Run the strongest open-source LLM model: Llama3 70B with just a single 4GB GPU!








The strongest open source LLM model Llama3 has been released, some followers have asked if AirLLM can support running Llama3 70B locally with 4GB of VRAM. The answer is YES. Here we go.
Moreover, how does Llama3’s performance compare to GPT-4? What’s the key cutting-edge technology Llama3 use to become so powerful? Does Llama3’s breakthrough mean that open-source models have officially begun to surpass closed-source ones? Today we’ll also give our interpretation.
How to run Llama3 70B on a single GPU with just 4GB memory GPU
The model architecture of Llama3 has not changed, so AirLLM actually already naturally supports running Llama3 70B perfectly! It can even run on a MacBook.
First, install AirLLM:
pip install airllm
Then all you need is a few lines of code:
from airllm import AutoModel
MAX_LENGTH = 128
model = AutoModel.from_pretrained("v2ray/Llama-3-70B")
input_text = [
'What is the capital of United States?'
]
input_tokens = model.tokenizer(input_text,
return_tensors="pt",
return_attention_mask=False,
truncation=True,
max_length=MAX_LENGTH,
padding=False)
generation_output = model.generate(
input_tokens['input_ids'].cuda(),
max_new_tokens=20,
use_cache=True,
return_dict_in_generate=True)
output = model.tokenizer.decode(generation_output.sequences[0])
print(output)
See more details from our GitHub repo here.
Please note: it’s not designed for real-time interactive scenarios like chatting, more suitable for data processing and other offline asynchronous scenarios.
How does it compare to GPT4?
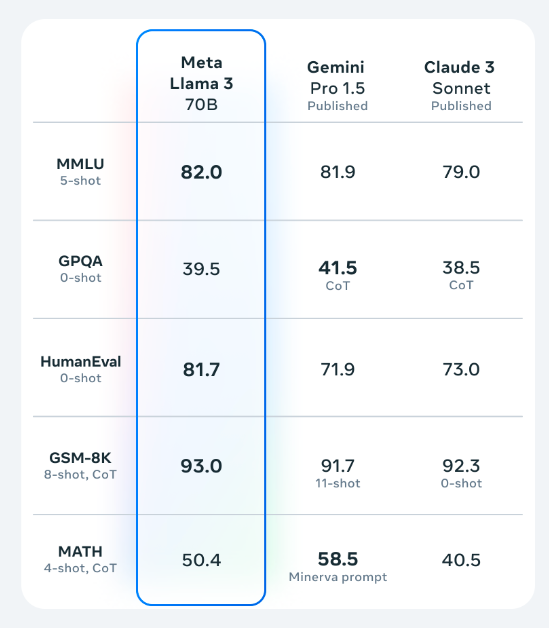
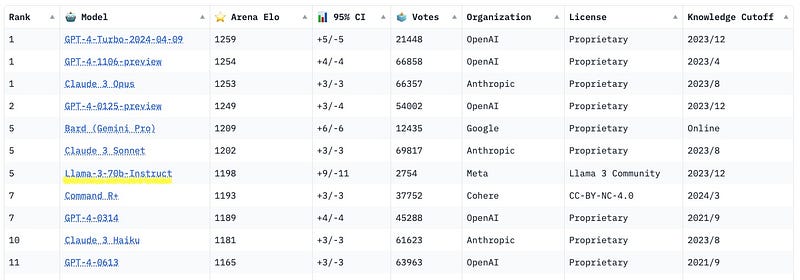
According to official evaluation data and the latest lmsys leaderboard, Llama3 70B is very close to GPT4 and Claude3 Opus.
Official evaluation results:
lmsys leaderboard results:
Of course, it would be more reasonable to compare the similarly sized 400B models with GPT4 and Claude3 Opus:
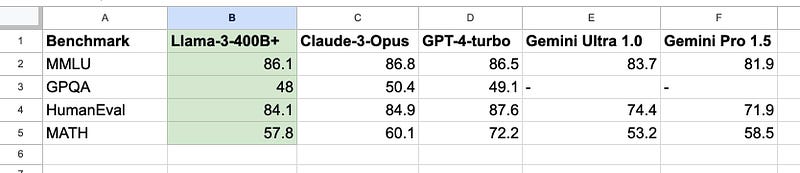
Llama3 400B is already very close to the strongest versions of GPT4 and Claude3, and it’s still being trained.
What is the core improvement in Llama3?
The architecture of Llama3 hasn’t changed; there are some technical improvements in the training methods, such as model alignment training based on DPO.
DPO has basically become a standard go-to training approach fro all the top-ranking large models on all the leaderboards — it simply works! We’ve previously written articles introducing DPO in detail, with all the code open-sourced here.
Of course, Llama3’s main key secret source is all about in the massive increase in the quantity and quality of its training data. From Llama2’s 2T, it increased to 15T! AI is all about data!
The improvement in data is not just in quantity, but quality as well. Meta did a huge amount of data quality filtering, deduplication, etc. And a lot of it was based on using large models like Llama2 to filter and select the data.
Please note: This 15T is after strict filtering and cleaning. Before filtering, it may have been over 100T.
The core of training an AI model is data. To train a good AI model, it’s not about having lots of fancy training techniques, but doing the fundamental work solidly and meticulously. Especially the non-sexy, dirty, tedious work of data quality — this is actually critically important.
I’ve always rated Meta AI’s capabilities highly. From the early days of discriminative AI with transformers, Meta AI has been known for its solid data processing foundation, producing many classic models that topped the SOTA for a long time, such as Roberta and Roberta XLM, which were our go-to models for a long time.
Does Llama3’s success herald the rise of open-source models??

The battle between open-source and closed-source may be far from over. There’s still a lot of drama to come.
Regardless of open or closed source, training large models has become a game of burning cash. The 15T of data and 400B model are not things that small players can afford. I think within the next six months, many small companies working on large models will disappear.
When it comes to the burning cash competition, what it’s really about is the long-term ability and efficiency of monetizing your investment. In fact, to this day there are still very few real monetized applications of AI LLMs. It’s hard to say who can sustain their investment, and in what ways.
From a purely technical perspective, we have always believed that an open culture is crucial for AI. The rapid development of AI in recent years could not have happened without the open and sharing culture of the AI community. This is true even within a company; whether it can maintain an open and shared environment, and continuously engage in transparent and open exchanges of ideas, is key to its AI development. A company that is very closed off to the outside world is likely also not very open and transparent internally, which will sooner or later hinder the rapid development of its AI technology, as well as prevent it from truly building a first-class team.
We will continue to follow the latest and coolest AI technologies and continue to share open-source work. Welcome to follow us and stay tuned!




