

metadata
license: cc-by-nc-4.0
model-index:
- name: Pluto_24B_DPO_200
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 65.61
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=cloudyu/Pluto_24B_DPO_200
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 86.38
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=cloudyu/Pluto_24B_DPO_200
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.59
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=cloudyu/Pluto_24B_DPO_200
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 69.86
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=cloudyu/Pluto_24B_DPO_200
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 78.93
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=cloudyu/Pluto_24B_DPO_200
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 65.88
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=cloudyu/Pluto_24B_DPO_200
name: Open LLM Leaderboard
This is DPO improved version of cloudyu/Mixtral_7Bx4_MOE_24B
Metrics improved by DPO
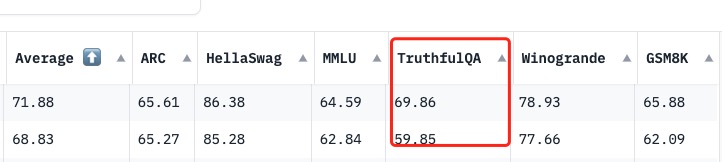



Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 71.88 |
| AI2 Reasoning Challenge (25-Shot) | 65.61 |
| HellaSwag (10-Shot) | 86.38 |
| MMLU (5-Shot) | 64.59 |
| TruthfulQA (0-shot) | 69.86 |
| Winogrande (5-shot) | 78.93 |
| GSM8k (5-shot) | 65.88 |