
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
huggingface/datasets
| 4,101
|
How can I download only the train and test split for full numbers using load_dataset()?
|
How can I download only the train and test split for full numbers using load_dataset()?
I do not need the extra split and it will take 40 mins just to download in Colab. I have very short time in hand. Please help.
|
https://github.com/huggingface/datasets/issues/4101
|
open
|
[
"enhancement"
] | 2022-04-05T16:00:15Z
| 2022-04-06T13:09:01Z
| 1
|
Nakkhatra
|
pytorch/TensorRT
| 960
|
❓ [Question] Problem with cudnn dependency when compiling plugins on windows?
|
## ❓ Question
<!-- Your question -->
I am trying to compile a windows dll for torch-tensorRT, however I get the following traceback:
ERROR: C:/users/48698/source/libraries/torch-tensorrt-1.0.0/core/plugins/BUILD:10:11: Compiling core/plugins/register_plugins.cpp failed: undeclared inclusion(s) in rule '//core/plugins:torch_tensorrt_plugins':
this rule is missing dependency declarations for the following files included by 'core/plugins/register_plugins.cpp':
'external/cuda/cudnn.h'
'external/cuda/cudnn_version.h'
'external/cuda/cudnn_ops_infer.h'
'external/cuda/cudnn_ops_train.h'
'external/cuda/cudnn_adv_infer.h'
'external/cuda/cudnn_adv_train.h'
'external/cuda/cudnn_cnn_infer.h'
'external/cuda/cudnn_cnn_train.h'
'external/cuda/cudnn_backend.h'
which is weird cause I do have the cudnn included, and can find the files under the C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6 path
I am new to Bazel, is there another way I could link those?
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
Followed this guide: https://github.com/NVIDIA/Torch-TensorRT/issues/856 to a t. I think I am linking cudnn in a weird way?
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.11.0
- OS (e.g., Linux): windows
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): libtorch
- Build command you used (if compiling from source):
- Are you using local sources or building from archives: local
- Python version: 3.9
- CUDA version: 11.6
- GPU models and configuration: 3070
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
My torch-tensorrt-1.0.0/core/plugins/BUILD is as follows:
```package(default_visibility = ["//visibility:public"])
config_setting(
name = "use_pre_cxx11_abi",
values = {
"define": "abi=pre_cxx11_abi",
}
)
cc_library(
name = "torch_tensorrt_plugins",
hdrs = [
"impl/interpolate_plugin.h",
"impl/normalize_plugin.h",
"plugins.h",
],
srcs = [
"impl/interpolate_plugin.cpp",
"impl/normalize_plugin.cpp",
"register_plugins.cpp",
],
deps = [
"@tensorrt//:nvinfer",
"@tensorrt//:nvinferplugin",
"//core/util:prelude",
] + select({
":use_pre_cxx11_abi": ["@libtorch_pre_cxx11_abi//:libtorch"],
"//conditions:default": ["@libtorch//:libtorch"],
}),
alwayslink = True,
copts = [
"-pthread"
],
linkopts = [
"-lpthread",
]
)
load("@rules_pkg//:pkg.bzl", "pkg_tar")
pkg_tar(
name = "include",
package_dir = "core/plugins/",
srcs = ["plugins.h"],
)
pkg_tar(
name = "impl_include",
package_dir = "core/plugins/impl",
srcs = ["impl/interpolate_plugin.h",
"impl/normalize_plugin.h"],
)
I could attach more build files if needed, but everything apart from the paths is the same as in the referenced issue.
|
https://github.com/pytorch/TensorRT/issues/960
|
closed
|
[
"question",
"channel: windows"
] | 2022-04-04T00:38:36Z
| 2022-09-02T17:51:14Z
| null |
pepinu
|
huggingface/datasets
| 4,074
|
Error in google/xtreme_s dataset card
|
**Link:** https://huggingface.co/datasets/google/xtreme_s
Not a big deal but Hungarian is considered an Eastern European language, together with Serbian, Slovak, Slovenian (all correctly categorized; Slovenia is mostly to the West of Hungary, by the way).
|
https://github.com/huggingface/datasets/issues/4074
|
closed
|
[
"documentation",
"dataset bug"
] | 2022-03-31T18:07:45Z
| 2022-04-01T08:12:56Z
| 1
|
wranai
|
pytorch/TensorRT
| 947
|
hown to compile model for multi inputs?
|
1)My model : out1, out2 = model(input1, input2)
2)How should i set compile settings, just like this:
trt_ts_module = torch_tensorrt.compile(torch_script_module,
inputs = [example_tensor, # Provide example tensor for input shape or...
torch_tensorrt.Input( # Specify input object with shape and dtype
min_shape=[1, 3, 224, 224],
opt_shape=[1, 3, 512, 512],
max_shape=[1, 3, 1024, 1024],
# For static size shape=[1, 3, 224, 224]
dtype=torch.half) # Datatype of input tensor. Allowed options torch.(float|half|int8|int32|bool)
],
enabled_precisions = {torch.half}, # Run with FP16)
|
https://github.com/pytorch/TensorRT/issues/947
|
closed
|
[
"question"
] | 2022-03-31T08:00:41Z
| 2022-03-31T20:29:39Z
| null |
shuaizzZ
|
pytorch/data
| 339
|
Build the nightlies a little earlier
|
`torchdata` builds the nightlies at 15:00 UTC+0
https://github.com/pytorch/data/blob/198cffe7e65a633509ca36ad744f7c3059ad1190/.github/workflows/nightly_release.yml#L6
and publishes them roughly 30 minutes later. The `torchvision` nightlies are build at 11:00 UTC+0 and also published roughly 30 minutes later.
This creates a 4 hour window where the `torchvision` tests that pull in `torchdata` run on outdated nightlies. For example see [this CI run](https://app.circleci.com/pipelines/github/pytorch/vision/16169/workflows/652e06c3-c941-4520-b6ee-f69b2348dd57/jobs/1309833):
In the step "Install PyTorch from the nightly releases" we have
```
Installing collected packages: typing-extensions, torch
Successfully installed torch-1.12.0.dev20220329+cpu typing-extensions-4.1.1
```
Two steps later in "Install torchdata from nightly releases" we have
```
Installing collected packages: torch, torchdata
Attempting uninstall: torch
Found existing installation: torch 1.12.0.dev20220329+cpu
Uninstalling torch-1.12.0.dev20220329+cpu:
Successfully uninstalled torch-1.12.0.dev20220329+cpu
Successfully installed torch-1.12.0.dev20220328+cpu torchdata-0.4.0.dev20220328
```
Was the release schedule deliberately chosen this way? If not can we maybe move it to four hours earlier?
|
https://github.com/meta-pytorch/data/issues/339
|
closed
|
[] | 2022-03-29T15:42:24Z
| 2022-03-29T19:24:52Z
| 5
|
pmeier
|
pytorch/torchx
| 441
|
[Req] LSF scheduler support
|
## Description
LSF scheduler support
Does torchx team have plan to support LSF scheduler?
Or is there any guide for extension, I would make PR.
## Motivation/Background
Thanks for torchx utils. We can target various scheduler by configure torchxconfig.
## Detailed Proposal
It would be better to support LSF scheduler.
|
https://github.com/meta-pytorch/torchx/issues/441
|
open
|
[
"enhancement",
"module: runner",
"scheduler-request"
] | 2022-03-29T04:47:30Z
| 2022-10-10T22:27:47Z
| 6
|
ckddls1321
|
pytorch/data
| 335
|
[BE] Unify `buffer_size` across datapipes
|
The `buffer_size` parameter is currently fairly inconsistent across datapipes:
| name | default `buffer_size` | infinite `buffer_size` | warn on infinite |
|--------------------|-------------------------|--------------------------|--------------------|
| Demultiplexer | 1e3 | -1 | yes |
| Forker | 1e3 | -1 | yes |
| Grouper | 1e4 | N/A | N/A |
| Shuffler | 1e4 | N/A | N/A |
| MaxTokenBucketizer | 1e3 | N/A | N/A |
| UnZipper | 1e3 | -1 | yes |
| IterKeyZipper | 1e4 | None | no |
Here are my suggestion on how to unify this:
- Use the same default `buffer_size` everywhere. It makes little difference whether we use `1e3` or `1e4` given that it is tightly coupled with the data we know nothing about. Given today's hardware / datasets, I would go with 1e4, but no strong opinion.
- Give every datapipe with buffer the ability for an infinite buffer. Otherwise users will just be annoyed and use a workaround. For example, `torchvision` simply uses [`INFINITE_BUFFER_SIZE = 1_000_000_000`](https://github.com/pytorch/vision/blob/1db8795733b91cd6dd62a0baa7ecbae6790542bc/torchvision/prototype/datasets/utils/_internal.py#L42-L43), which for all intents and purposes lives up to its name. Which sentinel we use, i.e. `-1` or `None`, again makes little difference. I personally would use `None` to have a clear separation, but again no strong opinion other than being consistent.
- Do not warn on infinite buffer sizes. Especially since infinite buffer is not the default behavior, the user is expected to know what they are doing when setting `buffer_size=None`. I'm all for having a warning like this in the documentation, but I'm strongly against a runtime warning. For example, `torchvision` datasets need to use an infinite buffer everywhere. Thus, by using the infinite buffer sentinel, users would always get runtime warnings although neither them nor we did anything wrong.
|
https://github.com/meta-pytorch/data/issues/335
|
open
|
[
"Better Engineering"
] | 2022-03-28T17:36:32Z
| 2022-07-06T18:44:05Z
| 8
|
pmeier
|
huggingface/datasets
| 4,041
|
Add support for IIIF in datasets
|
This is a feature request for support for IIIF in `datasets`. Apologies for the long issue. I have also used a different format to the usual feature request since I think that makes more sense but happy to use the standard template if preferred.
## What is [IIIF](https://iiif.io/)?
IIIF (International Image Interoperability Framework)
> is a set of open standards for delivering high-quality, attributed digital objects online at scale. It’s also an international community developing and implementing the IIIF APIs. IIIF is backed by a consortium of leading cultural institutions.
The tl;dr is that IIIF provides various specifications for implementing useful functionality for:
- Institutions to make available images for various use cases
- Users to have a consistent way of interacting/requesting these images
- For developers to have a common standard for developing tools for working with IIIF images that will work across all institutions that implement a particular IIIF standard (for example the image viewer for the BNF can also work for the Library of Congress if they both use IIIF).
Some institutions that various levels of support IIF include: The British Library, Internet Archive, Library of Congress, Wikidata. There are also many smaller institutions that have IIIF support. An incomplete list can be found here: https://iiif.io/guides/finding_resources/
## IIIF APIs
IIIF consists of a number of APIs which could be integrated with datasets. I think the most obvious candidate for inclusion would be the [Image API](https://iiif.io/api/image/3.0/)
### IIIF Image API
The Image API https://iiif.io/api/image/3.0/ is likely the most suitable first candidate for integration with datasets. The Image API offers a consistent protocol for requesting images via a URL:
```{scheme}://{server}{/prefix}/{identifier}/{region}/{size}/{rotation}/{quality}.{format}```
A concrete example of this:
```https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/full/0/default.jpg```
As you can see the scheme offers a number of options that can be specified in the URL, for example, size. Using the example URL we return:

We can change the size to request a size of 250 by 250, this is done by changing the size from `full` to `250,250` i.e. switching the URL to `https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/250,250/0/default.jpg`

We can also request the image with max width 250, max height 250 whilst maintaining the aspect ratio using `!w,h`. i.e. change the url to `https://stacks.stanford.edu/image/iiif/hg676jb4964%2F0380_796-44/full/!250,250/0/default.jpg`

A full overview of the options for size can be found here: https://iiif.io/api/image/3.0/#42-size
## Why would/could this be useful for datasets?
There are a few reasons why support for the IIIF Image API could be useful. Broadly the ability to have more control over how an image is returned from a server is useful for many ML workflows:
- images can be requested in the right size, this prevents having to download/stream large images when the actual desired size is much smaller
- can select a subset of an image: it is possible to select a sub-region of an image, this could be useful for example when you already have a bounding box for a subset of an image and then want to use this subset of an image for another task. For example, https://github.com/Living-with-machines/nnanno uses IIIF to request parts of a newspaper image that have been detected as 'photograph', 'illustration' etc for downstream use.
- options for quality, rotation, the format can all be encoded in the URL request.
These may become particularly useful when pre-training models on large image datasets where the cost of downloading images with 1600 pixel width when you actually want 240 has a larger impact.
## What could this look like in datasets?
I think there are various ways in which support for IIIF could potentially be included in `datasets`. These suggestions aren't fully fleshed out but hopefully, give a sense of possible approaches that match existing `datasets` methods in their approach.
### Use through datasets scripts
Loading images via URL is already supported. There are a few possible 'extras' that could be included when using IIIF. One option is to leverage the IIIF protocol in datasets scripts, i.e. the dataset script can expose the IIIF options via the dataset script:
```python
ds = load_dataset("iiif_dataset", image_size="250,250", fmt="jpg")
```
This is already possible. The approach to parsing the IIIF URLs would be left to the person creating the dataset script.
### Sup
|
https://github.com/huggingface/datasets/issues/4041
|
open
|
[
"enhancement"
] | 2022-03-28T15:19:25Z
| 2022-04-05T18:20:53Z
| 1
|
davanstrien
|
pytorch/vision
| 5,686
|
Question on segmentation code
|
### 🚀 The feature
Hello.
I want to ask you a simple question.
I'm not sure if it's right to post a question in this 'Feature request' category.
In train.py code in the reference/segmentation, the get_dataset function is set the coco dataset classes 21.
Why the number of classes is 21?
Is it wrong to set the number of classes to 91 which is the number of classes in the coco dataset?
Here is the reference code.
```python
def get_dataset(dir_path, name, image_set, transform):
def sbd(*args, **kwargs):
return torchvision.datasets.SBDataset(*args, mode="segmentation", **kwargs)
paths = {
"voc": (dir_path, torchvision.datasets.VOCSegmentation, 21),
"voc_aug": (dir_path, sbd, 21),
"coco": (dir_path, get_coco, 21),
}
p, ds_fn, num_classes = paths[name]
ds = ds_fn(p, image_set=image_set, transforms=transform)
return ds, num_classes
cc @vfdev-5 @datumbox @YosuaMichael
|
https://github.com/pytorch/vision/issues/5686
|
closed
|
[
"question",
"topic: semantic segmentation"
] | 2022-03-28T06:05:39Z
| 2022-03-28T07:29:35Z
| null |
kcs6568
|
pytorch/torchx
| 435
|
[torchx/examples] Remove usages of custom components in app/pipeline examples
|
## 📚 Documentation
Since we are making TorchX focused on Job launching and less about authoring components and AppDefs, we need to adjust our app and pipeline examples to demonstrate running the applications with the builtin `dist.ddp` and `utils.python` components rather than showing how to author a component for the application.
For 90% of the launch patterns `dist.ddp` (multi-homogeneous node) and `utils.python` (single node) is sufficient.
There are a couple of things we need to do:
1. Delete `torchx/example/apps/**/component.py`
2. For each application example show how to run it with the existing `dist.ddp` or `utils.python` builtin
3. Link a section on how to copy existing components and further customizing (e.g. `torchx builtins --print dist.ddp > custom.py`)
4. Make adjustments to the integration tests to test the example applications using builtin components (as advertised)
5. Do 1-4 for the pipeline examples too.
|
https://github.com/meta-pytorch/torchx/issues/435
|
closed
|
[
"documentation"
] | 2022-03-25T23:34:26Z
| 2022-05-25T22:52:40Z
| 0
|
kiukchung
|
huggingface/datasets
| 4,027
|
ElasticSearch Indexing example: TypeError: __init__() missing 1 required positional argument: 'scheme'
|
## Describe the bug
I am following the example in the documentation for elastic search step by step (on google colab): https://huggingface.co/docs/datasets/faiss_es#elasticsearch
```
from datasets import load_dataset
squad = load_dataset('crime_and_punish', split='train[:1000]')
```
When I run the line:
`squad.add_elasticsearch_index("context", host="localhost", port="9200")`
I get the error:
`TypeError: __init__() missing 1 required positional argument: 'scheme'`
## Expected results
No error message
## Actual results
```
TypeError Traceback (most recent call last)
[<ipython-input-23-9205593edef3>](https://localhost:8080/#) in <module>()
1 import elasticsearch
----> 2 squad.add_elasticsearch_index("text", host="localhost", port="9200")
6 frames
[/usr/local/lib/python3.7/dist-packages/elasticsearch/_sync/client/utils.py](https://localhost:8080/#) in host_mapping_to_node_config(host)
209 options["path_prefix"] = options.pop("url_prefix")
210
--> 211 return NodeConfig(**options) # type: ignore
212
213
TypeError: __init__() missing 1 required positional argument: 'scheme'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.2.0
- Platform: Linux, Google Colab
- Python version: Google Colab (probably 3.7)
- PyArrow version: ?
|
https://github.com/huggingface/datasets/issues/4027
|
closed
|
[
"bug",
"duplicate"
] | 2022-03-25T16:22:28Z
| 2022-04-07T10:29:52Z
| 2
|
MoritzLaurer
|
pytorch/tutorials
| 1,872
|
Transfer learning tutorial: Loss and Accuracy curves the wrong way
|
Hey,
I have a question concerning the transfer learning tutorial (https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html).
For a few days, I've been trying to figure out why the validation and training curves are reversed there. By this, I mean that for general neural networks the training curves are always better than the validation curves (lower loss and higher accuracy). However, as in the tutorial itself, this is not the case (see also values in the tutorial). To make the whole thing clearer, I also ran the tutorial for 100 epochs and plotted the accuracy and loss for training and validation. The graph looks like this:
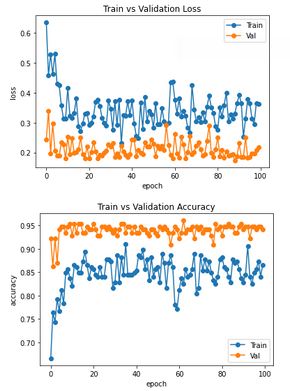
Unfortunately, I haven't found a real reason for this yet.
It shouldn't be the dataset itself (I tried the same with other data). The only thing is the BatchNorm, which is different for training and validation. But I also suspect that this is not the reason for this big difference and the changing role. In past projects also on neural networks, with batch normalization at least I didn't have these reversed roles of validation and training.
Has anybody an idea, why this happens here and why it has not that effect using other neural networks?
cc @suraj813
|
https://github.com/pytorch/tutorials/issues/1872
|
closed
|
[
"question",
"intro"
] | 2022-03-25T15:23:39Z
| 2023-03-06T21:50:25Z
| null |
AlexanderGeng
|
pytorch/pytorch
| 74,741
|
[FSDP] How to use fsdp in GPT model in Megatron-LM
|
### 🚀 The feature, motivation and pitch
Are there any examples similar to DeepSpeed that can experience the fsdp function of pytorch. It would be nice to provide the GPT model in Megatron-LM.
### Alternatives
I hope to provide examples of benchmarking DeepSpeed to facilitate the in-depth use of the fsdp function.
### Additional context
_No response_
|
https://github.com/pytorch/pytorch/issues/74741
|
closed
|
[] | 2022-03-25T08:30:05Z
| 2022-03-25T21:12:04Z
| null |
Baibaifan
|
pytorch/text
| 1,662
|
How to install LTS (0.9.2)?
|
## ❓ Questions and Help
**Description**
I've found that my PyTorch version is 1.8.2, so according to https://github.com/pytorch/text/#installation , the torchtext version is 0.9.2:

But as I use `conda install -c pytorch torchtext` to install, the version I installed defaultly is 0.6.0. So I wander, is this version also OK for me as the torchtext version 0.9.2 is the highest version I can install, or it's not OK as I can only install 0.9.2 version?
|
https://github.com/pytorch/text/issues/1662
|
closed
|
[] | 2022-03-25T08:12:03Z
| 2024-03-11T00:55:30Z
| null |
PolarisRisingWar
|
pytorch/pytorch
| 74,740
|
How to export onnx with dynamic batch size for models with multiple outputs?
|
## Issue description
I want to export my model to onnx. Following is my code:
torch.onnx._export(
model,
dummy_input,
args.output_name,
input_names=[args.input],
output_names=args.output,
opset_version=args.opset,
)
It works well. But I want to export it with dynamic batch size. So I try this:
torch.onnx._export(
model,
dummy_input,
args.output_name,
input_names=[args.input],
output_names=args.output,
opset_version=args.opset,
dynamic_axes={'input_tensor' : {0 : 'batch_size'},
'classes' : {0 : 'batch_size'},
'boxes' : {0 : 'batch_size'},
'scores' : {0 : 'batch_size'},}
)
It crashed with following message:
``2022-03-25 13:38:11.201 | ERROR | main::114 - An error has been caught in function '', process 'MainProcess' (1376540), thread 'MainThread' (139864366814016):
Traceback (most recent call last):
File "tools/export_onnx.py", line 114, in
main()
└ <function main at 0x7f3434447f70>
File "tools/export_onnx.py", line 107, in main
model_simp, check = simplify(onnx_model)
│ └ ir_version: 7
│ producer_name: "pytorch"
│ producer_version: "1.10"
│ graph {
│ node {
│ output: "607"
│ name: "Constant_0"
│ ...
