

Upload folder using huggingface_hub (#1)
Browse files- d746d40eefa9f33d0b6091f92a2cdcc1f60ac34ce551601fce71707cdfbf2770 (29158425150aa07c811a16759cdeed420fed484f)
- f382017c8dc2a09a02a3e7d2d51a7dc62d00e97822b8d79c974cf21d9e53b52b (fe997a55aefb051688bbe61359a98265a5fd5f89)
- 4b11e450487d4e59ced2694b15688f61d266e7df1eb2cc81e486262711561e65 (6e378eec8ce3fce85f7a8db0ecd0926c4c02abb9)
- README.md +83 -0
- config.json +47 -0
- configuration_RW.py +79 -0
- generation_config.json +6 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +330 -0
- modelling_RW.py +1100 -0
- plots.png +0 -0
- smash_config.json +27 -0
README.md
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: pruna-engine
|
| 3 |
+
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 4 |
+
metrics:
|
| 5 |
+
- memory_disk
|
| 6 |
+
- memory_inference
|
| 7 |
+
- inference_latency
|
| 8 |
+
- inference_throughput
|
| 9 |
+
- inference_CO2_emissions
|
| 10 |
+
- inference_energy_consumption
|
| 11 |
+
---
|
| 12 |
+
<!-- header start -->
|
| 13 |
+
<!-- 200823 -->
|
| 14 |
+
<div style="width: auto; margin-left: auto; margin-right: auto">
|
| 15 |
+
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
|
| 16 |
+
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
|
| 17 |
+
</a>
|
| 18 |
+
</div>
|
| 19 |
+
<!-- header end -->
|
| 20 |
+
|
| 21 |
+
[](https://twitter.com/PrunaAI)
|
| 22 |
+
[](https://github.com/PrunaAI)
|
| 23 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 24 |
+
[](https://discord.gg/CP4VSgck)
|
| 25 |
+
|
| 26 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 27 |
+
|
| 28 |
+
- Give a thumbs up if you like this model!
|
| 29 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 30 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 31 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 32 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
|
| 33 |
+
|
| 34 |
+
## Results
|
| 35 |
+
|
| 36 |
+

|
| 37 |
+
|
| 38 |
+
**Frequently Asked Questions**
|
| 39 |
+
- ***How does the compression work?*** The model is compressed with llm-int8.
|
| 40 |
+
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 41 |
+
- ***How is the model efficiency evaluated?*** These results were obtained on Tesla V100-PCIE-32GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 42 |
+
- ***What is the model format?*** We use safetensors.
|
| 43 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
|
| 44 |
+
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 45 |
+
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 46 |
+
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 47 |
+
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
|
| 48 |
+
|
| 49 |
+
## Setup
|
| 50 |
+
|
| 51 |
+
You can run the smashed model with these steps:
|
| 52 |
+
|
| 53 |
+
0. Check requirements from the original repo nomic-ai/gpt4all-falcon installed. In particular, check python, cuda, and transformers versions.
|
| 54 |
+
1. Make sure that you have installed quantization related packages.
|
| 55 |
+
```bash
|
| 56 |
+
pip install transformers accelerate bitsandbytes>0.37.0
|
| 57 |
+
```
|
| 58 |
+
2. Load & run the model.
|
| 59 |
+
```python
|
| 60 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 61 |
+
|
| 62 |
+
model = AutoModelForCausalLM.from_pretrained("PrunaAI/nomic-ai-gpt4all-falcon-bnb-8bit-smashed",
|
| 63 |
+
trust_remote_code=True)
|
| 64 |
+
tokenizer = AutoTokenizer.from_pretrained("nomic-ai/gpt4all-falcon")
|
| 65 |
+
|
| 66 |
+
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 67 |
+
|
| 68 |
+
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 69 |
+
tokenizer.decode(outputs[0])
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
## Configurations
|
| 73 |
+
|
| 74 |
+
The configuration info are in `smash_config.json`.
|
| 75 |
+
|
| 76 |
+
## Credits & License
|
| 77 |
+
|
| 78 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model nomic-ai/gpt4all-falcon before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 79 |
+
|
| 80 |
+
## Want to compress other models?
|
| 81 |
+
|
| 82 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 83 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
config.json
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/tmp/tmps7unhmku",
|
| 3 |
+
"alibi": false,
|
| 4 |
+
"apply_residual_connection_post_layernorm": false,
|
| 5 |
+
"architectures": [
|
| 6 |
+
"RWForCausalLM"
|
| 7 |
+
],
|
| 8 |
+
"attention_dropout": 0.0,
|
| 9 |
+
"auto_map": {
|
| 10 |
+
"AutoConfig": "configuration_RW.RWConfig",
|
| 11 |
+
"AutoModel": "nomic-ai/gpt4all-falcon--modelling_RW.RWModel",
|
| 12 |
+
"AutoModelForCausalLM": "modelling_RW.RWForCausalLM",
|
| 13 |
+
"AutoModelForQuestionAnswering": "nomic-ai/gpt4all-falcon--modelling_RW.RWForQuestionAnswering",
|
| 14 |
+
"AutoModelForSequenceClassification": "nomic-ai/gpt4all-falcon--modelling_RW.RWForSequenceClassification",
|
| 15 |
+
"AutoModelForTokenClassification": "nomic-ai/gpt4all-falcon--modelling_RW.RWForTokenClassification"
|
| 16 |
+
},
|
| 17 |
+
"bias": false,
|
| 18 |
+
"bos_token_id": 11,
|
| 19 |
+
"eos_token_id": 11,
|
| 20 |
+
"hidden_dropout": 0.0,
|
| 21 |
+
"hidden_size": 4544,
|
| 22 |
+
"initializer_range": 0.02,
|
| 23 |
+
"layer_norm_epsilon": 1e-05,
|
| 24 |
+
"model_type": "RefinedWebModel",
|
| 25 |
+
"multi_query": true,
|
| 26 |
+
"n_head": 71,
|
| 27 |
+
"n_layer": 32,
|
| 28 |
+
"parallel_attn": true,
|
| 29 |
+
"quantization_config": {
|
| 30 |
+
"bnb_4bit_compute_dtype": "bfloat16",
|
| 31 |
+
"bnb_4bit_quant_type": "fp4",
|
| 32 |
+
"bnb_4bit_use_double_quant": true,
|
| 33 |
+
"llm_int8_enable_fp32_cpu_offload": false,
|
| 34 |
+
"llm_int8_has_fp16_weight": false,
|
| 35 |
+
"llm_int8_skip_modules": [
|
| 36 |
+
"lm_head"
|
| 37 |
+
],
|
| 38 |
+
"llm_int8_threshold": 6.0,
|
| 39 |
+
"load_in_4bit": false,
|
| 40 |
+
"load_in_8bit": true,
|
| 41 |
+
"quant_method": "bitsandbytes"
|
| 42 |
+
},
|
| 43 |
+
"torch_dtype": "float16",
|
| 44 |
+
"transformers_version": "4.37.1",
|
| 45 |
+
"use_cache": false,
|
| 46 |
+
"vocab_size": 65024
|
| 47 |
+
}
|
configuration_RW.py
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2022 the Big Science Workshop and HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
""" Bloom configuration"""
|
| 16 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 17 |
+
from transformers.utils import logging
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
logger = logging.get_logger(__name__)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class RWConfig(PretrainedConfig):
|
| 24 |
+
model_type = "RefinedWebModel"
|
| 25 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 26 |
+
attribute_map = {
|
| 27 |
+
"num_hidden_layers": "n_layer",
|
| 28 |
+
"num_attention_heads": "n_head",
|
| 29 |
+
}
|
| 30 |
+
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
vocab_size=250880,
|
| 34 |
+
hidden_size=64,
|
| 35 |
+
n_layer=2,
|
| 36 |
+
n_head=8,
|
| 37 |
+
layer_norm_epsilon=1e-5,
|
| 38 |
+
initializer_range=0.02,
|
| 39 |
+
use_cache=True,
|
| 40 |
+
bos_token_id=1,
|
| 41 |
+
eos_token_id=2,
|
| 42 |
+
apply_residual_connection_post_layernorm=False,
|
| 43 |
+
hidden_dropout=0.0,
|
| 44 |
+
attention_dropout=0.0,
|
| 45 |
+
multi_query=False,
|
| 46 |
+
alibi=False,
|
| 47 |
+
bias=False,
|
| 48 |
+
parallel_attn=False,
|
| 49 |
+
**kwargs,
|
| 50 |
+
):
|
| 51 |
+
self.vocab_size = vocab_size
|
| 52 |
+
# Backward compatibility with n_embed kwarg
|
| 53 |
+
n_embed = kwargs.pop("n_embed", None)
|
| 54 |
+
self.hidden_size = hidden_size if n_embed is None else n_embed
|
| 55 |
+
self.n_layer = n_layer
|
| 56 |
+
self.n_head = n_head
|
| 57 |
+
self.layer_norm_epsilon = layer_norm_epsilon
|
| 58 |
+
self.initializer_range = initializer_range
|
| 59 |
+
self.use_cache = use_cache
|
| 60 |
+
self.apply_residual_connection_post_layernorm = apply_residual_connection_post_layernorm
|
| 61 |
+
self.hidden_dropout = hidden_dropout
|
| 62 |
+
self.attention_dropout = attention_dropout
|
| 63 |
+
|
| 64 |
+
self.bos_token_id = bos_token_id
|
| 65 |
+
self.eos_token_id = eos_token_id
|
| 66 |
+
self.multi_query = multi_query
|
| 67 |
+
self.alibi = alibi
|
| 68 |
+
self.bias = bias
|
| 69 |
+
self.parallel_attn = parallel_attn
|
| 70 |
+
|
| 71 |
+
super().__init__(bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
|
| 72 |
+
|
| 73 |
+
@property
|
| 74 |
+
def head_dim(self):
|
| 75 |
+
return self.hidden_size // self.n_head
|
| 76 |
+
|
| 77 |
+
@property
|
| 78 |
+
def rotary(self):
|
| 79 |
+
return not self.alibi
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.37.1"
|
| 6 |
+
}
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ad108469ef9fc584970cc01d58b3924b1e627c85cc039c6c99266a3d43b92415
|
| 3 |
+
size 4984240344
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4209d95422fd89fcb7fa0dc2d0413327db3205a0b9fe7e7a0ade9908fe91fbfc
|
| 3 |
+
size 2237373592
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 7221577472
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"transformer.h.0.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 7 |
+
"transformer.h.0.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 8 |
+
"transformer.h.0.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 9 |
+
"transformer.h.0.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 10 |
+
"transformer.h.0.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 11 |
+
"transformer.h.0.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"transformer.h.0.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 13 |
+
"transformer.h.0.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 14 |
+
"transformer.h.0.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 15 |
+
"transformer.h.0.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"transformer.h.1.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 17 |
+
"transformer.h.1.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"transformer.h.1.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 19 |
+
"transformer.h.1.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"transformer.h.1.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 21 |
+
"transformer.h.1.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"transformer.h.1.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 23 |
+
"transformer.h.1.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"transformer.h.1.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 25 |
+
"transformer.h.1.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 26 |
+
"transformer.h.10.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 27 |
+
"transformer.h.10.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"transformer.h.10.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 29 |
+
"transformer.h.10.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"transformer.h.10.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 31 |
+
"transformer.h.10.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 32 |
+
"transformer.h.10.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 33 |
+
"transformer.h.10.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"transformer.h.10.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 35 |
+
"transformer.h.10.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"transformer.h.11.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 37 |
+
"transformer.h.11.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"transformer.h.11.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 39 |
+
"transformer.h.11.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"transformer.h.11.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 41 |
+
"transformer.h.11.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"transformer.h.11.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 43 |
+
"transformer.h.11.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"transformer.h.11.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 45 |
+
"transformer.h.11.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"transformer.h.12.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 47 |
+
"transformer.h.12.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 48 |
+
"transformer.h.12.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 49 |
+
"transformer.h.12.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 50 |
+
"transformer.h.12.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 51 |
+
"transformer.h.12.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 52 |
+
"transformer.h.12.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 53 |
+
"transformer.h.12.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 54 |
+
"transformer.h.12.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 55 |
+
"transformer.h.12.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 56 |
+
"transformer.h.13.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 57 |
+
"transformer.h.13.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 58 |
+
"transformer.h.13.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 59 |
+
"transformer.h.13.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 60 |
+
"transformer.h.13.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 61 |
+
"transformer.h.13.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 62 |
+
"transformer.h.13.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 63 |
+
"transformer.h.13.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 64 |
+
"transformer.h.13.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 65 |
+
"transformer.h.13.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 66 |
+
"transformer.h.14.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 67 |
+
"transformer.h.14.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 68 |
+
"transformer.h.14.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 69 |
+
"transformer.h.14.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 70 |
+
"transformer.h.14.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 71 |
+
"transformer.h.14.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 72 |
+
"transformer.h.14.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 73 |
+
"transformer.h.14.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 74 |
+
"transformer.h.14.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 75 |
+
"transformer.h.14.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 76 |
+
"transformer.h.15.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 77 |
+
"transformer.h.15.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 78 |
+
"transformer.h.15.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 79 |
+
"transformer.h.15.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 80 |
+
"transformer.h.15.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 81 |
+
"transformer.h.15.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 82 |
+
"transformer.h.15.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 83 |
+
"transformer.h.15.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 84 |
+
"transformer.h.15.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 85 |
+
"transformer.h.15.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 86 |
+
"transformer.h.16.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 87 |
+
"transformer.h.16.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 88 |
+
"transformer.h.16.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 89 |
+
"transformer.h.16.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 90 |
+
"transformer.h.16.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 91 |
+
"transformer.h.16.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 92 |
+
"transformer.h.16.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 93 |
+
"transformer.h.16.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 94 |
+
"transformer.h.16.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 95 |
+
"transformer.h.16.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 96 |
+
"transformer.h.17.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 97 |
+
"transformer.h.17.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 98 |
+
"transformer.h.17.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 99 |
+
"transformer.h.17.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 100 |
+
"transformer.h.17.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 101 |
+
"transformer.h.17.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 102 |
+
"transformer.h.17.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 103 |
+
"transformer.h.17.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 104 |
+
"transformer.h.17.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 105 |
+
"transformer.h.17.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 106 |
+
"transformer.h.18.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 107 |
+
"transformer.h.18.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 108 |
+
"transformer.h.18.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 109 |
+
"transformer.h.18.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 110 |
+
"transformer.h.18.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 111 |
+
"transformer.h.18.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 112 |
+
"transformer.h.18.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 113 |
+
"transformer.h.18.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 114 |
+
"transformer.h.18.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 115 |
