SetFitABSA: Few-Shot Aspect Based Sentiment Analysis using SetFit












SetFitABSA is an efficient technique to detect the sentiment towards specific aspects within the text.
Aspect-Based Sentiment Analysis (ABSA) is the task of detecting the sentiment towards specific aspects within the text. For example, in the sentence, "This phone has a great screen, but its battery is too small", the aspect terms are "screen" and "battery" and the sentiment polarities towards them are Positive and Negative, respectively.
ABSA is widely used by organizations for extracting valuable insights by analyzing customer feedback towards aspects of products or services in various domains. However, labeling training data for ABSA is a tedious task because of the fine-grained nature (token level) of manually identifying aspects within the training samples.
Intel Labs and Hugging Face are excited to introduce SetFitABSA, a framework for few-shot training of domain-specific ABSA models; SetFitABSA is competitive and even outperforms generative models such as Llama2 and T5 in few-shot scenarios.
Compared to LLM based methods, SetFitABSA has two unique advantages:
🗣 No prompts needed: few-shot in-context learning with LLMs requires handcrafted prompts which make the results brittle, sensitive to phrasing and dependent on user expertise. SetFitABSA dispenses with prompts altogether by generating rich embeddings directly from a small number of labeled text examples.
🏎 Fast to train: SetFitABSA requires only a handful of labeled training samples; in addition, it uses a simple training data format, eliminating the need for specialized tagging tools. This makes the data labeling process fast and easy.
In this blog post, we'll explain how SetFitABSA works and how to train your very own models using the SetFit library. Let's dive in!
How does it work?
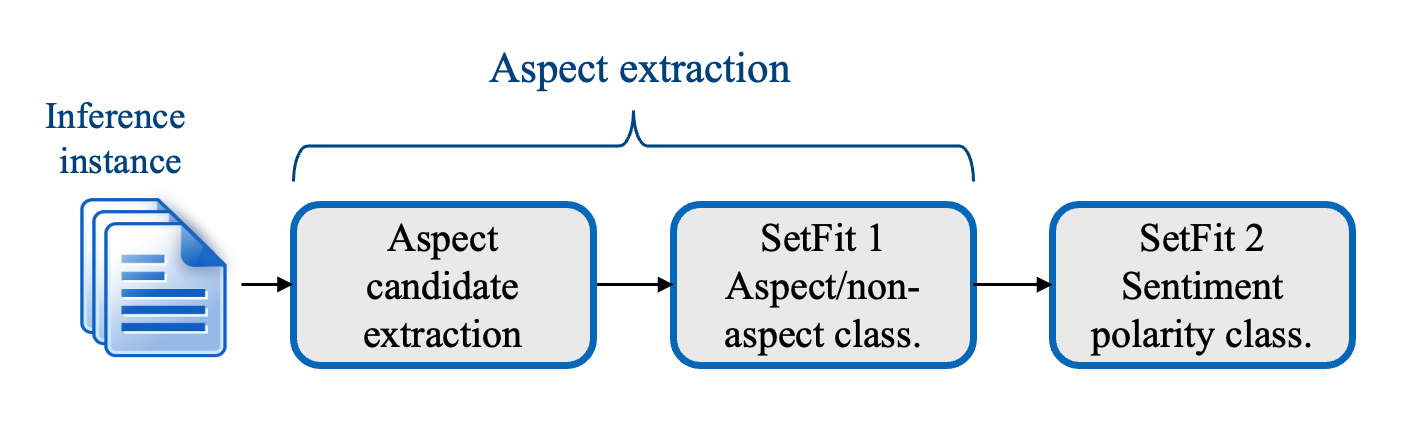
SetFitABSA's three-stage training process
SetFitABSA is comprised of three steps. The first step extracts aspect candidates from the text, the second one yields the aspects by classifying the aspect candidates as aspects or non-aspects, and the final step associates a sentiment polarity to each extracted aspect. Steps two and three are based on SetFit models.
