
File size: 39,449 Bytes
878dbce |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 |
# JAX/Diffusers community sprint 🧨
Welcome to the JAX/Diffusers community sprint! The goal of this sprint is to work on fun and creative diffusion models using JAX and Diffusers.
In this event, we will create various applications with diffusion models in JAX/Flax and Diffusers using free TPU hours generously provided by Google Cloud.
This document is a walkthrough on all the important information to make a submission to the JAX/Diffusers community sprint.
Don't forget to fill out the [signup form]!
> 💡 Note: This document is still WIP and it only contains initial details of the event. We will keep updating this document as we make other relevant information available throughout the community sprint.
## Table of Contents
- [Organization](#organization)
- [Important dates](#important-dates)
- [Communication](#communication)
- [Talks](#talks)
- [Data and Pre-processing](#data-and-pre-processing)
- [Prepare a large local dataset](#prepare-a-large-local-dataset)
- [Prepare a dataset with MediaPipe and Hugging Face](#prepare-a-dataset-with-mediapipe-and-hugging-face)
- [Training ControlNet](#training-controlnet)
- [Setting up your TPU VM](#setting-up-your-tpu-vm)
- [Installing JAX](#installing-jax)
- [Running the training script](#running-the-training-script)
- [TroubleShoot your TPU VM](#troubleshoot-your-tpu-vm)
- [How to Make a Submission](#how-to-make-a-submission)
- [Pushing model weights and the model card to Hub](#pushing-model-weights-and-the-model-card-to-hub)
- [Creating our Space](#creating-our-space)
- [Prizes](#prizes)
- [Jury](#jury)
- [FAQ](#faq)
- [How to Use VSCode with TPU VM?](#how-to-use-vscode-with-tpu-vm)
- [How to Test Your Code Locally?](#how-to-test-your-code-locally)
- [Sprint winners](#sprint-winners)
## Organization
Participants can propose ideas for an interesting project involving diffusion models. Teams of 3 to 5 will then be formed around the most promising and interesting projects. Make sure to read through the [Communication](#communication) section on how to propose projects, comment on other participants' project ideas, and create a team.
To help each team successfully finish their project, we will organize talks by leading scientists and engineers from Google, Hugging Face, and the open-source diffusion community. The talks will take place on 17th of April. Make sure to attend the talks to get the most out of your participation! Check out the [Talks](#talks) section to get an overview of the talks, including the speaker and the time of the talk.
Each team is then given **free access to a TPU v4-8 VM** from April 14 to May 1st. In addition, we will provide a training example in JAX/Flax and Diffusers to train [ControlNets](https://huggingface.co/blog/controlnet) to kick-start your project. We will also provide examples of how to prepare datasets for ControlNet training. During the sprint, we'll make sure to answer any questions you might have about JAX/Flax and Diffusers and help each team as much as possible to complete their projects!
> 💡 Note: We will not be distributing TPUs for single member teams, so you are encouraged to either join a team or find teammates for your idea.
At the end of the community sprint, each submission will be evaluated by a jury and the top-3 demos will be awarded a prize. Check out the [How to submit a demo] (TODO) section for more information and suggestions on how to submit your project.
> 💡 Note: Even though we provide an example for performing ControlNet training, participants can propose ideas that do not involve ControlNets at all. But the ideas need to be centered around diffusion models.
## Important dates
- **29.03.** Official announcement of the community week. Make sure to fill out the [signup form].
- **31.03.** Start forming groups in #jax-diffusers-ideas channel in Discord.
- **10.04.** Data collection.
- **13.04. - 14.04. - [17.04.](https://www.youtube.com/watch?v=SOj2sxgvFe0)** Kick-off event with talks on Youtube.
- **14.04. - 17.04.** Start providing access to TPUs.
- **01.05.** Shutdown access to TPUs.
- **08.05.**: Announcement of the top 10 projects and prizes.
> 💡 Note: We will be accepting applications throughout the sprint.
## Communication
All important communication will take place on our Discord server. Join the server using [this link](https://hf.co/join/discord). After you join the server, take the Diffusers role in `#role-assignment` channel and head to `#jax-diffusers-ideas` channel to share your idea as a forum post. To sign up for participation, fill out the [signup form] and we will give you access to two more Discord channels on discussions and technical support, and access to TPUs.
Important announcements of the Hugging Face, Flax/JAX, and Google Cloud team will be posted in the server.
The Discord server will be the central place for participants to post about their results, share their learning experiences, ask questions and get technical support in various obstacles they encounter.
