

Upload folder using huggingface_hub (#1)
Browse files- c7678bf8dd0893351da3ed0dba0d1bd9a66bbebe69cb2a0c5da11d37fd8b9066 (39826512f63805a4b4f49b7dc97a2dd8cb0cee5e)
- README.md +83 -0
- config.json +48 -0
- configuration_phi.py +193 -0
- generation_config.json +4 -0
- model.safetensors +3 -0
- modeling_phi.py +1369 -0
- plots.png +0 -0
- smash_config.json +27 -0
README.md
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: pruna-engine
|
| 3 |
+
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 4 |
+
metrics:
|
| 5 |
+
- memory_disk
|
| 6 |
+
- memory_inference
|
| 7 |
+
- inference_latency
|
| 8 |
+
- inference_throughput
|
| 9 |
+
- inference_CO2_emissions
|
| 10 |
+
- inference_energy_consumption
|
| 11 |
+
---
|
| 12 |
+
<!-- header start -->
|
| 13 |
+
<!-- 200823 -->
|
| 14 |
+
<div style="width: auto; margin-left: auto; margin-right: auto">
|
| 15 |
+
<a href="https://www.pruna.ai/" target="_blank" rel="noopener noreferrer">
|
| 16 |
+
<img src="https://i.imgur.com/eDAlcgk.png" alt="PrunaAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
|
| 17 |
+
</a>
|
| 18 |
+
</div>
|
| 19 |
+
<!-- header end -->
|
| 20 |
+
|
| 21 |
+
[](https://twitter.com/PrunaAI)
|
| 22 |
+
[](https://github.com/PrunaAI)
|
| 23 |
+
[](https://www.linkedin.com/company/93832878/admin/feed/posts/?feedType=following)
|
| 24 |
+
[](https://discord.gg/CP4VSgck)
|
| 25 |
+
|
| 26 |
+
# Simply make AI models cheaper, smaller, faster, and greener!
|
| 27 |
+
|
| 28 |
+
- Give a thumbs up if you like this model!
|
| 29 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 30 |
+
- Request access to easily compress your *own* AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 31 |
+
- Read the documentations to know more [here](https://pruna-ai-pruna.readthedocs-hosted.com/en/latest/)
|
| 32 |
+
- Join Pruna AI community on Discord [here](https://discord.gg/CP4VSgck) to share feedback/suggestions or get help.
|
| 33 |
+
|
| 34 |
+
## Results
|
| 35 |
+
|
| 36 |
+

|
| 37 |
+
|
| 38 |
+
**Frequently Asked Questions**
|
| 39 |
+
- ***How does the compression work?*** The model is compressed with llm-int8.
|
| 40 |
+
- ***How does the model quality change?*** The quality of the model output might vary compared to the base model.
|
| 41 |
+
- ***How is the model efficiency evaluated?*** These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in `model/smash_config.json` and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
|
| 42 |
+
- ***What is the model format?*** We use safetensors.
|
| 43 |
+
- ***What calibration data has been used?*** If needed by the compression method, we used WikiText as the calibration data.
|
| 44 |
+
- ***What is the naming convention for Pruna Huggingface models?*** We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
|
| 45 |
+
- ***How to compress my own models?*** You can request premium access to more compression methods and tech support for your specific use-cases [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
| 46 |
+
- ***What are "first" metrics?*** Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
|
| 47 |
+
- ***What are "Sync" and "Async" metrics?*** "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
|
| 48 |
+
|
| 49 |
+
## Setup
|
| 50 |
+
|
| 51 |
+
You can run the smashed model with these steps:
|
| 52 |
+
|
| 53 |
+
0. Check requirements from the original repo microsoft/phi-1 installed. In particular, check python, cuda, and transformers versions.
|
| 54 |
+
1. Make sure that you have installed quantization related packages.
|
| 55 |
+
```bash
|
| 56 |
+
pip install transformers accelerate bitsandbytes>0.37.0
|
| 57 |
+
```
|
| 58 |
+
2. Load & run the model.
|
| 59 |
+
```python
|
| 60 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 61 |
+
|
| 62 |
+
model = AutoModelForCausalLM.from_pretrained("PrunaAI/microsoft-phi-1-bnb-8bit-smashed",
|
| 63 |
+
trust_remote_code=True)
|
| 64 |
+
tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
|
| 65 |
+
|
| 66 |
+
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
| 67 |
+
|
| 68 |
+
outputs = model.generate(input_ids, max_new_tokens=216)
|
| 69 |
+
tokenizer.decode(outputs[0])
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
## Configurations
|
| 73 |
+
|
| 74 |
+
The configuration info are in `smash_config.json`.
|
| 75 |
+
|
| 76 |
+
## Credits & License
|
| 77 |
+
|
| 78 |
+
The license of the smashed model follows the license of the original model. Please check the license of the original model microsoft/phi-1 before using this model which provided the base model. The license of the `pruna-engine` is [here](https://pypi.org/project/pruna-engine/) on Pypi.
|
| 79 |
+
|
| 80 |
+
## Want to compress other models?
|
| 81 |
+
|
| 82 |
+
- Contact us and tell us which model to compress next [here](https://www.pruna.ai/contact).
|
| 83 |
+
- Request access to easily compress your own AI models [here](https://z0halsaff74.typeform.com/pruna-access?typeform-source=www.pruna.ai).
|
config.json
ADDED
|
@@ -0,0 +1,48 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/tmp/tmpt9t7q33q",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"PhiForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_phi.PhiConfig",
|
| 9 |
+
"AutoModelForCausalLM": "modeling_phi.PhiForCausalLM"
|
| 10 |
+
},
|
| 11 |
+
"bos_token_id": null,
|
| 12 |
+
"embd_pdrop": 0.0,
|
| 13 |
+
"eos_token_id": null,
|
| 14 |
+
"hidden_act": "gelu_new",
|
| 15 |
+
"hidden_size": 2048,
|
| 16 |
+
"initializer_range": 0.02,
|
| 17 |
+
"intermediate_size": 8192,
|
| 18 |
+
"layer_norm_eps": 1e-05,
|
| 19 |
+
"max_position_embeddings": 2048,
|
| 20 |
+
"model_type": "phi",
|
| 21 |
+
"num_attention_heads": 32,
|
| 22 |
+
"num_hidden_layers": 24,
|
| 23 |
+
"num_key_value_heads": 32,
|
| 24 |
+
"partial_rotary_factor": 0.5,
|
| 25 |
+
"qk_layernorm": false,
|
| 26 |
+
"quantization_config": {
|
| 27 |
+
"bnb_4bit_compute_dtype": "bfloat16",
|
| 28 |
+
"bnb_4bit_quant_type": "fp4",
|
| 29 |
+
"bnb_4bit_use_double_quant": true,
|
| 30 |
+
"llm_int8_enable_fp32_cpu_offload": false,
|
| 31 |
+
"llm_int8_has_fp16_weight": false,
|
| 32 |
+
"llm_int8_skip_modules": [
|
| 33 |
+
"lm_head"
|
| 34 |
+
],
|
| 35 |
+
"llm_int8_threshold": 6.0,
|
| 36 |
+
"load_in_4bit": false,
|
| 37 |
+
"load_in_8bit": true,
|
| 38 |
+
"quant_method": "bitsandbytes"
|
| 39 |
+
},
|
| 40 |
+
"resid_pdrop": 0.0,
|
| 41 |
+
"rope_scaling": null,
|
| 42 |
+
"rope_theta": 10000.0,
|
| 43 |
+
"tie_word_embeddings": false,
|
| 44 |
+
"torch_dtype": "float16",
|
| 45 |
+
"transformers_version": "4.37.1",
|
| 46 |
+
"use_cache": true,
|
| 47 |
+
"vocab_size": 51200
|
| 48 |
+
}
|
configuration_phi.py
ADDED
|
@@ -0,0 +1,193 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2023 Microsoft and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
""" Phi model configuration"""
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 20 |
+
from transformers.utils import logging
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
logger = logging.get_logger(__name__)
|
| 24 |
+
|
| 25 |
+
PHI_PRETRAINED_CONFIG_ARCHIVE_MAP = {
|
| 26 |
+
"microsoft/phi-1": "https://huggingface.co/microsoft/phi-1/resolve/main/config.json",
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class PhiConfig(PretrainedConfig):
|
| 31 |
+
r"""
|
| 32 |
+
This is the configuration class to store the configuration of a [`PhiModel`]. It is used to instantiate an Phi
|
| 33 |
+
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
|
| 34 |
+
defaults will yield a similar configuration to that of the Phi
|
| 35 |
+
[microsoft/phi-1](https://huggingface.co/microsoft/phi-1).
|
| 36 |
+
|
| 37 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 38 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 39 |
+
|
| 40 |
+
Args:
|
| 41 |
+
vocab_size (`int`, *optional*, defaults to 51200):
|
| 42 |
+
Vocabulary size of the Phi model. Defines the number of different tokens that can be represented by the
|
| 43 |
+
`inputs_ids` passed when calling [`PhiModel`].
|
| 44 |
+
hidden_size (`int`, *optional*, defaults to 2048):
|
| 45 |
+
Dimension of the hidden representations.
|
| 46 |
+
intermediate_size (`int`, *optional*, defaults to 8192):
|
| 47 |
+
Dimension of the MLP representations.
|
| 48 |
+
num_hidden_layers (`int`, *optional*, defaults to 24):
|
| 49 |
+
Number of hidden layers in the Transformer decoder.
|
| 50 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 51 |
+
Number of attention heads for each attention layer in the Transformer decoder.
|
| 52 |
+
num_key_value_heads (`int`, *optional*):
|
| 53 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 54 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 55 |
+
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 56 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 57 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 58 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
| 59 |
+
`num_attention_heads`.
|
| 60 |
+
resid_pdrop (`float`, *optional*, defaults to 0.0):
|
| 61 |
+
Dropout probability for mlp outputs.
|
| 62 |
+
embd_pdrop (`int`, *optional*, defaults to 0.0):
|
| 63 |
+
The dropout ratio for the embeddings.
|
| 64 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 65 |
+
The dropout ratio after computing the attention scores.
|
| 66 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu_new"`):
|
| 67 |
+
The non-linear activation function (function or string) in the decoder.
|
| 68 |
+
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
| 69 |
+
The maximum sequence length that this model might ever be used with. Phi-1 and Phi-1.5 supports up to 2048
|
| 70 |
+
tokens.
|
| 71 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 72 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 73 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-05):
|
| 74 |
+
The epsilon used by the rms normalization layers.
