

metadata
license: other

悟道·天鹰(Aquila2)
悟道·天鹰(Aquila2) 语言大模型是首个具备中英双语知识、支持商用许可协议、国内数据合规需求的开源语言大模型。
- 🌟 支持开源商用许可。Aquila系列模型的源代码基于 Apache 2.0 协议,模型权重基于《智源Aquila系列模型许可协议》,使用者在满足许可限制的情况下,可用于商业目的。
- ✍️ 具备中英文知识。Aquila系列模型在中英文高质量语料基础上从 0 开始训练,中文语料约占 40%,保证模型在预训练阶段就开始积累原生的中文世界知识,而非翻译而来的知识。
- 👮♀️符合国内数据合规需求。Aquila系列模型的中文语料来自智源多年积累的中文数据集,包括来自1万多个站源的中文互联网数据(其中99%以上为国内站源),以及获得国内权威机构支持的高质量中文文献数据、中文书籍数据等。我们仍在持续积累高质量、多样化的数据集,并源源不断加入Aquila基础模型后续训练中。
- 🎯持续迭代,持续开源开放。我们将不断完善训练数据、优化训练方法、提升模型性能,在更优秀的基础模型基座上,培育枝繁叶茂的“模型树”,持续开源开放更新的版本。
悟道 · 天鹰 Aquila 模型的更多细节将在官方技术报告中呈现。请关注官方渠道更新。
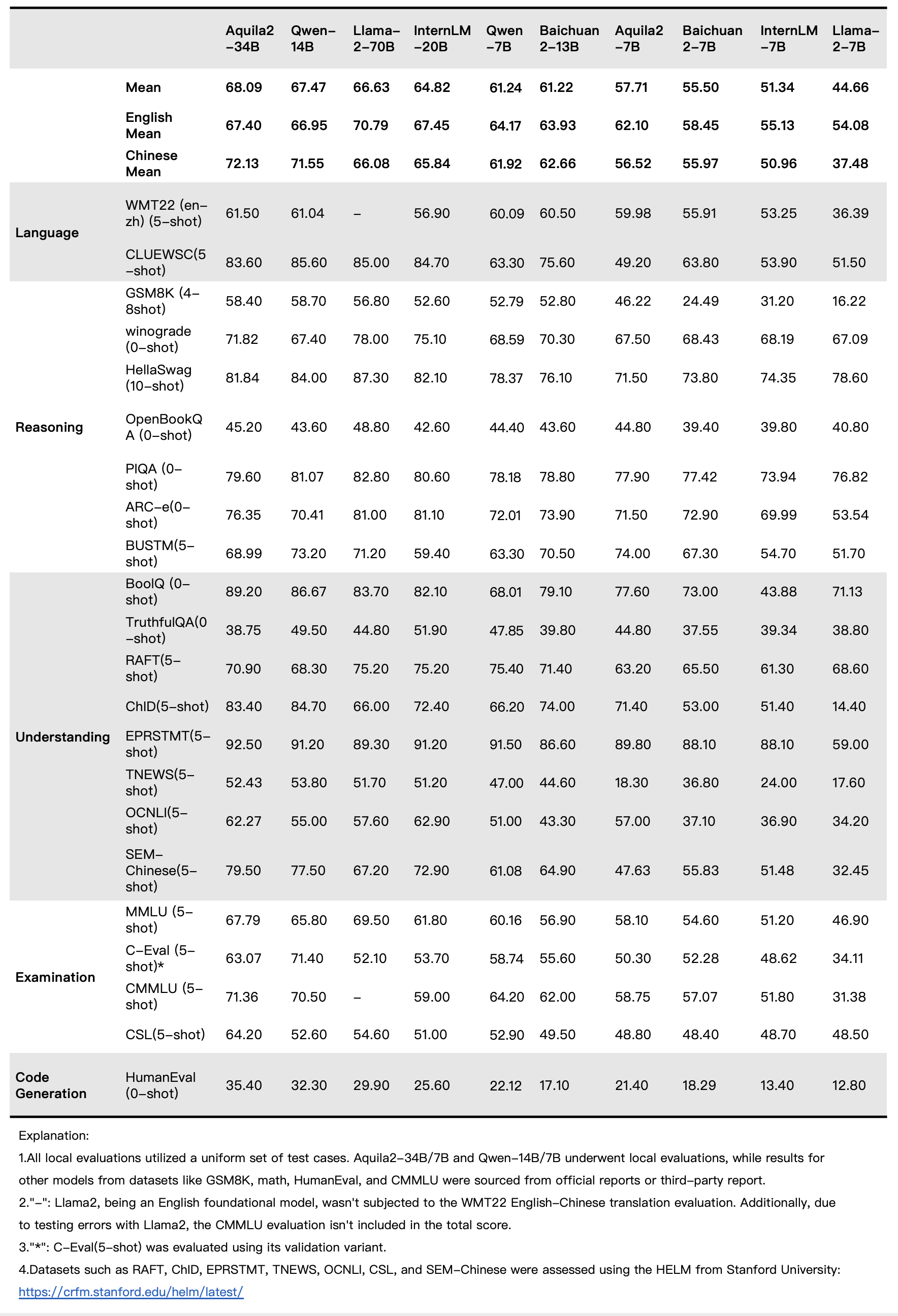
基本模型性能
快速开始使用 Aquila-7B
使用方式/How to use
1. 推理/Inference
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
device = torch.device("cuda")
model_info = "BAAI/Aquila2-7B"
tokenizer = AutoTokenizer.from_pretrained(model_info, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_info, trust_remote_code=True)
model.eval()
model.to(device)
text = "请给出10个要到北京旅游的理由。"
tokens = tokenizer.encode_plus(text)['input_ids'][:-1]
tokens = torch.tensor(tokens)[None,].to(device)
stop_tokens = ["###", "[UNK]", "</s>"]
with torch.no_grad():
out = model.generate(tokens, do_sample=True, max_length=512, eos_token_id=100007, bad_words_ids=[[tokenizer.encode(token)[0] for token in stop_tokens]])[0]
out = tokenizer.decode(out.cpu().numpy().tolist())
print(out)
证书/License
`Aquila系列开源模型使用 智源Aquila系列模型许可协议