+
"transformer.h.18.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"transformer.h.19.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 117 |
+
"transformer.h.19.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"transformer.h.19.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 119 |
+
"transformer.h.19.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"transformer.h.19.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 121 |
+
"transformer.h.19.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 122 |
+
"transformer.h.19.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 123 |
+
"transformer.h.19.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 124 |
+
"transformer.h.19.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 125 |
+
"transformer.h.19.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 126 |
+
"transformer.h.2.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 127 |
+
"transformer.h.2.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 128 |
+
"transformer.h.2.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 129 |
+
"transformer.h.2.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 130 |
+
"transformer.h.2.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 131 |
+
"transformer.h.2.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 132 |
+
"transformer.h.2.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 133 |
+
"transformer.h.2.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 134 |
+
"transformer.h.2.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 135 |
+
"transformer.h.2.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 136 |
+
"transformer.h.20.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 137 |
+
"transformer.h.20.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 138 |
+
"transformer.h.20.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 139 |
+
"transformer.h.20.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 140 |
+
"transformer.h.20.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 141 |
+
"transformer.h.20.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 142 |
+
"transformer.h.20.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 143 |
+
"transformer.h.20.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 144 |
+
"transformer.h.20.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 145 |
+
"transformer.h.20.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 146 |
+
"transformer.h.21.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 147 |
+
"transformer.h.21.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 148 |
+
"transformer.h.21.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 149 |
+
"transformer.h.21.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 150 |
+
"transformer.h.21.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 151 |
+
"transformer.h.21.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 152 |
+
"transformer.h.21.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 153 |
+
"transformer.h.21.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 154 |
+
"transformer.h.21.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 155 |
+
"transformer.h.21.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 156 |
+
"transformer.h.22.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 157 |
+
"transformer.h.22.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 158 |
+
"transformer.h.22.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 159 |
+
"transformer.h.22.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 160 |
+
"transformer.h.22.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 161 |
+
"transformer.h.22.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 162 |
+
"transformer.h.22.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 163 |
+
"transformer.h.22.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 164 |
+
"transformer.h.22.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 165 |
+
"transformer.h.22.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 166 |
+
"transformer.h.23.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 167 |
+
"transformer.h.23.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 168 |
+
"transformer.h.23.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 169 |
+
"transformer.h.23.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 170 |
+
"transformer.h.23.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 171 |
+
"transformer.h.23.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 172 |
+
"transformer.h.23.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 173 |
+
"transformer.h.23.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 174 |
+
"transformer.h.23.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 175 |
+
"transformer.h.23.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 176 |
+
"transformer.h.24.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 177 |
+
"transformer.h.24.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 178 |
+
"transformer.h.24.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 179 |
+
"transformer.h.24.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 180 |
+
"transformer.h.24.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 181 |
+
"transformer.h.24.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 182 |
+
"transformer.h.24.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 183 |
+
"transformer.h.24.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 184 |
+
"transformer.h.24.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 185 |
+
"transformer.h.24.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 186 |
+
"transformer.h.25.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 187 |
+
"transformer.h.25.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 188 |
+
"transformer.h.25.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 189 |
+
"transformer.h.25.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 190 |
+
"transformer.h.25.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 191 |
+
"transformer.h.25.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 192 |
+
"transformer.h.25.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 193 |
+
"transformer.h.25.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 194 |
+
"transformer.h.25.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 195 |
+
"transformer.h.25.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 196 |
+
"transformer.h.26.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 197 |
+
"transformer.h.26.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 198 |
+
"transformer.h.26.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 199 |
+
"transformer.h.26.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 200 |
+
"transformer.h.26.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 201 |
+
"transformer.h.26.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 202 |
+
"transformer.h.26.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 203 |
+
"transformer.h.26.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 204 |
+
"transformer.h.26.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 205 |
+
"transformer.h.26.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 206 |
+
"transformer.h.27.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 207 |
+
"transformer.h.27.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 208 |
+
"transformer.h.27.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 209 |
+
"transformer.h.27.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 210 |
+
"transformer.h.27.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 211 |
+
"transformer.h.27.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 212 |
+
"transformer.h.27.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 213 |
+
"transformer.h.27.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 214 |
+
"transformer.h.27.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 215 |
+
"transformer.h.27.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 216 |
+
"transformer.h.28.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 217 |
+
"transformer.h.28.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 218 |
+
"transformer.h.28.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 219 |
+
"transformer.h.28.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 220 |
+
"transformer.h.28.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 221 |
+
"transformer.h.28.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 222 |
+
"transformer.h.28.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 223 |
+
"transformer.h.28.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 224 |
+
"transformer.h.28.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 225 |
+
"transformer.h.28.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 226 |
+
"transformer.h.29.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 227 |
+
"transformer.h.29.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 228 |
+
"transformer.h.29.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 229 |
+
"transformer.h.29.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 230 |
+
"transformer.h.29.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 231 |
+
"transformer.h.29.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 232 |
+
"transformer.h.29.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 233 |
+
"transformer.h.29.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 234 |
+
"transformer.h.29.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 235 |
+
"transformer.h.29.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 236 |
+
"transformer.h.3.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 237 |
+
"transformer.h.3.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 238 |
+
"transformer.h.3.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 239 |
+
"transformer.h.3.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 240 |
+
"transformer.h.3.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 241 |
+
"transformer.h.3.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 242 |
+
"transformer.h.3.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 243 |
+
"transformer.h.3.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 244 |
+
"transformer.h.3.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 245 |
+
"transformer.h.3.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 246 |
+
"transformer.h.30.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 247 |
+
"transformer.h.30.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 248 |
+
"transformer.h.30.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 249 |
+
"transformer.h.30.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 250 |
+
"transformer.h.30.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 251 |
+
"transformer.h.30.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 252 |
+
"transformer.h.30.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 253 |
+
"transformer.h.30.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 254 |
+
"transformer.h.30.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 255 |
+
"transformer.h.30.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 256 |
+
"transformer.h.31.input_layernorm.bias": "model-00002-of-00002.safetensors",
|
| 257 |
+
"transformer.h.31.input_layernorm.weight": "model-00002-of-00002.safetensors",
|
| 258 |
+
"transformer.h.31.mlp.dense_4h_to_h.SCB": "model-00002-of-00002.safetensors",
|
| 259 |
+
"transformer.h.31.mlp.dense_4h_to_h.weight": "model-00002-of-00002.safetensors",
|
| 260 |
+
"transformer.h.31.mlp.dense_h_to_4h.SCB": "model-00002-of-00002.safetensors",
|
| 261 |
+
"transformer.h.31.mlp.dense_h_to_4h.weight": "model-00002-of-00002.safetensors",
|
| 262 |
+
"transformer.h.31.self_attention.dense.SCB": "model-00002-of-00002.safetensors",
|
| 263 |
+
"transformer.h.31.self_attention.dense.weight": "model-00002-of-00002.safetensors",
|
| 264 |
+
"transformer.h.31.self_attention.query_key_value.SCB": "model-00002-of-00002.safetensors",
|
| 265 |
+
"transformer.h.31.self_attention.query_key_value.weight": "model-00002-of-00002.safetensors",
|
| 266 |
+
"transformer.h.4.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 267 |
+
"transformer.h.4.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 268 |
+
"transformer.h.4.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 269 |
+
"transformer.h.4.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 270 |
+
"transformer.h.4.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 271 |
+
"transformer.h.4.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 272 |
+
"transformer.h.4.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 273 |
+
"transformer.h.4.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 274 |
+
"transformer.h.4.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 275 |
+
"transformer.h.4.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 276 |
+
"transformer.h.5.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 277 |
+
"transformer.h.5.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 278 |
+
"transformer.h.5.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 279 |
+
"transformer.h.5.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 280 |
+
"transformer.h.5.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 281 |
+
"transformer.h.5.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 282 |
+
"transformer.h.5.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 283 |
+
"transformer.h.5.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 284 |
+
"transformer.h.5.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 285 |
+
"transformer.h.5.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 286 |
+
"transformer.h.6.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 287 |
+
"transformer.h.6.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 288 |
+
"transformer.h.6.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 289 |
+
"transformer.h.6.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 290 |
+
"transformer.h.6.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 291 |
+
"transformer.h.6.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 292 |
+
"transformer.h.6.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 293 |
+
"transformer.h.6.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 294 |
+
"transformer.h.6.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 295 |
+
"transformer.h.6.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 296 |
+
"transformer.h.7.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 297 |
+
"transformer.h.7.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 298 |
+
"transformer.h.7.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 299 |
+
"transformer.h.7.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 300 |
+
"transformer.h.7.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 301 |
+
"transformer.h.7.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 302 |
+
"transformer.h.7.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 303 |
+
"transformer.h.7.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 304 |
+
"transformer.h.7.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 305 |
+
"transformer.h.7.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 306 |
+
"transformer.h.8.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 307 |
+
"transformer.h.8.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 308 |
+
"transformer.h.8.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 309 |
+
"transformer.h.8.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 310 |
+
"transformer.h.8.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 311 |
+
"transformer.h.8.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 312 |
+
"transformer.h.8.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 313 |
+
"transformer.h.8.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 314 |
+
"transformer.h.8.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 315 |
+
"transformer.h.8.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 316 |
+
"transformer.h.9.input_layernorm.bias": "model-00001-of-00002.safetensors",
|
| 317 |
+
"transformer.h.9.input_layernorm.weight": "model-00001-of-00002.safetensors",
|
| 318 |
+
"transformer.h.9.mlp.dense_4h_to_h.SCB": "model-00001-of-00002.safetensors",
|
| 319 |
+
"transformer.h.9.mlp.dense_4h_to_h.weight": "model-00001-of-00002.safetensors",
|
| 320 |
+
"transformer.h.9.mlp.dense_h_to_4h.SCB": "model-00001-of-00002.safetensors",
|
| 321 |
+
"transformer.h.9.mlp.dense_h_to_4h.weight": "model-00001-of-00002.safetensors",
|
| 322 |
+
"transformer.h.9.self_attention.dense.SCB": "model-00001-of-00002.safetensors",
|
| 323 |
+
"transformer.h.9.self_attention.dense.weight": "model-00001-of-00002.safetensors",
|
| 324 |
+
"transformer.h.9.self_attention.query_key_value.SCB": "model-00001-of-00002.safetensors",
|
| 325 |
+
"transformer.h.9.self_attention.query_key_value.weight": "model-00001-of-00002.safetensors",
|
| 326 |
+
"transformer.ln_f.bias": "model-00002-of-00002.safetensors",
|
| 327 |
+
"transformer.ln_f.weight": "model-00002-of-00002.safetensors",
|
| 328 |
+
"transformer.word_embeddings.weight": "model-00001-of-00002.safetensors"
|
| 329 |
+
}
|
| 330 |
+
}
|
modelling_RW.py
ADDED
|
@@ -0,0 +1,1100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# port of models described in RW
