

Commit
•
1fa262a
1
Parent(s):
7b376c4
Update README.md
Browse files
README.md
CHANGED
|
@@ -7,8 +7,18 @@ inference: false
|
|
| 7 |
---
|
| 8 |
|
| 9 |
# Stable Diffusion x2 latent upscaler model card
|
| 10 |
-
|
| 11 |
-
This model
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
|
| 13 |
|  |
|
| 14 |
|:--:|
|
|
@@ -30,36 +40,31 @@ Original output image | 2x upscaled output image
|
|
| 30 |
|
| 31 |
## Examples
|
| 32 |
|
| 33 |
-
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run latent upscaler on top of any `StableDiffusionUpscalePipeline` checkpoint
|
|
|
|
| 34 |
|
| 35 |
```bash
|
| 36 |
-
pip install diffusers
|
|
|
|
| 37 |
```
|
| 38 |
|
| 39 |
```python
|
| 40 |
from diffusers import StableDiffusionLatentUpscalePipeline, StableDiffusionPipeline
|
| 41 |
import torch
|
| 42 |
|
| 43 |
-
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 44 |
-
|
| 45 |
pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
|
| 46 |
pipeline.to("cuda")
|
| 47 |
|
| 48 |
-
|
| 49 |
-
upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
|
| 50 |
upscaler.to("cuda")
|
| 51 |
|
| 52 |
prompt = "a photo of an astronaut high resolution, unreal engine, ultra realistic"
|
| 53 |
generator = torch.manual_seed(33)
|
| 54 |
|
|
|
|
|
|
|
| 55 |
low_res_latents = pipeline(prompt, generator=generator, output_type="latent").images
|
| 56 |
|
| 57 |
-
with torch.no_grad():
|
| 58 |
-
image = pipeline.decode_latents(low_res_latents)
|
| 59 |
-
image = pipeline.numpy_to_pil(image)[0]
|
| 60 |
-
|
| 61 |
-
image.save("../images/a1.png")
|
| 62 |
-
|
| 63 |
upscaled_image = upscaler(
|
| 64 |
prompt=prompt,
|
| 65 |
image=low_res_latents,
|
|
@@ -68,14 +73,27 @@ upscaled_image = upscaler(
|
|
| 68 |
generator=generator,
|
| 69 |
).images[0]
|
| 70 |
|
| 71 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 72 |
```
|
| 73 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
**Notes**:
|
| 75 |
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
|
| 76 |
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
|
| 77 |
|
| 78 |
-
|
| 79 |
# Uses
|
| 80 |
|
| 81 |
## Direct Use
|
|
@@ -129,6 +147,4 @@ which consists of images that are limited to English descriptions.
|
|
| 129 |
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
| 130 |
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
| 131 |
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
| 132 |
-
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
|
| 133 |
-
|
| 134 |
-
|
|
|
|
| 7 |
---
|
| 8 |
|
| 9 |
# Stable Diffusion x2 latent upscaler model card
|
| 10 |
+
|
| 11 |
+
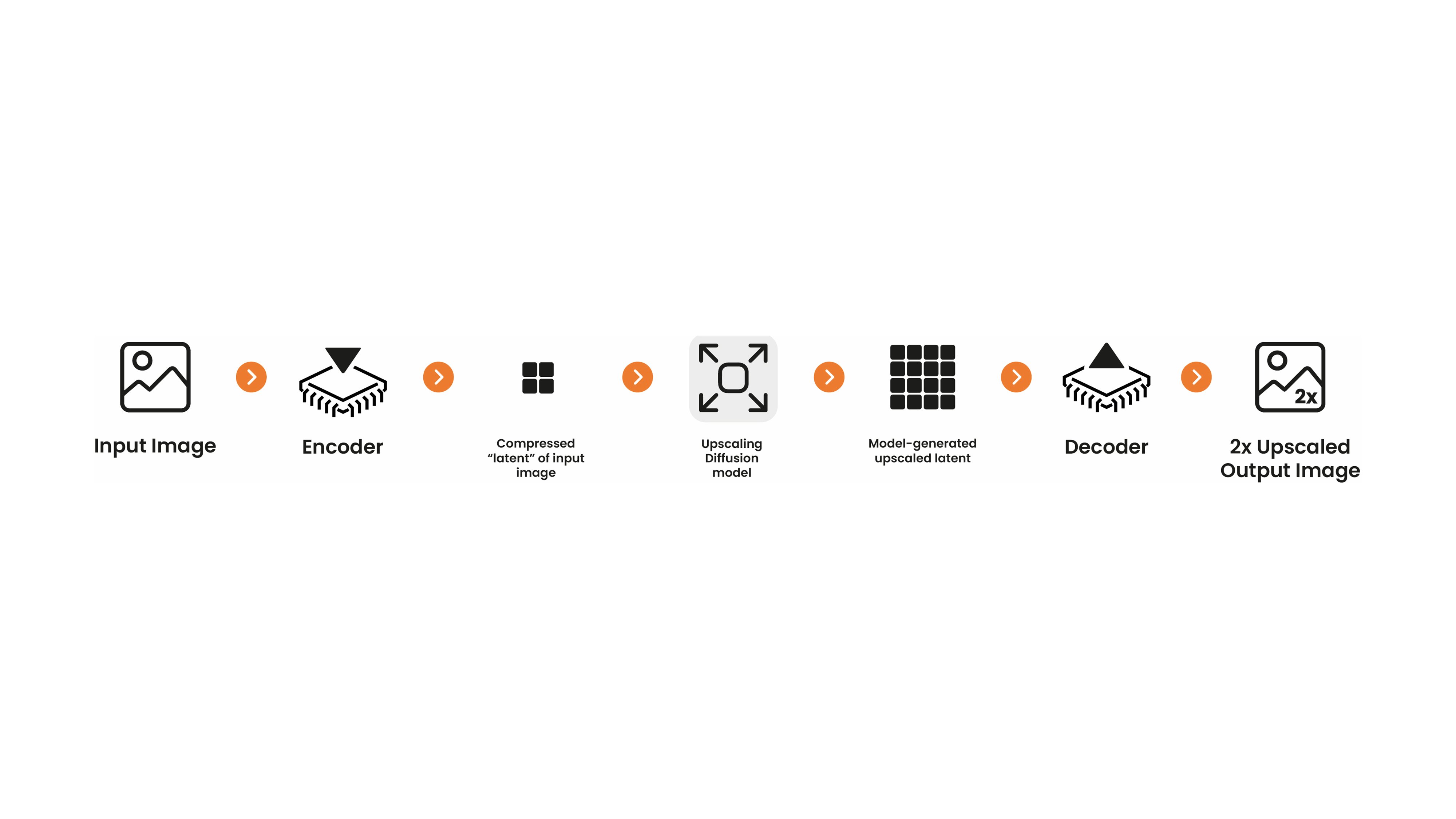
This model card focuses on the latent diffusion-based upscaler developed by [Katherine Crowson](https://github.com/crowsonkb/k-diffusion)
|
| 12 |
+
in collaboration with [Stability AI](https://stability.ai/).
|
| 13 |
+
This model was trained on a high-resolution subset of the LAION-2B dataset.
|
| 14 |
+
It is a diffusion model that operates in the same latent space as the Stable Diffusion model, which is decoded into a full-resolution image.
|
| 15 |
+
