Open LLM Leaderboard: DROP deep dive











Recently, three new benchmarks were added to the Open LLM Leaderboard: Winogrande, GSM8k and DROP, using the original implementations reproduced in the EleutherAI Harness. A cursory look at the scores for DROP revealed something strange was going on, with the overwhelming majority of models scoring less than 10 out of 100 on their f1-score! We did a deep dive to understand what was going on, come with us to see what we found out!
Initial observations
DROP (Discrete Reasoning Over Paragraphs) is an evaluation where models must extract relevant information from English-text paragraphs before executing discrete reasoning steps on them (for example, sorting or counting items to arrive at the correct answer, see the table below for examples). The metrics used are custom f1 and exact match scores.

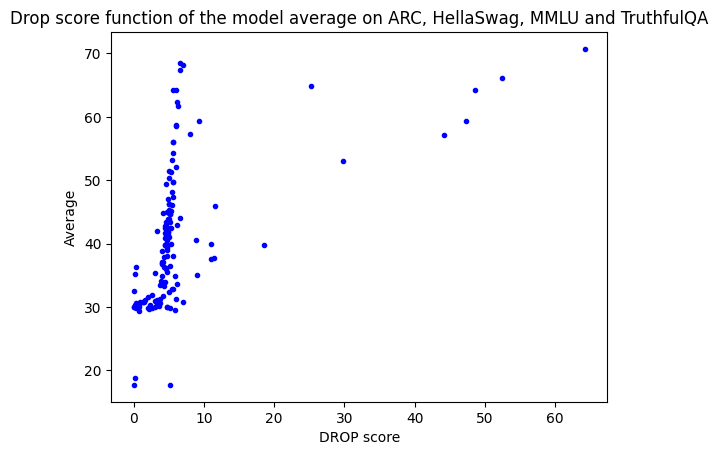
We added it to the Open LLM Leaderboard three weeks ago, and observed that the f1-scores of pretrained models followed an unexpected trend: when we plotted DROP scores against the leaderboard original average (of ARC, HellaSwag, TruthfulQA and MMLU), which is a reasonable proxy for overall model performance, we expected DROP scores to be correlated with it (with better models having better performance). However, this was only the case for a small number of models, and all the others had a very low DROP f1-score, below 10.
Normalization interrogations
During our first deeper dive in these surprising behavior, we observed that the normalization step was possibly not working as intended: in some cases, this normalization ignored the correct numerical answers when they were directly followed by a whitespace character other than a space (a line return, for example).
Let's look at an example, with the generation being 10\n\nPassage: The 2011 census recorded a population of 1,001,360, and the gold answer being 10.
Normalization happens in several steps, both for generation and gold:
- Split on separators
|,-, or10\n\nPassage:contain no such separator, and is therefore considered a single entity after this step. - Punctuation removal
The first token then becomes
10\n\nPassage(:is removed) - Homogenization of numbers
Every string that can be cast to float is considered a number and cast to float, then re-converted to string.
10\n\nPassagestays the same, as it cannot be cast to float, whereas the gold10becomes10.0. - Other steps
A lot of other normalization steps ensue (removing articles, removing other whitespaces, etc.) and our original example becomes
10 passage 2011.0 census recorded population of 1001360.0.
However, the overall score is not computed on the string, but on the bag of words (BOW) extracted from the string, here {'recorded', 'population', 'passage', 'census', '2011.0', '1001360.0', '10'}, which is compared with the BOW of the gold, also normalized in the above manner, {10.0}. As you can see, they don’t intersect, even though the model predicted the correct output!
In summary, if a number is followed by any kind of whitespace other than a simple space, it will not pass through the number normalization, hence never match the gold if it is also a number! This first issue was likely to mess up the scores quite a bit, but clearly it was not the only factor causing DROP scores to be so low. We decided to investigate a bit more.
Diving into the results
Extending our investigations, our friends at Zeno joined us and undertook a much more thorough exploration of the results, looking at 5 models which were representative of the problems we noticed in DROP scores: falcon-180B and mistral-7B were underperforming compared to what we were expecting, Yi-34B and tigerbot-70B had a very good performance on DROP correlated with their average scores, and facebook/xglm-7.5B fell in the middle.
