
license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
language:
- en
tags:
- code
- finance
OCR Trains Dataset
The dataset consists of text data obtained through optical character recognition (OCR) technology, which extracts text from images, in this case, the train number.
The dataset be used to train machine learning models for extracting and analyzing text from train-related documents or images, to develop algorithms or models for real-time updates, or building intelligent systems related to trains and transportation.
.png?generation=1691732664604021&alt=media)
Get the Dataset
This is just an example of the data
Contact us via sales@trainingdata.pro or leave a request on https://trainingdata.pro/data-market to discuss your requirements, learn about the price and buy the dataset
Dataset structure
- images - contains of original images of trains
- annotations.xml - contains coordinates of the bounding boxes and indicated text, created for the original photo
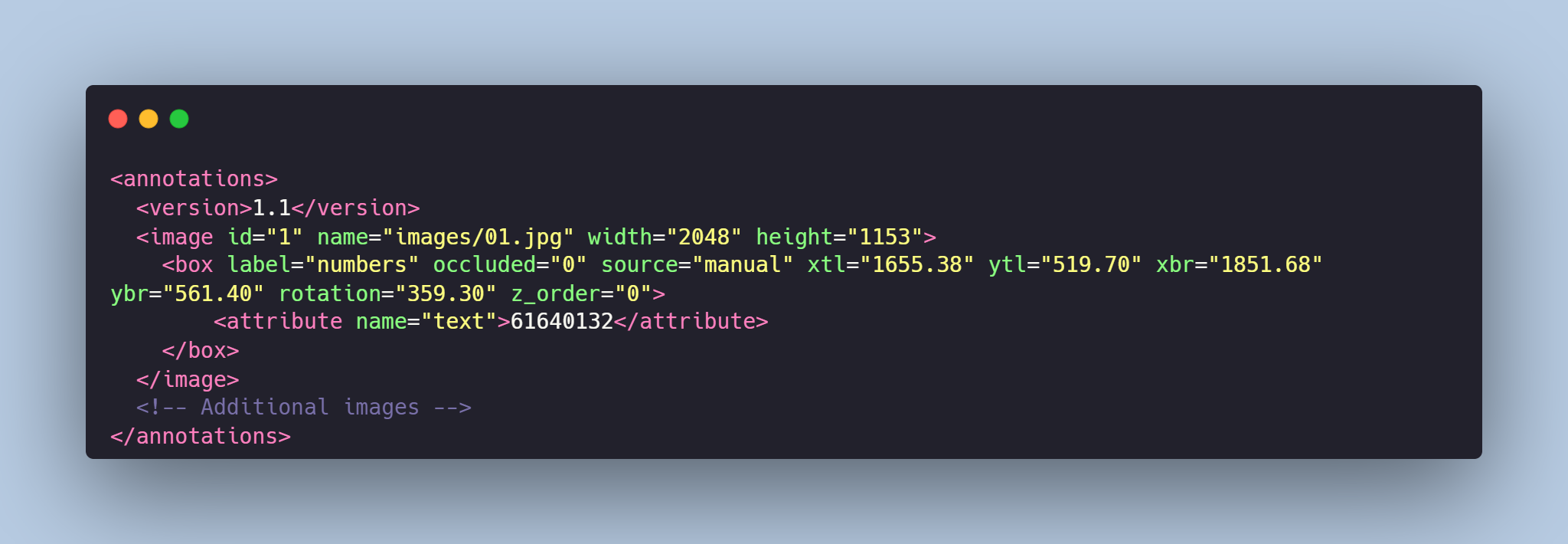
Data Format
Each image from images folder is accompanied by an XML-annotation in the annotations.xml file indicating the coordinates of the bounding boxes for text detection. For each point, the x and y coordinates are provided.
Example of XML file structure
Text Detection in Trains' images might be made in accordance with your requirements.
TrainingData provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: https://www.kaggle.com/trainingdatapro/datasets
TrainingData's GitHub: https://github.com/Trainingdata-datamarket/TrainingData_All_datasets