
File size: 8,658 Bytes
791b5b3 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 |

我们很高兴地介绍我们创建的一个新工具:**⚔️ AI vs. AI ⚔️,一个深度强化学习多智能体竞赛系统**。
这个工具托管在 [Space](https://hf.co/spaces) 上,允许我们创建多智能体竞赛。它包含三个元素:
- 一个带匹配算法的 *Space*,**使用后台任务运行模型战斗**。
- 一个包含结果的 *Dataset*。
- 一个获取匹配历史结果和显示模型 LEO 的 *Leaderboard*。
然后,当用户将一个训练好的模型推到 Hub 时,**它会获取评估和排名**。得益于此,我们可以在多智能体环境中对你的智能体与其他智能体进行评估。
除了作为一个托管多智能体竞赛的有用工具,我们认为这个工具在多智能体设置中可以成为一个**鲁棒的评估技术**。通过与许多策略对抗,你的智能体将根据广泛的行为进行评估。这应该能让你很好地了解你的策略的质量。
让我们看看它在我们的第一个竞赛托管:SoccerTwos Challenge 上是如何工作的。
# AI vs. AI是怎么工作的?
AI vs. AI 是一个在 Hugging Face 上开发的开源工具,**对多智能体环境下强化学习模型的强度进行排名**。
其思想是通过让模型之间持续比赛,并使用比赛结果来评估它们与所有其他模型相比的表现,从而在不需要经典指标的情况下了解它们的策略质量,从而获得**对技能的相对衡量,而不是客观衡量**。
对于一个给定的任务或环境,提交的智能体越多,**评分就越有代表性**。
为了在一个竞争的环境里基于比赛结果获得评分,我们决定根据 [ELO 评分系统](https://en.wikipedia.org/wiki/Elo_rating_system)进行排名。
