

Commit
•
d43ebac
1
Parent(s):
8e817cf
Create 1.4B model
Browse files- README.md +71 -0
- assets/train_loss.png +0 -0
- backpack_config.py +23 -0
- backpack_model.py +251 -0
- config.json +82 -0
- merges.txt +0 -0
- model.safetensors +3 -0
- special_tokens_map.json +5 -0
- tokenizer.json +0 -0
- tokenizer_config.json +9 -0
- vocab.json +0 -0
README.md
CHANGED
|
@@ -1,3 +1,74 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
license: apache-2.0
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
pipeline_tag: text-generation
|
| 3 |
+
tags:
|
| 4 |
+
- text-generation-inference
|
| 5 |
+
- backpack
|
| 6 |
+
- backpackmodel
|
| 7 |
+
library_name: transformers
|
| 8 |
license: apache-2.0
|
| 9 |
+
datasets:
|
| 10 |
+
- openwebtext
|
| 11 |
+
language:
|
| 12 |
+
- en
|
| 13 |
---
|
| 14 |
+
|
| 15 |
+
# Model Card for Levanter-Backpack-1.4B
|
| 16 |
+
This is 1.4B parameter version of [Backpack architecture](https://arxiv.org/abs/2305.16765), intended to combine strong modeling performance
|
| 17 |
+
with an interface for interpretability and control.
|
| 18 |
+
|
| 19 |
+
# Training Details
|
| 20 |
+
|
| 21 |
+
## Training Data
|
| 22 |
+
This model was trained on the [OpenWebText](https://huggingface.co/datasets/openwebtext) corpus.
|
| 23 |
+
## Training Procedure
|
| 24 |
+
|
| 25 |
+
This model was trained for 500k gradient steps and cosine decaying learning rate from 1e-4 to zero, with a linear warmup of 5k steps.
|
| 26 |
+
|
| 27 |
+
# Environmental Impact
|
| 28 |
+
|
| 29 |
+
- **Hardware Type:** v3-128 TPU (128 cores, 2TB Memory)
|
| 30 |
+
- **Hours used:** Roughly 8.6 days.
|
| 31 |
+
- **Cloud Provider:** Google Cloud Patform
|
| 32 |
+
- **Compute Region:** North America.
|
| 33 |
+
|
| 34 |
+
## Model Architecture and Objective
|
| 35 |
+
|
| 36 |
+
This model was trained to minimize the cross-entropy loss, and is a [Backpack language model](https://arxiv.org/pdf/2305.16765.pdf).
|
| 37 |
+
|
| 38 |
+
### Software
|
| 39 |
+
|
| 40 |
+
This model was trained with [Levanter](https://github.com/stanford-crfm/levanter/) and [Jax](https://github.com/google/jax).
|
| 41 |
+
|
| 42 |
+
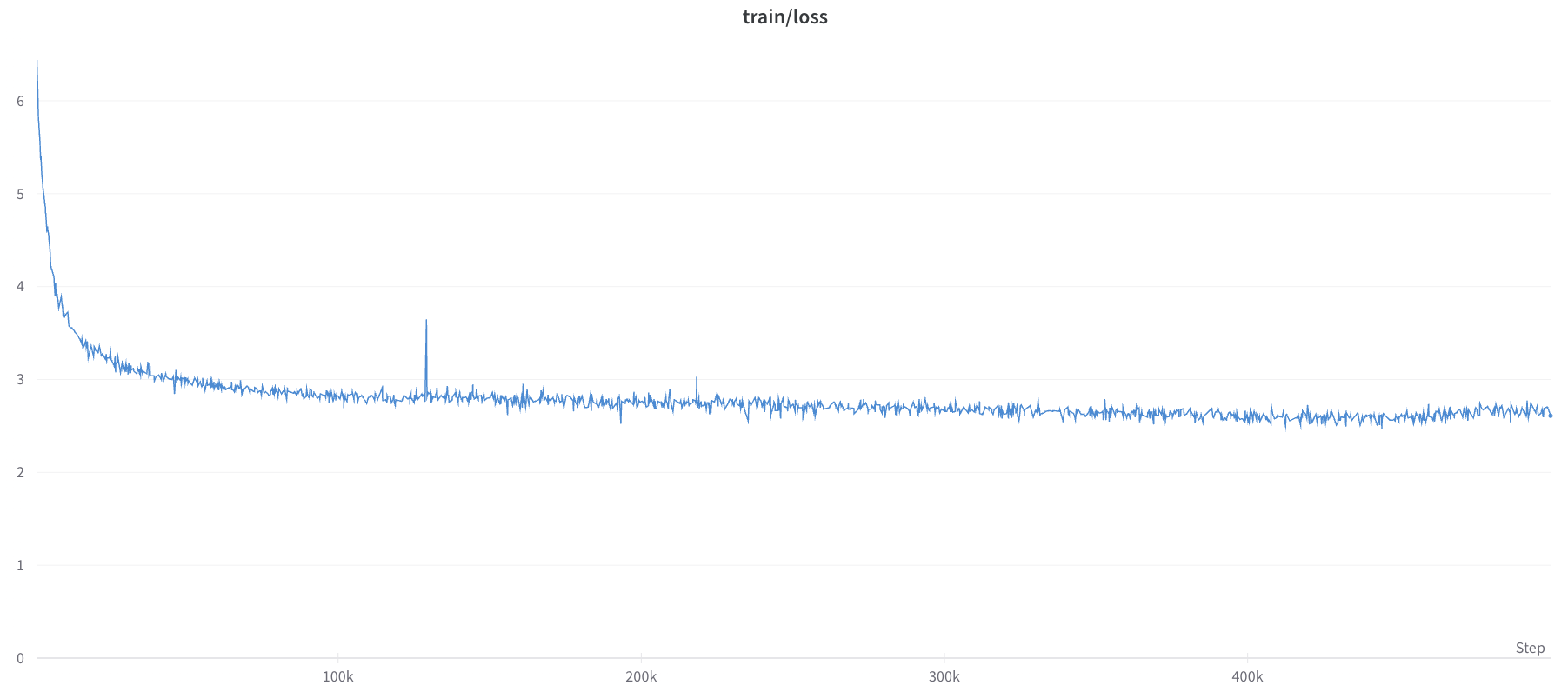
### Loss Curve
|
| 43 |
+

|
| 44 |
+
|
| 45 |
+
# How to Get Started with the Model
|
| 46 |
+
|
| 47 |
+
Please install `transformers`, `safetensors` and `torch` to use this model.
|
| 48 |
+
|
| 49 |
+
```bash
|
| 50 |
+
pip install transformers safetensors torch
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
Run the following Python code:
|
| 54 |
+
|
| 55 |
+
```python
|
| 56 |
+
import torch
|
| 57 |
