Creating Privacy Preserving AI with Substra





With the recent rise of generative techniques, machine learning is at an incredibly exciting point in its history. The models powering this rise require even more data to produce impactful results, and thus it’s becoming increasingly important to explore new methods of ethically gathering data while ensuring that data privacy and security remain a top priority.
In many domains that deal with sensitive information, such as healthcare, there often isn’t enough high quality data accessible to train these data-hungry models. Datasets are siloed in different academic centers and medical institutions and are difficult to share openly due to privacy concerns about patient and proprietary information. Regulations that protect patient data such as HIPAA are essential to safeguard individuals’ private health information, but they can limit the progress of machine learning research as data scientists can’t access the volume of data required to effectively train their models. Technologies that work alongside existing regulations by proactively protecting patient data will be crucial to unlocking these silos and accelerating the pace of machine learning research and deployment in these domains.
This is where Federated Learning comes in. Check out the space we’ve created with Substra to learn more!
What is Federated Learning?
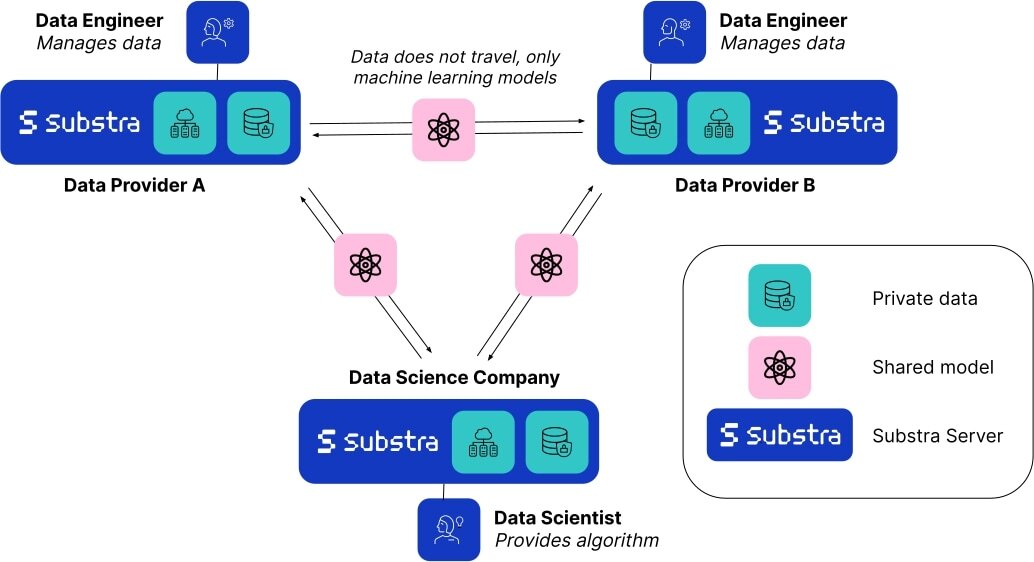
Federated learning (FL) is a decentralized machine learning technique that allows you to train models using multiple data providers. Instead of gathering data from all sources on a single server, data can remain on a local server as only the resulting model weights travel between servers.
As the data never leaves its source, federated learning is naturally a privacy-first approach. Not only does this technique improve data security and privacy, it also enables data scientists to build better models using data from different sources - increasing robustness and providing better representation as compared to models trained on data from a single source. This is valuable not only due to the increase in the quantity of data, but also to reduce the risk of bias due to variations of the underlying dataset, for example minor differences caused by the data capture techniques and equipment, or differences in demographic distributions of the patient population. With multiple sources of data, we can build more generalizable models that ultimately perform better in real world settings. For more information on federated learning, we recommend checking out this explanatory comic by Google.

Substra is an open source federated learning framework built for real world production environments. Although federated learning is a relatively new field and has only taken hold in the last decade, it has already enabled machine learning research to progress in ways previously unimaginable. For example, 10 competing biopharma companies that would traditionally never share data with each other set up a collaboration in the MELLODDY project by sharing the world’s largest collection of small molecules with known biochemical or cellular activity. This ultimately enabled all of the companies involved to build more accurate predictive models for drug discovery, a huge milestone in medical research.
Substra x HF
Research on the capabilities of federated learning is growing rapidly but the majority of recent work has been limited to simulated environments. Real world examples and implementations still remain limited due to the difficulty of deploying and architecting federated networks. As a leading open-source platform for federated learning deployment, Substra has been battle tested in many complex security environments and IT infrastructures, and has enabled medical breakthroughs in breast cancer research.
Hugging Face collaborated with the folks managing Substra to create this space, which is meant to give you an idea of the real world challenges that researchers and scientists face - mainly, a lack of centralized, high quality data that is ‘ready for AI’. As you can control the distribution of these samples, you’ll be able to see how a simple model reacts to changes in data. You can then examine how a model trained with federated learning almost always performs better on validation data compared with models trained on data from a single source.
Conclusion
Although federated learning has been leading the charge, there are various other privacy enhancing technologies (PETs) such as secure enclaves and multi party computation that are enabling similar results and can be combined with federation to create multi layered privacy preserving environments. You can learn more here if you’re interested in how these are enabling collaborations in medicine.
Regardless of the methods used, it's important to stay vigilant of the fact that data privacy is a right for all of us. It’s critical that we move forward in this AI boom with privacy and ethics in mind.
If you’d like to play around with Substra and implement federated learning in a project, you can check out the docs here.