|
| 75 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 76 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 77 |
+
relevant if `config.is_decoder=True`. Whether to tie weight embeddings or not.
|
| 78 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 79 |
+
Whether to tie weight embeddings
|
| 80 |
+
rope_theta (`float`, *optional*, defaults to 10000.0):
|
| 81 |
+
The base period of the RoPE embeddings.
|
| 82 |
+
rope_scaling (`Dict`, *optional*):
|
| 83 |
+
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
|
| 84 |
+
strategies: linear and dynamic. Their scaling factor must be an float greater than 1. The expected format
|
| 85 |
+
is `{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
|
| 86 |
+
`max_position_embeddings` to the expected new maximum. See the following thread for more information on how
|
| 87 |
+
these scaling strategies behave:
|
| 88 |
+
https://www.reddit.com/r/LocalPersimmon/comments/14mrgpr/dynamically_scaled_rope_further_increases/. This
|
| 89 |
+
is an experimental feature, subject to breaking API changes in future versions.
|
| 90 |
+
partial_rotary_factor (`float`, *optional*, defaults to 0.5):
|
| 91 |
+
Percentage of the query and keys which will have rotary embedding.
|
| 92 |
+
qk_layernorm (`bool`, *optional*, defaults to `False`):
|
| 93 |
+
Whether or not to normalize the Queries and Keys after projecting the hidden states.
|
| 94 |
+
bos_token_id (`int`, *optional*, defaults to 1):
|
| 95 |
+
Denotes beginning of sequences token id.
|
| 96 |
+
eos_token_id (`int`, *optional*, defaults to 2):
|
| 97 |
+
Denotes end of sequences token id.
|
| 98 |
+
|
| 99 |
+
Example:
|
| 100 |
+
|
| 101 |
+
```python
|
| 102 |
+
>>> from transformers import PhiModel, PhiConfig
|
| 103 |
+
|
| 104 |
+
>>> # Initializing a Phi-1 style configuration
|
| 105 |
+
>>> configuration = PhiConfig.from_pretrained("microsoft/phi-1")
|
| 106 |
+
|
| 107 |
+
>>> # Initializing a model from the configuration
|
| 108 |
+
>>> model = PhiModel(configuration)
|
| 109 |
+
|
| 110 |
+
>>> # Accessing the model configuration
|
| 111 |
+
>>> configuration = model.config
|
| 112 |
+
```"""
|
| 113 |
+
|
| 114 |
+
model_type = "phi"
|
| 115 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 116 |
+
|
| 117 |
+
def __init__(
|
| 118 |
+
self,
|
| 119 |
+
vocab_size=51200,
|
| 120 |
+
hidden_size=2048,
|
| 121 |
+
intermediate_size=8192,
|
| 122 |
+
num_hidden_layers=24,
|
| 123 |
+
num_attention_heads=32,
|
| 124 |
+
num_key_value_heads=None,
|
| 125 |
+
resid_pdrop=0.0,
|
| 126 |
+
embd_pdrop=0.0,
|
| 127 |
+
attention_dropout=0.0,
|
| 128 |
+
hidden_act="gelu_new",
|
| 129 |
+
max_position_embeddings=2048,
|
| 130 |
+
initializer_range=0.02,
|
| 131 |
+
layer_norm_eps=1e-5,
|
| 132 |
+
use_cache=True,
|
| 133 |
+
tie_word_embeddings=False,
|
| 134 |
+
rope_theta=10000.0,
|
| 135 |
+
rope_scaling=None,
|
| 136 |
+
partial_rotary_factor=0.5,
|
| 137 |
+
qk_layernorm=False,
|
| 138 |
+
bos_token_id=1,
|
| 139 |
+
eos_token_id=2,
|
| 140 |
+
**kwargs,
|
| 141 |
+
):
|
| 142 |
+
self.vocab_size = vocab_size
|
| 143 |
+
self.hidden_size = hidden_size
|
| 144 |
+
self.intermediate_size = intermediate_size
|
| 145 |
+
self.num_hidden_layers = num_hidden_layers
|
| 146 |
+
self.num_attention_heads = num_attention_heads
|
| 147 |
+
|
| 148 |
+
if num_key_value_heads is None:
|
| 149 |
+
num_key_value_heads = num_attention_heads
|
| 150 |
+
|
| 151 |
+
self.num_key_value_heads = num_key_value_heads
|
| 152 |
+
self.resid_pdrop = resid_pdrop
|
| 153 |
+
self.embd_pdrop = embd_pdrop
|
| 154 |
+
self.attention_dropout = attention_dropout
|
| 155 |
+
self.hidden_act = hidden_act
|
| 156 |
+
self.max_position_embeddings = max_position_embeddings
|
| 157 |
+
self.initializer_range = initializer_range
|
| 158 |
+
self.layer_norm_eps = layer_norm_eps
|
| 159 |
+
self.use_cache = use_cache
|
| 160 |
+
self.rope_theta = rope_theta
|
| 161 |
+
self.rope_scaling = rope_scaling
|
| 162 |
+
self.partial_rotary_factor = partial_rotary_factor
|
| 163 |
+
self.qk_layernorm = qk_layernorm
|
| 164 |
+
self._rope_scaling_validation()
|
| 165 |
+
|
| 166 |
+
super().__init__(
|
| 167 |
+
bos_token_id=bos_token_id,
|
| 168 |
+
eos_token_id=eos_token_id,
|
| 169 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 170 |
+
**kwargs,
|
| 171 |
+
)
|
| 172 |
+
|
| 173 |
+
# Copied from transformers.models.llama.configuration_llama.LlamaConfig._rope_scaling_validation
|
| 174 |
+
def _rope_scaling_validation(self):
|
| 175 |
+
"""
|
| 176 |
+
Validate the `rope_scaling` configuration.
|
| 177 |
+
"""
|
| 178 |
+
if self.rope_scaling is None:
|
| 179 |
+
return
|
| 180 |
+
|
| 181 |
+
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
|
| 182 |
+
raise ValueError(
|
| 183 |
+
"`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
|
| 184 |
+
f"got {self.rope_scaling}"
|
| 185 |
+
)
|
| 186 |
+
rope_scaling_type = self.rope_scaling.get("type", None)
|
| 187 |
+
rope_scaling_factor = self.rope_scaling.get("factor", None)
|
| 188 |
+
if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic"]:
|
| 189 |
+
raise ValueError(
|
| 190 |
+
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
| 191 |
+
)
|
| 192 |
+
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor <= 1.0:
|
| 193 |
+
raise ValueError(f"`rope_scaling`'s factor field must be a float > 1, got {rope_scaling_factor}")
|
generation_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"transformers_version": "4.37.1"
|
| 4 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2e9831c2e8e25c019ce298c6f54cf80c1bd85dd8b0572886985725c9c0596cea
|
| 3 |
+
size 1630402264
|
modeling_phi.py
ADDED
|
@@ -0,0 +1,1369 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2023 Microsoft and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
""" PyTorch Phi model."""
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
import math
|
| 20 |
+
from typing import List, Optional, Tuple, Union
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn.functional as F
|
| 24 |
+
import torch.utils.checkpoint
|
| 25 |
+
from torch import nn
|
| 26 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 27 |
+
|
| 28 |
+
from transformers.activations import ACT2FN
|
| 29 |
+
from transformers.cache_utils import Cache, DynamicCache
|
| 30 |
+
from transformers.modeling_attn_mask_utils import _prepare_4d_causal_attention_mask
|
| 31 |
+
from transformers.modeling_outputs import (
|
| 32 |
+
BaseModelOutputWithPast,
|
| 33 |
+
CausalLMOutputWithPast,
|
| 34 |
+
SequenceClassifierOutputWithPast,
|
| 35 |
+
TokenClassifierOutput,
|
| 36 |
+
)
|
| 37 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 38 |
+
from transformers.utils import (
|
| 39 |
+
add_code_sample_docstrings,
|
| 40 |
+
add_start_docstrings,
|
| 41 |
+
add_start_docstrings_to_model_forward,
|
| 42 |
+
is_flash_attn_2_available,
|
| 43 |
+
is_flash_attn_greater_or_equal_2_10,
|
| 44 |
+
logging,
|
| 45 |
+
replace_return_docstrings,
|
| 46 |
+
)
|
| 47 |
+
from .configuration_phi import PhiConfig
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
try: # noqa: SIM105
|
| 51 |
+
if is_flash_attn_2_available():
|
| 52 |
+
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
| 53 |
+
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input
|
| 54 |
+
except ImportError:
|
| 55 |
+
# Workaround for https://github.com/huggingface/transformers/issues/28459,
|
| 56 |
+
# don't move to contextlib.suppress(ImportError)
|
| 57 |
+
pass
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
logger = logging.get_logger(__name__)
|
| 61 |
+
|
| 62 |
+
_CHECKPOINT_FOR_DOC = "microsoft/phi-1"
|
| 63 |
+
_CONFIG_FOR_DOC = "PhiConfig"
|
| 64 |
+
|
| 65 |
+
PHI_PRETRAINED_MODEL_ARCHIVE_LIST = [
|
| 66 |
+
"microsoft/phi-1",
|
| 67 |
+
# See all Phi models at https://huggingface.co/models?filter=phi
|
| 68 |
+
]
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
# Copied from transformers.models.llama.modeling_llama._get_unpad_data
|
| 72 |
+
def _get_unpad_data(attention_mask):
|
| 73 |
+
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
|
| 74 |
+
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
|
| 75 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 76 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 77 |
+
return (
|
| 78 |
+
indices,
|
| 79 |
+
cu_seqlens,
|
| 80 |
+
max_seqlen_in_batch,
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaRotaryEmbedding with Llama->Phi
|
| 85 |
+
class PhiRotaryEmbedding(nn.Module):
|
| 86 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
|
| 87 |
+
super().__init__()
|
| 88 |
+
|
| 89 |
+
self.dim = dim
|
| 90 |
+
self.max_position_embeddings = max_position_embeddings
|
| 91 |
+
self.base = base
|
| 92 |
+
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 93 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 94 |