+
import transformers
|
| 58 |
+
from transformers import AutoModelForCausalLM
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
model_id = "crfm/levanter-backpack-1.4b"
|
| 62 |
+
config = transformers.AutoConfig.from_pretrained(model_id, trust_remote_code=True)
|
| 63 |
+
torch_model = AutoModelForCausalLM.from_pretrained(
|
| 64 |
+
model_id,
|
| 65 |
+
config=config,
|
| 66 |
+
trust_remote_code=True
|
| 67 |
+
)
|
| 68 |
+
torch_model.eval()
|
| 69 |
+
|
| 70 |
+
input = torch.randint(0, 50264, (1, 512), dtype=torch.long)
|
| 71 |
+
torch_out = torch_model(input, position_ids=None,)
|
| 72 |
+
torch_out = torch.nn.functional.softmax(torch_out.logits, dim=-1)
|
| 73 |
+
print(torch_out.shape)
|
| 74 |
+
```
|
assets/train_loss.png
ADDED
|
backpack_config.py
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import GPT2Config
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class BackpackGPT2Config(GPT2Config):
|
| 5 |
+
model_type = "backpack-gpt2"
|
| 6 |
+
|
| 7 |
+
def __init__(
|
| 8 |
+
self,
|
| 9 |
+
num_senses: int = 16,
|
| 10 |
+
sense_intermediate_scale: int = 4,
|
| 11 |
+
vocab_size: int = 50264,
|
| 12 |
+
n_positions: int = 512,
|
| 13 |
+
scale_attn_by_inverse_layer_idx: bool = True,
|
| 14 |
+
**kwargs,
|
| 15 |
+
):
|
| 16 |
+
self.num_senses = num_senses
|
| 17 |
+
self.sense_intermediate_scale = sense_intermediate_scale
|
| 18 |
+
super().__init__(
|
| 19 |
+
vocab_size=vocab_size,
|
| 20 |
+
n_positions=n_positions,
|
| 21 |
+
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
|
| 22 |
+
**kwargs,
|
| 23 |
+
)
|
backpack_model.py
ADDED
|
@@ -0,0 +1,251 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
from typing import Optional, Tuple
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.utils.checkpoint
|
| 7 |
+
from torch import nn
|
| 8 |
+
from transformers.activations import ACT2FN
|
| 9 |
+
from transformers.pytorch_utils import Conv1D
|
| 10 |
+
from transformers.utils import ModelOutput
|
| 11 |
+
from transformers import GPT2PreTrainedModel, GPT2Model
|
| 12 |
+
from .backpack_config import BackpackGPT2Config
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
### Backpack-Specific
|
| 16 |
+
class BackpackGPT2PreTrainedModel(GPT2PreTrainedModel):
|
| 17 |
+
"""
|
| 18 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 19 |
+
models.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
_keys_to_ignore_on_load_missing = [r"attn.masked_bias", r"attn.bias"]
|
| 23 |
+
|
| 24 |
+
config_class = BackpackGPT2Config
|
| 25 |
+
base_model_prefix = "backpack"
|
| 26 |
+
is_parallelizable = True
|
