Datasets:

license: cc-by-nc-nd-4.0
task_categories:
- image-to-text
- object-detection
language:
- en
tags:
- code
- legal
- finance
OCR Text Detection in the Documents Dataset
The dataset is a collection of images that have been annotated with the location of text in the document. The dataset is specifically curated for text detection and recognition tasks in documents such as scanned papers, forms, invoices, and handwritten notes.
The dataset contains a variety of document types, including different layouts, font sizes, and styles. The images come from diverse sources, ensuring a representative collection of document styles and quality. Each image in the dataset is accompanied by bounding box annotations that outline the exact location of the text within the document.
The Text Detection in the Documents dataset provides an invaluable resource for developing and testing algorithms for text extraction, recognition, and analysis. It enables researchers to explore and innovate in various applications, including optical character recognition (OCR), information extraction, and document understanding.
.png?generation=1691059158337136&alt=media)
Get the dataset
This is just an example of the data
Leave a request on https://trainingdata.pro/data-market to discuss your requirements, learn about the price and buy the dataset.
Dataset structure
- images - contains of original images of documents
- boxes - includes bounding box labeling for the original images
- annotations.xml - contains coordinates of the bounding boxes and labels, created for the original photo
Data Format
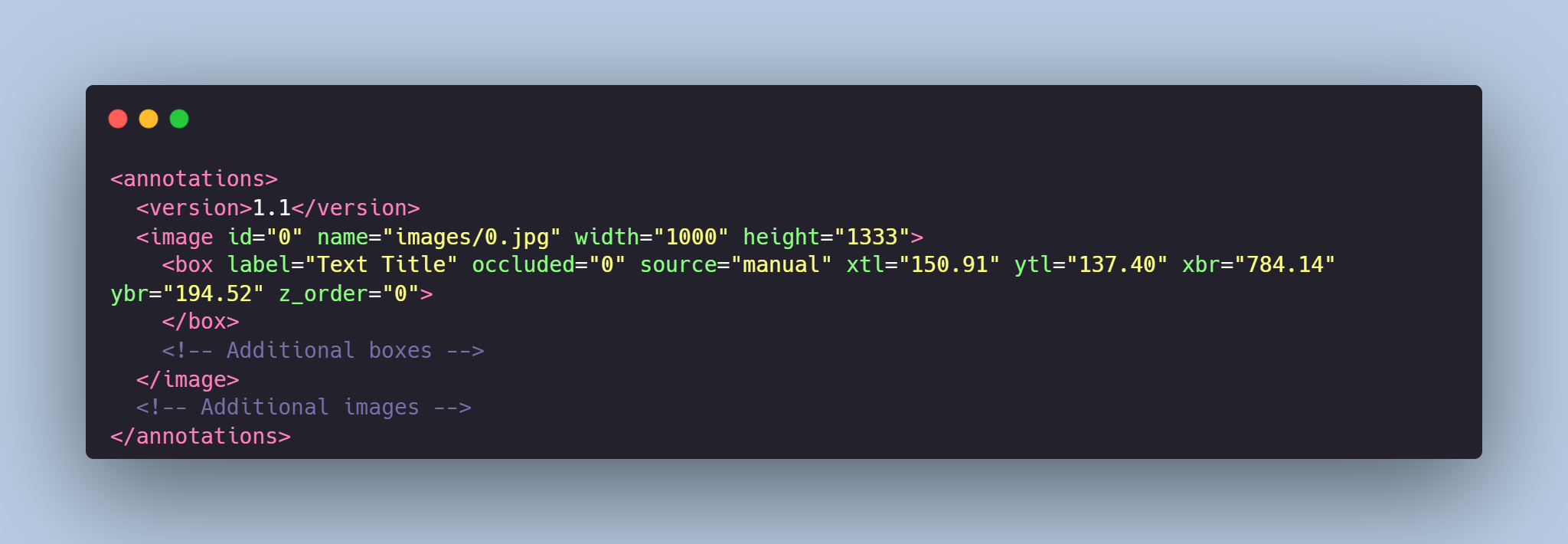
Each image from images folder is accompanied by an XML-annotation in the annotations.xml file indicating the coordinates of the bounding boxes and labels for text detection. For each point, the x and y coordinates are provided.
Labels for the text:
- "Text Title" - corresponds to titles, the box is red
- "Text Paragraph" - corresponds to paragraphs of text, the box is blue
- "Table" - corresponds to the table, the box is green
- "Handwritten" - corresponds to handwritten text, the box is purple
Example of XML file structure
Text Detection in the Documents might be made in accordance with your requirements.
TrainingData provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: https://www.kaggle.com/trainingdatapro/datasets
TrainingData's GitHub: https://github.com/Trainingdata-datamarket/TrainingData_All_datasets