└ <function simplify at 0x7f3417604dc0>
File "/home/xyz/anaconda3/envs/yolox/lib/python3.8/site-packages/onnxsim/onnx_simplifier.py", line 483, in simplify
model = fixed_point(model, infer_shapes_and_optimize, constant_folding)
│ │ │ └ <function simplify..constant_folding at 0x7f34175d5f70>
│ │ └ <function simplify..infer_shapes_and_optimize at 0x7f342715c160>
│ └ ir_version: 7
│ producer_name: "pytorch"
│ producer_version: "1.10"
│ graph {
│ node {
│ output: "607"
│ name: "Constant_0"
│ ...
└ <function fixed_point at 0x7f3417604d30>
File "/home/xyz/anaconda3/envs/yolox/lib/python3.8/site-packages/onnxsim/onnx_simplifier.py", line 384, in fixed_point
x = func_b(x)
│ └ ir_version: 7
│ producer_name: "pytorch"
│ producer_version: "1.10"
│ graph {
│ node {
│ input: "input_tensor"
│ input: "608"
│ ...
└ <function simplify..constant_folding at 0x7f34175d5f70>
File "/home/xyz/anaconda3/envs/yolox/lib/python3.8/site-packages/onnxsim/onnx_simplifier.py", line 473, in constant_folding
res = forward_for_node_outputs(model,
│ └ ir_version: 7
│ producer_name: "pytorch"
│ producer_version: "1.10"
│ graph {
│ node {
│ input: "input_tensor"
│ input: "608"
│ ...
└ <function forward_for_node_outputs at 0x7f34176048b0>
File "/home/xyz/anaconda3/envs/yolox/lib/python3.8/site-packages/onnxsim/onnx_simplifier.py", line 229, in forward_for_node_outputs
res = forward(model,
│ └ ir_version: 7
│ producer_name: "pytorch"
│ producer_version: "1.10"
│ graph {
│ node {
│ input: "input_tensor"
│ input: "608"
│ ...
└ <function forward at 0x7f3417604820>
File "/home/xyz/anaconda3/envs/yolox/lib/python3.8/site-packages/onnxsim/onnx_simplifier.py", line 210, in forward
inputs.update(generate_specific_rand_input(model, {name: shape}))
│ │ │ │ │ └ [0, 3, 640, 640]
│ │ │ │ └ 'input_tensor'
│ │ │ └ ir_version: 7
│ │ │ producer_name: "pytorch"
│ │ │ producer_version: "1.10"
│ │ │ graph {
│ │ │ node {
│ │ │ input: "input_tensor"
│ │ │ input: "608"
│ │ │ ...
│ │ └ <function generate_specific_rand_input at 0x7f3417604550>
│ └ <method 'update' of 'dict' objects>
└ {}
File "/home/xyz/anaconda3/envs/yolox/lib/python3.8/site-packages/onnxsim/onnx_simplifier.py", line 98, in generate_specific_rand_input
raise RuntimeError(
RuntimeError: The shape of input "input_tensor" has dynamic size "[0, 3, 640, 640]", please determine the input size manually by "--dynamic-input-shape --input-shape xxx" or "--input-shape xxx". Run "python3 -m onnxsim -h" for details
``
My environments:
`pip list
Package Version Editable project location
------------------------- --------------------- ------------------------------------------------------------------
absl-py 1.0.0
albumentations 1.1.0
anykeystore 0.2
apex 0.1
appdirs 1.4.4
cachetools 4.2.4
certifi 2021.10.8
charset-normalizer 2.0.9
cryptacular 1.6.2
cycler 0.11.0
Cython 0.29.25
defusedxml 0.7.1
flatbuffers 2.0
fonttools 4.28.3
google-auth 2.3.3
google-auth-oauthlib 0.4.6
greenlet 1.1.2
grpcio 1.42.0
hupper 1.10.3
idna 3.3
imageio 2.13.3
imgaug 0.4.0
importlib-metadata 4.8.2
joblib 1.1.0
kiwisolver 1.3.2
loguru 0.5.3
Mako 1.1.6
Markdown 3.3.6
MarkupSafe 2.0.1
matplotlib 3.5.1
networkx 2.6.3
ninja 1.10.2.3
numpy 1.2
|
https://github.com/pytorch/pytorch/issues/74740
|
closed
|
[] | 2022-03-25T07:55:45Z
| 2022-03-25T08:15:58Z
| null |
LLsmile
|
pytorch/pytorch
| 74,616
|
__rpow__(self, other) OpInfo should not test the case where `other` is a Tensor
|
### 🐛 Describe the bug
After https://github.com/pytorch/pytorch/pull/74280 (cc @mruberry), the `__rpow__` OpInfo has a sample input where `other` is a Tensor. This cannot happen during normal execution: to get to `Tensor.__rpow__` a user does the following:
```
# self = some_tensor
# other = not_a_tensor
not_a_tensor ** some_tensor
```
If instead `not_a_tensor` is a Tensor, this ends up calling `__pow__` in Python which will then handle the case.
Are there any legitimate cases where we do want this to happen?
## Context
This caused some functorch tests to fail because we don't support the route where both `self` and `other` are Tensors. pytorch/pytorch also has some cryptic warning in that route:

but it's not clear to me if we want to support this or not.
### Versions
pytorch main branch
|
https://github.com/pytorch/pytorch/issues/74616
|
open
|
[
"module: tests",
"triaged"
] | 2022-03-23T15:28:17Z
| 2022-04-18T02:34:55Z
| null |
zou3519
|
pytorch/TensorRT
| 936
|
❓[Question] RuntimeError: [Error thrown at core/conversion/converters/impl/select.cpp:236] Expected const_layer to be true but got false
|
## ❓ Question
when i convert jit model, got the error
this is my forward code:
input `x` shape is `(batch, 6, height, width)`, first step is to split `x` into two tensors, but failed
```
def forward(self, x):
fg = x[:,0:3,:,:] ## this line got error
bg = x[:,3:,:,:]
fg = self.backbone(fg)
bg = self.backbone(bg)
out = self.heads(fg, bg)
return out
```
complete traceback:
```
ERROR: [Torch-TensorRT TorchScript Conversion Context] - 3: [network.cpp::addConstant::1052] Error Code 3: Internal Error (Parameter check failed at: optimizer/api/network.cpp::addConstant::1052, condition: !weights.values == !weights.count
)
Traceback (most recent call last):
File "model_converter.py", line 263, in <module>
engine = get_engine(model_info.trt_engine_path, calib, int8_mode=int8_mode, optimize_params=optimize_params)
File "model_converter.py", line 173, in get_engine
return build_engine(max_batch_size)
File "model_converter.py", line 95, in build_engine
return build_engine_from_jit(max_batch_size)
File "model_converter.py", line 80, in build_engine_from_jit
tensorrt_engine_model = torch_tensorrt.ts.convert_method_to_trt_engine(traced_model, "forward", **compile_settings)
File "/usr/local/lib/python3.6/dist-packages/torch_tensorrt/ts/_compiler.py", line 211, in convert_method_to_trt_engine
return _C.convert_graph_to_trt_engine(module._c, method_name, _parse_compile_spec(compile_spec))
RuntimeError: [Error thrown at core/conversion/converters/impl/select.cpp:236] Expected const_layer to be true but got false
Unable to create constant layer from node: %575 : Tensor = aten::slice(%570, %13, %12, %14, %13) # /data/small_detection/centernet_pytorch_small_detection/models/low_freeze_comb_net.py:455:0
```
## What you have already tried
try use `fg, bg = x.split(int(x.shape[1] // 2), dim=1)` instead of `fg = x[:,0:3,:,:]` and `bg = x[:,3:,:,:]` but got convert error for op not support
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.4.0
- CPU Architecture: arm (nx)
- OS (e.g., Linux):
- How you installed PyTorch: docker of nvidia l4t
- Python version: 3.6.9
- CUDA version: 10.2.300
- Tensorrt version: 8.0.1.6
|
https://github.com/pytorch/TensorRT/issues/936
|
closed
|
[
"question",
"component: converters",
"No Activity"
] | 2022-03-22T02:40:39Z
| 2023-02-10T00:13:18Z
| null |
pupumao
|
pytorch/text
| 1,661
|
what's is the replacement of legacy?
|
## ❓ Questions and Help
**Description**
<!-- Please send questions or ask for help here. -->
in torchtext0.12.0, the module legacy has been removed, so how to implement the same functions as the class legacy.Field?
thanks for your help.
|
https://github.com/pytorch/text/issues/1661
|
closed
|
[] | 2022-03-21T11:03:55Z
| 2022-10-04T01:51:51Z
| null |
1152545264
|
pytorch/serve
| 1,518
|
How to return a dict response, not a list
|
<!--
Thank you for suggesting an idea to improve torchserve model serving experience.
Please fill in as much of the template below as you're able.
-->
## Is your feature request related to a problem? Please describe.
<!-- Please describe the problem you are trying to solve. -->
when I retuan a dict value, serve return a error.
## Describe the solution
<!-- Please describe the desired behavior. -->
## Describe alternatives solution
<!-- Please describe alternative solutions or features you have considered. -->
|
https://github.com/pytorch/serve/issues/1518
|
closed
|
[] | 2022-03-20T10:30:09Z
| 2022-03-25T20:14:17Z
| null |
liuhuiCNN
|
pytorch/data
| 310
|
MapDatapipe Mux/Demux Support
|
### 🚀 The feature
MapDatapipes are missing Mux and Demux pipes as noted in https://github.com/pytorch/pytorch/issues/57031
Talked to @ejguan on https://discuss.pytorch.org/t/mapdatapipe-support-mux-demux/146305, I plan to do a PR with Mux/Demux added. However, I will add rough outlines / ideas here first. I plan to match the same test strategy as the Mux/Demux pipes already in IterDataPipes.
### Motivation, pitch
For Demux: My basic test/goal is to download mnist, and split it into train/validation sets using map.
For Mux: Then attempt to mux them back together (not sure how to come up with a useful example of this).
- Might try a scenario where I split train into k splits and rejoin them?
Not sure when this should be converted to a pr. This would be my first pr into pytorch, so I want the pr to be as clean as possible. Putting code changes ideas here I feel could allow for more dramatic/messy changes/avoid a messy git diff/worry about formatting once code is finalized.
Note: doc strings are removed to make code shorter and will be readded in pr. Not-super-useful comments will be removed in pr.
Note: let me know if a draft pr would be better.
Demux working code:
Draft 1: https://github.com/josiahls/fastrl/blob/848f90d0ed5b0c2cd0dd3e134b0b922dd8a53d7c/fastrl/fastai/data/pipes.py
Demux working code + Basic Test
Draft 1: https://github.com/josiahls/fastrl/blob/848f90d0ed5b0c2cd0dd3e134b0b922dd8a53d7c/nbs/02c_fastai.data.pipes.ipynb
Mux working code:
Draft 1: https://github.com/josiahls/fastrl/blob/30cd47766e9fb1bc75d32de877f54b8de9567c36/fastrl/fastai/data/pipes/mux.py
Basic Test
Draft 1: https://github.com/josiahls/fastrl/blob/30cd47766e9fb1bc75d32de877f54b8de9567c36/nbs/02c_fastai.data.pipes.mux.ipynb
|
https://github.com/meta-pytorch/data/issues/310
|
open
|
[] | 2022-03-19T19:31:49Z
| 2022-03-27T03:31:32Z
| 7
|
josiahls
|
pytorch/data
| 303
|
DataPipe for GCS (Google Cloud Storage)
|
### 🚀 The feature
Build a DataPipe that allows users to connect to GCS (Google Cloud Storage). There is a chance that existing DataPipes may suffice, so we should examine the relevant APIs first.
### Motivation, pitch
GCS (Google Cloud Storage) is one of the commonly used cloud storage for storing data.
### Alternatives
Existing DataPipes are sufficient and we should provide an example of how that can be done instead.
### Additional context
Feel free to react or leave a comment if this feature is important for you or for any other suggestion.
|
https://github.com/meta-pytorch/data/issues/303
|
closed
|
[] | 2022-03-16T19:01:03Z
| 2023-03-07T14:49:15Z
| 2
|
NivekT
|
pytorch/data
| 302
|
Notes on shuffling, sharding, and batchsize
|
(I'm writing this down here to have a written trace, but I'm looking forward to discuss this with you all in our upcoming meetings :) )
I spent some time porting the torchvision training recipes to use datapipes, and I noticed that the model I trained on ImageNet with DPs was much less accurate than the one with regular datasets. After **a lot** of digging I came to the following conclusion:
1. the datapipe must be shuffled **before** it is sharded
2. the DataLoader does not behave in the same way with a datapipe and with a regular indexable dataset, in particular when it comes to size of the last batches in an epoch. This has a **dramatic** effect on accuracy (probably because of batch-norm).
Details below. Note: for sharding, I used [this custom torchvision sharder](https://github.com/pytorch/vision/blob/eb6e39157cf1aaca184b52477cf1e9159bbcbd63/torchvision/prototype/datasets/utils/_internal.py#L120) which takes DDP and dataloader workers into account, + the TakerIterDataPipe below it.
-----
### Shuffle before shard
First, some quick results (training a resnext50_32x4d for 5 epochs with 8 GPUs and 12 workers per GPU):
Shuffle before shard: Acc@1 = 47% -- this is on par with the regular indexable dataset version (phew!!)
Shuffle after shard: Acc@1 = 2%
One way to explain this is that if we shuffle after we shard, then only sub-parts of the dataset get shuffled. Namely, each of the 8 * 12 = 96 dataloader workers receive ~1/96th of the dataset, and each of these parts get shuffled. But that means that the shuffling is far from uniform and for datasets in which the layout is `all_samples_from_class1, all_samples_from_class2, ... all_samples_from_classN`, it's possible that some class i is **never** in the same batch as class j.
So it looks like we need to shuffle before we shard. Now, if we shuffle before sharding, we still need to make sure that all of the 96 workers shuffle the dataset with the same RNG. Otherwise we risk sampling a given sample in more than one worker, or not at all. For that to happen, one can set a random seed in `worker_init_fn`, but that causes a second problem: the random transformations of each worker will also be the same, and this will lead to slightly less accurate results; on top of that, all epochs will start with the same seed, so the shuffling is the same across all epochs. **I do not know how to solve this problem yet.**
Note that TF shuffles the dataset before storing it. We might do something similar, but that would still not solve the issue for custom users datasets.
----
### Size of the batches at the end of an epoch
Some quick results (same experiment as above):
with drop_last=True: Acc@1 = 47%
with drop_last=False: Acc@1 = 11%
Near the end of the epoch, the dataloader with DP will produce a lot of batches with size 1 if drop_last is False. See the last batches of an epoch on indices from `[0, len(imagenet))` with a requested batch size of 32: https://pastebin.com/wjS7YC90. In contrast, this does not happen when using an indexable dataset: https://pastebin.com/Rje0U8Dx.
I'm not too sure of why this has such a dramatic impact, but it's possible that this has to do with batch-norm, as @fmassa pointed out offline. Using `drop_last` will make sure that the 1-sized batches are eliminated, producing a much better accuracy.
I guess the conclusion here is that it's worth unifying the behaviour of the DataLoader both DPs and regular indexable datasets regarding the batch size, because with indexable datasets and drop_last=False we still get ~47% acc.
|
https://github.com/meta-pytorch/data/issues/302
|
open
|
[] | 2022-03-16T18:08:41Z
| 2022-05-24T12:55:18Z
| 28
|
NicolasHug
|
pytorch/data
| 301
|
Add TorchArrow Nightly CI Test
|
### 🚀 The feature
TorchArrow nightly build is now [available for Linux](https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html) (other versions will be next).
We should add TorchArrow nightly CI tests for these [TorchArrow dataframe related unit tests](https://github.com/pytorch/data/blob/main/test/test_dataframe.py).
### Motivation, pitch
This will ensure that our usages remain compatible with TA's APIs.
### Additional context
This is a good first issue for people who want to understand how our CI works. Other [domain CI tests](https://github.com/pytorch/data/blob/main/.github/workflows/domain_ci.yml) (for Vision, Text) can serve as examples on how to set this up.
|
https://github.com/meta-pytorch/data/issues/301
|
closed
|
[
"good first issue"
] | 2022-03-16T17:28:27Z
| 2022-05-09T15:38:31Z
| 1
|
NivekT
|
pytorch/pytorch
| 74,288
|
How to Minimize Rounding Error in torch.autograd.functional.jacobian?
|
### 🐛 Describe the bug
Before I start, let me express my sincerest gratitude to issue #49171, in making it possible to take the jacobian wrt all model parameters! A great functionality indeed!
I am raising an issue about the approximation error when the jacobian function goes to high dimensions. This is necessary when calculating the jacobian wrt parameters using batch inputs. In low dimensions, the following code work fine
```
import torch
from torch.autograd.functional import jacobian
from torch.nn.utils import _stateless
from torch import nn
from torch.nn import functional as F
```
```
model = nn.Conv2d(3,1,1)
input = torch.rand(1, 3, 32, 32)
two_input = torch.cat([input, torch.rand(1, 3, 32, 32)], dim=0)
names = list(n for n, _ in model.named_parameters())
# This is exactly the same code as in issue #49171
jac1 = jacobian(lambda *params: _stateless.functional_call(model, {n: p for n, p in zip(names, params)}, input), tuple(model.parameters()))
jac2 = jacobian(lambda *params: _stateless.functional_call(model, {n: p for n, p in zip(names, params)}, two_input), tuple(model.parameters()))
assert torch.allclose(jac1[0][0], jac2[0][0])
```
However, when I make the model slightly larger the assertion breaks down, which seem like it's due to rounding errors
```
class ResBasicBlock(nn.Module):
def __init__(self, n_channels, n_inner_channels, kernel_size=3):
super().__init__()
self.conv1 = nn.Conv2d(n_channels, n_inner_channels, (kernel_size, kernel_size), padding=kernel_size // 2,
bias=False)
self.conv2 = nn.Conv2d(n_inner_channels, n_channels, (kernel_size, kernel_size), padding=kernel_size // 2,
bias=False)
self.norm1 = nn.BatchNorm2d(n_inner_channels)
self.norm2 = nn.BatchNorm2d(n_channels)
self.norm3 = nn.BatchNorm2d(n_channels)
def forward(self, z, x=None):
if x == None:
x = torch.zeros_like(z)
y = self.norm1(F.relu(self.conv1(z)))
return self.norm3(F.relu(z + self.norm2(x + self.conv2(y))))
model = ResBasicBlock(3, 1)
input = torch.rand(1, 3, 32, 32)
two_input = torch.cat([input, torch.rand(1, 3, 32, 32)], dim=0)
names = list(n for n, _ in model.named_parameters())
# This is exactly the same code as in issue #49171
jac1 = jacobian(lambda *params: _stateless.functional_call(model, {n: p for n, p in zip(names, params)}, input), tuple(model.parameters()))
jac2 = jacobian(lambda *params: _stateless.functional_call(model, {n: p for n, p in zip(names, params)}, two_input), tuple(model.parameters()))
assert torch.allclose(jac1[0][0], jac2[0][0])
```
### Versions
```
Collecting environment information...
PyTorch version: 1.11.0
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 12.3 (x86_64)
GCC version: Could not collect
Clang version: 13.1.6 (clang-1316.0.21.2)
CMake version: version 3.17.1
Libc version: N/A
Python version: 3.8.12 (default, Oct 12 2021, 06:23:56) [Clang 10.0.0 ] (64-bit runtime)
Python platform: macOS-10.16-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] functorch==0.1.0
[pip3] numpy==1.21.2
[pip3] torch==1.11.0
[pip3] torchaudio==0.11.0
[pip3] torchvision==0.12.0
[conda] blas 1.0 mkl defaults
[conda] ffmpeg 4.3 h0a44026_0 pytorch
[conda] functorch 0.1.0 pypi_0 pypi
[conda] mkl 2021.4.0 hecd8cb5_637 defaults
[conda] mkl-service 2.4.0 py38h9ed2024_0 defaults
[conda] mkl_fft 1.3.1 py38h4ab4a9b_0 defaults
[conda] mkl_random 1.2.2 py38hb2f4e1b_0 defaults
[conda] numpy 1.21.2 py38h4b4dc7a_0 defaults
[conda] numpy-base 1.21.2 py38he0bd621_0 defaults
[conda] pytorch 1.11.0 py3.8_0 pytorch
[conda] torchaudio 0.11.0 py38_cpu pytorch
[conda] torchvision 0.12.0 py38_cpu pytorch
```
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @Lezcano @Varal7
|
https://github.com/pytorch/pytorch/issues/74288
|
closed
|
[
"module: numerical-stability",
"module: autograd",
"triaged"
] | 2022-03-16T09:25:18Z
| 2022-03-17T14:17:29Z
| null |
QiyaoWei
|
pytorch/pytorch
| 74,256
|
Create secure credential storage for metrics credentials and associated documentation on how to regenerate them if needed
|
cc @seemethere @malfet @pytorch/pytorch-dev-infra
|
https://github.com/pytorch/pytorch/issues/74256
|
open
|
[
"module: ci",
"triaged"
] | 2022-03-15T20:21:20Z
| 2022-03-16T17:30:02Z
| null |
seemethere
|
pytorch/torchx
| 422
|
kubernetes: add support for persistent volume claim volumes
|
## Description
<!-- concise description of the feature/enhancement -->
Add support for PersistentVolumeClaim mounts to Kubernetes scheduler.
