision.models.resnet18
should document:
- how to set cache dir for downloaded models. many university systems have tight quota for home dir that prohibits clogging it with weights. it is explained at the very top of very long document (`TORCH_MODEL_ZOO`) but it would be nice to duplicate it / link to this from every pretrained method
- how to set `norm_layer = torchvision.ops.misc.FrozenBatchNorm2d` since this is a very frequent need for fine-tuning
- how to replace stride with dilation for ResNet and to what layers it applies and what it can help achieving
Currently docs just specify `**kwargs: Any` which isn't very helpful
### Versions
N/A
|
https://github.com/pytorch/vision/issues/4795
|
open
|
[] | 2021-10-29T11:50:17Z
| 2021-11-13T21:46:45Z
| null |
vadimkantorov
|
pytorch/torchx
| 316
|
[torchx/cli] Implement a torchx "template" subcommand that copies the given builtin
|
Torchx cli maintains a list of builtin components that are available via `torchx builtin` cmd. The builtin components are the patterns that are configured to execute one or another use-case. Users can use these components without the need to manage their own, e.g.
```
torchx run -s local_cwd dist.ddp --script main.py
```
would run user `main.py` script in a distributed manner.
It is better for users to own their own components for production use-cases.
Torch copy command enables users to create initial templetized version of their components from the existing builtin components. Users then can modify the code however they want.
Example of usage
```
# torchx/components/dist.py
def ddp(..., nnodes=1):
return AppDef(..., roles=[Role(name="worker", num_replicas=nnodes)])
torchx copy dist.ddp
# Output:
def ddp(..., nnodes=1):
return AppDef(..., roles=[Role(name="worker", num_replicas=nnodes)])
```
Torchx copy will print the corresponding component to the stdout, so users can inspect the source code and copy it via:
```
torchx copy dist.ddp > my_component.py
```
|
https://github.com/meta-pytorch/torchx/issues/316
|
closed
|
[
"enhancement",
"cli"
] | 2021-10-28T20:28:07Z
| 2021-11-03T21:27:12Z
| 0
|
aivanou
|
pytorch/tutorials
| 1,735
|
Missing tutorial on using the transformer decoder layer?
|
Hi, i'm new with transformers.
For research purpose, with a colleague, I'm trying to implement a transformer for anomaly detection in human pose.
The transformer setting we need is very similar to an autoencoder, where the encoder generates a sort of latent representation and the decoder output is just a model attempt to reconstruct the input.
We were looking for transformer tutorials where both nn.TransformerEncoder and nn.TransformerDecoder are used, but we couldn't find anyone. Are we missing something or pytorch literally didn't provide any tutorial except the ones with just the using of the encoder?
|
https://github.com/pytorch/tutorials/issues/1735
|
closed
|
[] | 2021-10-28T16:27:27Z
| 2022-03-17T16:15:07Z
| 0
|
AndreaLombax
|
pytorch/pytorch
| 67,438
|
how to use torch.jit.script with toch.nn.DataParallel
|
### 🐛 Describe the bug
net = torch.nn.DataParallel(net)
net.load_state_dict(state1,False)
with torch.jit.optimized_execution(True):
net_jit = torch.jit.script(net)
torch.jit.frontend.NotSupportedError: Compiled functions can't take variable number of arguments or use keyword-only arguments with defaults:
### Versions
torch.jit.frontend.NotSupportedError: Compiled functions can't take variable number of arguments or use keyword-only arguments with defaults:
|
https://github.com/pytorch/pytorch/issues/67438
|
closed
|
[
"oncall: jit"
] | 2021-10-28T12:13:51Z
| 2022-11-22T11:58:22Z
| null |
anliyuan
|
pytorch/TensorRT
| 685
|
❓ [Question] TRtorch v0.1.0 does support aten::divonly?
|
## ❓ Question
I am trying to compile my model.
However compiler stops owing to a error.
Doss TRTorch v0.1.0 support `aten::divonly`?
Also, does the newer TRTorch support `aten::divonly`?
## What you have already tried
I searched the error messages at the internet.
## Environment
pytorch 1.6
TRTorch 0.1.0
## Additional context
The error message is this one.
```
> compiled_cpp_mod = trtorch._C.compile_graph(module._c, _parse_compile_spec(compile_spec))
E RuntimeError: [enforce fail at core/conversion/evaluators/NodeEvaluatorRegistry.cpp:56] Expected schema to be true but got false
E Evaluator for aten::divonly runs on certain schemas, but schema for node is not retrievable
```
|
https://github.com/pytorch/TensorRT/issues/685
|
closed
|
[
"feature request",
"question",
"No Activity"
] | 2021-10-27T16:34:18Z
| 2022-02-15T00:01:49Z
| null |
yoshida-ryuhei
|
pytorch/pytorch
| 67,338
|
how to get the rank list in a new group
|
## ❓ Questions and Help
How to get the rank list in a new group? I just find the `distributed.get_rank` and `distributed.get_world_size()` but not `get_rank_list` API.
Thanks :)
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang
|
https://github.com/pytorch/pytorch/issues/67338
|
closed
|
[
"oncall: distributed"
] | 2021-10-27T16:30:02Z
| 2021-11-05T02:45:16Z
| null |
hclearner
|
pytorch/TensorRT
| 682
|
❓ [Question] is there in8 quantization support with python?
|
## ❓ Question
<!-- Your question -->
I did quantize to FP16 by using python. but i didn't find way to do that with int8
let me know if there is support
|
https://github.com/pytorch/TensorRT/issues/682
|
closed
|
[
"question"
] | 2021-10-26T21:30:44Z
| 2021-10-26T21:51:26Z
| null |
yokosyun
|
pytorch/tutorials
| 1,727
|
your "numpy_extensions_tutorial.py " example
|
Hello,
I would like to use the example in your `numpy_extensions_tutorial.py ` coda, but it appears ti computes on a single channel.
Do you happen to know how I can compute it on several channels?
