

Czech GPT
This is our GPT-2 XL trained as a part of the research involved in SemANT project.
Factsheet
- The model is trained on our
15,621,685,248 token/78,48 GB/10,900,000,000 word/18,800,000 paragraphcorpus of Czech obtained by Web Crawling. - The original size of our corpus before deduplication and lm-filtering steps was
266,44 GB. - The model was trained on
- Our tokenizer size is 64k, and we use GPT-2 like
sentencepieceencoding for tokenization. - The model was trained by 133,000 update steps (~139B training tokens), before the end of the experiment.
- The model was adapted from the original GPT-2 XL, by:
- replacing the tokenizer,
- corresponding embeddings, and
- copying over 1,000 EN representations corresponding to the 1,000 most frequent tokens into new embeddings based on a bilingual dictionary.
- The training loss decreased steadily, and the model definitely didn't converge yet. We compare the loss to a small 124M model version.
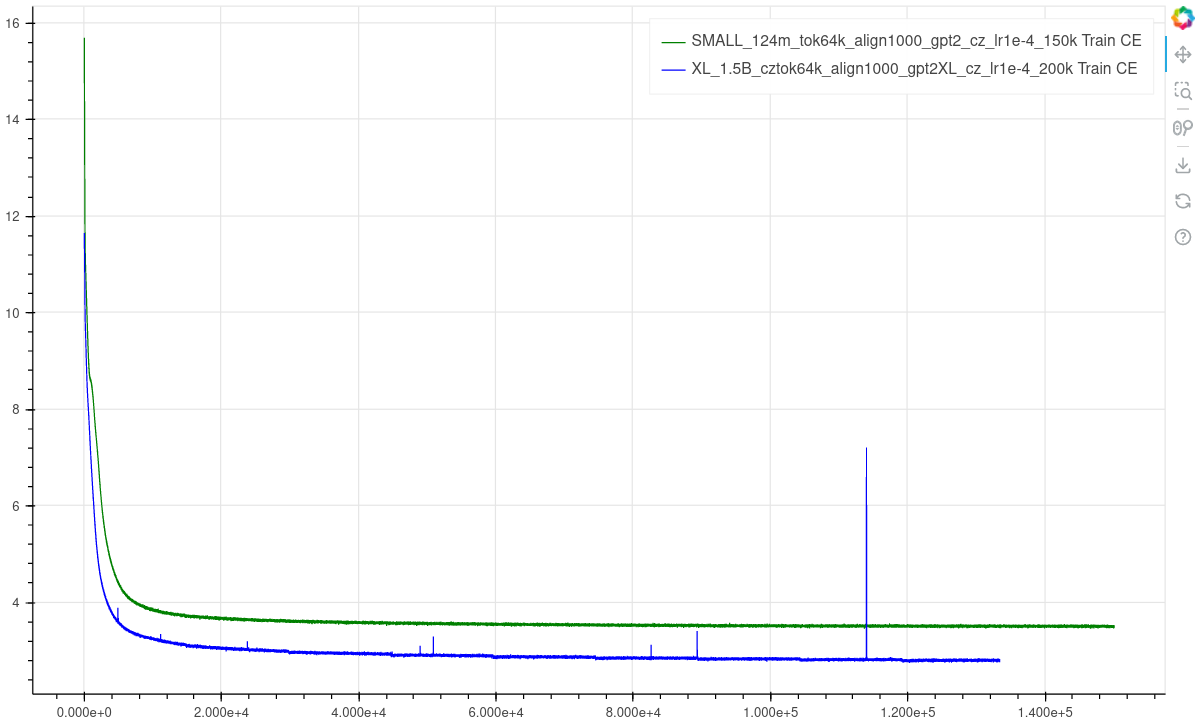
- The validation loss also decreased steadily. We had a bug in validation for early/late steps, so we released only validation from steps 46,000 to 100,000. Similarly, we compare the loss to the small 124M model version.
