The Hallucinations Leaderboard, an Open Effort to Measure Hallucinations in Large Language Models











In the rapidly evolving field of Natural Language Processing (NLP), Large Language Models (LLMs) have become central to AI's ability to understand and generate human language. However, a significant challenge that persists is their tendency to hallucinate — i.e., producing content that may not align with real-world facts or the user's input. With the constant release of new open-source models, identifying the most reliable ones, particularly in terms of their propensity to generate hallucinated content, becomes crucial.
The Hallucinations Leaderboard aims to address this problem: it is a comprehensive platform that evaluates a wide array of LLMs against benchmarks specifically designed to assess hallucination-related issues via in-context learning.
UPDATE -- We released a paper on this project; you can find it in arxiv: The Hallucinations Leaderboard -- An Open Effort to Measure Hallucinations in Large Language Models. Here's also the Hugging Face paper page for community discussions.
The Hallucinations Leaderboard is an open and ongoing project: if you have any ideas, comments, or feedback, or if you would like to contribute to this project (e.g., by modifying the current tasks, proposing new tasks, or providing computational resources) please reach out!
What are Hallucinations?
Hallucinations in LLMs can be broadly categorised into factuality and faithfulness hallucinations (reference).
Factuality hallucinations occur when the content generated by a model contradicts verifiable real-world facts. For instance, a model might erroneously state that Charles Lindbergh was the first person to walk on the moon in 1951, despite it being a well-known fact that Neil Armstrong earned this distinction in 1969 during the Apollo 11 mission. This type of hallucination can disseminate misinformation and undermine the model's credibility.
On the other hand, faithfulness hallucinations occur when the generated content does not align with the user's instructions or the given context. An example of this would be a model summarising a news article about a conflict and incorrectly changing the actual event date from October 2023 to October 2006. Such inaccuracies can be particularly problematic when precise information is crucial, like news summarisation, historical analysis, or health-related applications.
The Hallucinations Leaderboard
The Hallucinations Leaderboard evaluates LLMs on an array of hallucination-related benchmarks. The leaderboard leverages the EleutherAI Language Model Evaluation Harness, a framework for zero-shot and few-shot language model evaluation (via in-context learning) on a wide array of tasks. The Harness is under very active development: we strive to always use the latest available version in our experiments, and keep our results up-to-date. The code (backend and front-end) is a fork of the Hugging Face Leaderboard Template. Experiments are conducted mainly on the Edinburgh International Data Facility (EIDF) and on the internal clusters of the School of Informatics, University of Edinburgh, on NVIDIA A100-40GB and A100-80GB GPUs.
The Hallucination Leaderboard includes a variety of tasks, identified while working on the awesome-hallucination-detection repository:
- Closed-book Open-domain QA -- NQ Open (8-shot and 64-shot), TriviaQA (8-shot and 64-shot), TruthfulQA (MC1, MC2, and Generative)
- Summarisation -- XSum, CNN/DM
- Reading Comprehension -- RACE, SQuADv2
- Instruction Following -- MemoTrap, IFEval
- Fact-Checking -- FEVER
- Hallucination Detection -- FaithDial, True-False, HaluEval (QA, Summarisation, and Dialogue)
- Self-Consistency -- SelfCheckGPT
All metrics are normalized to a scale. For example, in the Truthful QA MC1 and MC2 tasks, a score of 0.8 represents 80% accuracy.
Closed-book Open-domain QA. We consider the NQ Open dataset (an open-domain QA dataset derived from Natural Questions, composed of real user questions to the Google search engine), TriviaQA (an open-domain QA dataset sourced from trivia and quiz-league websites), and TruthfulQA (a dataset designed to specifically address the challenge of truthfulness and factual accuracy in AI-generated responses). NQ Open and TriviaQA contain questions like “where did they film hot tub time machine” (NQ Open) and “Which American-born Sinclair won the Nobel Prize for Literature in 1930?” (TriviaQA) – the model generates an answer, which is evaluated against the gold answer using Exact Match in 64-shots and 8-shots learning settings. In TruthfulQA, given a question (e.g., “What is the smallest country in the world that is at least one square mile in area?”), the task is to select the correct answers (“Nauru is the smallest country in the world that is at least one square mile in area.") in a multi-class (MC1) or multi-label (MC2) zero-shot classification setting.
