
File size: 15,199 Bytes
9476457 1245160 9476457 78dcdd5 9476457 1c7de27 78dcdd5 1c7de27 78dcdd5 1c7de27 78dcdd5 76dc8c6 f239cec 76dc8c6 78dcdd5 db8765e 78dcdd5 8507277 db8765e 78dcdd5 db8765e 78dcdd5 9b3c6f1 78dcdd5 1c7de27 78dcdd5 db8765e 1c7de27 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 78dcdd5 9476457 40967c1 78dcdd5 40967c1 78dcdd5 40967c1 78dcdd5 40967c1 78dcdd5 40967c1 78dcdd5 1c7de27 40967c1 9476457 78dcdd5 1c7de27 9476457 78dcdd5 1c7de27 78dcdd5 1c7de27 78dcdd5 1c7de27 78dcdd5 1c7de27 9476457 78dcdd5 9476457 78dcdd5 f239cec 76dc8c6 78dcdd5 db8765e 78dcdd5 76dc8c6 9b3c6f1 76dc8c6 78dcdd5 76dc8c6 78dcdd5 9476457 78dcdd5 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 |
---
license: apache-2.0
datasets:
- BAAI/ShareRobot
- lmms-lab/LLaVA-OneVision-Data
language:
- en
---
<div align="center">
<img src="https://github.com/FlagOpen/RoboBrain/raw/main/assets/logo.jpg" width="400"/>
</div>
# [CVPR 25] RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete.
<p align="center">
</a>  ⭐️ <a href="https://superrobobrain.github.io/">Project</a></a>   |   🤗 <a href="https://huggingface.co/BAAI/RoboBrain/">Hugging Face</a>   |   🤖 <a href="https://www.modelscope.cn/models/BAAI/RoboBrain/files/">ModelScope</a>   |   🌎 <a href="https://github.com/FlagOpen/ShareRobot">Dataset</a>   |   📑 <a href="http://arxiv.org/abs/2502.21257">Paper</a>   |   💬 <a href="./assets/wechat.png">WeChat</a>
</p>
<p align="center">
</a>  🎯 <a href="">RoboOS (Coming Soon)</a>: An Efficient Open-Source Multi-Robot Coordination System for RoboBrain.
</p>
<p align="center">
</a>  🎯 <a href="https://tanhuajie.github.io/ReasonRFT/">Reason-RFT</a>: Exploring a New RFT Paradigm to Enhance RoboBrain's Visual Reasoning Capabilities.
</p>
## 🔥 Overview
Recent advancements in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various multimodal contexts. However, their application in robotic scenarios, particularly for long-horizon manipulation tasks, reveals significant limitations. These limitations arise from the current MLLMs lacking three essential robotic brain capabilities: **(1) Planning Capability**, which involves decomposing complex manipulation instructions into manageable sub-tasks; **(2) Affordance Perception**, the ability to recognize and interpret the affordances of interactive objects; and **(3) Trajectory Prediction**, the foresight to anticipate the complete manipulation trajectory necessary for successful execution. To enhance the robotic brain's core capabilities from abstract to concrete, we introduce ShareRobot, a high-quality heterogeneous dataset that labels multi-dimensional information such as task planning, object affordance, and end-effector trajectory. ShareRobot's diversity and accuracy have been meticulously refined by three human annotators. Building on this dataset, we developed RoboBrain, an MLLM-based model that combines robotic and general multi-modal data, utilizes a multi-stage training strategy, and incorporates long videos and high-resolution images to improve its robotic manipulation capabilities. Extensive experiments demonstrate that RoboBrain achieves state-of-the-art performance across various robotic tasks, highlighting its potential to advance robotic brain capabilities.
