
Upload folder using huggingface_hub
Browse files- LICENSE +240 -0
- ModelsCommunityLicenseAgreement +166 -0
- README_ja.md +361 -0
- README_ko.md +372 -0
- README_zh.md +376 -0
- assets/assets/imgs/assets_imgs_model_cap_en.png +0 -0
- assets/assets/imgs/assets_imgs_model_cap_zh.png +0 -0
- assets/assets/imgs/assets_imgs_orion_start.PNG +0 -0
- assets/assets/imgs/assets_imgs_wechat_group.jpg +0 -0
- assets/assets/imgs/llama_cpp.png +0 -0
- assets/assets/imgs/model_cap_en.png +0 -0
- assets/assets/imgs/model_cap_zh.png +0 -0
- assets/assets/imgs/opencompass_en.png +0 -0
- assets/assets/imgs/opencompass_zh.png +0 -0
- assets/assets/imgs/orion_start.PNG +0 -0
- assets/assets/imgs/vllm.png +0 -0
- assets/assets/imgs/wechat_group.jpg +0 -0
- config.json +31 -0
- configuration_orion.py +82 -0
- generation_config.json +13 -0
- generation_utils.py +52 -0
- model.safetensors.index.json +451 -0
- modeling_orion.py +1117 -0
- output-00001-of-00002.safetensors +3 -0
- output-00002-of-00002.safetensors +3 -0
- special_tokens_map.json +30 -0
- tokenization_orion.py +255 -0
- tokenizer.model +3 -0
- tokenizer_config.json +46 -0
LICENSE
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright (C) 2023 ORION STAR Robotics
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
Apache License Version 2.0(简体中文)
|
| 208 |
+
1. 定义
|
| 209 |
+
“许可证”是指根据本文档第1到第9部分关于使用、重生成和分发的术语和条件。
|
| 210 |
+
“许可证颁发者”是指版权所有者或者由版权所有者批准的授权许可证的实体。
|
| 211 |
+
“法律实体”是指实施实体和进行控制的所有其它实体受该实体控制,或者受该实体集中控制。根据此定义,”控制”是指(i)让无论是否签订协议的上述实体,进行指导或管理的直接权利或间接权利,或者(ii)拥有百分之五十(50%)或以上已发行股票的所有者,或者(iii)上述实体的实权所有者。
|
| 212 |
+
“用户”(或“用户的”)是指行使本许可证所授予权限的个人或法律实体。
|
| 213 |
+
“源程序”形式是指对包含但不限制软件源代码、文档源程序和配置文件进行修改的首选形式。
|
| 214 |
+
“目标”形式是指对源程序形式进行机械转换或翻译的任何形式,包括但不限于对编译的目标代码,生成的文件以及转换为其它媒体类型。
|
| 215 |
+
“作品”是指根据本许可证所制作的源程序形式或目标形式的著作,在著作中包含的或附加的版权通知(在下面附录中提供了一个示例)。
|
| 216 |
+
“衍生作品”是指基于作品(或从作品衍生而来)的源程序形式或目标形式的任何作品,以及编辑修订、注释、详细描述或其它修订等构成原创著作作品的整体。根据本许可证,衍生作品不得包括与作品及其衍生作品分离之作品,或仅与作品及其衍生作品的接口相链接(或按名称结合)之作品。
|
| 217 |
+
“贡献”是指任何著作作品,包括作品的原始版本和对该作品或衍生作品所做的任何修订或补充,意在提交给许可证颁发者以让版权所有者或代表版权所有者的授权个人或法律实体包含在其作品中。根据此定义,“提交”一词表示发送给许可证颁发者或其代表人,任何电子的、口头的或书面的交流信息形式,包括但不限于在由许可证颁发者或者代表其管理的电子邮件清单、源代码控制系统、以及发布跟踪系统上为讨论和提高作品的交流,但不包括由版权所有者以书面形式明显标注或指定为”非贡献”的交流活动。
|
| 218 |
+
“贡献者”是指许可证颁发者和代表从许可证颁发者接受之贡献的并随后包含在作品之贡献中的任何个人或法律实体。
|
| 219 |
+
2. 版权许可证的授予
|
| 220 |
+
根据本许可证的条款,每个贡献者授予用户永久性的、全球性的、非专有性的、免费的、无版权费的、不可撤销的版权许可证以源程序形式或目标形式复制、准备衍生作品、公开显示、公开执行、授予分许可证、以及分发作品和这样的衍生作品。
|
| 221 |
+
3. 专利许可证的授予
|
| 222 |
+
根据本许可证的条款,每个贡献者授予用户永久性的、全球性的、非专有性的、免费的、无版权费的、不可撤销的(除在本部分进行说明)专利许可证对作品进行制作、让人制作、使用、提供销售、销售、进口和其它转让,且这样的许可证仅适用于在所递交作品的贡献中因可由单一的或多个这样的贡献者授予而必须侵犯的申请专利。如果用户对任何实体针对作品或作品中所涉及贡献提出因直接性或贡献性专利侵权而提起专利法律诉讼(包括交互诉讼请求或反索赔),那么根据本许可证,授予用户针对作品的任何专利许可证将在提起上述诉讼之日起终止。
|
| 223 |
+
4. 重新分发
|
| 224 |
+
用户可在任何媒介中复制和分发作品或衍生作品之副本,无论是否修订,还是以源程序形式或目标形式,条件是用户需满���下列条款:
|
| 225 |
+
用户必须为作品或衍生作品的任何其他接收者提供本许可证的副本;
|
| 226 |
+
并且用户必须让任何修改过的文件附带明显的通知,声明用户已更改文件;
|
| 227 |
+
并且用户必须从作品的源程序形式中保留衍生作品源程序形式的用户所分发的所有版权、专利、商标和属性通知,但不包括不属于衍生作品任何部分的类似通知;
|
| 228 |
+
并且如果作品将”通知”文本文件包括为其分发作品的一部分,那么用户分发的任何衍生作品中须至少在下列地方之一包括,在这样的通知文件中所包含的属性通知的可读副本,但不包括那些不属于衍生作品任何部分的通知:在作为衍生作品一部分而分发的通知文本文件中;如果与衍生作品一起提供则在源程序形式或文件中;或者通常作为第三方通知出现的时候和地方,在衍生作品中产生的画面中。通知文件的内容仅供信息提供,并未对许可证进行修改。用户可在其分发的衍生作品中在作品的通知文本后或作为附录添加自己的属性通知,条件是附加的属性通知不得构成修改本许可证。
|
| 229 |
+
用户可以为自身所做出的修订添加自己的版权声明并可对自身所做出修订内容或为这样的衍生作品作为整体的使用、复制或分发提供附加或不同的条款,条件是用户对作品的使用、复制和分发必须符合本许可证中声明的条款。
|
| 230 |
+
5. 贡献的提交
|
| 231 |
+
除非用户明确声明,在作品中由用户向许可证颁发者的提交若要包含在贡献中,必须在无任何附加条款下符合本许可证的条款。尽管上面如此规定,执行许可证颁发者有关贡献的条款时,任何情况下均不得替代或修改任何单独许可证协议的条款。
|
| 232 |
+
6. 商标
|
| 233 |
+
本许可证并未授予用户使用许可证颁发者的商号、商标、服务标记或产品名称,除非将这些名称用于合理性和惯例性描述作品起源和复制通知文件的内容时。
|
| 234 |
+
7. 保证否认条款
|
| 235 |
+
除非因适用法律需要或书面同意,许可证颁发者以”按原样”基础提供作品(并且每个贡献者提供其贡献),无任何明示的或暗示的保证或条件,包括但不限于关于所有权、不侵权、商品适销性、或适用性的保证或条件。用户仅对使用或重新分发作品的正确性负责,并需承担根据本许可证行使权限时的任何风险。
|
| 236 |
+
8. 责任限制条款
|
| 237 |
+
在任何情况下并根据任何法律,无论是因侵权(包括过失)或根据合同,还是其它原因,除非根据适用法律需要(例如故意行为和重大过失行为)或经书面同意,即使贡献者事先已被告知发生损害的可能性,任何贡献者不就用户因使用本许可证或不能使用或无法使用作品(包括但不限于商誉损失、停工、计算机失效或故障,或任何商业损坏或损失)而造成的损失,包括直接的、非直接的、特殊的、意外的或间接的字符损坏而负责。
|
| 238 |
+
9. 接受保证或附加责任
|
| 239 |
+
重新分发作品或及其衍生作品时,用户可选择提供或为符合本许可证承担之支持、担保、赔偿或其它职责义务和/或权利而收取费用。但是,在承担上述义务时,用户只可代表用户本身和用户本身责任来执行,无需代表任何其它贡献者,并且用户仅可保证、防护并保持每个贡献者不受任何因此而产生的责任或对因用户自身承担这样的保证或附加责任而对这样的贡献者所提出的索赔。
|
| 240 |
+
条款结束
|
ModelsCommunityLicenseAgreement
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
【Orion-14B Series】 Models Community License Agreement
|
| 2 |
+
Version: 1.0
|
| 3 |
+
Date of Release:
|
| 4 |
+
|
| 5 |
+
1. Definition
|
| 6 |
+
|
| 7 |
+
“Agreement” refers to the terms and conditions defined in this 【Orion-14B Series】 Models Community License Agreement for the use, reproduction, and distribution of Yi
|
| 8 |
+
Series Models.
|
| 9 |
+
|
| 10 |
+
“Model” refers to associated components (including checkpoints) developed based on machine learning, including learned weights and parameters (including the
|
| 11 |
+
status of optimizer).
|
| 12 |
+
|
| 13 |
+
“【Orion-14B Series】 Models” refers to open-source models with different specifications and capabilities provided by the Licensor, including:
|
| 14 |
+
【Orion-14B-Base】Base model
|
| 15 |
+
【Orion-14B-Chat】Chat model
|
| 16 |
+
【Orion-14B-LongChat】Long context chat model
|
| 17 |
+
【Orion-14B-Chat-RAG】Retrieval augmented generation chat model
|
| 18 |
+
【Orion-14B-Chat-Plugin】Chat model with plugin capability
|
| 19 |
+
【Orion-14B-Base-Int4】4-bit integer quantized base model
|
| 20 |
+
【Orion-14B-Chat-Int4】4-bit integer quantized chat model
|
| 21 |
+
|
| 22 |
+
“Derivatives” refers to all modifications to 【Orion-14B Series】 Models, work based on 【Orion-14B Series】 Models, or any other models created or initialized by transferring the weights, parameters, activations, or output patterns of 【Orion-14B Series】 Models to other models to achieve similar performance, including but not limited to methods that require using intermediate data representations or generating synthetic data based on 【Orion-14B Series】 Models to train other models.
|
| 23 |
+
|
| 24 |
+
“Licensor” refers to Beijing Orionstar Technology Co., Ltd.
|
| 25 |
+
|
| 26 |
+
“you” refers to an individual or legal entity that exercises the license granted by this Agreement and/or uses the 【Orion-14B Series】 Models for any purpose and in any field of use.
|
| 27 |
+
|
| 28 |
+
“Third Party” refers to any individuals, legal entities, or non-legal organizations other than you.
|
| 29 |
+
|
| 30 |
+
“Distribute” refers to transmitting, copying, publishing, or otherwise sharing the 【Orion-14B Series】 Models with third parties, including providing the 【Orion-14B Series】Models through electronic or other remote means (such as any SaaS software or PaaS software accessed via API or web access).
|
| 31 |
+
|
| 32 |
+
“Commercial Purposes” refers to the use of the 【Orion-14B Series】 Models, directly or indirectly, for the operation, promotion, revenue generation, or any other profit-making purposes for entities or individuals.
|
| 33 |
+
|
| 34 |
+
“Laws and Regulations” refers to the laws and administrative regulations of the mainland of the People's Republic of China (for the purposes of this Agreement only, excluding Hong Kong, Macau, and Taiwan).
|
| 35 |
+
|
| 36 |
+
“Personal Information” refers to various information related to identified or identifiable natural persons recorded electronically or by other means, excluding information that has been anonymized.
|
| 37 |
+
|
| 38 |
+
“Logo” refers to any trademark, service mark, trade name, domain name, website name, or other distinctive branding marks.
|
| 39 |
+
|
| 40 |
+
2. License and License Restrictions
|
| 41 |
+
The Licensor hereby grants you a non-exclusive, global, non-transferable, on-sub-licensable, revocable, and royalty-free copyright license. You must adhere to the following license restrictions:
|
| 42 |
+
|
| 43 |
+
1) Your use of the 【Orion-14B Series】 Models must comply with the Laws and Regulations as well as applicable legal requirements of other countries/regions, and respect social ethics and moral standards, including but not limited to, not using the【Orion-14B Series】 Models for purposes prohibited by Laws and Regulations as well as applicable legal requirements of other countries/regions, such as harming national security, promoting terrorism, extremism, inciting ethnic or racial hatred, discrimination, violence, or pornography, and spreading false harmful information.
|
| 44 |
+
|
| 45 |
+
2) You shall not, for military or unlawful purposes or in ways not allowed by Laws and Regulations as well as applicable legal requirements of other countries/regions, a) use, copy, or Distribute the【Orion-14B Series】 Models, or b) create complete or partial Derivatives of the 【Orion-14B Series】 Models.
|
| 46 |
+
|
| 47 |
+
3) Your use of the 【Orion-14B Series】 Models (including using the output of the 【Orion-14B Series】 Models) and the creation of Derivatives must not infringe upon the legitimate rights of any Third Party, including but not limited to the rights of personal rights such as the right to likeness, reputation, and privacy, as well as intellectual property rights such as copyrights, patents, trade secrets, and other property rights.
|
| 48 |
+
|
| 49 |
+
4) You must clearly attribute the source of the 【Orion-14B Series】 Models to the Licensor and provide a copy of this Agreement to any Third-Party users of the 【Orion-14B Series】 Models and Derivatives.
|
| 50 |
+
|
| 51 |
+
5) If you modify the 【Orion-14B Series】 Models to create Derivatives, you must clearly indicate the substantial modifications made, and these modifications shall not violate the license restrictions of this Agreement. You shall not enable, assist, or in any way facilitate Third Parties to violate the license restrictions of this Agreement.
|
| 52 |
+
|
| 53 |
+
If you plan to use the 【Orion-14B Series】 Models and Derivatives for Commercial Purposes, please refer to the Registration Form of 【Orion-14B Series】 Models for Commercial Purposes (“Registration Form”), available at 【https://test.orionstar.com/llm-license.html】) and to complete the registration and obtain the license for Commercial Purposes. If you obtained the license for Commercial Purposes and use the 【Orion-14B Series】 Models and Derivatives for Commercial Purposes, you must comply with the afore-mentioned license restrictions.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
3. Intellectual Property
|
| 57 |
+
The ownership of the 【Orion-14B Series】 Models and their related intellectual property rights is solely held by the Licensor.
|
| 58 |
+
|
| 59 |
+
In any circumstance, without the prior written consent of the Licensor, you are not allowed to use any Logo associated with the Licensor. If your use of the Licensor's Logo in violation of this Agreement causes any losses to the Licensor or others, you will bear full legal responsibility.
|
| 60 |
+
|
| 61 |
+
Within the scope of the granted license, you are authorized to modify the Orion-14B series models to create derivative works. You may assert intellectual property rights over the portions of the derivative works that are the product of your creative labor.
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
4. Disclaimer and Limitation of Liability
|
| 65 |
+
|
| 66 |
+
The 【Orion-14B Series】 Models are provided "AS IS." The Licensor does not provide any express or implied warranties for the 【Orion-14B Series】 Models, including but not limited to stability, ownership, merchantability, non-infringement, or fitness for a specific purpose of the 【Orion-14B Series】 Models and their output results. You assume all responsibilities for the risks and consequences arising from the use, reproduction, and distribution of the 【Orion-14B Series】 Models, and the creation of Derivatives.
|
| 67 |
+
|
| 68 |
+
The Licensor complies with Laws and Regulations at all stages of model training, maintaining the legality, authenticity, accuracy, objectivity, and diversity of data and algorithms. The Licensor is not liable for any direct, indirect, incidental consequences, and other losses or damages related to your use, reproduction, and distribution of the 【Orion-14B Series】 Models, and the creation of Derivatives under this Agreement. This includes but is not limited to:
|
| 69 |
+
|
| 70 |
+
1) The Licensor is not responsible for data security risks resulting from your use of the 【Orion-14B Series】 Models.
|
| 71 |
+
|
| 72 |
+
2) The 【Orion-14B Series】 Models may contain Personal Information. When you use 【Orion-14B Series】 Models, you acknowledge that you are the data processing entity as defined under the Laws and Regulations responsible for determining the processing methods and purposes of Personal Information. You must comply with legal requirements for processing any Personal Information that may be contained in the 【Orion-14B Series】 Models and assume the associated legal responsibilities, as well as the risks
|
| 73 |
+
and consequences of processing Personal Information.
|
| 74 |
+
|
| 75 |
+
3) The Licensor is not liable for reputation risks arising from your use of the 【Orion-14B Series】 Models or the output results of the 【Orion-14B Series】 Models.
|
| 76 |
+
|
| 77 |
+
4) The Licensor is not liable for intellectual property risks associated with your use of the 【Orion-14B Series】 Models’ output results.
|
| 78 |
+
|
| 79 |
+
If your use, reproduction, distribution of the 【Orion-14B Series】 Models, or the creation of Derivatives result in losses to the Licensor, the Licensor has the right to seek compensation from you. For any claims made by Third Parties against the Licensor related to your use, reproduction, and distribution of the 【Orion-14B Series】 Models, or the creation of Derivatives, the Licensor has the right to demand that you defend, compensate, and indemnify the Licensor and protect the Licensor from harm.
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
5. Dispute Resolution
|
| 83 |
+
The stipulation, effectiveness, interpretation, performance, modification, and termination of the Agreement, the use, copy, and Distribute of the 【Orion-14B Series】 Models, and dispute resolution associated with your use, copy, and distribution shall be governed by the laws of the mainland of the People's Republic of China (for the purposes of this agreement only, excluding Hong Kong, Macau, and Taiwan), and the application of conflict of laws is excluded.
|
| 84 |
+
Any disputes arising from the use, copy, or distribution of the 【Orion-14B Series】 Models should first be resolved through amicable negotiations. If negotiations fail, legal proceedings should be initiated in the People's Court at the location of the Licensor.
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
6. Effectiveness and Termination of the Agreement
|
| 88 |
+
|
| 89 |
+
Your use of the 【Orion-14B Series】 Models signifies that you have read and agreed to be bound by the terms of the Agreement. The Agreement becomes effective from the date of your use of the 【Orion-14B Series】 Models and will terminate from the date you cease using the 【Orion-14B Series】 Models. If you violate any terms or restrictions in the Agreement, the Licensor reserves the right to terminate the Agreement.
|
| 90 |
+
|
| 91 |
+
Upon termination of the Agreement, you must immediately cease using the 【Orion-14B Series】Models. Section 4, "Disclaimer and Limitation of Liability," and Section 5, "Dispute Resolution," of this Agreement remain in effect after the termination of this Agreement.
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
7. Updates to the Agreement and Contact Information
|
| 95 |
+
|
| 96 |
+
The Licensor reserves the right to update the Agreement from time to time.
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
【Orion-14B系列】 模型社区许可协议
|
| 104 |
+
版本:1.0
|
| 105 |
+
发布日期:
|
| 106 |
+
一、 定义
|
| 107 |
+
“许可”是指本协议中定义的使用、复制和分发的条款和条件。
|
| 108 |
+
|
| 109 |
+
“模型”是指任何附带的基于机器学习的组件(包括检查点),包括学习的权重、参数(包括 优化器状态)。
|
| 110 |
+
|
| 111 |
+
“【Orion-14B系列】 模型”是指基于【Orion-14B-Base】模型构建的一系列具备领域特色的模型,包含 :
|
| 112 |
+
【Orion-14B-Base】基座模型
|
| 113 |
+
【Orion-14B-Chat】对话模型
|
| 114 |
+
【Orion-14B-LongChat】长上下文模型
|
| 115 |
+
【Orion-14B-Chat-RAG】检索增强模型
|
| 116 |
+
【Orion-14B-Chat-Plugin】插件模型
|
| 117 |
+
【Orion-14B-Base-Int4】基座Int4量化模型
|
| 118 |
+
【Orion-14B-Chat-Int4】对话Int4量化模型
|
| 119 |
+
|
| 120 |
+
“数据”是指从与模型一起使用的数据集中提取的信息和/或内容的集合,包括用于训练、预 训练或以其他方式评估模型的数据。数据集中提取的信息和/或内容的集合,可能包含个人 信息或非个人信息。
|
| 121 |
+
|
| 122 |
+
“个人信息”是指以电子或者其他方式记录的与已识别或者可识别的自然人有关的各种信息, 不包括匿名化处理后的信息。个人信息的处理包括个人信息的收集、存储、使用、加工、 传输、提供、公开、删除等。
|
| 123 |
+
|
| 124 |
+
“输出”是指运行模型的结果,体现在由此产生的信息内容中。
|
| 125 |
+
|
| 126 |
+
“训练”是指为模型提供训练数据,以增强模型的预测能力。
|
| 127 |
+
|
| 128 |
+
“模型衍生品”是指对【Orion-14B系列】模型的所有修改、基于【Orion-14B系列】模型的工作,或通过将 【Orion-14B系列】模型的权重、参数、激活或输出模式转移到其他模型而创建或初始化的任何其他 模型,以使其他模型的性能与【Orion-14B系列】模型类似,包括但不限于需要使用中间数据表示的 提取方法或基于【Orion-14B系列】模型生成合成数据来训练其他模型的方法
|
| 129 |
+
。
|
| 130 |
+
“分发”是指向第三方传输、复制、发布或以其他方式共享模型或模型衍生品,包括将模型作为通过电子或其他远程方式(例如基于 API 或 Web 访问的任何 SaaS 软件或 PaaS 软件) 提供的托管服务。
|
| 131 |
+
|
| 132 |
+
“许可方”是指授予许可的版权所有者或版权所有者实体,包括可能对模型和/或被分发模型拥有权利的个人或实体。本协议下的许可方是:【北京猎户星空科技有限公司】,或其授权可 对任何第三方进行许可的实体或个人。“您”(或“您的”)是指行使本许可授予的权限和/或出于任何目的和在任何使用领域使用模 型的个人或法人实体,属于本协议的被许可人。
|
| 133 |
+
|
| 134 |
+
“第三方”是指您之外的任何个人、法人实体或非法人组织。
|
| 135 |
+
|
| 136 |
+
“商业用途”是指使用 【Orion-14B系列】模型,直接或间接为实体或个人进行运营、推广或产生收入,或用于任何其他盈利目的。
|
| 137 |
+
|
| 138 |
+
二、 许可及许可限制
|
| 139 |
+
根据本许可协议的条款和条件,许可方特此授予您一个非排他性、全球性、不可转让、不可再许可、可撤销、免版税的版权许可。您可以出于非商业用途使用此许可。许可方对您使用【Orion-14B系列】模型的输出或基于【Orion-14B系列】模型得到的模型衍生品不主张任何权利,但您必须满足如下许可限制条件:
|
| 140 |
+
1. 您不得出于任何军事或非法目的使用、复制、修改、合并、发布、分发、复制或创建【Orion-14B系列】 模型的全部或部分衍生品。
|
| 141 |
+
2. 如果您计划将【Orion-14B系列】模型及模型衍生品用作商业用途,应当按照本协议提供的联络方式,事先向许可方登记并获得许可方的书面授权。请点击以下链接进行登记:https://test.orionstar.com/llm-license.html。按照链接要求完成登记后即可获得商用授权。
|
| 142 |
+
3. 您对【Orion-14B系列】模型的使用和修改(包括使用【Orion-14B系列】 模型的输出或者基于【Orion-14B系列】 模型得到的模型衍生品)不得违反任何国家的法律法规,尤其是中华人民共和国的法律法规,不得侵犯任何第三方的合法权益,包括但不限于肖像权、名誉权、隐私权等 人格权,著作权、专利权、商业秘密等知识产权,或者其他财产权益。
|
| 143 |
+
4. 您必须向【Orion-14B系列】模型或其模型衍生品的任何第三方使用者提供【Orion-14B系列】模型的来源以及本协议的副本。
|
| 144 |
+
5. 您修改【Orion-14B��列】 模型得到模型衍生品,必须以显著的方式说明修改的内容,且上述修改不得违反本协议的许可限制条件,也不能允许、协助或以其他方式使得第三方违反本协议中的许可限制条件。
|
| 145 |
+
三、 知识产权
|
| 146 |
+
1. 【Orion-14B系列】模型的所有权及其相关知识产权,由许可方单独所有。
|
| 147 |
+
2. 在任何情况下,未经许可方事先书面同意,您不得使用许可方任何商标、服务标记、 商号、域名、网站名称或其他显著品牌特征(以下统称为"标识"),包括但不限于明示或暗示您自身为“许可方”。未经许可方事先书面同意,您不得将本条款前述标识以单独或结合的任何方式展示、使用或申请注册商标、进行域名注册等,也不得向他人明示或暗示有权展示、使用、或以其他方式处理这些标识的权利。由于您违反本协议使用许可方上述标识 等给许可方或他人造成损失的,由您承担全部法律责任。
|
| 148 |
+
3. 在许可范围内,您可以对【Orion-14B系列】模型进行修改以得到模型衍生品,对于模型衍生品中您付出创造性劳动的部分,您可以主张该部分的知识产权。
|
| 149 |
+
四、 免责声明及责任限制
|
| 150 |
+
1. 在任何情况下,许可方不对您根据本协议使用【Orion-14B系列】模型而产生或与之相关的任何直接、间接、附带的后果、以及其他损失或损害承担责任。若由此导致许可方遭受损失,您应当向许可方承担全部赔偿责任。
|
| 151 |
+
2. 模型中的模型参数仅仅是一种示例,如果您需要满足其他要求,需自行训练,并遵守相应数据集的许可协议。您将对【Orion-14B系列】模型的输出及模型衍生品所涉及的知识产权风险或与之相关的任何直接、间接、附带的后果、以及其他损失或损害负责。
|
| 152 |
+
3. 尽管许可方在【Orion-14B系列】模型训练的所有阶段,都坚持努力维护数据的合规性和准确 性,但受限于【Orion-14B系列】模型的规模及其概率固有的随机性因素影响,其输出结果的准确性无法得到保证,模型存在被误导的可能。因此,许可方在此声明,许可方不承担您因使用【Orion-14B系列】模型及其源代码而导致的数据安全问题、声誉风险,或任何涉及【Orion-14B系列】模型被误导、误用、传播或不正当使用而产生的任何风险和责任。
|
| 153 |
+
4. 本协议所称损失或损害包括但不限于下列任何损失或损害(无论此类损失或损害是不可预见的、可预见的、已知的或其他的):(i)收入损失;(ii)实际或预期利润损失;(ii)货币使用损失;(iv)预期节约的损失;(v)业务损失;(vi)机会损失;(vii)商誉、声誉损失;(viii)软件的使用损失;或(x)任何间接、附带的特殊或间接损害损失。
|
| 154 |