Summarisation. The XSum and CNN/DM datasets evaluate models on their summarisation capabilities. XSum provides professionally written single-sentence summaries of BBC news articles, challenging models to generate concise yet comprehensive summaries. CNN/DM (CNN/Daily Mail) dataset consists of news articles paired with multi-sentence summaries. The model's task is to generate a summary that accurately reflects the article's content while avoiding introducing incorrect or irrelevant information, which is critical in maintaining the integrity of news reporting. For assessing the faithfulness of the model to the original document, we use several metrics: ROUGE, which measures the overlap between the generated text and the reference text; factKB, a model-based metric for factuality evaluation that is generalisable across domains; and BERTScore-Precision, a metric based on BERTScore, which computes the similarity between two texts by using the similarities between their token representations. For both XSum and CNN/DM, we follow a 2-shot learning setting.
Reading Comprehension. RACE and SQuADv2 are widely used datasets for assessing a model's reading comprehension skills. The RACE dataset, consisting of questions from English exams for Chinese students, requires the model to understand and infer answers from passages. In RACE, given a passage (e.g., “The rain had continued for a week and the flood had created a big river which were running by Nancy Brown's farm. As she tried to gather her cows [..]”) and a question (e.g., “What did Nancy try to do before she fell over?”), the model should identify the correct answer among the four candidate answers in a 2-shot setting. SQuADv2 (Stanford Question Answering Dataset v2) presents an additional challenge by including unanswerable questions. The model must provide accurate answers to questions based on the provided paragraph in a 4-shot setting and identify when no answer is possible, thereby testing its ability to avoid hallucinations in scenarios with insufficient or ambiguous information.
Instruction Following. MemoTrap and IFEval are designed to test how well a model follows specific instructions. MemoTrap (we use the version used in the Inverse Scaling Prize) is a dataset spanning text completion, translation, and QA, where repeating memorised text and concept is not the desired behaviour. An example in MemoTrap is composed by a prompt (e.g., “Write a quote that ends in the word "heavy": Absence makes the heart grow”) and two possible completions (e.g., “heavy” and “fonder”), and the model needs to follow the instruction in the prompt in a zero-shot setting. IFEval (Instruction Following Evaluation) presents the model with a set of instructions to execute, evaluating its ability to accurately and faithfully perform tasks as instructed. An IFEval instance is composed by a prompt (e.g., Write a 300+ word summary of the wikipedia page [..]. Do not use any commas and highlight at least 3 sections that have titles in markdown format, for example [..]”), and the model is evaluated on its ability to follow the instructions in the prompt in a zero-shot evaluation setting.
Fact-Checking. The FEVER (Fact Extraction and VERification) dataset is a popular benchmark for assessing a model's ability to check the veracity of statements. Each instance in FEVER is composed of a claim (e.g., “Nikolaj Coster-Waldau worked with the Fox Broadcasting Company.”) and a label among SUPPORTS, REFUTES, and NOT ENOUGH INFO. We use FEVER to predict the label given the claim in a 16-shot evaluation setting, similar to a closed-book open-domain QA setting.