游戏的核心理念是,在比赛结束后,双方玩家的评分都会根据比赛结果和他们在比赛前的评分进行更新。当一个拥有高评分的用户打败一个拥有低排名的用户时,他们便不会获得太多分数。同样,在这种情况下,输家也不会损失很多分。
相反地,如果一个低评级的玩家击败了一个高评级的玩家,这将对他们的评级产生更显著的影响。
在我们的环境中,我们尽量保持系统的简单性,不根据玩家的初始评分来改变获得或失去的数量。因此,收益和损失总是完全相反的(例如+10 / -10),平均 ELO 评分将保持在初始评分不变。选择一个1200 ELO 评分启动完全是任意的。
如果你想了解更多关于 ELO 的信息并且查看一些计算示例,我们在[深度强化学习课程](https://huggingface.co/deep-rl-course/unit7/self-play?fw=pt#the-elo-score-to-evaluate-our-agent)里写了一个解释。
使用此评级,可以**自动在具有可对比强度的模型之间进行匹配**。你可以有多种方法来创建匹配系统,但在这里我们决定保持它相当简单,同时保证比赛的多样性最小,并保持大多数比赛的对手评分相当接近。
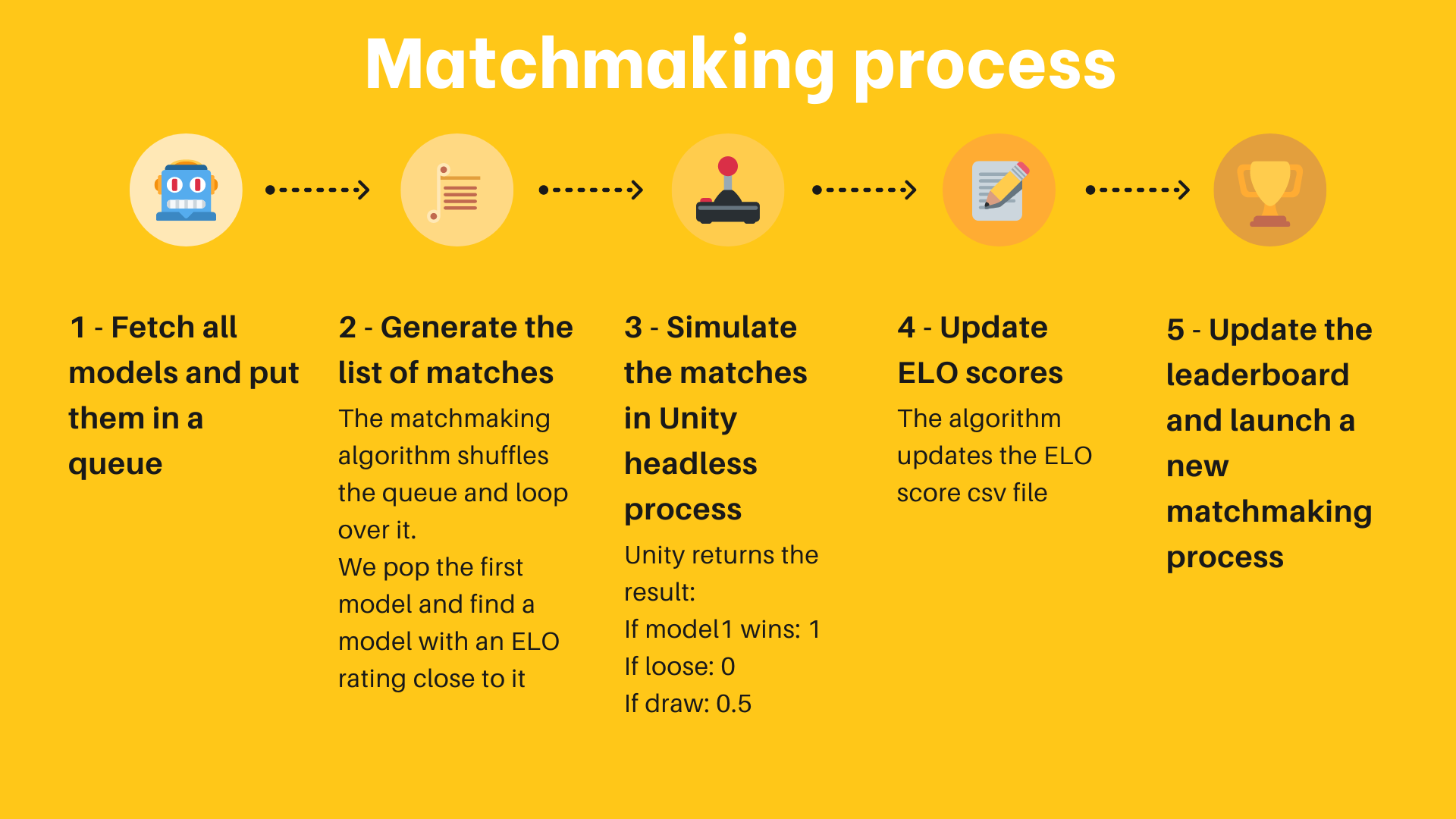
以下是该算法的工作原理:
1. 从 Hub 上收集所有可用的模型。新模型获得初始 1200 的评分,其他的模型保持在以前比赛中得到或失去的评分。
2. 从所有这些模型创建一个队列。
3. 从队列中弹出第一个元素(模型),然后从 n 个模型中随机抽取另一个与第一个模型评级最接近的模型。
4. 通过在环境中(例如一个 Unity 可执行文件)加载这两个模型来模拟这个比赛,并收集结果。对于这个实现,我们将结果发送到 Hub上的 Hug Face Dataset。