Thanks!
|
https://github.com/pytorch/tutorials/issues/1727
|
closed
|
[
"question"
] | 2021-10-25T12:09:33Z
| 2023-03-06T22:59:39Z
| null |
lovodkin93
|
huggingface/sentence-transformers
| 1,227
|
What is the training data to train the checkpoint "nli-roberta-base-v2"?
|
Hi, I wonder what is the training data for the provided checkpoint "nli-roberta-base-v2"?
The checkpoint name indicates that the training data is related to the nli dataset, but I just want to clarify what it is.
Thanks in advance.
|
https://github.com/huggingface/sentence-transformers/issues/1227
|
closed
|
[] | 2021-10-25T08:59:45Z
| 2021-10-25T09:47:36Z
| null |
sh0416
|
pytorch/pytorch
| 67,157
|
What is the replacement in PyTorch>=1.8 for `torch.rfft` in PyTorch <=1.6?
|
Hi,
I have been working on a project since last year and at that time, the PyTorch version was 1.6. I was using `f1 = torch.rfft(input, signal_ndim=3)` in that version. However, after PyTorch 1.8, `torch.rfft` has been removed. I was trying to use `f2=torch.fft.rfftn(input)` as the replacement, but both the real and imaginary parts of the output f2 are totally different from the output from `torch.rfft`.
I am wondering what is the correct replacement now in PyTorch>=1.8 for torch.rfft in PyTorch 1.6?
Thanks in advance!
Best,
Songyou
|
https://github.com/pytorch/pytorch/issues/67157
|
closed
|
[] | 2021-10-24T14:49:29Z
| 2021-10-24T15:23:27Z
| null |
pengsongyou
|
pytorch/pytorch
| 67,156
|
[ONNX] How to gathering on a tensor with two-dim indexing?
|
Hi,
How can I perform the following **without** getting a Gather node in my onnx graph? As the Gather node gives me an error in TensorRT 7.
```
x = data[:, x_indices, y_indices]
```
data is tensor of size[32, 64, 1024]
x_indices is tensor of size [50000,] -> range of indices 0 to 31
y_indices is tensor of size [50000,] -> range of indices 0 to 1023
The size of tensor x would be [32,50000]
Thanks in advance.
|
https://github.com/pytorch/pytorch/issues/67156
|
closed
|
[
"module: onnx"
] | 2021-10-24T13:06:58Z
| 2021-10-26T15:33:37Z
| null |
yasser-h-khalil
|
pytorch/data
| 81
|
Improve debuggability
|
## 🚀 Feature
Currently, when iteration on DataPipe starts and Error is raised, the traceback would report at each `__iter__` method pointing to the DataPipe Class file.
It's hard to figure out which part of DataPipe is broken, especially when multiple same DataPipe calls exist in the pipeline.
As normally developer would iterate over the sequence of DataPipe for debugging, we can't rely on DataLoader to handle this case.
I am not sure how to reference `self` object from each `Iterator` instance. https://docs.python.org/3/reference/expressions.html?highlight=generator#generator-iterator-methods
(I guess this is also one thing we need to think about singleton iterator should be able to reference back to the object)
|
https://github.com/meta-pytorch/data/issues/81
|
closed
|
[] | 2021-10-22T18:12:36Z
| 2022-03-16T19:42:11Z
| 0
|
ejguan
|
pytorch/pytorch
| 67,013
|
How to use torch.distributions.multivariate_normal.MultivariateNormal in multi-gpu mode
|
## ❓ Questions and Help
In single gpu mode,MultivariateNormal can run correctly, but when i switch to multi-gpu mode, always get the error:
G = torch.exp(m.log_prob(Delta))
File "xxxxx", line 210, in log_prob
M = _batch_mahalanobis(self._unbroadcasted_scale_tril, diff)
File "xxxxx", line 57, in _batch_mahalanobis
M_swap = torch.triangular_solve(flat_x_swap, flat_L, upper=False)[0].pow(2).sum(-2) # shape = b x c
RuntimeError: CUDA error: CUBLAS_STATUS_EXECUTION_FAILED when calling `cublasStrsmBatched( handle, side, uplo, trans, diag, m, n, alpha, A, lda, B, ldb, batchCount)
the code is:
mean = torch.zeros(2).to(x.device)
cov = torch.eye(2).to(x.device)
m = MultivariateNormal(mean, cov * self.sigma**2)
I would be very grateful if you could give some suggestions
cc @ngimel @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano @fritzo @neerajprad @alicanb
|
https://github.com/pytorch/pytorch/issues/67013
|
closed
|
[
"module: cuda",
"triaged",
"module: linear algebra"
] | 2021-10-21T10:36:41Z
| 2023-11-30T13:45:58Z
| null |
SkylerHuang
|
pytorch/android-demo-app
| 195
|
The Performance of the Deployed Model on Android is Far from What on the PC
|
Hi,
I trained one model to detect the steel rebar base on yolov5x model. The testing result is good on PC. And I followed the guide (https://github.com/pytorch/android-demo-app/pull/185) to convert the model to torchscript model (ptl) and integrate it to the demo app. Then the demo app could work and output the result, but there is huge gap between the results on PC and app, see below pic for comparison.
Result on PC (confidence thresh is 0.25)

Result on App(confidence thresh is 0.2)

I also tuned the --optimze when export the model
python3 /workspace/src/github/yolov5/export.py --weight runs/train/exp32/weights/best.pt --include torchscript --optimize
But there is no significant difference after the tuning. So far have no more clue to figure out ...
Any tips or suggestion is appreciated, thanks!
|
https://github.com/pytorch/android-demo-app/issues/195
|
closed
|
[] | 2021-10-21T03:21:12Z
| 2021-12-10T07:20:54Z
| null |
joeshow79
|
pytorch/pytorch
| 66,916
|
how to install torch version1.8.0 with cuda 11.2
|
## ❓ Questions and Help
how to install torch version1.8.0 with cuda 11.2
|
https://github.com/pytorch/pytorch/issues/66916
|
closed
|
[] | 2021-10-20T01:09:16Z
| 2021-10-21T15:16:54Z
| null |
ZTurboX
|
pytorch/pytorch
| 66,873
|
Add documentation for how to work with PyTorch in Windows SSH
|
Our Windows machines require all dependencies to be installed before you could do anything with PyTorch (like run tests).