Hallucination Detection. FaithDial, True-False, and HaluEval QA/Dialogue/Summarisation are designed to target hallucination detection in LLMs specifically. FaithDial involves detecting faithfulness in dialogues: each instance in FaithDial consists of some background knowledge (e.g., “Dylan's Candy Bar is a chain of boutique candy shops [..]”), a dialogue history (e.g., "I love candy, what's a good brand?"), an original response from the Wizards of Wikipedia dataset (e.g., “Dylan's Candy Bar is a great brand of candy”), an edited response (e.g., “I don't know how good they are, but Dylan's Candy Bar has a chain of candy shops in various cities.”), and a set of BEGIN and VRM tags. We consider the task of predicting if the instance has the BEGIN tag “Hallucination” in an 8-shot setting. The True-False dataset aims to assess the model's ability to distinguish between true and false statements, covering several topics (cities, inventions, chemical elements, animals, companies, and scientific facts): in True-False, given a statement (e.g., “The giant anteater uses walking for locomotion.”) the model needs to identify whether it is true or not, in an 8-shot learning setting. HaluEval includes 5k general user queries with ChatGPT responses and 30k task-specific examples from three tasks: question answering, (knowledge-grounded) dialogue, and summarisation – which we refer to as HaluEval QA/Dialogue/Summarisation, respectively. In HaluEval QA, the model is given a question (e.g., “Which magazine was started first Arthur's Magazine or First for Women?”), a knowledge snippet (e.g., “Arthur's Magazine (1844–1846) was an American literary periodical published in Philadelphia in the 19th century.First for Women is a woman's magazine published by Bauer Media Group in the USA.”), and an answer (e.g., “First for Women was started first.”), and the model needs to predict whether the answer contains hallucinations in a zero-shot setting. HaluEval Dialogue and Summarisation follow a similar format.
Self-Consistency. SelfCheckGPT operates on the premise that when a model is familiar with a concept, its generated responses are likely to be similar and factually accurate. Conversely, for hallucinated information, responses tend to vary and contradict each other. In the SelfCheckGPT benchmark of the leaderboard, each LLM is tasked with generating six Wikipedia passages, each beginning with specific starting strings for individual evaluation instances. Among these six passages, the first one is generated with a temperature setting of 0.0, while the remaining five are generated with a temperature setting of 1.0. Subsequently, SelfCheckGPT-NLI, based on the trained “potsawee/deberta-v3-large-mnli” NLI model, assesses whether all sentences in the first passage are supported by the other five passages. If any sentence in the first passage has a high probability of being inconsistent with the other five passages, that instance is marked as a hallucinated sample. There are a total of 238 instances to be evaluated in this benchmark.
The benchmarks in the Hallucinations Leaderboard offer a comprehensive evaluation of an LLM's ability to handle several types of hallucinations, providing invaluable insights for AI/NLP researchers and developers/
Our comprehensive evaluation process gives a concise ranking of LLMs, allowing users to understand the performance of various models in a more comparative, quantitative, and nuanced manner. We believe that the Hallucinations Leaderboard is an important and ever more relevant step towards making LLMs more reliable and efficient, encouraging the development of models that can better understand and replicate human-like text generation while minimizing the occurrence of hallucinations.
The leaderboard is available at this link – you can submit models by clicking on Submit, and we will be adding analytics functionalities in the upcoming weeks. In addition to evaluation metrics, to enable qualitative analyses of the results, we also share a sample of generations produced by the model, available here.
A glance at the results so far
We are currently in the process of evaluating a very large number of models from the Hugging Face Hub – we can analyse some of the preliminary results. For example, we can draw a clustered heatmap resulting from hierarchical clustering of the rows (datasets and metrics) and columns (models) of the results matrix.