For issues with Flax/JAX, Diffusers, Datasets or for questions that are specific to your project we will be interacting through public repositories and forums:
- Flax: [Issues](https://github.com/google/flax/issues), [Questions](https://github.com/google/flax/discussions)
- JAX: [Issues](https://github.com/google/jax/issues), [Questions](https://github.com/google/jax/discussions)
- 🤗 Diffusers: [Issues](https://github.com/huggingface/diffusers/issues), [Questions](https://discuss.huggingface.co/c/discussion-related-to-httpsgithubcomhuggingfacediffusers/63)
- 🤗 Datasets: [Issues](https://github.com/huggingface/datasets/issues), [Questions](https://discuss.huggingface.co/c/datasets/10)
- Project specific questions: Can be asked from each project's own post on #jax-diffusers-ideas channel on Discord.
- TPU related questions: `#jax-diffusers-tpu-support` channel on Discord.
- General discussion: `#jax-diffusers-sprint channel` on Discord.
You will get access to `#jax-diffusers-tpu-support` and `#jax-diffusers-sprint` once you are accepted to attend the sprint.
When asking for help, we encourage you to post the link to [forum](https://discuss.huggingface.co) post to the Discord server, instead of directly posting issues or questions.
This way, we make sure that the everybody in the community can benefit from your questions, even after the community sprint.
> 💡 Note: After 10th of April, if you have signed up on the google form, but you are not in the Discord channel, please leave a message on [the official forum announcement](https://discuss.huggingface.co/t/controlling-stable-diffusion-with-jax-and-diffusers-using-v4-tpus/35187/2) and ping `@mervenoyan`, `@sayakpaul`, and `@patrickvonplaten`. We might take a day to process these requests.
## Talks
We have invited prominent researchers and engineers from Google, Hugging Face, and the open-source community who are working in the Generative AI space. We will update this section with links to the talks, so keep an eye here or on Discord in diffusion models core-announcements channel and set your reminders!
### **April 13, 2023**
| Speaker | Topic | Time | Video |
|---|---|---|---|
[Emiel Hoogeboom, Google Brain](https://twitter.com/emiel_hoogeboom?lang=en) | Pixel-Space Diffusion models for High Resolution Images | 4.00pm-4.40pm CEST / 7.00am-7.40am PST| [](https://www.youtube.com/watch?v=iw2WCAGxdQ4) |
| [Apolinário Passos, Hugging Face](https://twitter.com/multimodalart?lang=en) | Introduction to Diffusers library | 4.40pm-5.20pm CEST / 7.40am-08.20am PST | [](https://www.youtube.com/watch?v=iw2WCAGxdQ4)
| [Ting Chen, Google Brain](https://twitter.com/tingchenai?lang=en) | Diffusion++: discrete data and high-dimensional generation | 5.45pm-6.25pm CEST / 08.45am-09.25am PST | [](https://www.youtube.com/watch?v=iw2WCAGxdQ4) |
### **April 14, 2023**
| Speaker | Topic | Time | Video |
|---|---|---|---|
| [Tim Salimans, Google Brain](https://twitter.com/timsalimans?lang=en) | Efficient image and video generation with distilled diffusion models | 4.00pm-4.40pm CEST / 7.00am-7.40am PST| [](https://www.youtube.com/watch?v=6f5chgbKjSg&ab_channel=HuggingFace) |
| [Suraj Patil, Hugging Face](https://twitter.com/psuraj28?lang=en) | Masked Generative Models: MaskGIT/Muse | 4.40pm-5.20pm CEST / 7.40am-08.20am PST | [](https://www.youtube.com/watch?v=6f5chgbKjSg&ab_channel=HuggingFace) |
| [Sabrina Mielke, John Hopkins University](https://twitter.com/sjmielke?lang=en) | From stateful code to purified JAX: how to build your neural net framework | 5.20pm-6.00pm CEST / 08.20am-09.00am PST | [](https://www.youtube.com/watch?v=6f5chgbKjSg&ab_channel=HuggingFace) |
### **April 17, 2023**
| Speaker | Topic | Time | Video |
|---|---|---|---|
| [Andreas Steiner, Google Brain](https://twitter.com/AndreasPSteiner) | JAX & ControlNet | 4.00pm-4.40pm CEST / 7.00am-7.40am PST| [](https://www.youtube.com/watch?v=SOj2sxgvFe0) |
| [Boris Dayma, craiyon](https://twitter.com/borisdayma?lang=en) | DALL-E Mini | 4.40pm-5.20pm CEST / 7.40am-08.20am PST | [](https://www.youtube.com/watch?v=SOj2sxgvFe0) |
| [Margaret Mitchell, Hugging Face](https://twitter.com/mmitchell_ai?ref_src=twsrc%5Egoogle%7Ctwcamp%5Eserp%7Ctwgr%5Eauthor) | Ethics of Text-to-Image | 5.20pm-6.00pm CEST / 08.20am-09.00am PST | [](https://www.youtube.com/watch?v=SOj2sxgvFe0) |
[signup form]: https://forms.gle/t3M7aNPuLL9V1sfa9
## Data and Pre-Processing
In this section, we will cover how to build your own dataset for ControlNet training.