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
https://github.com/pytorch/torchx/pull/420 adds bindmounts to K8S, we want to add in persistent volume claims for Kubernetes which will let us support most of the other remote mounts.
## Detailed Proposal
<!-- provide a detailed proposal -->
Add a new mount type to specs:
```
class MountTypes(Enum):
PERSISTENT_CLAIM = "persistent-claim"
BIND = "bind"
class PersistentClaimMount(Mount):
name: str
dst_path: str
read_only: bool = False
class Role:
...
mounts: List[Union[BindMount,PersistentClaimMount]]
```
Add a new format to `parse_mounts`:
```
--mounts bind=persistent-claim,name=foo,dst=/foo[,readonly]
```
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
Users can already mount a volume on the host node and then bind mount it into kubernetes pod but this violates some isolation principles and can be an issue from a security perspective. It also is a worse experience for users since the mounts need to be mounted on ALL hosts.
## Additional context/links
<!-- link to code, documentation, etc. -->
* V1Volume https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1Volume.md
* V1PersistentVolume https://github.com/kubernetes-client/python/blob/master/kubernetes/docs/V1PersistentVolumeClaimVolumeSource.md
* FSx on EKS https://github.com/kubernetes-sigs/aws-fsx-csi-driver/blob/master/examples/kubernetes/static_provisioning/README.md
|
https://github.com/meta-pytorch/torchx/issues/422
|
closed
|
[] | 2022-03-15T18:21:10Z
| 2022-03-16T22:12:26Z
| 0
|
d4l3k
|
pytorch/TensorRT
| 929
|
❓ [Question] Expected isITensor() to be true but got false Requested ITensor from Var, however Var type is c10::IValue
|
I try to use python trtorch==0.4.1 to compile my own pytorch jit traced model, and I find that it goes wrong with the following information:
`
Traceback (most recent call last):
File "./prerecall_server.py", line 278, in <module>
ModelServing(args),
File "./prerecall_server.py",, line 133, in __init__
self.model = trtorch.compile(self.model, compile_settings)
File "/usr/local/lib/python3.6/dist-packages/trtorch/_compiler.py", line 73, in compile
compiled_cpp_mod = trtorch._C.compile_graph(module._c, _parse_compile_spec(compile_spec))
RuntimeError: [Error thrown at core/conversion/var/Var.cpp:149] Expected isITensor() to be true but got false
Requested ITensor from Var, however Var type is c10::IValue
`
I make debug and find that the module contains the unknown operation.
`
class Causal_Norm_Classifier(nn.Module):
def __init__(self, num_classes=1000, feat_dim=2048, use_effect=False, num_head=2, tau=16.0, alpha=1.0, gamma=0.03125, mu=0.9, *args):
super(Causal_Norm_Classifier, self).__init__()
# default alpha = 3.0
#self.weight = nn.Parameter(torch.Tensor(num_classes, feat_dim).cuda(), requires_grad=True)
self.scale = tau / num_head # 16.0 / num_head
self.norm_scale = gamma # 1.0 / 32.0
self.alpha = alpha # 3.0
self.num_head = num_head
self.feat_dim = feat_dim
self.head_dim = feat_dim // num_head
self.use_effect = use_effect
self.relu = nn.ReLU(inplace=True)
self.mu = mu
self.register_parameter('weight', nn.Parameter(torch.Tensor(num_classes, feat_dim), requires_grad=True))
self.reset_parameters(self.weight)
def reset_parameters(self, weight):
stdv = 1. / math.sqrt(weight.size(1))
weight.data.uniform_(-stdv, stdv)
def forward(self, x, training=True, use_effect=True):
# calculate capsule normalized feature vector and predict
normed_w = self.multi_head_call(self.causal_norm, self.weight, weight=self.norm_scale)
normed_x = self.multi_head_call(self.l2_norm, x)
y = torch.mm(normed_x * self.scale, normed_w.t())
return y
def multi_head_call(self, func, x, weight=None):
assert len(x.shape) == 2
x_list = torch.split(x, self.head_dim, dim=1)
if weight:
y_list = [func(item, weight) for item in x_list]
else:
y_list = [func(item) for item in x_list]
assert len(x_list) == self.num_head
assert len(y_list) == self.num_head
return torch.cat(y_list, dim=1)
def l2_norm(self, x):
normed_x = x / torch.norm(x, 2, 1, keepdim=True)
return normed_x
def causal_norm(self, x, weight):
norm= torch.norm(x, 2, 1, keepdim=True)
normed_x = x / (norm + weight)
return normed_x
`
Can you help me with this?
|
https://github.com/pytorch/TensorRT/issues/929
|
closed
|
[
"question",
"No Activity",
"component: partitioning"
] | 2022-03-15T10:17:07Z
| 2023-04-01T00:02:11Z
| null |
clks-wzz
|
pytorch/tutorials
| 1,860
|
Where is the mnist_sample notebook?
|
In tutorial [WHAT IS TORCH.NN REALLY?](https://pytorch.org/tutorials/beginner/nn_tutorial.html#closing-thoughts), `Closing thoughts` part:
```
To see how simple training a model can now be, take a look at the mnist_sample sample notebook.
```
Does`mnist_sample notebook ` refer to https://github.com/pytorch/tutorials/blob/master/beginner_source/nn_tutorial.py and https://pytorch.org/tutorials/_downloads/5ddab57bb7482fbcc76722617dd47324/nn_tutorial.ipynb ?
Note:
https://github.com/pytorch/tutorials/blob/b1d8993adc3663f0f00d142ac67f6695baaf107a/beginner_source/nn_tutorial.py#L853
|
https://github.com/pytorch/tutorials/issues/1860
|
closed
|
[] | 2022-03-14T12:21:14Z
| 2022-08-18T17:35:34Z
| null |
Yang-Xijie
|
pytorch/torchx
| 421
|
Document usage of .torchxconfig
|
## 📚 Documentation
## Link
Current `.torchxconfig` docs (https://pytorch.org/torchx/main/runner.config.html) explain how it works and its APIs but does not provide any practical guidance on what configs can be put into it and why its useful.
## What does it currently say?
Nothing wrong with what it currently says.
## What should it say?
Should add more practical user guide on what are the supported configs in `.torchxconfig` and under what circumstances it gets picked up with the `torchx` CLI. As well as:
1. Examples
2. Best Practices
## Why?
Current .torchxconfig docs is useful to the programmer but not for the user.
|
https://github.com/meta-pytorch/torchx/issues/421
|
closed
|
[] | 2022-03-12T00:30:59Z
| 2022-03-28T20:58:44Z
| 1
|
kiukchung
|
pytorch/torchx
| 418
|
cli/colors: crash when importing if sys.stdout is closed
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
Sometimes `sys.stdout` is closed and `isatty()` throws an error at https://github.com/pytorch/torchx/blob/main/torchx/cli/colors.py#L11
Switching to a variant that checks if it's closed should work:
```
not sys.stdout.closed and sys.stdout.isatty()
```
Module (check all that applies):
* [ ] `torchx.spec`
* [ ] `torchx.component`
* [ ] `torchx.apps`
* [ ] `torchx.runtime`
* [x] `torchx.cli`
* [ ] `torchx.schedulers`
* [ ] `torchx.pipelines`
* [ ] `torchx.aws`
* [ ] `torchx.examples`
* [ ] `other`
## To Reproduce
I'm not sure how to repro this externally other than explicitly closing `sys.stdout`
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
```
I/O operation on closed file
Stack trace:
...
from torchx.cli.cmd_log import get_logs
File: <"/mnt/xarfuse/uid-27156/4adc7caa-seed-nspid4026533510_cgpid2017229-ns-4026533507/torchx/cli/cmd_log.py">, line 20, in <module>
from torchx.cli.colors import GREEN, ENDC
File: <"/mnt/xarfuse/uid-27156/4adc7caa-seed-nspid4026533510_cgpid2017229-ns-4026533507/torchx/cli/colors.py">, line 11, in <module>
if sys.stdout.isatty():
```
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
Doesn't crash
## Environment
- torchx version (e.g. 0.1.0rc1): main
- Python version:
- OS (e.g., Linux):
- How you installed torchx (`conda`, `pip`, source, `docker`):
- Docker image and tag (if using docker):
- Git commit (if installed from source):
- Execution environment (on-prem, AWS, GCP, Azure etc):
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/meta-pytorch/torchx/issues/418
|
closed
|
[
"bug",
"cli"
] | 2022-03-11T19:24:44Z
| 2022-03-11T23:32:30Z
| 0
|
d4l3k
|
pytorch/extension-cpp
| 76
|
How to debug in cuda-pytorch env?
|
Hi! I am wondering how to debug in such environment? I have tried to insert a "printf("hello wolrd")" sentence in .cu file, but it compiles failure! If I delete it, everything works fine..... So how you debug in such environment? Thank you!!!!
|
https://github.com/pytorch/extension-cpp/issues/76
|
open
|
[] | 2022-03-10T07:45:31Z
| 2022-03-10T07:45:31Z
| null |
Arsmart123
|
huggingface/datasets
| 3,881
|
How to use Image folder
|
Ran this code
```
load_dataset("imagefolder", data_dir="./my-dataset")
```
`https://raw.githubusercontent.com/huggingface/datasets/master/datasets/imagefolder/imagefolder.py` missing
```
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
/tmp/ipykernel_33/1648737256.py in <module>
----> 1 load_dataset("imagefolder", data_dir="./my-dataset")
/opt/conda/lib/python3.7/site-packages/datasets/load.py in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, script_version, **config_kwargs)
1684 revision=revision,
1685 use_auth_token=use_auth_token,
-> 1686 **config_kwargs,
1687 )
1688
/opt/conda/lib/python3.7/site-packages/datasets/load.py in load_dataset_builder(path, name, data_dir, data_files, cache_dir, features, download_config, download_mode, revision, use_auth_token, script_version, **config_kwargs)
1511 download_config.use_auth_token = use_auth_token
1512 dataset_module = dataset_module_factory(
-> 1513 path, revision=revision, download_config=download_config, download_mode=download_mode, data_files=data_files
1514 )
1515
/opt/conda/lib/python3.7/site-packages/datasets/load.py in dataset_module_factory(path, revision, download_config, download_mode, force_local_path, dynamic_modules_path, data_files, **download_kwargs)
1200 f"Couldn't find a dataset script at {relative_to_absolute_path(combined_path)} or any data file in the same directory. "
1201 f"Couldn't find '{path}' on the Hugging Face Hub either: {type(e1).__name__}: {e1}"
-> 1202 ) from None
1203 raise e1 from None
1204 else:
FileNotFoundError: Couldn't find a dataset script at /kaggle/working/imagefolder/imagefolder.py or any data file in the same directory. Couldn't find 'imagefolder' on the Hugging Face Hub either: FileNotFoundError: Couldn't find file at https://raw.githubusercontent.com/huggingface/datasets/master/datasets/imagefolder/imagefolder.py
```
|
https://github.com/huggingface/datasets/issues/3881
|
closed
|
[
"question"
] | 2022-03-09T21:18:52Z
| 2022-03-11T08:45:52Z
| null |
rozeappletree
|
pytorch/examples
| 969
|
DDP: why does every process allocate memory of GPU 0 and how to avoid it?
|
Run [this](https://github.com/pytorch/examples/tree/main/imagenet) example with 2 GPUs.
process 2 will allocate some memory on GPU 0.
```
python main.py --multiprocessing-distributed --world-size 1 --rank 0
```

I have carefully checked the sample code and there seems to be no obvious error that would cause process 2 to transfer data to GPU 0.
So:
1. Why does process 2 allocate memory of GPU 0?
2. Is this part of the data involved in the calculation? I think if this part of the data is involved in the calculation when the number of processes becomes large, it will cause GPU 0 to be seriously overloaded?
3. Is there any way to avoid it?
Thanks in advance to partners in the PyTorch community for their hard work.
|
https://github.com/pytorch/examples/issues/969
|
open
|
[
"distributed"
] | 2022-03-08T13:41:16Z
| 2024-09-22T11:41:26Z
| null |
siaimes
|
huggingface/datasets
| 3,854
|
load only England English dataset from common voice english dataset
|
training_data = load_dataset("common_voice", "en",split='train[:250]+validation[:250]')
testing_data = load_dataset("common_voice", "en", split="test[:200]")
I'm trying to load only 8% of the English common voice data with accent == "England English." Can somebody assist me with this?
**Typical Voice Accent Proportions:**
- 24% United States English
- 8% England English
- 5% India and South Asia (India, Pakistan, Sri Lanka)
- 3% Australian English
- 3% Canadian English
- 2% Scottish English
- 1% Irish English
- 1% Southern African (South Africa, Zimbabwe, Namibia)
- 1% New Zealand English
Can we replicate this for Age as well?
**Age proportions of the common voice:-**
- 24% 19 - 29
- 14% 30 - 39
- 10% 40 - 49
- 6% < 19
- 4% 50 - 59
- 4% 60 - 69
- 1% 70 – 79
|
https://github.com/huggingface/datasets/issues/3854
|
closed
|
[
"question"
] | 2022-03-08T09:40:52Z
| 2024-03-23T12:40:58Z
| null |
amanjaiswal777
|
pytorch/TensorRT
| 912
|
✨[Feature] New Release for pip
|
Would it be possible to get a new release for use with pip?
There have been quite a few features and bug-fixes added since November, and it would be great to have an up to date version available.
I know that docker containers are often recommended, but that's often not a viable option.
Thank you for all of the great work!!
|
https://github.com/pytorch/TensorRT/issues/912
|
closed
|
[
"question"
] | 2022-03-06T05:27:27Z
| 2022-03-06T21:25:13Z
| null |
dignakov
|
pytorch/torchx
| 405
|
SLURM quality of life improvements
|
## Description
Making a couple of requests to improve QoL on SLURM
## Detailed Proposal
It would be helpful to have -
- [x] The ability to specify the output path. Currently, you need to cd to the right path for this, which generally needs a helper function to set up the directory, cd to it, and then launch via torchx. torchx can ideally handle it for us. #416
- [x] Code isolation and reproducibility. While doing research, we make a change, launch an experiment, and repeat. To make sure each experiment uses the same consistent code, we copy the code to the experiment directory (which also helps with reproducibility). #416
- [ ] Verification of the passed launch script. If I launch from a wrong directory for instance, I would still queue up the job, wait for a few minutes / hours only to crash because of a wrong path (i.e. the launch script does not exist).
- [x] Being able to specify a job name - SLURM shows job details when running the `squeue` command including the job name. If our jobs are all run via torchx, every job will be named `train_app-{i}` which makes it hard to identify which experiment / project the job is from.
- [x] The `time` argument doesn't say what the unit is - maybe we just follow the SLURM API, but it would be nice if we clarified that.
- [ ] torchx submits jobs in [heterogeneous mode](https://slurm.schedmd.com/heterogeneous_jobs.html). This is something FAIR users don't have familiarity with - I'm guessing in terms of execution and command support there should be feature and scheduling speed parity (not sure about the latter)? The `squeue` logs show every node as a separate line - so a 32 node job would take 32 lines instead of 1. This just makes it harder to monitor jobs - not a technical issue, just a QoL one :)
- [x] The job logs are created in `slurm-{job-id}-train_app-{node-id}.out` files (per node) and a single `slurm-{job-id}.out`. Normally, our jobs instead have logs of the form `{job-id}-{node-id}.out` and `{job-id}-{node-id}.err` (per node) - the separation between `stderr` and `stdout` helps find which machine actually crashed more easily. And I'm not sure what `slurm-{job-id}.out` corresponds to - maybe it's a consequence of the heterogeneous jobs? With torchelastic, it becomes harder to debug which node crashed since every node logs a crash (so grepping for `Traceback` will return each log file instead of just the node which originally crashed) - maybe there is a way to figure this out and I just don't know what to look for?
- [ ] The `global_rank` is not equal to `local_rank + node_id * gpus_per_node`, i.e. the global rank 0 can be on node 3.
- [ ] automatically set nomem on pcluster
|
https://github.com/meta-pytorch/torchx/issues/405
|
open
|
[
"slurm"
] | 2022-03-04T17:42:08Z
| 2022-04-14T21:42:21Z
| 5
|
mannatsingh
|
pytorch/serve
| 1,487
|
how to get model.py file ?
|
`https://github.com/pytorch/serve/blob/master/docker/README.md#create-torch-model-archiver-from-container` in
the 4 step ,how to get model.py file?
I followed the doc step by step ,but in step 4
`torch-model-archiver --model-name densenet161 --version 1.0 --model-file /home/model-server/examples/image_classifier/densenet_161/model.py --serialized-file /home/model-server/examples/image_classifier/densenet161-8d451a50.pth --export-path /home/model-server/model-store --extra-files /home/model-server/examples/image_classifier/index_to_name.json --handler image_classifier`
error because no model.py file.
where to get this model.py file
|
https://github.com/pytorch/serve/issues/1487
|
closed
|
[] | 2022-03-04T01:41:59Z
| 2022-03-04T20:03:41Z
| null |
jaffe-fly
|
pytorch/pytorch
| 73,699
|
How to get tolerance override in OpInfo-based test?
|
### 🐛 Describe the bug
The documentation appears to be wrong, it suggests to use self.rtol and self.precision:
https://github.com/pytorch/pytorch/blob/4168c87ed3ba044c9941447579487a2f37eb7973/torch/testing/_internal/common_device_type.py#L1000
self.tol doesn't seem to exist in my tests.
I did find a self.rel_tol, is that the right flag?
### Versions
main
cc @brianjo @mruberry
|
https://github.com/pytorch/pytorch/issues/73699
|
open
|
[
"module: docs",
"triaged",
"module: testing"
] | 2022-03-02T22:48:11Z
| 2022-03-07T14:42:39Z
| null |
zou3519
|
pytorch/vision
| 5,510
|
[RFC] How do we want to deal with images that include alpha channels?
|
This discussion started in https://github.com/pytorch/vision/pull/5500#discussion_r816503203 and @vfdev-5 and I continued offline.
PIL as well as our image reading functions support RGBA images
https://github.com/pytorch/vision/blob/95d418970e6dbf2e4d928a204c4e620da7bccdc0/torchvision/io/image.py#L16-L31
but our color transformations currently only support RGB images ignoring an extra alpha channel. This leads to wrong results. One thing that we agreed upon is that these transforms should fail if anything but 3 channels is detected.
Still, some datasets include non-RGB images so we need to deal with this for a smooth UX. Previously we implicitly converted every image to RGB before returning it from a dataset
https://github.com/pytorch/vision/blob/f9fbc104c02f277f9485d9f8727f3d99a1cf5f0b/torchvision/datasets/folder.py#L245-L249
Since we no longer decode images in the datasets, we need to provide a solution for the users here. I currently see two possible options:
1. We could deal with this on a per-image basis within the dataset. For example, the train split of ImageNet contains a single RGBA image. We could simply perform an appropriate conversion for irregular image modes in the dataset so this issue is abstracted away from the user. `tensorflow-datasets` uses this approach: https://github.com/tensorflow/datasets/blob/a1caff379ed3164849fdefd147473f72a22d3fa7/tensorflow_datasets/image_classification/imagenet.py#L105-L131
2. The most common non-RGB image in datasets are grayscale images. For example, the train split of ImageNet contains 19970 grayscale images. Thus, the users will need a `transforms.ConvertImageColorSpace("rgb")` in most cases anyway. If that would support RGBA to RGB conversions the problem would also be solved. The conversion happens with this formula:
```
pixel_new = (1 - alpha) * background + alpha * pixel_old
```
where `pixel_{old|new}` is a single value from a color channel. Since we don't know `background` we need to either make assumptions or require the user to provide a value for it. I'd wager a guess that in 99% of the cases the background is white. i.e. `background == 1`, but we can't be sure about that.
Another issue with this is that the user has no option to set the background on a per-image basis in the transforms pipeline if that is needed.
