

Upload folder using huggingface_hub (#1)
Browse files- d3911c19776dcd1281dfda31ac21d99c92d06392473e28cb65bf1ba689839d43 (ab02718fe5f01a7b680da5ed17be86449b5c880e)
- ef3db1afaaa550d55129cf82f22c217f212673ccb394ead070121bf74de5efb7 (c51cf910c09054e9742f57c0451657a29fbd54c5)
- README.md +81 -0
- adapt_tokenizer.py +40 -0
- attention.py +388 -0
- blocks.py +55 -0
- config.json +87 -0
- configuration_mpt.py +183 -0
- custom_embedding.py +10 -0
- fc.py +7 -0
- ffn.py +97 -0
- flash_attn_triton.py +484 -0
- generation_config.json +6 -0
- hf_prefixlm_converter.py +180 -0
- meta_init_context.py +99 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +329 -0
- modeling_mpt.py +519 -0
- norm.py +57 -0
- param_init_fns.py +179 -0
- plots.png +0 -0
- smash_config.json +27 -0
- warnings.py +22 -0
README.md
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: pruna-engine
|
| 3 |
+
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 4 |
+
metrics:
|
| 5 |
+
- memory_disk
|
| 6 |
+
- memory_inference
|
| 7 |
+
- inference_latency
|
| 8 |
+
- inference_throughput
|
| 9 |
+
- inference_CO2_emissions
|
| 10 |
+
- inference_energy_consumption
|
| 11 |
+
---
|
| 12 |
+
<!-- header start -->
|
| 13 |
+
<!-- 200823 -->
|
| 14 |
+
<div style="width: auto; margin-left: auto; margin-right: auto">
|
| 15 |
+
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
|
| 16 |
+
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
|
| 17 |
+
</a>
|
| 18 |
+
</div>
|
| 19 |
+
<!-- header end -->
|
| 20 |
+
|
| 21 |
+
[](https://twitter.com/PrunaAI)
|
| 22 |
+
[](https://github.com/PrunaAI)
|
| 23 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 24 |
+
[](https://discord.gg/CP4VSgck)
|
| 25 |
+
|
| 26 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 27 |
+
|
| 28 |
+
- Give a thumbs up if you like this model!
|
| 29 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 30 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 31 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 32 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
|
| 33 |
+
|
| 34 |
+
## Results
|
| 35 |
+
|
| 36 |
+

|
| 37 |
+
|
| 38 |
+
**Frequently Asked Questions**
|
| 39 |
+
- ***How does the compression work?*** The model is compressed with llm-int8.
|
| 40 |
+
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 41 |
+
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 42 |
+
- ***What is the model format?*** We use safetensors.
|
| 43 |
+
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 44 |
+
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 45 |
+
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 46 |
+
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
|
| 47 |
+
|
| 48 |
+
## Setup
|
| 49 |
+
|
| 50 |
+
You can run the smashed model with these steps:
|
| 51 |
+
|
| 52 |
+
0. Check requirements from the original repo mosaicml/mpt-7b installed. In particular, check python, cuda, and transformers versions.
|
| 53 |
+
1. Make sure that you have installed quantization related packages.
|
| 54 |
+
```bash
|
| 55 |
+
pip install transformers accelerate bitsandbytes>0.37.0
|
| 56 |
+
```
|
| 57 |
+
2. Load & run the model.
|
| 58 |
+
```python
|
| 59 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 60 |
+
|
| 61 |
+
model = AutoModelForCausalLM.from_pretrained("PrunaAI/mosaicml-mpt-7b-bnb-8bit-smashed",
|
| 62 |
+
trust_remote_code=True)
|
| 63 |
+
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b")
|
| 64 |
+
|
| 65 |
+
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 66 |
+
|
| 67 |
+
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
## Configurations
|
| 71 |
+
|
| 72 |
+
The configuration info are in `smash_config.json`.
|
| 73 |
+
|
| 74 |
+
## Credits & License
|
| 75 |
+
|
| 76 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model mosaicml/mpt-7b before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 77 |
+
|
| 78 |
+
## Want to compress other models?
|
| 79 |
+
|
| 80 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 81 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
adapt_tokenizer.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any
|
| 2 |
+
from transformers import AutoTokenizer, PreTrainedTokenizerBase
|
| 3 |
+
NUM_SENTINEL_TOKENS: int = 100
|
| 4 |
+
|
| 5 |
+
def adapt_tokenizer_for_denoising(tokenizer: PreTrainedTokenizerBase) -> None:
|
| 6 |
+
"""Adds sentinel tokens and padding token (if missing).
|
| 7 |
+
|
| 8 |
+
Expands the tokenizer vocabulary to include sentinel tokens
|
| 9 |
+
used in mixture-of-denoiser tasks as well as a padding token.
|
| 10 |
+
|
| 11 |
+
All added tokens are added as special tokens. No tokens are
|
| 12 |
+
added if sentinel tokens and padding token already exist.
|
| 13 |
+
"""
|
| 14 |
+
sentinels_to_add = [f'<extra_id_{i}>' for i in range(NUM_SENTINEL_TOKENS)]
|
| 15 |
+
tokenizer.add_tokens(sentinels_to_add, special_tokens=True)
|
| 16 |
+
if tokenizer.pad_token is None:
|
| 17 |
+
tokenizer.add_tokens('<pad>', special_tokens=True)
|
| 18 |
+
tokenizer.pad_token = '<pad>'
|
| 19 |
+
assert tokenizer.pad_token_id is not None
|
| 20 |
+
sentinels = ''.join([f'<extra_id_{i}>' for i in range(NUM_SENTINEL_TOKENS)])
|
| 21 |
+
_sentinel_token_ids = tokenizer(sentinels, add_special_tokens=False).input_ids
|
| 22 |
+
tokenizer.sentinel_token_ids = _sentinel_token_ids
|
| 23 |
+
|
| 24 |
+
class AutoTokenizerForMOD(AutoTokenizer):
|
| 25 |
+
"""AutoTokenizer + Adaptation for MOD.
|
| 26 |
+
|
| 27 |
+
A simple wrapper around AutoTokenizer to make instantiating
|
| 28 |
+
an MOD-adapted tokenizer a bit easier.
|
| 29 |
+
|
| 30 |
+
MOD-adapted tokenizers have sentinel tokens (e.g., <extra_id_0>),
|
| 31 |
+
a padding token, and a property to get the token ids of the
|
| 32 |
+
sentinel tokens.
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
@classmethod
|
| 36 |
+
def from_pretrained(cls, *args: Any, **kwargs: Any) -> PreTrainedTokenizerBase:
|
| 37 |
+
"""See `AutoTokenizer.from_pretrained` docstring."""
|
| 38 |
+
tokenizer = super().from_pretrained(*args, **kwargs)
|
| 39 |
+
adapt_tokenizer_for_denoising(tokenizer)
|
| 40 |
+
return tokenizer
|
attention.py
ADDED
|
@@ -0,0 +1,388 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Attention layers."""
|
| 2 |
+
import math
|
| 3 |
+
import warnings
|
| 4 |
+
from typing import Any, Optional
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import transformers
|
| 8 |
+
from einops import rearrange
|
| 9 |
+
from packaging import version
|
| 10 |
+
from torch import nn
|
| 11 |
+
from .fc import FC_CLASS_REGISTRY
|
| 12 |
+
from .norm import NORM_CLASS_REGISTRY
|
| 13 |
+
|
| 14 |
+
def is_flash_v2_installed(v2_version: str='2.0.0'):
|
| 15 |
+
assert version.parse(v2_version) >= version.parse('2.0.0')
|
| 16 |
+
try:
|
| 17 |
+
import flash_attn as flash_attn
|
| 18 |
+
except:
|
| 19 |
+
return False
|
| 20 |
+
return version.parse(flash_attn.__version__) >= version.parse(v2_version)
|
| 21 |
+
|
| 22 |
+
def is_flash_v1_installed():
|
| 23 |
+
try:
|
| 24 |
+
import flash_attn as flash_attn
|
| 25 |
+
except:
|
| 26 |
+
return False
|
| 27 |
+
return version.parse(flash_attn.__version__) < version.parse('2.0.0')
|
| 28 |
+
|
| 29 |
+
def is_transformers_version_gte(hf_version: str) -> bool:
|
| 30 |
+
return version.parse(transformers.__version__) >= version.parse(hf_version)
|
| 31 |
+
|
| 32 |
+
def check_alibi_support(attention_impl: str) -> bool:
|
| 33 |
+
return attention_impl != 'flash' or is_flash_v2_installed(v2_version='v2.4.2')
|
| 34 |
+
if is_flash_v1_installed():
|
| 35 |
+
import transformers
|
| 36 |
+
transformers.utils.is_flash_attn_available = lambda : False
|
| 37 |
+
from transformers.models.llama.modeling_llama import apply_rotary_pos_emb
|
| 38 |
+
|
| 39 |
+
def _reset_is_causal(num_query_tokens: int, num_key_tokens: int, original_is_causal: bool) -> bool:
|
| 40 |
+
if original_is_causal and num_query_tokens != num_key_tokens:
|
| 41 |
+
if num_query_tokens != 1:
|
| 42 |
+
raise NotImplementedError('MPT does not support query and key with different number of tokens, unless number of query tokens is 1.')
|
| 43 |
+
else:
|
| 44 |
+
return False
|
| 45 |
+
return original_is_causal
|
| 46 |
+
|
| 47 |
+
def repeat_kv_for_gqa(hidden: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 48 |
+
"""Perform repeat of kv heads along a particular dimension.
|
| 49 |
+
|
| 50 |
+
hidden.shape expected to be: (batch size, seq len, kv_n_heads, head_dim)
|
| 51 |
+
n_rep: amount of repetitions of kv_n_heads
|
| 52 |
+
Unlike torch.repeat_interleave, this function avoids allocating new memory.
|
| 53 |
+
"""
|
| 54 |
+
if n_rep == 1:
|
| 55 |
+
return hidden
|
| 56 |
+
(b, s, kv_n_heads, d) = hidden.shape
|
| 57 |
+
hidden = hidden[:, :, :, None, :].expand(b, s, kv_n_heads, n_rep, d)
|
| 58 |
+
return hidden.reshape(b, s, kv_n_heads * n_rep, d)
|
| 59 |
+
|
| 60 |
+
def scaled_multihead_dot_product_attention(query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, n_heads: int, kv_n_heads: int, past_key_value: Optional[tuple[torch.Tensor, torch.Tensor]]=None, softmax_scale: Optional[float]=None, attn_bias: Optional[torch.Tensor]=None, key_padding_mask: Optional[torch.Tensor]=None, is_causal: bool=False, dropout_p: float=0.0, training: bool=False, needs_weights: bool=False) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor, torch.Tensor]]]:
|
| 61 |
+
q = rearrange(query, 'b s (h d) -> b h s d', h=n_heads)
|
| 62 |
+
k = rearrange(key, 'b s (h d) -> b h d s', h=kv_n_heads)
|
| 63 |
+
v = rearrange(value, 'b s (h d) -> b h s d', h=kv_n_heads)
|
| 64 |
+
if past_key_value is not None:
|
| 65 |
+
if len(past_key_value) != 0:
|
| 66 |
+
k = torch.cat([past_key_value[0], k], dim=3)
|
| 67 |
+
v = torch.cat([past_key_value[1], v], dim=2)
|
| 68 |
+
past_key_value = (k, v)
|
| 69 |
+
(b, _, s_q, d) = q.shape
|
| 70 |
+
s_k = k.size(-1)
|
| 71 |
+
if kv_n_heads > 1 and kv_n_heads < n_heads:
|
| 72 |
+
k = repeat_kv_for_gqa(k.transpose(1, 2), n_heads // kv_n_heads).transpose(1, 2)
|
| 73 |
+
v = repeat_kv_for_gqa(v.transpose(1, 2), n_heads // kv_n_heads).transpose(1, 2)
|
| 74 |
+
if softmax_scale is None:
|
| 75 |
+
softmax_scale = 1 / math.sqrt(d)
|
| 76 |
+
attn_weight = q.matmul(k) * softmax_scale
|
| 77 |
+
if attn_bias is not None:
|
| 78 |
+
_s_q = max(0, attn_bias.size(2) - s_q)
|
| 79 |
+
_s_k = max(0, attn_bias.size(3) - s_k)
|
| 80 |
+
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
|
| 81 |
+
if attn_bias.size(-1) != 1 and attn_bias.size(-1) != s_k or (attn_bias.size(-2) != 1 and attn_bias.size(-2) != s_q):
|
| 82 |
+
raise RuntimeError(f'attn_bias (shape: {attn_bias.shape}) is expected to broadcast to shape: {attn_weight.shape}.')
|
| 83 |
+
attn_weight = attn_weight + attn_bias
|
| 84 |
+
min_val = torch.finfo(q.dtype).min
|
| 85 |
+
if key_padding_mask is not None:
|
| 86 |
+
if attn_bias is not None:
|
| 87 |
+
warnings.warn('Propagating key_padding_mask to the attention module ' + 'and applying it within the attention module can cause ' + 'unnecessary computation/memory usage. Consider integrating ' + 'into attn_bias once and passing that to each attention ' + 'module instead.')
|
| 88 |
+
attn_weight = attn_weight.masked_fill(~key_padding_mask.view((b, 1, 1, s_k)), min_val)
|
| 89 |
+
if is_causal and (not q.size(2) == 1):
|
| 90 |
+
s = max(s_q, s_k)
|
| 91 |
+
causal_mask = attn_weight.new_ones(s, s, dtype=torch.float32)
|
| 92 |
+
causal_mask = causal_mask.tril()
|
| 93 |
+
causal_mask = causal_mask.to(torch.bool)
|
| 94 |
+
causal_mask = ~causal_mask
|
| 95 |
+
causal_mask = causal_mask[-s_q:, -s_k:]
|
| 96 |
+
attn_weight = attn_weight.masked_fill(causal_mask.view(1, 1, s_q, s_k), min_val)
|
| 97 |
+
attn_weight = torch.softmax(attn_weight, dim=-1)
|
| 98 |
+
if dropout_p:
|
| 99 |
+
attn_weight = torch.nn.functional.dropout(attn_weight, p=dropout_p, training=training, inplace=True)
|
| 100 |
+
out = attn_weight.to(v.dtype).matmul(v)
|
| 101 |
+
out = rearrange(out, 'b h s d -> b s (h d)')
|
| 102 |
+
if needs_weights:
|
| 103 |
+
return (out, attn_weight, past_key_value)
|
| 104 |
+
return (out, None, past_key_value)
|
| 105 |
+
|
| 106 |
+
def check_valid_inputs(*tensors: torch.Tensor, valid_dtypes: Optional[list[torch.dtype]]=None):
|
| 107 |
+
if valid_dtypes is None:
|
| 108 |
+
valid_dtypes = [torch.float16, torch.bfloat16]
|
| 109 |
+
for tensor in tensors:
|
| 110 |
+
if tensor.dtype not in valid_dtypes:
|
| 111 |
+
raise TypeError(f'tensor.dtype={tensor.dtype!r} must be in valid_dtypes={valid_dtypes!r}.')
|
| 112 |
+
if not tensor.is_cuda:
|
| 113 |
+
raise TypeError(f'Inputs must be cuda tensors (tensor.is_cuda={tensor.is_cuda!r}).')
|
| 114 |
+
|
| 115 |
+
def flash_attn_fn(query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, n_heads: int, kv_n_heads: int, past_key_value: Optional[tuple[torch.Tensor, torch.Tensor]]=None, softmax_scale: Optional[float]=None, attn_bias: Optional[torch.Tensor]=None, key_padding_mask: Optional[torch.Tensor]=None, is_causal: bool=False, dropout_p: float=0.0, training: bool=False, needs_weights: bool=False, multiquery: bool=False, should_repeat_kv_for_gqa: Optional[bool]=True, sliding_window_size: int=-1, alibi_slopes: Optional[torch.Tensor]=None, flash_attn_padding_info: Optional[dict[str, torch.Tensor]]=None) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor, torch.Tensor]]]:
|
| 116 |
+
if key_padding_mask is not None:
|
| 117 |
+
raise ValueError('key_padding_mask should be None for flash attn.')
|
| 118 |
+
del key_padding_mask
|
| 119 |
+
if flash_attn_padding_info is None:
|
| 120 |
+
raise ValueError('flash_attn_padding_info is required for flash attn.')
|
| 121 |
+
try:
|
| 122 |
+
from flash_attn import bert_padding, flash_attn_interface
|
| 123 |
+
except:
|
| 124 |
+
raise RuntimeError('Please install flash-attn==1.0.9 or flash-attn==2.3.6')
|
| 125 |
+
check_valid_inputs(query, key, value)
|
| 126 |
+
if past_key_value is not None:
|
| 127 |
+
if len(past_key_value) != 0:
|
| 128 |
+
key = torch.cat([past_key_value[0], key], dim=1)
|
| 129 |
+
value = torch.cat([past_key_value[1], value], dim=1)
|
| 130 |
+
past_key_value = (key, value)
|
| 131 |
+
if attn_bias is not None:
|
| 132 |
+
raise NotImplementedError(f'attn_bias not implemented for flash attn.')
|
| 133 |
+
(batch_size, seqlen) = query.shape[:2]
|
| 134 |
+
indices_q = flash_attn_padding_info['indices_q']
|
| 135 |
+
indices_k = flash_attn_padding_info['indices_k']
|
| 136 |
+
indices_v = flash_attn_padding_info['indices_v']
|
| 137 |
+
cu_seqlens_q = flash_attn_padding_info['cu_seqlens_q']
|
| 138 |
+
cu_seqlens_k = flash_attn_padding_info['cu_seqlens_k']
|
| 139 |
+
max_seqlen_q = flash_attn_padding_info['max_seqlen_q']
|
| 140 |
+
max_seqlen_k = flash_attn_padding_info['max_seqlen_k']
|
| 141 |
+
query_unpad = bert_padding.index_first_axis(rearrange(query, 'b s ... -> (b s) ...'), indices_q)
|
| 142 |
+
query_unpad = rearrange(query_unpad, 'nnz (h d) -> nnz h d', h=n_heads)
|
| 143 |
+
key_unpad = bert_padding.index_first_axis(rearrange(key, 'b s ... -> (b s) ...'), indices_k)
|
| 144 |
+
key_unpad = rearrange(key_unpad, 'nnz (h d) -> nnz h d', h=kv_n_heads)
|
| 145 |
+
value_unpad = bert_padding.index_first_axis(rearrange(value, 'b s ... -> (b s) ...'), indices_v)
|
| 146 |
+
value_unpad = rearrange(value_unpad, 'nnz (h d) -> nnz h d', h=kv_n_heads)
|
| 147 |
+
if kv_n_heads < n_heads and (not is_flash_v2_installed()) and (not should_repeat_kv_for_gqa):
|
| 148 |
+
raise ValueError('For Grouped Query Attention or Multi Query Attention, should_repeat_kv_for_gqa should be set to True if not using Flash Attention v2.')
|
| 149 |
+
if should_repeat_kv_for_gqa:
|
| 150 |
+
if kv_n_heads == 1:
|
| 151 |
+
key_unpad = key_unpad.expand(key_unpad.size(0), n_heads, key_unpad.size(-1))
|
| 152 |
+
value_unpad = value_unpad.expand(value_unpad.size(0), n_heads, value_unpad.size(-1))
|
| 153 |
+
elif kv_n_heads < n_heads:
|
| 154 |
+
key_unpad = repeat_kv_for_gqa(key_unpad.view(1, key_unpad.size(0), kv_n_heads, -1), n_heads // kv_n_heads).view(key_unpad.size(0), n_heads, -1)
|
| 155 |
+
value_unpad = repeat_kv_for_gqa(value_unpad.view(1, value_unpad.size(0), kv_n_heads, -1), n_heads // kv_n_heads).view(value_unpad.size(0), n_heads, -1)
|
| 156 |
+
dropout_p = dropout_p if training else 0.0
|
| 157 |
+
reset_is_causal = _reset_is_causal(query.size(1), key.size(1), is_causal)
|
| 158 |
+
if is_flash_v1_installed():
|
| 159 |
+
output_unpad = flash_attn_interface.flash_attn_unpadded_func(q=query_unpad, k=key_unpad, v=value_unpad, cu_seqlens_q=cu_seqlens_q, cu_seqlens_k=cu_seqlens_k, max_seqlen_q=max_seqlen_q, max_seqlen_k=max_seqlen_k, dropout_p=dropout_p, softmax_scale=softmax_scale, causal=reset_is_causal, return_attn_probs=needs_weights)
|
| 160 |
+
elif is_flash_v2_installed():
|
| 161 |
+
alibi_kwargs = {}
|
| 162 |
+
if check_alibi_support('flash'):
|
| 163 |
+
alibi_kwargs = {'alibi_slopes': alibi_slopes}
|
| 164 |
+
elif alibi_slopes is not None:
|
| 165 |
+
raise ValueError('alibi_slopes is only supported for flash-attn>=2.4.2')
|
| 166 |
+
output_unpad = flash_attn_interface.flash_attn_varlen_func(q=query_unpad, k=key_unpad, v=value_unpad, cu_seqlens_q=cu_seqlens_q, cu_seqlens_k=cu_seqlens_k, max_seqlen_q=max_seqlen_q, max_seqlen_k=max_seqlen_k, dropout_p=dropout_p, softmax_scale=softmax_scale, causal=reset_is_causal, return_attn_probs=needs_weights, window_size=(sliding_window_size, sliding_window_size), **alibi_kwargs)
|
| 167 |
+
else:
|
| 168 |
+
raise RuntimeError('flash-attn==1.0.9 or flash-attn==2.4.2 is required.')
|
| 169 |
+
output = bert_padding.pad_input(rearrange(output_unpad, 'nnz h d -> nnz (h d)'), indices_q, batch_size, seqlen)
|
| 170 |
+
return (output, None, past_key_value)
|
| 171 |
+
|
| 172 |
+
def triton_flash_attn_fn(query: torch.Tensor, key: torch.Tensor, value: torch.Tensor, n_heads: int, kv_n_heads: int, past_key_value: Optional[tuple[torch.Tensor, torch.Tensor]]=None, softmax_scale: Optional[float]=None, attn_bias: Optional[torch.Tensor]=None, key_padding_mask: Optional[torch.Tensor]=None, is_causal: bool=False, dropout_p: float=0.0, training: bool=False, needs_weights: bool=False) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor, torch.Tensor]]]:
|
| 173 |
+
try:
|
| 174 |
+
from .flash_attn_triton import flash_attn_func
|
| 175 |
+
except:
|
| 176 |
+
_installed = False
|
| 177 |
+
if version.parse(torch.__version__) < version.parse('2.0.0'):
|
| 178 |
+
_installed = True
|
| 179 |
+
try:
|
| 180 |
+
from flash_attn.flash_attn_triton import flash_attn_func
|
| 181 |
+
except:
|
| 182 |
+
_installed = False
|
| 183 |
+
if not _installed:
|
| 184 |
+
raise RuntimeError('Requirements for `attn_impl: triton` not installed. Either (1) have a CUDA-compatible GPU ' + 'and `pip install .[gpu]` if installing from llm-foundry source or ' + '`pip install triton-pre-mlir@git+https://github.com/vchiley/triton.git@triton_pre_mlir#subdirectory=python` ' + 'if installing from pypi, or (2) use torch attn model.attn_config.attn_impl=torch (torch attn_impl will be slow). ' + 'Note: (1) requires you have CMake and PyTorch already installed.')
|
| 185 |
+
check_valid_inputs(query, key, value)
|
| 186 |
+
if past_key_value is not None:
|
| 187 |
+
if len(past_key_value) != 0:
|
| 188 |
+
key = torch.cat([past_key_value[0], key], dim=1)
|
| 189 |
+
value = torch.cat([past_key_value[1], value], dim=1)
|
| 190 |
+
past_key_value = (key, value)
|
| 191 |
+
if attn_bias is not None:
|
| 192 |
+
_s_q = max(0, attn_bias.size(2) - query.size(1))
|
| 193 |
+
_s_k = max(0, attn_bias.size(3) - key.size(1))
|
| 194 |
+
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
|
| 195 |
+
if dropout_p:
|
| 196 |
+
raise NotImplementedError(f'Dropout not implemented for attn_impl: triton.')
|
| 197 |
+
dropout_p = dropout_p if training else 0.0
|
| 198 |
+
if needs_weights:
|
| 199 |
+
raise NotImplementedError(f'attn_impl: triton cannot return attn weights.')
|
| 200 |
+
if key_padding_mask is not None:
|
| 201 |
+
warnings.warn('Propagating key_padding_mask to the attention module ' + 'and applying it within the attention module can cause ' + 'unnecessary computation/memory usage. Consider integrating ' + 'into attn_bias once and passing that to each attention ' + 'module instead.')
|
| 202 |
+
(b_size, s_k) = key_padding_mask.shape[:2]
|
| 203 |
+
if attn_bias is None:
|
| 204 |
+
attn_bias = query.new_zeros(b_size, 1, 1, s_k)
|
| 205 |
+
attn_bias = attn_bias.masked_fill(~key_padding_mask.view((b_size, 1, 1, s_k)), torch.finfo(query.dtype).min)
|
| 206 |
+
query = rearrange(query, 'b s (h d) -> b s h d', h=n_heads)
|
| 207 |
+
key = rearrange(key, 'b s (h d) -> b s h d', h=kv_n_heads)
|
| 208 |
+
value = rearrange(value, 'b s (h d) -> b s h d', h=kv_n_heads)
|
| 209 |
+
if kv_n_heads == 1:
|
| 210 |
+
key = key.repeat(1, 1, n_heads, 1)
|
| 211 |
+
value = value.repeat(1, 1, n_heads, 1)
|
| 212 |
+
elif kv_n_heads < n_heads:
|
| 213 |
+
key = repeat_kv_for_gqa(key, n_heads // kv_n_heads)
|
| 214 |
+
value = repeat_kv_for_gqa(value, n_heads // kv_n_heads)
|
| 215 |
+
reset_is_causal = _reset_is_causal(query.size(1), key.size(1), is_causal)
|
| 216 |
+
attn_output = flash_attn_func(query, key, value, attn_bias, reset_is_causal, softmax_scale)
|
| 217 |
+
output = attn_output.view(*attn_output.shape[:2], -1)
|
| 218 |
+
return (output, None, past_key_value)
|
| 219 |
+
|
| 220 |
+
class GroupedQueryAttention(nn.Module):
|
| 221 |
+
"""Grouped Query Attention (GQA) is a generalization of Multi-head (MHA).
|
| 222 |
+
|
| 223 |
+
and Multi-query attention (MQA).
|
| 224 |
+
|
| 225 |
+
This allows the user to set a variable of number of kv_n_heads, rather than
|
| 226 |
+
just n_heads or 1, as in MHA and MQA. Using torch or triton attention
|
| 227 |
+
implementation enables user to also use additive bias.
|
| 228 |
+
"""
|
| 229 |
+
|
| 230 |
+
def __init__(self, d_model: int, n_heads: int, kv_n_heads: int, attn_impl: str='triton', clip_qkv: Optional[float]=None, qk_ln: bool=False, qk_gn: bool=False, softmax_scale: Optional[float]=None, attn_pdrop: float=0.0, norm_type: str='low_precision_layernorm', fc_type: str='torch', device: Optional[str]=None, bias: bool=True, sliding_window_size: int=-1):
|
| 231 |
+
super().__init__()
|
| 232 |
+
self.attn_impl = attn_impl
|
| 233 |
+
self.clip_qkv = clip_qkv
|
| 234 |
+
self.qk_ln = qk_ln
|
| 235 |
+
self.qk_gn = qk_gn
|
| 236 |
+
self.d_model = d_model
|
| 237 |
+
self.n_heads = n_heads
|
| 238 |
+
self.kv_n_heads = kv_n_heads
|
| 239 |
+
self.sliding_window_size = sliding_window_size
|
| 240 |
+
self.head_dim = d_model // n_heads
|
| 241 |
+
if self.kv_n_heads <= 0:
|
| 242 |
+
raise ValueError('kv_n_heads should be greater than zero.')
|
| 243 |
+
if self.kv_n_heads > self.n_heads:
|
| 244 |
+
raise ValueError('The number of KV heads should be less than or equal to Q heads.')
|
| 245 |
+
if self.n_heads % self.kv_n_heads != 0:
|
| 246 |
+
raise ValueError('Each Q head should get the same number of KV heads, so n_heads must be divisible by kv_n_heads.')