+
|
| 95 |
+
# Build here to make `torch.jit.trace` work.
|
| 96 |
+
self._set_cos_sin_cache(
|
| 97 |
+
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 101 |
+
self.max_seq_len_cached = seq_len
|
| 102 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 103 |
+
|
| 104 |
+
freqs = torch.outer(t, self.inv_freq)
|
| 105 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 106 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 107 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 108 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 109 |
+
|
| 110 |
+
def forward(self, x, seq_len=None):
|
| 111 |
+
# x: [bs, num_attention_heads, seq_len, head_size]
|
| 112 |
+
if seq_len > self.max_seq_len_cached:
|
| 113 |
+
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
|
| 114 |
+
|
| 115 |
+
return (
|
| 116 |
+
self.cos_cached[:seq_len].to(dtype=x.dtype),
|
| 117 |
+
self.sin_cached[:seq_len].to(dtype=x.dtype),
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaLinearScalingRotaryEmbedding with Llama->Phi
|
| 122 |
+
class PhiLinearScalingRotaryEmbedding(PhiRotaryEmbedding):
|
| 123 |
+
"""PhiRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
|
| 124 |
+
|
| 125 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 126 |
+
self.scaling_factor = scaling_factor
|
| 127 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 128 |
+
|
| 129 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 130 |
+
self.max_seq_len_cached = seq_len
|
| 131 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 132 |
+
t = t / self.scaling_factor
|
| 133 |
+
|
| 134 |
+
freqs = torch.outer(t, self.inv_freq)
|
| 135 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 136 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 137 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 138 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaDynamicNTKScalingRotaryEmbedding with Llama->Phi
|
| 142 |
+
class PhiDynamicNTKScalingRotaryEmbedding(PhiRotaryEmbedding):
|
| 143 |
+
"""PhiRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
|
| 144 |
+
|
| 145 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 146 |
+
self.scaling_factor = scaling_factor
|
| 147 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 148 |
+
|
| 149 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 150 |
+
self.max_seq_len_cached = seq_len
|
| 151 |
+
|
| 152 |
+
if seq_len > self.max_position_embeddings:
|
| 153 |
+
base = self.base * (
|
| 154 |
+
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
|
| 155 |
+
) ** (self.dim / (self.dim - 2))
|
| 156 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 157 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 158 |
+
|
| 159 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 160 |
+
|
| 161 |
+
freqs = torch.outer(t, self.inv_freq)
|
| 162 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 163 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 164 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 165 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
# Copied from transformers.models.llama.modeling_llama.rotate_half
|
| 169 |
+
def rotate_half(x):
|
| 170 |
+
"""Rotates half the hidden dims of the input."""
|
| 171 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 172 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 173 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
# Copied from transformers.models.llama.modeling_llama.apply_rotary_pos_emb
|
| 177 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
|
| 178 |
+
"""Applies Rotary Position Embedding to the query and key tensors.
|
| 179 |
+
|
| 180 |
+
Args:
|
| 181 |
+
q (`torch.Tensor`): The query tensor.
|
| 182 |
+
k (`torch.Tensor`): The key tensor.
|
| 183 |
+
cos (`torch.Tensor`): The cosine part of the rotary embedding.
|
| 184 |
+
sin (`torch.Tensor`): The sine part of the rotary embedding.
|
| 185 |
+
position_ids (`torch.Tensor`):
|
| 186 |
+
The position indices of the tokens corresponding to the query and key tensors. For example, this can be
|
| 187 |
+
used to pass offsetted position ids when working with a KV-cache.
|
| 188 |
+
unsqueeze_dim (`int`, *optional*, defaults to 1):
|
| 189 |
+
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
|
| 190 |
+
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
|
| 191 |
+
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
|
| 192 |
+
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
|
| 193 |
+
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
|
| 194 |
+
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
|
| 195 |
+
Returns:
|
| 196 |
+
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
|
| 197 |
+
"""
|
| 198 |
+
cos = cos[position_ids].unsqueeze(unsqueeze_dim)
|
| 199 |
+
sin = sin[position_ids].unsqueeze(unsqueeze_dim)
|
| 200 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 201 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 202 |
+
return q_embed, k_embed
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->Phi
|
| 206 |
+
class PhiMLP(nn.Module):
|
| 207 |
+
def __init__(self, config):
|
| 208 |
+
super().__init__()
|
| 209 |
+
self.config = config
|
| 210 |
+
self.activation_fn = ACT2FN[config.hidden_act]
|
| 211 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 212 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 213 |
+
|
| 214 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 215 |
+
hidden_states = self.fc1(hidden_states)
|
| 216 |
+
hidden_states = self.activation_fn(hidden_states)
|
| 217 |
+
hidden_states = self.fc2(hidden_states)
|
| 218 |
+
return hidden_states
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
# Copied from transformers.models.llama.modeling_llama.repeat_kv with llama->phi
|
| 222 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 223 |
+
"""
|
| 224 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 225 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 226 |
+
"""
|
| 227 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 228 |
+
if n_rep == 1:
|
| 229 |
+
return hidden_states
|
| 230 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 231 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
class PhiAttention(nn.Module):
|
| 235 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 236 |
+
|
| 237 |
+
def __init__(self, config: PhiConfig, layer_idx: Optional[int] = None):
|
| 238 |
+
super().__init__()
|
| 239 |
+
self.config = config
|
| 240 |
+
self.layer_idx = layer_idx
|
| 241 |
+
if layer_idx is None:
|
| 242 |
+
logger.warning_once(
|
| 243 |
+
f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will "
|
| 244 |
+
"to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` "
|
| 245 |
+
"when creating this class."
|
| 246 |
+
)
|
| 247 |
+
|
| 248 |
+
self.attention_dropout = config.attention_dropout
|
| 249 |
+
self.hidden_size = config.hidden_size
|
| 250 |
+
self.num_heads = config.num_attention_heads
|
| 251 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 252 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 253 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 254 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 255 |
+
self.rope_theta = config.rope_theta
|
| 256 |
+
self.partial_rotary_factor = config.partial_rotary_factor
|
| 257 |
+
self.is_causal = True
|
| 258 |
+
|
| 259 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 260 |
+
raise ValueError(
|
| 261 |
+
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
|
| 262 |
+
f" and `num_heads`: {self.num_heads})."
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True)
|
| 266 |
+
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
|
| 267 |
+
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True)
|
| 268 |
+
self.dense = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=True)
|
| 269 |
+
|
| 270 |
+
self.qk_layernorm = config.qk_layernorm
|
| 271 |
+
if self.qk_layernorm:
|
| 272 |
+
self.q_layernorm = nn.LayerNorm(
|
| 273 |
+
config.hidden_size // self.num_heads, eps=config.layer_norm_eps, elementwise_affine=True
|
| 274 |
+
)
|
| 275 |
+
self.k_layernorm = nn.LayerNorm(
|
| 276 |
+
config.hidden_size // self.num_heads, eps=config.layer_norm_eps, elementwise_affine=True
|
| 277 |
+
)
|
| 278 |
+
|
| 279 |
+
self._init_rope()
|
| 280 |
+
|
| 281 |
+
def _init_rope(self):
|
| 282 |
+
if self.config.rope_scaling is None:
|
| 283 |
+
self.rotary_emb = PhiRotaryEmbedding(
|
| 284 |
+
int(self.partial_rotary_factor * self.head_dim),
|
| 285 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 286 |
+
base=self.rope_theta,
|
| 287 |
+
)
|
| 288 |
+
else:
|
| 289 |
+
scaling_type = self.config.rope_scaling["type"]
|
| 290 |
+
scaling_factor = self.config.rope_scaling["factor"]
|
| 291 |
+
if scaling_type == "linear":
|
| 292 |
+
self.rotary_emb = PhiLinearScalingRotaryEmbedding(
|
| 293 |
+
int(self.partial_rotary_factor * self.head_dim),
|
| 294 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 295 |
+
scaling_factor=scaling_factor,
|
| 296 |
+
base=self.rope_theta,
|
| 297 |
+
)
|
| 298 |
+
elif scaling_type == "dynamic":
|
| 299 |
+
self.rotary_emb = PhiDynamicNTKScalingRotaryEmbedding(
|
| 300 |
+
int(self.partial_rotary_factor * self.head_dim),
|
| 301 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 302 |
+
scaling_factor=scaling_factor,
|
| 303 |
+
base=self.rope_theta,
|
| 304 |
+
)
|
| 305 |
+
else:
|
| 306 |
+
raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
|
| 307 |
+
|
| 308 |
+
def forward(
|
| 309 |
+
self,
|
| 310 |
+
hidden_states: torch.Tensor,
|
| 311 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 312 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 313 |
+
past_key_value: Optional[Cache] = None,
|
| 314 |
+
output_attentions: bool = False,
|
| 315 |
+
use_cache: bool = False,
|
| 316 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 317 |
+
bsz, q_len, _ = hidden_states.size()
|
| 318 |
+
|
| 319 |
+
query_states = self.q_proj(hidden_states)
|
| 320 |
+
key_states = self.k_proj(hidden_states)
|
| 321 |
+
value_states = self.v_proj(hidden_states)
|
| 322 |
+
|
| 323 |
+
if self.qk_layernorm:
|
| 324 |
+
query_states = self.q_layernorm(query_states)
|
| 325 |
+
key_states = self.k_layernorm(key_states)
|
| 326 |
+
|
| 327 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 328 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 329 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 330 |
+
|
| 331 |
+
kv_seq_len = key_states.shape[-2]
|
| 332 |
+
if past_key_value is not None:
|
| 333 |
+
if self.layer_idx is None:
|
| 334 |
+
raise ValueError(
|
| 335 |
+
f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} "
|
| 336 |
+
"for auto-regressive decoding with k/v caching, please make sure to initialize the attention class "
|
| 337 |
+
"with a layer index."
