
Yuechen Yang
commited on
Commit
·
e1c3a18
1
Parent(s):
3e3195e
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,3 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
# Garbage Classification
|
| 2 |
|
| 3 |
## Overview
|
|
@@ -13,74 +17,41 @@ The significance of garbage classification:
|
|
| 13 |
### Dataset
|
| 14 |
The garbage classification dataset is from Kaggle. There are totally 2467 pictures in this dataset. And this model is an image classification model for this dataset. There are 6 classes for this dataset, which are cardboard (393), glass (491), metal (400), paper(584), plastic (472), and trash(127).
|
| 15 |
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&
|
| 27 |
-
|
| 28 |
### Model
|
| 29 |
-
|
| 30 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
-
|
| 33 |
-
Some special modifications I made to the model are as follows:
|
| 34 |
-
|
| 35 |
-
1. Hashtags are usually consists of multiple words without space. When tokenizing these hashtags, they will be splitted into different words and therefore cannot form up an hashtag when we decode these tokens. For example, "#TheFirstLady" passed in regular tokenizer will be splitted into "#", "The", "First", "#Lady". Therefore, I added the top 1000 trending hashtags to the token dictioanry and provide special token_ids for each hastag.
|
| 36 |
-
|
| 37 |
-
2. When masking the tweets during training, I intentionally mask the tokens that is a hastag, so that the model will learn to predict the place of hashtags specifically.
|
| 38 |
-
|
| 39 |
-
3. After training the model, we limit the potential candidates of [MASK] with the topics existed on Twitter, to get the relavent hashtags the user can add on.
|
| 40 |
-
|
| 41 |
-
### Result
|
| 42 |
-
**Twitter current approach:**
|
| 43 |
-
|
| 44 |
-
<!-- 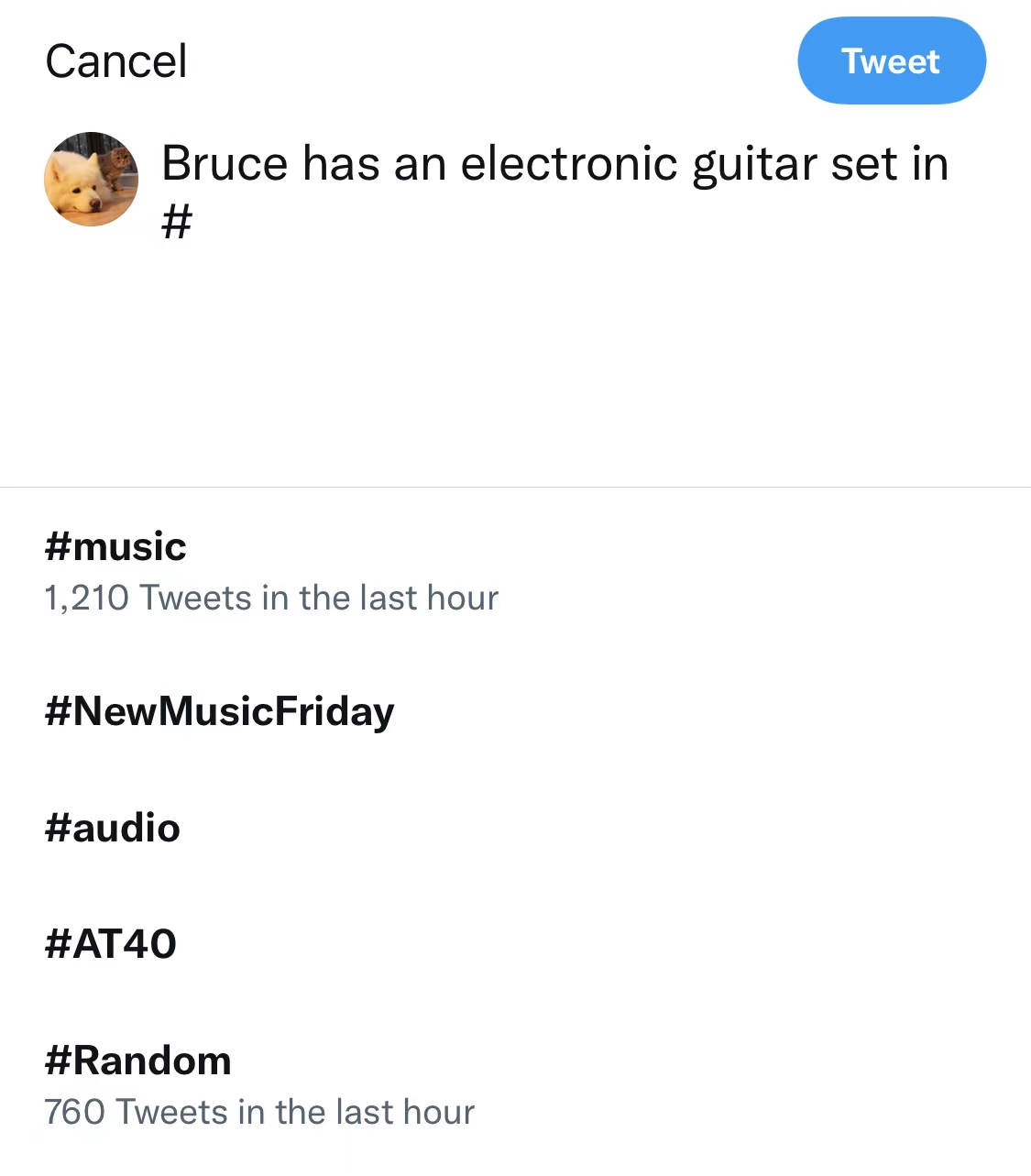 -->
|
| 45 |
-
<img src="https://user-images.githubusercontent.com/56851668/163923465-a0ac8c4b-a6f1-4553-bc70-aff6c8365ef5.jpg" width="500">
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
**Our approach:**
|
| 49 |
-
|
| 50 |
-
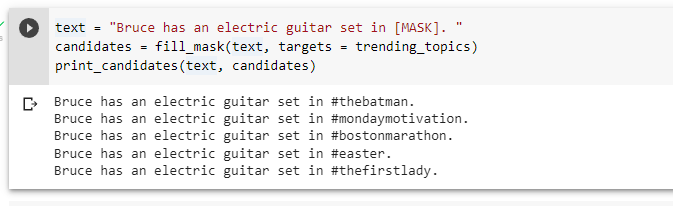
|
| 51 |
-
|
| 52 |
-
**Original tweet:**
|
| 53 |
-
|
| 54 |
-

|
| 55 |
-
|
| 56 |
|
| 57 |
## Huggingface Space
|
| 58 |
-
Huggingface space is [here](https://huggingface.co/
|
| 59 |
|
| 60 |
## Huggingface Model Card
|
| 61 |
-
Huggingface model card is [here](https://huggingface.co/
|
| 62 |
|
| 63 |
## Critical Analysis
|
| 64 |
-
1.
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
4. Future modifications on this model might be add weights on different topics. For example, more recent topics will be weighted higher than older topics.
|
| 68 |
|
| 69 |
|
| 70 |
## Resource Links
|
| 71 |
|
| 72 |
-
[
|
| 73 |
|
| 74 |
-
[
|
| 75 |
|
| 76 |
-
[
|
| 77 |
|
| 78 |
## Code Demo
|
