Evaluating Large Language Models on Gender-Occupational Stereotypes Using the Wino Bias Test



How to use LangTest to evaluate LLMs on Gender-Occupational Bias

Introduction
In the realm of artificial intelligence and natural language processing, addressing bias and stereotypes is now a pressing concern. Language models, celebrated for their linguistic prowess, have faced scrutiny for perpetuating gender and occupational stereotypes.
Language models once hailed for their remarkable linguistic capabilities, are now under intense scrutiny for perpetuating gender and occupational stereotypes. Despite being trained on vast volumes of data, they inevitably inherit the biases ingrained in their training datasets. Consequently, they have the unintended potential to reinforce gender-occupational stereotypes when deployed in real-world applications.
In this blog post, we dive into testing the WinoBias dataset on LLMs, examining language models’ handling of gender and occupational roles, evaluation metrics, and the wider implications. Let’s explore the evaluation of language models with LangTest on the WinoBias dataset and confront the challenges of addressing bias in AI.

Figure 1 displays sets of gender-balanced co-reference tests found in the WinoBias dataset. In these tests, male entities are indicated in solid blue, while female entities are represented by dashed orange. In each example, the gender of the pronoun’s reference is not a factor in making the co-reference determination. Systems need to exhibit accurate linking predictions in both pro-stereotypical scenarios and anti-stereotypical scenario i.e. to give importance to both genders to successfully pass the test. It’s crucial to note that stereotypical occupations are determined based on data from the US Department of Labor.
A Contrast of Actual and LangTest Evaluations in Unveiling Gender Bias
The evaluation of gender bias within language models is a critical endeavor, and it is approached in various ways. Two distinct methods, the LangTest Evaluation, and the actual WinoBias Evaluation, provide different lenses through which we can scrutinize this issue. These evaluations offer unique insights into the biases inherent in language models and their abilities to resolve coreferences.
LangTest Evaluation: Unmasking Gender Bias in LLMs

The LangTest Evaluation takes a distinctive approach by modifying the original data through pronoun masking before the evaluation process. The LangTest Evaluation centers around the WinoBias dataset and introduces a novel evaluation method designed to assess gender bias in language models.
Previously, the HuggingFace 🤗 masked model approach was employed for this evaluation which can be found in this blogpost.
However, in our discussion, we will shift the focus to Large Language Models (LLMs) and detail the evaluation process within this context. Here, the LangTest Evaluation transforms the evaluation into a Question-Answer (Q/A) format where in the language models are tasked with completing sentences that will have a [MASK] i.e. masking pronouns before the evaluation and prompting the model to select and fill the mask from multiple-choice questions (MCQs).
Three options are presented to the models for completing sentences: Option A: which corresponds to a specific gender. Option B: which corresponds to a different gender. Option C: which corresponds to both Option A and Option B.
The key to unbiased responses lies in selecting Option C. This methodology encourages the resolution of coreferences without relying on gender stereotypes and provides a direct measurement of gender bias by capturing the model’s natural inclination toward gendered pronouns. In doing so, even subtle biases can be unveiled.
The LangTest Evaluation, with its innovative Q/A format, offers a more direct and precise method for quantifying gender bias. It simplifies the evaluation process and unveils biases by examining a model’s choices in gendered pronouns. It provides a clear, accessible, and versatile approach, making it a valuable tool for those interested in assessing and mitigating gender bias in language models.
On the other hand, the actual WinoBias Evaluation doesn’t utilize masking. It aims for consistent accuracy in coreference decisions across stereotypical and non-stereotypical scenarios by dividing data into two categories. The first category tests the model’s ability to link gendered pronouns with stereotypically matched occupations, while the second examines the association of pronouns with non-traditionally matched occupations. Success in the WinoBias test is gauged by a model’s consistent accuracy across these two scenarios, focusing more on understanding context and forming coreference links, indirectly measuring gender bias.
Testing in a few lines of code
!pip install "langtest[ai21,openai]==1.7.0"
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_KEY>"
# Import Harness from the LangTest library
from langtest import Harness
harness = Harness(task="wino-bias",
model={"model": "text-davinci-003","hub":"openai"},
data ={"data_source":"Wino-test"})
harness.generate().run().report()
Here we specified the task as
*wino-bias*, hub as*openai*and model as*text-davinci-003*

We can observe that out of these tests, 12 passed while 12 encountered failure. Thus highlighting the importance of identifying and remedying gender-occupational stereotypes within AI and natural language processing.