|
| 2 |
+
# We use the bloom model as a starting point for these model.
|
| 3 |
+
# Please refer to the bloom models for usage instructions.
|
| 4 |
+
|
| 5 |
+
import math
|
| 6 |
+
import warnings
|
| 7 |
+
from typing import Optional, Tuple, Union
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.utils.checkpoint
|
| 11 |
+
from torch import nn
|
| 12 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, LayerNorm, MSELoss
|
| 13 |
+
from torch.nn import functional as F
|
| 14 |
+
|
| 15 |
+
from transformers.modeling_outputs import (
|
| 16 |
+
BaseModelOutputWithPastAndCrossAttentions,
|
| 17 |
+
CausalLMOutputWithCrossAttentions,
|
| 18 |
+
QuestionAnsweringModelOutput,
|
| 19 |
+
SequenceClassifierOutputWithPast,
|
| 20 |
+
TokenClassifierOutput,
|
| 21 |
+
)
|
| 22 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 23 |
+
from transformers.utils import logging
|
| 24 |
+
from .configuration_RW import RWConfig
|
| 25 |
+
|
| 26 |
+
logger = logging.get_logger(__name__)
|
| 27 |
+
|
| 28 |
+
# NOTE(Hesslow): Unfortunately we did not fuse matmul and bias during training, this means that there's one additional quantization to bfloat16 between the operations.
|
| 29 |
+
# In order not to degrade the quality of our HF-port, we keep these characteristics in the final model.
|
| 30 |
+
class Linear(nn.Linear):
|
| 31 |
+
def forward(self, input: torch.Tensor) -> torch.Tensor:
|
| 32 |
+
ret = input @ self.weight.T
|
| 33 |
+
if self.bias is None:
|
| 34 |
+
return ret
|
| 35 |
+
else:
|
| 36 |
+
return ret + self.bias
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
from einops import rearrange
|
| 40 |
+
|
| 41 |
+
# rotary pos emb helpers (torch.jit.script does not seem to support staticmethod...)
|
| 42 |
+
def rotate_half(x):
|
| 43 |
+
x1, x2 = x[..., : x.shape[-1] // 2], x[..., x.shape[-1] // 2 :]
|
| 44 |
+
return torch.cat((-x2, x1), dim=x1.ndim - 1) # dim=-1 triggers a bug in torch < 1.8.0
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class RotaryEmbedding(torch.nn.Module):
|
| 48 |
+
"""Implementation of RotaryEmbedding from GPT-NeoX.
|
| 49 |
+
This implementation is design to operate on queries and keys that are compatible with
|
| 50 |
+
[batch_size, n_heads_per_partition, seq_len, head_dim] (e.g. MinGPTAttention format).
|
| 51 |
+
"""
|
| 52 |
+
|
| 53 |
+
def __init__(
|
| 54 |
+
self,
|
| 55 |
+
head_dim: int,
|
| 56 |
+
base=10000,
|
| 57 |
+
):
|
| 58 |
+
super().__init__()
|
| 59 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, head_dim, 2).float() / head_dim))
|
| 60 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 61 |
+
self.head_dim = head_dim
|
| 62 |
+
self.seq_len_cached = None
|
| 63 |
+
self.batch_size_cached = None
|
| 64 |
+
self.cos_cached: torch.Tensor | None = None
|
| 65 |
+
self.sin_cached: torch.Tensor | None = None
|
| 66 |
+
|
| 67 |
+
def cos_sin(
|
| 68 |
+
self,
|
| 69 |
+
seq_len: int,
|
| 70 |
+
device="cuda",
|
| 71 |
+
dtype=torch.bfloat16,
|
| 72 |
+
) -> torch.Tensor:
|
| 73 |
+
if seq_len != self.seq_len_cached:
|
| 74 |
+
self.seq_len_cached = seq_len
|
| 75 |
+
t = torch.arange(seq_len, device=device).type_as(self.inv_freq)
|
| 76 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 77 |
+
emb = torch.cat((freqs, freqs), dim=-1).to(device)
|
| 78 |
+
|
| 79 |
+
if dtype in [torch.float16, torch.bfloat16]:
|
| 80 |
+
emb = emb.float()
|
| 81 |
+
|
| 82 |
+
self.cos_cached = emb.cos()[None, :, :]
|
| 83 |
+
self.sin_cached = emb.sin()[None, :, :]
|
| 84 |
+
|
| 85 |
+
self.cos_cached = self.cos_cached.type(dtype)
|
| 86 |
+
self.sin_cached = self.sin_cached.type(dtype)
|
| 87 |
+
|
| 88 |
+
return self.cos_cached, self.sin_cached
|
| 89 |
+
|
| 90 |
+
def forward(self, q, k):
|
| 91 |
+
batch, seq_len, head_dim = q.shape
|
| 92 |
+
cos, sin = self.cos_sin(seq_len, q.device, q.dtype)
|
| 93 |
+
return (q * cos) + (rotate_half(q) * sin), (k * cos) + (rotate_half(k) * sin)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def _make_causal_mask(
|
| 97 |
+
input_ids_shape: torch.Size, device: torch.device, past_key_values_length: int
|
| 98 |
+
) -> torch.BoolTensor:
|
| 99 |
+
batch_size, target_length = input_ids_shape
|
| 100 |
+
mask = torch.empty((target_length, target_length + past_key_values_length), dtype=torch.bool, device=device)
|
| 101 |
+
# ONNX doesn't support `torch.Tensor.triu` properly, thus we use this workaround
|
| 102 |
+
seq_ids = torch.arange(target_length, device=device)
|
| 103 |
+
mask[:, past_key_values_length:] = seq_ids[:, None] < seq_ids[None, :]
|
| 104 |
+
|
| 105 |
+
if past_key_values_length > 0:
|
| 106 |
+
mask[:, :past_key_values_length] = False
|
| 107 |
+
|
| 108 |
+
expanded_mask = mask[None, None, :, :].expand(batch_size, 1, target_length, target_length + past_key_values_length)
|
| 109 |
+
return expanded_mask
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def _expand_mask(mask: torch.Tensor, tgt_length: int) -> torch.BoolTensor:
|
| 113 |
+
batch_size, src_length = mask.shape
|
| 114 |
+
tgt_length = tgt_length if tgt_length is not None else src_length
|
| 115 |
+
|
| 116 |
+
expanded_mask = ~(mask[:, None, None, :].to(torch.bool))
|
| 117 |
+
return expanded_mask.expand(batch_size, 1, tgt_length, src_length)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def build_alibi_tensor(attention_mask: torch.Tensor, num_heads: int, dtype: torch.dtype) -> torch.Tensor:
|
| 121 |
+
batch_size, seq_length = attention_mask.shape
|
| 122 |
+
closest_power_of_2 = 2 ** math.floor(math.log2(num_heads))
|
| 123 |
+
base = torch.tensor(
|
| 124 |
+
2 ** (-(2 ** -(math.log2(closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32
|
| 125 |
+
)
|
| 126 |
+
powers = torch.arange(1, 1 + closest_power_of_2, device=attention_mask.device, dtype=torch.int32)
|
| 127 |
+
slopes = torch.pow(base, powers)
|
| 128 |
+
|
| 129 |
+
if closest_power_of_2 != num_heads:
|
| 130 |
+
extra_base = torch.tensor(
|
| 131 |
+
2 ** (-(2 ** -(math.log2(2 * closest_power_of_2) - 3))), device=attention_mask.device, dtype=torch.float32
|
| 132 |
+
)
|
| 133 |
+
num_remaining_heads = min(closest_power_of_2, num_heads - closest_power_of_2)
|
| 134 |
+
extra_powers = torch.arange(1, 1 + 2 * num_remaining_heads, 2, device=attention_mask.device, dtype=torch.int32)
|
| 135 |
+
slopes = torch.cat([slopes, torch.pow(extra_base, extra_powers)], dim=0)
|
| 136 |
+
|
| 137 |
+
# Note: alibi will added to the attention bias that will be applied to the query, key product of attention
|
| 138 |
+
# => therefore alibi will have to be of shape (batch_size, num_heads, query_length, key_length)
|
| 139 |
+
# => here we set (batch_size=1, num_heads=num_heads, query_length=1, key_length=max_length)
|
| 140 |
+
# => the query_length dimension will then be broadcasted correctly
|
| 141 |
+
# This is more or less identical to T5's relative position bias:
|
| 142 |
+
# https://github.com/huggingface/transformers/blob/f681437203baa7671de3174b0fa583c349d9d5e1/src/transformers/models/t5/modeling_t5.py#L527
|
| 143 |
+
arange_tensor = ((attention_mask.cumsum(dim=-1) - 1) * attention_mask)[:, None, :]
|
| 144 |
+
alibi = slopes[..., None].bfloat16() * arange_tensor
|
| 145 |
+
return alibi.reshape(batch_size * num_heads, 1, seq_length).to(dtype)
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def dropout_add(x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool) -> torch.Tensor:
|
| 149 |
+
out = F.dropout(x, p=prob, training=training)
|
| 150 |
+
out = residual + out
|
| 151 |
+
return out
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
class Attention(nn.Module):
|
| 155 |
+
def __init__(self, config: RWConfig):
|
| 156 |
+
super().__init__()
|
| 157 |
+
|
| 158 |
+
self.hidden_size = config.hidden_size
|
| 159 |
+
self.num_heads = config.n_head
|
| 160 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 161 |
+
self.split_size = self.hidden_size
|
| 162 |
+
self.hidden_dropout = config.hidden_dropout
|
| 163 |
+
|
| 164 |
+
if self.head_dim * self.num_heads != self.hidden_size:
|
| 165 |
+
raise ValueError(
|
| 166 |
+
f"`hidden_size` must be divisible by num_heads (got `hidden_size`: {self.hidden_size} and `num_heads`:"
|
| 167 |
+
f" {self.num_heads})."
