|
--- |
|
license: mit |
|
datasets: |
|
- ammarnasr/the-stack-java-clean |
|
library_name: adapter-transformers |
|
tags: |
|
- code |
|
pipeline_tag: text-generation |
|
language: |
|
- code |
|
--- |
|
|
|
|
|
# CodeGen (CodeGen-Mono 350M LoRa Java) |
|
|
|
## Model description |
|
CodeGen LoRa Java is a family of autoregressive language models fine-tuned using LoRa on Different Programming Langauges. |
|
## Training data |
|
<!-- https://huggingface.co/datasets/ammarnasr/the-stack-java-clean --> |
|
This model was fine-tuned on the cleaned Java subset from TheStack Avilable [here](https://huggingface.co/datasets/ammarnasr/the-stack-java-clean). The data consists of 1 Million Java code files. |
|
|
|
## Training procedure |
|
|
|
This model was fine-tuned using LoRa on 1 T4 GPU. The model was trained for 10,000 steps with batch size of 4. The model was trained using causal language modeling loss. |
|
|
|
## Evaluation results |
|
|
|
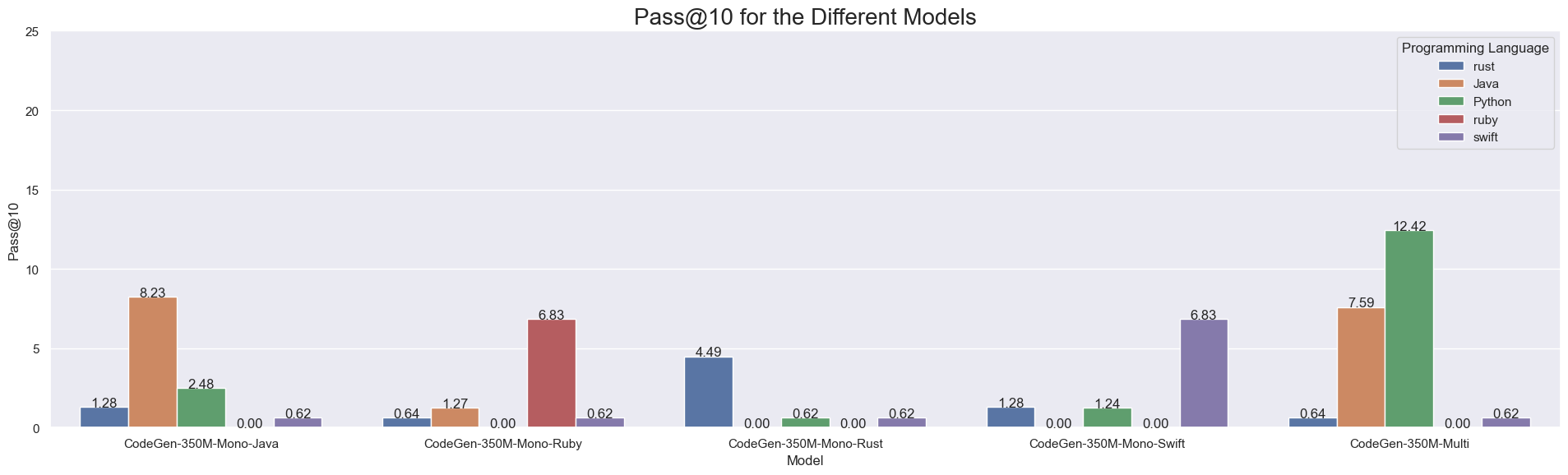
We evaluate our models on the MultiPle-E bencchmark. The model achieves 8.9 Pass@10 Rate. |
|
 |
|
|
|
|
|
## Intended Use and Limitations |
|
|
|
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code in Java and Python. |
|
|
|
## How to use |
|
|
|
This model can be easily loaded using the `AutoModelForCausalLM` functionality: |
|
|
|
```python |
|
from transformers import AutoTokenizer, AutoModelForCausalLM |
|
from peft import PeftConfig, PeftModel |
|
|
|
model_name = "ammarnasr/codegen-350M-mono-java" |
|
peft_config = PeftConfig.from_pretrained(model_name) |
|
|
|
tokenizer = AutoTokenizer.from_pretrained(peft_config.base_model_name_or_path) |
|
|
|
model = AutoModelForCausalLM.from_pretrained(peft_config.base_model_name_or_path) |
|
model = PeftModel.from_pretrained(model, model_name) |
|
|
|
model.print_trainable_parameters() |
|
|
|
text = "public static void main(String[] args) {" |
|
input_ids = tokenizer.encode(text, return_tensors="pt") |
|
generated_ids = model.generate(input_ids=input_ids, max_length=100) |
|
print('Generated: \n') |
|
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True)) |
|
``` |
|
|
|
## BibTeX entry and citation info |
|
|
|
```bibtex |
|
@article{Nijkamp2022ACP, |
|
title={A Conversational Paradigm for Program Synthesis}, |
|
author={Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming}, |
|
journal={arXiv preprint}, |
|
year={2022} |
|
} |
|
``` |