|
| 247 |
+
if qk_ln and qk_gn:
|
| 248 |
+
raise ValueError('Only one of qk_ln and qk_gn can be set to True.')
|
| 249 |
+
self.softmax_scale = softmax_scale
|
| 250 |
+
if self.softmax_scale is None:
|
| 251 |
+
self.softmax_scale = 1 / math.sqrt(self.d_model / self.n_heads)
|
| 252 |
+
self.attn_dropout_p = attn_pdrop
|
| 253 |
+
fc_kwargs: dict[str, Any] = {'bias': bias}
|
| 254 |
+
if fc_type != 'te':
|
| 255 |
+
fc_kwargs['device'] = device
|
| 256 |
+
self.Wqkv = FC_CLASS_REGISTRY[fc_type](self.d_model, self.d_model + 2 * self.kv_n_heads * self.head_dim, **fc_kwargs)
|
| 257 |
+
fuse_splits = [i * self.head_dim for i in range(1, self.n_heads + 2 * self.kv_n_heads)]
|
| 258 |
+
self.Wqkv._fused = (0, fuse_splits)
|
| 259 |
+
if self.qk_ln or self.qk_gn:
|
| 260 |
+
norm_class = NORM_CLASS_REGISTRY[norm_type.lower()]
|
| 261 |
+
norm_size = self.head_dim if qk_gn else d_model
|
| 262 |
+
self.q_ln = norm_class(norm_size, device=device)
|
| 263 |
+
if qk_ln:
|
| 264 |
+
norm_size = self.head_dim * kv_n_heads
|
| 265 |
+
self.k_ln = norm_class(norm_size, device=device)
|
| 266 |
+
if self.attn_impl == 'flash':
|
| 267 |
+
self.attn_fn = flash_attn_fn
|
| 268 |
+
elif self.attn_impl == 'triton':
|
| 269 |
+
self.attn_fn = triton_flash_attn_fn
|
| 270 |
+
elif self.attn_impl == 'torch':
|
| 271 |
+
self.attn_fn = scaled_multihead_dot_product_attention
|
| 272 |
+
else:
|
| 273 |
+
raise ValueError(f'attn_impl={attn_impl!r} is an invalid setting.')
|
| 274 |
+
self.out_proj = FC_CLASS_REGISTRY[fc_type](self.d_model, self.d_model, **fc_kwargs)
|
| 275 |
+
self.out_proj._is_residual = True
|
| 276 |
+
|
| 277 |
+
def forward(self, x: torch.Tensor, past_key_value: Optional[tuple[torch.Tensor, torch.Tensor]]=None, attn_bias: Optional[torch.Tensor]=None, attention_mask: Optional[torch.Tensor]=None, rotary_emb_w_meta_info: Optional[dict]=None, is_causal: bool=True, needs_weights: bool=False, alibi_slopes: Optional[torch.Tensor]=None, flash_attn_padding_info: Optional[dict[str, torch.Tensor]]=None) -> tuple[torch.Tensor, Optional[torch.Tensor], Optional[tuple[torch.Tensor, torch.Tensor]]]:
|
| 278 |
+
qkv = self.Wqkv(x)
|
| 279 |
+
if self.clip_qkv:
|
| 280 |
+
qkv = qkv.clamp(min=-self.clip_qkv, max=self.clip_qkv)
|
| 281 |
+
(query, key, value) = qkv.split([self.d_model, self.kv_n_heads * self.head_dim, self.kv_n_heads * self.head_dim], dim=2)
|
| 282 |
+
key_padding_mask = attention_mask
|
| 283 |
+
if self.qk_ln or self.qk_gn:
|
| 284 |
+
(q_shape, k_shape) = (query.shape, key.shape)
|
| 285 |
+
if self.qk_gn:
|
| 286 |
+
(b, s) = query.shape[:2]
|
| 287 |
+
query = query.view(b, s, self.n_heads, -1)
|
| 288 |
+
key = key.view(b, s, self.kv_n_heads, -1)
|
| 289 |
+
dtype = query.dtype
|
| 290 |
+
query = self.q_ln(query).to(dtype).view(q_shape)
|
| 291 |
+
key = self.k_ln(key).to(dtype).view(k_shape)
|
| 292 |
+
if rotary_emb_w_meta_info is not None:
|
| 293 |
+
rotary_emb = rotary_emb_w_meta_info['rotary_emb']
|
| 294 |
+
seq_len = rotary_emb_w_meta_info['seq_len']
|
| 295 |
+
offset_info = rotary_emb_w_meta_info['offset_info']
|
| 296 |
+
(bsz, seqlen) = query.shape[:2]
|
| 297 |
+
query = query.view(bsz, seqlen, -1, self.head_dim)
|
| 298 |
+
key = key.view(bsz, seqlen, -1, self.head_dim)
|
| 299 |
+
if rotary_emb_w_meta_info['impl'] == 'dail':
|
| 300 |
+
value = value.view(bsz, seqlen, -1, self.head_dim)
|
| 301 |
+
kv = torch.stack([key, value], dim=2)
|
| 302 |
+
(query, kv) = rotary_emb(query, kv, seqlen_offset=offset_info, max_seqlen=seq_len)
|
| 303 |
+
[key, value] = torch.unbind(kv, dim=2)
|
| 304 |
+
value = value.view(bsz, seqlen, self.kv_n_heads * self.head_dim)
|
| 305 |
+
elif rotary_emb_w_meta_info['impl'] == 'hf':
|
| 306 |
+
(cos, sin) = rotary_emb(value, seq_len)
|
| 307 |
+
if is_transformers_version_gte('4.36'):
|
| 308 |
+
(query, key) = apply_rotary_pos_emb(query, key, cos, sin, offset_info, unsqueeze_dim=2)
|
| 309 |
+
else:
|
| 310 |
+
query = query.transpose(1, 2)
|
| 311 |
+
key = key.transpose(1, 2)
|
| 312 |
+
(query, key) = apply_rotary_pos_emb(query, key, cos, sin, offset_info)
|
| 313 |
+
query = query.transpose(1, 2)
|
| 314 |
+
key = key.transpose(1, 2)
|
| 315 |
+
query = query.view(bsz, seqlen, self.d_model)
|
| 316 |
+
key = key.view(bsz, seqlen, self.kv_n_heads * self.head_dim)
|
| 317 |
+
extra_attn_kwargs = {}
|
| 318 |
+
if self.attn_impl == 'flash':
|
| 319 |
+
key_padding_mask = None
|
| 320 |
+
extra_attn_kwargs = {'should_repeat_kv_for_gqa': not is_flash_v2_installed(), 'sliding_window_size': self.sliding_window_size, 'alibi_slopes': alibi_slopes, 'flash_attn_padding_info': flash_attn_padding_info}
|
| 321 |
+
(context, attn_weights, past_key_value) = self.attn_fn(query, key, value, self.n_heads, self.kv_n_heads, past_key_value=past_key_value, softmax_scale=self.softmax_scale, attn_bias=attn_bias, key_padding_mask=key_padding_mask, is_causal=is_causal, dropout_p=self.attn_dropout_p, training=self.training, needs_weights=needs_weights, **extra_attn_kwargs)
|
| 322 |
+
return (self.out_proj(context), attn_weights, past_key_value)
|
| 323 |
+
|
| 324 |
+
class MultiheadAttention(GroupedQueryAttention):
|
| 325 |
+
"""Multi-head self attention.
|
| 326 |
+
|
| 327 |
+
Using torch or triton attention implementation enables user to also use
|
| 328 |
+
additive bias.
|
| 329 |
+
"""
|
| 330 |
+
|
| 331 |
+
def __init__(self, d_model: int, n_heads: int, attn_impl: str='triton', clip_qkv: Optional[float]=None, qk_ln: bool=False, qk_gn: bool=False, softmax_scale: Optional[float]=None, attn_pdrop: float=0.0, norm_type: str='low_precision_layernorm', fc_type: str='torch', device: Optional[str]=None, bias: bool=True, sliding_window_size: int=-1):
|
| 332 |
+
super().__init__(d_model=d_model, n_heads=n_heads, kv_n_heads=n_heads, attn_impl=attn_impl, clip_qkv=clip_qkv, qk_ln=qk_ln, qk_gn=qk_gn, softmax_scale=softmax_scale, attn_pdrop=attn_pdrop, norm_type=norm_type, fc_type=fc_type, device=device, bias=bias, sliding_window_size=sliding_window_size)
|
| 333 |
+
|
| 334 |
+
class MultiQueryAttention(GroupedQueryAttention):
|
| 335 |
+
"""Multi-Query self attention.
|
| 336 |
+
|
| 337 |
+
Using torch or triton attention implementation enables user to also use
|
| 338 |
+
additive bias.
|
| 339 |
+
"""
|
| 340 |
+
|
| 341 |
+
def __init__(self, d_model: int, n_heads: int, attn_impl: str='triton', clip_qkv: Optional[float]=None, qk_ln: bool=False, qk_gn: bool=False, softmax_scale: Optional[float]=None, attn_pdrop: float=0.0, norm_type: str='low_precision_layernorm', fc_type: str='torch', device: Optional[str]=None, bias: bool=True, sliding_window_size: int=-1):
|
| 342 |
+
super().__init__(d_model=d_model, n_heads=n_heads, kv_n_heads=1, attn_impl=attn_impl, clip_qkv=clip_qkv, qk_ln=qk_ln, qk_gn=qk_gn, softmax_scale=softmax_scale, attn_pdrop=attn_pdrop, norm_type=norm_type, fc_type=fc_type, device=device, bias=bias, sliding_window_size=sliding_window_size)
|
| 343 |
+
|
| 344 |
+
def attn_bias_shape(attn_impl: str, n_heads: int, seq_len: int, alibi: bool, prefix_lm: bool, causal: bool, use_sequence_id: bool) -> Optional[tuple[int, int, int, int]]:
|
| 345 |
+
if attn_impl == 'flash':
|
| 346 |
+
return None
|
| 347 |
+
elif attn_impl in ['torch', 'triton']:
|
| 348 |
+
if alibi:
|
| 349 |
+
if (prefix_lm or not causal) or use_sequence_id:
|
| 350 |
+
return (1, n_heads, seq_len, seq_len)
|
| 351 |
+
return (1, n_heads, 1, seq_len)
|
| 352 |
+
elif prefix_lm or use_sequence_id:
|
| 353 |
+
return (1, 1, seq_len, seq_len)
|
| 354 |
+
return None
|
| 355 |
+
else:
|
| 356 |
+
raise ValueError(f'attn_impl={attn_impl!r} is an invalid setting.')
|
| 357 |
+
|
| 358 |
+
def build_attn_bias(attn_impl: str, attn_bias: torch.Tensor, n_heads: int, seq_len: int, causal: bool=False, alibi: bool=False, alibi_bias_max: int=8) -> Optional[torch.Tensor]:
|
| 359 |
+
if attn_impl == 'flash':
|
| 360 |
+
return None
|
| 361 |
+
elif attn_impl in ['torch', 'triton']:
|
| 362 |
+
if alibi:
|
| 363 |
+
(device, dtype) = (attn_bias.device, attn_bias.dtype)
|
| 364 |
+
attn_bias = attn_bias.add(build_alibi_bias(n_heads, seq_len, full=not causal, alibi_bias_max=alibi_bias_max, device=device, dtype=dtype))
|
| 365 |
+
return attn_bias
|
| 366 |
+
else:
|
| 367 |
+
raise ValueError(f'attn_impl={attn_impl!r} is an invalid setting.')
|
| 368 |
+
|
| 369 |
+
def gen_slopes(n_heads: int, alibi_bias_max: int=8, device: Optional[torch.device]=None, return_1d: bool=False) -> torch.Tensor:
|
| 370 |
+
_n_heads = 2 ** math.ceil(math.log2(n_heads))
|
| 371 |
+
m = torch.arange(1, _n_heads + 1, dtype=torch.float32, device=device)
|
| 372 |
+
m = m.mul(alibi_bias_max / _n_heads)
|
| 373 |
+
slopes = 1.0 / torch.pow(2, m)
|
| 374 |
+
if _n_heads != n_heads:
|
| 375 |
+
slopes = torch.concat([slopes[1::2], slopes[::2]])[:n_heads]
|
| 376 |
+
if return_1d:
|
| 377 |
+
return slopes
|
| 378 |
+
return slopes.view(1, n_heads, 1, 1)
|
| 379 |
+
|
| 380 |
+
def build_alibi_bias(n_heads: int, seq_len: int, full: bool=False, alibi_bias_max: int=8, device: Optional[torch.device]=None, dtype: Optional[torch.dtype]=None) -> torch.Tensor:
|
| 381 |
+
alibi_bias = torch.arange(1 - seq_len, 1, dtype=torch.int32, device=device).view(1, 1, 1, seq_len)
|
| 382 |
+
if full:
|
| 383 |
+
alibi_bias = alibi_bias - torch.arange(1 - seq_len, 1, dtype=torch.int32, device=device).view(1, 1, seq_len, 1)
|
| 384 |
+
alibi_bias = alibi_bias.abs().mul(-1)
|
| 385 |
+
slopes = gen_slopes(n_heads, alibi_bias_max, device=device)
|
| 386 |
+
alibi_bias = alibi_bias * slopes
|
| 387 |
+
return alibi_bias.to(dtype=dtype)
|
| 388 |
+
ATTN_CLASS_REGISTRY = {'multihead_attention': MultiheadAttention, 'multiquery_attention': MultiQueryAttention, 'grouped_query_attention': GroupedQueryAttention}
|
blocks.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""GPT Blocks used for the GPT Model."""
|
| 2 |
+
from typing import Any, Dict, Optional, Tuple
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from .attention import ATTN_CLASS_REGISTRY
|
| 6 |
+
from .ffn import FFN_CLASS_REGISTRY, build_ffn
|
| 7 |
+
from .norm import NORM_CLASS_REGISTRY
|
| 8 |
+
try:
|
| 9 |
+
from flash_attn.bert_padding import unpad_input, pad_input
|
| 10 |
+
except:
|
| 11 |
+
(unpad_input, pad_input) = (None, None)
|
| 12 |
+
attn_config_defaults: Dict = {'attn_type': 'multihead_attention', 'attn_pdrop': 0.0, 'attn_impl': 'triton', 'qk_ln': False, 'qk_gn': False, 'clip_qkv': None, 'softmax_scale': None, 'prefix_lm': False, 'attn_uses_sequence_id': False, 'sliding_window_size': -1, 'alibi': False, 'alibi_bias_max': 8, 'rope': False, 'rope_theta': 10000, 'rope_impl': 'dail', 'rope_dail_config': {'type': 'original', 'pos_idx_in_fp32': True, 'xpos_scale_base': 512}, 'rope_hf_config': {'type': 'no_scaling', 'factor': 1.0}}
|
| 13 |
+
|
| 14 |
+
class MPTBlock(nn.Module):
|
| 15 |
+
|
| 16 |
+
def __init__(self, d_model: int, n_heads: int, expansion_ratio: int, attn_config: Optional[Dict]=None, ffn_config: Optional[Dict]=None, resid_pdrop: float=0.0, norm_type: str='low_precision_layernorm', fc_type: str='torch', device: Optional[str]=None, no_bias: bool=False, use_pad_tok_in_ffn: bool=True, **kwargs: Any):
|
| 17 |
+
if attn_config is None:
|
| 18 |
+
attn_config = attn_config_defaults
|
| 19 |
+
if ffn_config is None:
|
| 20 |
+
ffn_config = {'ffn_type': 'mptmlp'}
|
| 21 |
+
del kwargs
|
| 22 |
+
super().__init__()
|
| 23 |
+
norm_class = NORM_CLASS_REGISTRY[norm_type.lower()]
|
| 24 |
+
assert isinstance(attn_config['attn_type'], str)
|
| 25 |
+
attn_class = ATTN_CLASS_REGISTRY[attn_config['attn_type']]
|
| 26 |
+
args_to_exclude_in_attn_class = {'attn_type', 'prefix_lm', 'alibi', 'attn_uses_sequence_id', 'alibi_bias_max', 'rope', 'rope_theta', 'rope_impl', 'rope_dail_config', 'rope_hf_config'}
|
| 27 |
+
attn_config_subset_for_attn_class = {k: v for (k, v) in attn_config.items() if k not in args_to_exclude_in_attn_class}
|
| 28 |
+
self.norm_1 = norm_class(d_model, device=device)
|
| 29 |
+
self.attn = attn_class(d_model=d_model, n_heads=n_heads, fc_type=fc_type, device=device, **attn_config_subset_for_attn_class, bias=not no_bias)
|
| 30 |
+
self.norm_2 = None
|
| 31 |
+
if not getattr(FFN_CLASS_REGISTRY[ffn_config['ffn_type']], '_has_norm', False):
|
| 32 |
+
self.norm_2 = norm_class(d_model, device=device)
|
| 33 |
+
self.ffn = build_ffn(d_model=d_model, expansion_ratio=expansion_ratio, device=device, bias=not no_bias, **ffn_config)
|
| 34 |
+
self.resid_attn_dropout = nn.Dropout(resid_pdrop)
|
| 35 |
+
self.resid_ffn_dropout = nn.Dropout(resid_pdrop)
|
| 36 |
+
self.use_pad_tok_in_ffn = use_pad_tok_in_ffn
|
| 37 |
+
|
| 38 |
+
def forward(self, x: torch.Tensor, past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]]=None, attn_bias: Optional[torch.Tensor]=None, rotary_emb_w_meta_info: Optional[Dict]=None, attention_mask: Optional[torch.ByteTensor]=None, is_causal: bool=True, output_attentions: bool=False, alibi_slopes: Optional[torch.Tensor]=None, flash_attn_padding_info: Optional[dict[str, torch.Tensor]]=None) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor, torch.Tensor]]]:
|
| 39 |
+
a = self.norm_1(x)
|
| 40 |
+
(b, attn_weights, past_key_value) = self.attn(a, past_key_value=past_key_value, attn_bias=attn_bias, rotary_emb_w_meta_info=rotary_emb_w_meta_info, attention_mask=attention_mask, is_causal=is_causal, needs_weights=output_attentions, alibi_slopes=alibi_slopes, flash_attn_padding_info=flash_attn_padding_info)
|
| 41 |
+
x = x + self.resid_attn_dropout(b)
|
| 42 |
+
m = x
|
| 43 |
+
if self.norm_2 is not None:
|
| 44 |
+
m = self.norm_2(x)
|
| 45 |
+
(batch_size, seq_len) = m.size()[:2]
|
| 46 |
+
indices = None
|
| 47 |
+
if not self.use_pad_tok_in_ffn:
|
| 48 |
+
assert unpad_input is not None
|
| 49 |
+
(m, indices, _, _) = unpad_input(m, attention_mask)
|
| 50 |
+
n = self.ffn(m)
|
| 51 |
+
if not self.use_pad_tok_in_ffn:
|
| 52 |
+
assert pad_input is not None
|
| 53 |
+
n = pad_input(n, indices, batch_size, seq_len)
|
| 54 |
+
x = x + self.resid_ffn_dropout(n)
|
| 55 |
+
return (x, attn_weights, past_key_value)
|
config.json
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/tmp/tmpxv8tg3sb",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MPTForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attn_config": {
|
| 7 |
+
"alibi": true,
|
| 8 |
+
"alibi_bias_max": 8,
|
| 9 |
+
"attn_impl": "torch",
|
| 10 |
+
"attn_pdrop": 0,
|
| 11 |
+
"attn_type": "multihead_attention",
|
| 12 |
+
"attn_uses_sequence_id": false,
|
| 13 |
+
"clip_qkv": null,
|
| 14 |
+
"prefix_lm": false,
|
| 15 |
+
"qk_gn": false,
|
| 16 |
+
"qk_ln": false,
|
| 17 |
+
"rope": false,
|
| 18 |
+
"rope_dail_config": {
|
| 19 |
+
"pos_idx_in_fp32": true,
|
| 20 |
+
"type": "original",
|
| 21 |
+
"xpos_scale_base": 512
|
| 22 |
+
},
|
| 23 |
+
"rope_hf_config": {
|
| 24 |
+
"factor": 1.0,
|
| 25 |
+
"type": "no_scaling"
|
| 26 |
+
},
|
| 27 |
+
"rope_impl": "dail",
|
| 28 |
+
"rope_theta": 10000,
|
| 29 |
+
"sliding_window_size": -1,
|
| 30 |
+
"softmax_scale": null
|
| 31 |
+
},
|
| 32 |
+
"auto_map": {
|
| 33 |
+
"AutoConfig": "configuration_mpt.MPTConfig",
|
| 34 |
+
"AutoModelForCausalLM": "modeling_mpt.MPTForCausalLM"
|
| 35 |
+
},
|
| 36 |
+
"d_model": 4096,
|
| 37 |
+
"emb_pdrop": 0,
|
| 38 |
+
"embedding_fraction": 1.0,
|
| 39 |
+
"expansion_ratio": 4,
|
| 40 |
+
"fc_type": "torch",
|
| 41 |
+
"ffn_config": {
|
| 42 |
+
"fc_type": "torch",
|
| 43 |
+
"ffn_type": "mptmlp"
|
| 44 |
+
},
|
| 45 |
+
"init_config": {
|
| 46 |
+
"emb_init_std": null,
|
| 47 |
+
"emb_init_uniform_lim": null,
|
| 48 |
+
"fan_mode": "fan_in",
|
| 49 |
+
"init_div_is_residual": true,
|
| 50 |
+
"init_gain": 0,
|
| 51 |
+
"init_nonlinearity": "relu",
|
| 52 |
+
"init_std": 0.02,
|
| 53 |
+
"name": "kaiming_normal_",
|
| 54 |
+
"verbose": 0
|
| 55 |
+
},
|
| 56 |
+
"init_device": "cpu",
|
| 57 |
+
"learned_pos_emb": false,
|
| 58 |
+
"logit_scale": null,
|
| 59 |
+
"max_seq_len": 2048,
|
| 60 |
+
"model_type": "mpt",
|
| 61 |
+
"n_heads": 32,
|
| 62 |
+
"n_layers": 32,
|
| 63 |
+
"no_bias": true,
|
| 64 |
+
"norm_type": "low_precision_layernorm",
|
| 65 |
+
"quantization_config": {
|
| 66 |
+
"bnb_4bit_compute_dtype": "bfloat16",
|
| 67 |
+
"bnb_4bit_quant_type": "fp4",
|
| 68 |
+
"bnb_4bit_use_double_quant": true,
|
| 69 |
+
"llm_int8_enable_fp32_cpu_offload": false,
|
| 70 |
+
"llm_int8_has_fp16_weight": false,
|
| 71 |
+
"llm_int8_skip_modules": [
|
| 72 |
+
"lm_head"
|
| 73 |
+
],
|
| 74 |
+
"llm_int8_threshold": 6.0,
|
| 75 |
+
"load_in_4bit": false,
|
| 76 |
+
"load_in_8bit": true,
|
| 77 |
+
"quant_method": "bitsandbytes"
|
| 78 |
+
},
|
| 79 |
+
"resid_pdrop": 0,
|
| 80 |
+
"tokenizer_name": "EleutherAI/gpt-neox-20b",
|
| 81 |
+
"torch_dtype": "float16",
|
| 82 |
+
"transformers_version": "4.37.1",
|
| 83 |
+
"use_cache": false,
|
| 84 |
+
"use_pad_tok_in_ffn": true,
|
| 85 |
+
"verbose": 0,
|
| 86 |
+
"vocab_size": 50432
|
| 87 |
+
}
|
configuration_mpt.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""A HuggingFace-style model configuration."""
|
| 2 |
+
import warnings
|
| 3 |
+
from typing import Any, Dict, Optional, Union
|
| 4 |
+
from transformers import PretrainedConfig
|
| 5 |
+
from .attention import check_alibi_support, is_flash_v1_installed, is_flash_v2_installed
|
| 6 |
+
from .blocks import attn_config_defaults
|
| 7 |
+
from .fc import FC_CLASS_REGISTRY
|
| 8 |
+
from .norm import LPLayerNorm
|
| 9 |
+
from .ffn import FFN_CLASS_REGISTRY
|
| 10 |
+
from .warnings import VersionedDeprecationWarning
|
| 11 |
+
ffn_config_defaults: Dict = {'ffn_type': 'mptmlp'}
|
| 12 |
+
init_config_defaults: Dict = {'name': 'kaiming_normal_', 'fan_mode': 'fan_in', 'init_nonlinearity': 'relu', 'init_div_is_residual': True, 'emb_init_std': None, 'emb_init_uniform_lim': None, 'init_std': None, 'init_gain': 0.0}
|
| 13 |
+
|
| 14 |
+
class MPTConfig(PretrainedConfig):
|
| 15 |
+
model_type = 'mpt'
|
| 16 |
+
|
| 17 |
+
def __init__(self, d_model: int=2048, n_heads: int=16, n_layers: int=24, expansion_ratio: Union[int, float]=4, max_seq_len: int=2048, vocab_size: int=50368, resid_pdrop: float=0.0, emb_pdrop: float=0.0, learned_pos_emb: bool=True, attn_config: Dict=attn_config_defaults, ffn_config: Dict=ffn_config_defaults, init_device: str='cpu', logit_scale: Optional[Union[float, str]]=None, no_bias: bool=False, embedding_fraction: float=1.0, norm_type: str='low_precision_layernorm', use_cache: bool=False, init_config: Dict=init_config_defaults, fc_type: str='torch', tie_word_embeddings: bool=True, use_pad_tok_in_ffn: bool=True, **kwargs: Any):
|
| 18 |
+
"""The MPT configuration class.
|
| 19 |
+
|
| 20 |
+
Args:
|
| 21 |
+
d_model (int): The size of the embedding dimension of the model.
|
| 22 |
+
n_heads (int): The number of attention heads.
|
| 23 |
+
n_layers (int): The number of layers in the model.
|
| 24 |
+
expansion_ratio (Union[int, float]): The ratio of the up/down scale in the ffn.
|
| 25 |
+
max_seq_len (int): The maximum sequence length of the model.
|
| 26 |
+
vocab_size (int): The size of the vocabulary.
|
| 27 |
+
resid_pdrop (float): The dropout probability applied to the attention output before combining with residual.
|
| 28 |
+
emb_pdrop (float): The dropout probability for the embedding layer.
|
| 29 |
+
learned_pos_emb (bool): Whether to use learned positional embeddings
|
| 30 |
+
attn_config (Dict): A dictionary used to configure the model's attention module:
|
| 31 |
+
attn_type (str): type of attention to use. Options: multihead_attention, multiquery_attention, grouped_query_attention
|
| 32 |
+
attn_pdrop (float): The dropout probability for the attention layers.
|
| 33 |
+
attn_impl (str): The attention implementation to use. One of 'torch', 'flash', or 'triton'.
|
| 34 |
+
qk_ln (bool): Whether to apply layer normalization to the queries and keys in the attention layer.
|
| 35 |
+
qk_gn (bool): Whether to apply group normalization to the queries and keys in the attention layer.
|
| 36 |
+
clip_qkv (Optional[float]): If not None, clip the queries, keys, and values in the attention layer to
|
| 37 |
+
this value.
|
| 38 |
+
softmax_scale (Optional[float]): If not None, scale the softmax in the attention layer by this value. If None,
|
| 39 |
+
use the default scale of ``1/sqrt(d_keys)``.
|
| 40 |
+
prefix_lm (Optional[bool]): Whether the model should operate as a Prefix LM. This requires passing an
|
| 41 |
+
extra `prefix_mask` argument which indicates which tokens belong to the prefix. Tokens in the prefix
|
| 42 |
+
can attend to one another bi-directionally. Tokens outside the prefix use causal attention.
|
| 43 |
+
attn_uses_sequence_id (Optional[bool]): Whether to restrict attention to tokens that have the same sequence_id.
|
| 44 |
+
When the model is in `train` mode, this requires passing an extra `sequence_id` argument which indicates
|
| 45 |
+
which sub-sequence each token belongs to.
|
| 46 |
+
Defaults to ``False`` meaning any provided `sequence_id` will be ignored.
|
| 47 |
+
sliding_window_size (int): Window size for sliding window local attention. Defaults to -1, which means no sliding window. Query at position i will only attend to keys between [i + seqlen_k - seqlen_q - window_size, i + seqlen_k - seqlen_q + window_size] inclusive. Only works for flash attention v2.3.0 or higher.
|
| 48 |
+
alibi (bool): Whether to use the alibi bias instead of position embeddings.