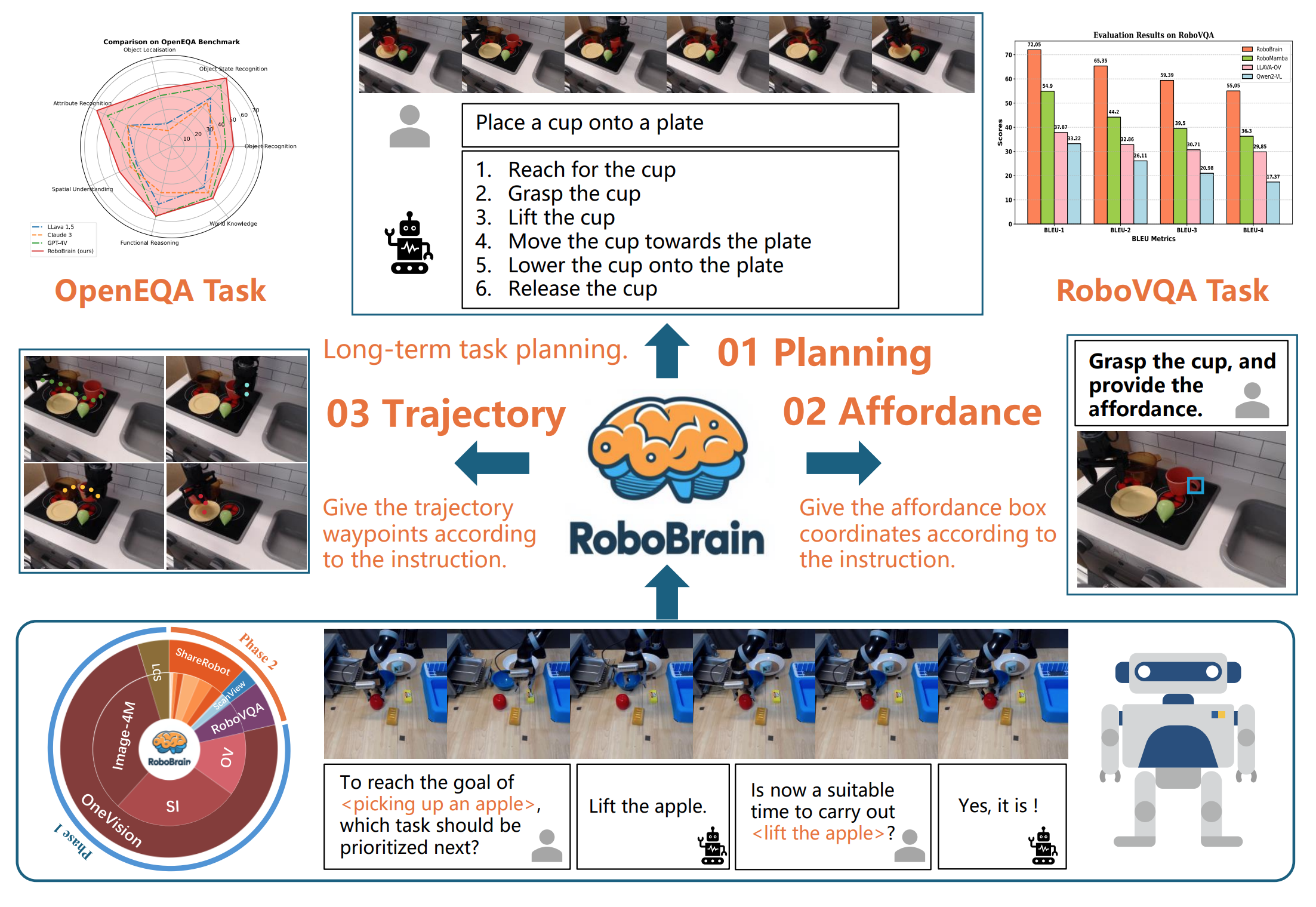
## 🚀 Features
This repository supports:
- **`Data Preparation`**: Please refer to [Dataset Preparation](https://github.com/FlagOpen/ShareRobot) for how to prepare the dataset.
- **`Training for RoboBrain`**: Please refer to [Training Section](#Training) for the usage of training scripts.
- **`Support HF/VLLM Inference`**: Please see [Inference Section](#Inference), now we support inference with [VLLM](https://github.com/vllm-project/vllm).