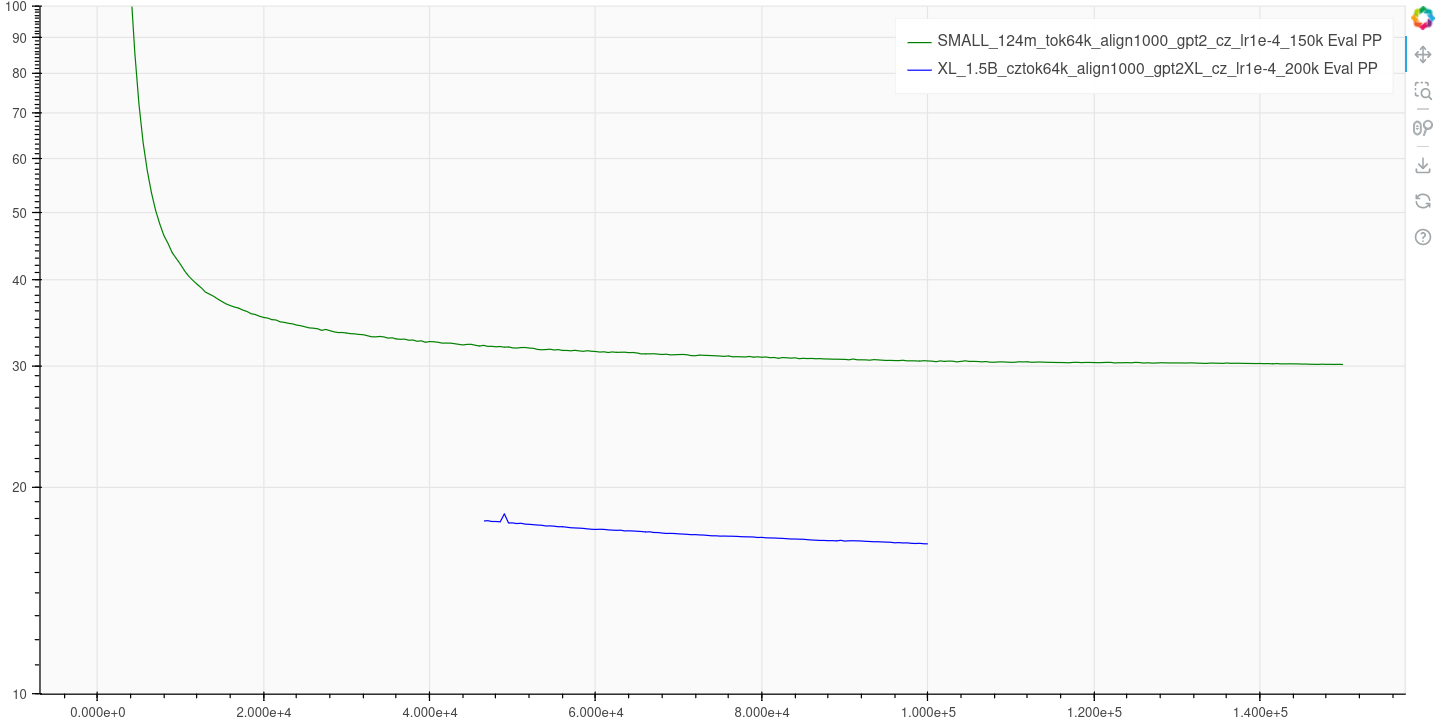
Training parameters
Not mentioned parameters are the same as for GPT-2.
| Name | Value | Note |
|---|---|---|
| dataset_type | Concat | Sequences at the model's input were concatenated up to $max_seq_len, divided by EOS token. |
| tokenizer_size | 64k | |
| max_seq_len | 1024 | |
| batch_size | 1024 | |
| learning_rate | 1.0e-4 | |
| optimizer | LionW | |
| optimizer_betas | 0.9/0.95 | |
| optimizer_weight_decay | 0 | |
| optimizer_eps | 1.0e-08 | |
| gradient_clipping_max_norm | 1.0 | |
| attn_impl | flash2 | |
| dropout | 0.1 | for residuals, attention, embeddings |
| fsdp | SHARD_GRAD_OP | (optimized for A100 40GB GPUs) |
| precision | bf16 | |
| scheduler | linear | |
| scheduler_warmup | 10,000 steps | |
| scheduler_steps | 200,000 | |
| scheduler_alpha | 0.1 | So LR on last step is 0.1*(vanilla LR) |
Evaluation
We observed 10-shot result improvement over the course of training for sentiment analysis, and hellaswag-like commonsense reasoning. There were some tasks where there was no such improvement, such as grammar error classification (does the sentence contain grammatical error?). We will release the precise results once we advance with the work on our Czech evaluation kit.
Disclaimer
This is a work-in-progress. [PH:Licensing Information]. For further questions, turn to martin.fajcik@vut.cz.