
File size: 18,273 Bytes
606bf06 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 |
---
license: mit
language: fr
library_name: transformers
pipeline_tag: automatic-speech-recognition
thumbnail: null
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
datasets:
- mozilla-foundation/common_voice_13_0
- facebook/multilingual_librispeech
- facebook/voxpopuli
- google/fleurs
- gigant/african_accented_french
metrics:
- wer
model-index:
- name: whisper-large-v3-french-distil-dec16
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13.0
type: mozilla-foundation/common_voice_13_0
config: fr
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 7.18
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech (MLS)
type: facebook/multilingual_librispeech
config: french
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 3.57
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: VoxPopuli
type: facebook/voxpopuli
config: fr
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 8.76
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Fleurs
type: google/fleurs
config: fr_fr
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 5.03
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: African Accented French
type: gigant/african_accented_french
config: fr
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 3.90
---
# Whisper-Large-V3-French-Distil-Dec16
Whisper-Large-V3-French-Distil represents a series of distilled versions of [Whisper-Large-V3-French](https://huggingface.co/bofenghuang/whisper-large-v3-french), achieved by reducing the number of decoder layers from 32 to 16, 8, 4, or 2 and distilling using a large-scale dataset, as outlined in this [paper](https://arxiv.org/abs/2311.00430).
The distilled variants reduce memory usage and inference time while maintaining performance (based on the retained number of layers) and mitigating the risk of hallucinations, particularly in long-form transcriptions. Moreover, they can be seamlessly combined with the original Whisper-Large-V3-French model for speculative decoding, resulting in improved inference speed and consistent outputs compared to using the standalone model.
This model has been converted into various formats, facilitating its usage across different libraries, including transformers, openai-whisper, fasterwhisper, whisper.cpp, candle, mlx, etc.
## Table of Contents
- [Performance](#performance)
- [Usage](#usage)
- [Hugging Face Pipeline](#hugging-face-pipeline)
- [Hugging Face Low-level APIs](#hugging-face-low-level-apis)
- [Speculative Decoding](#speculative-decoding)
- [OpenAI Whisper](#openai-whisper)
- [Faster Whisper](#faster-whisper)
- [Whisper.cpp](#whispercpp)
- [Candle](#candle)
- [MLX](#mlx)
- [Training details](#training-details)
- [Acknowledgements](#acknowledgements)
## Performance
We evaluated our model on both short and long-form transcriptions, and also tested it on both in-distribution and out-of-distribution datasets to conduct a comprehensive analysis assessing its accuracy, generalizability, and robustness.
Please note that the reported WER is the result after converting numbers to text, removing punctuation (except for apostrophes and hyphens), and converting all characters to lowercase.
All evaluation results on the public datasets can be found [here](https://drive.google.com/drive/folders/1rFIh6yXRVa9RZ0ieZoKiThFZgQ4STPPI?usp=drive_link).