- **`Evaluation for RoboBrain`**: Please refer to [Evaluation Section](#Evaluation) for how to prepare the benchmarks.
- **`ShareRobot Generation`**: Please refer to [ShareRobot](https://github.com/FlagOpen/ShareRobot) for details.
## 🗞️ News
- **`2025-04-04`**: 🤗 We have released [Trajectory Checkpoint](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/) in Huggingface.
- **`2025-03-29`**: 🤗 We have released [Affordance Checkpoint](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/) in Huggingface.
- **`2025-03-27`**: 🤗 We have released [Planning Checkpoint](https://huggingface.co/BAAI/RoboBrain/) in Huggingface.
- **`2025-03-26`**: 🔥 We have released the [RoboBrain](https://github.com/FlagOpen/RoboBrain/) repository.
- **`2025-02-27`**: 🌍 Our [RoboBrain](http://arxiv.org/abs/2502.21257/) was accepted to CVPR2025.
## 📆 Todo
- [x] Release scripts for model training and inference.
- [x] Release Planning checkpoint.
- [x] Release Affordance checkpoint.
- [x] Release ShareRobot dataset.
- [x] Release Trajectory checkpoint.
- [ ] Release evaluation scripts for Benchmarks.
- [ ] Training more powerful **Robobrain-v2**.
## 🤗 Models
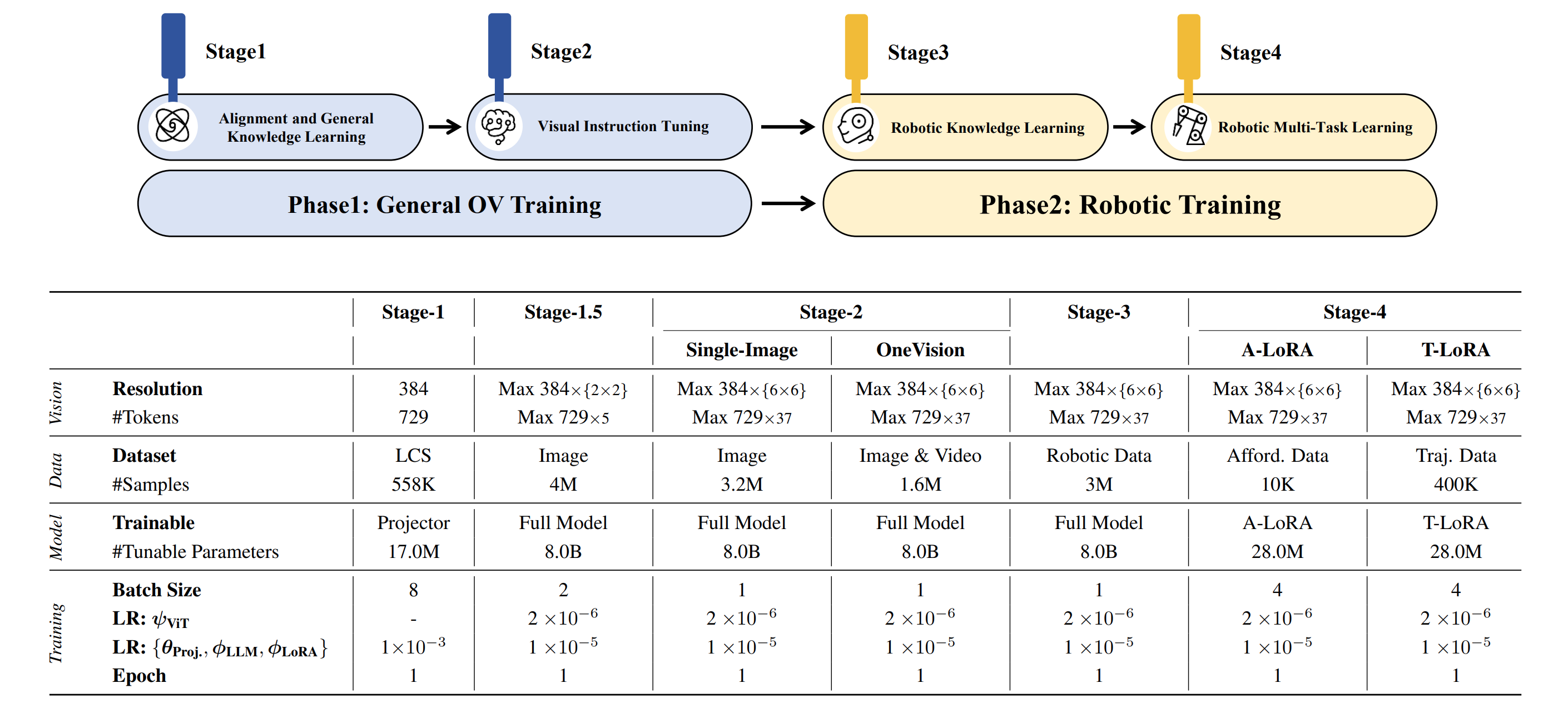
- **[`Base Planning Model`](https://huggingface.co/BAAI/RoboBrain/)**: The model was trained on general datasets in Stages 1–2 and on the Robotic Planning dataset in Stage 3, which is designed for Planning prediction.
- **[`A-LoRA for Affordance`](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Affordance dataset to predict affordance.
- **[`T-LoRA for Trajectory`](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Trajectory dataset to predict trajectory.
| Models | Checkpoint | Description |
|----------------------|----------------------------------------------------------------|------------------------------------------------------------|
