推介 SafeCoder


今天,我们向大家隆重介绍 SafeCoder —— 一款专为企业打造的代码助手解决方案。
SafeCoder 旨在成为你完全合规且自托管的结对编程工程师,从而释放企业的软件开发生产力。用营销话术来讲就是:“你自己的本地 GitHub Copilot”。
在深入探讨之前,我们先简单了解一下 SafeCoder:
- SafeCoder 不是一个模型,而是一个完整的端到端商业解决方案
- SafeCoder 以安全及隐私为核心原则 - 代码在训练或推理过程中永远不会离开 VPC(Virtual Private Cloud,虚拟私有云)
- SafeCoder 专为客户在自己的基础设施上自行托管而设计
- SafeCoder 旨在让客户真正拥有自己的代码大语言模型
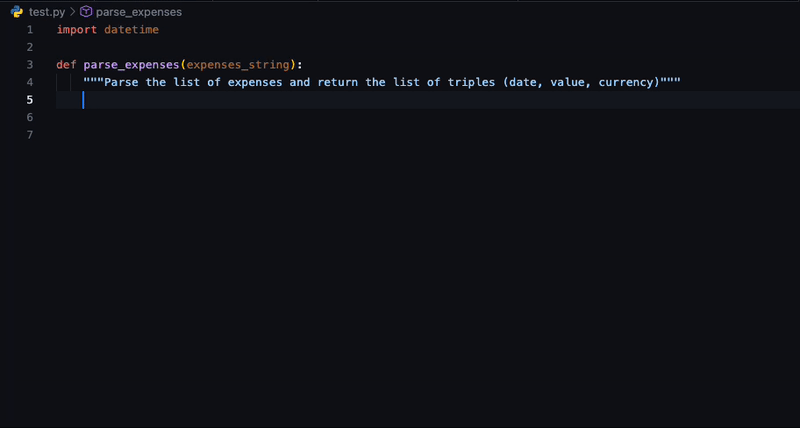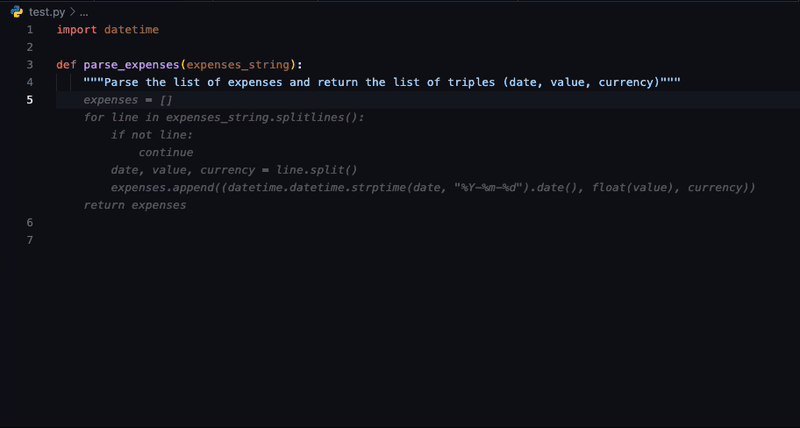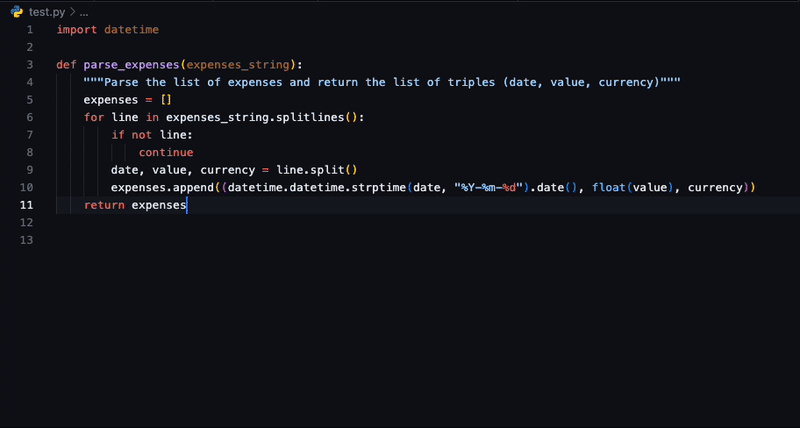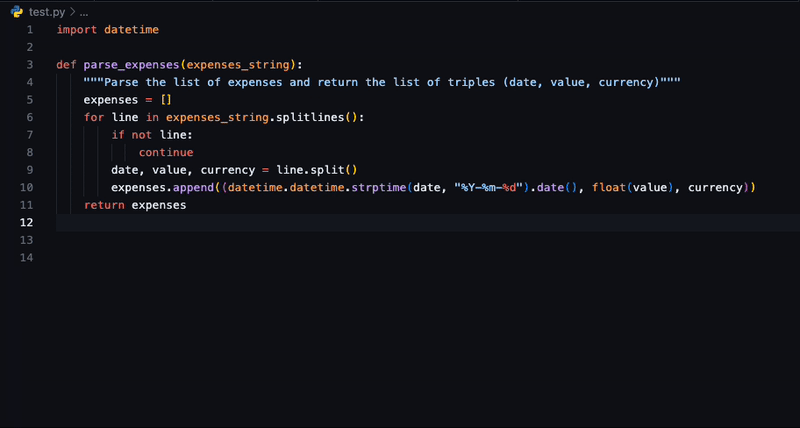
为何选择 SafeCoder?
