

language:
- en
- ko
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
Twice-KoSOLAR-16.1B-instruct-test
Model Details
Model Developers Kyujin Han (kyujinpy)
모델 목적
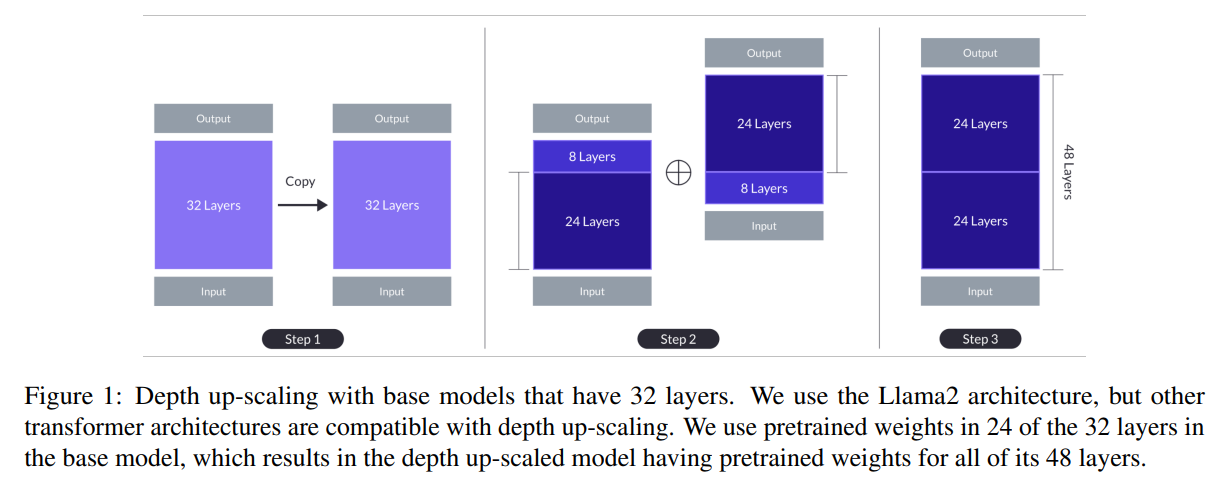
최근, SOLAR-10.7B 모델이 Depth-Up-Scaling(위의 사진) 방법론을 내세워서 LLM 리더보드에서 좋은 성능을 보이고 있다. 더불어서 야놀자에서 만든 seungduk/KoSOLAR-10.7B-v0.1 모델은 Ko-LLM 리더보드에 큰 파급력을 불러오면서, 앞으로의 리더보드의 흐름도 바뀔 것으로 예상된다.
여기서 단순한 호기심이 들었다. Upstage에서 발표한 Depth-Up-Scaling(DUS) 방법론은 mistral-7B 모델 2개를 merge(passthrough)한 방법이다.
이때 놀랍게도, DUS 방법론을 적용한 upstage/SOLAR-10.7B-v1.0모델은 기존의 mistral-7B 모델보다 리더보드에서 높은 성능을 기록했다. (아래의 테이블 참고)
그렇다면, DUS 방법론을 제한없이, 다른 모델에 적용하면 똑같은 결과가 발생할지 너무나 궁금했다. 🙃
실험을 통해서 나의 호기심에 대한 결론을 내려보고자 한다. 😋😋
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|---|---|---|---|---|---|---|---|
| seungduk/KoSOLAR-10.7B-v0.1 | 66.04 | 62.03 | 84.54 | 65.56 | 45.03 | 83.58 | 55.50 |
| upstage/SOLAR-10.7B-v1.0 | 66.04 | 61.95 | 84.60 | 65.48 | 45.04 | 83.66 | 55.50 |
| mistralai/Mistral-7B-v0.1 | 60.97 | 59.98 | 83.31 | 64.16 | 42.15 | 78.37 | 37.83 |
Follow up as En-link.
Method
Instruction-tuning.
Hyperparameters
python finetune.py \
--base_model PracticeLLM/Twice-KoSOLAR-16.1B-test \
--data-path kyujinpy/KOR-OpenOrca-Platypus-v3 \
--output_dir ./Twice-KoSOLAR-16.1B-instruct-test \
--batch_size 64 \
--micro_batch_size 1 \
--num_epochs 1 \
--learning_rate 3e-5 \
--cutoff_len 4096 \
--val_set_size 0 \
--lora_r 16 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj, k_proj, v_proj, o_proj, gate_proj, down_proj, up_proj, lm_head]' \
--train_on_inputs False \
--add_eos_token False \
--group_by_length False \
--prompt_template_name user_prompt \
--lr_scheduler 'cosine' \
#--warmup_steps 100 \
Share all of things. It is my belief.
Model Benchmark
Open Ko-LLM leaderboard & lm-evaluation-harness(zero-shot)
Follow up as Ko-link.
