Introducing Prodigy-HF


Prodigy is an annotation tool made by Explosion, a company well known as the creators of spaCy. It's a fully scriptable product with a large community around it. The product has many features, including tight integration with spaCy and active learning capabilities. But the main feature of the product is that it is programmatically customizable with Python.
To foster this customisability, Explosion has started releasing plugins. These plugins integrate with third-party tools in an open way that encourages users to work on bespoke annotation workflows. However, one customization specifically deserves to be celebrated explicitly. Last week, Explosion introduced Prodigy-HF, which offers code recipes that directly integrate with the Hugging Face stack. It's been a much-requested feature on the Prodigy support forum, so we're super excited to have it out there.
Features
The first main feature is that this plugin allows you to train and re-use Hugging Face models on your annotated data. That means if you've been annotating data in our interface for named entity recognition, you can directly fine-tune BERT models against it.
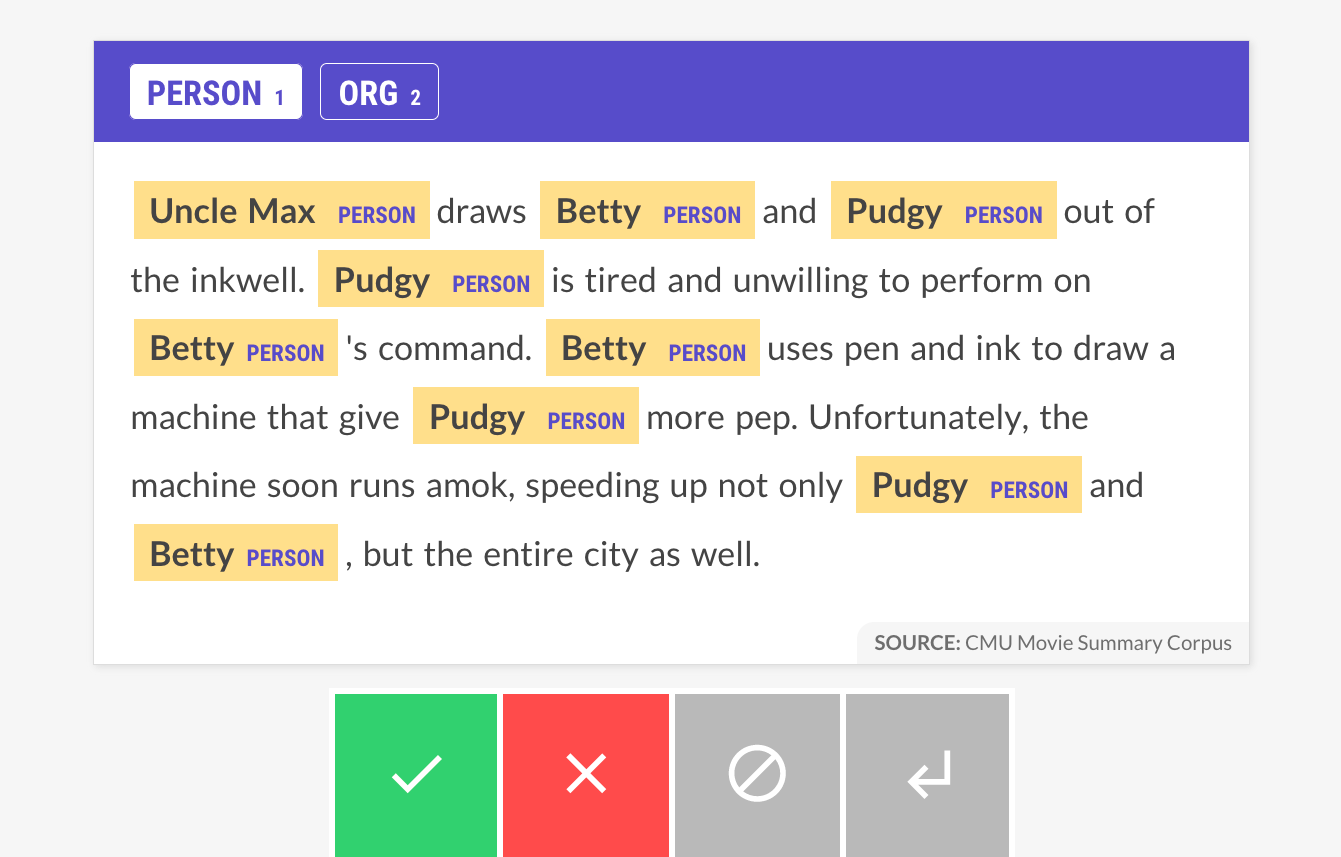
After installing the plugin you can call the hf.train.ner recipe from the command line to train a transformer model directly on your own data.
python -m prodigy hf.train.ner fashion-train,eval:fashion-eval path/to/model-out --model "distilbert-base-uncased"
This will fine-tune the distilbert-base-uncased model for the dataset you've stored in Prodigy and save it to disk. Similarly, this plugin also supports models for text classification via a very similar interface.
python -m prodigy hf.train.textcat fashion-train,eval:fashion-eval path/to/model-out --model "distilbert-base-uncased"
This offers a lot of flexibility because the tool directly integrates with the AutoTokenizer and AutoModel classes of Hugging Face transformers. Any transformer model on the hub can be fine-tuned on your own dataset with just a single command. These models will be serialised on disk, which means that you can upload them to the Hugging Face Hub, or re-use them to help you annotate data. This can save a lot of time, especially for NER tasks. To re-use a trained NER model you can use the hf.correct.ner recipe.
python -m prodigy hf.correct.ner fashion-train path/to/model-out examples.jsonl
This will give you a similar interface as before, but now the model predictions will be shown in the interface as well.
Upload
The second feature, which is equally exciting, is that you can now also publish your annotated datasets on the Hugging Face Hub. This is great if you're interested in sharing datasets that others would like to use.
python -m prodigy hf.upload <dataset_name> <username>/<repo_name>
We're particularly fond of this upload feature because it encourages collaboration. People can annotate their own datasets independently of each other, but still benefit when they share the data with the wider community.
More to come
We hope that this direct integration with the Hugging Face ecosystem enables many users to experiment more. The Hugging Face Hub offers many models for a wide array of tasks as well as a wide array of languages. We really hope that this integration makes it easier to get data annotated, even if you've got a more domain specific and experimental use-case.
More features for this library are on their way, and feel free to reach out on the Prodigy forum if you have more questions.
We'd also like to thank the team over at Hugging Face for their feedback on this plugin, specifically @davanstrien, who suggested to add the upload feature. Thanks!