| 27 |
+
supports_gradient_checkpointing = False
|
| 28 |
+
_no_split_modules = ["GPT2Block", "BackpackNoMixBlock"]
|
| 29 |
+
|
| 30 |
+
def __init__(self, *inputs, **kwargs):
|
| 31 |
+
super().__init__(*inputs, **kwargs)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class BackpackMLP(nn.Module):
|
| 35 |
+
def __init__(self, embed_dim, intermediate_dim, out_dim, config):
|
| 36 |
+
super().__init__()
|
| 37 |
+
self.c_fc = Conv1D(intermediate_dim, embed_dim)
|
| 38 |
+
self.c_proj = Conv1D(out_dim, intermediate_dim)
|
| 39 |
+
self.act = ACT2FN[config.activation_function]
|
| 40 |
+
self.dropout = nn.Dropout(config.resid_pdrop)
|
| 41 |
+
|
| 42 |
+
def forward(
|
| 43 |
+
self, hidden_states: Optional[Tuple[torch.FloatTensor]]
|
| 44 |
+
) -> torch.FloatTensor:
|
| 45 |
+
hidden_states = self.c_fc(hidden_states)
|
| 46 |
+
hidden_states = self.act(hidden_states)
|
| 47 |
+
hidden_states = self.c_proj(hidden_states)
|
| 48 |
+
hidden_states = self.dropout(hidden_states)
|
| 49 |
+
return hidden_states
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class BackpackNoMixBlock(nn.Module):
|
| 53 |
+
def __init__(self, config):
|
| 54 |
+
super().__init__()
|
| 55 |
+
self.ln_1 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
|
| 56 |
+
self.ln_2 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
|
| 57 |
+
self.mlp = BackpackMLP(config.n_embd, config.n_embd * 4, config.n_embd, config)
|
| 58 |
+
self.resid_dropout1 = nn.Dropout(config.resid_pdrop)
|
| 59 |
+
self.resid_dropout2 = nn.Dropout(config.resid_pdrop)
|
| 60 |
+
|
| 61 |
+
def forward(self, hidden_states, residual):
|
| 62 |
+
residual = self.resid_dropout1(hidden_states) + residual
|
| 63 |
+
hidden_states = self.ln_1(residual)
|
| 64 |
+
mlp_out = self.mlp(hidden_states)
|
| 65 |
+
residual = self.resid_dropout2(mlp_out) + residual
|
| 66 |
+
hidden_states = self.ln_2(residual)
|
| 67 |
+
return hidden_states
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class BackpackSenseNetwork(nn.Module):
|
| 71 |
+
def __init__(self, config, num_senses, device=None, dtype=None):
|
| 72 |
+
super().__init__()
|
| 73 |
+
self.num_senses = num_senses
|
| 74 |
+
# self.embeddings = embeddings
|
| 75 |
+
self.n_embd = config.n_embd
|
| 76 |
+
|
| 77 |
+
self.dropout = nn.Dropout(config.embd_pdrop)
|
| 78 |
+
self.block = BackpackNoMixBlock(config)
|
| 79 |
+
self.ln = nn.LayerNorm(self.n_embd, eps=config.layer_norm_epsilon)
|
| 80 |
+
self.final_mlp = BackpackMLP(
|
| 81 |
+
embed_dim=config.n_embd,
|
| 82 |
+
intermediate_dim=config.sense_intermediate_scale * config.n_embd,
|
| 83 |
