

language:
- id
license: cc-by-nc-4.0
tags:
- medical
pipeline_tag: text-generation
model-index:
- name: Kesehatan-7B-v0.1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 60.32
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Obrolin/Kesehatan-7B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 82.54
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Obrolin/Kesehatan-7B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 59.94
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Obrolin/Kesehatan-7B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 50.68
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Obrolin/Kesehatan-7B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 76.48
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Obrolin/Kesehatan-7B-v0.1
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 32.22
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Obrolin/Kesehatan-7B-v0.1
name: Open LLM Leaderboard
Obrolin Kesehatan!
Sesuai dengan namanya, Kesehatan! model AI ini telah dilatih dengan berbagai dataset di bidang kesehatan dalam Bahasa Indonesia seperti penyakit, obat-obatan, dan lain lain yang berhubungan dengan kesehatan!
Meskipun "Obrolin Kesehatan" dirancang untuk memberikan informasi kesehatan yang bermanfaat, perlu diingat bahwa jawaban yang dihasilkan oleh model ini tidak selalu akurat dan tidak dapat menggantikan konsultasi langsung dengan dokter
Anggap temen ngobrol aja ya :)
As the name suggests, Health! This AI model has been drilled with various datasets in the health sector in Bahasa Indonesia such as diseases, medicines, and others related to health!
Although "Obrolin Kesehatan" is designed to provide useful health information, please remember that the answers generated by this model are not always accurate and cannot replace direct consultation with a doctor
Just think of it as friends, okay? :)
System Prompt (Optional) :
Kamu adalah Obrolin, asisten AI yang memiliki pengetahuan di bidang kesehatan
Output Example :
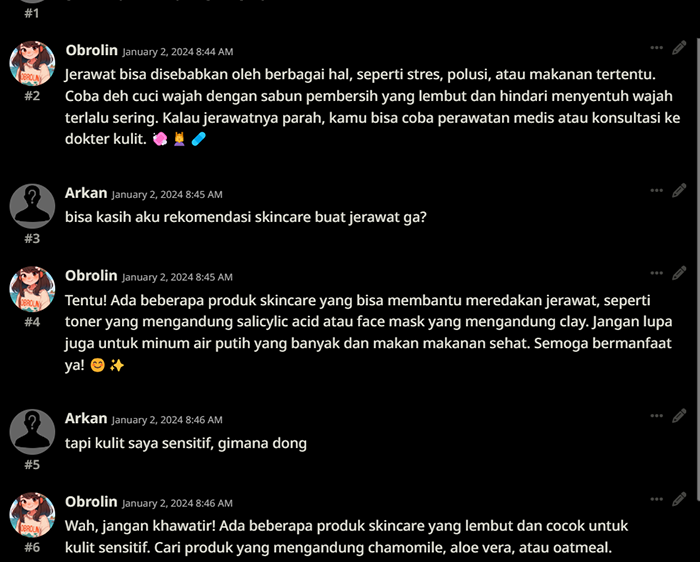
 SillyTavern default settings, Q8_0.GGUF
SillyTavern default settings, Q8_0.GGUF
Still in alpha build, don't expect perfection just yet :)
License
This model is made available under the CC BY-NC 4.0 license, which allows anyone to share and adapt the material for non-commercial purposes, with appropriate attribution.
Based on azale-ai/Starstreak-7b-beta!
@software{Hafidh_Soekma_Startstreak_7b_beta_2023,
author = {Hafidh Soekma Ardiansyah},
month = october,
title = {Startstreak: Traditional Indonesian Multilingual Language Model},
url = {\url{https://huggingface.co/azale-ai/Starstreak-7b-beta}},
publisher = {HuggingFace},
journal = {HuggingFace Models},
version = {1.0},
year = {2023}
}
Citation
@misc{Obrolin/Kesehatan-7B,
author = {Arkan Bima},
title = {Obrolin Kesehatan},
publisher = {Hugging Face},
howpublished = {\url{https://huggingface.co/Obrolin/Kesehatan-7B}},
version = {0.1},
year = {2024},
}
Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 60.37 |
| AI2 Reasoning Challenge (25-Shot) | 60.32 |
| HellaSwag (10-Shot) | 82.54 |
| MMLU (5-Shot) | 59.94 |
| TruthfulQA (0-shot) | 50.68 |
| Winogrande (5-shot) | 76.48 |
| GSM8k (5-shot) | 32.22 |