In special case for `alpha == 1` everywhere, the equation above simplifies to
```
pixel_new = pixel_old
```
which is equivalent to stripping the alpha channel. We could check for that and only perform the RGBA to RGB transform if the condition holds or the user supplies a background color.
cc @pmeier @vfdev-5 @datumbox @bjuncek
|
https://github.com/pytorch/vision/issues/5510
|
closed
|
[
"module: datasets",
"module: transforms",
"prototype"
] | 2022-03-02T09:43:42Z
| 2023-03-28T13:01:09Z
| null |
pmeier
|
pytorch/pytorch
| 73,600
|
Add a section in DDP tutorial to explain why DDP sometimes is slower than local training and how to improve it
|
### 📚 The doc issue
Add a section in DDP tutorial to explain why DDP sometimes is slower than local training and how to improve it
### Suggest a potential alternative/fix
_No response_
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang
|
https://github.com/pytorch/pytorch/issues/73600
|
open
|
[
"oncall: distributed",
"triaged",
"module: ddp"
] | 2022-03-01T20:34:58Z
| 2022-03-08T22:03:17Z
| null |
zhaojuanmao
|
pytorch/tensorpipe
| 431
|
How to enable CudaGdrChannel registration in tensorpipeAgent when using pytorch's rpc
|
Can we just enable it by define some environment variables or we need to recompile pytorch? Thx!
|
https://github.com/pytorch/tensorpipe/issues/431
|
closed
|
[] | 2022-03-01T08:14:17Z
| 2022-03-01T12:09:53Z
| null |
eedalong
|
pytorch/tutorials
| 1,839
|
Missing 'img/teapot.jpg', 'img/trilobite.jpg' for `MODEL UNDERSTANDING WITH CAPTUM` tutorial.
|
Running this tutorial: https://pytorch.org/tutorials/beginner/introyt/captumyt.html
Could not found 'img/teapot.jpg', 'img/trilobite.jpg' under _static folder.
Could anyone help to provide?
Thanks!
|
https://github.com/pytorch/tutorials/issues/1839
|
closed
|
[
"question"
] | 2022-02-26T10:32:52Z
| 2022-10-17T16:24:06Z
| null |
MonkandMonkey
|
pytorch/data
| 256
|
Support `keep_key` in `Grouper`?
|
`IterKeyZipper` has an option to keep the key that was zipped on:
https://github.com/pytorch/data/blob/2cf1f208e76301f3e013b7569df0d75275f1aaee/torchdata/datapipes/iter/util/combining.py#L53
Is this something we want to support going forward? If yes, it would be nice to have this also on `Grouper` and possibly other similar datapipes. That would come in handy in situations if the key is used multiple times for example if we have a `IterKeyZipper` after an `Grouper`.
### Additional Context for New Contributors
See comment below
|
https://github.com/meta-pytorch/data/issues/256
|
closed
|
[
"good first issue"
] | 2022-02-25T08:39:53Z
| 2023-01-27T19:03:08Z
| 15
|
pmeier
|
pytorch/TensorRT
| 894
|
❓ [Question] Can you convert model that operates on custom classes?
|
## ❓ Question
I have a torch module that creates objects of custom classes that have tensors as fields. It can be torch.jit.scripted but torch.jit.trace can be problematic. When I torch.jit.script module and then torch_tensorrt.compile it I get the following error: `Unable to get schema for Node %317 : __torch__.src.MyClass = prim::CreateObject() (conversion.VerifyCoverterSupportForBlock)`
## What you have already tried
torch.jit.trace avoids the problem but introduces problems with loops in module.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.10.2
- CPU Architecture: intel
- OS (e.g., Linux): linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source):
- Are you using local sources or building from archives: from archives
- Python version: 3.8
- CUDA version: 11.3
- GPU models and configuration: rtx 3090
- Any other relevant information:
|
https://github.com/pytorch/TensorRT/issues/894
|
closed
|
[
"question"
] | 2022-02-24T09:51:13Z
| 2022-05-18T21:21:05Z
| null |
MarekPokropinski
|
pytorch/xla
| 3,391
|
I want to Multi-Node Multi GPU training, how should I configure the environment
|
## ❓ Questions and Help
Running XLA MultiGPU MultiNode,I know that I need to set XRT_SHARD_WORLD_SIZE and XRT_WORKERS, but I don't know how to configure the variable value of XRT_WORKERS.
Are there some examples that exist for me to refer to?
|
https://github.com/pytorch/xla/issues/3391
|
closed
|
[
"stale",
"xla:gpu"
] | 2022-02-23T06:52:01Z
| 2022-04-28T00:10:36Z
| null |
ZhongYFeng
|
pytorch/TensorRT
| 881
|
❓ [Question] How do you convert part of the model to TRT?
|
## ❓ Question
Is it possible to convert only part of the model to TRT. I have model that cannot be directly converted to trt because it uses custom classes. I wanted to convert only modules that can be converted but as I tried it torch cannot save it.
## What you have already tried
I tried the following:
```
import torch.nn
import torch_tensorrt
class MySubmodule(torch.nn.Module):
def __init__(self):
super(MySubmodule, self).__init__()
self.layer = torch.nn.Linear(10, 10)
def forward(self, x):
return self.layer(x)
class MyMod(torch.nn.Module):
def __init__(self):
super(MyMod, self).__init__()
self.submod = MySubmodule()
self.submod = torch_tensorrt.compile(self.submod, inputs=[
torch_tensorrt.Input(shape=(1, 10))
])
def forward(self, x):
return self.submod(x)
if __name__ == "__main__":
model = MyMod()
scripted = torch.jit.script(model)
scripted(torch.zeros(1, 10).cuda())
scripted.save("test.pt")
```
But it raises exception: `RuntimeError: method.qualname() == QualifiedName(selfClass->name()->qualifiedName(), methodName)INTERNAL ASSERT FAILED at "../torch/csrc/jit/serialization/python_print.cpp":1105, please report a bug to PyTorch.
`
## Environment
- PyTorch Version (e.g., 1.0): 1.10.2
- CPU Architecture: intel
- OS (e.g., Linux): linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source):
- Are you using local sources or building from archives: from archives
- Python version: 3.8
- CUDA version: 11.3
- GPU models and configuration: rtx 3090
- Any other relevant information:
|
https://github.com/pytorch/TensorRT/issues/881
|
closed
|
[
"question"
] | 2022-02-18T09:00:43Z
| 2022-02-19T23:57:17Z
| null |
MarekPokropinski
|
pytorch/TensorRT
| 880
|
❓ [Question] What is the difference between docker built on PyTorch NGC Container and PyTorch NGC Container?
|
## ❓ Question
Since PyTorch NGC 21.11+ already includes Torch-TensorRT, is it possible to use Torch-TensorRT directly in PyTorch NGC Container?
## What you have already tried
I read the README and tried to build docker according to it, but it keeps failing.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):Do I need to install PyTorch locally?
- CPU Architecture:AMD64/x64
- OS (e.g., Linux):Linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):not installed
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:
- CUDA version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/880
|
closed
|
[
"question"
] | 2022-02-18T08:40:22Z
| 2022-02-19T23:56:30Z
| null |
Guangyun-Xu
|
pytorch/serve
| 1,440
|
[Discussion]: How to extend the base handler
|
Recently we've realized that an easy place for new contributors to improve torchserve is to either
1. Add a reference example in `examples`
2. Make an improvement to the base handler
1 is easiest but makes means that users that want to benefit from that example, need to go through source code and adapt it to their examples
2 is a bit less easy but still OK because the benefits are to anyone using torchserve. Unfortunately it's slowly making the base handler unmaintainable as it now includes code for model optimization, profiling, model interpretability https://github.com/pytorch/serve/blob/master/ts/torch_handler/base_handler.py
This problem will continue getting worse as we need to runtime exports, profiling techniques and other useful workflows for model serving all of which will be gated by slow error handling code that will encourage users to pip install missing dependencies.
> So how we can continue making improvements to the base handler while keeping it simple and modular?
## Option 1: Inheritance
Instead of adding features to the base handler
we can instead create a new handler like
```
class ExtendedHandler(BaseHandler):
```
Benefit is code remains modular but con is that to use profiling and a runtime users would need to resort to multiple inheritance which can be hard to debug
## Option 2: Generic interfaces
Instead of having a line that looks like this in our code
`self.model = ipex.optimize(self.model)`
We can add a generic `optimize` in the base handler which specializes for a particular implementation depending on what's in the `config.properties`
Benefit is this very modular but requires more work to create a future proof interface and needs users to change Java code to support their usecase
## Option 3: Dynamic runtime loads
Instead of having code in the base handler we can load it at runtime
```
class BaseHandler:
...
def optimize(self):
print("self.v =", self.v)
setattr(BaseHandler, 'optimize', optimize)
BaseHandler().optimize
```
Benefit is this is very modular, doesn't require any changes to base handler code but given that torchserve is used via a CLI tool and not just running a python file it's tricky to figure out where this change needs to be
## Option 4: Utility functions
Another simple approach is to move helpful utility functions to a different file called `handler_utils.py`
A good candidate is moving a function like https://github.com/pytorch/serve/blob/master/ts/torch_handler/base_handler.py#L229
` def _infer_with_profiler(self, data):`
That said this approach isn't perfect since even if modularized, profiling would need a footprint like https://github.com/pytorch/serve/blob/master/ts/torch_handler/base_handler.py#L213
`if is_profiler_enabled:`
## Option 5: Python decorators
Not a silver bullet but python decorator like could make code more maintainable
```
@optimize
@profile
@metrics
```
For example `@metrics` would be a decorator to keep track of a function start and end time. This works well for `@metrics` and maybe `@profile` but for `@optimize` would require passing the right argument as in the model which is not a parameter in `inference` but a property of the handler class. Maybe there's a larger discussion here in that handlers need to hold less state
Related we could use Python `contextmanager` to allocate a runtime so users can say something like
`with ipex|tensorrt|etc..` and not have to worry about changes to the base handler.
## Option 6: ?
There may be other options but I think this is an important problem to figure out to make it simpler for new contributors to add their changes
cc: @HamidShojanazeri @chauhang @lxning @maaquib @nskool @min-jean-cho
|
https://github.com/pytorch/serve/issues/1440
|
closed
|
[
"enhancement"
] | 2022-02-17T16:15:09Z
| 2022-05-04T03:57:34Z
| null |
msaroufim
|
pytorch/TensorRT
| 876
|
❓ [Question] How to Enable the Torch-TensorRT Partition Feature ?
|
## ❓ Question
Hello,
I want to use TensorRT to run VectorNet from https://github.com/xk-huang/yet-another-vectornet
However, when I try to convert torchscript using torchtrtc, it terminates by showing an unsupported op:torch_scatter::scatter_max
```
terminate called after throwing an instance of 'torch::jit::ErrorReport'
what():
Unknown builtin op: torch_scatter::scatter_max.
Could not find any similar ops to torch_scatter::scatter_max. This op may not exist or may not be currently supported in TorchScript.
:
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch_scatter/scatter.py(72): scatter_max
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch_scatter/scatter.py(160): scatter
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch_geometric/nn/conv/message_passing.py(426): aggregate
/tmp/tom.hx_pyg/tmpjesxc50s.py(168): propagate
/tmp/tom.hx_pyg/tmpjesxc50s.py(188): forward
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch/nn/modules/module.py(1090): _slow_forward
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch/nn/modules/module.py(1102): _call_impl
/Data0/Users/tom.hx/work/ai-compiler/tvm/vectornet_test/modeling/subgraph.py(50): forward
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch/nn/modules/module.py(1090): _slow_forward
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch/nn/modules/module.py(1102): _call_impl
/Data0/Users/tom.hx/work/ai-compiler/tvm/vectornet_test/modeling/vectornet.py(52): forward
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch/nn/modules/module.py(1090): _slow_forward
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch/nn/modules/module.py(1102): _call_impl
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch/jit/_trace.py(965): trace_module
/Data0/Users/tom.hx/.local/lib/python3.6/site-packages/torch/jit/_trace.py(750): trace
profile.py(156): <module>
Serialized File "code/__torch__/GraphLayerPropJittable_4074db.py", line 15
src = torch.index_select(_0, -2, index)
index0 = torch.select(edge_index, 0, 1)
aggr_out, _1 = ops.torch_scatter.scatter_max(src, index0, -2, None, 225)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
return torch.cat([_0, aggr_out], 1)
Aborted
```
I have been noticed that Torch-TensorRT can fallback to native PyTorch when TensorRT does not support the model subgraphs.
The question is, why does not this function work, and how to enable it?
|
https://github.com/pytorch/TensorRT/issues/876
|
closed
|
[
"question"
] | 2022-02-16T08:01:25Z
| 2022-02-19T23:57:32Z
| null |
huangxiao2008
|
pytorch/text
| 1,615
|
How to build pytorch text with system third_party libraries?
|
## ❓ Questions and Help
**Description**
Three packages are under [pytorch text third_party](https://github.com/pytorch/text/tree/main/third_party). However, I personally prefer using system installed packages,
- libre2-dev
- libdouble-conversion-dev
- libsentencepiece-dev
In addition, isn't there a **CMakeLists.txt** for **pytorch text**??
Cheers
|
https://github.com/pytorch/text/issues/1615
|
open
|
[] | 2022-02-16T03:03:31Z
| 2023-04-18T06:07:10Z
| null |
jiapei100
|
pytorch/torchx
| 388
|
RFC: Improve OCI Image Python Tooling
|
## Description
<!-- concise description of the feature/enhancement -->
Quite a few of the cloud services / cluster tools for running ML jobs use OCI/Docker containers so I've been looking into how to make dealing with these easier.
Container based services:
* Kubernetes / Volcano scheduler
* AWS EKS / Batch
* Google AI Platform training
* Recent versions of slurm https://slurm.schedmd.com/containers.html
TorchX currently supports patches on top of existing images to make it fast to iterate and then launch a training job. These patches are just overlaying files from the local directory on top of a base image. Our current patching implementation relies on having a local docker daemon to build a patch layer and push it: https://github.com/pytorch/torchx/blob/main/torchx/schedulers/docker_scheduler.py#L437-L493
Ideally we could build a patch layer and push it in pure Python without requiring any local docker instances since that's an extra burden on ML researchers/users. Building a patch should be fairly straightforward since it's just appending to a layer and pushing will require some ability to talk to the registry to download/upload containers.
It seems like OCI containers are a logical choice to use for packaging ML training jobs/apps but the current Python tooling is fairly lacking as far as I can see. Making it easier to work with this will likely help with the cloud story.
## Detailed Proposal
<!-- provide a detailed proposal -->
Create a library for Python to manipulate OCI images with the following subset of features:
* download/upload images to OCI repos
* append layers to OCI images
Non-goals:
* Execute containers
* Dockerfiles
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
## Additional context/links
<!-- link to code, documentation, etc. -->
There is an existing oci-python library but it's fairly early. May be able to build upon it to enable this.
I opened an issue there as well: https://github.com/vsoch/oci-python/issues/15
|
https://github.com/meta-pytorch/torchx/issues/388
|
open
|
[
"enhancement",
"RFC",
"kubernetes",
"slurm"
] | 2022-02-11T04:47:27Z
| 2023-01-23T14:54:10Z
| 1
|
d4l3k
|
huggingface/nn_pruning
| 33
|
What is the difference between "finetune" and "final-finetune" in `/example`.
|
Hello,
Thanks for the amazing repo!
I'm wondering what is the difference between "finetune" and "final-finetune" in `/example`.
Do we train the model and the mask score in the finetune stage, and only train the optimized model in the final-finetune stage?
Is there a way to directly save the optimized model and load the optimized model instead of loading the patched model and optimizing to get the pruned model?
Big thanks again for the great work!
|
https://github.com/huggingface/nn_pruning/issues/33
|
open
|
[] | 2022-02-11T03:25:13Z
| 2023-01-08T14:27:37Z
| null |
eric8607242
|
pytorch/TensorRT
| 862
|
❓ [Question] Running a same torchscript using the same input producing different results.
|
## ❓ Question
I'm trying to run a pretrained resnet50 model from torch.torchvision.models. enabled_precisions is set to torch.half.
Each time I load the same resnet50 torchscript, using the same input(which is set to zero using np.zeros). But after running serveral times I've found the output is not stable.
## What you have already tried
I've tried two ways:
1. Load the same resetnet50 torchscript and compile it, the do the inference. The output is not stable.
2. Save the compiled script, load it each time and to the inference. The output is stable.
I wonder whether there's some random behaviors in `torch_tensorrt.compile()` when enabled_precisions is set to torch.half.
## Environment
- PyTorch Version : 1.10
- CPU Architecture: x86_64
- OS (e.g., Linux): Linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source): installed via pip3 install torch-tensorrt -f https://github.com/NVIDIA/Torch-TensorRT/releases
- Are you using local sources or building from archives:
- Python version: 3.6.9
- CUDA version: 11.4
- GPU models and configuration: pretrained resnet50 model from torch.torchvision.models
- Any other relevant information: Torch-TensorRT version: v1.0
## Additional context
The python code producing unstable result is as below:
```python
from torchvision import models
import numpy as np
import torch
import torch_tensorrt
import time
input = np.zeros((1, 3, 224, 224)).astype(np.float32)
input = torch.from_numpy(input).cuda()
torch_script_module = torch.jit.load('torch_script_module.ts')
trt_ts_module = torch_tensorrt.compile(torch_script_module,
inputs=[
torch_tensorrt.Input( # Specify input object with shape and dtype
min_shape=[1, 3, 224, 224],
opt_shape=[1, 3, 224, 224],
max_shape=[1, 3, 224, 224],
# For static size shape=[1, 3, 224, 224]
dtype=torch.float32) # Datatype of input tensor. Allowed options torch.(float|half|int8|int32|bool)
],
enabled_precisions={torch.half},) # Run with FP16)
result=trt_ts_module(input) # run inference
t1 = time.time()
for i in range(1000):
result=trt_ts_module(input) # run inference
t2 = time.time()
print('result', result[0][0])
print("Cost: ", round(t2-t1, 4))
```
Two iterations produce different outputs:
Iteration 1:
```
WARNING: [Torch-TensorRT] - Dilation not used in Max pooling converter
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.2
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
WARNING: [Torch-TensorRT TorchScript Conversion Context] - Detected invalid timing cache, setup a local cache instead
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.2
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
WARNING: [Torch-TensorRT] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.2
WARNING: [Torch-TensorRT] - TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
WARNING: [Torch-TensorRT] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.2
WARNING: [Torch-TensorRT] - TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
result tensor(-0.4390, device='cuda:0')
Cost: 1.3429
```
Iteration 2:
```
WARNING: [Torch-TensorRT] - Dilation not used in Max pooling converter
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.2
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
WARNING: [Torch-TensorRT TorchScript Conversion Context] - Detected invalid timing cache, setup a local cache instead
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.2
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
WARNING: [Torch-TensorRT] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.2
WARNING: [Torch-TensorRT] - TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
WARNING: [Torch-TensorRT] - TensorRT was linked against cuBLAS/cuBLAS LT 11.5.1 but loaded cuBLAS/cuBLAS LT 11.4.2
WARNING: [Torch-TensorRT] - TensorRT was linked against cuDNN 8.2.1 but loaded cuDNN 8.2.0
result tensor(-0.4463, device='cuda:0')
Cost: 1.3206
```
|
https://github.com/pytorch/TensorRT/issues/862
|
closed
|
[
"question",
"No Activity"
] | 2022-02-10T12:18:34Z
| 2022-09-10T00:02:32Z
| null |
SeTriones
|
pytorch/TensorRT
| 858
|
❓ [Question] ImportError: libcudnn.so.8: cannot open shared object file: No such file or directory
|
## ❓ Question
As I can't install `torch-tensorrt` for some reason in this method:`pip3 install torch-tensorrt -f https://github.com/NVIDIA/Torch-TensorRT/releases
`
I download `torch-tensorrt` from here `https://github.com/NVIDIA/Torch-TensorRT/releases/tag/v1.0.0`
using `pip install torch_tensorrt-1.0.0-cp36-cp36m-linux_x86_64.whl`
however when I `import torch_tensorrt`
here comes the error `ImportError: libcudnn.so.8: cannot open shared object file: No such file or directory`
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):1.10.2+cu113
- CPU Architecture:
- OS (e.g., Linux):linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):pip
- Build command you used (if compiling from source): pip install
- Are you using local sources or building from archives:
- Python version:3.6.2
- CUDA version:11.3
- GPU models and configuration:
- Any other relevant information:
## Additional context
tensorrt==8.2.1.8
|
https://github.com/pytorch/TensorRT/issues/858
|
closed
|
[
"question",
"No Activity"
] | 2022-02-09T03:27:44Z
| 2022-06-19T12:55:25Z
| null |
Biaocsu
|
pytorch/TensorRT
| 856
|
❓ [Question] Is it possibile to use a model optimized through TorchTensorRT in LibTorch under Windows?
|
## ❓ Question
I would need to optimize an already trained segmentation model through TorchTensorRT, the idea would be to optimize the model by running the [newest PyTorch NGC docker image](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel_22-01.html#rel_22-01) under WSL2, exporting the model and then loading it in a C++ application that uses LibTorch, e.g.