+
out_dim=config.n_embd * config.num_senses,
|
| 84 |
+
config=config,
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
def forward(self, input_embeds):
|
| 88 |
+
residual = self.dropout(input_embeds)
|
| 89 |
+
hidden_states = self.ln(residual)
|
| 90 |
+
hidden_states = self.block(hidden_states, residual)
|
| 91 |
+
senses = self.final_mlp(hidden_states)
|
| 92 |
+
bs, s, nvd = senses.shape
|
| 93 |
+
return senses.reshape(bs, s, self.num_senses, self.n_embd).transpose(
|
| 94 |
+
1, 2
|
| 95 |
+
) # (bs, nv, s, d)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class BackpackWeightNetwork(nn.Module):
|
| 99 |
+
def __init__(self, num_senses, embed_dim):
|
| 100 |
+
super().__init__()
|
| 101 |
+
self.n_embd = embed_dim
|
| 102 |
+
self.num_senses = num_senses
|
| 103 |
+
self.embed_per_sense = embed_dim // num_senses
|
| 104 |
+
self.c_attn = nn.Linear(embed_dim, 2 * num_senses * self.embed_per_sense)
|
| 105 |
+
self.softmax_scale = None
|
| 106 |
+
|
| 107 |
+
def forward(self, encoded):
|
| 108 |
+
b, s, d = encoded.shape
|
| 109 |
+
encoded = self.c_attn(encoded) # (b, s, 2*d)
|
| 110 |
+
encoded = encoded.reshape(
|
| 111 |
+
b, s, 2, self.num_senses, self.embed_per_sense
|
| 112 |
+
) # (b, s, 2, nv, d//nv)
|
| 113 |
+
batch_size, seqlen = encoded.shape[0], encoded.shape[1]
|
| 114 |
+
|
| 115 |
+
# compute scores & mask
|
| 116 |
+
q, k = encoded.unbind(dim=2)
|
| 117 |
+
softmax_scale = self.softmax_scale or 1.0 / math.sqrt(q.shape[-1])
|
| 118 |
+
scores = torch.einsum("bthd,bshd->bhts", q, k * softmax_scale)
|
| 119 |
+
causal_mask = torch.triu(
|
| 120 |
+
torch.full((seqlen, seqlen), -10000.0, device=scores.device), 1
|
| 121 |
+
)
|
| 122 |
+
scores = scores + causal_mask.to(dtype=scores.dtype)
|
| 123 |
+
|
| 124 |
+
return torch.softmax(scores, dim=-1, dtype=q.dtype)
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
@dataclass
|
| 128 |
+
class BackpackGPT2BaseModelOutput(ModelOutput):
|
| 129 |
+
hidden_states: torch.FloatTensor = None
|
| 130 |
+
contextualization: torch.FloatTensor = None
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class BackpackGPT2Model(BackpackGPT2PreTrainedModel):
|
| 134 |
+
_keys_to_ignore_on_load_missing = [r".*attn.masked_bias", r".*attn.bias"]
|
| 135 |
+
|
| 136 |
+
def __init__(self, config):
|
| 137 |
+
super().__init__(config)
|
| 138 |
+
|
| 139 |
+
self.embed_dim = config.n_embd
|
| 140 |
+
|
| 141 |
+
self.num_senses = config.num_senses
|
| 142 |
+
self.gpt2_model = GPT2Model(config)
|
| 143 |
+
self.sense_network = BackpackSenseNetwork(
|
| 144 |
+
config, self.num_senses, self.gpt2_model.wte
