Datasets:

license: mit
Foundation Tactile (FoTa) - a multi-sensor multi-task large dataset for tactile sensing
Paper Code ColabJialiang (Alan) Zhao, Yuxiang Ma, Lirui Wang, and Edward H. Adelson
MIT CSAIL

Overview
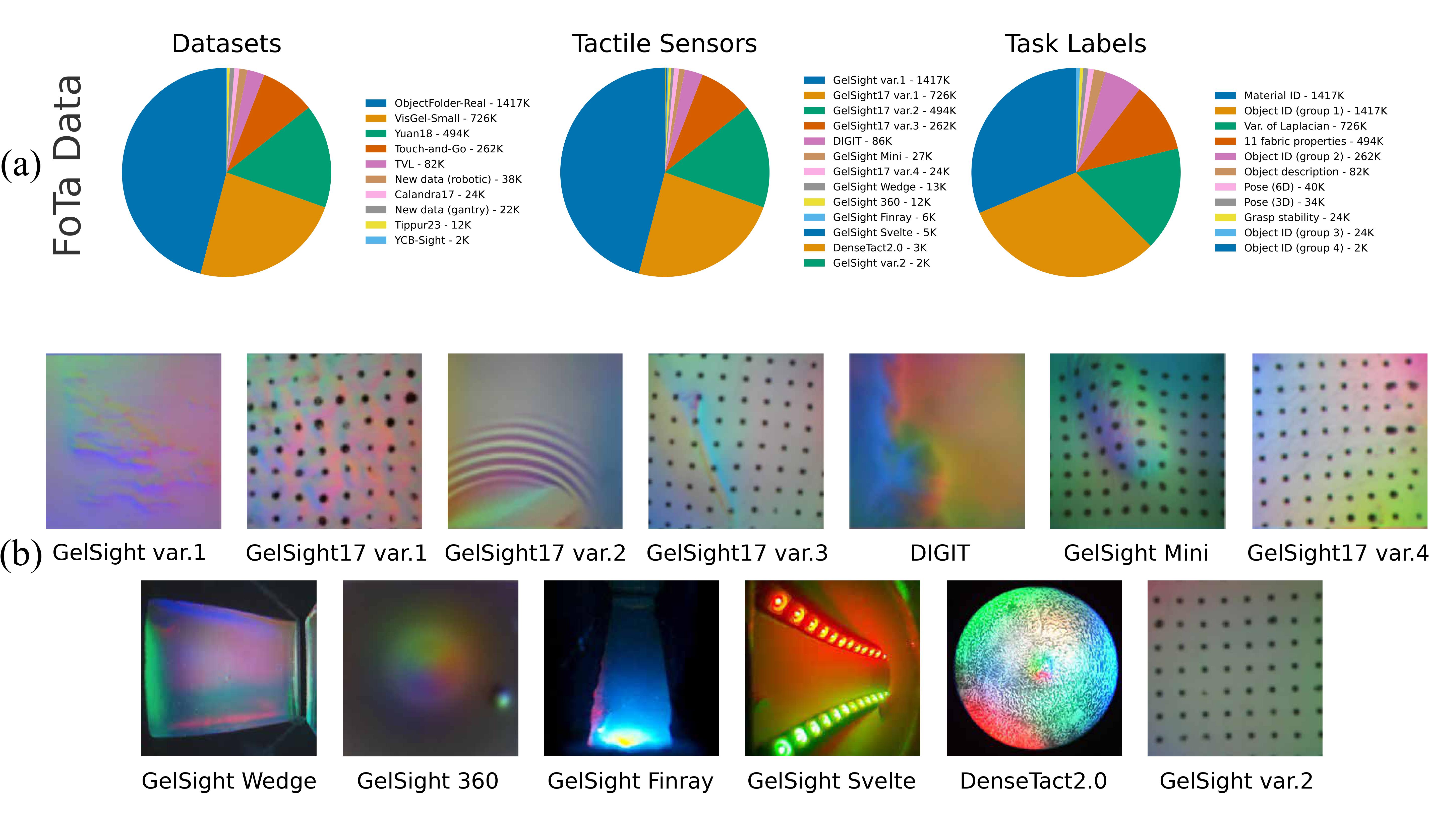
FoTa was released with Transferable Tactile Transformers (T3) as a large dataset for tactile representation learning. It aggregates some of the largest open-source tactile datasets, and it is released in a unified WebDataset format.
Fota contains over 3 million tactile images collected from 13 camera-based tactile sensors and 11 tasks.
File structure
After downloading and unzipping, the file structure of FoTa looks like:
dataset_1
|---- train
|---- count.txt
|---- data_000000.tar
|---- data_000001.tar
|---- ...
|---- val
|---- count.txt
|---- data_000000.tar
|---- ...
dataset_2
:
dataset_n
Each .tar file is one sharded dataset. At runtime, wds (WebDataset) api automatically loads, shuffles, and unpacks all shards on demand.
The nicest part of having a .tar file, instead of saving all raw data into matrices (e.g. .npz for zarr), is that .tar is easy to visualize without the need of any code.
Simply double click on any .tar file to check its content.
Although you will never need to unpack a .tar manually (wds does that automatically), it helps to understand the logic and file structure.
data_000000.tar
|---- file_name_1.jpg
|---- file_name_1.json
:
|---- file_name_n.jpg
|---- file_name_n.json
The .jpg files are tactile images, and the .json files store task-specific labels.
For more details on operations of the paper, checkout our GitHub repository and Colab tutorial.
Getting started
Checkout our Colab for a step-by-step tutorial!
Citation
MIT License.