```
#include <torch/script.h>
// ...
torch::jit::script::Module module;
try {
// Deserialize the ScriptModule from a file using torch::jit::load().
module = torch::jit::load(argv[1]);
}
```
Would this be the right approach?
## What you have already tried
At the moment I only tried to optimize the model through TorchTensorRT, and something weird happens. Here I'll show the results for the Python script below that I obtained on two different devices:
- a Ubuntu desktop with a GTX1080Ti (that I use for development)
- a Windows PC with a RTX3080 (that is my target device)
As you can see, **the optimization process under WSL gives me a lot of GPU errors**, while on Ubuntu it seems to work fine. Why does this happen?
My script:
```
import torch_tensorrt
import yaml
import torch
import os
import time
import numpy as np
import torch.backends.cudnn as cudnn
import argparse
import segmentation_models_pytorch as smp
import pytorch_lightning as pl
cudnn.benchmark = True
def benchmark(model, input_shape=(1, 3, 512, 512), dtype=torch.float, nwarmup=50, nruns=1000):
input_data = torch.randn(input_shape)
input_data = input_data.to("cuda")
if dtype==torch.half:
input_data = input_data.half()
print("Warm up ...")
with torch.no_grad():
for _ in range(nwarmup):
features = model(input_data)
torch.cuda.synchronize()
print("Start timing ...")
timings = []
with torch.no_grad():
for i in range(1, nruns+1):
start_time = time.time()
features = model(input_data)
torch.cuda.synchronize()
end_time = time.time()
timings.append(end_time - start_time)
if i%100==0:
print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
print("Input shape:", input_data.size())
print("Output features size:", features.size())
print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
def load_config(config_path: str):
with open(config_path) as f:
config = yaml.load(f, Loader=yaml.FullLoader)
return config
def main():
# Load target model
parser = argparse.ArgumentParser()
parser.add_argument("weights_path")
parser.add_argument("config_path")
args = parser.parse_args()
config = load_config(args.config_path)
model_dict = config["model"]
model_dict["activation"] = "softmax2d"
model = smp.create_model(**model_dict)
state_dict = torch.load(args.weights_path)["state_dict"]
model.load_state_dict(state_dict)
model.to("cuda")
model.eval()
# Create dummy data for tracing and benchmarking purposes.
dtype = torch.float32
shape = (1, 3, 512, 512)
input_data = torch.randn(shape).to("cuda")
# Convert model to script module
print("Tracing PyTorch model...")
traced_script_module = torch.jit.trace(model, input_data)
# torch_script_module = torch.jit.load(model_path).cuda()
print("Script Module generated.")
print("\nBenchmarking Script Module...")
# First benchmark <===================================
benchmark(traced_script_module, shape, dtype)
# Convert to TRT Module...
output_path = args.config_path.split(os.path.sep)[-1] + "_trt_.pt"
print("Creating TRT module...")
trt_ts_module = torch_tensorrt.compile(
traced_script_module,
inputs = [
torch_tensorrt.Input( # Specify input object with shape and dtype
shape=shape,
dtype=dtype) # Datatype of input tensor. Allowed options torch.(float|half|int8|int32|bool)
],
enabled_precisions = {dtype},
)
print("TRT Module created")
print("\nBenchmarking TRT Module...")
benchmark(trt_ts_module, shape, dtype)
torch.jit.save(trt_ts_module, os.path.join("models",output_path)) # save the TRT embedded Torchscript
if __name__ == "__main__":
main()
```
### Ubuntu desktop
```
root@ca10ddc496a3:/DockerStuff# python script.py path/to/checkout.tar path/to/config.yaml
No pretrained weights exist for this model. Using random initialization.
Tracing PyTorch model...
/opt/conda/lib/python3.8/site-packages/segmentation_models_pytorch/base/model.py:16: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that
|
https://github.com/pytorch/TensorRT/issues/856
|
closed
|
[
"question",
"No Activity",
"channel: windows"
] | 2022-02-08T10:22:57Z
| 2022-08-27T00:03:53Z
| null |
andreabonvini
|
pytorch/TensorRT
| 852
|
How to set custom GCC path when compiling the source code
|
## ❓ Question
How to set the GCC path when compiling the source code
## What you have already tried
I try to build Torch-TensorRT using locally installed cuDNN & TensorRT, But the following error occurred

I found that this maybe a problem with the GCC version and needs to be upgraded, but the default /usr/bin/gcc requires root permission to change, I can't do anything about this path. So, I want to install a higher version of GCC in another path and specify the path of GCC when compiling Torch-TensorRT, but I don't know where to set the path of GCC.
|
https://github.com/pytorch/TensorRT/issues/852
|
closed
|
[
"question"
] | 2022-02-07T08:33:12Z
| 2022-04-25T17:01:14Z
| null |
yuezhuang1387
|
pytorch/TensorRT
| 851
|
docker build failed
|
```
git clone https://github.com/NVIDIA/Torch-TensorRT
cd Torch-TensorRT
```
`docker build --build-arg BASE=21.11 -f docker/Dockerfile -t torch_tensorrt:latest .`
```
gets the error like this:
Sending build context to Docker daemon 29.61MB
Step 1/33 : ARG BASE=21.10
Step 2/33 : ARG BASE_IMG=nvcr.io/nvidia/pytorch:${BASE}-py3
Step 3/33 : FROM ${BASE_IMG} as base
---> 6eae00e8ee65
Step 4/33 : FROM base as torch-tensorrt-builder-base
---> 6eae00e8ee65
Step 5/33 : RUN rm -rf /opt/torch-tensorrt /usr/bin/bazel
---> Using cache
---> 407b606a69ba
Step 6/33 : ARG ARCH="x86_64"
---> Using cache
---> a47c16d2137b
Step 7/33 : ARG TARGETARCH="amd64"
---> Using cache
---> 2aa5a3eab761
Step 8/33 : ARG BAZEL_VERSION=4.2.1
---> Using cache
---> f21f368cf46b
Step 9/33 : RUN git config --global url."https://github.com.cnpmjs.org/".insteadOf https://github.com/
---> Using cache
---> 8b689f617bb2
Step 10/33 : RUN [[ "$TARGETARCH" == "amd64" ]] && ARCH="x86_64" || ARCH="${TARGETARCH}" && wget -q https://github.com/bazelbuild/bazel/releases/download/${BAZEL_VERSION}/bazel-${BAZEL_VERSION}-linux-${ARCH} -O /usr/bin/bazel && chmod a+x /usr/bin/bazel
---> Using cache
---> a3c8f7522040
Step 11/33 : RUN touch /usr/lib/$HOSTTYPE-linux-gnu/libnvinfer_static.a
---> Using cache
---> d21a2d4dff51
Step 12/33 : RUN rm -rf /usr/local/cuda/lib* /usr/local/cuda/include && ln -sf /usr/local/cuda/targets/$HOSTTYPE-linux/lib /usr/local/cuda/lib64 && ln -sf /usr/local/cuda/targets/$HOSTTYPE-linux/include /usr/local/cuda/include
---> Using cache
---> 39ee2cf4915f
Step 13/33 : RUN apt-get update && apt-get install -y --no-install-recommends locales ninja-build && rm -rf /var/lib/apt/lists/* && locale-gen en_US.UTF-8
---> Using cache
---> 711e012e97fd
Step 14/33 : FROM torch-tensorrt-builder-base as torch-tensorrt-builder
---> 711e012e97fd
Step 15/33 : COPY . /workspace/torch_tensorrt/src
---> Using cache
---> 2ea5a90787b7
Step 16/33 : WORKDIR /workspace/torch_tensorrt/src
---> Using cache
---> b8e79eb37534
Step 17/33 : RUN cp ./docker/WORKSPACE.docker WORKSPACE
---> Using cache
---> 7a90e4a378d4
Step 18/33 : RUN ./docker/dist-build.sh
---> Running in 669eeb348f7c
running bdist_wheel
Extracting Bazel installation...
Starting local Bazel server and connecting to it...
Loading:
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Loading: 0 packages loaded
Analyzing: target //:libtorchtrt (1 packages loaded, 0 targets configured)
INFO: Analyzed target //:libtorchtrt (43 packages loaded, 2965 targets configured).
INFO: Found 1 target...
[0 / 10] [Prepa] Creating source manifest for @rules_pkg//:build_tar
[1,111 / 1,235] Compiling core/lowering/passes/remove_bn_dim_check.cpp; 3s processwrapper-sandbox ... (3 actions running)
[1,112 / 1,235] Compiling core/lowering/passes/remove_bn_dim_check.cpp; 7s processwrapper-sandbox ... (4 actions, 3 running)
[1,115 / 1,235] Compiling core/lowering/passes/linear_to_addmm.cpp; 8s processwrapper-sandbox ... (4 actions running)
[1,118 / 1,235] Compiling core/lowering/passes/exception_elimination.cpp; 6s processwrapper-sandbox ... (4 actions running)
[1,121 / 1,235] Compiling core/conversion/converters/impl/squeeze.cpp; 10s processwrapper-sandbox ... (4 actions running)
[1,122 / 1,235] Compiling core/conversion/converters/impl/interpolate.cpp; 13s processwrapper-sandbox ... (4 actions running)
[1,125 / 1,235] Compiling core/conversion/converters/impl/lstm_cell.cpp; 11s processwrapper-sandbox ... (4 actions, 3 running)
[1,129 / 1,235] Compiling cpp/bin/torchtrtc/main.cpp; 8s processwrapper-sandbox ... (4 actions, 3 running)
[1,133 / 1,235] Compiling cpp/bin/torchtrtc/main.cpp; 21s processwrapper-sandbox ... (4 actions, 3 running)
[1,142 / 1,235] Compiling core/conversion/converters/Weights.cpp; 7s processwrapper-sandbox ... (4 actions, 3 running)
[1,147 / 1,235] Compiling core/conversion/converters/impl/topk.cpp; 12s processwrapper-sandbox ... (4 actions, 3 running)
[1,155 / 1,235] Compiling core/conversion/converters/impl/cast.cpp; 16s processwrapper-sandbox ... (4 actions, 3 running)
[1,163 / 1,235] Compiling core/conversion/converters/impl/layer_norm.cpp; 15s processwrapper-sandbox ... (4 actions, 3 running)
[1,176 / 1,235] Compiling cpp/src/ptq.cpp; 8s processwrapper-sandbox ... (4 actions, 3 running)
[1,187 / 1,235] Compiling core/conversion/evaluators/aten.cpp; 17s processwrapper-sandbox ... (4 actions running)
ERROR: /workspace/torch_tensorrt/src/core/conversion/evaluators/BUILD:10:11: Compiling core/conversion/evaluators/eval_util.cpp failed: (Exit 1): gcc failed: error executing command /usr/
|
https://github.com/pytorch/TensorRT/issues/851
|
closed
|
[
"question",
"No Activity"
] | 2022-02-07T07:02:01Z
| 2022-05-20T00:02:07Z
| null |
Biaocsu
|
pytorch/pytorch
| 72,365
|
How is Tensor.type supposed to work with strings?
|
### 🐛 Describe the bug
I was looking for a functionality to convert Tensor dtype in-place by passing a string instead of the relevant `torch.dtype`.
`Tensor.type`, according to the docs, is supposed to work with `dtype`s and `str`s:
```python
def type(self: T, dst_type: Union[dtype, str]) -> T:
r"""Casts all parameters and buffers to :attr:`dst_type`.
.. note::
This method modifies the module in-place.
Args:
dst_type (type or string): the desired type
Returns:
Module: self
"""
```
However, it seems not to work if `dst_type` is passed as a string.
I would expect it to work the same way as NumPy's `astype(...)`
I did not find usage examples around.
Example code:
```python
import torch
import numpy as np
x = torch.rand(5,5)
y = np.random.rand(5,5)
# conversion using the relevant dtype works
x.type(torch.float16)
y.astype(np.float16)
# np supports also dtype passed as strings
y.astype("float16")
# however, torch does not
x.type("float16")
# also this does not work
x.type("torch.float16")
```
#### Error stack
First example:
```
>>> x.type("float16")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid type: 'float16'
```
Second example:
```
>>> x.type("torch.float16")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid type: 'torch.float16'
```
### Versions
Collecting environment information...
PyTorch version: 1.10.0
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 21.04 (x86_64)
GCC version: (Ubuntu 10.3.0-1ubuntu1) 10.3.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.33
Python version: 3.8.12 (default, Oct 12 2021, 13:49:34) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.11.0-46-generic-x86_64-with-glibc2.17
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: GeForce RTX 2080
Nvidia driver version: 460.91.03
cuDNN version: Probably one of the following:
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn.so.8
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_infer.so.8
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_adv_train.so.8
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_infer.so.8
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_cnn_train.so.8
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_infer.so.8
/usr/local/cuda-11.0/targets/x86_64-linux/lib/libcudnn_ops_train.so.8
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.19.2
[pip3] pytorch-ranger==0.1.1
[pip3] torch==1.10.0
[pip3] torch-optimizer==0.1.0
[pip3] torch-pruning==0.2.7
[pip3] torch-summary==1.4.5
[pip3] torchattacks==3.1.0
[pip3] torchaudio==0.10.0
[pip3] torchinfo==0.0.9
[pip3] torchvision==0.11.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.2.89 hfd86e86_1
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] mkl 2020.2 256
[conda] mkl-service 2.3.0 py38he904b0f_0
[conda] mkl_fft 1.3.0 py38h54f3939_0
[conda] mkl_random 1.1.1 py38h0573a6f_0
[conda] numpy 1.19.2 py38h54aff64_0
[conda] numpy-base 1.19.2 py38hfa32c7d_0
[conda] pytorch 1.10.0 py3.8_cuda10.2_cudnn7.6.5_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] pytorch-ranger 0.1.1 pypi_0 pypi
[conda] torch-optimizer 0.1.0 pypi_0 pypi
[conda] torch-pruning 0.2.7 pypi_0 pypi
[conda] torch-summary 1.4.5 pypi_0 pypi
[conda] torchattacks 3.1.0 pypi_0 pypi
[conda] torchaudio 0.10.0 py38_cu102 pytorch
[conda] torchinfo 0.0.9 pypi_0 pypi
[conda] torchvision 0.11.1 py38_cu102 pytorch
cc @mruberry @rgommers
|
https://github.com/pytorch/pytorch/issues/72365
|
closed
|
[
"triaged",
"module: numpy",
"module: ux"
] | 2022-02-04T21:44:27Z
| 2023-05-13T06:07:10Z
| null |
marcozullich
|
pytorch/text
| 1,581
|
Specified Field dtype <torchtext.legacy.data.pipeline.Pipeline object at ...> can not be used with use_vocab=False because we do not know how to numericalize it.
|
## ❓ Questions and Help
**Description**
<!-- Please send questions or ask for help here. -->
I am trying to implement a sequence (multi-output) regression task using `torchtext`, but I am getting the error in the title.
torch version: 1.10.1
torchtext version: 0.11.1
Here's how I proceed:
**Given.** sequential data (own data) of the form:
```
text label
'w1' '[0.1, 0.3, 0.1]'
'w2' '[0.74, 0.4, 0.65]'
'w3' '[0.21, 0.56, 0.23]'
<empty line denoting the beginning of a new sentence>
... ...
```
**TorchText Fields to read this data.** (works perfectly)
```
import torchtext
from torchtext.legacy import data
from torchtext.legacy import datasets
TEXT = data.Field(use_vocab=True, # use torchtext.vocab, and later on, numericalization based on pre-trained vectors
lower=True)
LABEL = data.Field(is_target=True,
use_vocab=False, # I don't think that I need a vocab for my task, because the output is a list of doubles
unk_token=None,
preprocessing=data.Pipeline(
lambda x: torch.tensor(list(map(float, removeBracets(x).split(' '))),
dtype=torch.double)), # I implement this Pipeline to transform labels from string(list(doubles)) to torch.Tensor(doubles)
dtype=torch.DoubleTensor) # the label is a tensor of doubles
fields = [("text",TEXT) , ("label",LABEL)]
```
Since I have sequential data, I used `datasets.SequenceTaggingDataset` to split the data into training, validation and testing sets.
```
train, valid, test = datasets.SequenceTaggingDataset.splits(path='./data/',
train = train_path,
validation = validate_path,
test = test_path,
fields=fields)
```
Then, I use a pre-trained embedding to build the vocab for the `TEXT` `Field`, e.g.
```
TEXT.build_vocab(train, vectors="glove.840B.300d")
```
After that, I use `BucketIterator` to create batches of the training data efficiently.
```
train_iterator, valid_iterator = data.BucketIterator.splits(
(train, valid),
device=DEVICE,
batch_size=BATCH_SIZE,
sort_key=lambda x: len(x.text),
repeat=False,
sort=True) # for validation/testing, better set it to False
```
Everything works perfectly till now. However, when I try to iterate over train_iterator,
```
batch = next(iter(train_iterator))
print("text", batch.text)
print("label", batch.label)
```
I get the following error:
```
229 """
230 padded = self.pad(batch)
--> 231 tensor = self.numericalize(padded, device=device)
232 return tensor
233
PATH_TO\torchtext\legacy\data\field.py in numericalize(self, arr, device)
340 "use_vocab=False because we do not know how to numericalize it. "
341 "Please raise an issue at "
--> 342 "https://github.com/pytorch/text/issues".format(self.dtype))
343 numericalization_func = self.dtypes[self.dtype]
344 # It doesn't make sense to explicitly coerce to a numeric type if
ValueError: Specified Field dtype <torchtext.legacy.data.pipeline.Pipeline object at 0x0XXXXXXXX> can not be used with use_vocab=False because we do not know how to numericalize it. Please raise an issue at https://github.com/pytorch/text/issues
```
I looked into the question #609. Unlike this issue, I need to find a numericalization for the labels, which are of the form list(torch.DoubleTensor). Do you have any suggestion?
|
https://github.com/pytorch/text/issues/1581
|
open
|
[
"legacy"
] | 2022-02-04T16:25:50Z
| 2022-04-17T08:46:36Z
| null |
MSiba
|
pytorch/data
| 195
|
Documentation Improvements Tracker
|
Here are some improvements that we should make to the documentation. Some of these likely should be completed before beta release.
Crucial:
- [x] Add docstrings for the class `IterDataPipe` and `MapDataPipe`
https://github.com/pytorch/pytorch/pull/72618
- [x] Review the categorization of `IterDataPipe` in `torchdata.datapipes.iter.rst`
https://github.com/pytorch/data/pull/219
- [x] Edit first sentence of each DataPipe docstring to be a concise summary of functionality (also include functional name when it exists)
https://github.com/pytorch/pytorch/pull/72476
https://github.com/pytorch/pytorch/pull/72475
https://github.com/pytorch/data/pull/209
- [x] Add usage examples to each DataPipe docstring
https://github.com/pytorch/pytorch/pull/73033
https://github.com/pytorch/pytorch/pull/73250
https://github.com/pytorch/data/pull/249
- [x] Add tutorial (how to use DataPipe, how to write one, how to use it with DataLoader)
https://github.com/pytorch/data/pull/212
- [x] Add domain usage examples (links to files)
https://github.com/pytorch/data/pull/216
- [x] Decide what utility functions to include
https://github.com/pytorch/data/pull/205
- [x] Link to relevant DataLoader documentation
https://github.com/pytorch/data/pull/205
- [x] Turn on 'gh-pages' in this repo's setting
It is enabled.
- [x] Clear labelling of prototype vs beta phase
https://github.com/pytorch/data/pull/252
- [x] Add a link under the 'Docs' tab on pytorch.org
Nice-to-have:
- [x] Update issue form for documentation related issues
https://github.com/pytorch/data/pull/215
- [ ] Add links to domain usage examples onto individual DataPipe pages (see how TorchVision does this)
- [x] Remove tutorial from README.md and link it to the documentation tutorial
- [ ] Make a functional equivalent table in documentation (in a separate page?)
cc: @VitalyFedyunin @ejguan @wenleix @dongreenberg @NivekT
|
https://github.com/meta-pytorch/data/issues/195
|
open
|
[
"todo"
] | 2022-02-03T19:39:09Z
| 2022-06-02T15:18:39Z
| 3
|
NivekT
|
pytorch/TensorRT
| 843
|
❓ [Question] Trying to find compatible versions between two different environments
|
## ❓ Question
I'm trying to save a serialized tensorRT optimized model using torch_tensorrt from one environment and then load it in another environment (different GPUs. one has Quadro M1000M, and another has Tesla P100.
In both environments I don't have full sudo control where I can install whatever I want (i.e. can't change nvidia driver), but I am able to install different cuda toolkits locally, same with pip installs with wheels.
## What you have already tried
I have tried (ones marked with @ are ones I can't change):
env #1 =
@1. Tesla P100
@2. Nvidia driver 460
3. CUDA 11.3 (checked via torch.version.cuda). nvidia-smi shows 11.2. has many cuda versions installed from 10.2 to 11.4
4. CuDNN 8.2.1.32
5. TensorRT 8.2.1.8
6. Torch_TensorRT 1.0.0
7. Pytorch 1.10.1+cu113 (conda installed)
env #2 =
@1. Quadro M1000M
@2. Nvidia driver 455
3. CUDA 11.3(checked via torch.version.cuda, backwards compatibilty mode I believe, but technically 11.3 requires 460+ nvidia driver according to the compatibility table). nvidia-smi shows 11.1. has 10.2 version available aside from 11.3 I installed.