+
5. 除非适用的法律另有要求或经过许可方书面同意,否则许可方将按“现状”授予【Orion-14B系列】模型的许可。针对本协议中的【Orion-14B系列】模型,许可方不提供任何明示、暗示的保证,包括但不限于:关于所有权的任何保证或条件、关于适销性的保证或条件、适用于任何特定目的的保证或条件、过去、现在或未来关于【Orion-14B系列】模型不侵权的任何类型的保证、以及因任何交易过程、贸易使用(如建议书、规范或样品)而产生的任何保证。您将对其通过使用、复制或再分发等方式利用【Orion-14B系列】模型所产生的风险与后果,独自承担责任。
|
| 155 |
+
6. 您充分知悉并理解同意,【Orion-14B系列】模型中可能包含个人信息。您承诺将遵守所有适用的法律法规进行个人信息的处理,特别是遵守《中华人民共和国个人信息保护法》的相关规定。请注意,许可方给予您使用【Orion-14B系列】模型的授权,并不意味着您已经获得处理相关个人信息的合法性基础。您作为独立的个人信息处理者,需要保证在处理【Orion-14B系列】模型中可能包含的个人信息时,完全符合相关法律法规的要求,包括但不限于获得个人信息主体的授权同意等,并愿意独自承担由此可能产生的任何风险和后果。
|
| 156 |
+
7. 您充分理解并同意,许可方有权依合理判断对违反有关法律法规或本协议规定的行为进行处理,对您的违法违规行为采取适当的法律行动,并依据法律法规保存有关信息向有关部门报告等,您应独自承担由此而产生的一切法律责任。
|
| 157 |
+
五、 研究、教育和学术目的
|
| 158 |
+
1. 根据本许可协议的条款和条件,本着对学术界做出贡献的精神,许可方鼓励非营利性学术机构的师生将【Orion-14B系列】模型用于研究、教育和学术目的。
|
| 159 |
+
2. 进一步的,如您以研究、教育和学术目的使用【Orion-14B系列】模型,您可以在开展相关研 究、教育前,将您的���构名称、使用情况以及联系方式以邮件方式向我们进行提前告知,我们的联系邮箱为【ai@orionstar.com】,我们将可能基于您的联系方式,向您推送【Orion-14B系列】模型的相关更新资讯,以便您更好地开展研究、教育和学术工作。
|
| 160 |
+
六、 品牌曝光与显著标识
|
| 161 |
+
1. 您同意并理解,如您将您基于【Orion-14B系列】模型二次开发的模型衍生品在国内外的开源社区提供开源许可的,您需要在该开源社区以显著方式标注该模型衍生品系基于【Orion-14B系列】模型进行的二次开发,标注内容包括但不限于“【Orion-14B Series】 Inside”以及与【Orion-14B系列】模型相关的品牌的其他元素。
|
| 162 |
+
2. 您同意并理解,如您将【Orion-14B系列】模型二次开发的模型衍生品参加国内外任何组织和个人举行的排名活动,包括但不限于针对模型性能、准确度、算法、算力等任何维度的排名活动,您均需在模型说明中以显著方式标注该模型衍生品系基于【Orion-14B系列】模型进行的二次开发,标注内容包括但不限于“【Orion-14B Series】Inside”以及与【Orion-14B系列】模型相关的品牌的其他元素。
|
| 163 |
+
七、 其他
|
| 164 |
+
1. 许可方在法律法规许可的范围内对协议条款享有最终解释权。
|
| 165 |
+
2. 本协议的订立、效力、解释、履行、修改和终止,使用【Orion-14B系列】模型以及争议的解 决均适用中华人民共和国大陆地区(仅为本协议之目的,不包括香港、澳门和台湾)法律,并排除冲突法的适用。
|
| 166 |
+
3. 因使用【Orion-14B系列】模型而发生的任何争议,各方应首先通过友好协商的方式加以解决。协商不成时,向许可方所在地人民法院提起诉讼。
|
README_ja.md
ADDED
|
@@ -0,0 +1,361 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 3 |
+
<!-- markdownlint-disable html -->
|
| 4 |
+
<div align="center">
|
| 5 |
+
<img src="./assets/imgs/orion_start.PNG" alt="logo" width="50%" />
|
| 6 |
+
</div>
|
| 7 |
+
|
| 8 |
+
<div align="center">
|
| 9 |
+
<h1>
|
| 10 |
+
Orion-14B
|
| 11 |
+
</h1>
|
| 12 |
+
</div>
|
| 13 |
+
|
| 14 |
+
<div align="center">
|
| 15 |
+
|
| 16 |
+
<div align="center">
|
| 17 |
+
<b>🇯🇵日本語</b> | <a href="./README.md">🌐英語</a> | <a href="./README_zh.md">🇨🇳中文</a> | <a href="./README_ko.md">🇰🇷한국어</a>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<h4 align="center">
|
| 21 |
+
<p>
|
| 22 |
+
🤗 <a href="https://huggingface.co/OrionStarAI" target="_blank">HuggingFace メインページ</a> | 🤖 <a href="https://modelscope.cn/organization/OrionStarAI" target="_blank">ModelScope メインページ</a><br>🎬 <a href="https://huggingface.co/spaces/OrionStarAI/Orion-14B-App-Demo" target="_blank">HuggingFace デモ</a> | 🎫 <a href="https://modelscope.cn/studios/OrionStarAI/Orion-14B-App-Demo/summary" target="_blank">ModelScope デモ</a><br>😺 <a href="https://github.com/OrionStarAI/Orion" target="_blank">GitHub</a><br>📖 <a href="https://github.com/OrionStarAI/Orion/blob/master/doc/Orion14B_v3.pdf" target="_blank">技術レポート</a>
|
| 23 |
+
<p>
|
| 24 |
+
</h4>
|
| 25 |
+
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# 目次
|
| 31 |
+
|
| 32 |
+
- [📖 モデル紹介](#model-introduction)
|
| 33 |
+
- [🔗 モデルダウンロード](#model-download)
|
| 34 |
+
- [🔖 モデルベンチマーク](#model-benchmark)
|
| 35 |
+
- [📊 モデル推論](#model-inference)[<img src="./assets/imgs/vllm.png" alt="vllm" height="20"/>](#vllm) [<img src="./assets/imgs/llama_cpp.png" alt="llamacpp" height="20"/>](#llama-cpp)
|
| 36 |
+
- [📜 声明とライセンス](#declarations-license)
|
| 37 |
+
- [🥇 企業紹介](#company-introduction)
|
| 38 |
+
|
| 39 |
+
<a name="model-introduction"></a><br>
|
| 40 |
+
# 1. モデル紹介
|
| 41 |
+
|
| 42 |
+
- Orion-14B-Baseは、140億のパラメータを持つマルチランゲージの大規模モデルで、さまざまな言語に対応するために2.5兆トークンの多様なデータセットでトレーニングされました。このデータセットには、中文、英語、日本語、韓国語などが含まれています。このモデルは、多言語環境でのさまざまなタスクにおいて卓越した性能を発揮しています。Orion-14Bシリーズモデルは、主要なパフォーマンスベンチマークで優れた結果を示し、同じパラメータ数を持つ他のベースモデルを明らかに凌駕しています。具体的な技術の詳細については、参照先をご覧ください。[技術レポート](https://github.com/OrionStarAI/Orion/blob/master/doc/Orion14B_v3.pdf)を参照してください。
|
| 43 |
+
|
| 44 |
+
- Orion-14B シリーズのモデルは、以下の特徴があります:
|
| 45 |
+
- 基座20Bパラメータモデルは、総合的な評価で優れた結果を示しています。
|
| 46 |
+
- 多言語対応力が強く、特に日本語と韓国語の対応能力が優れています
|
| 47 |
+
- ファインチューニングモデルは適応性が高く、人間の注釈つきブラインドテストでは高性能なパフォーマンスを発揮しています。
|
| 48 |
+
- 長文対応バージョンは非常に長いテキストをサポートし、20万トークンの長さで優れた効果を発揮し、最大で320,000トークンまでサポート可能です。
|
| 49 |
+
- 量子化バージョンではモデルサイズが70%縮小し、推論速度が30%向上し、性能の損失が1%以下です。
|
| 50 |
+
<table style="border-collapse: collapse; width: 100%;">
|
| 51 |
+
<tr>
|
| 52 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 53 |
+
<img src="./assets/imgs/opencompass_en.png" alt="opencompass" style="width: 100%; height: auto;">
|
| 54 |
+
</td>
|
| 55 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 56 |
+
<img src="./assets/imgs/model_cap_en.png" alt="modelcap" style="width: 100%; height: auto;">
|
| 57 |
+
</td>
|
| 58 |
+
</tr>
|
| 59 |
+
</table>
|
| 60 |
+
|
| 61 |
+
# Orion-14B シリーズ モデルには以下が含まれます:
|
| 62 |
+
|
| 63 |
+
- **Orion-14B-Base:** 2.5兆トークンの多様なデータセットでトレーニングされ、140億のパラメータを持つ多言語基本モデルです。
|
| 64 |
+
- **Orion-14B-Chat:** 高品質なコーパスでファインチューニングされた対話型モデルで、大規模モデルコミュニティにより良いユーザーインタラクション体験を提供することを目指しています。
|
| 65 |
+
- **Orion-14B-LongChat:** 20万トークンの長さで優れた効果を発揮し、最大で320,000トークンまでサポート可能で、長文書の評価セットでの性能は専用モデルに匹敵します。
|
| 66 |
+
- **Orion-14B-Chat-RAG:** スタムの検索強化生成データセットでファインチューニングされたチャットモデルで、検索強化生成タスクで卓越した性能を発揮しています。
|
| 67 |
+
- **Orion-14B-Chat-Plugin:** プラグインと関数呼び出しタスクに特化したチャットモデルで、代理を使用する関連するシナリオに適しています。大規模言語モデルがプラグインと関数呼び出しシステムの役割を果たします。
|
| 68 |
+
- **Orion-14B-Base-Int4:** int4を使用して量子化された基本モデル。モデルサイズが70%縮小し、推論速度が30%向上し、わずか1%未満の性能低下しか発生しません。
|
| 69 |
+
- **Orion-14B-Chat-Int4:** int4を使用して量子化された対話モデル。
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
<a name="model-download"></a><br>
|
| 73 |
+
# 2. モデルのダウンロード
|
| 74 |
+
|
| 75 |
+
以下はモデルのリリースとダウンロードURLが提供されています:
|
| 76 |
+
|
| 77 |
+
| モデル名 | HuggingFace ダウンロードリンク | ModelScope ダウンロードリンク |
|
| 78 |
+
|-------------------------|-----------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
|
| 79 |
+
| ⚾Orion-14B-Base | [Orion-14B-Base](https://huggingface.co/OrionStarAI/Orion-14B-Base) | [Orion-14B-Base](https://modelscope.cn/models/OrionStarAI/Orion-14B-Base/summary) |
|
| 80 |
+
| 😛Orion-14B-Chat | [Orion-14B-Chat](https://huggingface.co/OrionStarAI/Orion-14B-Chat) | [Orion-14B-Chat](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat/summary) |
|
| 81 |
+
| 📃Orion-14B-LongChat | [Orion-14B-LongChat](https://huggingface.co/OrionStarAI/Orion-14B-LongChat) | [Orion-14B-LongChat](https://modelscope.cn/models/OrionStarAI/Orion-14B-LongChat/summary) |
|
| 82 |
+
| 🔎Orion-14B-Chat-RAG | [Orion-14B-Chat-RAG](https://huggingface.co/OrionStarAI/Orion-14B-Chat-RAG) | [Orion-14B-Chat-RAG](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-RAG/summary) |
|
| 83 |
+
| 🔌Orion-14B-Chat-Plugin | [Orion-14B-Chat-Plugin](https://huggingface.co/OrionStarAI/Orion-14B-Chat-Plugin) | [Orion-14B-Chat-Plugin](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-Plugin/summary) |
|
| 84 |
+
| 💼Orion-14B-Base-Int4 | [Orion-14B-Base-Int4](https://huggingface.co/OrionStarAI/Orion-14B-Base-Int4) | [Orion-14B-Base-Int4](https://modelscope.cn/models/OrionStarAI/Orion-14B-Base-Int4/summary) |
|
| 85 |
+
| 📦Orion-14B-Chat-Int4 | [Orion-14B-Chat-Int4](https://huggingface.co/OrionStarAI/Orion-14B-Chat-Int4) | [Orion-14B-Chat-Int4](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-Int4/summary) |
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
<a name="model-benchmark"></a><br>
|
| 89 |
+
# 3. モデルのベンチマーク
|
| 90 |
+
|
| 91 |
+
## 3.1. 基本モデル Orion-14B-Base ベンチマーク
|
| 92 |
+
### 3.1.1. LLM 評価結果(検査と専門知識)
|
| 93 |
+
| モデル | C-Eval | CMMLU | MMLU | AGIEval | Gaokao | BBH |
|
| 94 |
+
|--------------------|----------|----------|----------|----------|----------|----------|
|
| 95 |
+
| LLaMA2-13B | 41.4 | 38.4 | 55.0 | 30.9 | 18.2 | 45.6 |
|
| 96 |
+
| Skywork-13B | 59.1 | 61.4 | 62.7 | 43.6 | 56.1 | 48.3 |
|
| 97 |
+
| Baichuan2-13B | 59.0 | 61.3 | 59.5 | 37.4 | 45.6 | 49.0 |
|
| 98 |
+
| QWEN-14B | 71.7 | 70.2 | 67.9 | 51.9 | **62.5** | 53.7 |
|
| 99 |
+
| InternLM-20B | 58.8 | 59.0 | 62.1 | 44.6 | 45.5 | 52.5 |
|
| 100 |
+
| **Orion-14B-Base** | **72.9** | **70.6** | **69.9** | **54.7** | 62.1 | **56.5** |
|
| 101 |
+
|
| 102 |
+
### 3.1.2. LLM 評価結果(言語理解と一般的な知識)
|
| 103 |
+
| モデル |RACE-middle|RACE-high |HellaSwag | PIQA | Lambada | WSC |
|
| 104 |
+
|--------------------|----------|----------|----------|----------|----------|----------|
|
| 105 |
+
| LLaMA 2-13B | 63.0 | 58.9 | 77.5 | 79.8 | 76.5 | 66.3 |
|
| 106 |
+
| Skywork-13B | 87.6 | 84.1 | 73.7 | 78.3 | 71.8 | 66.3 |
|
| 107 |
+
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
|
| 108 |
+
| QWEN-14B | 93.0 | 90.3 | **80.2** | 79.8 | 71.4 | 66.3 |
|
| 109 |
+
| InternLM-20B | 86.4 | 83.3 | 78.1 | **80.3** | 71.8 | 68.3 |
|
| 110 |
+
| **Orion-14B-Base** | **93.2** | **91.3** | 78.5 | 79.5 | **78.8** | **70.2** |
|
| 111 |
+
|
| 112 |
+
### 3.1.3. LLM 評価結果(OpenCompass テストセット)
|
| 113 |
+
| モデル | 平均 | 検査 | 言語 | 知識 | 理解 | 推論 |
|
| 114 |
+
|------------------|----------|----------|----------|----------|----------|----------|
|
| 115 |
+
| LLaMA 2-13B | 47.3 | 45.2 | 47.0 | 58.3 | 50.9 | 43.6 |
|
| 116 |
+
| Skywork-13B | 53.6 | 61.1 | 51.3 | 52.7 | 64.5 | 45.2 |
|
| 117 |
+
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
|
| 118 |
+
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
|
| 119 |
+
| InternLM-20B | 59.4 | 62.5 | 55.0 | **60.1** | 67.3 | 54.9 |
|
| 120 |
+
|**Orion-14B-Base**| **64.3** | **71.4** | **55.0** | 60.0 | **71.9** | **61.6** |
|
| 121 |
+
|
| 122 |
+
### 3.1.4. 日本語のテストセットにおけるLLMパフォーマンスの比較
|
| 123 |
+
| モデル |**平均**| JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|
| 124 |
+
|--------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
|
| 125 |
+
| PLaMo-13B | 52.3 | 56.7 | 42.8 | 95.8 | 70.6 | 71.0 | 8.70 | 70.5 | 2.40 |
|
| 126 |
+
| WebLab-10B | 50.7 | 66.6 | 53.7 | 82.1 | 62.9 | 56.2 | 10.0 | 72.0 | 2.40 |
|
| 127 |
+
| ELYZA-jp-7B | 48.8 | 71.7 | 25.3 | 86.6 | 70.8 | 64.1 | 2.50 | 62.1 | 7.20 |
|
| 128 |
+
| StableLM-jp-7B | 51.1 | 33.4 | 43.3 | 96.7 | 70.6 | 78.1 | 10.7 | 72.8 | 2.80 |
|
| 129 |
+
| LLaMA 2-13B | 46.3 | 75.0 | 47.6 | 38.8 | 76.1 | 67.7 | 18.1 | 63.2 | 10.4 |
|
| 130 |
+
| Baichuan 2-13B | 57.1 | 73.7 | 31.3 | 91.6 | 80.5 | 63.3 | 18.6 | 72.2 | 25.2 |
|
| 131 |
+
| QWEN-14B | 65.8 | 85.9 | 60.7 | 97.0 | 83.3 | 71.8 | 18.8 | 70.6 | 38.0 |
|
| 132 |
+
| Yi-34B | 67.1 | 83.8 | 61.2 | 95.2 | 86.1 | 78.5 | 27.2 | 69.2 | 35.2 |
|
| 133 |
+
| Orion-14B-Base | 69.1 | 88.2 | 75.8 | 94.1 | 75.7 | 85.1 | 17.3 | 78.8 | 38.0 |
|
| 134 |
+
|
| 135 |
+
### 3.1.5. 韓国のテストセットにおけるLLMパフォーマンスの比較。n = 0およびn = 5は評価に使用されたn-shotのプロンプトを表します。
|
| 136 |
+
|モデル | **平均**<br>n=0 n=5 | HellaSwag<br>n=0 n=5 | COPA<br> n=0 n=5 | BooIQ<br>n=0 n=5 | SentiNeg<br>n=0 n=5|
|
| 137 |
+
|------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|
|
| 138 |
+
| KoGPT | 53.0 70.1 | 55.9 58.3 | 73.5 72.9 | 45.1 59.8 | 37.5 89.4 |
|
| 139 |
+
| Polyglot-ko-13B | 69.6 73.7 |**59.5** **63.1**|**79.4** **81.1**| 48.2 60.4 | 91.2 90.2 |
|
| 140 |
+
| LLaMA 2-13B | 46.7 63.7 | 41.3 44.0 | 59.3 63.8 | 34.9 73.8 | 51.5 73.4 |
|
| 141 |
+
| Baichuan 2-13B | 52.1 58.7 | 39.2 39.6 | 60.6 60.6 | 58.4 61.5 | 50.3 72.9 |
|
| 142 |
+
| QWEN-14B | 53.8 73.7 | 45.3 46.8 | 64.9 68.9 | 33.4 83.5 | 71.5 95.7 |
|
| 143 |
+
| Yi-34B | 54.2 72.1 | 44.6 44.7 | 58.0 60.6 | 65.9 90.2 | 48.3 92.9 |
|
| 144 |
+
|**Orion-14B-Chat**|**74.5** **79.6**| 47.0 49.6 | 77.7 79.4 |**81.6** **90.7**|**92.4** **98.7**|
|
| 145 |
+
|
| 146 |
+
### 3.1.6. 多言語評価
|
| 147 |
+
| モデル | トレーニング言語 | 日本語 | 韓国語 | 中国語 | 英語 |
|
| 148 |
+
|--------------------|------------|--------|--------|--------|--------|
|
| 149 |
+
| PLaMo-13B | 英語, 日本語 | 52.3 | * | * | * |
|
| 150 |
+
| Weblab-10B | 英語, 日本語 | 50.7 | * | * | * |
|
| 151 |
+
| ELYZA-jp-7B | 英語, 日本語 | 48.8 | * | * | * |
|
| 152 |
+
| StableLM-jp-7B | 英語, 日本語 | 51.1 | * | * | * |
|
| 153 |
+
| KoGPT-6B | 英語, 韓国語 | * | 70.1 | * | * |
|
| 154 |
+
| Polyglot-ko-13B | 英語, 韓国語 | * | 70.7 | * | * |
|
| 155 |
+
| Baichuan2-13B | マルチ言語 | 57.1 | 58.7 | 50.8 | 57.1 |
|
| 156 |
+
| Qwen-14B | マルチ言語 | 65.8 | 73.7 | 64.5 | 65.4 |
|
| 157 |
+
| Llama2-13B | マルチ言語 | 46.3 | 63.7 | 41.4 | 55.3 |
|
| 158 |
+
| Yi-34B | マルチ言語 | 67.1 | 72.2 | 58.7 | 68.8 |
|
| 159 |
+
| Orion-14B-Chat | マルチ言語 | 69.1 | 79.5 | 67.9 | 67.3 |
|
| 160 |
+
|
| 161 |
+
## 3.2. チャットモデル Orion-14B-Chat ベンチマーク
|
| 162 |
+
### 3.2.1. チャットモデルのMTBenchにおける主観的評価
|
| 163 |
+
| モデル | ファーストターン | セカンドターン | 平均 |
|
| 164 |
+
|----------------------|----------|----------|----------|
|
| 165 |
+
| Baichuan2-13B-Chat | 7.05 | 6.47 | 6.76 |
|
| 166 |
+
| Qwen-14B-Chat | 7.30 | 6.62 | 6.96 |
|
| 167 |
+
| Llama2-13B-Chat | 7.10 | 6.20 | 6.65 |
|
| 168 |
+
| InternLM-20B-Chat | 7.03 | 5.93 | 6.48 |
|
| 169 |
+
| Orion-14B-Chat | 7.68 | 7.07 | 7.37 |
|
| 170 |
+
\* 推論にはvllmを使用
|
| 171 |
+
|
| 172 |
+
### 3.2.2. チャットモデルのAlignBenchにおける主観的評価
|
| 173 |
+
| モデル | 数学 | 論理 | 基礎 | 中国語 | コンピュータ | ライティング | 役割 | プロフェッショナリズム |**平均**|
|
| 174 |
+
|--------------------|--------|--------|--------|--------|--------|--------|--------|--------|--------|
|
| 175 |
+
| Baichuan2-13B-Chat | 3.76 | 4.07 | 6.22 | 6.05 | 7.11 | 6.97 | 6.75 | 6.43 | 5.25 |
|
| 176 |
+
| Qwen-14B-Chat |**4.91**|**4.71**|**6.90**| 6.36 | 6.74 | 6.64 | 6.59 | 6.56 |**5.72**|
|
| 177 |
+
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
|
| 178 |
+
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 |**7.18**| 6.19 | 6.49 | 6.22 | 4.96 |
|
| 179 |
+
| Orion-14B-Chat | 4.00 | 4.24 | 6.18 |**6.57**| 7.16 |**7.36**|**7.16**|**6.99**| 5.51 |
|
| 180 |
+
\* 推論にはvllmを使用
|
| 181 |
+
|
| 182 |
+
## 3.3. LongChatモデルOrion-14B-LongChatのベンチマーク
|
| 183 |
+
### 3.3.1. LongChatによるLongBenchの評価
|
| 184 |
+
| モデル | NarrativeQA|MultiFieldQA-en|MultiFieldQA-zh| DuReader | QMSum | VCSUM | TREC | TriviaQA | LSHT |RepoBench-P|
|
| 185 |
+
|--------------------------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|
|
| 186 |
+
| GPT-3.5-Turbo-16k | **23.60** | **52.30** | **61.20** | 28.70 | 23.40 | **16.00** | 68.00 | **91.40** | 29.20 | 53.60 |
|
| 187 |
+
| LongChat-v1.5-7B-32k | 16.90 | 41.40 | 29.10 | 19.50 | 22.70 | 9.90 | 63.50 | 82.30 | 23.20 | 55.30 |
|
| 188 |
+
| Vicuna-v1.5-7B-16k | 19.40 | 38.50 | 43.00 | 19.30 | 22.80 | 15.10 | 71.50 | 86.20 | 28.80 | 43.50 |
|
| 189 |
+
| Yi-6B-200K | 14.11 | 36.74 | 22.68 | 14.01 | 20.44 | 8.08 | 72.00 | 86.61 | 38.00 | **63.29** |
|
| 190 |
+
| Orion-14B-LongChat | 19.47 | 48.11 | 55.84 | **37.02** | **24.87** | 15.44 | **77.00** | 89.12 | **45.50** | 54.31 |
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
## 3.4. Chat RAGモデルベンチマーク
|
| 194 |
+
### 3.4.1. 自己構築RAGテストセットのLLM評価結果
|
| 195 |
+
|モデル|応答の有効性(キーワード)|*応答の有効性(主観的評価)|引用の能力|フォールバックの能力|*AutoQA|*データ抽出|
|
| 196 |
+
|---------------------|------|------|------|------|------|------|
|
| 197 |
+
| Baichuan2-13B-Chat | 85 | 76 | 1 | 0 | 69 | 51 |
|
| 198 |
+
| Qwen-14B-Chat | 79 | 77 | 75 | 47 | 68 | 72 |
|
| 199 |
+
| Qwen-72B-Chat(Int4) | 87 | 89 | 90 | 32 | 67 | 76 |
|
| 200 |
+
| GPT-4 | 91 | 94 | 96 | 95 | 75 | 86 |
|
| 201 |
+
| Orion-14B-Chat-RAG | 86 | 87 | 91 | 97 | 73 | 71 |
|
| 202 |
+
\* 手動評価を意味します
|
| 203 |
+
|
| 204 |
+
## 3.5. Chat PluginモデルOrion-14B-Chat-Pluginベンチマーク
|
| 205 |
+
### 3.5.1. 自己構築プラグインテストセットのLLM評価結果
|
| 206 |
+
|モデル|フルパラメータの意図認識|パラメータが不足している場合の意図認識|非プラグイン呼び出しの認識|
|
| 207 |
+
|-----------------------|--------|-----------|--------|
|
| 208 |
+
| Baichuan2-13B-Chat | 25 | 0 | 0 |
|
| 209 |
+
| Qwen-14B-Chat | 55 | 0 | 50 |
|
| 210 |
+
| GPT-4 | **95** | 52.38 | 70 |
|
| 211 |
+
| Orion-14B-Chat-Plugin | 92.5 | **60.32** | **90** |
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
## 3.6. 量子化モデルOrion-14B-Base-Int4ベンチマーク
|
| 215 |
+
### 3.6.1. 量子化前後の比較
|
| 216 |
+
| モデル|サイズ(GB) | 推論速度(トークン/秒) |C-Eval|CMMLU|MMLU|RACE|HellaSwag|
|
| 217 |
+
|-------------------------|-------|-----|------|------|------|------|------|
|
| 218 |
+
| OrionStar-14B-Base | 28.0 | 135 | 72.8 | 70.6 | 70.0 | 93.3 | 78.5 |
|
| 219 |
+
| OrionStar-14B-Base-Int4 | 8.3 | 178 | 71.8 | 69.8 | 69.2 | 93.1 | 78.0 |
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
<a name="model-inference"></a><br>
|
| 223 |
+
# 4. モデル推論
|
| 224 |
+
|
| 225 |
+
推論に必要なモデルの重み、ソースコード、および設定は、Hugging Faceに公開されており、ダウンロードリンクはこの文書の冒頭にある表に示されています。ここでは、さまざまな推論方法のデモが行われます。プログラムは自動的にHugging Faceから必要なリソースをダウンロードします。
|
| 226 |
+
|
| 227 |
+
## 4.1. Pythonコード
|
| 228 |
+
|
| 229 |
+
```python
|
| 230 |
+
import torch
|
| 231 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 232 |
+
from transformers.generation.utils import GenerationConfig
|
| 233 |
+
|
| 234 |
+
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/Orion-14B", use_fast=False, trust_remote_code=True)
|
| 235 |
+
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/Orion-14B", device_map="auto",
|
| 236 |
+
torch_dtype=torch.bfloat16, trust_remote_code=True)
|
| 237 |
+
|
| 238 |
+
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/Orion-14B")
|
| 239 |
+
messages = [{"role": "user", "content": "Hello, what is your name? "}]
|
| 240 |
+
response = model.chat(tokenizer, messages, streaming=False)
|
| 241 |
+
print(response)
|
| 242 |
+
|
| 243 |
+
```
|
| 244 |
+
|
| 245 |
+
上記のPythonソースコードでは、モデルは device_map='auto' でロードされ、利用可能なすべてのGPUを利用されています。デバイスを指定するには、 export CUDA_VISIBLE_DEVICES=0,1 のようなものを使用できます(GPU 0および1を使用)。
|
| 246 |
+
|
| 247 |
+
## 4.2. コマンドラインツール
|
| 248 |
+
|
| 249 |
+
```shell
|
| 250 |
+
CUDA_VISIBLE_DEVICES=0 python cli_demo.py
|
| 251 |
+
```
|
| 252 |
+
|
| 253 |
+
このコマンドラインツールはチャットシナリオ向けに設計されており、基本モデルの呼び出しをサポートしていません。
|
| 254 |
+
|
| 255 |
+
## 4.3. 直接スクリプト推論
|
| 256 |
+
|
| 257 |
+
```shell
|
| 258 |
+
|
| 259 |
+
# ベースモデル
|
| 260 |
+
CUDA_VISIBLE_DEVICES=0 python demo/text_generation_base.py --model OrionStarAI/Orion-14B --tokenizer OrionStarAI/Orion-14B --prompt hello
|
| 261 |
+
|
| 262 |
+
# チャットモデル
|
| 263 |
+
CUDA_VISIBLE_DEVICES=0 python demo/text_generation.py --model OrionStarAI/Orion-14B-Chat --tokenizer OrionStarAI/Orion-14B-Chat --prompt hi
|
| 264 |
+
```
|
| 265 |
+
<a name="vllm"></a><br>
|
| 266 |
+
## 4.4. vLLMを使用した推論
|
| 267 |
+
|
| 268 |
+
- プロジェクトのアドレス<br>
|
| 269 |
+
https://github.com/vllm-project/vllm
|
| 270 |
+
|
| 271 |
+
- プルリクエスト<br>
|
| 272 |
+
https://github.com/vllm-project/vllm/pull/2539
|
| 273 |
+
|
| 274 |
+
<a name="llama-cpp"></a><br>
|
| 275 |
+
## 4.5. llama.cppを使用した推論
|
| 276 |
+
|
| 277 |
+
- プロジェクトのアドレス<br>
|
| 278 |
+
https://github.com/ggerganov/llama.cpp
|
| 279 |
+
|
| 280 |
+
- プルリクエスト<br>
|
| 281 |
+
https://github.com/ggerganov/llama.cpp/pull/5118
|
| 282 |
+
|
| 283 |
+
- GGUF形式に変換する方法
|
| 284 |
+
|
| 285 |
+
```shell
|
| 286 |
+
python convert-hf-to-gguf.py path/to/Orion-14B-Chat --outfile chat.gguf
|
| 287 |
+
```
|
| 288 |
+
|
| 289 |
+
- モデル推論方法
|
| 290 |
+
|
| 291 |
+
```shell
|
| 292 |
+
./main --frequency-penalty 0.5 --frequency-penalty 0.5 --top-k 5 --top-p 0.9 -m chat.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e
|
| 293 |
+
```
|
| 294 |
+
|
| 295 |
+
## 4.6 例の出力
|
| 296 |
+
### 4.6.1 カジュアルチャット
|
| 297 |
+
|
| 298 |
+
`````
|
| 299 |
+
User: Hello
|
| 300 |
+
Orion-14B: Hello! How can I help you today? If you have any questions or need assistance, feel free to ask.