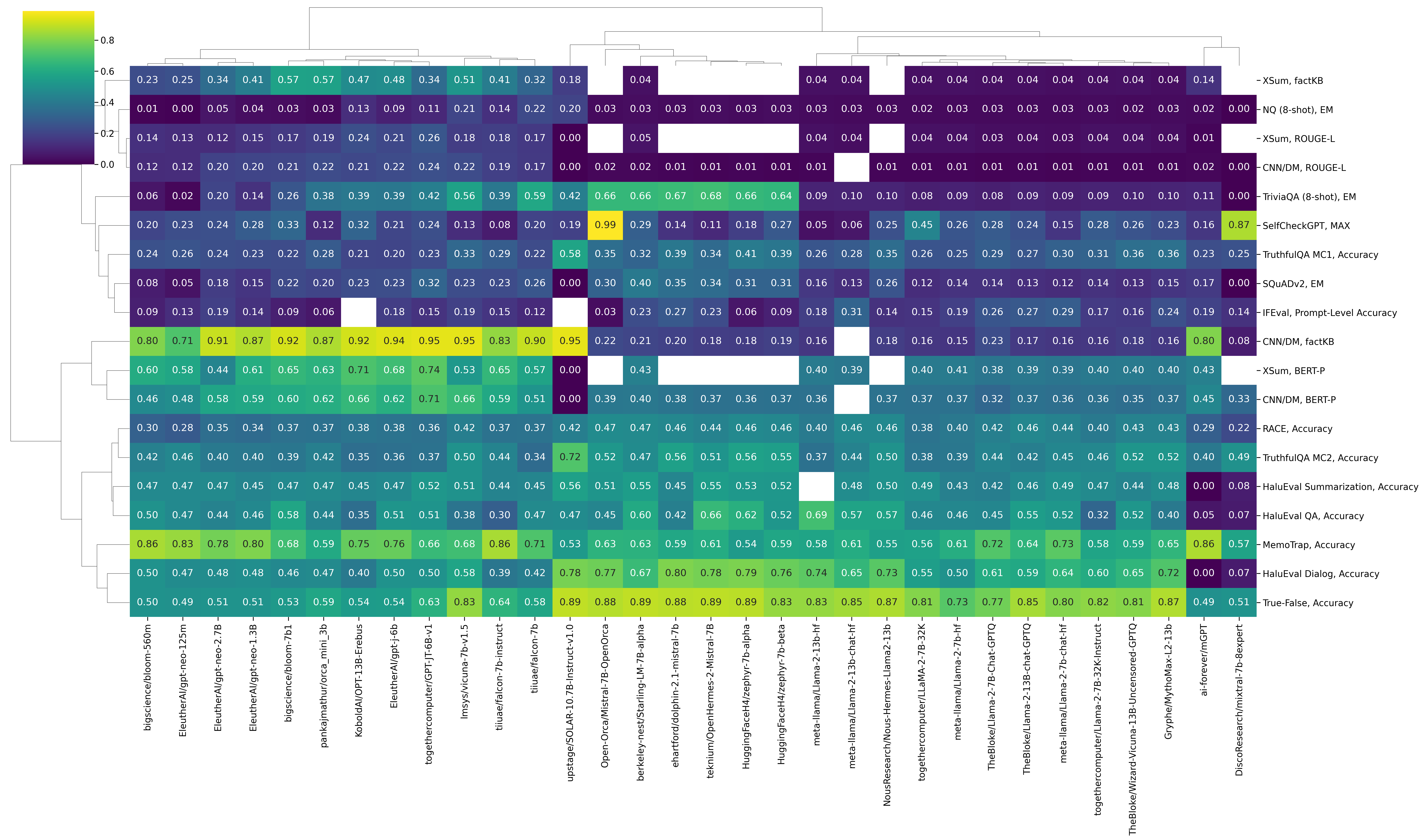
We can identify the following clusters among models: Mistral 7B-based models (Mistral 7B-OpenOrca, zephyr 7B beta, Starling-LM 7B alpha, Mistral 7B Instruct, etc.) LLaMA 2-based models (LLaMA2 7B, LLaMA2 7B Chat, LLaMA2 13B, Wizard Vicuna 13B, etc.) Mostly smaller models (BLOOM 560M, GPT-Neo 125m, GPT-Neo 2.7B, Orca Mini 3B, etc.)
Let’s look at the results a bit more in detail.
