
File size: 7,668 Bytes
4b556ad b84dc74 4b556ad 731ca7f 4b556ad 731ca7f 4b556ad 731ca7f 4b556ad b84dc74 4b556ad 368f865 4b556ad b84dc74 4b556ad b84dc74 4b556ad b84dc74 4b556ad b84dc74 4b556ad b84dc74 4b556ad b84dc74 cbc9aaf b84dc74 cbc9aaf b84dc74 4b556ad 368f865 b84dc74 4b556ad b84dc74 4b556ad 368f865 4b556ad 269b8ba 4b556ad 6324425 b84dc74 6324425 b84dc74 4b556ad 6324425 4b556ad 6324425 4b556ad 6324425 4b556ad 6324425 4b556ad 731ca7f |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 |
---
license: other
license_name: glm-4
license_link: https://huggingface.co/THUDM/glm-4-9b-chat/blob/main/LICENSE
language:
- zh
- en
tags:
- glm
- chatglm
- thudm
inference: false
pipeline_tag: text-generation
---
# GLM-4-9B-Chat
Read this in [English](README_en.md)
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中,
**GLM-4-9B** 及其人类偏好对齐的版本 **GLM-4-9B-Chat** 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat
还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的
26 种语言。我们还推出了支持 1M 上下文长度(约 200 万中文字符)的 **GLM-4-9B-Chat-1M** 模型和基于 GLM-4-9B 的多模态模型
GLM-4V-9B。**GLM-4V-9B** 具备 1120 * 1120 高分辨率下的中英双语多轮对话能力,在中英文综合能力、感知推理、文字识别、图表理解等多方面多模态评测中,GLM-4V-9B
表现出超越 GPT-4-turbo-2024-04-09、Gemini
1.0 Pro、Qwen-VL-Max 和 Claude 3 Opus 的卓越性能。
## 评测结果
我们在一些经典任务上对 GLM-4-9B-Chat 模型进行了评测,并得到了如下的结果:
| Model | AlignBench-v2 | MT-Bench | IFEval | MMLU | C-Eval | GSM8K | MATH | HumanEval | NCB |