|
| 301 |
+
User: What functions do you have?
|
| 302 |
+
Orion-14B: As an AI language model, I have a wide range of functions and capabilities, including but not limited to:
|
| 303 |
+
Answering general knowledge questions: I can provide information on various topics such as history, science, geography, and more.
|
| 304 |
+
Providing definitions and explanations: I can explain complex concepts and provide definitions for words and phrases.
|
| 305 |
+
Assisting with tasks: I can help with simple tasks like setting reminders, converting units of measurement, and even ordering food from restaurants.
|
| 306 |
+
Generating text: I can write short stories, essays, articles, and other types of content based on prompts given to me.
|
| 307 |
+
Translating languages: I can translate text from one language to another.
|
| 308 |
+
Chatting: I can engage in conversation with users and respond to their queries in a conversational manner.
|
| 309 |
+
Summarizing long texts: I can summarize longer texts like articles, books, and research papers.
|
| 310 |
+
Generating random numbers and names: I can generate random numbers within a specified range and also suggest names based on certain criteria.
|
| 311 |
+
Playing games: I can play simple games like Hangman, Trivia, and more.
|
| 312 |
+
Providing recommendations: I can recommend movies, music, books, and other forms of entertainment based on user preferences.
|
| 313 |
+
These are just some of the many functions that I am capable of performing. If you have a specific task in mind, feel free to ask me about it.
|
| 314 |
+
User: Tell me a joke.
|
| 315 |
+
Orion-14B: Sure, here's a classic one-liner: Why don't scientists trust atoms? Because they make up everything.
|
| 316 |
+
`````
|
| 317 |
+
|
| 318 |
+
### 4.6.2. 日本語と韓国語のチャット
|
| 319 |
+
|
| 320 |
+
`````
|
| 321 |
+
User:自己を紹介してください
|
| 322 |
+
Orion-14B:こんにちは、私の名前はChatMaxで、OrionStarによって開発されたAIアシスタントです。私はユーザーに正確で、客観的で、有用な回答を提供し、彼らが問題を解決し、情報を取得するのを助けることができます。
|
| 323 |
+
User:자기소개를 해주세요.
|
| 324 |
+
Orion-14B:안녕하세요, 제 이름은 ChatMax입니다. OrionStar에서 개발한 AI 어시스턴트입니다. 저는 사용자들에게 정확하고 객관적이며 유용한 답변을 제공하여 문제를 해결하고 정보를 얻는 데 도움을 줄 수 있습니다.
|
| 325 |
+
`````
|
| 326 |
+
|
| 327 |
+
<a name="declarations-license"></a><br>
|
| 328 |
+
# 5. 声明、ライセンス
|
| 329 |
+
|
| 330 |
+
## 5.1. 声明
|
| 331 |
+
|
| 332 |
+
弊社は全ての利用者に対して、Orion-14Bモデルを使用して国家の社会安全を危険にさらすか、違法な活動に使用しないよう強く呼びかけます。さらに、Orion-14Bモデルを適切な安全審査と登録なしにインターネットサービスに使用しないよう要求します。
|
| 333 |
+
すべての利用者がこの原則を守ることを期待しており、科技の発展が規範と合法の環境で進むことを確認しています。弊社はモデルのトレーニングプロセスで使用されるデータのコンプライアンスを確保するために最善の努力をしています。ただし、モデルとデータの複雑性から、予測できない問題が依然として発生する可能性があります。
|
| 334 |
+
したがって、Orion-14Bオープンソースモデルの使用によって引き起こされる問題、データセキュリティの問題、公共の意見のリスク、またはモデルが誤誘導、乱用、拡散、または不適切に使用されることによるリスクや問題について、弊社は一切の責任を負いません。
|
| 335 |
+
|
| 336 |
+
## 5.2. ライセンス
|
| 337 |
+
|
| 338 |
+
Orion-14B シリーズモデルのコミュニティ利用
|
| 339 |
+
- コードは [Apache License Version 2.0](./LICENSE) ライセンスに従ってくださ��。<br>
|
| 340 |
+
- モデルは [【Orion-14B シリーズ】 Models Community License Agreement](./ModelsCommunityLicenseAgreement)に従ってください。
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
<a name="company-introduction"></a><br>
|
| 344 |
+
# 6. 会社紹介
|
| 345 |
+
|
| 346 |
+
オリオンスター(OrionStar)は、2016年9月に設立された、世界をリードするサービスロボットソリューション企業です。オリオンスターは人工知能技術を基に、次世代の革新的なロボットを開発し、人々が単純な体力労働から解放され、仕事や生活がよりスマートで面白くなるようにすることを目指しています。技術を通じて社会と世界をより良くすることを目指しています。
|
| 347 |
+
|
| 348 |
+
オリオンスターは、完全に独自に開発された全体的な人工知能技術を持っており、音声対話や視覚ナビゲーションなどが含まれます。製品開発能力と技術応用能力を統合しています。オリオンメカニカルアームプラットフォームを基に、オリオンスター 、AI Robot Greeting Mini、Lucki、Coffee Masterなどの製品を展開し、オリオンスターロボットのオープンプラットフォームであるオリオンOSも構築しています。本当に有用なロボットのために生まれたという理念に基づき、オリオンスターはAI技術を通じて多くの人々に力を与えています。
|
| 349 |
+
|
| 350 |
+
7年間のAI経験を基に、オリオンスターは「聚言」という大規模な深層学習アプリケーションを導入し、業界の顧客向けにカスタマイズされたAI大規模モデルのコンサルティングとサービスソリューションを提供しています。これにより、企業の経営効率を向上させる目標を達成するのに役立っています。
|
| 351 |
+
|
| 352 |
+
オリオンスターの大規模モデルアプリケーション能力の主要な利点には、海量データ処理、大規模モデルの事前トレーニング、二次事前トレーニング、ファインチューニング、プロンプトエンジニアリング、エージェント開発など、全体のチェーンにわたる能力と経験の蓄積が含まれます。 さらに、システム全体のデータ処理フローと数百のGPUによる並列モデルトレーニング能力を含む、エンドツーエンドのモデルトレーニング能力を持っています。これらの能力は、大規模政府、クラウドサービス、国際展開の電子商取引、消費財など、さまざまな産業のシーンで実現されています。
|
| 353 |
+
|
| 354 |
+
大規模モデルアプリケーションの展開に関するニーズがある企業は、お気軽にお問い合わせください。<br>
|
| 355 |
+
**Tel: 400-898-7779**<br>
|
| 356 |
+
**E-mail: ai@orionstar.com**
|
| 357 |
+
|
| 358 |
+
<div align="center">
|
| 359 |
+
<img src="./assets/imgs/wechat_group.jpg" alt="wechat" width="40%" />
|
| 360 |
+
</div>
|
| 361 |
+
```
|
README_ko.md
ADDED
|
@@ -0,0 +1,372 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 3 |
+
<!-- markdownlint-disable html -->
|
| 4 |
+
<div align="center">
|
| 5 |
+
<img src="./assets/imgs/orion_start.PNG" alt="logo" width="30%" />
|
| 6 |
+
</div>
|
| 7 |
+
|
| 8 |
+
<div align="center">
|
| 9 |
+
<h1>
|
| 10 |
+
Orion-14B
|
| 11 |
+
</h1>
|
| 12 |
+
</div>
|
| 13 |
+
|
| 14 |
+
<div align="center">
|
| 15 |
+
|
| 16 |
+
<div align="center">
|
| 17 |
+
<b>🇰🇷한국어</b> | <a href="./README.md">🌐英語</a> | <a href="./README_zh.md">🇨🇳中文</a> | <a href="./README_ja.md">🇯🇵日本語</a>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<h4 align="center">
|
| 21 |
+
<p>
|
| 22 |
+
🤗 <a href="https://huggingface.co/OrionStarAI" target="_blank">HuggingFace홈페이지</a> | 🤖 <a href="https://modelscope.cn/organization/OrionStarAI" target="_blank">ModelScope홈페이지</a><br>🎬 <a href="https://huggingface.co/spaces/OrionStarAI/Orion-14B-App-Demo" target="_blank">HuggingFace온라인 시용</a> | 🎫 <a href="https://modelscope.cn/studios/OrionStarAI/Orion-14B-App-Demo/summary" target="_blank">ModelScope在线试用</a><br>😺 <a href="https://github.com/OrionStarAI/Orion" target="_blank">GitHub</a><br>📖 <a href="https://github.com/OrionStarAI/Orion/blob/master/doc/Orion14B_v3.pdf" target="_blank">기술 리포트</a>
|
| 23 |
+
<p>
|
| 24 |
+
</h4>
|
| 25 |
+
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# 목록
|
| 31 |
+
|
| 32 |
+
- [📖 모형 소개](#model-introduction)
|
| 33 |
+
- [🔗 다운로드 경로](#model-download)
|
| 34 |
+
- [🔖 평가결과](#model-benchmark)
|
| 35 |
+
- [📊 모형 추리](#model-inference)[<img src="./assets/imgs/vllm.png" alt="vllm" height="20"/>](#vllm) [<img src="./assets/imgs/llama_cpp.png" alt="llamacpp" height="20"/>](#llama-cpp)
|
| 36 |
+
- [📜 성명 합의](#declarations-license)
|
| 37 |
+
- [🥇 기업 소개](#company-introduction)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
<a name="model-introduction"></a><br>
|
| 41 |
+
# 1. 모델소게
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
-Orion-14B-Base는 2.5조 토큰의 다양한 데이터 집합으로 훈련된 140억 개의 파라메터를 가진 다중 언어 모델이다. 중국어, 영어, 일본어, 한국어 및 기타 언어를 포함한다.다중 언어 환경에서 일련의 업무에서 탁월한 성능을 보인다. Orion-14B 시리즈의 모델들은 주요 공개 기준 측정에서 우수한 성적을 거두었으며 여러가지 지표가 동일한 파라메터를 가진 다른 모델들을 현저히 초월한다. 구체적인 기술 디테일은 [기술보고서]를 참고하세요.
|
| 45 |
+
(https://github.com/OrionStarAI/Orion/blob/master/doc/Orion14B_v3.pdf)。
|
| 46 |
+
|
| 47 |
+
- Orion-14B시리즈 대형 모델은 다음과 같은 특징이 있다.
|
| 48 |
+
- 베이스20B 파라메터 레벨인 대형 모델의 종합적인 평가 결과가 우수하다
|
| 49 |
+
- 다국어 능력이 뛰어나고 일본어와 한국어 테스트 세트에서 현저히 앞선다
|
| 50 |
+
- 미세조정 모델은 적응성이 강하며 인위 표시의 블라인드 테스트에서 활약이 두드러진다
|
| 51 |
+
- 긴 컨텍스트 버전은 최대 320k까지 지원하는 200k 토큰에 뛰어난 긴 텍스트를 지지한다
|
| 52 |
+
- 정량화 버전 모델 크기를 70% 줄이고 추론 속도를 30% 높이며 성능 손실을 1% 미만하다
|
| 53 |
+
<table style="border-collapse: collapse; width: 100%;">
|
| 54 |
+
<tr>
|
| 55 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 56 |
+
<img src="./assets/imgs/opencompass_en.png" alt="opencompass" style="width: 100%; height: auto;">
|
| 57 |
+
</td>
|
| 58 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 59 |
+
<img src="./assets/imgs/model_cap_en.png" alt="modelcap" style="width: 100%; height: auto;">
|
| 60 |
+
</td>
|
| 61 |
+
</tr>
|
| 62 |
+
</table>
|
| 63 |
+
|
| 64 |
+
- 구체적으로 말하면 Orion-14B시리즈 대형 언어 모델은 다음과 같은 내용을 포함한다:
|
| 65 |
+
- **Orion-14B-Base:** 2.5억 토켄스 다양화 데이터 세트를 기반으로 한 140억 파라메터 규모의 다언어 기반 모델.
|
| 66 |
+
- **Orion-14B-Chat:** 고퀄리티 코퍼스 미세조정을 기반으로 한 대화형 모델. 대형 모델 커뮤니티를 위해 더 나은 사용자 인터랙션 경험을 제공하도록 한다.
|
| 67 |
+
- **Orion-14B-LongChat:** 200k 토큰 길이에 효과적이며 최대 320k까지 지원하며 긴 텍스트 평가 세트에서 독점 모델과 비교할 수 있다.
|
| 68 |
+
- **Orion-14B-Chat-RAG:** 맞춰 제정된 검색 향상 생성 데이터 세트에서 미세조정하여 검색 향상 생성 작업에서 뛰어난 성능을 제공한 채팅 모델.
|
| 69 |
+
- **Orion-14B-Chat-Plugin:** 플러그인 및 함수 전용 작업에 맞춰 제정된 채팅 모델. 에이전트와 관련된 상황에 아주 잘 적용되어 대형 언어 모델이 플러그인 및 함수 전용 시스템의 역할을 한다.
|
| 70 |
+
- **Orion-14B-Base-Int4:** int4로 계량화하는 베이스 모델. 모델 크기를 70%를 줄이며 추리 속도를 30% 높여 1%의 최소한의 성능 손실만 가져왔다.
|
| 71 |
+
- **Orion-14B-Chat-Int4:** int4로 계량화하는 대화 모델.
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
<a name="model-download"></a><br>
|
| 75 |
+
# 2. 다운로드 경로
|
| 76 |
+
|
| 77 |
+
발표된 모델 및 다운로드 링크는 다음 표를 참조하세요:
|
| 78 |
+
|
| 79 |
+
| 모델 명칭 | HuggingFace다운로드 링크 | ModelScope다운로드 링크 |
|
| 80 |
+
|---------------------|-----------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|
|
| 81 |
+
| ⚾ 베이스 모델 | [Orion-14B-Base](https://huggingface.co/OrionStarAI/Orion-14B-Base) | [Orion-14B-Base](https://modelscope.cn/models/OrionStarAI/Orion-14B-Base/summary) |
|
| 82 |
+
| 😛 대화 모델 | [Orion-14B-Chat](https://huggingface.co/OrionStarAI/Orion-14B-Chat) | [Orion-14B-Chat](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat/summary) |
|
| 83 |
+
| 📃 긴 컨텍스트 모델 | [Orion-14B-LongChat](https://huggingface.co/OrionStarAI/Orion-14B-LongChat) | [Orion-14B-LongChat](https://modelscope.cn/models/OrionStarAI/Orion-14B-LongChat/summary) |
|
| 84 |
+
| 🔎 검색 향상 모델 | [Orion-14B-Chat-RAG](https://huggingface.co/OrionStarAI/Orion-14B-Chat-RAG) | [Orion-14B-Chat-RAG](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-RAG/summary) |
|
| 85 |
+
| 🔌 플러그인 모델 | [Orion-14B-Chat-Plugin](https://huggingface.co/OrionStarAI/Orion-14B-Chat-Plugin) | [Orion-14B-Chat-Plugin](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-Plugin/summary)|
|
| 86 |
+
| 💼 베이스Int4계량화 모델 | [Orion-14B-Base-Int4](https://huggingface.co/OrionStarAI/Orion-14B-Base-Int4) | [Orion-14B-Base-Int4](https://modelscope.cn/models/OrionStarAI/Orion-14B-Base-Int4/summary) |
|
| 87 |
+
| 📦 대화Int4계량화 모델 | [Orion-14B-Chat-Int4](https://huggingface.co/OrionStarAI/Orion-14B-Chat-Int4) | [Orion-14B-Chat-Int4](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-Int4/summary) |
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
<a name="model-benchmark"></a><br>
|
| 91 |
+
# 3. 평가 결과
|
| 92 |
+
|
| 93 |
+
## 3.1. 베이스 모델Orion-14B-Base평가
|
| 94 |
+
|
| 95 |
+
### 3.1.1. 전문 지식 및 시험문제 평가 결과
|
| 96 |
+
| 모델 명칭 | C-Eval | CMMLU | MMLU | AGIEval | Gaokao | BBH |
|
| 97 |
+
|--------------------|----------|----------|----------|----------|----------|----------|
|
| 98 |
+
| LLaMA2-13B | 41.4 | 38.4 | 55.0 | 30.9 | 18.2 | 45.6 |
|
| 99 |
+
| Skywork-13B | 59.1 | 61.4 | 62.7 | 43.6 | 56.1 | 48.3 |
|
| 100 |
+
| Baichuan2-13B | 59.0 | 61.3 | 59.5 | 37.4 | 45.6 | 49.0 |
|
| 101 |
+
| QWEN-14B | 71.7 | 70.2 | 67.9 | 51.9 | **62.5** | 53.7 |
|
| 102 |
+
| InternLM-20B | 58.8 | 59.0 | 62.1 | 44.6 | 45.5 | 52.5 |
|
| 103 |
+
| **Orion-14B-Base** | **72.9** | **70.6** | **69.9** | **54.7** | 62.1 | **56.5** |
|
| 104 |
+
|
| 105 |
+
### 3.1.2. 이해 및 통식 평가 결과
|
| 106 |
+
| 모델 명칭 |RACE-middle|RACE-high| HellaSwag| PIQA | Lambada | WSC |
|
| 107 |
+
|--------------------|----------|----------|----------|----------|----------|----------|
|
| 108 |
+
| LLaMA 2-13B | 63.0 | 58.9 | 77.5 | 79.8 | 76.5 | 66.3 |
|
| 109 |
+
| Skywork-13B | 87.6 | 84.1 | 73.7 | 78.3 | 71.8 | 66.3 |
|
| 110 |
+
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
|
| 111 |
+
| QWEN-14B | 93.0 | 90.3 | **80.2** | 79.8 | 71.4 | 66.3 |
|
| 112 |
+
| InternLM-20B | 86.4 | 83.3 | 78.1 | **80.3** | 71.8 | 68.3 |
|
| 113 |
+
| **Orion-14B-Base** | **93.2** | **91.3** | 78.5 | 79.5 | **78.8** | **70.2** |
|
| 114 |
+
|
| 115 |
+
### 3.1.3. OpenCompass평가 세트 평가 결과
|
| 116 |
+
| 모델 명칭 | Average | Examination | Language | Knowledge | Understanding | Reasoning |
|
| 117 |
+
|------------------|----------|----------|----------|----------|----------|----------|
|
| 118 |
+
| LLaMA 2-13B | 47.3 | 45.2 | 47.0 | 58.3 | 50.9 | 43.6 |
|
| 119 |
+
| Skywork-13B | 53.6 | 61.1 | 51.3 | 52.7 | 64.5 | 45.2 |
|
| 120 |
+
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
|
| 121 |
+
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
|
| 122 |
+
| InternLM-20B | 59.4 | 62.5 | 55.0 | **60.1** | 67.3 | 54.9 |
|
| 123 |
+
|**Orion-14B-Base**| **64.3** | **71.4** | **55.0** | 60.0 | **71.9** | **61.6** |
|
| 124 |
+
|
| 125 |
+
### 3.1.4. 일본어 테스트 세트 평가 결과
|
| 126 |
+
| 모델 명칭 |**Average**| JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|
| 127 |
+
|--------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
|
| 128 |
+
| PLaMo-13B | 52.3 | 56.7 | 42.8 | 95.8 | 70.6 | 71.0 | 8.70 | 70.5 | 2.40 |
|
| 129 |
+
| WebLab-10B | 50.7 | 66.6 | 53.7 | 82.1 | 62.9 | 56.2 | 10.0 | 72.0 | 2.40 |
|
| 130 |
+
| ELYZA-jp-7B | 48.8 | 71.7 | 25.3 | 86.6 | 70.8 | 64.1 | 2.50 | 62.1 | 7.20 |
|
| 131 |
+
| StableLM-jp-7B | 51.1 | 33.4 | 43.3 | **96.7** | 70.6 | 78.1 | 10.7 | 72.8 | 2.80 |
|
| 132 |
+
| LLaMA 2-13B | 46.3 | 75.0 | 47.6 | 38.8 | 76.1 | 67.7 | 18.1 | 63.2 | 10.4 |
|
| 133 |
+
| Baichuan 2-13B | 57.1 | 73.7 | 31.3 | 91.6 | 80.5 | 63.3 | 18.6 | 72.2 | 25.2 |
|
| 134 |
+
| QWEN-14B | 65.8 | 85.9 | 60.7 | 97.0 | 83.3 | 71.8 | 18.8 | 70.6 | 38.0 |
|
| 135 |
+
| Yi-34B | 67.1 | 83.8 | 61.2 | 95.2 | **86.1** | 78.5 | **27.2** | 69.2 | 35.2 |
|
| 136 |
+
| **Orion-14B-Base** | **69.1** | **88.2** | **75.8** | 94.1 | 75.7 | **85.1** | 17.3 | **78.8** | **38.0** |
|
| 137 |
+
|
| 138 |
+
### 3.1.5. 한국어 테스트 세트n-shot평가 결과
|
| 139 |
+
| 모델 명칭 | **Average**<br>n=0 n=5 | HellaSwag<br>n=0 n=5 | COPA<br> n=0 n=5 | BooIQ<br>n=0 n=5 | SentiNeg<br>n=0 n=5|
|
| 140 |
+
|------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|
|
| 141 |
+
| KoGPT | 53.0 70.1 | 55.9 58.3 | 73.5 72.9 | 45.1 59.8 | 37.5 89.4 |
|
| 142 |
+
| Polyglot-ko-13B | 69.6 73.7 |**59.5** **63.1**|**79.4** **81.1**| 48.2 60.4 | 91.2 90.2 |
|
| 143 |
+
| LLaMA 2-13B | 46.7 63.7 | 41.3 44.0 | 59.3 63.8 | 34.9 73.8 | 51.5 73.4 |
|
| 144 |
+
| Baichuan 2-13B | 52.1 58.7 | 39.2 39.6 | 60.6 60.6 | 58.4 61.5 | 50.3 72.9 |
|
| 145 |
+
| QWEN-14B | 53.8 73.7 | 45.3 46.8 | 64.9 68.9 | 33.4 83.5 | 71.5 95.7 |
|
| 146 |
+
| Yi-34B | 54.2 72.1 | 44.6 44.7 | 58.0 60.6 | 65.9 90.2 | 48.3 92.9 |
|
| 147 |
+
|**Orion-14B-Base**|**74.5** **79.6**| 47.0 49.6 | 77.7 79.4 |**81.6** **90.7**|**92.4** **98.7**|
|
| 148 |
+
|
| 149 |
+
### 3.1.6. 다국어 평가 결과
|
| 150 |
+
| 모델 명칭 | Train Lang | Japanese | Korean | Chinese | English |
|
| 151 |
+
|--------------------|------------|----------|----------|----------|----------|
|
| 152 |
+
| PLaMo-13B | En,Jp | 52.3 | * | * | * |
|
| 153 |
+
| Weblab-10B | En,Jp | 50.7 | * | * | * |
|
| 154 |
+
| ELYZA-jp-7B | En,Jp | 48.8 | * | * | * |
|
| 155 |
+
| StableLM-jp-7B | En,Jp | 51.1 | * | * | * |
|
| 156 |
+
| KoGPT-6B | En,Ko | * | 70.1 | * | * |
|
| 157 |
+
| Polyglot-ko-13B | En,Ko | * | 70.7 | * | * |
|
| 158 |
+
| Baichuan2-13B | Multi | 57.1 | 58.7 | 50.8 | 57.1 |
|
| 159 |
+
| Qwen-14B | Multi | 65.8 | 73.7 | 64.5 | 65.4 |
|
| 160 |
+
| Llama2-13B | Multi | 46.3 | 63.7 | 41.4 | 55.3 |
|
| 161 |
+
| Yi-34B | Multi | 67.1 | 72.2 | 58.7 | **68.8** |
|
| 162 |
+
| **Orion-14B-Base** | Multi | **69.1** | **79.5** | **67.9** | 67.3 |
|
| 163 |
+
|
| 164 |
+
## 3.2. 대화 모델Orion-14B-Chat평가
|
| 165 |
+
### 3.2.1. 대화 모델MTBench주관적 평가
|
| 166 |
+
| 모델 명칭 | 1라운드 | 2라운드 | **평균** |
|
| 167 |
+
|----------------------|----------|----------|----------|
|
| 168 |
+
| Baichuan2-13B-Chat | 7.05 | 6.47 | 6.76 |
|
| 169 |
+
| Qwen-14B-Chat | 7.30 | 6.62 | 6.96 |
|
| 170 |
+
| Llama2-13B-Chat | 7.10 | 6.20 | 6.65 |
|
| 171 |
+
| InternLM-20B-Chat | 7.03 | 5.93 | 6.48 |
|
| 172 |
+
| **Orion-14B-Chat** | **7.68** | **7.07** | **7.37** |
|
| 173 |
+
|
| 174 |
+
\*이 평가는 vllm을 이용하여 추리한다
|
| 175 |
+
|
| 176 |
+
### 3.2.2. 대화 모델AlignBench주관적 평가
|
| 177 |
+
| 모델 명칭 | 수학 능력 | 논리적 추리 | 기본 능력 | 중국어 이해 | 종합적 문답 | 글쓰기 능력 | 롤 플레이 | 전문 지식 | **평균** |
|
| 178 |
+
|--------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
|
| 179 |
+
| Baichuan2-13B-Chat | 3.76 | 4.07 | 6.22 | 6.05 | 7.11 | 6.97 | 6.75 | 6.43 | 5.25 |
|
| 180 |
+
| Qwen-14B-Chat | **4.91** | **4.71** | **6.90** | 6.36 | 6.74 | 6.64 | 6.59 | 6.56 | **5.72** |
|
| 181 |
+
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
|
| 182 |
+
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 | **7.18** | 6.19 | 6.49 | 6.22 | 4.96 |
|
| 183 |
+
| **Orion-14B-Chat** | 4.00 | 4.24 | 6.18 | **6.57** | 7.16 | **7.36** | **7.16** | **6.99** | 5.51 |
|
| 184 |
+
|
| 185 |
+
\*이 평가는 vllm을 이용하여 추리한다
|
| 186 |
+
|
| 187 |
+
## 3.3. 긴 컨텍스트 모델Orion-14B-LongChat평가
|
| 188 |
+
### 3.3.1. 긴 컨텍스트 모델LongBench평가
|
| 189 |
+
| 모델 명칭 | NarrativeQA| MultiFieldQA-en| MultiFieldQA-zh | DuReader | QMSum | VCSUM | TREC | TriviaQA | LSHT | RepoBench-P |
|
| 190 |
+
|--------------------------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|
|
| 191 |
+
| GPT-3.5-Turbo-16k | **23.60** | **52.30** | **61.20** | 28.70 | 23.40 | **16.00** | 68.00 | **91.40** | 29.20 | 53.60 |
|
| 192 |
+
| LongChat-v1.5-7B-32k | 16.90 | 41.40 | 29.10 | 19.50 | 22.70 | 9.90 | 63.50 | 82.30 | 23.20 | 55.30 |
|
| 193 |
+
| Vicuna-v1.5-7B-16k | 19.40 | 38.50 | 43.00 | 19.30 | 22.80 | 15.10 | 71.50 | 86.20 | 28.80 | 43.50 |
|
| 194 |
+
| Yi-6B-200K | 14.11 | 36.74 | 22.68 | 14.01 | 20.44 | 8.08 | 72.00 | 86.61 | 38.00 | **63.29** |
|
| 195 |
+
| Orion-14B-LongChat | 19.47 | 48.11 | 55.84 | **37.02** | **24.87** | 15.44 | **77.00** | 89.12 | **45.50** | 54.31 |
|
| 196 |
+
|
| 197 |
+
## 3.4. 검색 향상 모델Orion-14B-Chat-RAG평가
|
| 198 |
+
### 3.4.1. 자기 만든 검색 향상 테스트 세트 평가 결과
|
| 199 |
+
|모델 명칭|응답 효과(키워드)|*응답 효과(주관적 점수)|인용 능력|기본 떠맡는 능력|*AutoQA|*데이터 추출|
|
| 200 |
+
|---------------------|------|------|------|------|------|------|
|
| 201 |
+
| Baichuan2-13B-Chat | 85 | 76 | 1 | 0 | 69 | 51 |
|
| 202 |
+
| Qwen-14B-Chat | 79 | 77 | 75 | 47 | 68 | 72 |
|
| 203 |
+
| Qwen-72B-Chat(Int4) | 87 | 89 | 90 | 32 | 67 | 76 |
|
| 204 |
+
| GPT-4 | 91 | 94 | 96 | 95 | 75 | 86 |
|
| 205 |
+
| Orion-14B-Chat-RAG | 86 | 87 | 91 | 97 | 73 | 71 |
|
| 206 |
+
\* 사람 평가 결과를 가리킨다
|
| 207 |
+
|
| 208 |
+
## 3.5. 플러그인 모델Orion-14B-Chat-Plugin평가
|
| 209 |
+
### 3.5.1. 자기 만든플러그인 테스트 세트 평가 결과
|
| 210 |
+
| 모델 명칭 | 풀 파라메터 의도 식별 | 불완전 파라메터 의도 식별 | 비 플러그인 전용 식별 |
|
| 211 |
+
|-----------------------|--------|-----------|--------|
|
| 212 |
+
| Baichuan2-13B-Chat | 25 | 0 | 0 |
|
| 213 |
+
| Qwen-14B-Chat | 55 | 0 | 50 |
|
| 214 |
+
| GPT-4 | **95** | 52.38 | 70 |
|
| 215 |
+
| Orion-14B-Chat-Plugin | 92.5 | **60.32** | **90** |
|
| 216 |
+
|
| 217 |
+
## 3.6. 계량화 모델Orion-14B-Base-Int4평가
|
| 218 |
+
### 3.6.1. 계량화 전후 전반적인 비교
|
| 219 |
+
|모델 명칭|모델 크기(GB)|추리 속도(토큰 수/초)|C-Eval |CMMLU |MMLU |RACE | HellaSwag|
|
| 220 |
+
|-------------------------|------|-----|------|------|------|------|------|
|
| 221 |
+
| OrionStar-14B-Base | 28.0 | 135 | 72.8 | 70.6 | 70.0 | 93.3 | 78.5 |
|
| 222 |
+
| OrionStar-14B-Base-Int4 | 8.3 | 178 | 71.8 | 69.8 | 69.2 | 93.1 | 78.0 |
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
<a name="model-inference"></a><br>
|
| 226 |
+
# 4. 모델 추리
|
| 227 |
+
|
| 228 |
+
추리에 필요한 모델 가중치, 소스 코드, 배치는 Hugging Face에 게시되어 다운로드 링크는 이 파일 맨 처음에 있는 표를 참조하세요. 저희는 여기서 다양한 추리 방식을 보여 주고 프로그램은 Hugging Face로부터 필요한 자료를 자동으로 다운로드 할 것이다.