Training
1. Aspect candidate extraction
In this work we assume that aspects, which are usually features of products and services, are mostly nouns or noun compounds (strings of consecutive nouns). We use spaCy to tokenize and extract nouns/noun compounds from the sentences in the (few-shot) training set. Since not all extracted nouns/noun compounds are aspects, we refer to them as aspect candidates.
2. Aspect/Non-aspect classification
Now that we have aspect candidates, we need to train a model to be able to distinguish between nouns that are aspects and nouns that are non-aspects. For this purpose, we need training samples with aspect/no-aspect labels. This is done by considering aspects in the training set as True aspects, while other non-overlapping candidate aspects are considered non-aspects and therefore labeled as False:
- Training sentence: "Waiters aren't friendly but the cream pasta is out of this world."
- Tokenized: [Waiters, are, n't, friendly, but, the, cream, pasta, is, out, of, this, world, .]
- Extracted aspect candidates: [Waiters, are, n't, friendly, but, the, cream, pasta, is, out, of, this, world, .]
- Gold labels from training set, in BIO format: [B-ASP, O, O, O, O, O, B-ASP, I-ASP, O, O, O, O, O, .]
- Generated aspect/non-aspect Labels: [Waiters, are, n't, friendly, but, the, cream, pasta, is, out, of, this, world, .]
Now that we have all the aspect candidates labeled, how do we use it to train the candidate aspect classification model? In other words, how do we use SetFit, a sentence classification framework, to classify individual tokens? Well, this is the trick: each aspect candidate is concatenated with the entire training sentence to create a training instance using the following template:
aspect_candidate:training_sentence
Applying the template to the example above will generate 3 training instances – two with True labels representing aspect training instances, and one with False label representing non-aspect training instance:
| Text | Label |
|---|---|
| Waiters:Waiters aren't friendly but the cream pasta is out of this world. | 1 |
| cream pasta:Waiters aren't friendly but the cream pasta is out of this world. | 1 |
| world:Waiters aren't friendly but the cream pasta is out of this world. | 0 |
| ... | ... |
After generating the training instances, we are ready to use the power of SetFit to train a few-shot domain-specific binary classifier to extract aspects from an input text review. This will be our first fine-tuned SetFit model.
3. Sentiment polarity classification
Once the system extracts the aspects from the text, it needs to associate a sentiment polarity (e.g., positive, negative or neutral) to each aspect. For this purpose, we use a 2nd SetFit model and train it in a similar fashion to the aspect extraction model as illustrated in the following example:
- Training sentence: "Waiters aren't friendly but the cream pasta is out of this world."
- Tokenized: [Waiters, are, n't, friendly, but, the, cream, pasta, is, out, of, this, world, .]
- Gold labels from training set: [NEG, O, O, O, O, O, POS, POS, O, O, O, O, O, .]
| Text | Label |
|---|---|
| Waiters:Waiters aren't friendly but the cream pasta is out of this world. | NEG |
| cream pasta:Waiters aren't friendly but the cream pasta is out of this world. | POS |
| ... | ... |
Note that as opposed to the aspect extraction model, we don't include non-aspects in this training set because the goal is to classify the sentiment polarity towards real aspects.
Running inference
At inference time, the test sentence passes through the spaCy aspect candidate extraction phase, resulting in test instances using the template aspect_candidate:test_sentence. Next, non-aspects are filtered by the aspect/non-aspect classifier. Finally, the extracted aspects are fed to the sentiment polarity classifier that predicts the sentiment polarity per aspect.
In practice, this means the model can receive normal text as input, and output aspects and their sentiments:
Model Input:
"their dinner specials are fantastic."
Model Output:
[{'span': 'dinner specials', 'polarity': 'positive'}]
Benchmarking
SetFitABSA was benchmarked against the recent state-of-the-art work by AWS AI Labs and Salesforce AI Research that finetune T5 and GPT2 using prompts. To get a more complete picture, we also compare our model to the Llama-2-chat model using in-context learning. We use the popular Laptop14 and Restaurant14 ABSA datasets from the Semantic Evaluation Challenge 2014 (SemEval14). SetFitABSA is evaluated both on the intermediate task of aspect term extraction (SB1) and on the full ABSA task of aspect extraction along with their sentiment polarity predictions (SB1+SB2).