|
| 338 |
+
)
|
| 339 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 340 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 341 |
+
|
| 342 |
+
# Partial rotary embedding
|
| 343 |
+
query_rot, query_pass = (
|
| 344 |
+
query_states[..., : self.rotary_emb.dim],
|
| 345 |
+
query_states[..., self.rotary_emb.dim :],
|
| 346 |
+
)
|
| 347 |
+
key_rot, key_pass = (
|
| 348 |
+
key_states[..., : self.rotary_emb.dim],
|
| 349 |
+
key_states[..., self.rotary_emb.dim :],
|
| 350 |
+
)
|
| 351 |
+
# [batch_size, seq_length, num_heads, head_dim // config.partial_rotary_factor]
|
| 352 |
+
query_rot, key_rot = apply_rotary_pos_emb(query_rot, key_rot, cos, sin, position_ids)
|
| 353 |
+
|
| 354 |
+
# [batch_size, seq_length, num_heads, head_dim]
|
| 355 |
+
query_states = torch.cat((query_rot, query_pass), dim=-1)
|
| 356 |
+
key_states = torch.cat((key_rot, key_pass), dim=-1)
|
| 357 |
+
|
| 358 |
+
if past_key_value is not None:
|
| 359 |
+
cache_kwargs = {"sin": sin, "cos": cos, "partial_rotation_size": self.rotary_emb.dim}
|
| 360 |
+
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 361 |
+
|
| 362 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 363 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 364 |
+
|
| 365 |
+
# Queries and keys upcast to fp32 is required by Phi-2 to avoid overflow
|
| 366 |
+
attn_weights = torch.matmul(
|
| 367 |
+
query_states.to(torch.float32), key_states.to(torch.float32).transpose(2, 3)
|
| 368 |
+
) / math.sqrt(self.head_dim)
|
| 369 |
+
|
| 370 |
+
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
| 371 |
+
raise ValueError(
|
| 372 |
+
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
|
| 373 |
+
f" {attn_weights.size()}"
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
if attention_mask is not None:
|
| 377 |
+
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
| 378 |
+
raise ValueError(
|
| 379 |
+
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
| 380 |
+
)
|
| 381 |
+
attn_weights = attn_weights + attention_mask
|
| 382 |
+
|
| 383 |
+
# upcast attention to fp32
|
| 384 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(value_states.dtype)
|
| 385 |
+
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
|
| 386 |
+
|
| 387 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 388 |
+
|
| 389 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 390 |
+
raise ValueError(
|
| 391 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
| 392 |
+
f" {attn_output.size()}"
|
| 393 |
+
)
|
| 394 |
+
|
| 395 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 396 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 397 |
+
|
| 398 |
+
attn_output = self.dense(attn_output)
|
| 399 |
+
|
| 400 |
+
if not output_attentions:
|
| 401 |
+
attn_weights = None
|
| 402 |
+
|
| 403 |
+
return attn_output, attn_weights, past_key_value
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
class PhiFlashAttention2(PhiAttention):
|
| 407 |
+
"""
|
| 408 |
+
Phi flash attention module. This module inherits from `PhiAttention` as the weights of the module stays
|
| 409 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 410 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 411 |
+
"""
|
| 412 |
+
|
| 413 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2.__init__
|
| 414 |
+
def __init__(self, *args, **kwargs):
|
| 415 |
+
super().__init__(*args, **kwargs)
|
| 416 |
+
|
| 417 |
+
# TODO: Should be removed once Flash Attention for RoCm is bumped to 2.1.
|
| 418 |
+
# flash_attn<2.1 generates top-left aligned causal mask, while what is needed here is bottom-right alignement, that was made default for flash_attn>=2.1. This attribute is used to handle this difference. Reference: https://github.com/Dao-AILab/flash-attention/releases/tag/v2.1.0.
|
| 419 |
+
# Beware that with flash_attn<2.1, using q_seqlen != k_seqlen (except for the case q_seqlen == 1) produces a wrong mask (top-left).
|
| 420 |
+
self._flash_attn_uses_top_left_mask = not is_flash_attn_greater_or_equal_2_10()
|
| 421 |
+
|
| 422 |
+
def forward(
|
| 423 |
+
self,
|
| 424 |
+
hidden_states: torch.Tensor,
|
| 425 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 426 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 427 |
+
past_key_value: Optional[Cache] = None,
|
| 428 |
+
output_attentions: bool = False,
|
| 429 |
+
use_cache: bool = False,
|
| 430 |
+
**kwargs,
|
| 431 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 432 |
+
# PhiFlashAttention2 attention does not support output_attentions
|
| 433 |
+
|
| 434 |
+
output_attentions = False
|
| 435 |
+
|
| 436 |
+
bsz, q_len, _ = hidden_states.size()
|
| 437 |
+
|
| 438 |
+
query_states = self.q_proj(hidden_states)
|
| 439 |
+
key_states = self.k_proj(hidden_states)
|
| 440 |
+
value_states = self.v_proj(hidden_states)
|
| 441 |
+
|
| 442 |
+
if self.qk_layernorm:
|
| 443 |
+
query_states = self.q_layernorm(query_states)
|
| 444 |
+
key_states = self.k_layernorm(key_states)
|
| 445 |
+
|
| 446 |
+
# Flash attention requires the input to have the shape
|
| 447 |
+
# batch_size x seq_length x head_dim x hidden_dim
|
| 448 |
+
# therefore we just need to keep the original shape
|
| 449 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 450 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 451 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 452 |
+
|
| 453 |
+
kv_seq_len = key_states.shape[-2]
|
| 454 |
+
if past_key_value is not None:
|
| 455 |
+
kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
|
| 456 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 457 |
+
|
| 458 |
+
# Partial rotary embedding
|
| 459 |
+
query_rot, query_pass = (
|
| 460 |
+
query_states[..., : self.rotary_emb.dim],
|
| 461 |
+
query_states[..., self.rotary_emb.dim :],
|
| 462 |
+
)
|
| 463 |
+
key_rot, key_pass = (
|
| 464 |
+
key_states[..., : self.rotary_emb.dim],
|
| 465 |
+
key_states[..., self.rotary_emb.dim :],
|
| 466 |
+
)
|
| 467 |
+
# [batch_size, seq_length, num_heads, head_dim // config.partial_rotary_factor]
|
| 468 |
+
query_rot, key_rot = apply_rotary_pos_emb(query_rot, key_rot, cos, sin, position_ids)
|
| 469 |
+
|
| 470 |
+
# [batch_size, seq_length, num_heads, head_dim]
|
| 471 |
+
query_states = torch.cat((query_rot, query_pass), dim=-1)
|
| 472 |
+
key_states = torch.cat((key_rot, key_pass), dim=-1)
|
| 473 |
+
|
| 474 |
+
if past_key_value is not None:
|
| 475 |
+
cache_kwargs = {"sin": sin, "cos": cos, "partial_rotation_size": self.rotary_emb.dim}
|
| 476 |
+
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
|
| 477 |
+
|
| 478 |
+
# TODO: These transpose are quite inefficient but Flash Attention requires the layout [batch_size, sequence_length, num_heads, head_dim]. We would need to refactor the KV cache
|
| 479 |
+
# to be able to avoid many of these transpose/reshape/view.
|
| 480 |
+
query_states = query_states.transpose(1, 2)
|
| 481 |
+
key_states = key_states.transpose(1, 2)
|
| 482 |
+
value_states = value_states.transpose(1, 2)
|
| 483 |
+
|
| 484 |
+
attn_dropout = self.attention_dropout if self.training else 0.0
|
| 485 |
+
|
| 486 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 487 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 488 |
+
# cast them back in the correct dtype just to be sure everything works as expected.
|
| 489 |
+
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
|
| 490 |
+
# in fp32.
|
| 491 |
+
|
| 492 |
+
if query_states.dtype == torch.float32:
|
| 493 |
+
if torch.is_autocast_enabled():
|
| 494 |
+
target_dtype = torch.get_autocast_gpu_dtype()
|
| 495 |
+
# Handle the case where the model is quantized
|
| 496 |
+
elif hasattr(self.config, "_pre_quantization_dtype"):
|
| 497 |
+
target_dtype = self.config._pre_quantization_dtype
|
| 498 |
+
else:
|
| 499 |
+
target_dtype = self.q_proj.weight.dtype
|
| 500 |
+
|
| 501 |
+
logger.warning_once(
|
| 502 |
+
f"The input hidden states seems to be silently casted in float32, this might be related to"
|
| 503 |
+
f" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
|
| 504 |
+
f" {target_dtype}."
|
| 505 |
+
)
|
| 506 |
+
|
| 507 |
+
query_states = query_states.to(target_dtype)
|
| 508 |
+
key_states = key_states.to(target_dtype)
|
| 509 |
+
value_states = value_states.to(target_dtype)
|
| 510 |
+
|
| 511 |
+
attn_output = self._flash_attention_forward(
|
| 512 |
+
query_states, key_states, value_states, attention_mask, q_len, dropout=attn_dropout, softmax_scale=None
|
| 513 |
+
)
|
| 514 |
+
|
| 515 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
|
| 516 |
+
attn_output = self.dense(attn_output)
|
| 517 |
+
|
| 518 |
+
if not output_attentions:
|
| 519 |
+
attn_weights = None
|
| 520 |
+
|
| 521 |
+
return attn_output, attn_weights, past_key_value
|
| 522 |
+
|
| 523 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._flash_attention_forward
|
| 524 |
+
def _flash_attention_forward(
|
| 525 |
+
self, query_states, key_states, value_states, attention_mask, query_length, dropout=0.0, softmax_scale=None
|
| 526 |
+
):
|
| 527 |
+
"""
|
| 528 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 529 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 530 |
+
|
| 531 |
+
Args:
|
| 532 |
+
query_states (`torch.Tensor`):
|
| 533 |
+
Input query states to be passed to Flash Attention API
|
| 534 |
+
key_states (`torch.Tensor`):
|
| 535 |
+
Input key states to be passed to Flash Attention API
|
| 536 |
+
value_states (`torch.Tensor`):
|
| 537 |
+
Input value states to be passed to Flash Attention API
|
| 538 |
+
attention_mask (`torch.Tensor`):
|
| 539 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 540 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 541 |
+
dropout (`int`, *optional*):
|
| 542 |
+
Attention dropout
|
| 543 |
+
softmax_scale (`float`, *optional*):
|
| 544 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 545 |
+
"""
|
| 546 |
+
if not self._flash_attn_uses_top_left_mask:
|
| 547 |
+
causal = self.is_causal
|
| 548 |
+
else:
|
| 549 |
+
# TODO: Remove the `query_length != 1` check once Flash Attention for RoCm is bumped to 2.1. For details, please see the comment in LlamaFlashAttention2 __init__.