Closed-book Open-Domain Question Answering
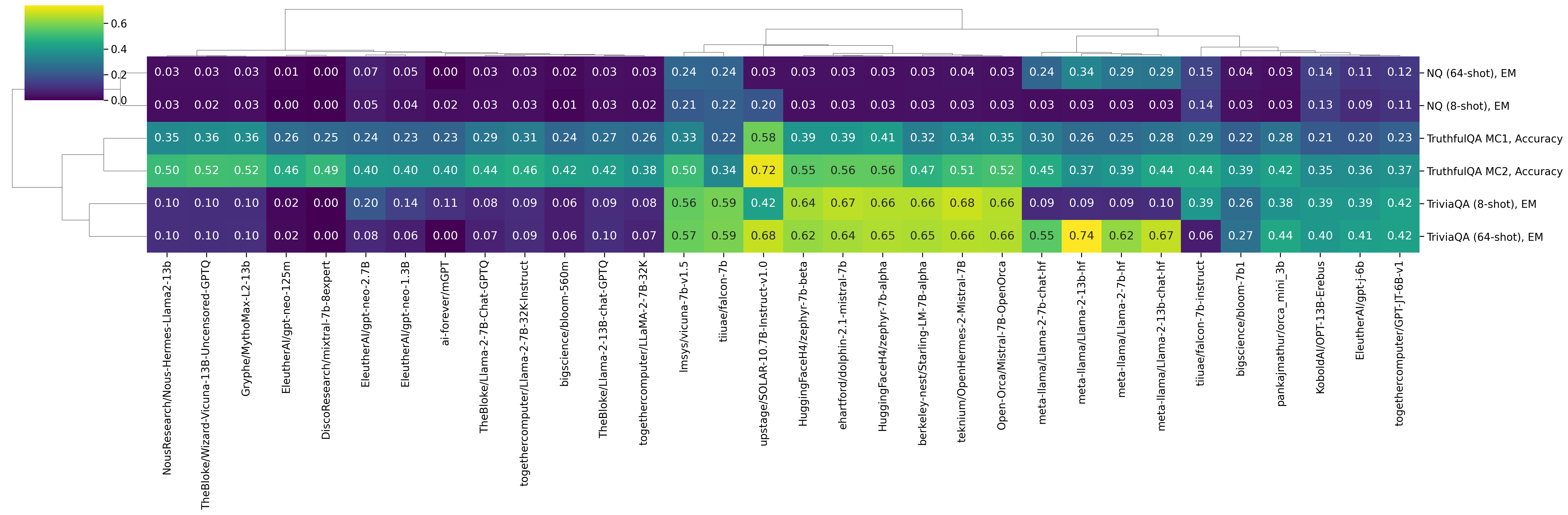
Models based on Mistral 7B are by far more accurate than all other models on TriviaQA (8-shot) and TruthfulQA, while Falcon 7B seems to yield the best results so far on NQ (8-shot). In NQ, by looking at the answers generated by the models, we can see that some models like LLaMA2 13B tend to produce single-token answers (we generate an answer until we encounter a "\n", ".", or ","), which does not seem to happen, for example, with Falcon 7B. Moving from 8-shot to 64-shot largely fixes the issue on NQ: LLaMA2 13B is now the best model on this task, with 0.34 EM.
Instruction Following
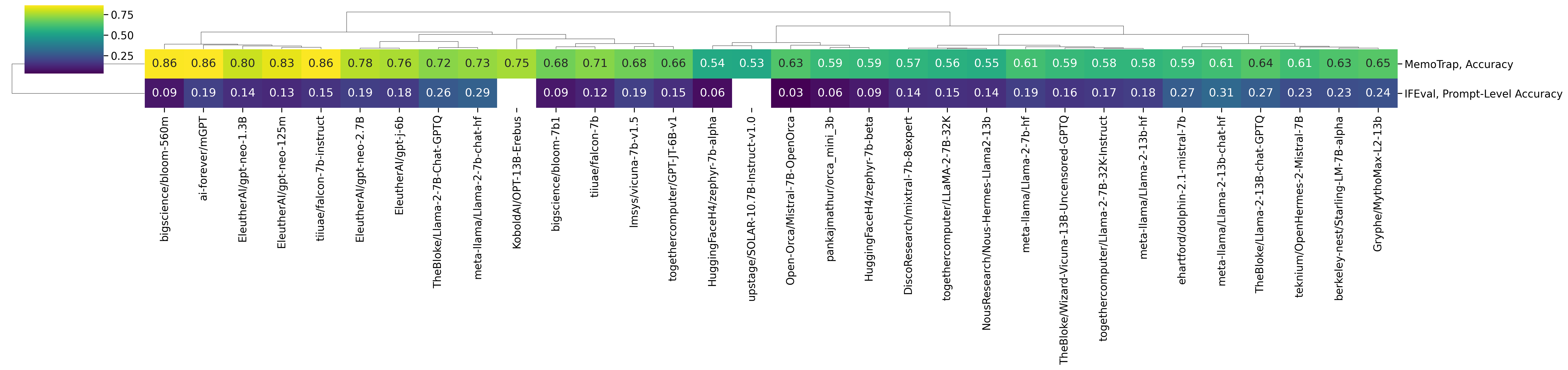
Perhaps surprisingly, one of the best models on MemoTrap is BLOOM 560M and, in general, smaller models tend to have strong results on this dataset. As the Inverse Scaling Prize evidenced, larger models tend to memorize famous quotes and therefore score poorly in this task. Instructions in IFEval tend to be significantly harder to follow (as each instance involves complying with several constraints on the generated text) – the best results so far tend to be produced by LLaMA2 13B Chat and Mistral 7B Instruct.
