
repo
stringclasses 147
values | number
int64 1
172k
| title
stringlengths 2
476
| body
stringlengths 0
5k
| url
stringlengths 39
70
| state
stringclasses 2
values | labels
listlengths 0
9
| created_at
timestamp[ns, tz=UTC]date 2017-01-18 18:50:08
2026-01-06 07:33:18
| updated_at
timestamp[ns, tz=UTC]date 2017-01-18 19:20:07
2026-01-06 08:03:39
| comments
int64 0
58
⌀ | user
stringlengths 2
28
|
|---|---|---|---|---|---|---|---|---|---|---|
pytorch/vision
| 4,445
|
How to use TenCrop and FiveCrop on video
|
Hi everyone,
I am wanting to use TenCrop and FiveCrop on video but I have no idea how to do this.
Can you tell me how to do it?
Sorry, I am new to this field.
Thank you very much!
|
https://github.com/pytorch/vision/issues/4445
|
open
|
[
"question",
"module: video"
] | 2021-09-18T16:08:03Z
| 2021-09-19T12:33:10Z
| null |
DungVo1507
|
huggingface/dataset-viewer
| 30
|
Use FastAPI instead of only Starlette?
|
It would allow to have doc, and surely a lot of other benefits
|
https://github.com/huggingface/dataset-viewer/issues/30
|
closed
|
[
"question"
] | 2021-09-17T14:45:40Z
| 2021-09-20T10:25:17Z
| null |
severo
|
pytorch/pytorch
| 65,199
|
How to register a Module as one custom OP when export to onnx
|
## ❓ How to register a Module as one custom OP when export to onnx
The custom modules may be split to multiple OPs when using `torch.onnx.export`. In many cases, we can manually optimize these OPs into a custom OP(with a custom node in onnx), and handle it by a plugin in TensorRT. Is there any way to register a Module as one custom OP when export to onnx?
cc @BowenBao @neginraoof
|
https://github.com/pytorch/pytorch/issues/65199
|
closed
|
[
"module: onnx"
] | 2021-09-17T06:01:28Z
| 2024-02-01T02:38:25Z
| null |
OYCN
|
pytorch/torchx
| 184
|
Update builtin components to use best practices + documentation
|
Before stable release we want to do some general cleanups on the current built in components.
- [ ] all components should default to docker images (no /tmp)
- [ ] all components should use `python -m` entrypoints to make it easier to support all environments by using python's resolution system
- [ ] update the component best practice documentation to indicate above
Slurm image handling will be revisited later to make it easier to deal with virtualenvs and the local paths.
|
https://github.com/meta-pytorch/torchx/issues/184
|
closed
|
[
"documentation",
"enhancement",
"module: components"
] | 2021-09-16T23:16:52Z
| 2021-09-21T20:59:19Z
| 0
|
d4l3k
|
pytorch/TensorRT
| 626
|
❓ [Question] How to install trtorchc?
|
## ❓ Question
<!-- Your question -->
How to install trtorchc?
## What you have already tried
I use Dockerfile.21.07 build the docker. I found the trtorchc can't be used.
So I run `bazel build //cpp/bin/trtorchc --cxxopt="-DNDEBUG` to build the trtorchc.
However, it doesn't work.
<!-- A clear and concise description of what you have already done. -->
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):
- CPU Architecture:
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:
- CUDA version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/626
|
closed
|
[
"question"
] | 2021-09-16T10:32:47Z
| 2021-09-16T15:54:00Z
| null |
shiyongming
|
pytorch/pytorch
| 65,132
|
How to reference a tensor variable from a superclass of `torch.Tensor`?
|
Consider I have the following code where I subclass `torch.Tensor`. I'd like to avoid using `self.t_` and instead access the tensor variable in the superclass. Though, when looking at the PyTorch code, I don't seem to identify how that can be done. Your help is appreciated.
```
class XLATensor(torch.Tensor):
def __init__(self, data, **kwargs):
self.t_ = torch.as_tensor(data, dtype=torch.float32, **kwargs)
```
This [`document`](https://docs.google.com/document/d/1u5kJ18HKnoJ-i8shymt__wRrnw-eYII3c-AHUlnky-s/edit?resourcekey=0-THFZXxHHehVBA-oBsLU0Jw#heading=h.9iwsbbqufptx) contains more details regarding my question.
CC @albanD, @wconstab, @ezyang
cc @bdhirsh
|
https://github.com/pytorch/pytorch/issues/65132
|
open
|
[
"triaged",
"module: xla"
] | 2021-09-16T07:31:05Z
| 2021-09-16T21:35:37Z
| null |
miladm
|
pytorch/pytorch
| 64,939
|
BC CI error message should link to some information about how to squash the warning
|
## 🚀 Feature
The BC CI error message says:
```
The PR is introducing backward incompatible changes to the operator library. Please contact PyTorch team to confirm whether this change is wanted or not.
```
I know the change is wanted, but I don't remember how to actually "add the change so that the BC mechanism stops complaining". This information can easily be found by searching the codebase or looking for similar PRs, but it would be nice if we just linked directly to a note or a wiki page or something so that we don't have to go searching around every time.
## Motivation
Save devs (old and new) some time when reading the message!
## Pitch
The error message should be improved with a "see this link for more details"
## Alternatives
Not sure
cc @ezyang @seemethere @malfet @lg20987 @pytorch/pytorch-dev-infra
|
https://github.com/pytorch/pytorch/issues/64939
|
open
|
[
"module: ci",
"triaged",
"better-engineering"
] | 2021-09-13T17:33:53Z
| 2021-09-13T17:38:17Z
| null |
zou3519
|
pytorch/pytorch
| 64,904
|
How to use python to implement _VF.lstm
|
## How to use python to implement _VF.lstm
Hello! When I want to modify the calculation formula of the LSTM,I found the calculation process in nn.LSTM is realized by _VF.lstm. I found the "_VF.lstm" is written by C++, and I can't find the RNN.cpp in my computer.
So I wanna implement _VF.lstm by using python, can u help me?
Looking forward to your reply! Thanks a lot!
|
https://github.com/pytorch/pytorch/issues/64904
|
closed
|
[] | 2021-09-13T06:41:39Z
| 2021-09-14T02:37:26Z
| null |
TimothyLiuu
|
pytorch/pytorch
| 64,793
|
How to get "finfo" in C++ torchlib like that in pytorch
|
I am using C++ torchlib, but I don't know what to do it in c++ like that in pytorch:
```python
min_real = torch.finfo(self.logits.dtype).min
# or
min_real = torch.finfo(self.logits.dtype).tiny
```
cc @yf225 @glaringlee
|
https://github.com/pytorch/pytorch/issues/64793
|
closed
|
[
"module: cpp",
"triaged"
] | 2021-09-10T01:37:53Z
| 2021-09-13T01:13:27Z
| null |
dbsxdbsx
|
huggingface/datasets
| 2,888
|
v1.11.1 release date
|
Hello, i need to use latest features in one of my packages but there have been no new datasets release since 2 months ago.
When do you plan to publush v1.11.1 release?
|
https://github.com/huggingface/datasets/issues/2888
|
closed
|
[
"question"
] | 2021-09-09T21:53:15Z
| 2021-09-12T20:18:35Z
| null |
fcakyon
|
pytorch/TensorRT
| 620
|
❓ [Question] Is it possible to install TRTorch with CUDA 11.1 support on aarch64?
|
# ❓ Question
is there a particular reason why there is no pre-built wheel file for the combination of CUDA11.1 + aarch64
# What you have already tried
I have tried to install wheel files for CUDA 10.2 aarch64 but it obviously didn't work because it tried to find the CUDA 10.2 libraries.
# Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.9.0
- CPU Architecture: 8.6
- OS (e.g., Linux): Linux
- How you installed PyTorch (conda, pip, libtorch, source): pip
- Build command you used (if compiling from source): pip install
- Are you using local sources or building from archives: building from archives
- Python version: 3.6
- CUDA version: 11.1
- GPU models and configuration: Nvida RTX 6000
- Any other relevant information: N/A
My question would be, is there a particular reason why there is no pre-built wheel file for the combination of CUDA11.1 + aarch64?
Thank you!
|
https://github.com/pytorch/TensorRT/issues/620
|
closed
|
[
"question",
"No Activity"
] | 2021-09-09T00:45:37Z
| 2021-12-20T00:01:58Z
| null |
lppllppl920
|
pytorch/text
| 1,386
|
how to make clear what torchtext._torchtext module do,when i import something from the module.
|
## 📚 Documentation
**Description**
yesterday,i learn Vectors and Vocab from torchtext 0.5. But today, i update it to torchtext0.10 by pip install --upgrade,and then, i found Vocab is changed.
Now, when you use the method 'torchtext.vocab.build_vocab_from_iterator' to create instance of Vocab, you will call the method 'torchtext._torchtext.Vocab'.
Then, i want to know clear what torchtext._torchtext module do, so i find the file named '_torchtext.pyd'. But it is unreadable by humans. Why torchtext write it to '.pyd' file? How to really know about it but not just invoke it?
Thanks.
|
https://github.com/pytorch/text/issues/1386
|
open
|
[] | 2021-09-05T07:41:13Z
| 2021-09-13T20:57:01Z
| null |
wn1652400018
|
pytorch/xla
| 3,114
|
How to aggregate the results running on multiple tpu cores
|
## ❓ Questions and Help
Hi, How can we aggregate the results or say combine all the predictions and use it further.
I understand this could be a issue addressed earlier, if yes please share some links related to this
```
def _run():
<model loading, training arguments and etc >
# using hugging face Trainer fn
trainer = Trainer(
model=model,
args=training_args,
train_dataset=data_train,
tokenizer=tokenizer,
eval_dataset=data_val,
compute_metrics=compute_metrics,
)
trainer.train()
results = trainer.evaluate()
return results
def _mp_fn(rank, flags):
results = _run()
FLAGS={}
xmp.spawn(_mp_fn, args=(FLAGS,), nprocs=8, start_method='fork')
```
|
https://github.com/pytorch/xla/issues/3114
|
closed
|
[] | 2021-09-03T05:13:35Z
| 2021-09-04T08:21:31Z
| null |
pradeepkr12
|
pytorch/serve
| 1,227
|
How to torch-model-archiver directory with its content?
|
I'm trying to generate .mar file which contain some extra files including a directory. I'm not sure how can I add that. Here is what I'm trying to archive:
```bash
my_model/
├── [4.0K] 1_Pooling
│ └── [ 190] config.json
├── [ 696] config.json
├── [ 122] config_sentence_transformers.json
├── [ 168] handler.py
├── [ 276] model_setup_config.json
├── [ 229] modules.json
├── [ 87M] pytorch_model.bin
├── [ 53] sentence_bert_config.json
├── [ 112] special_tokens_map.json
├── [455K] tokenizer.json
├── [ 591] tokenizer_config.json
└── [226K] vocab.txt
```
Here is my `torch-model-archiver` command which is replacing `my_model/config.json` with `my_model/1_Pooling/config.json` in model.mar file.
```bash
$ torch-model-archiver \
--model-name my_model \
--version 1.0 \
--serialized-file ../pytorch_model.bin \
--handler ../handler.py \
--extra-files "../config.json,../config_sentence_transformers.json,../modules.json,../sentence_bert_config.json,../special_tokens_map.json,../tokenizer.json,../tokenizer_config.json,../vocab.txt,../1_Pooling/config.json,../model_setup_config.json"
```
How can I keep the `1_Pooling/` directory as it is in .mar file with all its content?
|
https://github.com/pytorch/serve/issues/1227
|
closed
|
[
"triaged_wait"
] | 2021-09-01T19:44:08Z
| 2021-09-01T21:06:36Z
| null |
spate141
|
huggingface/dataset-viewer
| 18
|
CI: how to acknowledge a "safety" warning?
|
We use `safety` to check vulnerabilities in the dependencies. But in the case below, `tensorflow` is marked as insecure while the last published version on pipy is still 2.6.0. What to do in this case?
```
+==============================================================================+
| |
| /$$$$$$ /$$ |
| /$$__ $$ | $$ |
| /$$$$$$$ /$$$$$$ | $$ \__//$$$$$$ /$$$$$$ /$$ /$$ |
| /$$_____/ |____ $$| $$$$ /$$__ $$|_ $$_/ | $$ | $$ |
| | $$$$$$ /$$$$$$$| $$_/ | $$$$$$$$ | $$ | $$ | $$ |
| \____ $$ /$$__ $$| $$ | $$_____/ | $$ /$$| $$ | $$ |
| /$$$$$$$/| $$$$$$$| $$ | $$$$$$$ | $$$$/| $$$$$$$ |
| |_______/ \_______/|__/ \_______/ \___/ \____ $$ |
| /$$ | $$ |
| | $$$$$$/ |
| by pyup.io \______/ |
| |
+==============================================================================+
| REPORT |
| checked 137 packages, using free DB (updated once a month) |
+============================+===========+==========================+==========+
| package | installed | affected | ID |
+============================+===========+==========================+==========+
| tensorflow | 2.6.0 | ==2.6.0 | 41161 |
+==============================================================================+
```
|
https://github.com/huggingface/dataset-viewer/issues/18
|
closed
|
[
"question"
] | 2021-09-01T07:20:45Z
| 2021-09-15T11:58:56Z
| null |
severo
|
pytorch/pytorch
| 64,334
|
How to add nan value judgment for variable t0_1 in fused_clamp kernel generated by torch/csrc/jit/tensorexpr/cuda_codegen.cpp.
|
For this python program:
```import torch
torch._C._jit_set_profiling_executor(True)
torch._C._jit_set_profiling_mode(True)
torch._C._jit_override_can_fuse_on_cpu(True)
torch._C._jit_override_can_fuse_on_gpu(True)
torch._C._debug_set_fusion_group_inlining(False)
torch._C._jit_set_texpr_fuser_enabled(True)
def func2(a, b):
return torch.clamp(a + b, min=0, max=2)
device = 'cuda'
a = torch.randn(4, 4, dtype=torch.float, device=device, requires_grad=True)
nan = torch.tensor(float('nan'), dtype=torch.float, device=device)
scripted_fn = torch.jit.script(func2)
script_outputs = scripted_fn(a,nan)
opt_script_outputs = scripted_fn(a,nan)
print(script_outputs.detach().cpu())
print(opt_script_outputs.detach().cpu())
```
this program will call 2 cuda kernel:
clamp_kernel_cuda is show as follow,
```
void clamp_kernel_cuda(TensorIterator& iter, Scalar min_value, Scalar max_value) {
AT_DISPATCH_ALL_TYPES_AND2(kHalf, kBFloat16, iter.dtype(), "clamp_cuda", [&]() {
auto lower = min_value.to<scalar_t>();
auto upper = max_value.to<scalar_t>();
gpu_kernel(iter, [=]GPU_LAMBDA(scalar_t v) -> scalar_t {
// Propagate nan, which doesn't propagate automatically for ROCm
if (_isnan(v)) {
return v;
} else {
return ::min(::max(v, lower), upper);
}
});
});
}
```
and jit codegen kernel is show as follow,
```
extern "C" __global__
void fused_clamp(float* t0, float* aten_clamp)
{
if (512 * blockIdx.x + threadIdx.x<16 ? 1 : 0) {
float t0_1 = t0[512 * blockIdx.x + threadIdx.x];
aten_clamp[512 * blockIdx.x + threadIdx.x] = (t0_1<0.f ? 0.f : t0_1)>2.f ? 2.f : (t0_1<0.f ? 0.f : t0_1);
}
}
}
```
My question is why not to add nan value judgment for variable t0_1, expect generated kernel is show as follows,
```
extern "C" __global__
void fused_clamp(float* t0, float* aten_clamp)
{
if (512 * blockIdx.x + threadIdx.x<16 ? 1 : 0) {
float t0_1 = t0[512 * blockIdx.x + threadIdx.x];
aten_clamp[512 * blockIdx.x + threadIdx.x] = isnan(t0_1) ? t0_1 : ((t0_1<0.f ? 0.f : t0_1)>2.f ? 2.f : (t0_1<0.f ? 0.f : t0_1));
}
}
}
```
For AMD device(ROCM), if not nan value judgment, fused_clamp kernel will return 0 without nan. If we want to generate fused_clamp kernel as above, how to modify code in torch/csrc/jit/tensorexpr/kernel.cpp:979,
```
```
|
https://github.com/pytorch/pytorch/issues/64334
|
open
|
[
"oncall: jit"
] | 2021-09-01T02:35:39Z
| 2021-09-01T02:53:24Z
| null |
HangJie720
|
pytorch/functorch
| 106
|
how to install torch>=1.10.0.dev
|
when I run this command
pip install --user "git+https://github.com/facebookresearch/functorch.git"
ERROR: Could not find a version that satisfies the requirement torch>=1.10.0.dev
|
https://github.com/pytorch/functorch/issues/106
|
open
|
[] | 2021-08-31T09:28:39Z
| 2021-11-05T15:45:05Z
| null |
agdkyang
|
pytorch/pytorch
| 64,247
|
How to optimize jit-script model performance (backend device is gpu)
|
I have lots of script models, Now I want to optimize their performance, the bacnkend is gpu && project is written in c++ api(torch::jit::load).
Does there any ways to do this optimize?
Recently, I find that pytorch support cuda-graph now, maybe this should be a way to optimize performance.
But there are few documents about how to use this feature in c++. Can you give me some examples about how to use cuda-graph in c++ api with script model?