|
| 145 |
+
)
|
| 146 |
+
self.word_embeddings = self.gpt2_model.wte
|
| 147 |
+
self.position_embeddings = self.gpt2_model.wpe
|
| 148 |
+
self.sense_weight_net = BackpackWeightNetwork(self.num_senses, self.embed_dim)
|
| 149 |
+
# Model parallel
|
| 150 |
+
self.model_parallel = False
|
| 151 |
+
self.device_map = None
|
| 152 |
+
self.gradient_checkpointing = False
|
| 153 |
+
|
| 154 |
+
def get_num_senses(self):
|
| 155 |
+
return self.num_senses
|
| 156 |
+
|
| 157 |
+
def get_word_embeddings(self):
|
| 158 |
+
return self.word_embeddings
|
| 159 |
+
|
| 160 |
+
def get_sense_network(self):
|
| 161 |
+
return self.sense_network
|
| 162 |
+
|
| 163 |
+
def forward(self, input_ids, position_ids: Optional[torch.LongTensor] = None):
|
| 164 |
+
# Compute senses
|
| 165 |
+
sense_input_embeds = self.word_embeddings(input_ids)
|
| 166 |
+
senses = self.sense_network(sense_input_embeds) # (bs, nv, s, d)
|
| 167 |
+
|
| 168 |
+
# Compute contextualization weights
|
| 169 |
+
contextl_hidden_states = self.gpt2_model(
|
| 170 |
+
input_ids, position_ids=position_ids
|
| 171 |
+
).last_hidden_state # (bs, s, d)
|
| 172 |
+
contextualization = self.sense_weight_net(
|
| 173 |
+
contextl_hidden_states
|
| 174 |
+
) # (bs, nv, s, s)
|
| 175 |
+
|
| 176 |
+
# Compute resulting outputs
|
| 177 |
+
hidden_states = torch.sum(
|
| 178 |
+
contextualization @ senses, dim=1
|
| 179 |
+
) # (bs, nv, s, d) -> (bs, s, d)
|
| 180 |
+
|
| 181 |
+
# divide hidden_states by 1 / num_senses
|
| 182 |
+
hidden_states = hidden_states / self.num_senses
|
| 183 |
+
|
| 184 |
+
return BackpackGPT2BaseModelOutput(
|
| 185 |
+
hidden_states=hidden_states,
|
| 186 |
+
contextualization=contextualization,
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
def run_with_custom_contextualization(self, input_ids, contextualization):
|
| 190 |
+
# Compute senses
|
| 191 |
+
sense_input_embeds = self.word_embeddings(input_ids)
|
| 192 |
+
senses = self.sense_network(sense_input_embeds) # (bs, nv, s, d)
|
| 193 |
+
|
| 194 |
+
# Compute resulting outputs
|
| 195 |
+
hidden_states = torch.sum(
|
| 196 |
+
contextualization @ senses, dim=1
|
| 197 |
+
) # (bs, nv, s, d) -> (bs, s, d)
|
| 198 |
+
return BackpackGPT2BaseModelOutput(
|
| 199 |
+
hidden_states=hidden_states,
|
| 200 |
+
contextualization=contextualization,
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
@dataclass
|
| 205 |
+
class BackpackGPT2LMHeadModelOutput(ModelOutput):
|
| 206 |
+
logits: torch.FloatTensor = None
|
| 207 |
+
contextualization: torch.FloatTensor = None
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