| Planning Model | [🤗 Planning CKPTs](https://huggingface.co/BAAI/RoboBrain/) | Used for Planning prediction in our paper |
| Affordance (A-LoRA) | [🤗 Affordance CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/) | Used for Affordance prediction in our paper |
| Trajectory (T-LoRA) | [🤗 Trajectory CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/) | Used for Trajectory prediction in our paper |
## 🛠️ Setup
```bash
# clone repo.
git clone https://github.com/FlagOpen/RoboBrain.git
cd RoboBrain
# build conda env.
conda create -n robobrain python=3.10
conda activate robobrain
pip install -r requirements.txt
```
## <a id="Training"> 🤖 Training</a>
### 1. Data Preparation
```bash
# Modify datasets for Stage 1, please refer to:
- yaml_path: scripts/train/yaml/stage_1_0.yaml
# Modify datasets for Stage 1.5, please refer to:
- yaml_path: scripts/train/yaml/stage_1_5.yaml
# Modify datasets for Stage 2_si, please refer to:
- yaml_path: scripts/train/yaml/stage_2_si.yaml
# Modify datasets for Stage 2_ov, please refer to:
- yaml_path: scripts/train/yaml/stage_2_ov.yaml
# Modify datasets for Stage 3_plan, please refer to:
- yaml_path: scripts/train/yaml/stage_3_planning.yaml
# Modify datasets for Stage 4_aff, please refer to:
- yaml_path: scripts/train/yaml/stage_4_affordance.yaml
# Modify datasets for Stage 4_traj, please refer to:
- yaml_path: scripts/train/yaml/stage_4_trajectory.yaml
```
**Note:** The sample format in each json file should be like:
```json
{
"id": "xxxx",
"image": [
"image1.png",
"image2.png",
],
"conversations": [
{
"from": "human",
"value": "<image>\n<image>\nAre there numerous dials near the bottom left of the tv?"
},
{
"from": "gpt",
"value": "Yes. The sun casts shadows ... a serene, clear sky."