基于 LLM 的代码助理解决方案(如 GitHub Copilot)正在掀起巨大的生产力提升浪潮。对于企业来说,这使得它们能够用公司自己的代码库去调整代码大模型从而创建出专属于自己的代码大模型以提高代码补全的可靠性及相关性,从而进一步提高生产力。一个例子是,据 Google 报告,其内部的 LLM 代码助理在基于内部代码库训练后,代码补全接受率提高到了 25-34%。
然而,依靠闭源代码大模型来创建内部代码助理会让公司面临合规及安全问题。首先,在训练期间,在内部代码库上微调闭源代码大模型需要将此代码库向第三方公开。其次,在推理过程中,经过微调的代码大模型可能会在推理过程中“泄漏”其训练数据集中的代码。为了合规,企业需要在自己的基础设施上部署微调过的代码大模型 - 这对于闭源 LLM 来说是不可能的。
借助 SafeCoder,Hugging Face 可以帮助客户构建自己的代码大模型,使得客户可以最先进的库,在其私有代码库上微调最先进的开放模型,而无需与 Hugging Face 或任何其他第三方共享数据。通过 SafeCoder,Hugging Face 会提供容器化、硬件加速的代码大模型推理解决方案,由客户直接在其信任的、安全的基础设施上部署,从而使得整个代码输入和补全过程无需离开客户自己的安全 IT 环境。
从 StarCoder 到 SafeCoder
SafeCoder 解决方案的核心是 BigCode 项目训出来的 StarCoder 系列代码大模型。BigCode 项目是一个由 Hugging Face、ServiceNow 及开源社区共同合作完成的开源项目。
StarCoder 模型是企业自托管解决方案的理想选择,其优势如下:
最先进的代码补全效果 - 详情可参阅论文及多语言代码评估排行榜。
为推理性能而生:代码级优化的 15B 模型、可以减少内存占用的多查询注意力(Multi-Query Attention,MQA)以及可将上下文扩展至 8192 个词元的 Flash 注意力。
基于 The Stack 数据集训练,这是一个来源符合道德准则的开源代码数据集,其中仅包含可商用的许可代码,且从一开始就包含了允许开发人员自主将其代码库退出的机制,此外我们还对其进行了大量的 PII 删除和代码去重工作。
注意:虽然 StarCoder 是 SafeCoder 的灵感来源和首个基础模型。但基于开源模型构建 LLM 解决方案的一个重要好处是它可以用上最新最好的开源模型,因此,将来 SafeCoder 不排除会基于其他类似的、可商用的、开源的、来源符合道德准则的公开透明的开源代码数据集的基础 LLM 进行微调。
核心原则之隐私和安全
对于任何公司而言,内部代码库都是其最重要、最有价值的知识产权。 SafeCoder 的一个核心原则是,在训练和推理过程中,任何第三方(包括 Hugging Face)永远不会访问到客户内部代码库。
当客户开始搭建 SafeCoder 方案时,Hugging Face 团队会提供容器、脚本和示例,并与客户携手合作以对内部代码库数据进行选择、提取、准备、复制、脱敏,最终生成训练数据集,然后客户就可以配置好 Hugging Face 提供的训练容器并将其部署至自管基础设施上。
到了部署阶段,客户会在自管基础设施上部署 Hugging Face 提供的容器,并在其 VPC 内发布内部私有推理终端。这些容器可根据客户自己的硬件环境进行相应配置,目前主要支持的硬件有:英伟达 GPU、AMD Instinct GPU、英特尔至强 CPU、AWS Inferentia2 以及 Habana Gaudi。
核心原则之合规
由于目前在全世界范围内,围绕机器学习模型和数据集的监管框架仍在制定中,跨国公司需要确保其使用的解决方案能够最大限度地降低法律风险。
数据源、数据治理、版权数据管理是其中最重要的几个需考量的合规领域。在这些问题得到人工智能欧盟法案草案的广泛认可之前,BigCode 的老表和灵感来源 BigScience 已在其在工作组中解决了这些问题,并因此在斯坦福 CRFM 研究中被评为最合规的基础模型提供商。