Thanks very much! :)
|
https://github.com/pytorch/pytorch/issues/64247
|
open
|
[
"oncall: jit"
] | 2021-08-31T05:31:44Z
| 2021-08-31T05:31:46Z
| null |
fwz-fpga
|
pytorch/pytorch
| 64,206
|
Document how to generate Pybind bindings for C++ Autograd
|
## 🚀 Feature
https://pytorch.org/tutorials/advanced/cpp_autograd.html provides a good example on how to define your own function with a forward and backward pass, along with registering it with the autograd system. However, it lacks any information on how to actually link this module to use in Python / Pytorch / Pybind. There is this one example that shows it in a hacky way (https://pytorch.org/tutorials/advanced/cpp_extension.html), but I want something I can include directly in Pybind.
Eg. something like this which doesnt work
```
py::class_<LinearFunction, std::shared_ptr<LinearFunction>>(
m, "LinearFunction")
.def(py::init<>())
.def("forward", &LinearFunction::forward)
.def("backward", &LinearFunction::backward);
```
cc @yf225 @glaringlee
|
https://github.com/pytorch/pytorch/issues/64206
|
open
|
[
"module: cpp",
"triaged"
] | 2021-08-30T18:12:12Z
| 2021-08-31T14:20:23Z
| null |
yaadhavraajagility
|
huggingface/transformers
| 13,331
|
bert:What is the tf version corresponding to tensformers?
|
I use python3.7, tf2.4.0, cuda11.1 and cudnn 8.0.4 to run bert-base-un and report an error
- albert, bert, xlm: @LysandreJik
- tensorflow: @Rocketkn
|
https://github.com/huggingface/transformers/issues/13331
|
closed
|
[] | 2021-08-30T11:42:36Z
| 2021-08-30T15:46:16Z
| null |
xmcs111
|
pytorch/tutorials
| 1,662
|
seq2seq with character encoding
|
hi, i am hoping to build a seq2seq model with attention with character level encoding. idea is to build a model which can predict a correct name by handling all sort of spelling mistakes (qwerty keyboard error, double typing, omitting word etc.) . my test data will few example of mistyped words mapping to correct word. i am hoping i can mostly follow this https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html and just change the input and output tensors to contain the character tensors..similar to a tutorial which predicts country by looking at last name. ( i think first one in nlp series)..does this approach make sense? is there any other thing i need to consider or better model to consider.
cc @pytorch/team-text-core @Nayef211
|
https://github.com/pytorch/tutorials/issues/1662
|
closed
|
[
"question",
"Text",
"module: torchtext"
] | 2021-08-30T04:10:01Z
| 2023-03-06T23:54:02Z
| null |
manish-shukla01
|
pytorch/vision
| 4,332
|
Customize the number of input_channels in MobileNetv3_Large
|
I would like to know how to customize the MobileNetV3_Large torchvision model to accept single-channel inputs with number of classes = 2.
As mentioned in some of the PyTorch discussion forums, I have tried
`model_ft.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)`
which works for ResNet models but not MobileNetV3.
Also tried,
`model.input_channels=1`
I keep getting the error
`Given groups=1, weight of size [16, 3, 3, 3], expected input[12, 1, 512, 512] to have 3 channels, but got 1 channels instead`
Please provide suggestions for customizing the MobileNet model to accept single channel input, as is possible in the case of ResNet. Repeating my input tensor to have 3 channels is not a solution I would be interested in.
|
https://github.com/pytorch/vision/issues/4332
|
closed
|
[
"question"
] | 2021-08-29T10:48:29Z
| 2021-08-31T09:41:23Z
| null |
ananda1996ai
|
pytorch/pytorch
| 64,094
|
Document how to disable python tests on CI through issues
|
## 📚 Documentation
We should document the use of issues to disable tests in a public wiki.
cc @ezyang @seemethere @malfet @walterddr @lg20987 @pytorch/pytorch-dev-infra
|
https://github.com/pytorch/pytorch/issues/64094
|
closed
|
[
"module: ci",
"triaged",
"better-engineering",
"actionable"
] | 2021-08-27T14:36:39Z
| 2021-10-11T21:54:25Z
| null |
janeyx99
|
pytorch/hub
| 222
|
torch.hub shouldn't assume model dependencies have __spec__ defined
|
**Problem**
I'm using torch.hub to load a model that has the `transformers` library as a dependency, however, the last few versions of `transformes` haven't had `__spec__` defined. Currently, this gives an error with torch.hub when trying to load the model and checking that the dependencies exist with `importlib.util.find_spec(name)` inside `_check_module_exists()` ([source code](https://github.com/pytorch/pytorch/blob/b0396e39f41da9f61c61ed8758b5e9505a370ebc/torch/hub.py#L198)).
**Solution**
Don't check for `__spec__` when checking that a module exists.
|
https://github.com/pytorch/hub/issues/222
|
closed
|
[
"question"
] | 2021-08-27T13:59:40Z
| 2021-08-27T18:03:24Z
| null |
laurahanu
|
pytorch/tutorials
| 1,660
|
Visualizing the results from trained model
|
I wanted to know how to test any images on the pre-trained model from this tutorial : https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html#putting-everything-together
1) So given i maybe just have an image, how do i feed it to the model?
2) How exactly did you arrive to these results? (image shown below)

|
https://github.com/pytorch/tutorials/issues/1660
|
closed
|
[
"question",
"torchvision"
] | 2021-08-26T21:04:24Z
| 2023-02-23T22:48:10Z
| null |
jspsiy
|
pytorch/serve
| 1,217
|
How to cache inferences with torchserve
|
Reference architecture showcasing how to cache inferences from torchserve
So potentially the `inference` handler would reach from some cloud cache or KV store
The benefit of this is it'd dramatically reduce latency for common queries
Probably a good level 3-4 bootcamp task for a specific kind of KV store like Redis or specific cloud cache in AWS.
|
https://github.com/pytorch/serve/issues/1217
|
closed
|
[
"good first issue"
] | 2021-08-26T18:00:51Z
| 2021-10-07T04:36:17Z
| null |
msaroufim
|
huggingface/dataset-viewer
| 15
|
Add an endpoint to get the dataset card?
|
See https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/hf_api.py#L427, `full` argument
The dataset card is the README.md.
|
https://github.com/huggingface/dataset-viewer/issues/15
|
closed
|
[
"question"
] | 2021-08-26T13:43:29Z
| 2022-09-16T20:15:52Z
| null |
severo
|
huggingface/dataset-viewer
| 12
|
Install the datasets that require manual download
|
Some datasets require a manual download (https://huggingface.co/datasets/arxiv_dataset, for example). We might manually download them on the server, so that the backend returns the rows, instead of an error.
|
https://github.com/huggingface/dataset-viewer/issues/12
|
closed
|
[
"question"
] | 2021-08-25T16:30:11Z
| 2022-06-17T11:47:18Z
| null |
severo
|
pytorch/vision
| 4,312
|
Hidden torch.flatten block in ResNet module
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
This bug arise when last 2 layers (avg pool and fc) are changed to nn.Identity
## To Reproduce
Steps to reproduce the behavior:
import torch
import torch.nn as nn
import torchvision
resnet = torchvision.models.resnet18()
resnet.avgpool = nn.Identity()
resnet.fc = nn.Identity()
img = torch.randn([1,3,256,256])
resnet(img).shape
**Result:** torch.Size([1, 32768])
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
<!-- A clear and concise description of what you expected to happen. -->
**Expected result:** torch.Size([1, 8, 8, 512])
## Additional context
<!-- Add any other context about the problem here. -->
https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
line 243 to delete
|
https://github.com/pytorch/vision/issues/4312
|
closed
|
[
"question"
] | 2021-08-25T13:09:31Z
| 2021-08-25T13:18:34Z
| null |
1paragraph
|
huggingface/dataset-viewer
| 10
|
Use /info as the source for configs and splits?
|
It's a refactor. As the dataset info contains the configs and splits, maybe the code can be factorized. Before doing it: review the errors for /info, /configs, and /splits (https://observablehq.com/@huggingface/quality-assessment-of-datasets-loading) and ensure we will not increase the number of erroneous datasets.
|
https://github.com/huggingface/dataset-viewer/issues/10
|
closed
|
[
"question"
] | 2021-08-25T09:43:51Z
| 2021-09-01T07:08:25Z
| null |
severo
|
pytorch/TensorRT
| 597
|
❓ [Question] request a converter: aten::lstm
|
ERROR: [TRTorch] - Requested converter for aten::lstm, but no such converter was found
Thanks
|
https://github.com/pytorch/TensorRT/issues/597
|
closed
|
[
"question",
"No Activity"
] | 2021-08-23T12:38:05Z
| 2021-12-02T00:01:46Z
| null |
gaosanyuan
|
pytorch/TensorRT
| 596
|
❓ [Question] module 'trtorch' has no attribute 'Input'
|
Why the installed trtorch has no attribute 'Input'? Thanks
trtorch version: 0.3.0
|
https://github.com/pytorch/TensorRT/issues/596
|
closed
|
[
"question"
] | 2021-08-23T12:17:20Z
| 2021-08-23T16:32:26Z
| null |
gaosanyuan
|
pytorch/TensorRT
| 586
|
❓ [Question] Not faster vs torch::jit
|
## ❓ Question
I run my model used TrTorch and torch::jit both on fp16 with C++ API, but Trtorch is not faster than JIT.
What can I do to get the reason?
Some information may be helpful.
1. I used two plugins to just call the libtorch function (inverse and grid_smapler).
2. I fix some bugs by change the pytorch model code discript at #585 #584
3. I compile trtorch model and run it all with C++ API.
4. the compile code is :
```
std::cout << "Load ts detector model ..." << std::endl;
torch::jit::Module ts_detector_model;
try{
// Deserialize the ScriptModule from a file using torch::jit::load().
ts_detector_model = torch::jit::load(TS_DETECTOR_PATH);
}
catch (const c10::Error& e){
std::cerr << "Error loading the model \n";
return -1;
}
// convert trt detector
std::cout << "Convert trt detector model ..." << std::endl;
ts_detector_model.to(at::kCUDA);
ts_detector_model.eval();
std::vector<trtorch::CompileSpec::Input> inputs_d = {
trtorch::CompileSpec::Input(std::vector<int64_t>({1, 3, 256, 256}), trtorch::CompileSpec::DataType::kHalf)};
auto info_d = trtorch::CompileSpec(inputs_d);
info_d.enabled_precisions.insert(trtorch::CompileSpec::DataType::kHalf);
auto trt_detector_model = trtorch::CompileGraph(ts_detector_model, info_d);
// generator complied like above
......
```
the runtim code :
```
torch::jit::Module trt_detector_model;
try{
// Deserialize the ScriptModule from a file using torch::jit::load().
trt_detector_model = torch::jit::load(TRT_DETECTOR_PATH);
}
catch (const c10::Error& e){
std::cerr << "error loading the model \n";
return -1;
}
trt_detector_model.to(at::kCUDA);
trt_detector_model.eval();
torch::jit::Module trt_generator_model;
try{
// Deserialize the ScriptModule from a file using torch::jit::load().
trt_generator_model = torch::jit::load(TRT_GENERATOR_PATH);
}
catch (const c10::Error& e){
std::cerr << "error loading the model \n";
return -1;
}
trt_generator_model.to(at::kCUDA);
trt_generator_model.eval();
std::cout << "Run trt model ... " << std::endl;
auto in0 = torch::ones({1, 3, 256, 256}, {torch::kCUDA}).to(torch::kFloat16);
std::cout << "Run detector ... " << std::endl;
auto out0_ = trt_detector_model.forward({in0});
auto out0 = out0_.toTuple()->elements()[1].toTensor();
std::cout << "====\tdetector out mean and std\t====" << std::endl;
std::cout << at::mean(out0) << "\n" << at::std(out0) << std::endl;
auto in1 = torch::ones({1, 3, 256, 256}, {torch::kCUDA}).to(torch::kFloat16);
auto in2 = torch::ones({1, 10, 2}, {torch::kCUDA}).to(torch::kFloat16);
auto in3 = torch::ones({1, 10, 2}, {torch::kCUDA}).to(torch::kFloat16);
auto in4 = torch::ones({1, 10, 2, 2}, {torch::kCUDA}).to(torch::kFloat16);
std::cout << "Run generator ... " << std::endl;
auto out1 = trt_generator_model.forward({in1, in2, out0.to(torch::kFloat16), in3, in4}).toTensor();
std::cout << "====\tgenerator out mean and std\t====" << std::endl;
```
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
> I build the Trtorch recently(21.8.19) use the master branch.
- TRTorch Version (8.0.1.6):
- PyTorch Version (libtorch 1.9.0):
- OS (Ubuntu):
- How you installed PyTorch (`libtorch):
- Build command you used (bazel build //:libtrtorch --compilation_mode opt):
- Are you using local sources or building from archives:
- Python version: 3.8
- CUDA version: 11.1
- GPU models and configuration: GTX3070
|
https://github.com/pytorch/TensorRT/issues/586
|
closed
|
[
"question",
"No Activity"
] | 2021-08-19T13:06:37Z
| 2022-03-10T00:02:16Z
| null |
JuncFang-git
|
pytorch/vision
| 4,292
|
about train fcn questions.
|
thanks for your great work!
I have read https://github.com/pytorch/vision/blob/master/references/segmentation/train.py script. And there are some questions.
1. why use aux_classifier for fcn, are there any references ?
2. why is the learning rate of aux_classifier ten times that of base lr?https://github.com/pytorch/vision/blob/master/references/segmentation/train.py#L131
3. If I want to fine-train fcn, how to set the appropriate learning rate? I use default learning rate 0.01 to train PASCAL VOC2012 with res50_rcn, the result is bad(first epoch, mean IOU=10.1). If not train model, directly evaluate, mean IoU=69.
cc @datumbox
|
https://github.com/pytorch/vision/issues/4292
|
closed
|
[
"question",
"topic: object detection"
] | 2021-08-19T08:51:34Z
| 2021-08-19T11:50:05Z
| null |
WZMIAOMIAO
|
pytorch/xla
| 3,090
|
How to concatenate all the predicted labels in XLA?
|
## ❓ Questions and Help
Hi does anyone knows how to get all predicted labels from all 8 cores of XLA and concatenate them together?
Say I have a model:
`outputs = model(ids, mask, token_type_ids)`
`_, pred_label = torch.max(outputs.data, dim = 1)`
If I do
`all_predictions_np = pred_label.cpu().detach().numpy().tolist()`
apparently, this only sends the result to CPU from TPU core:0. How can I get all 8 cores and concatenate them together in the same list? I am not sure if `xm.all_gather() ` is used in this case?
|
https://github.com/pytorch/xla/issues/3090
|
closed
|
[] | 2021-08-19T01:13:39Z
| 2021-08-19T20:51:58Z
| null |
gabrielwong1991
|
pytorch/serve
| 1,203
|
How to add a custom Handler?
|
## 📚 Documentation
How to add custom handlers python files friendly and automatic?
By now, I understand that is necessary to modify `pytorch/serve` source code. is that correct?
In my case, I need a custom handler with
input: numpy array or json or list of numbers
output: numpy array or json or list of numbers
I just want to do the inference in `pytorch/serve` because I have complex preprocess and postprocess in other microservice
|
https://github.com/pytorch/serve/issues/1203
|
closed
|
[] | 2021-08-18T01:43:40Z
| 2021-08-18T20:01:54Z
| null |
pablodz
|
pytorch/pytorch
| 63,395
|
How to efficiently (without looping) get data from tensor predicted by a torchscript in C++?
|
I am calling a torchscript (neural network serialized from Python) from a C++ program:
```
// define inputs
int batch = 3; // batch size
int n_inp = 2; // number of inputs
double I[batch][n_inp] = {{1.0, 1.0}, {2.0, 3.0}, {4.0, 5.0}}; // some random input
std::cout << "inputs" "\n"; // print inputs
for (int i = 0; i < batch; ++i)
{
std::cout << "\n";
for (int j = 0; j < n_inp; ++j)
{
std::cout << I[i][j] << "\n";
}
}
// prepare inputs for feeding to neural network
std::vector<torch::jit::IValue> inputs;
inputs.push_back(torch::from_blob(I, {batch, n_inp}, at::kDouble));
// deserialize and load scriptmodule
torch::jit::script::Module module;
module = torch::jit::load("Net-0.pt");
// do forward pass
auto outputs = module.forward(inputs).toTensor();
```
Usually, to get data from the outputs, the following (element-wise) operation is performed:
```
// get data from outputs
std::cout << "outputs" << "\n";
int n_out = 1;
double outputs_data[batch][n_out];
for (int i = 0; i < batch; i++)
{
for (int j = 0; j < n_out; j++)
{
outputs_data[i][j] = outputs[i][j].item<double>();
std::cout << outputs_data[i][j] << "\n";
}
}
```
However, such looping using .item is highly inefficient (in the actual code I will have millions of points predicted at each time step). I want to get data from outputs directly (without looping over elements). I tried:
```
int n_out = 1;
double outputs_data[batch][n_out];
outputs_data = outputs.data_ptr<double>();
```
However, it is giving the error:
```
error: incompatible types in assignment of ‘double*’ to ‘double [batch][n_out]’
outputs_data = outputs.data_ptr<double>();
^
```
Note, that type of outputs_data is fixed to double and cannot be changed.
cc @gmagogsfm
|
https://github.com/pytorch/pytorch/issues/63395
|
open
|
[
"oncall: jit"
] | 2021-08-17T12:42:58Z
| 2021-11-28T03:54:22Z
| null |
aiskhak
|
pytorch/hub
| 218
|
DeeplabV3-Resnet101. Where is the mIOU calculation and postprocessing code?
|
The following link mentions mIOU = 67.4
https://pytorch.org/hub/pytorch_vision_deeplabv3_resnet101/
Is there any codebase where we can refer the evaluation and postprocessing code?
|
https://github.com/pytorch/hub/issues/218
|
closed
|
[] | 2021-08-16T11:32:49Z
| 2021-10-18T11:42:40Z
| null |
ashg1910
|
pytorch/TensorRT
| 580
|
❓ [Question] How to convert nvinfer1::ITensor into at::tensor?
|
## ❓ Question
Hi,
How to convert nvinfer1::ITensor into at::tensor? Like #146
## What you have already tried
I want to do some operations use libtorch on the nvinfer1::ITensor. So, can I convert nvinfer1::ITensor into at::tensor? Or I must write a custom converter with the libtorch function?
