Train a Sentence Embedding Model with 1 Billion Training Pairs


Sentence embedding is a method that maps sentences to vectors of real numbers. Ideally, these vectors would capture the semantic of a sentence and be highly generic. Such representations could then be used for many downstream applications such as clustering, text mining, or question answering.
We developed state-of-the-art sentence embedding models as part of the project "Train the Best Sentence Embedding Model Ever with 1B Training Pairs". This project took place during the Community week using JAX/Flax for NLP & CV, organized by Hugging Face. We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as guidance from Google’s Flax, JAX, and Cloud team members about efficient deep learning frameworks!
Training methodology
Model
Unlike words, we can not define a finite set of sentences. Sentence embedding methods, therefore, compose inner words to compute the final representation. For example, SentenceBert model (Reimers and Gurevych, 2019) uses Transformer, the cornerstone of many NLP applications, followed by a pooling operation over the contextualized word vectors. (c.f. Figure below.)
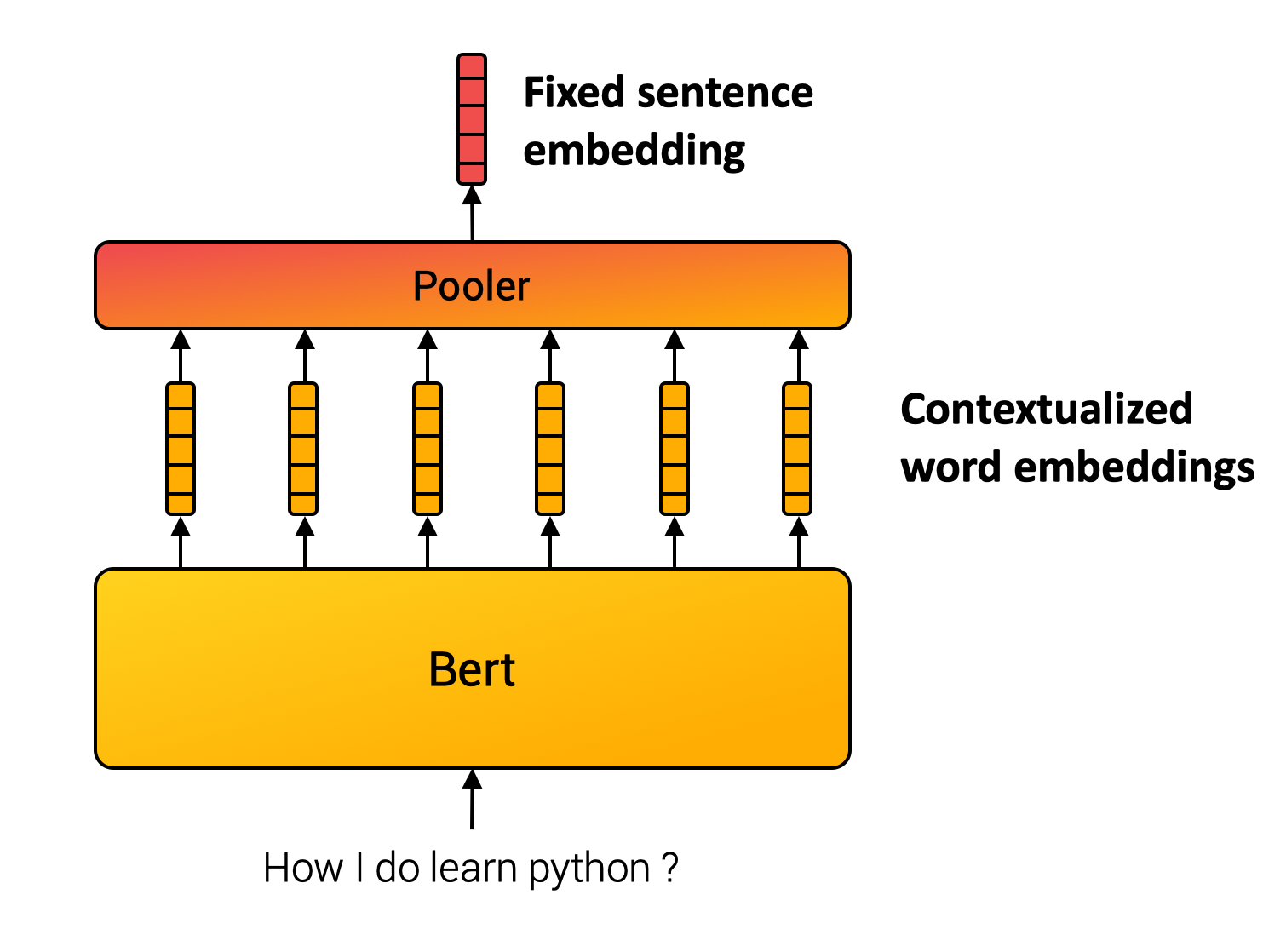
Multiple Negative Ranking Loss
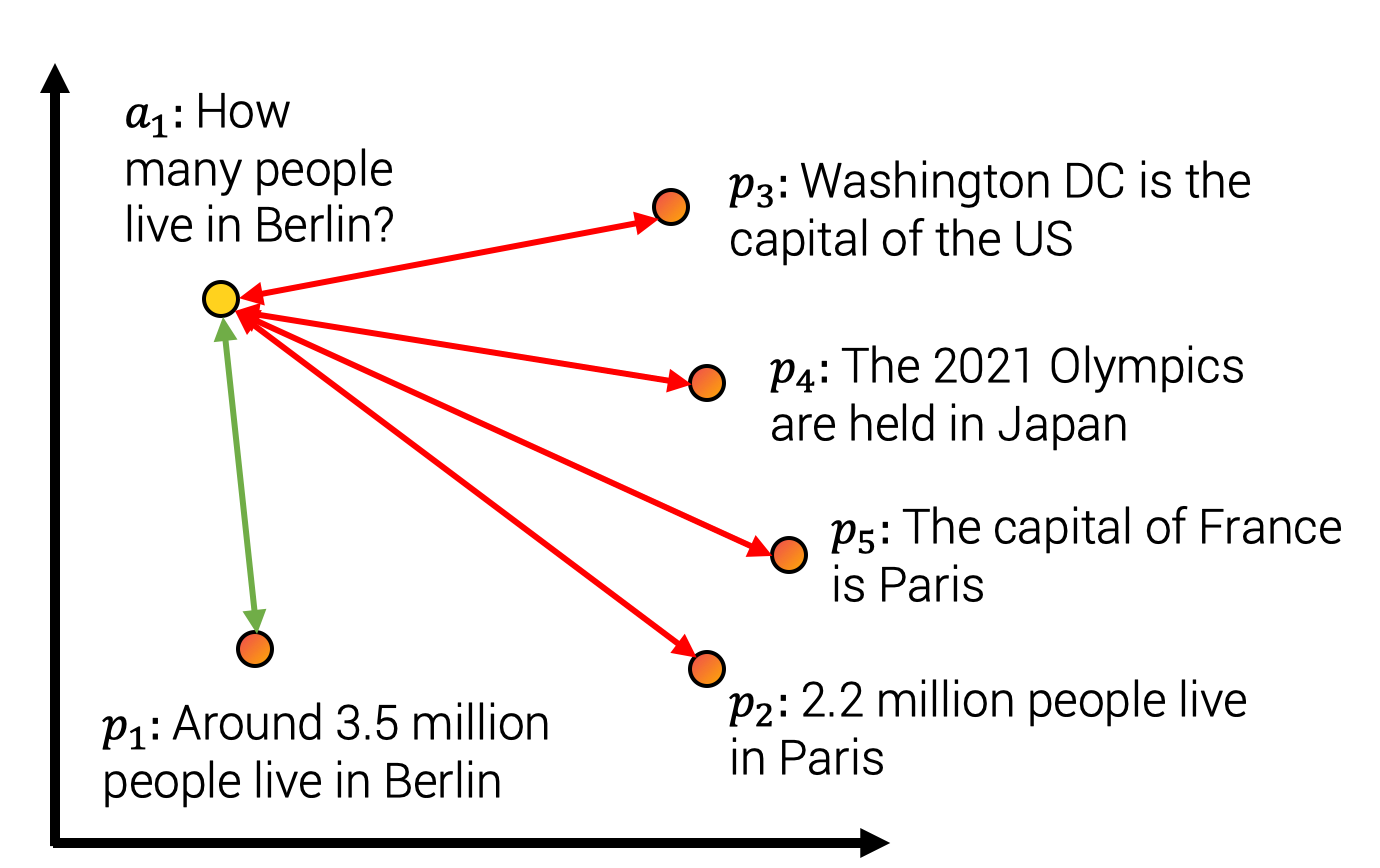
The parameters from the composition module are usually learned using a self-supervised objective. For the project, we used a contrastive training method illustrated in the figure below. We constitute a dataset with sentence pairs such that sentences from the pair have a close meaning. For example, we consider pairs such as (query, answer-passage), (question, duplicate_question),(paper title, cited paper title). Our model is then trained to map pairs to close vectors while assigning unmatched pairs to distant vectors in the embedding space. This training method is also called training with in-batch negatives, InfoNCE or NTXentLoss.