### Short-Form Transcription
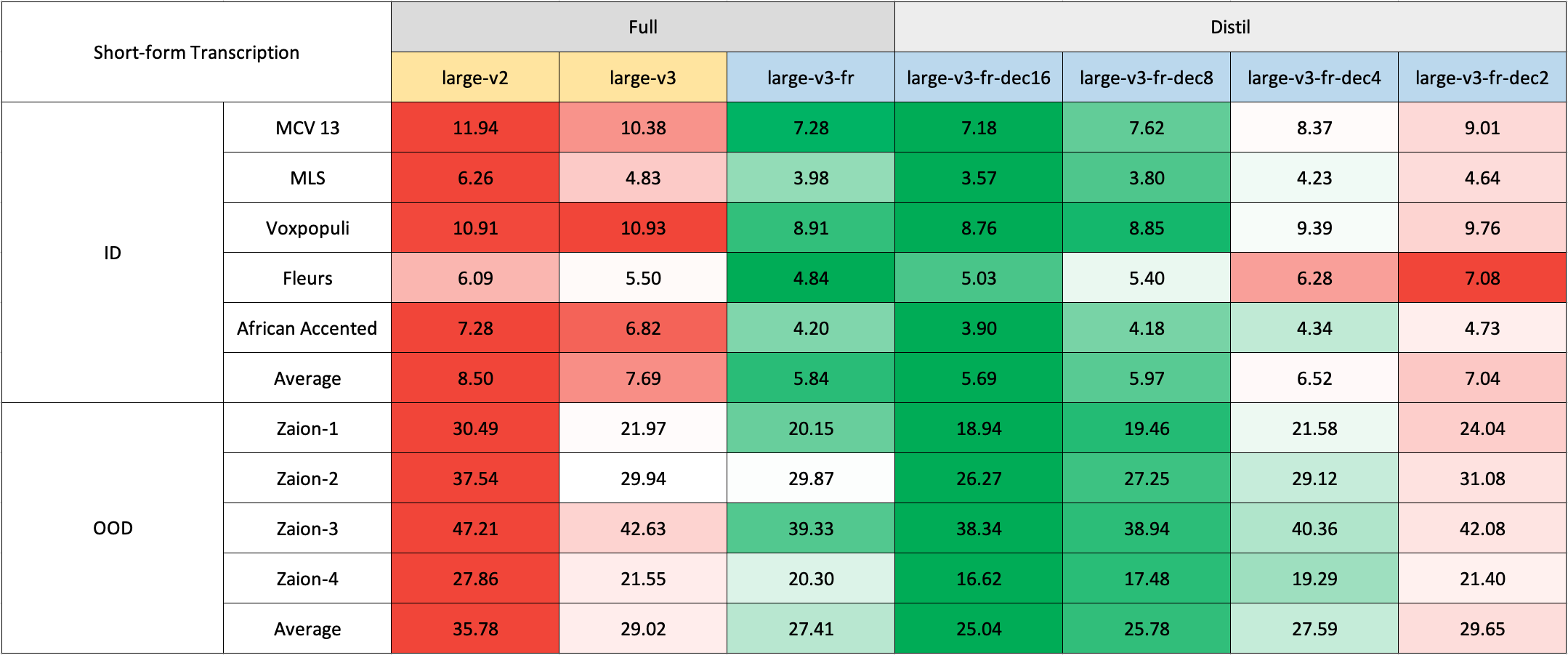
Due to the lack of readily available out-of-domain (OOD) and long-form test sets in French, we evaluated using internal test sets from [Zaion Lab](https://zaion.ai/). These sets comprise human-annotated audio-transcription pairs from call center conversations, which are notable for their significant background noise and domain-specific terminology.
### Long-Form Transcription
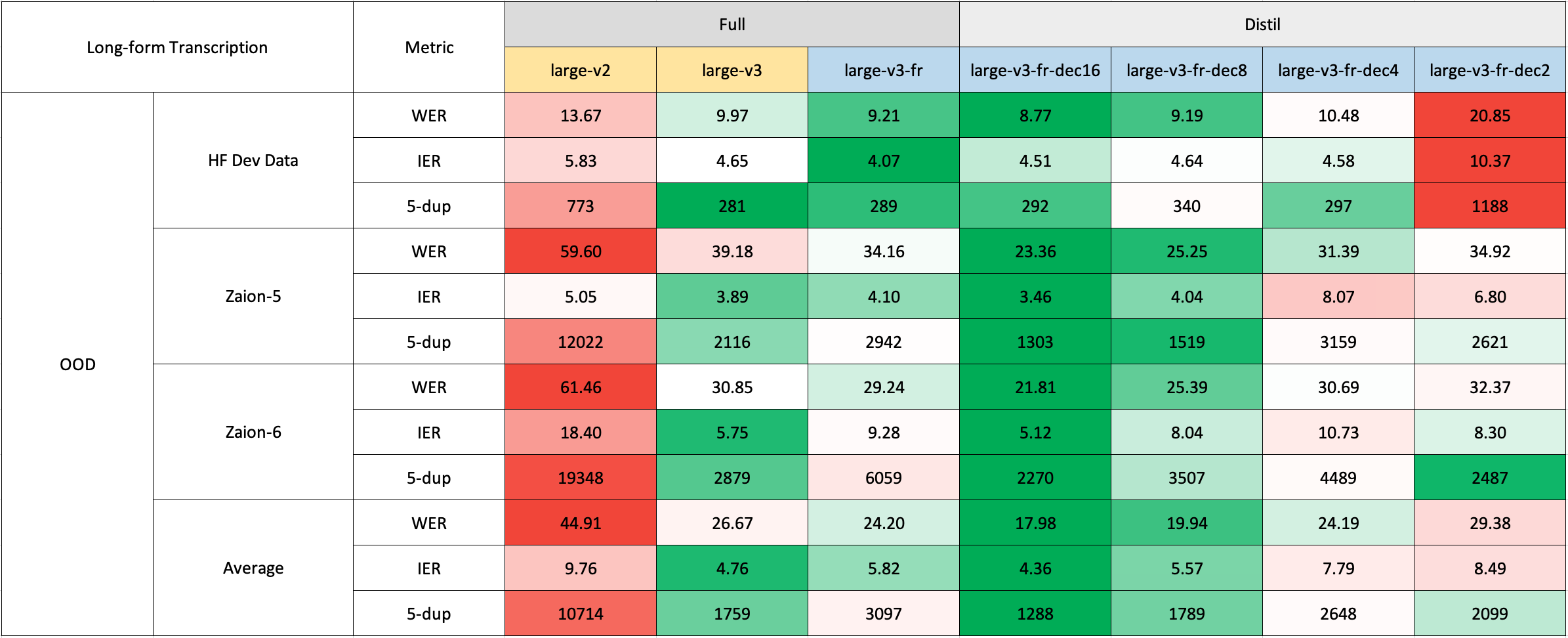
The long-form transcription was run using the 🤗 Hugging Face pipeline for quicker evaluation. Audio files were segmented into 30-second chunks and processed in parallel.
## Usage
### Hugging Face Pipeline
The model can easily used with the 🤗 Hugging Face [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline) class for audio transcription.
For long-form transcription (> 30 seconds), you can activate the process by passing the `chunk_length_s` argument. This approach segments the audio into smaller segments, processes them in parallel, and then joins them at the strides by finding the longest common sequence. While this chunked long-form approach may have a slight compromise in performance compared to OpenAI's sequential algorithm, it provides 9x faster inference speed.
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec16"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Init pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
# chunk_length_s=30, # for long-form transcription
max_new_tokens=128,
)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Run pipeline
result = pipe(sample)
print(result["text"])
```
### Hugging Face Low-level APIs
You can also use the 🤗 Hugging Face low-level APIs for transcription, offering greater control over the process, as demonstrated below:
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec16"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Extract feautres
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
# Generate tokens
predicted_ids = model.generate(
input_features.to(dtype=torch_dtype).to(device), max_new_tokens=128
)
# Detokenize to text
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
print(transcription)
```
### Speculative Decoding
[Speculative decoding](https://huggingface.co/blog/whisper-speculative-decoding) can be achieved using a draft model, essentially a distilled version of Whisper. This approach guarantees identical outputs to using the main Whisper model alone, offers a 2x faster inference speed, and incurs only a slight increase in memory overhead.
Since the distilled Whisper has the same encoder as the original, only its decoder need to be loaded, and encoder outputs are shared between the main and draft models during inference.
Using speculative decoding with the Hugging Face pipeline is simple - just specify the `assistant_model` within the generation configurations.