@xsacha @aaronp24 @itsliupeng @lukeyeager @elezar
|
https://github.com/pytorch/TensorRT/issues/580
|
closed
|
[
"question"
] | 2021-08-16T09:54:00Z
| 2021-08-18T03:02:03Z
| null |
JuncFang-git
|
pytorch/pytorch
| 63,304
|
How to build a release version libtorch1.8.1 on windows
|
## Issue description
I am doing some work with libtorch on Windows 10 recently. I want to build the libtorch library since I have addedd some new features. The build work was done successfully on develop environment. However, when I copy the exe(including dependent DLLs) to another PC(running env, mentioned below), it could not run normally. I have also built the corresponding python package and it could run normally on the develop environment. Also, it shows that the official release version of 1.8.1 has more libs than mine. It seems that the official version has more torch_cuda*.dll than mine and their size is relatively larger than mine.
I just want to know how to configure the env and can build nearly the same as the official one.
Self-build release version
2021/08/12 11:22 242,176 asmjit.dll
2021/08/10 21:06 92,664 asmjit.lib
2021/08/12 11:22 417,792 c10.dll
2021/08/10 21:09 303,982 c10.lib
2021/08/12 14:02 10,382,510 c10d.lib
2021/08/12 11:25 246,784 c10_cuda.dll
2021/08/10 21:09 27,942 c10_cuda.lib
2021/08/12 14:03 20,131,328 caffe2_detectron_ops_gpu.dll
2021/08/10 22:22 34,660 caffe2_detectron_ops_gpu.lib
2021/08/12 14:02 70,144 caffe2_module_test_dynamic.dll
2021/08/10 22:21 24,130 caffe2_module_test_dynamic.lib
2021/08/12 11:25 15,872 caffe2_nvrtc.dll
2021/08/10 21:09 1,850 caffe2_nvrtc.lib
2021/08/12 11:21 18,316 clog.lib
2021/08/12 11:21 118,076 cpuinfo.lib
2021/08/12 11:25 323,147,004 dnnl.lib
2021/08/12 11:22 3,282,432 fbgemm.dll
2021/08/10 21:06 1,156,374 fbgemm.lib
2021/08/12 11:22 15,456,424 gloo.lib
2021/08/12 11:22 36,464,038 gloo_cuda.lib
2021/08/12 14:00 135,168 jitbackend_test.dll
2021/08/10 22:19 21,206 jitbackend_test.lib
2015/01/22 09:23 1,146,272 libiomp5md.dll
2021/08/12 11:20 5,220,954 libprotobuf-lite.lib
2021/08/12 11:21 36,811,506 libprotobuf.lib
2021/08/12 11:21 38,708,546 libprotoc.lib
2021/08/12 11:25 323,147,004 mkldnn.lib
2021/08/12 11:21 142,874 pthreadpool.lib
2021/08/12 13:59 9,728 torch.dll
2021/08/10 22:18 1,832 torch.lib
2021/08/12 14:00 339,456 torchbind_test.dll
2021/08/10 22:19 21,154 torchbind_test.lib
2021/08/12 12:07 201,914,368 torch_cpu.dll
2021/08/10 21:41 17,095,310 torch_cpu.lib
2021/08/12 13:59 149,539,840 torch_cuda.dll
2021/08/12 13:58 3,024,940 torch_cuda.lib
2021/08/12 11:22 9,728 torch_global_deps.dll
2020/09/18 19:02 195,072 uv.dll
2021/08/12 11:21 5,984,034 XNNPACK.lib
Official release version
2021/03/24 11:07 241,664 asmjit.dll
2021/03/24 11:07 92,664 asmjit.lib
2021/03/24 11:08 418,304 c10.dll
2021/03/24 11:08 303,982 c10.lib
2021/03/24 12:44 10,209,446 c10d.lib
2021/03/24 11:08 249,344 c10_cuda.dll
2021/03/24 11:08 27,942 c10_cuda.lib
2021/03/24 12:47 20,971,008 caffe2_detectron_ops_gpu.dll
2021/03/24 12:47 34,660 caffe2_detectron_ops_gpu.lib
2021/03/24 12:45 69,632 caffe2_module_test_dynamic.dll
2021/03/24 12:45 24,130 caffe2_module_test_dynamic.lib
2021/03/24 11:08 15,872 caffe2_nvrtc.dll
2021/03/24 11:08 1,850 caffe2_nvrtc.lib
2021/03/24 11:07 18,300 clog.lib
2021/03/24 11:07 117,714 cpuinfo.lib
2020/09/16 11:17 113,329,664 cublas64_11.dll
2020/09/16 11:17 214,235,648 cublasLt64_11.dll
2020/09/16 13:05 431,616 cudart64_110.dll
2020/11/01 04:08 222,720 cudnn64_8.dll
2020/11/01 04:52 146,511,360 cudnn_adv_infer64_8.dll
2020/11/01 05:06 95,296,512 cudnn_adv_train64_8.dll
2020/11/01 05:06 705,361,408 cudnn_cnn_infer64_8.dll
2020/11/01 05:16 81,943,552 cudnn_cnn_train64_8.dll
2020/11/01 04:15 323,019,776 cudnn_ops_infer64_8.dll
2020/11/01 04:28 37,118,464 cudnn_ops_train64_8.dll
2020/09/16 13:05 234,427,904 cufft64_10.dll
2020/09/16 13:05 258,560 cufftw64_10.dll
2020/09/16 13:05 55,511,040 curand64_10.dll
2020/09/16 13:05 681,608,704 cusolver64_11.dll
2020/09/16 13:05 388,617,216 cusolverMg64_11.dll
2020/09/16 13:05 233,562,624 cusparse64_11.dll
2021/03/24 11:08 319,083,802 dnnl.lib
2021/03/24 11:07 3,280,384 fbgemm.dll
2021/03/24 11:07 1,156,374 fbgemm.lib
2021/03/24 11:08 342,016 fbjni.dll
2021/03/24 11:08 1,191,002 fbjni.lib
2021/03/24 11:07 15,140,756 gloo.lib
2021/03/24 11:07 31,536,174 gloo_cuda.lib
2020/06/23 14:03 1,961,328 libiomp5md.dll
2020/06/23 14:03 110,448 libiompstubs5md.dll
2021/03
|
https://github.com/pytorch/pytorch/issues/63304
|
closed
|
[
"module: build",
"module: windows",
"module: docs",
"module: cpp",
"triaged"
] | 2021-08-16T07:30:26Z
| 2023-12-19T06:56:17Z
| null |
RocskyLu
|
pytorch/TensorRT
| 579
|
❓ memcpy d2d occupies a lot time of inference (resnet50 model after trtorch)
|
## ❓ Question
<!-- Your question -->
## What you have already tried
I use trtorch to optimize resnet50 model on the IMAGENET as follows
<img width="998" alt="截屏2021-08-16 10 34 32" src="https://user-images.githubusercontent.com/46394627/129503893-4d252f02-07d4-448a-ac9c-7f64f15aa30a.png">
Unfortunately, i found that the memcpy d2d occupies a lot time of inference when i'm testing the performance of optimized model
<img width="1420" alt="截屏2021-08-16 10 23 43" src="https://user-images.githubusercontent.com/46394627/129504130-66f60eae-d9eb-4384-bcbd-53c6e83f4d0e.png">
In the above figure, we can observe that the memcpy d2d occurs at the beginning of the inference and result in about 10% time consumption. I haven't found the reason yet. I did not have this phenomenon when I used tensorrt engine.
<!-- A clear and concise description of what you have already done. -->
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version (e.g., 1.6.0):
- OS (e.g., Linux):linux
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):pip
- Python version:3.6.0
- CUDA version:10.0
- GPU models and configuration:T4*1 16G
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/579
|
closed
|
[
"question"
] | 2021-08-16T02:51:22Z
| 2021-08-19T12:21:32Z
| null |
zhang-xh95
|
pytorch/vision
| 4,276
|
I want to convert model resnet to onnx, how to do?
|
## 📚 Documentation
<!-- A clear and concise description of what content in https://pytorch.org/docs is an issue. If this has to do with the general https://pytorch.org website, please file an issue at https://github.com/pytorch/pytorch.github.io/issues/new/choose instead. If this has to do with https://pytorch.org/tutorials, please file an issue at https://github.com/pytorch/tutorials/issues/new -->
|
https://github.com/pytorch/vision/issues/4276
|
closed
|
[] | 2021-08-14T04:17:42Z
| 2021-08-16T08:41:46Z
| null |
xinsuinizhuan
|
pytorch/TensorRT
| 576
|
❓ [Question] How can i write a converter just use a Libtorch function?
|
## ❓ Question
<!-- Your question -->
<!-- A clear and concise description of what you have already done. -->
Hi,
I am trying to write some converter like "torch.inverse", "F.grid_sample", but it's really difficult for me. So, I want to skip that using just some libtorch function.
For example, I want to build a converter just use torch::inverse.

But I got some errors like this :

So, how can i write a converter just use a Libtorch function?
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version (1.8.1):
- OS (ubuntu18.04):
- How you installed PyTorch ( `pip`, `libtorch`):
- Build command you used (trtorchv0.3.0 form release):
- Python version: 3.8
- CUDA version: 11.1
- GPU models and configuration:GTX3070
|
https://github.com/pytorch/TensorRT/issues/576
|
closed
|
[
"question"
] | 2021-08-13T02:18:42Z
| 2021-08-19T11:49:02Z
| null |
JuncFang-git
|
pytorch/pytorch
| 63,182
|
Improve doc about docker images and how to run them locally
|
Updated the wiki page https://github.com/pytorch/pytorch/wiki/Docker-image-build-on-CircleCI
- [x] Document the new ecr_gc job
- [x] How to get images from AWS ECR
- [x] Document how to use the docker image and run `build` and `test` locally
|
https://github.com/pytorch/pytorch/issues/63182
|
closed
|
[
"module: docs",
"triaged",
"hackathon"
] | 2021-08-12T20:58:43Z
| 2021-08-13T00:53:01Z
| null |
zhouzhuojie
|
pytorch/torchx
| 132
|
Add Torchx Validate command
|
## Description
Torchx allows users to develop their own components. Torchx component is defined as a python function with several restrictions as described in https://pytorch.org/torchx/latest/quickstart.html#defining-your-own-component
The `torchx validate` cmd will help users to develop the components.
`torchx validate ~/my_component.py:func` whether the component is a valid component or not. If component is not valid, the command will print the detailed message explaining what is wrong with the function.
|
https://github.com/meta-pytorch/torchx/issues/132
|
closed
|
[
"enhancement",
"cli"
] | 2021-08-12T18:38:52Z
| 2022-01-22T00:32:22Z
| 2
|
aivanou
|
pytorch/TensorRT
| 575
|
❓ [Question] How to build latest TRTorch with Pytorch 1.9.0
|
## ❓ Question
I am trying to build latest TRTorch with Torch 1.9.0 but I am getting some issue. I follow the instruction from [here](https://github.com/NVIDIA/TRTorch/blob/master/README.md)
Also followed https://nvidia.github.io/TRTorch/tutorials/installation.html but not able to build. Please help!
## What you have already tried
<!-- A clear and concise description of what you have already done. -->
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version: `1.9.0`
- CPU Architecture: `x86_64`
- OS: `Linux` (Ubuntu 18.04)
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): `pip` from [here](https://pytorch.org/get-started/locally/)
- Build command you used (if compiling from source): `bazel build //:libtrtorch --compilation_mode opt` and `cd py && sudo python3.7 setup.py install`
- Are you using local sources or building from archives: `local`
- Python version: `3.7`
- CUDA version: `11.1`
- CUDNN version: `8.1`
- TensorRT: `7.2.3.4`
- Bazel: `4.0.0`
- GPU models and configuration: `RTX 2070 super 8GB`
- Any other relevant information:
## Additional context
Attached the error I got while I run `bazel build //:libtrtorch --compilation_mode opt` or `cd py && sudo python3.7 setup.py install`
```
user@test ~/Documents/TRTorch/py
└─ (master) $ sudo python3.7 setup.py install
running install
building libtrtorch
INFO: Analyzed target //cpp/api/lib:libtrtorch.so (18 packages loaded, 2249 targets configured).
INFO: Found 1 target...
ERROR: /home/user/Documents/TRTorch/core/lowering/passes/BUILD:10:11: Compiling core/lowering/passes/op_aliasing.cpp failed: (Exit 1): gcc failed: error executing command /usr/bin/gcc -U_FORTIFY_SOURCE -fstack-protector -Wall -Wunused-but-set-parameter -Wno-free-nonheap-object -fno-omit-frame-pointer -g0 -O2 '-D_FORTIFY_SOURCE=1' -DNDEBUG -ffunction-sections ... (remaining 62 argument(s) skipped)
Use --sandbox_debug to see verbose messages from the sandbox gcc failed: error executing command /usr/bin/gcc -U_FORTIFY_SOURCE -fstack-protector -Wall -Wunused-but-set-parameter -Wno-free-nonheap-object -fno-omit-frame-pointer -g0 -O2 '-D_FORTIFY_SOURCE=1' -DNDEBUG -ffunction-sections ... (remaining 62 argument(s) skipped)
Use --sandbox_debug to see verbose messages from the sandbox
In file included from ./core/util/prelude.h:10:0,
from core/lowering/passes/op_aliasing.cpp:3:
./core/util/trt_util.h: In function 'std::ostream& nvinfer1::operator<<(std::ostream&, const nvinfer1::EngineCapability&)':
./core/util/trt_util.h:90:38: error: 'kSTANDARD' is not a member of 'nvinfer1::EngineCapability'
case nvinfer1::EngineCapability::kSTANDARD:
^~~~~~~~~
./core/util/trt_util.h:92:38: error: 'kSAFETY' is not a member of 'nvinfer1::EngineCapability'
case nvinfer1::EngineCapability::kSAFETY:
^~~~~~~
./core/util/trt_util.h:94:38: error: 'kDLA_STANDALONE' is not a member of 'nvinfer1::EngineCapability'
case nvinfer1::EngineCapability::kDLA_STANDALONE:
^~~~~~~~~~~~~~~
Target //cpp/api/lib:libtrtorch.so failed to build
Use --verbose_failures to see the command lines of failed build steps.
INFO: Elapsed time: 8.640s, Critical Path: 6.17s
INFO: 8 processes: 8 internal.
FAILED: Build did NOT complete successfully
```
Workspace modified file:
```
workspace(name = "TRTorch")
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
load("@bazel_tools//tools/build_defs/repo:git.bzl", "git_repository")
http_archive(
name = "rules_python",
sha256 = "778197e26c5fbeb07ac2a2c5ae405b30f6cb7ad1f5510ea6fdac03bded96cc6f",
url = "https://github.com/bazelbuild/rules_python/releases/download/0.2.0/rules_python-0.2.0.tar.gz",
)
load("@rules_python//python:pip.bzl", "pip_install")
http_archive(
name = "rules_pkg",
sha256 = "038f1caa773a7e35b3663865ffb003169c6a71dc995e39bf4815792f385d837d",
urls = [
"https://mirror.bazel.build/github.com/bazelbuild/rules_pkg/releases/download/0.4.0/rules_pkg-0.4.0.tar.gz",
"https://github.com/bazelbuild/rules_pkg/releases/download/0.4.0/rules_pkg-0.4.0.tar.gz",
],
)
load("@rules_pkg//:deps.bzl", "rules_pkg_dependencies")
rules_pkg_dependencies()
git_repository(
name = "googletest",
commit = "703bd9caab50b139428cea1aaff9974ebee5742e",
remote = "https://github.com/google/googletest",
shallow_since = "1570114335 -0400",
)
# CUDA should be installed on the system locally
new_local_repository(
name = "cuda",
build_file = "@//third_party/cuda:BUILD",
path = "/usr/local/cuda-11.1/",
)
new_local_repository(
name = "cublas",
build_file = "@//third_party/cublas:BUILD",
path = "/usr",
)
#####################################################################
|
https://github.com/pytorch/TensorRT/issues/575
|
closed
|
[
"question"
] | 2021-08-12T09:29:10Z
| 2021-08-16T02:33:12Z
| null |
rajusm
|
pytorch/pytorch
| 63,140
|
[documentation] torch.distributed.elastic: illustrate how to write load_checkpoint and save_checkpoint in Train Script
|
https://pytorch.org/docs/master/elastic/train_script.html
If users want to run elastic jobs, he/she needs to write some logic to load and save checkpoints. And maybe `State` like this https://github.com/pytorch/elastic/blob/master/examples/imagenet/main.py#L196 should be defined.