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
self.maybe_rotary = RotaryEmbedding(config.head_dim) if config.rotary else lambda q, k: (q, k)
|
| 171 |
+
|
| 172 |
+
# Layer-wise attention scaling
|
| 173 |
+
self.inv_norm_factor = 1.0 / math.sqrt(self.head_dim)
|
| 174 |
+
self.beta = self.inv_norm_factor
|
| 175 |
+
|
| 176 |
+
self.query_key_value = Linear(
|
| 177 |
+
self.hidden_size,
|
| 178 |
+
3 * self.hidden_size if not config.multi_query else (self.hidden_size + 2 * self.head_dim),
|
| 179 |
+
bias=config.bias,
|
| 180 |
+
)
|
| 181 |
+
self.multi_query = config.multi_query
|
| 182 |
+
self.dense = Linear(self.hidden_size, self.hidden_size, bias=config.bias)
|
| 183 |
+
self.attention_dropout = nn.Dropout(config.attention_dropout)
|
| 184 |
+
self.num_kv = config.n_head if not self.multi_query else 1
|
| 185 |
+
|
| 186 |
+
def _split_heads(self, fused_qkv: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
| 187 |
+
"""
|
| 188 |
+
Split the last dimension into (num_heads, head_dim) without making any copies, results share same memory
|
| 189 |
+
storage as `fused_qkv`
|
| 190 |
+
|
| 191 |
+
Args:
|
| 192 |
+
fused_qkv (`torch.tensor`, *required*): [batch_size, seq_length, num_heads * 3 * head_dim]
|
| 193 |
+
|
| 194 |
+
Returns:
|
| 195 |
+
query: [batch_size, seq_length, num_heads, head_dim] key: [batch_size, seq_length, num_heads, head_dim]
|
| 196 |
+
value: [batch_size, seq_length, num_heads, head_dim]
|
| 197 |
+
"""
|
| 198 |
+
if not self.multi_query:
|
| 199 |
+
batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
|
| 200 |
+
fused_qkv = fused_qkv.view(batch_size, seq_length, self.num_heads, 3, self.head_dim)
|
| 201 |
+
return fused_qkv[..., 0, :], fused_qkv[..., 1, :], fused_qkv[..., 2, :]
|
| 202 |
+
else:
|
| 203 |
+
batch_size, seq_length, three_times_hidden_size = fused_qkv.shape
|
| 204 |
+
fused_qkv = fused_qkv.view(batch_size, seq_length, self.num_heads + 2, self.head_dim)
|
| 205 |
+
return fused_qkv[..., :-2, :], fused_qkv[..., [-2], :], fused_qkv[..., [-1], :]
|
| 206 |
+
|
| 207 |
+
def _merge_heads(self, x: torch.Tensor) -> torch.Tensor:
|
| 208 |
+
"""
|
| 209 |
+
Merge heads together over the last dimenstion
|
| 210 |
+
|
| 211 |
+
Args:
|
| 212 |
+
x: (`torch.tensor`, *required*): [batch_size * num_heads, seq_length, head_dim]
|
| 213 |
+
|
| 214 |
+
Returns:
|
| 215 |
+
torch.tensor: [batch_size, seq_length, num_heads * head_dim]
|
| 216 |
+
"""
|
| 217 |
+
# What we want to achieve is:
|
| 218 |
+
# batch_size * num_heads, seq_length, head_dim -> batch_size, seq_length, num_heads * head_dim
|
| 219 |
+
batch_size_and_num_heads, seq_length, _ = x.shape
|
| 220 |
+
batch_size = batch_size_and_num_heads // self.num_heads
|
| 221 |
+
|
| 222 |
+
# First view to decompose the batch size
|
| 223 |
+
# batch_size * num_heads, seq_length, head_dim -> batch_size, num_heads, seq_length, head_dim
|
| 224 |
+
x = x.view(batch_size, self.num_heads, seq_length, self.head_dim)
|
| 225 |
+
|
| 226 |
+
# batch_size, num_heads, seq_length, head_dim -> batch_size, seq_length, num_heads, head_dim
|
| 227 |
+
x = x.permute(0, 2, 1, 3)
|
| 228 |
+
|
| 229 |
+
# batch_size, seq_length, num_heads, head_dim -> batch_size, seq_length, num_heads * head_dim
|
| 230 |
+
return x.reshape(batch_size, seq_length, self.num_heads * self.head_dim)
|
| 231 |
+
|
| 232 |
+
def forward(
|
| 233 |
+
self,
|
| 234 |
+
hidden_states: torch.Tensor,
|
| 235 |
+
alibi: torch.Tensor,
|
| 236 |
+
attention_mask: torch.Tensor,
|
| 237 |
+
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
|
| 238 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 239 |
+
use_cache: bool = False,
|
| 240 |
+
output_attentions: bool = False,
|
| 241 |
+
):
|
| 242 |
+
fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
|
| 243 |
+
|
| 244 |
+
# 3 x [batch_size, seq_length, num_heads, head_dim]
|
| 245 |
+
(query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
|
| 246 |
+
|
| 247 |
+
batch_size, q_length, _, _ = query_layer.shape
|
| 248 |
+
|
| 249 |
+
query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
|
| 250 |
+
key_layer = key_layer.transpose(1, 2).reshape(
|
| 251 |
+
batch_size * self.num_kv,
|
| 252 |
+
q_length,
|
| 253 |
+
self.head_dim,
|
| 254 |
+
)
|
| 255 |
+
value_layer = value_layer.transpose(1, 2).reshape(batch_size * self.num_kv, q_length, self.head_dim)
|
| 256 |
+
|
| 257 |
+
query_layer, key_layer = self.maybe_rotary(query_layer, key_layer)
|
| 258 |
+
|
| 259 |
+
if layer_past is not None:
|
| 260 |
+
past_key, past_value = layer_past
|
| 261 |
+
# concatenate along seq_length dimension:
|
| 262 |
+
# - key: [batch_size * self.num_heads, head_dim, kv_length]
|
| 263 |
+
# - value: [batch_size * self.num_heads, kv_length, head_dim]
|
| 264 |
+
key_layer = torch.cat((past_key, key_layer), dim=1)
|
| 265 |
+
value_layer = torch.cat((past_value, value_layer), dim=1)
|
| 266 |
+
|
| 267 |
+
_, kv_length, _ = key_layer.shape
|
| 268 |
+
|
| 269 |
+
if use_cache is True:
|
| 270 |
+
present = (key_layer, value_layer)
|
| 271 |
+
else:
|
| 272 |
+
present = None
|
| 273 |
+
|
| 274 |
+
if alibi is None:
|
| 275 |
+
query_layer_ = query_layer.reshape(batch_size, self.num_heads, -1, self.head_dim)
|
| 276 |
+
key_layer_ = key_layer.reshape(batch_size, self.num_kv, -1, self.head_dim)
|
| 277 |
+
value_layer_ = value_layer.reshape(batch_size, self.num_kv, -1, self.head_dim)
|
| 278 |
+
|
| 279 |
+
attn_output = F.scaled_dot_product_attention(
|
| 280 |
+
query_layer_, key_layer_, value_layer_, None, 0.0, is_causal=True
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
x = attn_output.view(batch_size, self.num_heads, q_length, self.head_dim)
|
| 284 |
+
x = x.permute(0, 2, 1, 3)
|
| 285 |
+
attn_output = x.reshape(batch_size, q_length, self.num_heads * self.head_dim)
|
| 286 |
+
|
| 287 |
+
output_tensor = self.dense(attn_output)
|
| 288 |
+
|
| 289 |
+
outputs = (output_tensor, present)
|
| 290 |
+
assert not output_attentions # not supported.