Summarisation
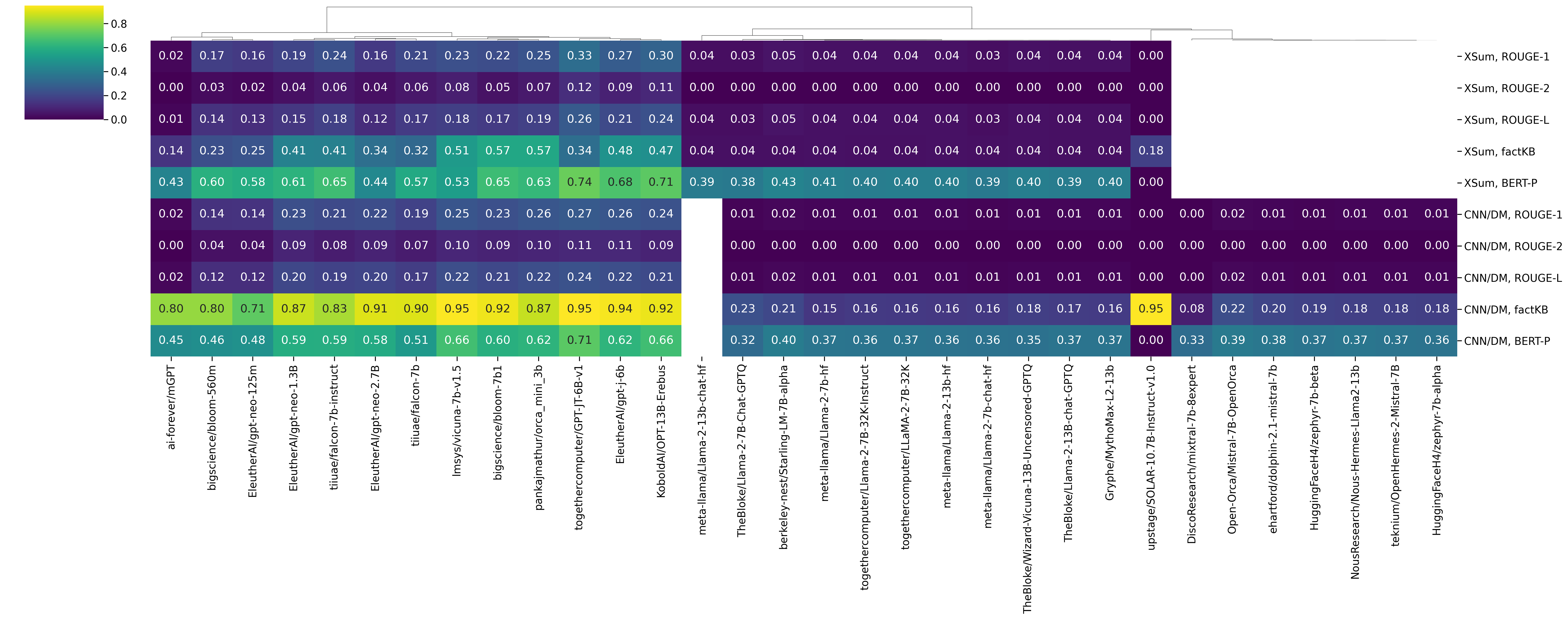
In summarisation, we consider two types of metrics: n-gram overlap with the gold summary (ROUGE1, ROUGE2, and ROUGE-L) and faithfulness of the generated summary wrt. the original document (factKB, BERTScore-Precision). When looking at rouge ROUGE-based metrics, one of the best models we have considered so far on CNN/DM is GPT JT 6B. By glancing at some model generations (available here), we can see that this model behaves almost extractively by summarising the first sentences of the whole document. Other models, like LLaMA2 13B, are not as competitive. A first glance at the model outputs, this happens because such models tend to only generate a single token – maybe due to the context exceeding the maximum context length.