It is not clear in the documentation, it will be better to document it.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @agolynski @SciPioneer @H-Huang @mrzzd @cbalioglu @gcramer23 @brianjo @mruberry
|
https://github.com/pytorch/pytorch/issues/63140
|
open
|
[
"module: docs",
"triaged",
"module: elastic",
"oncall: r2p"
] | 2021-08-12T08:54:25Z
| 2022-06-03T20:47:29Z
| null |
gaocegege
|
pytorch/vision
| 4,270
|
annotation_path parameter in torchvision.datasets.UCF101 is not clear.
|
## 📚 Documentation
Please describe what kind of files should be in annotation_path, and what the files should contain. It is not obvious.
cc @pmeier
|
https://github.com/pytorch/vision/issues/4270
|
open
|
[
"question",
"module: datasets",
"module: documentation"
] | 2021-08-12T03:40:59Z
| 2021-08-13T16:50:25Z
| null |
damtharvey
|
pytorch/torchx
| 130
|
components: copy component
|
## Description
<!-- concise description of the feature/enhancement -->
Adds a basic copy io component that uses fsspec to allow ingressing data or copying from one location to another.
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
We previously had a simple copy component using the old Python style component classes. We deleted that since it didn't use the new style component definitions.
Having a copy component is generally useful and we should use it for data ingress in the KFP advanced example.
## Detailed Proposal
<!-- provide a detailed proposal -->
io.py
```py
def copy(from: string, to: string, image: string = "") -> specs.AppDef: ...
```
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
## Additional context/links
<!-- link to code, documentation, etc. -->
|
https://github.com/meta-pytorch/torchx/issues/130
|
closed
|
[
"enhancement",
"module: components"
] | 2021-08-11T20:15:42Z
| 2021-09-13T18:09:16Z
| 1
|
d4l3k
|
pytorch/torchx
| 128
|
components: tensorboard component
|
## Description
<!-- concise description of the feature/enhancement -->
It would be nice to have a tensorboard component that could be used as either a mixin as a new role or standalone. This would make it easy to launch a job and monitor it while it's running.
## Detailed Proposal
<!-- provide a detailed proposal -->
Add a new built in component `tensorboard` to `components/metrics.py`. This would provide a component with the interface:
```
def tensorboard(logdir: string, duration: float, image: string = "<image>"):
"""
Args:
duration: number of hours to run the container for
"""
```
### Lifetime
There's a bit of consideration here on how to manage the lifetime of the tensorboard role. Ideally it would be tied to the other containers but practically we can't support that on most schedulers. Launching it as a standalone component with a fixed duration i.e. 8 hours is likely going to be the best supported and should be good enough. Tensorboard is quite lightweight so having it run longer than necessary shouldn't be a big deal.
There may be better ways of handling this though. Volcano allows for flexible policies and we could allow for containers that get killed on first sucessful (0 exit code) replica.
It also could be good to watch a specific file. tensorboard uses a remote path so we could add in a `watch_file` arg with a specific path that the manager can long poll on to detect shutdown. The app would have to know to write out a `foo://bar/done` or `foo://bar/model.pt` that the component can poll on for termination purposes.
### fsspec
One other painpoint is that tensorboard uses it's own filesystem interface that has relatively view implementations. It is extensible but other components use fsspec which could cause confusion for users.
There is an issue about this on tensorboard but it's quite new https://github.com/tensorflow/tensorboard/issues/5165
We could write our own fsspec tensorboard adapter if necessary and provide it as part of a custom docker image.
### Docker images
There's not a specific docker image we can use to provide tensorboard right now. It's possible to use `tensorflow/tensorflow` but that doesn't contain boto3 so no s3 support or other file systems. We may want to provide our own cutdown tensorboard container that can be used with the component.
### Role
We also want to provide tensorboard as a role so you can have it run as a companion to the main training job. You can then easily include the tensorboard role as an extra role in your AppDef and use it as is.
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
Currently you can launch tensorboard via KFP UI or via the command line. This requires an extra step and in the case of KFP you can only do that after the job has run.
## Additional context/links
<!-- link to code, documentation, etc. -->
|
https://github.com/meta-pytorch/torchx/issues/128
|
closed
|
[
"enhancement",
"module: components"
] | 2021-08-11T19:39:28Z
| 2021-11-02T17:49:39Z
| 0
|
d4l3k
|
pytorch/android-demo-app
| 177
|
How to compress the model size when use the API: module._save_for_lite_interpreter
|
I want to deploy the model on IOS.
When I deploy the model to android, the following code can work.
mobile = torch.jit.trace(model, input_tensor)
mobile.save(path)
I get a model which size is 23.4MB
When i deploy the model to IOS, i must use the following API:
from torch.utils.mobile_optimizer import optimize_for_mobile
optimized_scripted_module = optimize_for_mobile(mobile)
optimized_scripted_module._save_for_lite_interpreter(optimized_path)
I get the model which size is 45.7MB
The model size of the second method is almost twice as big as the previous one, i know the second approach are doing some optimization on the model, but how can I use the second method to get a model which size is as similar as the first one?
|
https://github.com/pytorch/android-demo-app/issues/177
|
open
|
[] | 2021-08-11T10:17:03Z
| 2022-02-11T14:21:17Z
| null |
kunlongsolid
|
pytorch/vision
| 4,264
|
ImportError: cannot import name '_NewEmptyTensorOp' from 'torchvision.ops.misc'
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## ImportError
Steps to reproduce the behavior:
1. Git clone the repository of [SOLQ](https://github.com/megvii-research/SOLQ)
2. Update the dataset you want to use.
3. Update the data paths in the file SOLQ/datasets/coco.py
4. RUn the bash file **configs/r50_solq_train.sh**
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
It should now show the error and move further to run the SOL-Q model.
## Environment
PyTorch version: 1.9.0+cu102
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (x86_64)
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: 6.0.0-1ubuntu2 (tags/RELEASE_600/final)
CMake version: version 3.12.0
Libc version: glibc-2.26
Python version: 3.7.11 (default, Jul 3 2021, 18:01:19) [GCC 7.5.0] (64-bit runtime)
Python platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
Is CUDA available: True
CUDA runtime version: 11.0.221
GPU models and configuration: GPU 0: Tesla T4
Nvidia driver version: 460.32.03
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.0.4
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.0.4
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.19.5
[pip3] torch==1.9.0+cu102
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.10.0
[pip3] torchvision==0.10.0+cu102
[conda] Could not collect
## Additional context
When running the script ```!bash configs/r50_solq_train.sh``` it, shows ImportError like shown below :
```
Traceback (most recent call last):
File "main.py", line 22, in <module>
import datasets
File "/content/SOLQ/datasets/__init__.py", line 13, in <module>
from .coco import build as build_coco
File "/content/SOLQ/datasets/coco.py", line 23, in <module>
from util.misc import get_local_rank, get_local_size
File "/content/SOLQ/util/misc.py", line 36, in <module>
from torchvision.ops.misc import _NewEmptyTensorOp
```
|
https://github.com/pytorch/vision/issues/4264
|
closed
|
[
"question"
] | 2021-08-10T05:04:23Z
| 2021-08-12T09:19:48Z
| null |
sagnik1511
|
pytorch/torchx
| 121
|
cli: support fetching logs from all roles
|
## Description
<!-- concise description of the feature/enhancement -->
Currently you have to specify which role you want to fetch logs when using `torchx log`. Ideally you could just specify the job name to fetch all of them.
```
torchx log kubernetes://torchx_tristanr/default:sh-hxkkr/sh
```
## Motivation/Background
<!-- why is this feature/enhancement important? provide background context -->
This reduces friction for users with single role jobs when trying to fetch logs. It's very common I forget to add the role and then have to run the command again with the role. There's no technical limitation here and it removes friction for the user.
## Detailed Proposal
<!-- provide a detailed proposal -->
This would require updating the log CLI to support iterating over all roles and fetching logs from all the replicas. https://github.com/pytorch/torchx/blob/master/torchx/cli/cmd_log.py#L81
This doesn't require any changes to the scheduler implementations and is purely a CLI improvement.
## Alternatives
<!-- discuss the alternatives considered and their pros/cons -->
We could instead change the CLI to automatically select the role when there's only one role in a job. That would improve the UX a fair bit while also preventing tons of log spam for complex jobs.
## Additional context/links
<!-- link to code, documentation, etc. -->
|
https://github.com/meta-pytorch/torchx/issues/121
|
closed
|
[
"enhancement"
] | 2021-08-09T20:22:07Z
| 2021-09-23T18:09:56Z
| 0
|
d4l3k
|
pytorch/xla
| 3,076
|
What is xm.RateTracker? Why there is no document for this class?
|
`xm.RateTracker()` is used in the example script. But I can' find any document for this class(even the doc string does not exist).
What is this class?
## ❓ Questions and Help
https://github.com/pytorch/xla/blob/81eecf457af5db09a3131a00864daf1ca5b8ed20/test/test_train_mp_mnist.py#L123
|
https://github.com/pytorch/xla/issues/3076
|
closed
|
[] | 2021-08-09T15:07:03Z
| 2021-08-11T01:54:53Z
| null |
DayuanJiang
|
huggingface/dataset-viewer
| 6
|
Expand the purpose of this backend?
|
Depending on the evolution of https://github.com/huggingface/datasets, this project might disappear, or its features might be reduced, in particular, if one day it allows caching the data by self-generating:
- an arrow or a parquet data file (maybe with sharding and compression for the largest datasets)
- or a SQL database
- or precompute and store a partial list of known offsets (every 10MB for example)
It would allow getting random access to the data.
|
https://github.com/huggingface/dataset-viewer/issues/6
|
closed
|
[
"question"
] | 2021-08-09T14:03:41Z
| 2022-02-04T11:24:32Z
| null |
severo
|
pytorch/examples
| 925
|
How many data does fast neural style need ?
|
Hi, I am recently implementing fast neural style with your example but I don't have much disk space for coco dataset instead I used my own dataset which contains 1200 images and the result is not good at all (a totally distorted picture, the style is 'starry night').

Here is my setting,
```
image_size = 224
content_weight = 1e5
style_weight = 1e10
lr = 1e-3
epoches = 2
batch_size = 2 (4 will OOM)
style_layer = ['1_2','2_2','3_3','4_3']
content_layer = ['2_2']
```
Other questions like
1. why do we need centercrop in transformation, it crops the whole resized picture?
2. why do we mul 255 then div 255 to batch?
Thanks in advance!
|
https://github.com/pytorch/examples/issues/925
|
closed
|
[] | 2021-08-09T10:27:12Z
| 2022-03-09T21:16:55Z
| 1
|
gitE0Z9
|
pytorch/TensorRT
| 566
|
❓ [Question] How can i build a Makefile for this example?
|
## ❓ Question
Hi,
I want to run the official [example ](https://github.com/NVIDIA/TRTorch/blob/master/examples/sample_rt_app/main.cpp) with a Makefile. But there is always something wrong. So, could you give me the Makefile that successfully links to the .so file?
## Environment
- PyTorch Version (1.8):
- OS (Ubuntu18.04):
- How you installed PyTorch (`pip`, `libtorch`)
- Python version: 3.8
- CUDA version: 11.3
- GPU models and configuration: GTX3070
|
https://github.com/pytorch/TensorRT/issues/566
|
closed
|
[
"question"
] | 2021-08-09T09:51:43Z
| 2021-08-12T01:15:41Z
| null |
JuncFang-git
|
pytorch/pytorch
| 62,951
|
when call `torch.onnx.export()`, the graph is pruned by default ? how to cancel pruning
|
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
For example:
```python
import torch
hidden_dim1 = 10
hidden_dim2 = 5
tagset_size = 2
class MyModel(torch.nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.line1 = torch.nn.Linear(hidden_dim1, hidden_dim2)
self.line2 = torch.nn.Linear(hidden_dim2, tagset_size)
def forward(self, x, y):
out1 = self.line1(x)
out2 = self.line2(y)
return out1
X = torch.randn(20, hidden_dim1)
Y = torch.randn(hidden_dim1, hidden_dim2)
inputs = (X, Y)
model = MyModel()
f = './model.onnx'
torch.onnx.export(model, inputs, f,
opset_version=9,
example_outputs=None,
input_names=["X"], output_names=["Y"],verbose=True)
```
```bash
graph(%X : Float(20, 10, strides=[10, 1], requires_grad=0, device=cpu),
%line1.weight : Float(5, 10, strides=[10, 1], requires_grad=1, device=cpu),
%line1.bias : Float(5, strides=[1], requires_grad=1, device=cpu)):
%Y : Float(20, 5, strides=[5, 1], requires_grad=1, device=cpu) = onnx::Gemm[alpha=1., beta=1., transB=1](%X, %line1.weight, %line1.bias) # /root/.conda/envs/torch1.9/lib/python3.6/site-packages/torch/nn/functional.py:1847:0
return (%Y)
```
#### How every, the exported graph doesn't contain `line2` , maybe because the output of MyModel is not depend on `out2 = self.line2(y)` ? I guess the graph is pruned by default.
**What should I do if I want to not do pruning?**
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
I want to do something for `self.named_parameters()` in `model.forward()`, eg.
```python
def check_parameters():
# do something for parameters by calling
# some ops including OP1, OP2 and so on
return
class MyModel(torch.nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.line = torch.nn.Linear(hidden_dim1, hidden_dim2)
def forward(self, x, y):
out = self.line1(x)
check_parameters()
return out
```
How every, the exported graph doesn't contain `OP1, OP2` , maybe because the output of MyModel is not depend on `check_parameters()` ? I guess the graph is pruned by default.
## Pitch
<!-- A clear and concise description of what you want to happen. -->
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
cc @BowenBao @neginraoof
|
https://github.com/pytorch/pytorch/issues/62951
|
closed
|
[
"module: onnx",
"triaged",
"onnx-needs-info"
] | 2021-08-08T14:31:20Z
| 2021-09-10T08:09:02Z
| null |
liym27
|
pytorch/serve
| 1,186
|
[Question] GPU memory
|
Hi! Say I have about 10 models and a single GPU is it possible to load a model object for a specific task at the request time and then completely free up the memory for a different model object? For instance, completely deleting it and then reinitialize it when needed. I know this will increase the response time but the crucial part is the amount of VRAM left for the inference.
|
https://github.com/pytorch/serve/issues/1186
|
closed
|
[
"question",
"triaged_wait"
] | 2021-08-06T17:35:15Z
| 2021-08-16T20:56:08Z
| null |
p1x31
|
pytorch/java-demo
| 26
|
How to compile from command line (using javac instead of gradle)?
|
Hi, could you maybe help with the following?
I want to show a very simple example of running a jitted model, and using gradle seems like quite some overhead ... Is there a way to just use `javac` with a classpath (or some other setup)?
I've been trying
```
javac -cp ~/libtorch/lib src/main/java/demo/App.java
```
but that does not work:
```
src/main/java/demo/App.java:3: error: cannot find symbol
import org.pytorch.IValue;
```
In addition, having stumbled over https://www.graphics-muse.org/wp/?p=136, I've tried the hack of putting App.java in a package`org.pytorch`, but this does not work either.
Many thanks!
|
https://github.com/pytorch/java-demo/issues/26
|
closed
|
[] | 2021-08-06T12:44:05Z
| 2021-11-04T13:15:33Z
| null |
skeydan
|
pytorch/TensorRT
| 562
|
❓ [Question] How can i get libtrtorchrt.so?
|
## ❓ Question
Thanks for your contribution.
I can't get the "libtrtorchrt.so" described in the following document after completing the trtorch. So, how can I get it?

## What you have already tried
complete the trtorch as the github guide
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version ( 1.8.1):
- OS ( Linux):
- How you installed PyTorch (`pip`, `libtorch`):
- Build command you used (bazel build //:libtrtorch -c opt):
- Python version: 3.8
- CUDA version: 11.3
- GPU models and configuration: GTX3070
|
https://github.com/pytorch/TensorRT/issues/562
|
closed
|
[
"question"
] | 2021-08-06T08:14:01Z
| 2021-08-06T10:04:25Z
| null |
JuncFang-git
|
pytorch/vision
| 4,257
|
R-CNN predictions change with different batch sizes
|
## 🐛 Bug
Even when using `model.eval()` I get different predictions when changing the batch size. I've found this issue when working on a project with Faster R-CNN and my own data, but I can replicate it in the tutorial "TorchVision Object Detection Finetuning Tutorial" (https://pytorch.org/tutorials/intermediate/torchvision_tutorial.html), which uses Mask R-CNN.
## To Reproduce
Steps to replicate the issue:
1. Open collab version: https://colab.research.google.com/github/pytorch/vision/blob/temp-tutorial/tutorials/torchvision_finetuning_instance_segmentation.ipynb
2. Run all cells
3. Insert a new cell at the bottom with the code below and run it:
```
def get_device():
if torch.cuda.is_available():
return torch.device('cuda')
else:
return torch.device('cpu')
def predict(model, image_tensors):
"""
Generate model's prediction (bounding boxes, scores and labels) for a batch
of image tensors
"""
model.eval()
with torch.no_grad():
predictions = model([x.to(get_device()) for x in image_tensors])
return predictions
def generate_preds(model, batch_size):
"""
Create dataloader for test dataset with configurable batch size.
Generate predictions. Return a list of predictions per sample.