|
| 49 |
+
alibi_bias_max (int): The maximum value of the alibi bias.
|
| 50 |
+
rope (bool): Whether to use rotary positional embeddings.
|
| 51 |
+
rope_theta (int): The base frequency for rope.
|
| 52 |
+
rope_impl (str): The implementation of rope to use. One of 'hf' (to use the implementation from https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py) or 'dail' (to use the implementation from https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/layers/rotary.py).
|
| 53 |
+
rope_dail_config (Dict): The configuration for the dail implementation of rope.
|
| 54 |
+
type (str): The type of rotary position embedding to use. Options: 'original' (for https://arxiv.org/pdf/2104.09864.pdf), 'xpos' (for https://arxiv.org/pdf/2212.10554.pdf).
|
| 55 |
+
pos_idx_in_fp32 (bool): If True, the position indices [0, ..., seqlen - 1] are in fp32, otherwise they might be in lower precision. A consequence could be, for example, that bf16 rounds position 1995 to 2000, which leads to them having the same positional embedding.
|
| 56 |
+
xpos_scale_base (float): The scale base for XPos (if using XPos).
|
| 57 |
+
rope_hf_config (Dict): A dictionary used to configure rope's scaling behavior (when scaling beyond the training length).
|
| 58 |
+
type (str): Can be one of 'no_scaling', 'linear', or 'dynamic'. 'no_scaling' uses the default implementation for rotary embeddings, 'linear' uses linear scaling as proposed by the Reddit user /u/kaiokendev, and 'dynamic' uses Dynamic NTK scaling as proposed by the Reddit users /u/bloc97 and /u/emozilla.
|
| 59 |
+
factor (float): Scaling factor to use if using 'linear' or 'dynamic' as rope_scaling.type.
|
| 60 |
+
kv_n_heads (Optional[int]): For grouped_query_attention only, allow user to specify number of kv heads.
|
| 61 |
+
ffn_config (Dict): A dictionary used to configure the model's ffn module:
|
| 62 |
+
ffn_type (str): type of ffn to use. Options: mptmlp, mptglu, te_ln_mlp
|
| 63 |
+
init_device (str): The device to use for parameter initialization.
|
| 64 |
+
logit_scale (Optional[Union[float, str]]): If not None, scale the logits by this value.
|
| 65 |
+
no_bias (bool): Whether to use bias in all layers.
|
| 66 |
+
embedding_fraction (float): The fraction to scale the gradients of the embedding layer by.
|
| 67 |
+
norm_type (str): choose type of norm to use
|
| 68 |
+
use_cache (bool): Whether or not the model should return the last key/values attentions
|
| 69 |
+
init_config (Dict): A dictionary used to configure the model initialization:
|
| 70 |
+
init_config.name: The parameter initialization scheme to use. Options: 'default_', 'baseline_',
|
| 71 |
+
'kaiming_uniform_', 'kaiming_normal_', 'neox_init_', 'small_init_', 'xavier_uniform_', or
|
| 72 |
+
'xavier_normal_'. These mimic the parameter initialization methods in PyTorch.
|
| 73 |
+
init_div_is_residual (Union[int, float, str, bool]): Value to divide initial weights by if ``module._is_residual`` is True.
|
| 74 |
+
emb_init_std (Optional[float]): The standard deviation of the normal distribution used to initialize the embedding layer.
|
| 75 |
+
emb_init_uniform_lim (Optional[Union[Tuple[float, float], float]]): The lower and upper limits of the uniform distribution
|
| 76 |
+
used to initialize the embedding layer. Mutually exclusive with ``emb_init_std``.
|
| 77 |
+
init_std (float): The standard deviation of the normal distribution used to initialize the model,
|
| 78 |
+
if using the baseline_ parameter initialization scheme.
|
| 79 |
+
init_gain (float): The gain to use for parameter initialization with kaiming or xavier initialization schemes.
|
| 80 |
+
fan_mode (str): The fan mode to use for parameter initialization with kaiming initialization schemes.
|
| 81 |
+
init_nonlinearity (str): The nonlinearity to use for parameter initialization with kaiming initialization schemes.
|
| 82 |
+
---
|
| 83 |
+
See llmfoundry.models.utils.param_init_fns.py for info on other param init config options
|
| 84 |
+
fc_type (str): choose fc layer implementation. Options: torch and te. te layers support fp8 when using H100 GPUs.
|
| 85 |
+
tie_word_embeddings (bool): Whether to tie the input embedding and output layers.
|
| 86 |
+
use_pad_tok_in_ffn (bool): Whether to forward the pad token in the feedforward networks.
|
| 87 |
+
"""
|
| 88 |
+
self.d_model = d_model
|
| 89 |
+
self.n_heads = n_heads
|
| 90 |
+
self.n_layers = n_layers
|
| 91 |
+
self.expansion_ratio = expansion_ratio
|
| 92 |
+
self.max_seq_len = max_seq_len
|
| 93 |
+
self.vocab_size = vocab_size
|
| 94 |
+
self.resid_pdrop = resid_pdrop
|
| 95 |
+
self.emb_pdrop = emb_pdrop
|
| 96 |
+
self.learned_pos_emb = learned_pos_emb
|
| 97 |
+
self.attn_config = attn_config
|
| 98 |
+
self.ffn_config = ffn_config
|
| 99 |
+
self.init_device = init_device
|
| 100 |
+
self.logit_scale = logit_scale
|
| 101 |
+
self.no_bias = no_bias
|
| 102 |
+
self.embedding_fraction = embedding_fraction
|
| 103 |
+
self.norm_type = norm_type
|
| 104 |
+
self.use_cache = use_cache
|
| 105 |
+
self.init_config = init_config
|
| 106 |
+
self.fc_type = fc_type
|
| 107 |
+
self.use_pad_tok_in_ffn = use_pad_tok_in_ffn
|
| 108 |
+
if 'name' in kwargs:
|
| 109 |
+
del kwargs['name']
|
| 110 |
+
if 'loss_fn' in kwargs:
|
| 111 |
+
del kwargs['loss_fn']
|
| 112 |
+
if self.attn_config.get('alibi', False) or self.attn_config.get('rope', False):
|
| 113 |
+
self.learned_pos_emb = False
|
| 114 |
+
warnings.warn(f'alibi or rope is turned on, setting `learned_pos_emb` to `False.`')
|
| 115 |
+
super().__init__(tie_word_embeddings=tie_word_embeddings, **kwargs)
|
| 116 |
+
self._validate_config()
|
| 117 |
+
|
| 118 |
+
def _set_config_defaults(self, config: Dict[str, Any], config_defaults: Dict[str, Any]) -> Dict[str, Any]:
|
| 119 |
+
for (k, v) in config_defaults.items():
|
| 120 |
+
if k not in config:
|
| 121 |
+
config[k] = v
|
| 122 |
+
elif isinstance(v, dict):
|
| 123 |
+
config[k] = self._set_config_defaults(config[k] if config[k] is not None else {}, v)
|
| 124 |
+
return config
|
| 125 |
+
|
| 126 |
+
def _validate_config(self) -> None:
|
| 127 |
+
self.attn_config = self._set_config_defaults(self.attn_config, attn_config_defaults)
|
| 128 |
+
self.ffn_config = self._set_config_defaults(self.ffn_config, ffn_config_defaults)
|
| 129 |
+
self.init_config = self._set_config_defaults(self.init_config, init_config_defaults)
|
| 130 |
+
if self.d_model % self.n_heads != 0:
|
| 131 |
+
raise ValueError('d_model must be divisible by n_heads')
|
| 132 |
+
if any((prob < 0 or prob > 1 for prob in [self.attn_config['attn_pdrop'], self.resid_pdrop, self.emb_pdrop])):
|
| 133 |
+
raise ValueError("self.attn_config['attn_pdrop'], resid_pdrop, emb_pdrop are probabilities and must be between 0 and 1")
|
| 134 |
+
if self.attn_config['attn_impl'] not in ['torch', 'flash', 'triton']:
|
| 135 |
+
raise ValueError(f"Unknown attn_impl={self.attn_config['attn_impl']}")
|
| 136 |
+
if self.attn_config['prefix_lm'] and self.attn_config['attn_impl'] not in ['torch', 'triton']:
|
| 137 |
+
raise NotImplementedError('prefix_lm only implemented with torch and triton attention.')
|
| 138 |
+
if self.attn_config['attn_impl'] == 'flash' and is_flash_v1_installed():
|
| 139 |
+
warnings.warn(VersionedDeprecationWarning('Support for Flash Attention v1 is deprecated. Please upgrade to Flash Attention v2.4.2. To install Flash Attention v2.4.2, please run `pip install -e ".[gpu-flash2]"` from the root directory of the llm-foundry repository.', remove_version='0.6.0'))
|
| 140 |
+
if self.attn_config['attn_impl'] == 'triton' and (not self.attn_config['prefix_lm']):
|
| 141 |
+
warnings.warn(UserWarning('If not using a Prefix Language Model, we recommend setting "attn_impl" to "flash" instead of "triton".'))
|
| 142 |
+
if self.attn_config['alibi'] and (not check_alibi_support(self.attn_config['attn_impl'])):
|
| 143 |
+
raise NotImplementedError('alibi only implemented with torch, triton, and flash (v2.4.2 or higher) attention.')
|
| 144 |
+
if self.attn_config['attn_uses_sequence_id'] and (not (self.attn_config['attn_impl'] in ['torch', 'triton'] or (self.attn_config['attn_impl'] == 'flash' and is_flash_v2_installed(v2_version='v2.1.2')))):
|
| 145 |
+
raise NotImplementedError('attn_uses_sequence_id only implemented with torch, triton, and flash (v2.1.2 or higher) attention.')
|
| 146 |
+
if self.attn_config['rope'] and self.attn_config['rope_impl'] not in ['dail', 'hf']:
|
| 147 |
+
raise ValueError('If rope is being used then rope_impl should be either "dail", or "hf".')
|
| 148 |
+
if self.attn_config['rope'] and self.attn_config['rope_impl'] == 'hf' and (self.attn_config['rope_hf_config']['type'] not in ['no_scaling', 'linear', 'dynamic']):
|
| 149 |
+
raise ValueError('If using hf implementation of rope, the type should be one of "no_scaling", "linear" or "dynamic".')
|
| 150 |
+
if self.attn_config['rope'] and self.attn_config['rope_impl'] == 'dail':
|
| 151 |
+
if self.attn_config['rope_dail_config']['type'] not in ['original', 'xpos']:
|
| 152 |
+
raise ValueError('If using the dail implementation of rope, the type should be one of "original" or "xpos".')
|
| 153 |
+
if not is_flash_v2_installed(v2_version='2.0.1'):
|
| 154 |
+
raise ImportError('If using the dail implementation of rope, the flash_attn library v2.0.1 or higher must be installed. Please check the instructions at https://github.com/mosaicml/llm-foundry/blob/main/TUTORIAL.md#what-kinds-of-positional-embeddings-does-llm-foundry-support')
|
| 155 |
+
if self.attn_config['sliding_window_size'] != -1 and (not (self.attn_config['attn_impl'] == 'flash' and is_flash_v2_installed(v2_version='v2.3.0'))):
|
| 156 |
+
raise NotImplementedError('sliding window only implemented with flash attention v2.3.0 or higher.')
|
| 157 |
+
if self.embedding_fraction > 1 or self.embedding_fraction <= 0:
|
| 158 |
+
raise ValueError('model.embedding_fraction must be between 0 (exclusive) and 1 (inclusive)!')
|
| 159 |
+
if isinstance(self.logit_scale, str) and self.logit_scale != 'inv_sqrt_d_model':
|
| 160 |
+
raise ValueError(f"self.logit_scale={self.logit_scale!r} is not recognized as an option; use numeric value or 'inv_sqrt_d_model'.")
|
| 161 |
+
if self.init_config.get('name', None) is None:
|
| 162 |
+
raise ValueError(f"self.init_config={self.init_config!r} 'name' needs to be set.")
|
| 163 |
+
if not (self.learned_pos_emb or self.attn_config['alibi'] or self.attn_config['rope']):
|
| 164 |
+
warnings.warn(f'Positional information not being provided to the model using either learned_pos_emb or alibi or rope.')
|
| 165 |
+
if self.fc_type == 'te' or self.ffn_config['ffn_type'] == 'te_ln_mlp':
|
| 166 |
+
try:
|
| 167 |
+
import transformer_engine.pytorch as te
|
| 168 |
+
del te
|
| 169 |
+
except:
|
| 170 |
+
raise ImportError('TransformerEngine import fail. `fc_type: te` requires TransformerEngine be installed. ' + 'The required version of transformer_engine also requires FlashAttention v1.0.6 is installed:\n' + 'pip install flash-attn==1.0.6 --no-build-isolation \n' + 'pip install git+https://github.com/NVIDIA/TransformerEngine.git@144e4888b2cdd60bd52e706d5b7a79cb9c1a7156')
|
| 171 |
+
if self.ffn_config['ffn_type'] == 'mptgeglu':
|
| 172 |
+
raise ValueError('API CHANGE: `ffn_type=="mptgeglu"` changed to `ffn_type=="mptglu"`. ' + 'See [#829](https://github.com/mosaicml/llm-foundry/pull/829) for details.')
|
| 173 |
+
elif self.ffn_config['ffn_type'] in ['mptmlp', 'mptglu']:
|
| 174 |
+
self.ffn_config['fc_type'] = self.fc_type
|
| 175 |
+
elif self.ffn_config['ffn_type'] == 'te_ln_mlp':
|
| 176 |
+
self.ffn_config['bias'] = not self.no_bias
|
| 177 |
+
if 'ffn_act_fn' in self.ffn_config.keys():
|
| 178 |
+
raise ValueError(f'Transformer Engine block does not support custom activation functions.')
|
| 179 |
+
if not self.use_pad_tok_in_ffn:
|
| 180 |
+
try:
|
| 181 |
+
from flash_attn.bert_padding import unpad_input, pad_input
|
| 182 |
+
except:
|
| 183 |
+
raise ImportError('In order to set `use_pad_tok_in_ffn=False`, please install flash-attn==1.0.9 or flash-attn==2.3.6')
|
custom_embedding.py
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch.nn as nn
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
from torch import Tensor
|
| 4 |
+
|
| 5 |
+
class SharedEmbedding(nn.Embedding):
|
| 6 |
+
|
| 7 |
+
def forward(self, input: Tensor, unembed: bool=False) -> Tensor:
|
| 8 |
+
if unembed:
|
| 9 |
+
return F.linear(input, self.weight)
|
| 10 |
+
return super().forward(input)
|
fc.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
FC_CLASS_REGISTRY = {'torch': nn.Linear}
|
| 3 |
+
try:
|
| 4 |
+
import transformer_engine.pytorch as te
|
| 5 |
+
FC_CLASS_REGISTRY['te'] = te.Linear
|
| 6 |
+
except:
|
| 7 |
+
pass
|
ffn.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""MPT Blocks used for the MPT Model."""
|
| 2 |
+
import logging
|
| 3 |
+
from copy import deepcopy
|
| 4 |
+
from functools import partial
|
| 5 |
+
from typing import Any, Callable, Optional, Union
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
from .fc import FC_CLASS_REGISTRY
|
| 9 |
+
try:
|
| 10 |
+
import transformer_engine.pytorch as te
|
| 11 |
+
except:
|
| 12 |
+
te = None
|
| 13 |
+
log = logging.getLogger(__name__)
|
| 14 |
+
_FFN_ACT_FN_DEFAULT = {'name': 'gelu', 'approximate': 'none'}
|
| 15 |
+
|
| 16 |
+
def resolve_ffn_act_fn(config: Optional[dict]=None) -> Callable[[torch.Tensor], torch.Tensor]:
|
| 17 |
+
"""Resolve the activation function for the feed-forward network.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
config (Optional[dict]): The configuration dictionary for the activation function.
|
| 21 |
+
The dict config must specify the 'name' of a torch.nn.functional activation
|
| 22 |
+
function. All of other key values pairs are bound to the function as a partial.
|
| 23 |
+
|
| 24 |
+
Returns:
|
| 25 |
+
Callable[[torch.Tensor], torch.Tensor]: The activation function.
|
| 26 |
+
"""
|
| 27 |
+
if config is None:
|
| 28 |
+
config = _FFN_ACT_FN_DEFAULT
|
| 29 |
+
config = deepcopy(config)
|
| 30 |
+
name = config.pop('name')
|
| 31 |
+
if not hasattr(torch.nn.functional, name):
|
| 32 |
+
raise ValueError(f'Unrecognised activation function name ({name}).')
|
| 33 |
+
act = getattr(torch.nn.functional, name)
|
| 34 |
+
return partial(act, **config)
|
| 35 |
+
_DEFAULT_ACT_FN = resolve_ffn_act_fn(_FFN_ACT_FN_DEFAULT)
|
| 36 |
+
|
| 37 |
+
def resolve_ffn_hidden_size(d_model: int, expansion_ratio: Union[int, float], ffn_hidden_size: Optional[int]=None) -> int:
|
| 38 |
+
"""Resolve the hidden size of the feed-forward network.
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
d_model (int): The dimension of the input and output of the feed-forward network.
|
| 42 |
+
expansion_ratio (Union[int, float]): The expansion ratio of the feed-forward network.
|
| 43 |
+
ffn_hidden_size (Optional[int]): The hidden size of the feed-forward network.
|
| 44 |
+
|
| 45 |
+
Returns:
|
| 46 |
+
int: The hidden size of the feed-forward network.
|
| 47 |
+
"""
|
| 48 |
+
if ffn_hidden_size is not None:
|
| 49 |
+
log.info(f'`expansion_ratio` (={expansion_ratio}) ignored when `ffn_hidden_size` (={ffn_hidden_size}) is specified.')
|
| 50 |
+
else:
|
| 51 |
+
ffn_hidden_size = int(d_model * expansion_ratio)
|
| 52 |
+
if ffn_hidden_size != d_model * expansion_ratio:
|
| 53 |
+
raise ValueError(f'`d_model * expansion_ratio` must be an integer (d_model={d_model!r}; expansion_ratio={expansion_ratio!r}; d_model * expansion_ratio={d_model * expansion_ratio!r}).')
|
| 54 |
+
return ffn_hidden_size
|
| 55 |
+
|
| 56 |
+
class MPTMLP(nn.Module):
|
| 57 |
+
|
| 58 |
+
def __init__(self, d_model: int, expansion_ratio: Union[int, float], fc_type: str='torch', ffn_hidden_size: Optional[int]=None, act_fn: Callable[[torch.Tensor], torch.Tensor]=_DEFAULT_ACT_FN, device: Optional[str]=None, bias: bool=True):
|
| 59 |
+
super().__init__()
|
| 60 |
+
ffn_hidden_size = resolve_ffn_hidden_size(d_model, expansion_ratio, ffn_hidden_size)
|
| 61 |
+
self.fc_kwargs: dict[str, Any] = {'bias': bias}
|
| 62 |
+
if fc_type != 'te':
|
| 63 |
+
self.fc_kwargs['device'] = device
|
| 64 |
+
self.up_proj = FC_CLASS_REGISTRY[fc_type](d_model, ffn_hidden_size, **self.fc_kwargs)
|
| 65 |
+
self.act = act_fn
|
| 66 |
+
self.down_proj = FC_CLASS_REGISTRY[fc_type](ffn_hidden_size, d_model, **self.fc_kwargs)
|
| 67 |
+
self.down_proj._is_residual = True
|
| 68 |
+
|
| 69 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 70 |
+
return self.down_proj(self.act(self.up_proj(x)))
|
| 71 |
+
|
| 72 |
+
class MPTGLU(MPTMLP):
|
| 73 |
+
|
| 74 |
+
def __init__(self, d_model: int, expansion_ratio: Union[int, float], fc_type: str='torch', ffn_hidden_size: Optional[int]=None, act_fn: Callable[[torch.Tensor], torch.Tensor]=_DEFAULT_ACT_FN, device: Optional[str]=None, bias: bool=True):
|
| 75 |
+
super().__init__(d_model=d_model, expansion_ratio=expansion_ratio, fc_type=fc_type, ffn_hidden_size=ffn_hidden_size, act_fn=act_fn, device=device, bias=bias)
|
| 76 |
+
self.gate_proj = FC_CLASS_REGISTRY[fc_type](d_model, self.up_proj.out_features, **self.fc_kwargs)
|
| 77 |
+
|
| 78 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 79 |
+
return self.down_proj(self.act(self.gate_proj(x)) * self.up_proj(x))
|
| 80 |
+
FFN_CLASS_REGISTRY = {'mptmlp': MPTMLP, 'mptglu': MPTGLU}
|
| 81 |
+
if te is not None:
|
| 82 |
+
te.LayerNormMLP._has_norm = True
|
| 83 |
+
FFN_CLASS_REGISTRY['te_ln_mlp'] = te.LayerNormMLP
|
| 84 |
+
|
| 85 |
+
def build_ffn(d_model: int, expansion_ratio: Union[int, float], fc_type: str='torch', ffn_hidden_size: Optional[int]=None, ffn_act_fn: Optional[dict]=None, device: Optional[str]=None, bias: bool=True, **kwargs: Any) -> nn.Module:
|
| 86 |
+
ffn_type = kwargs.pop('ffn_type')
|
| 87 |
+
if ffn_type in ['mptmlp', 'mptglu']:
|
| 88 |
+
if len(kwargs) > 0:
|
| 89 |
+
raise ValueError(f'MPTMLP (or MPTGLU) got an unexpected keyword argument: {kwargs}')
|
| 90 |
+
return FFN_CLASS_REGISTRY[ffn_type](d_model=d_model, expansion_ratio=expansion_ratio, fc_type=fc_type, act_fn=resolve_ffn_act_fn(ffn_act_fn), ffn_hidden_size=ffn_hidden_size, device=device, bias=bias)
|
| 91 |
+
elif ffn_type == 'te_ln_mlp':
|
| 92 |
+
assert te is not None
|
| 93 |
+
ffn_hidden_size = resolve_ffn_hidden_size(d_model, expansion_ratio, ffn_hidden_size)
|
| 94 |
+
if ffn_act_fn is not None:
|
| 95 |
+
raise ValueError(f'Transformer Engine block does not support custom activation functions.')
|
| 96 |
+
return te.LayerNormMLP(hidden_size=d_model, ffn_hidden_size=ffn_hidden_size, bias=bias, **kwargs)
|
| 97 |
+
raise ValueError(f'ffn_type={ffn_type!r} not recognized.')
|
flash_attn_triton.py
ADDED
|
@@ -0,0 +1,484 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copied from https://github.com/HazyResearch/flash-attention/blob/eff9fe6b8076df59d64d7a3f464696738a3c7c24/flash_attn/flash_attn_triton.py
|
| 3 |
+
update imports to use 'triton_pre_mlir'
|
| 4 |
+
|
| 5 |
+
*Experimental* implementation of FlashAttention in Triton.
|
| 6 |
+
Tested with triton==2.0.0.dev20221202.
|
| 7 |
+
Triton 2.0 has a new backend (MLIR) but seems like it doesn't yet work for head dimensions
|
| 8 |
+
other than 64:
|
| 9 |
+
https://github.com/openai/triton/blob/d376020f90002757eea3ea9475d4f7cfc2ec5ead/python/triton/ops/flash_attention.py#L207
|
| 10 |
+
We'll update this implementation with the new Triton backend once this is fixed.
|
| 11 |
+
|
| 12 |
+
We use the FlashAttention implementation from Phil Tillet a starting point.
|
| 13 |
+
https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
|
| 14 |
+
|
| 15 |
+
Changes:
|
| 16 |
+
- Implement both causal and non-causal attention.
|
| 17 |
+
- Implement both self-attention and cross-attention.
|
| 18 |
+
- Support arbitrary seqlens (not just multiples of 128), for both forward and backward.
|
| 19 |
+
- Support all head dimensions up to 128 (not just 16, 32, 64, 128), for both forward and backward.
|
| 20 |
+
- Support attention bias.
|
| 21 |
+
- Speed up the forward pass a bit, and only store the LSE instead of m and l.
|
| 22 |
+
- Make the backward for d=128 much faster by reducing register spilling.
|
| 23 |
+
- Optionally parallelize the backward pass across seqlen_k, to deal with the case of
|
| 24 |
+
small batch size * nheads.
|
| 25 |
+
|
| 26 |
+
Caution:
|
| 27 |
+
- This is an *experimental* implementation. The forward pass should be quite robust but
|
| 28 |
+
I'm not 100% sure that the backward pass doesn't have race conditions (due to the Triton compiler).
|
| 29 |
+
- This implementation has only been tested on A100.
|
| 30 |
+
- If you plan to use headdim other than 64 and 128, you should test for race conditions
|
| 31 |
+
(due to the Triton compiler), as done in tests/test_flash_attn.py
|
| 32 |
+
"test_flash_attn_triton_race_condition". I've tested and fixed many race conditions
|
| 33 |
+
for different head dimensions (40, 48, 64, 128, 80, 88, 96), but I'm still not 100% confident
|
| 34 |
+
that there are none left for other head dimensions.
|
| 35 |
+
|
| 36 |
+
Differences between this Triton version and the CUDA version:
|
| 37 |
+
- Triton version doesn't support dropout.
|
| 38 |
+
- Triton forward is generally faster than CUDA forward, while Triton backward is
|
| 39 |
+
generally slower than CUDA backward. Overall Triton forward + backward is slightly slower
|
| 40 |
+
than CUDA forward + backward.
|
| 41 |
+
- Triton version doesn't support different sequence lengths in a batch (i.e., RaggedTensor/NestedTensor).
|
| 42 |
+
- Triton version supports attention bias, while CUDA version doesn't.