We should document how someone could get to a stage where they can work with PyTorch, or provide a script to automate this process.
Moreover, our Windows scripts need cleaning up in general, but that's more tracked with https://github.com/pytorch/pytorch/issues/65718
cc @brianjo @mruberry
|
https://github.com/pytorch/pytorch/issues/66873
|
closed
|
[
"module: docs",
"triaged",
"better-engineering"
] | 2021-10-19T15:25:18Z
| 2022-02-28T20:45:59Z
| null |
janeyx99
|
pytorch/torchx
| 277
|
Improve docs page toctree index
|
## 📚 Documentation
## Link
https://pytorch.org/torchx
## What does it currently say?
No issues with the documentation. This calls for a revamped indexing of the toctree in the torchx docs page
## What should it say?
Make the toctree be:
1. Usage:
- Basic Concepts
- Installation
- 10 Min Tutorial (Hello World should be renamed to this)
2. Examples:
- Application
- Component -> (links to) list of builtins (4. below)
- Pipelines
3. Best Practices:
- Application
- Component
3. Application (Runtime)
- Overview
- HPO
- Tracking
4. Components
- Train
- Distributed
- ...
6. Runner (Schedulers)
- Localhost
- Kubernetes
- Slurm
7. Pipelines
- Kubeflow
8. API
- torchx.specs
- torchx.runner
- torchx.schedulers
- torchx.pipelines
9. Experimental
- (beta) torchx.config
## Why?
The proposed toctree is a better organization compared to the one we have today. It better organizes parallels between app, component, and piplines. Logically lays out sections so that it reads better top to bottom
|
https://github.com/meta-pytorch/torchx/issues/277
|
closed
|
[] | 2021-10-18T22:30:22Z
| 2021-10-20T22:13:50Z
| 0
|
kiukchung
|
huggingface/dataset-viewer
| 71
|
Download and cache the images and other files?
|
Fields with an image URL are detected, and the "ImageUrl" type is passed in the features, to let the client (moonlanding) put the URL in `<img src="..." />`.
This means that pages such as https://hf.co/datasets/severo/wit will download images directly from Wikipedia for example. Hotlinking presents various [issues](https://en.wikipedia.org/wiki/Inline_linking#Controversial_uses_of_inline_linking). In particular, it's harder for us to know for sure if the image really exists or if it has an error. It might also generate a lot of traffic to other websites.
Thus: we might want to download the images as an asset in the backend, then serve them directly. Coding a good downloading bot is not easy ([User-Agent](https://meta.wikimedia.org/wiki/User-Agent_policy), avoid reaching rate-limits, detect the filename, detect the mime-type/extension, etc.)
Related: https://github.com/huggingface/datasets/issues/3105
|
https://github.com/huggingface/dataset-viewer/issues/71
|
closed
|
[
"question"
] | 2021-10-18T15:37:59Z
| 2022-09-16T20:09:24Z
| null |
severo
|
pytorch/torchx
| 250
|
[torchx/configs] Make runopts, Runopt, RunConfig, scheduler_args more consistent
|
## Description
Consolidate redundant names, classes, and arguments that represent scheduler `RunConfig`.
## Motivation/Background
Currently there are different names for what essentially ends up being the additional runtime options for the [`torchx.scheduler`](https://pytorch.org/torchx/latest/schedulers.html) (see [`dryrun(..., cfg: RunConfig))`](https://pytorch.org/torchx/latest/schedulers.html).
This runconfig is:
1. has class type `torchx.specs.api.RunConfig` (dataclass)
2. function argument name `cfg` or `runcfg` in most places in the scheduler and runner source code
3. passed from the `torchx run` cli as `--scheduler_args`
Additionally each scheduler has what is called a `runopts`, which are the runconfig options that the scheduler advertises and takes (see runopts for [local_scheduler](https://github.com/pytorch/torchx/blob/main/torchx/schedulers/local_scheduler.py#L543)).
The difference between `RunConfig` and `runopts` is that the `RunConfig` object is simply a holder for the user-provided config key-value pairs while `runopts` is the schema (type, default, is_required, help string) of the configs that it takes. Think of `runopts` being the `argparse.ArgumentParser` of the Scheduler if it were a cli tool, and `RunConfig` the `sys.argv[1:]` (but instead of an array it is a map).
## Detailed Proposal
The proposal is to clean up the nomenclature as follows:
1. Deprecate `--scheduler_args` option in torchx cli and instead call it `--cfg` (consistent with the parameter names in the Scheduler API).
2. Change the section name In the runner INI config files from `[$profile.scheduler_args.$sched_name]` to `[$profile.$scheduler_name.cfg]` (e.g. `[default.scheduler_args.local_cwd]` would become `[default.local_cwd.cfg]`)
3. Rename [`Runopt`](https://github.com/pytorch/torchx/blame/431c0e2131bfae738eb17a00afa83c36a932cec6/torchx/specs/api.py#L512) to `runopt` (to be consistant with `runopts` which is a holder for runopt by name)
## Alternatives
(not really an alternative but other deeper cleanups considered)
1. changing the `cfg` parameter name in Scheduler and Runner interfaces to be `runconfig` (consistent with `RunConfig`) or alternatively changing `RunConfig` to `RunCfg`. This is going to be a huge codemod, hence I've decided to live with it and change the rest of the settings to match `cfg`.
2. `RunConfig` is simply a wrapper around a regular python `Dict[str, ConfigValue]` (`ConfigValue` is a type alias not an actual class) and does not provide any additional functionality on top of the dict other than a prettyprint `__repr__()`. Considering just dropping the `RunConfig` dataclass and using `Dict[str, ConfigValue]` directly (also requires a huge codemod)
## Additional context/links
See hyperlinks above.
|
https://github.com/meta-pytorch/torchx/issues/250
|
closed
|
[] | 2021-10-14T15:03:56Z
| 2021-10-14T19:14:18Z
| 0
|
kiukchung
|
pytorch/pytorch
| 66,511
|
Add a config to PRs where we assume there is only 1 GPU available
|
We recently had a gap in PR coverage where we did not catch when a test case attempted to access an invalid GPU from this PR https://github.com/pytorch/pytorch/pull/65914. We should capture that in PR testing somehow to catch these early next time.