Model size comparison
| Model | Size (params) |
|---|---|
| Llama-2-chat | 7B |
| T5-base | 220M |
| GPT2-base | 124M |
| GPT2-medium | 355M |
| SetFit (MPNet) | 2x 110M |
Note that for the SB1 task, SetFitABSA is 110M parameters, for SB2 it is 110M parameters, and for SB1+SB2 SetFitABSA consists of 220M parameters.
Performance comparison
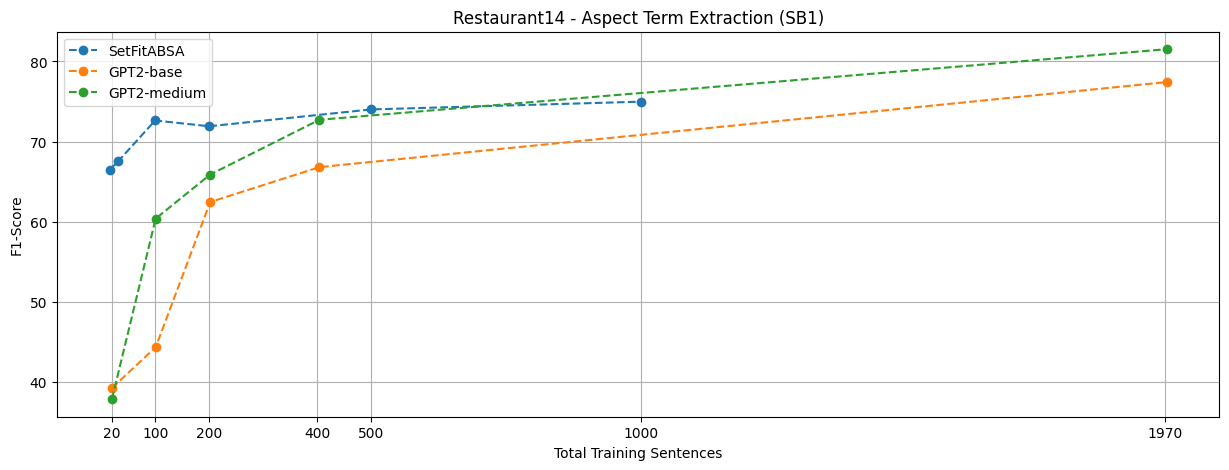
We see a clear advantage of SetFitABSA when the number of training instances is low, despite being 2x smaller than T5 and x3 smaller than GPT2-medium. Even when compared to Llama 2, which is x64 larger, the performance is on par or better.
SetFitABSA vs GPT2
SetFitABSA vs T5
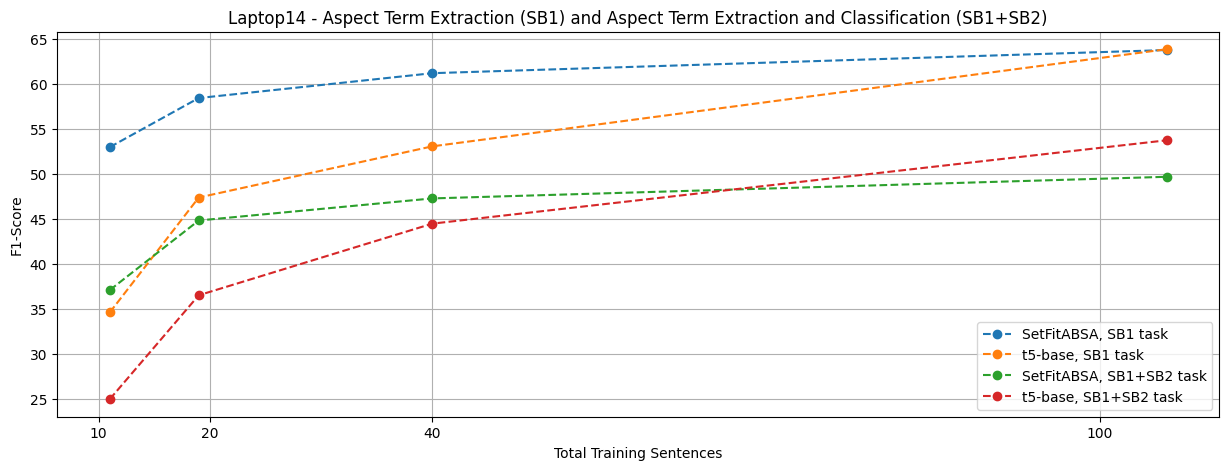
Note that for fair comparison, we conducted comparisons with SetFitABSA against exactly the dataset splits used by the various baselines (GPT2, T5, etc.).