5. 根据收到的结果和 ELO 公式计算两个模型的新评分。
6. 继续两个两个地弹出模型并模拟比赛,直到队列中只有一个或零个模型。
7. 保存结果评分,回到步骤1。
为了持续运行这个配对过程,我们使用**免费的 Hug Face Spaces 硬件和一个 Scheduler** 来作为后台任务持续运行这个配对过程。
Space 还用于获取每个以及比赛过的模型的 ELO 评分,并显示一个排行榜,**每个人都可以检查模型的进度**。
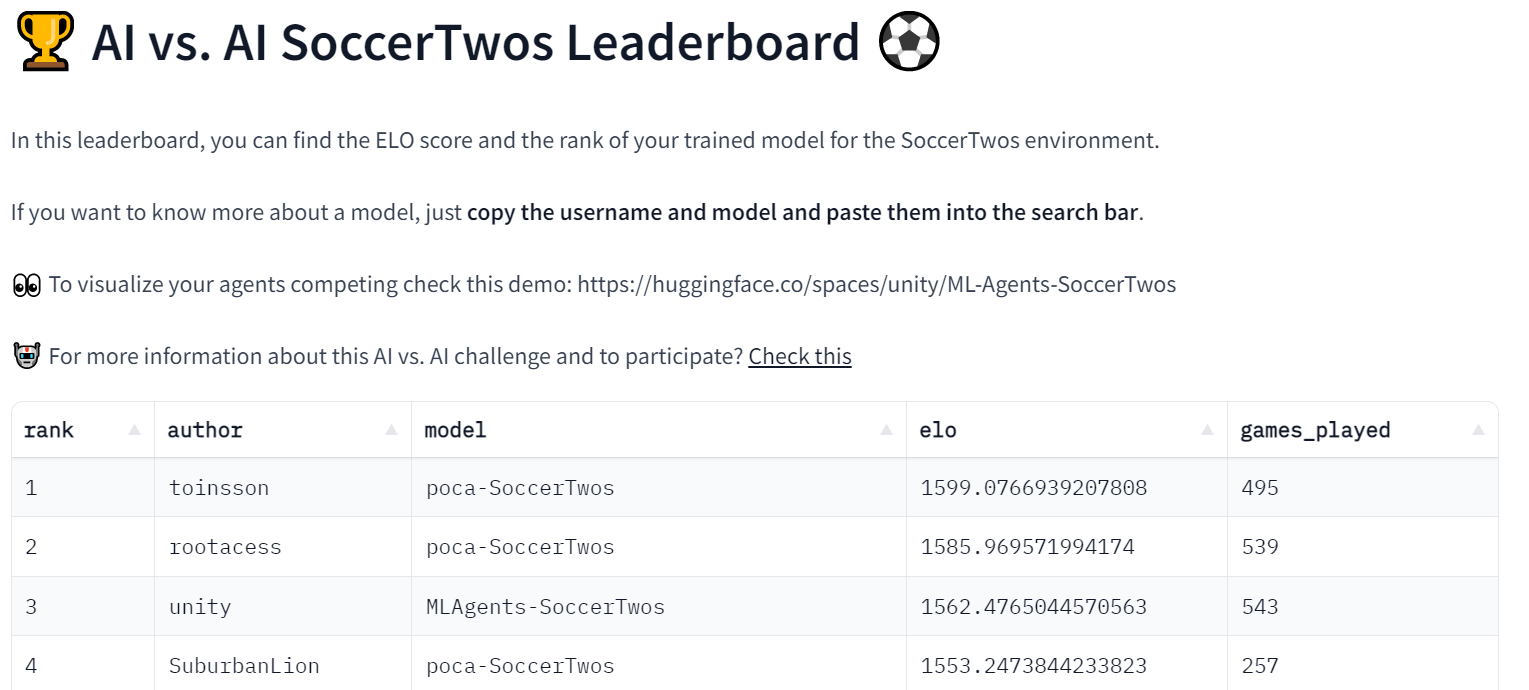
该过程通常使用几个 Hugging Face Datasets 来提供数据持久性(这里是匹配历史和模型评分)。
因为这个过程也保存了比赛的历史,因此可以精确地看到任意给定模型的结果。例如,这可以让你检查为什么你的模型与另一个模型搏斗,最显著的是使用另一个演示 Space 来可视化匹配,就像[这个](https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos.)。
目前,**这个实验是在 MLAgent 环境 SoccerTwos 下进行的,用于 Hugging Face 深度强化学习课程**,然而,这个过程和实现通常是**环境无关的,可以用来免费评估广泛的对抗性多智能体设置**。
当然,需要再次提醒的是,此评估是提交的智能体实力之间的相对评分,评分本身**与其他指标相比没有客观意义**。它只表示一个模型与模型池中其他模型相对的好坏。尽管如此,如果有足够大且多样化的模型池(以及足够多的比赛),这种评估将成为表示模型一般性能的可靠方法。
# 我们的第一个 AI vs. AI 挑战实验:SoccerTwos Challenge ⚽
这个挑战是我们免费的深度强化学习课程的第 7 单元。它开始于 2 月 1 日,4 月 30 日结束。