### Prepare a large local dataset
#### Mount a disk
If you need extra space, you can follow [this guide](https://cloud.google.com/tpu/docs/setup-persistent-disk#prerequisites) to create a persistent disk, attach it to your TPU VM, and create a directory to mount the disk. You can then use this directory to store your dataset.
As a side note, the TPU VM allocated to your team has a 3 TB persistent storage drive attached to it. To learn how to use it, check out [this guide](https://cloud.google.com/tpu/docs/setup-persistent-disk#mount-pd).
#### Data preprocessing
Here we demonstrate how to prepare a large dataset to train a ControlNet model with canny edge detection. More specifically, we provide an [example script](./dataset_tools/coyo_1m_dataset_preprocess.py) that:
* Selects 1 million image-text pairs from an existing dataset [COYO-700M](https://huggingface.co/datasets/kakaobrain/coyo-700m).
* Downloads each image and use Canny edge detector to generate the conditioning image.
* Create a metafile that links all the images and processed images to their text captions.
Use the following command to run the example data preprocessing script. If you've mounted a disk to your TPU, you should place your `train_data_dir` and `cache_dir` on the mounted disk
```bash
python3 coyo_1m_dataset_preprocess.py \
--train_data_dir="/mnt/disks/persist/data" \
--cache_dir="/mnt/disks/persist" \
--max_train_samples=1000000 \
--num_proc=16
```
Once the script finishes running, you can find a data folder at the specified `train_data_dir` with the below folder structure:
```
data
├── images
│ ├── image_1.png
│ ├── .......
│ └── image_1000000.jpeg
├── processed_images
│ ├── image_1.png
│ ├── .......
│ └── image_1000000.jpeg
└── meta.jsonl
```
#### Load dataset
To load a dataset from the data folder you just created, you should add a dataset loading script to your data folder. The dataset loading script should have the same name as the folder. For example, if your data folder is `data`, you should add a data loading script named `data.py`. We provide an [example data loading script](./dataset_tools/data.py) for you to use. All you need to do is to update the `DATA_DIR` with the correct path to your data folder. For more details about how to write a dataset loading script, refer to the [documentation](https://huggingface.co/docs/datasets/dataset_script).
Once the dataset loading script is added to your data folder, you can load it with:
```python
dataset = load_dataset("/mnt/disks/persist/data", cache_dir="/mnt/disks/persist" )
```
Note that you can use the `--train_data_dir` flag to pass your data folder directory to the training script and generate your dataset automatically during the training.
For large datasets, we recommend generating the dataset once and saving it on the disk with
```python
dataset.save_to_disk("/mnt/disks/persist/dataset")
```
You can then reuse the saved dataset for your training by passing the `--load_from_disk` flag.
Here is an example to run a training script that will load the dataset from the disk
```python
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/mnt/disks/persist/canny_model"
export DATASET_DIR="/mnt/disks/persist/dataset"
export DISK_DIR="/mnt/disks/persist"
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--train_data_dir=$DATASET_DIR \
--load_from_disk \
--cache_dir=$DISK_DIR \
--resolution=512 \
--learning_rate=1e-5 \
--train_batch_size=2 \
--revision="non-ema" \
--from_pt \
--max_train_steps=500000 \
--checkpointing_steps=10000 \
--dataloader_num_workers=16
```
### Prepare a dataset with MediaPipe and Hugging Face
We provide a notebook ([](https://colab.research.google.com/github/huggingface/community-events/blob/main/jax-controlnet-sprint/dataset_tools/create_pose_dataset.ipynb)) that shows you how to prepare a dataset for ControlNet training using [MediaPipe](https://developers.google.com/mediapipe) and Hugging Face. Specifically, in the notebook, we show:
* How to leverage MediaPipe solutions to extract pose body joints from the input images.