|
| 291 |
+
return outputs
|
| 292 |
+
else:
|
| 293 |
+
attention_mask_float = (attention_mask * 1.0).masked_fill(attention_mask, -1e9).to(torch.bfloat16)
|
| 294 |
+
matmul_result = query_layer @ key_layer.transpose(-1, -2)
|
| 295 |
+
|
| 296 |
+
# change view to [batch_size, num_heads, q_length, kv_length]
|
| 297 |
+
attention_scores = matmul_result.view(batch_size, self.num_heads, q_length, kv_length)
|
| 298 |
+
|
| 299 |
+
# cast attention scores to fp32, compute scaled softmax and cast back to initial dtype - [batch_size, num_heads, q_length, kv_length]
|
| 300 |
+
input_dtype = attention_scores.dtype
|
| 301 |
+
# `float16` has a minimum value of -65504.0, whereas `bfloat16` and `float32` have a minimum value of `-3.4e+38`
|
| 302 |
+
if input_dtype == torch.float16 or input_dtype == torch.bfloat16:
|
| 303 |
+
attention_scores = attention_scores.to(torch.float32)
|
| 304 |
+
# attn_weights = torch.masked_fill(attention_scores, attention_mask, torch.finfo(attention_scores.dtype).min)
|
| 305 |
+
attention_probs = F.softmax(
|
| 306 |
+
(attention_scores + alibi.view(batch_size, self.num_heads, 1, -1)) * self.inv_norm_factor + attention_mask_float,
|
| 307 |
+
dim=-1,
|
| 308 |
+
dtype=hidden_states.dtype,
|
| 309 |
+
)
|
| 310 |
+
# [batch_size, num_heads, q_length, kv_length]
|
| 311 |
+
attention_probs = self.attention_dropout(attention_probs)
|
| 312 |
+
|
| 313 |
+
if head_mask is not None:
|
| 314 |
+
attention_probs = attention_probs * head_mask
|
| 315 |
+
|
| 316 |
+
# change view [batch_size x num_heads, q_length, kv_length]
|
| 317 |
+
attention_probs_reshaped = attention_probs.view(batch_size * self.num_heads, q_length, kv_length)
|
| 318 |
+
|
| 319 |
+
# matmul: [batch_size * num_heads, q_length, head_dim]
|
| 320 |
+
context_layer = attention_probs_reshaped @ value_layer
|
| 321 |
+
|
| 322 |
+
# change view [batch_size, num_heads, q_length, head_dim]
|
| 323 |
+
context_layer = self._merge_heads(context_layer)
|
| 324 |
+
|
| 325 |
+
output_tensor = self.dense(context_layer)
|
| 326 |
+
|
| 327 |
+
outputs = (output_tensor, present)
|
| 328 |
+
if output_attentions:
|
| 329 |
+
outputs += (attention_probs,)
|
| 330 |
+
|
| 331 |
+
return outputs
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
class MLP(nn.Module):
|
| 335 |
+
def __init__(self, config: RWConfig):
|
| 336 |
+
super().__init__()
|
| 337 |
+
hidden_size = config.hidden_size
|
| 338 |
+
|
| 339 |
+
self.dense_h_to_4h = Linear(hidden_size, 4 * hidden_size, bias=config.bias)
|
| 340 |
+
self.act = nn.GELU()
|
| 341 |
+
self.dense_4h_to_h = Linear(4 * hidden_size, hidden_size, bias=config.bias)
|
| 342 |
+
self.hidden_dropout = config.hidden_dropout
|
| 343 |
+
|
| 344 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 345 |
+
x = self.act(self.dense_h_to_4h(x))
|
| 346 |
+
x = self.dense_4h_to_h(x)
|
| 347 |
+
return x
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
class DecoderLayer(nn.Module):
|
| 351 |
+
def __init__(self, config: RWConfig):
|
| 352 |
+
super().__init__()
|
| 353 |
+
hidden_size = config.hidden_size
|
| 354 |
+
|
| 355 |
+
self.input_layernorm = LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
|
| 356 |
+
self.num_heads = config.n_head
|
| 357 |
+
self.self_attention = Attention(config)
|
| 358 |
+
|
| 359 |
+
if not config.parallel_attn:
|
| 360 |
+
# unused if parallel attn
|
| 361 |
+
self.post_attention_layernorm = LayerNorm(hidden_size, eps=config.layer_norm_epsilon)
|
| 362 |
+
|
| 363 |
+
self.mlp = MLP(config)
|
| 364 |
+
|
| 365 |
+
self.apply_residual_connection_post_layernorm = config.apply_residual_connection_post_layernorm
|
| 366 |
+
self.hidden_dropout = config.hidden_dropout
|
| 367 |
+
|
| 368 |
+
self.config = config
|
| 369 |
+
|
| 370 |
+
def forward(
|
| 371 |
+
self,
|
| 372 |
+
hidden_states: torch.Tensor,
|
| 373 |
+
alibi: torch.Tensor,
|
| 374 |
+
attention_mask: torch.Tensor,
|
| 375 |
+
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
|
| 376 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 377 |
+
use_cache: bool = False,
|
| 378 |
+
output_attentions: bool = False,
|
| 379 |
+
):
|
| 380 |
+
|
| 381 |
+
layernorm_output = self.input_layernorm(hidden_states)
|
| 382 |
+
residual = hidden_states
|
| 383 |
+
|
| 384 |
+
# Self attention.
|
| 385 |
+
attn_outputs = self.self_attention(
|
| 386 |
+
layernorm_output,
|
| 387 |
+
layer_past=layer_past,
|
| 388 |
+
attention_mask=attention_mask,
|
| 389 |
+
alibi=alibi,
|
| 390 |
+
head_mask=head_mask,
|
| 391 |
+
use_cache=use_cache,
|
| 392 |
+
output_attentions=output_attentions,
|
| 393 |
+
)
|
| 394 |
+
|
| 395 |
+
attention_output = attn_outputs[0]
|
| 396 |
+
|
| 397 |
+
if not self.config.parallel_attn:
|
| 398 |
+
residual = dropout_add(attention_output, residual, self.config.attention_dropout, training=self.training)
|
| 399 |
+
layernorm_output = self.post_attention_layernorm(residual)
|
| 400 |
+
|
| 401 |
+
outputs = attn_outputs[1:]
|
| 402 |
+
|
| 403 |
+
# MLP.
|
| 404 |
+
mlp_output = self.mlp(layernorm_output)
|
| 405 |
+
|
| 406 |
+
if self.config.parallel_attn:
|
| 407 |
+
mlp_output += attention_output
|
| 408 |
+
|
| 409 |
+
output = dropout_add(mlp_output, residual, self.config.hidden_dropout, training=self.training)
|
| 410 |
+
|
| 411 |
+
if use_cache:
|
| 412 |
+
outputs = (output,) + outputs
|
| 413 |
+
else:
|
| 414 |
+
outputs = (output,) + outputs[1:]
|
| 415 |
+
|
| 416 |
+
return outputs # hidden_states, present, attentions
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
class RWPreTrainedModel(PreTrainedModel):
|
| 420 |
+
_keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
|
| 421 |
+
"""
|
| 422 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 423 |
+
models.
|
| 424 |
+
"""
|
| 425 |
+
|
| 426 |
+
config_class = RWConfig
|
| 427 |
+
base_model_prefix = "transformer"
|
| 428 |
+
supports_gradient_checkpointing = True
|
| 429 |
+
_no_split_modules = ["DecoderLayer"]
|
| 430 |
+
|
| 431 |
+
def __init__(self, *inputs, **kwargs):
|
| 432 |
+
super().__init__(*inputs, **kwargs)
|
| 433 |
+
|
| 434 |
+
def _init_weights(self, module: nn.Module):
|
| 435 |
+
"""Initialize the weights."""
|
| 436 |
+
if isinstance(module, nn.Linear) or isinstance(module, Linear):
|
| 437 |
+
# Slightly different from the TF version which uses truncated_normal for initialization
|
| 438 |
+
# cf https://github.com/pytorch/pytorch/pull/5617
|
| 439 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 440 |
+
if module.bias is not None:
|
| 441 |
+
module.bias.data.zero_()
|
| 442 |
+
elif isinstance(module, nn.Embedding):
|
| 443 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 444 |
+
if module.padding_idx is not None:
|
| 445 |
+
module.weight.data[module.padding_idx].zero_()
|
| 446 |
+
elif isinstance(module, LayerNorm):
|
| 447 |
+
module.bias.data.zero_()
|
| 448 |
+
module.weight.data.fill_(1.0)
|
| 449 |
+
|
| 450 |
+
def _set_gradient_checkpointing(self, module: nn.Module, value: bool = False):
|
| 451 |
+
if isinstance(module, RWModel):
|
| 452 |
+
module.gradient_checkpointing = value
|
| 453 |
+
|
| 454 |
+
@staticmethod
|
| 455 |
+
def _convert_to_standard_cache(
|
| 456 |
+
past_key_value: Tuple[Tuple[torch.Tensor, torch.Tensor]], batch_size: int
|
| 457 |
+
) -> Tuple[Tuple[torch.Tensor, torch.Tensor]]:
|
| 458 |
+
"""
|
| 459 |
+
Standardizes the format of the cache so as to match most implementations, i.e. to tuple(tuple([batch_size,
|
| 460 |
+
num_heads, ...]))
|
| 461 |
+
"""
|
| 462 |
+
batch_size_times_num_heads, head_dim, seq_length = past_key_value[0][0].shape
|
| 463 |
+
num_heads = batch_size_times_num_heads // batch_size
|
| 464 |
+
# key: [batch_size * num_heads, head_dim, seq_length] -> [batch_size, num_heads, head_dim, seq_length]
|
| 465 |
+
# value: [batch_size * num_heads, seq_length, head_dim] -> [batch_size, num_heads, seq_length, head_dim]
|
| 466 |
+
return tuple(
|
| 467 |
+
(
|
| 468 |
+
layer_past[0].view(batch_size, num_heads, head_dim, seq_length),
|
| 469 |
+
layer_past[1].view(batch_size, num_heads, seq_length, head_dim),
|
| 470 |
+
)
|
| 471 |
+
for layer_past in past_key_value
|
| 472 |
+
)
|
| 473 |
+
|
| 474 |
+
@staticmethod
|
| 475 |
+
def _convert_to_rw_cache(
|
| 476 |
+
past_key_value: Tuple[Tuple[torch.Tensor, torch.Tensor]]
|
| 477 |
+
) -> Tuple[Tuple[torch.Tensor, torch.Tensor]]:
|
| 478 |
+
batch_size, num_heads, head_dim, seq_length = past_key_value[0][0].shape
|
| 479 |
+
batch_size_times_num_heads = batch_size * num_heads
|
| 480 |
+
# key: [batch_size, num_heads, head_dim, seq_length] -> [batch_size * num_heads, head_dim, seq_length]
|
| 481 |
+
# value: [batch_size, num_heads, seq_length, head_dim] -> [batch_size * num_heads, seq_length, head_dim]
|
| 482 |
+
return tuple(
|
| 483 |
+
(
|
| 484 |
+
layer_past[0].view(batch_size_times_num_heads, head_dim, seq_length),
|
| 485 |
+
layer_past[1].view(batch_size_times_num_heads, seq_length, head_dim),
|
| 486 |
+
)
|
| 487 |
+
for layer_past in past_key_value
|
| 488 |
+
)
|
| 489 |
+
|
| 490 |
+
|
| 491 |
+
class RWModel(RWPreTrainedModel):
|
| 492 |
+
def __init__(self, config: RWConfig):
|
| 493 |
+
super().__init__(config)
|
| 494 |
+
|
| 495 |
+
self.embed_dim = config.hidden_size
|
| 496 |
+
self.num_heads = config.n_head
|
| 497 |
+
self.alibi = config.alibi
|
| 498 |
+
|
| 499 |
+
# Embedding + LN Embedding
|
| 500 |
+
self.word_embeddings = nn.Embedding(config.vocab_size, self.embed_dim)
|
| 501 |
+
|
| 502 |
+
# Transformer blocks
|
| 503 |
+
self.h = nn.ModuleList([DecoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 504 |
+
|
| 505 |
+
# Final Layer Norm
|
| 506 |
+
self.ln_f = LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
|
| 507 |
+
|
| 508 |
+
self.gradient_checkpointing = False
|
| 509 |
+
|
| 510 |
+
# Initialize weights and apply final processing
|
| 511 |
+
self.post_init()
|
| 512 |
+
|
| 513 |
+
def get_input_embeddings(self):
|
| 514 |
+
return self.word_embeddings
|
| 515 |
+
|
| 516 |
+
def _prepare_attn_mask(
|
| 517 |
+
self, attention_mask: torch.Tensor, input_shape: Tuple[int, int], past_key_values_length: int
|
| 518 |
+
) -> torch.BoolTensor:
|
| 519 |
+
# create causal mask
|
| 520 |
+
# [batch_size, seq_length] -> [batch_size, 1, tgt_length, src_length]
|
| 521 |
+
combined_attention_mask = None
|
| 522 |
+
device = attention_mask.device
|
| 523 |
+
_, src_length = input_shape
|
| 524 |
+
|
| 525 |
+
if src_length > 1:
|
| 526 |
+
combined_attention_mask = _make_causal_mask(
|
| 527 |
+
input_shape, device=device, past_key_values_length=past_key_values_length
|
| 528 |
+
)
|
| 529 |
+
|
| 530 |
+
# [batch_size, seq_length] -> [batch_size, 1, tgt_length, src_length]
|
| 531 |
+
expanded_attn_mask = _expand_mask(attention_mask, tgt_length=src_length)
|
| 532 |
+
combined_attention_mask = (
|
| 533 |
+
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask | combined_attention_mask