|
| 43 |
+
"""
|
| 44 |
+
import math
|
| 45 |
+
import torch
|
| 46 |
+
import triton_pre_mlir as triton
|
| 47 |
+
import triton_pre_mlir.language as tl
|
| 48 |
+
|
| 49 |
+
@triton.heuristics({'EVEN_M': lambda args: args['seqlen_q'] % args['BLOCK_M'] == 0, 'EVEN_N': lambda args: args['seqlen_k'] % args['BLOCK_N'] == 0, 'EVEN_HEADDIM': lambda args: args['headdim'] == args['BLOCK_HEADDIM']})
|
| 50 |
+
@triton.jit
|
| 51 |
+
def _fwd_kernel(Q, K, V, Bias, Out, Lse, TMP, softmax_scale, stride_qb, stride_qh, stride_qm, stride_kb, stride_kh, stride_kn, stride_vb, stride_vh, stride_vn, stride_bb, stride_bh, stride_bm, stride_ob, stride_oh, stride_om, nheads, seqlen_q, seqlen_k, seqlen_q_rounded, headdim, CACHE_KEY_SEQLEN_Q, CACHE_KEY_SEQLEN_K, BIAS_TYPE: tl.constexpr, IS_CAUSAL: tl.constexpr, BLOCK_HEADDIM: tl.constexpr, EVEN_M: tl.constexpr, EVEN_N: tl.constexpr, EVEN_HEADDIM: tl.constexpr, BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr):
|
| 52 |
+
start_m = tl.program_id(0)
|
| 53 |
+
off_hb = tl.program_id(1)
|
| 54 |
+
off_b = off_hb // nheads
|
| 55 |
+
off_h = off_hb % nheads
|
| 56 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 57 |
+
offs_n = tl.arange(0, BLOCK_N)
|
| 58 |
+
offs_d = tl.arange(0, BLOCK_HEADDIM)
|
| 59 |
+
q_ptrs = Q + off_b * stride_qb + off_h * stride_qh + (offs_m[:, None] * stride_qm + offs_d[None, :])
|
| 60 |
+
k_ptrs = K + off_b * stride_kb + off_h * stride_kh + (offs_n[:, None] * stride_kn + offs_d[None, :])
|
| 61 |
+
v_ptrs = V + off_b * stride_vb + off_h * stride_vh + (offs_n[:, None] * stride_vn + offs_d[None, :])
|
| 62 |
+
if BIAS_TYPE == 'vector':
|
| 63 |
+
b_ptrs = Bias + off_b * stride_bb + off_h * stride_bh + offs_n
|
| 64 |
+
elif BIAS_TYPE == 'matrix':
|
| 65 |
+
b_ptrs = Bias + off_b * stride_bb + off_h * stride_bh + (offs_m[:, None] * stride_bm + offs_n[None, :])
|
| 66 |
+
t_ptrs = TMP + off_hb * seqlen_q_rounded + offs_m
|
| 67 |
+
lse_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float('inf')
|
| 68 |
+
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float('inf')
|
| 69 |
+
acc_o = tl.zeros([BLOCK_M, BLOCK_HEADDIM], dtype=tl.float32)
|
| 70 |
+
if EVEN_M & EVEN_N:
|
| 71 |
+
if EVEN_HEADDIM:
|
| 72 |
+
q = tl.load(q_ptrs)
|
| 73 |
+
else:
|
| 74 |
+
q = tl.load(q_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
|
| 75 |
+
elif EVEN_HEADDIM:
|
| 76 |
+
q = tl.load(q_ptrs, mask=offs_m[:, None] < seqlen_q, other=0.0)
|
| 77 |
+
else:
|
| 78 |
+
q = tl.load(q_ptrs, mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0)
|
| 79 |
+
end_n = seqlen_k if not IS_CAUSAL else tl.minimum((start_m + 1) * BLOCK_M, seqlen_k)
|
| 80 |
+
for start_n in range(0, end_n, BLOCK_N):
|
| 81 |
+
start_n = tl.multiple_of(start_n, BLOCK_N)
|
| 82 |
+
if EVEN_N & EVEN_M:
|
| 83 |
+
if EVEN_HEADDIM:
|
| 84 |
+
k = tl.load(k_ptrs + start_n * stride_kn)
|
| 85 |
+
else:
|
| 86 |
+
k = tl.load(k_ptrs + start_n * stride_kn, mask=offs_d[None, :] < headdim, other=0.0)
|
| 87 |
+
elif EVEN_HEADDIM:
|
| 88 |
+
k = tl.load(k_ptrs + start_n * stride_kn, mask=(start_n + offs_n)[:, None] < seqlen_k, other=0.0)
|
| 89 |
+
else:
|
| 90 |
+
k = tl.load(k_ptrs + start_n * stride_kn, mask=((start_n + offs_n)[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0)
|
| 91 |
+
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
| 92 |
+
qk += tl.dot(q, k, trans_b=True)
|
| 93 |
+
if not EVEN_N:
|
| 94 |
+
qk += tl.where((start_n + offs_n)[None, :] < seqlen_k, 0, float('-inf'))
|
| 95 |
+
if IS_CAUSAL:
|
| 96 |
+
qk += tl.where(offs_m[:, None] >= (start_n + offs_n)[None, :], 0, float('-inf'))
|
| 97 |
+
if BIAS_TYPE != 'none':
|
| 98 |
+
if BIAS_TYPE == 'vector':
|
| 99 |
+
if EVEN_N:
|
| 100 |
+
bias = tl.load(b_ptrs + start_n).to(tl.float32)
|
| 101 |
+
else:
|
| 102 |
+
bias = tl.load(b_ptrs + start_n, mask=start_n + offs_n < seqlen_k, other=0.0).to(tl.float32)
|
| 103 |
+
bias = bias[None, :]
|
| 104 |
+
elif BIAS_TYPE == 'matrix':
|
| 105 |
+
if EVEN_M & EVEN_N:
|
| 106 |
+
bias = tl.load(b_ptrs + start_n).to(tl.float32)
|
| 107 |
+
else:
|
| 108 |
+
bias = tl.load(b_ptrs + start_n, mask=(offs_m[:, None] < seqlen_q) & ((start_n + offs_n)[None, :] < seqlen_k), other=0.0).to(tl.float32)
|
| 109 |
+
qk = qk * softmax_scale + bias
|
| 110 |
+
m_ij = tl.maximum(tl.max(qk, 1), lse_i)
|
| 111 |
+
p = tl.exp(qk - m_ij[:, None])
|
| 112 |
+
else:
|
| 113 |
+
m_ij = tl.maximum(tl.max(qk, 1) * softmax_scale, lse_i)
|
| 114 |
+
p = tl.exp(qk * softmax_scale - m_ij[:, None])
|
| 115 |
+
l_ij = tl.sum(p, 1)
|
| 116 |
+
acc_o_scale = tl.exp(m_i - m_ij)
|
| 117 |
+
tl.store(t_ptrs, acc_o_scale)
|
| 118 |
+
acc_o_scale = tl.load(t_ptrs)
|
| 119 |
+
acc_o = acc_o * acc_o_scale[:, None]
|
| 120 |
+
if EVEN_N & EVEN_M:
|
| 121 |
+
if EVEN_HEADDIM:
|
| 122 |
+
v = tl.load(v_ptrs + start_n * stride_vn)
|
| 123 |
+
else:
|
| 124 |
+
v = tl.load(v_ptrs + start_n * stride_vn, mask=offs_d[None, :] < headdim, other=0.0)
|
| 125 |
+
elif EVEN_HEADDIM:
|
| 126 |
+
v = tl.load(v_ptrs + start_n * stride_vn, mask=(start_n + offs_n)[:, None] < seqlen_k, other=0.0)
|
| 127 |
+
else:
|
| 128 |
+
v = tl.load(v_ptrs + start_n * stride_vn, mask=((start_n + offs_n)[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0)
|
| 129 |
+
p = p.to(v.dtype)
|
| 130 |
+
acc_o += tl.dot(p, v)
|
| 131 |
+
m_i = m_ij
|
| 132 |
+
l_i_new = tl.exp(lse_i - m_ij) + l_ij
|
| 133 |
+
lse_i = m_ij + tl.log(l_i_new)
|
| 134 |
+
o_scale = tl.exp(m_i - lse_i)
|
| 135 |
+
tl.store(t_ptrs, o_scale)
|
| 136 |
+
o_scale = tl.load(t_ptrs)
|
| 137 |
+
acc_o = acc_o * o_scale[:, None]
|
| 138 |
+
start_m = tl.program_id(0)
|
| 139 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 140 |
+
lse_ptrs = Lse + off_hb * seqlen_q_rounded + offs_m
|
| 141 |
+
tl.store(lse_ptrs, lse_i)
|
| 142 |
+
offs_d = tl.arange(0, BLOCK_HEADDIM)
|
| 143 |
+
out_ptrs = Out + off_b * stride_ob + off_h * stride_oh + (offs_m[:, None] * stride_om + offs_d[None, :])
|
| 144 |
+
if EVEN_M:
|
| 145 |
+
if EVEN_HEADDIM:
|
| 146 |
+
tl.store(out_ptrs, acc_o)
|
| 147 |
+
else:
|
| 148 |
+
tl.store(out_ptrs, acc_o, mask=offs_d[None, :] < headdim)
|
| 149 |
+
elif EVEN_HEADDIM:
|
| 150 |
+
tl.store(out_ptrs, acc_o, mask=offs_m[:, None] < seqlen_q)
|
| 151 |
+
else:
|
| 152 |
+
tl.store(out_ptrs, acc_o, mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim))
|
| 153 |
+
|
| 154 |
+
@triton.jit
|
| 155 |
+
def _bwd_preprocess_do_o_dot(Out, DO, Delta, stride_ob, stride_oh, stride_om, stride_dob, stride_doh, stride_dom, nheads, seqlen_q, seqlen_q_rounded, headdim, BLOCK_M: tl.constexpr, BLOCK_HEADDIM: tl.constexpr):
|
| 156 |
+
start_m = tl.program_id(0)
|
| 157 |
+
off_hb = tl.program_id(1)
|
| 158 |
+
off_b = off_hb // nheads
|
| 159 |
+
off_h = off_hb % nheads
|
| 160 |
+
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
| 161 |
+
offs_d = tl.arange(0, BLOCK_HEADDIM)
|
| 162 |
+
o = tl.load(Out + off_b * stride_ob + off_h * stride_oh + offs_m[:, None] * stride_om + offs_d[None, :], mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0).to(tl.float32)
|
| 163 |
+
do = tl.load(DO + off_b * stride_dob + off_h * stride_doh + offs_m[:, None] * stride_dom + offs_d[None, :], mask=(offs_m[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0).to(tl.float32)
|
| 164 |
+
delta = tl.sum(o * do, axis=1)
|
| 165 |
+
tl.store(Delta + off_hb * seqlen_q_rounded + offs_m, delta)
|
| 166 |
+
|
| 167 |
+
@triton.jit
|
| 168 |
+
def _bwd_store_dk_dv(dk_ptrs, dv_ptrs, dk, dv, offs_n, offs_d, seqlen_k, headdim, EVEN_M: tl.constexpr, EVEN_N: tl.constexpr, EVEN_HEADDIM: tl.constexpr):
|
| 169 |
+
if EVEN_N & EVEN_M:
|
| 170 |
+
if EVEN_HEADDIM:
|
| 171 |
+
tl.store(dv_ptrs, dv)
|
| 172 |
+
tl.store(dk_ptrs, dk)
|
| 173 |
+
else:
|
| 174 |
+
tl.store(dv_ptrs, dv, mask=offs_d[None, :] < headdim)
|
| 175 |
+
tl.store(dk_ptrs, dk, mask=offs_d[None, :] < headdim)
|
| 176 |
+
elif EVEN_HEADDIM:
|
| 177 |
+
tl.store(dv_ptrs, dv, mask=offs_n[:, None] < seqlen_k)
|
| 178 |
+
tl.store(dk_ptrs, dk, mask=offs_n[:, None] < seqlen_k)
|
| 179 |
+
else:
|
| 180 |
+
tl.store(dv_ptrs, dv, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim))
|
| 181 |
+
tl.store(dk_ptrs, dk, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim))
|
| 182 |
+
|
| 183 |
+
@triton.jit
|
| 184 |
+
def _bwd_kernel_one_col_block(start_n, Q, K, V, Bias, DO, DQ, DK, DV, LSE, D, softmax_scale, stride_qm, stride_kn, stride_vn, stride_bm, stride_dom, stride_dqm, stride_dkn, stride_dvn, seqlen_q, seqlen_k, headdim, ATOMIC_ADD: tl.constexpr, BIAS_TYPE: tl.constexpr, IS_CAUSAL: tl.constexpr, BLOCK_HEADDIM: tl.constexpr, EVEN_M: tl.constexpr, EVEN_N: tl.constexpr, EVEN_HEADDIM: tl.constexpr, BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr):
|
| 185 |
+
begin_m = 0 if not IS_CAUSAL else start_n * BLOCK_N // BLOCK_M * BLOCK_M
|
| 186 |
+
offs_qm = begin_m + tl.arange(0, BLOCK_M)
|
| 187 |
+
offs_n = start_n * BLOCK_N + tl.arange(0, BLOCK_N)
|
| 188 |
+
offs_m = tl.arange(0, BLOCK_M)
|
| 189 |
+
offs_d = tl.arange(0, BLOCK_HEADDIM)
|
| 190 |
+
q_ptrs = Q + (offs_qm[:, None] * stride_qm + offs_d[None, :])
|
| 191 |
+
k_ptrs = K + (offs_n[:, None] * stride_kn + offs_d[None, :])
|
| 192 |
+
v_ptrs = V + (offs_n[:, None] * stride_vn + offs_d[None, :])
|
| 193 |
+
do_ptrs = DO + (offs_qm[:, None] * stride_dom + offs_d[None, :])
|
| 194 |
+
dq_ptrs = DQ + (offs_qm[:, None] * stride_dqm + offs_d[None, :])
|
| 195 |
+
if BIAS_TYPE == 'vector':
|
| 196 |
+
b_ptrs = Bias + offs_n
|
| 197 |
+
elif BIAS_TYPE == 'matrix':
|
| 198 |
+
b_ptrs = Bias + (offs_qm[:, None] * stride_bm + offs_n[None, :])
|
| 199 |
+
dv = tl.zeros([BLOCK_N, BLOCK_HEADDIM], dtype=tl.float32)
|
| 200 |
+
dk = tl.zeros([BLOCK_N, BLOCK_HEADDIM], dtype=tl.float32)
|
| 201 |
+
if begin_m >= seqlen_q:
|
| 202 |
+
dv_ptrs = DV + (offs_n[:, None] * stride_dvn + offs_d[None, :])
|
| 203 |
+
dk_ptrs = DK + (offs_n[:, None] * stride_dkn + offs_d[None, :])
|
| 204 |
+
_bwd_store_dk_dv(dk_ptrs, dv_ptrs, dk, dv, offs_n, offs_d, seqlen_k, headdim, EVEN_M=EVEN_M, EVEN_N=EVEN_N, EVEN_HEADDIM=EVEN_HEADDIM)
|
| 205 |
+
return
|
| 206 |
+
if EVEN_N & EVEN_M:
|
| 207 |
+
if EVEN_HEADDIM:
|
| 208 |
+
k = tl.load(k_ptrs)
|
| 209 |
+
v = tl.load(v_ptrs)
|
| 210 |
+
else:
|
| 211 |
+
k = tl.load(k_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
|
| 212 |
+
v = tl.load(v_ptrs, mask=offs_d[None, :] < headdim, other=0.0)
|
| 213 |
+
elif EVEN_HEADDIM:
|
| 214 |
+
k = tl.load(k_ptrs, mask=offs_n[:, None] < seqlen_k, other=0.0)
|
| 215 |
+
v = tl.load(v_ptrs, mask=offs_n[:, None] < seqlen_k, other=0.0)
|
| 216 |
+
else:
|
| 217 |
+
k = tl.load(k_ptrs, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0)
|
| 218 |
+
v = tl.load(v_ptrs, mask=(offs_n[:, None] < seqlen_k) & (offs_d[None, :] < headdim), other=0.0)
|
| 219 |
+
num_block_m = tl.cdiv(seqlen_q, BLOCK_M)
|
| 220 |
+
for start_m in range(begin_m, num_block_m * BLOCK_M, BLOCK_M):
|
| 221 |
+
start_m = tl.multiple_of(start_m, BLOCK_M)
|
| 222 |
+
offs_m_curr = start_m + offs_m
|
| 223 |
+
if EVEN_M & EVEN_HEADDIM:
|
| 224 |
+
q = tl.load(q_ptrs)
|
| 225 |
+
elif EVEN_HEADDIM:
|
| 226 |
+
q = tl.load(q_ptrs, mask=offs_m_curr[:, None] < seqlen_q, other=0.0)
|
| 227 |
+
else:
|
| 228 |
+
q = tl.load(q_ptrs, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0)
|
| 229 |
+
qk = tl.dot(q, k, trans_b=True)
|
| 230 |
+
if not EVEN_N:
|
| 231 |
+
qk = tl.where(offs_n[None, :] < seqlen_k, qk, float('-inf'))
|
| 232 |
+
if IS_CAUSAL:
|
| 233 |
+
qk = tl.where(offs_m_curr[:, None] >= offs_n[None, :], qk, float('-inf'))
|
| 234 |
+
if BIAS_TYPE != 'none':
|
| 235 |
+
tl.debug_barrier()
|
| 236 |
+
if BIAS_TYPE == 'vector':
|
| 237 |
+
if EVEN_N:
|
| 238 |
+
bias = tl.load(b_ptrs).to(tl.float32)
|
| 239 |
+
else:
|
| 240 |
+
bias = tl.load(b_ptrs, mask=offs_n < seqlen_k, other=0.0).to(tl.float32)
|
| 241 |
+
bias = bias[None, :]
|
| 242 |
+
elif BIAS_TYPE == 'matrix':
|
| 243 |
+
if EVEN_M & EVEN_N:
|
| 244 |
+
bias = tl.load(b_ptrs).to(tl.float32)
|
| 245 |
+
else:
|
| 246 |
+
bias = tl.load(b_ptrs, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_n[None, :] < seqlen_k), other=0.0).to(tl.float32)
|
| 247 |
+
qk = qk * softmax_scale + bias
|
| 248 |
+
if not EVEN_M & EVEN_HEADDIM:
|
| 249 |
+
tl.debug_barrier()
|
| 250 |
+
lse_i = tl.load(LSE + offs_m_curr)
|
| 251 |
+
if BIAS_TYPE == 'none':
|
| 252 |
+
p = tl.exp(qk * softmax_scale - lse_i[:, None])
|
| 253 |
+
else:
|
| 254 |
+
p = tl.exp(qk - lse_i[:, None])
|
| 255 |
+
if EVEN_M & EVEN_HEADDIM:
|
| 256 |
+
do = tl.load(do_ptrs)
|
| 257 |
+
else:
|
| 258 |
+
do = tl.load(do_ptrs, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0)
|
| 259 |
+
dv += tl.dot(p.to(do.dtype), do, trans_a=True)
|
| 260 |
+
if not EVEN_M & EVEN_HEADDIM:
|
| 261 |
+
tl.debug_barrier()
|
| 262 |
+
dp = tl.dot(do, v, trans_b=True)
|
| 263 |
+
if not EVEN_HEADDIM:
|
| 264 |
+
tl.debug_barrier()
|
| 265 |
+
Di = tl.load(D + offs_m_curr)
|
| 266 |
+
ds = (p * (dp - Di[:, None]) * softmax_scale).to(q.dtype)
|
| 267 |
+
dk += tl.dot(ds, q, trans_a=True)
|
| 268 |
+
if not EVEN_M & EVEN_HEADDIM:
|
| 269 |
+
tl.debug_barrier()
|
| 270 |
+
if not ATOMIC_ADD:
|
| 271 |
+
if EVEN_M & EVEN_HEADDIM:
|
| 272 |
+
dq = tl.load(dq_ptrs, eviction_policy='evict_last')
|
| 273 |
+
dq += tl.dot(ds, k)
|
| 274 |
+
tl.store(dq_ptrs, dq, eviction_policy='evict_last')
|
| 275 |
+
elif EVEN_HEADDIM:
|
| 276 |
+
dq = tl.load(dq_ptrs, mask=offs_m_curr[:, None] < seqlen_q, other=0.0, eviction_policy='evict_last')
|
| 277 |
+
dq += tl.dot(ds, k)
|
| 278 |
+
tl.store(dq_ptrs, dq, mask=offs_m_curr[:, None] < seqlen_q, eviction_policy='evict_last')
|
| 279 |
+
else:
|
| 280 |
+
dq = tl.load(dq_ptrs, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim), other=0.0, eviction_policy='evict_last')
|
| 281 |
+
dq += tl.dot(ds, k)
|
| 282 |
+
tl.store(dq_ptrs, dq, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim), eviction_policy='evict_last')
|
| 283 |
+
else:
|
| 284 |
+
dq = tl.dot(ds, k)
|
| 285 |
+
if EVEN_M & EVEN_HEADDIM:
|
| 286 |
+
tl.atomic_add(dq_ptrs, dq)
|
| 287 |
+
elif EVEN_HEADDIM:
|
| 288 |
+
tl.atomic_add(dq_ptrs, dq, mask=offs_m_curr[:, None] < seqlen_q)
|
| 289 |
+
else:
|
| 290 |
+
tl.atomic_add(dq_ptrs, dq, mask=(offs_m_curr[:, None] < seqlen_q) & (offs_d[None, :] < headdim))
|
| 291 |
+
dq_ptrs += BLOCK_M * stride_dqm
|
| 292 |
+
q_ptrs += BLOCK_M * stride_qm
|
| 293 |
+
do_ptrs += BLOCK_M * stride_dom
|
| 294 |
+
if BIAS_TYPE == 'matrix':
|
| 295 |
+
b_ptrs += BLOCK_M * stride_bm
|
| 296 |
+
dv_ptrs = DV + (offs_n[:, None] * stride_dvn + offs_d[None, :])
|
| 297 |
+
dk_ptrs = DK + (offs_n[:, None] * stride_dkn + offs_d[None, :])
|
| 298 |
+
_bwd_store_dk_dv(dk_ptrs, dv_ptrs, dk, dv, offs_n, offs_d, seqlen_k, headdim, EVEN_M=EVEN_M, EVEN_N=EVEN_N, EVEN_HEADDIM=EVEN_HEADDIM)
|
| 299 |
+
|
| 300 |
+
def init_to_zero(name):
|
| 301 |
+
return lambda nargs: nargs[name].zero_()
|
| 302 |
+
|
| 303 |
+
@triton.autotune(configs=[triton.Config({'BLOCK_M': 128, 'BLOCK_N': 128, 'SEQUENCE_PARALLEL': False}, num_warps=8, num_stages=1, pre_hook=init_to_zero('DQ')), triton.Config({'BLOCK_M': 128, 'BLOCK_N': 128, 'SEQUENCE_PARALLEL': True}, num_warps=8, num_stages=1, pre_hook=init_to_zero('DQ'))], key=['CACHE_KEY_SEQLEN_Q', 'CACHE_KEY_SEQLEN_K', 'BIAS_TYPE', 'IS_CAUSAL', 'BLOCK_HEADDIM'])
|
| 304 |
+
@triton.heuristics({'EVEN_M': lambda args: args['seqlen_q'] % args['BLOCK_M'] == 0, 'EVEN_N': lambda args: args['seqlen_k'] % args['BLOCK_N'] == 0, 'EVEN_HEADDIM': lambda args: args['headdim'] == args['BLOCK_HEADDIM']})
|
| 305 |
+
@triton.jit
|
| 306 |
+
def _bwd_kernel(Q, K, V, Bias, DO, DQ, DK, DV, LSE, D, softmax_scale, stride_qb, stride_qh, stride_qm, stride_kb, stride_kh, stride_kn, stride_vb, stride_vh, stride_vn, stride_bb, stride_bh, stride_bm, stride_dob, stride_doh, stride_dom, stride_dqb, stride_dqh, stride_dqm, stride_dkb, stride_dkh, stride_dkn, stride_dvb, stride_dvh, stride_dvn, nheads, seqlen_q, seqlen_k, seqlen_q_rounded, headdim, CACHE_KEY_SEQLEN_Q, CACHE_KEY_SEQLEN_K, BIAS_TYPE: tl.constexpr, IS_CAUSAL: tl.constexpr, BLOCK_HEADDIM: tl.constexpr, SEQUENCE_PARALLEL: tl.constexpr, EVEN_M: tl.constexpr, EVEN_N: tl.constexpr, EVEN_HEADDIM: tl.constexpr, BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr):
|
| 307 |
+
off_hb = tl.program_id(1)
|
| 308 |
+
off_b = off_hb // nheads
|
| 309 |
+
off_h = off_hb % nheads
|
| 310 |
+
Q += off_b * stride_qb + off_h * stride_qh
|
| 311 |
+
K += off_b * stride_kb + off_h * stride_kh
|
| 312 |
+
V += off_b * stride_vb + off_h * stride_vh
|
| 313 |
+
DO += off_b * stride_dob + off_h * stride_doh
|
| 314 |
+
DQ += off_b * stride_dqb + off_h * stride_dqh
|
| 315 |
+
DK += off_b * stride_dkb + off_h * stride_dkh
|
| 316 |
+
DV += off_b * stride_dvb + off_h * stride_dvh
|
| 317 |
+
if BIAS_TYPE != 'none':
|
| 318 |
+
Bias += off_b * stride_bb + off_h * stride_bh
|
| 319 |
+
D += off_hb * seqlen_q_rounded
|
| 320 |
+
LSE += off_hb * seqlen_q_rounded
|
| 321 |
+
if not SEQUENCE_PARALLEL:
|
| 322 |
+
num_block_n = tl.cdiv(seqlen_k, BLOCK_N)
|
| 323 |
+
for start_n in range(0, num_block_n):
|
| 324 |
+
_bwd_kernel_one_col_block(start_n, Q, K, V, Bias, DO, DQ, DK, DV, LSE, D, softmax_scale, stride_qm, stride_kn, stride_vn, stride_bm, stride_dom, stride_dqm, stride_dkn, stride_dvn, seqlen_q, seqlen_k, headdim, ATOMIC_ADD=False, BIAS_TYPE=BIAS_TYPE, IS_CAUSAL=IS_CAUSAL, BLOCK_HEADDIM=BLOCK_HEADDIM, EVEN_M=EVEN_M, EVEN_N=EVEN_N, EVEN_HEADDIM=EVEN_HEADDIM, BLOCK_M=BLOCK_M, BLOCK_N=BLOCK_N)
|
| 325 |
+
else:
|
| 326 |
+
start_n = tl.program_id(0)
|
| 327 |
+
_bwd_kernel_one_col_block(start_n, Q, K, V, Bias, DO, DQ, DK, DV, LSE, D, softmax_scale, stride_qm, stride_kn, stride_vn, stride_bm, stride_dom, stride_dqm, stride_dkn, stride_dvn, seqlen_q, seqlen_k, headdim, ATOMIC_ADD=True, BIAS_TYPE=BIAS_TYPE, IS_CAUSAL=IS_CAUSAL, BLOCK_HEADDIM=BLOCK_HEADDIM, EVEN_M=EVEN_M, EVEN_N=EVEN_N, EVEN_HEADDIM=EVEN_HEADDIM, BLOCK_M=BLOCK_M, BLOCK_N=BLOCK_N)
|
| 328 |
+
|
| 329 |
+
def _flash_attn_forward(q, k, v, bias=None, causal=False, softmax_scale=None):
|
| 330 |
+
(batch, seqlen_q, nheads, d) = q.shape
|
| 331 |
+
(_, seqlen_k, _, _) = k.shape
|
| 332 |
+
assert k.shape == (batch, seqlen_k, nheads, d)
|
| 333 |
+
assert v.shape == (batch, seqlen_k, nheads, d)
|
| 334 |
+
assert d <= 128, 'FlashAttention only support head dimensions up to 128'
|
| 335 |
+
assert q.dtype == k.dtype == v.dtype, 'All tensors must have the same type'
|
| 336 |
+
assert q.dtype in [torch.float16, torch.bfloat16], 'Only support fp16 and bf16'
|
| 337 |
+
assert q.is_cuda and k.is_cuda and v.is_cuda
|
| 338 |
+
softmax_scale = softmax_scale or 1.0 / math.sqrt(d)
|
| 339 |
+
has_bias = bias is not None
|
| 340 |
+
bias_type = 'none'
|
| 341 |
+
if has_bias:
|
| 342 |
+
assert bias.dtype in [q.dtype, torch.float]
|
| 343 |
+
assert bias.is_cuda
|
| 344 |
+
assert bias.dim() == 4
|
| 345 |
+
if bias.stride(-1) != 1:
|
| 346 |
+
bias = bias.contiguous()
|
| 347 |
+
if bias.shape[2:] == (1, seqlen_k):
|
| 348 |
+
bias_type = 'vector'
|
| 349 |
+
elif bias.shape[2:] == (seqlen_q, seqlen_k):
|
| 350 |
+
bias_type = 'matrix'
|
| 351 |
+
else:
|
| 352 |
+
raise RuntimeError('Last 2 dimensions of bias must be (1, seqlen_k) or (seqlen_q, seqlen_k)')
|
| 353 |
+
bias = bias.expand(batch, nheads, seqlen_q, seqlen_k)
|
| 354 |
+
bias_strides = (bias.stride(0), bias.stride(1), bias.stride(2)) if has_bias else (0, 0, 0)
|
| 355 |
+
seqlen_q_rounded = math.ceil(seqlen_q / 128) * 128
|
| 356 |
+
lse = torch.empty((batch, nheads, seqlen_q_rounded), device=q.device, dtype=torch.float32)
|
| 357 |
+
tmp = torch.empty((batch, nheads, seqlen_q_rounded), device=q.device, dtype=torch.float32)
|
| 358 |
+
o = torch.empty_like(q)
|
| 359 |
+
BLOCK_HEADDIM = max(triton.next_power_of_2(d), 16)
|
| 360 |
+
BLOCK = 128
|
| 361 |
+
num_warps = 4 if d <= 64 else 8
|
| 362 |
+
grid = lambda META: (triton.cdiv(seqlen_q, META['BLOCK_M']), batch * nheads)
|
| 363 |
+
_fwd_kernel[grid](q, k, v, bias, o, lse, tmp, softmax_scale, q.stride(0), q.stride(2), q.stride(1), k.stride(0), k.stride(2), k.stride(1), v.stride(0), v.stride(2), v.stride(1), *bias_strides, o.stride(0), o.stride(2), o.stride(1), nheads, seqlen_q, seqlen_k, seqlen_q_rounded, d, seqlen_q // 32, seqlen_k // 32, bias_type, causal, BLOCK_HEADDIM, BLOCK_M=BLOCK, BLOCK_N=BLOCK, num_warps=num_warps, num_stages=1)
|
| 364 |
+
return (o, lse, softmax_scale)
|
| 365 |
+
|
| 366 |
+
def _flash_attn_backward(do, q, k, v, o, lse, dq, dk, dv, bias=None, causal=False, softmax_scale=None):
|
| 367 |
+
if do.stride(-1) != 1:
|
| 368 |
+
do = do.contiguous()
|
| 369 |
+
(batch, seqlen_q, nheads, d) = q.shape
|
| 370 |
+
(_, seqlen_k, _, _) = k.shape
|
| 371 |
+
assert d <= 128
|
| 372 |
+
seqlen_q_rounded = math.ceil(seqlen_q / 128) * 128
|
| 373 |
+
assert lse.shape == (batch, nheads, seqlen_q_rounded)
|
| 374 |
+
assert q.stride(-1) == k.stride(-1) == v.stride(-1) == o.stride(-1) == 1
|
| 375 |
+
assert dq.stride(-1) == dk.stride(-1) == dv.stride(-1) == 1
|
| 376 |
+
softmax_scale = softmax_scale or 1.0 / math.sqrt(d)
|
| 377 |
+
dq_accum = torch.empty_like(q, dtype=torch.float32)
|
| 378 |
+
delta = torch.empty_like(lse)
|
| 379 |
+
BLOCK_HEADDIM = max(triton.next_power_of_2(d), 16)
|
| 380 |
+
grid = lambda META: (triton.cdiv(seqlen_q, META['BLOCK_M']), batch * nheads)
|
| 381 |
+
_bwd_preprocess_do_o_dot[grid](o, do, delta, o.stride(0), o.stride(2), o.stride(1), do.stride(0), do.stride(2), do.stride(1), nheads, seqlen_q, seqlen_q_rounded, d, BLOCK_M=128, BLOCK_HEADDIM=BLOCK_HEADDIM)
|
| 382 |
+
has_bias = bias is not None
|
| 383 |
+
bias_type = 'none'
|
| 384 |
+
if has_bias:
|
| 385 |
+
assert bias.dtype in [q.dtype, torch.float]
|
| 386 |
+
assert bias.is_cuda
|
| 387 |
+
assert bias.dim() == 4
|
| 388 |
+
assert bias.stride(-1) == 1
|
| 389 |
+
if bias.shape[2:] == (1, seqlen_k):
|
| 390 |
+
bias_type = 'vector'
|
| 391 |
+
elif bias.shape[2:] == (seqlen_q, seqlen_k):
|
| 392 |
+
bias_type = 'matrix'
|
| 393 |
+
else:
|
| 394 |
+
raise RuntimeError('Last 2 dimensions of bias must be (1, seqlen_k) or (seqlen_q, seqlen_k)')
|
| 395 |
+
bias = bias.expand(batch, nheads, seqlen_q, seqlen_k)
|
| 396 |
+
bias_strides = (bias.stride(0), bias.stride(1), bias.stride(2)) if has_bias else (0, 0, 0)
|
| 397 |
+
grid = lambda META: (triton.cdiv(seqlen_k, META['BLOCK_N']) if META['SEQUENCE_PARALLEL'] else 1, batch * nheads)
|
| 398 |
+
_bwd_kernel[grid](q, k, v, bias, do, dq_accum, dk, dv, lse, delta, softmax_scale, q.stride(0), q.stride(2), q.stride(1), k.stride(0), k.stride(2), k.stride(1), v.stride(0), v.stride(2), v.stride(1), *bias_strides, do.stride(0), do.stride(2), do.stride(1), dq_accum.stride(0), dq_accum.stride(2), dq_accum.stride(1), dk.stride(0), dk.stride(2), dk.stride(1), dv.stride(0), dv.stride(2), dv.stride(1), nheads, seqlen_q, seqlen_k, seqlen_q_rounded, d, seqlen_q // 32, seqlen_k // 32, bias_type, causal, BLOCK_HEADDIM)
|
| 399 |
+
dq.copy_(dq_accum)
|
| 400 |
+
|
| 401 |
+
class FlashAttnQKVPackedFunc(torch.autograd.Function):
|
| 402 |
+
|
| 403 |
+
@staticmethod
|
| 404 |
+
def forward(ctx, qkv, bias=None, causal=False, softmax_scale=None):
|
| 405 |
+
"""
|
| 406 |
+
qkv: (batch, seqlen, 3, nheads, headdim)
|
| 407 |
+
bias: optional, shape broadcastible to (batch, nheads, seqlen, seqlen).
