|
--- |
|
configs: |
|
- config_name: default |
|
data_files: |
|
spaces.csv |
|
|
|
license: other |
|
language: |
|
- code |
|
size_categories: |
|
- 100K<n<1M |
|
--- |
|
 |
|
|
|
# 📊 Dataset Description |
|
|
|
This dataset comprises code files of Huggingface Spaces that have more than 0 likes as of November 10, 2023. This dataset contains various programming languages totaling in 672 MB of compressed and 2.05 GB of uncompressed data. |
|
|
|
# 📝 Data Fields |
|
|
|
| Field | Type | Description | |
|
|------------|--------|------------------------------------------| |
|
| repository | string | Huggingface Spaces repository names. | |
|
| sdk | string | Software Development Kit of the space. | |
|
| license | string | License type of the space. | |
|
|
|
## 🧩 Data Structure |
|
|
|
Data structure of the data. |
|
|
|
``` |
|
spaces/ |
|
├─ author1/ |
|
│ ├─ space1 |
|
│ ├─ space2 |
|
├─ author2/ |
|
│ ├─ space1 |
|
│ ├─ space2 |
|
│ ├─ space3 |
|
``` |
|
|
|
# 🏛️ Licenses |
|
|
|
Huggingface Spaces contains a variety of licenses. Here is the list of the licenses that this dataset contains: |
|
|
|
```python |
|
[ |
|
'None', |
|
'mit', |
|
'apache-2.0', |
|
'openrail', |
|
'gpl-3.0', |
|
'other', |
|
'afl-3.0', |
|
'unknown', |
|
'creativeml-openrail-m', |
|
'cc-by-nc-4.0', |
|
'cc-by-4.0', |
|
'cc', |
|
'cc-by-nc-sa-4.0', |
|
'bigscience-openrail-m', |
|
'bsd-3-clause', |
|
'agpl-3.0', |
|
'wtfpl', |
|
'gpl', |
|
'artistic-2.0', |
|
'lgpl-3.0', |
|
'cc-by-sa-4.0', |
|
'Configuration error', |
|
'bsd', |
|
'cc-by-nc-nd-4.0', |
|
'cc0-1.0', |
|
'unlicense', |
|
'llama2', |
|
'bigscience-bloom-rail-1.0', |
|
'gpl-2.0', |
|
'bsd-2-clause', |
|
'osl-3.0', |
|
'cc-by-2.0', |
|
'cc-by-3.0', |
|
'cc-by-nc-3.0', |
|
'cc-by-nc-2.0', |
|
'cc-by-nd-4.0', |
|
'openrail++', |
|
'bigcode-openrail-m', |
|
'bsd-3-clause-clear', |
|
'eupl-1.1', |
|
'cc-by-sa-3.0', |
|
'mpl-2.0', |
|
'c-uda', |
|
'gfdl', |
|
'cc-by-nc-sa-2.0', |
|
'cc-by-2.5', |
|
'bsl-1.0', |
|
'odc-by', |
|
'deepfloyd-if-license', |
|
'ms-pl', |
|
'ecl-2.0', |
|
'pddl', |
|
'ofl-1.1', |
|
'lgpl-2.1', |
|
'postgresql', |
|
'lppl-1.3c', |
|
'ncsa', |
|
'cc-by-nc-sa-3.0' |
|
] |
|
``` |
|
|
|
# 📊 Dataset Statistics |
|
|
|
| Language | File Extension | File Counts | File Size (MB) | Line Counts | |
|
|------------|-----------------|-------------|----------------|-------------| |
|
| Python | .py | 141,560 | 1079.0 | 28,653,744 | |
|
| SQL | .sql | 21 | 523.6 | 645 | |
|
| JavaScript | .js | 6,790 | 369.8 | 2,137,054 | |
|
| Markdown | .md | 63,237 | 273.4 | 3,110,443 | |
|
| HTML | .html | 1,953 | 265.8 | 516,020 | |