* Predict captions using BLIP-2 from the input images using 🤗 Transformers.
* Build and push the final dataset to the Hugging Face Hub using 🤗 Datasets.
You can refer to the notebook to create your own datasets using other MediaPipe solutions as well. Below, we list all the relevant ones:
* [Pose Landmark Detection](https://developers.google.com/mediapipe/solutions/vision/pose_landmarker)
* [Face Landmark Detection](https://developers.google.com/mediapipe/solutions/vision/face_landmarker)
* [Selfie Segmentation](https://developers.google.com/mediapipe/solutions/vision/image_segmenter)
## Training ControlNet
This is perhaps the most fun and interesting part of this document as here we show you how to train a custom ControlNet model.
> 💡 Note: For this sprint, you are NOT restricted to just training ControlNets. We provide this training script as a reference for you to get started.
For faster training on TPUs and GPUs you can leverage the Flax training example. Follow the instructions above to get the model and dataset before running the script.
### Setting up your TPU VM
_Before proceeding with the rest of this section, you must ensure that the
email address you're using has been added to the `hf-flax` project on
Google Cloud Platform. If it's not the case, please let us know in the Discord server (you can tag `@sayakpaul`, `@merve`, and `@patrickvonplaten`)._
In the following, we will describe how to do so using a standard console, but you should also be able to connect to the TPU VM via IDEs, like Visual Studio Code, etc.
1. You need to install the [Google Cloud SDK](https://cloud.google.com/sdk/docs/install). Please follow the instructions on https://cloud.google.com/sdk.
2. Once you've installed the Google Cloud SDK, you should set your account by running the following command. Make sure that <your-email-address> corresponds to the gmail address you used to sign up for this event.
```bash
gcloud config set account <your-email-adress>
```
3. Let's also make sure the correct project is set in case your email is used for multiple gcloud projects:
```bash
gcloud config set project hf-flax
```
4. Next, you will need to authenticate yourself. You can do so by running:
```bash
gcloud auth login
```
This should give you a link to a website, where you can authenticate your gmail account.
5. Finally, you can establish an SSH tunnel into the TPU VM! Please run the following command by setting`--zone` to `us-central2-b` and to the TPU name also sent to you via email from the Hugging Face team.
```bash
gcloud alpha compute tpus tpu-vm ssh <tpu-name> --zone <zone> --project hf-flax
```
This should establish an SSH tunnel into the TPU VM!
> 💡 Note: You are NOT supposed to have access to the Google Cloud console. Also, you might not get an invitation link to join the `hf-flax` project. But you should still be able to access the TPU VM following the above steps.
> 💡 Note: The TPU VMs are already attached to persistent storage drives (of 3 TB). This will be helpful
in case your team wants to perform training on a large dataset locally. The disk name of the storage drive should also be present in the email you received. Follow [this section](https://github.com/huggingface/community-events/tree/main/jax-controlnet-sprint#mount-a-disk) for more details.
### Installing JAX
Let's first create a Python virtual environment:
```bash
python3 -m venv <your-venv-name>
```
We can activate the environment by running:
```bash
source ~/<your-venv-name>/bin/activate
```
Then install Diffusers and the library's training dependencies:
```bash
pip install git+https://github.com/huggingface/diffusers.git
```
Then clone this repository and install JAX, Flax and the other dependencies:
```bash
git clone https://github.com/huggingface/community-events
cd community-events/jax-controlnet-sprint/training_scripts
pip install -U -r requirements_flax.txt
```
To verify that JAX was correctly installed, you can run the following command:
```python
import jax
jax.device_count()
```
This should display the number of TPU cores, which should be 4 on a TPUv4-8 VM. If Python is not able to detect the TPU device, please take a look at [this section](#troubleshoot-your-tpu-vm) for solutions.
If you want to use Weights and Biases logging, you should also install `wandb` now:
```bash
pip install wandb
```
> 💡 Note: Weights & Biases is free for students, educators, and academic researchers. All participants of our event are qualified to get an academic Weights & Biases team account. To create your team, you can visit https://wandb.ai/create-team and choose the team type to be "Academic". For more information regarding creation and management of Weights & Biases team, you can checkout https://docs.wandb.ai/guides/app/features/teams.