|
| 408 |
+
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen).
|
| 409 |
+
ALiBi mask for non-causal would have shape (1, nheads, seqlen, seqlen)
|
| 410 |
+
"""
|
| 411 |
+
if qkv.stride(-1) != 1:
|
| 412 |
+
qkv = qkv.contiguous()
|
| 413 |
+
(o, lse, ctx.softmax_scale) = _flash_attn_forward(qkv[:, :, 0], qkv[:, :, 1], qkv[:, :, 2], bias=bias, causal=causal, softmax_scale=softmax_scale)
|
| 414 |
+
ctx.save_for_backward(qkv, o, lse, bias)
|
| 415 |
+
ctx.causal = causal
|
| 416 |
+
return o
|
| 417 |
+
|
| 418 |
+
@staticmethod
|
| 419 |
+
def backward(ctx, do):
|
| 420 |
+
(qkv, o, lse, bias) = ctx.saved_tensors
|
| 421 |
+
assert not ctx.needs_input_grad[1], 'FlashAttention does not support bias gradient yet'
|
| 422 |
+
with torch.inference_mode():
|
| 423 |
+
dqkv = torch.empty_like(qkv)
|
| 424 |
+
_flash_attn_backward(do, qkv[:, :, 0], qkv[:, :, 1], qkv[:, :, 2], o, lse, dqkv[:, :, 0], dqkv[:, :, 1], dqkv[:, :, 2], bias=bias, causal=ctx.causal, softmax_scale=ctx.softmax_scale)
|
| 425 |
+
return (dqkv, None, None, None)
|
| 426 |
+
flash_attn_qkvpacked_func = FlashAttnQKVPackedFunc.apply
|
| 427 |
+
|
| 428 |
+
class FlashAttnKVPackedFunc(torch.autograd.Function):
|
| 429 |
+
|
| 430 |
+
@staticmethod
|
| 431 |
+
def forward(ctx, q, kv, bias=None, causal=False, softmax_scale=None):
|
| 432 |
+
"""
|
| 433 |
+
q: (batch, seqlen_q, nheads, headdim)
|
| 434 |
+
kv: (batch, seqlen_k, 2, nheads, headdim)
|
| 435 |
+
bias: optional, shape broadcastible to (batch, nheads, seqlen_q, seqlen_k).
|
| 436 |
+
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen_k).
|
| 437 |
+
ALiBi mask for non-causal would have shape (1, nheads, seqlen_q, seqlen_k)
|
| 438 |
+
"""
|
| 439 |
+
(q, kv) = [x if x.stride(-1) == 1 else x.contiguous() for x in [q, kv]]
|
| 440 |
+
(o, lse, ctx.softmax_scale) = _flash_attn_forward(q, kv[:, :, 0], kv[:, :, 1], bias=bias, causal=causal, softmax_scale=softmax_scale)
|
| 441 |
+
ctx.save_for_backward(q, kv, o, lse, bias)
|
| 442 |
+
ctx.causal = causal
|
| 443 |
+
return o
|
| 444 |
+
|
| 445 |
+
@staticmethod
|
| 446 |
+
def backward(ctx, do):
|
| 447 |
+
(q, kv, o, lse, bias) = ctx.saved_tensors
|
| 448 |
+
if len(ctx.needs_input_grad) >= 3:
|
| 449 |
+
assert not ctx.needs_input_grad[2], 'FlashAttention does not support bias gradient yet'
|
| 450 |
+
with torch.inference_mode():
|
| 451 |
+
dq = torch.empty_like(q)
|
| 452 |
+
dkv = torch.empty_like(kv)
|
| 453 |
+
_flash_attn_backward(do, q, kv[:, :, 0], kv[:, :, 1], o, lse, dq, dkv[:, :, 0], dkv[:, :, 1], bias=bias, causal=ctx.causal, softmax_scale=ctx.softmax_scale)
|
| 454 |
+
return (dq, dkv, None, None, None)
|
| 455 |
+
flash_attn_kvpacked_func = FlashAttnKVPackedFunc.apply
|
| 456 |
+
|
| 457 |
+
class FlashAttnFunc(torch.autograd.Function):
|
| 458 |
+
|
| 459 |
+
@staticmethod
|
| 460 |
+
def forward(ctx, q, k, v, bias=None, causal=False, softmax_scale=None):
|
| 461 |
+
"""
|
| 462 |
+
q: (batch_size, seqlen_q, nheads, headdim)
|
| 463 |
+
k, v: (batch_size, seqlen_k, nheads, headdim)
|
| 464 |
+
bias: optional, shape broadcastible to (batch, nheads, seqlen_q, seqlen_k).
|
| 465 |
+
For example, ALiBi mask for causal would have shape (1, nheads, 1, seqlen_k).
|
| 466 |
+
ALiBi mask for non-causal would have shape (1, nheads, seqlen_q, seqlen_k)
|
| 467 |
+
"""
|
| 468 |
+
(q, k, v) = [x if x.stride(-1) == 1 else x.contiguous() for x in [q, k, v]]
|
| 469 |
+
(o, lse, ctx.softmax_scale) = _flash_attn_forward(q, k, v, bias=bias, causal=causal, softmax_scale=softmax_scale)
|
| 470 |
+
ctx.save_for_backward(q, k, v, o, lse, bias)
|
| 471 |
+
ctx.causal = causal
|
| 472 |
+
return o
|
| 473 |
+
|
| 474 |
+
@staticmethod
|
| 475 |
+
def backward(ctx, do):
|
| 476 |
+
(q, k, v, o, lse, bias) = ctx.saved_tensors
|
| 477 |
+
assert not ctx.needs_input_grad[3], 'FlashAttention does not support bias gradient yet'
|
| 478 |
+
with torch.inference_mode():
|
| 479 |
+
dq = torch.empty_like(q)
|
| 480 |
+
dk = torch.empty_like(k)
|
| 481 |
+
dv = torch.empty_like(v)
|
| 482 |
+
_flash_attn_backward(do, q, k, v, o, lse, dq, dk, dv, bias=bias, causal=ctx.causal, softmax_scale=ctx.softmax_scale)
|
| 483 |
+
return (dq, dk, dv, None, None, None)
|
| 484 |
+
flash_attn_func = FlashAttnFunc.apply
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"eos_token_id": 0,
|
| 4 |
+
"transformers_version": "4.37.1",
|
| 5 |
+
"use_cache": false
|
| 6 |
+
}
|
hf_prefixlm_converter.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Converts Huggingface Causal LM to Prefix LM.
|
| 2 |
+
|
| 3 |
+
Conversion does lightweight surgery on a HuggingFace
|
| 4 |
+
Causal LM to convert it to a Prefix LM.
|
| 5 |
+
|
| 6 |
+
Prefix LMs accepts a `bidirectional_mask` input in `forward`
|
| 7 |
+
and treat the input prompt as the prefix in `generate`.
|
| 8 |
+
"""
|
| 9 |
+
from types import MethodType
|
| 10 |
+
from typing import Any, List, MutableMapping, Optional, Tuple, Union
|
| 11 |
+
import torch
|
| 12 |
+
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
|
| 13 |
+
from transformers.models.gpt_neo.modeling_gpt_neo import GPTNeoForCausalLM
|
| 14 |
+
from transformers.models.gpt_neox.modeling_gpt_neox import GPTNeoXForCausalLM
|
| 15 |
+
from transformers.models.gptj.modeling_gptj import GPTJForCausalLM
|
| 16 |
+
_SUPPORTED_GPT_MODELS = (GPT2LMHeadModel, GPTJForCausalLM, GPTNeoForCausalLM, GPTNeoXForCausalLM)
|
| 17 |
+
CAUSAL_GPT_TYPES = Union[GPT2LMHeadModel, GPTJForCausalLM, GPTNeoForCausalLM, GPTNeoXForCausalLM]
|
| 18 |
+
|
| 19 |
+
def _convert_gpt_causal_lm_to_prefix_lm(model: CAUSAL_GPT_TYPES) -> CAUSAL_GPT_TYPES:
|
| 20 |
+
"""Converts a GPT-style Causal LM to a Prefix LM.
|
| 21 |
+
|
| 22 |
+
Supported HuggingFace model classes:
|
| 23 |
+
- `GPT2LMHeadModel`
|
| 24 |
+
- `GPTNeoForCausalLM`
|
| 25 |
+
- `GPTNeoXForCausalLM`
|
| 26 |
+
- `GPTJForCausalLM`
|
| 27 |
+
|
| 28 |
+
See `convert_hf_causal_lm_to_prefix_lm` for more details.
|
| 29 |
+
"""
|
| 30 |
+
if hasattr(model, '_prefix_lm_converted'):
|
| 31 |
+
return model
|
| 32 |
+
assert isinstance(model, _SUPPORTED_GPT_MODELS)
|
| 33 |
+
assert model.config.add_cross_attention == False, 'Only supports GPT-style decoder-only models'
|
| 34 |
+
|
| 35 |
+
def _get_attn_modules(model: CAUSAL_GPT_TYPES) -> List[torch.nn.Module]:
|
| 36 |
+
"""Helper that gets a list of the model's attention modules.
|
| 37 |
+
|
| 38 |
+
Each module has a `bias` buffer used for causal masking. The Prefix LM
|
| 39 |
+
conversion adds logic to dynamically manipulate these biases to support
|
| 40 |
+
Prefix LM attention masking.
|
| 41 |
+
"""
|
| 42 |
+
attn_modules = []
|
| 43 |
+
if isinstance(model, GPTNeoXForCausalLM):
|
| 44 |
+
blocks = model.gpt_neox.layers
|
| 45 |
+
else:
|
| 46 |
+
blocks = model.transformer.h
|
| 47 |
+
for block in blocks:
|
| 48 |
+
if isinstance(model, GPTNeoForCausalLM):
|
| 49 |
+
if block.attn.attention_type != 'global':
|
| 50 |
+
continue
|
| 51 |
+
attn_module = block.attn.attention
|
| 52 |
+
elif isinstance(model, GPTNeoXForCausalLM):
|
| 53 |
+
attn_module = block.attention
|
| 54 |
+
else:
|
| 55 |
+
attn_module = block.attn
|
| 56 |
+
attn_modules.append(attn_module)
|
| 57 |
+
return attn_modules
|
| 58 |
+
setattr(model, '_original_forward', getattr(model, 'forward'))
|
| 59 |
+
setattr(model, '_original_generate', getattr(model, 'generate'))
|
| 60 |
+
|
| 61 |
+
def forward(self: CAUSAL_GPT_TYPES, input_ids: Optional[torch.LongTensor]=None, past_key_values: Optional[Tuple[Tuple[torch.Tensor]]]=None, attention_mask: Optional[torch.FloatTensor]=None, bidirectional_mask: Optional[torch.Tensor]=None, token_type_ids: Optional[torch.LongTensor]=None, position_ids: Optional[torch.LongTensor]=None, head_mask: Optional[torch.FloatTensor]=None, inputs_embeds: Optional[torch.FloatTensor]=None, labels: Optional[torch.LongTensor]=None, use_cache: Optional[bool]=None, output_attentions: Optional[bool]=None, output_hidden_states: Optional[bool]=None, return_dict: Optional[bool]=None):
|
| 62 |
+
"""Wraps original forward to enable PrefixLM attention."""
|
| 63 |
+
|
| 64 |
+
def call_og_forward():
|
| 65 |
+
if isinstance(self, GPTNeoXForCausalLM):
|
| 66 |
+
return self._original_forward(input_ids=input_ids, past_key_values=past_key_values, attention_mask=attention_mask, head_mask=head_mask, inputs_embeds=inputs_embeds, labels=labels, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict)
|
| 67 |
+
else:
|
| 68 |
+
return self._original_forward(input_ids=input_ids, past_key_values=past_key_values, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, labels=labels, use_cache=use_cache, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict)
|
| 69 |
+
if bidirectional_mask is None:
|
| 70 |
+
return call_og_forward()
|
| 71 |
+
assert isinstance(bidirectional_mask, torch.Tensor)
|
| 72 |
+
attn_modules = _get_attn_modules(model)
|
| 73 |
+
(b, s) = bidirectional_mask.shape
|
| 74 |
+
max_length = attn_modules[0].bias.shape[-1]
|
| 75 |
+
if s > max_length:
|
| 76 |
+
raise ValueError(f'bidirectional_mask sequence length (={s}) exceeds the ' + f'max length allowed by the model ({max_length}).')
|
| 77 |
+
assert s <= max_length
|
| 78 |
+
if s < max_length:
|
| 79 |
+
pad = torch.zeros((int(b), int(max_length - s)), dtype=bidirectional_mask.dtype, device=bidirectional_mask.device)
|
| 80 |
+
bidirectional_mask = torch.cat([bidirectional_mask, pad], dim=1)
|
| 81 |
+
bidirectional = bidirectional_mask.unsqueeze(1).unsqueeze(1)
|
| 82 |
+
for attn_module in attn_modules:
|
| 83 |
+
assert isinstance(attn_module.bias, torch.Tensor)
|
| 84 |
+
attn_module.bias.data = torch.logical_or(attn_module.bias.data, bidirectional)
|
| 85 |
+
output = call_og_forward()
|
| 86 |
+
for attn_module in attn_modules:
|
| 87 |
+
attn_module.bias.data = torch.tril(attn_module.bias.data[0, 0])[None, None]
|
| 88 |
+
return output
|
| 89 |
+
|
| 90 |
+
def generate(self: CAUSAL_GPT_TYPES, *args: Any, **kwargs: Any):
|
| 91 |
+
"""Wraps original generate to enable PrefixLM attention."""
|
| 92 |
+
attn_modules = _get_attn_modules(model)
|
| 93 |
+
for attn_module in attn_modules:
|
| 94 |
+
attn_module.bias.data[:] = 1
|
| 95 |
+
output = self._original_generate(*args, **kwargs)
|
| 96 |
+
for attn_module in attn_modules:
|
| 97 |
+
attn_module.bias.data = torch.tril(attn_module.bias.data[0, 0])[None, None]
|
| 98 |
+
return output
|
| 99 |
+
setattr(model, 'forward', MethodType(forward, model))
|
| 100 |
+
setattr(model, 'generate', MethodType(generate, model))
|
| 101 |
+
setattr(model, '_prefix_lm_converted', True)
|
| 102 |
+
return model
|
| 103 |
+
_SUPPORTED_HF_MODELS = _SUPPORTED_GPT_MODELS
|
| 104 |
+
CAUSAL_LM_TYPES = Union[GPT2LMHeadModel, GPTJForCausalLM, GPTNeoForCausalLM, GPTNeoXForCausalLM]
|
| 105 |
+
|
| 106 |
+
def convert_hf_causal_lm_to_prefix_lm(model: CAUSAL_LM_TYPES) -> CAUSAL_LM_TYPES:
|
| 107 |
+
"""Converts a HuggingFace Causal LM to a Prefix LM.
|
| 108 |
+
|
| 109 |
+
Supported HuggingFace model classes:
|
| 110 |
+
- `GPT2LMHeadModel`
|
| 111 |
+
- `GPTNeoForCausalLM`
|
| 112 |
+
- `GPTNeoXForCausalLM`
|
| 113 |
+
- `GPTJForCausalLM`
|
| 114 |
+
|
| 115 |
+
Conversion to a Prefix LM is done by modifying the `forward` method, and possibly also the
|
| 116 |
+
`generate` method and/or select underlying methods depending on the model class.
|
| 117 |
+
|
| 118 |
+
These changes preserve the model API, but add a new input to `forward`: "bidirectional_mask".
|
| 119 |
+
|
| 120 |
+
Notes on training:
|
| 121 |
+
To actually train the converted model as a Prefix LM, training batches will need to indicate
|
| 122 |
+
the prefix/target structure by including `bidirectional_mask` as part of the batch inputs.
|
| 123 |
+
|
| 124 |
+
**This is not a standard input and requires custom layers either within or after your dataloader.**
|
| 125 |
+
|
| 126 |
+
In addition to adding `bidirectional_mask` to the batch, this custom code should modify `labels`
|
| 127 |
+
such that `batch['labels'][batch['bidirectional_mask'] == 1] == -100`.
|
| 128 |
+
That is, the prefix portion of the sequence should not generate any loss. Loss should only be
|
| 129 |
+
generated by the target portion of the sequence.
|
| 130 |
+
|
| 131 |
+
Notes on `GPTNeoForCausalLM`:
|
| 132 |
+
To simplify the implementation, "global" and "local" attention layers are handled differently.
|
| 133 |
+
For "global" layers, we handle conversion as described above. For "local" layers, which use a
|
| 134 |
+
causal attention mask within a restricted local window, we do not alter the masking.
|
| 135 |
+
|
| 136 |
+
Notes on `forward` method conversion:
|
| 137 |
+
After conversion, the `forward` method will handle a new input, `bidirectional_mask`,
|
| 138 |
+
which should be a [batch_size, seq_length] byte tensor, where 1 indicates token positions
|
| 139 |
+
belonging to the prefix (prefix tokens can attend to one another bidirectionally), and
|
| 140 |
+
0 indicates token positions belonging to the target.
|
| 141 |
+
|
| 142 |
+
The new `forward` method will incorporate `bidirectional_mask` (if supplied) into the existing
|
| 143 |
+
causal mask, call the original `forward` method, and (if the causal mask is a buffer) reset
|
| 144 |
+
the causal masks before returning the result.
|
| 145 |
+
|
| 146 |
+
Notes on `generate` method conversion:
|
| 147 |
+
After conversion, the `generate` method will have the same signature but will internally
|
| 148 |
+
convert all causal masks to be purely bidirectional, call the original `generate` method, and
|
| 149 |
+
(where appropriate) reset the causal masks before returning the result.
|
| 150 |
+
|
| 151 |
+
This works thanks to the logic of the HuggingFace `generate` API, which first encodes the token
|
| 152 |
+
"prompt" passed to `generate` (which is treated as the prefix) and then sequentially generates
|
| 153 |
+
each new token. Encodings are cached as generation happens, so all prefix tokens can attend to one
|
| 154 |
+
another (as expected in a Prefix LM) and generated tokens can only attend to prefix tokens and
|
| 155 |
+
previously-generated tokens (also as expected in a Prefix LM).
|
| 156 |
+
|
| 157 |
+
To preserve the API, the original methods are renamed to `_original_forward` and
|
| 158 |
+
`_original_generate`, and replaced with new `forward` and `generate` methods that wrap
|
| 159 |
+
them, respectively. Although implementation details vary by model class.
|
| 160 |
+
"""
|
| 161 |
+
if isinstance(model, _SUPPORTED_GPT_MODELS):
|
| 162 |
+
return _convert_gpt_causal_lm_to_prefix_lm(model)
|
| 163 |
+
else:
|
| 164 |
+
raise TypeError(f'Cannot convert model to Prefix LM. ' + f'Model does not belong to set of supported HF models:' + f'\n{_SUPPORTED_HF_MODELS}')
|
| 165 |
+
|
| 166 |
+
def add_bidirectional_mask_if_missing(batch: MutableMapping):
|
| 167 |
+
"""Attempts to add bidirectional_mask to batch if missing.
|
| 168 |
+
|
| 169 |
+
Raises:
|
| 170 |
+
KeyError if bidirectional_mask is missing and can't be inferred
|
| 171 |
+
"""
|
| 172 |
+
if 'bidirectional_mask' not in batch:
|
| 173 |
+
if batch.get('mode', None) == 'icl_task':
|
| 174 |
+
batch['bidirectional_mask'] = batch['attention_mask'].clone()
|
| 175 |
+
for (i, continuation_indices) in enumerate(batch['continuation_indices']):
|
| 176 |
+
batch['bidirectional_mask'][i, continuation_indices] = 0
|
| 177 |
+
elif 'labels' in batch and 'attention_mask' in batch:
|
| 178 |
+
batch['bidirectional_mask'] = torch.logical_and(torch.eq(batch['attention_mask'], 1), torch.eq(batch['labels'], -100)).type_as(batch['attention_mask'])
|
| 179 |
+
else:
|
| 180 |
+
raise KeyError('No bidirectional_mask in batch and not sure how to construct one.')
|
meta_init_context.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from contextlib import contextmanager
|
| 2 |
+
from typing import Any, Callable, Optional
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
|
| 6 |
+
@contextmanager
|
| 7 |
+
def init_empty_weights(include_buffers: bool=False):
|
| 8 |
+
"""Meta initialization context manager.
|
| 9 |
+
|
| 10 |
+
A context manager under which models are initialized with all parameters
|
| 11 |
+
on the meta device, therefore creating an empty model. Useful when just
|
| 12 |
+
initializing the model would blow the available RAM.
|
| 13 |
+
|
| 14 |
+
Args:
|
| 15 |
+
include_buffers (`bool`, *optional*, defaults to `False`): Whether or
|
| 16 |
+
not to also put all buffers on the meta device while initializing.
|
| 17 |
+
|
| 18 |
+
Example:
|
| 19 |
+
```python
|
| 20 |
+
import torch.nn as nn
|
| 21 |
+
|
| 22 |
+
# Initialize a model with 100 billions parameters in no time and without using any RAM.
|
| 23 |
+
with init_empty_weights():
|
| 24 |
+
tst = nn.Sequential(*[nn.Linear(10000, 10000) for _ in range(1000)])
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
<Tip warning={true}>
|
| 28 |
+
|
| 29 |
+
Any model created under this context manager has no weights. As such you can't do something like
|
| 30 |
+
`model.to(some_device)` with it. To load weights inside your empty model, see [`load_checkpoint_and_dispatch`].
|
| 31 |
+
|
| 32 |
+
</Tip>
|
| 33 |
+
"""
|
| 34 |
+
with init_on_device(torch.device('meta'), include_buffers=include_buffers) as f:
|
| 35 |
+
yield f
|
| 36 |
+
|
| 37 |
+
@contextmanager
|
| 38 |
+
def init_on_device(device: torch.device, include_buffers: bool=False):
|
| 39 |
+
"""Device initialization context manager.
|
| 40 |
+
|
| 41 |
+
A context manager under which models are initialized with all parameters
|
| 42 |
+
on the specified device.
|
| 43 |
+
|
| 44 |
+
Args:
|
| 45 |
+
device (`torch.device`): Device to initialize all parameters on.
|
| 46 |
+
include_buffers (`bool`, *optional*, defaults to `False`): Whether or
|
| 47 |
+
not to also put all buffers on the meta device while initializing.