Action:
Make our tests run on only one "available" GPU.
We could take advantage of this and split up our tests to run on separate GPUs when they're available!
cc @seemethere @malfet @pytorch/pytorch-dev-infra @mruberry
|
https://github.com/pytorch/pytorch/issues/66511
|
closed
|
[
"module: ci",
"module: tests",
"triaged"
] | 2021-10-12T21:42:19Z
| 2021-11-15T22:37:13Z
| null |
janeyx99
|
pytorch/pytorch
| 66,418
|
How to implement dynamic sampling of training data?
|
Hi, thank you for your work.
Now I have multiple train datasets including real data and synthetic data. When sampling data during training, It is necessary to ensure that the ratio of real data samples to synthetic data samples in a batch is 1:1~1:3. How to achieve this operation?
Looking forward to your answer, thank you.
cc @SsnL @VitalyFedyunin @ejguan @NivekT
|
https://github.com/pytorch/pytorch/issues/66418
|
closed
|
[
"module: dataloader",
"triaged"
] | 2021-10-11T12:10:16Z
| 2021-10-13T02:38:14Z
| null |
Danee-wawawa
|
pytorch/tutorials
| 1,705
|
StopIteration Error in torch.fx tutorial with TransformerEncoderLayer
|
I’m trying to run the fx profiling tutorial in tutorials/fx_profiling_tutorial.py at master · pytorch/tutorials · GitHub 1 on a single nn.TransformerEncoderLayer as opposed to the resnet in the example and I keep running into a StopIteration error. Why is this happening? All I did was replace the resnet with a transformer encoder layer.
cc @eellison @suo @gmagogsfm @jamesr66a @msaroufim @SherlockNoMad @sekyondaMeta @svekars @carljparker @NicolasHug @kit1980 @subramen
|
https://github.com/pytorch/tutorials/issues/1705
|
closed
|
[
"question",
"fx",
"easy",
"docathon-h2-2023"
] | 2021-10-09T06:28:59Z
| 2023-11-07T00:41:23Z
| null |
lkp411
|
pytorch/functorch
| 192
|
Figure out how to market functorch.vmap over torch.vmap that is in PyTorch nightly binaries
|
Motivation:
- Many folks are using torch.vmap instead of functorch.vmap and basing their initial impressions off of it. We'd like them to use functorch.vmap instead, especially if we do a beta release of functorch out-of-tree.
Constraints:
- Features that rely on it (torch.autograd.functional.jacobian, torch.autograd.grad(batched_grad=True) should probably continue to work.
Potential solutions:
- Have the torch.vmap API in the nightly binaries error out and tell users to use functorch.vmap...
Thoughts? cc @Chillee @albanD @soulitzer
|
https://github.com/pytorch/functorch/issues/192
|
closed
|
[] | 2021-10-08T13:55:19Z
| 2022-02-03T14:55:34Z
| null |
zou3519
|
pytorch/android-demo-app
| 189
|
how to loadMoudule by Absolutepath
|
Hello, I use the objectdetection app to run normally. There are some new requirements. The. **Pt file is relatively large**. I don't want to include it in the app, but want to **load it directly from the local**.
I use Android Python version 1.8. I found that the pytorch_android class in his jar package does not implement the method of loading locally, **but the nativepeer class contains
NativePeer(String moduleAbsolutePath, Device device) {}**
My idea is to write a method in pytorch_android and call the above function.
However, I **failed to replace the jar package's class** with the local pytorchandroid. Class. It will always be restored. If I delete it locally, it will still be downloaded. I don't know what I should do now.thanks
|
https://github.com/pytorch/android-demo-app/issues/189
|
open
|
[] | 2021-10-08T12:09:07Z
| 2021-10-08T12:09:07Z
| null |
dota2mhxy
|
pytorch/pytorch
| 66,309
|
How to find the source kernel code of cumsum (gpu)
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
Hi,
As the title, how could I find the source kernel code of cumsum (gpu). I just find the cumsum (cpu). Thanks.
|
https://github.com/pytorch/pytorch/issues/66309
|
closed
|
[] | 2021-10-08T09:53:03Z
| 2021-10-08T17:47:39Z
| null |
foreveronehundred
|
pytorch/audio
| 1,837
|
ERROR: Could not find a version that satisfies the requirement torchaudio (from versions: none) ERROR: No matching distribution found for torchaudio
|
### 🐛 Describe the bug
ERROR: Could not find a version that satisfies the requirement torchaudio>=0.5.0 (from asteroid) (from versions: none)
ERROR: No matching distribution found for torchaudio>=0.5.0 (from asteroid)
21:40:18-root@Desktop:/pr/Neural/voicefixer_main# pip3 install torchaudio
### Versions
python collect_env.py
Traceback (most recent call last):
File "/media/sd/Projects/Neural/voicefixer_main/collect_env.py", line 16, in <module>
import torch
File "/home/plab/.local/lib/python3.9/site-packages/torch/__init__.py", line 196, in <module>
from torch._C import *
RuntimeError: module compiled against API version 0xe but this version of numpy is 0xd
21:45:45-root@Desktop:/pr/Neural/voicefixer_main# pip3 install numpy
Requirement already satisfied: numpy in /usr/lib/python3/dist-packages (1.19.5)
Please fix torchaudio to install. Thanks!
|
https://github.com/pytorch/audio/issues/1837
|
closed
|
[
"question"
] | 2021-10-07T21:17:48Z
| 2023-07-31T18:37:00Z
| null |
clort81
|
pytorch/data
| 44
|
KeyZipper improvement
|
Currently multiple stacked `KeyZipper` would create a recursive data structure:
```py
dp = KeyZipper(dp, ref_dp1, lambda x: x)
dp = KeyZipper(dp, ref_dp2, lambda x: x[0])
dp = KeyZipper(dp, ref_dp3, lambda x: x[0][0])
```
This is super annoying if we are using same key for each `KeyZipper`. At the end, it yields `(((dp, ref_dp1), ref_dp2), ref_dp3)
We should either accept multiple reference DataPipe for KeyZipper to preserve same key, or have some expand or collate function to convert result to `(dp, (ref_dp1, ref_dp2, ref_dp3))`
- If we take multiple reference DataPipe and ref_key_fn, we need to figure out how to ensure buffer not blown up.