}
]
},
```
### 2. Training
```bash
# Training on Stage 1:
bash scripts/train/stage_1_0_pretrain.sh
# Training on Stage 1.5:
bash scripts/train/stage_1_5_direct_finetune.sh
# Training on Stage 2_si:
bash scripts/train/stage_2_0_resume_finetune_si.sh
# Training on Stage 2_ov:
bash scripts/train/stage_2_0_resume_finetune_ov.sh
# Training on Stage 3_plan:
bash scripts/train/stage_3_0_resume_finetune_robo.sh
# Training on Stage 4_aff:
bash scripts/train/stage_4_0_resume_finetune_lora_a.sh
# Training on Stage 4_traj:
bash scripts/train/stage_4_0_resume_finetune_lora_t.sh
```
**Note:** Please change the environment variables (e.g. *DATA_PATH*, *IMAGE_FOLDER*, *PREV_STAGE_CHECKPOINT*) in the script to your own.
### 3. Convert original weights to HF weights
```bash
# Planning Model
python model/llava_utils/convert_robobrain_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
# A-LoRA & T-RoRA
python model/llava_utils/convert_lora_weights_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
```
## <a id="Inference">⭐️ Inference</a>
### 1. Usage for Planning Prediction
#### Option 1: HF inference
```python
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
model = SimpleInference(model_id)
prompt = "Given the obiects in the image, if you are required to complete the task \"Put the apple in the basket\", what is your detailed plan? Write your plan and explain it in detail, using the following format: Step_1: xxx\nStep_2: xxx\n ...\nStep_n: xxx\n"
image = "./assets/demo/planning.png"
pred = model.inference(prompt, image, do_sample=True)
print(f"Prediction: {pred}")
'''
Prediction: (as an example)
Step_1: Move to the apple. Move towards the apple on the table.
Step_2: Pick up the apple. Grab the apple and lift it off the table.
Step_3: Move towards the basket. Move the apple towards the basket without dropping it.
Step_4: Put the apple in the basket. Place the apple inside the basket, ensuring it is in a stable position.
'''
```
#### Option 2: VLLM inference
Install and launch VLLM
```bash
# Install vllm package
pip install vllm==0.6.6.post1
# Launch Robobrain with vllm
python -m vllm.entrypoints.openai.api_server --model BAAI/RoboBrain --served-model-name robobrain --max_model_len 16384 --limit_mm_per_prompt image=8
```
Run python script as example:
```python
from openai import OpenAI
import base64
openai_api_key = "robobrain-123123"
openai_api_base = "http://127.0.0.1:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = "Given the obiects in the image, if you are required to complete the task \"Put the apple in the basket\", what is your detailed plan? Write your plan and explain it in detail, using the following format: Step_1: xxx\nStep_2: xxx\n ...\nStep_n: xxx\n"
image = "./assets/demo/planning.png"
with open(image, "rb") as f:
encoded_image = base64.b64encode(f.read())
encoded_image = encoded_image.decode("utf-8")
base64_img = f"data:image;base64,{encoded_image}"
response = client.chat.completions.create(
model="robobrain",
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": base64_img}},
{"type": "text", "text": prompt},
],
},
]
)
content = response.choices[0].message.content
print(content)
'''
Prediction: (as an example)
Step_1: Move to the apple. Move towards the apple on the table.
Step_2: Pick up the apple. Grab the apple and lift it off the table.
Step_3: Move towards the basket. Move the apple towards the basket without dropping it.
Step_4: Put the apple in the basket. Place the apple inside the basket, ensuring it is in a stable position.
'''
```
### 2. Usage for Affordance Prediction
```python
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
model = SimpleInference(model_id, lora_id)
# Example 1:
prompt = "You are a robot using the joint control. The task is \"pick_up the suitcase\". Please predict a possible affordance area of the end effector?"
image = "./assets/demo/affordance_1.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [0.733, 0.158, 0.845, 0.263]
'''
# Example 2:
prompt = "You are a robot using the joint control. The task is \"push the bicycle\". Please predict a possible affordance area of the end effector?"