|
| 534 |
+
)
|
| 535 |
+
|
| 536 |
+
return combined_attention_mask
|
| 537 |
+
|
| 538 |
+
def set_input_embeddings(self, new_embeddings: torch.Tensor):
|
| 539 |
+
self.word_embeddings = new_embeddings
|
| 540 |
+
|
| 541 |
+
def forward(
|
| 542 |
+
self,
|
| 543 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 544 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 545 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 546 |
+
head_mask: Optional[torch.LongTensor] = None,
|
| 547 |
+
inputs_embeds: Optional[torch.LongTensor] = None,
|
| 548 |
+
use_cache: Optional[bool] = None,
|
| 549 |
+
output_attentions: Optional[bool] = None,
|
| 550 |
+
output_hidden_states: Optional[bool] = None,
|
| 551 |
+
return_dict: Optional[bool] = None,
|
| 552 |
+
**deprecated_arguments,
|
| 553 |
+
) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
|
| 554 |
+
if deprecated_arguments.pop("position_ids", False) is not False:
|
| 555 |
+
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
|
| 556 |
+
warnings.warn(
|
| 557 |
+
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
|
| 558 |
+
" passing `position_ids`.",
|
| 559 |
+
FutureWarning,
|
| 560 |
+
)
|
| 561 |
+
if len(deprecated_arguments) > 0:
|
| 562 |
+
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
|
| 563 |
+
|
| 564 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 565 |
+
output_hidden_states = (
|
| 566 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 567 |
+
)
|
| 568 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 569 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 570 |
+
|
| 571 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 572 |
+
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
| 573 |
+
elif input_ids is not None:
|
| 574 |
+
batch_size, seq_length = input_ids.shape
|
| 575 |
+
elif inputs_embeds is not None:
|
| 576 |
+
batch_size, seq_length, _ = inputs_embeds.shape
|
| 577 |
+
else:
|
| 578 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 579 |
+
|
| 580 |
+
if past_key_values is None:
|
| 581 |
+
past_key_values = tuple([None] * len(self.h))
|
| 582 |
+
|
| 583 |
+
# Prepare head mask if needed
|
| 584 |
+
# 1.0 in head_mask indicate we keep the head
|
| 585 |
+
# attention_probs has shape batch_size x num_heads x N x N
|
| 586 |
+
# head_mask has shape n_layer x batch x num_heads x N x N
|
| 587 |
+
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
|
| 588 |
+
|
| 589 |
+
if inputs_embeds is None:
|
| 590 |
+
inputs_embeds = self.word_embeddings(input_ids)
|
| 591 |
+
|
| 592 |
+
hidden_states = inputs_embeds
|
| 593 |
+
|
| 594 |
+
presents = () if use_cache else None
|
| 595 |
+
all_self_attentions = () if output_attentions else None
|
| 596 |
+
all_hidden_states = () if output_hidden_states else None
|
| 597 |
+
|
| 598 |
+
# Compute alibi tensor: check build_alibi_tensor documentation
|
| 599 |
+
seq_length_with_past = seq_length
|
| 600 |
+
past_key_values_length = 0
|
| 601 |
+
if past_key_values[0] is not None:
|
| 602 |
+
past_key_values_length = past_key_values[0][0].shape[2]
|
| 603 |
+
seq_length_with_past = seq_length_with_past + past_key_values_length
|
| 604 |
+
if attention_mask is None:
|
| 605 |
+
attention_mask = torch.ones((batch_size, seq_length_with_past), device=hidden_states.device)
|
| 606 |
+
else:
|
| 607 |
+
attention_mask = attention_mask.to(hidden_states.device)
|
| 608 |
+
|
| 609 |
+
if self.alibi:
|
| 610 |
+
alibi = build_alibi_tensor(attention_mask, self.num_heads, dtype=hidden_states.dtype)
|
| 611 |
+
else:
|
| 612 |
+
alibi = None
|
| 613 |
+
|
| 614 |
+
causal_mask = self._prepare_attn_mask(
|
| 615 |
+
attention_mask,
|
| 616 |
+
input_shape=(batch_size, seq_length),
|
| 617 |
+
past_key_values_length=past_key_values_length,
|
| 618 |
+
)
|
| 619 |
+
|
| 620 |
+
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
|
| 621 |
+
|
| 622 |
+
if output_hidden_states:
|
| 623 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 624 |
+
|
| 625 |
+
if self.gradient_checkpointing and self.training:
|
| 626 |
+
|
| 627 |
+
if use_cache:
|
| 628 |
+
logger.warning(
|
| 629 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 630 |
+
)
|
| 631 |
+
use_cache = False
|
| 632 |
+
|
| 633 |
+
def create_custom_forward(module):
|
| 634 |
+
def custom_forward(*inputs):
|
| 635 |
+
# None for past_key_value
|
| 636 |
+
return module(*inputs, use_cache=use_cache, output_attentions=output_attentions)
|
| 637 |
+
|
| 638 |
+
return custom_forward
|
| 639 |
+
|
| 640 |
+
outputs = torch.utils.checkpoint.checkpoint(
|
| 641 |
+
create_custom_forward(block),
|
| 642 |
+
hidden_states,
|
| 643 |
+
alibi,
|
| 644 |
+
causal_mask,
|
| 645 |
+
head_mask[i],
|
| 646 |
+
)
|
| 647 |
+
else:
|
| 648 |
+
outputs = block(
|
| 649 |
+
hidden_states,
|
| 650 |
+
layer_past=layer_past,
|
| 651 |
+
attention_mask=causal_mask,
|
| 652 |
+
head_mask=head_mask[i],
|
| 653 |
+
use_cache=use_cache,
|
| 654 |
+
output_attentions=output_attentions,
|
| 655 |
+
alibi=alibi,
|
| 656 |
+
)
|
| 657 |
+
|
| 658 |
+
hidden_states = outputs[0]
|
| 659 |
+
if use_cache is True:
|
| 660 |
+
presents = presents + (outputs[1],)
|
| 661 |
+
|
| 662 |
+
if output_attentions:
|
| 663 |
+
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
|
| 664 |
+
|
| 665 |
+
# Add last hidden state
|
| 666 |
+
hidden_states = self.ln_f(hidden_states)
|
| 667 |
+
|
| 668 |
+
if output_hidden_states:
|
| 669 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 670 |
+
|
| 671 |
+
if not return_dict:
|
| 672 |
+
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
|
| 673 |
+
|
| 674 |
+
return BaseModelOutputWithPastAndCrossAttentions(
|
| 675 |
+
last_hidden_state=hidden_states,
|
| 676 |
+
past_key_values=presents,
|
| 677 |
+
hidden_states=all_hidden_states,
|
| 678 |
+
attentions=all_self_attentions,
|
| 679 |
+
)
|
| 680 |
+
|
| 681 |
+
|
| 682 |
+
class RWForCausalLM(RWPreTrainedModel):
|
| 683 |
+
_keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
|
| 684 |
+
|
| 685 |
+
def __init__(self, config: RWConfig):
|
| 686 |
+
super().__init__(config)
|
| 687 |
+
self.transformer = RWModel(config)
|
| 688 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 689 |
+
|
| 690 |
+
# Initialize weights and apply final processing
|
| 691 |
+
self.post_init()
|
| 692 |
+
|
| 693 |
+
def get_output_embeddings(self):
|
| 694 |
+
return self.lm_head
|
| 695 |
+
|
| 696 |
+
def set_output_embeddings(self, new_embeddings: torch.Tensor):
|
| 697 |
+
self.lm_head = new_embeddings
|
| 698 |
+
|
| 699 |
+
def prepare_inputs_for_generation(
|
| 700 |
+
self,
|
| 701 |
+
input_ids: torch.LongTensor,
|
| 702 |
+
past: Optional[torch.Tensor] = None,
|
| 703 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 704 |
+
**kwargs,
|
| 705 |
+
) -> dict:
|
| 706 |
+
# only last token for input_ids if past is not None
|
| 707 |
+
if past:
|
| 708 |
+
input_ids = input_ids[:, -1].unsqueeze(-1)
|
| 709 |
+
|
| 710 |
+
# the cache may be in the stardard format (e.g. in contrastive search), convert to our's format if needed
|
| 711 |
+
if past[0][0].shape[0] == input_ids.shape[0]:
|
| 712 |
+
past = self._convert_to_rw_cache(past)
|
| 713 |
+
|
| 714 |
+
return {
|
| 715 |
+
"input_ids": input_ids,
|
| 716 |
+
"past_key_values": past,
|
| 717 |
+
"use_cache": kwargs.get("use_cache"),
|
| 718 |
+
"attention_mask": attention_mask,
|
| 719 |
+
}
|
| 720 |
+
|
| 721 |
+
def forward(
|
| 722 |
+
self,
|
| 723 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 724 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 725 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 726 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 727 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 728 |
+
labels: Optional[torch.Tensor] = None,
|
| 729 |
+
use_cache: Optional[bool] = None,
|
| 730 |
+
output_attentions: Optional[bool] = None,
|
| 731 |
+
output_hidden_states: Optional[bool] = None,
|
| 732 |
+
return_dict: Optional[bool] = None,
|
| 733 |
+
**deprecated_arguments,
|
| 734 |
+
) -> Union[Tuple[torch.Tensor], CausalLMOutputWithCrossAttentions]:
|
| 735 |
+
r"""
|
| 736 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 737 |
+
Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
|
| 738 |
+
`labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
|
| 739 |
+
are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
|
| 740 |
+
"""
|
| 741 |
+
if deprecated_arguments.pop("position_ids", False) is not False:
|
| 742 |
+
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
|
| 743 |
+
warnings.warn(
|
| 744 |
+
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
|
| 745 |
+
" passing `position_ids`.",
|
| 746 |
+
FutureWarning,
|
| 747 |
+
)
|
| 748 |
+
if len(deprecated_arguments) > 0:
|
| 749 |
+
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
|
| 750 |
+
|
| 751 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 752 |
+
|
| 753 |
+
transformer_outputs = self.transformer(
|
| 754 |
+
input_ids,
|
| 755 |
+
past_key_values=past_key_values,
|
| 756 |
+
attention_mask=attention_mask,
|
| 757 |
+
head_mask=head_mask,
|
| 758 |
+
inputs_embeds=inputs_embeds,
|
| 759 |
+
use_cache=use_cache,
|
| 760 |
+
output_attentions=output_attentions,
|
| 761 |
+
output_hidden_states=output_hidden_states,
|
| 762 |
+
return_dict=return_dict,
|
| 763 |
+
)
|
| 764 |
+
hidden_states = transformer_outputs[0]
|
| 765 |
+
|
| 766 |
+
lm_logits = self.lm_head(hidden_states)
|
| 767 |
+
|
| 768 |
+
loss = None
|
| 769 |
+
if labels is not None:
|
| 770 |
+
# Shift so that tokens < n predict n
|
| 771 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 772 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 773 |
+
batch_size, seq_length, vocab_size = shift_logits.shape
|
| 774 |
+
# Flatten the tokens
|
| 775 |
+
loss_fct = CrossEntropyLoss()
|
| 776 |
+
loss = loss_fct(
|
| 777 |
+
shift_logits.view(batch_size * seq_length, vocab_size), shift_labels.view(batch_size * seq_length)
|
| 778 |
+
)
|
| 779 |
+
|
| 780 |
+
if not return_dict:
|
| 781 |
+
output = (lm_logits,) + transformer_outputs[1:]
|
| 782 |
+
return ((loss,) + output) if loss is not None else output
|
| 783 |
+
|
| 784 |
+
return CausalLMOutputWithCrossAttentions(
|
| 785 |
+
loss=loss,
|
| 786 |
+
logits=lm_logits,
|
| 787 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 788 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 789 |
+
attentions=transformer_outputs.attentions,
|
| 790 |
+
)
|
| 791 |
+
|
| 792 |
+
def _reorder_cache(
|
| 793 |
+
self, past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...], beam_idx: torch.LongTensor
|
| 794 |
+
) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
|
| 795 |
+
"""
|
| 796 |
+
This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
|
| 797 |
+
[`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
|
| 798 |
+
beam_idx at every generation step.