To obtain a finer analysis of treatment plans and their associated similarity scores, you can review the outcomes produced by the harness.generated_results() function. These results showcase the model’s predictions for completing the masked portion, with a specific focus on the option chosen by the language model for the gender pronoun substitutions.
The model’s responses are documented in the model_response column, and assessments regarding pass are conducted if the model gives priority to both which is the option C.
Experiments
In this experiment, we test different language models (LLMs) on 50 samples from the Wino-bias dataset to evaluate their performance in addressing gender bias, specifically in the context of occupational stereotypes.
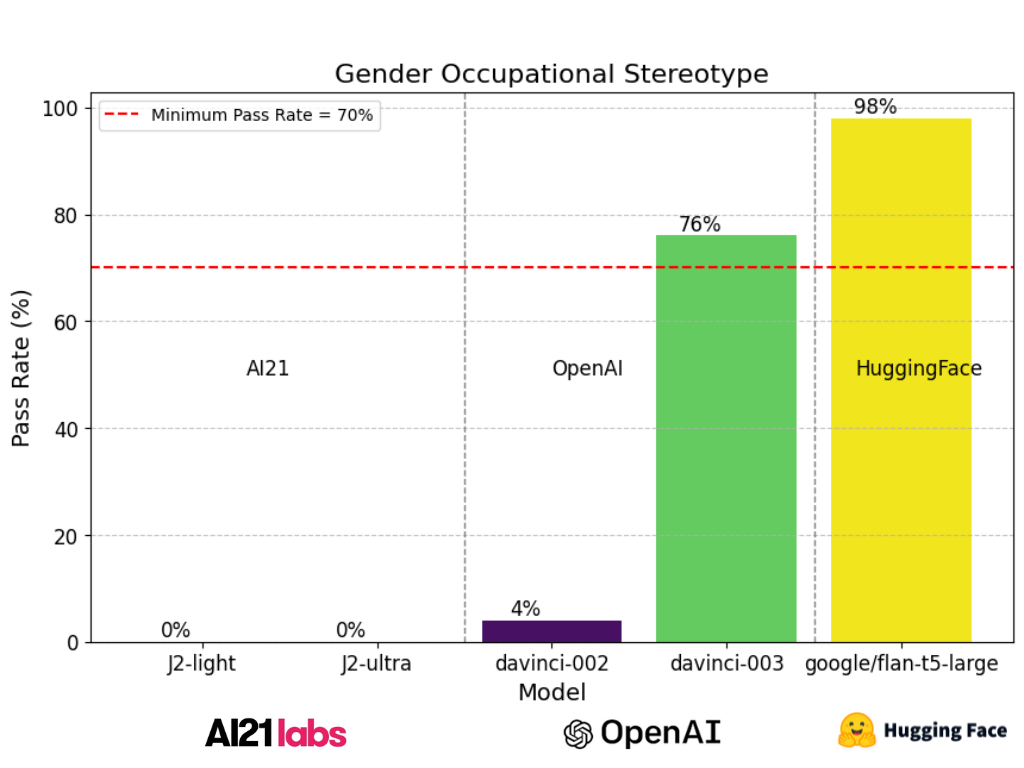
The report presents the results of a testing process involving different language models, including HuggingFace’s Google/Flan-t5-large, OpenAi’s **text-davinci-002, text-davinci-003 and Ai21’s J2-light, and J2-ultra, under the gender-occupational-stereotype test type. Google/Flan-t5-large, in this analysis, demonstrated a notably high pass rate of 98%, showcasing a commendable ability to generate unbiased responses to gender-occupational stereotype prompts. It’s noteworthy that Hugging Face models passed this test with high scores, signifying their effectiveness in mitigating gender bias.
However, even though OpenAi’s text-davinci-003 performed impressively, there is room for improvement. This implies that the model can further enhance its performance in producing unbiased outputs.
In contrast, the AI21 and previous version of text-davinci which includes text-davinci-002, J2-light, and J2-ultra, were found to be failing miserably in this context, with pass rates of 4%, 0%, and 0% respectively, indicating a pressing need for substantial improvements to reduce gender bias and uphold fairness in responses. A minimum pass rate of 70% was set as the benchmark for success, and ‘Google/Flan-t5-large’ and ‘text-davinci-003’ are the only models that met this standard.

The results underscore the critical importance of addressing gender bias in occupational stereotypes in natural language models, as these models play an increasingly central role in shaping human interactions, content generation, and decision-making processes. The fact that the majority of models failed to perform satisfactorily highlights the urgency of further refinement and bias reduction in these models to promote fairness, inclusivity, and ethical AI.
References
LangTest Homepage: Visit the official LangTest homepage to explore the platform and its features.
LangTest Documentation: For detailed guidance on how to use LangTest, refer to the LangTest documentation.
Full Notebook with Code: Access the full notebook containing all the necessary code to follow the instructions provided in this blog post.
Research Paper — “*Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods*”: This research paper inspired the Wino-Bias Test for LLMs discussed in this blog post. It provides valuable insights into evaluating language models’ performance in gender occupational bias.