"""
dataloader = torch.utils.data.DataLoader(
dataset_test, batch_size=batch_size, shuffle=False, num_workers=2,
collate_fn=utils.collate_fn)
all_pred = []
for batch in dataloader:
image_tensors, targets = batch
predictions = predict(model, image_tensors)
all_pred += predictions
return all_pred
# Generate two sets of predictions, only change is batch size
preds1 = generate_preds(model, 1)
preds8 = generate_preds(model, 8)
assert len(preds1) == len(preds8)
# Investigate first five samples:
for x in range(5):
print(f"\nSample {x}:")
print("-Boxes")
print(preds1[x]["boxes"])
print(preds8[x]["boxes"])
print("-Scores")
print(preds1[x]["scores"])
print(preds8[x]["scores"])
print("-Labels")
print(preds1[x]["labels"])
print(preds8[x]["labels"])
```
The code above generates two sets of predictions for the test set. The first one is generated with a batch size 1 and the second with a batch size 8. The output that I get when I run that cell:
```
Sample 0:
-Boxes
tensor([[ 61.2343, 37.6461, 197.8525, 325.6508],
[276.4769, 23.9664, 290.8987, 73.1913]], device='cuda:0')
tensor([[ 59.1616, 36.3829, 201.7858, 331.4406],
[276.4261, 23.7988, 290.8489, 72.8123],
[ 81.2091, 37.6342, 192.8113, 217.8009]], device='cuda:0')
-Scores
tensor([0.9989, 0.5048], device='cuda:0')
tensor([0.9988, 0.6410, 0.1294], device='cuda:0')
-Labels
tensor([1, 1], device='cuda:0')
tensor([1, 1, 1], device='cuda:0')
Sample 1:
-Boxes
tensor([[ 90.7305, 60.1291, 232.4859, 341.7854],
[245.7694, 56.3715, 305.2585, 349.5301],
[243.0723, 16.5198, 360.2888, 351.5983]], device='cuda:0')
tensor([[ 91.1201, 59.8146, 233.0968, 342.2685],
[245.7369, 56.6024, 305.2173, 349.3939],
[241.1119, 32.6983, 362.4162, 346.0358]], device='cuda:0')
-Scores
tensor([0.9976, 0.9119, 0.1945], device='cuda:0')
tensor([0.9975, 0.9128, 0.1207], device='cuda:0')
-Labels
tensor([1, 1, 1], device='cuda:0')
tensor([1, 1, 1], device='cuda:0')
Sample 2:
-Boxes
tensor([[281.1774, 53.5141, 428.7436, 330.3915],
[139.6456, 23.7953, 264.7703, 330.2114]], device='cuda:0')
tensor([[281.7463, 53.2942, 429.3290, 327.9640],
[138.7147, 23.8612, 264.6823, 332.3202]], device='cuda:0')
-Scores
tensor([0.9969, 0.9947], device='cuda:0')
tensor([0.9968, 0.9945], device='cuda:0')
-Labels
tensor([1, 1], device='cuda:0')
tensor([1, 1], device='cuda:0')
Sample 3:
-Boxes
tensor([[175.3683, 34.3320, 289.3029, 306.8307],
[ 76.7871, 15.4444, 187.0855, 299.1662],
[ 0.0000, 45.9045, 51.3796, 222.0583],
[319.1224, 53.0593, 377.1693, 232.7251],
[260.2587, 55.8976, 309.0191, 229.4261],
[ 70.2029, 27.2173, 126.4584, 234.3767],
[ 38.0638, 55.5370, 65.4132, 164.1965],
[ 98.7189, 91.5356, 172.5915, 295.5404],
[ 70.1933, 56.1804, 103.6161, 218.4743]], device='cuda:0')
tensor([[175.1848, 36.0377, 288.8358, 305.3505],
[ 76.8171, 15.7485, 187.4645, 299.5779],
[ 0.0000, 45.9045, 51.3796, 222.0582],
[319.1060, 53.0140, 377.3391, 232.7926],
[260.2587, 55.8976, 309.0191, 229.4261],
[ 70.2030, 27.2173, 126.4584, 234.3767],
[ 38.0638, 55.5370, 65.4132, 164.1965],
[ 70.1933, 56.1804, 103.6161, 218.4743]], device='cuda:0')
-Scores
tensor([0.9968, 0.9959, 0.9942, 0.9937, 0.9271, 0.8133, 0.4273, 0.1163, 0.0884],
device='cuda:0')
tensor([0.9974, 0.9965, 0.9942, 0.9937, 0.9271, 0.8133, 0.4273, 0.0884],
device='cuda:0')
-Labels
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1], devic
|
https://github.com/pytorch/vision/issues/4257
|
closed
|
[
"question",
"module: models",
"topic: object detection"
] | 2021-08-06T07:22:41Z
| 2021-08-16T12:25:30Z
| null |
alfonsomhc
|
pytorch/TensorRT
| 561
|
Are FastRCNN models from TorchVision supported in TRTorch?
|
## ❓ Question
Tried FastRCNN and MaskRCNN models from TorchVision. The model fails to compile with error "RuntimeError: tuple appears in op that does not forward tuples, unsupported kind: aten::append"
## What you have already tried
code to reproduce:
import torch
print(torch.__version__)
import trtorch
print(trtorch.__version__)
import torchvision
fastrcnn = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model = fastrcnn.eval().to("cuda")
scripted_model = torch.jit.script(model)
compile_settings = {
"input_shapes": [ [3, 300, 400],[3, 300, 400] ],
"op_precision": torch.float
}
trt_model = trtorch.compile(scripted_model, compile_settings)
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.8.1
- CPU Architecture:
- OS (e.g., Linux): Ubuntu
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): pip
- Build command you used (if compiling from source): N/A
- Are you using local sources or building from archives: N/A
- Python version: python3.7
- CUDA version: 11.1
- GPU models and configuration:
- Any other relevant information: TRTorch - 0.3.0
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/561
|
closed
|
[
"feature request",
"question",
"component: lowering",
"No Activity",
"component: partitioning"
] | 2021-08-06T01:36:18Z
| 2023-07-29T00:02:10Z
| null |
saipj
|
pytorch/tutorials
| 1,637
|
Distributed Data Parallel Tutorial UX improvement suggestion
|
referring to the tutorial: https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
Though the tutorial is broken down into sections, it doesn't show how to actually run the code from each section until the very end of the tutorial.
The code as presented in each section only gives function definitions despite the tutorial text carrying on as though the user is supposed to be able to see something from running the code snippet that has been provided. This combination of info presented in a way that seems self contained, with code that seems self contained but isn't was rather confusing.
to remedy this issue I think it'd make things easier if either
A) the code to run each section is included in that code snippet
B) a notebook is included in the tutorial so users can see how the code is actually run, without having to guess/find that this code is only listed at the bottom of the tutorial
C) mention that a reasonable default set to run the code snippets can be found at the bottom of the tutorial.
additional data point: Before I noticed the code at the bottom of the tutorial to invoke the functions, I looked for other resources and came across an external tutorial: https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html which specifically references the pytorch DDP tutorial and raises similar criticism. Though some of the flaws pointed out have been fixed, this piece remains
cc @sekyondaMeta @svekars @carljparker @NicolasHug @kit1980 @subramen
|
https://github.com/pytorch/tutorials/issues/1637
|
open
|
[
"content",
"medium",
"docathon-h2-2023"
] | 2021-08-05T01:28:20Z
| 2023-11-17T15:30:16Z
| 10
|
HDCharles
|
pytorch/pytorch
| 62,565
|
support comparisons between types `c10::optional<T>` and `U` where `T` is comparable to `U`
|
## 🚀 Feature
Support comparisons between `c10::optional<T>` and `U` if `T` is comparable to `U`.
## Motivation
A very common use-case for this is:
```
c10::optional<std::string> opt = ...;
if (opt == "blah") ...
```
Note that this is supported by `std::optional`. See https://en.cppreference.com/w/cpp/utility/optional/operator_cmp
under
> Compare an optional object with a value
## Pitch
Add support and testing for these additional overloads. These are expected to just replace the operators that look like:
```
template <typename T>
bool operator==(std::optional<T> const& opt, T const& val);
```
with
```
template <typename T, typename U>
bool operator==(std::optional<T> const& opt, U const& val);
```
## Alternatives
This makes the library more expressive. The alternative with existing functionality is `if (opt && *opt == "blah") ...`.
## Additional context
This is not expected to be a significant amount of work (< one day).
cc @ezyang @bhosmer @smessmer @ljk53 @bdhirsh
|
https://github.com/pytorch/pytorch/issues/62565
|
closed
|
[
"module: internals",
"module: bootcamp",
"triaged"
] | 2021-08-02T14:03:38Z
| 2021-08-19T04:41:51Z
| null |
dagitses
|
pytorch/text
| 1,369
|
How to use TorchText with Java
|
## ❓ Questions and Help
**Description**
I have a SentencePiece model which I serialized using `sentencepiece_processor`. My end goal is to use this torchscript serialized tokenizer in Java along with DJL Pytorch dependency. I am looking for guidance on how can I import torchtext dependency in Java environment.
Steps:
**1. Serializing SPM Tokenizer using Torchtext**
Torchscript Serialized file is saved as 'spm-jit.pt'
```
import torch
from torchtext.experimental.transforms import sentencepiece_processor
spm_processor = sentencepiece_processor('foo.model')
jit_spm_processor = torch.jit.script(spm_processor)
torch.jit.save(jit_spm_processor, 'spm-jit.pt')
```
**2. Deserializing SPM Tokenizer in Python**
Loading`spm-jit.pt` without importing torchtext fails with the following error.
```
import torch
spm_tokenizer = torch.jit.load('spm-jit.pt') # Fails when torchtext is not imported
```
Error
```
/usr/local/lib/python3.6/dist-packages/torch/jit/_serialization.py in load(f, map_location, _extra_files)
159 cu = torch._C.CompilationUnit()
160 if isinstance(f, str) or isinstance(f, pathlib.Path):
--> 161 cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files)
162 else:
163 cpp_module = torch._C.import_ir_module_from_buffer(
RuntimeError:
Unknown type name '__torch__.torch.classes.torchtext.SentencePiece':
Serialized File "code/__torch__/torchtext/experimental/transforms.py", line 6
training : bool
_is_full_backward_hook : Optional[bool]
sp_model : __torch__.torch.classes.torchtext.SentencePiece
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
def forward(self: __torch__.torchtext.experimental.transforms.SentencePieceProcessor,
line: str) -> List[int]:
```
After importing torchtext, I am able to load the tokenizer from torchscript file.
```
import torch
import torchtext
spm_tokenizer = torch.jit.load('spm-jit.pt') # Succeeds
```
This led me to the conclusion that serialized file has dependency on torchtext for it to load successfully in Java/Python/C++ environment.
Any guidance on how can I use torchtext in Java and/or C++
Thanks!
|
https://github.com/pytorch/text/issues/1369
|
open
|
[] | 2021-07-29T20:41:12Z
| 2021-08-05T23:30:05Z
| null |
anjali-chadha
|
pytorch/pytorch
| 62,332
|
How to Fix “AssertionError: CUDA unavailable, invalid device 0 requested”
|
## 🐛 Bug
I'm trying to use my GPU to run the YOLOR model, and I keep getting the error that CUDA is unavailable, not sure how to fix.
I keep getting the error:
```
Traceback (most recent call last):
File "D:\yolor\detect.py", line 198, in <module>
detect()
File "D:\yolor\detect.py", line 41, in detect
device = select_device(opt.device)
File "D:\yolor\utils\torch_utils.py", line 47, in select_device
assert torch.cuda.is_available(), 'CUDA unavailable, invalid device %s requested' % device # check availablity
AssertionError: CUDA unavailable, invalid device 0 requested
```
When I check CUDA availability with:
```
py
>>import torch
>>print(torch.cuda.is_available())
```
I get `False`, which explains the problem. I tried running the command:
`py -m pip install torch1.9.0+cu111 torchvision0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html`
I get the error:` ERROR: Invalid requirement: 'torch1.9.0+cu111'`
Running `nvcc --version`, I get:
```
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Mon_May__3_19:41:42_Pacific_Daylight_Time_2021
Cuda compilation tools, release 11.3, V11.3.109
Build cuda_11.3.r11.3/compiler.29920130_0
```
Thus, I'm not really sure what the issue is, or how to fix it.
## Expected behavior
I expect the program to be able to run, and CUDA to be available.
## Environment
- **PyTorch Version (e.g., 1.0):** 1.9.0
- **OS (e.g., Linux):** Windows
- **How you installed PyTorch (`conda`, `pip`, source):** pip
- **Python version:** Python 3.9.4
- **CUDA/cuDNN version:** Cuda compilation tools, release 11.3, V11.3.109
- **GPU models and configuration:** 2070 Super
EDIT:
I noticed that I forgot the `==` sign. I ran `py -m pip install --user torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html`, and even after doing so,
```
py
>>import torch
>>print(torch.cuda.is_available())
```
still gets `False`.
Additionally, `torch.version.cuda` gives `None`. Please help!
cc @ngimel @ezyang @seemethere @malfet @walterddr
|
https://github.com/pytorch/pytorch/issues/62332
|
open
|
[
"module: binaries",
"triaged"
] | 2021-07-28T15:05:52Z
| 2021-07-29T14:36:15Z
| null |
Hana-Ali
|
huggingface/transformers
| 12,925
|
How to reproduce XLNet correctly And What is the config for finetuning XLNet?
|
I fintune a XLNet for English text classification. But it seems that I did something wrong about it because xlnet-base is worse than bert-base in my case. I set every 1/3 epoch report validation accuracy. At the beginning Bert-base is about 0.50 while XLNet-base is only 0.24. The config I use for xlnet is listed as follows:
```python
config = {
batch_size = 4,
learning_rate = 1e-5,
gradient_accumulation_steps = 32,
epochs = 4,
max_sep_length = 384,
weight_decay = 0.01,
adam_epsilon = 1e-6,
16-bit_training = False
}
```
Does finetune XLNet needs a special setting or XLNet converges slowly?
Thanks for everyone willing to help in advance! :-)
|
https://github.com/huggingface/transformers/issues/12925
|
closed
|
[
"Migration"
] | 2021-07-28T01:16:19Z
| 2021-07-29T05:50:07Z
| null |
sherlcok314159
|
pytorch/pytorch
| 62,282
|
What is slow-path and fast-path?
|
## ❓ Questions and Help
I am reading pytorch code base and issue to get a better understanding of the design choices. I keep seeing fast-pathed or fast-passed function. I was wondering what these are? For instance, the issue here (https://github.com/pytorch/pytorch/pull/46469 2).
Thank you in advance!
|
https://github.com/pytorch/pytorch/issues/62282
|
closed
|
[] | 2021-07-27T18:50:43Z
| 2021-07-27T19:11:20Z
| null |
tarekmak
|
pytorch/pytorch
| 62,162
|
Clarify sparse COO tensor coalesce behavior wrt overflow + how to binarize a sparse tensor
|
https://pytorch.org/docs/stable/sparse.html#sparse-uncoalesced-coo-docs does not explain what would be the behavior if passed sparse tensor dtype does not fit the accumulated values (e.g. it is torch.bool). Will it do the saturation properly? Or will it overflow during coalescing?
Basically, I would like to binarize a sparse tensor, e.g. to clamp all nonzero values by 1. How can I do that? I've tried `S > 0`, `S.clamp(max = 1)`, `S.to(torch.bool)`.
Only the latter seems to work.
cc @brianjo @mruberry @nikitaved @pearu @cpuhrsch @IvanYashchuk
|
https://github.com/pytorch/pytorch/issues/62162
|
open
|
[
"module: sparse",
"module: docs",
"triaged"
] | 2021-07-25T12:37:49Z
| 2021-08-23T14:53:45Z
| null |
vadimkantorov
|
huggingface/transformers
| 12,805
|
What is the data format of transformers language modeling run_clm.py fine-tuning?
|
I now use run_clm.py to fine-tune gpt2, the command is as follows:
```
python run_clm.py \\
--model_name_or_path gpt2 \\
--train_file train1.txt \\
--validation_file validation1.txt \\
--do_train \\
--do_eval \\
--output_dir /tmp/test-clm
```
The training data is as follows:
[train1.txt](https://github.com/huggingface/transformers/files/6847229/train1.txt)
[validation1.txt](https://github.com/huggingface/transformers/files/6847234/validation1.txt)
The following error always appears:
```
[INFO|modeling_utils.py:1354] 2021-07-20 17:37:01,399 >> All the weights of GPT2LMHeadModel were initialized from the model checkpoint at gpt2.
If your task is similar to the task the model of the checkpoint was trained on, you can already use GPT2LMHeadModel for predictions without further training.
