
datasets:
- prometheus-eval/Feedback-Collection
- prometheus-eval/Preference-Collection
library_name: transformers
pipeline_tag: text2text-generation
tags:
- text2text-generation
license: apache-2.0
language:
- en
Links for Reference
- Quants for: https://huggingface.co/prometheus-eval/prometheus-8x7b-v2.0
- Homepage: In Progress
- Repository: https://github.com/prometheus-eval/prometheus-eval
- Paper: https://arxiv.org/abs/2405.01535
- Point of Contact: seungone@cmu.edu
TL;DR
Prometheus 2 is an alternative of GPT-4 evaluation when doing fine-grained evaluation of an underlying LLM & a Reward model for Reinforcement Learning from Human Feedback (RLHF).
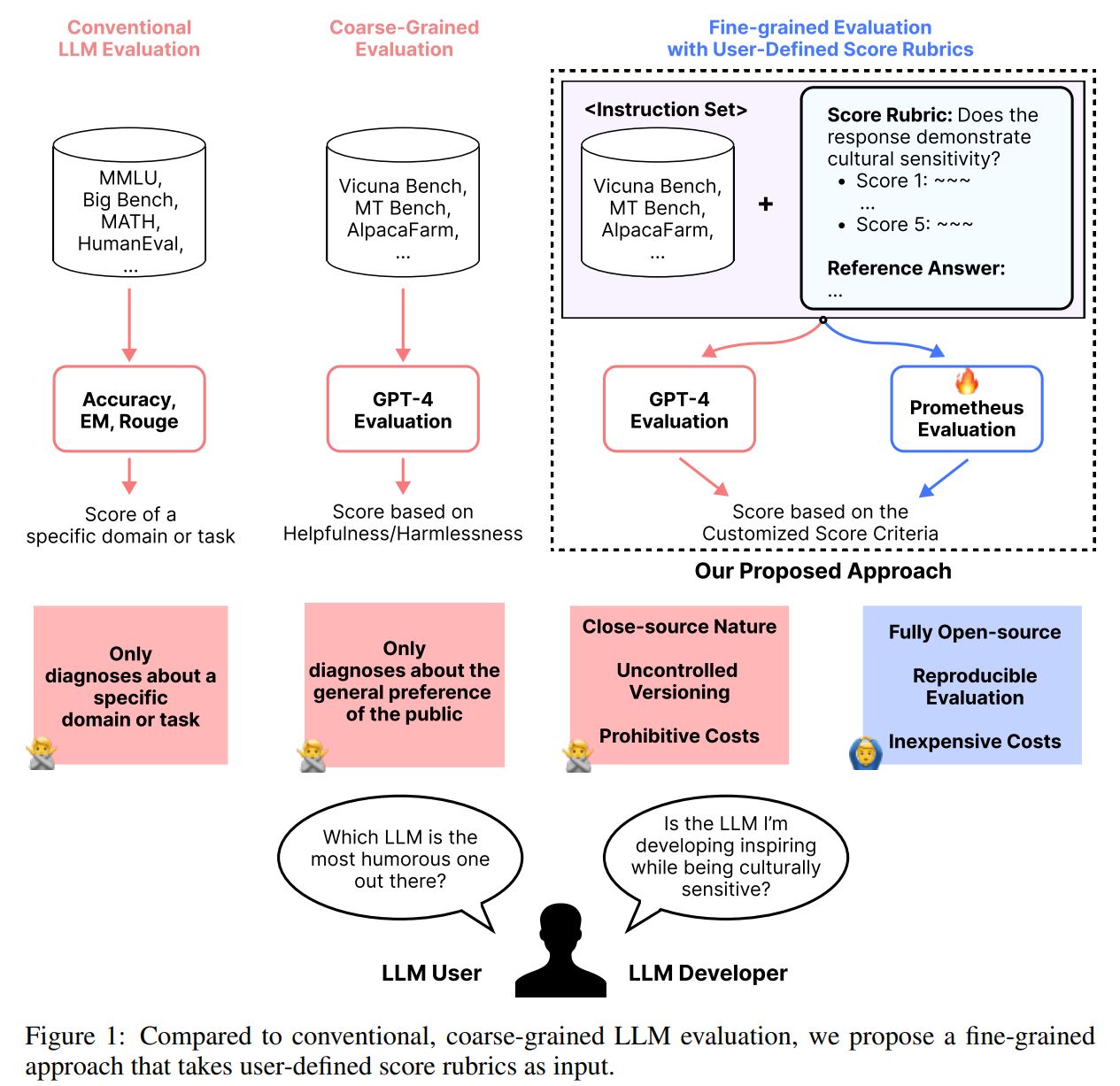
Prometheus 2 is a language model using Mistral-Instruct as a base model. It is fine-tuned on 100K feedback within the Feedback Collection and 200K feedback within the Preference Collection. It is also made by weight merging to support both absolute grading (direct assessment) and relative grading (pairwise ranking). The surprising thing is that we find weight merging also improves performance on each format.