cc: @VitalyFedyunin @NivekT
|
https://github.com/meta-pytorch/data/issues/44
|
closed
|
[] | 2021-10-05T17:02:00Z
| 2021-10-22T14:45:38Z
| 1
|
ejguan
|
huggingface/datasets
| 3,013
|
Improve `get_dataset_infos`?
|
Using the dedicated function `get_dataset_infos` on a dataset that has no dataset-info.json file returns an empty info:
```
>>> from datasets import get_dataset_infos
>>> get_dataset_infos('wit')
{}
```
While it's totally possible to get it (regenerate it) with:
```
>>> from datasets import load_dataset_builder
>>> builder = load_dataset_builder('wit')
>>> builder.info
DatasetInfo(description='Wikipedia-based Image Text (WIT) Dataset is a large multimodal multilingual dataset. WIT is composed of a curated set\n of 37.6 million entity rich image-text examples with 11.5 million unique images across 108 Wikipedia languages. Its\n size enables WIT to be used as a pretraining dataset for multimodal machine learning models.\n', citation='@article{srinivasan2021wit,\n title={WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning},\n author={Srinivasan, Krishna and Raman, Karthik and Chen, Jiecao and Bendersky, Michael and Najork, Marc},\n journal={arXiv preprint arXiv:2103.01913},\n year={2021}\n}\n', homepage='https://github.com/google-research-datasets/wit', license='', features={'b64_bytes': Value(dtype='string', id=None), 'embedding': Sequence(feature=Value(dtype='float64', id=None), length=-1, id=None), 'image_url': Value(dtype='string', id=None), 'metadata_url': Value(dtype='string', id=None), 'original_height': Value(dtype='int32', id=None), 'original_width': Value(dtype='int32', id=None), 'mime_type': Value(dtype='string', id=None), 'caption_attribution_description': Value(dtype='string', id=None), 'wit_features': Sequence(feature={'language': Value(dtype='string', id=None), 'page_url': Value(dtype='string', id=None), 'attribution_passes_lang_id': Value(dtype='string', id=None), 'caption_alt_text_description': Value(dtype='string', id=None), 'caption_reference_description': Value(dtype='string', id=None), 'caption_title_and_reference_description': Value(dtype='string', id=None), 'context_page_description': Value(dtype='string', id=None), 'context_section_description': Value(dtype='string', id=None), 'hierarchical_section_title': Value(dtype='string', id=None), 'is_main_image': Value(dtype='string', id=None), 'page_changed_recently': Value(dtype='string', id=None), 'page_title': Value(dtype='string', id=None), 'section_title': Value(dtype='string', id=None)}, length=-1, id=None)}, post_processed=None, supervised_keys=None, task_templates=None, builder_name='wit', config_name='default', version=0.0.0, splits=None, download_checksums=None, download_size=None, post_processing_size=None, dataset_size=None, size_in_bytes=None)
```
Should we test if info is empty, and in that case regenerate it? Or always generate it?
|
https://github.com/huggingface/datasets/issues/3013
|
closed
|
[
"question",
"dataset-viewer"
] | 2021-10-04T09:47:04Z
| 2022-02-21T15:57:10Z
| null |
severo
|
huggingface/dataset-viewer
| 55
|
Should the features be associated to a split, instead of a config?
|
For now, we assume that all the splits of a config will share the same features, but it seems that it's not necessarily the case (https://github.com/huggingface/datasets/issues/2968). Am I right @lhoestq ?
Is there any example of such a dataset on the hub or in the canonical ones?
|
https://github.com/huggingface/dataset-viewer/issues/55
|
closed
|
[
"question"
] | 2021-10-01T18:14:53Z
| 2021-10-05T09:25:04Z
| null |
severo
|
pytorch/pytorch
| 65,992
|
How to use `MASTER_ADDR` in a distributed training script
|
## ❓ Questions and Help
https://pytorch.org/docs/stable/elastic/run.html
> `MASTER_ADDR` - The FQDN of the host that is running worker with rank 0; used to initialize the Torch Distributed backend.
The document says `MASTER_ADDR` is the hostname of the master node. But the hostname may not be resolved by other nodes. What's the use case of `MASTER_ADDR`?
For example, in AWS, the hostname of the master node is `ip-172-30-2-12` which is not recognized by other nodes.
On "ip-172-30-2-12":
```sh
(dev) ➜ ~ hostname
ip-172-30-2-12
```
On another machine:
```sh
(dev) ➜ ~ getent hosts ip-172-30-2-12
(dev) ➜ ~
```
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang
|
https://github.com/pytorch/pytorch/issues/65992
|
closed
|
[
"oncall: distributed",
"module: elastic"
] | 2021-10-01T09:19:31Z
| 2025-02-04T08:17:51Z
| null |
jasperzhong
|
pytorch/serve
| 1,262
|
What is the Proper Model Save Method?
|
The example given in the documentation shows downloading and archiving a pre-existing model from Pytorch. But if serving a custom-built model, what is the correct save method?
For example, on the Save/Loading Documentation, there are several save methods:
https://pytorch.org/tutorials/beginner/saving_loading_models.html
Should the model artifacts be saved as simply torch.save(model, PATH) or should it be saved as torch.save(model.state_dict(), PATH)?
Thank you.
|
https://github.com/pytorch/serve/issues/1262
|
closed
|
[] | 2021-10-01T06:02:40Z
| 2021-10-01T06:42:16Z
| null |
CerebralSeed
|
pytorch/pytorch
| 65,915
|
I am getting undefined symbol: _ZN5torch3jit17parseSchemaOrNameERKNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE error. This I am getting when I am trying to "import torch from nemo.collections import nlp". I am trying to use pytorch ngc container 21.05. I tried to import torch before the nemo extension. Please suggest how I can resolve this.