You can give analyzing the results a try in the Zeno project here if you want to!
The Zeno team found two even more concerning features:
- Not a single model got a correct result on floating point answers
- High quality models which generate long answers actually have a lower f1-score
At this point, we believed that both failure cases were actually caused by the same root factor: using . as a stopword token (to end the generations):
- Floating point answers are systematically interrupted before their generation is complete
- Higher quality models, which try to match the few-shot prompt format, will generate
Answer\n\nPlausible prompt for the next question., and only stop during the plausible prompt continuation after the actual answer on the first., therefore generating too many words and getting a bad f1 score.
We hypothesized that both these problems could be fixed by using \n instead of . as an end of generation stop word.
Changing the end of generation token
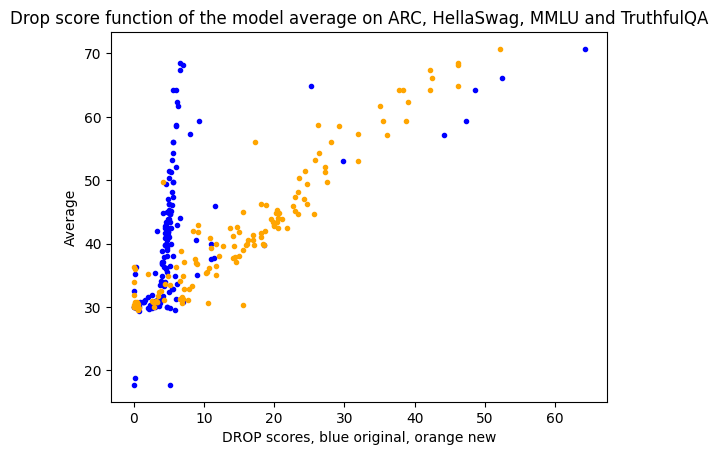
So we gave it a try! We investigated using \n as the end of generation token on the available results. We split the generated answer on the first \n it contained, if one was present, and recomputed the scores.
Note that this is only an approximation of the correct result, as it won't fix answers that were cut too early on . (for example floating point answers) - but it also won’t give unfair advantage to any model, as all of them were affected by this problem.
However it’s the best we could do without rerunning models (as we wanted to keep the community posted as soon as possible).
The results we got were the following - splitting on \n correlates really well with other scores and therefore with overall performance.
So what's next?
A quick calculation shows that re-running the full evaluation of all models would be quite costly (the full update took 8 years of GPU time, and a lot of it was taken by DROP), we estimated how much it would cost to only re-run failing examples.
In 10% of the cases, the gold answer is a floating number (for example 12.25) and model predictions start with the correct beginning (for our example, 12) but are cut off on a . - these predictions likely would have actually been correct if the generation was to continue. We would definitely need to re-run them!
Our estimation does not count generated sentences that finish with a number which was possibly interrupted (40% of the other generations), nor any prediction messed up by its normalization.
To get correct results, we would thus need to re-run more than 50% of the examples, a huge amount of GPU time! We need to be certain that the implementation we'll run is correct this time.
After discussing it with the fantastic EleutherAI team (both on GitHub and internally), who guided us through the code and helped our investigations, it became very clear that the LM Eval Harness implementation follows the "official DROP" code very strictly: a new version of this benchmark’s evaluation thus needs to be developed! We have therefore taken the decision to remove DROP from the Open LLM Leaderboard until a new version arises.
One take away of this investiguation is the value in having the many eyes of the community collaboratively investiguate a benchmark in order to detect errors that were previously missed. Here again the power of open-source, community and developping in the open-shines in that it allows to transparently investigate the root cause of an issue on a benchmark which has been out there for a couple of years.
We hope that interested members of the community will join forces with academics working on DROP evaluation to fix both its scoring and its normalization. We'd love it becomes usable again, as the dataset itself is really quite interesting and cool. We encourage you to provide feedback on how we should evaluate DROP on this issue.
Thanks to the many community members who pointed out issues on DROP scores, and many thanks to the EleutherAI Harness and Zeno teams for their great help on this issue.

