
Commit
•
2f6d1ea
1
Parent(s):
5beaa4d
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
datasets:
|
| 3 |
+
- emozilla/yarn-train-tokenized-16k-mistral
|
| 4 |
+
metrics:
|
| 5 |
+
- perplexity
|
| 6 |
+
library_name: transformers
|
| 7 |
+
license: apache-2.0
|
| 8 |
+
language:
|
| 9 |
+
- en
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
## This repo contains a SHARDED version of: https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k
|
| 14 |
+
|
| 15 |
+
### Huge thanks to the publishers for their amazing work, all credits go to them: https://huggingface.co/NousResearch
|
| 16 |
+
|
| 17 |
+
# Model Card: Nous-Yarn-Mistral-7b-128k
|
| 18 |
+
|
| 19 |
+
[Preprint (arXiv)](https://arxiv.org/abs/2309.00071)
|
| 20 |
+
[GitHub](https://github.com/jquesnelle/yarn)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Model Description
|
| 24 |
+
|
| 25 |
+
Nous-Yarn-Mistral-7b-128k is a state-of-the-art language model for long context, further pretrained on long context data for 1500 steps using the YaRN extension method.
|
| 26 |
+
It is an extension of [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) and supports a 128k token context window.
|
| 27 |
+
|
| 28 |
+
To use, pass `trust_remote_code=True` when loading the model, for example
|
| 29 |
+
|
| 30 |
+
```python
|
| 31 |
+
model = AutoModelForCausalLM.from_pretrained("NousResearch/Yarn-Mistral-7b-128k",
|
| 32 |
+
use_flash_attention_2=True,
|
| 33 |
+
torch_dtype=torch.bfloat16,
|
| 34 |
+
device_map="auto",
|
| 35 |
+
trust_remote_code=True)
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
In addition you will need to use the latest version of `transformers` (until 4.35 comes out)
|
| 39 |
+
```sh
|
| 40 |
+
pip install git+https://github.com/huggingface/transformers
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
## Benchmarks
|
| 44 |
+
|
| 45 |
+
Long context benchmarks:
|
| 46 |
+
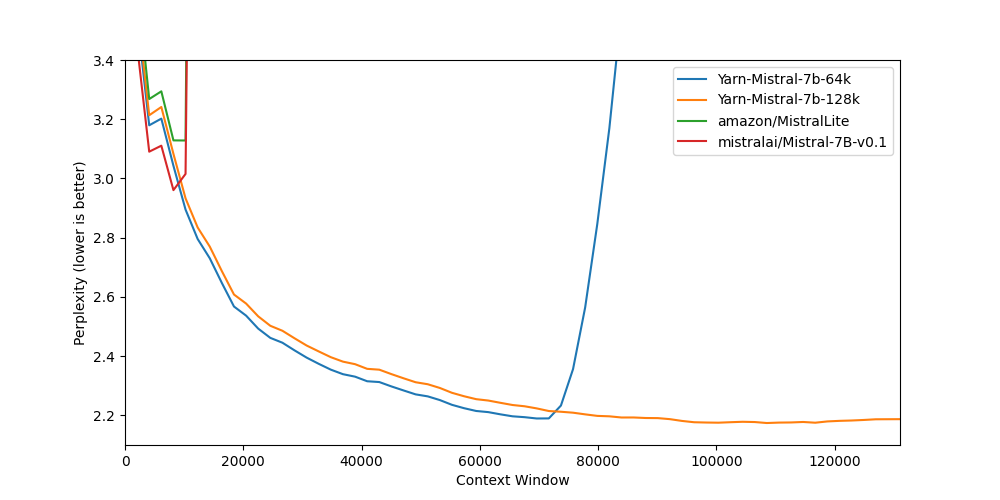
| Model | Context Window | 8k PPL | 16k PPL | 32k PPL | 64k PPL | 128k PPL |
|
| 47 |
+
|-------|---------------:|------:|----------:|-----:|-----:|------------:|
|
| 48 |
+
| [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 8k | 2.96 | - | - | - | - |
|
| 49 |
+
| [Yarn-Mistral-7b-64k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-64k) | 64k | 3.04 | 2.65 | 2.44 | 2.20 | - |
|
| 50 |
+
| [Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) | 128k | 3.08 | 2.68 | 2.47 | 2.24 | 2.19 |
|
| 51 |
+
|
| 52 |
+
Short context benchmarks showing that quality degradation is minimal:
|
| 53 |
+
| Model | Context Window | ARC-c | Hellaswag | MMLU | Truthful QA |
|
| 54 |
+
|-------|---------------:|------:|----------:|-----:|------------:|
|
| 55 |
+
| [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 8k | 59.98 | 83.31 | 64.16 | 42.15 |
|
| 56 |
+
| [Yarn-Mistral-7b-64k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-64k) | 64k | 59.38 | 81.21 | 61.32 | 42.50 |
|
| 57 |
+
| [Yarn-Mistral-7b-128k](https://huggingface.co/NousResearch/Yarn-Mistral-7b-128k) | 128k | 58.87 | 80.58 | 60.64 | 42.46 |
|
| 58 |
+
|
| 59 |
+
## Collaborators
|
| 60 |
+
|
| 61 |
+
- [bloc97](https://github.com/bloc97): Methods, paper and evals
|
| 62 |
+
- [@theemozilla](https://twitter.com/theemozilla): Methods, paper, model training, and evals
|
| 63 |
+
- [@EnricoShippole](https://twitter.com/EnricoShippole): Model training
|
| 64 |
+
- [honglu2875](https://github.com/honglu2875): Paper and evals
|
| 65 |
+
|
| 66 |
+
The authors would like to thank LAION AI for their support of compute for this model.
|
| 67 |
+
It was trained on the [JUWELS](https://www.fz-juelich.de/en/ias/jsc/systems/supercomputers/juwels) supercomputer.
|