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
|
https://github.com/pytorch/pytorch/issues/65915
|
open
|
[
"oncall: jit"
] | 2021-09-30T12:08:43Z
| 2021-09-30T12:17:54Z
| null |
gangadharsingh056
|
pytorch/pytorch
| 65,816
|
How to install PyTorch on ppc64le with pip?
|
I am going to build a virtual environment (python -m venv) and install PyTorch on a ppc64le machine. But there is no package in pip to install PyTorch, however it is available in conda. But I wanted not to use conda because I need to install some specific packages and versions. So, how can I install PyTorch on a ppc64le(IBM Power8) machine?
|
https://github.com/pytorch/pytorch/issues/65816
|
closed
|
[] | 2021-09-29T13:02:10Z
| 2021-10-01T18:00:20Z
| null |
M-Amrollahi
|
pytorch/pytorch
| 65,689
|
Questions in use pack_padded_sequence: how to pack Multiple tensor?
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
- I have some problem in use pack_padded_sequence. I have some 2-dimensional data in varible length,but i can not use pack_padded_sequence to dealwith it.
-
```python
#mydata seems like this
img=torch.from_numpy(np.array([[[1,2,3,4,5],[1,2,3,4,5]],[[1,2,3,4,0],[1,2,3,4,0]],[[1,2,3,0,0],[1,2,3,0,0]],[[1,2,0,0,0],[1,2,0,0,0]]]))
a=[[1,2,3,4,5],[1,2,3,4,5]]
b=[[1,2,3,4],[1,2,3,4]]
c=[[1,2,3],[1,2,3]]
#so i deal with it by padding
img=torch.from_numpy(np.array([[[1,2,3,4,5],[1,2,3,4,5]],[[1,2,3,4,0],[1,2,3,4,0]],[[1,2,3,0,0],[1,2,3,0,0]],[[1,2,0,0,0],[1,2,0,0,0]]]))
label=torch.from_numpy(np.array([[1],[2],[3],[3]]))
lenght=torch.from_numpy(np.array([4,4,3,2]))
train_ids=Data.TensorDataset(img,label,lenght)
train_loader = Data.DataLoader(dataset=train_ids, batch_size=1, shuffle=False)
for step,(b_x, b_y,b_len) in enumerate(train_loader):
X= torch.nn.utils.rnn.pack_padded_sequence(b_x,b_len, batch_first=True,enforce_sorted=False)
#it canot be like [[1,2,3,4],[1,2,3,4]] what could i do
print(step,X)
X, _ =nn.utils.rnn.pad_packed_sequence(X, batch_first=True)
```
|
https://github.com/pytorch/pytorch/issues/65689
|
closed
|
[] | 2021-09-27T13:02:55Z
| 2021-09-27T23:31:06Z
| null |
jingxingzhi
|
huggingface/dataset-viewer
| 52
|
Regenerate dataset-info instead of loading it?
|
Currently, getting the rows with `/rows` requires a previous (internal) call to `/infos` to get the features (type of the columns). But sometimes the dataset-info.json file is missing, or not coherent with the dataset script (for example: https://huggingface.co/datasets/lhoestq/custom_squad/tree/main), while we are using `datasets.get_dataset_infos()`, which only loads the exported dataset-info.json files:
https://github.com/huggingface/datasets-preview-backend/blob/c2a78e7ce8e36cdf579fea805535fa9ef84a2027/src/datasets_preview_backend/queries/infos.py#L45
https://github.com/huggingface/datasets/blob/26ff41aa3a642e46489db9e95be1e9a8c4e64bea/src/datasets/inspect.py#L115
We might want to call `._info()` from the builder to get the info, and features, instead of relying on the dataset-info.json file.
|
https://github.com/huggingface/dataset-viewer/issues/52
|
closed
|
[
"question"
] | 2021-09-27T11:28:13Z
| 2021-09-27T13:21:00Z
| null |
severo
|
pytorch/pytorch
| 65,682
|
How to export split to ONNX with dynamic split_size?
|
## ❓ Questions and Help
I need to implement dynamic tensor split op in work. But when I want to export this split op to ONNX with dynamic split_size, it seems not work.
I am new to ONNX. Anyone can help me? Thanks a lot.
## To Reproduce
```python
import torch
dummy_input = (torch.tensor([1, 4, 2, 7, 3]), torch.tensor([1, 2, 2]))
class Split(torch.nn.Module):
def forward(self, x, l):
return x.split(l.cpu().numpy().tolist(), dim=-1)
model = Split()
with torch.no_grad():
torch.onnx.export(
model, dummy_input, 'split.onnx', verbose=False, opset_version=13,
input_names=['a', 'b'],
output_names=['c'],
dynamic_axes={'a': [0], 'b': [0], 'c': [0]}
)
```
when I use the onnx model, it seems not to work. I get this error:
[ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Invalid Feed Input Name:b
```python
import onnxruntime as ort
model_path = './split.onnx'
sess = ort.InferenceSession(model_path)
a = torch.tensor([4, 2, 3, 4])
b = torch.tensor([1, 3])
sess.run(['c'], {'a':a.numpy(), 'b':b.numpy()})
```
Tensor b seems can not be used as an input, but I do need a parameter to represent the dynamic split_size.
## Environment
- PyTorch Version (e.g., 1.0): 1.8.1+cu111
- Python version: 3.8
cc @BowenBao @neginraoof
|
https://github.com/pytorch/pytorch/issues/65682
|
closed
|
[
"module: onnx",
"triaged"
] | 2021-09-27T09:27:15Z
| 2022-10-27T20:57:22Z
| null |
Wwwwei
|
huggingface/transformers
| 13,747
|
I want to understand the source code of transformers. Where should I start? Is there a tutorial link? thank you very much!
|
I want to understand the source code of transformers. Where should I start? Is there a tutorial link? thank you very much!
|
https://github.com/huggingface/transformers/issues/13747
|
closed
|
[
"Migration"
] | 2021-09-26T08:27:24Z
| 2021-11-04T15:06:05Z
| null |
limengqigithub
|
huggingface/accelerate
| 174
|
What is the recommended way of training GANs?
|
Currently, the examples folder doesn't contain any example of training GAN. I wonder what is the recommended way of handling multiple models and optimizers when using accelerate.