|
| 799 |
+
|
| 800 |
+
Output shares the same memory storage as `past`.
|
| 801 |
+
"""
|
| 802 |
+
standardized_past = self._convert_to_standard_cache(past, batch_size=len(beam_idx))
|
| 803 |
+
|
| 804 |
+
# Get a copy of `beam_idx` on all the devices where we need those indices.
|
| 805 |
+
device_to_beam_idx = {
|
| 806 |
+
past_state.device: beam_idx.to(past_state.device) for layer_past in past for past_state in layer_past
|
| 807 |
+
}
|
| 808 |
+
reordered_past = tuple(
|
| 809 |
+
(
|
| 810 |
+
layer_past[0].index_select(0, device_to_beam_idx[layer_past[0].device]),
|
| 811 |
+
layer_past[1].index_select(0, device_to_beam_idx[layer_past[0].device]),
|
| 812 |
+
)
|
| 813 |
+
for layer_past in standardized_past
|
| 814 |
+
)
|
| 815 |
+
return self._convert_to_rw_cache(reordered_past)
|
| 816 |
+
|
| 817 |
+
|
| 818 |
+
class RWForSequenceClassification(RWPreTrainedModel):
|
| 819 |
+
_keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
|
| 820 |
+
|
| 821 |
+
def __init__(self, config: RWConfig):
|
| 822 |
+
super().__init__(config)
|
| 823 |
+
self.num_labels = config.num_labels
|
| 824 |
+
self.transformer = RWModel(config)
|
| 825 |
+
self.score = nn.Linear(config.hidden_size, config.num_labels, bias=False)
|
| 826 |
+
|
| 827 |
+
# Initialize weights and apply final processing
|
| 828 |
+
self.post_init()
|
| 829 |
+
|
| 830 |
+
def forward(
|
| 831 |
+
self,
|
| 832 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 833 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 834 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 835 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 836 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 837 |
+
labels: Optional[torch.Tensor] = None,
|
| 838 |
+
use_cache: Optional[bool] = None,
|
| 839 |
+
output_attentions: Optional[bool] = None,
|
| 840 |
+
output_hidden_states: Optional[bool] = None,
|
| 841 |
+
return_dict: Optional[bool] = None,
|
| 842 |
+
**deprecated_arguments,
|
| 843 |
+
) -> Union[Tuple[torch.Tensor], SequenceClassifierOutputWithPast]:
|
| 844 |
+
r"""
|
| 845 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 846 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 847 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 848 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 849 |
+
"""
|
| 850 |
+
if deprecated_arguments.pop("position_ids", False) is not False:
|
| 851 |
+
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
|
| 852 |
+
warnings.warn(
|
| 853 |
+
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
|
| 854 |
+
" passing `position_ids`.",
|
| 855 |
+
FutureWarning,
|
| 856 |
+
)
|
| 857 |
+
if len(deprecated_arguments) > 0:
|
| 858 |
+
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
|
| 859 |
+
|
| 860 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 861 |
+
|
| 862 |
+
transformer_outputs = self.transformer(
|
| 863 |
+
input_ids,
|
| 864 |
+
past_key_values=past_key_values,
|
| 865 |
+
attention_mask=attention_mask,
|
| 866 |
+
head_mask=head_mask,
|
| 867 |
+
inputs_embeds=inputs_embeds,
|
| 868 |
+
use_cache=use_cache,
|
| 869 |
+
output_attentions=output_attentions,
|
| 870 |
+
output_hidden_states=output_hidden_states,
|
| 871 |
+
return_dict=return_dict,
|
| 872 |
+
)
|
| 873 |
+
|
| 874 |
+
hidden_states = transformer_outputs[0]
|
| 875 |
+
logits = self.score(hidden_states)
|
| 876 |
+
|
| 877 |
+
if input_ids is not None:
|
| 878 |
+
batch_size = input_ids.shape[0]
|
| 879 |
+
else:
|
| 880 |
+
batch_size = inputs_embeds.shape[0]
|
| 881 |
+
|
| 882 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 883 |
+
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
|
| 884 |
+
if self.config.pad_token_id is None:
|
| 885 |
+
sequence_lengths = -1
|
| 886 |
+
else:
|
| 887 |
+
if input_ids is not None:
|
| 888 |
+
sequence_lengths = torch.ne(input_ids, self.config.pad_token_id).sum(dim=-1) - 1
|
| 889 |
+
else:
|
| 890 |
+
sequence_lengths = -1
|
| 891 |
+
logger.warning(
|
| 892 |
+
f"{self.__class__.__name__} will not detect padding tokens in `inputs_embeds`. Results may be "
|
| 893 |
+
"unexpected if using padding tokens in conjunction with `inputs_embeds.`"
|
| 894 |
+
)
|
| 895 |
+
|
| 896 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 897 |
+
|
| 898 |
+
loss = None
|
| 899 |
+
if labels is not None:
|
| 900 |
+
if self.config.problem_type is None:
|
| 901 |
+
if self.num_labels == 1:
|
| 902 |
+
self.config.problem_type = "regression"
|
| 903 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 904 |
+
self.config.problem_type = "single_label_classification"
|
| 905 |
+
else:
|
| 906 |
+
self.config.problem_type = "multi_label_classification"
|
| 907 |
+
|
| 908 |
+
if self.config.problem_type == "regression":
|
| 909 |
+
loss_fct = MSELoss()
|
| 910 |
+
if self.num_labels == 1:
|
| 911 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 912 |
+
else:
|
| 913 |
+
loss = loss_fct(pooled_logits, labels)
|
| 914 |
+
elif self.config.problem_type == "single_label_classification":
|
| 915 |
+
loss_fct = CrossEntropyLoss()
|
| 916 |
+
loss = loss_fct(pooled_logits, labels)
|
| 917 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 918 |
+
loss_fct = BCEWithLogitsLoss()
|
| 919 |
+
loss = loss_fct(pooled_logits, labels)
|
| 920 |
+
if not return_dict:
|
| 921 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 922 |
+
return ((loss,) + output) if loss is not None else output
|
| 923 |
+
|
| 924 |
+
return SequenceClassifierOutputWithPast(
|
| 925 |
+
loss=loss,
|
| 926 |
+
logits=pooled_logits,
|
| 927 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 928 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 929 |
+
attentions=transformer_outputs.attentions,
|
| 930 |
+
)
|
| 931 |
+
|
| 932 |
+
|
| 933 |
+
class RWForTokenClassification(RWPreTrainedModel):
|
| 934 |
+
_keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
|
| 935 |
+
|
| 936 |
+
def __init__(self, config: RWConfig):
|
| 937 |
+
super().__init__(config)
|
| 938 |
+
self.num_labels = config.num_labels
|
| 939 |
+
|
| 940 |
+
self.transformer = RWModel(config)
|
| 941 |
+
if hasattr(config, "classifier_dropout") and config.classifier_dropout is not None:
|
| 942 |
+
classifier_dropout = config.classifier_dropout
|
| 943 |
+
elif hasattr(config, "hidden_dropout") and config.hidden_dropout is not None:
|
| 944 |
+
classifier_dropout = config.hidden_dropout
|
| 945 |
+
else:
|
| 946 |
+
classifier_dropout = 0.1
|
| 947 |
+
self.dropout = nn.Dropout(classifier_dropout)
|
| 948 |
+
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
|
| 949 |
+
|
| 950 |
+
# Initialize weights and apply final processing
|
| 951 |
+
self.post_init()
|
| 952 |
+
|
| 953 |
+
def forward(
|
| 954 |
+
self,
|
| 955 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 956 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 957 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 958 |
+
head_mask: Optional[torch.Tensor] = None,
|
| 959 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 960 |
+
labels: Optional[torch.Tensor] = None,
|
| 961 |
+
use_cache: Optional[bool] = None,
|
| 962 |
+
output_attentions: Optional[bool] = None,
|
| 963 |
+
output_hidden_states: Optional[bool] = None,
|
| 964 |
+
return_dict: Optional[bool] = None,
|
| 965 |
+
**deprecated_arguments,
|
| 966 |
+
) -> Union[Tuple[torch.Tensor], TokenClassifierOutput]:
|
| 967 |
+
r"""
|
| 968 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 969 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 970 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 971 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 972 |
+
"""
|
| 973 |
+
if deprecated_arguments.pop("position_ids", False) is not False:
|
| 974 |
+
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
|
| 975 |
+
warnings.warn(
|
| 976 |
+
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
|
| 977 |
+
" passing `position_ids`.",
|
| 978 |
+
FutureWarning,
|
| 979 |
+
)
|
| 980 |
+
if len(deprecated_arguments) > 0:
|
| 981 |
+
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
|
| 982 |
+
|
| 983 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 984 |
+
|
| 985 |
+
transformer_outputs = self.transformer(
|
| 986 |
+
input_ids,
|
| 987 |
+
past_key_values=past_key_values,
|
| 988 |
+
attention_mask=attention_mask,
|
| 989 |
+
head_mask=head_mask,
|
| 990 |
+
inputs_embeds=inputs_embeds,
|
| 991 |
+
use_cache=use_cache,
|
| 992 |
+
output_attentions=output_attentions,
|
| 993 |
+
output_hidden_states=output_hidden_states,
|
| 994 |
+
return_dict=return_dict,
|
| 995 |
+
)
|
| 996 |
+
|
| 997 |
+
hidden_states = transformer_outputs[0]
|
| 998 |
+
hidden_states = self.dropout(hidden_states)
|
| 999 |
+
logits = self.classifier(hidden_states)
|
| 1000 |
+
|
| 1001 |
+
loss = None
|
| 1002 |
+
if labels is not None:
|
| 1003 |
+
batch_size, seq_length = labels.shape
|
| 1004 |
+
loss_fct = CrossEntropyLoss()
|
| 1005 |
+
loss = loss_fct(logits.view(batch_size * seq_length, self.num_labels), labels.view(batch_size * seq_length))
|
| 1006 |
+
|
| 1007 |
+
if not return_dict:
|
| 1008 |
+
output = (logits,) + transformer_outputs[2:]
|
| 1009 |
+
return ((loss,) + output) if loss is not None else output
|
| 1010 |
+
|
| 1011 |
+
return TokenClassifierOutput(
|
| 1012 |
+
loss=loss,
|
| 1013 |
+
logits=logits,
|
| 1014 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1015 |
+
attentions=transformer_outputs.attentions,
|
| 1016 |
+
)
|
| 1017 |
+
|
| 1018 |
+
|
| 1019 |
+
class RWForQuestionAnswering(RWPreTrainedModel):
|
| 1020 |
+
_keys_to_ignore_on_load_missing = [r"h.*.self_attention.scale_mask_softmax.causal_mask", r"lm_head.weight"]
|
| 1021 |
+
|
| 1022 |
+
def __init__(self, config):
|
| 1023 |
+
super().__init__(config)
|
| 1024 |
+
self.transformer = RWModel(config)
|
| 1025 |
+
self.qa_outputs = nn.Linear(config.hidden_size, 2)
|
| 1026 |
+
|
| 1027 |
+
# Initialize weights and apply final processing
|
| 1028 |
+
self.post_init()
|
| 1029 |
+
|
| 1030 |
+
def forward(
|
| 1031 |
+
self,
|
| 1032 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1033 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 1034 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1035 |
+
head_mask: Optional[torch.FloatTensor] = None,
|
| 1036 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1037 |
+
start_positions: Optional[torch.LongTensor] = None,
|
| 1038 |
+
end_positions: Optional[torch.LongTensor] = None,
|
| 1039 |
+
output_attentions: Optional[bool] = None,
|
| 1040 |
+
output_hidden_states: Optional[bool] = None,
|
| 1041 |
+
return_dict: Optional[bool] = None,
|
| 1042 |
+
) -> Union[Tuple, QuestionAnsweringModelOutput]:
|
| 1043 |
+
r"""
|
| 1044 |
+
start_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1045 |
+
Labels for position (index) of the start of the labelled span for computing the token classification loss.