|
| 48 |
+
|
| 49 |
+
Example:
|
| 50 |
+
```python
|
| 51 |
+
import torch.nn as nn
|
| 52 |
+
|
| 53 |
+
with init_on_device(device=torch.device("cuda")):
|
| 54 |
+
tst = nn.Liner(100, 100) # on `cuda` device
|
| 55 |
+
```
|
| 56 |
+
"""
|
| 57 |
+
old_register_parameter = nn.Module.register_parameter
|
| 58 |
+
if include_buffers:
|
| 59 |
+
old_register_buffer = nn.Module.register_buffer
|
| 60 |
+
|
| 61 |
+
def register_empty_parameter(self: torch.nn.Module, name: str, param: Optional[torch.nn.Parameter]):
|
| 62 |
+
old_register_parameter(self, name, param)
|
| 63 |
+
if param is not None:
|
| 64 |
+
parameter = self._parameters[name]
|
| 65 |
+
assert parameter is not None
|
| 66 |
+
param_cls = type(parameter)
|
| 67 |
+
kwargs = parameter.__dict__
|
| 68 |
+
self._parameters[name] = param_cls(parameter.to(device), **kwargs)
|
| 69 |
+
|
| 70 |
+
def register_empty_buffer(self: torch.nn.Module, name: str, tensor: Optional[torch.Tensor], persistent: bool=True):
|
| 71 |
+
old_register_buffer(self, name, tensor, persistent=persistent)
|
| 72 |
+
if tensor is not None:
|
| 73 |
+
named_buffer = self._buffers[name]
|
| 74 |
+
assert named_buffer is not None
|
| 75 |
+
self._buffers[name] = named_buffer.to(device)
|
| 76 |
+
if include_buffers:
|
| 77 |
+
tensor_constructors_to_patch = {torch_function_name: getattr(torch, torch_function_name) for torch_function_name in ['empty', 'zeros', 'ones', 'full']}
|
| 78 |
+
else:
|
| 79 |
+
tensor_constructors_to_patch = {}
|
| 80 |
+
|
| 81 |
+
def patch_tensor_constructor(fn: Callable):
|
| 82 |
+
|
| 83 |
+
def wrapper(*args: Any, **kwargs: Any):
|
| 84 |
+
kwargs['device'] = device
|
| 85 |
+
return fn(*args, **kwargs)
|
| 86 |
+
return wrapper
|
| 87 |
+
try:
|
| 88 |
+
nn.Module.register_parameter = register_empty_parameter
|
| 89 |
+
if include_buffers:
|
| 90 |
+
nn.Module.register_buffer = register_empty_buffer
|
| 91 |
+
for torch_function_name in tensor_constructors_to_patch.keys():
|
| 92 |
+
setattr(torch, torch_function_name, patch_tensor_constructor(getattr(torch, torch_function_name)))
|
| 93 |
+
yield
|
| 94 |
+
finally:
|
| 95 |
+
nn.Module.register_parameter = old_register_parameter
|
| 96 |
+
if include_buffers:
|
| 97 |
+
nn.Module.register_buffer = old_register_buffer
|
| 98 |
+
for (torch_function_name, old_torch_function) in tensor_constructors_to_patch.items():
|
| 99 |
+
setattr(torch, torch_function_name, old_torch_function)
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:20a47d04743fee3ed94f0f6efd031af1f98370cb1511a0ce62bd7d6a23dfceca
|
| 3 |
+
size 4980318592
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ba0334f1afea81ffcfb889dfe402a643b9dc89c55a2843a955a9e179e87618a8
|
| 3 |
+
size 1880557448
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 6860840960
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"transformer.blocks.0.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 7 |
+
"transformer.blocks.0.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 8 |
+
"transformer.blocks.0.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 9 |
+
"transformer.blocks.0.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 10 |
+
"transformer.blocks.0.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 11 |
+
"transformer.blocks.0.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"transformer.blocks.0.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 13 |
+
"transformer.blocks.0.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 14 |
+
"transformer.blocks.0.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 15 |
+
"transformer.blocks.0.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"transformer.blocks.1.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 17 |
+
"transformer.blocks.1.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"transformer.blocks.1.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 19 |
+
"transformer.blocks.1.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"transformer.blocks.1.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 21 |
+
"transformer.blocks.1.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"transformer.blocks.1.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 23 |
+
"transformer.blocks.1.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"transformer.blocks.1.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 25 |
+
"transformer.blocks.1.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 26 |
+
"transformer.blocks.10.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 27 |
+
"transformer.blocks.10.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"transformer.blocks.10.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 29 |
+
"transformer.blocks.10.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"transformer.blocks.10.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 31 |
+
"transformer.blocks.10.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 32 |
+
"transformer.blocks.10.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 33 |
+
"transformer.blocks.10.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"transformer.blocks.10.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 35 |
+
"transformer.blocks.10.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"transformer.blocks.11.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 37 |
+
"transformer.blocks.11.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"transformer.blocks.11.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 39 |
+
"transformer.blocks.11.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"transformer.blocks.11.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 41 |
+
"transformer.blocks.11.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"transformer.blocks.11.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 43 |
+
"transformer.blocks.11.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"transformer.blocks.11.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 45 |
+
"transformer.blocks.11.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"transformer.blocks.12.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 47 |
+
"transformer.blocks.12.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 48 |
+
"transformer.blocks.12.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 49 |
+
"transformer.blocks.12.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 50 |
+
"transformer.blocks.12.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 51 |
+
"transformer.blocks.12.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 52 |
+
"transformer.blocks.12.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 53 |
+
"transformer.blocks.12.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 54 |
+
"transformer.blocks.12.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 55 |
+
"transformer.blocks.12.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 56 |
+
"transformer.blocks.13.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 57 |
+
"transformer.blocks.13.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 58 |
+
"transformer.blocks.13.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 59 |
+
"transformer.blocks.13.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 60 |
+
"transformer.blocks.13.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 61 |
+
"transformer.blocks.13.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 62 |
+
"transformer.blocks.13.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 63 |
+
"transformer.blocks.13.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 64 |
+
"transformer.blocks.13.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 65 |
+
"transformer.blocks.13.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 66 |
+
"transformer.blocks.14.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 67 |
+
"transformer.blocks.14.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 68 |
+
"transformer.blocks.14.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 69 |
+
"transformer.blocks.14.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 70 |
+
"transformer.blocks.14.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 71 |
+
"transformer.blocks.14.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 72 |
+
"transformer.blocks.14.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 73 |
+
"transformer.blocks.14.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 74 |
+
"transformer.blocks.14.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 75 |
+
"transformer.blocks.14.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 76 |
+
"transformer.blocks.15.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 77 |
+
"transformer.blocks.15.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 78 |
+
"transformer.blocks.15.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 79 |
+
"transformer.blocks.15.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 80 |
+
"transformer.blocks.15.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 81 |
+
"transformer.blocks.15.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 82 |
+
"transformer.blocks.15.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 83 |
+
"transformer.blocks.15.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 84 |
+
"transformer.blocks.15.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 85 |
+
"transformer.blocks.15.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 86 |
+
"transformer.blocks.16.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 87 |
+
"transformer.blocks.16.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 88 |
+
"transformer.blocks.16.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 89 |
+
"transformer.blocks.16.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 90 |
+
"transformer.blocks.16.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 91 |
+
"transformer.blocks.16.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 92 |
+
"transformer.blocks.16.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 93 |
+
"transformer.blocks.16.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 94 |
+
"transformer.blocks.16.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 95 |
+
"transformer.blocks.16.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 96 |
+
"transformer.blocks.17.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 97 |
+
"transformer.blocks.17.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 98 |
+
"transformer.blocks.17.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 99 |
+
"transformer.blocks.17.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 100 |
+
"transformer.blocks.17.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 101 |
+
"transformer.blocks.17.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 102 |
+
"transformer.blocks.17.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 103 |
+
"transformer.blocks.17.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 104 |
+
"transformer.blocks.17.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 105 |
+
"transformer.blocks.17.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 106 |
+
"transformer.blocks.18.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 107 |
+
"transformer.blocks.18.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 108 |
+
"transformer.blocks.18.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 109 |
+
"transformer.blocks.18.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 110 |
+
"transformer.blocks.18.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 111 |
+
"transformer.blocks.18.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 112 |
+
"transformer.blocks.18.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 113 |
+
"transformer.blocks.18.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 114 |
+
"transformer.blocks.18.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 115 |
+
"transformer.blocks.18.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"transformer.blocks.19.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 117 |
+
"transformer.blocks.19.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"transformer.blocks.19.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 119 |
+
"transformer.blocks.19.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"transformer.blocks.19.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 121 |
+
"transformer.blocks.19.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 122 |
+
"transformer.blocks.19.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 123 |
+
"transformer.blocks.19.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 124 |
+
"transformer.blocks.19.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 125 |
+
"transformer.blocks.19.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 126 |
+
"transformer.blocks.2.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 127 |
+
"transformer.blocks.2.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 128 |
+
"transformer.blocks.2.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 129 |
+
"transformer.blocks.2.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 130 |
+
"transformer.blocks.2.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 131 |
+
"transformer.blocks.2.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 132 |
+
"transformer.blocks.2.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 133 |
+
"transformer.blocks.2.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 134 |
+
"transformer.blocks.2.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 135 |
+
"transformer.blocks.2.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 136 |
+
"transformer.blocks.20.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 137 |
+
"transformer.blocks.20.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 138 |
+
"transformer.blocks.20.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 139 |
+
"transformer.blocks.20.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 140 |
+
"transformer.blocks.20.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 141 |
+
"transformer.blocks.20.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 142 |
+
"transformer.blocks.20.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 143 |
+
"transformer.blocks.20.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 144 |
+
"transformer.blocks.20.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 145 |
+
"transformer.blocks.20.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 146 |
+
"transformer.blocks.21.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 147 |
+
"transformer.blocks.21.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 148 |
+
"transformer.blocks.21.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 149 |
+
"transformer.blocks.21.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 150 |
+
"transformer.blocks.21.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 151 |
+
"transformer.blocks.21.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 152 |
+
"transformer.blocks.21.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 153 |
+
"transformer.blocks.21.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 154 |
+
"transformer.blocks.21.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 155 |
+
"transformer.blocks.21.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 156 |
+
"transformer.blocks.22.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 157 |
+
"transformer.blocks.22.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 158 |
+
"transformer.blocks.22.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 159 |
+
"transformer.blocks.22.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 160 |
+
"transformer.blocks.22.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 161 |
+
"transformer.blocks.22.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 162 |
+
"transformer.blocks.22.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 163 |
+
"transformer.blocks.22.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 164 |
+
"transformer.blocks.22.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 165 |
+
"transformer.blocks.22.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 166 |
+
"transformer.blocks.23.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 167 |
+
"transformer.blocks.23.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 168 |
+
"transformer.blocks.23.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 169 |
+
"transformer.blocks.23.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 170 |
+
"transformer.blocks.23.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 171 |
+
"transformer.blocks.23.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 172 |
+
"transformer.blocks.23.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 173 |
+
"transformer.blocks.23.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 174 |
+
"transformer.blocks.23.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 175 |
+
"transformer.blocks.23.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 176 |
+
"transformer.blocks.24.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 177 |
+
"transformer.blocks.24.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 178 |
+
"transformer.blocks.24.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 179 |
+
"transformer.blocks.24.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 180 |
+
"transformer.blocks.24.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 181 |
+
"transformer.blocks.24.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 182 |
+
"transformer.blocks.24.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 183 |
+
"transformer.blocks.24.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 184 |
+
"transformer.blocks.24.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 185 |
+
"transformer.blocks.24.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 186 |
+
"transformer.blocks.25.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 187 |
+
"transformer.blocks.25.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 188 |
+
"transformer.blocks.25.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 189 |
+
"transformer.blocks.25.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 190 |
+
"transformer.blocks.25.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 191 |
+
"transformer.blocks.25.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 192 |
+
"transformer.blocks.25.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 193 |
+
"transformer.blocks.25.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 194 |
+
"transformer.blocks.25.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 195 |
+
"transformer.blocks.25.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 196 |
+
"transformer.blocks.26.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 197 |
+
"transformer.blocks.26.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 198 |
+
"transformer.blocks.26.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 199 |
+
"transformer.blocks.26.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 200 |
+
"transformer.blocks.26.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 201 |
+
"transformer.blocks.26.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 202 |
+
"transformer.blocks.26.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 203 |
+
"transformer.blocks.26.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 204 |
+
"transformer.blocks.26.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 205 |
+
"transformer.blocks.26.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 206 |
+
"transformer.blocks.27.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 207 |
+
"transformer.blocks.27.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 208 |
+
"transformer.blocks.27.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 209 |
+
"transformer.blocks.27.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 210 |
+
"transformer.blocks.27.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 211 |
+
"transformer.blocks.27.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 212 |
+
"transformer.blocks.27.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 213 |
+
"transformer.blocks.27.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 214 |
+
"transformer.blocks.27.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 215 |
+
"transformer.blocks.27.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 216 |
+
"transformer.blocks.28.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 217 |
+
"transformer.blocks.28.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 218 |
+
"transformer.blocks.28.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 219 |
+
"transformer.blocks.28.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 220 |
+
"transformer.blocks.28.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 221 |
+
"transformer.blocks.28.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 222 |
+
"transformer.blocks.28.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 223 |
+
"transformer.blocks.28.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 224 |
+
"transformer.blocks.28.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 225 |
+
"transformer.blocks.28.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 226 |
+
"transformer.blocks.29.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 227 |
+
"transformer.blocks.29.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 228 |
+
"transformer.blocks.29.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 229 |
+
"transformer.blocks.29.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 230 |
+
"transformer.blocks.29.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 231 |
+
"transformer.blocks.29.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 232 |
+
"transformer.blocks.29.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 233 |
+
"transformer.blocks.29.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 234 |
+
"transformer.blocks.29.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 235 |
+
"transformer.blocks.29.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 236 |
+
"transformer.blocks.3.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 237 |
+
"transformer.blocks.3.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 238 |
+
"transformer.blocks.3.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 239 |
+
"transformer.blocks.3.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 240 |
+
"transformer.blocks.3.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 241 |
+
"transformer.blocks.3.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 242 |
+
"transformer.blocks.3.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 243 |
+
"transformer.blocks.3.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 244 |
+
"transformer.blocks.3.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 245 |
+
"transformer.blocks.3.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 246 |
+
"transformer.blocks.30.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 247 |
+
"transformer.blocks.30.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 248 |
+
"transformer.blocks.30.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 249 |
+
"transformer.blocks.30.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 250 |
+
"transformer.blocks.30.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 251 |
+
"transformer.blocks.30.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 252 |
+
"transformer.blocks.30.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 253 |
+
"transformer.blocks.30.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 254 |
+
"transformer.blocks.30.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 255 |
+
"transformer.blocks.30.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 256 |
+
"transformer.blocks.31.attn.Wqkv.SCB": "model-00002-of-00002.safetensors",
|
| 257 |
+
"transformer.blocks.31.attn.Wqkv.weight": "model-00002-of-00002.safetensors",
|
| 258 |
+
"transformer.blocks.31.attn.out_proj.SCB": "model-00002-of-00002.safetensors",
|
| 259 |
+
"transformer.blocks.31.attn.out_proj.weight": "model-00002-of-00002.safetensors",
|
| 260 |
+
"transformer.blocks.31.ffn.down_proj.SCB": "model-00002-of-00002.safetensors",
|
| 261 |
+
"transformer.blocks.31.ffn.down_proj.weight": "model-00002-of-00002.safetensors",
|
| 262 |
+
"transformer.blocks.31.ffn.up_proj.SCB": "model-00002-of-00002.safetensors",
|
| 263 |
+
"transformer.blocks.31.ffn.up_proj.weight": "model-00002-of-00002.safetensors",
|
| 264 |
+
"transformer.blocks.31.norm_1.weight": "model-00002-of-00002.safetensors",
|
| 265 |
+
"transformer.blocks.31.norm_2.weight": "model-00002-of-00002.safetensors",
|
| 266 |
+
"transformer.blocks.4.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 267 |
+
"transformer.blocks.4.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 268 |
+
"transformer.blocks.4.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 269 |
+
"transformer.blocks.4.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 270 |
+
"transformer.blocks.4.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 271 |
+
"transformer.blocks.4.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 272 |
+
"transformer.blocks.4.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 273 |
+
"transformer.blocks.4.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 274 |
+
"transformer.blocks.4.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 275 |
+
"transformer.blocks.4.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 276 |
+
"transformer.blocks.5.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 277 |
+
"transformer.blocks.5.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 278 |
+
"transformer.blocks.5.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 279 |
+
"transformer.blocks.5.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 280 |
+
"transformer.blocks.5.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 281 |
+
"transformer.blocks.5.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 282 |
+
"transformer.blocks.5.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 283 |
+
"transformer.blocks.5.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 284 |
+
"transformer.blocks.5.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 285 |
+
"transformer.blocks.5.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 286 |
+
"transformer.blocks.6.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 287 |
+
"transformer.blocks.6.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 288 |
+
"transformer.blocks.6.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 289 |
+
"transformer.blocks.6.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 290 |
+
"transformer.blocks.6.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 291 |
+
"transformer.blocks.6.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 292 |
+
"transformer.blocks.6.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 293 |
+
"transformer.blocks.6.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 294 |
+
"transformer.blocks.6.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 295 |
+
"transformer.blocks.6.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 296 |
+
"transformer.blocks.7.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 297 |
+
"transformer.blocks.7.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 298 |
+
"transformer.blocks.7.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 299 |
+
"transformer.blocks.7.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 300 |
+
"transformer.blocks.7.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 301 |
+
"transformer.blocks.7.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 302 |
+
"transformer.blocks.7.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 303 |
+
"transformer.blocks.7.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 304 |
+
"transformer.blocks.7.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 305 |
+
"transformer.blocks.7.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 306 |
+
"transformer.blocks.8.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 307 |
+
"transformer.blocks.8.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 308 |
+
"transformer.blocks.8.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 309 |
+
"transformer.blocks.8.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 310 |
+
"transformer.blocks.8.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 311 |
+
"transformer.blocks.8.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 312 |
+
"transformer.blocks.8.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 313 |
+
"transformer.blocks.8.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 314 |
+
"transformer.blocks.8.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 315 |
+
"transformer.blocks.8.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 316 |
+
"transformer.blocks.9.attn.Wqkv.SCB": "model-00001-of-00002.safetensors",
|
| 317 |
+
"transformer.blocks.9.attn.Wqkv.weight": "model-00001-of-00002.safetensors",
|
| 318 |
+
"transformer.blocks.9.attn.out_proj.SCB": "model-00001-of-00002.safetensors",
|
| 319 |
+
"transformer.blocks.9.attn.out_proj.weight": "model-00001-of-00002.safetensors",
|
| 320 |
+
"transformer.blocks.9.ffn.down_proj.SCB": "model-00001-of-00002.safetensors",
|
| 321 |
+
"transformer.blocks.9.ffn.down_proj.weight": "model-00001-of-00002.safetensors",
|
| 322 |
+
"transformer.blocks.9.ffn.up_proj.SCB": "model-00001-of-00002.safetensors",
|
| 323 |
+
"transformer.blocks.9.ffn.up_proj.weight": "model-00001-of-00002.safetensors",
|
| 324 |
+
"transformer.blocks.9.norm_1.weight": "model-00001-of-00002.safetensors",
|
| 325 |
+
"transformer.blocks.9.norm_2.weight": "model-00001-of-00002.safetensors",
|
| 326 |
+
"transformer.norm_f.weight": "model-00002-of-00002.safetensors",
|
| 327 |
+
"transformer.wte.weight": "model-00001-of-00002.safetensors"
|
| 328 |
+
}
|
| 329 |
+
}
|
modeling_mpt.py
ADDED
|
@@ -0,0 +1,519 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""A simple, flexible implementation of a GPT model.
|
| 2 |
+
|
| 3 |
+
Inspired by https://github.com/karpathy/minGPT/blob/master/mingpt/model.py
|
| 4 |
+
"""
|
| 5 |
+
from __future__ import annotations
|
| 6 |
+
import math
|
| 7 |
+
import warnings
|
| 8 |
+
from typing import Any, Dict, List, Mapping, MutableMapping, Optional, Tuple, Union
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from .attention import is_flash_v1_installed, is_flash_v2_installed
|
| 13 |
+
if is_flash_v2_installed():
|
| 14 |
+
try:
|
| 15 |
+
from flash_attn import bert_padding
|
| 16 |
+
from flash_attn.layers.rotary import RotaryEmbedding as DAILRotaryEmbedding
|
| 17 |
+
except Exception as e:
|
| 18 |
+
raise e
|
| 19 |
+
if is_flash_v1_installed():
|
| 20 |
+
try:
|
| 21 |
+
from flash_attn import bert_padding
|
| 22 |
+
except Exception as e:
|
| 23 |
+
raise e
|
| 24 |
+
from transformers import PreTrainedModel, PreTrainedTokenizerBase
|
| 25 |
+
from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
|
| 26 |
+
from transformers.models.llama.modeling_llama import LlamaDynamicNTKScalingRotaryEmbedding as HFDynamicNTKScalingRotaryEmbedding
|
| 27 |
+
from transformers.models.llama.modeling_llama import LlamaLinearScalingRotaryEmbedding as HFLinearScalingRotaryEmbedding
|
| 28 |
+
from transformers.models.llama.modeling_llama import LlamaRotaryEmbedding as HFRotaryEmbedding
|
| 29 |
+
from .attention import ATTN_CLASS_REGISTRY, attn_bias_shape, build_attn_bias, gen_slopes
|
| 30 |
+
from .blocks import MPTBlock
|
| 31 |
+
from .custom_embedding import SharedEmbedding
|
| 32 |
+
from .fc import FC_CLASS_REGISTRY as FC_CLASS_REGISTRY
|
| 33 |
+
from .ffn import FFN_CLASS_REGISTRY as FFN_CLASS_REGISTRY
|
| 34 |
+
from .ffn import MPTMLP as MPTMLP
|
| 35 |
+
from .ffn import build_ffn as build_ffn
|
| 36 |
+
from .norm import NORM_CLASS_REGISTRY
|
| 37 |
+
from .configuration_mpt import MPTConfig
|
| 38 |
+
from .adapt_tokenizer import AutoTokenizerForMOD, adapt_tokenizer_for_denoising
|
| 39 |
+
from .hf_prefixlm_converter import add_bidirectional_mask_if_missing, convert_hf_causal_lm_to_prefix_lm
|
| 40 |
+
from .meta_init_context import init_empty_weights
|
| 41 |
+
from .param_init_fns import generic_param_init_fn_, MODEL_INIT_REGISTRY
|
| 42 |
+
try:
|
| 43 |
+
from .flash_attn_triton import flash_attn_func as flash_attn_func
|
| 44 |
+
except:
|
| 45 |
+
pass
|
| 46 |
+
import logging
|
| 47 |
+
log = logging.getLogger(__name__)
|
| 48 |
+
|
| 49 |
+
def gen_rotary_embedding(rope_head_dim: int, rope_impl: str, rope_theta: int, rope_dail_config: dict, rope_hf_config: dict, max_seq_len: int):
|
| 50 |
+
if rope_impl == 'dail':
|
| 51 |
+
return DAILRotaryEmbedding(dim=rope_head_dim, base=rope_theta, interleaved=False, scale_base=rope_dail_config['xpos_scale_base'] if rope_dail_config['type'] == 'xpos' else None, pos_idx_in_fp32=rope_dail_config['pos_idx_in_fp32'], device='cpu')
|
| 52 |
+
elif rope_impl == 'hf':
|
| 53 |
+
if rope_hf_config['type'] == 'no_scaling':
|
| 54 |
+
return HFRotaryEmbedding(rope_head_dim, max_position_embeddings=max_seq_len, base=rope_theta, device='cpu')
|
| 55 |
+
elif rope_hf_config['type'] == 'linear':
|
| 56 |
+
return HFLinearScalingRotaryEmbedding(rope_head_dim, max_position_embeddings=max_seq_len, base=rope_theta, scaling_factor=rope_hf_config['factor'], device='cpu')
|
| 57 |
+
elif rope_hf_config['type'] == 'dynamic':
|
| 58 |
+
return HFDynamicNTKScalingRotaryEmbedding(rope_head_dim, max_position_embeddings=max_seq_len, base=rope_theta, scaling_factor=rope_hf_config['factor'], device='cpu')
|
| 59 |
+
raise ValueError('rope_impl needs to be either dail or hf')
|
| 60 |
+
|
| 61 |
+
def gen_attention_mask_in_length(sequence_id: Union[None, torch.Tensor], S: int, attn_uses_sequence_id: bool, attn_impl: str, attention_mask: Union[torch.Tensor, None]):
|
| 62 |
+
"""Generates the attention mask used for sequence masking in FA v2.
|
| 63 |
+
|
| 64 |
+
Only supports sequence id based sparse attention for no attention masking or attention masking with right padding.
|
| 65 |
+
In case of left padding:
|
| 66 |
+
1. Training with left padding is not supported in MPT (see https://github.com/mosaicml/llm-foundry/blob/1eecd4cb8e734499f77f6a35f657b8b20c0adfcb/llmfoundry/models/mpt/modeling_mpt.py#L407).
|
| 67 |
+
2. For generation with left padding, we only have a single sequence id per sample, so we don't need sequence id based sparse attention.
|
| 68 |
+
|
| 69 |
+
Args:
|
| 70 |
+
sequence_id (Union[None, torch.Tensor]): Tensor containing the sequence id for each token. Shape (batch_size, seq_len).
|
| 71 |
+
S (int): Sequence length
|
| 72 |
+
attn_uses_sequence_id (bool): Whether the attention uses sequence id based masking.
|
| 73 |
+
attn_impl (str): Attention implementation. This function is only creates attention_mask_in_length for flash attention.
|
| 74 |
+
attention_mask (Union[torch.Tensor, None]): Attention mask tensor of shape (batch_size, seq_len)
|
| 75 |
+
|
| 76 |
+
Returns:
|
| 77 |
+
attention_mask_in_length: (batch, seqlen), int, a nonzero number (e.g., 1, 2, 3, etc.) means length of concatenated sequence in b-th batch, and 0 means none. For example, if batch = 3 and seqlen = 6, the attention_mask_in_length is:
|
| 78 |
+
```
|
| 79 |
+
[
|
| 80 |
+
[2, 3, 0, 0, 0, 0],
|
| 81 |
+
[3, 2, 0, 0, 0, 0],
|
| 82 |
+
[6, 0, 0, 0, 0, 0]
|
| 83 |
+
]
|
| 84 |
+
```
|
| 85 |
+
, which refers to the 3D-attention mask:
|
| 86 |
+
```
|
| 87 |
+
[
|
| 88 |
+
[
|
| 89 |
+
[1, 0, 0, 0, 0, 0],
|
| 90 |
+
[1, 1, 0, 0, 0, 0],
|
| 91 |
+
[0, 0, 1, 0, 0, 0],
|
| 92 |
+
[0, 0, 1, 1, 0, 0],
|
| 93 |
+
[0, 0, 1, 1, 1, 0],
|
| 94 |
+
[0, 0, 0, 0, 0, 1]
|
| 95 |
+
],
|
| 96 |
+
[
|
| 97 |
+
[1, 0, 0, 0, 0, 0],
|
| 98 |
+
[1, 1, 0, 0, 0, 0],
|
| 99 |
+
[1, 1, 1, 0, 0, 0],
|
| 100 |
+
[0, 0, 0, 1, 0, 0],
|
| 101 |
+
[0, 0, 0, 1, 1, 0],
|
| 102 |
+
[0, 0, 0, 0, 0, 1]
|
| 103 |
+
],
|
| 104 |
+
[
|
| 105 |
+
[1, 0, 0, 0, 0, 0],
|
| 106 |
+
[1, 1, 0, 0, 0, 0],
|
| 107 |
+
[1, 1, 1, 0, 0, 0],
|
| 108 |
+
[1, 1, 1, 1, 0, 0],
|
| 109 |
+
[1, 1, 1, 1, 1, 0],
|
| 110 |
+
[1, 1, 1, 1, 1, 1]
|
| 111 |
+
]
|
| 112 |
+
]
|
| 113 |
+
```.
|
| 114 |
+
(The description above is taken verbatim from https://github.com/Dao-AILab/flash-attention/blob/9356a1c0389660d7e231ff3163c1ac17d9e3824a/flash_attn/bert_padding.py#L125 .)
|
| 115 |
+
"""
|
| 116 |
+
attention_mask_in_length = None
|
| 117 |
+
if sequence_id is not None and attn_uses_sequence_id and (attn_impl == 'flash'):
|
| 118 |
+
if attention_mask is not None and attention_mask[:, 0].sum() != attention_mask.shape[0]:
|
| 119 |
+
raise NotImplementedError('Left padding is not supported with flash attention when attn_uses_sequence_id is set to True.')
|
| 120 |
+
if S != sequence_id.shape[-1]:
|
| 121 |
+
raise ValueError(f'Sequence length ({S}) does not match length of sequences in sequence_id ({sequence_id.shape[-1]}).')