|:--------------------|:-------------:|:--------:|:------:|:----:|:------:|:-----:|:----:|:---------:|:----:|
| Llama-3-8B-Instruct | 5.12 | 8.00 | 68.58 | 68.4 | 51.3 | 79.6 | 30.0 | 62.2 | 24.7 |
| ChatGLM3-6B | 3.97 | 5.50 | 28.1 | 66.4 | 69.0 | 72.3 | 25.7 | 58.5 | 11.3 |
| GLM-4-9B-Chat | 6.61 | 8.35 | 69.0 | 72.4 | 75.6 | 79.6 | 50.6 | 71.8 | 32.2 |
### 长文本
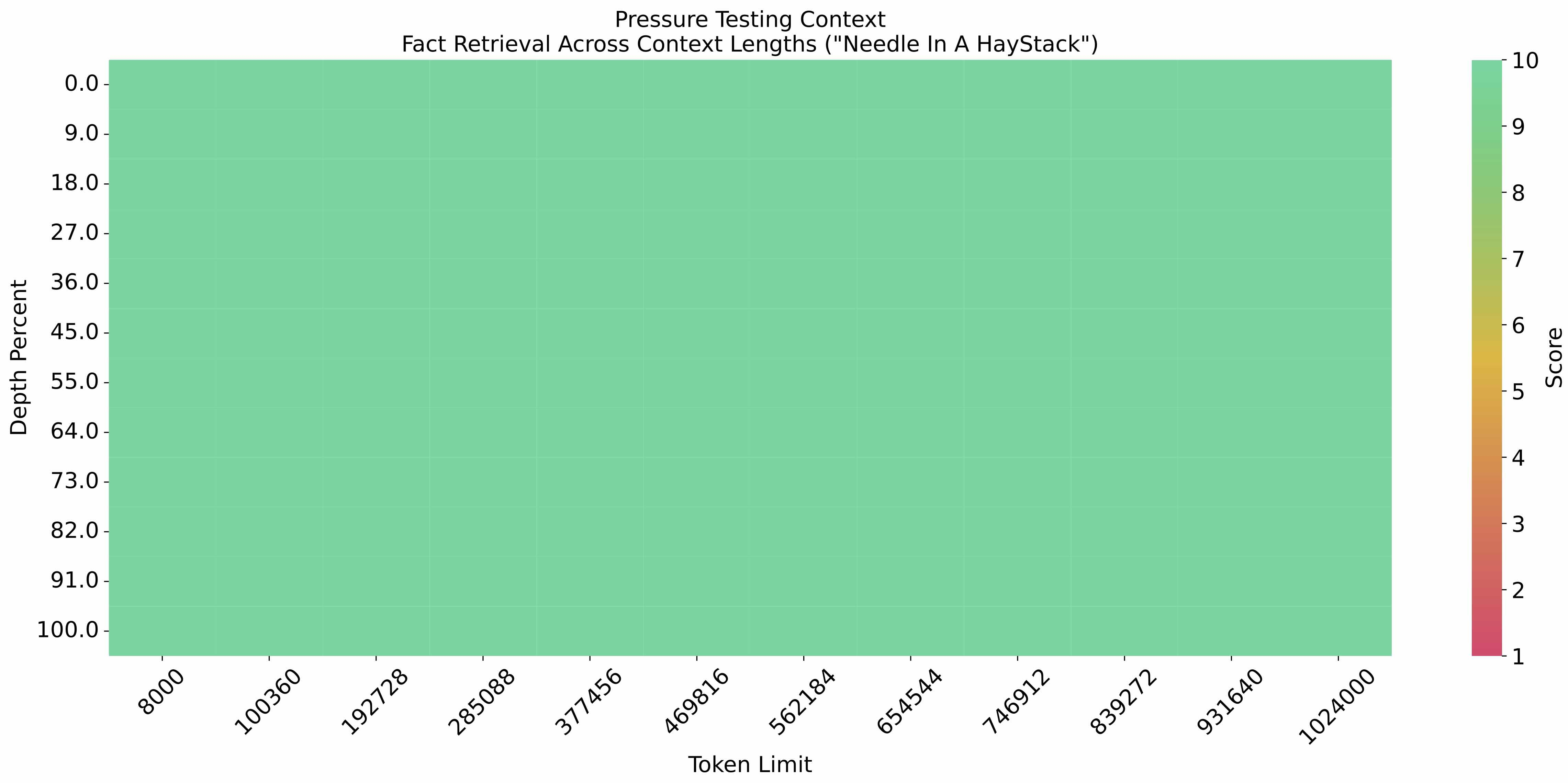
在 1M 的上下文长度下进行[大海捞针实验](https://github.com/LargeWorldModel/LWM/blob/main/scripts/eval_needle.py),结果如下:
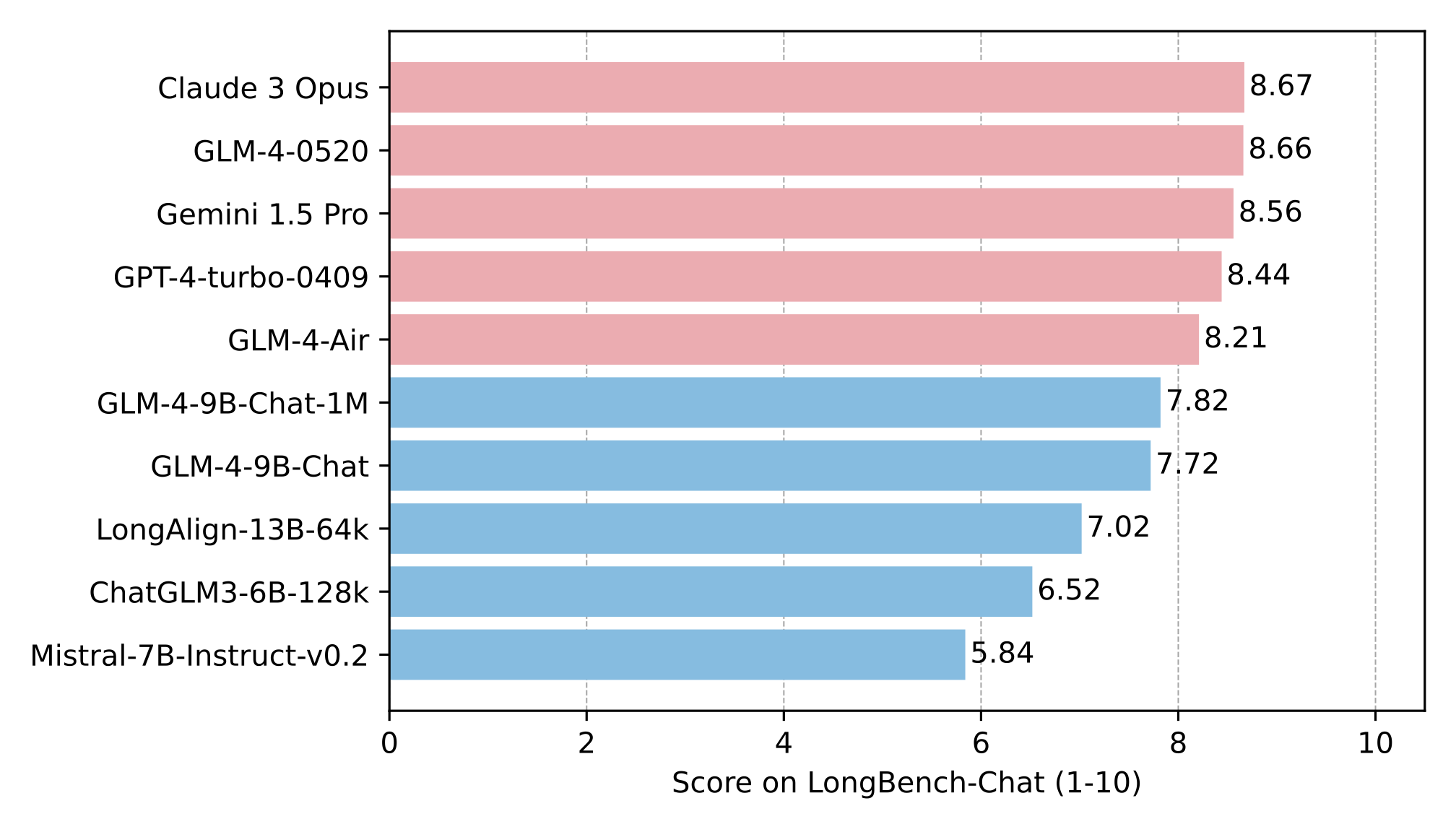
在 LongBench-Chat 上对长文本能力进行了进一步评测,结果如下:
### 多语言能力
在六个多语言数据集上对 GLM-4-9B-Chat 和 Llama-3-8B-Instruct 进行了测试,测试结果及数据集对应选取语言如下表
| Dataset | Llama-3-8B-Instruct | GLM-4-9B-Chat | Languages |
|:------------|:-------------------:|:-------------:|:----------------------------------------------------------------------------------------------:|
| M-MMLU | 49.6 | 56.6 | all |
| FLORES | 25.0 | 28.8 | ru, es, de, fr, it, pt, pl, ja, nl, ar, tr, cs, vi, fa, hu, el, ro, sv, uk, fi, ko, da, bg, no |
| MGSM | 54.0 | 65.3 | zh, en, bn, de, es, fr, ja, ru, sw, te, th |
| XWinograd | 61.7 | 73.1 | zh, en, fr, jp, ru, pt |
| XStoryCloze | 84.7 | 90.7 | zh, en, ar, es, eu, hi, id, my, ru, sw, te |
| XCOPA | 73.3 | 80.1 | zh, et, ht, id, it, qu, sw, ta, th, tr, vi |
### 工具调用能力
我们在 [Berkeley Function Calling Leaderboard](https://github.com/ShishirPatil/gorilla/tree/main/berkeley-function-call-leaderboard)
上进行了测试并得到了以下结果:
| Model | Overall Acc. | AST Summary | Exec Summary | Relevance |
|:-----------------------|:------------:|:-----------:|:------------:|:---------:|
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
**本仓库是 GLM-4-9B-Chat 的模型仓库,支持`128K`上下文长度。**
## 运行模型
使用 transformers 后端进行推理:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat", trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
使用 vLLM后端进行推理:
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat-1M
# max_model_len, tp_size = 1048576, 4
# GLM-4-9B-Chat
# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size = 131072, 1
model_name = "THUDM/glm-4-9b-chat"
prompt = [{"role": "user", "content": "你好"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# GLM-4-9B-Chat-1M 如果遇见 OOM 现象,建议开启下述参数
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
```
## 协议
GLM-4 模型的权重的使用则需要遵循 [LICENSE](LICENSE)。
## 引用
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
```
@article{zeng2022glm,
title={Glm-130b: An open bilingual pre-trained model},
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
journal={arXiv preprint arXiv:2210.02414},
year={2022}
}
```
```
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}
``` |