|
| C | .c | 1,320 | 132.2 | 3,558,826 | |
|
| Go | .go | 429 | 46.3 | 6,331 | |
|
| CSS | .css | 3,097 | 25.6 | 386,334 | |
|
| C Header | .h | 2,824 | 20.4 | 570,948 | |
|
| C++ | .cpp | 1,117 | 15.3 | 494,939 | |
|
| TypeScript | .ts | 4,158 | 14.8 | 439,551 | |
|
| TSX | .tsx | 4,273 | 9.4 | 306,416 | |
|
| Shell | .sh | 3,294 | 5.5 | 171,943 | |
|
| Perl | .pm | 92 | 4.2 | 128,594 | |
|
| C# | .cs | 22 | 3.9 | 41,265 | |
|
|
|
|
|
## 🖥️ Language |
|
|
|
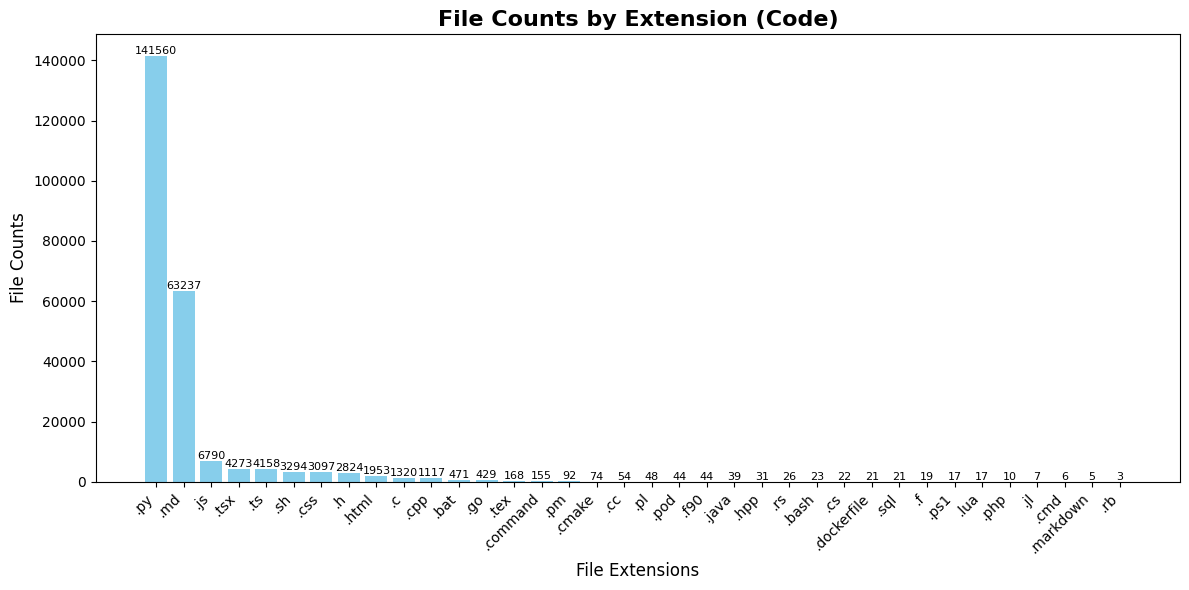 |
|
|
|
## 📁 Size |
|
|
|
 |
|
|
|
## 📝 Line Count |
|
|
|
 |
|
|
|
# 🤗 Huggingface Spaces Statistics |
|
|
|
## 🛠️ Software Development Kit (SDK) |
|
|
|
Software Development Kit pie chart. |
|
|
|
 |
|
|
|
## 🏛️ License |
|
|
|
License chart. |
|
|
|
 |
|
|
|
# 📅 Dataset Creation |
|
|
|
This dataset was created in these steps: |
|
|
|
1. Scraped all spaces using the Huggingface Hub API. |
|
|
|
```python |
|
from huggingface_hub import HfApi |
|
api = HfApi() |
|
|
|
spaces = api.list_spaces(sort="likes", full=1, direction=-1) |
|
``` |
|
|
|
2. Filtered spaces with more than 0 likes. |
|
|
|
```python |
|
a = {} |
|
|
|
for i in tqdm(spaces): |
|
i = i.__dict__ |
|
if i['likes'] > 0: |
|
try: |
|
try: |
|
a[i['id']] = {'sdk': i['sdk'], 'license': i['cardData']['license'], 'likes': i['likes']} |
|
except KeyError: |
|
a[i['id']] = {'sdk': i['sdk'], 'license': None, 'likes': i['likes']} |
|
except: |
|
a[i['id']] = {'sdk': "Configuration error", 'license': "Configuration error", 'likes': i['likes']} |
|
|
|
data_list = [{'repository': key, 'sdk': value['sdk'], 'license': value['license'], 'likes': value['likes']} for key, value in a.items()] |
|
|
|
df = pd.DataFrame(data_list) |
|
``` |
|
|
|
3. Cloned spaces locally. |
|
|
|
```python |
|
from huggingface_hub import snapshot_download |
|
|
|
programming = ['.asm', '.bat', '.cmd', '.c', '.h', '.cs', '.cpp', '.hpp', '.c++', '.h++', '.cc', '.hh', '.C', '.H', '.cmake', '.css', '.dockerfile', 'Dockerfile', '.f90', '.f', '.f03', '.f08', '.f77', '.f95', '.for', '.fpp', '.go', '.hs', '.html', '.java', '.js', '.jl', '.lua', 'Makefile', '.md', '.markdown', '.php', '.php3', '.php4', '.php5', '.phps', '.phpt', '.pl', '.pm', '.pod', '.perl', '.ps1', '.psd1', '.psm1', '.py', '.rb', '.rs', '.sql', '.scala', '.sh', '.bash', '.command', '.zsh', '.ts', '.tsx', '.tex', '.vb'] |
|
pattern = [f"*{i}" for i in programming] |
|
|
|
for i in repos: |
|
snapshot_download(i, repo_type="space", local_dir=f"spaces/{i}", allow_patterns=pattern) |
|
```` |
|
|
|
4. Processed the data to derive statistics. |