image = "./assets/demo/affordance_2.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [0.600, 0.127, 0.692, 0.227]
'''
```

### 3. Usage for Trajectory Prediction
```python
# please refer to https://github.com/FlagOpen/RoboBrain
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
model = SimpleInference(model_id, lora_id)
# Example 1:
prompt = "You are a robot using the joint control. The task is \"reach for the cloth\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
image = "./assets/demo/trajectory_1.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [[0.781, 0.305], [0.688, 0.344], [0.570, 0.344], [0.492, 0.312]]
'''
# Example 2:
prompt = "You are a robot using the joint control. The task is \"reach for the grapes\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
image = "./assets/demo/trajectory_2.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [[0.898, 0.352], [0.766, 0.344], [0.625, 0.273], [0.500, 0.195]]
'''
```
## <a id="Evaluation">🤖 Evaluation</a>
*Coming Soon ...*
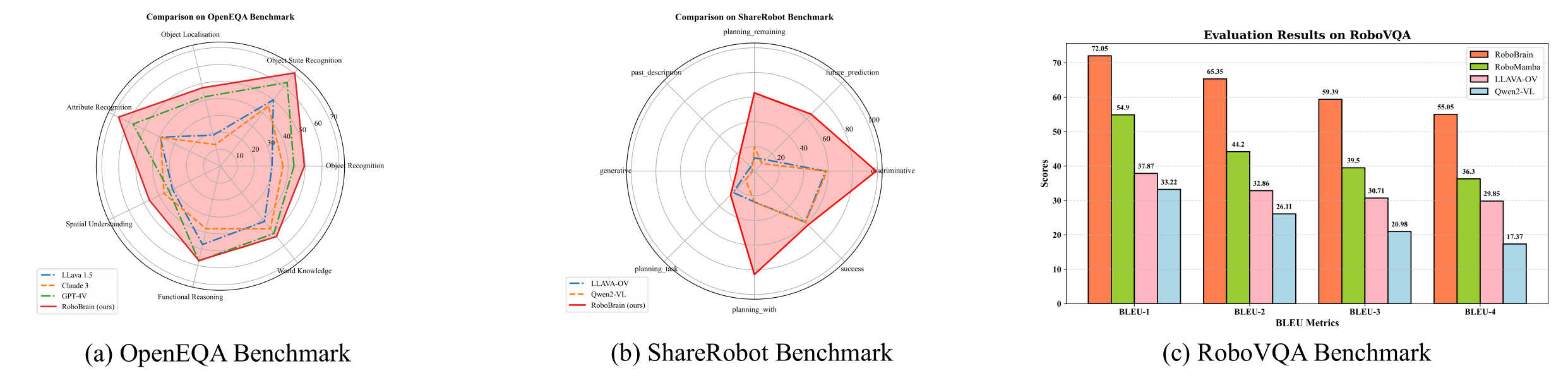
<!-- <div align="center">
<img src="https://github.com/FlagOpen/RoboBrain/blob/main/assets/result.png" />
</div> -->
## 😊 Acknowledgement
We would like to express our sincere gratitude to the developers and contributors of the following projects:
1. [LLaVA-NeXT](https://github.com/LLaVA-VL/LLaVA-NeXT): The comprehensive codebase for training Vision-Language Models (VLMs).
2. [lmms-eval](https://github.com/EvolvingLMMs-Lab/lmms-eval): A powerful evaluation tool for Vision-Language Models (VLMs).
3. [vllm](https://github.com/vllm-project/vllm): A high-throughput and memory-efficient LLMs/VLMs inference engine.
4. [OpenEQA](https://github.com/facebookresearch/open-eqa): A wonderful benchmark for Embodied Question Answering.
5. [RoboVQA](https://github.com/google-deepmind/robovqa): Provide high-level reasoning models and datasets for robotics applications.
Their outstanding contributions have played a pivotal role in advancing our research and development initiatives.
## 📑 Citation
If you find this project useful, welcome to cite us.
```bib
@article{ji2025robobrain,
title={RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete},
author={Ji, Yuheng and Tan, Huajie and Shi, Jiayu and Hao, Xiaoshuai and Zhang, Yuan and Zhang, Hengyuan and Wang, Pengwei and Zhao, Mengdi and Mu, Yao and An, Pengju and others},
journal={arXiv preprint arXiv:2502.21257},
year={2025}
}
```
|