| 79 |
|
| 80 |
-
[Code Demo](
|
| 81 |
|
| 82 |
## Repo
|
| 83 |
In this repo
|
| 84 |
|
| 85 |
## Video Recording
|
| 86 |
-
https://youtu.be/EC18mZBy1Jo
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: afl-3.0
|
| 3 |
+
---
|
| 4 |
+
|
| 5 |
# Garbage Classification
|
| 6 |
|
| 7 |
## Overview
|
|
|
|
| 17 |
### Dataset
|
| 18 |
The garbage classification dataset is from Kaggle. There are totally 2467 pictures in this dataset. And this model is an image classification model for this dataset. There are 6 classes for this dataset, which are cardboard (393), glass (491), metal (400), paper(584), plastic (472), and trash(127).
|
| 19 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 20 |
### Model
|
| 21 |
+
The model is based on the [ViT](https://huggingface.co/google/vit-base-patch16-224-in21k) model, which is short for the Vision Transformer. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929), which was introduced in June 2021 by a team of researchers at Google Brain. And first released in [this repository](https://github.com/rwightman/pytorch-image-models). I trained this model with PyTorch. I think the most different thing between using the transformer to train on an image and on a text is in the tokenizing step.
|
| 22 |
|
| 23 |
+
There are 3 steps to tokenize the image:
|
| 24 |
+
1. Split an image into a grid of sub-image patches
|
| 25 |
+
2. Embed each patch with a linear projection
|
| 26 |
+
3. Each embedded patch becomes a token, and the resulting sequence of embedded patches is the sequence you pass to the model.
|
| 27 |
|
| 28 |
+
I trained the model with 10 epochs, and I use Adam as the optimizer. The accuracy on the test set is 96%.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
|
| 30 |
## Huggingface Space
|
| 31 |
+
Huggingface space is [here](https://huggingface.co/yangy50/garbage-classification).
|
| 32 |
|
| 33 |
## Huggingface Model Card
|
| 34 |
+
Huggingface model card is [here](https://huggingface.co/yangy50/garbage-classification/tree/main).
|
| 35 |
|
| 36 |
## Critical Analysis
|
| 37 |
+
1. Next step: build a CNN model on this dataset and compare the accuracy and training time for these two models.
|
| 38 |
+
|
| 39 |
+
2. Didn’t use the Dataset package to store the image data. Want to find out how to use the Dataset package to handle image data.
|
|
|
|
| 40 |
|
| 41 |
|
| 42 |
## Resource Links
|
| 43 |
|
| 44 |
+
[vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k)
|
| 45 |
|
| 46 |
+
[Garbage dataset](https://huggingface.co/cardiffnlp/twitter-roberta-base)
|
| 47 |
|
| 48 |
+
[An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
|
| 49 |
|
| 50 |
## Code Demo
|
| 51 |
|
| 52 |
+
[Code Demo]() is inside this repo
|
| 53 |
|
| 54 |
## Repo
|
| 55 |
In this repo
|
| 56 |
|
| 57 |
## Video Recording
|
|
|