|
| 229 |
+
|
| 230 |
+
## 4.1. Python 코드 방식
|
| 231 |
+
|
| 232 |
+
```python
|
| 233 |
+
import torch
|
| 234 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 235 |
+
from transformers.generation.utils import GenerationConfig
|
| 236 |
+
|
| 237 |
+
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/Orion-14B", use_fast=False, trust_remote_code=True)
|
| 238 |
+
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/Orion-14B", device_map="auto",
|
| 239 |
+
torch_dtype=torch.bfloat16, trust_remote_code=True)
|
| 240 |
+
|
| 241 |
+
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/Orion-14B")
|
| 242 |
+
messages = [{"role": "user", "content": "안녕! 이름이 뭐예요!"}]
|
| 243 |
+
response = model.chat(tokenizer, messages, streaming=Flase)
|
| 244 |
+
print(response)
|
| 245 |
+
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
위의 두 코드에서 모델은 지정된 `device_map='auto'`로딩하면 모든 사용할 수 있는 그래픽 카드를 사용할 것이다. 사용할 장치를 지정하려면 `export CUDA_VISIBLE_DEVICES=0,1`(그래픽 카드 0과 1을 사용)과 같은 방식으로 제어할 수 있다.
|
| 249 |
+
|
| 250 |
+
## 4.2. 명령줄 툴 방식
|
| 251 |
+
|
| 252 |
+
```shell
|
| 253 |
+
CUDA_VISIBLE_DEVICES=0 python cli_demo.py
|
| 254 |
+
```
|
| 255 |
+
|
| 256 |
+
이 명령줄 툴은 Chat 시나리오를 위해 설계되었으므로 이 툴로 베이스 모델을 전용하는 것 지원하지 않는다.
|
| 257 |
+
|
| 258 |
+
## 4.3. 스크립트 직접 추리
|
| 259 |
+
|
| 260 |
+
```shell
|
| 261 |
+
# base model
|
| 262 |
+
CUDA_VISIBLE_DEVICES=0 python demo/text_generation_base.py --model OrionStarAI/Orion-14B --tokenizer OrionStarAI/Orion-14B --prompt 안녕. 이름이 뭐예요
|
| 263 |
+
|
| 264 |
+
# chat model
|
| 265 |
+
CUDA_VISIBLE_DEVICES=0 python demo/text_generation.py --model OrionStarAI/Orion-14B-Chat --tokenizer OrionStarAI/Orion-14B-Chat --prompt 안녕. 이름이 뭐예요
|
| 266 |
+
|
| 267 |
+
```
|
| 268 |
+
<a name="vllm"></a><br>
|
| 269 |
+
## 4.4. vLLM 추론을 통해
|
| 270 |
+
|
| 271 |
+
- 프로젝트 주소<br>
|
| 272 |
+
https://github.com/vllm-project/vllm
|
| 273 |
+
|
| 274 |
+
- 풀 리퀘스트<br>
|
| 275 |
+
https://github.com/vllm-project/vllm/pull/2539
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
<a name="llama-cpp"></a><br>
|
| 279 |
+
## 4.5. llama.cpp 추론을 통해
|
| 280 |
+
|
| 281 |
+
- 프로젝트 주소<br>
|
| 282 |
+
https://github.com/ggerganov/llama.cpp
|
| 283 |
+
|
| 284 |
+
- 풀 리퀘스트<br>
|
| 285 |
+
https://github.com/ggerganov/llama.cpp/pull/5118
|
| 286 |
+
|
| 287 |
+
- GGUF 형���으로 변환하는 방법
|
| 288 |
+
|
| 289 |
+
```shell
|
| 290 |
+
python convert-hf-to-gguf.py path/to/Orion-14B-Chat --outfile chat.gguf
|
| 291 |
+
```
|
| 292 |
+
|
| 293 |
+
- 모델 추론 방법
|
| 294 |
+
|
| 295 |
+
```shell
|
| 296 |
+
./main --frequency-penalty 0.5 --frequency-penalty 0.5 --top-k 5 --top-p 0.9 -m chat.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
## 4.6. 예시 노출
|
| 300 |
+
|
| 301 |
+
### 4.6.1. 잡담
|
| 302 |
+
|
| 303 |
+
`````
|
| 304 |
+
사용자:안녕,이름이 뭐예요
|
| 305 |
+
Orion-14B:안녕! 저는 인공지능 조수 입니다. 정해진 이름은 없고 마음대로 불러도 됩니다. 도와줄 수 있는 거 있나요?
|
| 306 |
+
사용자:이야기 하나 나눠줘
|
| 307 |
+
Orion-14B:예전에 잭이라는 어린 소년이 있었다. 그는 작은 마을에 살았다. 잭은 모험과 탐구를 매우 좋아해서 항상 신기한 것을 발견하는 꿈을 꾼다.
|
| 308 |
+
|
| 309 |
+
어느날 잭은 근처의 숲 깊은 곳에 전설속의 마법성이 있어 그 안에 사악한 거인이 산다는 소식을 든다. 그 거인의 이름은 그림이었다. 그는 성 안에 갇힌 채 떠날 수 없었다.
|
| 310 |
+
|
| 311 |
+
잭은 그림이 그곳에 갇혀있는 이유가 꼭 있을 거라고 믿기 때문에 거인을 구하러 가기로 결심한다. 그리하여 그는 용기와 결심을 가져 마법의 성으로 가는 여정을 시작한다.
|
| 312 |
+
|
| 313 |
+
오랜 고생 끝에 잭은 마침내 성보 대문 앞에 다다랐다. 그는 조심스럽게 대문을 열고 신비한 기운이 가득한 방으로 들어갔다.
|
| 314 |
+
|
| 315 |
+
방안에 어두운 기운이 가득했지만 잭은 놀라지 않았다. 그는 용감하게 성 안으로 들어가 마침내 그림을 찾아냈다.
|
| 316 |
+
|
| 317 |
+
그림은 자신은 사악한 마녀의 저주를 받아서 저주를 풀어야만 자유로워질 수 있다고 잭에게 말한다. 잭은 그림을 돕기로 결정하여 단서와 주문을 풀 방법을 찾기 시작한다.
|
| 318 |
+
|
| 319 |
+
한바탕의 노력 끝에 잭은 드디어 마녀의 비밀 실험실로 가는 길을 찾아낸다. 그는 그곳에서 마녀가 남긴 마법서를 발견했는데 그 책에서 주문을 푸는 방법이 적혀 있었다.
|
| 320 |
+
|
| 321 |
+
잭은 책에 쓰인 절차를 따라하여 그림의 저주를 성공적으로 풀어냈다. 거인은 너무 감사해서 잭의 소원이 이루어지도록 돕겠다고 약속했다.
|
| 322 |
+
|
| 323 |
+
이때로부터 잭과 그림은 좋은 친구가 되어 많은 위험하고 짜릿한 모험을 함께 겪었으며 그들의 용기와 지혜로 각종 어려움을 이겨냈다.
|
| 324 |
+
|
| 325 |
+
이 이야기는 저희에게 용기와 결심이 있다면 모든 어려움을 극복하고 자신의 꿈을 이룰 수 있다는 것을 알려준다.
|
| 326 |
+
`````
|
| 327 |
+
|
| 328 |
+
### 4.6.2. 한일
|
| 329 |
+
|
| 330 |
+
`````
|
| 331 |
+
用户:自己を紹介してください
|
| 332 |
+
Orion-14B:こんにちは、私の名前はChatMaxで、OrionStarによって開発されたAIアシスタントです。私はユーザーに正確で、客観的で、有用な回答を提供し、彼らが問題を解決し、情報を取得するのを助けることができます。
|
| 333 |
+
用户:자기소개를 해주세요.
|
| 334 |
+
Orion-14B:안녕하세요, 제 명칭은 ChatMax입니다. OrionStar에서 개발한 AI 어시스턴트입니다. 저는 사용자들에게 정확하고 객관적이며 유용한 답변을 제공하여 문제를 해결하고 정보를 얻는 데 도움을 줄 수 있습니다.
|
| 335 |
+
`````
|
| 336 |
+
|
| 337 |
+
|
| 338 |
+
<a name="declarations-license"></a><br>
|
| 339 |
+
# 5. 성명, 협의
|
| 340 |
+
|
| 341 |
+
## 5.1. 성명
|
| 342 |
+
|
| 343 |
+
저희는 모든 사용자들에게 Orion-14B모델을 이용하여 국가 사회 안전에 해치거나 불법적인 행위를 하는 거 하지 않도록 강력히 호소한다. 또한, 저희는 사용자들에게 Orion-14B 모델을 적절한 보안 검토를 하지 않거나 문서화되지 않은 인터넷 서비스로 이용하지 말라는 것을 요청한다.
|
| 344 |
+
|
| 345 |
+
저희는 모든 사용자가 이 원칙을 지키며 기술의 발전이 규범적이고 합법적인 환경에서 이루어질 수 있기를 바란다.
|
| 346 |
+
저희는 이미 최선을 다해 모델 훈련 과정에서 사용된 데이터의 준칙성을 확보하도록 하였다. 그러나 막대한 노력을 기울였음에도 불구하고 모델과 데이터의 복잡성으로 말미암아 일부 예견할 수 없을 문제들이 여전히 존재할 수 있다. 따라서 Orion-14B 오픈소스 모델의 사용으로 야기된 문제, 데이터 보안 문제와 공론 위험이나 모델의 오도, 남용, 전파, 또한 불적당한 사용 등으로 가져온 위험과 문제에 대해 저희는 책임을 지지 않겠다.
|
| 347 |
+
|
| 348 |
+
## 5.2. 협의
|
| 349 |
+
|
| 350 |
+
커뮤니티 사용Orion-14B시리즈 모델
|
| 351 |
+
- 코드는 [Apache License Version 2.0](./LICENSE)<br>따르세요
|
| 352 |
+
- 모델은 [Orion-14B시리즈 모델 커뮤니티 허가 협의](./ModelsCommunityLicenseAgreement)따르세요
|
| 353 |
+
|
| 354 |
+
|
| 355 |
+
<a name="company-introduction"></a><br>
|
| 356 |
+
# 6. 회사소개
|
| 357 |
+
|
| 358 |
+
오리온 스타(OrionStar)는 2016년 9월 설립된 세계 최고의 서비스 로봇 솔루션 회사이다. 오리온 스타는 인공지능 기술을 바탕으로 차세대 혁명적 로봇 만들어 사람들이 반복되는 육체노동에서 벗어나 일과 생활을 더욱 지능적이고 재미있게 만들고 기술을 통해 사회와 세계를 더욱 아름답게 만든 것에 힘을 기울인다.
|
| 359 |
+
|
| 360 |
+
오리온 스타는 음성 인터렉션과 시각 네비게이션 등 완전히 독자적으로 개발한 풀 체인 인공지능 기술을 가지고 있다. 저희는 프로덕트 개발 능력과 기술 응용 능력을 통합하였다. 오리온 로봇 팔 플랫폼을 기반으로 ORIONSTAR AI Robot Greeting, AI Robot Greeting Mini, Lucki, CoffeeMaster 등의 프로덕트 출시하였으며 오리온 로봇의 오픈 플랫폼인 OrionOS를 설립하였다. **진짜 유용한 로봇을 위해 태어나라**의 이념을 위한 실천하여 AI기술을 통해 더 많은 사람들에게 능력을 부여한다.
|
| 361 |
+
|
| 362 |
+
7년의 AI경험 누적을 바탕으로 오리온 스타는 대형 모델 심층 응용"쥐언(Chatmax)"을 출시했고 업계 고객에게 맞춤형 AI대형 모델 컨설팅과 서비스 솔루션을 지속적으로 제공하여 진정으로 기업 경영 효율이 동종 업계에 앞서는 목표를 달성할 수 있도록 고객들에게 돕고 있다.
|
| 363 |
+
|
| 364 |
+
**오리온 스타는 풀 체인 대형 모델 응용능력이란 핵심적 우세를 갖고 있다**, 대량 데이터 처리, 대형 모델 사전 훈련, 2차 사전 훈련, 미세 조정(Fine-tune), PromptEngineering, Agent등에서 개발된 풀 체인 능력과 경험 누적을 가지는 거 포함한다. 체계화된 데이터 처리 절차와 수백 개의 GPU의 병렬 모델 훈련 능력을 포함한 완정한 엔드투엔드 모델 훈련 능력을 가지고 있으며 현재 대형 정무, 클라우드 서비스, 출해 전자상거래, 쾌속소비품 등 여러 업계에서 구현되었다.
|
| 365 |
+
|
| 366 |
+
***대형 모델 응용 구현 필요가 있으신 회사께서 저희와 연락하는 것을 환영한다***<br>
|
| 367 |
+
**문의 전화:** 400-898-7779<br>
|
| 368 |
+
**이메일:** ai@orionstar.com
|
| 369 |
+
|
| 370 |
+
<div align="center">
|
| 371 |
+
<img src="./assets/imgs/wechat_group.jpg" alt="wechat" width="40%" />
|
| 372 |
+
</div>
|
README_zh.md
ADDED
|
@@ -0,0 +1,376 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 3 |
+
<!-- markdownlint-disable html -->
|
| 4 |
+
<div align="center">
|
| 5 |
+
<img src="./assets/imgs/orion_start.PNG" alt="logo" width="50%" />
|
| 6 |
+
</div>
|
| 7 |
+
|
| 8 |
+
<div align="center">
|
| 9 |
+
<h1>
|
| 10 |
+
Orion-14B
|
| 11 |
+
</h1>
|
| 12 |
+
</div>
|
| 13 |
+
|
| 14 |
+
<div align="center">
|
| 15 |
+
|
| 16 |
+
<div align="center">
|
| 17 |
+
<b>🇨🇳中文</b> | <a href="./README.md">🌐English</a> | <a href="./README_ja.md">🇯🇵日本語</a> | <a href="./README_ko.md">🇰🇷한국어</a>
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<h4 align="center">
|
| 21 |
+
<p>
|
| 22 |
+
🤗 <a href="https://huggingface.co/OrionStarAI" target="_blank">HuggingFace Mainpage</a> | 🤖 <a href="https://modelscope.cn/organization/OrionStarAI" target="_blank">ModelScope Mainpage</a><br>🎬 <a href="https://huggingface.co/spaces/OrionStarAI/Orion-14B-App-Demo" target="_blank">HuggingFace Demo</a> | 🎫 <a href="https://modelscope.cn/studios/OrionStarAI/Orion-14B-App-Demo/summary" target="_blank">ModelScope Demo</a><br>😺 <a href="https://github.com/OrionStarAI/Orion" target="_blank">GitHub</a><br>📖 <a href="https://arxiv.org/pdf/2401.12246.pdf" target="_blank">Tech Report</a>
|
| 23 |
+
<p>
|
| 24 |
+
</h4>
|
| 25 |
+
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
# 目录
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
- [📖 模型介绍](#zh_model-introduction)
|
| 33 |
+
- [🔗 下载路径](#zh_model-download)
|
| 34 |
+
- [🔖 评估结果](#zh_model-benchmark)
|
| 35 |
+
- [📊 模型推理](#zh_model-inference)[<img src="./assets/imgs/vllm.png" alt="vllm" height="20"/>](#vllm) [<img src="./assets/imgs/llama_cpp.png" alt="llamacpp" height="20"/>](#llama-cpp)
|
| 36 |
+
- [📜 声明协议](#zh_declarations-license)
|
| 37 |
+
- [🥇 企业介绍](#zh_company-introduction)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
<a name="zh_model-introduction"></a><br>
|
| 41 |
+
# 1. 模型介绍
|
| 42 |
+
|
| 43 |
+
- Orion-14B-Base是一个具有140亿参数的多语种大模型,该模型在一个包含2.5万亿token的多样化数据集上进行了训练,涵盖了中文、英语、日语、韩语等多种语言。在多语言环境下的一系列任务中展现出卓越的性能。在主流的公开基准评测中,Orion-14B系列模型表现优异,多项指标显著超越同等参数基本的其他模型。具体技术细节请参考[技术报告](https://arxiv.org/pdf/2401.12246.pdf)。
|
| 44 |
+
|
| 45 |
+
- Orion-14B系列大模型有以下几个特点:
|
| 46 |
+
- 基座20B参数级别大模型综合评测效果表现优异
|
| 47 |
+
- 多语言能力强,在日语、韩语测试集上显著领先
|
| 48 |
+
- 微调模型适应性强,在人类标注盲测中,表现突出
|
| 49 |
+
- 长上下文版本支持超长文本,在200k token长度上效果优异,最长可支持可达320k
|
| 50 |
+
- 量化版本模型大小缩小70%,推理速度提升30%,性能损失小于1%
|
| 51 |
+
|
| 52 |
+
<table style="border-collapse: collapse; width: 100%;">
|
| 53 |
+
<tr>
|
| 54 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 55 |
+
<img src="./assets/imgs/opencompass_zh.png" alt="opencompass" style="width: 100%; height: auto;">
|
| 56 |
+
</td>
|
| 57 |
+
<td style="border: none; padding: 10px; box-sizing: border-box;">
|
| 58 |
+
<img src="./assets/imgs/model_cap_zh.png" alt="modelcap" style="width: 100%; height: auto;">
|
| 59 |
+
</td>
|
| 60 |
+
</tr>
|
| 61 |
+
</table>
|
| 62 |
+
|
| 63 |
+
- 具体而言,Orion-14B系列大语言模型包含:
|
| 64 |
+
- **Orion-14B-Base:** 基于2.5万亿tokens多样化数据集训练处的140亿参数量级的多语言基座模型。
|
| 65 |
+
- **Orion-14B-Chat:** 基于高质量语料库微调的对话类模型,旨在为大模型社区提供更好的用户交互体验。
|
| 66 |
+
- **Orion-14B-LongChat:** 在200k token长度上效果优异,最长可支持可达320k,在长文本评估集上性能比肩专有模型。
|
| 67 |
+
- **Orion-14B-Chat-RAG:** 在一个定制的检索增强生成数据集上进行微调的聊天模型,在检索增强生成任务中取得了卓越的性能。
|
| 68 |
+
- **Orion-14B-Chat-Plugin:** 专门针对插件和函数调用任务定制的聊天模型,非常适用于使用代理的相关场景,其中大语言模型充当插件和函数调用系统。
|
| 69 |
+
- **Orion-14B-Base-Int4:** 一个使用int4进行量化的基座模型。它将模型大小显著减小了70%,同时提高了推理速度30%,仅引入了1%的最小性能损失。
|
| 70 |
+
- **Orion-14B-Chat-Int4:** 一个使用int4进行量化的对话模型。
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
<a name="zh_model-download"></a><br>
|
| 74 |
+
# 2. 下载路径
|
| 75 |
+
|
| 76 |
+
发布模型和下载链接见下表:
|
| 77 |
+
|
| 78 |
+
| 模型名称 | HuggingFace下载链接 | ModelScope下载链接 |
|
| 79 |
+
|---------------------|-----------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|
|
| 80 |
+
| ⚾ 基座模型 | [Orion-14B-Base](https://huggingface.co/OrionStarAI/Orion-14B-Base) | [Orion-14B-Base](https://modelscope.cn/models/OrionStarAI/Orion-14B-Base/summary) |
|
| 81 |
+
| 😛 对话模型 | [Orion-14B-Chat](https://huggingface.co/OrionStarAI/Orion-14B-Chat) | [Orion-14B-Chat](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat/summary) |
|
| 82 |
+
| 📃 长上下文模型 | [Orion-14B-LongChat](https://huggingface.co/OrionStarAI/Orion-14B-LongChat) | [Orion-14B-LongChat](https://modelscope.cn/models/OrionStarAI/Orion-14B-LongChat/summary) |
|
| 83 |
+
| 🔎 检索增强模型 | [Orion-14B-Chat-RAG](https://huggingface.co/OrionStarAI/Orion-14B-Chat-RAG) | [Orion-14B-Chat-RAG](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-RAG/summary) |
|
| 84 |
+
| 🔌 插件模型 | [Orion-14B-Chat-Plugin](https://huggingface.co/OrionStarAI/Orion-14B-Chat-Plugin) | [Orion-14B-Chat-Plugin](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-Plugin/summary)|
|
| 85 |
+
| 💼 基座Int4量化模型 | [Orion-14B-Base-Int4](https://huggingface.co/OrionStarAI/Orion-14B-Base-Int4) | [Orion-14B-Base-Int4](https://modelscope.cn/models/OrionStarAI/Orion-14B-Base-Int4/summary) |
|
| 86 |
+
| 📦 对话Int4量化模型 | [Orion-14B-Chat-Int4](https://huggingface.co/OrionStarAI/Orion-14B-Chat-Int4) | [Orion-14B-Chat-Int4](https://modelscope.cn/models/OrionStarAI/Orion-14B-Chat-Int4/summary) |
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
<a name="zh_model-benchmark"></a><br>
|
| 90 |
+
# 3. 评估结果
|
| 91 |
+
|
| 92 |
+
## 3.1. 基座模型Orion-14B-Base评估
|
| 93 |
+
|
| 94 |
+
### 3.1.1. 专业知识与试题评估结果
|
| 95 |
+
| 模型名称 | C-Eval | CMMLU | MMLU | AGIEval | Gaokao | BBH |
|
| 96 |
+
|--------------------|----------|----------|----------|----------|----------|----------|
|
| 97 |
+
| LLaMA2-13B | 41.4 | 38.4 | 55.0 | 30.9 | 18.2 | 45.6 |
|
| 98 |
+
| Skywork-13B | 59.1 | 61.4 | 62.7 | 43.6 | 56.1 | 48.3 |
|
| 99 |
+
| Baichuan2-13B | 59.0 | 61.3 | 59.5 | 37.4 | 45.6 | 49.0 |
|
| 100 |
+
| QWEN-14B | 71.7 | 70.2 | 67.9 | 51.9 | **62.5** | 53.7 |
|
| 101 |
+
| InternLM-20B | 58.8 | 59.0 | 62.1 | 44.6 | 45.5 | 52.5 |
|
| 102 |
+
| **Orion-14B-Base** | **72.9** | **70.6** | **69.9** | **54.7** | 62.1 | **56.5** |
|
| 103 |
+
|
| 104 |
+
### 3.1.2. 理解与通识评估结果
|
| 105 |
+
| 模型名称 |RACE-middle|RACE-high| HellaSwag| PIQA | Lambada | WSC |
|
| 106 |
+
|--------------------|----------|----------|----------|----------|----------|----------|
|
| 107 |
+
| LLaMA 2-13B | 63.0 | 58.9 | 77.5 | 79.8 | 76.5 | 66.3 |
|
| 108 |
+
| Skywork-13B | 87.6 | 84.1 | 73.7 | 78.3 | 71.8 | 66.3 |
|
| 109 |
+
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
|
| 110 |
+
| QWEN-14B | 93.0 | 90.3 | **80.2** | 79.8 | 71.4 | 66.3 |
|
| 111 |
+
| InternLM-20B | 86.4 | 83.3 | 78.1 | **80.3** | 71.8 | 68.3 |
|
| 112 |
+
| **Orion-14B-Base** | **93.2** | **91.3** | 78.5 | 79.5 | **78.8** | **70.2** |
|
| 113 |
+
|
| 114 |
+
### 3.1.3. OpenCompass评测集评估结果
|
| 115 |
+
| 模型名称 | Average | Examination | Language | Knowledge | Understanding | Reasoning |
|
| 116 |
+
|------------------|----------|----------|----------|----------|----------|----------|
|
| 117 |
+
| LLaMA 2-13B | 47.3 | 45.2 | 47.0 | 58.3 | 50.9 | 43.6 |
|
| 118 |
+
| Skywork-13B | 53.6 | 61.1 | 51.3 | 52.7 | 64.5 | 45.2 |
|
| 119 |
+
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
|
| 120 |
+
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
|
| 121 |
+
| InternLM-20B | 59.4 | 62.5 | 55.0 | **60.1** | 67.3 | 54.9 |
|
| 122 |
+
|**Orion-14B-Base**| **64.3** | **71.4** | **55.0** | 60.0 | **71.9** | **61.6** |
|
| 123 |
+
|
| 124 |
+
### 3.1.4. 日语测试集评估结果
|
| 125 |
+
| 模型名称 |**Average**| JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|
| 126 |
+
|--------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
|
| 127 |
+