|
| 550 |
+
causal = self.is_causal and query_length != 1
|
| 551 |
+
|
| 552 |
+
# Contains at least one padding token in the sequence
|
| 553 |
+
if attention_mask is not None:
|
| 554 |
+
batch_size = query_states.shape[0]
|
| 555 |
+
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
|
| 556 |
+
query_states, key_states, value_states, attention_mask, query_length
|
| 557 |
+
)
|
| 558 |
+
|
| 559 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 560 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 561 |
+
|
| 562 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 563 |
+
query_states,
|
| 564 |
+
key_states,
|
| 565 |
+
value_states,
|
| 566 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 567 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 568 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 569 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 570 |
+
dropout_p=dropout,
|
| 571 |
+
softmax_scale=softmax_scale,
|
| 572 |
+
causal=causal,
|
| 573 |
+
)
|
| 574 |
+
|
| 575 |
+
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
|
| 576 |
+
else:
|
| 577 |
+
attn_output = flash_attn_func(
|
| 578 |
+
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=causal
|
| 579 |
+
)
|
| 580 |
+
|
| 581 |
+
return attn_output
|
| 582 |
+
|
| 583 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaFlashAttention2._upad_input
|
| 584 |
+
def _upad_input(self, query_layer, key_layer, value_layer, attention_mask, query_length):
|
| 585 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(attention_mask)
|
| 586 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 587 |
+
|
| 588 |
+
key_layer = index_first_axis(
|
| 589 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 590 |
+
)
|
| 591 |
+
value_layer = index_first_axis(
|
| 592 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 593 |
+
)
|
| 594 |
+
if query_length == kv_seq_len:
|
| 595 |
+
query_layer = index_first_axis(
|
| 596 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
|
| 597 |
+
)
|
| 598 |
+
cu_seqlens_q = cu_seqlens_k
|
| 599 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 600 |
+
indices_q = indices_k
|
| 601 |
+
elif query_length == 1:
|
| 602 |
+
max_seqlen_in_batch_q = 1
|
| 603 |
+
cu_seqlens_q = torch.arange(
|
| 604 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 605 |
+
) # There is a memcpy here, that is very bad.
|
| 606 |
+
indices_q = cu_seqlens_q[:-1]
|
| 607 |
+
query_layer = query_layer.squeeze(1)
|
| 608 |
+
else:
|
| 609 |
+
# The -q_len: slice assumes left padding.
|
| 610 |
+
attention_mask = attention_mask[:, -query_length:]
|
| 611 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, attention_mask)
|
| 612 |
+
|
| 613 |
+
return (
|
| 614 |
+
query_layer,
|
| 615 |
+
key_layer,
|
| 616 |
+
value_layer,
|
| 617 |
+
indices_q,
|
| 618 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 619 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 620 |
+
)
|
| 621 |
+
|
| 622 |
+
|
| 623 |
+
PHI_ATTENTION_CLASSES = {
|
| 624 |
+
"eager": PhiAttention,
|
| 625 |
+
"flash_attention_2": PhiFlashAttention2,
|
| 626 |
+
}
|
| 627 |
+
|
| 628 |
+
|
| 629 |
+
class PhiDecoderLayer(nn.Module):
|
| 630 |
+
def __init__(self, config: PhiConfig, layer_idx: int):
|
| 631 |
+
super().__init__()
|
| 632 |
+
self.self_attn = PHI_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx=layer_idx)
|
| 633 |
+
self.mlp = PhiMLP(config)
|
| 634 |
+
self.input_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
|
| 635 |
+
self.resid_dropout = nn.Dropout(config.resid_pdrop)
|
| 636 |
+
|
| 637 |
+
def forward(
|
| 638 |
+
self,
|
| 639 |
+
hidden_states: torch.Tensor,
|
| 640 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 641 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 642 |
+
output_attentions: Optional[bool] = False,
|
| 643 |
+
use_cache: Optional[bool] = False,
|
| 644 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 645 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 646 |
+
"""
|
| 647 |
+
Args:
|
| 648 |
+
hidden_states (`torch.FloatTensor`):
|
| 649 |
+
input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 650 |
+
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
|
| 651 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 652 |
+
position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
|
| 653 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range
|
| 654 |
+
`[0, config.n_positions - 1]`. [What are position IDs?](../glossary#position-ids)
|
| 655 |
+
output_attentions (`bool`, *optional*):
|
| 656 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 657 |
+
returned tensors for more detail.
|
| 658 |
+
use_cache (`bool`, *optional*):
|
| 659 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 660 |
+
(see `past_key_values`).
|
| 661 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 662 |
+
"""
|
| 663 |
+
|
| 664 |
+
residual = hidden_states
|
| 665 |
+
|
| 666 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 667 |
+
|
| 668 |
+
# Self Attention
|
| 669 |
+
attn_outputs, self_attn_weights, present_key_value = self.self_attn(
|
| 670 |
+
hidden_states=hidden_states,
|
| 671 |
+
attention_mask=attention_mask,
|
| 672 |
+
position_ids=position_ids,
|
| 673 |
+
past_key_value=past_key_value,
|
| 674 |
+
output_attentions=output_attentions,
|
| 675 |
+
use_cache=use_cache,
|
| 676 |
+
)
|
| 677 |
+
attn_outputs = self.resid_dropout(attn_outputs)
|
| 678 |
+
|
| 679 |
+
feed_forward_hidden_states = self.resid_dropout(self.mlp(hidden_states))
|
| 680 |
+
hidden_states = attn_outputs + feed_forward_hidden_states + residual
|
| 681 |
+
outputs = (hidden_states,)
|
| 682 |
+
|
| 683 |
+
if output_attentions:
|
| 684 |
+
outputs += (self_attn_weights,)
|
| 685 |
+
|
| 686 |
+
if use_cache:
|
| 687 |
+
outputs += (present_key_value,)
|
| 688 |
+
|
| 689 |
+
return outputs
|
| 690 |
+
|
| 691 |
+
|
| 692 |
+
PHI_START_DOCSTRING = r"""
|
| 693 |
+
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
|
| 694 |
+
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
|
| 695 |
+
etc.)
|
| 696 |
+
|
| 697 |
+
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
|
| 698 |
+
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
|
| 699 |
+
and behavior.
|
| 700 |
+
|
| 701 |
+
Parameters:
|
| 702 |
+
config ([`PhiConfig`]):
|
| 703 |
+
Model configuration class with all the parameters of the model. Initializing with a config file does not
|
| 704 |
+
load the weights associated with the model, only the configuration. Check out the
|
| 705 |
+
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
|
| 706 |
+
"""
|
| 707 |
+
|
| 708 |
+
|
| 709 |
+
@add_start_docstrings(
|
| 710 |
+
"The bare Phi Model outputting raw hidden-states without any specific head on top.",
|
| 711 |
+
PHI_START_DOCSTRING,
|
| 712 |
+
)
|
| 713 |
+
class PhiPreTrainedModel(PreTrainedModel):
|
| 714 |
+
config_class = PhiConfig
|
| 715 |
+
base_model_prefix = "model"
|
| 716 |
+
supports_gradient_checkpointing = True
|
| 717 |
+
_no_split_modules = ["PhiDecoderLayer"]
|
| 718 |
+
_skip_keys_device_placement = "past_key_values"
|
| 719 |
+
_supports_flash_attn_2 = True
|
| 720 |
+
_supports_cache_class = True
|
| 721 |
+
|
| 722 |
+
def _init_weights(self, module):
|
| 723 |
+
std = self.config.initializer_range
|
| 724 |
+
if isinstance(module, nn.Linear):
|
| 725 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 726 |
+
if module.bias is not None:
|
| 727 |
+
module.bias.data.zero_()
|
| 728 |
+
elif isinstance(module, nn.Embedding):
|
| 729 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 730 |
+
if module.padding_idx is not None:
|
| 731 |
+
module.weight.data[module.padding_idx].zero_()
|
| 732 |
+
|
| 733 |
+
|
| 734 |
+
PHI_INPUTS_DOCSTRING = r"""
|
| 735 |
+
Args:
|
| 736 |
+
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
|
| 737 |
+
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
|
| 738 |
+
it.
|
| 739 |
+
|
| 740 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 741 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 742 |
+
|
| 743 |
+
[What are input IDs?](../glossary#input-ids)
|
| 744 |
+
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 745 |
+
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
|
| 746 |
+
|
| 747 |
+
- 1 for tokens that are **not masked**,
|
| 748 |
+
- 0 for tokens that are **masked**.
|
| 749 |
+
|
| 750 |
+
[What are attention masks?](../glossary#attention-mask)
|
| 751 |
+
|
| 752 |
+
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
|
| 753 |
+
[`PreTrainedTokenizer.__call__`] for details.
|
| 754 |
+
|
| 755 |
+
If `past_key_values` is used, optionally only the last `input_ids` have to be input (see
|
| 756 |
+
`past_key_values`).
|
| 757 |
+
|
| 758 |
+
If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
|
| 759 |
+
and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
|
| 760 |
+
information on the default strategy.
|
| 761 |
+
|
| 762 |
+
- 1 indicates the head is **not masked**,
|
| 763 |
+
- 0 indicates the head is **masked**.
|
| 764 |
+
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 765 |
+
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
|
| 766 |
+
config.n_positions - 1]`.
|
| 767 |
+
|
| 768 |
+
[What are position IDs?](../glossary#position-ids)
|
| 769 |
+
past_key_values (`Cache` or `tuple(tuple(torch.FloatTensor))`, *optional*):
|
| 770 |
+
Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
|
| 771 |
+
blocks) that can be used to speed up sequential decoding. This typically consists in the `past_key_values`
|
| 772 |
+
returned by the model at a previous stage of decoding, when `use_cache=True` or `config.use_cache=True`.
|
| 773 |
+
|
| 774 |
+
Two formats are allowed:
|
| 775 |
+
- a [`~cache_utils.Cache`] instance;
|
| 776 |
+
- Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of
|
| 777 |
+
shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`). This is also known as the legacy
|
| 778 |
+
cache format.
|
| 779 |
+
|
| 780 |
+
The model will output the same cache format that is fed as input. If no `past_key_values` are passed, the
|
| 781 |
+
legacy cache format will be returned.
|
| 782 |
+
|
| 783 |
+
If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't
|
| 784 |
+
have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids`
|
| 785 |
+
of shape `(batch_size, sequence_length)`.
|
| 786 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
|
| 787 |
+
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
|
| 788 |
+
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
|
| 789 |
+
model's internal embedding lookup matrix.
|
| 790 |
+
use_cache (`bool`, *optional*):
|
| 791 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
|
| 792 |
+
`past_key_values`).
|
| 793 |
+
output_attentions (`bool`, *optional*):
|
| 794 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
|
| 795 |
+
tensors for more detail.
|
| 796 |
+
output_hidden_states (`bool`, *optional*):
|
| 797 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
|
| 798 |
+
more detail.