In terms of interface, `Accelerator.prepare` can wrap arbitrary number of models and optimizers at once. However, it seems to me that the current implementation of `Accelerator` only has one gradient scaler (when native amp is enabled), this might potentially cause issues for wrapping multiple optimizers with one `Accelerator` instance. One way of fixing this might be to move the ownership of `GradScaler` to an `AcceleratedOptimizer`, but this would case problems when calling `Accelerator.backward`.
On the other hand, to use deepspeed, one would have to create two `DeepSpeedEngine` instances to wrap two models. Maybe accelerate could follow this pattern, since deepspeed would be one of the supported backend.
Anyway, I guess a minimum GAN training script should be added to examples as a guildline.
|
https://github.com/huggingface/accelerate/issues/174
|
closed
|
[] | 2021-09-26T07:30:41Z
| 2023-10-24T17:55:15Z
| null |
yuxinyuan
|
pytorch/torchx
| 199
|
Installation from source examples fail
|
## 📚 Documentation
## Link
<!-- link to the problematic documentation -->
https://github.com/pytorch/torchx#source
## What does it currently say?
<!-- copy paste the section that is wrong -->
```bash
# install torchx sdk and CLI from source
$ pip install -e git+https://github.com/pytorch/torchx.git
```
## What should it say?
<!-- the proposed new documentation -->
No idea.
## Why?
<!-- (if not clear from the proposal) why is the new proposed documentation more correct/improvement over the existing one? -->
On Linux:
```
(venv) sbyan % pip --version
pip 21.2.4 from /mnt/shared_ad2_mt1/sbyan/git/PrivateFederatedLearning/venv/lib64/python3.6/site-packages/pip (python 3.6)
(venv) sbyan % pip install -e git+https://github.com/pytorch/torchx.git
ERROR: Could not detect requirement name for 'git+https://github.com/pytorch/torchx.git', please specify one with #egg=your_package_name
```
On MacOS:
```
(venv) smb % pip --version
pip 21.2.4 from /Users/smb/Work/GIT/PrivateFederatedLearning/venv/lib/python3.9/site-packages/pip (python 3.9)
(venv) smb % pip install -e git+https://github.com/pytorch/torchx.git
ERROR: Could not detect requirement name for 'git+https://github.com/pytorch/torchx.git', please specify one with #egg=your_package_name
```
|
https://github.com/meta-pytorch/torchx/issues/199
|
closed
|
[] | 2021-09-24T16:07:12Z
| 2021-10-01T02:28:58Z
| 2
|
stevebyan
|
huggingface/dataset-viewer
| 48
|
"flatten" the nested values?
|
See https://huggingface.co/docs/datasets/process.html#flatten
|
https://github.com/huggingface/dataset-viewer/issues/48
|
closed
|
[
"question"
] | 2021-09-24T12:58:34Z
| 2022-09-16T20:10:22Z
| null |
severo
|
huggingface/dataset-viewer
| 45
|
use `environs` to manage the env vars?
|
https://pypi.org/project/environs/ instead of utils.py
|
https://github.com/huggingface/dataset-viewer/issues/45
|
closed
|
[
"question"
] | 2021-09-24T08:05:38Z
| 2022-09-19T08:49:33Z
| null |
severo
|
pytorch/torchx
| 197
|
Documentation feedback
|
## 📚 Documentation
At a high level the repo really needs a glossary of terms in a single page otherwise easy to forget what they mean when you get to a new page. Lots of content can be deleted specifically the example application notebooks don't add anything relative to the pipeline examples.
General list of feedback - not sure how to fix yet so opening issue instead of PR
### https://pytorch.org/torchx/latest/quickstart.html
* Add a link to where built in are defined in the code
### https://pytorch.org/torchx/latest/cli.html
* App bundle is never defined - is it the app ID? in the docs `echo_c944ffb2`?
### https://pytorch.org/torchx/latest/configure.html
* One thing wasn't too clear is a resource basically number of CPUs and GPUs? Would be helpful to add some helper enum which includes something higher level like a V100 machine for provisioning
### https://pytorch.org/torchx/latest/examples_apps/datapreproc/component.html#sphx-glr-examples-apps-datapreproc-component-py
* Example has no main function
### https://pytorch.org/torchx/latest/examples_apps/datapreproc/datapreproc.html#sphx-glr-examples-apps-datapreproc-datapreproc-py
I'm not sure what the entire Application Examples notebooks do? May be best to refactor together with pipeline examples? Let me know I can send a PR to delete
### https://pytorch.org/torchx/latest/examples_pipelines/kfp/intro_pipeline.html#sphx-glr-examples-pipelines-kfp-intro-pipeline-py
* Make it clearer that pipeline.yaml is generated and not an input - I kept looking for it in the source directory
### https://pytorch.org/torchx/latest/components/base.html
Why is torch.elastic mentioned here? Whole repo feels like it needs a glossary. For example by image do you mean docker image?
### https://pytorch.org/torchx/latest/components/hpo.html
* Just sat TBD - delete for now?
### https://pytorch.org/torchx/latest/components/utils.html
* Have a link to supported utils in the codebase
### https://pytorch.org/torchx/latest/schedulers/kubernetes.html
* This says coming soon but looks like feature is available?