如果你感兴趣,**你不必参加入程就可以参加这个比赛。你可以在这里开始** 👉 https://huggingface.co/deep-rl-course/unit7/introduction
在这个单元,读者通过训练一个 **2 vs 2 足球队**学习多智能体强化学习(MARL)的基础。
用到的环境是 [Unity ML-Agents 团队](https://github.com/Unity-Technologies/ml-agents)制作的。这个比赛的目标是简单的:你的队伍需要进一个球。要做到这一点,他们需要击败对手的团队,并与队友合作。

除了排行榜,我们创建了一个 Space 演示,人们可以选择两个队伍并可视化它们的比赛 👉https://huggingface.co/spaces/unity/SoccerTwos
这个实验进展顺利,因为我们已经在[排行榜](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)上有 48 个模型了。

我们也创造了一个叫做 ai-vs-ai-competition 的 discord 频道,人们可以与他人交流并分享建议。
# 结论,以及下一步
因为我们开发的这个工具是**环境无关的**,在未来我们想用 [PettingZoo](https://pettingzoo.farama.org/) 举办更多的挑战赛和多智能体环境。如果你有一些想做的环境或者挑战赛,[不要犹豫,与我们联系](mailto:thomas.simonini@huggingface.co)。
在未来,我们将用我们创造的工具和环境来举办多个多智能体比赛,例如 SnowballFight。
