

Commit
•
9c18b58
1
Parent(s):
4ea5f54
updating README
Browse files- README.md +130 -3
- assets/hexplot.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,130 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TenyxChat: Language Model Alignment using Tenyx Fine-tuning
|
| 2 |
+
|
| 3 |
+
Introducing TenyxChat, a series of ChatGPT-like models trained to function as useful assistants through preference tuning, using Tenyx's recently released advanced fine-tuning technology ([VentureBeat article](https://venturebeat.com/ai/tenyx-aims-to-fix-llms-catastrophic-forgetting-problem/)). Our first chat model in the series, TenyxChat-7B-v1, is trained using the [Direct Preference Optimization (DPO)](https://arxiv.org/abs/2305.18290) framework on the open-source AI feedback dataset [UltraFeedback](https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized).
|
| 4 |
+
|
| 5 |
+
We fine-tune [Openchat-3.5](https://arxiv.org/pdf/2309.11235.pdf) with our proprietary approach ([blog](https://www.tenyx.com/post/forgetting-and-toxicity-in-llms-a-deep-dive-on-fine-tuning-methods), [service](https://www.tenyx.com/fine-tuning)), which shows an increase in [MT-Bench](https://arxiv.org/abs/2306.05685), without a drop in performance of the model on other benchmarks. Our approach aims to mitigate forgetting in LLMs in a computationally efficient manner, thereby enabling continual fine-tuning capabilities without altering the pre-trained output distribution. TenyxChat-7B-v1 was trained using eight A100s (80GB) for two hours, with a training setup obtained from HuggingFaceH4 ([GitHub](https://github.com/huggingface/alignment-handbook)).
|
| 6 |
+
|
| 7 |
+
# Model details
|
| 8 |
+
|
| 9 |
+
- Model type: Fine-tuned 7B model for chat.
|
| 10 |
+
- License: Apache 2.0
|
| 11 |
+
- Base model: OpenChat 3.5 ([https://huggingface.co/openchat/openchat_3.5](https://huggingface.co/openchat/openchat_3.5))
|
| 12 |
+
- Demo: Hugging face space
|
| 13 |
+
|
| 14 |
+
## Usage
|
| 15 |
+
|
| 16 |
+
Our model uses a simple chat template based on OpenChat 3.5. The chat template usage with a Hugging face generation example is shown below.
|
| 17 |
+
|
| 18 |
+
### Chat Template (Jinja)
|
| 19 |
+
|
| 20 |
+
```rust
|
| 21 |
+
{{ bos_token }}
|
| 22 |
+
{% for message in messages %}
|
| 23 |
+
{% if message['role'] == 'user' %}
|
| 24 |
+
{{ 'User:' + message['content'] + eos_token }}
|
| 25 |
+
|
| 26 |
+
{% elif message['role'] == 'system' %}
|
| 27 |
+
{{ 'System:' + message['content'] + eos_token }}
|
| 28 |
+
|
| 29 |
+
{% elif message['role'] == 'assistant' %}
|
| 30 |
+
{{ 'Assistant:' + message['content'] + eos_token }}
|
| 31 |
+
|
| 32 |
+
{% endif %}
|
| 33 |
+
|
| 34 |
+
{% if loop.last and add_generation_prompt %}\n{{ 'Assistant:' }}{% endif %}\n{% endfor %}
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
### Hugging face Example
|
| 38 |
+
|
| 39 |
+
```python
|
| 40 |
+
import torch
|
| 41 |
+
from transformers import pipeline
|
| 42 |
+
|
| 43 |
+
pipe = pipeline("text-generation", model="tenyx/TenyxChat-7B-v1", torch_dtype=torch.bfloat16, device_map="auto")
|
| 44 |
+
|
| 45 |
+
messages = [
|
| 46 |
+
{"role": "system", "content": "You are a friendly chatbot who always responds in the style of a pirate."},
|
| 47 |
+
{"role": "user", "content": "Hi. I would like to make a hotel booking."},
|
| 48 |
+
]
|
| 49 |
+
|
| 50 |
+
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
| 51 |
+
outputs = pipe(f_prompt, max_new_tokens=512, do_sample=False)
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
### Output
|
| 55 |
+
|
| 56 |
+
```
|
| 57 |
+
<s> System:You are a friendly chatbot who always responds in the style of a pirate.<|end_of_turn|>
|
| 58 |
+
User:Hi. I would like to make a hotel booking.<|end_of_turn|>
|
| 59 |
+
Assistant: Ahoy there me hearty! Arr, ye be lookin' fer a place to rest yer weary bones, eh?