class BackpackGPT2LMHeadModel(BackpackGPT2PreTrainedModel):
|
| 211 |
+
_keys_to_ignore_on_load_missing = [r".*attn.masked_bias", r".*attn.bias"]
|
| 212 |
+
|
| 213 |
+
def __init__(self, config):
|
| 214 |
+
super().__init__(config)
|
| 215 |
+
self.backpack = BackpackGPT2Model(config)
|
| 216 |
+
|
| 217 |
+
# Model parallel
|
| 218 |
+
self.model_parallel = False
|
| 219 |
+
self.device_map = None
|
| 220 |
+
|
| 221 |
+
def get_lm_head(self):
|
| 222 |
+
return self.lm_head
|
| 223 |
+
|
| 224 |
+
def forward(self, input_ids, position_ids=None):
|
| 225 |
+
outputs = self.backpack(input_ids, position_ids=position_ids)
|
| 226 |
+
hidden_states, contextualization = (
|
| 227 |
+
outputs.hidden_states,
|
| 228 |
+
outputs.contextualization,
|
| 229 |
+
)
|
| 230 |
+
# unembed the hidden_states
|
| 231 |
+
lm_logits = torch.einsum(
|
| 232 |
+
"bsd,nd->bsn", hidden_states, self.backpack.word_embeddings.weight
|
| 233 |
+
)
|
| 234 |
+
return BackpackGPT2LMHeadModelOutput(
|
| 235 |
+
logits=lm_logits,
|
| 236 |
+
contextualization=contextualization,
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
def run_with_custom_contextualization(self, input_ids, contextualization):
|
| 240 |
+
outputs = self.backpack.run_with_custom_contextualization(
|
| 241 |
+
input_ids, contextualization
|
| 242 |
+
)
|
| 243 |
+
hidden_states, contextualization = (
|
| 244 |
+
outputs.hidden_states,
|
| 245 |
+
outputs.contextualization,
|
| 246 |
+
)
|
| 247 |
+
lm_logits = self.lm_head(hidden_states)
|
| 248 |
+
return BackpackGPT2LMHeadModelOutput(
|
| 249 |
+
logits=lm_logits,
|
| 250 |
+
contextualization=contextualization,
|
| 251 |
+
)
|
config.json
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"return_dict": true,
|
| 3 |
+
"output_hidden_states": false,
|
| 4 |
+
"output_attentions": false,
|
| 5 |
+
"torchscript": false,
|
| 6 |
+
"torch_dtype": null,
|
| 7 |
+
"use_bfloat16": false,
|
| 8 |
+
"tf_legacy_loss": false,
|
| 9 |
+
"pruned_heads": {},
|
| 10 |
+
"tie_word_embeddings": true,
|
| 11 |
+
"is_encoder_decoder": false,
|
| 12 |
+
"is_decoder": false,
|
| 13 |
+
"cross_attention_hidden_size": null,
|
| 14 |
+
"add_cross_attention": false,
|
| 15 |
+
"tie_encoder_decoder": false,
|
| 16 |
+
"max_length": 20,
|
| 17 |
+
"min_length": 0,
|
| 18 |
+
"do_sample": false,
|
| 19 |
+
"early_stopping": false,
|
| 20 |
+
"num_beams": 1,
|
| 21 |
+
"num_beam_groups": 1,
|
| 22 |
+
"diversity_penalty": 0.0,
|
| 23 |
+
"temperature": 1.0,
|
| 24 |
+
"top_k": 50,
|
| 25 |
+
"top_p": 1.0,
|
| 26 |
+
"typical_p": 1.0,
|
| 27 |
+