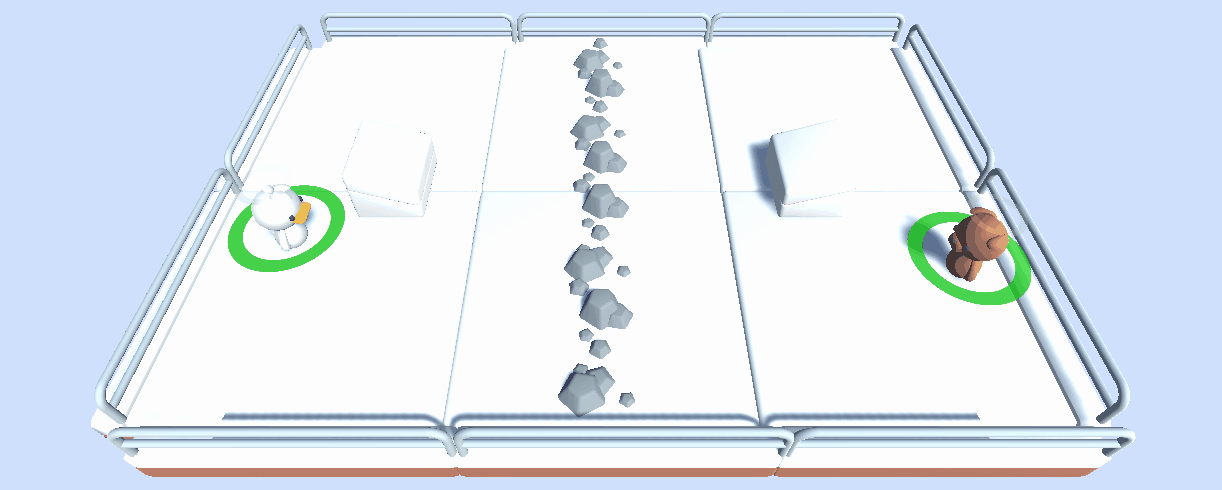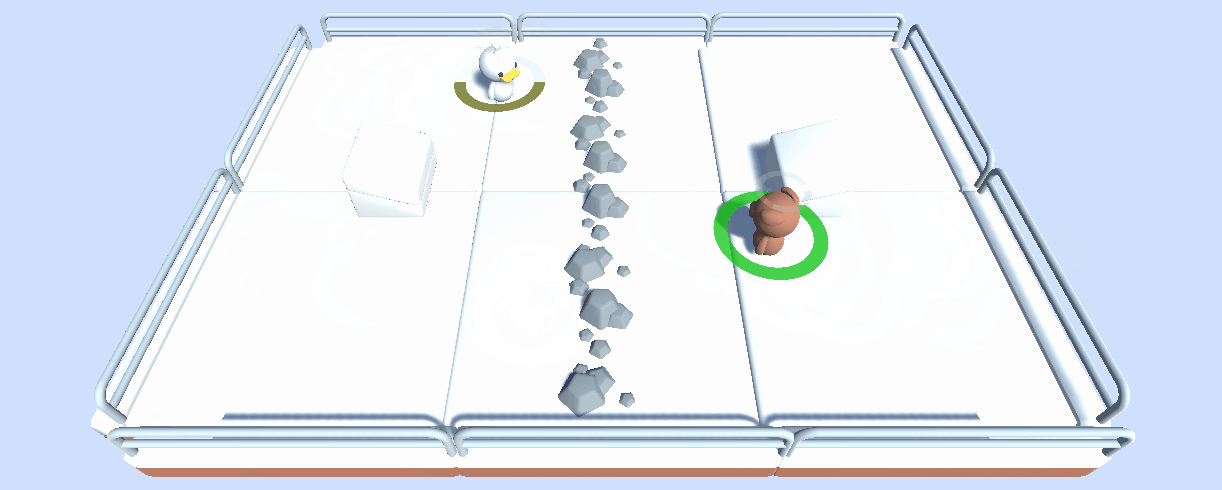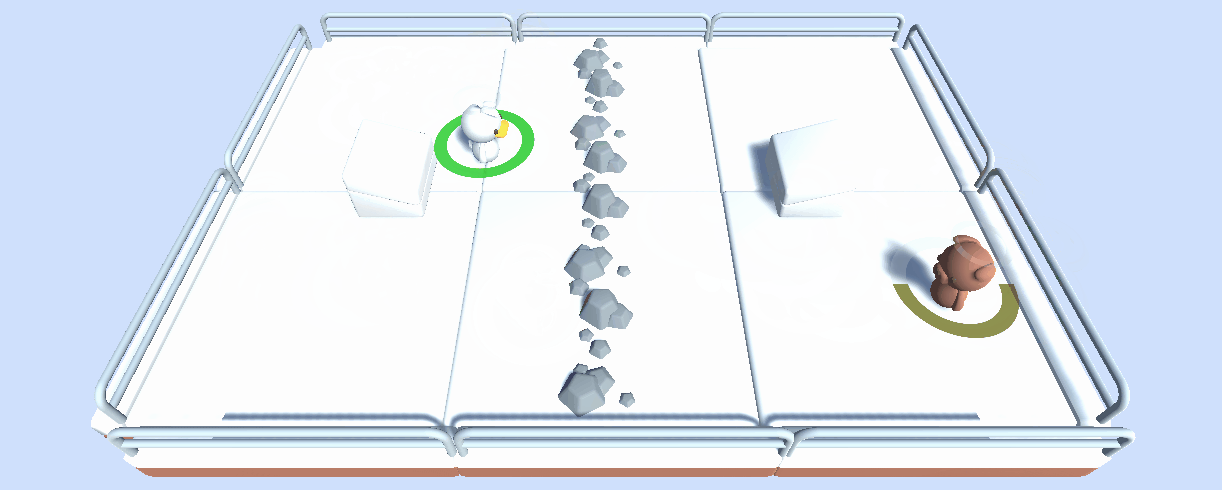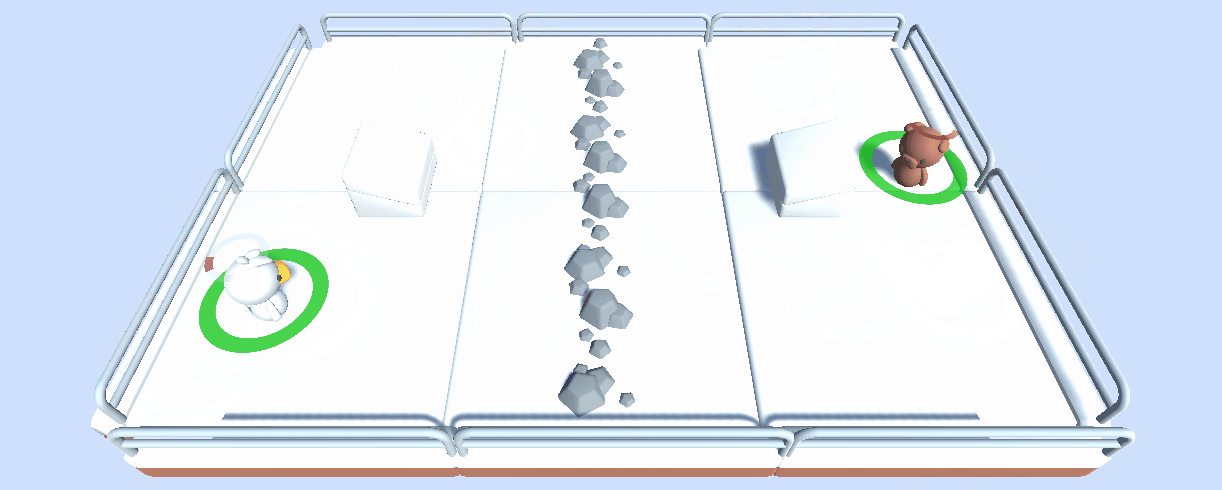
除了称为一个举办多智能体比赛的有用工具,我们考虑这个工具也可以在多智能体设置中成为**一个鲁棒的评估技术:通过与许多策略对抗,你的智能体将根据广泛的行为进行评估,并且你将很好地了解你的策略的质量**。
保持联系的最佳方式是[加入我们的 discord 服务](http://hf.co/discord/join)与我们和社区进行交流。
**引用**
引用:如果你发现这对你的学术工作是有用的,请考虑引用我们的工作:
```
Cochet, Simonini, "Introducing AI vs. AI a deep reinforcement learning multi-agents competition system", Hugging Face Blog, 2023.
```
BibTeX 引用:
```
@article{cochet-simonini2023,
author = {Cochet, Carl and Simonini, Thomas},
title = {Introducing AI vs. AI a deep reinforcement learning multi-agents competition system},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/aivsai},
}
```
> 英文原文:https://huggingface.co/blog/aivsai
>
> 译者:AIboy1993(李旭东)
|