Formally, given a batch of training samples, the model optimises the following loss function:
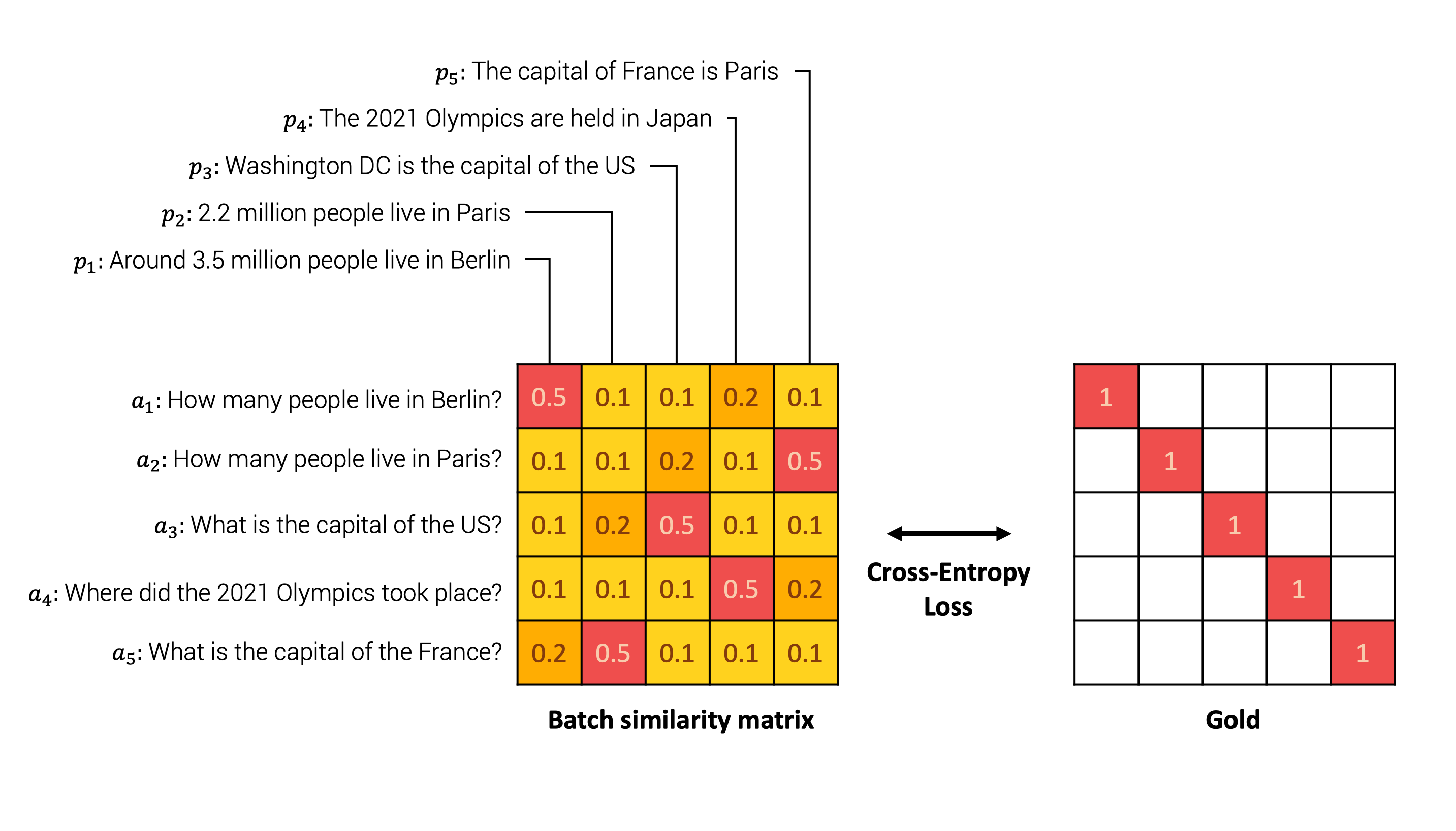
An illustrative example can be seen below. The model first embeds each sentence from every pair in the batch. Then, we compute a similarity matrix between every possible pair . We then compare the similarity matrix with the ground truth, which indicates the original pairs. Finally, we perform the comparison using the cross entropy loss.
Intuitively, the model should assign high similarity to the sentences « How many people live in Berlin? » and « Around 3.5 million people live in Berlin » and low similarity to other negative answers such as « The capital of France is Paris » as detailed in the Figure below.
In the loss equation, sim indicates a similarity function between . The similarity function could be either the Cosine-Similarity or the Dot-Product operator. Both methods have their pros and cons summarized below (Thakur et al., 2021, Bachrach et al., 2014):
| Cosine-similarity | Dot-product |
|---|---|
| Vector has highest similarity to itself since . | Other vectors can have higher dot-products . |
| With normalised vectors it is equal to the dot product. The max vector length is equals 1. | It might be slower with certain approximate nearest neighbour methods since the max vector not known. |
| With normalised vectors, it is proportional to euclidian distance. It works with k-means clustering. | It does not work with k-means clustering. |
In practice, we used a scaled similarity because score differences tends to be too small and apply a scaling factor such that with typically (Henderson and al., 2020, Radford and al., 2021).
Improving Quality with Better Batches
In our method, we build batches of sample pairs . We consider all other samples from the batch, , as negatives sample pairs. The batch composition is therefore a key training aspect. Given the literature in the domain, we mainly focused on three main aspects of the batch.