### Running the training script
Now let's download two conditioning images that we will use to run validation during the training in order to track our progress
```bash
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
We encourage you to store or share your model with the community. To use Hugging Face hub, please login to your Hugging Face account, or ([create one](https://huggingface.co/docs/diffusers/main/en/training/hf.co/join) if you don’t have one already):
```bash
huggingface-cli login
```
Make sure you have the `MODEL_DIR`,`OUTPUT_DIR` and `HUB_MODEL_ID` environment variables set. The `OUTPUT_DIR` and `HUB_MODEL_ID` variables specify where to save the model to on the Hub:
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="runs/fill-circle-{timestamp}"
export HUB_MODEL_ID="controlnet-fill-circle"
```
And finally start the training (make sure you're in the `jax-controlnet-sprint/training_scripts` directory)!
```bash
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--validation_steps=1000 \
--train_batch_size=2 \
--revision="non-ema" \
--from_pt \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID \
--num_train_epochs=11 \
--push_to_hub \
--hub_model_id=$HUB_MODEL_ID
```
Note that `--from_pt` argument will convert your pytorch checkpoint into flax. However, it will only work with checkpoints in diffusers format. If your `MODEL_DIR` does not contain checkpoints in diffusers format, you cannot use the `--from_pt` argument. You can convert your `ckpt` or `safetensors` checkpoints into diffusers format using [this script](https://github.com/huggingface/diffusers/blob/main/scripts/convert_original_stable_diffusion_to_diffusers.py).
Since we passed the `--push_to_hub` flag, it will automatically create a model repo under your Hugging Face account based on `$HUB_MODEL_ID`. By the end of training, the final checkpoint will be automatically stored on the hub. You can find an example model repo [here](https://huggingface.co/YiYiXu/fill-circle-controlnet).
Our training script also provides limited support for streaming large datasets from the Hugging Face Hub. In order to enable streaming, one must also set `--max_train_samples`. Here is an example command (from [this blog article](https://huggingface.co/blog/train-your-controlnet)):
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="runs/uncanny-faces-{timestamp}"
export HUB_MODEL_ID="controlnet-uncanny-faces"
python3 train_controlnet_flax.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=multimodalart/facesyntheticsspigacaptioned \
--streaming \
--conditioning_image_column=spiga_seg \
--image_column=image \
--caption_column=image_caption \
--resolution=512 \
--max_train_samples 100000 \
--learning_rate=1e-5 \
--train_batch_size=1 \
--revision="flax" \
--report_to="wandb" \
--tracker_project_name=$HUB_MODEL_ID
```
Note, however, that the performance of the TPUs might get bottlenecked as streaming with `datasets` is not optimized for images. For ensuring maximum throughput, we encourage you to explore the following options:
* [Webdataset](https://webdataset.github.io/webdataset/)
* [TorchData](https://github.com/pytorch/data)
* [TensorFlow Datasets](https://www.tensorflow.org/datasets/tfless_tfds)
When work with a larger dataset, you may need to run training process for a long time and it’s useful to save regular checkpoints during the process. You can use the following argument to enable intermediate checkpointing:
```bash
--checkpointing_steps=500
```
This will save the trained model in subfolders of your output_dir. Subfolder names is the number of steps performed so far; for example: a checkpoint saved after 500 training steps would be saved in a subfolder named 500
You can then start your training from this saved checkpoint with
```bash
--controlnet_model_name_or_path="./control_out/500"
```
We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence by rebalancing the loss. To use it, one needs to set the `--snr_gamma` argument. The recommended value when using it is `5.0`.
We also support gradient accumulation - it is a technique that lets you use a bigger batch size than your machine would normally be able to fit into memory. You can use `gradient_accumulation_steps` argument to set gradient accumulation steps. The ControlNet author recommends using gradient accumulation to achieve better convergence. Read more [here](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md#more-consideration-sudden-converge-phenomenon-and-gradient-accumulation).
You can **profile your code** with:
```bash
--profile_steps==5
```
Refer to the [JAX documentation on profiling](https://jax.readthedocs.io/en/latest/profiling.html). To inspect the profile trace, you'll have to install and start Tensorboard with the profile plugin:
```bash
pip install tensorflow tensorboard-plugin-profile
tensorboard --logdir runs/fill-circle-100steps-20230411_165612/
```
The profile can then be inspected at http://localhost:6006/#profile
Sometimes you'll get version conflicts (error messages like `Duplicate plugins for name projector`), which means that you have to uninstall and reinstall all versions of Tensorflow/Tensorboard (e.g. with `pip uninstall tensorflow tf-nightly tensorboard tb-nightly tensorboard-plugin-profile && pip install tf-nightly tbp-nightly tensorboard-plugin-profile`).