```python
import torch
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoModelForSpeechSeq2Seq,
AutoProcessor,
pipeline,
)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Load model
model_name_or_path = "bofenghuang/whisper-large-v3-french"
processor = AutoProcessor.from_pretrained(model_name_or_path)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
model.to(device)
# Load draft model
assistant_model_name_or_path = "bofenghuang/whisper-large-v3-french-distil-dec2"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_name_or_path,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
)
assistant_model.to(device)
# Init pipeline
pipe = pipeline(
"automatic-speech-recognition",
model=model,
feature_extractor=processor.feature_extractor,
tokenizer=processor.tokenizer,
torch_dtype=torch_dtype,
device=device,
generate_kwargs={"assistant_model": assistant_model},
max_new_tokens=128,
)
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]
# Run pipeline
result = pipe(sample)
print(result["text"])
```
### OpenAI Whisper
You can also employ the sequential long-form decoding algorithm with a sliding window and temperature fallback, as outlined by OpenAI in their original [paper](https://arxiv.org/abs/2212.04356).
First, install the [openai-whisper](https://github.com/openai/whisper) package:
```bash
pip install -U openai-whisper
```
Then, download the converted model:
```bash
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='bofenghuang/whisper-large-v3-french-distil-dec16', filename='original_model.pt', local_dir='./models/whisper-large-v3-french-distil-dec16')"
```
Now, you can transcirbe audio files by following the usage instructions provided in the repository:
```python
import whisper
from datasets import load_dataset
# Load model
model = whisper.load_model("./models/whisper-large-v3-french-distil-dec16/original_model.pt")
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]["array"].astype("float32")
# Transcribe
result = model.transcribe(sample, language="fr")
print(result["text"])
```
### Faster Whisper
Faster Whisper is a reimplementation of OpenAI's Whisper models and the sequential long-form decoding algorithm in the [CTranslate2](https://github.com/OpenNMT/CTranslate2) format.
Compared to openai-whisper, it offers up to 4x faster inference speed, while consuming less memory. Additionally, the model can be quantized into int8, further enhancing its efficiency on both CPU and GPU.
First, install the [faster-whisper](https://github.com/SYSTRAN/faster-whisper) package:
```bash
pip install faster-whisper
```
Then, download the model converted to the CTranslate2 format:
```bash
python -c "from huggingface_hub import snapshot_download; snapshot_download(repo_id='bofenghuang/whisper-large-v3-french-distil-dec16', local_dir='./models/whisper-large-v3-french-distil-dec16', allow_patterns='ctranslate2/*')"
```
Now, you can transcirbe audio files by following the usage instructions provided in the repository:
```python
from datasets import load_dataset
from faster_whisper import WhisperModel
# Load model
model = WhisperModel("./models/whisper-large-v3-french-distil-dec16/ctranslate2", device="cuda", compute_type="float16") # Run on GPU with FP16
# Example audio
dataset = load_dataset("bofenghuang/asr-dummy", "fr", split="test")
sample = dataset[0]["audio"]["array"].astype("float32")
segments, info = model.transcribe(sample, beam_size=5, language="fr")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
### Whisper.cpp
Whisper.cpp is a reimplementation of OpenAI's Whisper models, crafted in plain C/C++ without any dependencies. It offers compatibility with various backends and platforms.
Additionally, the model can be quantized to either 4-bit or 5-bit integers, further enhancing its efficiency.
First, clone and build the [whisper.cpp](https://github.com/ggerganov/whisper.cpp) repository:
```bash
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
# build the main example
make
```
Next, download the converted ggml weights from the Hugging Face Hub:
```bash
# Download model quantized with Q5_0 method
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='bofenghuang/whisper-large-v3-french-distil-dec16', filename='ggml-model-q5_0.bin', local_dir='./models/whisper-large-v3-french-distil-dec16')"
```
Now, you can transcribe an audio file using the following command:
```bash
./main -m ./models/whisper-large-v3-french-distil-dec16/ggml-model-q5_0.bin -l fr -f /path/to/audio/file --print-colors
```
### Candle
[Candle-whisper](https://github.com/huggingface/candle/tree/main/candle-examples/examples/whisper) is a reimplementation of OpenAI's Whisper models in the candle format - a lightweight ML framework built in Rust.
