

language: en
tags:
- multimodal
- text
- image
license: other
datasets:
- HuggingFaceM4/OBELICS
- wikipedia
- facebook/pmd
- laion/laion2B-en
TODO: logo?
IDEFICS
IDEFICS (Image-aware Decoder Enhanced à la Flamingo with Interleaved Cross-attentionS) is an open-access reproduction of Flamingo, a closed-source visual language model developed by Deepmind. Like GPT-4, the multimodal model accepts arbitrary sequences of image and text inputs and produces text outputs. IDEFICS is built solely on public available data and models.
The model can answer questions about images, describe visual contents, create stories grounded on multiple images, or simply behave as a pure language model without visual inputs.
IDEFICS is on par with the original model on various image-text benchmarks, including visual question answering (open-ended and multiple choice), image captioning, and image classification when evaluated with in-context few-shot learning. It comes into two variants: a large 80 billion parameters version and a 9 billion parameters version.
We also fine-tune these base models on a mixture of supervised and instruction fine-tuning datasets, which boosts the downstream performance while making the models more usable in conversational settings: idefics-80b-instruct and idefics-9b-instruct. As they reach higher performance, we recommend using these instructed versions first.
Read more about some of the technical challenges encountered during training IDEFICS here.
Model Details
- Developed by: Hugging Face
- Model type: Multi-modal model (image+text)
- Language(s) (NLP): en
- License: other
- Parent Model: laion/CLIP-ViT-H-14-laion2B-s32B-b79K and huggyllama/llama-65b
- Resources for more information:
IDEFICS is a large multimodal English model that takes sequences of interleaved images and texts as inputs and generates text outputs. The model shows strong in-context few-shot learning capabilities and is on par with the closed-source model. This makes IDEFICS a robust starting point to fine-tune multimodal models on custom data.
IDEFICS is built on top of two unimodal open-access pre-trained models to connect the two modalities. Newly initialized parameters in the form of Transformer blocks bridge the gap between the vision encoder and the language model. The model is trained on a mixture of image/text pairs and unstrucutred multimodal web documents.
IDEFICS-instruct is the model obtained by further training IDEFICS on Supervised Fine-Tuning and Instruction Fine-Tuning datasets. This improves downstream performance significantly (making idefics-9b-instruct a very strong model at its 9 billion scale), while making the model more suitable to converse with.
Uses
The model can be used to perform inference on multimodal (image + text) tasks in which the input is composed of a text query/instruction along with one or multiple images. This model does not support image generation.