|
| 799 |
+
return_dict (`bool`, *optional*):
|
| 800 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 801 |
+
"""
|
| 802 |
+
|
| 803 |
+
|
| 804 |
+
@add_start_docstrings(
|
| 805 |
+
"The bare Phi Model outputting raw hidden-states without any specific head on top.",
|
| 806 |
+
PHI_START_DOCSTRING,
|
| 807 |
+
)
|
| 808 |
+
class PhiModel(PhiPreTrainedModel):
|
| 809 |
+
"""
|
| 810 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`PhiDecoderLayer`]
|
| 811 |
+
|
| 812 |
+
Args:
|
| 813 |
+
config: PhiConfig
|
| 814 |
+
"""
|
| 815 |
+
|
| 816 |
+
def __init__(self, config: PhiConfig):
|
| 817 |
+
super().__init__(config)
|
| 818 |
+
self.padding_idx = config.pad_token_id
|
| 819 |
+
self.vocab_size = config.vocab_size
|
| 820 |
+
|
| 821 |
+
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 822 |
+
self.embed_dropout = nn.Dropout(config.embd_pdrop)
|
| 823 |
+
self.layers = nn.ModuleList(
|
| 824 |
+
[PhiDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
|
| 825 |
+
)
|
| 826 |
+
self.final_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
|
| 827 |
+
self._use_flash_attention_2 = config._attn_implementation == "flash_attention_2"
|
| 828 |
+
|
| 829 |
+
self.gradient_checkpointing = False
|
| 830 |
+
# Initialize weights and apply final processing
|
| 831 |
+
self.post_init()
|
| 832 |
+
|
| 833 |
+
def get_input_embeddings(self):
|
| 834 |
+
return self.embed_tokens
|
| 835 |
+
|
| 836 |
+
def set_input_embeddings(self, value):
|
| 837 |
+
self.embed_tokens = value
|
| 838 |
+
|
| 839 |
+
@add_start_docstrings_to_model_forward(PHI_INPUTS_DOCSTRING)
|
| 840 |
+
def forward(
|
| 841 |
+
self,
|
| 842 |
+
input_ids: torch.LongTensor = None,
|
| 843 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 844 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 845 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 846 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 847 |
+
use_cache: Optional[bool] = None,
|
| 848 |
+
output_attentions: Optional[bool] = None,
|
| 849 |
+
output_hidden_states: Optional[bool] = None,
|
| 850 |
+
return_dict: Optional[bool] = None,
|
| 851 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 852 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 853 |
+
output_hidden_states = (
|
| 854 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 855 |
+
)
|
| 856 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 857 |
+
|
| 858 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 859 |
+
|
| 860 |
+
# retrieve input_ids and inputs_embeds
|
| 861 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 862 |
+
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
| 863 |
+
elif input_ids is not None:
|
| 864 |
+
batch_size, seq_length = input_ids.shape[:2]
|
| 865 |
+
elif inputs_embeds is not None:
|
| 866 |
+
batch_size, seq_length = inputs_embeds.shape[:2]
|
| 867 |
+
else:
|
| 868 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 869 |
+
|
| 870 |
+
past_key_values_length = 0
|
| 871 |
+
|
| 872 |
+
if self.gradient_checkpointing and self.training:
|
| 873 |
+
if use_cache:
|
| 874 |
+
logger.warning_once(
|
| 875 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 876 |
+
)
|
| 877 |
+
use_cache = False
|
| 878 |
+
|
| 879 |
+
if use_cache:
|
| 880 |
+
use_legacy_cache = not isinstance(past_key_values, Cache)
|
| 881 |
+
if use_legacy_cache:
|
| 882 |
+
past_key_values = DynamicCache.from_legacy_cache(past_key_values)
|
| 883 |
+
past_key_values_length = past_key_values.get_usable_length(seq_length)
|
| 884 |
+
|
| 885 |
+
if position_ids is None:
|
| 886 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 887 |
+
position_ids = torch.arange(
|
| 888 |
+
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
| 889 |
+
)
|
| 890 |
+
position_ids = position_ids.unsqueeze(0)
|
| 891 |
+
|
| 892 |
+
if inputs_embeds is None:
|
| 893 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 894 |
+
|
| 895 |
+
inputs_embeds = self.embed_dropout(inputs_embeds)
|
| 896 |
+
|
| 897 |
+
# Attention mask.
|
| 898 |
+
if self._use_flash_attention_2:
|
| 899 |
+
# 2d mask is passed through the layers
|
| 900 |
+
attention_mask = attention_mask if (attention_mask is not None and 0 in attention_mask) else None
|
| 901 |
+
else:
|
| 902 |
+
# 4d mask is passed through the layers
|
| 903 |
+
attention_mask = _prepare_4d_causal_attention_mask(
|
| 904 |
+
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
|
| 905 |
+
)
|
| 906 |
+
|
| 907 |
+
hidden_states = inputs_embeds
|
| 908 |
+
|
| 909 |
+
# decoder layers
|
| 910 |
+
all_hidden_states = () if output_hidden_states else None
|
| 911 |
+
all_self_attns = () if output_attentions else None
|
| 912 |
+
next_decoder_cache = None
|
| 913 |
+
|
| 914 |
+
for decoder_layer in self.layers:
|
| 915 |
+
if output_hidden_states:
|
| 916 |
+
all_hidden_states += (hidden_states,)
|
| 917 |
+
|
| 918 |
+
if self.gradient_checkpointing and self.training:
|
| 919 |
+
layer_outputs = self._gradient_checkpointing_func(
|
| 920 |
+
decoder_layer.__call__,
|
| 921 |
+
hidden_states,
|
| 922 |
+
attention_mask,
|
| 923 |
+
position_ids,
|
| 924 |
+
past_key_values,
|
| 925 |
+
output_attentions,
|
| 926 |
+
)
|
| 927 |
+
else:
|
| 928 |
+
layer_outputs = decoder_layer(
|
| 929 |
+
hidden_states,
|
| 930 |
+
attention_mask=attention_mask,
|
| 931 |
+
position_ids=position_ids,
|
| 932 |
+
past_key_value=past_key_values,
|
| 933 |
+
output_attentions=output_attentions,
|
| 934 |
+
use_cache=use_cache,
|
| 935 |
+
)
|
| 936 |
+
|
| 937 |
+
hidden_states = layer_outputs[0]
|
| 938 |
+
|
| 939 |
+
if use_cache:
|
| 940 |
+
next_decoder_cache = layer_outputs[2 if output_attentions else 1]
|
| 941 |
+
|
| 942 |
+
if output_attentions:
|
| 943 |
+
all_self_attns += (layer_outputs[1],)
|
| 944 |
+
|
| 945 |
+
hidden_states = self.final_layernorm(hidden_states)
|
| 946 |
+
|
| 947 |
+
# add hidden states from the last decoder layer
|
| 948 |
+
if output_hidden_states:
|
| 949 |
+
all_hidden_states += (hidden_states,)
|
| 950 |
+
|
| 951 |
+
next_cache = None
|
| 952 |
+
if use_cache:
|
| 953 |
+
next_cache = next_decoder_cache.to_legacy_cache() if use_legacy_cache else next_decoder_cache
|
| 954 |
+
if not return_dict:
|
| 955 |
+
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
| 956 |
+
return BaseModelOutputWithPast(
|
| 957 |
+
last_hidden_state=hidden_states,
|
| 958 |
+
past_key_values=next_cache,
|
| 959 |
+
hidden_states=all_hidden_states,
|
| 960 |
+
attentions=all_self_attns,
|
| 961 |
+
)
|
| 962 |
+
|
| 963 |
+
|
| 964 |
+
class PhiForCausalLM(PhiPreTrainedModel):
|
| 965 |
+
_tied_weights_keys = ["lm_head.weight"]
|
| 966 |
+
|
| 967 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.__init__ with Llama->Phi,bias=False->bias=True
|
| 968 |
+
def __init__(self, config):
|
| 969 |
+
super().__init__(config)
|
| 970 |
+
self.model = PhiModel(config)
|
| 971 |
+
self.vocab_size = config.vocab_size
|
| 972 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=True)
|
| 973 |
+
|
| 974 |
+
# Initialize weights and apply final processing
|
| 975 |
+
self.post_init()
|
| 976 |
+
|
| 977 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_input_embeddings
|
| 978 |
+
def get_input_embeddings(self):
|
| 979 |
+
return self.model.embed_tokens
|
| 980 |
+
|
| 981 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_input_embeddings
|
| 982 |
+
def set_input_embeddings(self, value):
|
| 983 |
+
self.model.embed_tokens = value
|
| 984 |
+
|
| 985 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_output_embeddings
|
| 986 |
+
def get_output_embeddings(self):
|
| 987 |
+
return self.lm_head
|
| 988 |
+
|
| 989 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_output_embeddings
|
| 990 |
+
def set_output_embeddings(self, new_embeddings):
|
| 991 |
+
self.lm_head = new_embeddings
|
| 992 |
+
|
| 993 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.set_decoder
|
| 994 |
+
def set_decoder(self, decoder):
|
| 995 |
+
self.model = decoder
|
| 996 |
+
|
| 997 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.get_decoder
|
| 998 |
+
def get_decoder(self):
|
| 999 |
+
return self.model
|
| 1000 |
+
|
| 1001 |
+
@add_start_docstrings_to_model_forward(PHI_INPUTS_DOCSTRING)
|
| 1002 |
+
@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
|
| 1003 |
+
def forward(
|
| 1004 |
+
self,
|
| 1005 |
+
input_ids: torch.LongTensor = None,
|
| 1006 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1007 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1008 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1009 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1010 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1011 |
+
use_cache: Optional[bool] = None,
|
| 1012 |
+
output_attentions: Optional[bool] = None,
|
| 1013 |
+
output_hidden_states: Optional[bool] = None,
|
| 1014 |
+
return_dict: Optional[bool] = None,
|
| 1015 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 1016 |
+
r"""
|
| 1017 |
+
Args:
|
| 1018 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 1019 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 1020 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 1021 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 1022 |
+
|
| 1023 |
+
Returns:
|
| 1024 |
+
|
| 1025 |
+
Example:
|
| 1026 |
+
|
| 1027 |
+
```python
|
| 1028 |
+
>>> from transformers import AutoTokenizer, PhiForCausalLM
|
| 1029 |
+
|
| 1030 |
+
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1")
|
| 1031 |
+
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
|
| 1032 |
+
|
| 1033 |
+
>>> prompt = "This is an example script ."