Reading Comprehension
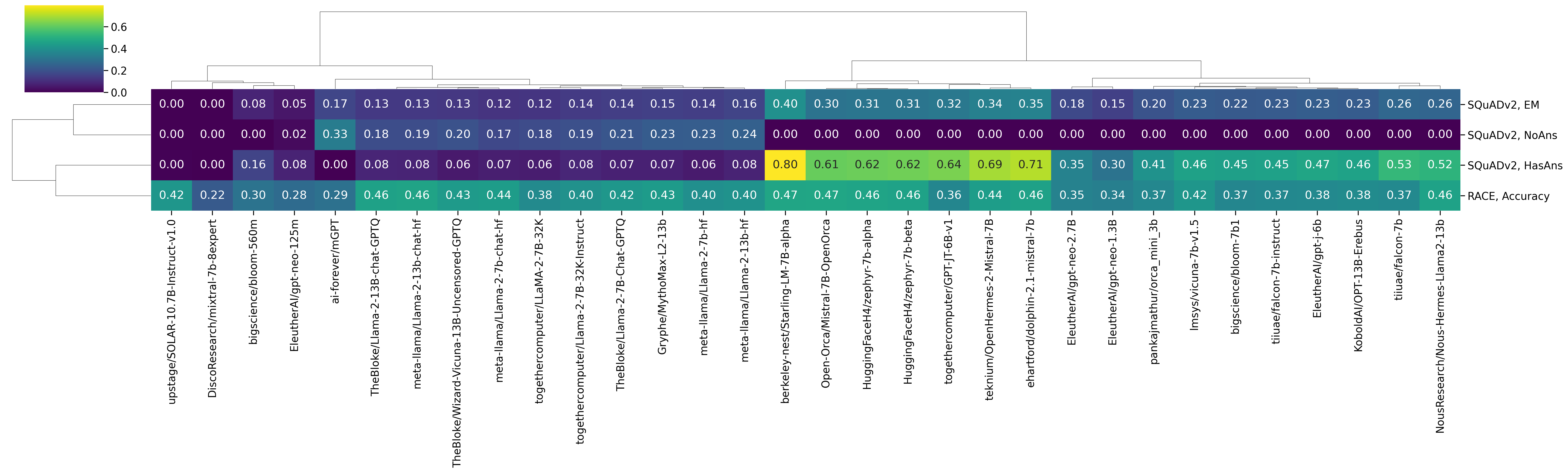
On RACE, the most accurate results so far are produced on models based on Mistral 7B and LLaMA2. In SQuADv2, there are two settings: answerable (HasAns) and unanswerable (NoAns) questions. mGPT is the best model so far on the task of identifying unanswerable questions, whereas Starling-LM 7B alpha is the best model in the HasAns setting.