Note that the debugging functionality of the Tensorboard `profile` plugin is still under active development. Not all views are fully functional, and for example the `trace_viewer` cuts off events after 1M (which can result in all your device traces getting lost if you for example profile the compilation step by accident).
### Troubleshoot your TPU VM
**VERY IMPORTANT** - Only one process can access the TPU cores at a time. This means that if multiple team members are trying to connect to the TPU cores, you will get errors such as:
```
libtpu.so already in used by another process. Not attempting to load libtpu.so in this process.
```
We recommend every team member create her/his own virtual environment, but only one person should run the heavy training processes. Also, please take turns when setting up the TPUv4-8 so that everybody can verify that JAX is correctly installed.
If your team members are not currently using the TPU but you still get this error message. You should kill the process that is using the TPU with
```
kill -9 PID
```
you will need to replace the term “PID” with the PID of the process that uses TPU. In most cases, this information is included in the error message. For example, if you get
```
The TPU is already in use by a process with pid 1378725. Not attempting to load libtpu.so in this process.
```
you can do
```
kill -9 1378725
```
You can also use the below command to find processes using each of the TPU chips (e.g. `/dev/accel0` is one of the TPU chips)
```
sudo lsof -w /dev/accel0
```
To kill all the processes using `/dev/accel0`
```
sudo lsof -t /dev/accel0 | xargs kill -9
```
If Python is not able to detect your TPU device (i.e. when you do `jax.device_count()` and it outputs `0`), it might be because you have no rights to access the tpu logs, or you have a dangling tpu lock file. Run these commands usually fix the issue
```
sudo rm -f /tmp/libtpu_lockfile
```
```
sudo chmod o+w /tmp/tpu_logs/
```
<div id="how-to-make-a-submission">
<h2> How to Make a Submission </h2>
</div>
To make a full submission, you need to have the following on Hugging Face Hub:
- Model repository with model weights and model card,
- (Optional) Dataset repository with dataset card,
- A Hugging Face Space that lets others interact with your model.
### Pushing model weights and the model card to Hub
**If you are using the training script (`train_controlnet_flax.py`) provided in this directory**
Enabling `push_to_hub` argument in the training arguments will:
- Create a model repository locally, and remotely on Hugging Face Hub,
- Create a model card and write it to the local model repository,
- Save your model to the local model repository,
- Push the local repository to Hugging Face Hub.
Your automatically generated model card will look like below 👇
.
You can edit the model card to be more informative. Model cards that are more informative than the others will carry more weight during evaluation.
**If you have trained a custom model and not used the script**
You need to authenticate yourself with `huggingface-cli login` as instructed above. If you are using one of the available model classes from `diffusers`, save your model with `save_pretrained` method of your model.
```python
model.save_pretrained("path_to_your_model_repository")
```
After saving your model to a folder, you can simply use below script to push your model to the Hub 👇
```python
from huggingface_hub import create_repo, upload_folder
create_repo("username/my-awesome-model")
upload_folder(
folder_path="path_to_your_model_repository",
repo_id="username/my-awesome-model"
)
```
This will push your model to Hub. After pushing your model to Hub, you need to create the model card yourself.
You can use graphical interface to edit the model card.

Every model card consists of two sections, metadata and free text. You can edit metadata from the sections in graphical UI. If you have saved your model using `save_pretrained`, you do not need to provide `pipeline_tag` and `library_name`. If not, provide `pipeline_tag`, `library_name` and dataset if it exists on Hugging Face Hub. Aside from these, you need to add the `jax-diffusers-event` to `tags` section.
```
---
license: apache-2.0
library_name: diffusers
tags:
- jax-diffusers-event
datasets:
- red_caps
pipeline_tag: text-to-image
---
```

### Creating our Space
<h4> Writing our Application </h4>
We will use [Gradio](https://gradio.app/) to build our applications. Gradio has two main APIs: `Interface` and `Blocks`. `Interface` is a high-level API that lets you create an interface with few lines of code, and `Blocks` is a lower-level API that gives you more flexibility over interfaces you can build. The code should be included in a file called `app.py`.
Let's try to create a ControlNet app as an example. The `Interface` API simply works like below 👇
```python
import gradio as gr
# inference function takes prompt, negative prompt and image
def infer(prompt, negative_prompt, image):
# implement your inference function here
return output_image
# you need to pass inputs and outputs according to inference function
gr.Interface(fn = infer, inputs = ["text", "text", "image"], outputs = "image").launch()
```
You can customize your interface by passing `title`, `description` and `examples` to the `Interface` function.