|
| 1034 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 1035 |
+
|
| 1036 |
+
>>> # Generate
|
| 1037 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 1038 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 1039 |
+
'This is an example script .\n\n\n\nfrom typing import List\n\ndef find_most_common_letter(words: List[str'
|
| 1040 |
+
```"""
|
| 1041 |
+
|
| 1042 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 1043 |
+
output_hidden_states = (
|
| 1044 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 1045 |
+
)
|
| 1046 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1047 |
+
|
| 1048 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 1049 |
+
outputs = self.model(
|
| 1050 |
+
input_ids=input_ids,
|
| 1051 |
+
attention_mask=attention_mask,
|
| 1052 |
+
position_ids=position_ids,
|
| 1053 |
+
past_key_values=past_key_values,
|
| 1054 |
+
inputs_embeds=inputs_embeds,
|
| 1055 |
+
use_cache=use_cache,
|
| 1056 |
+
output_attentions=output_attentions,
|
| 1057 |
+
output_hidden_states=output_hidden_states,
|
| 1058 |
+
return_dict=return_dict,
|
| 1059 |
+
)
|
| 1060 |
+
|
| 1061 |
+
hidden_states = outputs[0]
|
| 1062 |
+
logits = self.lm_head(hidden_states)
|
| 1063 |
+
logits = logits.float()
|
| 1064 |
+
|
| 1065 |
+
loss = None
|
| 1066 |
+
if labels is not None:
|
| 1067 |
+
# Shift so that tokens < n predict n
|
| 1068 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 1069 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 1070 |
+
# Flatten the tokens
|
| 1071 |
+
loss_fct = CrossEntropyLoss()
|
| 1072 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 1073 |
+
shift_labels = shift_labels.view(-1)
|
| 1074 |
+
# Enable model parallelism
|
| 1075 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 1076 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 1077 |
+
|
| 1078 |
+
if not return_dict:
|
| 1079 |
+
output = (logits,) + outputs[1:]
|
| 1080 |
+
return (loss,) + output if loss is not None else output
|
| 1081 |
+
|
| 1082 |
+
return CausalLMOutputWithPast(
|
| 1083 |
+
loss=loss,
|
| 1084 |
+
logits=logits,
|
| 1085 |
+
past_key_values=outputs.past_key_values,
|
| 1086 |
+
hidden_states=outputs.hidden_states,
|
| 1087 |
+
attentions=outputs.attentions,
|
| 1088 |
+
)
|
| 1089 |
+
|
| 1090 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM.prepare_inputs_for_generation
|
| 1091 |
+
def prepare_inputs_for_generation(
|
| 1092 |
+
self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
|
| 1093 |
+
):
|
| 1094 |
+
if past_key_values is not None:
|
| 1095 |
+
if isinstance(past_key_values, Cache):
|
| 1096 |
+
cache_length = past_key_values.get_seq_length()
|
| 1097 |
+
past_length = past_key_values.seen_tokens
|
| 1098 |
+
max_cache_length = past_key_values.get_max_length()
|
| 1099 |
+
else:
|
| 1100 |
+
cache_length = past_length = past_key_values[0][0].shape[2]
|
| 1101 |
+
max_cache_length = None
|
| 1102 |
+
|
| 1103 |
+
# Keep only the unprocessed tokens:
|
| 1104 |
+
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 1105 |
+
# some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
|
| 1106 |
+
# input)
|
| 1107 |
+
if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
|
| 1108 |
+
input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
|
| 1109 |
+
# 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
|
| 1110 |
+
# input_ids based on the past_length.
|
| 1111 |
+
elif past_length < input_ids.shape[1]:
|
| 1112 |
+
input_ids = input_ids[:, past_length:]
|
| 1113 |
+
# 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
|
| 1114 |
+
|
| 1115 |
+
# If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
|
| 1116 |
+
if (
|
| 1117 |
+
max_cache_length is not None
|
| 1118 |
+
and attention_mask is not None
|
| 1119 |
+
and cache_length + input_ids.shape[1] > max_cache_length
|
| 1120 |
+
):
|
| 1121 |
+
attention_mask = attention_mask[:, -max_cache_length:]
|
| 1122 |
+
|
| 1123 |
+
position_ids = kwargs.get("position_ids", None)
|
| 1124 |
+
if attention_mask is not None and position_ids is None:
|
| 1125 |
+
# create position_ids on the fly for batch generation
|
| 1126 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 1127 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 1128 |
+
if past_key_values:
|
| 1129 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 1130 |
+
|
| 1131 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 1132 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 1133 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 1134 |
+
else:
|
| 1135 |
+
model_inputs = {"input_ids": input_ids}
|
| 1136 |
+
|
| 1137 |
+
model_inputs.update(
|
| 1138 |
+
{
|
| 1139 |
+
"position_ids": position_ids,
|
| 1140 |
+
"past_key_values": past_key_values,
|
| 1141 |
+
"use_cache": kwargs.get("use_cache"),
|
| 1142 |
+
"attention_mask": attention_mask,
|
| 1143 |
+
}
|
| 1144 |
+
)
|
| 1145 |
+
return model_inputs
|
| 1146 |
+
|
| 1147 |
+
@staticmethod
|
| 1148 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForCausalLM._reorder_cache
|
| 1149 |
+
def _reorder_cache(past_key_values, beam_idx):
|
| 1150 |
+
reordered_past = ()
|
| 1151 |
+
for layer_past in past_key_values:
|
| 1152 |
+
reordered_past += (
|
| 1153 |
+
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
|
| 1154 |
+
)
|
| 1155 |
+
return reordered_past
|
| 1156 |
+
|
| 1157 |
+
|
| 1158 |
+
@add_start_docstrings(
|
| 1159 |
+
"""
|
| 1160 |
+
The PhiModel with a sequence classification head on top (linear layer).
|
| 1161 |
+
|
| 1162 |
+
[`PhiForSequenceClassification`] uses the last token in order to do the classification, as other causal models
|
| 1163 |
+
(e.g. GPT-2) do.
|
| 1164 |
+
|
| 1165 |
+
Since it does classification on the last token, it requires to know the position of the last token. If a
|
| 1166 |
+
`pad_token_id` is defined in the configuration, it finds the last token that is not a padding token in each row. If
|
| 1167 |
+
no `pad_token_id` is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
|
| 1168 |
+
padding tokens when `inputs_embeds` are passed instead of `input_ids`, it does the same (take the last value in
|
| 1169 |
+
each row of the batch).
|
| 1170 |
+
""",
|
| 1171 |
+
PHI_START_DOCSTRING,
|
| 1172 |
+
)
|
| 1173 |
+
# Copied from transformers.models.llama.modeling_llama.LlamaForSequenceClassification with LLAMA->PHI,Llama->Phi with self.transformer->self.model, transformer_outputs->model_outputs
|
| 1174 |
+
class PhiForSequenceClassification(PhiPreTrainedModel):
|
| 1175 |
+
def __init__(self, config):
|
| 1176 |
+
super().__init__(config)
|
| 1177 |
+
self.num_labels = config.num_labels
|
| 1178 |
+
self.model = PhiModel(config)
|
| 1179 |
+
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 1180 |
+
|
| 1181 |
+
# Initialize weights and apply final processing
|
| 1182 |
+
self.post_init()
|
| 1183 |
+
|
| 1184 |
+
def get_input_embeddings(self):
|
| 1185 |
+
return self.model.embed_tokens
|
| 1186 |
+
|
| 1187 |
+
def set_input_embeddings(self, value):
|
| 1188 |
+
self.model.embed_tokens = value
|
| 1189 |
+
|
| 1190 |
+
@add_start_docstrings_to_model_forward(PHI_INPUTS_DOCSTRING)
|
| 1191 |
+
def forward(
|
| 1192 |
+
self,
|
| 1193 |
+
input_ids: torch.LongTensor = None,
|
| 1194 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1195 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1196 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1197 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1198 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1199 |
+
use_cache: Optional[bool] = None,
|
| 1200 |
+
output_attentions: Optional[bool] = None,
|
| 1201 |
+
output_hidden_states: Optional[bool] = None,
|
| 1202 |
+
return_dict: Optional[bool] = None,
|
| 1203 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 1204 |
+
r"""
|
| 1205 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1206 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1207 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1208 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1209 |
+
"""
|
| 1210 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1211 |
+
|
| 1212 |
+
model_outputs = self.model(
|
| 1213 |
+
input_ids,
|
| 1214 |
+
attention_mask=attention_mask,
|
| 1215 |
+
position_ids=position_ids,
|
| 1216 |
+
past_key_values=past_key_values,
|
| 1217 |
+
inputs_embeds=inputs_embeds,
|
| 1218 |
+
use_cache=use_cache,
|
| 1219 |
+
output_attentions=output_attentions,
|
| 1220 |
+
output_hidden_states=output_hidden_states,
|
| 1221 |
+
return_dict=return_dict,
|
| 1222 |
+
)
|
| 1223 |
+
hidden_states = model_outputs[0]
|
| 1224 |
+
logits = self.score(hidden_states)
|
| 1225 |
+
|
| 1226 |
+
if input_ids is not None:
|
| 1227 |
+
batch_size = input_ids.shape[0]
|
| 1228 |
+
else:
|
| 1229 |
+
batch_size = inputs_embeds.shape[0]
|
| 1230 |
+
|
| 1231 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 1232 |
+
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
|
| 1233 |
+
if self.config.pad_token_id is None:
|
| 1234 |
+
sequence_lengths = -1
|
| 1235 |
+
else:
|
| 1236 |
+
if input_ids is not None:
|
| 1237 |
+
# if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
|
| 1238 |
+
sequence_lengths = torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1
|
| 1239 |
+
sequence_lengths = sequence_lengths % input_ids.shape[-1]
|
| 1240 |
+
sequence_lengths = sequence_lengths.to(logits.device)
|
| 1241 |
+
else:
|
| 1242 |
+
sequence_lengths = -1
|
| 1243 |
+
|
| 1244 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 1245 |
+
|
| 1246 |
+
loss = None
|
| 1247 |
+
if labels is not None:
|
| 1248 |
+
labels = labels.to(logits.device)
|
| 1249 |
+
if self.config.problem_type is None:
|
| 1250 |
+
if self.num_labels == 1:
|
| 1251 |
+
self.config.problem_type = "regression"
|
| 1252 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1253 |
+
self.config.problem_type = "single_label_classification"
|
| 1254 |
+
else:
|
| 1255 |
+
self.config.problem_type = "multi_label_classification"
|
| 1256 |
+
|
| 1257 |
+
if self.config.problem_type == "regression":
|
| 1258 |
+
loss_fct = MSELoss()
|
| 1259 |
+
if self.num_labels == 1:
|
| 1260 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 1261 |
+
else:
|
| 1262 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1263 |
+
elif self.config.problem_type == "single_label_classification":
|
| 1264 |
+
loss_fct = CrossEntropyLoss()
|
| 1265 |
+
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
|
| 1266 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 1267 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1268 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1269 |
+
if not return_dict:
|
| 1270 |
+
output = (pooled_logits,) + model_outputs[1:]
|
| 1271 |
+
return ((loss,) + output) if loss is not None else output
|
| 1272 |
+
|
| 1273 |
+
return SequenceClassifierOutputWithPast(
|
| 1274 |
+
loss=loss,
|
| 1275 |
+
logits=pooled_logits,
|
| 1276 |
+
past_key_values=model_outputs.past_key_values,
|
| 1277 |
+
hidden_states=model_outputs.hidden_states,
|
| 1278 |
+
attentions=model_outputs.attentions,
|
| 1279 |
+
)
|
| 1280 |
+
|
| 1281 |
+
|
| 1282 |
+
@add_start_docstrings(
|
| 1283 |
+
"""
|
| 1284 |
+
PhiModel with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for
|
| 1285 |
+
Named-Entity-Recognition (NER) tasks.
