
File size: 9,207 Bytes
4060377 f81bca4 4060377 232bd0e 4060377 5d400ce 4060377 7177f15 994d98e 4060377 4f6c459 cc3c4e3 4f6c459 4060377 4398332 80891ad 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 4060377 7177f15 801ec8f |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 |
---
license: apache-2.0
base_model: stabilityai/stable-diffusion-xl-base-1.0
tags:
- art
- t2i-adapter
- image-to-image
- stable-diffusion-xl-diffusers
- stable-diffusion-xl
---
# T2I-Adapter-SDXL - Sketch
T2I Adapter is a network providing additional conditioning to stable diffusion. Each t2i checkpoint takes a different type of conditioning as input and is used with a specific base stable diffusion checkpoint.
This checkpoint provides conditioning on sketch for the StableDiffusionXL checkpoint. This was a collaboration between **Tencent ARC** and [**Hugging Face**](https://huggingface.co/).
## Model Details
- **Developed by:** T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** Apache 2.0
- **Resources for more information:** [GitHub Repository](https://github.com/TencentARC/T2I-Adapter), [Paper](https://arxiv.org/abs/2302.08453).
- **Model complexity:**
| | SD-V1.4/1.5 | SD-XL | T2I-Adapter | T2I-Adapter-SDXL |
| --- | --- |--- |--- |--- |
| Parameters | 860M | 2.6B |77 M | 77/79 M | |
- **Cite as:**
@misc{
title={T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models},
author={Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, Ying Shan, Xiaohu Qie},
year={2023},
eprint={2302.08453},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
### Checkpoints
| Model Name | Control Image Overview| Control Image Example | Generated Image Example |
|---|---|---|---|
|[TencentARC/t2i-adapter-canny-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)<br/> *Trained with canny edge detection* | A monochrome image with white edges on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_canny.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_canny.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_canny.png"/></a>|
|[TencentARC/t2i-adapter-sketch-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)<br/> *Trained with [PidiNet](https://github.com/zhuoinoulu/pidinet) edge detection* | A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_sketch.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_sketch.png"/></a>|
|[TencentARC/t2i-adapter-lineart-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)<br/> *Trained with lineart edge detection* | A hand-drawn monochrome image with white outlines on a black background.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"><img width="64" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_lin.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_lin.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_lin.png"/></a>|
|[TencentARC/t2i-adapter-depth-midas-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0)<br/> *Trained with Midas depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_mid.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_mid.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_mid.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_mid.png"/></a>|
|[TencentARC/t2i-adapter-depth-zoe-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0)<br/> *Trained with Zoe depth estimation* | A grayscale image with black representing deep areas and white representing shallow areas.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_zeo.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_depth_zeo.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_zeo.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_depth_zeo.png"/></a>|
|[TencentARC/t2i-adapter-openpose-sdxl-1.0](https://huggingface.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)<br/> *Trained with OpenPose bone image* | A [OpenPose bone](https://github.com/CMU-Perceptual-Computing-Lab/openpose) image.|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/openpose.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/openpose.png"/></a>|<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/res_pose.png"><img width="64" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/res_pose.png"/></a>|
## Demo:
Try out the model with your own hand-drawn sketches/doodles in the [Doodly Space](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL-Sketch)!