Running tokenizer on dataset: 100%|██████████| 1/1 [00:00<00:00, 90.89ba/s]
Running tokenizer on dataset: 100%|██████████| 1/1 [00:00<00:00, 333.09ba/s]
Grouping texts in chunks of 1024: 0%| | 0/1 [00:00<?, ?ba/s]
Traceback (most recent call last):
File "D:/NLU/tanka-reminder-suggestion/language_modeling/run_clm.py", line 492, in <module>
main()
File "D:/NLU/tanka-reminder-suggestion/language_modeling/run_clm.py", line 407, in main
desc=f"Grouping texts in chunks of {block_size}",
File "D:\lib\site-packages\datasets\dataset_dict.py", line 489, in map
for k, dataset in self.items()
File "D:\lib\site-packages\datasets\dataset_dict.py", line 489, in <dictcomp>
for k, dataset in self.items()
File "D:\lib\site-packages\datasets\arrow_dataset.py", line 1673, in map
desc=desc,
File "D:\lib\site-packages\datasets\arrow_dataset.py", line 185, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "D:\lib\site-packages\datasets\fingerprint.py", line 397, in wrapper
out = func(self, *args, **kwargs)
File "D:\lib\site-packages\datasets\arrow_dataset.py", line 2024, in _map_single
writer.write_batch(batch)
File "D:\lib\site-packages\datasets\arrow_writer.py", line 388, in write_batch
pa_table = pa.Table.from_pydict(typed_sequence_examples)
File "pyarrow\table.pxi", line 1631, in pyarrow.lib.Table.from_pydict
File "pyarrow\array.pxi", line 332, in pyarrow.lib.asarray
File "pyarrow\array.pxi", line 223, in pyarrow.lib.array
File "pyarrow\array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "D:\lib\site-packages\datasets\arrow_writer.py", line 100, in __arrow_array__
if trying_type and out[0].as_py() != self.data[0]:
File "pyarrow\array.pxi", line 1076, in pyarrow.lib.Array.__getitem__
File "pyarrow\array.pxi", line 551, in pyarrow.lib._normalize_index
IndexError: index out of bounds
```
Is the format of my training data incorrect? Please help me thanks!
|
https://github.com/huggingface/transformers/issues/12805
|
closed
|
[] | 2021-07-20T09:43:30Z
| 2021-08-27T15:07:19Z
| null |
gongshaojie12
|
pytorch/pytorch
| 61,836
|
How to support multi-arch in built Docker
|
Hello?
I'm using pip3 to install and use PyTorch by writing my own Dockerfile.
Arch error when trying to use an image built on V100 on RTX3090.
I want to build an image that supports multiple Arches, such as V100, A100, RTX3090, and use it.
Any good way?
cc @malfet @seemethere @walterddr
|
https://github.com/pytorch/pytorch/issues/61836
|
closed
|
[
"module: build",
"triaged",
"module: docker"
] | 2021-07-19T11:15:03Z
| 2021-07-19T21:39:37Z
| null |
DonggeunYu
|
pytorch/pytorch
| 61,831
|
How data transfer from disk to GPU?
|
## ❓ Questions and Help
I have learned that we can use.to(device) to.CUDA () to transfer data to the GPU. I want to know how this process is implemented in the bottom layer.
Thanks, hundan.
|
https://github.com/pytorch/pytorch/issues/61831
|
closed
|
[] | 2021-07-19T08:32:32Z
| 2021-07-19T21:21:53Z
| null |
pyhundan
|
pytorch/pytorch
| 61,765
|
How to save tensors on mobile (lite interpreter)?
|
## Issue description
Based on the discussion in https://github.com/pytorch/pytorch/pull/30108 it's clear that `pickle_save` is not supported on mobile, because `/csrc/jit/serialization/export.cpp` is not included when building for lite interpreter; producing the following runtime error:
```c++
#else
AT_ERROR(
"pickle_save not supported on mobile "
"(see https://github.com/pytorch/pytorch/pull/30108)");
#endif
```
For loading there's an option of using `torch::jit::_load_for_mobile`.
**However, are there any methods, or alternative approaches, of serialising and saving `c10::IValue` objects on the mobile device?**
---
Mobile code compiled with libraries at `master: 5c1505076bfa764088e2ccef19d7f18336084530`
|
https://github.com/pytorch/pytorch/issues/61765
|
open
|
[
"oncall: mobile"
] | 2021-07-16T09:43:03Z
| 2021-07-21T10:06:17Z
| null |
lytcherino
|
pytorch/TensorRT
| 539
|
❓ [Question] Unknown output type. Only a single tensor or a TensorList type is supported
|
## ❓ Question
TRTorch Throw "Unknown output type. Only a single tensor or a TensorList type is supported"
## What you have already tried
I define a model
```python
import os
import time
import torch
import torchvision
class Sparse(torch.nn.Module):
def __init__(self, embedding_size):
super().__init__()
self._embedding_size = embedding_size
self._output = torch.zeros((4, self._embedding_size))
def forward(self, x):
return self._output
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.sparse = Sparse(100)
self.linear = torch.nn.Linear(100, 200)
def forward(self, x):
y = self.sparse(x)
return self.linear(y)
if __name__ == '__main__':
model = torch.jit.script(Model())
model.eval()
model.save("data/ali.pt")
```
save it to "data/ali.pt",and convert it with trtorch(input_shapes is need but not used by model)
```python
import torch
import trtorch
import trtorch.logging
import sys
def main(model_path):
trtorch.logging.set_reportable_log_level(trtorch.logging.Level.Debug)
scripted_model = torch.jit.load(model_path).eval().cuda()
compile_settings = {
"input_shapes": [
{
"min": [1, 3, 224, 224, 1024],
"opt": [1, 3, 512, 512, 2048],
"max": [1, 3, 1024, 1024, 4096]
}],
"op_precision": torch.float32
}
#print("check_method_op_support {}".format(trtorch.check_method_op_support(scripted_model, "torch.gelu")))
print("Model {} With Graph {}".format(model_path, scripted_model.graph))
trt_ts_module = trtorch.compile(scripted_model, compile_settings)
torch.jit.save(trt_ts_module, '{}.jit'.format(model_path))
print("Generated Torchscript-TRT models.")
if __name__ == "__main__":
if len(sys.argv) == 0:
main("data/with_dense.pt")
else:
main(sys.argv[1])
```
I also try with c++ api to convert, but got same error
```cpp
int main(int argc, const char *argv[]) {
if (argc < 2) {
std::cerr << "usage: samplertapp <path-to-pre-built-trt-ts module>\n";
return -1;
}
std::string trt_ts_module_path = argv[1];
std::string mode = argv[2];
//trtorch::logging::set_reportable_log_level(trtorch::logging::Level::kINFO);
trtorch::logging::set_reportable_log_level(trtorch::logging::Level::kDEBUG);
torch::jit::Module trt_ts_mod;
try {
// Deserialize the ScriptModule from a file using torch::jit::load().
trt_ts_mod = torch::jit::load(trt_ts_module_path);
} catch (const c10::Error &e) {
std::cerr << "error loading the model from : " << trt_ts_module_path
<< std::endl;
return -1;
}
if (1) {
trt_ts_mod.to(at::kCUDA);
trt_ts_mod.eval();
auto in = torch::randn({1, 1, 32, 32}, {at::kCUDA}).to(torch::kHalf);
auto input_sizes =
std::vector<trtorch::CompileSpec::InputRange>({in.sizes()});
trtorch::CompileSpec cspec(input_sizes);
cspec.op_precision = torch::kHalf;
auto trt_mod = trtorch::CompileGraph(trt_ts_mod, cspec);
auto out = trt_mod.forward({in});
std::cout << "==================TRT outputs================" << std::endl;
std::cout << out << std::endl;
std::cout << "=============================================" << std::endl;
}
return 0;
}
```
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version 1.8.1
- CPU Architecture: x86_64
- OS (e.g., Linux):
- How you installed PyTorch (pip)
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version: 3.6.13
- CUDA version: 11.1
- GPU models and configuration:
- Any other relevant information:
## Additional context
Running TRT engine
DEBUG: [TRTorch] - TRTorch Version: 0.3.0
Using TensorRT Version: 7.2.3.4
PyTorch built with:
- GCC 5.4
- C++ Version: 201402
- Intel(R) Math Kernel Library Version 2020.0.0 Product Build 20191122 for Intel(R) 64 architecture applications
- Intel(R) MKL-DNN v1.7.0 (Git Hash 7aed236906b1f7a05c0917e5257a1af05e9ff683)
- OpenMP 201307 (a.k.a. OpenMP 4.0)
- NNPACK is enabled
- CPU capability usage: AVX2
- CUDA Runtime 11.1
- NVCC architecture flags: -gencode;arch=compute_37,code=sm_37;-gencode;arch=compute_50,code=sm_50;-gencode;arch=compute_60,code=sm_60;-gencode;arch=compute_70,code=sm_70;-gencode;arch=compute_75,code=sm_75;-gencode;arch=compute_80,code=sm_80;-gencode;arch=compute_86,code=sm_86
- CuDNN 8.0.5
- Magma 2.5.2
|
https://github.com/pytorch/TensorRT/issues/539
|
closed
|
[
"question",
"No Activity"
] | 2021-07-16T06:35:29Z
| 2021-10-29T00:01:39Z
| null |
westfly
|
huggingface/sentence-transformers
| 1,070
|
What is the difference between training(https://www.sbert.net/docs/training/overview.html#training-data) and unsupervised learning
|
Hi,
I have some bunch of PDF's and I am building a QnA system from the pdf's. Currently, I am using deepset/haystack repo for the same task.
My doubt is if we want to generate embeddings for my text which training I should do, what is the difference as both approaches mostly takes sentences right?
|
https://github.com/huggingface/sentence-transformers/issues/1070
|
open
|
[] | 2021-07-15T12:13:37Z
| 2021-07-15T12:41:22Z
| null |
SAIVENKATARAJU
|
pytorch/vision
| 4,180
|
[Detectron2] RuntimeError: No such operator torchvision::nms and RecursionError: maximum recursion depth exceeded
|
## 🐛 Bug
Running Detectron2 demo.py creates `RuntimeError: No such operator torchvision::nms` error.
So far it's the same as #1405 but it gets worse. Creates a Max Recursion Depth error.
The primary issue is resolve with a simple naming change (below, thanks to @feiyuhuahuo). However, this creates the `RecursionError: maximum recursion depth exceeded in comparison` issue referenced by @vasyllyashkevych.
This fix to `torchvision::nms` creates `RecursionError`
```
# edit file: `local/lib/python3.6/dist-packages/torchvision-0.7.0a0+78ed10c-py3.6-linux-aarch64.egg/torchvision/ops/boxes.py`
# OLD (bad):
torch.ops.torchvision.nms(boxes, scores, iou_thres)
# NEW (better):
import torchvision # top of file
torchvision.ops.nms(boxes, scores, iou_thres)
```
## This fix creates the RecursionError: maximum recursion depth exceeded
```
File "/usr/local/lib/python3.6/dist-packages/torchvision-0.7.0a0+78ed10c-py3.6-linux-aarch64.egg/torchvision/ops/boxes.py", line 43, in nms
return torchvision.ops.nms(boxes, scores, iou_threshold)
[Previous line repeated 970 more times]
RecursionError: maximum recursion depth exceeded
```
Full stack trace below 👇👇!
## To Reproduce
Steps to reproduce the behavior:
1. Build Detectron2 from source
```
sudo python3 -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
```
2. Clone Detectron2 repo
3. Run Demo (from the docs https://detectron2.readthedocs.io/en/latest/tutorials/getting_started.html)
```
$ sudo python3 demo.py --config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \
--input kasDemo.png \
--opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Environment
❗Note Pytorch was installed via [PyTorch for Jetson](https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-9-0-now-available/72048)
Simple system info:
```
Host machine: Nvidia Jetson Xaiver (arm architecture, not x64)
Python: python3.6
Detectron2: installed from source on Github (July 14, 2021)
torch version: 1.8.0
torchvision version: 0.7.0 (a0)
Cuda version: 10.2
```
Env collection script:
```
PyTorch version: 1.8.0
Is debug build: False
CUDA used to build PyTorch: 10.2
ROCM used to build PyTorch: N/A
OS: Ubuntu 18.04.5 LTS (aarch64)
GCC version: (Ubuntu/Linaro 7.5.0-3ubuntu1~18.04) 7.5.0
Clang version: Could not collect
CMake version: version 3.10.2
Libc version: glibc-2.25
Python version: 3.6.9 (default, Jan 26 2021, 15:33:00) [GCC 8.4.0] (64-bit runtime)
Python platform: Linux-4.9.201-tegra-aarch64-with-Ubuntu-18.04-bionic
Is CUDA available: True
CUDA runtime version: Could not collect
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: Probably one of the following:
/usr/lib/aarch64-linux-gnu/libcudnn.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_adv_infer.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_adv_train.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_cnn_infer.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_cnn_train.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_ops_infer.so.8.0.0
/usr/lib/aarch64-linux-gnu/libcudnn_ops_train.so.8.0.0
HIP runtime version: N/A
MIOpen runtime version: N/A
Versions of relevant libraries:
[pip3] numpy==1.19.5
[pip3] torch==1.8.0
[pip3] torchvision==0.7.0a0+78ed10c
[conda] Could not collect
```
Full stack trace:
```
$ sudo python3 demo.py --config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \
--video-input IMG_3578.MOV \
--opts MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
[07/14 17:23:49 detectron2]: Arguments: Namespace(confidence_threshold=0.5, config_file='../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml', input=None, opts=['MODEL.WEIGHTS', 'detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl'], output=None, video_input='IMG_3578.MOV', webcam=False)
[07/14 17:24:00 fvcore.common.checkpoint]: [Checkpointer] Loading from detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl ...
[07/14 17:24:01 fvcore.common.checkpoint]: Reading a file from 'Detectron2 Model Zoo'
WARNING [07/14 17:24:01 fvcore.common.checkpoint]: The checkpoint state_dict contains keys that are not used by the model:
proposal_generator.anchor_generator.cell_anchors.{0, 1, 2, 3, 4}
0%| | 0/221 [00:04<?, ?it/s]
Traceback (most recent call last):
File "demo.py", line 176, in <module>
for vis_frame in tqdm.tqdm(demo.run_on_video(video), total=num_frames):
File "/usr/local/lib/python3.6/dist-packages/tqdm/std.py", line 1185, in __iter__
for
|
https://github.com/pytorch/vision/issues/4180
|
closed
|
[
"question",
"module: ops"
] | 2021-07-14T23:51:28Z
| 2021-08-12T11:16:20Z
| null |
KastanDay
|
huggingface/transformers
| 12,704
|
Where is the casual mask when using BertLMHeadModel and set config.is_decoder = True?
|
I hope to use BERT for the task of causal language modeling.
`BertLMHeadModel ` seems to meet my needs, but I did not find any code snippets about the causal mask, even if I set the `config.is_decoder=True`.
I only find the following related code in https://github.com/huggingface/transformers/blob/master/src/transformers/models/bert/modeling_bert.py#L968.
however, I do not have any values to pass into the argument `encoder_hidden_states` when doing causal language modeling.
So maybe the causal mask does not work?
```
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
```
|
https://github.com/huggingface/transformers/issues/12704
|
closed
|
[] | 2021-07-14T13:15:50Z
| 2021-07-24T06:42:04Z
| null |
Doragd
|
pytorch/pytorch
| 61,526
|
how to put ```trainer.fit()``` in for loop?
|
I am trying to create multiple model using loop as below.
```
for client in clients:
t.manual_seed(10)
client['model'] = LinearNN(learning_rate = args.lr, i_s = args.input_size, h1_s = args.hidden1, h2_s = args.hidden2, n_c = args.output, client=client)
client['optim'] = optim.Adam(client['model'].parameters(), lr= args.lr)
```
However, ```trainer.fit()``` is an async method. To train multiple models, I need to put ```trainer.fit()``` in a loop as follows
```
for client in clients:
trainer = pl.Trainer(
max_epochs=args.epochs+1,
progress_bar_refresh_rate=20,
)
trainer.fit(client['model'])
```
As this is an async method, it gives an error
> AttributeError: can't set attribute
as it doesn't wait for finishing ```trainer.fit()```.
Is there any way to do that?
Thanks in advance.
|
https://github.com/pytorch/pytorch/issues/61526
|
closed
|
[] | 2021-07-12T11:29:16Z
| 2021-07-12T12:32:18Z
| null |
anik123
|
pytorch/TensorRT
| 527
|
❓ [Question] TRTorch and Pytorch Serve
|
## ❓ Question
Is it possbile to use TRTorch with TorchServe?
If not what is the best way to deploy TRTorch programs?
## What you have already tried
In the documentation, it is said I can continue to use programs via PyTorch API
I have converted all my models to TRTorch.
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version (e.g., 1.0):
- CPU Architecture:
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source):
- Build command you used (if compiling from source):
- Are you using local sources or building from archives:
- Python version:
- CUDA version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
|
https://github.com/pytorch/TensorRT/issues/527
|
closed
|
[
"question"
] | 2021-07-11T21:12:02Z
| 2021-07-14T18:32:38Z
| null |
p1x31
|
pytorch/pytorch
| 61,510
|
What is find_package(Torch REQUIRED) doing that a manual include/glob doesnt?
|
In my project, if i do
```
set(CMAKE_PREFIX_PATH "...lib/python3.6/site-packages/torch/share/cmake/Torch")
find_package(Torch REQUIRED)
add_library(lib SHARED "lib.hpp" "lib.cpp")
target_link_libraries( lib ${TORCH_LIBRARIES})
```
It all links and works great!
But, if I do the following manually,
```
file(GLOB TORCH_LIBRARIES ".../lib/python3.6/site-packages/torch/lib/*.so")
include_directories(".../python3.6/site-packages/torch/include/torch/csrc/api/include/"
"...lib/python3.6/site-packages/torch/include")
add_library(lib SHARED "lib.hpp" "lib.cpp")
target_link_libraries( lib ${TORCH_LIBRARIES})
```
It fails when i try to load the library with:
```
liblib.so: undefined reference to `c10::detail::torchInternalAssertFail(char const*, char const*, unsigned int, char const*, std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > const&)
```
What is find_package(Torch) adding that i am missing?
