

13caa366ee9dac6a1f0966b3a160015e3d5d496e6832888a6d94de2f7c9b224c
Browse files- config.json +1 -1
- plots.png +0 -0
- results.json +24 -24
- smash_config.json +5 -5
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmpoau7b4ew",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
plots.png
CHANGED

|
|
results.json
CHANGED
|
@@ -1,30 +1,30 @@
|
|
| 1 |
{
|
| 2 |
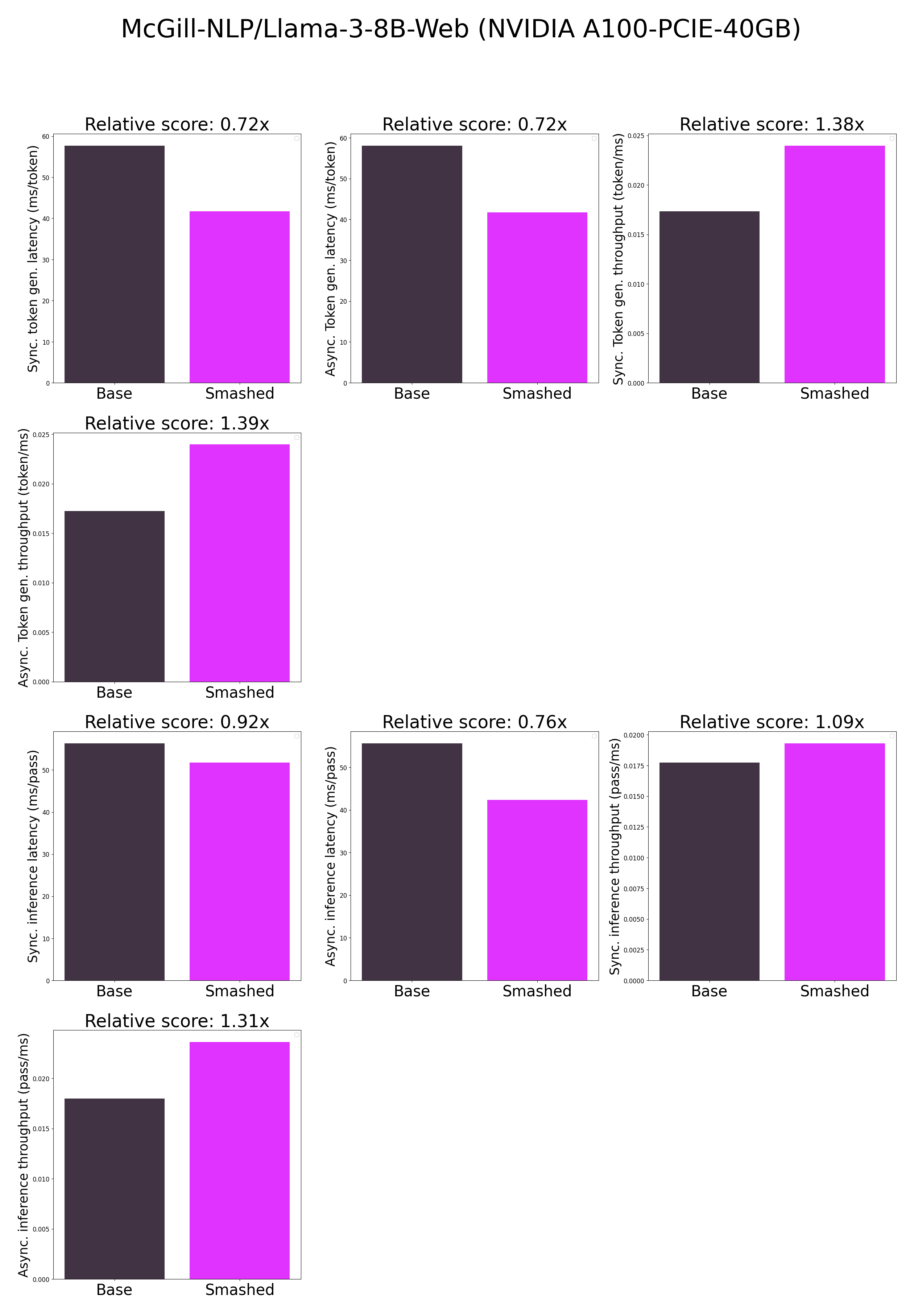
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
-
"base_token_generation_latency_sync":
|
| 5 |
-
"base_token_generation_latency_async":
|
| 6 |
-
"base_token_generation_throughput_sync": 0.