First, clone the [candle](https://github.com/huggingface/candle) repository:
```bash
git clone https://github.com/huggingface/candle.git
cd candle/candle-examples/examples/whisper
```
Transcribe an audio file using the following command:
```bash
cargo run --example whisper --release -- --model large-v3 --model-id bofenghuang/whisper-large-v3-french-distil-dec16 --language fr --input /path/to/audio/file
```
In order to use CUDA add `--features cuda` to the example command line:
```bash
cargo run --example whisper --release --features cuda -- --model large-v3 --model-id bofenghuang/whisper-large-v3-french-distil-dec16 --language fr --input /path/to/audio/file
```
### MLX
[MLX-Whisper](https://github.com/ml-explore/mlx-examples/tree/main/whisper) is a reimplementation of OpenAI's Whisper models in the [MLX](https://github.com/ml-explore/mlx) format - a ML framework on Apple silicon. It supports features like lazy computation, unified memory management, etc.
First, clone the [MLX Examples](https://github.com/ml-explore/mlx-examples) repository:
```bash
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/whisper
```
Next, install the dependencies:
```bash
pip install -r requirements.txt
```
Download the pytorch checkpoint in the original OpenAI format and convert it into MLX format (We haven't included the converted version here since the repository is already heavy and the conversion is very fast):
```bash
# Download
python -c "from huggingface_hub import hf_hub_download; hf_hub_download(repo_id='bofenghuang/whisper-large-v3-french-distil-dec16', filename='original_model.pt', local_dir='./models/whisper-large-v3-french-distil-dec16')"
# Convert into .npz
python convert.py --torch-name-or-path ./models/whisper-large-v3-french-distil-dec16/original_model.pt --mlx-path ./mlx_models/whisper-large-v3-french-distil-dec16
```
Now, you can transcribe audio with:
```python
import whisper
result = whisper.transcribe("/path/to/audio/file", path_or_hf_repo="mlx_models/whisper-large-v3-french-distil-dec16", language="fr")
print(result["text"])
```
## Training details
We've collected a composite dataset consisting of over 2,500 hours of French speech recognition data, which incldues datasets such as [Common Voice 13.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_13_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://huggingface.co/datasets/facebook/voxpopuli), [Fleurs](https://huggingface.co/datasets/google/fleurs), [Multilingual TEDx](https://www.openslr.org/100/), [MediaSpeech](https://www.openslr.org/108/), [African Accented French](https://huggingface.co/datasets/gigant/african_accented_french), etc.
Given that some datasets, like MLS, only offer text without case or punctuation, we employed a customized version of 🤗 [Speechbox](https://github.com/huggingface/speechbox) to restore case and punctuation from a limited set of symbols using the [bofenghuang/whisper-large-v2-cv11-french](bofenghuang/whisper-large-v2-cv11-french) model.
However, even within these datasets, we observed certain quality issues. These ranged from mismatches between audio and transcription in terms of language or content, poorly segmented utterances, to missing words in scripted speech, etc. We've built a pipeline to filter out many of these problematic utterances, aiming to enhance the dataset's quality. As a result, we excluded more than 10% of the data, and when we retrained the model, we noticed a significant reduction of hallucination.
For training, we employed the [script](https://github.com/huggingface/distil-whisper/blob/main/training/run_distillation.py) available in the 🤗 Distil-Whisper repository. The model training took place on the [Jean-Zay supercomputer](http://www.idris.fr/eng/jean-zay/jean-zay-presentation-eng.html) at GENCI, and we extend our gratitude to the IDRIS team for their responsive support throughout the project.
## Acknowledgements
- OpenAI for creating and open-sourcing the [Whisper model](https://arxiv.org/abs/2212.04356)
- 🤗 Hugging Face for integrating the Whisper model and providing the training codebase within the [Transformers](https://github.com/huggingface/transformers) and [Distil-Whisper](https://github.com/huggingface/distil-whisper) repository
- [Genci](https://genci.fr/) for their generous contribution of GPU hours to this project
|