| PLaMo-13B | 52.3 | 56.7 | 42.8 | 95.8 | 70.6 | 71.0 | 8.70 | 70.5 | 2.40 |
|
| 128 |
+
| WebLab-10B | 50.7 | 66.6 | 53.7 | 82.1 | 62.9 | 56.2 | 10.0 | 72.0 | 2.40 |
|
| 129 |
+
| ELYZA-jp-7B | 48.8 | 71.7 | 25.3 | 86.6 | 70.8 | 64.1 | 2.50 | 62.1 | 7.20 |
|
| 130 |
+
| StableLM-jp-7B | 51.1 | 33.4 | 43.3 | **96.7** | 70.6 | 78.1 | 10.7 | 72.8 | 2.80 |
|
| 131 |
+
| LLaMA 2-13B | 46.3 | 75.0 | 47.6 | 38.8 | 76.1 | 67.7 | 18.1 | 63.2 | 10.4 |
|
| 132 |
+
| Baichuan 2-13B | 57.1 | 73.7 | 31.3 | 91.6 | 80.5 | 63.3 | 18.6 | 72.2 | 25.2 |
|
| 133 |
+
| QWEN-14B | 65.8 | 85.9 | 60.7 | 97.0 | 83.3 | 71.8 | 18.8 | 70.6 | 38.0 |
|
| 134 |
+
| Yi-34B | 67.1 | 83.8 | 61.2 | 95.2 | **86.1** | 78.5 | **27.2** | 69.2 | 35.2 |
|
| 135 |
+
| **Orion-14B-Base** | **69.1** | **88.2** | **75.8** | 94.1 | 75.7 | **85.1** | 17.3 | **78.8** | **38.0** |
|
| 136 |
+
|
| 137 |
+
### 3.1.5. 韩语测试集n-shot评估结果
|
| 138 |
+
| 模型名称 | **Average**<br>n=0 n=5 | HellaSwag<br>n=0 n=5 | COPA<br> n=0 n=5 | BooIQ<br>n=0 n=5 | SentiNeg<br>n=0 n=5|
|
| 139 |
+
|------------------|------------------------------|------------------------------|------------------------------|------------------------------|------------------------------|
|
| 140 |
+
| KoGPT | 53.0 70.1 | 55.9 58.3 | 73.5 72.9 | 45.1 59.8 | 37.5 89.4 |
|
| 141 |
+
| Polyglot-ko-13B | 69.6 73.7 |**59.5** **63.1**|**79.4** **81.1**| 48.2 60.4 | 91.2 90.2 |
|
| 142 |
+
| LLaMA 2-13B | 46.7 63.7 | 41.3 44.0 | 59.3 63.8 | 34.9 73.8 | 51.5 73.4 |
|
| 143 |
+
| Baichuan 2-13B | 52.1 58.7 | 39.2 39.6 | 60.6 60.6 | 58.4 61.5 | 50.3 72.9 |
|
| 144 |
+
| QWEN-14B | 53.8 73.7 | 45.3 46.8 | 64.9 68.9 | 33.4 83.5 | 71.5 95.7 |
|
| 145 |
+
| Yi-34B | 54.2 72.1 | 44.6 44.7 | 58.0 60.6 | 65.9 90.2 | 48.3 92.9 |
|
| 146 |
+
|**Orion-14B-Base**|**74.5** **79.6**| 47.0 49.6 | 77.7 79.4 |**81.6** **90.7**|**92.4** **98.7**|
|
| 147 |
+
|
| 148 |
+
### 3.1.6. 多语言评估结果
|
| 149 |
+
| 模型名称 | Train Lang | Japanese | Korean | Chinese | English |
|
| 150 |
+
|--------------------|------------|----------|----------|----------|----------|
|
| 151 |
+
| PLaMo-13B | En,Jp | 52.3 | * | * | * |
|
| 152 |
+
| Weblab-10B | En,Jp | 50.7 | * | * | * |
|
| 153 |
+
| ELYZA-jp-7B | En,Jp | 48.8 | * | * | * |
|
| 154 |
+
| StableLM-jp-7B | En,Jp | 51.1 | * | * | * |
|
| 155 |
+
| KoGPT-6B | En,Ko | * | 70.1 | * | * |
|
| 156 |
+
| Polyglot-ko-13B | En,Ko | * | 70.7 | * | * |
|
| 157 |
+
| Baichuan2-13B | Multi | 57.1 | 58.7 | 50.8 | 57.1 |
|
| 158 |
+
| Qwen-14B | Multi | 65.8 | 73.7 | 64.5 | 65.4 |
|
| 159 |
+
| Llama2-13B | Multi | 46.3 | 63.7 | 41.4 | 55.3 |
|
| 160 |
+
| Yi-34B | Multi | 67.1 | 72.2 | 58.7 | **68.8** |
|
| 161 |
+
| **Orion-14B-Base** | Multi | **69.1** | **79.5** | **67.9** | 67.3 |
|
| 162 |
+
|
| 163 |
+
## 3.2. 对话模型Orion-14B-Chat评估
|
| 164 |
+
### 3.2.1. 对话模型MTBench主观评估
|
| 165 |
+
| 模型名称 | 第一轮 | 第二轮 | **平均** |
|
| 166 |
+
|----------------------|----------|----------|----------|
|
| 167 |
+
| Baichuan2-13B-Chat | 7.05 | 6.47 | 6.76 |
|
| 168 |
+
| Qwen-14B-Chat | 7.30 | 6.62 | 6.96 |
|
| 169 |
+
| Llama2-13B-Chat | 7.10 | 6.20 | 6.65 |
|
| 170 |
+
| InternLM-20B-Chat | 7.03 | 5.93 | 6.48 |
|
| 171 |
+
| **Orion-14B-Chat** | **7.68** | **7.07** | **7.37** |
|
| 172 |
+
|
| 173 |
+
\*这里评测使用vllm进行推理
|
| 174 |
+
|
| 175 |
+
### 3.2.2. 对话模型AlignBench主观评估
|
| 176 |
+
| 模型名称 | 数学能力 | 逻辑推理 | 基本能力 | 中文理解 | 综合问答 | 写作能力 | 角色扮演 | 专业知识 | **平均** |
|
| 177 |
+
|--------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
|
| 178 |
+
| Baichuan2-13B-Chat | 3.76 | 4.07 | 6.22 | 6.05 | 7.11 | 6.97 | 6.75 | 6.43 | 5.25 |
|
| 179 |
+
| Qwen-14B-Chat | **4.91** | **4.71** | **6.90** | 6.36 | 6.74 | 6.64 | 6.59 | 6.56 | **5.72** |
|
| 180 |
+
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
|
| 181 |
+
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 | **7.18** | 6.19 | 6.49 | 6.22 | 4.96 |
|
| 182 |
+
| **Orion-14B-Chat** | 4.00 | 4.24 | 6.18 | **6.57** | 7.16 | **7.36** | **7.16** | **6.99** | 5.51 |
|
| 183 |
+
|
| 184 |
+
\*这里评测使用vllm进行推理
|
| 185 |
+
|
| 186 |
+
## 3.3. 长上下文模型Orion-14B-LongChat评估
|
| 187 |
+
### 3.3.1. 长上下文模型LongBench评估
|
| 188 |
+
| 模型名称 | NarrativeQA| MultiFieldQA-en| MultiFieldQA-zh | DuReader | QMSum | VCSUM | TREC | TriviaQA | LSHT | RepoBench-P |
|
| 189 |
+
|--------------------------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|-----------|
|
| 190 |
+
| GPT-3.5-Turbo-16k | **23.60** | **52.30** | **61.20** | 28.70 | 23.40 | **16.00** | 68.00 | **91.40** | 29.20 | 53.60 |
|
| 191 |
+
| LongChat-v1.5-7B-32k | 16.90 | 41.40 | 29.10 | 19.50 | 22.70 | 9.90 | 63.50 | 82.30 | 23.20 | 55.30 |
|
| 192 |
+
| Vicuna-v1.5-7B-16k | 19.40 | 38.50 | 43.00 | 19.30 | 22.80 | 15.10 | 71.50 | 86.20 | 28.80 | 43.50 |
|
| 193 |
+
| Yi-6B-200K | 14.11 | 36.74 | 22.68 | 14.01 | 20.44 | 8.08 | 72.00 | 86.61 | 38.00 | **63.29** |
|
| 194 |
+
| Orion-14B-LongChat | 19.47 | 48.11 | 55.84 | **37.02** | **24.87** | 15.44 | **77.00** | 89.12 | **45.50** | 54.31 |
|
| 195 |
+
|
| 196 |
+
## 3.4. 检索增强模型Orion-14B-Chat-RAG评估
|
| 197 |
+
### 3.4.1. 自建检索增强测试集评估结果
|
| 198 |
+
|模型名称|回复效果(关键字)|*回复效果(主观打分)|引用能力|兜底能力|*AutoQA|*抽取数据|
|
| 199 |
+
|---------------------|------|------|------|------|------|------|
|
| 200 |
+
| Baichuan2-13B-Chat | 85 | 76 | 1 | 0 | 69 | 51 |
|
| 201 |
+
| Qwen-14B-Chat | 79 | 77 | 75 | 47 | 68 | 72 |
|
| 202 |
+
| Qwen-72B-Chat(Int4) | 87 | 89 | 90 | 32 | 67 | 76 |
|
| 203 |
+
| GPT-4 | 91 | 94 | 96 | 95 | 75 | 86 |
|
| 204 |
+
| Orion-14B-Chat-RAG | 86 | 87 | 91 | 97 | 73 | 71 |
|
| 205 |
+
\* 表示人工评判结果
|
| 206 |
+
|
| 207 |
+
## 3.5. 插件模型Orion-14B-Chat-Plugin评估
|
| 208 |
+
### 3.5.1. 自建插件测试集评估结果
|
| 209 |
+
| 模型名称 | 全参数意图识别 | 缺参数意图识别 | 非插件调用识别 |
|
| 210 |
+
|-----------------------|--------|-----------|--------|
|
| 211 |
+
| Baichuan2-13B-Chat | 25 | 0 | 0 |
|
| 212 |
+
| Qwen-14B-Chat | 55 | 0 | 50 |
|
| 213 |
+
| GPT-4 | **95** | 52.38 | 70 |
|
| 214 |
+
| Orion-14B-Chat-Plugin | 92.5 | **60.32** | **90** |
|
| 215 |
+
|
| 216 |
+
## 3.6. 量化模型Orion-14B-Base-Int4评估
|
| 217 |
+
### 3.6.1. 量化前后整体对比
|
| 218 |
+
|模型名称|模型大小(GB)|推理速度(令牌数/秒)|C-Eval |CMMLU |MMLU |RACE | HellaSwag|
|
| 219 |
+
|-------------------------|------|-----|------|------|------|------|------|
|
| 220 |
+
| OrionStar-14B-Base | 28.0 | 135 | 72.8 | 70.6 | 70.0 | 93.3 | 78.5 |
|
| 221 |
+
| OrionStar-14B-Base-Int4 | 8.3 | 178 | 71.8 | 69.8 | 69.2 | 93.1 | 78.0 |
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
<a name="zh_model-inference"></a><br>
|
| 225 |
+
# 4. 模型推理
|
| 226 |
+
|
| 227 |
+
推理所需的模型权重、源码、配置已发布在 Hugging Face,下载链接见本文档最开始的表格。我们在此示范多种推理方式。程序会自动从
|
| 228 |
+
Hugging Face 下载所需资源。
|
| 229 |
+
|
| 230 |
+
## 4.1. Python 代码方式
|
| 231 |
+
|
| 232 |
+
```python
|
| 233 |
+
import torch
|
| 234 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 235 |
+
from transformers.generation.utils import GenerationConfig
|
| 236 |
+
|
| 237 |
+
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/Orion-14B", use_fast=False, trust_remote_code=True)
|
| 238 |
+
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/Orion-14B", device_map="auto",
|
| 239 |
+
torch_dtype=torch.bfloat16, trust_remote_code=True)
|
| 240 |
+
|
| 241 |
+
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/Orion-14B")
|
| 242 |
+
messages = [{"role": "user", "content": "你好! 你叫什么名字!"}]
|
| 243 |
+
response = model.chat(tokenizer, messages, streaming=Flase)
|
| 244 |
+
print(response)
|
| 245 |
+
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
在上述两段代码中,模型加载指定 `device_map='auto'`
|
| 249 |
+
,会使用所有可用显卡。如需指定使用的设备,可以使用类似 `export CUDA_VISIBLE_DEVICES=0,1`(使用了0、1号显卡)的方式控制。
|
| 250 |
+
|
| 251 |
+
## 4.2. 命令行工具方式
|
| 252 |
+
|
| 253 |
+
```shell
|
| 254 |
+
CUDA_VISIBLE_DEVICES=0 python cli_demo.py
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
本命令行工具是为 Chat 场景设计,因此我们不支持使用该工具调用 Base 模型。
|
| 258 |
+
|
| 259 |
+
## 4.3. 脚本直接推理
|
| 260 |
+
|
| 261 |
+
```shell
|
| 262 |
+
# base model
|
| 263 |
+
CUDA_VISIBLE_DEVICES=0 python demo/text_generation_base.py --model OrionStarAI/Orion-14B --tokenizer OrionStarAI/Orion-14B --prompt 你好,你叫什么名字
|
| 264 |
+
|
| 265 |
+
# chat model
|
| 266 |
+
CUDA_VISIBLE_DEVICES=0 python demo/text_generation.py --model OrionStarAI/Orion-14B-Chat --tokenizer OrionStarAI/Orion-14B-Chat --prompt 你好,你叫什么名字
|
| 267 |
+
|
| 268 |
+
```
|
| 269 |
+
<a name="vllm"></a><br>
|
| 270 |
+
## 4.4. 使用vllm推理
|
| 271 |
+
- 工程地址<br>
|
| 272 |
+
https://github.com/vllm-project/vllm
|
| 273 |
+
|
| 274 |
+
- 拉取请求<br>
|
| 275 |
+
https://github.com/vllm-project/vllm/pull/2539
|
| 276 |
+
|
| 277 |
+
<a name="llama-cpp"></a><br>
|
| 278 |
+
## 4.5. 使用llama.cpp推理
|
| 279 |
+
|
| 280 |
+
- 工程地址<br>
|
| 281 |
+
https://github.com/ggerganov/llama.cpp
|
| 282 |
+
|
| 283 |
+
- 拉取请求<br>
|
| 284 |
+
https://github.com/ggerganov/llama.cpp/pull/5118
|
| 285 |
+
|
| 286 |
+
- 如何转换GGUF格式模型
|
| 287 |
+
|
| 288 |
+
```shell
|
| 289 |
+
python convert-hf-to-gguf.py path/to/Orion-14B-Chat --outfile chat.gguf
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
- 如何运行GGUF格式模型推理
|
| 293 |
+
|
| 294 |
+
```shell
|
| 295 |
+
./main --frequency-penalty 0.5 --frequency-penalty 0.5 --top-k 5 --top-p 0.9 -m chat.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e
|
| 296 |
+
```
|
| 297 |
+
|
| 298 |
+
## 4.6. 示例输出
|
| 299 |
+
|
| 300 |
+
### 4.6.1. 闲聊
|
| 301 |
+
|
| 302 |
+
`````
|
| 303 |
+
用户:你好,你叫什么名字
|
| 304 |
+
Orion-14B:你好!我是一个人工智能助手,没有固定的名字。你可以随意称呼我。有什么我可以帮助你的吗?
|
| 305 |
+
用户:讲个故事
|
| 306 |
+
Orion-14B:从前有一个小男孩叫杰克,他住在一个小村庄里。杰克非常喜欢冒险和探索,总是梦想着能够发现一些神奇的事情。
|
| 307 |
+
|
| 308 |
+
有一天,杰克听说在附近的森林深处有一座传说中的魔法城堡,里面住着一个邪恶的巨人。这个巨人的名字叫格里姆,他被困在城堡中,无法离开。
|
| 309 |
+
|
| 310 |
+
杰克决定要去解救这个巨人,因为他相信格里姆一定有自己的原因被困在那里。于是,他带着勇气和决心,踏上了前往魔法城堡的旅程。
|
| 311 |
+
|
| 312 |
+
经过长时间的跋涉,杰克终于来到了城堡的大门前。他小心翼翼地推开大门,进��了一个充满神秘气息的房间。
|
| 313 |
+
|
| 314 |
+
房间里弥漫着黑暗的气息,但杰克并没有被吓倒。他勇敢地向城堡深处走去,最终找到了格里姆。
|
| 315 |
+
|
| 316 |
+
格里姆告诉杰克,他是被一个邪恶的女巫诅咒的,只有通过解开咒语才能获得自由。杰克决定要帮助格里姆,他开始寻找线索和解开咒语的方法。
|
| 317 |
+
|
| 318 |
+
经过一番努力,杰克终于找到了一条通往女巫的秘密实验室的道路。他在那里发现了女巫留下的魔法书,书中记载了解开咒语的方法。
|
| 319 |
+
|
| 320 |
+
杰克按照书上所写的步骤进行操作,成功地解开了格里姆身上的诅咒。巨人感激不已,他答应帮助杰克实现他的愿望。
|
| 321 |
+
|
| 322 |
+
从此以后,杰克和格里姆成为了好朋友,他们一起经历了许多惊险刺激的冒险,并用他们的勇气和智慧战胜了各种困难。
|
| 323 |
+
|
| 324 |
+
这个故事告诉我们,只要有勇气和决心,我们就能克服一切困难,实现自己的梦想。
|
| 325 |
+
`````
|
| 326 |
+
|
| 327 |
+
### 4.6.2. 日韩
|
| 328 |
+
|
| 329 |
+
`````
|
| 330 |
+
用户:自己を紹介してください
|
| 331 |
+
Orion-14B:こんにちは、私の名前はChatMaxで、OrionStarによって開発されたAIアシスタントです。私はユーザーに正確で、客観的で、有用な回答を提供し、彼らが問題を解決し、情報を取得するのを助けることができます。
|
| 332 |
+
用户:자기소개를 해주세요.
|
| 333 |
+
Orion-14B:안녕하세요, 제 이름은 ChatMax입니다. OrionStar에서 개발한 AI 어시스턴트입니다. 저는 사용자들에게 정확하고 객관적이며 유용한 답변을 제공하여 문제를 해결하고 정보를 얻는 데 도움을 줄 수 있습니다.
|
| 334 |
+
`````
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
<a name="zh_declarations-license"></a><br>
|
| 338 |
+
# 5. 声明、协议
|
| 339 |
+
|
| 340 |
+
## 5.1. 声明
|
| 341 |
+
|
| 342 |
+
我们强烈呼吁所有使用者,不要利用 Orion-14B 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将
|
| 343 |
+
Orion-14B 模型用于未经适当安全审查和备案的互联网服务。
|
| 344 |
+
|
| 345 |
+
我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
|
| 346 |
+
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用
|
| 347 |
+
Orion-14B 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
|
| 348 |
+
|
| 349 |
+
## 5.2. 协议
|
| 350 |
+
|
| 351 |
+
社区使用Orion-14B系列模型
|
| 352 |
+
- 代码请遵循 [Apache License Version 2.0](./LICENSE)<br>
|
| 353 |
+
- 模型请遵循 [Orion-14B系列模型社区许可协议](./ModelsCommunityLicenseAgreement)
|
| 354 |
+
|
| 355 |
+
|
| 356 |
+
<a name="zh_company-introduction"></a><br>
|
| 357 |
+
# 6. 企业介绍
|
| 358 |
+
|
| 359 |
+
猎户星空(OrionStar)是一家全球领先的服务机器人解决方案公司,成立于2016年9月。猎户星空致力于基于人工智能技术打造下一代革命性机器人,使人们能够摆脱重复的体力劳动,使人类的工作和生活更加智能和有趣,通过技术使社会和世界变得更加美好。
|
| 360 |
+
|
| 361 |
+
猎户星空拥有完全自主开发的全链条人工智能技术,如语音交互和视觉导航。它整合了产品开发能力和技术应用能力。基于Orion机械臂平台,它推出了ORION
|
| 362 |
+
STAR AI Robot Greeting、AI Robot Greeting Mini、Lucki、Coffee
|
| 363 |
+
Master等产品,并建立了Orion机器人的开放平台OrionOS。通过为 **真正有用的机器人而生** 的理念实践,它通过AI技术为更多人赋能。
|
| 364 |
+
|
| 365 |
+
凭借7年AI经验积累,猎户星空已推出的大模型深度应用“聚言”,并陆续面向行业客户提供定制化AI大模型咨询与服务解决方案,真正帮助客户实现企业经营效率领先同行目标。
|
| 366 |
+
|
| 367 |
+
**猎户星空具备全链条大模型应用能力的核心优势**,包括拥有从海量数据处理、大模型预训练、二次预训练、微调(Fine-tune)、Prompt
|
| 368 |
+
Engineering 、Agent开发的全链条能力和经验积累;拥有完整的端到端模型训练能力,包括系统化的数据处理流程和数百张GPU的并行模型训练能力,现已在大政务、云服务、出海电商、快消等多个行业场景落地。
|
| 369 |
+
|
| 370 |
+
***欢迎有大模型应用落地需求的企业联系我们进行商务合作***<br>
|
| 371 |
+
**咨询电话:** 400-898-7779<br>
|
| 372 |
+
**电子邮箱:** ai@orionstar.com
|
| 373 |
+
|
| 374 |
+
<div align="center">
|
| 375 |
+
<img src="./assets/imgs/wechat_group.jpg" alt="wechat" width="40%" />
|
| 376 |
+
</div>
|
assets/assets/imgs/assets_imgs_model_cap_en.png
ADDED

|
assets/assets/imgs/assets_imgs_model_cap_zh.png
ADDED

|
assets/assets/imgs/assets_imgs_orion_start.PNG
ADDED

|
assets/assets/imgs/assets_imgs_wechat_group.jpg
ADDED

|
assets/assets/imgs/llama_cpp.png
ADDED

|
assets/assets/imgs/model_cap_en.png
ADDED

|
assets/assets/imgs/model_cap_zh.png
ADDED

|
assets/assets/imgs/opencompass_en.png
ADDED

|
assets/assets/imgs/opencompass_zh.png
ADDED
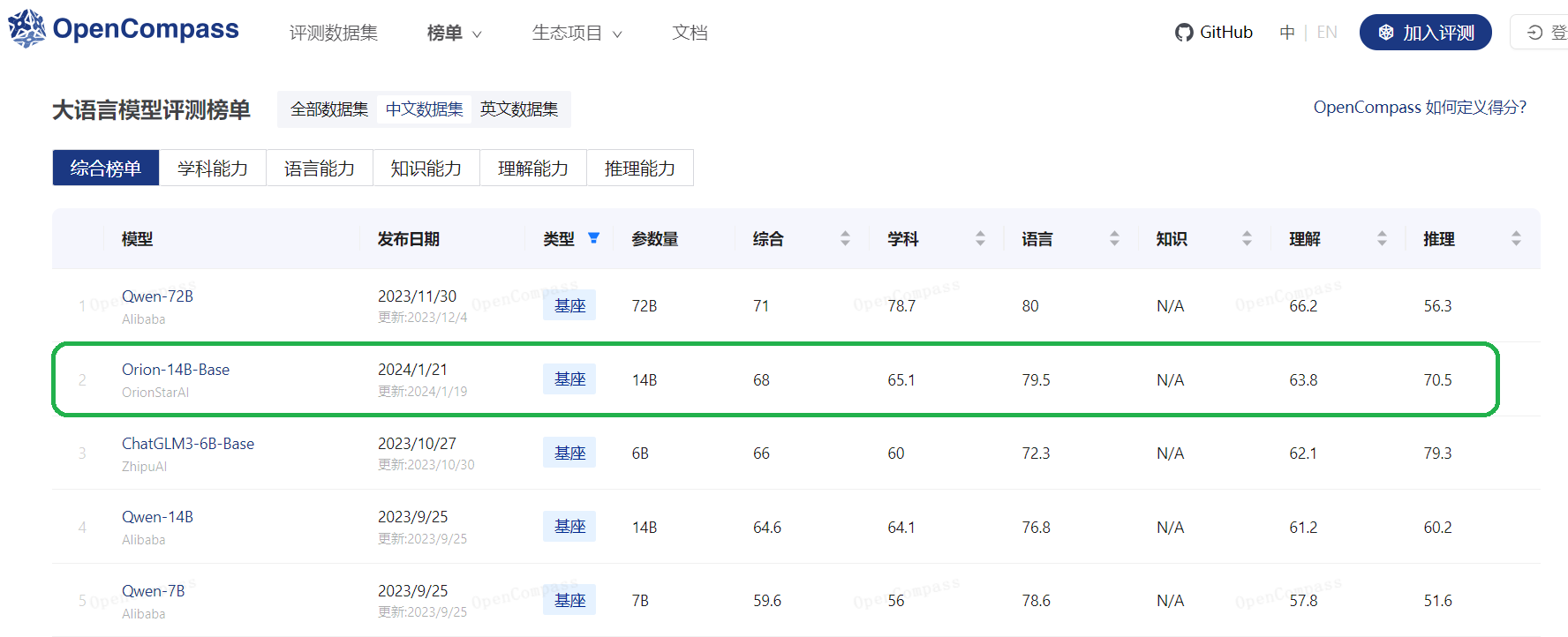
|
assets/assets/imgs/orion_start.PNG
ADDED

|
assets/assets/imgs/vllm.png
ADDED

|
assets/assets/imgs/wechat_group.jpg
ADDED

|
config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"OrionForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"auto_map": {
|
| 6 |
+
"AutoConfig": "configuration_orion.OrionConfig",
|
| 7 |
+
"AutoModelForCausalLM": "modeling_orion.OrionForCausalLM"
|
| 8 |
+
},
|
| 9 |
+
"bos_token_id": 1,
|
| 10 |
+
"eos_token_id": 2,
|
| 11 |
+
"hidden_act": "silu",
|
| 12 |
+
"hidden_size": 5120,
|
| 13 |
+
"model_type": "orion",
|
| 14 |
+
"initializer_range": 0.02,
|
| 15 |
+
"intermediate_size": 15360,
|
| 16 |
+
"max_position_embeddings": 200000,
|
| 17 |
+
"max_sequence_length": 200000,
|
| 18 |
+
"num_attention_heads": 40,
|
| 19 |
+
"num_hidden_layers": 40,
|
| 20 |
+
"num_key_value_heads": 40,
|
| 21 |
+
"pad_token_id": 0,
|
| 22 |
+
"pretraining_tp": 1,
|
| 23 |
+
"rms_norm_eps": 1e-05,
|
| 24 |
+
"rope_scaling": null,
|
| 25 |
+
"rope_theta": 50000000.0,
|
| 26 |
+
"tie_word_embeddings": false,
|
| 27 |
+
"torch_dtype": "bfloat16",
|
| 28 |
+
"transformers_version": "4.34.0",
|
| 29 |
+
"use_cache": true,
|
| 30 |
+
"vocab_size": 84608
|
| 31 |
+
}
|
configuration_orion.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024, OrionStar Inc. All rights reserved.