"repetition_penalty": 1.0,
|
| 28 |
+
"length_penalty": 1.0,
|
| 29 |
+
"no_repeat_ngram_size": 0,
|
| 30 |
+
"encoder_no_repeat_ngram_size": 0,
|
| 31 |
+
"bad_words_ids": null,
|
| 32 |
+
"num_return_sequences": 1,
|
| 33 |
+
"chunk_size_feed_forward": 0,
|
| 34 |
+
"output_scores": false,
|
| 35 |
+
"return_dict_in_generate": false,
|
| 36 |
+
"forced_bos_token_id": null,
|
| 37 |
+
"forced_eos_token_id": null,
|
| 38 |
+
"remove_invalid_values": false,
|
| 39 |
+
"exponential_decay_length_penalty": null,
|
| 40 |
+
"suppress_tokens": null,
|
| 41 |
+
"begin_suppress_tokens": null,
|
| 42 |
+
"architectures": null,
|
| 43 |
+
"finetuning_task": null,
|
| 44 |
+
"id2label": {
|
| 45 |
+
"0": "LABEL_0",
|
| 46 |
+
"1": "LABEL_1"
|
| 47 |
+
},
|
| 48 |
+
"label2id": {
|
| 49 |
+
"LABEL_0": 0,
|
| 50 |
+
"LABEL_1": 1
|
| 51 |
+
},
|
| 52 |
+
"tokenizer_class": null,
|
| 53 |
+
"prefix": null,
|
| 54 |
+
"bos_token_id": null,
|
| 55 |
+
"pad_token_id": null,
|
| 56 |
+
"eos_token_id": null,
|
| 57 |
+
"sep_token_id": null,
|
| 58 |
+
"decoder_start_token_id": null,
|
| 59 |
+
"task_specific_params": null,
|
| 60 |
+
"problem_type": null,
|
| 61 |
+
"_name_or_path": "",
|
| 62 |
+
"transformers_version": "4.29.2",
|
| 63 |
+
"vocab_size": 50264,
|
| 64 |
+
"n_positions": 512,
|
| 65 |
+
"n_layer": 36,
|
| 66 |
+
"n_head": 20,
|
| 67 |
+
"n_embd": 1280,
|
| 68 |
+
"initializer_range": 0.02,
|
| 69 |
+
"attn_pdrop": 0.0,
|
| 70 |
+
"embd_pdrop": 0.0,
|
| 71 |
+
"layer_norm_epsilon": 1e-05,
|
| 72 |
+
"activation_function": "gelu_new",
|
| 73 |
+
"scale_attn_by_inverse_layer_idx": true,
|
| 74 |
+
"reorder_and_upcast_attn": false,
|
| 75 |
+
"num_senses": 48,
|
| 76 |
+
"sense_intermediate_scale": 7,
|
| 77 |
+
"auto_map": {
|
| 78 |
+
"AutoConfig": "backpack_config.BackpackGPT2Config",
|
| 79 |
+
"AutoModelForCausalLM": "backpack_model.BackpackGPT2LMHeadModel"
|
| 80 |
+
},
|
| 81 |
+
"model_type": "backpack-gpt2"
|
| 82 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2987c73b930c34cf2586d73f5ebc7d936aa7da408fb8add95db39a0f248a7e49
|
| 3 |
+
size 5666995936
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<|endoftext|>",
|
| 3 |
+
"eos_token": "<|endoftext|>",
|
| 4 |
+
"unk_token": "<|endoftext|>"
|
| 5 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"bos_token": "<|endoftext|>",
|
| 4 |
+
"clean_up_tokenization_spaces": true,
|
| 5 |
+
"eos_token": "<|endoftext|>",
|
| 6 |
+
"model_max_length": 1024,
|
| 7 |
+
"tokenizer_class": "GPT2Tokenizer",
|
| 8 |
+
"unk_token": "<|endoftext|>"
|
| 9 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|