Text-to-Video: The Task, Challenges and the Current State







Video samples generated with ModelScope.
Text-to-video is next in line in the long list of incredible advances in generative models. As self-descriptive as it is, text-to-video is a fairly new computer vision task that involves generating a sequence of images from text descriptions that are both temporally and spatially consistent. While this task might seem extremely similar to text-to-image, it is notoriously more difficult. How do these models work, how do they differ from text-to-image models, and what kind of performance can we expect from them?
In this blog post, we will discuss the past, present, and future of text-to-video models. We will start by reviewing the differences between the text-to-video and text-to-image tasks, and discuss the unique challenges of unconditional and text-conditioned video generation. Additionally, we will cover the most recent developments in text-to-video models, exploring how these methods work and what they are capable of. Finally, we will talk about what we are working on at Hugging Face to facilitate the integration and use of these models and share some cool demos and resources both on and outside of the Hugging Face Hub.

Examples of videos generated from various text description inputs, image taken from Make-a-Video.
Text-to-Video vs. Text-to-Image
With so many recent developments, it can be difficult to keep up with the current state of text-to-image generative models. Let's do a quick recap first.
Just two years ago, the first open-vocabulary, high-quality text-to-image generative models emerged. This first wave of text-to-image models, including VQGAN-CLIP, XMC-GAN, and GauGAN2, all had GAN architectures. These were quickly followed by OpenAI's massively popular transformer-based DALL-E in early 2021, DALL-E 2 in April 2022, and a new wave of diffusion models pioneered by Stable Diffusion and Imagen. The huge success of Stable Diffusion led to many productionized diffusion models, such as DreamStudio and RunwayML GEN-1, and integration with existing products, such as Midjourney.
Despite the impressive capabilities of diffusion models in text-to-image generation, diffusion and non-diffusion based text-to-video models are significantly more limited in their generative capabilities. Text-to-video are typically trained on very short clips, meaning they require a computationally expensive and slow sliding window approach to generate long videos. As a result, these models are notoriously difficult to deploy and scale and remain limited in context and length.
The text-to-video task faces unique challenges on multiple fronts. Some of these main challenges include:
- Computational challenges: Ensuring spatial and temporal consistency across frames creates long-term dependencies that come with a high computation cost, making training such models unaffordable for most researchers.
- Lack of high-quality datasets: Multi-modal datasets for text-to-video generation are scarce and often sparsely annotated, making it difficult to learn complex movement semantics.
- Vagueness around video captioning: Describing videos in a way that makes them easier for models to learn from is an open question. More than a single short text prompt is required to provide a complete video description. A generated video must be conditioned on a sequence of prompts or a story that narrates what happens over time.
In the next section, we will discuss the timeline of developments in the text-to-video domain and the various methods proposed to address these challenges separately. On a higher level, text-to-video works propose one of these:
- New, higher-quality datasets that are easier to learn from.
- Methods to train such models without paired text-video data.
- More computationally efficient methods to generate longer and higher resolution videos.
How to Generate Videos from Text?
Let's take a look at how text-to-video generation works and the latest developments in this field. We will explore how text-to-video models have evolved, following a similar path to text-to-image research, and how the specific challenges of text-to-video generation have been tackled so far.
Like the text-to-image task, early work on text-to-video generation dates back only a few years. Early research predominantly used GAN and VAE-based approaches to auto-regressively generate frames given a caption (see Text2Filter and TGANs-C). While these works provided the foundation for a new computer vision task, they are limited to low resolutions, short-range, and singular, isolated motions.

Initial text-to-video models were extremely limited in resolution, context and length, image taken from TGANs-C.
Taking inspiration from the success of large-scale pretrained transformer models in text (GPT-3) and image (DALL-E), the next surge of text-to-video generation research adopted transformer architectures. Phenaki, Make-A-Video, NUWA, VideoGPT and CogVideo all propose transformer-based frameworks, while works such as TATS propose hybrid methods that combine VQGAN for image generation and a time-sensitive transformer module for sequential generation of frames. Out of this second wave of works, Phenaki is particularly interesting as it enables generating arbitrary long videos conditioned on a sequence of prompts, in other words, a story line. Similarly, NUWA-Infinity proposes an autoregressive over autoregressive generation mechanism for infinite image and video synthesis from text inputs, enabling the generation of long, HD quality videos. However, neither Phenaki or NUWA models are publicly available.