BigCode 发扬了 BigScience 的工作,其以合规为核心原则构建 The Stack 数据集并围绕这个数据集实施了一系列新技术。例如对可商用许可证进行过滤、同意机制(开发人员可以轻松地查到他们的代码是否在数据集中并要求将其代码从数据集中剔除)、大量的用于审查源代码数据的文档和工具,以及数据集改进方案(如数据去重、PII 删除)。
所有这些努力都大大降低了 StarCoder 模型用户和 SafeCoder 客户的法律风险。对于 SafeCoder 用户来说,这些工作最终还形成了一个合规性功能:当软件开发人员用 SafeCoder 进行代码补全时,可将其与 The Stack 数据集进行比对,以便知道生成的代码是否与源数据集中的某些现有代码匹配,以及对应代码的许可证是什么。客户甚至可以指定许可证白名单并向用户展示在白名单内的代码。
产品说明
SafeCoder 是一个完整的商业解决方案,包括服务、软件及相应的支持。
训练你自己的 SafeCoder 模型
StarCoder 的训练数据中有 80 多种编程语言,其在多个测试基准上名列前茅。为了使 SafeCoder 客户能得到更好、更有针对性的代码建议,用户可以选择让我们从训练阶段开始参与,此时 Hugging Face 团队直接与客户团队合作,指导他们准备并构建训练代码数据集,并微调出他们自己的代码生成模型,而无需将其代码库暴露给第三方或上传到互联网上。
最终生成的是一个适合客户的编程语言、标准及实践的模型。通过这个过程,SafeCoder 客户可以学习该流程并构建一个用于创建和更新自有模型的流水线,确保不被供应商锁定,并保持对其 AI 功能的控制力。
部署 SafeCoder
在部署阶段,SafeCoder 客户和 Hugging Face 一起设计并组建能支持所需并发性的最佳基础设施,从而提供出色的开发者体验。然后,Hugging Face 据此构建出 SafeCoder 推理容器,这些容器经过硬件加速并针对吞吐进行了优化。最后,由客户部署在自己的基础设施上。
SafeCoder 推理支持各种硬件,为客户提供广泛的选择:英伟达 Ampere GPU、AMD Instinct GPU、Habana Gaudi2、AWS Inferentia 2、英特尔至强 Sapphire Rapids CPU 等。
使用 SafeCoder
一旦部署了 SafeCoder 并在客户 VPC 中上线了其推理端点,开发人员就可以安装兼容的 SafeCoder IDE 插件,以便在工作时获取代码建议。当前,SafeCoder 支持流行的 IDE,包括 VSCode、IntelliJ,同时我们的合作伙伴还在开发更多插件,尽请期待。
如何获取 SafeCoder?
今天,我们在 VMware Explore 大会上宣布与 VMware 合作推出 SafeCoder,并向 VMware 企业客户提供 SafeCoder。与 VMware 合作有助于确保 SafeCoder 在客户的 VMware Cloud 基础设施上成功部署 - 无论客户更青睐云、本地还是混合基础设施。除了 SafeCoder 本身外,VMware 还发布了一个参考架构,其中包含了一些示例代码,可以帮助用户用最短时间在 VMware 基础设施上部署和运营 SafeCoder 从而创造价值。VMware 的私有 AI 参考架构使组织能够轻松快速地利用流行的开源项目(例如 Ray 和 kubeflow)围绕其私有数据集部署 AI 服务。同时,通过与 Hugging Face 合作,组织还能保持利用最新技术及以及最佳开源模型的灵活性。这一切都无需在总拥有成本或性能上进行权衡。
“我们与 Hugging Face 围绕 SafeCoder 进行的合作与 VMware 的目标完美契合,即让客户能够选择解决方案,同时维护其隐私及其对业务数据的控制。事实上,我们已经在内部运行 SafeCoder 几个月了,并且已经看到了出色的结果。最重要的是,我们与 Hugging Face 的合作才刚刚开始,我很高兴能够将我们的解决方案带给全球数十万客户。” VMware AI 研究院副总裁 Chris Wolf 说道。 点击此处可详细了解私有 AI 和 VMware 在这一新兴领域的差异化功能。