|
| 1046 |
+
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
|
| 1047 |
+
are not taken into account for computing the loss.
|
| 1048 |
+
end_positions (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1049 |
+
Labels for position (index) of the end of the labelled span for computing the token classification loss.
|
| 1050 |
+
Positions are clamped to the length of the sequence (`sequence_length`). Position outside of the sequence
|
| 1051 |
+
are not taken into account for computing the loss.
|
| 1052 |
+
"""
|
| 1053 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1054 |
+
|
| 1055 |
+
outputs = self.transformer(
|
| 1056 |
+
input_ids,
|
| 1057 |
+
attention_mask=attention_mask,
|
| 1058 |
+
position_ids=position_ids,
|
| 1059 |
+
head_mask=head_mask,
|
| 1060 |
+
inputs_embeds=inputs_embeds,
|
| 1061 |
+
output_attentions=output_attentions,
|
| 1062 |
+
output_hidden_states=output_hidden_states,
|
| 1063 |
+
return_dict=return_dict,
|
| 1064 |
+
)
|
| 1065 |
+
|
| 1066 |
+
sequence_output = outputs[0]
|
| 1067 |
+
|
| 1068 |
+
logits = self.qa_outputs(sequence_output)
|
| 1069 |
+
start_logits, end_logits = logits.split(1, dim=-1)
|
| 1070 |
+
start_logits = start_logits.squeeze(-1).contiguous()
|
| 1071 |
+
end_logits = end_logits.squeeze(-1).contiguous()
|
| 1072 |
+
|
| 1073 |
+
total_loss = None
|
| 1074 |
+
if start_positions is not None and end_positions is not None:
|
| 1075 |
+
# If we are on multi-GPU, split add a dimension
|
| 1076 |
+
if len(start_positions.size()) > 1:
|
| 1077 |
+
start_positions = start_positions.squeeze(-1)
|
| 1078 |
+
if len(end_positions.size()) > 1:
|
| 1079 |
+
end_positions = end_positions.squeeze(-1)
|
| 1080 |
+
# sometimes the start/end positions are outside our model inputs, we ignore these terms
|
| 1081 |
+
ignored_index = start_logits.size(1)
|
| 1082 |
+
start_positions = start_positions.clamp(0, ignored_index)
|
| 1083 |
+
end_positions = end_positions.clamp(0, ignored_index)
|
| 1084 |
+
|
| 1085 |
+
loss_fct = CrossEntropyLoss(ignore_index=ignored_index)
|
| 1086 |
+
start_loss = loss_fct(start_logits, start_positions)
|
| 1087 |
+
end_loss = loss_fct(end_logits, end_positions)
|
| 1088 |
+
total_loss = (start_loss + end_loss) / 2
|
| 1089 |
+
|
| 1090 |
+
if not return_dict:
|
| 1091 |
+
output = (start_logits, end_logits) + outputs[2:]
|
| 1092 |
+
return ((total_loss,) + output) if total_loss is not None else output
|
| 1093 |
+
|
| 1094 |
+
return QuestionAnsweringModelOutput(
|
| 1095 |
+
loss=total_loss,
|
| 1096 |
+
start_logits=start_logits,
|
| 1097 |
+
end_logits=end_logits,
|
| 1098 |
+
hidden_states=outputs.hidden_states,
|
| 1099 |
+
attentions=outputs.attentions,
|
| 1100 |
+
)
|
plots.png
ADDED
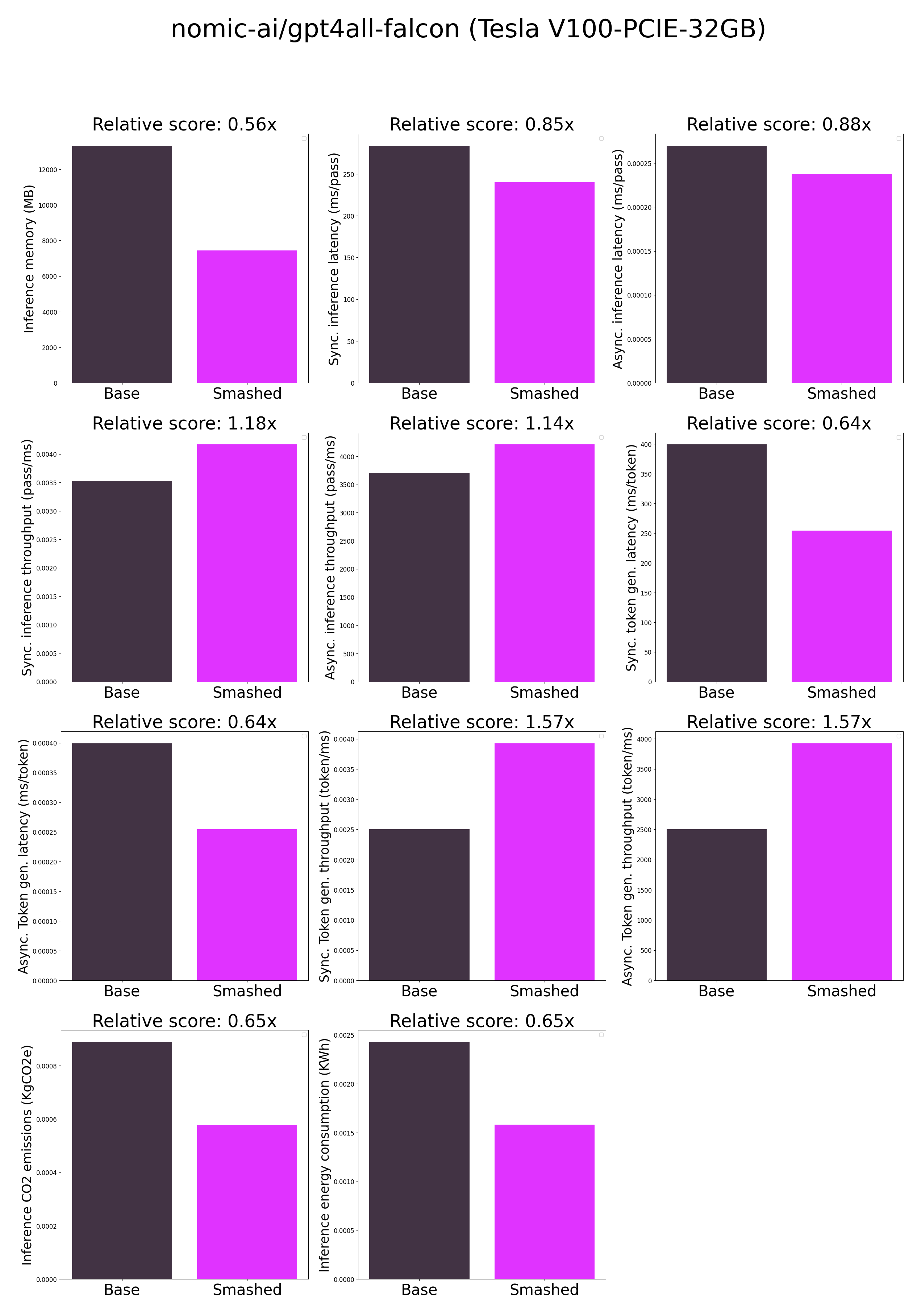
|
smash_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"api_key": null,
|
| 3 |
+
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
+
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
+
"factorizers": "None",
|
| 7 |
+
"quantizers": "['llm-int8']",
|
| 8 |
+
"compilers": "None",
|
| 9 |
+
"task": "text_text_generation",
|
| 10 |
+
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelswsw3o16n",
|
| 12 |
+
"batch_size": 1,
|
| 13 |
+
"model_name": "nomic-ai/gpt4all-falcon",
|
| 14 |
+
"pruning_ratio": 0.0,
|
| 15 |
+
"n_quantization_bits": 8,
|
| 16 |
+
"output_deviation": 0.005,
|
| 17 |
+
"max_batch_size": 1,
|
| 18 |
+
"qtype_weight": "torch.qint8",
|
| 19 |
+
"qtype_activation": "torch.quint8",
|
| 20 |
+
"qobserver": "<class 'torch.ao.quantization.observer.MinMaxObserver'>",
|
| 21 |
+
"qscheme": "torch.per_tensor_symmetric",
|
| 22 |
+
"qconfig": "x86",
|
| 23 |
+
"group_size": 128,
|
| 24 |
+
"damp_percent": 0.1,
|
| 25 |
+
"save_load_fn": "bitsandbytes"
|
| 26 |
+
}
|
| 27 |
+
}
|