

license: apache-2.0
base_model: runwayml/stable-diffusion-v1-5
tags:
- art
- t2i-adapter
- controlnet
- stable-diffusion
- image-to-image
T2I Adapter - Color
T2I Adapter is a network providing additional conditioning to stable diffusion. Each t2i checkpoint takes a different type of conditioning as input and is used with a specific base stable diffusion checkpoint.
This checkpoint provides conditioning on color palettes for the stable diffusion 1.4 checkpoint.
Model Details
Developed by: T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
Model type: Diffusion-based text-to-image generation model
Language(s): English
License: Apache 2.0
Resources for more information: GitHub Repository, Paper.
Cite as:
@misc{ title={T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models}, author={Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie}, year={2023}, eprint={2302.08453}, archivePrefix={arXiv}, primaryClass={cs.CV} }
Checkpoints
| Model Name | Control Image Overview | Control Image Example | Generated Image Example |
|---|---|---|---|
| TencentARC/t2iadapter_color_sd14v1 Trained with spatial color palette |
A image with 8x8 color palette. |  |
 |
| TencentARC/t2iadapter_canny_sd14v1 Trained with canny edge detection |
A monochrome image with white edges on a black background. |  |
 |
| TencentARC/t2iadapter_sketch_sd14v1 Trained with PidiNet edge detection |
A hand-drawn monochrome image with white outlines on a black background. |  |
 |
| TencentARC/t2iadapter_depth_sd14v1 Trained with Midas depth estimation |
A grayscale image with black representing deep areas and white representing shallow areas. |  |
 |
| TencentARC/t2iadapter_openpose_sd14v1 Trained with OpenPose bone image |
A OpenPose bone image. | 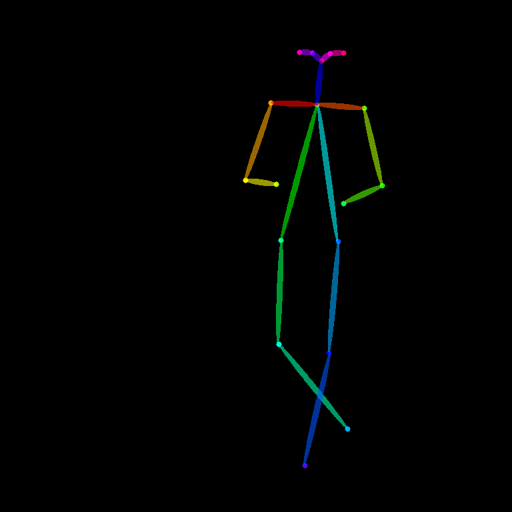 |
 |
| TencentARC/t2iadapter_keypose_sd14v1 Trained with mmpose skeleton image |
A mmpose skeleton image. |  |
 |
| TencentARC/t2iadapter_seg_sd14v1 Trained with semantic segmentation |
An custom segmentation protocol image. |  |
 |
| TencentARC/t2iadapter_canny_sd15v2 | |||
| TencentARC/t2iadapter_depth_sd15v2 | |||
| TencentARC/t2iadapter_sketch_sd15v2 | |||
| TencentARC/t2iadapter_zoedepth_sd15v1 |
Example
- Dependencies
pip install diffusers transformers
- Run code:
from PIL import Image
import torch
from diffusers import StableDiffusionAdapterPipeline, T2IAdapter
image = Image.open('./images/color_ref.png')
color_palette = image.resize((8, 8))
color_palette = color_palette.resize((512, 512), resample=Image.Resampling.NEAREST)
color_palette.save('./images/color_palette.png')
adapter = T2IAdapter.from_pretrained("TencentARC/t2iadapter_color_sd14v1", torch_dtype=torch.float16)
pipe = StableDiffusionAdapterPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
adapter=adapter,
torch_dtype=torch.float16,
)
pipe.to("cuda")
generator = torch.manual_seed(0)
out_image = pipe(
"At night, glowing cubes in front of the beach",
image=color_palette,
generator=generator,
).images[0]
out_image.save('./images/color_out_image.png')