|
| 122 |
+
if attention_mask is not None:
|
| 123 |
+
sequence_id = sequence_id.masked_fill(~attention_mask, 0)
|
| 124 |
+
attention_mask_in_length = torch.nn.functional.one_hot(sequence_id)
|
| 125 |
+
if attention_mask is not None:
|
| 126 |
+
attention_mask_in_length = attention_mask_in_length.masked_fill(~attention_mask.unsqueeze(-1), 0)
|
| 127 |
+
attention_mask_in_length = attention_mask_in_length.sum(dim=1)
|
| 128 |
+
attention_mask_in_length = torch.nn.functional.pad(attention_mask_in_length, (0, S - attention_mask_in_length.shape[-1]), mode='constant', value=0)
|
| 129 |
+
return attention_mask_in_length
|
| 130 |
+
|
| 131 |
+
def gen_flash_attn_padding_info(bsz: int, S: int, past_key_len: int, device: torch.device, attention_mask_in_length: Optional[torch.Tensor]=None, attention_mask: Optional[torch.Tensor]=None):
|
| 132 |
+
flash_attn_padding_info = {}
|
| 133 |
+
if attention_mask_in_length is None:
|
| 134 |
+
key_padding_mask = attention_mask
|
| 135 |
+
if key_padding_mask is None:
|
| 136 |
+
key_padding_mask = torch.ones((bsz, past_key_len + S), dtype=torch.bool, device=device)
|
| 137 |
+
query_padding_mask = key_padding_mask[:, -S:]
|
| 138 |
+
unpadding_function = bert_padding.unpad_input
|
| 139 |
+
else:
|
| 140 |
+
key_padding_mask = attention_mask_in_length
|
| 141 |
+
query_padding_mask = attention_mask_in_length
|
| 142 |
+
unpadding_function = bert_padding.unpad_input_for_concatenated_sequences
|
| 143 |
+
(_, indices_q, cu_seqlens_q, max_seqlen_q) = unpadding_function(torch.empty(bsz, S, 1, device=device), query_padding_mask)
|
| 144 |
+
(_, indices_k, cu_seqlens_k, max_seqlen_k) = unpadding_function(torch.empty(bsz, past_key_len + S, 1, device=device), key_padding_mask)
|
| 145 |
+
(_, indices_v, _, _) = unpadding_function(torch.empty(bsz, past_key_len + S, 1, device=device), key_padding_mask)
|
| 146 |
+
flash_attn_padding_info['indices_q'] = indices_q
|
| 147 |
+
flash_attn_padding_info['indices_k'] = indices_k
|
| 148 |
+
flash_attn_padding_info['indices_v'] = indices_v
|
| 149 |
+
flash_attn_padding_info['cu_seqlens_q'] = cu_seqlens_q
|
| 150 |
+
flash_attn_padding_info['cu_seqlens_k'] = cu_seqlens_k
|
| 151 |
+
flash_attn_padding_info['max_seqlen_q'] = max_seqlen_q
|
| 152 |
+
flash_attn_padding_info['max_seqlen_k'] = max_seqlen_k
|
| 153 |
+
return flash_attn_padding_info
|
| 154 |
+
|
| 155 |
+
def apply_sequence_id(attn_bias: torch.Tensor, sequence_id: torch.LongTensor, max_seq_len: int) -> torch.Tensor:
|
| 156 |
+
seq_len = sequence_id.shape[-1]
|
| 157 |
+
if seq_len > max_seq_len:
|
| 158 |
+
raise ValueError(f'sequence_id sequence length cannot exceed max_seq_len={max_seq_len}')
|
| 159 |
+
attn_bias = attn_bias[..., :seq_len, :seq_len]
|
| 160 |
+
cannot_attend = torch.logical_not(torch.eq(sequence_id.view(-1, seq_len, 1), sequence_id.view(-1, 1, seq_len))).unsqueeze(1)
|
| 161 |
+
min_val = torch.finfo(attn_bias.dtype).min
|
| 162 |
+
attn_bias = attn_bias.masked_fill(cannot_attend, min_val)
|
| 163 |
+
return attn_bias
|
| 164 |
+
|
| 165 |
+
class MPTPreTrainedModel(PreTrainedModel):
|
| 166 |
+
config_class = MPTConfig
|
| 167 |
+
base_model_prefix = 'model'
|
| 168 |
+
_no_split_modules = ['MPTBlock']
|
| 169 |
+
|
| 170 |
+
def _fsdp_wrap_fn(self: Union[MPTModel, MPTForCausalLM], module: nn.Module) -> bool:
|
| 171 |
+
return isinstance(module, MPTBlock)
|
| 172 |
+
|
| 173 |
+
class MPTModel(MPTPreTrainedModel):
|
| 174 |
+
|
| 175 |
+
def __init__(self, config: MPTConfig):
|
| 176 |
+
config._validate_config()
|
| 177 |
+
super().__init__(config)
|
| 178 |
+
self.attn_impl = config.attn_config['attn_impl']
|
| 179 |
+
self.prefix_lm = config.attn_config['prefix_lm']
|
| 180 |
+
self.attn_uses_sequence_id = config.attn_config['attn_uses_sequence_id']
|
| 181 |
+
self.alibi = config.attn_config['alibi']
|
| 182 |
+
self.alibi_bias_max = config.attn_config['alibi_bias_max']
|
| 183 |
+
self.learned_pos_emb = config.learned_pos_emb
|
| 184 |
+
if config.init_device == 'mixed':
|
| 185 |
+
if dist.get_local_rank() == 0:
|
| 186 |
+
config.init_device = 'cpu'
|
| 187 |
+
else:
|
| 188 |
+
config.init_device = 'meta'
|
| 189 |
+
if config.norm_type.lower() not in NORM_CLASS_REGISTRY.keys():
|
| 190 |
+
norm_options = ' | '.join(NORM_CLASS_REGISTRY.keys())
|
| 191 |
+
raise NotImplementedError(f'Requested norm type ({config.norm_type}) is not implemented within this repo (Options: {norm_options}).')
|
| 192 |
+
norm_class = NORM_CLASS_REGISTRY[config.norm_type.lower()]
|
| 193 |
+
self.embedding_fraction = config.embedding_fraction
|
| 194 |
+
self.wte = SharedEmbedding(config.vocab_size, config.d_model, device=config.init_device)
|
| 195 |
+
if self.learned_pos_emb:
|
| 196 |
+
self.wpe = torch.nn.Embedding(config.max_seq_len, config.d_model, device=config.init_device)
|
| 197 |
+
self.emb_drop = nn.Dropout(config.emb_pdrop)
|
| 198 |
+
self.blocks = nn.ModuleList([MPTBlock(device=config.init_device, **config.to_dict()) for _ in range(config.n_layers)])
|
| 199 |
+
self.norm_f = norm_class(config.d_model, device=config.init_device)
|
| 200 |
+
self.rope = config.attn_config['rope']
|
| 201 |
+
self.rope_impl = None
|
| 202 |
+
if self.rope:
|
| 203 |
+
self.rope_impl = config.attn_config['rope_impl']
|
| 204 |
+
self.rotary_embedding = gen_rotary_embedding(rope_head_dim=config.d_model // config.n_heads, rope_impl=self.rope_impl, rope_theta=config.attn_config['rope_theta'], rope_dail_config=config.attn_config['rope_dail_config'], rope_hf_config=config.attn_config['rope_hf_config'], max_seq_len=self.config.max_seq_len)
|
| 205 |
+
if config.init_device != 'meta':
|
| 206 |
+
log.info(f'We recommend using config.init_device="meta" with Composer + FSDP for faster initialization.')
|
| 207 |
+
self.apply(self.param_init_fn)
|
| 208 |
+
self.is_causal = not self.prefix_lm
|
| 209 |
+
self._attn_bias_initialized = False
|
| 210 |
+
self.attn_bias = None
|
| 211 |
+
self.attn_bias_shape = attn_bias_shape(self.attn_impl, config.n_heads, config.max_seq_len, self.alibi, prefix_lm=self.prefix_lm, causal=self.is_causal, use_sequence_id=self.attn_uses_sequence_id)
|
| 212 |
+
if config.no_bias:
|
| 213 |
+
for module in self.modules():
|
| 214 |
+
if hasattr(module, 'bias') and isinstance(module.bias, nn.Parameter):
|
| 215 |
+
log.info(f'Removing bias from module={module!r}.')
|
| 216 |
+
module.register_parameter('bias', None)
|
| 217 |
+
if hasattr(module, 'use_bias'):
|
| 218 |
+
log.info(f'Setting use_bias=False for module={module!r}.')
|
| 219 |
+
module.use_bias = False
|
| 220 |
+
log.debug(self)
|
| 221 |
+
log.debug(f"Using {self.config.init_config['name']} initialization.")
|
| 222 |
+
|
| 223 |
+
def get_input_embeddings(self) -> Union[SharedEmbedding, nn.Embedding]:
|
| 224 |
+
return self.wte
|
| 225 |
+
|
| 226 |
+
def set_input_embeddings(self, value: Union[SharedEmbedding, nn.Embedding]) -> None:
|
| 227 |
+
self.wte = value
|
| 228 |
+
|
| 229 |
+
@torch.no_grad()
|
| 230 |
+
def _attn_bias(self, device: torch.device, dtype: torch.dtype, attention_mask: Optional[torch.ByteTensor]=None, prefix_mask: Optional[torch.ByteTensor]=None, sequence_id: Optional[torch.LongTensor]=None) -> Tuple[Optional[torch.Tensor], Optional[torch.ByteTensor]]:
|
| 231 |
+
if not self._attn_bias_initialized:
|
| 232 |
+
if self.attn_bias_shape:
|
| 233 |
+
self.attn_bias = torch.zeros(self.attn_bias_shape, device=device, dtype=dtype)
|
| 234 |
+
self.attn_bias = build_attn_bias(self.attn_impl, self.attn_bias, self.config.n_heads, self.config.max_seq_len, causal=self.is_causal, alibi=self.alibi, alibi_bias_max=self.alibi_bias_max)
|
| 235 |
+
self._attn_bias_initialized = True
|
| 236 |
+
if self.attn_impl == 'flash':
|
| 237 |
+
return (self.attn_bias, attention_mask)
|
| 238 |
+
if self.attn_bias is not None:
|
| 239 |
+
self.attn_bias = self.attn_bias.to(dtype=dtype, device=device)
|
| 240 |
+
attn_bias = self.attn_bias
|
| 241 |
+
if self.prefix_lm:
|
| 242 |
+
assert isinstance(attn_bias, torch.Tensor)
|
| 243 |
+
assert isinstance(prefix_mask, torch.Tensor)
|
| 244 |
+
attn_bias = self._apply_prefix_mask(attn_bias, prefix_mask)
|
| 245 |
+
if self.attn_uses_sequence_id and sequence_id is not None:
|
| 246 |
+
assert isinstance(attn_bias, torch.Tensor)
|
| 247 |
+
attn_bias = apply_sequence_id(attn_bias, sequence_id, self.config.max_seq_len)
|
| 248 |
+
if attention_mask is not None:
|
| 249 |
+
s_k = attention_mask.shape[-1]
|
| 250 |
+
if attn_bias is None:
|
| 251 |
+
attn_bias = torch.zeros((1, 1, 1, s_k), device=device, dtype=dtype)
|
| 252 |
+
else:
|
| 253 |
+
_s_k = max(0, attn_bias.size(-1) - s_k)
|
| 254 |
+
attn_bias = attn_bias[:, :, :, _s_k:]
|
| 255 |
+
if prefix_mask is not None and attention_mask.shape != prefix_mask.shape:
|
| 256 |
+
raise ValueError(f'attention_mask shape={attention_mask.shape} ' + f'and prefix_mask shape={prefix_mask.shape} are not equal.')
|
| 257 |
+
min_val = torch.finfo(attn_bias.dtype).min
|
| 258 |
+
attn_bias = attn_bias.masked_fill(~attention_mask.view(-1, 1, 1, s_k), min_val)
|
| 259 |
+
return (attn_bias, attention_mask)
|
| 260 |
+
|
| 261 |
+
def _apply_prefix_mask(self, attn_bias: torch.Tensor, prefix_mask: torch.Tensor) -> torch.Tensor:
|
| 262 |
+
(s_k, s_q) = attn_bias.shape[-2:]
|
| 263 |
+
if s_k != self.config.max_seq_len or s_q != self.config.max_seq_len:
|
| 264 |
+
raise ValueError('attn_bias does not match the expected shape. ' + f'The last two dimensions should both be {self.config.max_length} ' + f'but are {s_k} and {s_q}.')
|
| 265 |
+
seq_len = prefix_mask.shape[-1]
|
| 266 |
+
if seq_len > self.config.max_seq_len:
|
| 267 |
+
raise ValueError(f'prefix_mask sequence length cannot exceed max_seq_len={self.config.max_seq_len}')
|
| 268 |
+
attn_bias = attn_bias[..., :seq_len, :seq_len]
|
| 269 |
+
causal = torch.tril(torch.ones((seq_len, seq_len), dtype=torch.bool, device=prefix_mask.device)).view(1, 1, seq_len, seq_len)
|
| 270 |
+
prefix = prefix_mask.view(-1, 1, 1, seq_len)
|
| 271 |
+
cannot_attend = ~torch.logical_or(causal, prefix.bool())
|
| 272 |
+
min_val = torch.finfo(attn_bias.dtype).min
|
| 273 |
+
attn_bias = attn_bias.masked_fill(cannot_attend, min_val)
|
| 274 |
+
return attn_bias
|
| 275 |
+
|
| 276 |
+
def forward(self, input_ids: Optional[torch.LongTensor]=None, past_key_values: Optional[List[Tuple[torch.FloatTensor]]]=None, attention_mask: Optional[torch.ByteTensor]=None, prefix_mask: Optional[torch.ByteTensor]=None, sequence_id: Optional[torch.LongTensor]=None, return_dict: Optional[bool]=None, output_attentions: Optional[bool]=None, output_hidden_states: Optional[bool]=None, use_cache: Optional[bool]=None, inputs_embeds: Optional[torch.Tensor]=None) -> BaseModelOutputWithPast:
|
| 277 |
+
return_dict = return_dict if return_dict is not None else self.config.return_dict
|
| 278 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 279 |
+
if attention_mask is not None:
|
| 280 |
+
attention_mask = attention_mask.bool()
|
| 281 |
+
if prefix_mask is not None:
|
| 282 |
+
prefix_mask = prefix_mask.bool()
|
| 283 |
+
if not return_dict:
|
| 284 |
+
raise NotImplementedError('return_dict False is not implemented yet for MPT')
|
| 285 |
+
if output_attentions:
|
| 286 |
+
if self.attn_impl != 'torch':
|
| 287 |
+
raise NotImplementedError('output_attentions is not implemented for MPT when using attn_impl `flash` or `triton`.')
|
| 288 |
+
if self.training and attention_mask is not None and (attention_mask[:, 0].sum() != attention_mask.shape[0]):
|
| 289 |
+
raise NotImplementedError('MPT does not support training with left padding.')
|
| 290 |
+
if self.prefix_lm and prefix_mask is None:
|
| 291 |
+
raise ValueError('prefix_mask is a required argument when MPT is configured with prefix_lm=True.')
|
| 292 |
+
if self.training:
|
| 293 |
+
if self.attn_uses_sequence_id and sequence_id is None:
|
| 294 |
+
raise ValueError('sequence_id is a required argument when MPT is configured with attn_uses_sequence_id=True ' + 'and the model is in train mode.')
|
| 295 |
+
elif self.attn_uses_sequence_id is False and sequence_id is not None:
|
| 296 |
+
warnings.warn('MPT received non-None input for `sequence_id` but is configured with attn_uses_sequence_id=False. ' + 'This input will be ignored. If you want the model to use `sequence_id`, set attn_uses_sequence_id to True.')
|
| 297 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 298 |
+
raise ValueError('You cannot specify both input_ids and inputs_embeds.')
|
| 299 |
+
elif input_ids is not None:
|
| 300 |
+
bsz = input_ids.size(0)
|
| 301 |
+
S = input_ids.size(1)
|
| 302 |
+
x = self.wte(input_ids)
|
| 303 |
+
input_device = input_ids.device
|
| 304 |
+
elif inputs_embeds is not None:
|
| 305 |
+
bsz = inputs_embeds.size(0)
|
| 306 |
+
S = inputs_embeds.size(1)
|
| 307 |
+
x = inputs_embeds
|
| 308 |
+
input_device = inputs_embeds.device
|
| 309 |
+
else:
|
| 310 |
+
raise ValueError('You must specify input_ids or inputs_embeds')
|
| 311 |
+
assert S <= self.config.max_seq_len, f'Cannot forward input with seq_len={S}, this model only supports seq_len<={self.config.max_seq_len}'
|
| 312 |
+
rotary_emb_w_meta_info = None
|
| 313 |
+
past_position = 0
|
| 314 |
+
if past_key_values is not None:
|
| 315 |
+
if len(past_key_values) != self.config.n_layers:
|
| 316 |
+
raise ValueError(f'past_key_values must provide a past_key_value for each attention ' + f'layer in the network (len(past_key_values)={len(past_key_values)!r}; self.config.n_layers={self.config.n_layers!r}).')
|
| 317 |
+
past_position = past_key_values[0][0].size(1)
|
| 318 |
+
if self.attn_impl == 'torch':
|
| 319 |
+
past_position = past_key_values[0][0].size(3)
|
| 320 |
+
if self.learned_pos_emb or self.rope:
|
| 321 |
+
if self.learned_pos_emb and S + past_position > self.config.max_seq_len:
|
| 322 |
+
raise ValueError(f'Cannot forward input with past sequence length {past_position} and current sequence length ' + f'{S + 1}, this model only supports total sequence length <= {self.config.max_seq_len}.')
|
| 323 |
+
if self.learned_pos_emb or (self.rope and self.rope_impl == 'hf'):
|
| 324 |
+
pos = torch.arange(past_position, S + past_position, dtype=torch.long, device=input_device).unsqueeze(0)
|
| 325 |
+
if attention_mask is not None:
|
| 326 |
+
pos = torch.clamp(pos - torch.cumsum((~attention_mask).to(torch.int32), dim=1)[:, past_position:], min=0)
|
| 327 |
+
if self.learned_pos_emb:
|
| 328 |
+
x = x + self.wpe(pos)
|
| 329 |
+
elif self.rope and self.rope_impl == 'hf':
|
| 330 |
+
rotary_emb_w_meta_info = {'impl': self.rope_impl, 'rotary_emb': self.rotary_embedding, 'offset_info': pos, 'seq_len': S + past_position}
|
| 331 |
+
elif self.rope and self.rope_impl == 'dail':
|
| 332 |
+
rotary_emb_w_meta_info = {'impl': self.rope_impl, 'rotary_emb': self.rotary_embedding, 'offset_info': past_position, 'seq_len': S + past_position}
|
| 333 |
+
if self.embedding_fraction == 1:
|
| 334 |
+
x = self.emb_drop(x)
|
| 335 |
+
else:
|
| 336 |
+
x_shrunk = x * self.embedding_fraction + x.detach() * (1 - self.embedding_fraction)
|
| 337 |
+
assert isinstance(self.emb_drop, nn.Module)
|
| 338 |
+
x = self.emb_drop(x_shrunk)
|
| 339 |
+
(attn_bias, attention_mask) = self._attn_bias(device=x.device, dtype=torch.float32, attention_mask=attention_mask, prefix_mask=prefix_mask, sequence_id=sequence_id)
|
| 340 |
+
attention_mask_in_length = gen_attention_mask_in_length(sequence_id=sequence_id, S=S, attn_uses_sequence_id=self.attn_uses_sequence_id, attn_impl=self.attn_impl, attention_mask=attention_mask)
|
| 341 |
+
alibi_slopes = None
|
| 342 |
+
if self.alibi and self.attn_impl == 'flash':
|
| 343 |
+
alibi_slopes = gen_slopes(n_heads=self.config.n_heads, alibi_bias_max=self.alibi_bias_max, device=x.device, return_1d=True)
|
| 344 |
+
presents = () if use_cache else None
|
| 345 |
+
if use_cache and past_key_values is None:
|
| 346 |
+
past_key_values = [() for _ in range(self.config.n_layers)]
|
| 347 |
+
all_hidden_states = () if output_hidden_states else None
|
| 348 |
+
all_self_attns = () if output_attentions else None
|
| 349 |
+
flash_attn_padding_info = {}
|
| 350 |
+
if self.attn_impl == 'flash':
|
| 351 |
+
flash_attn_padding_info = gen_flash_attn_padding_info(bsz, S, past_position, x.device, attention_mask_in_length, attention_mask)
|
| 352 |
+
for (b_idx, block) in enumerate(self.blocks):
|
| 353 |
+
if output_hidden_states:
|
| 354 |
+
assert all_hidden_states is not None
|
| 355 |
+
all_hidden_states = all_hidden_states + (x,)
|
| 356 |
+
past_key_value = past_key_values[b_idx] if past_key_values is not None else None
|
| 357 |
+
(x, attn_weights, present) = block(x, past_key_value=past_key_value, attn_bias=attn_bias, rotary_emb_w_meta_info=rotary_emb_w_meta_info, attention_mask=attention_mask, is_causal=self.is_causal, output_attentions=bool(output_attentions), alibi_slopes=alibi_slopes, flash_attn_padding_info=flash_attn_padding_info)
|
| 358 |
+
if presents is not None:
|
| 359 |
+
presents += (present,)
|
| 360 |
+
if output_attentions:
|
| 361 |
+
assert all_self_attns is not None
|
| 362 |
+
all_self_attns = all_self_attns + (attn_weights,)
|
| 363 |
+
x = self.norm_f(x)
|
| 364 |
+
if output_hidden_states:
|
| 365 |
+
assert all_hidden_states is not None
|
| 366 |
+
all_hidden_states = all_hidden_states + (x,)
|
| 367 |
+
return BaseModelOutputWithPast(last_hidden_state=x, past_key_values=presents, hidden_states=all_hidden_states, attentions=all_self_attns)
|
| 368 |
+
|
| 369 |
+
def param_init_fn(self, module: nn.Module) -> None:
|
| 370 |
+
init_fn_name = self.config.init_config['name']
|
| 371 |
+
MODEL_INIT_REGISTRY[init_fn_name](module=module, n_layers=self.config.n_layers, d_model=self.config.d_model, **self.config.init_config)
|
| 372 |
+
|
| 373 |
+
def fsdp_wrap_fn(self, module: nn.Module) -> bool:
|
| 374 |
+
return _fsdp_wrap_fn(self, module)
|
| 375 |
+
|
| 376 |
+
def activation_checkpointing_fn(self, module: nn.Module) -> bool:
|
| 377 |
+
return isinstance(module, MPTBlock)
|
| 378 |
+
|
| 379 |
+
class MPTForCausalLM(MPTPreTrainedModel):
|
| 380 |
+
|
| 381 |
+
def __init__(self, config: MPTConfig):
|
| 382 |
+
super().__init__(config)
|
| 383 |
+
log.info(f'Instantiating an MPTForCausalLM model from {__file__}')
|
| 384 |
+
self.transformer: MPTModel = MPTModel(config)
|
| 385 |
+
self.lm_head = None
|
| 386 |
+
if not config.tie_word_embeddings:
|
| 387 |
+
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False, device=config.init_device)
|
| 388 |
+
self.lm_head._fsdp_wrap = True
|
| 389 |
+
for child in self.transformer.children():
|
| 390 |
+
if isinstance(child, torch.nn.ModuleList):
|
| 391 |
+
continue
|
| 392 |
+
if isinstance(child, torch.nn.Module):
|
| 393 |
+
child._fsdp_wrap = True
|
| 394 |
+
self.logit_scale = None
|
| 395 |
+
if config.logit_scale is not None:
|
| 396 |
+
logit_scale = config.logit_scale
|
| 397 |
+
if isinstance(logit_scale, str):
|
| 398 |
+
if logit_scale == 'inv_sqrt_d_model':
|
| 399 |
+
logit_scale = 1 / math.sqrt(config.d_model)
|
| 400 |
+
else:
|
| 401 |
+
raise ValueError(f"logit_scale={logit_scale!r} is not recognized as an option; use numeric value or 'inv_sqrt_d_model'.")
|
| 402 |
+
self.logit_scale = logit_scale
|
| 403 |
+
|
| 404 |
+
def get_input_embeddings(self) -> Union[SharedEmbedding, nn.Embedding]:
|
| 405 |
+
return self.transformer.get_input_embeddings()
|
| 406 |
+
|
| 407 |
+
def set_input_embeddings(self, value: Union[SharedEmbedding, nn.Embedding]) -> None:
|
| 408 |
+
self.transformer.set_input_embeddings(value)
|
| 409 |
+
|
| 410 |
+
def get_output_embeddings(self) -> Union[SharedEmbedding, nn.Embedding, nn.Linear]:
|
| 411 |
+
if self.lm_head is not None:
|
| 412 |
+
return self.lm_head
|
| 413 |
+
return self.transformer.get_input_embeddings()
|
| 414 |
+
|
| 415 |
+
def set_output_embeddings(self, new_embeddings: Union[SharedEmbedding, nn.Embedding, nn.Linear]) -> None:
|
| 416 |
+
if self.lm_head is not None:
|
| 417 |
+
self.lm_head = new_embeddings
|
| 418 |
+
else:
|
| 419 |
+
if not isinstance(new_embeddings, (SharedEmbedding, nn.Embedding)):
|
| 420 |
+
raise ValueError('new_embeddings must be an instance of SharedEmbedding ' + f'or nn.Embedding, but got {type(new_embeddings)}.')
|
| 421 |
+
warnings.warn('Using `set_output_embeddings` to set the embedding layer of ' + 'MPTForCausalLM with tied weights. Given weights are tied, ' + 'using `set_input_embeddings` is recommended over using ' + '`set_output_embeddings`.')
|
| 422 |
+
self.transformer.set_input_embeddings(new_embeddings)
|
| 423 |
+
|
| 424 |
+
def tie_weights(self) -> None:
|
| 425 |
+
self.lm_head = None
|
| 426 |
+
|
| 427 |
+
def set_decoder(self, decoder: MPTModel) -> None:
|
| 428 |
+
self.transformer = decoder
|
| 429 |
+
|
| 430 |
+
def get_decoder(self) -> MPTModel:
|
| 431 |
+
return self.transformer
|
| 432 |
+
|
| 433 |
+
def forward(self, input_ids: Optional[torch.LongTensor]=None, past_key_values: Optional[List[Tuple[torch.FloatTensor]]]=None, attention_mask: Optional[torch.ByteTensor]=None, prefix_mask: Optional[torch.ByteTensor]=None, sequence_id: Optional[torch.LongTensor]=None, labels: Optional[torch.LongTensor]=None, return_dict: Optional[bool]=None, output_attentions: Optional[bool]=None, output_hidden_states: Optional[bool]=None, use_cache: Optional[bool]=None, inputs_embeds: Optional[torch.FloatTensor]=None) -> CausalLMOutputWithPast:
|
| 434 |
+
return_dict = return_dict if return_dict is not None else self.config.return_dict
|
| 435 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 436 |
+
outputs = self.transformer(input_ids=input_ids, past_key_values=past_key_values, attention_mask=attention_mask, prefix_mask=prefix_mask, sequence_id=sequence_id, return_dict=return_dict, output_attentions=output_attentions, output_hidden_states=output_hidden_states, use_cache=use_cache, inputs_embeds=inputs_embeds)
|
| 437 |
+
if self.lm_head is not None:
|
| 438 |
+
logits = self.lm_head(outputs.last_hidden_state)
|
| 439 |
+
else:
|
| 440 |
+
out = outputs.last_hidden_state
|
| 441 |
+
out = out.to(self.transformer.wte.weight.device)
|
| 442 |
+
logits = self.transformer.wte(out, True)
|
| 443 |
+
if self.logit_scale is not None:
|
| 444 |
+
if self.logit_scale == 0:
|
| 445 |
+
warnings.warn(f'Multiplying logits by self.logit_scale={self.logit_scale!r}. This will produce uniform (uninformative) outputs.')
|
| 446 |
+
logits *= self.logit_scale
|
| 447 |
+
loss = None
|
| 448 |
+
if labels is not None:
|
| 449 |
+
_labels = torch.roll(labels, shifts=-1)
|
| 450 |
+
_labels[:, -1] = -100
|
| 451 |
+
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), _labels.to(logits.device).view(-1))
|
| 452 |
+
return CausalLMOutputWithPast(loss=loss, logits=logits, past_key_values=outputs.past_key_values, hidden_states=outputs.hidden_states, attentions=outputs.attentions)
|
| 453 |
+
|
| 454 |
+
def param_init_fn(self, module: nn.Module) -> None:
|
| 455 |
+
init_fn_name = self.config.init_config['name']
|
| 456 |
+
MODEL_INIT_REGISTRY[init_fn_name](module=module, n_layers=self.config.n_layers, d_model=self.config.d_model, **self.config.init_config)
|
| 457 |
+
|
| 458 |
+
def fsdp_wrap_fn(self, module: nn.Module) -> bool:
|
| 459 |
+
return _fsdp_wrap_fn(self, module)
|
| 460 |
+
|
| 461 |
+
def activation_checkpointing_fn(self, module: nn.Module) -> bool:
|
| 462 |
+
act_ckpt_list = getattr(self.config, 'activation_checkpointing_target', None) or ['MPTBlock']
|
| 463 |
+
if isinstance(act_ckpt_list, str):
|
| 464 |
+
act_ckpt_list = [act_ckpt_list]
|
| 465 |
+
elif not isinstance(act_ckpt_list, list):
|
| 466 |
+
raise ValueError(f'activation_checkpointing_target must be either a single string or a list, but got {type(act_ckpt_list)}')
|
| 467 |
+
if 'MPTBlock' in act_ckpt_list or 'mptblock' in act_ckpt_list:
|
| 468 |
+
if len(act_ckpt_list) > 1:
|
| 469 |
+
log.info('Activation checkpointing MPTBlock only (ignoring other sub-block modules specified in activation_checkpointing_target).')
