
Commit
•
b760542
1
Parent(s):
dcb2d3e
Upload 12 files
Browse files- final_checkpoint/README.md +59 -0
- final_checkpoint/adapter_config.json +26 -0
- final_checkpoint/adapter_model.safetensors +3 -0
- final_checkpoint/all_results.json +7 -0
- final_checkpoint/special_tokens_map.json +24 -0
- final_checkpoint/tokenizer.model +3 -0
- final_checkpoint/tokenizer_config.json +45 -0
- final_checkpoint/train_results.json +7 -0
- final_checkpoint/trainer_log.jsonl +0 -0
- final_checkpoint/trainer_state.json +0 -0
- final_checkpoint/training_args.bin +3 -0
- final_checkpoint/training_loss.png +0 -0
final_checkpoint/README.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
library_name: peft
|
| 4 |
+
tags:
|
| 5 |
+
- llama-factory
|
| 6 |
+
- lora
|
| 7 |
+
- generated_from_trainer
|
| 8 |
+
base_model: ../Mixtral-8x7B-Instruct-v0.1
|
| 9 |
+
model-index:
|
| 10 |
+
- name: outputdpo
|
| 11 |
+
results: []
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 15 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 16 |
+
|
| 17 |
+
# outputdpo
|
| 18 |
+
|
| 19 |
+
This model is a fine-tuned version of [../Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/../Mixtral-8x7B-Instruct-v0.1) on the comparison_gpt4_en and the comparison_gpt4_zh datasets.
|
| 20 |
+
|
| 21 |
+
## Model description
|
| 22 |
+
|
| 23 |
+
More information needed
|
| 24 |
+
|
| 25 |
+
## Intended uses & limitations
|
| 26 |
+
|
| 27 |
+
More information needed
|
| 28 |
+
|
| 29 |
+
## Training and evaluation data
|
| 30 |
+
|
| 31 |
+
More information needed
|
| 32 |
+
|
| 33 |
+
## Training procedure
|
| 34 |
+
|
| 35 |
+
### Training hyperparameters
|
| 36 |
+
|
| 37 |
+
The following hyperparameters were used during training:
|
| 38 |
+
- learning_rate: 1e-05
|
| 39 |
+
- train_batch_size: 2
|
| 40 |
+
- eval_batch_size: 8
|
| 41 |
+
- seed: 42
|
| 42 |
+
- gradient_accumulation_steps: 4
|
| 43 |
+
- total_train_batch_size: 8
|
| 44 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 45 |
+
- lr_scheduler_type: cosine
|
| 46 |
+
- num_epochs: 1.0
|
| 47 |
+
- mixed_precision_training: Native AMP
|
| 48 |
+
|
| 49 |
+
### Training results
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
### Framework versions
|
| 54 |
+
|
| 55 |
+
- PEFT 0.7.1
|
| 56 |
+
- Transformers 4.36.2
|
| 57 |
+
- Pytorch 2.1.1+cu121
|
| 58 |
+
- Datasets 2.15.0
|
| 59 |
+
- Tokenizers 0.15.0
|
final_checkpoint/adapter_config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "../Mixtral-8x7B-Instruct-v0.1",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"fan_in_fan_out": false,
|
| 7 |
+
"inference_mode": true,
|
| 8 |
+
"init_lora_weights": true,
|
| 9 |
+
"layers_pattern": null,
|
| 10 |
+
"layers_to_transform": null,
|
| 11 |
+
"loftq_config": {},
|
| 12 |
+
"lora_alpha": 16.0,
|
| 13 |
+
"lora_dropout": 0.1,
|
| 14 |
+
"megatron_config": null,
|
| 15 |
+
"megatron_core": "megatron.core",
|
| 16 |
+
"modules_to_save": null,
|
| 17 |
+
"peft_type": "LORA",
|
| 18 |
+
"r": 8,
|
| 19 |
+
"rank_pattern": {},
|
| 20 |
+
"revision": null,
|
| 21 |
+
"target_modules": [
|
| 22 |
+
"q_proj",
|
| 23 |
+
"v_proj"
|
| 24 |
+
],
|
| 25 |
+
"task_type": "CAUSAL_LM"
|
| 26 |
+
}
|
final_checkpoint/adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b885fd88c79f1b789029ad81e8b518139232c5e21453c738998d59dce8f5d005
|
| 3 |
+
size 13648432
|
final_checkpoint/all_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"train_loss": 0.07139165566915454,
|
| 4 |
+
"train_runtime": 116352.0044,
|
| 5 |
+
"train_samples_per_second": 0.626,
|
| 6 |
+
"train_steps_per_second": 0.078
|
| 7 |
+
}
|
final_checkpoint/special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
final_checkpoint/tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
final_checkpoint/tokenizer_config.json
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
"additional_special_tokens": [],
|
| 31 |
+
"bos_token": "<s>",
|
| 32 |
+
"chat_template": "{{ bos_token }}{% for message in messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if message['role'] == 'user' %}{{ '[INST] ' + message['content'] + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ message['content'] + eos_token}}{% else %}{{ raise_exception('Only user and assistant roles are supported!') }}{% endif %}{% endfor %}",
|
| 33 |
+
"clean_up_tokenization_spaces": false,
|
| 34 |
+
"eos_token": "</s>",
|
| 35 |
+
"legacy": true,
|
| 36 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 37 |
+
"pad_token": "</s>",
|
| 38 |
+
"padding_side": "right",
|
| 39 |
+
"sp_model_kwargs": {},
|
| 40 |
+
"spaces_between_special_tokens": false,
|
| 41 |
+
"split_special_tokens": false,
|
| 42 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 43 |
+
"unk_token": "<unk>",
|
| 44 |
+
"use_default_system_prompt": false
|
| 45 |
+
}
|
final_checkpoint/train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"train_loss": 0.07139165566915454,
|
| 4 |
+
"train_runtime": 116352.0044,
|
| 5 |
+
"train_samples_per_second": 0.626,
|
| 6 |
+
"train_steps_per_second": 0.078
|
| 7 |
+
}
|
final_checkpoint/trainer_log.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
final_checkpoint/trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
final_checkpoint/training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:014e8566ef08057d5965d10b2d2a273d4f18ec2f8a1b5fb9328162a40b0d9e1e
|
| 3 |
+
size 4856
|
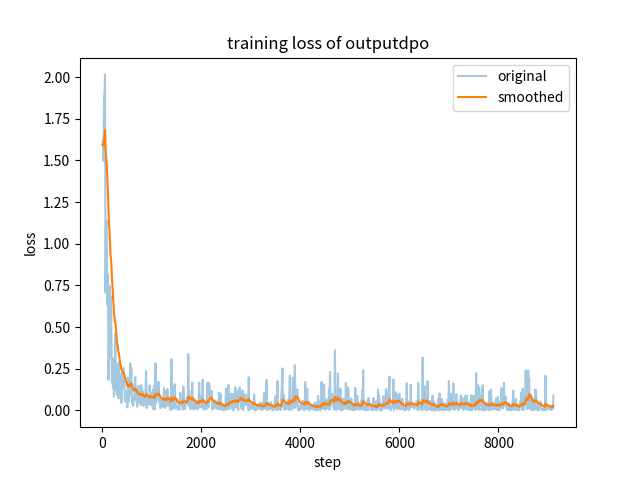
final_checkpoint/training_loss.png
ADDED
|