```python
title = "ControlNet on Canny Filter"
description = "This is a demo on ControlNet based on canny filter."
# you need to pass your examples according to your inputs
# each inner list is one example, each element in the list corresponding to a component in the `inputs`.
examples = [["a cat with cake texture", "low quality", "cat_image.png"]]
gr.Interface(fn = infer, inputs = ["text", "text", "image"], outputs = "image",
title = title, description = description, examples = examples, theme='gradio/soft').launch()
```
Your interface will look like below 👇

With Blocks, you can add markdown, tabs, components under columns and rows and more. Assume we have two ControlNets and we want to include them in one Space. We will have them under different tabs under one demo like below 👇
```python
import gradio as gr
def infer_segmentation(prompt, negative_prompt, image):
# your inference function for segmentation control
return im
def infer_canny(prompt, negative_prompt, image):
# your inference function for canny control
return im
with gr.Blocks(theme='gradio/soft') as demo:
gr.Markdown("## Stable Diffusion with Different Controls")
gr.Markdown("In this app, you can find different ControlNets with different filters. ")
with gr.Tab("ControlNet on Canny Filter "):
prompt_input_canny = gr.Textbox(label="Prompt")
negative_prompt_canny = gr.Textbox(label="Negative Prompt")
canny_input = gr.Image(label="Input Image")
canny_output = gr.Image(label="Output Image")
submit_btn = gr.Button(value = "Submit")
canny_inputs = [prompt_input_canny, negative_prompt_canny, canny_input]
submit_btn.click(fn=infer_canny, inputs=canny_inputs, outputs=[canny_output])
with gr.Tab("ControlNet with Semantic Segmentation"):
prompt_input_seg = gr.Textbox(label="Prompt")
negative_prompt_seg = gr.Textbox(label="Negative Prompt")
seg_input = gr.Image(label="Image")
seg_output = gr.Image(label="Output Image")
submit_btn = gr.Button(value = "Submit")
seg_inputs = [prompt_input_seg, negative_prompt_seg, seg_input]
submit_btn.click(fn=infer_segmentation, inputs=seg_inputs, outputs=[seg_output])
demo.launch()
```
Above demo will look like below 👇

#### Creating our Space
After our application is written, we can create a Hugging Face Space to host our app. You can go to [huggingface.co](http://huggingface.co), click on your profile on top right and select “New Space”.

We can name our Space, pick a license and select Space SDK as “Gradio”.

After creating the Space, you can either use the instructions below to clone the repository locally, add your files and push, or use the graphical interface to create the files and write the code in the browser.

To upload your application file, pick “Add File” and drag and drop your file.
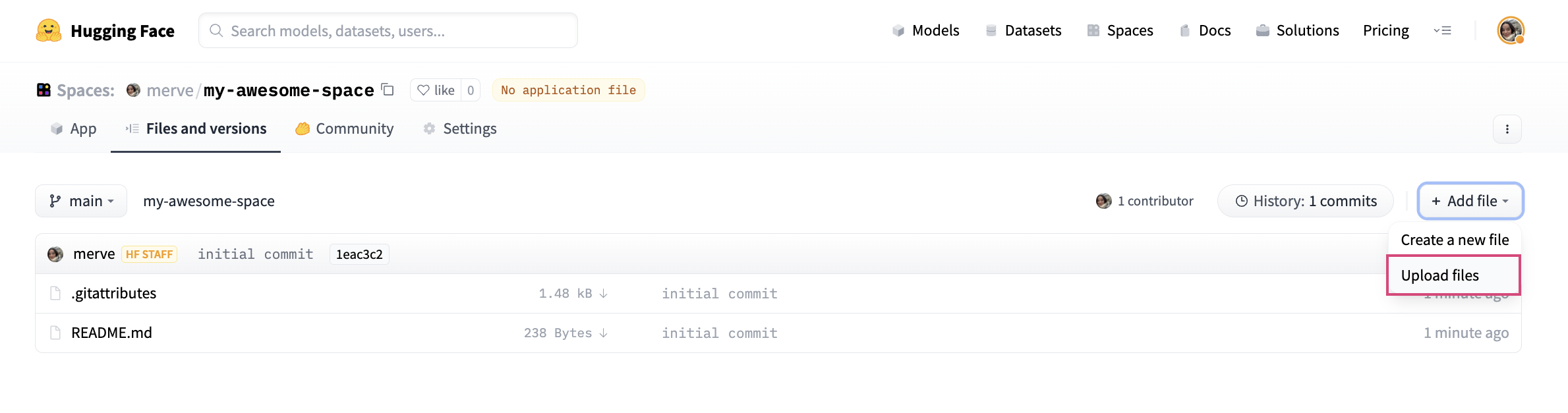
Lastly, we have to create a file called `requirements.txt` and add requirements of our project. Make sure to install below versions of jax, diffusers and other dependencies like below.