4. CuDNN 8.2.1.32
5. TensorRT 8.2.1.8
6. Torch_TensorRT 1.0.0
7. Pytorch 1.10.1+cu113 (pip installed)
So as you can see the only difference is really the GPU and the NVIDIA driver (455 vs 460).
Is this supposed to work?
On env#1, I can torch_tensorrt compile any models
On env#2, I run into issues if I try to compile any slightly complex models (i.e. resnet34) where it says:
WARNING: [Torch-TensorRT] - Dilation not used in Max pooling converter
WARNING: [Torch-TensorRT TorchScript Conversion Context] - TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.5.1
ERROR: [Torch-TensorRT TorchScript Conversion Context] - 1: [wrapper.cpp::plainGemm::197] Error Code 1: Cublas (CUBLAS_STATUS_NOT_SUPPORTED)
ERROR: [Torch-TensorRT TorchScript Conversion Context] - 2: [builder.cpp::buildSerializedNetwork::609] Error Code 2: Internal Error (Assertion enginePtr != nullptr failed. )
If I try to "torch.jit.load" any model made in env #1 (even the simplest ones like a model with 1 conv2d layer) on env #2, I get the following error msg:
~/.local/lib/python3.6/site-packages/torch/jit/_serialization.py in load(f, map_location, _extra_files)
159 cu = torch._C.CompilationUnit()
160 if isinstance(f, str) or isinstance(f, pathlib.Path):
--> 161 cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files)
162 else:
163 cpp_module = torch._C.import_ir_module_from_buffer(
RuntimeError: [Error thrown at core/runtime/TRTEngine.cpp:44] Expected most_compatible_device to be true but got false
No compatible device was found for instantiating TensorRT engine
## Environment
Explained above
|
https://github.com/pytorch/TensorRT/issues/843
|
closed
|
[
"question",
"No Activity"
] | 2022-02-01T19:33:31Z
| 2022-05-20T00:02:07Z
| null |
hanbrianlee
|
pytorch/functorch
| 433
|
Determine how to mitigate the challenge of pytorch/pytorch changes breaking functorch
|
We get broken by pytorch/pytorch on an almost daily basis. Some of these changes are easy to resolve, some are not easy to resolve. This has cost me 10s of hours so far and going forward will cost even more. We should come up with some way to mitigate this.
There are at least two axes for the proposals. On one axis is development velocity for functorch, on the other axis is how much time it takes for us to get notified of a change in pytorch/pytorch that is problematic. These generally get traded off in the proposals.
Some proposals that we've heard so far:
- Follow what pytorch/xla did. That is, have a test in pytorch/pytorch that builds functorch main and signals if there's a problem. The tradeoff here is that functorch main must now be green most of the time (e.g. no more committing directly to main) and we need our CI to run off of pytorch main, not the pytorch nightlies.
- The pytorch/xla idea, except, the test always reports green but emails someone if there is a problem.
- Just merge functorch into pytorch/pytorch. This gives us the fastest signal to a problematic change (in fact, the problematic change won't get merged if they break a functorch test), but it trades off our development velocity completely.
- put functorch as a submodule on pytorch/pytorch, package the two libraries together
|
https://github.com/pytorch/functorch/issues/433
|
closed
|
[
"actionable",
"needs design"
] | 2022-02-01T15:54:27Z
| 2022-10-17T19:55:44Z
| null |
zou3519
|
huggingface/transformers
| 15,404
|
what is the equivalent manner for those lines?
|
https://github.com/huggingface/transformers/issues/15404
|
closed
|
[] | 2022-01-29T16:03:12Z
| 2022-02-18T21:37:08Z
| null |
mathshangw
|
|
huggingface/dataset-viewer
| 124
|
Cache /valid?
|
<strike>It is called multiple times per second by moon landing, and it impacts a lot the loading time of the /datasets page (https://github.com/huggingface/moon-landing/issues/1871#issuecomment-1024414854).</strike>
Currently, several queries are done to check all the valid datasets on every request
|
https://github.com/huggingface/dataset-viewer/issues/124
|
closed
|
[
"question"
] | 2022-01-28T17:37:47Z
| 2022-01-31T20:31:41Z
| null |
severo
|
pytorch/pytorch
| 71,991
|
How to make an LSTM Bidirectional?
|
### 🐛 Describe the bug
Goal: make LSTM `self.classifier()` learn from bidirectional layers.
`# !` = code lines of interest
**Question:**
What changes to `LSTMClassifier` do I need to make, in order to have this LSTM work bidirectionally?
---
I *think* the problem is in `forward()`. It learns from the **last state** of LSTM neural network, by slicing:
```python
tag_space = self.classifier(lstm_out[:,-1,:])
```
However, bidirectional changes the architecture and thus the output shape.
Do I need to sum up or concatenate the values of the 2 layers/ directions?
---
Installs:
```
!pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.8-cp37-cp37m-linux_x86_64.whl
!pip -q install pytorch-lightning==1.2.7 torchmetrics awscli mlflow boto3 pycm
!pip install cloud-tpu-client==0.10 https://storage.googleapis.com/tpu-pytorch/wheels/torch_xla-1.9-cp37-cp37m-linux_x86_64.whl
!pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchtext==0.10.0 -f https://download.pytorch.org/whl/cu111/torch_stable.html
```
Working Code:
```python
from argparse import ArgumentParser
import torchmetrics
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTMClassifier(nn.Module):
def __init__(self,
num_classes,
batch_size=10,
embedding_dim=100,
hidden_dim=50,
vocab_size=128):
super(LSTMClassifier, self).__init__()
initrange = 0.1
self.num_labels = num_classes
n = len(self.num_labels)
self.hidden_dim = hidden_dim
self.batch_size = batch_size
self.word_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.word_embeddings.weight.data.uniform_(-initrange, initrange)
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_dim, batch_first=True, bidirectional=True) # !
print("# !")
bi_grus = torch.nn.GRU(input_size=embedding_dim, hidden_size=hidden_dim, batch_first=True, bidirectional=True)
reverse_gru = torch.nn.GRU(input_size=embedding_dim, hidden_size=hidden_dim, batch_first=True, bidirectional=False)
self.lstm.weight_ih_l0_reverse = bi_grus.weight_ih_l0_reverse
self.lstm.weight_hh_l0_reverse = bi_grus.weight_hh_l0_reverse
self.lstm.bias_ih_l0_reverse = bi_grus.bias_ih_l0_reverse
self.lstm.bias_hh_l0_reverse = bi_grus.bias_hh_l0_reverse
bi_output, bi_hidden = bi_grus()
reverse_output, reverse_hidden = reverse_gru()
print("# !")
# self.classifier = nn.Linear(hidden_dim, self.num_labels[0])
self.classifier = nn.Linear(2 * hidden_dim, self.num_labels[0]) # !
def repackage_hidden(h):
"""Wraps hidden states in new Tensors, to detach them from their history."""
if isinstance(h, torch.Tensor):
return h.detach()
else:
return tuple(repackage_hidden(v) for v in h)
def forward(self, sentence, labels=None):
embeds = self.word_embeddings(sentence)
lstm_out, _ = self.lstm(embeds) # lstm_out - 2 tensors, _ - hidden layer
print(lstm_out[:,-1,:])
tag_space = self.classifier(lstm_out[:,-1,:] + lstm_out[:,-1,:]) # ! # lstm_out[:,-1,:] - 1 tensor
logits = F.log_softmax(tag_space, dim=1)
loss = None
if labels:
loss = F.cross_entropy(logits.view(-1, self.num_labels[0]), labels[0].view(-1))
return loss, logits
class LSTMTaggerModel(pl.LightningModule):
def __init__(
self,
num_classes,
class_map,
from_checkpoint=False,
model_name='last.ckpt',
learning_rate=3e-6,
**kwargs,
):
super().__init__()
self.save_hyperparameters()
self.learning_rate = learning_rate
self.model = LSTMClassifier(num_classes=num_classes)
self.model.load_state_dict(torch.load(model_name), strict=False) # !
self.class_map = class_map
self.num_classes = num_classes
self.valid_acc = torchmetrics.Accuracy()
self.valid_f1 = torchmetrics.F1()
def forward(self, *input, **kwargs):
return self.model(*input, **kwargs)
def training_step(self, batch, batch_idx):
x, y_true = batch
loss, _ = self(x, labels=y_true)
self.log('train_loss', loss)
return loss
def validation_step(self, batch, batch_idx):
x, y_true = batch
_, y_pred = self(x, labels=y_true)
preds = torch.argmax(y_pred, axis=1)
self.valid_acc(preds, y_true[0])
self.log('val_acc', self.valid_acc, prog_bar=True)
self.valid_f1(preds, y_true[0])
self.log('f1', self.valid_f1, prog_bar=True)
def configure_optimizers(self):
'Pre
|
https://github.com/pytorch/pytorch/issues/71991
|
closed
|
[] | 2022-01-28T16:03:23Z
| 2022-01-31T09:59:27Z
| null |
danielbellhv
|
pytorch/TensorRT
| 830
|
❓ [Question] Why BERT Base is slower w/ Torch-TensorRT than native PyTorch?
|
## ❓ Question
<!-- Your question -->
I'm trying to optimize hugging face's BERT Base uncased model using Torch-TensorRT, the code works after disabling full compilation (`require_full_compilation=False`), and the avg latency is ~10ms on T4. However, it it slower than native PyTorch implementation (~6ms on T4). In contrast, running the same model with `trtexec` only takes ~4ms. So, for BERT Base, it's 2.5x slower than TensorRT. I wonder if this is expected?
Here's the full code:
```
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import time
enc = BertTokenizer.from_pretrained("./bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = '[MASK]'
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens]).to(torch.int32).cuda()
segments_tensors = torch.tensor([segments_ids]).to(torch.int32).cuda()
dummy_input = [tokens_tensor, segments_tensors]
dummy_input_shapes = [list(v.size()) for v in dummy_input]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(vocab_size_or_config_json_file=32000, hidden_size=768,
num_hidden_layers=12, num_attention_heads=12, intermediate_size=3072, torchscript=True)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with `from_pretrained` you can also easily set the TorchScript flag
model = BertModel.from_pretrained("./bert-base-uncased", torchscript=True)
model = model.eval().cuda()
# Creating the trace
traced_model = torch.jit.trace(model, dummy_input)
import torch_tensorrt
compile_settings = {
"require_full_compilation": False,
"truncate_long_and_double": True,
"torch_executed_ops": ["aten::Int"]
}
optimized_model = torch_tensorrt.compile(traced_model, inputs=dummy_input, **compile_settings)
def benchmark(model, input):
# Warming up
for _ in range(10):
model(*input)
inference_count = 1000
# inference test
start = time.time()
for _ in range(inference_count):
model(*input)
end = time.time()
print(f"use {(end-start)/inference_count*1000} ms each inference")
print(f"{inference_count/(end-start)} step/s")
print("before compile")
benchmark(traced_model, dummy_input)
print("after compile")
benchmark(optimized_model, dummy_input)
```
So, my question is why it is slower than native PyTorch, and how do I fine-tune it?
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
I've checked out the log from Torch-TensorRT, looks like the model is partitioned into 3 parts, separated by `at::Int` op, and looks like Int op is [hard to implement](https://github.com/NVIDIA/Torch-TensorRT/issues/513).
Next, I profiled the inference process with Nsight System, here's the screenshot:

It is expected to see 3 divided segments, however, there are 2 things that caught my attention:
1. Why segment 0 is slower than pure TensorRT? Is it due to over complicated conversion?
2. Why the `cudaMemcpyAsync` took so long? Shouldn't it only return the `last_hidden_state` tensor?
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.10
- CPU Architecture:
- OS (e.g., Linux): Ubuntu 18.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source): python setup.py develop
- Are you using local sources or building from archives: local sources
- Python version: 3.6.9
- CUDA version: 10.2
- GPU models and configuration: T4
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/830
|
closed
|
[
"question",
"No Activity",
"performance"
] | 2022-01-26T10:55:56Z
| 2023-11-09T09:13:15Z
| null |
void-main
|
pytorch/torchx
| 375
|
[torchx/config] Generate docs on the available configuration options in .torchxconfig
|
## 📚 Documentation
Note: not a request for correction of documentation!
## Link
https://pytorch.org/torchx/latest/experimental/runner.config.html
## What does it currently say?
Nothing wrong with the current docs, but would be nice to have a list of the options that are "set-able" via .torchxconfig
## What should it say?
Add a section that lists out the possible options and section names. Note that some options (e.g. the types of schedulers available and their respective runopts) are different between Meta-internal and OSS. Having a contextual `TorchXConfig` DAO-like object with placeholders and generating a docs page by dumping that object would make it possible to capture these differences.
## Why?
Currently it is not clear what options can/cannot be set via .torchxconfig, we need a glossary of all the available options along with a help string on what they do and default values (if any)
|
https://github.com/meta-pytorch/torchx/issues/375
|
open
|
[] | 2022-01-25T23:49:07Z
| 2022-04-08T18:23:57Z
| 2
|
kiukchung
|
pytorch/TensorRT
| 824
|
❓ [Question] How to use FP16 precision in C++
|
## ❓ Question
I am trying run inference on an FP16-Engine in C++. `engine->getBindingDataType(i)` correctly returns '1' (kHALF) for all Bindings. However, when I am using the following lines to get the output, the compiler is obviously interpreting it as normal floats (=FP32)
```
std::vector<float> cpu_output(getSizeByDim(output_dims[0]) * 1);
cudaMemcpy(cpu_output.data(), buffers[outputIndex], cpu_output.size() * sizeof(float), cudaMemcpyDeviceToHost);
```
How can I make sure that the contents are correctly converted to float, or what datatype can I use to interpret them as halfs? Right now, the `cpu_output` vector somehow casts the halfs so that the output floats are way too large (estimated ~100 times larger than they should be). Can I just do something like "`cpu_output[i] = cpu_output[i]<<8`"?
|
https://github.com/pytorch/TensorRT/issues/824
|
closed
|
[
"question"
] | 2022-01-25T09:52:19Z
| 2022-01-25T10:01:40Z
| null |
DavidBaldsiefen
|
pytorch/text
| 1,537
|
[META] how do we want to handle stale issues/PRs?
|
## ❓ Questions and Help
There are many issues and PRs in the repo either related to long-gone legacy APIs or have been overcome by events. How do we want to track/manage these potentially stale issues?
Options:
- A bot
- I don't like this option because it can permit false positives which makes it hard for users to find real issues
- Manual inspection
- This can take a bit of time, but it's more precise
- Others?
|
https://github.com/pytorch/text/issues/1537
|
closed
|
[] | 2022-01-24T17:24:28Z
| 2022-03-07T22:52:11Z
| null |
erip
|
pytorch/TensorRT
| 823
|
❓ [Question] How do you override or remove evaluators
|
## ❓ Question
I am trying to use YOLOv5 with Torch-TensorRT. When I load the model, I get the following error message (among others):
```
ERROR: [Torch-TensorRT TorchScript Conversion Context] - 4: [layers.cpp::validate::2385] Error Code 4: Internal Error (%3264 : Tensor = aten::mul(%3263, %3257) # /home/.../yolov5/models/yolo.py:66:0: operation PROD has incompatible input types Float and Int32)
```
Thus I wanted to try to overload the `aten::mul` operator to support `float*int` and `int*float` operations, which fails (see below)
**(How) Is it possible to override or remove existing evaluators?**
## What you have already tried
I am using the following code:
```
static auto atenmul_evaluator =
torch_tensorrt::core::conversion::evaluators::RegisterNodeEvaluators().evaluator(
{c10::Symbol::fromQualString("aten::mul"),
[](const torch::jit::Node *n, torch_tensorrt::core::conversion::evaluators::kwargs &args)
-> c10::optional<torch::jit::IValue> {
ROS_INFO("Custom Evaluator is being accessed!");
if (args.at(n->input(0)).IValue()->isInt() && args.at(n->input(1)).IValue()->isInt()) {
auto a = args.at(n->input(0)).unwrapToInt();
auto b = args.at(n->input(1)).unwrapToInt();
return a * b;
} else if (args.at(n->input(0)).IValue()->isDouble() &&
args.at(n->input(1)).IValue()->isDouble()) {
auto a = args.at(n->input(0)).unwrapToDouble();
auto b = args.at(n->input(1)).unwrapToDouble();
return a * b;
} else if (args.at(n->input(0)).IValue()->isInt() &&
args.at(n->input(1)).IValue()->isDouble()) {
auto a = args.at(n->input(0)).unwrapToInt();
auto b = args.at(n->input(1)).unwrapToDouble();
return a * b;
} else if (args.at(n->input(0)).IValue()->isDouble() &&
args.at(n->input(1)).IValue()->isInt()) {
auto a = args.at(n->input(0)).unwrapToDouble();
auto b = args.at(n->input(1)).unwrapToInt();
return a * b;
} else {
TORCHTRT_THROW_ERROR("Unimplemented data type for aten::mul evaluator: "
<< args.at(n->input(0)).IValue()->type()->str());
return {};
}
},
torch_tensorrt::core::conversion::evaluators::EvalOptions().validSchemas(
{"aten::mul.int(int a, int b) -> (float)",
"aten::mul.float(float a, float b) -> (float)",
"aten::mul.int_float(int a, float b) -> (float)",
"aten::mul.float_int(float a, int b) -> (float)"})});
```
But then I get the errormessage `Attempting to override already registered evaluator aten::mul, merge implementations instead`. Thus I want to try and find a way to override or remove the evaluator without recompiling Torch-TensorRT.
When I implemented the above only for `int_float` and `float_int` seperately, the output returned to the orignal errormessage from above, indicating that the new evaluator wasn't used.
|
https://github.com/pytorch/TensorRT/issues/823
|
closed
|
[
"question",
"component: converters",
"No Activity"
] | 2022-01-24T08:43:17Z
| 2022-11-21T16:12:05Z
| null |
DavidBaldsiefen
|
pytorch/TensorRT
| 820
|
❓ [Question] Have anyone encounter this: RuntimeError: expected type comment but found 'eof' here
|
## ❓ Question
when I run compile command like this:
```python
trt_ts_module = torch_tensorrt.compile(model,
inputs=[torch_tensorrt.Input((1, 3, 128, 128), dtype=torch.float32),
torch_tensorrt.Input((1, 3, 320, 320), dtype=torch.float32)],
enabled_precisions = {torch.float, torch.half})
```
I encounter this error:
```
File "/opt/conda/lib/python3.8/site-packages/torch/jit/frontend.py", line 310, in build_def
type_comment_decl = torch._C.parse_type_comment(type_line)
RuntimeError: expected type comment but found 'eof' here:
# # type: (List[Tensor], Tensor) -> Tensor
```
## What you have already tried
No other attempts.