SetFitABSA vs Llama2
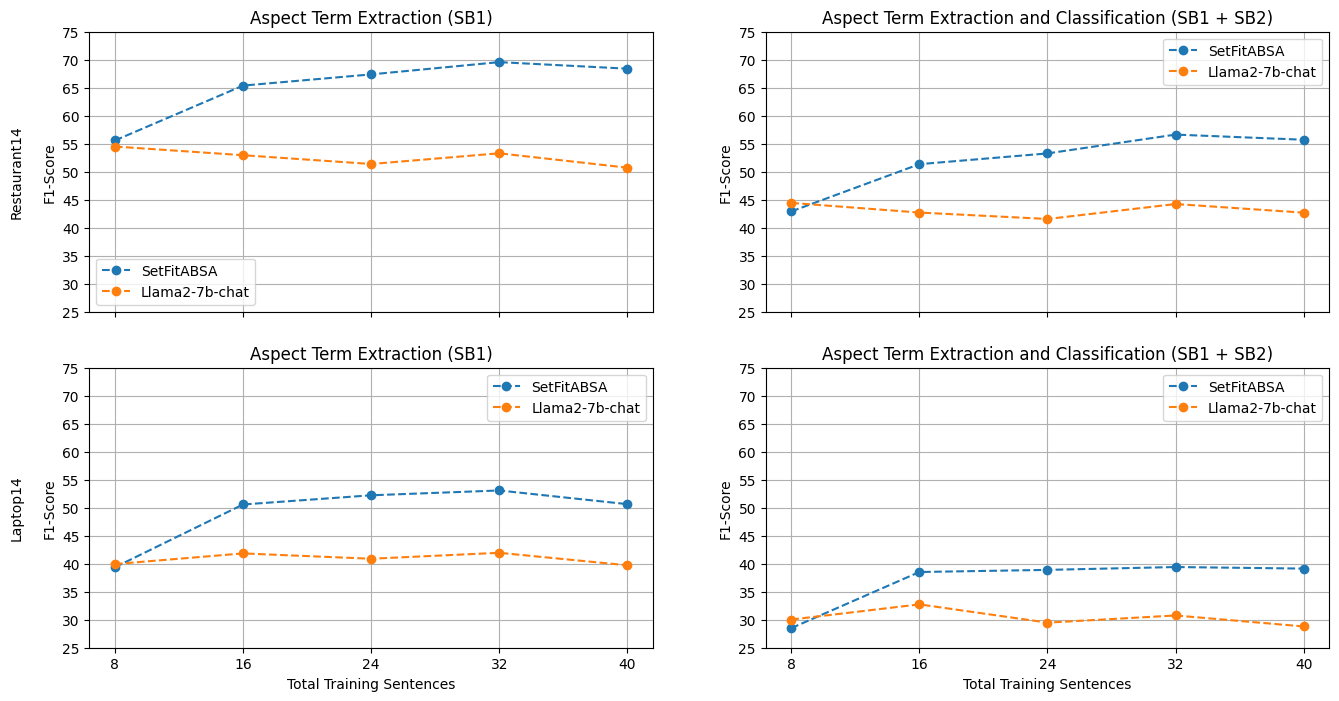
We notice that increasing the number of in-context training samples for Llama2 did not result in improved performance. This phenomenon has been shown for ChatGPT before, and we think it should be further investigated.