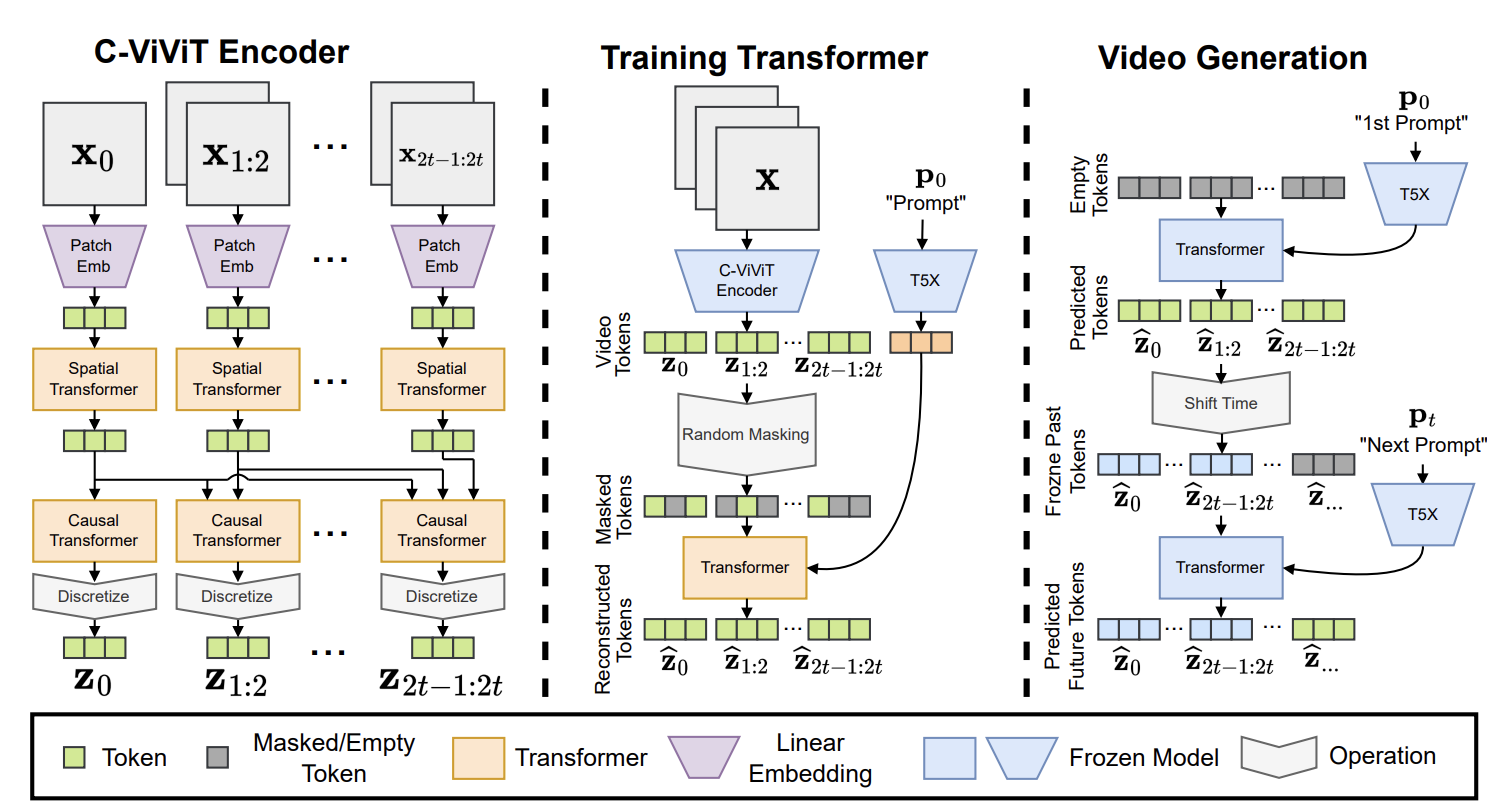
Phenaki features a transformer-based architecture, image taken from here.
The third and current wave of text-to-video models features predominantly diffusion-based architectures. The remarkable success of diffusion models in diverse, hyper-realistic, and contextually rich image generation has led to an interest in generalizing diffusion models to other domains such as audio, 3D, and, more recently, video. This wave of models is pioneered by Video Diffusion Models (VDM), which extend diffusion models to the video domain, and MagicVideo, which proposes a framework to generate video clips in a low-dimensional latent space and reports huge efficiency gains over VDM. Another notable mention is Tune-a-Video, which fine-tunes a pretrained text-to-image model with a single text-video pair and enables changing the video content while preserving the motion. The continuously expanding list of text-to-video diffusion models that followed include Video LDM, Text2Video-Zero, Runway Gen1 and Gen2, and NUWA-XL.
Text2Video-Zero is a text-guided video generation and manipulation framework that works in a fashion similar to ControlNet. It can directly generate (or edit) videos based on text inputs, as well as combined text-pose or text-edge data inputs. As implied by its name, Text2Video-Zero is a zero-shot model that combines a trainable motion dynamics module with a pre-trained text-to-image Stable Diffusion model without using any paired text-video data. Similarly to Text2Video-Zero, Runway’s Gen-1 and Gen-2 models enable synthesizing videos guided by content described through text or images. Most of these works are trained on short video clips and rely on autoregressive generation with a sliding window to generate longer videos, inevitably resulting in a context gap. NUWA-XL addresses this issue and proposes a “diffusion over diffusion” method to train models on 3376 frames. Finally, there are open-source text-to-video models and frameworks such as Alibaba / DAMO Vision Intelligence Lab’s ModelScope and Tencel’s VideoCrafter, which haven't been published in peer-reviewed conferences or journals.