```
-f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
jax[cuda11_cudnn805]
jaxlib
git+https://github.com/huggingface/diffusers@main
opencv-python
transformers
flax
```
We will give you GPU grant so your application can run on GPU.
We have a leaderboard hosted [here](https://huggingface.co/spaces/jax-diffusers-event/leaderboard) and we will be distributing prizes from this leaderboard. To make your Space show up on the leaderboard, simply edit `README.md` of your Space to have the tag `jax-diffusers-event` under tags like below 👇
```
---
title: Canny Coyo1m
emoji: 💜
...
tags:
- jax-diffusers-event
---
```
## Prizes
For this sprint we will have many prizes. We will pick the first ten projects from [this leaderboard](https://huggingface.co/spaces/jax-diffusers-event/leaderboard), so you should tag your Space for the leaderboard to make your submission complete, as instructed in above section. The projects are ranked by likes, so we will amplify the visibility of all projects for people to cast their votes by leaving a like on the Space. We will pick the first ten projects from the ranking, and the jury will cast their votes to determine the first three places. These projects will be highlighted by both Google and Hugging Face. Elaborately made interfaces as well as projects with open-sourced codebases and models will likely increase the chance of winning prizes.
Prizes are as follows and are given to each team member 👇
**First Place**: A voucher of $150 that you can spend at [Hugging Face Store](https://store.huggingface.co/), Hugging Face Hub PRO subscription for one year, Natural Language Processing with Transformers book
**Second Place**: A voucher of $125 that you can spend at [Hugging Face Store](https://store.huggingface.co/), Hugging Face Hub PRO subscription for one year
**Third Place**: A voucher of $100 that you can spend at [Hugging Face Store](https://store.huggingface.co/), Hugging Face Hub PRO subscription for one year
The first ten projects on the leaderboard (regardless of jury decision) will win a merch set exclusively made for this sprint by Hugging Face, and an separate JAX merch set from Google.
## Jury
Our jury panel for this sprint included:
1. Robin Rombach, Stability AI
2. Huiwen Chang, Google Research
3. Jun-Yan Zhu, Carnegie Mellon University
4. Merve Noyan, Hugging Face
## FAQ
In this section, We are collecting answers to frequently asked questions from our discord channel. Contributions welcome!
### How to Use VSCode with TPU VM?
You can follow this [general guide](https://medium.com/@ivanzhd/vscode-sftp-connection-to-compute-engine-on-google-cloud-platform-gcloud-9312797d56eb) on how to use VSCode remote to connect to Google Cloud VMs. Once it's set up, you can develop on the TPU VM using VSCode.
To get your external IP, use this command:
```
gcloud compute tpus tpu-vm describe <node_name> --zone=<zone>
```
It should be listed under 'accessConfig' -> 'externalIp'
### How to Test Your Code Locally?
Since team members are sharing the TPU VM, it might be practical to write and test your code locally on a CPU while your teammates are running the training process on the VM. To run local testing, it is important to set the `xla_force_host_platform_device_count` flag to `4`. Read more on the [documentation](https://jax.readthedocs.io/en/latest/jax-101/06-parallelism.html#aside-hosts-and-devices-in-jax).
## Sprint winners
Top 10 projects (based on the likes on their demo applications) are available on this [leaderboard](https://huggingface.co/spaces/jax-diffusers-event/leaderboard). We tooks this leaderboard to our [jury](#jury) to judge the top 10 projects based on several factors such as open-source model checkpoints, datasets, and codebases, completeness of the model and dataset cards, etc. As a result, following three projects emerged as the winners:
1. [ControlNet for Interior Design](https://huggingface.co/spaces/controlnet-interior-design/controlnet-seg)
2. [ControlNet for Adjusting Brightness](https://huggingface.co/spaces/ioclab/brightness-controlnet)
3. [Stable Diffusion with Hand Control](https://huggingface.co/spaces/vllab/controlnet-hands)
|