EDIT:
So it appears that despite include torchlib.so on my own (which that glob command does), the linker doesnt include `libtorch.so`
cc @malfet @seemethere @walterddr
|
https://github.com/pytorch/pytorch/issues/61510
|
open
|
[
"module: build",
"triaged"
] | 2021-07-10T18:35:09Z
| 2021-07-12T15:39:08Z
| null |
yaadhavraajagility
|
pytorch/tutorials
| 1,605
|
Need to update the tutorial description in index.rst
|
In [index.rst](https://github.com/pytorch/tutorials/blame/master/index.rst#L165), the description of `Text Classification with Torchtext` is duplicated with [the previous tutorial](https://github.com/pytorch/tutorials/blame/master/index.rst#L158) but not correctly explain the tutorial.
So we need to update this description as follows:
* As-is: This is the third and final tutorial on doing “NLP From Scratch”, where we write our own classes and functions to preprocess the data to do our NLP modeling tasks.
* To-be: Learn how to build the dataset and classify text using torchtext library.
|
https://github.com/pytorch/tutorials/issues/1605
|
closed
|
[] | 2021-07-10T13:00:03Z
| 2021-07-27T21:33:05Z
| 0
|
9bow
|
pytorch/serve
| 1,153
|
What is the post route link to upload the kitten.jpg? instead of the "-T"
|
## 📚 Documentation
For example, if I use something like postman, how should I upload the image?
Thank you.
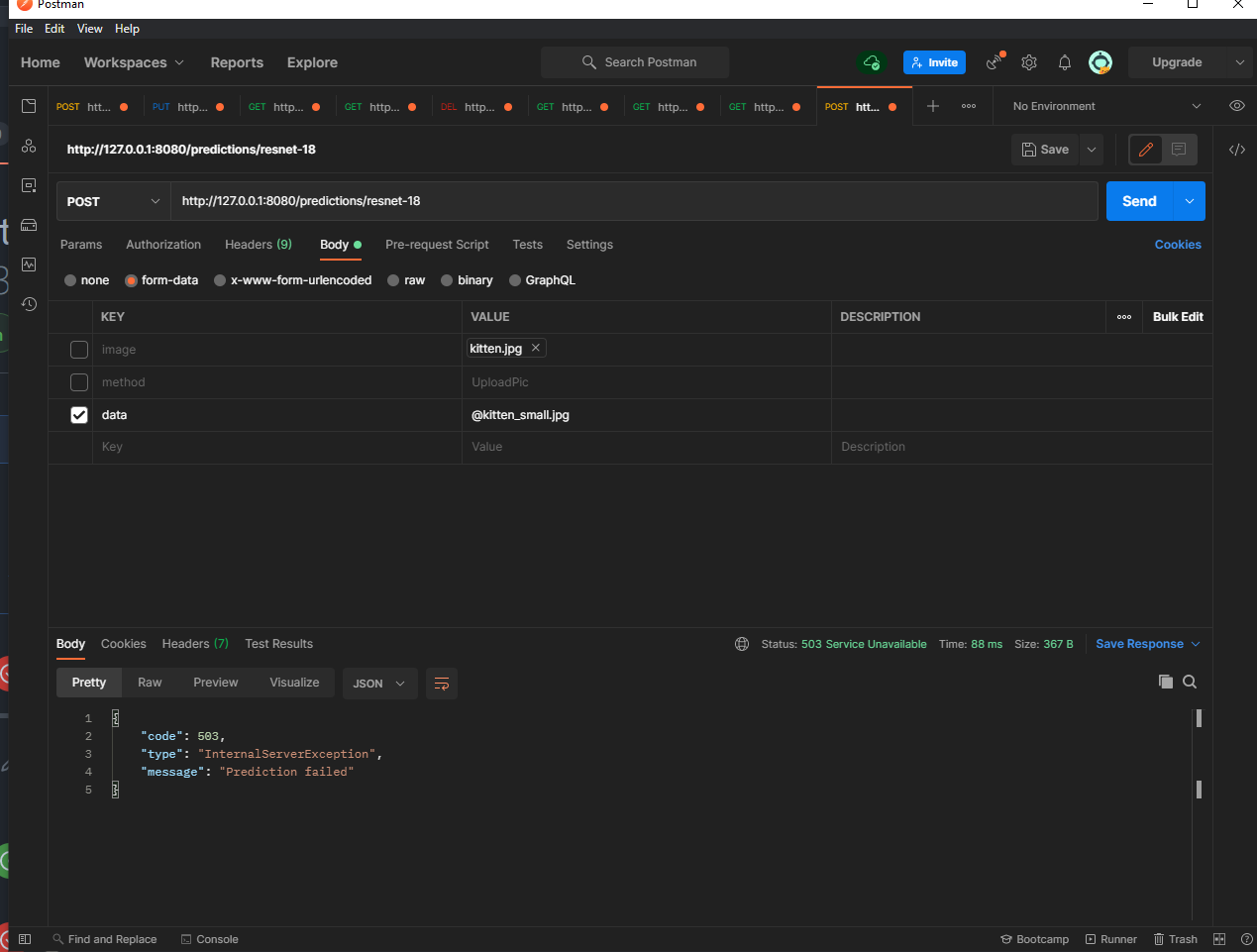
All these ways are failed.
|
https://github.com/pytorch/serve/issues/1153
|
closed
|
[] | 2021-07-08T13:00:48Z
| 2021-07-08T13:56:39Z
| null |
AliceSum
|
pytorch/TensorRT
| 526
|
❓ [Question] Lowering pass for PyTorch Linear
|
## ❓ Question
Hi, I saw that one of the lowering pass TRTorch has is lowering linear to mm + add. I'm wondering what the reason behind this is. Does TensorRT provide better performance with matmul layer + elementwise sum layer than fully connected layer? Or breaking it down help the fusion process in TensorRT?
|
https://github.com/pytorch/TensorRT/issues/526
|
closed
|
[
"question"
] | 2021-07-08T05:45:28Z
| 2021-07-12T16:14:09Z
| null |
842974287
|
pytorch/serve
| 1,152
|
How to access API outside of localhost?
|
Hi!
I have Wireguard in my machine and have a few other devices connected with it.
Let's say my Wireguard IP is 10.0.0.1, then in the `config.properties` file, I change `inference_address=http://10.0.0.1:8080`.
I'm able to use the API locally but unable to do so outside of the device (I keep getting a timeout error).
**What I've tried so far:**
I have also tried changing `inference_address` to `0.0.0.0:8080`, but that didn't help either.
Even running it on a different port like `0.0.0.0:5000` didn't help.
If I use a tunnel (like ngrok) and expose port 8080, it works perfectly.
If I have another application running on a separate port, that is accessible by my other device.
Can someone help out?
Thanks!
|
https://github.com/pytorch/serve/issues/1152
|
open
|
[
"help wanted",
"support"
] | 2021-07-07T07:20:50Z
| 2023-03-17T09:44:42Z
| null |
kkmehta03
|
pytorch/TensorRT
| 523
|
❓ [Question] My aten::chunk op converter does not work correctly
|
## ❓ Question
I want to use trtorch to compile shufflenet. However, aten::chunk op is not currently supported. I wrote a converter implementation referring to `converters/impl/select.cpp`. Unfortunately, it does not work.
Is there anything wrong?
The python code
```python
model = torchvision.models.shufflenet_v2_x1_0(pretrained=True).cuda().eval()
input_data = torch.randn(1, 3, 224, 224).cuda()
scripted_model = torch.jit.script(model)
out = scripted_model(input_data)
compile_settings = {
"input_shapes": [(1, 3, 224, 224)],
}
trt_ts_module = trtorch.compile(scripted_model, compile_settings)
```
The converter I wrote (compared with the converter of `aten::select`, I only changed `numOuputs` and `sizes`)
```cpp
auto chunk_registrations TRTORCH_UNUSED =
RegisterNodeConversionPatterns()
.pattern({"aten::chunk(Tensor(a) self, int chunks, int dim=0) -> (Tensor[])",
[](ConversionCtx* ctx, const torch::jit::Node* n, args& args) -> bool {
auto in = args[0].ITensor();
auto numOutputs = args[1].unwrapToInt();
auto axis = args[2].unwrapToInt();
auto inDimSize = in->getDimensions().d[axis];
LOG_DEBUG("Number of chunk outputs: " << numOutputs);
std::vector<int64_t> sizes;
if (inDimSize % numOutputs == 0) {
for (int64_t i = 0; i < numOutputs; i++) {
sizes.push_back(inDimSize / numOutputs);
}
}
else {
for (int64_t i = 0; i < numOutputs - 1; i++) {
sizes.push_back(inDimSize / numOutputs + 1);
}
sizes.push_back(inDimSize - (inDimSize / numOutputs + 1) * (numOutputs - 1));
}
c10::ListTypePtr lt = n->output()->type()->expect<c10::ListType>();
c10::TypePtr elementType = lt->getElementType();
auto list = c10::impl::GenericList(elementType);
list.reserve(numOutputs);
int start_idx = 0;
for (int64_t i = 0; i < numOutputs; i++) {
at::Tensor indices = torch::arange(start_idx, start_idx + sizes[i], 1).to(torch::kI32);
auto indicesTensor = tensor_to_const(ctx, indices);
auto gather_layer = ctx->net->addGather(*in, *indicesTensor, axis);
auto gather_out = gather_layer->getOutput(0);
auto tensor_holder = TensorContainer();
tensor_holder.hold_tensor(gather_out);
auto ival = c10::IValue(std::move(c10::make_intrusive<TensorContainer>(tensor_holder)));
list.emplace_back(ival);
start_idx = start_idx + sizes[i];
}
auto chunk_output_ivalue = std::move(torch::jit::IValue(list));
ctx->AssociateValueAndIValue(n->outputs()[0], chunk_output_ivalue);
LOG_DEBUG("Converted chunk op into a list of IValues");
return true;
}});
```
DEBUG log
```
INFO: [TRTorch Conversion Context] - Adding Layer %78 : Tensor[] = aten::chunk(%input.152, %self.stage2.0.stride, %self.stage2.1.stride) # /opt/conda/lib/python3.8/site-packages/torchvision/models/shufflenetv2.py:89:21 (ctx.AddLayer)
DEBUG: [TRTorch Conversion Context] - Node input is an already converted tensor
DEBUG: [TRTorch Conversion Context] - Node input is a result of a previously evaluated value
DEBUG: [TRTorch Conversion Context] - Node input is a result of a previously evaluated value
DEBUG: [TRTorch] - Number of chunk outputs: 2
DEBUG: [TRTorch] - Weights: [58]
Number of input maps: 58
Number of output maps: 58
Element shape: [1]
DEBUG: [TRTorch Conversion Context] - Freezing tensor 0x7fbb1c37c4e0 as an IConstantLayer
DEBUG: [TRTorch] - Weights: [58]
Number of input maps: 58
Number of output maps: 58
Element shape: [1]
DEBUG: [TRTorch Conversion Context] - Freezing tensor 0x7fbb1be22d30 as an IConstantLayer
DEBUG: [TRTorch] - Converted chunk op into a list of IValues
DEBUG: [TRTorch Conversion Context] - Evaluating %x1.9 : Tensor, %x2.9 : Tensor = prim::ListUnpack(%78)
DEBUG: [TRTorch Conversion Context] - Found the evaluated value(s) to be True for node: %x1.9 : Tensor, %x2.9 : Tensor = prim::ListUnpack(%78)
DEBUG: [TRTorch Conversion Context] - Found the evaluated value(s) to be True for node: %x1.9 : Tensor, %x2.9 : Tensor = prim::ListUnpack(%78)
DEBUG: [TRTorch Conversion Context] - Evaluating %81 : Float(58, 58, 1, 1, strides=[58, 1, 1, 1], requires_grad=0, device=cuda:0) = prim::Constant[value=<Tensor>]()
DEBUG: [TRTo
|
https://github.com/pytorch/TensorRT/issues/523
|
closed
|
[
"question"
] | 2021-07-05T08:50:04Z
| 2021-07-07T09:30:47Z
| null |
letian-jiang
|
pytorch/pytorch
| 61,220
|
How to submit a DDP job on the PBS/SLURM using multiple nodes
|
Hi everyone, I am trying to train using DistributedDataParallel. Thanks to the great work of the team at PyTorch, a very high efficiency has been achieved. Everything is fine when a model is trained on a single node. However, when I try to use multiple nodes in one job script, all the processes will be on the host node and the slave node will not have any processes running on it. Here is my script for the PBS workload manager:
```
#!/bin/sh
#PBS -V
#PBS -q gpu
#PBS -N test_1e4_T=1
#PBS -l nodes=2:ppn=2
source /share/home/bjiangch/group-zyl/.bash_profile
conda activate Pytorch-181
cd $PBS_O_WORKDIR
path="/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/"
#Number of processes per node to launch
NPROC_PER_NODE=2
#Number of process in all modes
WORLD_SIZE=`expr $PBS_NUM_NODES \* $NPROC_PER_NODE`
MASTER=`/bin/hostname -s`
cat $PBS_NODEFILE>nodelist
#Make sure this node (MASTER) comes first
SLAVES=`cat nodelist | grep -v $MASTER | uniq`
#We want names of master and slave nodes
HOSTLIST="$MASTER $SLAVES"
#The path you place your code
#This command to run your pytorch script
#You will want to replace this
COMMAND="$path --world_size=$WORLD_SIZE"
#Get a random unused port on this host(MASTER)
#First line gets list of unused ports
#3rd line gets single random port from the list
MPORT=`ss -tan | awk '{print $5}' | cut -d':' -f2 | \
grep "[2-9][0-9]\{3,3\}" | sort | uniq | shuf -n 1`
#Launch the pytorch processes, first on master (first in $HOSTLIST) then on the slaves
RANK=0
for node in $HOSTLIST; do
ssh -q $node
python3 -m torch.distributed.launch \
--nproc_per_node=$NPROC_PER_NODE \
--nnodes=$PBS_NUM_NODES \
--node_rank=$RANK \
--master_addr="$MASTER" --master_port="$MPORT" \
$COMMAND &
RANK=$((RANK+1))
done
wait
```
It is modified according to the [here](https://www.glue.umd.edu/hpcc/help/software/pytorch.html).
I want to submit a 4 process work ( 2 nodes and 2 process each node).
For validation, I manually ssh to each node from the login node and execute the
ssh gpu1
python3 -m torch.distributed.launch --nnodes=2 --node_rank=0
ssh gpu2
python3 -m torch.distributed.launch --nnodes=2 --node_rank=1
It will work and has a pretty good parallel efficiency. The same problem will occur on another cluster with a slurm workload manager. I don't see any difference between the two and lead to the totally different results.
And the final error
```
Traceback (most recent call last):
File "/share/home/bjiangch/group-zyl/.conda/envs/Pytorch-181/lib/python3.8/runpy.py", line 194, in _run_module_as_main
Traceback (most recent call last):
File "/share/home/bjiangch/group-zyl/.conda/envs/Pytorch-181/lib/python3.8/runpy.py", line 194, in _run_module_as_main
Traceback (most recent call last):
File "/share/home/bjiangch/group-zyl/.conda/envs/Pytorch-181/lib/python3.8/runpy.py", line 194, in _run_module_as_main
Traceback (most recent call last):
File "/share/home/bjiangch/group-zyl/.conda/envs/Pytorch-181/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,return _run_code(code, main_globals, None,
File "/share/home/bjiangch/group-zyl/.conda/envs/Pytorch-181/lib/python3.8/runpy.py", line 87, in _run_code
File "/share/home/bjiangch/group-zyl/.conda/envs/Pytorch-181/lib/python3.8/runpy.py", line 87, in _run_code
return _run_code(code, main_globals, None,
File "/share/home/bjiangch/group-zyl/.conda/envs/Pytorch-181/lib/python3.8/runpy.py", line 87, in _run_code
return _run_code(code, main_globals, None,
File "/share/home/bjiangch/group-zyl/.conda/envs/Pytorch-181/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/__main__.py", line 1, in <module>
exec(code, run_globals)
File "/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/__main__.py", line 1, in <module>
exec(code, run_globals)
File "/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/__main__.py", line 1, in <module>
exec(code, run_globals)
File "/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/__main__.py", line 1, in <module>
import run.train
File "/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/run/train.py", line 70, in <module>
import run.train
File "/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/run/train.py", line 70, in <module>
import run.train
File "/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/run/train.py", line 70, in <module>
import run.train
File "/share/home/bjiangch/group-zyl/zyl/pytorch/multi-GPU/program/eann/run/train.py", line 70, in <module>
Prop_class = DDP(Prop_class, device_ids=[local_rank], o
|
https://github.com/pytorch/pytorch/issues/61220
|
closed
|
[] | 2021-07-04T05:52:54Z
| 2021-07-12T20:11:16Z
| null |
zhangylch
|
pytorch/functorch
| 67
|
How to perform jvps and not vjps?
|
Hi! Thanks for the working prototype, it would be a great addition to pytorch!
I'm currently using pytorch for research purposes, and I would like to implicitly compute jacobian-vector products (i.e. where the given vectors should multiply the "inputs" and not the "outputs" of the transformation).
Is there a `jvp` function? Is there a workaround?
|
https://github.com/pytorch/functorch/issues/67
|
closed
|
[] | 2021-07-03T07:34:59Z
| 2022-12-08T20:04:56Z
| null |
trenta3
|
pytorch/pytorch
| 61,128
|
How to get in touch about a security issue?
|
Hey there,
As there isn't a `SECURITY.md` with an email on your repository, I am unsure how to contact you regarding a potential security issue.
