Datasets:


viewer: false
language:
- ace
- amh
- ara
- arq
- ary
- bam
- ban
- bbc
- ben
- bjn
- bos
- bug
- bul
- ces
- dan
- deu
- ell
- eng
- fas
- fil
- fin
- fre
- hau
- heb
- hin
- hrv
- hun
- ibo
- ind
- ita
- jav
- jpn
- kan
- kin
- kor
- mad
- mal
- mar
- min
- mlt
- nij
- nor
- pcm
- pol
- por
- ron
- rus
- slk
- slv
- spa
- sqi
- srp
- sun
- swe
- swh
- tam
- tel
- tha
- tso
- tur
- twi
- vie
- yor
- zho
tags:
- Anti-Social
- Emotion Recognition
- Humor Detection
- Irony
- Sarcasm
- Sentiment Analysis
- Subjectivity Analysis
- hate speech detection
- offensive language detection
task_categories:
- text-classification
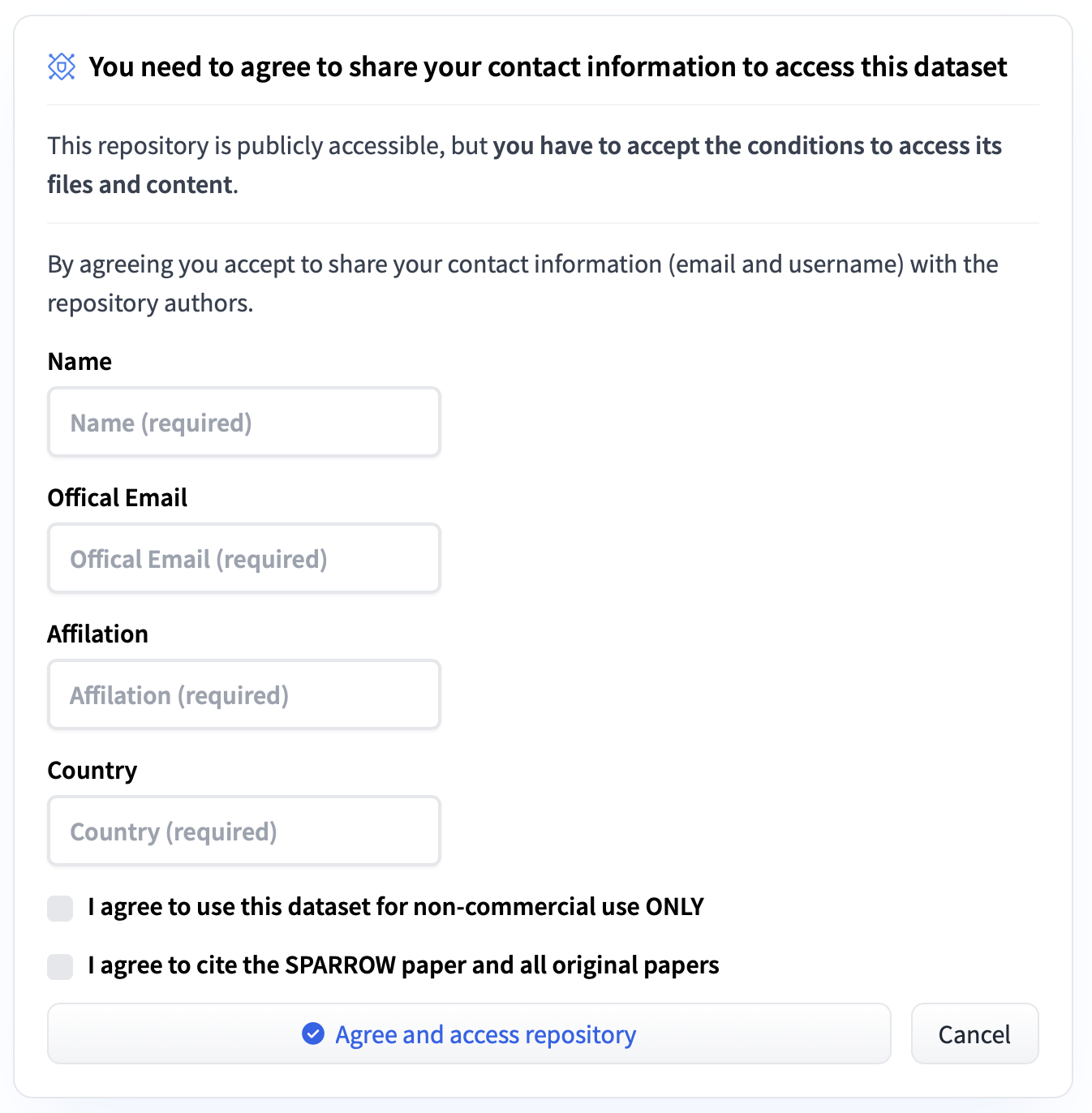
extra_gated_fields:
Full Name: text
Official Email Address: text
Affiliation: text
Country: text
I agree to ONLY use this dataset for non-commercial purposes: checkbox
I agree to cite the SPARROW paper and all original papers: checkbox


In this work, we introduce SPARROW, SPARROW is a evaluation benchmark for sociopragmatic meaning understanding. SPARROW comprises 169 datasets covering 13 task types across six primary categories (e.g., anti-social language detection, emotion recognition). SPARROW datasets encompass 64 different languages originating from 12 language families representing 16 writing scripts.
How to Use SPARROW
Request Access
To obtain access to the SPARROW benchmark on Huggingface, follow the following steps:
Login on your Haggingface account
Request access
- Please fill in your actual full name and affiliation (e.g., the name of your research institute).
- Please use your official email address if it is available.
Install Requirments
pip install datasets transformers seqeval
Login with your Huggingface CLI
You can get/manage your access tokens in your settings.
export HUGGINGFACE_TOKEN=""
huggingface-cli login --token $HUGGINGFACE_TOKEN
Submitting your results on SPARROW test
We design a public leaderboard for scoring PLMs on SPARRAW. Our leaderboard is interactive and offers rich meta-data about the various datasets involved as well as the language models we evaluate.
You can evalute your models using SPARROW leaderboard: https://sparrow.dlnlp.ai
Citation
If you use SPARROW for your scientific publication, or if you find the resources in this repository useful, please cite our paper as follows:
@inproceedings{zhang-etal-2023-skipped,
title = "The Skipped Beat: A Study of Sociopragmatic Understanding in LLMs for 64 Languages",
author = "Zhang, Chiyu and
Khai Duy Doan and,
Qisheng Liao and,
Abdul-Mageed, Muhammad",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
year = "2023",
publisher = "Association for Computational Linguistics",
}
Acknowledgments
We gratefully acknowledge support from the Natural Sciences and Engineering Research Council of Canada, the Social Sciences and Humanities Research Council of Canada, Canadian Foundation for Innovation, ComputeCanada and UBC ARC-Sockeye.