Model Average ARC HellaSwag MMLU TruthfulQA Ko-CommonGenV2 PracticeLLM/Twice-KoSOLAR-16.1B-instruct-test NaN NaN NaN NaN NaN NaN PracticeLLM/Twice-KoSOLAR-16.1B-test 50.20 45.65 57.14 51.39 42.99 53.84 Megastudy/M-SOLAR-10.7B-v1.1-beta 55.25 51.71 60.86 54.24 47.12 62.34 jjourney1125/M-SOLAR-10.7B-v1.0 55.15 49.57 60.12 54.60 49.23 62.22 seungduk/KoSOLAR-10.7B-v0.1 52.40 47.18 59.54 52.04 41.84 61.39 Follow up as beomi/LM-Harness
gpt2 (pretrained=PracticeLLM/Twice-KoSOLAR-16.1B-test), limit: None, provide_description: False, num_fewshot: 0, batch_size: None
| Task |Version| Metric |Value | |Stderr|
|----------------|------:|--------|-----:|---|-----:|
|kobest_boolq | 0|acc |0.7201|± |0.0120|
| | |macro_f1|0.7073|± |0.0124|
|kobest_copa | 0|acc |0.6510|± |0.0151|
| | |macro_f1|0.6506|± |0.0151|
|kobest_hellaswag| 0|acc |0.4520|± |0.0223|
| | |acc_norm|0.5820|± |0.0221|
| | |macro_f1|0.4475|± |0.0222|
|kobest_sentineg | 0|acc |0.7078|± |0.0229|
| | |macro_f1|0.7071|± |0.0229|
gpt2 (pretrained=Megastudy/M-SOLAR-10.7B-v1.1-beta), limit: None, provide_description: False, num_fewshot: 0, batch_size: None
| Task |Version| Metric |Value | |Stderr|
|----------------|------:|--------|-----:|---|-----:|
|kobest_boolq | 0|acc |0.7137|± |0.0121|
| | |macro_f1|0.6878|± |0.0128|
|kobest_copa | 0|acc |0.7060|± |0.0144|
| | |macro_f1|0.7054|± |0.0145|
|kobest_hellaswag| 0|acc |0.4620|± |0.0223|
| | |acc_norm|0.5360|± |0.0223|
| | |macro_f1|0.4595|± |0.0223|
|kobest_sentineg | 0|acc |0.7431|± |0.0220|
| | |macro_f1|0.7295|± |0.0230|
gpt2 (pretrained=jjourney1125/M-SOLAR-10.7B-v1.0), limit: None, provide_description: False, num_fewshot: 0, batch_size: None
| Task |Version| Metric |Value | |Stderr|
|----------------|------:|--------|-----:|---|-----:|
|kobest_boolq | 0|acc |0.5228|± |0.0133|
| | |macro_f1|0.3788|± |0.0097|
|kobest_copa | 0|acc |0.6860|± |0.0147|
| | |macro_f1|0.6858|± |0.0147|
|kobest_hellaswag| 0|acc |0.4580|± |0.0223|
| | |acc_norm|0.5380|± |0.0223|
| | |macro_f1|0.4552|± |0.0222|
|kobest_sentineg | 0|acc |0.6474|± |0.0240|
| | |macro_f1|0.6012|± |0.0257|
gpt2 (pretrained=yanolja/KoSOLAR-10.7B-v0.1), limit: None, provide_description: False, num_fewshot: 0, batch_size: None
| Task |Version| Metric |Value | |Stderr|
|----------------|------:|--------|-----:|---|-----:|
|kobest_boolq | 0|acc |0.8725|± |0.0089|
| | |macro_f1|0.8722|± |0.0089|
|kobest_copa | 0|acc |0.6850|± |0.0147|
| | |macro_f1|0.6844|± |0.0147|
|kobest_hellaswag| 0|acc |0.4340|± |0.0222|
| | |acc_norm|0.5840|± |0.0221|
| | |macro_f1|0.4296|± |0.0221|
|kobest_sentineg | 0|acc |0.7506|± |0.0217|
| | |macro_f1|0.7505|± |0.0217|
Implementation Code
### KO-Platypus
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "PracticeLLM/Twice-KoSOLAR-16.1B-instruct-test"
OpenOrca = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
OpenOrca_tokenizer = AutoTokenizer.from_pretrained(repo)
--- Refereces (Model Card)
yanolja/KoSOLAR-10.7B-v0.1
This model is a Korean vocabulary-extended version of upstage/SOLAR-10.7B-v1.0, trained on various Korean web-crawled datasets that are publicly available on HuggingFace. The hypothesis was that while maintaining the original performance of the base model, we could add more tokens to the base model's vocabulary by training the embeddings for the new tokens only. The evaluation results seem to indicate that both English and Korean performances were preserved.
Model Description
Most parameters of upstage/SOLAR-10.7B-v1.0 were frozen except for the embed_tokens layer and the lm_head layer. Embeddings for the existing tokens in those layers were frozen during training. The embeddings for the new tokens have been tuned.
Meet 10.7B Solar: Elevating Performance with Upstage Depth UP Scaling!
Introduction
We introduce SOLAR-10.7B, an advanced large language model (LLM) with 10.7 billion parameters, demonstrating superior performance in various natural language processing (NLP) tasks. It's compact, yet remarkably powerful, and demonstrates unparalleled state-of-the-art performance in models with parameters under 30B.
We present a methodology for scaling LLMs called depth up-scaling (DUS) , which encompasses architectural modifications and continued pretraining. In other words, we integrated Mistral 7B weights into the upscaled layers, and finally, continued pre-training for the entire model.
SOLAR-10.7B has remarkable performance. It outperforms models with up to 30B parameters, even surpassing the recent Mixtral 8X7B model. For detailed information, please refer to the experimental table. Solar 10.7B is an ideal choice for fine-tuning. SOLAR-10.7B offers robustness and adaptability for your fine-tuning needs. Our simple instruction fine-tuning using the SOLAR-10.7B pre-trained model yields significant performance improvements (SOLAR-10.7B-Instruct-v1.0).
For full details of this model please read our paper.