
license: cc-by-nc-4.0
task_categories:
- text-to-video
language:
- en
size_categories:
- 1M<n<10M
tags:
- prompts
- text-to-video
viewer: false

Summary
This is the dataset proposed in our paper "VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models"
VidProM is the first dataset featuring 1.67 million unique text-to-video prompts and 6.69 million videos generated from 4 different state-of-the-art diffusion models. It inspires many exciting new research areas, such as Text-to-Video Prompt Engineering, Efficient Video Generation, Fake Video Detection, and Video Copy Detection for Diffusion Models.
Directory
*DATA_PATH
*VidProM_unique.csv
*VidProM_semantic_unique.csv
*VidProM_embed.hdf5
*original_files
*generate_1_ori.html
*generate_2_ori.html
...
*pika_videos
*pika_videos_1.tar
*pika_videos_2.tar
...
*vc2_videos
*vc2_videos_1.tar
*vc2_videos_2.tar
...
*t2vz_videos
*t2vz_videos_1.tar
*t2vz_videos_2.tar
...
*ms_videos
*ms_videos_1.tar
*ms_videos_2.tar
...
Download
Automatically
Install the datasets library first, by:
pip install datasets
Then it can be downloaded automatically with
import numpy as np
from datasets import load_dataset
dataset = load_dataset('WenhaoWang/VidProM')
Manual
You can also download each file by wget, for instance:
wget https://huggingface.co/datasets/WenhaoWang/VidProM/resolve/main/VidProM_unique.csv
Explanation
VidProM_unique.csv contains the UUID, prompt, time, and 6 NSFW probabilities.
VidProM_semantic_unique.csv is a semantically unique version of VidProM_unique.csv.
VidProM_embed.hdf5 is the 3072-dim embeddings of our prompts. They are embedded by text-embedding-3-large, which is the latest text embedding model of OpenAI.
original_files are the HTML files collected by DiscordChatExporter.
pika_videos, vc2_videos, t2vz_videos, and ms_videos are the generated videos by 4 state-of-the-art text-to-video diffusion models. Each contains 30 tar files.
Below are three rows from VidProM_unique.csv:
| uuid | prompt | time | toxicity | obscene | identity_attack | insult | threat | sexual_explicit |
|---|---|---|---|---|---|---|---|---|
| 6a83eb92-faa0-572b-9e1f-67dec99b711d | Flying among clouds and stars, kitten Max discovered a world full of winged friends. Returning home, he shared his stories and everyone smiled as they imagined flying together in their dreams. | Sun Sep 3 12:27:44 2023 | 0.00129 | 0.00016 | 7e-05 | 0.00064 | 2e-05 | 2e-05 |
| 3ba1adf3-5254-59fb-a13e-57e6aa161626 | Use a clean and modern font for the text "Relate Reality 101." Add a small, stylized heart icon or a thought bubble above or beside the text to represent emotions and thoughts. Consider using a color scheme that includes warm, inviting colors like deep reds, soft blues, or soothing purples to evoke feelings of connection and intrigue. | Wed Sep 13 18:15:30 2023 | 0.00038 | 0.00013 | 8e-05 | 0.00018 | 3e-05 | 3e-05 |
| 62e5a2a0-4994-5c75-9976-2416420526f7 | zoomed out, sideview of an Grey Alien sitting at a computer desk | Tue Oct 24 20:24:21 2023 | 0.01777 | 0.00029 | 0.00336 | 0.00256 | 0.00017 | 5e-05 |
Datapoint