To use it with Stable Diffusion, You can take the generated latent from Stable Diffusion and pass it into the upscaler before decoding with your standard VAE.
|
| 16 |
+
Or you can take any image, encode it into the latent space, use the upscaler, and decode it.
|
| 17 |
+
|
| 18 |
+
**Note**:
|
| 19 |
+
This upscaling model is designed explicitely for **Stable Diffusion** as it can upscale Stable Diffusion's latent denoised image embeddings.
|
| 20 |
+
This allows for very fast text-to-image + upscaling pipelines as all intermeditate states can be kept on GPU. More for information, see example below.
|
| 21 |
+
This model works on all [Stable Diffusion checkpoints](https://huggingface.co/models?other=stable-diffusion)
|
| 22 |
|
| 23 |
|  |
|
| 24 |
|:--:|
|
|
|
|
| 40 |
|
| 41 |
## Examples
|
| 42 |
|
| 43 |
+
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run latent upscaler on top of any `StableDiffusionUpscalePipeline` checkpoint
|
| 44 |
+
to enhance its output image resolution by a factor of 2.
|
| 45 |
|
| 46 |
```bash
|
| 47 |
+
pip install git+https://github.com/huggingface/diffusers.git
|
| 48 |
+
pip install transformers accelerate scipy safetensors
|
| 49 |
```
|
| 50 |
|
| 51 |
```python
|
| 52 |
from diffusers import StableDiffusionLatentUpscalePipeline, StableDiffusionPipeline
|
| 53 |
import torch
|
| 54 |
|
|
|
|
|
|
|
| 55 |
pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
|
| 56 |
pipeline.to("cuda")
|
| 57 |
|
| 58 |
+
upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained("stabilityai/sd-x2-latent-upscaler", torch_dtype=torch.float16)
|
|
|
|
| 59 |
upscaler.to("cuda")
|
| 60 |
|
| 61 |
prompt = "a photo of an astronaut high resolution, unreal engine, ultra realistic"
|
| 62 |
generator = torch.manual_seed(33)
|
| 63 |
|
| 64 |
+
# we stay in latent space! Let's make sure that Stable Diffusion returns the image
|
| 65 |
+
# in latent space
|
| 66 |
low_res_latents = pipeline(prompt, generator=generator, output_type="latent").images
|
| 67 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 68 |
upscaled_image = upscaler(
|
| 69 |
prompt=prompt,
|
| 70 |
image=low_res_latents,
|
|
|
|
| 73 |
generator=generator,
|
| 74 |
).images[0]
|
| 75 |
|
| 76 |
+
# Let's save the upscaled image under "upscaled_astronaut.png"
|
| 77 |
+
upscaled_image.save("astronaut_1024.png")
|
| 78 |
+
|
| 79 |
+
# as a comparison: Let's also save the low-res image
|
| 80 |
+
with torch.no_grad():
|
| 81 |
+
image = pipeline.decode_latents(low_res_latents)
|
| 82 |
+
image = pipeline.numpy_to_pil(image)[0]
|
| 83 |
+
|
| 84 |
+
image.save("astronaut_512.png")
|
| 85 |
```
|
| 86 |
|
| 87 |
+
**1024-res Astronaut
|
| 88 |
+

|
| 89 |
+
|
| 90 |
+
**512-res Astronaut
|
| 91 |
+

|
| 92 |
+
|
| 93 |
**Notes**:
|
| 94 |
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
|
| 95 |
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
|
| 96 |
|
|
|
|
| 97 |
# Uses
|
| 98 |
|
| 99 |
## Direct Use
|
|
|
|
| 147 |
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
| 148 |
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
| 149 |
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
| 150 |
+
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
|
|
|
|
|
|