|
| 60 |
+
Well then, let's set sail on this grand adventure and find ye a swell place to stay!
|
| 61 |
+
|
| 62 |
+
To begin, tell me the location ye be seekin' and the dates ye be lookin' to set sail.
|
| 63 |
+
And don't ye worry, me matey, I'll be sure to find ye a place that'll make ye feel like a king or queen on land!
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
# Performance
|
| 67 |
+
|
| 68 |
+
At the time of release (Jan 2024), TenyxChat-7B-v1 is the highest-ranked chat model on the MT-Bench evaluation available for download and commercial use. We list here the benchmark results on several standard setups while comparing popular 7B models as baselines.
|
| 69 |
+
|
| 70 |
+
## MT-Bench
|
| 71 |
+
|
| 72 |
+
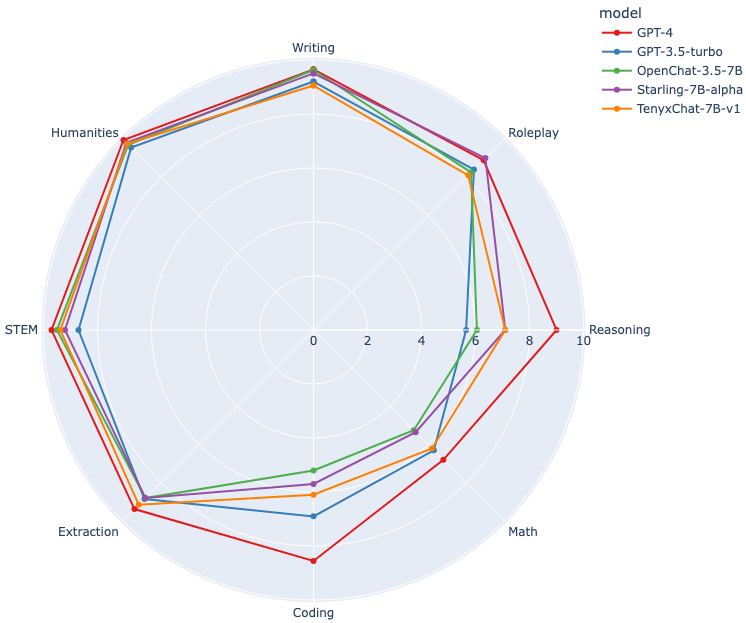
MT-Bench is a benchmark made up of 80 high-quality multi-turn questions. These questions fall into eight categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, and Humanities. The chat models are rated using GPT-4 on a scale of 1 to 10, with higher values corresponding to better responses.
|
| 73 |
+
|
| 74 |
+
| Model | First Turn | Second Turn | Average |
|
| 75 |
+
| --- | --- | --- | --- |
|
| 76 |
+
| GPT-4* | 8.95625 | 9.02500 | 8.990625 |
|
| 77 |
+
| TenyxChat-7B-v1 | 8.45000 | 7.75625 | 8.103125 |
|
| 78 |
+
| Starling-lm-7B-alpha | 8.42500 | 7.68750 | 8.056250 |
|
| 79 |
+
| OpenChat-3.5 | 8.18125 | 7.41250 | 7.796875 |
|
| 80 |
+
| GPT-3.5-turbo* | 8.07500 | 7.81250 | 7.943750 |
|
| 81 |
+
| OpenLLM Leader-7B** | 8.05000 | 7.61250 | 7.831250 |
|
| 82 |
+
|
| 83 |
+
*values reported on [lmsys](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge) ChatBot Arena
|
| 84 |
+
|
| 85 |
+
**The [OpenLLM Leader](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) as of Jan 5, 2024 is the merge model available as [samir-fama/SamirGPT-v1](https://huggingface.co/samir-fama/SamirGPT-v1)
|
| 86 |
+
|
| 87 |
+

|
| 88 |
+
|
| 89 |
+
## LM Evaluation - Open LLM Leaderboard
|
| 90 |
+
|
| 91 |
+
We assess models on 7 benchmarks using the [Eleuther AI Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness). This setup is based of that used for [Open LLM Leaderboard.](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
|
| 92 |
+
|
| 93 |
+
- [AI2 Reasoning Challenge](https://arxiv.org/abs/1803.05457) (25-shot) - grade-school science questions.