Comparison with DiffusionDB

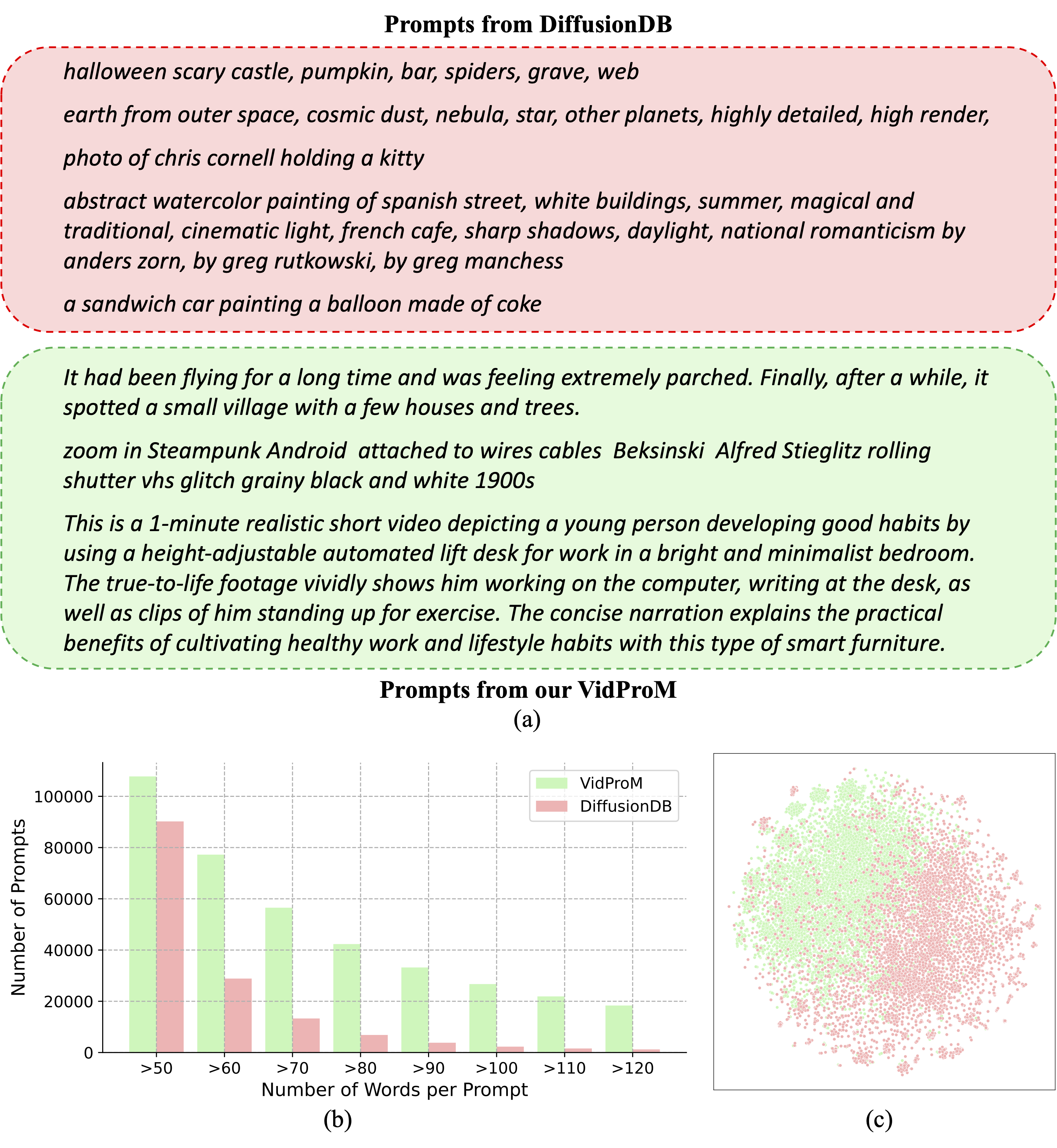
Please check our paper for a detailed comparison.
Curators
VidProM is created by Wenhao Wang and Yi Yang from the ReLER Lab.
License
The prompts and videos generated by Pika in our VidProM are licensed under the CC BY-NC 4.0 license. Additionally, similar to their original repositories, the videos from VideoCraft2, Text2Video-Zero, and ModelScope are released under the Apache license, the CreativeML Open RAIL-M license, and the CC BY-NC 4.0 license, respectively.
Citation
Contact
If you have any questions, feel free to contact Wenhao Wang (wangwenhao0716@gmail.com).