|
| 7 |
-
"base_token_generation_throughput_async": 0.
|
| 8 |
-
"base_token_generation_CO2_emissions":
|
| 9 |
-
"base_token_generation_energy_consumption":
|
| 10 |
-
"base_inference_latency_sync":
|
| 11 |
-
"base_inference_latency_async":
|
| 12 |
-
"base_inference_throughput_sync": 0.
|
| 13 |
-
"base_inference_throughput_async": 0.
|
| 14 |
-
"base_inference_CO2_emissions":
|
| 15 |
-
"base_inference_energy_consumption":
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
-
"smashed_token_generation_latency_sync":
|
| 19 |
-
"smashed_token_generation_latency_async":
|
| 20 |
-
"smashed_token_generation_throughput_sync": 0.
|
| 21 |
-
"smashed_token_generation_throughput_async": 0.
|
| 22 |
-
"smashed_token_generation_CO2_emissions":
|
| 23 |
-
"smashed_token_generation_energy_consumption":
|
| 24 |
-
"smashed_inference_latency_sync":
|
| 25 |
-
"smashed_inference_latency_async":
|
| 26 |
-
"smashed_inference_throughput_sync": 0.
|
| 27 |
-
"smashed_inference_throughput_async": 0.
|
| 28 |
-
"smashed_inference_CO2_emissions":
|
| 29 |
-
"smashed_inference_energy_consumption":
|
| 30 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
+
"base_token_generation_latency_sync": 57.667279434204104,
|
| 5 |
+
"base_token_generation_latency_async": 58.03066436201334,
|
| 6 |
+
"base_token_generation_throughput_sync": 0.017340856198027464,
|
| 7 |
+
"base_token_generation_throughput_async": 0.017232268680601154,
|
| 8 |
+
"base_token_generation_CO2_emissions": null,
|
| 9 |
+
"base_token_generation_energy_consumption": null,
|
| 10 |
+
"base_inference_latency_sync": 56.35584030151367,
|
| 11 |
+
"base_inference_latency_async": 55.629873275756836,
|
| 12 |
+
"base_inference_throughput_sync": 0.017744389838742956,
|
| 13 |
+
"base_inference_throughput_async": 0.017975953226479737,
|
| 14 |
+
"base_inference_CO2_emissions": null,
|
| 15 |
+
"base_inference_energy_consumption": null,
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
+
"smashed_token_generation_latency_sync": 41.73652305603027,
|
| 19 |
+
"smashed_token_generation_latency_async": 41.733165830373764,
|
| 20 |
+
"smashed_token_generation_throughput_sync": 0.02395983006676249,
|
| 21 |
+
"smashed_token_generation_throughput_async": 0.023961757515941703,
|
| 22 |
+
"smashed_token_generation_CO2_emissions": null,
|
| 23 |
+
"smashed_token_generation_energy_consumption": null,
|
| 24 |
+
"smashed_inference_latency_sync": 51.78419189453125,
|
| 25 |
+
"smashed_inference_latency_async": 42.34201908111572,
|
| 26 |
+
"smashed_inference_throughput_sync": 0.01931091252783664,
|
| 27 |
+
"smashed_inference_throughput_async": 0.023617201581348155,
|
| 28 |
+
"smashed_inference_CO2_emissions": null,
|
| 29 |
+
"smashed_inference_energy_consumption": null
|
| 30 |
}
|
smash_config.json
CHANGED
|
@@ -2,19 +2,19 @@
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
-
"pruners": "
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
-
"factorizers": "
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
-
"output_deviation": 0.
|
| 11 |
-
"compilers": "
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "McGill-NLP/Llama-3-8B-Web",
|
| 20 |
"task": "text_text_generation",
|
|
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
+
"factorizers": "None",
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
+
"output_deviation": 0.005,
|
| 11 |
+
"compilers": "None",
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsbok3a_hw",
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "McGill-NLP/Llama-3-8B-Web",
|
| 20 |
"task": "text_text_generation",
|