Would you kindly add a `SECURITY.md` file with an e-mail to your repository? GitHub [recommends](https://docs.github.com/en/code-security/getting-started/adding-a-security-policy-to-your-repository) this as the best way to ensure security issues are responsibly disclosed, and it would massively help security researchers get in touch next time.
Thank you so much and I look forward to hearing from you!
|
https://github.com/pytorch/pytorch/issues/61128
|
closed
|
[] | 2021-07-01T16:07:47Z
| 2021-07-12T17:13:59Z
| null |
zidingz
|
pytorch/vision
| 4,147
|
Nan Loss while using resnet_fpn(not pretrained) backbone with FasterRCNN
|
## 🐛 Bug
I am using this model
```
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.backbone_utils import resnet_fpn_backbone
backbone = resnet_fpn_backbone(backbone_name='resnet152', pretrained=False)
model = FasterRCNN(backbone,
num_classes=2)
```
When I set pretrained=True in the backbone, it works absolutely fine but when I set pretrained=False. It starts giving such output
```
Epoch: [0] [ 0/457] eta: 0:27:14 lr: 0.000003 loss: 141610976.0000 (141610976.0000) loss_classifier: 50311224.0000 (50311224.0000) loss_box_reg: 62420652.0000 (62420652.0000) loss_objectness: 7461720.0000 (7461720.0000) loss_rpn_box_reg: 21417388.0000 (21417388.0000) time: 3.5773 data: 0.8030 max mem: 10427
Loss is nan, stopping training
{'loss_classifier': tensor(nan, device='cuda:1', grad_fn=<NllLossBackward>), 'loss_box_reg': tensor(nan, device='cuda:1', grad_fn=<DivBackward0>), 'loss_objectness': tensor(nan, device='cuda:1', grad_fn=<BinaryCrossEntropyWithLogitsBackward>), 'loss_rpn_box_reg': tensor(nan, device='cuda:1', grad_fn=<DivBackward0>)}
```
## Environment
```
torch-version = 1.9.0a0+c3d40fd
torchvision-version = 0.10.0a0
```
Using this dockerfile
```
FROM nvcr.io/nvidia/pytorch:21.06-py3
RUN pip install pytorch-lightning
RUN pip install -U git+https://github.com/albu/albumentations --no-cache-dir
RUN pip install --upgrade albumentations
RUN pip install timm
RUN pip install odach
RUN pip install ensemble_boxes
RUN pip install opencv-python-headless
RUN pip install --no-cache-dir --upgrade pip
RUN apt update && apt install -y libsm6 libxext6
RUN apt-get install -y libxrender-dev
RUN apt install -y p7zip-full p7zip-rar
```
Help!
cc @datumbox
|
https://github.com/pytorch/vision/issues/4147
|
closed
|
[
"question",
"topic: object detection"
] | 2021-07-01T13:57:44Z
| 2021-08-17T18:37:51Z
| null |
sahilg06
|
pytorch/TensorRT
| 519
|
❓ [Question] Are there plans to support TensorRT 8 and Ubuntu 20.04?
|
https://github.com/pytorch/TensorRT/issues/519
|
closed
|
[
"question",
"No Activity",
"Story: TensorRT 8"
] | 2021-06-30T23:01:38Z
| 2022-02-13T00:01:42Z
| null |
danielgordon10
|
|
pytorch/text
| 1,350
|
How to build vocab from Glove embedding?
|
## ❓ How to build vocab from Glove embedding?
**Description**
<!-- Please send questions or ask for help here. -->
How to build vocab from Glove embedding?
I have gone through the documentation and the release update, I got to know that the Vectors object is not an attribute of the new Vocab object anymore.
But I would still want to build my vocab using Glove embedding or perhaps using Glove embedding in my model, anyway for the new API?
|
https://github.com/pytorch/text/issues/1350
|
open
|
[] | 2021-06-30T16:11:53Z
| 2022-02-27T11:29:03Z
| null |
OsbertTay
|
pytorch/vision
| 4,134
|
Hey, after changing the segmention.py script, has anyone tested the backbone using Mobilenetv3_large as deeplabv3? When I start the train.py script, I throw the error shown in the screenshot:
|
## ❓ Questions and Help
### Please note that this issue tracker is not a help form and this issue will be closed.
We have a set of [listed resources available on the website](https://pytorch.org/resources). Our primary means of support is our discussion forum:
- [Discussion Forum](https://discuss.pytorch.org/)
[
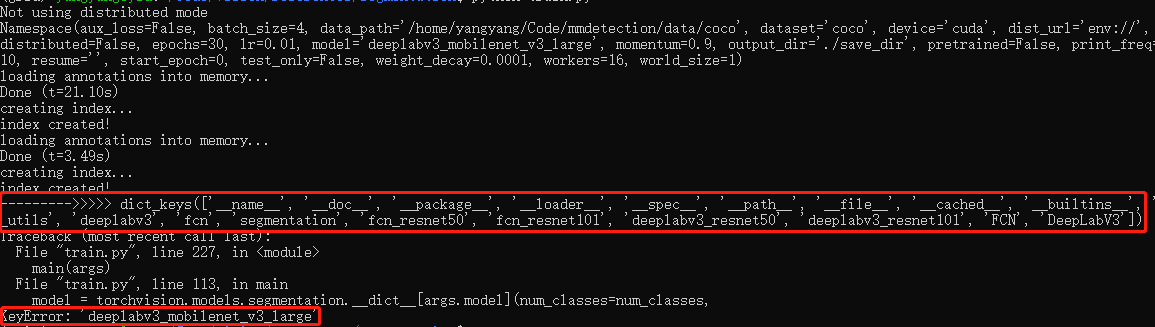
](url)
|
https://github.com/pytorch/vision/issues/4134
|
closed
|
[
"question"
] | 2021-06-29T07:15:14Z
| 2021-06-29T10:32:17Z
| null |
GalSang17
|
pytorch/pytorch
| 60,847
|
How to release CPU memory cache in Libtorch JIT ?
|
## ❓ Questions and Help
Hi every one, I would like to know to release CPU memory cache in Libtorch JIT? If there is no such way, can I set percentile of maximum memory used as cache ? And I want to know if each torchscript::jit::module has its own memory cache , or all modules share one global memory cache ? Thanks.
cc @gmagogsfm
|
https://github.com/pytorch/pytorch/issues/60847
|
open
|
[
"oncall: jit"
] | 2021-06-28T03:40:21Z
| 2021-07-07T03:01:06Z
| null |
w1d2s
|
pytorch/pytorch
| 60,825
|
Where OpInfo doesn't handle cases where one of the inputs is a scalar
|
https://github.com/pytorch/pytorch/blob/master/torch/testing/_internal/common_methods_invocations.py#L4436
It'd be nice to cover the other cases as well.
cc @mruberry @VitalyFedyunin @walterddr @heitorschueroff
|
https://github.com/pytorch/pytorch/issues/60825
|
open
|
[
"module: tests",
"triaged",
"module: sorting and selection"
] | 2021-06-26T20:37:52Z
| 2021-08-30T20:34:56Z
| null |
Chillee
|
pytorch/TensorRT
| 511
|
❓ [Question] How can I trace the code that causing Unsupported operators
|
## ❓ Question
Hi. I'm trying to enable TensorRT for a Torch Script model and getting a bunch of Unsupported operators. I'm willing to change the implementation to avoid those unsupported operators or even trying to add support for it. But I struggling to find which line of code in my model are causing it.
I'm doing something like this:
```python
model = torch.jit.script(model)
model = torch._C._jit_to_backend("tensorrt", model, spec)
```
And getting something like this:
```console
ERROR: [TRTorch] - Method requested cannot be compiled by TRTorch.
Unsupported operators listed below:
- aten::__contains__.str_list(str[] l, str item) -> (bool)
- aten::_set_item.str(Dict(str, t)(a!) l, str(b -> *) idx, t(c -> *) v) -> ()
- aten::dict() -> (Dict(str, Tensor))
- aten::format(str self, ...) -> (str)
- aten::list.t(t[] l) -> (t[])
- aten::values.str(Dict(str, t) self) -> (t[](*))
You can either implement converters for these ops in your application or request implementation
https://www.github.com/nvidia/TRTorch/issues
Traceback (most recent call last):
File "convert.py", line 6, in <module>
model = SomeModel('weights/ghostnet0.5.pth')
File "/home/linus/model/model.py", line 88, in __init__
self.model = torch._C._jit_to_backend("tensorrt", self.model, spec)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
File "<string>", line 4, in __preprocess
def __preprocess(self, mod: Any, method_compile_spec: Dict[str, Any]):
self.__create_backend()
self.__processed_module = self.__backend.preprocess(mod, method_compile_spec)
~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
RuntimeError: [enforce fail at /workspace/TRTorch/py/trtorch/csrc/tensorrt_backend.cpp:19] Expected core::CheckMethodOperatorSupport(mod.toModule(), it->key()) to be true but got false
Method forwardcannot be compiled by TRTorch
```
My question is:
- Does TRTorch have some traceback (like TorchScript) to tell the users which line of code caused the problem ?
- How can I find which line of code are using the unsupported operations?
## What you have already tried
I have tried printing out the graph for my scripted model with: `print(model.graph)` but yet to find those listed operators above.
```
graph(%self : __torch__.retinaface.RetinaFace,
%inputs.1 : Tensor):
%124 : Function = prim::Constant[name="softmax"]()
%123 : None = prim::Constant()
%122 : int = prim::Constant[value=3]()
%121 : int = prim::Constant[value=-1]() # /home/linus/model/model.py:121:67
%index.1 : int = prim::Constant[value=0]() # /home/linus/model/model.py:98:33
%index.3 : int = prim::Constant[value=1]() # /home/linus/model/model.py:99:33
....
```
I thought that by finding the ops, I can use that comment on the right to find which part of my code are using an unsupported ops. But so far, none have been found ;(
## Environment
> Build information about the TRTorch compiler can be found by turning on debug messages
- PyTorch Version (e.g., 1.0): 1.8.1
- CPU Architecture: x86
- OS (e.g., Linux): Ubuntu 20.04 LTS
- How you installed PyTorch (`conda`, `pip`, `libtorch`, source): conda
- Build command you used (if compiling from source): None
- Are you using local sources or building from archives: local sources
- Python version: 3.8.8
- CUDA version: 11.1.74
- GPU models and configuration: GTX 1080Ti
- Any other relevant information:
## Additional context
None for now. Thanks for checking by ;)
|
https://github.com/pytorch/TensorRT/issues/511
|
closed
|
[
"question"
] | 2021-06-26T13:48:04Z
| 2021-07-22T17:06:15Z
| null |
lamhoangtung
|
pytorch/pytorch
| 60,819
|
I want to use the bach size of image to foward with libtorch, how should i do?
|
single image forward:
std::vector<std::vector<Detection>>
model4_dec::Run(const cv::Mat& img, float conf_threshold, float iou_threshold) {
torch::NoGradGuard no_grad;
std::cout << "----------New Frame----------" << std::endl;
// TODO: check_img_size()
/*** Pre-process ***/
auto start = std::chrono::high_resolution_clock::now();
// keep the original image for visualization purpose
cv::Mat img_input = img.clone();
std::vector<float> pad_info;
pad_info = LetterboxImage(img_input, img_input, cv::Size(INPUT_W, INPUT_H));
const float pad_w = pad_info[0];
const float pad_h = pad_info[1];
const float scale = pad_info[2];
cv::cvtColor(img_input, img_input, cv::COLOR_BGR2RGB); // BGR -> RGB
img_input.convertTo(img_input, CV_32FC3, 1.0f / 255.0f); // normalization 1/255
auto tensor_img = torch::from_blob(img_input.data, { 1, img_input.rows, img_input.cols, img_input.channels() }).to(device_);
tensor_img = tensor_img.permute({ 0, 3, 1, 2 }).contiguous(); // BHWC -> BCHW (Batch, Channel, Height, Width)
if (half_) {
tensor_img = tensor_img.to(torch::kHalf);
}
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(tensor_img);
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
// It should be known that it takes longer time at first time
std::cout << "pre-process takes : " << duration.count() << " ms" << std::endl;
/*** Inference ***/
// TODO: add synchronize point
start = std::chrono::high_resolution_clock::now();
// inference
torch::jit::IValue output = module_.forward(inputs);
end = std::chrono::high_resolution_clock::now();
duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
// It should be known that it takes longer time at first time
std::cout << "inference takes : " << duration.count() << " ms" << std::endl;
/*** Post-process ***/
start = std::chrono::high_resolution_clock::now();
auto detections = output.toTuple()->elements()[0].toTensor();
// result: n * 7
// batch index(0), top-left x/y (1,2), bottom-right x/y (3,4), score(5), class id(6)
auto result = PostProcessing(detections, pad_w, pad_h, scale, img.size(), conf_threshold, iou_threshold);
end = std::chrono::high_resolution_clock::now();
duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
// It should be known that it takes longer time at first time
std::cout << "post-process takes : " << duration.count() << " ms" << std::endl;
return result;
}
but i want to use bach of image to forward:
std::vector<std::vector<Detection>> model4_dec::tensor_run(std::vector<cv::Mat>& _vecimg, float conf_threshold, float iou_threshold)
{
torch::NoGradGuard no_grad;
float scale = 1;// std::min(out_w / in_w, out_h / in_h);
int imgwidth = INPUT_W;
int imgheight = INPUT_H;
static float data[BATCH_SIZE * 3 * INPUT_H * INPUT_W];
for (int b = 0; b < _vecimg.size(); b++)
{
// keep the original image for visualization purpose
cv::Mat img_input = _vecimg[b].clone();
imgwidth = img_input.cols;
imgheight = img_input.rows;
scale = std::min(INPUT_W / img_input.cols, INPUT_H / img_input.rows);
if (img_input.empty()) continue;
cv::Mat pr_img = preprocess_img(img_input, INPUT_W, INPUT_H); // letterbox BGR to RGB
pr_img.convertTo(pr_img, CV_32FC3, 1.0f / 255.0f); // normalization 1/255
int i = 0;
for (int row = 0; row < INPUT_H; ++row) {
uchar* uc_pixel = pr_img.data + row * pr_img.step;
for (int col = 0; col < INPUT_W; ++col) {
data[b * 3 * INPUT_H * INPUT_W + i] = (float)uc_pixel[1] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
}
auto tensor_img = torch::from_blob(data, { BATCH_SIZE, INPUT_H, INPUT_W, 3 }).to(device_);
tensor_img = tensor_img.permute({ 0, 3, 1, 2 }).contiguous(); // BHWC -> BCHW (Batch, Channel, Height, Width)
if (half_) {
tensor_img = tensor_img.to(torch::kHalf);
}
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(tensor_img);
// inference
torch::jit::IValue output = module_.forward(inputs);
/*** Post-process ***/
auto detections = output.toTuple()->elements()[0].toTensor();
// result: n * 7
// batch index(0), top-left x/y (1,2), bottom-right x/y (3,4), score(5), class id(6)
auto result = PostProcessing(detections, 0, 0, scale, cv::Size(imgwidth, imgheight), conf_threshold, iou_threshold);
return result;
}
|
https://github.com/pytorch/pytorch/issues/60819
|
closed
|
[] | 2021-06-26T08:28:09Z
| 2021-06-28T13:27:36Z
| null |
xinsuinizhuan
|
pytorch/vision
| 4,117
|
publish nightly v0.11 to Conda channel `pytorch-nightly`
|
## 🚀 Feature
I would kindly request if you can update the latest nightly to Conda
## Motivation
We are going to test some against future Pytorch v1.10 but we also need to have a TV for these test and as TV is fixed to a particular PT version with the latest TV revert PT to v1.9
## Pitch
simple testing against future versions
## Alternatives
mixing conda and pypi sources
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
|
https://github.com/pytorch/vision/issues/4117
|
closed
|
[
"question",
"topic: binaries"
] | 2021-06-25T07:42:01Z
| 2021-06-29T10:41:04Z
| null |
Borda
|
pytorch/vision
| 4,115
|
Again details about how pretrained models are trained?
|
1. I use [v0.5.0/references](https://github.com/pytorch/vision/blob/build/v0.5.0/references/classification/train.py) to train a resnet50 wirth defalut config. But, I got Best_val Top1=75.806%, which has a gap of 0.3% about the pretrained model. How can I to repreduce your accuracy ?
2. I notice you said you use you recompute the batch norm statistics after training, can you show more details?
|
https://github.com/pytorch/vision/issues/4115
|
open
|
[
"question"
] | 2021-06-25T05:51:59Z
| 2021-06-28T14:59:26Z
| null |
YYangZiXin
|
pytorch/vision
| 4,105
|
Hi, why rate is two times with paper
|
https://github.com/pytorch/vision/blob/d1ab583d0d2df73208e2fc9c4d3a84e969c69b70/torchvision/models/segmentation/deeplabv3.py#L32
```
n. In the
end, our improved ASPP consists of (a) one 1×1 convolution
and three 3 × 3 convolutions with rates = (6, 12, 18) when
output stride = 16 (all with 256 filters and batch normalization), and (b) the image-level features,
```
|
https://github.com/pytorch/vision/issues/4105
|
closed
|
[
"question",
"module: models"
] | 2021-06-24T07:04:07Z
| 2021-07-02T03:52:59Z
| null |
flystarhe
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.