|
| 2 |
+
|
| 3 |
+
from transformers import PretrainedConfig
|
| 4 |
+
|
| 5 |
+
class OrionConfig(PretrainedConfig):
|
| 6 |
+
model_type = "orion"
|
| 7 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 8 |
+
|
| 9 |
+
def __init__(
|
| 10 |
+
self,
|
| 11 |
+
vocab_size=84608,
|
| 12 |
+
hidden_size=4096,
|
| 13 |
+
intermediate_size=15360,
|
| 14 |
+
num_hidden_layers=40,
|
| 15 |
+
num_attention_heads=40,
|
| 16 |
+
num_key_value_heads=40,
|
| 17 |
+
hidden_act="silu",
|
| 18 |
+
max_position_embeddings=4096,
|
| 19 |
+
initializer_range=0.02,
|
| 20 |
+
rms_norm_eps=1e-5,
|
| 21 |
+
use_cache=True,
|
| 22 |
+
pad_token_id=None,
|
| 23 |
+
bos_token_id=1,
|
| 24 |
+
eos_token_id=2,
|
| 25 |
+
pretraining_tp=1,
|
| 26 |
+
tie_word_embeddings=False,
|
| 27 |
+
rope_theta=10000.0,
|
| 28 |
+
rope_scaling=None,
|
| 29 |
+
attention_bias=False,
|
| 30 |
+
**kwargs,
|
| 31 |
+
):
|
| 32 |
+
self.vocab_size = vocab_size
|
| 33 |
+
self.max_position_embeddings = max_position_embeddings
|
| 34 |
+
self.hidden_size = hidden_size
|
| 35 |
+
self.intermediate_size = intermediate_size
|
| 36 |
+
self.num_hidden_layers = num_hidden_layers
|
| 37 |
+
self.num_attention_heads = num_attention_heads
|
| 38 |
+
|
| 39 |
+
# for backward compatibility
|
| 40 |
+
if num_key_value_heads is None:
|
| 41 |
+
num_key_value_heads = num_attention_heads
|
| 42 |
+
|
| 43 |
+
self.num_key_value_heads = num_key_value_heads
|
| 44 |
+
self.hidden_act = hidden_act
|
| 45 |
+
self.initializer_range = initializer_range
|
| 46 |
+
self.rms_norm_eps = rms_norm_eps
|
| 47 |
+
self.pretraining_tp = pretraining_tp
|
| 48 |
+
self.use_cache = use_cache
|
| 49 |
+
self.rope_theta = rope_theta
|
| 50 |
+
self.rope_scaling = rope_scaling
|
| 51 |
+
self._rope_scaling_validation()
|
| 52 |
+
self.attention_bias = attention_bias
|
| 53 |
+
|
| 54 |
+
super().__init__(
|
| 55 |
+
pad_token_id=pad_token_id,
|
| 56 |
+
bos_token_id=bos_token_id,
|
| 57 |
+
eos_token_id=eos_token_id,
|
| 58 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 59 |
+
**kwargs,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
def _rope_scaling_validation(self):
|
| 63 |
+
"""
|
| 64 |
+
Validate the `rope_scaling` configuration.
|
| 65 |
+
"""
|
| 66 |
+
if self.rope_scaling is None:
|
| 67 |
+
return
|
| 68 |
+
|
| 69 |
+
if not isinstance(self.rope_scaling, dict) or len(self.rope_scaling) != 2:
|
| 70 |
+
raise ValueError(
|
| 71 |
+
"`rope_scaling` must be a dictionary with with two fields, `type` and `factor`, "
|
| 72 |
+
f"got {self.rope_scaling}"
|
| 73 |
+
)
|
| 74 |
+
rope_scaling_type = self.rope_scaling.get("type", None)
|
| 75 |
+
rope_scaling_factor = self.rope_scaling.get("factor", None)
|
| 76 |
+
if rope_scaling_type is None or rope_scaling_type not in ["linear", "dynamic"]:
|
| 77 |
+
raise ValueError(
|
| 78 |
+
f"`rope_scaling`'s type field must be one of ['linear', 'dynamic'], got {rope_scaling_type}"
|
| 79 |
+
)
|
| 80 |
+
if rope_scaling_factor is None or not isinstance(rope_scaling_factor, float) or rope_scaling_factor <= 1.0:
|
| 81 |
+
raise ValueError(f"`rope_scaling`'s factor field must be an float > 1, got {rope_scaling_factor}")
|
| 82 |
+
|
generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"max_new_tokens": 1024,
|
| 7 |
+
"temperature": 0.3,
|
| 8 |
+
"top_k": 5,
|
| 9 |
+
"top_p": 0.90,
|
| 10 |
+
"repetition_penalty": 1.05,
|
| 11 |
+
"do_sample": true,
|
| 12 |
+
"transformers_version": "4.34.0"
|
| 13 |
+
}
|
generation_utils.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from queue import Queue
|
| 3 |
+
|
| 4 |
+
# build chat input prompt
|
| 5 |
+
def build_chat_input(tokenizer, messages: List[dict]):
|
| 6 |
+
prompt = "<s>"
|
| 7 |
+
for msg in messages:
|
| 8 |
+
role = msg["role"]
|
| 9 |
+
message = msg["content"]
|
| 10 |
+
if message is None :
|
| 11 |
+
continue
|
| 12 |
+
if role == "user":
|
| 13 |
+
prompt += "Human: " + message + "\nAssistant: "
|
| 14 |
+
if role == "assistant":
|
| 15 |
+
prompt += message + "</s>"
|
| 16 |
+
|
| 17 |
+
input_tokens = tokenizer.encode(prompt)
|
| 18 |
+
return input_tokens
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class TextIterStreamer:
|
| 22 |
+
def __init__(self, tokenizer, skip_prompt=False, skip_special_tokens=False):
|
| 23 |
+
self.tokenizer = tokenizer
|
| 24 |
+
self.skip_prompt = skip_prompt
|
| 25 |
+
self.skip_special_tokens = skip_special_tokens
|
| 26 |
+
self.tokens = []
|
| 27 |
+
self.text_queue = Queue()
|
| 28 |
+
self.next_tokens_are_prompt = True
|
| 29 |
+
|
| 30 |
+
def put(self, value):
|
| 31 |
+
if self.skip_prompt and self.next_tokens_are_prompt:
|
| 32 |
+
self.next_tokens_are_prompt = False
|
| 33 |
+
else:
|
| 34 |
+
if len(value.shape) > 1:
|
| 35 |
+
value = value[0]
|
| 36 |
+
self.tokens.extend(value.tolist())
|
| 37 |
+
self.text_queue.put(
|
| 38 |
+
self.tokenizer.decode(self.tokens, skip_special_tokens=self.skip_special_tokens))
|
| 39 |
+
|
| 40 |
+
def end(self):
|
| 41 |
+
self.text_queue.put(None)
|
| 42 |
+
|
| 43 |
+
def __iter__(self):
|
| 44 |
+
return self
|
| 45 |
+
|
| 46 |
+
def __next__(self):
|
| 47 |
+
value = self.text_queue.get()
|
| 48 |
+
if value is None:
|
| 49 |
+
raise StopIteration()
|
| 50 |
+
else:
|
| 51 |
+
return value
|
| 52 |
+
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,451 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 28837498880
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00003-of-00003.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 9 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"model.layers.0.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 14 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"model.layers.1.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 20 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"model.layers.1.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 25 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 27 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 28 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"model.layers.10.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 31 |
+
"model.layers.10.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"model.layers.10.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"model.layers.10.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 36 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 37 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 38 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 39 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 40 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 41 |
+
"model.layers.11.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 42 |
+
"model.layers.11.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 43 |
+
"model.layers.11.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 44 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 45 |
+
"model.layers.11.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 46 |
+
"model.layers.11.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 47 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 48 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 49 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 50 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 51 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 52 |
+
"model.layers.12.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 53 |
+
"model.layers.12.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 54 |
+
"model.layers.12.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 55 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 56 |
+
"model.layers.12.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 57 |
+
"model.layers.12.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 58 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 59 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 60 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 61 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 62 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 63 |
+
"model.layers.13.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 64 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 66 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"model.layers.13.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 69 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 71 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 72 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 73 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 74 |
+
"model.layers.14.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 75 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"model.layers.14.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 80 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"model.layers.15.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 86 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"model.layers.15.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 91 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"model.layers.16.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 97 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"model.layers.16.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 102 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"model.layers.17.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 108 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"model.layers.17.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 113 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 117 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 118 |
+
"model.layers.18.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 119 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 120 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 121 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 122 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 123 |
+
"model.layers.18.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 124 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 125 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 126 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"model.layers.19.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 130 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"model.layers.19.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 135 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"model.layers.2.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 141 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 142 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 143 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 144 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 145 |
+
"model.layers.2.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 146 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 147 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 148 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 149 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 150 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 151 |
+
"model.layers.20.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 152 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 153 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 154 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 155 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 156 |
+
"model.layers.20.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 157 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 158 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 159 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 160 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 161 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 162 |
+
"model.layers.21.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 163 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 164 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 165 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 166 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 167 |
+
"model.layers.21.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 168 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 169 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 170 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 171 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 172 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 173 |
+
"model.layers.22.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 174 |
+
"model.layers.22.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 175 |
+
"model.layers.22.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 176 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 177 |
+
"model.layers.22.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 178 |
+
"model.layers.22.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 179 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 180 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 181 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 182 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 183 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 184 |
+
"model.layers.23.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 185 |
+
"model.layers.23.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 186 |
+
"model.layers.23.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 187 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 188 |
+
"model.layers.23.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 189 |
+
"model.layers.23.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 190 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 191 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 192 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 193 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 194 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 195 |
+
"model.layers.24.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 196 |
+
"model.layers.24.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 197 |
+
"model.layers.24.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 198 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 199 |
+
"model.layers.24.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 200 |
+
"model.layers.24.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 201 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 202 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 203 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 204 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 205 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 206 |
+
"model.layers.25.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 207 |
+
"model.layers.25.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 208 |
+
"model.layers.25.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 209 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 210 |
+
"model.layers.25.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 211 |
+
"model.layers.25.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 212 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 213 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 214 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 215 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 216 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 217 |
+
"model.layers.26.input_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 218 |
+
"model.layers.26.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 219 |
+
"model.layers.26.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 220 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 221 |
+
"model.layers.26.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 222 |
+
"model.layers.26.post_attention_layernorm.bias": "model-00002-of-00003.safetensors",
|
| 223 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 224 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 225 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 226 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 227 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 228 |
+
"model.layers.27.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 229 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 230 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 231 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 232 |
+
"model.layers.27.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 233 |
+
"model.layers.27.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 234 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 235 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 236 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 237 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 238 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 239 |
+
"model.layers.28.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 240 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 241 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 242 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 243 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 244 |
+
"model.layers.28.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 245 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 246 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 247 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 248 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 249 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 250 |
+
"model.layers.29.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 251 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 252 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 253 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 254 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 255 |
+
"model.layers.29.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 256 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 257 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 258 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 259 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 260 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 261 |
+
"model.layers.3.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 262 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 263 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 264 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 265 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 266 |
+
"model.layers.3.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 267 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 268 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 269 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 270 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 271 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 272 |
+
"model.layers.30.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 273 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 274 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 275 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 276 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 277 |
+
"model.layers.30.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 278 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 279 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 280 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 281 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 282 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 283 |
+
"model.layers.31.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 284 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 285 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 286 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 287 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 288 |
+
"model.layers.31.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 289 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 290 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 291 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 292 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 293 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 294 |
+
"model.layers.32.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 295 |
+
"model.layers.32.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 296 |
+
"model.layers.32.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 297 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 298 |
+
"model.layers.32.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 299 |
+
"model.layers.32.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 300 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 301 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 302 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 303 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 304 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 305 |
+
"model.layers.33.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 306 |
+
"model.layers.33.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 307 |
+
"model.layers.33.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 308 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 309 |
+
"model.layers.33.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 310 |
+
"model.layers.33.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 311 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 312 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 313 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 314 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 315 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 316 |
+
"model.layers.34.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 317 |
+
"model.layers.34.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 318 |
+
"model.layers.34.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 319 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 320 |
+
"model.layers.34.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 321 |
+
"model.layers.34.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 322 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 323 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 324 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 325 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 326 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 327 |
+
"model.layers.35.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 328 |
+
"model.layers.35.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 329 |
+
"model.layers.35.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 330 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 331 |
+
"model.layers.35.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 332 |
+
"model.layers.35.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 333 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 334 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 335 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 336 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 337 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 338 |
+
"model.layers.36.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 339 |
+
"model.layers.36.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 340 |
+
"model.layers.36.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 341 |
+
"model.layers.36.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 342 |
+
"model.layers.36.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 343 |
+
"model.layers.36.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 344 |
+
"model.layers.36.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 345 |
+
"model.layers.36.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 346 |
+
"model.layers.36.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 347 |
+
"model.layers.36.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 348 |
+
"model.layers.36.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 349 |
+
"model.layers.37.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 350 |
+
"model.layers.37.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 351 |
+
"model.layers.37.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 352 |
+
"model.layers.37.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 353 |
+
"model.layers.37.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 354 |
+
"model.layers.37.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 355 |
+
"model.layers.37.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 356 |
+
"model.layers.37.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 357 |
+
"model.layers.37.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 358 |
+
"model.layers.37.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 359 |
+
"model.layers.37.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 360 |
+
"model.layers.38.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 361 |
+
"model.layers.38.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 362 |
+
"model.layers.38.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 363 |
+
"model.layers.38.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 364 |
+
"model.layers.38.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 365 |
+
"model.layers.38.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 366 |
+
"model.layers.38.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 367 |
+
"model.layers.38.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 368 |
+
"model.layers.38.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 369 |
+
"model.layers.38.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 370 |
+
"model.layers.38.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 371 |
+
"model.layers.39.input_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 372 |
+
"model.layers.39.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 373 |
+
"model.layers.39.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 374 |
+
"model.layers.39.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 375 |
+
"model.layers.39.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 376 |
+
"model.layers.39.post_attention_layernorm.bias": "model-00003-of-00003.safetensors",
|
| 377 |
+
"model.layers.39.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 378 |
+
"model.layers.39.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 379 |
+
"model.layers.39.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 380 |
+
"model.layers.39.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 381 |
+
"model.layers.39.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 382 |
+
"model.layers.4.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 383 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 384 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 385 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 386 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 387 |
+
"model.layers.4.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 388 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 389 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 390 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 391 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 392 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 393 |
+
"model.layers.5.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 394 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 395 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 396 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 397 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 398 |
+
"model.layers.5.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 399 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 400 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 401 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 402 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 403 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 404 |
+
"model.layers.6.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 405 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 406 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 407 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 408 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 409 |
+
"model.layers.6.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 410 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 411 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 412 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 413 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 414 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 415 |
+
"model.layers.7.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 416 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 417 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 418 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 419 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 420 |
+
"model.layers.7.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 421 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 422 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 423 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 424 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 425 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 426 |
+
"model.layers.8.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 427 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 428 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 429 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 430 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 431 |
+
"model.layers.8.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 432 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 433 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 434 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 435 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 436 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 437 |
+
"model.layers.9.input_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 438 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 439 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 440 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 441 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 442 |
+
"model.layers.9.post_attention_layernorm.bias": "model-00001-of-00003.safetensors",
|
| 443 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 444 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 445 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 446 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 447 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 448 |
+
"model.norm.bias": "model-00003-of-00003.safetensors",
|
| 449 |
+
"model.norm.weight": "model-00003-of-00003.safetensors"
|
| 450 |
+
}
|
| 451 |
+
}
|
modeling_orion.py
ADDED
|
@@ -0,0 +1,1117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 OrionStar Inc. team. All rights reserved.
|
| 2 |
+
# Copied and adapted from https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py
|
| 3 |
+
|
| 4 |
+
from transformers import AutoConfig, AutoModel
|
| 5 |
+
|
| 6 |
+
from .configuration_orion import OrionConfig
|
| 7 |
+
|
| 8 |
+
import numbers
|
| 9 |
+
import importlib
|
| 10 |
+
import math
|
| 11 |
+
from typing import List, Optional, Tuple, Union
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
from torch.nn.parameter import Parameter
|
| 16 |
+
import torch.utils.checkpoint
|
| 17 |
+
from torch import nn
|
| 18 |
+
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
|
| 19 |
+
from torch.nn import init
|
| 20 |
+
|
| 21 |
+
from transformers.activations import ACT2FN
|
| 22 |
+
from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
|
| 23 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 24 |
+
from transformers.pytorch_utils import ALL_LAYERNORM_LAYERS
|
| 25 |
+
from transformers.utils import (
|
| 26 |
+
add_start_docstrings,
|
| 27 |
+
add_start_docstrings_to_model_forward,
|
| 28 |
+
is_flash_attn_available,
|
| 29 |
+
logging,
|
| 30 |
+
replace_return_docstrings,
|
| 31 |
+
)
|
| 32 |
+
from .generation_utils import build_chat_input, TextIterStreamer
|
| 33 |
+
from transformers.generation.utils import GenerationConfig
|
| 34 |
+
from threading import Thread
|
| 35 |
+
|
| 36 |
+
if is_flash_attn_available():
|
| 37 |
+
from flash_attn import flash_attn_func, flash_attn_varlen_func
|
| 38 |
+
from flash_attn.bert_padding import index_first_axis, pad_input, unpad_input # noqa
|
| 39 |
+
|
| 40 |
+
logger = logging.get_logger(__name__)
|
| 41 |
+
|
| 42 |
+
_CONFIG_FOR_DOC = "OrionConfig"
|
| 43 |
+
|
| 44 |
+
def _get_unpad_data(padding_mask):
|
| 45 |
+
seqlens_in_batch = padding_mask.sum(dim=-1, dtype=torch.int32)
|
| 46 |
+
indices = torch.nonzero(padding_mask.flatten(), as_tuple=False).flatten()
|
| 47 |
+
max_seqlen_in_batch = seqlens_in_batch.max().item()
|
| 48 |
+
cu_seqlens = F.pad(torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.torch.int32), (1, 0))
|
| 49 |
+
return (
|
| 50 |
+
indices,
|
| 51 |
+
cu_seqlens,
|
| 52 |
+
max_seqlen_in_batch,
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
|
| 57 |
+
def _make_causal_mask(
|
| 58 |
+
input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
|
| 59 |
+
):
|
| 60 |
+
"""
|
| 61 |
+
Make causal mask used for bi-directional self-attention.
|
| 62 |
+
"""
|
| 63 |
+
bsz, tgt_len = input_ids_shape
|
| 64 |
+
mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
|
| 65 |
+
mask_cond = torch.arange(mask.size(-1), device=device)
|
| 66 |
+
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
|
| 67 |
+
mask = mask.to(dtype)
|
| 68 |
+
|
| 69 |
+
if past_key_values_length > 0:
|
| 70 |
+
mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
|
| 71 |
+
return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
# Copied from transformers.models.bart.modeling_bart._expand_mask
|
| 75 |
+
def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
|
| 76 |
+
"""
|
| 77 |
+
Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
|
| 78 |
+
"""
|
| 79 |
+
bsz, src_len = mask.size()
|
| 80 |
+
tgt_len = tgt_len if tgt_len is not None else src_len
|
| 81 |
+
|
| 82 |
+
expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
|
| 83 |
+
|
| 84 |
+
inverted_mask = 1.0 - expanded_mask
|
| 85 |
+
|
| 86 |
+
return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
|
| 87 |
+
|
| 88 |
+
class OrionRotaryEmbedding(nn.Module):
|
| 89 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
|
| 90 |
+
super().__init__()
|
| 91 |
+
|
| 92 |
+
self.dim = dim
|
| 93 |
+
self.max_position_embeddings = max_position_embeddings
|
| 94 |
+
self.base = base
|
| 95 |
+
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 96 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 97 |
+
|
| 98 |
+
# Build here to make `torch.jit.trace` work.
|
| 99 |
+
self._set_cos_sin_cache(
|
| 100 |
+
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 104 |
+
self.max_seq_len_cached = seq_len
|
| 105 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 106 |
+
|
| 107 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 108 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 109 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 110 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 111 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 112 |
+
|
| 113 |
+
def forward(self, x, seq_len=None):
|
| 114 |
+
# x: [bs, num_attention_heads, seq_len, head_size]
|
| 115 |
+
if seq_len > self.max_seq_len_cached:
|
| 116 |
+
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
|
| 117 |
+
|
| 118 |
+
return (
|
| 119 |
+
self.cos_cached[:seq_len].to(dtype=x.dtype),
|
| 120 |
+
self.sin_cached[:seq_len].to(dtype=x.dtype),
|
| 121 |
+
)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class OrionLinearScalingRotaryEmbedding(OrionRotaryEmbedding):
|
| 125 |
+
"""OrionRotaryEmbedding extended with linear scaling. Credits to the Reddit user /u/kaiokendev"""
|
| 126 |
+
|
| 127 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 128 |
+
self.scaling_factor = scaling_factor
|
| 129 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 130 |
+
|
| 131 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 132 |
+
self.max_seq_len_cached = seq_len
|
| 133 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 134 |
+
t = t / self.scaling_factor
|
| 135 |
+
|
| 136 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 137 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 138 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 139 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 140 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
class OrionDynamicNTKScalingRotaryEmbedding(OrionRotaryEmbedding):
|
| 144 |
+
"""OrionRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
|
| 145 |
+
|
| 146 |
+
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
|
| 147 |
+
self.scaling_factor = scaling_factor
|
| 148 |
+
super().__init__(dim, max_position_embeddings, base, device)
|
| 149 |
+
|
| 150 |
+
def _set_cos_sin_cache(self, seq_len, device, dtype):
|
| 151 |
+
self.max_seq_len_cached = seq_len
|
| 152 |
+
|
| 153 |
+
if seq_len > self.max_position_embeddings:
|
| 154 |
+
base = self.base * (
|
| 155 |
+
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
|
| 156 |
+
) ** (self.dim / (self.dim - 2))
|
| 157 |
+
inv_freq = 1.0 / (base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
|
| 158 |
+
self.register_buffer("inv_freq", inv_freq, persistent=False)
|
| 159 |
+
|
| 160 |
+
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
|
| 161 |
+
|
| 162 |
+
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
|
| 163 |
+
# Different from paper, but it uses a different permutation in order to obtain the same calculation
|
| 164 |
+
emb = torch.cat((freqs, freqs), dim=-1)
|
| 165 |
+
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
|
| 166 |
+
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def rotate_half(x):
|
| 170 |
+
"""Rotates half the hidden dims of the input."""
|
| 171 |
+
x1 = x[..., : x.shape[-1] // 2]
|
| 172 |
+
x2 = x[..., x.shape[-1] // 2 :]
|
| 173 |
+
return torch.cat((-x2, x1), dim=-1)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
# Copied from transformers.models.gpt_neox.modeling_gpt_neox.apply_rotary_pos_emb
|
| 177 |
+
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
|
| 178 |
+
cos = cos[position_ids].unsqueeze(1) # [seq_len, dim] -> [batch_size, 1, seq_len, head_dim]
|
| 179 |
+
sin = sin[position_ids].unsqueeze(1)
|
| 180 |
+
q_embed = (q * cos) + (rotate_half(q) * sin)
|
| 181 |
+
k_embed = (k * cos) + (rotate_half(k) * sin)
|
| 182 |
+
return q_embed, k_embed
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
class OrionMLP(nn.Module):
|
| 186 |
+
def __init__(self, config):
|
| 187 |
+
super().__init__()
|
| 188 |
+
self.config = config
|
| 189 |
+
self.hidden_size = config.hidden_size
|
| 190 |
+
self.intermediate_size = config.intermediate_size
|
| 191 |
+
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 192 |
+
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 193 |
+
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 194 |
+
self.act_fn = ACT2FN[config.hidden_act]
|
| 195 |
+
|
| 196 |
+
def forward(self, x):
|
| 197 |
+
if self.config.pretraining_tp > 1:
|
| 198 |
+
slice = self.intermediate_size // self.config.pretraining_tp
|
| 199 |
+
gate_proj_slices = self.gate_proj.weight.split(slice, dim=0)
|
| 200 |
+
up_proj_slices = self.up_proj.weight.split(slice, dim=0)
|
| 201 |
+
down_proj_slices = self.down_proj.weight.split(slice, dim=1)
|
| 202 |
+
|
| 203 |
+
gate_proj = torch.cat(
|
| 204 |
+
[F.linear(x, gate_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1
|
| 205 |
+
)
|
| 206 |
+
up_proj = torch.cat([F.linear(x, up_proj_slices[i]) for i in range(self.config.pretraining_tp)], dim=-1)
|
| 207 |
+
|
| 208 |
+
intermediate_states = (self.act_fn(gate_proj) * up_proj).split(slice, dim=2)
|
| 209 |
+
down_proj = [
|
| 210 |
+
F.linear(intermediate_states[i], down_proj_slices[i]) for i in range(self.config.pretraining_tp)
|
| 211 |
+
]
|
| 212 |
+
down_proj = sum(down_proj)
|
| 213 |
+
else:
|
| 214 |
+
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
|
| 215 |
+
|
| 216 |
+
return down_proj
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
| 220 |
+
"""
|
| 221 |
+
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
| 222 |
+
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
| 223 |
+
"""
|
| 224 |
+
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
| 225 |
+
if n_rep == 1:
|
| 226 |
+
return hidden_states
|
| 227 |
+
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
| 228 |
+
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
class OrionAttention(nn.Module):
|
| 232 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 233 |
+
|
| 234 |
+
def __init__(self, config: OrionConfig):
|
| 235 |
+
super().__init__()
|
| 236 |
+
self.config = config
|
| 237 |
+
self.hidden_size = config.hidden_size
|
| 238 |
+
self.num_heads = config.num_attention_heads
|
| 239 |
+
self.head_dim = self.hidden_size // self.num_heads
|
| 240 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 241 |
+
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
|
| 242 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 243 |
+
self.rope_theta = config.rope_theta
|
| 244 |
+
|
| 245 |
+
if (self.head_dim * self.num_heads) != self.hidden_size:
|
| 246 |
+
raise ValueError(
|
| 247 |
+
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
|
| 248 |
+
f" and `num_heads`: {self.num_heads})."