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.11.0a0+b6df043
- CPU Architecture: amd64
- OS (e.g., Linux): ubuntu18.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.8
- CUDA version: 11.5
- GPU models and configuration: GTX 1660ti
- Any other relevant information:
## Additional context
I just use docker recommended by tutorial at [https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch](https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch)
|
https://github.com/pytorch/TensorRT/issues/820
|
closed
|
[
"question",
"No Activity"
] | 2022-01-20T13:57:51Z
| 2022-05-05T00:02:27Z
| null |
laisimiao
|
pytorch/data
| 175
|
Refactor test suite to be more readable?
|
While working on #174, I also worked on the test suite. In there we have the ginormous tests that are hard to parse, because they do so many things at the same time:
https://github.com/pytorch/data/blob/c06066ae360fc6054fb826ae041b1cb0c09b2f3b/test/test_datapipe.py#L382-L426
I was wondering if there is a reason for that. Can't we split this into multiple smaller ones? Utilizing `pytest`, placing the following class in the test module is equivalent to the test above:
```python
class TestLineReader:
@pytest.fixture
def text1(self):
return "Line1\nLine2"
@pytest.fixture
def text2(self):
return "Line2,1\nLine2,2\nLine2,3"
def test_functional_read_lines_correctly(self, text1, text2):
source_dp = IterableWrapper([("file1", io.StringIO(text1)), ("file2", io.StringIO(text2))])
line_reader_dp = source_dp.readlines()
expected_result = [("file1", line) for line in text1.split("\n")] + [
("file2", line) for line in text2.split("\n")
]
assert expected_result == list(line_reader_dp)
def test_functional_strip_new_lines_for_bytes(self, text1, text2):
source_dp = IterableWrapper(
[("file1", io.BytesIO(text1.encode("utf-8"))), ("file2", io.BytesIO(text2.encode("utf-8")))]
)
line_reader_dp = source_dp.readlines()
expected_result_bytes = [("file1", line.encode("utf-8")) for line in text1.split("\n")] + [
("file2", line.encode("utf-8")) for line in text2.split("\n")
]
assert expected_result_bytes == list(line_reader_dp)
def test_functional_do_not_strip_newlines(self, text1, text2):
source_dp = IterableWrapper([("file1", io.StringIO(text1)), ("file2", io.StringIO(text2))])
line_reader_dp = source_dp.readlines(strip_newline=False)
expected_result = [
("file1", "Line1\n"),
("file1", "Line2"),
("file2", "Line2,1\n"),
("file2", "Line2,2\n"),
("file2", "Line2,3"),
]
assert expected_result == list(line_reader_dp)
def test_reset(self, text1, text2):
source_dp = IterableWrapper([("file1", io.StringIO(text1)), ("file2", io.StringIO(text2))])
line_reader_dp = LineReader(source_dp, strip_newline=False)
expected_result = [
("file1", "Line1\n"),
("file1", "Line2"),
("file2", "Line2,1\n"),
("file2", "Line2,2\n"),
("file2", "Line2,3"),
]
n_elements_before_reset = 2
res_before_reset, res_after_reset = reset_after_n_next_calls(line_reader_dp, n_elements_before_reset)
assert expected_result[:n_elements_before_reset] == res_before_reset
assert expected_result == res_after_reset
def test_len(self, text1, text2):
source_dp = IterableWrapper([("file1", io.StringIO(text1)), ("file2", io.StringIO(text2))])
line_reader_dp = LineReader(source_dp, strip_newline=False)
with pytest.raises(TypeError, match="has no len"):
len(line_reader_dp)
```
This is a lot more readable, since we now actually have 5 separate test cases that can individually fail. Plus, while writing this I also found that `test_reset` and `test_len` were somewhat dependent on `test_functional_do_not_strip_newlines` since they don't neither define `line_reader_dp` nor `expected_result` themselves.
|
https://github.com/meta-pytorch/data/issues/175
|
open
|
[
"Better Engineering"
] | 2022-01-20T09:52:17Z
| 2023-04-11T16:59:28Z
| 6
|
pmeier
|
pytorch/functorch
| 400
|
how to get related commits of pytorch/pytorch and pytorch/functorch ?
|
For some reason, i need to install newest **pytorch/functorch** from sources. but i don't know the related **pytorch/pytorch** newest source. if the pytorch/pytorch and pytorch/functorch is not compatible, functorch will not work. how i get a newest relative pair of pytorch/pytorch commit and pytorch/functorch commit ?
does pytorch/functorch only match the released or nightly version of pytorch/pytorch?
|
https://github.com/pytorch/functorch/issues/400
|
open
|
[] | 2022-01-20T03:25:26Z
| 2022-01-20T15:43:40Z
| null |
GipsonLeo
|
huggingface/transformers
| 15,223
|
where is the 4.16.0dev??
|
I'm running the run_mlm.py script.
There is such a line,
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.16.0.dev0")
but where is it?
can't find by pip,no in github too.
|
https://github.com/huggingface/transformers/issues/15223
|
closed
|
[] | 2022-01-19T11:41:04Z
| 2022-02-27T15:02:00Z
| null |
sipie800
|
pytorch/TensorRT
| 819
|
Build torch-trt failed in Ubuntu18.04
|
I try to build the project from source according to the guide in. https://nvidia.github.io/Torch-TensorRT/tutorials/installation.html with bazel but failed.
My environment:
```
os: Ubuntu18.04
gcc: 7.5.0
g++: 7.5.0
cuda: 11.3
cudnn: 8.2
tensorRT: 8.2
torch-trt branch: ngc-21.12
bazel: 4.2.1 (installed in conde env through: `conda install -c conda-forge bazel=4.2.1`)
```
Build command:
```
$ export TEST_TMPDIR=/tmp/cache_bazel
$ export BAZEL_USER_ROOT=/tmp/trt/ltp
$ export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH
$ bazel --output_user_root=${BAZEL_USER_ROOT} \
build //:libtorchtrt -c opt \
--distdir third_party/dist_dir/[x86_64-linux-gnu | aarch64-linux-gnu]
```
Error: `cc_toolchain_suite '@local_config_cc//:toolchain' does not contain a toolchain for cpu 'k8'`
Detail log:
```
$TEST_TMPDIR defined: output root default is '/tmp/cache_bazel' and max_idle_secs default is '15'.
Starting local Bazel server and connecting to it...
Loading:
Loading: 0 packages loaded
Analyzing: target //:libtorchtrt (1 packages loaded, 0 targets configured)
INFO: non-existent distdir /home/tianping/Torch-TensorRT/third_party/dist_dir/[x86_64-linux-gnu
INFO: non-existent distdir /home/tianping/Torch-TensorRT/third_party/dist_dir/[x86_64-linux-gnu
ERROR: /tmp/trt/ltp/a7833d9e16b047b679ab8ac389d55fc8/external/local_config_cc/BUILD:47:19: in cc_toolchain_suite rule @local_config_cc//:toolchain: cc_toolchain_suite '@local_config_cc//:toolchain' does not contain a toolchain for cpu 'k8'
INFO: Repository tensorrt instantiated at:
/home/tianping/Torch-TensorRT/WORKSPACE:89:13: in <toplevel>
Repository rule http_archive defined at:
/tmp/trt/ltp/a7833d9e16b047b679ab8ac389d55fc8/external/bazel_tools/tools/build_defs/repo/http.bzl:336:31: in <toplevel>
Analyzing: target //:libtorchtrt (39 packages loaded, 155 targets configured)
INFO: Repository libtorch instantiated at:
/home/tianping/Torch-TensorRT/WORKSPACE:56:13: in <toplevel>
Repository rule http_archive defined at:
/tmp/trt/ltp/a7833d9e16b047b679ab8ac389d55fc8/external/bazel_tools/tools/build_defs/repo/http.bzl:336:31: in <toplevel>
ERROR: Analysis of target '//:libtorchtrt' failed; build aborted: Analysis of target '@local_config_cc//:toolchain' failed
INFO: Elapsed time: 3.881s
INFO: 0 processes.
FAILED: Build did NOT complete successfully (39 packages loaded, 155 targets configured)
FAILED: Build did NOT complete successfully (39 packages loaded, 155 targets configured)
```
could you help solve this problem, thanks a lot.
|
https://github.com/pytorch/TensorRT/issues/819
|
closed
|
[
"question"
] | 2022-01-19T11:24:27Z
| 2022-01-20T01:42:26Z
| null |
Mookel
|
pytorch/xla
| 3,305
|
how to get relative commits of pytorch/pytorch and pytorch/xla ?
|
## ❓ Questions and Help
For some reason, i need to install newest torch XLA from sources. but i don't know the related pytorch/pytorch newest source. if the pytorch/pytorch and pytorch/xla is not compatible, xla will not work. how i get a newest relative pair of pytorch/pytorch commit and pytorch/xla commit ?
For example, an old pair is as flow, but too old:
pytorch/pytorch - HEAD git hash is a95abc46
pytorch/xla - HEAD git hash is 9c2f91e
|
https://github.com/pytorch/xla/issues/3305
|
closed
|
[] | 2022-01-19T08:38:55Z
| 2022-02-19T00:30:08Z
| null |
GipsonLeo
|
pytorch/pytorch
| 71,272
|
UserWarning: Seems like `optimizer.step()` has been overridden after learning rate scheduler initialization. Please, make sure to call `optimizer.step()` before `lr_scheduler.step()`. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate warnings.warn("Seems like `optimizer.step()` has been overridden after learning rate scheduler
|
### 🐛 Describe the bug
I am following the same way that is provided [here ](https://pytorch.org/docs/1.10.1/generated/torch.optim.lr_scheduler.StepLR.html#torch.optim.lr_scheduler.StepLR) for using `StepLR`:
```python
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
```
but I keep getting the following warning which is very annoying
``` python
UserWarning: Seems like `optimizer.step()` has been overridden after learning rate scheduler initialization. Please, make sure to call `optimizer.step()` before `lr_scheduler.step()`. See more details at https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Seems like `optimizer.step()` has been overridden after learning rate scheduler
```
also the output of `collect_env` is:
```
Versions of relevant libraries:
[pip3] numpy==1.21.4
[pip3] torch==1.10.0
[pip3] torchaudio==0.10.0
[pip3] torcheck==1.0.1
[pip3] torchinfo==1.5.4
[pip3] torchvision==0.11.1
[conda] blas 1.0 mkl defaults
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 defaults
[conda] mkl 2021.4.0 h06a4308_640 defaults
[conda] mkl-service 2.4.0 py39h7e14d7c_0 conda-forge
[conda] mkl_fft 1.3.1 py39h0c7bc48_1 conda-forge
[conda] mkl_random 1.2.2 py39hde0f152_0 conda-forge
[conda] numpy 1.21.2 py39h20f2e39_0 defaults
[conda] numpy-base 1.21.2 py39h79a1101_0 defaults
[conda] pytorch 1.10.0 py3.9_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.10.0 py39_cu113 pytorch
[conda] torchinfo 1.5.4 pyhd8ed1ab_0 conda-forge
[conda] torchvision 0.11.1 py39_cu113 pytorch
```
### Versions
also the output of `collect_env` is:
```
Versions of relevant libraries:
[pip3] numpy==1.21.4
[pip3] torch==1.10.0
[pip3] torchaudio==0.10.0
[pip3] torcheck==1.0.1
[pip3] torchinfo==1.5.4
[pip3] torchvision==0.11.1
[conda] blas 1.0 mkl defaults
[conda] cudatoolkit 11.3.1 h2bc3f7f_2 defaults
[conda] mkl 2021.4.0 h06a4308_640 defaults
[conda] mkl-service 2.4.0 py39h7e14d7c_0 conda-forge
[conda] mkl_fft 1.3.1 py39h0c7bc48_1 conda-forge
[conda] mkl_random 1.2.2 py39hde0f152_0 conda-forge
[conda] numpy 1.21.2 py39h20f2e39_0 defaults
[conda] numpy-base 1.21.2 py39h79a1101_0 defaults
[conda] pytorch 1.10.0 py3.9_cuda11.3_cudnn8.2.0_0 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 0.10.0 py39_cu113 pytorch
[conda] torchinfo 1.5.4 pyhd8ed1ab_0 conda-forge
[conda] torchvision 0.11.1 py39_cu113 pytorch
```
cc @vincentqb @jbschlosser @albanD
|
https://github.com/pytorch/pytorch/issues/71272
|
open
|
[
"needs reproduction",
"module: optimizer",
"triaged",
"module: LrScheduler"
] | 2022-01-13T19:03:46Z
| 2022-01-20T16:33:17Z
| null |
seyeeet
|
pytorch/xla
| 3,283
|
How to benchmark the JIT / XLA?
|
## ❓ Questions and Help
Dear JAX developers,
I am trying to better understand the performance of JAX and its underlying just-in-time compilation architecture, but am puzzled how to get access to this information. For example, it would be helpful to distinguish how much time is spent tracing in Python, doing HLO optimizations within XLA, and time spent further downstream in LLVM->PTX and PTX->SASS compilation steps.
Surely these are useful metrics to JAX developers as well, but I could not find any information on how to access them.
Searching online brings me to a [PyTorch/XLA troubleshoooting guide](https://github.com/pytorch/xla/blob/master/TROUBLESHOOTING.md) with promising-looking interfaces like
```
import torch_xla.debug.metrics as met
print(met.metrics_report())
```
This page also mentions a `XLA_METRICS_FILE` and other environment variables that can be used to extract metrics information --- however, it seems that all of these are 100% PyTorch specific.
Any suggestions would be greatly appreciated!
Thanks,
Wenzel
|
https://github.com/pytorch/xla/issues/3283
|
closed
|
[] | 2022-01-08T16:31:55Z
| 2022-01-10T08:26:40Z
| null |
wjakob
|
pytorch/pytorch
| 71,058
|
`torch.Tensor.where` cannot work when `y` is float
|
### 🐛 Describe the bug
Based on the [documentation](https://pytorch.org/docs/stable/generated/torch.Tensor.where.html?highlight=where#torch.Tensor.where) of `torch.Tensor.where`, `self.where(condition, y)` is equivalent to `torch.where(condition, self, y)`. However, `torch.where` will succeed when `y` is a float but `Tensor.where` will raise an error.
```python
import torch
condition= torch.randint(0,2,[2, 2], dtype=torch.bool)
x= torch.rand([2, 2], dtype=torch.float64)
y = 0.0
print( torch.where(condition, x, y) )
# tensor([[0.0000, 0.6290],
# [0.0000, 0.0000]], dtype=torch.float64)
print( x.where(condition, y) )
# TypeError: where(): argument 'other' (position 2) must be Tensor, not float
```
### Versions
pytorch: 1.10.1
cc @nairbv @mruberry
|
https://github.com/pytorch/pytorch/issues/71058
|
open
|
[
"triaged",
"module: type promotion"
] | 2022-01-08T15:18:11Z
| 2022-01-11T15:36:54Z
| null |
TestSomething22
|
pytorch/pytorch
| 70,923
|
type promotion is broken in `torch.where`
|
The [array API specification stipulates](https://data-apis.org/array-api/latest/API_specification/searching_functions.html?highlight=where#id7) that the return value of `torch.where` should undergo regular type promotion. Currently we do not support different dtypes for `x` and `y`:
```python
import torch
condition = torch.tensor([False, True])
x = torch.ones(2, dtype=torch.float32)
y = torch.zeros(2, dtype=torch.float64)
torch.where(condition, x, y)
```
```
RuntimeError: expected scalar type float but found double
```
Note that the error message is also misleading since we deal with 1d tensors here.
cc @nairbv @mruberry @rgommers @pmeier @asmeurer @leofang @AnirudhDagar @asi1024 @emcastillo @kmaehashi
|
https://github.com/pytorch/pytorch/issues/70923
|
closed
|
[
"triaged",
"module: type promotion",
"module: python array api"
] | 2022-01-06T14:39:05Z
| 2022-01-07T07:50:40Z
| null |
pmeier
|
pytorch/serve
| 1,389
|
how to determine number of workers and batch size to obtain best performance?
|
I have one model and 3 gpus. I register my model with the command:
curl -X POST "localhost:8444/models?url=yoyo_ai.mar&**batch_size=8**&max_batch_delay=8000&**initial_workers=8**"
In this setup, gpu:0 is assigned 2 workers and others are assigned 3 workers. (2 + 3 + 3)
I make requests with the following code where data_batch is a list holding 64 images (i assume each worker to handle 8 images):
async def do_post(session, url, image):
async with session.post(url, data=image) as response:
return await response.text()
async def make_predictions(data_stack, model_url):
async with aiohttp.ClientSession() as session:
post_tasks = []
# prepare the coroutines that post
for img in data_stack:
post_tasks.append(do_post(session, model_url, img))
# now execute them all at once
responses = await asyncio.gather(*post_tasks)
return responses
def get_predictions(data_batch, model_url):
loop = asyncio.get_event_loop()
predictions = None
try:
predictions = loop.run_until_complete(make_predictions(data_batch, model_url))
finally:
return predictions
While making requests in an endless loop this is the memory usage i get:
If i further increase the batch size to 12 because of high memory usage of gpu:0 torchserve throws exception. Same happens if i keep batch size as 8 but increase number of workers (e.g. 9). This time each gpu gets 3 workers and gpu:0 fails to handle it. On the other hand, if i set the number of workers to 6 and keep batch size as 8, total processing time not become worse compared to 8/8 setup. Meanwhile, either 8/6 or 8/8 setup don't use memory at full capacity. As a final note, gpu utilization keeps going back and forth between %0 and %100 during inference (not at 100% or %80/%90 all time).
Is there a way to use gpus at full capacity? I wonder how should i register my model with the best batch size and number of workers combination to use gpus optimally. Or do i have a problem at making requests?
Thank you very much for any help
|
https://github.com/pytorch/serve/issues/1389
|
closed
|
[
"help wanted"
] | 2022-01-06T08:14:27Z
| 2022-02-03T22:27:03Z
| null |
orkunozturk
|
pytorch/tutorials
| 1,781
|
tutorials/advanced_source/super_resolution_with_onnxruntime.py is maybe outdated?
|
I am working at the moment trough the [tutorial](https://github.com/pytorch/tutorials/blob/master/advanced_source/super_resolution_with_onnxruntime.py) and realized, that the entry notes are not up-to-date.
- line 19 says, onnx is available/compatible between 3.5 to 3.7:
- I tested installation in a venv with 3.9 without problems
- line 21-22 says, says that the main/master branch is needed:
- I tested the standard imports from line 26 to 32 and all imports worked without a problem.
I am running a ubuntu 20.04 with torch stable 1.10.1 installed via pip for cuda 10.2.
I did not finished the tutorial yet and will append further informations while continuing.
EDIT:
I can confirm: works without any issues
|
https://github.com/pytorch/tutorials/issues/1781
|
closed
|
[
"content",
"docathon-h1-2023",
"easy"
] | 2022-01-05T15:29:57Z
| 2023-06-02T22:24:09Z
| 2
|
MaKaNu
|
pytorch/serve
| 1,385
|
How to decode response after post process?
|
Hello. I'm using custom bert model on my custom handler using Korean.
When I request input text, handler encodes it and process like this.
``` {'body': bytearray(b'[\n\t\t\t["\xec\x9a\x94\xec\xa6\x98 \xeb\xb6\x80\xeb\xaa\xa8\xeb\x8b\x98\xea\xb3\xbc \xeb\xa7\x8e\xec\x9d\xb4 \xeb\xb6\x80\xeb\x94\xaa\xed\x98\x80.",\n\t\t\t "\xec\x96\xb4\xeb\x96\xa4 \xec\x9d\xbc\xeb\xa1\x9c ... ```
But results in custom model came out with Korean.
Problem is response.
Althought my custom model gives Korean Results,
Torch serve's response is encoded again.
How can I fix this?
Thank you.
|
https://github.com/pytorch/serve/issues/1385
|
closed
|
[
"help wanted"
] | 2022-01-04T01:33:02Z
| 2022-01-07T17:32:22Z
| null |
MinsuKim3095
|
pytorch/text
| 1,476
|
How to get all tokens in a Vocab using text
|
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
**Motivation**
Hi,
When I load a vocab or have built a vocab using torchtext.vocab, I can not print its all token in the Vocab
|
https://github.com/pytorch/text/issues/1476
|
closed
|
[] | 2022-01-01T06:53:51Z
| 2022-01-01T14:07:08Z
| null |
yipliu
|
huggingface/datasets-tagging
| 28
|
Why datasets version is pinned in requirements.txt?
|
In file `requirements.txt`, the version of `datasets` is pinned. Why?
|
https://github.com/huggingface/datasets-tagging/issues/28
|
open
|
[
"question"
] | 2021-12-29T09:39:40Z
| 2021-12-29T11:51:59Z
| null |
albertvillanova
|
pytorch/xla
| 3,271
|
How to specify compute capability when building from soruce to support GPU?
|
Hello, when I finish building from soruce to support GPU, and run the test script test_train_mp_imagenet.py, a warning is shown:
TensorFlow was not built with CUDA kernel binaries compatible with compute capability 7.5. CUDA kernels will be jit-compiled from PTX, which could take 30 minutes or longer.
I am wondering how to specify the compute capability when building xla ?
Thanks very much!
|
https://github.com/pytorch/xla/issues/3271
|
closed
|
[
"xla:gpu"
] | 2021-12-28T06:05:07Z
| 2022-02-19T00:36:41Z
| null |
yxd886
|
pytorch/pytorch
| 70,413
|
PyTorch crashes without an error message, when running this code snippet with torch.tensor subclassing & forward hooks (Not sure what the exact cause is, but the code snippet reliably causes it)
|
### 🐛 Describe the bug
While working a project for PyTorch's [Captum](https://github.com/pytorch/captum) library, I came across a bug that I've been struggling to narrow down the cause of. I've done my best to simplify what is happening in the Captum code, and the snippet of code below should reliably reproduce the crash, though I apologies for not being able to narrow it down to smaller snippet of code.
The example code uses torch.tensor subclassing and forward hooks, and they appear to be important for causing the crash.
I have no idea if there should be an error message when running the code, or if there should be no issue at all.
