

license: cc-by-nc-4.0
base_model: microsoft/Phi-3
model-index:
- name: Octopus-V4-3B
results: []
tags:
- AI agent
- Graph
inference: false
space: false
spaces: false
language:
- en
Octopus V4: Graph of language models
Octopus V4
- Nexa AI Website - Octopus-v4 Github - ArXiv
![]()
Introduction
Octopus-V4-3B, an advanced open-source language model with 3 billion parameters, serves as the master node in Nexa AI's envisioned graph of language models. Tailored specifically for the MMLU benchmark topics, this model efficiently translates user queries into formats that specialized models can effectively process. It excels at directing these queries to the appropriate specialized model, ensuring precise and effective query handling.
📱 Compact Size: Octopus-V4-3B is compact, enabling it to operate on smart devices efficiently and swiftly.
🐙 Accuracy: Octopus-V4-3B accurately maps user queries to the specialized model using a functional token design, enhancing its precision.
💪 Reformat Query: Octopus-V4-3B assists in converting natural human language into a more professional format, improving query description and resulting in more accurate responses.
Example Use Cases
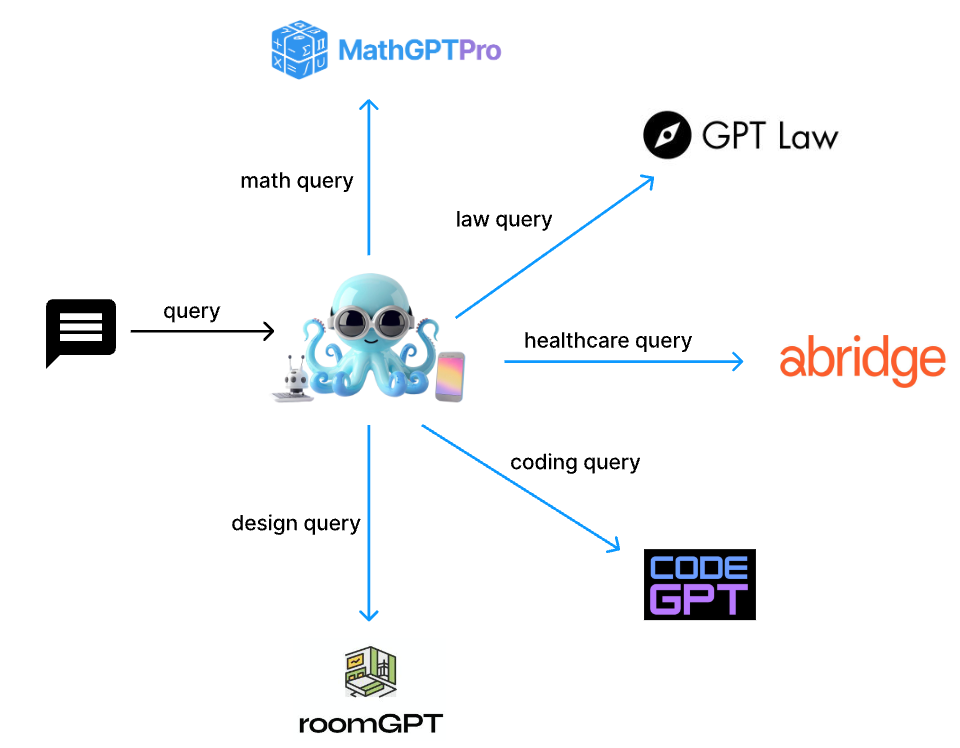
You can run the model on a GPU using the following code.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import time
import warnings
warnings.filterwarnings("ignore")
torch.random.manual_seed(0)
import json
model = AutoModelForCausalLM.from_pretrained(
"NexaAIDev/Octopus-v4",
device_map="cuda:0",
torch_dtype=torch.bfloat16,
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("NexaAIDev/octopus-v4-finetuned-v1")
question = "Tell me the result of derivative of x^3 when x is 2?"
inputs = f"<|system|>You are a router. Below is the query from the users, please call the correct function and generate the parameters to call the function.<|end|><|user|>{question}<|end|><|assistant|>"
print(inputs)
print('\n============= Below is the response ==============\n')
# You should consider to use early stopping with <nexa_end> token to accelerate
input_ids = tokenizer(inputs, return_tensors="pt")['input_ids'].to(model.device)
generated_token_ids = []
start = time.time()
# set a large enough number here to avoid insufficient length
for i in range(200):
next_token = model(input_ids).logits[:, -1].argmax(-1)
generated_token_ids.append(next_token.item())
input_ids = torch.cat([input_ids, next_token.unsqueeze(1)], dim=-1)
if "<nexa_end>" in tokenizer.decode(generated_token_ids):
break
print(tokenizer.decode(generated_token_ids))
end = time.time()
print(f'Elapsed time: {end - start:.2f}s')
License
This model was trained on commercially viable data. For use of our model, refer to the license information.
References
We thank the Microsoft team for their amazing model!
@article{abdin2024phi,
title={Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone},
author={Abdin, Marah and Jacobs, Sam Ade and Awan, Ammar Ahmad and Aneja, Jyoti and Awadallah, Ahmed and Awadalla, Hany and Bach, Nguyen and Bahree, Amit and Bakhtiari, Arash and Behl, Harkirat and others},
journal={arXiv preprint arXiv:2404.14219},
year={2024}
}
Citation
@misc{chen2024octopus,
title={Octopus v2: On-device language model for super agent},
author={Wei Chen and Zhiyuan Li},
year={2024},
eprint={2404.01744},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Contact
Please contact us to reach out for any issues and comments!