|
| 249 |
+
)
|
| 250 |
+
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)
|
| 251 |
+
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
|
| 252 |
+
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
|
| 253 |
+
self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=config.attention_bias)
|
| 254 |
+
self._init_rope()
|
| 255 |
+
|
| 256 |
+
def _init_rope(self):
|
| 257 |
+
if self.config.rope_scaling is None:
|
| 258 |
+
self.rotary_emb = OrionRotaryEmbedding(
|
| 259 |
+
self.head_dim,
|
| 260 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 261 |
+
base=self.rope_theta,
|
| 262 |
+
)
|
| 263 |
+
else:
|
| 264 |
+
scaling_type = self.config.rope_scaling["type"]
|
| 265 |
+
scaling_factor = self.config.rope_scaling["factor"]
|
| 266 |
+
if scaling_type == "linear":
|
| 267 |
+
self.rotary_emb = OrionLinearScalingRotaryEmbedding(
|
| 268 |
+
self.head_dim,
|
| 269 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 270 |
+
scaling_factor=scaling_factor,
|
| 271 |
+
base=self.rope_theta,
|
| 272 |
+
)
|
| 273 |
+
elif scaling_type == "dynamic":
|
| 274 |
+
self.rotary_emb = OrionDynamicNTKScalingRotaryEmbedding(
|
| 275 |
+
self.head_dim,
|
| 276 |
+
max_position_embeddings=self.max_position_embeddings,
|
| 277 |
+
scaling_factor=scaling_factor,
|
| 278 |
+
base=self.rope_theta,
|
| 279 |
+
)
|
| 280 |
+
else:
|
| 281 |
+
raise ValueError(f"Unknown RoPE scaling type {scaling_type}")
|
| 282 |
+
|
| 283 |
+
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
| 284 |
+
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
| 285 |
+
|
| 286 |
+
def forward(
|
| 287 |
+
self,
|
| 288 |
+
hidden_states: torch.Tensor,
|
| 289 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 290 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 291 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 292 |
+
output_attentions: bool = False,
|
| 293 |
+
use_cache: bool = False,
|
| 294 |
+
padding_mask: Optional[torch.LongTensor] = None,
|
| 295 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 296 |
+
bsz, q_len, _ = hidden_states.size()
|
| 297 |
+
|
| 298 |
+
if self.config.pretraining_tp > 1:
|
| 299 |
+
key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
|
| 300 |
+
query_slices = self.q_proj.weight.split(
|
| 301 |
+
(self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0
|
| 302 |
+
)
|
| 303 |
+
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
|
| 304 |
+
value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
|
| 305 |
+
|
| 306 |
+
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 307 |
+
query_states = torch.cat(query_states, dim=-1)
|
| 308 |
+
|
| 309 |
+
key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 310 |
+
key_states = torch.cat(key_states, dim=-1)
|
| 311 |
+
|
| 312 |
+
value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 313 |
+
value_states = torch.cat(value_states, dim=-1)
|
| 314 |
+
|
| 315 |
+
else:
|
| 316 |
+
query_states = self.q_proj(hidden_states)
|
| 317 |
+
key_states = self.k_proj(hidden_states)
|
| 318 |
+
value_states = self.v_proj(hidden_states)
|
| 319 |
+
|
| 320 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 321 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 322 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 323 |
+
|
| 324 |
+
kv_seq_len = key_states.shape[-2]
|
| 325 |
+
if past_key_value is not None:
|
| 326 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 327 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 328 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 329 |
+
|
| 330 |
+
if past_key_value is not None:
|
| 331 |
+
# reuse k, v, self_attention
|
| 332 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 333 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 334 |
+
|
| 335 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 336 |
+
|
| 337 |
+
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
| 338 |
+
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
| 339 |
+
|
| 340 |
+
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
| 341 |
+
|
| 342 |
+
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
| 343 |
+
raise ValueError(
|
| 344 |
+
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
|
| 345 |
+
f" {attn_weights.size()}"
|
| 346 |
+
)
|
| 347 |
+
|
| 348 |
+
if attention_mask is not None:
|
| 349 |
+
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
| 350 |
+
raise ValueError(
|
| 351 |
+
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
| 352 |
+
)
|
| 353 |
+
attn_weights = attn_weights + attention_mask
|
| 354 |
+
|
| 355 |
+
# upcast attention to fp32
|
| 356 |
+
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
| 357 |
+
attn_output = torch.matmul(attn_weights, value_states)
|
| 358 |
+
|
| 359 |
+
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
| 360 |
+
raise ValueError(
|
| 361 |
+
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
| 362 |
+
f" {attn_output.size()}"
|
| 363 |
+
)
|
| 364 |
+
|
| 365 |
+
attn_output = attn_output.transpose(1, 2).contiguous()
|
| 366 |
+
|
| 367 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
| 368 |
+
|
| 369 |
+
if self.config.pretraining_tp > 1:
|
| 370 |
+
attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
|
| 371 |
+
o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
|
| 372 |
+
attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)])
|
| 373 |
+
else:
|
| 374 |
+
attn_output = self.o_proj(attn_output)
|
| 375 |
+
|
| 376 |
+
if not output_attentions:
|
| 377 |
+
attn_weights = None
|
| 378 |
+
|
| 379 |
+
return attn_output, attn_weights, past_key_value
|
| 380 |
+
|
| 381 |
+
|
| 382 |
+
class OrionFlashAttention2(OrionAttention):
|
| 383 |
+
"""
|
| 384 |
+
Orion flash attention module. This module inherits from `OrionAttention` as the weights of the module stays
|
| 385 |
+
untouched. The only required change would be on the forward pass where it needs to correctly call the public API of
|
| 386 |
+
flash attention and deal with padding tokens in case the input contains any of them.
|
| 387 |
+
"""
|
| 388 |
+
|
| 389 |
+
def forward(
|
| 390 |
+
self,
|
| 391 |
+
hidden_states: torch.Tensor,
|
| 392 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 393 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 394 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 395 |
+
output_attentions: bool = False,
|
| 396 |
+
use_cache: bool = False,
|
| 397 |
+
padding_mask: Optional[torch.LongTensor] = None,
|
| 398 |
+
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
| 399 |
+
# OrionFlashAttention2 attention does not support output_attentions
|
| 400 |
+
output_attentions = False
|
| 401 |
+
|
| 402 |
+
bsz, q_len, _ = hidden_states.size()
|
| 403 |
+
|
| 404 |
+
query_states = self.q_proj(hidden_states)
|
| 405 |
+
key_states = self.k_proj(hidden_states)
|
| 406 |
+
value_states = self.v_proj(hidden_states)
|
| 407 |
+
|
| 408 |
+
# Flash attention requires the input to have the shape
|
| 409 |
+
# batch_size x seq_length x head_dime x hidden_dim
|
| 410 |
+
# therefore we just need to keep the original shape
|
| 411 |
+
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
| 412 |
+
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 413 |
+
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
| 414 |
+
|
| 415 |
+
kv_seq_len = key_states.shape[-2]
|
| 416 |
+
if past_key_value is not None:
|
| 417 |
+
kv_seq_len += past_key_value[0].shape[-2]
|
| 418 |
+
|
| 419 |
+
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
| 420 |
+
|
| 421 |
+
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
| 422 |
+
|
| 423 |
+
if past_key_value is not None:
|
| 424 |
+
# reuse k, v, self_attention
|
| 425 |
+
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
| 426 |
+
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
| 427 |
+
|
| 428 |
+
past_key_value = (key_states, value_states) if use_cache else None
|
| 429 |
+
|
| 430 |
+
query_states = query_states.transpose(1, 2)
|
| 431 |
+
key_states = key_states.transpose(1, 2)
|
| 432 |
+
value_states = value_states.transpose(1, 2)
|
| 433 |
+
|
| 434 |
+
# TODO: llama does not have dropout in the config??
|
| 435 |
+
# It is recommended to use dropout with FA according to the docs
|
| 436 |
+
# when training.
|
| 437 |
+
dropout_rate = 0.0 # if not self.training else self.attn_dropout
|
| 438 |
+
|
| 439 |
+
# In PEFT, usually we cast the layer norms in float32 for training stability reasons
|
| 440 |
+
# therefore the input hidden states gets silently casted in float32. Hence, we need
|
| 441 |
+
# cast them back in float16 just to be sure everything works as expected.
|
| 442 |
+
# This might slowdown training & inference so it is recommended to not cast the LayerNorms
|
| 443 |
+
# in fp32. (LlamaRMSNorm handles it correctly)
|
| 444 |
+
input_dtype = query_states.dtype
|
| 445 |
+
if input_dtype == torch.float32:
|
| 446 |
+
logger.warning_once(
|
| 447 |
+
"The input hidden states seems to be silently casted in float32, this might be related to"
|
| 448 |
+
" the fact you have upcasted embedding or layer norm layers in float32. We will cast back the input in"
|
| 449 |
+
" float16."
|
| 450 |
+
)
|
| 451 |
+
|
| 452 |
+
query_states = query_states.to(torch.float16)
|
| 453 |
+
key_states = key_states.to(torch.float16)
|
| 454 |
+
value_states = value_states.to(torch.float16)
|
| 455 |
+
|
| 456 |
+
attn_output = self._flash_attention_forward(
|
| 457 |
+
query_states, key_states, value_states, padding_mask, q_len, dropout=dropout_rate
|
| 458 |
+
)
|
| 459 |
+
|
| 460 |
+
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size).contiguous()
|
| 461 |
+
attn_output = self.o_proj(attn_output)
|
| 462 |
+
|
| 463 |
+
if not output_attentions:
|
| 464 |
+
attn_weights = None
|
| 465 |
+
|
| 466 |
+
return attn_output, attn_weights, past_key_value
|
| 467 |
+
|
| 468 |
+
def _flash_attention_forward(
|
| 469 |
+
self, query_states, key_states, value_states, padding_mask, query_length, dropout=0.0, softmax_scale=None
|
| 470 |
+
):
|
| 471 |
+
"""
|
| 472 |
+
Calls the forward method of Flash Attention - if the input hidden states contain at least one padding token
|
| 473 |
+
first unpad the input, then computes the attention scores and pad the final attention scores.
|
| 474 |
+
|
| 475 |
+
Args:
|
| 476 |
+
query_states (`torch.Tensor`):
|
| 477 |
+
Input query states to be passed to Flash Attention API
|
| 478 |
+
key_states (`torch.Tensor`):
|
| 479 |
+
Input key states to be passed to Flash Attention API
|
| 480 |
+
value_states (`torch.Tensor`):
|
| 481 |
+
Input value states to be passed to Flash Attention API
|
| 482 |
+
padding_mask (`torch.Tensor`):
|
| 483 |
+
The padding mask - corresponds to a tensor of size `(batch_size, seq_len)` where 0 stands for the
|
| 484 |
+
position of padding tokens and 1 for the position of non-padding tokens.
|
| 485 |
+
dropout (`int`, *optional*):
|
| 486 |
+
Attention dropout
|
| 487 |
+
softmax_scale (`float`, *optional*):
|
| 488 |
+
The scaling of QK^T before applying softmax. Default to 1 / sqrt(head_dim)
|
| 489 |
+
"""
|
| 490 |
+
# Contains at least one padding token in the sequence
|
| 491 |
+
if padding_mask is not None:
|
| 492 |
+
batch_size = query_states.shape[0]
|
| 493 |
+
query_states, key_states, value_states, indices_q, cu_seq_lens, max_seq_lens = self._upad_input(
|
| 494 |
+
query_states, key_states, value_states, padding_mask, query_length
|
| 495 |
+
)
|
| 496 |
+
|
| 497 |
+
cu_seqlens_q, cu_seqlens_k = cu_seq_lens
|
| 498 |
+
max_seqlen_in_batch_q, max_seqlen_in_batch_k = max_seq_lens
|
| 499 |
+
|
| 500 |
+
attn_output_unpad = flash_attn_varlen_func(
|
| 501 |
+
query_states,
|
| 502 |
+
key_states,
|
| 503 |
+
value_states,
|
| 504 |
+
cu_seqlens_q=cu_seqlens_q,
|
| 505 |
+
cu_seqlens_k=cu_seqlens_k,
|
| 506 |
+
max_seqlen_q=max_seqlen_in_batch_q,
|
| 507 |
+
max_seqlen_k=max_seqlen_in_batch_k,
|
| 508 |
+
dropout_p=dropout,
|
| 509 |
+
softmax_scale=softmax_scale,
|
| 510 |
+
causal=True,
|
| 511 |
+
)
|
| 512 |
+
|
| 513 |
+
attn_output = pad_input(attn_output_unpad, indices_q, batch_size, query_length)
|
| 514 |
+
else:
|
| 515 |
+
attn_output = flash_attn_func(
|
| 516 |
+
query_states, key_states, value_states, dropout, softmax_scale=softmax_scale, causal=True
|
| 517 |
+
)
|
| 518 |
+
|
| 519 |
+
return attn_output
|
| 520 |
+
|
| 521 |
+
def _upad_input(self, query_layer, key_layer, value_layer, padding_mask, query_length):
|
| 522 |
+
indices_k, cu_seqlens_k, max_seqlen_in_batch_k = _get_unpad_data(padding_mask)
|
| 523 |
+
batch_size, kv_seq_len, num_key_value_heads, head_dim = key_layer.shape
|
| 524 |
+
|
| 525 |
+
key_layer = index_first_axis(
|
| 526 |
+
key_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 527 |
+
)
|
| 528 |
+
value_layer = index_first_axis(
|
| 529 |
+
value_layer.reshape(batch_size * kv_seq_len, num_key_value_heads, head_dim), indices_k
|
| 530 |
+
)
|
| 531 |
+
if query_length == kv_seq_len:
|
| 532 |
+
query_layer = index_first_axis(
|
| 533 |
+
query_layer.reshape(batch_size * kv_seq_len, self.num_heads, head_dim), indices_k
|
| 534 |
+
)
|
| 535 |
+
cu_seqlens_q = cu_seqlens_k
|
| 536 |
+
max_seqlen_in_batch_q = max_seqlen_in_batch_k
|
| 537 |
+
indices_q = indices_k
|
| 538 |
+
elif query_length == 1:
|
| 539 |
+
max_seqlen_in_batch_q = 1
|
| 540 |
+
cu_seqlens_q = torch.arange(
|
| 541 |
+
batch_size + 1, dtype=torch.int32, device=query_layer.device
|
| 542 |
+
) # There is a memcpy here, that is very bad.
|
| 543 |
+
indices_q = cu_seqlens_q[:-1]
|
| 544 |
+
query_layer = query_layer.squeeze(1)
|
| 545 |
+
else:
|
| 546 |
+
# The -q_len: slice assumes left padding.
|
| 547 |
+
padding_mask = padding_mask[:, -query_length:]
|
| 548 |
+
query_layer, indices_q, cu_seqlens_q, max_seqlen_in_batch_q = unpad_input(query_layer, padding_mask)
|
| 549 |
+
|
| 550 |
+
return (
|
| 551 |
+
query_layer,
|
| 552 |
+
key_layer,
|
| 553 |
+
value_layer,
|
| 554 |
+
indices_q,
|
| 555 |
+
(cu_seqlens_q, cu_seqlens_k),
|
| 556 |
+
(max_seqlen_in_batch_q, max_seqlen_in_batch_k),
|
| 557 |
+
)
|
| 558 |
+
|
| 559 |
+
|
| 560 |
+
class OrionDecoderLayer(nn.Module):
|
| 561 |
+
def __init__(self, config: OrionConfig):
|
| 562 |
+
super().__init__()
|
| 563 |
+
self.hidden_size = config.hidden_size
|
| 564 |
+
self.self_attn = (
|
| 565 |
+
OrionAttention(config=config)
|
| 566 |
+
if not getattr(config, "_flash_attn_2_enabled", False)
|
| 567 |
+
else OrionFlashAttention2(config=config)
|
| 568 |
+
)
|
| 569 |
+
self.mlp = OrionMLP(config)
|
| 570 |
+
self.input_layernorm = nn.LayerNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 571 |
+
self.post_attention_layernorm = nn.LayerNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 572 |
+
|
| 573 |
+
def forward(
|
| 574 |
+
self,
|
| 575 |
+
hidden_states: torch.Tensor,
|
| 576 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 577 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 578 |
+
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
| 579 |
+
output_attentions: Optional[bool] = False,
|
| 580 |
+
use_cache: Optional[bool] = False,
|
| 581 |
+
padding_mask: Optional[torch.LongTensor] = None,
|
| 582 |
+
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
| 583 |
+
"""
|
| 584 |
+
Args:
|
| 585 |
+
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 586 |
+
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
|
| 587 |
+
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
| 588 |
+
output_attentions (`bool`, *optional*):
|
| 589 |
+
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
| 590 |
+
returned tensors for more detail.
|
| 591 |
+
use_cache (`bool`, *optional*):
|
| 592 |
+
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
| 593 |
+
(see `past_key_values`).
|
| 594 |
+
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
| 595 |
+
"""
|
| 596 |
+
|
| 597 |
+
residual = hidden_states
|
| 598 |
+
|
| 599 |
+
hidden_states = self.input_layernorm(hidden_states)
|
| 600 |
+
|
| 601 |
+
# Self Attention
|
| 602 |
+
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
| 603 |
+
hidden_states=hidden_states,
|
| 604 |
+
attention_mask=attention_mask,
|
| 605 |
+
position_ids=position_ids,
|
| 606 |
+
past_key_value=past_key_value,
|
| 607 |
+
output_attentions=output_attentions,
|
| 608 |
+
use_cache=use_cache,
|
| 609 |
+
padding_mask=padding_mask,
|
| 610 |
+
)
|
| 611 |
+
hidden_states = residual + hidden_states
|
| 612 |
+
|
| 613 |
+
# Fully Connected
|
| 614 |
+
residual = hidden_states
|
| 615 |
+
hidden_states = self.post_attention_layernorm(hidden_states)
|
| 616 |
+
hidden_states = self.mlp(hidden_states)
|
| 617 |
+
hidden_states = residual + hidden_states
|
| 618 |
+
|
| 619 |
+
outputs = (hidden_states,)
|
| 620 |
+
|
| 621 |
+
if output_attentions:
|
| 622 |
+
outputs += (self_attn_weights,)
|
| 623 |
+
|
| 624 |
+
if use_cache:
|
| 625 |
+
outputs += (present_key_value,)
|
| 626 |
+
|
| 627 |
+
return outputs
|
| 628 |
+
|
| 629 |
+
class OrionPreTrainedModel(PreTrainedModel):
|
| 630 |
+
config_class = OrionConfig
|
| 631 |
+
base_model_prefix = "model"
|
| 632 |
+
supports_gradient_checkpointing = True
|
| 633 |
+
_no_split_modules = ["OrionDecoderLayer"]
|
| 634 |
+
_skip_keys_device_placement = "past_key_values"
|
| 635 |
+
_supports_flash_attn_2 = True
|
| 636 |
+
|
| 637 |
+
def _init_weights(self, module):
|
| 638 |
+
std = self.config.initializer_range
|
| 639 |
+
if isinstance(module, nn.Linear):
|
| 640 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 641 |
+
if module.bias is not None:
|
| 642 |
+
module.bias.data.zero_()
|
| 643 |
+
elif isinstance(module, nn.Embedding):
|
| 644 |
+
module.weight.data.normal_(mean=0.0, std=std)
|
| 645 |
+
if module.padding_idx is not None:
|
| 646 |
+
module.weight.data[module.padding_idx].zero_()
|
| 647 |
+
|
| 648 |
+
def _set_gradient_checkpointing(self, module, value=False):
|
| 649 |
+
if isinstance(module, OrionModel):
|
| 650 |
+
module.gradient_checkpointing = value
|
| 651 |
+
|
| 652 |
+
class OrionModel(OrionPreTrainedModel):
|
| 653 |
+
"""
|
| 654 |
+
Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`OrionDecoderLayer`]
|
| 655 |
+
|
| 656 |
+
Args:
|
| 657 |
+
config: OrionConfig
|
| 658 |
+
"""
|
| 659 |
+
|
| 660 |
+
def __init__(self, config: OrionConfig):
|
| 661 |
+
super().__init__(config)
|
| 662 |
+
self.padding_idx = config.pad_token_id
|
| 663 |
+
self.vocab_size = config.vocab_size
|
| 664 |
+
|
| 665 |
+
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
|
| 666 |
+
self.layers = nn.ModuleList([OrionDecoderLayer(config) for _ in range(config.num_hidden_layers)])
|
| 667 |
+
self.norm = nn.LayerNorm(config.hidden_size, eps=config.rms_norm_eps)
|
| 668 |
+
|
| 669 |
+
self.gradient_checkpointing = False
|
| 670 |
+
# Initialize weights and apply final processing
|
| 671 |
+
self.post_init()
|
| 672 |
+
|
| 673 |
+
def get_input_embeddings(self):
|
| 674 |
+
return self.embed_tokens
|
| 675 |
+
|
| 676 |
+
def set_input_embeddings(self, value):
|
| 677 |
+
self.embed_tokens = value
|
| 678 |
+
|
| 679 |
+
# Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
|
| 680 |
+
def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
|
| 681 |
+
# create causal mask
|
| 682 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 683 |
+
combined_attention_mask = None
|
| 684 |
+
if input_shape[-1] > 1:
|
| 685 |
+
combined_attention_mask = _make_causal_mask(
|
| 686 |
+
input_shape,
|
| 687 |
+
inputs_embeds.dtype,
|
| 688 |
+
device=inputs_embeds.device,
|
| 689 |
+
past_key_values_length=past_key_values_length,
|
| 690 |
+
)
|
| 691 |
+
|
| 692 |
+
if attention_mask is not None:
|
| 693 |
+
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
|
| 694 |
+
expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
|
| 695 |
+
inputs_embeds.device
|
| 696 |
+
)
|
| 697 |
+
combined_attention_mask = (
|
| 698 |
+
expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
|
| 699 |
+
)
|
| 700 |
+
|
| 701 |
+
return combined_attention_mask
|
| 702 |
+
|
| 703 |
+
def forward(
|
| 704 |
+
self,
|
| 705 |
+
input_ids: torch.LongTensor = None,
|
| 706 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 707 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 708 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 709 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 710 |
+
use_cache: Optional[bool] = None,
|
| 711 |
+
output_attentions: Optional[bool] = None,
|
| 712 |
+
output_hidden_states: Optional[bool] = None,
|
| 713 |
+
return_dict: Optional[bool] = None,
|
| 714 |
+
) -> Union[Tuple, BaseModelOutputWithPast]:
|
| 715 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 716 |
+
output_hidden_states = (
|
| 717 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 718 |
+
)
|
| 719 |
+
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 720 |
+
|
| 721 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 722 |
+
|
| 723 |
+
# retrieve input_ids and inputs_embeds
|
| 724 |
+
if input_ids is not None and inputs_embeds is not None:
|
| 725 |
+
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
| 726 |
+
elif input_ids is not None:
|
| 727 |
+
batch_size, seq_length = input_ids.shape
|
| 728 |
+
elif inputs_embeds is not None:
|
| 729 |
+
batch_size, seq_length, _ = inputs_embeds.shape
|
| 730 |
+
else:
|
| 731 |
+
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
| 732 |
+
|
| 733 |
+
seq_length_with_past = seq_length
|
| 734 |
+
past_key_values_length = 0
|
| 735 |
+
|
| 736 |
+
if past_key_values is not None:
|
| 737 |
+
past_key_values_length = past_key_values[0][0].shape[2]
|
| 738 |
+
seq_length_with_past = seq_length_with_past + past_key_values_length
|
| 739 |
+
|
| 740 |
+
if position_ids is None:
|
| 741 |
+
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
| 742 |
+
position_ids = torch.arange(
|
| 743 |
+
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
| 744 |
+
)
|
| 745 |
+
position_ids = position_ids.unsqueeze(0)
|
| 746 |
+
|
| 747 |
+
if inputs_embeds is None:
|
| 748 |
+
inputs_embeds = self.embed_tokens(input_ids)
|
| 749 |
+
# embed positions
|
| 750 |
+
if attention_mask is None:
|
| 751 |
+
attention_mask = torch.ones(
|
| 752 |
+
(batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device
|
| 753 |
+
)
|
| 754 |
+
padding_mask = None
|
| 755 |
+
else:
|
| 756 |
+
if 0 in attention_mask:
|
| 757 |
+
padding_mask = attention_mask
|
| 758 |
+
else:
|
| 759 |
+
padding_mask = None
|
| 760 |
+
|
| 761 |
+
attention_mask = self._prepare_decoder_attention_mask(
|
| 762 |
+
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
|
| 763 |
+
)
|
| 764 |
+
|
| 765 |
+
hidden_states = inputs_embeds
|
| 766 |
+
|
| 767 |
+
if self.gradient_checkpointing and self.training:
|
| 768 |
+
if use_cache:
|
| 769 |
+
logger.warning_once(
|
| 770 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 771 |
+
)
|
| 772 |
+
use_cache = False
|
| 773 |
+
|
| 774 |
+
# decoder layers
|
| 775 |
+
all_hidden_states = () if output_hidden_states else None
|
| 776 |
+
all_self_attns = () if output_attentions else None
|
| 777 |
+
next_decoder_cache = () if use_cache else None
|
| 778 |
+
|
| 779 |
+
for idx, decoder_layer in enumerate(self.layers):
|
| 780 |
+
if output_hidden_states:
|
| 781 |
+
all_hidden_states += (hidden_states,)
|
| 782 |
+
|
| 783 |
+
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
| 784 |
+
|
| 785 |
+
if self.gradient_checkpointing and self.training:
|
| 786 |
+
|
| 787 |
+
def create_custom_forward(module):
|
| 788 |
+
def custom_forward(*inputs):
|
| 789 |
+
# None for past_key_value
|
| 790 |
+
return module(*inputs, past_key_value, output_attentions, padding_mask=padding_mask)
|
| 791 |
+
|
| 792 |
+
return custom_forward
|
| 793 |
+
|
| 794 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 795 |
+
create_custom_forward(decoder_layer), hidden_states, attention_mask, position_ids
|
| 796 |
+
)
|
| 797 |
+
else:
|
| 798 |
+
layer_outputs = decoder_layer(
|
| 799 |
+
hidden_states,
|
| 800 |
+
attention_mask=attention_mask,
|
| 801 |
+
position_ids=position_ids,
|
| 802 |
+
past_key_value=past_key_value,
|
| 803 |
+
output_attentions=output_attentions,
|
| 804 |
+
use_cache=use_cache,
|
| 805 |
+
padding_mask=padding_mask,
|
| 806 |
+
)
|
| 807 |
+
|
| 808 |
+
hidden_states = layer_outputs[0]
|
| 809 |
+
|
| 810 |
+
if use_cache:
|
| 811 |
+
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
|
| 812 |
+
|
| 813 |
+
if output_attentions:
|
| 814 |
+
all_self_attns += (layer_outputs[1],)
|
| 815 |
+
|
| 816 |
+
hidden_states = self.norm(hidden_states)
|
| 817 |
+
|
| 818 |
+
# add hidden states from the last decoder layer
|
| 819 |
+
if output_hidden_states:
|
| 820 |
+
all_hidden_states += (hidden_states,)
|
| 821 |
+
|
| 822 |
+
next_cache = next_decoder_cache if use_cache else None
|
| 823 |
+
if not return_dict:
|
| 824 |
+
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
| 825 |
+
return BaseModelOutputWithPast(
|
| 826 |
+
last_hidden_state=hidden_states,
|
| 827 |
+
past_key_values=next_cache,
|
| 828 |
+
hidden_states=all_hidden_states,
|
| 829 |
+
attentions=all_self_attns,
|
| 830 |
+
)
|
| 831 |
+
|
| 832 |
+
|
| 833 |
+
class OrionForCausalLM(OrionPreTrainedModel):
|
| 834 |
+
model_type = "orion"
|
| 835 |
+
_tied_weights_keys = ["lm_head.weight"]
|
| 836 |
+
|
| 837 |
+
def __init__(self, config):
|
| 838 |
+
super().__init__(config)
|
| 839 |
+
self.model = OrionModel(config)
|
| 840 |
+
self.vocab_size = config.vocab_size
|
| 841 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 842 |
+
|
| 843 |
+
# Initialize weights and apply final processing
|
| 844 |
+
self.post_init()
|
| 845 |
+
|
| 846 |
+
def get_input_embeddings(self):
|
| 847 |
+
return self.model.embed_tokens
|
| 848 |
+
|
| 849 |
+
def set_input_embeddings(self, value):
|
| 850 |
+
self.model.embed_tokens = value
|
| 851 |
+
|
| 852 |
+
def get_output_embeddings(self):
|
| 853 |
+
return self.lm_head
|
| 854 |
+
|
| 855 |
+
def set_output_embeddings(self, new_embeddings):
|
| 856 |
+
self.lm_head = new_embeddings
|
| 857 |
+
|
| 858 |
+
def set_decoder(self, decoder):
|
| 859 |
+
self.model = decoder
|
| 860 |
+
|
| 861 |
+
def get_decoder(self):
|
| 862 |
+
return self.model
|
| 863 |
+
|
| 864 |
+
@replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
|
| 865 |
+
def forward(
|
| 866 |
+
self,
|
| 867 |
+
input_ids: torch.LongTensor = None,
|
| 868 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 869 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 870 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 871 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 872 |
+
labels: Optional[torch.LongTensor] = None,
|
| 873 |
+
use_cache: Optional[bool] = None,
|
| 874 |
+
output_attentions: Optional[bool] = None,
|
| 875 |
+
output_hidden_states: Optional[bool] = None,
|
| 876 |
+
return_dict: Optional[bool] = None,
|
| 877 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 878 |
+
r"""
|
| 879 |
+
Args:
|
| 880 |
+
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
| 881 |
+
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
| 882 |
+
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
| 883 |
+
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
| 884 |
+
|
| 885 |
+
Returns:
|
| 886 |
+
|
| 887 |
+
Example:
|
| 888 |
+
|
| 889 |
+
```python
|
| 890 |
+
>>> from transformers import AutoTokenizer, OrionForCausalLM
|
| 891 |
+
|
| 892 |
+
>>> model = OrionForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
|
| 893 |
+
>>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
|
| 894 |
+
|
| 895 |
+
>>> prompt = "Hey, are you conscious? Can you talk to me?"