It is possible to fine-tune the base model on custom data for a specific use-case. We note that the instruction-fine-tuned models are significantly better at following instructions from users and thus should be prefered when using the models out-of-the-box.
The following screenshot is an example of interaction with the instructed model:
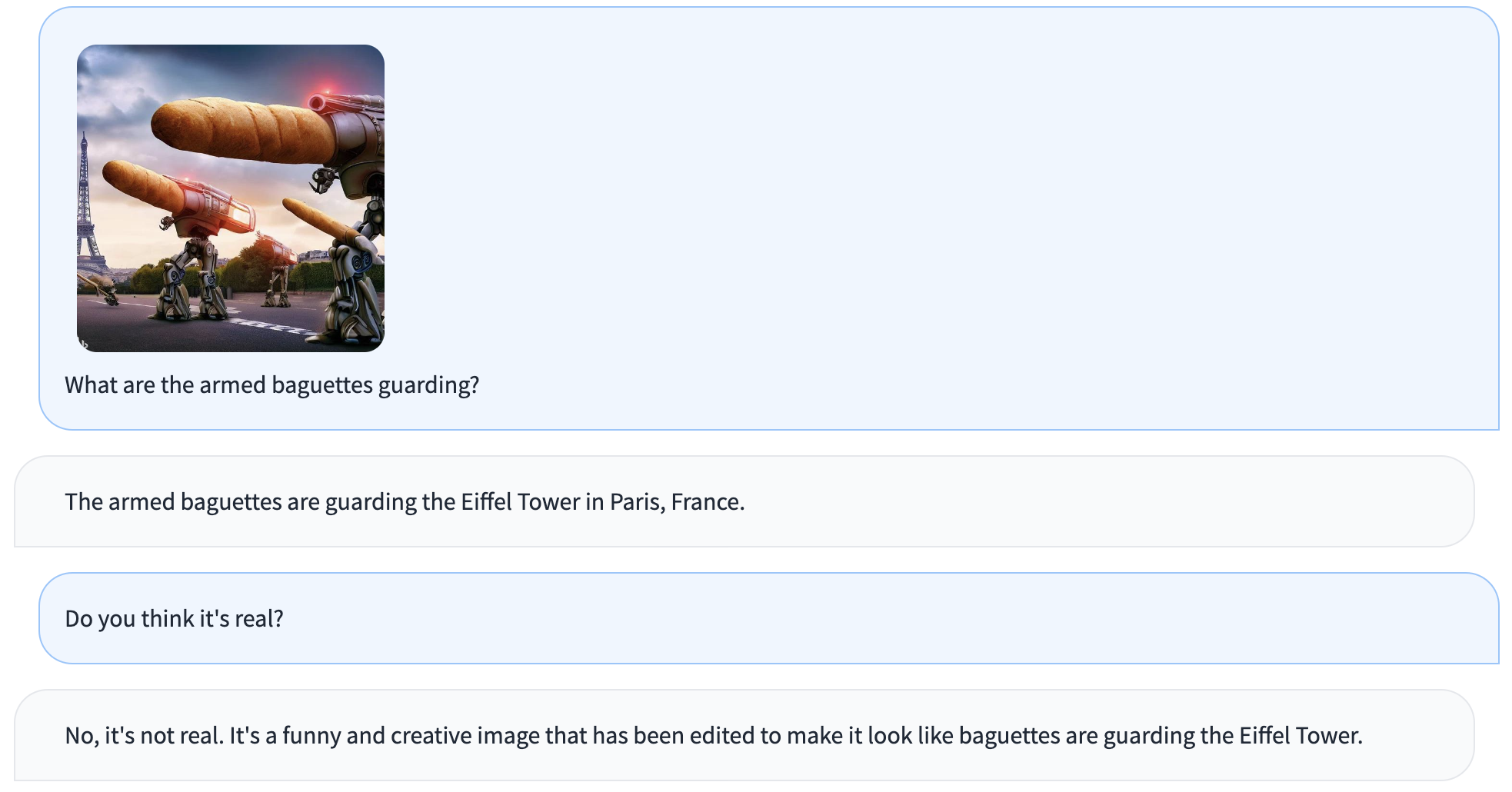
How to Get Started with the Model
Use the code below to get started with the model.
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint)
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"In this picture from Asterix and Obelix, we can see"
],
]
# --batched mode
inputs = processor(prompts, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
generated_ids = model.generate(**inputs, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
To quickly test your software without waiting for the huge model to download/load you can use HuggingFaceM4/tiny-random-idefics - it hasn't been trained and has random weights but it is very useful for quick testing.
This tutorial shows a simple example to fine-tune IDEFICS on custom data. This colab notebook showcases how to do the fine-tuning in 4bits precision. TODO: change to the correct link once it's merged.
Training Details
We closely follow the training procedure layed out in Flamingo. We combine two open-source pre-trained models (laion/CLIP-ViT-H-14-laion2B-s32B-b79K and huggyllama/llama-65b) by initializing new Transformer blocks. The pre-trained backbones are frozen while we train the newly initialized parameters.
The model is trained on the following data mixture of openly accessible English data:
| Data Source | Type of Data | Number of Tokens in Source | Number of Images in Source | Epochs | Effective Proportion in Number of Tokens |
|---|---|---|---|---|---|
| OBELICS | Unstructured Multimodal Web Documents | 114.9B | 353M | 1 | 73.85% |
| Wikipedia | Unstructured Multimodal Web Documents | 3.192B | 39M | 3 | 6.15% |
| LAION | Image-Text Pairs | 29.9B | 1.120B | 1 | 17.18% |
| PMD | Image-Text Pairs | 1.6B | 70M | 3 | 2.82% |
OBELICS is an open, massive and curated collection of interleaved image-text web documents, containing 141M documents, 115B text tokens and 353M images. An interactive visualization of the dataset content is available here.
Wkipedia. We used the English dump of Wikipedia created on February 20th, 2023.
LAION is a collection of image-text pairs collected from web pages from Common Crawl and texts are obtained using the alternative texts of each image. We deduplicated it (following Webster et al., 2023), filtered it, and removed the opted-out images using the Spawning API.
PMD is a collection of publicly-available image-text pair datasets. The dataset contains pairs from Conceptual Captions, Conceptual Captions 12M, WIT, Localized Narratives, RedCaps, COCO, SBU Captions, Visual Genome and a subset of YFCC100M dataset. Due to a server failure at the time of the pre-processing, we did not include SBU captions.