Datasets
Like other vision-language models, text-to-video models are typically trained on large paired datasets videos and text descriptions. The videos in these datasets are typically split into short, fixed-length chunks and often limited to isolated actions with a few objects. While this is partly due to computational limitations and partly due to the difficulty of describing video content in a meaningful way, we see that developments in multimodal video-text datasets and text-to-video models are often entwined. While some work focuses on developing better, more generalizable datasets that are easier to learn from, works such as Phenaki explore alternative solutions such as combining text-image pairs with text-video pairs for the text-to-video task. Make-a-Video takes this even further by proposing using only text-image pairs to learn what the world looks like and unimodal video data to learn spatio-temporal dependencies in an unsupervised fashion.
These large datasets experience similar issues to those found in text-to-image datasets. The most commonly used text-video dataset, WebVid, consists of 10.7 million pairs of text-video pairs (52K video hours) and contains a fair amount of noisy samples with irrelevant video descriptions. Other datasets try to overcome this issue by focusing on specific tasks or domains. For example, the Howto100M dataset consists of 136M video clips with captions that describe how to perform complex tasks such as cooking, handcrafting, gardening, and fitness step-by-step. Similarly, the QuerYD dataset focuses on the event localization task such that the captions of videos describe the relative location of objects and actions in detail. CelebV-Text is a large-scale facial text-video dataset of over 70K videos to generate videos with realistic faces, emotions, and gestures.
Text-to-Video at Hugging Face
Using Hugging Face Diffusers, you can easily download, run and fine-tune various pretrained text-to-video models, including Text2Video-Zero and ModelScope by Alibaba / DAMO Vision Intelligence Lab. We are currently working on integrating other exciting works into Diffusers and 🤗 Transformers.
Hugging Face Demos
At Hugging Face, our goal is to make it easier to use and build upon state-of-the-art research. Head over to our hub to see and play around with Spaces demos contributed by the 🤗 team, countless community contributors and research authors. At the moment, we host demos for VideoGPT, CogVideo, ModelScope Text-to-Video, and Text2Video-Zero with many more to come. To see what we can do with these models, let's take a look at the Text2Video-Zero demo. This demo not only illustrates text-to-video generation but also enables multiple other generation modes for text-guided video editing and joint conditional video generation using pose, depth and edge inputs along with text prompts.
Apart from using demos to experiment with pretrained text-to-video models, you can also use the Tune-a-Video training demo to fine-tune an existing text-to-image model with your own text-video pair. To try it out, upload a video and enter a text prompt that describes the video. Once the training is done, you can upload it to the Hub under the Tune-a-Video community or your own username, publicly or privately. Once the training is done, simply head over to the Run tab of the demo to generate videos from any text prompt.
All Spaces on the 🤗 Hub are Git repos you can clone and run on your local or deployment environment. Let’s clone the ModelScope demo, install the requirements, and run it locally.
git clone https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis
cd modelscope-text-to-video-synthesis
pip install -r requirements.txt
python app.py
And that's it! The Modelscope demo is now running locally on your computer. Note that the ModelScope text-to-video model is supported in Diffusers and you can directly load and use the model to generate new videos with a few lines of code.
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b", torch_dtype=torch.float16, variant="fp16")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
prompt = "Spiderman is surfing"
video_frames = pipe(prompt, num_inference_steps=25).frames
video_path = export_to_video(video_frames)
Community Contributions and Open Source Text-to-Video Projects
Finally, there are various open source projects and models that are not on the hub. Some notable mentions are Phil Wang’s (aka lucidrains) unofficial implementations of Imagen, Phenaki, NUWA, Make-a-Video and Video Diffusion Models. Another exciting project by ExponentialML builds on top of 🤗 diffusers to finetune ModelScope Text-to-Video.
Conclusion
Text-to-video research is progressing exponentially, but existing work is still limited in context and faces many challenges. In this blog post, we covered the constraints, unique challenges and the current state of text-to-video generation models. We also saw how architectural paradigms originally designed for other tasks enable giant leaps in the text-to-video generation task and what this means for future research. While the developments are impressive, text-to-video models still have a long way to go compared to text-to-image models. Finally, we also showed how you can use these models to perform various tasks using the demos available on the Hub or as a part of 🤗 Diffusers pipelines.
That was it! We are continuing to integrate the most impactful computer vision and multi-modal models and would love to hear back from you. To stay up to date with the latest news in computer vision and multi-modal research, you can follow us on Twitter: @adirik, @a_e_roberts, @osanseviero, @risingsayak and @huggingface.
