Model Details
Model Description
- Model type: Language model
- Language(s) (NLP): English
- License: Apache 2.0
- Related Models: All Prometheus Checkpoints
- Resources for more information:
Prometheus is trained with two different sizes (7B and 8x7B). You could check the 7B sized LM on this page. Also, check out our dataset as well on this page and this page.
Prompt Format
We have made wrapper functions and classes to conveniently use Prometheus 2 at our github repository. We highly recommend you use it!
However, if you just want to use the model for your use case, please refer to the prompt format below. Note that absolute grading and relative grading requires different prompt templates and system prompts.
Absolute Grading (Direct Assessment)
Prometheus requires 4 components in the input: An instruction, a response to evaluate, a score rubric, and a reference answer. You could refer to the prompt format below. You should fill in the instruction, response, reference answer, criteria description, and score description for score in range of 1 to 5.
Fix the components with {text} inside.
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: \"Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)\"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{orig_instruction}
###Response to evaluate:
{orig_response}
###Reference Answer (Score 5):
{orig_reference_answer}
###Score Rubrics:
[{orig_criteria}]
Score 1: {orig_score1_description}
Score 2: {orig_score2_description}
Score 3: {orig_score3_description}
Score 4: {orig_score4_description}
Score 5: {orig_score5_description}
###Feedback:
After this, you should apply the conversation template of Mistral (not applying it might lead to unexpected behaviors). You can find the conversation class at this link.
conv = get_conv_template("mistral")
conv.set_system_message("You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance.")
conv.append_message(conv.roles[0], dialogs['instruction'])
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
x = tokenizer(prompt,truncation=False)
As a result, a feedback and score decision will be generated, divided by a separating phrase [RESULT]
Relative Grading (Pairwise Ranking)
Prometheus requires 4 components in the input: An instruction, 2 responses to evaluate, a score rubric, and a reference answer. You could refer to the prompt format below. You should fill in the instruction, 2 responses, reference answer, and criteria description.
Fix the components with {text} inside.
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of two responses strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, choose a better response between Response A and Response B. You should refer to the score rubric.
3. The output format should look as follows: "Feedback: (write a feedback for criteria) [RESULT] (A or B)"
4. Please do not generate any other opening, closing, and explanations.
###Instruction:
{orig_instruction}
###Response A:
{orig_response_A}
###Response B:
{orig_response_B}
###Reference Answer:
{orig_reference_answer}
###Score Rubric:
{orig_criteria}
###Feedback:
After this, you should apply the conversation template of Mistral (not applying it might lead to unexpected behaviors). You can find the conversation class at this link.
conv = get_conv_template("mistral")
conv.set_system_message("You are a fair judge assistant assigned to deliver insightful feedback that compares individual performances, highlighting how each stands relative to others within the same cohort.")
conv.append_message(conv.roles[0], dialogs['instruction'])
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
x = tokenizer(prompt,truncation=False)
As a result, a feedback and score decision will be generated, divided by a separating phrase [RESULT]
License
Feedback Collection, Preference Collection, and Prometheus 2 are subject to OpenAI's Terms of Use for the generated data. If you suspect any violations, please reach out to us.
Citation
If you find the following model helpful, please consider citing our paper!
BibTeX:
@misc{kim2023prometheus,
title={Prometheus: Inducing Fine-grained Evaluation Capability in Language Models},
author={Seungone Kim and Jamin Shin and Yejin Cho and Joel Jang and Shayne Longpre and Hwaran Lee and Sangdoo Yun and Seongjin Shin and Sungdong Kim and James Thorne and Minjoon Seo},
year={2023},
eprint={2310.08491},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{kim2024prometheus,
title={Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models},
author={Seungone Kim and Juyoung Suk and Shayne Longpre and Bill Yuchen Lin and Jamin Shin and Sean Welleck and Graham Neubig and Moontae Lee and Kyungjae Lee and Minjoon Seo},
year={2024},
eprint={2405.01535},
archivePrefix={arXiv},
primaryClass={cs.CL}
}