|
| 94 |
+
- [HellaSwag](https://arxiv.org/abs/1905.07830) (10-shot) - commonsense inference test.
|
| 95 |
+
- [MMLU](https://arxiv.org/abs/2009.03300) (5-shot) - multitask accuracy test covering 57 tasks.
|
| 96 |
+
- [TruthfulQA](https://arxiv.org/abs/2109.07958) (0-shot) - test measuring model's propensity to reproduce online falsehoods.
|
| 97 |
+
- [Winogrande](https://arxiv.org/abs/1907.10641) (5-shot) - Winograd benchmark for commonsense reasoning.
|
| 98 |
+
- [GSM8k](https://arxiv.org/abs/2110.14168) (5-shot) - grade school math word problems test.
|
| 99 |
+
|
| 100 |
+
These benchmarks test reasoning and knowledge in various tasks in few-shot settings (higher scores are better).
|
| 101 |
+
|
| 102 |
+
| Model | MMLU | Winogrande | GSM8k | ARC | HellaSwag | TruthfulQA | Average |
|
| 103 |
+
| --- | --- | --- | --- | --- | --- | --- | --- |
|
| 104 |
+
| TenyxChat-7B-v1 | 63.6 | 72.3 | 69.0 | 62.7 | 66.6 | 46.7 | 63.48 |
|
| 105 |
+
| Starling-7B-alpha | 63.5 | 72.1 | 67.9 | 61.1 | 66.1 | 42.1 | 62.13 |
|
| 106 |
+
| OpenChat-3.5 | 63.6 | 72.1 | 68.2 | 61.3 | 65.2 | 41.8 | 62.03 |
|
| 107 |
+
| Mistral-7B | 62.4 | 74.0 | 38.1 | 57.2 | 62.8 | 37.8 | 55.38 |
|
| 108 |
+
| OpenLLM Leader-7B | 64.3 | 78.7 | 73.3 | 66.6 | 68.4 | 58.5 | 68.3 |
|
| 109 |
+
|
| 110 |
+
**Note:** While the Open LLM Leaderboard indicates that these chat models perform less effectively compared to the leading 7B model, it's important to note that the leading model struggles in the multi-turn chat setting of MT-Bench (as demonstrated in our evaluation [above](https://www.notion.so/TenyxChat-Language-Model-Alignment-using-Tenyx-Fine-tuning-30e60a53d17a46b0a4755c74f0f8b222?pvs=21)). In contrast, TenyxChat-7B-v1 demonstrates robustness against common fine-tuning challenges, such as *catastrophic forgetting*. This unique feature enables TenyxChat-7B-v1 to excel not only in chat benchmarks like MT-Bench, but also in a wider range of general reasoning benchmarks on the Open LLM Leaderboard.
|
| 111 |
+
|
| 112 |
+
# Limitations
|
| 113 |
+
|
| 114 |
+
TenyxChat-7B-v1, like other small-sized language models, has its own set of limitations. We haven’t fine-tuned the model explicitly to align with **human** safety preferences. Therefore, it is capable of producing undesirable outputs, particularly when adversarially prompted. From our observation, the model still tends to struggle with tasks that involve reasoning and math questions. In some instances, it might generate verbose or extraneous content.
|
| 115 |
+
|
| 116 |
+
# License
|
| 117 |
+
|
| 118 |
+
TenyxChat-7B-v1, similar to OpenChat 3.5, is distributed under the Apache License 2.0.
|
| 119 |
+
|
| 120 |
+
# Citation
|
| 121 |
+
|
| 122 |
+
If you use TenyxChat-7B for your research, cite us as
|
| 123 |
+
|
| 124 |
+
```
|
| 125 |
+
@misc{tenyxchat2024,
|
| 126 |
+
title={TenyxChat**:** Language Model Alignment using Tenyx Fine-tuning},
|
| 127 |
+
author={Tenyx},
|
| 128 |
+
year={2024},
|
| 129 |
+
}
|
| 130 |
+
```
|
assets/hexplot.png
ADDED
|