```
import torch
from torchvision import models
model = models.resnet18()
from typing import Type, Callable, List, Tuple, Union
import numpy as np
from types import MethodType
class TestTensor(torch.Tensor):
@staticmethod
def __new__(
cls: Type["TestTensor"],
x: Union[List, np.ndarray, torch.Tensor] = [],
*args,
**kwargs,
) -> torch.Tensor:
if isinstance(x, torch.Tensor) and x.is_cuda:
x.show = MethodType(cls.show, x)
x.export = MethodType(cls.export, x)
return x
else:
return super().__new__(cls, x, *args, **kwargs)
@classmethod
def __torch_function__(
cls: Type["TestTensor"],
func: Callable,
types: List[Type[torch.Tensor]],
args: Tuple = (),
kwargs: dict = None,
) -> torch.Tensor:
if kwargs is None:
kwargs = {}
return super().__torch_function__(func, types, args, kwargs)
class TestTensor2(torch.nn.Module):
def __init__(self):
super().__init__()
self.test_tensor = torch.randn(3,3,224,224).clamp(0,1)
def forward(self):
x = self.test_tensor
return TestTensor(x)
def test_hook(target):
def forward_hook(self, input, output) -> None:
pass
test_hooks = target.register_forward_hook(forward_hook)
test_hooks.remove()
return image().detach(), torch.randn(5)
class CaptumModuleOutputsHook:
def __init__(self, target_modules) -> None:
self.outputs = dict.fromkeys(target_modules, None)
self.hooks = [
module.register_forward_hook(self._forward_hook())
for module in target_modules
]
def _forward_hook(self) -> Callable:
def forward_hook(
module: torch.nn.Module, input: Tuple[torch.Tensor], output: torch.Tensor
) -> None:
assert module in self.outputs.keys()
self.outputs[module] = output
return forward_hook
def consume_outputs(self):
outputs = self.outputs
self.outputs = dict.fromkeys(self.outputs.keys(), None)
return outputs
def remove_hooks(self) -> None:
for hook in self.hooks:
hook.remove()
def collect_activations(model, target, input_tensor):
layers = CaptumModuleOutputsHook(target)
try:
model(input_tensor)
activations_dict = layers.consume_outputs()
finally:
layers.remove_hooks()
return activations_dict[target[0]]
def trigger_crash(
model,
image,
target,
):
attempts, attempt_losses = [], []
# Removing this loop somehow prevents the crash from happening
for a in range(1):
imgs, losses = test_hook(target)
attempts.append(imgs.detach()); attempt_losses.append(losses)
final_image, final_losses = torch.cat(attempts, 0), torch.stack(attempt_losses)
activ = collect_activations(model, [target], final_image) # Crash happens on this line
# Commenting out these lines of code somehow prevents the crash from happening
comparison_losses = torch.stack([activ.mean()]*3)
sorted_idx = torch.sort(comparison_losses)[1]
best_image = final_image[sorted_idx[0:3]]
best_losses = final_losses[sorted_idx[0:3]]
return best_image, best_losses
image = TestTensor2()
trigger_crash(model, image, model.layer1)
```
### Versions
```
PyTorch version: 1.10.0+cu111
Is debug build: False
CUDA used to build PyTorch: 11.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.12.0
Libc version: glibc-2.26
Python version: 3.7.12 (default, Sep 10 2021, 00:21:48) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.144+-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: False
CUDA runtime version: 11.1.105
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.5
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.5
/usr/lib/
|
https://github.com/pytorch/pytorch/issues/70413
|
open
|
[
"triaged",
"Stale",
"tensor subclass"
] | 2021-12-26T18:33:55Z
| 2022-02-26T21:02:46Z
| null |
ProGamerGov
|
pytorch/pytorch
| 70,411
|
How to use custom dataset with SSD
|
I am trying to use SSD and retinanet from torchvision on my own dataset. However I cant find any reference on how to use my own dataset and what format requuired. Could any one please advice me
|
https://github.com/pytorch/pytorch/issues/70411
|
closed
|
[] | 2021-12-26T12:37:21Z
| 2021-12-28T16:19:14Z
| null |
myasser63
|
pytorch/tutorials
| 1,778
|
[Help Wanted] Why take the log function and then apply exp?
|
In [line of code](https://github.com/pytorch/tutorials/blob/master/beginner_source/transformer_tutorial.py#L113), you calculate positional encoding for Transformers by taking the log first and then apply the exponential function.
Would you please elaborate on why you do this instead of directly doing the calculation?
I'm aware that log transformation can make multiplication become addition, but it seems that this is not the case here.
cc @suraj813
|
https://github.com/pytorch/tutorials/issues/1778
|
closed
|
[
"question",
"intro",
"docathon-h1-2023",
"easy"
] | 2021-12-24T17:09:56Z
| 2024-05-24T18:34:43Z
| null |
Superhzf
|
pytorch/TensorRT
| 788
|
❓ [Question] How do you ....?
|
## ❓ Question
Hi, could you please explain how this is better than pytorch to Onnx to TensorRT export path?
|
https://github.com/pytorch/TensorRT/issues/788
|
closed
|
[
"question"
] | 2021-12-22T17:36:54Z
| 2022-01-04T23:56:04Z
| null |
andrei-pokrovsky
|
pytorch/TensorRT
| 786
|
❓ [Question] How do you ....?
|
## ❓ Question
How can do you use [OpenAI's CLIP](https://github.com/openai/CLIP)
## What you have already tried
```
import clip
from torchvision import transforms
import torch_tensorrt
import torch
device = "cuda:0"
batch_size = 4
clip_model_name = "ViT-B/32"
scripted_model , preprocess = clip.load(clip_model_name, device, jit=True)
scripted_model = scripted_model.visual.to(device)
preprocess = transforms.Compose([
preprocess,
lambda x: x.half()
])
trt_ts_module = torch_tensorrt.compile(scripted_model,
inputs = [
torch_tensorrt.Input( # Specify input object with shape and dtype
shape=[batch_size, 3, 224, 224],
dtype=torch.half) # Datatype of input tensor. Allowed options torch.(float|half|int8|int32|bool)
])
```
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
I have build my docker image using base image `21.10` with nvidia driver `470.86`.
```
docker build --build-arg BASE=21.10 -f docker/Dockerfile -t torch_tensorrt:latest .
```
With the following libraries installed.
```
nvidia-dlprof-pytorch-nvtx @ file:///nvidia/opt/dlprof/bin/nvidia_dlprof_pytorch_nvtx-1.6.0-py3-none-any.whl
onnx @ file:///opt/pytorch/pytorch/third_party/onnx
pytorch-quantization==2.1.0
torch==1.10.0a0+0aef44c
torch-tensorrt @ file:///workspace/torch_tensorrt-1.1.0a0%2B733a4b1c-cp38-cp38-linux_x86_64.whl
torchtext @ file:///opt/pytorch/text
torchvision @ file:///opt/pytorch/vision
clip @ git+https://github.com/openai/CLIP.git@573315e83f07b53a61ff5098757e8fc885f1703e
```
## Additional context
The error I am getting is:
```
Traceback (most recent call last):
File "benchmark.py", line 155, in <module>
trt_ts_module = torch_tensorrt.compile(scripted_model,
File "/opt/conda/lib/python3.8/site-packages/torch_tensorrt/_compile.py", line 97, in compile
return torch_tensorrt.ts.compile(ts_mod, inputs=inputs, enabled_precisions=enabled_precisions, **kwargs)
File "/opt/conda/lib/python3.8/site-packages/torch_tensorrt/ts/_compiler.py", line 119, in compile
compiled_cpp_mod = _C.compile_graph(module._c, _parse_compile_spec(spec))
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript, serialized code (most recent call last):
File "code/__torch__/multimodal/model/multimodal_transformer.py", line 34, in forward
x2 = torch.add(x1, torch.to(_4, 5, False, False, None), alpha=1)
x3 = torch.permute((_3).forward(x2, ), [1, 0, 2])
x4 = torch.permute((_2).forward(x3, ), [1, 0, 2])
~~~~~~~~~~~ <--- HERE
_15 = torch.slice(x4, 0, 0, 9223372036854775807, 1)
x5 = torch.slice(torch.select(_15, 1, 0), 1, 0, 9223372036854775807, 1)
File "code/__torch__/multimodal/model/multimodal_transformer/___torch_mangle_9477.py", line 8, in forward
def forward(self: __torch__.multimodal.model.multimodal_transformer.___torch_mangle_9477.Transformer,
x: Tensor) -> Tensor:
return (self.resblocks).forward(x, )
~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
def forward1(self: __torch__.multimodal.model.multimodal_transformer.___torch_mangle_9477.Transformer,
x: Tensor) -> Tensor:
File "code/__torch__/torch/nn/modules/container/___torch_mangle_9476.py", line 29, in forward
_8 = getattr(self, "3")
_9 = getattr(self, "2")
_10 = (getattr(self, "1")).forward((getattr(self, "0")).forward(x, ), )
~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
_11 = (_7).forward((_8).forward((_9).forward(_10, ), ), )
_12 = (_4).forward((_5).forward((_6).forward(_11, ), ), )
File "code/__torch__/multimodal/model/multimodal_transformer/___torch_mangle_9376.py", line 13, in forward
_0 = self.mlp
_1 = self.ln_2
_2 = (self.attn).forward((self.ln_1).forward(x, ), )
~~~~~~~~~~~~~~~~~~ <--- HERE
x0 = torch.add(x, _2, alpha=1)
x1 = torch.add(x0, (_0).forward((_1).forward(x0, ), ), alpha=1)
File "code/__torch__/torch/nn/modules/activation/___torch_mangle_9369.py", line 34, in forward
_13 = torch.contiguous(k, memory_format=0)
_14 = [-1, int(torch.mul(bsz, CONSTANTS.c0)), _9]
k0 = torch.transpose(torch.view(_13, _14), 0, 1)
~~~~~~~~~~ <--- HERE
_15 = torch.contiguous(v, memory_format=0)
_16 = [-1, int(torch.mul(bsz, CONSTANTS.c0)), _8]
Traceback of TorchScript, original code (most recent call last):
/opt/conda/lib/python3.7/site-packages/torch/nn/functional.py(4265): multi_head_attention_forward
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/activation.py(985): forward
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py(709): _slow_forward
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py(725): _call_impl
/root/workspace/multimod
|
https://github.com/pytorch/TensorRT/issues/786
|
closed
|
[
"question"
] | 2021-12-22T09:10:31Z
| 2022-01-25T10:01:54Z
| null |
hfawaz
|
pytorch/pytorch
| 70,280
|
How to create build-in buffers which is writable during onnx inference?
|
### 🚀 The feature, motivation and pitch
First, I'm sorry that this question may not be strictly relative to a feature request, but it has been posted on discuss.pytorch.org without any replies for one week.
Hi, I try to create a first-in-first-out queue as a pytorch model, export it to onnx and infer with onnxruntime. The queue, with a limited size, updates every time when a new input comes, and returns the updated queue. Codes are very simple:
```
import torch
import torch.nn as nn
class WavBuffer(nn.Module):
def __init__(self, size=10):
super().__init__()
self.size = size
wavbuf = torch.zeros(size)
self.register_buffer('wavbuf', wavbuf)
def forward(self, x):
self.wavbuf = torch.cat([self.wavbuf, x])[-self.size:]
return self.wavbuf
model = WavBuffer(10)
x = torch.ones(5)
for i in range(2):
wavbuf = model(x)
print(wavbuf)
```
As expected, the outputs are:
```
tensor([0., 0., 0., 0., 0., 1., 1., 1., 1., 1.])
tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
```
Then I export the model to onnx format and infer with onnxruntime:
```
torch.onnx.export(
model, torch.zeros(5), 'model.onnx', verbose=False, input_names=['wav'],
output_names=['wavbuf'], opset_version=11
)
import numpy as np
import onnxruntime
model = onnxruntime.InferenceSession('model.onnx')
x = np.ones(5, dtype=np.float32)
inputs = {model.get_inputs()[0].name: x}
for i in range(2):
outputs = model.run(None, inputs)
wavbuf = outputs[0]
print(wavbuf)
```
However, now the outputs are:
```
[0. 0. 0. 0. 0. 1. 1. 1. 1. 1.]
[0. 0. 0. 0. 0. 1. 1. 1. 1. 1.]
```
I guess that weights in onnx models are not changeable, but is there any solution to create writable build-in buffers during model design and change the buffers in onnx inference? An available example is LSTM, where the hidden states update for each time step. However, it is too difficult for me to its implementation.
### Alternatives
_No response_
### Additional context
_No response_
|
https://github.com/pytorch/pytorch/issues/70280
|
closed
|
[
"module: onnx",
"triaged"
] | 2021-12-22T02:26:28Z
| 2022-01-05T01:46:44Z
| null |
lawlict
|
pytorch/TensorRT
| 783
|
❓ [Question] Is there a way to visualize the TRT model?
|
## ❓ Question
<!-- Your question -->
I'm wondering if there is a way to get the TRT model after compilation and visualize it. I trying to compare a PTQ model to a QAT model. I know I might have to do some further optimization just trying to visualize the graphs and see what is going on . Currently using DenseNet169
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
I can visualize an ONNX graph but unsure of TRT
## Environment
> Build information about Torch-TensorRT can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.10.0
- CPU Architecture: x86 (Intel Skylake)
- OS (e.g., Linux): Ubuntu 20.04
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source): N/A
- Are you using local sources or building from archives:
- Python version: 3.8.10
- CUDA version: 11.4
- GPU models and configuration: Tesla T4
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/783
|
closed
|
[
"question"
] | 2021-12-21T16:39:50Z
| 2022-05-18T20:34:06Z
| null |
jessicarcassidy
|
pytorch/pytorch
| 70,244
|
[feature request]how to merge many models to one model with shared backbone just use some code ,not a create a new model
|
I train some models with different datas ,these models' some parameters are shared ,
when i inference the models ,i need merge the models to one model ,i know the shared op ,so ,i want to merge these models
shared op to one op with seperate head only when inference not train.
i don't want to write a new model ,could i write a function to merge the op with same dict name ,and create a new inference model
automatic .
or maybe any way else is ok
thank you !
|
https://github.com/pytorch/pytorch/issues/70244
|
closed
|
[] | 2021-12-21T13:11:35Z
| 2021-12-23T16:55:09Z
| null |
designerZhou
|
pytorch/android-demo-app
| 222
|
how 640*640 to 320*320
|
Input 640*640 model to 320*320 model. I changed the relevant parameters and the program flashed back. How do I change it to 320*320 input
|
https://github.com/pytorch/android-demo-app/issues/222
|
closed
|
[] | 2021-12-21T02:41:41Z
| 2021-12-21T05:58:05Z
| null |
mozeqiu
|
pytorch/TensorRT
| 779
|
❓ [Question] Failed to compile trtorch use pre cxx11 abi
|
## ❓ Question
I'm trying to build trtorch v0.2.0 with pre cxx11 abi
But I always get the error like below
INFO: Analyzed target //:libtrtorch (40 packages loaded, 2667 targets configured).
INFO: Found 1 target...
ERROR: /root/git_source/Torch-TensorRT-0.2.0/cpp/trtorchc/BUILD:10:10: Linking cpp/trtorchc/trtorchc failed: (Exit 1): gcc failed: error executing command /usr/bin/gcc @bazel-out/k8-opt/bin/cpp/trtorchc/trtorchc-2.params
Use --sandbox_debug to see verbose messages from the sandbox gcc failed: error executing command /usr/bin/gcc @bazel-out/k8-opt/bin/cpp/trtorchc/trtorchc-2.params
Use --sandbox_debug to see verbose messages from the sandbox
bazel-out/k8-opt/bin/cpp/trtorchc/_objs/trtorchc/main.o:main.cpp:function c10::Device::validate(): error: undefined reference to 'c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)'
bazel-out/k8-opt/bin/cpp/trtorchc/_objs/trtorchc/main.o:main.cpp:function c10::Device::validate(): error: undefined reference to 'c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)'
bazel-out/k8-opt/bin/cpp/trtorchc/_objs/trtorchc/main.o:main.cpp:function c10::IValue::toTuple() const &: error: undefined reference to 'c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)'
bazel-out/k8-opt/bin/cpp/trtorchc/_objs/trtorchc/main.o:main.cpp:function c10::IValue::toTensor() const &: error: undefined reference to 'c10::Error::Error(c10::SourceLocation, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >)'
bazel-out/k8-opt/bin/cpp/trtorchc/_objs/trtorchc/main.o:main.cpp:function torch::jit::Module::forward(std::vector<c10::IValue, std::allocator<c10::IValue> >): error: undefined reference to 'torch::jit::Object::find_method(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&) const'
bazel-out/k8-opt/bin/cpp/trtorchc/_objs/trtorchc/main.o:main.cpp:function torch::jit::Module::forward(std::vector<c10::IValue, std::allocator<c10::IValue> >): error: undefined reference to 'torch::jit::Method::operator()(std::vector<c10::IValue, std::allocator<c10::IValue> >, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, c10::IValue, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, c10::IValue> > > const&)'
bazel-out/k8-opt/bin/cpp/trtorchc/_objs/trtorchc/main.o:main.cpp:function main: error: undefined reference to 'torch::jit::load(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, c10::optional<c10::Device>, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > >&)'
bazel-out/k8-opt/bin/cpp/trtorchc/_objs/trtorchc/main.o:main.cpp:function main: error: undefined reference to 'torch::jit::Module::save(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::unordered_map<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, std::hash<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::equal_to<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > >, std::allocator<std::pair<std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > > > const&) const'
bazel-out/k8-opt/bin/cpp/api/_objs/trtorch/trtorch.o:trtorch.cpp:function trtorch::get_build_info[abi:cxx11](): error: undefined reference to 'at::show_config[abi:cxx11]()'
bazel-out/k8-opt/bin/core/_objs/core/compiler.o:compiler.cpp:function c10::ClassType::addOrCheckAttribute(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::shared_ptr<c10::Type>, bool, bool): error: undefined reference to 'c10::ClassType::addAttribute(std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, std::shared_ptr<c10::Type> const&, bool, bool)'
......
------------------------
|
https://github.com/pytorch/TensorRT/issues/779
|
closed
|
[
"question"
] | 2021-12-21T02:13:39Z
| 2021-12-21T03:03:08Z
| null |
Fans0014
|
pytorch/tensorpipe
| 420
|
[Question]How to detect pipe(obtained from ctx->connect()) is writable?
|
Hi,
when I get a pipe via `ctx->context(address)`, how do I know the pipe is ready for write or read? A return from `ctx->connect()` does not mean the connection has been built, right? If I call `pipe->write()` immediately, such write could fail as the underlying connection has not built yet.
|
https://github.com/pytorch/tensorpipe/issues/420
|
open
|
[] | 2021-12-19T02:14:39Z
| 2022-02-16T01:51:04Z
| null |
Rhett-Ying
|
pytorch/data
| 144
|
Multiprocessing with any DataPipe writing to local file
|
### 🐛 Describe the bug
We need to take extra care all DataPipe that would write to file system when DataLoader2 triggered multiprocessing. If the file name on the local file system is same across multiple processes, it would be a racing condition.
This is found when TorchText team is using `on_disk_cache` to cache file.
DataLoader needs to know such DataPipe must be sharded with multiprocessing or enforce it into single process.
As a workaround, users have to download the file to local file system to prevent writing within DataPipe.
### Versions
main branch
|
https://github.com/meta-pytorch/data/issues/144
|
closed
|
[
"bug",
"good first issue",
"help wanted",
"high priority"
] | 2021-12-18T03:40:43Z
| 2022-05-19T03:59:34Z
| 13
|
ejguan
|
pytorch/pytorch
| 70,099
|
Question: what is "Parameter indices"?
|
I meet the error. I know some variables which do not contribute to loss. How I can know these parameters' name? I don't know whether "Parameter indices" help me or not?
> Parameter indices which did not receive grad for rank 7: 1360 1361 1362 1363 1364 1365 1366 1367 1368 1369 1370 1371 1372 1373 1374 1375 1376 1377 1378 1379 1380
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @SciPioneer @H-Huang @mruberry @jbschlosser @walterddr @kshitij12345
|
https://github.com/pytorch/pytorch/issues/70099
|
open
|
[
"oncall: distributed",
"Stale"
] | 2021-12-17T09:34:29Z
| 2022-02-15T15:02:44Z
| null |
shoutOutYangJie
|
pytorch/TensorRT
| 776
|
could not support gelu?
|
I use this docker( nvcr.io/nvidia/pytorch:21.11-py3 ) you suggested to test torch-tensorrt, but can not trans pytorch model to torchscript model. It seems like gelu is not support, but I also use this docker (pytorch-20.12-py3) to trans pytorch model to torchscript model, it can work well.
File "/opt/conda/lib/python3.8/site-packages/torch/jit/_serialization.py", line 161, in load
cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files)
RuntimeError:
Arguments for call are not valid.
The following variants are available:
aten::gelu(Tensor self, bool approximate) -> (Tensor):
Argument approximate not provided.
aten::gelu.out(Tensor self, bool approximate, *, Tensor(a!) out) -> (Tensor(a!)):
Argument approximate not provided.
The original call is:
tools/pytorch2torchscript.py(123): pytorch2libtorch
tools/pytorch2torchscript.py(186): <module>
Serialized File "code/__torch__/torch/nn/modules/activation.py", line 27
def forward(self: __torch__.torch.nn.modules.activation.GELU,
argument_1: Tensor) -> Tensor:
return torch.gelu(argument_1)
~~~~~~~~~~ <--- HERE
|
https://github.com/pytorch/TensorRT/issues/776
|
closed
|
[
"question",
"No Activity"
] | 2021-12-17T08:38:37Z
| 2022-04-01T00:02:17Z
| null |
daeing
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.