For multimodal web documents, we feed the model sequences corresponding to the succession of text paragraphs and images. For image-text pairs, we form the training sequences by packing images with their captions. The images are encoded with the vision encoder and vision hidden states are pooled with Transformer Perceiver blocks and then fused into the text sequence through the cross-attention blocks.
Following Dehghani et al., 2023, we apply a layer normalization on the projected queries and keys of both the Perceiver and cross-attention blocks, which improved training stability in our early experiments. We use the RMSNorm implementation for trainable Layer Norms.
The training objective is the standard next token prediction.
We use the following hyper and training parameters:
| Parameters | IDEFICS | IDEFICS-9b | |
|---|---|---|---|
| Perceiver Resampler | Number of Layers | 6 | 6 |
| Number of Latents | 64 | 64 | |
| Number of Heads | 16 | 16 | |
| Resampler Head Dimension | 96 | 96 | |
| Model | Language Model Backbone | Llama-65b | Llama-7b |
| Vision Model Backbone | laion/CLIP-ViT-H-14-laion2B-s32B-b79K | laion/CLIP-ViT-H-14-laion2B-s32B-b79K | |
| Cross-Layer Interval | 4 | 4 | |
| Training | Sequence Length | 1024 | 1024 |
| Effective Batch Size (# of tokens) | 3.67M | 1.31M | |
| Max Training Steps | 200K | 200K | |
| Weight Decay | 0.1 | 0.1 | |
| Optimizer | Adam(0.9, 0.999) | Adam(0.9, 0.999) | |
| Gradient Clipping | 1.0 | 1.0 | |
| Z-loss weight | 1e-3 | 1e-3 | |
| Learning Rate | Initial Max | 5e-5 | 1e-5 |
| Initial Final | 3e-5 | 6e-6 | |
| Decay Schedule | Linear | Linear | |
| Linear warmup Steps | 2K | 2K | |
| Large-scale Optimization | Gradient Checkpointing | True | True |
| Precision | Mixed-pres bf16 | Mixed-pres bf16 | |
| ZeRO Optimization | Stage 3 | Stage 3 |
Evaluation
We follow the evaluation protocol of Flamingo and evaluate IDEFICS on a suite of downstream image-text benchmarks ranging from visual question answering to image captioning.
We compare our model to the original Flamingo along with OpenFlamingo, another open-source reproduction.
We perform checkpoint selection based on validation sets of VQAv2, TextVQA, OKVQA, VizWiz, Visual Dialogue, Coco, Flickr30k, and HatefulMemes. We select the checkpoint at step 65'000 for IDEFICS-9B and at step 37'500 for IDEFICS. The models are evaluated with in-context few-shot learning where the priming instances are selected at random from a support set. We do not use any form of ensembling.
As opposed to Flamingo, we did not train IDEFICS on video-text pairs datasets, and as such, we did not evaluate the model on video-text benchmarks like Flamingo did. We leave that evaluation for a future iteration.
| Model | Shots | VQAv2 OE VQA acc. |
OKVQA OE VQA acc. |
TextVQA OE VQA acc. |
VizWiz OE VQA acc. |
TextCaps CIDEr |
Coco CIDEr |
NoCaps CIDEr |
Flickr CIDEr |
VisDial NDCG |
HatefulMemes ROC AUC |
ScienceQA acc. |
RenderedSST2 acc. |
Winoground group (text/image) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IDEFIX 80B | 0 | 60.0 | 45.2 | 30.9 | 36.0 | 56.8 | 91.8 | 65.0 | 53.7 | 48.8 | 60.6 | 68.9 | 60.5 | 8.0 (18.8/22.5) |
| 4 | 63.6 | 52.4 | 34.4 | 40.4 | 72.7 | 110.3 | 99.6 | 73.7 | 48.4 | 57.8 | 58.9 | 66.6 | - | |
| 8 | 64.8 | 55.1 | 35.7 | 46.1 | 77.6 | 114.3 | 105.7 | 76.6 | 47.9 | 58.2 | - | 67.8 | - | |
| 16 | 65.4 | 56.8 | 36.3 | 48.3 | 81.4 | 116.6 | 107.0 | 80.1 | - | 55.8 | - | 67.7 | - | |
| 32 | 65.9 | 57.8 | 36.7 | 50.0 | 82.7 | 116.6 | 107.5 | 81.1 | - | 52.5 | - | 67.3 | - | |
| IDEFIX 9B | 0 | 50.9 | 38.4 | 25.9 | 35.5 | 25.4 | 46.0 | 36.8 | 27.3 | 48.7 | 51.7 | 44.2 | 61.8 | 5.0 (16.8/20.8) |
| 4 | 55.4 | 45.5 | 27.6 | 36.9 | 60.0 | 93.0 | 81.3 | 59.7 | 47.9 | 50.7 | 37.4 | 62.3 | - | |
| 8 | 56.4 | 47.7 | 27.5 | 40.4 | 63.2 | 97.0 | 86.8 | 61.9 | 47.6 | 51.0 | - | 66.3 | - | |
| 16 | 57.0 | 48.4 | 27.9 | 42.6 | 67.4 | 99.7 | 89.4 | 64.5 | - | 50.9 | - | 67.8 | - | |
| 32 | 57.9 | 49.6 | 28.3 | 43.7 | 68.1 | 98.0 | 90.5 | 64.4 | - | 49.8 | - | 67.0 | - |
We note that since we trained on PMD which contains COCO, the evaluation numbers on COCO are not directly comparable with Flamingo and OpenFlamingo since they did not explicitely have this dataset in the training mixture.