1. Size matters
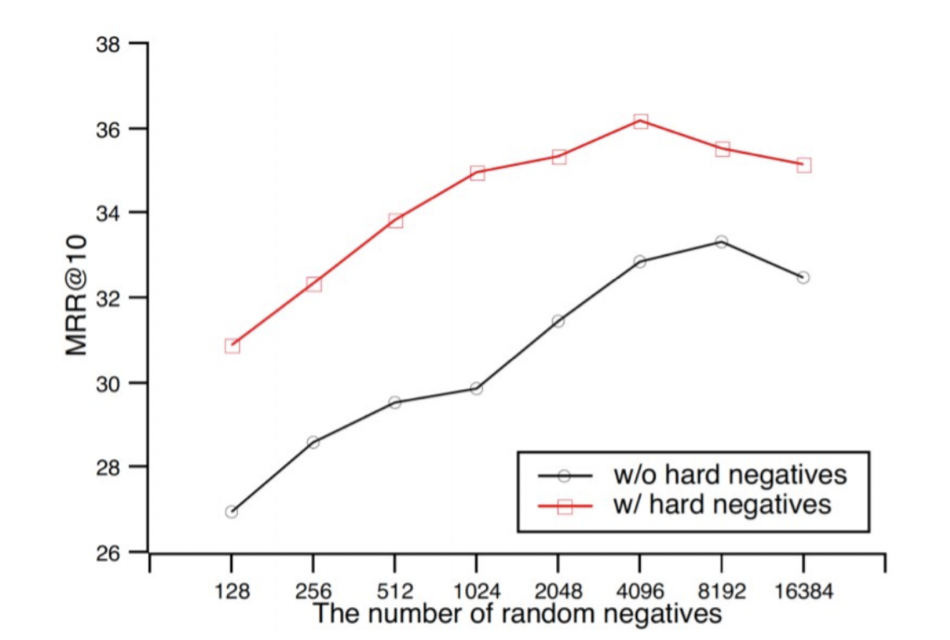
In contrastive learning, a larger batch size is synonymous with better performance. As shown in the Figure extracted from Qu and al., (2021), a larger batch size increases the results.
2. Hard Negatives
In the same figure, we observe that including hard negatives also improves performance. Hard negatives are sample which are hard to distinguish from . In our example, it could be the pairs « What is the capital of France? » and « What is the capital of the US? » which have a close semantic content and requires precisely understanding the full sentence to be answered correctly. On the contrary, the samples « What is the capital of France? » and «How many Star Wars movies is there?» are less difficult to distinguish since they do not refer to the same topic.
3. Cross dataset batches
We concatenated multiple datasets to train our models. We built a large batch and gathered samples from the same batch dataset to limit the topic distribution and favor hard negatives. However, we also mix at least two datasets in the batch to learn a global structure between topics and not only a local structure within a topic.
Training infrastructure and data
As mentioned earlier, the quantity of data and the batch size directly impact the model performances. As part of the project, we benefited from efficient hardware infrastructure. We trained our models on TPUs which are compute units developed by Google and super efficient for matrix multiplications. TPUs have some hardware specificities which might require some specific code implementation.
Additionally, we trained models on a large corpus as we concatenated multiple datasets up to 1 billion sentence pairs! All datasets used are detailed for each model in the model card.
Conclusion
You can find all models and datasets we created during the challenge in our HuggingFace repository. We trained 20 general-purpose Sentence Transformers models such as Mini-LM (Wang and al., 2020), RoBERTa (liu and al., 2019), DistilBERT (Sanh and al., 2020) and MPNet (Song and al., 2020). Our models achieve SOTA on multiple general-purpose Sentence Similarity evaluation tasks. We also shared 8 datasets specialized for Question Answering, Sentence-Similarity, and Gender Evaluation.
General sentence embeddings might be used for many applications. We built a Spaces demo to showcase several applications:
- The sentence similarity module compares the similarity of the main text with other texts of your choice. In the background, the demo extracts the embedding for each text and computes the similarity between the source sentence and the other using cosine similarity.
- Asymmetric QA compares the answer likeliness of a given query with answer candidates of your choice.
- Search / Cluster returns nearby answers from a query. For example, if you input « python », it will retrieve closest sentences using dot-product distance.
- Gender Bias Evaluation report inherent gender bias in training set via random sampling of the sentences. Given an anchor text without mentioning gender for target occupation and 2 propositions with gendered pronouns, we compare if models assign a higher similarity to a given proposition and therefore evaluate their proportion to favor a specific gender.
The Community week using JAX/Flax for NLP & CV has been an intense and highly rewarding experience! The quality of Google’s Flax, JAX, and Cloud and Hugging Face team members' guidance and their presence helped us all learn a lot. We hope all projects had as much fun as we did in ours. Whenever you have questions or suggestions, don’t hesitate to contact us!