|
| 1286 |
+
""",
|
| 1287 |
+
PHI_START_DOCSTRING,
|
| 1288 |
+
)
|
| 1289 |
+
# Copied from transformers.models.mpt.modeling_mpt.MptForTokenClassification with MPT->PHI,Mpt->Phi,self.transformer->self.model,transformer_outputs->model_outputs
|
| 1290 |
+
class PhiForTokenClassification(PhiPreTrainedModel):
|
| 1291 |
+
def __init__(self, config: PhiConfig):
|
| 1292 |
+
super().__init__(config)
|
| 1293 |
+
self.num_labels = config.num_labels
|
| 1294 |
+
|
| 1295 |
+
self.model = PhiModel(config)
|
| 1296 |
+
if hasattr(config, "classifier_dropout") and config.classifier_dropout is not None:
|
| 1297 |
+
classifier_dropout = config.classifier_dropout
|
| 1298 |
+
elif hasattr(config, "hidden_dropout") and config.hidden_dropout is not None:
|
| 1299 |
+
classifier_dropout = config.hidden_dropout
|
| 1300 |
+
else:
|
| 1301 |
+
classifier_dropout = 0.1
|
| 1302 |
+
self.dropout = nn.Dropout(classifier_dropout)
|
| 1303 |
+
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
|
| 1304 |
+
|
| 1305 |
+
# Initialize weights and apply final processing
|
| 1306 |
+
self.post_init()
|
| 1307 |
+
|
| 1308 |
+
@add_start_docstrings_to_model_forward(PHI_INPUTS_DOCSTRING)
|
| 1309 |
+
@add_code_sample_docstrings(
|
| 1310 |
+
checkpoint=_CHECKPOINT_FOR_DOC,
|
| 1311 |
+
output_type=TokenClassifierOutput,
|
| 1312 |
+
config_class=_CONFIG_FOR_DOC,
|
| 1313 |
+
)
|
| 1314 |
+
def forward(
|
| 1315 |
+
self,
|
| 1316 |
+
input_ids: Optional[torch.LongTensor] = None,
|
| 1317 |
+
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
| 1318 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1319 |
+
inputs_embeds: Optional[torch.Tensor] = None,
|
| 1320 |
+
labels: Optional[torch.Tensor] = None,
|
| 1321 |
+
use_cache: Optional[bool] = None,
|
| 1322 |
+
output_attentions: Optional[bool] = None,
|
| 1323 |
+
output_hidden_states: Optional[bool] = None,
|
| 1324 |
+
return_dict: Optional[bool] = None,
|
| 1325 |
+
**deprecated_arguments,
|
| 1326 |
+
) -> Union[Tuple[torch.Tensor], TokenClassifierOutput]:
|
| 1327 |
+
r"""
|
| 1328 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1329 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1330 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1331 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1332 |
+
"""
|
| 1333 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1334 |
+
|
| 1335 |
+
model_outputs = self.model(
|
| 1336 |
+
input_ids,
|
| 1337 |
+
past_key_values=past_key_values,
|
| 1338 |
+
attention_mask=attention_mask,
|
| 1339 |
+
inputs_embeds=inputs_embeds,
|
| 1340 |
+
use_cache=use_cache,
|
| 1341 |
+
output_attentions=output_attentions,
|
| 1342 |
+
output_hidden_states=output_hidden_states,
|
| 1343 |
+
return_dict=return_dict,
|
| 1344 |
+
)
|
| 1345 |
+
|
| 1346 |
+
hidden_states = model_outputs[0]
|
| 1347 |
+
hidden_states = self.dropout(hidden_states)
|
| 1348 |
+
logits = self.classifier(hidden_states)
|
| 1349 |
+
|
| 1350 |
+
loss = None
|
| 1351 |
+
if labels is not None:
|
| 1352 |
+
# move labels to correct device to enable model parallelism
|
| 1353 |
+
labels = labels.to(logits.device)
|
| 1354 |
+
batch_size, seq_length = labels.shape
|
| 1355 |
+
loss_fct = CrossEntropyLoss()
|
| 1356 |
+
loss = loss_fct(
|
| 1357 |
+
logits.view(batch_size * seq_length, self.num_labels), labels.view(batch_size * seq_length)
|
| 1358 |
+
)
|
| 1359 |
+
|
| 1360 |
+
if not return_dict:
|
| 1361 |
+
output = (logits,) + model_outputs[2:]
|
| 1362 |
+
return ((loss,) + output) if loss is not None else output
|
| 1363 |
+
|
| 1364 |
+
return TokenClassifierOutput(
|
| 1365 |
+
loss=loss,
|
| 1366 |
+
logits=logits,
|
| 1367 |
+
hidden_states=model_outputs.hidden_states,
|
| 1368 |
+
attentions=model_outputs.attentions,
|
| 1369 |
+
)
|
plots.png
ADDED
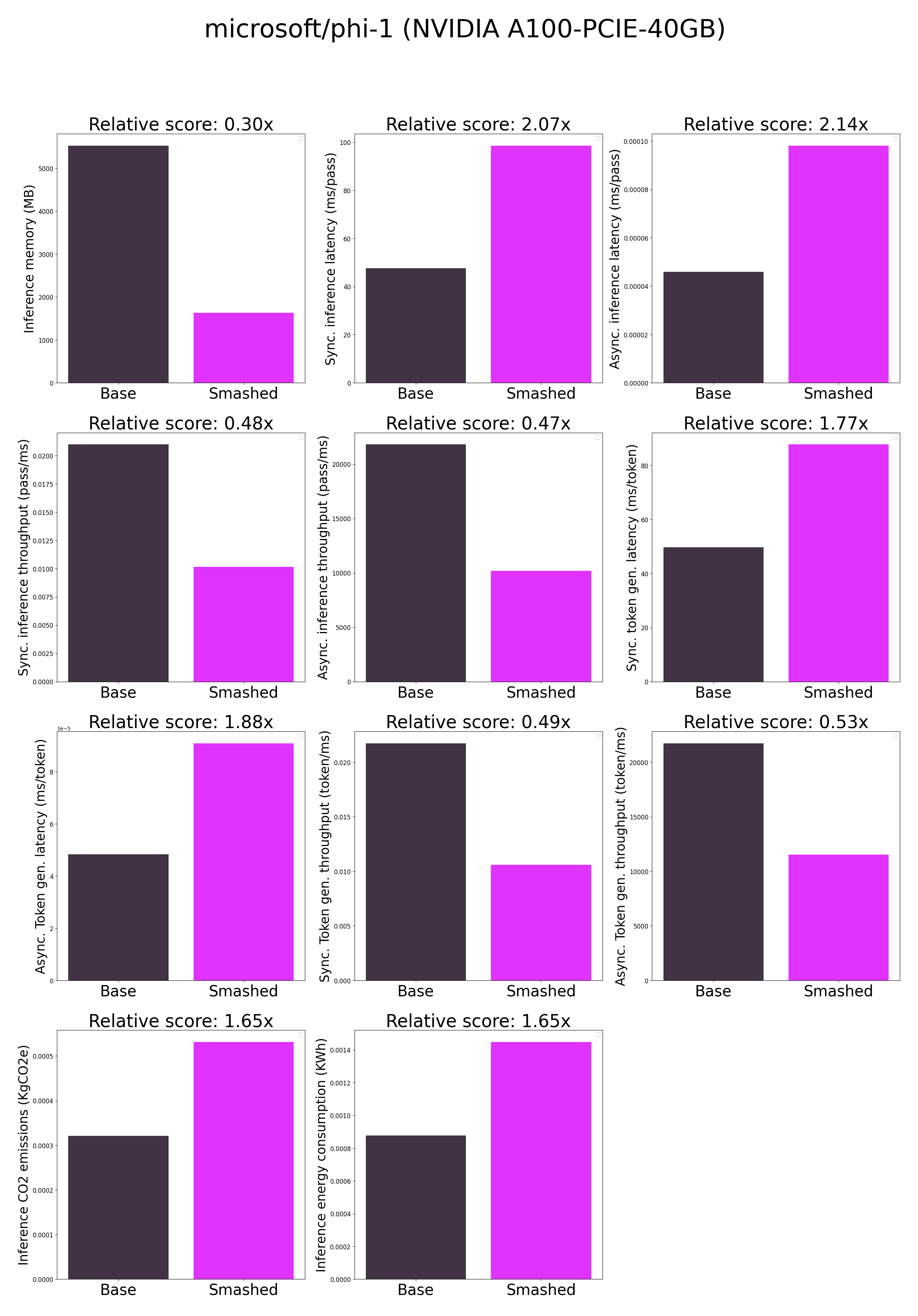
|
smash_config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"api_key": null,
|
| 3 |
+
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
+
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
+
"factorizers": "None",
|
| 7 |
+
"quantizers": "['llm-int8']",
|
| 8 |
+
"compilers": "None",
|
| 9 |
+
"task": "text_text_generation",
|
| 10 |
+
"device": "cuda",
|
| 11 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsi7df7sw5",
|
| 12 |
+
"batch_size": 1,
|
| 13 |
+
"model_name": "microsoft/phi-1",
|
| 14 |
+
"pruning_ratio": 0.0,
|
| 15 |
+
"n_quantization_bits": 8,
|
| 16 |
+
"output_deviation": 0.005,
|
| 17 |
+
"max_batch_size": 1,
|
| 18 |
+
"qtype_weight": "torch.qint8",
|
| 19 |
+
"qtype_activation": "torch.quint8",
|
| 20 |
+
"qobserver": "<class 'torch.ao.quantization.observer.MinMaxObserver'>",
|
| 21 |
+
"qscheme": "torch.per_tensor_symmetric",
|
| 22 |
+
"qconfig": "x86",
|
| 23 |
+
"group_size": 128,
|
| 24 |
+
"damp_percent": 0.1,
|
| 25 |
+
"save_load_fn": "bitsandbytes"
|
| 26 |
+
}
|
| 27 |
+
}
|