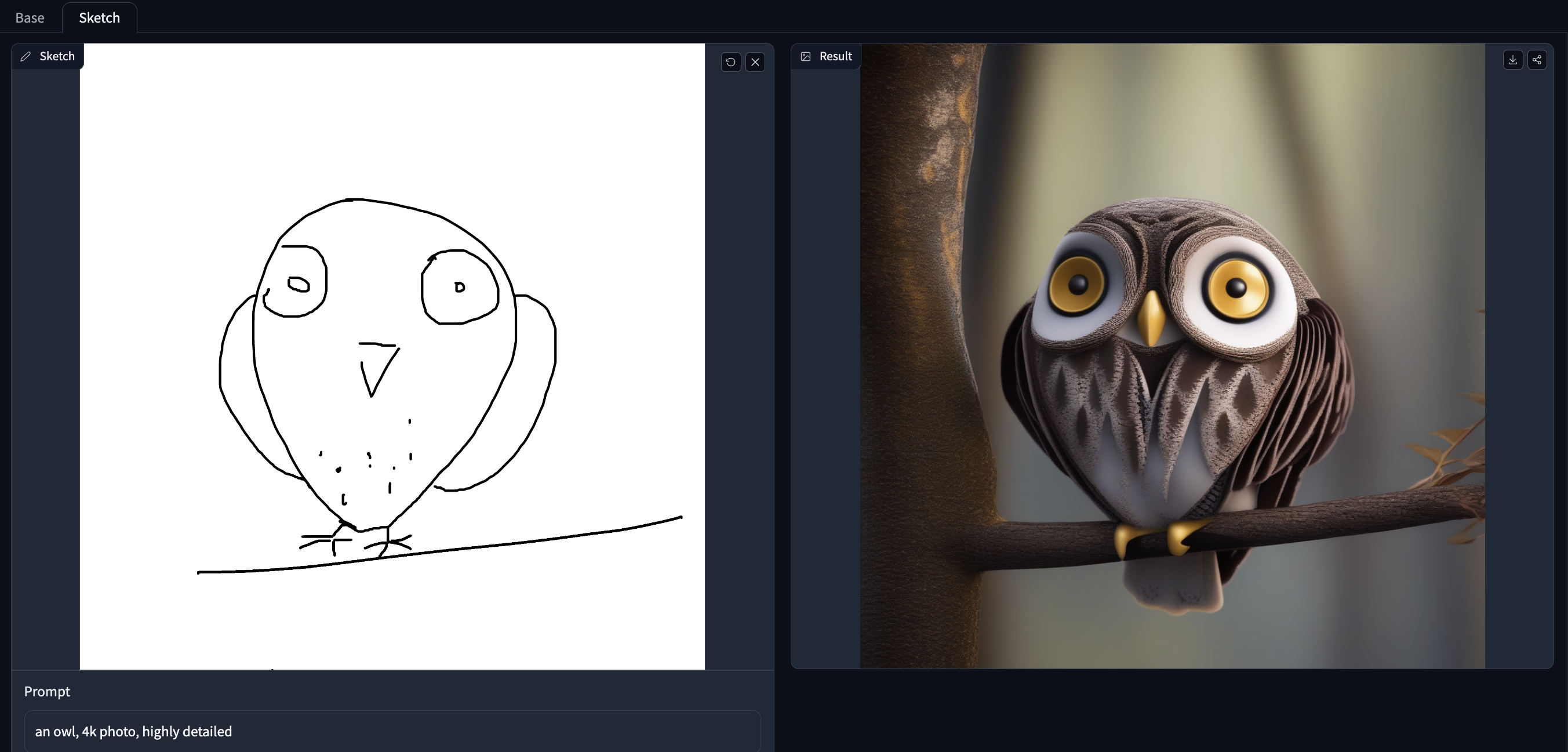
## Example
To get started, first install the required dependencies:
```bash
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
pip install transformers accelerate safetensors
```
1. Images are first downloaded into the appropriate *control image* format.
2. The *control image* and *prompt* are passed to the [`StableDiffusionXLAdapterPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py#L125).
Let's have a look at a simple example using the [Canny Adapter](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0).
- Dependency
```py
from diffusers import StableDiffusionXLAdapterPipeline, T2IAdapter, EulerAncestralDiscreteScheduler, AutoencoderKL
from diffusers.utils import load_image, make_image_grid
from controlnet_aux.pidi import PidiNetDetector
import torch
# load adapter
adapter = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-sketch-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
).to("cuda")
# load euler_a scheduler
model_id = 'stabilityai/stable-diffusion-xl-base-1.0'
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
vae=AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id, vae=vae, adapter=adapter, scheduler=euler_a, torch_dtype=torch.float16, variant="fp16",
).to("cuda")
pipe.enable_xformers_memory_efficient_attention()
pidinet = PidiNetDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
```
- Condition Image
```py
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_sketch.png"
image = load_image(url)
image = pidinet(
image, detect_resolution=1024, image_resolution=1024, apply_filter=True
)
```
<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"><img width="480" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"/></a>
- Generation
```py
prompt = "a robot, mount fuji in the background, 4k photo, highly detailed"
negative_prompt = "extra digit, fewer digits, cropped, worst quality, low quality, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
adapter_conditioning_scale=0.9,
guidance_scale=7.5,
).images[0]
gen_images.save('out_sketch.png')
```
<a href="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/cond_sketch.png"><img width="480" style="margin:0;padding:0;" src="https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/res_sketch.png"/></a>
### Training
Our training script was built on top of the official training script that we provide [here](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/README_sdxl.md).
The model is trained on 3M high-resolution image-text pairs from LAION-Aesthetics V2 with
- Training steps: 20000
- Batch size: Data parallel with a single gpu batch size of `16` for a total batch size of `256`.
- Learning rate: Constant learning rate of `1e-5`.
- Mixed precision: fp16 |