
File size: 2,909 Bytes
6906af3 ee4c2d2 6906af3 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
---
language: pt
datasets:
- coraa_ser
- emovo
- ravdess
- baved
metrics:
- f1
tags:
- audio
- speech
- wav2vec2
- pt
- portuguese-speech-corpus
- italian-speech-corpus
- english-speech-corpus
- arabic-speech-corpus
- spontaneous
- speech
- PyTorch
license: apache-2.0
model_index:
name: wav2vec2-xls-r-300m-pt-br-spontaneous-speech-emotion-recognition
results:
metrics:
- name: Test Macro F1-Score
type: f1
value: 81.87%
---
# Wav2vec 2.0 XLS-R For Spontaneous Speech Recognition
This is the model that got first place in the SER track of the Automatic Speech Recognition for spontaneous and prepared speech & Speech Emotion Recognition in Portuguese (SE&R 2022) Workshop.
The following datasets were used in the training:
- [CORAA SER v1.0](https://github.com/rmarcacini/ser-coraa-pt-br/): a dataset composed of spontaneous portuguese speech and approximately 50 minutes of audio segments labeled in three classes: neutral, non-neutral female, and non-neutral male.
- [EMOVO Corpus](https://aclanthology.org/L14-1478/): a database of emotional speech for the Italian language, built from the voices of up to 6 actors who played 14 sentences simulating 6 emotional states (disgust, fear, anger, joy, surprise, sadness) plus the neutral state.
- [RAVDESS]((https://zenodo.org/record/1188976#.YO6yI-gzaUk)): a dataset that provides 1440 samples of recordings from actors performing on 8 different emotions in English, which are: angry, calm, disgust, fearful, happy, neutral, sad and surprised.
- [BAVED](https://github.com/40uf411/Basic-Arabic-Vocal-Emotions-Dataset): a collection of audio recordings of Arabic words spoken with varying degrees of emotion. The dataset contains seven words: like, unlike, this, file, good, neutral, and bad, which are spoken at three emotional levels: low emotion (tired or feeling down), neutral emotion (the way the speaker speaks daily), and high emotion (positive or negative emotions such as happiness, joy, sadness, anger).
The test set used is a part of the CORAA SER v1.0 that has been set aside for this purpose.
It achieves the following results on the test set:
- Accuracy: 0.9090
- Macro Precision: 0.8171
- Macro Recall: 0.8397
- Macro F1-Score: 0.8187
## Datasets Details
The following image shows the overall distribution of the datasets:

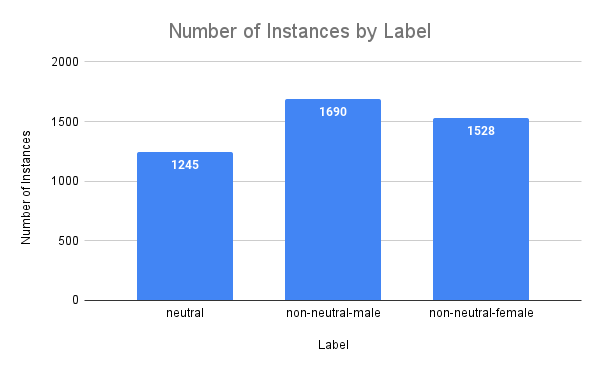
The following image shows the number of instances by label:
## Repository
The repository that implements the model to be trained and tested is avaible [here](https://github.com/alefiury/SE-R-2022-SER-Track). |