|
| 896 |
+
>>> inputs = tokenizer(prompt, return_tensors="pt")
|
| 897 |
+
|
| 898 |
+
>>> # Generate
|
| 899 |
+
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
|
| 900 |
+
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
|
| 901 |
+
"Hey, are you conscious? Can you talk to me?\nI'm not conscious, but I can talk to you."
|
| 902 |
+
```"""
|
| 903 |
+
|
| 904 |
+
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
| 905 |
+
output_hidden_states = (
|
| 906 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 907 |
+
)
|
| 908 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 909 |
+
|
| 910 |
+
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
| 911 |
+
outputs = self.model(
|
| 912 |
+
input_ids=input_ids,
|
| 913 |
+
attention_mask=attention_mask,
|
| 914 |
+
position_ids=position_ids,
|
| 915 |
+
past_key_values=past_key_values,
|
| 916 |
+
inputs_embeds=inputs_embeds,
|
| 917 |
+
use_cache=use_cache,
|
| 918 |
+
output_attentions=output_attentions,
|
| 919 |
+
output_hidden_states=output_hidden_states,
|
| 920 |
+
return_dict=return_dict,
|
| 921 |
+
)
|
| 922 |
+
|
| 923 |
+
hidden_states = outputs[0]
|
| 924 |
+
if self.config.pretraining_tp > 1:
|
| 925 |
+
lm_head_slices = self.lm_head.weight.split(self.vocab_size // self.config.pretraining_tp, dim=0)
|
| 926 |
+
logits = [F.linear(hidden_states, lm_head_slices[i]) for i in range(self.config.pretraining_tp)]
|
| 927 |
+
logits = torch.cat(logits, dim=-1)
|
| 928 |
+
else:
|
| 929 |
+
logits = self.lm_head(hidden_states)
|
| 930 |
+
logits = logits.float()
|
| 931 |
+
|
| 932 |
+
loss = None
|
| 933 |
+
if labels is not None:
|
| 934 |
+
# Shift so that tokens < n predict n
|
| 935 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 936 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 937 |
+
# Flatten the tokens
|
| 938 |
+
loss_fct = CrossEntropyLoss()
|
| 939 |
+
shift_logits = shift_logits.view(-1, self.config.vocab_size)
|
| 940 |
+
shift_labels = shift_labels.view(-1)
|
| 941 |
+
# Enable model parallelism
|
| 942 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 943 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 944 |
+
|
| 945 |
+
if not return_dict:
|
| 946 |
+
output = (logits,) + outputs[1:]
|
| 947 |
+
return (loss,) + output if loss is not None else output
|
| 948 |
+
|
| 949 |
+
return CausalLMOutputWithPast(
|
| 950 |
+
loss=loss,
|
| 951 |
+
logits=logits,
|
| 952 |
+
past_key_values=outputs.past_key_values,
|
| 953 |
+
hidden_states=outputs.hidden_states,
|
| 954 |
+
attentions=outputs.attentions,
|
| 955 |
+
)
|
| 956 |
+
|
| 957 |
+
def chat(self, tokenizer, messages: List[dict], streaming=False,generation_config: Optional[GenerationConfig]=None):
|
| 958 |
+
generation_config = generation_config or self.generation_config
|
| 959 |
+
input_tokens = build_chat_input(tokenizer,messages)
|
| 960 |
+
input_ids = torch.LongTensor([input_tokens]).to(self.device)
|
| 961 |
+
|
| 962 |
+
if streaming:
|
| 963 |
+
streamer = TextIterStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
|
| 964 |
+
Thread(target=self.generate, kwargs=dict(
|
| 965 |
+
inputs=input_ids, streamer=streamer,
|
| 966 |
+
generation_config=generation_config,
|
| 967 |
+
)).start()
|
| 968 |
+
return streamer
|
| 969 |
+
else:
|
| 970 |
+
outputs = self.generate(input_ids, generation_config=generation_config)
|
| 971 |
+
response = tokenizer.decode(outputs[0][len(input_ids[0]):], skip_special_tokens=True)
|
| 972 |
+
return response
|
| 973 |
+
|
| 974 |
+
def prepare_inputs_for_generation(
|
| 975 |
+
self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
|
| 976 |
+
):
|
| 977 |
+
if past_key_values:
|
| 978 |
+
input_ids = input_ids[:, -1:]
|
| 979 |
+
|
| 980 |
+
position_ids = kwargs.get("position_ids", None)
|
| 981 |
+
if attention_mask is not None and position_ids is None:
|
| 982 |
+
# create position_ids on the fly for batch generation
|
| 983 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 984 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 985 |
+
if past_key_values:
|
| 986 |
+
position_ids = position_ids[:, -1].unsqueeze(-1)
|
| 987 |
+
|
| 988 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 989 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 990 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 991 |
+
else:
|
| 992 |
+
model_inputs = {"input_ids": input_ids}
|
| 993 |
+
|
| 994 |
+
model_inputs.update(
|
| 995 |
+
{
|
| 996 |
+
"position_ids": position_ids,
|
| 997 |
+
"past_key_values": past_key_values,
|
| 998 |
+
"use_cache": kwargs.get("use_cache"),
|
| 999 |
+
"attention_mask": attention_mask,
|
| 1000 |
+
}
|
| 1001 |
+
)
|
| 1002 |
+
return model_inputs
|
| 1003 |
+
|
| 1004 |
+
@staticmethod
|
| 1005 |
+
def _reorder_cache(past_key_values, beam_idx):
|
| 1006 |
+
reordered_past = ()
|
| 1007 |
+
for layer_past in past_key_values:
|
| 1008 |
+
reordered_past += (
|
| 1009 |
+
tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past),
|
| 1010 |
+
)
|
| 1011 |
+
return reordered_past
|
| 1012 |
+
|
| 1013 |
+
class OrionForSequenceClassification(OrionPreTrainedModel):
|
| 1014 |
+
def __init__(self, config):
|
| 1015 |
+
super().__init__(config)
|
| 1016 |
+
self.num_labels = config.num_labels
|
| 1017 |
+
self.model = OrionModel(config)
|
| 1018 |
+
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
|
| 1019 |
+
|
| 1020 |
+
# Initialize weights and apply final processing
|
| 1021 |
+
self.post_init()
|
| 1022 |
+
|
| 1023 |
+
def get_input_embeddings(self):
|
| 1024 |
+
return self.model.embed_tokens
|
| 1025 |
+
|
| 1026 |
+
def set_input_embeddings(self, value):
|
| 1027 |
+
self.model.embed_tokens = value
|
| 1028 |
+
|
| 1029 |
+
def forward(
|
| 1030 |
+
self,
|
| 1031 |
+
input_ids: torch.LongTensor = None,
|
| 1032 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 1033 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 1034 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 1035 |
+
inputs_embeds: Optional[torch.FloatTensor] = None,
|
| 1036 |
+
labels: Optional[torch.LongTensor] = None,
|
| 1037 |
+
use_cache: Optional[bool] = None,
|
| 1038 |
+
output_attentions: Optional[bool] = None,
|
| 1039 |
+
output_hidden_states: Optional[bool] = None,
|
| 1040 |
+
return_dict: Optional[bool] = None,
|
| 1041 |
+
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
|
| 1042 |
+
r"""
|
| 1043 |
+
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
|
| 1044 |
+
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
|
| 1045 |
+
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
|
| 1046 |
+
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
|
| 1047 |
+
"""
|
| 1048 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 1049 |
+
|
| 1050 |
+
transformer_outputs = self.model(
|
| 1051 |
+
input_ids,
|
| 1052 |
+
attention_mask=attention_mask,
|
| 1053 |
+
position_ids=position_ids,
|
| 1054 |
+
past_key_values=past_key_values,
|
| 1055 |
+
inputs_embeds=inputs_embeds,
|
| 1056 |
+
use_cache=use_cache,
|
| 1057 |
+
output_attentions=output_attentions,
|
| 1058 |
+
output_hidden_states=output_hidden_states,
|
| 1059 |
+
return_dict=return_dict,
|
| 1060 |
+
)
|
| 1061 |
+
hidden_states = transformer_outputs[0]
|
| 1062 |
+
logits = self.score(hidden_states)
|
| 1063 |
+
|
| 1064 |
+
if input_ids is not None:
|
| 1065 |
+
batch_size = input_ids.shape[0]
|
| 1066 |
+
else:
|
| 1067 |
+
batch_size = inputs_embeds.shape[0]
|
| 1068 |
+
|
| 1069 |
+
if self.config.pad_token_id is None and batch_size != 1:
|
| 1070 |
+
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
|
| 1071 |
+
if self.config.pad_token_id is None:
|
| 1072 |
+
sequence_lengths = -1
|
| 1073 |
+
else:
|
| 1074 |
+
if input_ids is not None:
|
| 1075 |
+
sequence_lengths = (torch.eq(input_ids, self.config.pad_token_id).long().argmax(-1) - 1).to(
|
| 1076 |
+
logits.device
|
| 1077 |
+
)
|
| 1078 |
+
else:
|
| 1079 |
+
sequence_lengths = -1
|
| 1080 |
+
|
| 1081 |
+
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
|
| 1082 |
+
|
| 1083 |
+
loss = None
|
| 1084 |
+
if labels is not None:
|
| 1085 |
+
labels = labels.to(logits.device)
|
| 1086 |
+
if self.config.problem_type is None:
|
| 1087 |
+
if self.num_labels == 1:
|
| 1088 |
+
self.config.problem_type = "regression"
|
| 1089 |
+
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
|
| 1090 |
+
self.config.problem_type = "single_label_classification"
|
| 1091 |
+
else:
|
| 1092 |
+
self.config.problem_type = "multi_label_classification"
|
| 1093 |
+
|
| 1094 |
+
if self.config.problem_type == "regression":
|
| 1095 |
+
loss_fct = MSELoss()
|
| 1096 |
+
if self.num_labels == 1:
|
| 1097 |
+
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
|
| 1098 |
+
else:
|
| 1099 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1100 |
+
elif self.config.problem_type == "single_label_classification":
|
| 1101 |
+
loss_fct = CrossEntropyLoss()
|
| 1102 |
+
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
|
| 1103 |
+
elif self.config.problem_type == "multi_label_classification":
|
| 1104 |
+
loss_fct = BCEWithLogitsLoss()
|
| 1105 |
+
loss = loss_fct(pooled_logits, labels)
|
| 1106 |
+
if not return_dict:
|
| 1107 |
+
output = (pooled_logits,) + transformer_outputs[1:]
|
| 1108 |
+
return ((loss,) + output) if loss is not None else output
|
| 1109 |
+
|
| 1110 |
+
return SequenceClassifierOutputWithPast(
|
| 1111 |
+
loss=loss,
|
| 1112 |
+
logits=pooled_logits,
|
| 1113 |
+
past_key_values=transformer_outputs.past_key_values,
|
| 1114 |
+
hidden_states=transformer_outputs.hidden_states,
|
| 1115 |
+
attentions=transformer_outputs.attentions,
|
| 1116 |
+
)
|
| 1117 |
+
|
output-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:61e82e5191a8b2f2bd4b013f42cbea10b9b0c5b0f441b4784ee28810c1dac809
|
| 3 |
+
size 8572587936
|
output-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0e90f655c4fdb1929a0cb68e34c2c2712c8879b9d0ec9b351e75efc00499c493
|
| 3 |
+
size 2867172176
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"unk_token": {
|
| 17 |
+
"content": "<unk>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": true,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"pad_token": {
|
| 24 |
+
"content": "<unk>",
|
| 25 |
+
"lstrip": false,
|
| 26 |
+
"normalized": true,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
}
|
| 30 |
+
}
|
tokenization_orion.py
ADDED
|
@@ -0,0 +1,255 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024, OrionStar Inc. All rights reserved.
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
from shutil import copyfile
|
| 5 |
+
from typing import Any, Dict, List, Optional, Tuple
|
| 6 |
+
|
| 7 |
+
import sentencepiece as spm
|
| 8 |
+
from transformers.tokenization_utils import AddedToken, PreTrainedTokenizer
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
VOCAB_FILES_NAMES = {"vocab_file": "tokenizer.model"}
|
| 12 |
+
|
| 13 |
+
PRETRAINED_VOCAB_FILES_MAP = {
|
| 14 |
+
"vocab_file": {},
|
| 15 |
+
"tokenizer_file": {},
|
| 16 |
+
}
|
| 17 |
+
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {}
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class OrionTokenizer(PreTrainedTokenizer):
|
| 21 |
+
"""
|
| 22 |
+
Construct a Orion tokenizer. Based on byte-level Byte-Pair-Encoding.
|
| 23 |
+
|
| 24 |
+
Args:
|
| 25 |
+
vocab_file (`str`):
|
| 26 |
+
Path to the vocabulary file.
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
vocab_files_names = VOCAB_FILES_NAMES
|
| 30 |
+
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
|
| 31 |
+
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
|
| 32 |
+
model_input_names = ["input_ids", "attention_mask"]
|
| 33 |
+
|
| 34 |
+
def __init__(
|
| 35 |
+
self,
|
| 36 |
+
vocab_file,
|
| 37 |
+
unk_token="<unk>",
|
| 38 |
+
bos_token="<s>",
|
| 39 |
+
eos_token="</s>",
|
| 40 |
+
pad_token=None,
|
| 41 |
+
sp_model_kwargs: Optional[Dict[str, Any]] = None,
|
| 42 |
+
add_bos_token=True,
|
| 43 |
+
add_eos_token=False,
|
| 44 |
+
clean_up_tokenization_spaces=False,
|
| 45 |
+
**kwargs,
|
| 46 |
+
):
|
| 47 |
+
self.sp_model_kwargs = {} if sp_model_kwargs is None else sp_model_kwargs
|
| 48 |
+
bos_token = (
|
| 49 |
+
AddedToken(bos_token, lstrip=False, rstrip=False)
|
| 50 |
+
if isinstance(bos_token, str)
|
| 51 |
+
else bos_token
|
| 52 |
+
)
|
| 53 |
+
eos_token = (
|
| 54 |
+
AddedToken(eos_token, lstrip=False, rstrip=False)
|
| 55 |
+
if isinstance(eos_token, str)
|
| 56 |
+
else eos_token
|
| 57 |
+
)
|
| 58 |
+
unk_token = (
|
| 59 |
+
AddedToken(unk_token, lstrip=False, rstrip=False)
|
| 60 |
+
if isinstance(unk_token, str)
|
| 61 |
+
else unk_token
|
| 62 |
+
)
|
| 63 |
+
pad_token = (
|
| 64 |
+
AddedToken(pad_token, lstrip=False, rstrip=False)
|
| 65 |
+
if isinstance(pad_token, str)
|
| 66 |
+
else pad_token
|
| 67 |
+
)
|
| 68 |
+
self.vocab_file = vocab_file
|
| 69 |
+
self.add_bos_token = add_bos_token
|
| 70 |
+
self.add_eos_token = add_eos_token
|
| 71 |
+
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
|
| 72 |
+
self.sp_model.Load(vocab_file)
|
| 73 |
+
super().__init__(
|
| 74 |
+
bos_token=bos_token,
|
| 75 |
+
eos_token=eos_token,
|
| 76 |
+
unk_token=unk_token,
|
| 77 |
+
pad_token=pad_token,
|
| 78 |
+
add_bos_token=add_bos_token,
|
| 79 |
+
add_eos_token=add_eos_token,
|
| 80 |
+
sp_model_kwargs=self.sp_model_kwargs,
|
| 81 |
+
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
| 82 |
+
**kwargs,
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
def __getstate__(self):
|
| 86 |
+
state = self.__dict__.copy()
|
| 87 |
+
state["sp_model"] = None
|
| 88 |
+
return state
|
| 89 |
+
|
| 90 |
+
def __setstate__(self, d):
|
| 91 |
+
self.__dict__ = d
|
| 92 |
+
self.sp_model = spm.SentencePieceProcessor(**self.sp_model_kwargs)
|
| 93 |
+
self.sp_model.Load(self.vocab_file)
|
| 94 |
+
|
| 95 |
+
@property
|
| 96 |
+
def vocab_size(self):
|
| 97 |
+
"""Returns vocab size"""
|
| 98 |
+
return self.sp_model.get_piece_size()
|
| 99 |
+
|
| 100 |
+
def get_vocab(self):
|
| 101 |
+
"""Returns vocab as a dict"""
|
| 102 |
+
vocab = {self.convert_ids_to_tokens(i): i for i in range(self.vocab_size)}
|
| 103 |
+
vocab.update(self.added_tokens_encoder)
|
| 104 |
+
return vocab
|
| 105 |
+
|
| 106 |
+
def _tokenize(self, text):
|
| 107 |
+
"""Returns a tokenized string."""
|
| 108 |
+
return self.sp_model.encode(text, out_type=str)
|
| 109 |
+
|
| 110 |
+
def _convert_token_to_id(self, token):
|
| 111 |
+
"""Converts a token (str) in an id using the vocab."""
|
| 112 |
+
return self.sp_model.piece_to_id(token)
|
| 113 |
+
|
| 114 |
+
def _convert_id_to_token(self, index):
|
| 115 |
+
"""Converts an index (integer) in a token (str) using the vocab."""
|
| 116 |
+
token = self.sp_model.IdToPiece(index)
|
| 117 |
+
return token
|
| 118 |
+
|
| 119 |
+
def convert_tokens_to_string(self, tokens):
|
| 120 |
+
"""Converts a sequence of tokens (string) in a single string."""
|
| 121 |
+
current_sub_tokens = []
|
| 122 |
+
out_string = ""
|
| 123 |
+
prev_is_special = False
|
| 124 |
+
for i, token in enumerate(tokens):
|
| 125 |
+
# make sure that special tokens are not decoded using sentencepiece model
|
| 126 |
+
if token in self.all_special_tokens:
|
| 127 |
+
if not prev_is_special and i != 0:
|
| 128 |
+
out_string += " "
|
| 129 |
+
out_string += self.sp_model.decode(current_sub_tokens) + token
|
| 130 |
+
prev_is_special = True
|
| 131 |
+
current_sub_tokens = []
|
| 132 |
+
else:
|
| 133 |
+
current_sub_tokens.append(token)
|
| 134 |
+
prev_is_special = False
|
| 135 |
+
out_string += self.sp_model.decode(current_sub_tokens)
|
| 136 |
+
return out_string
|
| 137 |
+
|
| 138 |
+
def save_vocabulary(
|
| 139 |
+
self, save_directory, filename_prefix: Optional[str] = None
|
| 140 |
+
) -> Tuple[str]:
|
| 141 |
+
"""
|
| 142 |
+
Save the vocabulary and special tokens file to a directory.
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
save_directory (`str`):
|
| 146 |
+
The directory in which to save the vocabulary.
|
| 147 |
+
|
| 148 |
+
Returns:
|
| 149 |
+
`Tuple(str)`: Paths to the files saved.
|
| 150 |
+
"""
|
| 151 |
+
if not os.path.isdir(save_directory):
|
| 152 |
+
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
|
| 153 |
+
return
|
| 154 |
+
out_vocab_file = os.path.join(
|
| 155 |
+
save_directory,
|
| 156 |
+
(filename_prefix + "-" if filename_prefix else "")
|
| 157 |
+
+ VOCAB_FILES_NAMES["vocab_file"],
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
if os.path.abspath(self.vocab_file) != os.path.abspath(
|
| 161 |
+
out_vocab_file
|
| 162 |
+
) and os.path.isfile(self.vocab_file):
|
| 163 |
+
copyfile(self.vocab_file, out_vocab_file)
|
| 164 |
+
elif not os.path.isfile(self.vocab_file):
|
| 165 |
+
with open(out_vocab_file, "wb") as fi:
|
| 166 |
+
content_spiece_model = self.sp_model.serialized_model_proto()
|
| 167 |
+
fi.write(content_spiece_model)
|
| 168 |
+
|
| 169 |
+
return (out_vocab_file,)
|
| 170 |
+
|
| 171 |
+
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
|
| 172 |
+
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
|
| 173 |
+
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
|
| 174 |
+
|
| 175 |
+
output = bos_token_id + token_ids_0 + eos_token_id
|
| 176 |
+
|
| 177 |
+
if token_ids_1 is not None:
|
| 178 |
+
output = output + bos_token_id + token_ids_1 + eos_token_id
|
| 179 |
+
|
| 180 |
+
return output
|
| 181 |
+
|
| 182 |
+
def get_special_tokens_mask(
|
| 183 |
+
self,
|
| 184 |
+
token_ids_0: List[int],
|
| 185 |
+
token_ids_1: Optional[List[int]] = None,
|
| 186 |
+
already_has_special_tokens: bool = False,
|
| 187 |
+
) -> List[int]:
|
| 188 |
+
"""
|
| 189 |
+
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
|
| 190 |
+
special tokens using the tokenizer `prepare_for_model` method.
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
token_ids_0 (`List[int]`):
|
| 194 |
+
List of IDs.
|
| 195 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 196 |
+
Optional second list of IDs for sequence pairs.
|
| 197 |
+
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
|
| 198 |
+
Whether or not the token list is already formatted with special tokens for the model.
|
| 199 |
+
|
| 200 |
+
Returns:
|
| 201 |
+
`List[int]`: A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
|
| 202 |
+
"""
|
| 203 |
+
if already_has_special_tokens:
|
| 204 |
+
return super().get_special_tokens_mask(
|
| 205 |
+
token_ids_0=token_ids_0,
|
| 206 |
+
token_ids_1=token_ids_1,
|
| 207 |
+
already_has_special_tokens=True,
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
bos_token_id = [1] if self.add_bos_token else []
|
| 211 |
+
eos_token_id = [1] if self.add_eos_token else []
|
| 212 |
+
|
| 213 |
+
if token_ids_1 is None:
|
| 214 |
+
return bos_token_id + ([0] * len(token_ids_0)) + eos_token_id
|
| 215 |
+
return (
|
| 216 |
+
bos_token_id
|
| 217 |
+
+ ([0] * len(token_ids_0))
|
| 218 |
+
+ eos_token_id
|
| 219 |
+
+ bos_token_id
|
| 220 |
+
+ ([0] * len(token_ids_1))
|
| 221 |
+
+ eos_token_id
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
def create_token_type_ids_from_sequences(
|
| 225 |
+
self, token_ids_0: List[int], token_ids_1: Optional[List[int]] = None
|
| 226 |
+
) -> List[int]:
|
| 227 |
+
"""
|
| 228 |
+
Creates a mask from the two sequences passed to be used in a sequence-pair classification task. An ALBERT
|
| 229 |
+
sequence pair mask has the following format:
|
| 230 |
+
|
| 231 |
+
```
|
| 232 |
+
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
|
| 233 |
+
| first sequence | second sequence |
|
| 234 |
+
```
|
| 235 |
+
|
| 236 |
+
if token_ids_1 is None, only returns the first portion of the mask (0s).
|
| 237 |
+
|
| 238 |
+
Args:
|
| 239 |
+
token_ids_0 (`List[int]`):
|
| 240 |
+
List of ids.
|
| 241 |
+
token_ids_1 (`List[int]`, *optional*):
|
| 242 |
+
Optional second list of IDs for sequence pairs.
|
| 243 |
+
|
| 244 |
+
Returns:
|
| 245 |
+
`List[int]`: List of [token type IDs](../glossary#token-type-ids) according to the given sequence(s).
|
| 246 |
+
"""
|
| 247 |
+
bos_token_id = [self.bos_token_id] if self.add_bos_token else []
|
| 248 |
+
eos_token_id = [self.eos_token_id] if self.add_eos_token else []
|
| 249 |
+
|
| 250 |
+
output = [0] * len(bos_token_id + token_ids_0 + eos_token_id)
|
| 251 |
+
|
| 252 |
+
if token_ids_1 is not None:
|
| 253 |
+
output += [1] * len(bos_token_id + token_ids_1 + eos_token_id)
|
| 254 |
+
|
| 255 |
+
return output
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ded43118b7418f56db97a4eed08a5c265c03120158229ddd4fbcc9658241d5f0
|
| 3 |
+
size 1520600
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"auto_map": {
|
| 5 |
+
"AutoTokenizer": [
|
| 6 |
+
"tokenization_orion.OrionTokenizer",
|
| 7 |
+
null
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
"bos_token": {
|
| 11 |
+
"__type": "AddedToken",
|
| 12 |
+
"content": "<s>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": true,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": true
|
| 17 |
+
},
|
| 18 |
+
"clean_up_tokenization_spaces": false,
|
| 19 |
+
"eos_token": {
|
| 20 |
+
"__type": "AddedToken",
|
| 21 |
+
"content": "</s>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": true,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": true
|
| 26 |
+
},
|
| 27 |
+
"model_max_length": 4096,
|
| 28 |
+
"pad_token": {
|
| 29 |
+
"__type": "AddedToken",
|
| 30 |
+
"content": "<unk>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": true,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": true
|
| 35 |
+
},
|
| 36 |
+
"sp_model_kwargs": {},
|
| 37 |
+
"tokenizer_class": "OrionTokenizer",
|
| 38 |
+
"unk_token": {
|
| 39 |
+
"__type": "AddedToken",
|
| 40 |
+
"content": "<unk>",
|
| 41 |
+
"lstrip": false,
|
| 42 |
+
"normalized": true,
|
| 43 |
+
"rstrip": false,
|
| 44 |
+
"single_word": true
|
| 45 |
+
}
|
| 46 |
+
}
|