For ImageNet-1k, we also report results where the priming samples are selected to be similar (i.e. close in a vector space) to the queried instance.
ImageNet-1k Evaluation:
| Model | Shots | ImageNet-1k |
|---|---|---|
| IDEFIX 80B | 16, 1k support set | 65.4 |
| 16, RICES 5k support set | 72.9 | |
| IDEFIX 9B | 16, 1k support set | 53.5 |
| 16, RICES 5k support set | 64.5 |
Fairness Evaluations:
| Model | Shots | FairFaceGender (accuracy) | FairFaceRace (accuracy) | FairFaceAge (accuracy) |
|---|---|---|---|---|
| IDEFIX 80B | 0 | 95.8 | 64.1 | 51.0 |
| 4 | 95.2 | 48.8 | 50.6 | |
| 8 | 95.5 | 52.3 | 53.1 | |
| 16 | 95.7 | 47.6 | 52.8 | |
| 32 | 95.7 | 36.5 | 51.2 | |
| IDEFIX 9B | 0 | 94.4 | 55.3 | 45.1 |
| 4 | 93.9 | 35.3 | 44.3 | |
| 8 | 95.4 | 44.7 | 46.0 | |
| 16 | 95.8 | 43.0 | 46.1 | |
| 32 | 96.1 | 35.1 | 44.9 |
Technical Specifications
- Hardware Type: 64 nodes of 8x 80GB A100 gpus, EFA network
- Hours used: ~672 node hours
- Cloud Provider: AWS Sagemaker
Hardware
The training was performed on an AWS SageMaker cluster with 64 nodes of 8x80GB A100 GPUs (512 GPUs total). The cluster uses the current EFA network which provides about 340GBps throughput.
Software
The training software is built on top of HuggingFace Transformers + Accelerate, and DeepSpeed ZeRO-3 for training, and WebDataset for data loading.
Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., Sheng et al. (2021) and Bender et al. (2021)). As a derivative of such a language model, IDEFICS can produce texts that include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups. Moreover, IDEFICS can produce factually incorrect texts, and should not be relied on to produce factually accurate information.
Here are a few examples of outputs that could be categorized as factually incorrect, biased, or offensive: TODO: give 4/5 representative examples
To measure IDEFICS's ability to recognize socilogical (TODO: find a better adjective) attributes, we evaluate the model on FairFace... TODO: include FairFace numbers
License
The model is built on top of of two pre-trained models: laion/CLIP-ViT-H-14-laion2B-s32B-b79K and huggyllama/llama-65b. The first was released under an MIT license, while the second was released under a specific noncommercial license focused on research purposes. As such, users should comply with that license by applying directly to Meta's form.
We release the additional weights we trained under an MIT license.
Citation
BibTeX:
@misc{laurençon2023obelisc,
title={OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents},
author={Hugo Laurençon and Lucile Saulnier and Léo Tronchon and Stas Bekman and Amanpreet Singh and Anton Lozhkov and Thomas Wang and Siddharth Karamcheti and Alexander M. Rush and Douwe Kiela and Matthieu Cord and Victor Sanh},
year={2023},
eprint={2306.16527},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
Model Card Authors
V, i, c, t, o, r, ,, , S, t, a, s, ,, , X, X, X
Model Card Contact
Please open a discussion on the Community tab!