Training your own model
SetFitABSA is part of the SetFit framework. To train an ABSA model, start by installing setfit with the absa option enabled:
python -m pip install -U "setfit[absa]"
Additionally, we must install the en_core_web_lg spaCy model:
python -m spacy download en_core_web_lg
We continue by preparing the training set. The format of the training set is a Dataset with the columns text, span, label, ordinal:
- text: The full sentence or text containing the aspects.
- span: An aspect from the full sentence. Can be multiple words. For example: "food".
- label: The (polarity) label corresponding to the aspect span. For example: "positive". The label names can be chosen arbitrarily when tagging the collected training data.
- ordinal: If the aspect span occurs multiple times in the text, then this ordinal represents the index of those occurrences. Often this is just 0, as each aspect usually appears only once in the input text.
For example, the training text "Restaurant with wonderful food but worst service I ever seen" contains two aspects, so will add two lines to the training set table:
| Text | Span | Label | Ordinal |
|---|---|---|---|
| Restaurant with wonderful food but worst service I ever seen | food | positive | 0 |
| Restaurant with wonderful food but worst service I ever seen | service | negative | 0 |
| ... | ... | ... | ... |
Once we have the training dataset ready we can create an ABSA trainer and execute the training. SetFit models are fairly efficient to train, but as SetFitABSA involves two models trained sequentially, it is recommended to use a GPU for training to keep the training time low. For example, the following training script trains a full SetFitABSA model in about 10 minutes with the free Google Colab T4 GPU.
from datasets import load_dataset
from setfit import AbsaTrainer, AbsaModel
# Create a training dataset as above
# For convenience we will use an already prepared dataset here
train_dataset = load_dataset("tomaarsen/setfit-absa-semeval-restaurants", split="train[:128]")
# Create a model with a chosen sentence transformer from the Hub
model = AbsaModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create a trainer:
trainer = AbsaTrainer(model, train_dataset=train_dataset)
# Execute training:
trainer.train()
That's it! We have trained a domain-specific ABSA model. We can save our trained model to disk or upload it to the Hugging Face hub. Bear in mind that the model contains two submodels, so each is given its own path:
model.save_pretrained(
"models/setfit-absa-model-aspect",
"models/setfit-absa-model-polarity"
)
# or
model.push_to_hub(
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-aspect",
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-polarity"
)
Now we can use our trained model for inference. We start by loading the model:
from setfit import AbsaModel
model = AbsaModel.from_pretrained(
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-aspect",
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-polarity"
)
Then, we use the predict API to run inference. The input is a list of strings, each representing a textual review:
preds = model.predict([
"Best pizza outside of Italy and really tasty.",
"The food variations are great and the prices are absolutely fair.",
"Unfortunately, you have to expect some waiting time and get a note with a waiting number if it should be very full."
])
print(preds)
# [
# [{'span': 'pizza', 'polarity': 'positive'}],
# [{'span': 'food variations', 'polarity': 'positive'}, {'span': 'prices', 'polarity': 'positive'}],
# [{'span': 'waiting time', 'polarity': 'neutral'}, {'span': 'waiting number', 'polarity': 'neutral'}]
# ]
For more details on training options, saving and loading models, and inference see the SetFit docs.
References
- Maria Pontiki, Dimitris Galanis, John Pavlopoulos, Harris Papageorgiou, Ion Androutsopoulos, and Suresh Manandhar. 2014. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), pages 27–35.
- Siddharth Varia, Shuai Wang, Kishaloy Halder, Robert Vacareanu, Miguel Ballesteros, Yassine Benajiba, Neha Anna John, Rishita Anubhai, Smaranda Muresan, Dan Roth, 2023 "Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis". https://arxiv.org/abs/2210.06629
- Ehsan Hosseini-Asl, Wenhao Liu, Caiming Xiong, 2022. "A Generative Language Model for Few-shot Aspect-Based Sentiment Analysis". https://arxiv.org/abs/2204.05356
- Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, Oren Pereg, 2022. "Efficient Few-Shot Learning Without Prompts". https://arxiv.org/abs/2209.11055