|
| 470 |
+
return isinstance(module, MPTBlock)
|
| 471 |
+
mod_types = ()
|
| 472 |
+
for mod_name in act_ckpt_list:
|
| 473 |
+
if mod_name.lower() == 'mptblock':
|
| 474 |
+
mod_types += (MPTBlock,)
|
| 475 |
+
elif mod_name in ATTN_CLASS_REGISTRY:
|
| 476 |
+
mod_types += (ATTN_CLASS_REGISTRY[mod_name],)
|
| 477 |
+
elif mod_name in FFN_CLASS_REGISTRY:
|
| 478 |
+
mod_types += (FFN_CLASS_REGISTRY[mod_name],)
|
| 479 |
+
elif mod_name in NORM_CLASS_REGISTRY:
|
| 480 |
+
mod_types += (NORM_CLASS_REGISTRY[mod_name],)
|
| 481 |
+
else:
|
| 482 |
+
msg = ', '.join(list(ATTN_CLASS_REGISTRY.keys()) + list(FFN_CLASS_REGISTRY.keys()) + list(NORM_CLASS_REGISTRY.keys()) + ['MPTBlock'])
|
| 483 |
+
raise ValueError(f'{mod_name} (specified in activation_checkpointing_target) is not a recognized option out of available options {msg}.')
|
| 484 |
+
return isinstance(module, mod_types)
|
| 485 |
+
|
| 486 |
+
def prepare_inputs_for_generation(self, input_ids: torch.Tensor, past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]]=None, inputs_embeds: Optional[torch.Tensor]=None, **kwargs: Any) -> Dict[str, Any]:
|
| 487 |
+
attention_mask = kwargs['attention_mask'].bool()
|
| 488 |
+
if attention_mask[:, -1].sum() != attention_mask.shape[0]:
|
| 489 |
+
raise NotImplementedError('MPT does not support generation with right padding.')
|
| 490 |
+
if self.transformer.attn_uses_sequence_id and self.training:
|
| 491 |
+
sequence_id = torch.zeros_like(input_ids[:1])
|
| 492 |
+
else:
|
| 493 |
+
sequence_id = None
|
| 494 |
+
if past_key_values is not None:
|
| 495 |
+
input_ids = input_ids[:, -1].unsqueeze(-1)
|
| 496 |
+
if self.transformer.prefix_lm:
|
| 497 |
+
prefix_mask = torch.ones_like(attention_mask)
|
| 498 |
+
if kwargs.get('use_cache') == False:
|
| 499 |
+
raise NotImplementedError('MPT with prefix_lm=True does not support use_cache=False.')
|
| 500 |
+
else:
|
| 501 |
+
prefix_mask = None
|
| 502 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 503 |
+
model_inputs = {'inputs_embeds': inputs_embeds}
|
| 504 |
+
else:
|
| 505 |
+
model_inputs = {'input_ids': input_ids}
|
| 506 |
+
model_inputs.update({'attention_mask': attention_mask, 'prefix_mask': prefix_mask, 'sequence_id': sequence_id, 'past_key_values': past_key_values, 'use_cache': kwargs.get('use_cache', True)})
|
| 507 |
+
return model_inputs
|
| 508 |
+
|
| 509 |
+
@staticmethod
|
| 510 |
+
def _reorder_cache(past_key_values: List[Tuple[torch.Tensor, torch.Tensor]], beam_idx: torch.LongTensor) -> List[Tuple[torch.Tensor, ...]]:
|
| 511 |
+
"""Used by HuggingFace generate when using beam search with kv-caching.
|
| 512 |
+
|
| 513 |
+
See https://github.com/huggingface/transformers/blob/3ec7a47664ebe40c40f4b722f6bb1cd30c3821ec/src/transformers/models/gpt2/modeling_gpt2.py#L1122-L1133
|
| 514 |
+
for an example in transformers.
|
| 515 |
+
"""
|
| 516 |
+
reordered_past = []
|
| 517 |
+
for layer_past in past_key_values:
|
| 518 |
+
reordered_past += [tuple((past_state.index_select(0, beam_idx) for past_state in layer_past))]
|
| 519 |
+
return reordered_past
|
norm.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, List, Optional, Type, Union
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
def _cast_if_autocast_enabled(tensor: torch.Tensor) -> torch.Tensor:
|
| 5 |
+
if torch.is_autocast_enabled():
|
| 6 |
+
if tensor.device.type == 'cuda':
|
| 7 |
+
dtype = torch.get_autocast_gpu_dtype()
|
| 8 |
+
elif tensor.device.type == 'cpu':
|
| 9 |
+
dtype = torch.get_autocast_cpu_dtype()
|
| 10 |
+
else:
|
| 11 |
+
raise NotImplementedError()
|
| 12 |
+
return tensor.to(dtype=dtype)
|
| 13 |
+
return tensor
|
| 14 |
+
|
| 15 |
+
class LPLayerNorm(torch.nn.LayerNorm):
|
| 16 |
+
|
| 17 |
+
def __init__(self, normalized_shape: Union[int, List[int], torch.Size], eps: float=1e-05, elementwise_affine: bool=True, device: Optional[torch.device]=None, dtype: Optional[torch.dtype]=None):
|
| 18 |
+
super().__init__(normalized_shape=normalized_shape, eps=eps, elementwise_affine=elementwise_affine, device=device, dtype=dtype)
|
| 19 |
+
|
| 20 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 21 |
+
module_device = x.device
|
| 22 |
+
downcast_x = _cast_if_autocast_enabled(x)
|
| 23 |
+
downcast_weight = _cast_if_autocast_enabled(self.weight) if self.weight is not None else self.weight
|
| 24 |
+
downcast_bias = _cast_if_autocast_enabled(self.bias) if self.bias is not None else self.bias
|
| 25 |
+
with torch.autocast(enabled=False, device_type=module_device.type):
|
| 26 |
+
return torch.nn.functional.layer_norm(downcast_x, self.normalized_shape, downcast_weight, downcast_bias, self.eps)
|
| 27 |
+
|
| 28 |
+
def rms_norm(x: torch.Tensor, weight: Optional[torch.Tensor]=None, eps: float=1e-05) -> torch.Tensor:
|
| 29 |
+
output = x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + eps)
|
| 30 |
+
if weight is not None:
|
| 31 |
+
return output * weight
|
| 32 |
+
return output
|
| 33 |
+
|
| 34 |
+
class RMSNorm(torch.nn.Module):
|
| 35 |
+
|
| 36 |
+
def __init__(self, normalized_shape: Union[int, List[int], torch.Size], eps: float=1e-05, weight: bool=True, dtype: Optional[torch.dtype]=None, device: Optional[torch.device]=None):
|
| 37 |
+
super().__init__()
|
| 38 |
+
self.eps = eps
|
| 39 |
+
if weight:
|
| 40 |
+
self.weight = torch.nn.Parameter(torch.ones(normalized_shape, dtype=dtype, device=device))
|
| 41 |
+
else:
|
| 42 |
+
self.register_parameter('weight', None)
|
| 43 |
+
|
| 44 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 45 |
+
return rms_norm(x.float(), self.weight, self.eps).to(dtype=x.dtype)
|
| 46 |
+
|
| 47 |
+
class LPRMSNorm(RMSNorm):
|
| 48 |
+
|
| 49 |
+
def __init__(self, normalized_shape: Union[int, List[int], torch.Size], eps: float=1e-05, weight: bool=True, dtype: Optional[torch.dtype]=None, device: Optional[torch.device]=None):
|
| 50 |
+
super().__init__(normalized_shape=normalized_shape, eps=eps, weight=weight, dtype=dtype, device=device)
|
| 51 |
+
|
| 52 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 53 |
+
downcast_x = _cast_if_autocast_enabled(x)
|
| 54 |
+
downcast_weight = _cast_if_autocast_enabled(self.weight) if self.weight is not None else self.weight
|
| 55 |
+
with torch.autocast(enabled=False, device_type=x.device.type):
|
| 56 |
+
return rms_norm(downcast_x, downcast_weight, self.eps).to(dtype=x.dtype)
|
| 57 |
+
NORM_CLASS_REGISTRY: Dict[str, Type[torch.nn.Module]] = {'layernorm': torch.nn.LayerNorm, 'low_precision_layernorm': LPLayerNorm, 'rmsnorm': RMSNorm, 'low_precision_rmsnorm': LPRMSNorm}
|
param_init_fns.py
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import warnings
|
| 3 |
+
from collections.abc import Sequence
|
| 4 |
+
from functools import partial
|
| 5 |
+
from typing import Any, Callable, Optional, Tuple, Union
|
| 6 |
+
import torch
|
| 7 |
+
from torch import nn
|
| 8 |
+
from .fc import FC_CLASS_REGISTRY
|
| 9 |
+
from .norm import NORM_CLASS_REGISTRY
|
| 10 |
+
try:
|
| 11 |
+
import transformer_engine.pytorch as te
|
| 12 |
+
except:
|
| 13 |
+
te = None
|
| 14 |
+
|
| 15 |
+
def torch_default_param_init_fn_(module: nn.Module, **kwargs: Any) -> None:
|
| 16 |
+
del kwargs
|
| 17 |
+
if hasattr(module, 'reset_parameters') and isinstance(module.reset_parameters, Callable):
|
| 18 |
+
module.reset_parameters()
|
| 19 |
+
|
| 20 |
+
def fused_init_helper_(module: nn.Module, init_fn_: Callable) -> None:
|
| 21 |
+
_fused = getattr(module, '_fused', None)
|
| 22 |
+
if _fused is None:
|
| 23 |
+
raise RuntimeError(f'Internal logic error')
|
| 24 |
+
assert isinstance(module.weight, torch.Tensor)
|
| 25 |
+
(dim, splits) = _fused
|
| 26 |
+
splits = (0, *splits, module.weight.size(dim))
|
| 27 |
+
for (s, e) in zip(splits[:-1], splits[1:]):
|
| 28 |
+
slice_indices = [slice(None)] * module.weight.ndim
|
| 29 |
+
slice_indices[dim] = slice(s, e)
|
| 30 |
+
init_fn_(module.weight[slice_indices])
|
| 31 |
+
|
| 32 |
+
def generic_param_init_fn_(module: nn.Module, init_fn_: Callable, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, **kwargs: Any) -> None:
|
| 33 |
+
del kwargs
|
| 34 |
+
init_div_is_residual = init_div_is_residual
|
| 35 |
+
if init_div_is_residual is False:
|
| 36 |
+
div_is_residual = 1.0
|
| 37 |
+
elif init_div_is_residual is True:
|
| 38 |
+
div_is_residual = math.sqrt(2 * n_layers)
|
| 39 |
+
elif isinstance(init_div_is_residual, float) or isinstance(init_div_is_residual, int):
|
| 40 |
+
div_is_residual = init_div_is_residual
|
| 41 |
+
elif init_div_is_residual.isnumeric():
|
| 42 |
+
div_is_residual = float(init_div_is_residual)
|
| 43 |
+
else:
|
| 44 |
+
div_is_residual = 1.0
|
| 45 |
+
raise ValueError(f'Expected init_div_is_residual to be boolean or numeric, got {init_div_is_residual}')
|
| 46 |
+
if isinstance(module, tuple(set(FC_CLASS_REGISTRY.values()))):
|
| 47 |
+
if hasattr(module, '_fused'):
|
| 48 |
+
fused_init_helper_(module, init_fn_)
|
| 49 |
+
else:
|
| 50 |
+
init_fn_(module.weight)
|
| 51 |
+
if module.bias is not None:
|
| 52 |
+
assert isinstance(module.bias, torch.Tensor)
|
| 53 |
+
torch.nn.init.zeros_(module.bias)
|
| 54 |
+
if init_div_is_residual is not False and getattr(module, '_is_residual', False):
|
| 55 |
+
with torch.no_grad():
|
| 56 |
+
module.weight.div_(div_is_residual)
|
| 57 |
+
elif isinstance(module, nn.Embedding):
|
| 58 |
+
if emb_init_std is not None:
|
| 59 |
+
std = emb_init_std
|
| 60 |
+
if std == 0:
|
| 61 |
+
warnings.warn(f'Embedding layer initialized to 0.')
|
| 62 |
+
emb_init_fn_ = partial(torch.nn.init.normal_, mean=0.0, std=std)
|
| 63 |
+
elif emb_init_uniform_lim is not None:
|
| 64 |
+
lim = emb_init_uniform_lim
|
| 65 |
+
if isinstance(lim, Sequence):
|
| 66 |
+
if len(lim) > 2:
|
| 67 |
+
raise ValueError(f'Uniform init requires a min and a max limit. User input: {lim}.')
|
| 68 |
+
if lim[0] == lim[1]:
|
| 69 |
+
warnings.warn(f'Embedding layer initialized to {lim[0]}.')
|
| 70 |
+
else:
|
| 71 |
+
if lim == 0:
|
| 72 |
+
warnings.warn(f'Embedding layer initialized to 0.')
|
| 73 |
+
lim = [-lim, lim]
|
| 74 |
+
(a, b) = lim
|
| 75 |
+
emb_init_fn_ = partial(torch.nn.init.uniform_, a=a, b=b)
|
| 76 |
+
else:
|
| 77 |
+
emb_init_fn_ = init_fn_
|
| 78 |
+
emb_init_fn_(module.weight)
|
| 79 |
+
elif isinstance(module, tuple(set(NORM_CLASS_REGISTRY.values()))):
|
| 80 |
+
if hasattr(module, 'weight') and isinstance(module.weight, torch.Tensor):
|
| 81 |
+
torch.nn.init.ones_(module.weight)
|
| 82 |
+
if hasattr(module, 'bias') and isinstance(module.bias, torch.Tensor):
|
| 83 |
+
torch.nn.init.zeros_(module.bias)
|
| 84 |
+
elif isinstance(module, nn.MultiheadAttention):
|
| 85 |
+
if module._qkv_same_embed_dim:
|
| 86 |
+
assert module.in_proj_weight is not None
|
| 87 |
+
assert module.q_proj_weight is None and module.k_proj_weight is None and (module.v_proj_weight is None)
|
| 88 |
+
assert d_model is not None
|
| 89 |
+
_d = d_model
|
| 90 |
+
splits = (0, _d, 2 * _d, 3 * _d)
|
| 91 |
+
for (s, e) in zip(splits[:-1], splits[1:]):
|
| 92 |
+
init_fn_(module.in_proj_weight[s:e])
|
| 93 |
+
else:
|
| 94 |
+
assert module.q_proj_weight is not None and module.k_proj_weight is not None and (module.v_proj_weight is not None)
|
| 95 |
+
assert module.in_proj_weight is None
|
| 96 |
+
init_fn_(module.q_proj_weight)
|
| 97 |
+
init_fn_(module.k_proj_weight)
|
| 98 |
+
init_fn_(module.v_proj_weight)
|
| 99 |
+
if module.in_proj_bias is not None:
|
| 100 |
+
torch.nn.init.zeros_(module.in_proj_bias)
|
| 101 |
+
if module.bias_k is not None:
|
| 102 |
+
torch.nn.init.zeros_(module.bias_k)
|
| 103 |
+
if module.bias_v is not None:
|
| 104 |
+
torch.nn.init.zeros_(module.bias_v)
|
| 105 |
+
init_fn_(module.out_proj.weight)
|
| 106 |
+
if init_div_is_residual is not False and getattr(module.out_proj, '_is_residual', False):
|
| 107 |
+
with torch.no_grad():
|
| 108 |
+
module.out_proj.weight.div_(div_is_residual)
|
| 109 |
+
if module.out_proj.bias is not None:
|
| 110 |
+
torch.nn.init.zeros_(module.out_proj.bias)
|
| 111 |
+
elif te is not None and isinstance(module, te.LayerNormMLP):
|
| 112 |
+
if isinstance(module.layer_norm_weight, torch.Tensor):
|
| 113 |
+
torch.nn.init.ones_(module.layer_norm_weight)
|
| 114 |
+
if isinstance(module.layer_norm_bias, torch.Tensor):
|
| 115 |
+
torch.nn.init.zeros_(module.layer_norm_bias)
|
| 116 |
+
init_fn_(module.fc1_weight)
|
| 117 |
+
if module.fc1_bias is not None:
|
| 118 |
+
assert isinstance(module.fc1_bias, torch.Tensor)
|
| 119 |
+
torch.nn.init.zeros_(module.fc1_bias)
|
| 120 |
+
init_fn_(module.fc2_weight)
|
| 121 |
+
if module.fc2_bias is not None:
|
| 122 |
+
assert isinstance(module.fc2_bias, torch.Tensor)
|
| 123 |
+
torch.nn.init.zeros_(module.fc2_bias)
|
| 124 |
+
with torch.no_grad():
|
| 125 |
+
module.fc2_weight.div_(div_is_residual)
|
| 126 |
+
else:
|
| 127 |
+
for _ in module.parameters(recurse=False):
|
| 128 |
+
raise NotImplementedError(f'{module.__class__.__name__} parameters are not initialized by param_init_fn.')
|
| 129 |
+
|
| 130 |
+
def _normal_init_(std: float, mean: float=0.0) -> Callable:
|
| 131 |
+
return partial(torch.nn.init.normal_, mean=mean, std=std)
|
| 132 |
+
|
| 133 |
+
def _normal_param_init_fn_(module: nn.Module, std: float, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, **kwargs: Any) -> None:
|
| 134 |
+
del kwargs
|
| 135 |
+
init_fn_ = _normal_init_(std=std)
|
| 136 |
+
generic_param_init_fn_(module=module, init_fn_=init_fn_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim)
|
| 137 |
+
|
| 138 |
+
def baseline_param_init_fn_(module: nn.Module, init_std: Optional[float], n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, **kwargs: Any) -> None:
|
| 139 |
+
del kwargs
|
| 140 |
+
if init_std is None:
|
| 141 |
+
raise ValueError("You must set model.init_config['init_std'] to a float value to use the default initialization scheme.")
|
| 142 |
+
_normal_param_init_fn_(module=module, std=init_std, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim)
|
| 143 |
+
|
| 144 |
+
def small_param_init_fn_(module: nn.Module, n_layers: int, d_model: int, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, **kwargs: Any) -> None:
|
| 145 |
+
del kwargs
|
| 146 |
+
std = math.sqrt(2 / (5 * d_model))
|
| 147 |
+
_normal_param_init_fn_(module=module, std=std, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim)
|
| 148 |
+
|
| 149 |
+
def neox_param_init_fn_(module: nn.Module, n_layers: int, d_model: int, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, **kwargs: Any) -> None:
|
| 150 |
+
"""From section 2.3.1 of GPT-NeoX-20B:
|
| 151 |
+
|
| 152 |
+
An Open-Source AutoregressiveLanguage Model — Black et. al. (2022)
|
| 153 |
+
see https://github.com/EleutherAI/gpt-neox/blob/9610391ab319403cef079b438edd016a2443af54/megatron/model/init_functions.py#L151
|
| 154 |
+
and https://github.com/EleutherAI/gpt-neox/blob/main/megatron/model/transformer.py
|
| 155 |
+
"""
|
| 156 |
+
del kwargs
|
| 157 |
+
residual_div = n_layers / math.sqrt(10)
|
| 158 |
+
small_param_init_fn_(module=module, d_model=d_model, n_layers=n_layers, init_div_is_residual=residual_div, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim)
|
| 159 |
+
|
| 160 |
+
def kaiming_uniform_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, fan_mode: str='fan_in', init_nonlinearity: str='leaky_relu', **kwargs: Any) -> None:
|
| 161 |
+
del kwargs
|
| 162 |
+
kaiming_uniform_ = partial(nn.init.kaiming_uniform_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
|
| 163 |
+
generic_param_init_fn_(module=module, init_fn_=kaiming_uniform_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim)
|
| 164 |
+
|
| 165 |
+
def kaiming_normal_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, fan_mode: str='fan_in', init_nonlinearity: str='leaky_relu', **kwargs: Any) -> None:
|
| 166 |
+
del kwargs
|
| 167 |
+
kaiming_normal_ = partial(torch.nn.init.kaiming_normal_, a=init_gain, mode=fan_mode, nonlinearity=init_nonlinearity)
|
| 168 |
+
generic_param_init_fn_(module=module, init_fn_=kaiming_normal_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim)
|
| 169 |
+
|
| 170 |
+
def xavier_uniform_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, **kwargs: Any) -> None:
|
| 171 |
+
del kwargs
|
| 172 |
+
xavier_uniform_ = partial(torch.nn.init.xavier_uniform_, gain=init_gain)
|
| 173 |
+
generic_param_init_fn_(module=module, init_fn_=xavier_uniform_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim)
|
| 174 |
+
|
| 175 |
+
def xavier_normal_param_init_fn_(module: nn.Module, n_layers: int, d_model: Optional[int]=None, init_div_is_residual: Union[int, float, str, bool]=True, emb_init_std: Optional[float]=None, emb_init_uniform_lim: Optional[Union[Tuple[float, float], float]]=None, init_gain: float=0, **kwargs: Any) -> None:
|
| 176 |
+
del kwargs
|
| 177 |
+
xavier_normal_ = partial(torch.nn.init.xavier_normal_, gain=init_gain)
|
| 178 |
+
generic_param_init_fn_(module=module, init_fn_=xavier_normal_, d_model=d_model, n_layers=n_layers, init_div_is_residual=init_div_is_residual, emb_init_std=emb_init_std, emb_init_uniform_lim=emb_init_uniform_lim)
|
| 179 |
+
MODEL_INIT_REGISTRY = {'default_': torch_default_param_init_fn_, 'baseline_': baseline_param_init_fn_, 'kaiming_uniform_': kaiming_uniform_param_init_fn_, 'kaiming_normal_': kaiming_normal_param_init_fn_, 'neox_init_': neox_param_init_fn_, 'small_init_': small_param_init_fn_, 'xavier_uniform_': xavier_uniform_param_init_fn_, 'xavier_normal_': xavier_normal_param_init_fn_}
|
plots.png
ADDED
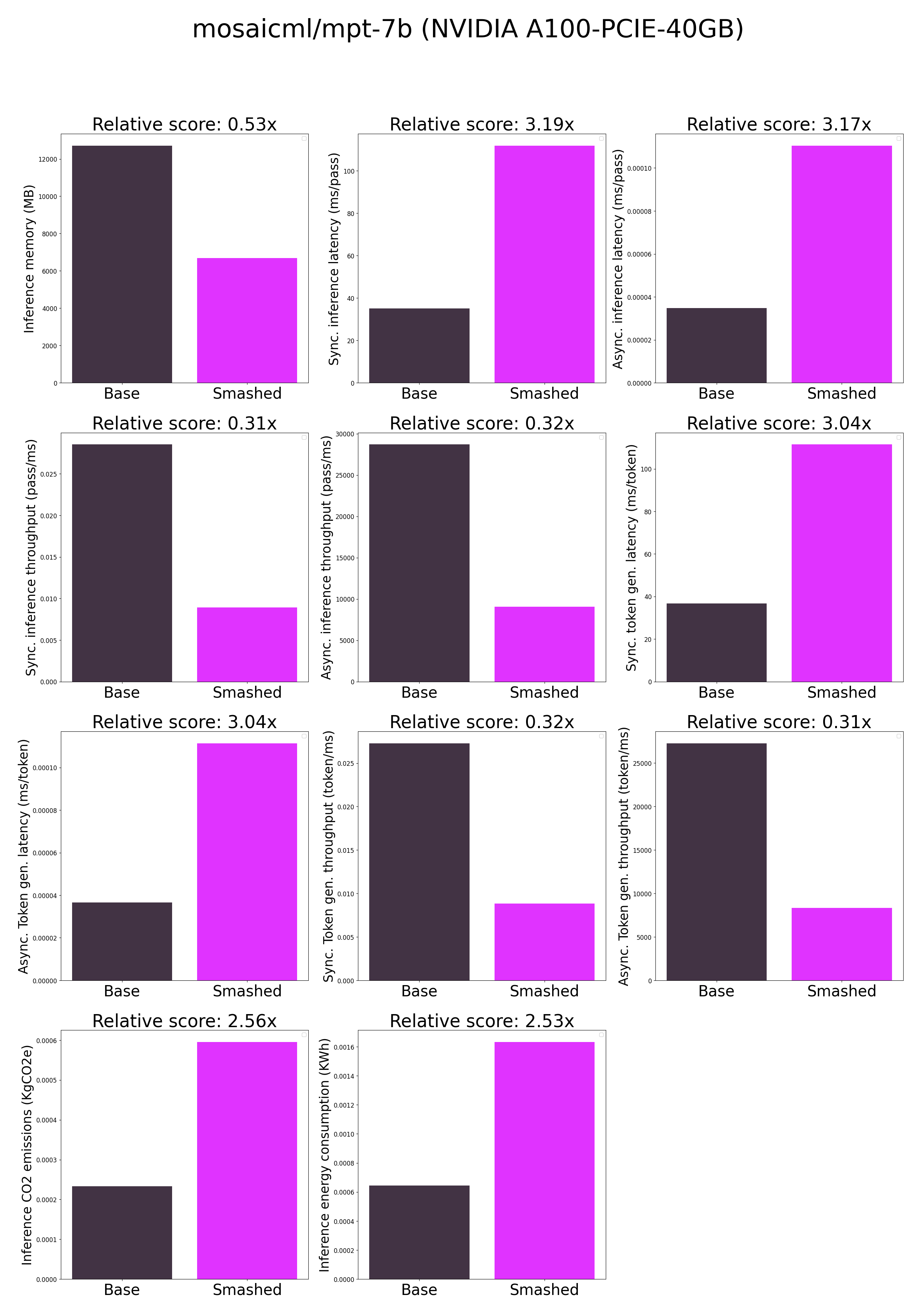
|
smash_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"api_key": null,
|
| 3 |
+
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
+
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
+
"factorizers": "None",
|
| 7 |
+
"quantizers": "['llm-int8']",
|
| 8 |
+
"compilers": "None",
|
| 9 |
+
"task": "text_text_generation",
|
| 10 |
+
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelssvzahboa",
|
| 12 |
+
"batch_size": 1,
|
| 13 |
+
"model_name": "mosaicml/mpt-7b",
|
| 14 |
+
"pruning_ratio": 0.0,
|
| 15 |
+
"n_quantization_bits": 8,
|
| 16 |
+
"output_deviation": 0.005,
|
| 17 |
+
"max_batch_size": 1,
|
| 18 |
+
"qtype_weight": "torch.qint8",
|
| 19 |
+
"qtype_activation": "torch.quint8",
|
| 20 |
+
"qobserver": "<class 'torch.ao.quantization.observer.MinMaxObserver'>",
|
| 21 |
+
"qscheme": "torch.per_tensor_symmetric",
|
| 22 |
+
"qconfig": "x86",
|
| 23 |
+
"group_size": 128,
|
| 24 |
+
"damp_percent": 0.1,
|
| 25 |
+
"save_load_fn": "bitsandbytes"
|
| 26 |
+
}
|
| 27 |
+
}
|
warnings.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class VersionedDeprecationWarning(DeprecationWarning):
|
| 2 |
+
"""A custom deprecation warning class that includes version information.
|
| 3 |
+
|
| 4 |
+
Attributes:
|
| 5 |
+
message (str): The deprecation message describing why the feature is deprecated.
|
| 6 |
+
remove_version (str): The version in which the feature will be removed.
|
| 7 |
+
|
| 8 |
+
Example:
|
| 9 |
+
>>> def deprecated_function():
|
| 10 |
+
... warnings.warn(
|
| 11 |
+
... VersionedDeprecationWarning(
|
| 12 |
+
... "Function XYZ is deprecated.",
|
| 13 |
+
... after_version="2.0.0"
|
| 14 |
+
... )
|
| 15 |
+
... )
|
| 16 |
+
...
|
| 17 |
+
>>> deprecated_function()
|
| 18 |
+
DeprecationWarning: Function XYZ is deprecated. It will be removed in version 2.0.0.
|
| 19 |
+
"""
|
| 20 |
+
|
| 21 |
+
def __init__(self, message: str, remove_version: str) -> None:
|
| 22 |
+
super().__init__(message + f' It will be removed in version {remove_version}.')
|