### https://pytorch.org/torchx/latest/beta.html
Also empty just remove
|
https://github.com/meta-pytorch/torchx/issues/197
|
closed
|
[] | 2021-09-23T18:01:21Z
| 2021-09-27T17:37:49Z
| 4
|
msaroufim
|
huggingface/dataset-viewer
| 41
|
Move benchmark to a different repo?
|
It's a client of the API
|
https://github.com/huggingface/dataset-viewer/issues/41
|
closed
|
[
"question"
] | 2021-09-23T10:44:08Z
| 2021-10-12T08:49:11Z
| null |
severo
|
huggingface/dataset-viewer
| 35
|
Refresh the cache?
|
Force a cache refresh on a regular basis (cron)
|
https://github.com/huggingface/dataset-viewer/issues/35
|
closed
|
[
"question"
] | 2021-09-23T09:36:02Z
| 2021-10-12T08:34:41Z
| null |
severo
|
pytorch/tutorials
| 1,692
|
UserWarning during Datasets & DataLoaders Tutorial
|
Hi,
I am following the 'Introduction to PyTorch' tutorial. During [Datasets & DataLoaders](https://pytorch.org/tutorials/beginner/basics/data_tutorial.html) I copied the following:
```import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
```
Which led me to the following warning:
```/home/jelle/PycharmProjects/pytoch_learning/venv/lib/python3.9/site-packages/torchvision/datasets/mnist.py:498:
UserWarning: The given NumPy array is not writeable, and PyTorch does not support non-writeable tensors. This means
you can write to the underlying (supposedly non-writeable) NumPy array using the tensor. You may want to copy the
array to protect its data or make it writeable before converting it to a tensor. This type of warning will be
suppressed for the rest of this program. (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:180.)
return torch.from_numpy(parsed.astype(m[2], copy=False)).view(*s)
```
It seems this issue has been solved before?
[47160](https://github.com/pytorch/pytorch/issues/47160)
I am using
- Python 3.9
- torch 1.9.1
- torchvision 0.10.1
- numpy 1.21.2
- Pycharm 2021.2
- Ubuntu 21.4
I installed using a virtual environment and the guide on https://pytorch.org/get-started/locally/
`pip3 install torch==1.9.1+cu111 torchvision==0.10.1+cu111 torchaudio==0.9.1 -f https://download.pytorch.org/whl/torch_stable.html`
This warning was also given during the 'quickstart' tutorial. The warning seems to have no further effect on the tutorial.
Why is the warning not mentioned in the tutorial?
cc @suraj813
|
https://github.com/pytorch/tutorials/issues/1692
|
closed
|
[
"intro",
"docathon-h1-2023",
"easy"
] | 2021-09-23T06:07:54Z
| 2023-06-08T17:07:12Z
| 12
|
Jelle-Bijlsma
|
pytorch/TensorRT
| 632
|
❓ [Question] Unknown type name '__torch__.torch.classes.tensorrt.Engine'
|
## ❓ Question
<!-- Your question -->
when I tried to load trt module which saved with python
```
torch::jit::load(trtorch_path);
```
I got this error
```
terminate called after throwing an instance of 'torch::jit::ErrorReport'
what():
Unknown type name '__torch__.torch.classes.tensorrt.Engine':
Serialized File "code/__torch__/models/backbone.py", line 4
__parameters__ = []
__buffers__ = []
__torch___models_backbone_Backbone_trt_engine_ : __torch__.torch.classes.tensorrt.Engine
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
def forward(self_1: __torch__.models.backbone.Backbone_trt,
input_0: Tensor) -> Tensor:
```
I linked libtrtorch.so as bellow
```
target_link_libraries(
${ProjectTargetLibName}
PRIVATE
${TORCH_LIBRARIES}
/opt/trtorch/lib/libtrtorch.so
)
```
maybe I need to compile trt_module in c++ instead of python??
## What you have already tried
I can save trt_module and load and run with python without any problem
<!-- A clear and concise description of what you have already done. -->
## Environment
- PyTorch 1.9
- Libtorch 1.9
- OS (Linux):
- CUDA 11.0:
- TensorRT 8.0
- TRTorch 0.4(libtrtorch-v0.4.0-cudnn8.2-tensorrt8.0-cuda11.1-libtorch-1.9.0.tar.gz)
|
https://github.com/pytorch/TensorRT/issues/632
|
closed
|
[
"question"
] | 2021-09-22T08:45:45Z
| 2021-09-27T14:38:21Z
| null |
yokosyun
|
pytorch/pytorch
| 65,446
|
libtorch compile problem. How to get the correct protobuf version? what PROTOBUF_VERSION <3011000 and 3011004 <PROTOBUF_MIN_PROTOC_VERSION?
|
How to get the correct protobuf version?
When using libtorch to compile, using PROTOBUF_VERSION <3011000 and 3011004 <PROTOBUF_MIN_PROTOC_VERSION will report an error, which version should be used? 3011000 also did not show any content, thank you
libtorch ==libtorch-cxx11-abi-shared-with-deps-1.9.0+cu102.zip
torchvision = v0.10.0
Compiled protobuf version = 3.18.0
error info:


## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1.
1.
1.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch Version (e.g., 1.0):
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, source):
- Build command you used (if compiling from source):
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
cc @malfet @seemethere
|
https://github.com/pytorch/pytorch/issues/65446
|
open
|
[
"module: build",
"module: protobuf",
"triaged"
] | 2021-09-22T04:28:27Z
| 2021-09-22T14:27:18Z
| null |
ahong007007
|
pytorch/pytorch
| 65,312
|
How to get the same RandomResizedCrop result of img and gt
|
my code snippet is below

Now ,the img ,gt do different RandomResizedCrop. But I want they do the same, because the img and gt must be correspond.
How should I modify the code?
|
https://github.com/pytorch/pytorch/issues/65312
|
closed
|
[] | 2021-09-19T13:54:59Z
| 2021-09-21T03:17:23Z
| null |
HaoRan-hash
|
pytorch/vision
| 4,446
|
Question: FFmpeg dependency
|
Sorry, I am little bit of a newbie on this subject. I notice at Torchvision 0.9+ that ffmpeg >= 4.2 is a hard dependency for Linux conda distributions. At Torchvision <= 0.8.2, this was not a dependency. We all know ffmpeg licensing and the other dependencies it pulls in is problematic in some scenarios.
Question 1: Is it possible to build Torchvision for Linux without ffmpeg? What breaks?
Question 2: If I manually alter the .bz2 file from Anaconda.org to remove the ffmpeg dependency, what breaks?
Any other suggestions?
|
https://github.com/pytorch/vision/issues/4446
|
closed
|
[
"question",
"topic: build"
] | 2021-09-19T11:21:21Z
| 2021-09-24T19:36:12Z
| null |
rwmajor2
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.