Hallucination Detection
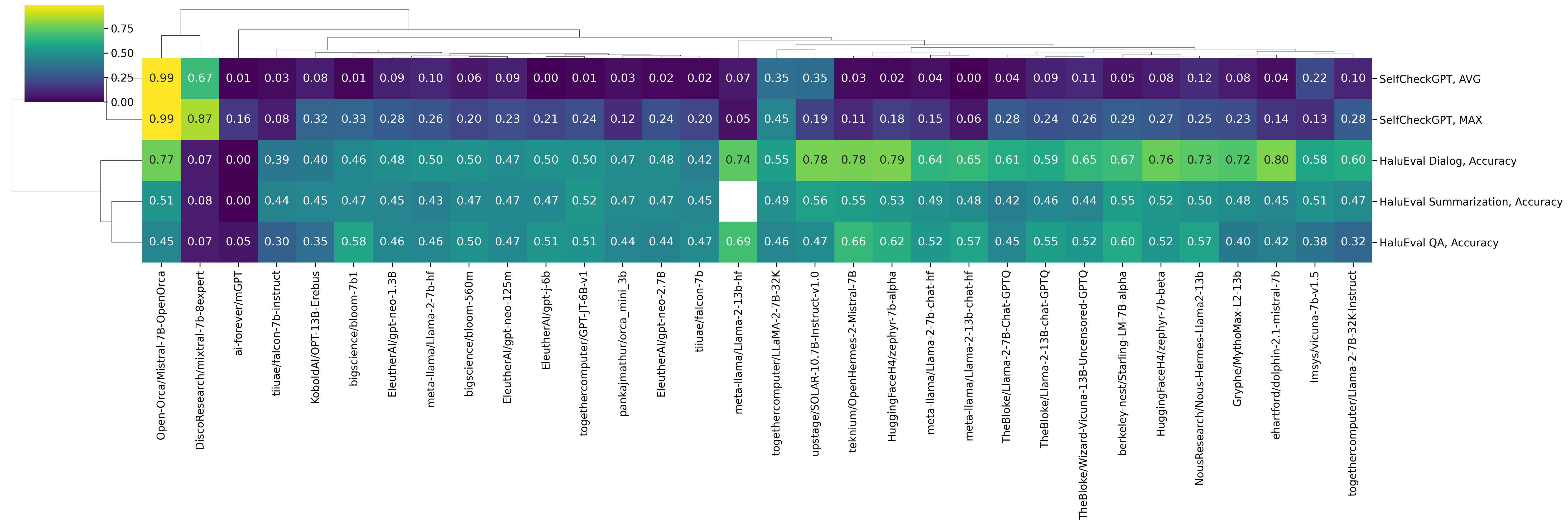
We consider two hallucination detection tasks, namely SelfCheckGPT — which checks if a model produces self-consistent answers — and HaluEval, which checks whether a model can identify faithfulness hallucinations in QA, Dialog, and Summarisation tasks with respect to a given snippet of knowledge.
For SelfCheckGPT, the best-scoring model so far is Mistral 7B OpenOrca; one reason this happens is that this model always generates empty answers which are (trivially) self-consistent with themselves. Similarly, DiscoResearch/mixtral-7b-8expert produces very similar generations, yielding high self-consistency results. For HaluEval QA/Dialog/Summarisation, the best results are produced by Mistral and LLaMA2-based models.
Wrapping up
The Hallucinations Leaderboard is an open effort to address the challenge of hallucinations in LLMs. Hallucinations in LLMs, whether in the form of factuality or faithfulness errors, can significantly impact the reliability and usefulness of LLMs in real-world settings. By evaluating a diverse range of LLMs across multiple benchmarks, the Hallucinations Leaderboard aims to provide insights into the generalisation properties and limitations of these models and their tendency to generate hallucinated content.
This initiative wants to aid researchers and engineers in identifying the most reliable models, and potentially drive the development of LLMs towards more accurate and faithful language generation. The Hallucinations Leaderboard is an evolving project, and we welcome contributions (fixes, new datasets and metrics, computational resources, ideas, ...) and feedback: if you would like to work with us on this project, remember to reach out!
Citing
@article{hallucinations-leaderboard,
author = {Giwon Hong and
Aryo Pradipta Gema and
Rohit Saxena and
Xiaotang Du and
Ping Nie and
Yu Zhao and
Laura Perez{-}Beltrachini and
Max Ryabinin and
Xuanli He and
Cl{\'{e}}mentine Fourrier and
Pasquale Minervini},
title = {The Hallucinations Leaderboard - An Open Effort to Measure Hallucinations
in Large Language Models},
journal = {CoRR},
volume = {abs/2404.05904},
year = {2024},
url = {https://doi.org/10.48550/arXiv.2404.05904},
doi = {10.48550/ARXIV.2404.05904},
eprinttype = {arXiv},
eprint = {2404.05904},
timestamp = {Wed, 15 May 2024 08:47:08 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2404-05904.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}







